
Группа крови, генотип и режим дня: на что обратить внимание тем, кто хочет похудеть | Статьи
В мире сегодня существует большое количество диет, однако универсального варианта, который подошел бы каждому, нет, а эффективность во многом зависит от уникальных особенностей каждого человека. На что при выборе обратить внимание тем, кто собрался похудеть и какие еще факторы при этом необходимо учитывать, разбирались «Известия».
По крови
Видов диет сегодня существует довольно много, большинство из них объединяет два ключевых требования — ограничение количества еды, которое человек потребляет в день, и акцент на определенный набор продуктов.
При этом просто отказ от вредной пищи — например, от жирного, сладкого или жареного, без сокращения порций, безусловно, положительно скажется на состоянии организма и даже, возможно, к незначительной потере веса. Но похудеть поможет вряд ли.
Рацион и график питания зависят от выбранной диеты. Некоторые специалисты, в том числе, рекомендуют ориентироваться на особенности организма, заложенные в нас природой.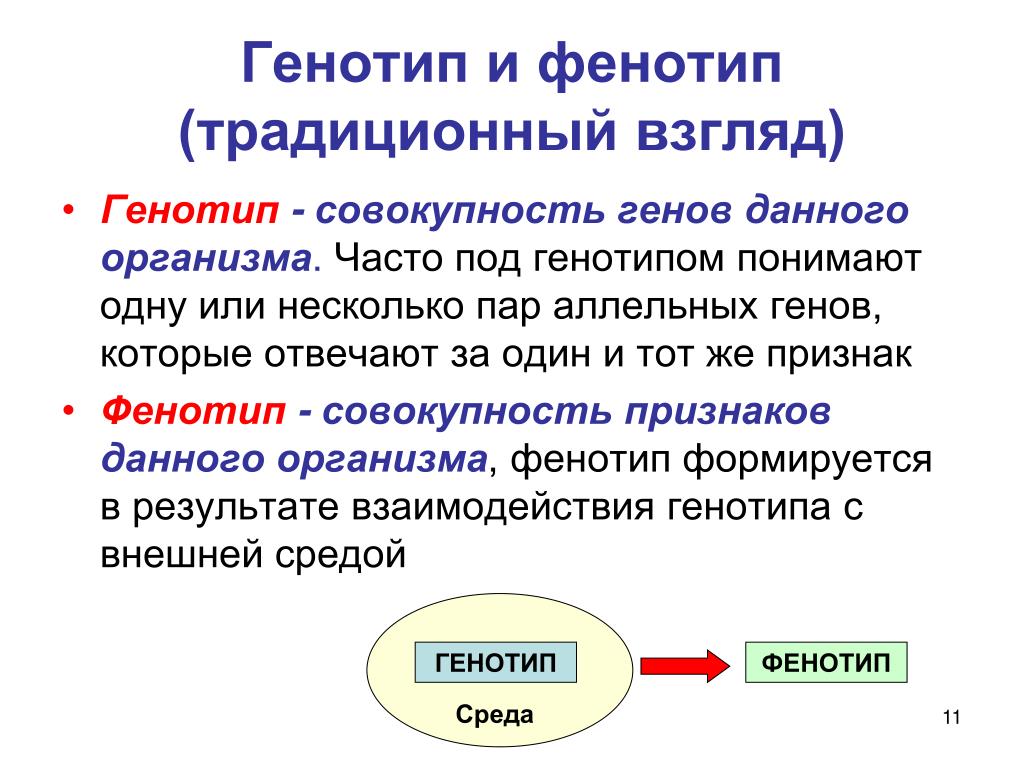
Так, диета американца Питера Д’Адамо основана на предположении, что людям с разными группами крови необходимы разные продукты.
По мнению ученого, людям с первой группой крови (она самая распространенная, ею обладают около 40% населения Земли) ближе мясная диета, которая предполагает наличие белка. Также подходит употребление рыбы и птицы с ограничением углеводов, зерновых и бобовых.
Фото: Depositphotos/timolina
«Людей со второй группой крови автор называет земледельцами. Ее обладателями являются примерно 39% населения земли. Соответственно, в их рационе должны преобладать овощи, фрукты, бобовые, зерновые без глютена. А вот мясо, молочные и кисломолочные продукты, кофе и алкоголь следует ограничить», — рассказала «Известиям» кандидат медицинских наук, врач-эндокринолог, врач-диетолог «СМ-Клиника» Ульяна Румянцева
Люди с третьей группой крови в этой системе относятся к кочевникам — это примерно 15% населения земли.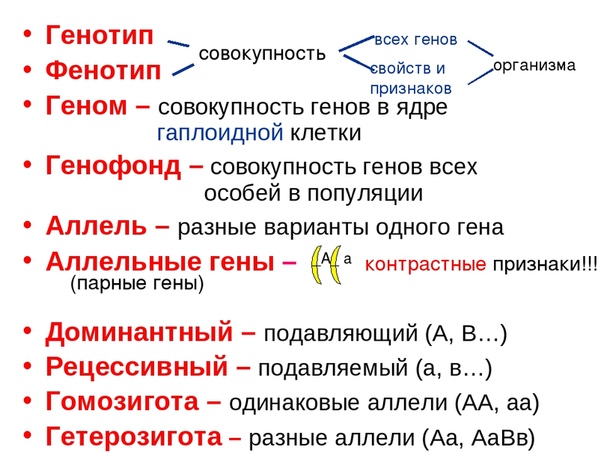 Им специалисты рекомендуют есть в основном овощи, фрукты, молочные и кисломолочные продукты, любое мясо кроме курицы. Исключить рекомендуется морепродукты и изделия из пшеничной муки.
Им специалисты рекомендуют есть в основном овощи, фрукты, молочные и кисломолочные продукты, любое мясо кроме курицы. Исключить рекомендуется морепродукты и изделия из пшеничной муки.
Четвертая группа крови — самая малочисленная. Она есть примерно у 6% населения и, по мнению Питера Д’Адамо, унаследовала черты второй и третьей групп. Такие люди, по мнению автора теории, могут есть практически все. Исключить предлагается говядину (и вообще красное мясо), кукурузу, фасоль и алкогольные напитки. А особенно подойти им может рыба, любое мясо кроме красного, молочные и кисломолочные продукты, бобовые, зерновые, овощи и фрукты.
Питание по генотипуПохожей градации придерживаются и сторонники теории питания по генотипу. Они считают, что подходящий рацион можно составить, исходя из генотипа. Который, в свою очередь, можно определить по комплекции человека.
Всего в этом случае предлагается пять возможных генотипов. «Следопытам» (высокий, с длинными ногами, пальцами и большим размером ступни) рекомендуется сделать акцент на продукты, богатые белком, овощи и зерновые культуры, а избегать — большинства молочных продуктов.
«Охотникам-собирателям» (к ним авторы диеты относят стройных и узкокостных людей среднего роста) рекомендуют рассмотреть диеты, состоящие из богатых белком продуктов в сочетании с фруктами и овощами. Остерегаться — жирных продуктов.
К «Исследователям» относят крепких и коренастых людей среднего роста — им предлагают обратить внимание на раздельное питание, а исключить — газировку, кофеин и соленые продукты.
«Пастухами» называют невысоких людей с мягкими округлыми чертами. В этом случае, считают авторы, оптимальной будет молочно-вегетарианская диета, при этом из-за низкой скорости метаболизма необходимо внимательно следить за количеством калорий.
Фото: Depositphotos/Nomadsoul
Наконец, к «Танцорам» относятся невысокие люди или люди среднего роста с сильными мышцами. Людям с такой конституцией в рамках этой системы предлагается, прежде всего, обращать внимание на режим питания — и следить за тем, чтобы не пропускать основные приемы пищи.
Но любая диета должна подбираться комплексно, обращают внимание специалисты, с учетом целого ряда уникальных для каждого человека факторов. И конечно, если у вас есть пищевая аллергия или непереносимость тех или иных продуктов — вне зависимости от выбранной диеты, эти продукты необходимо исключить.
Подсчет калорийВне зависимости от выбранной диеты, основной принцип похудения – в том, чтобы потреблять меньше калорий, чем вы тратите. Поэтому расчет необходимой нормы для каждого будет индивидуальным.
Зависит это, прежде всего, от пола. Считается, что в среднем для женщин ежедневная норма калорий в этом случае не должна превышать 1200-1500 калорий, для мужчин — 1600-1800 калорий.
При этом если вы хотите сбросить довольно большой вес в сжатые сроки, норма будет меньше, если готовы действовать постепенно, как рекомендует большинство специалистов — ее можно немного «растянуть».
Нагрузка — еще один важный фактор. Если у вас сидячая работа, большую часть дня вы проводите за компьютером, а регулярный спорт или прогулки еще не вошли у вас в привычку, норма калорий будет меньше.
Фото: Depositphotos/AntonLozovoy
Если же в течение дня вы много двигаетесь или привыкли интенсивно тренироваться — ориентироваться лучше на «верхнюю» планку нормы калорий.
Кроме того, при значительных физических нагрузках, в рацион стоит добавить больше белка, чтобы избежать истощения или постоянного чувства голода.
График и привычкиПриемы пищи лучше подстраивать под привычный вам распорядок дня. Если вы привыкли есть всего пару раз в день, но большими порциями, резкий переход на дробное питание вам удастся вряд ли.
Фото: Depositphotos/Kryzhov
Если же человек сова и привык поздно просыпаться и ложится, при этом с утра, как правило, не испытывает чувства голода, отказаться от приема пищи после шести вечера он, скорее всего, не сможет.
В этом случае, наоборот, возможны срывы и переедание.
Вместо этого лучше постепенно адаптировать привычный график приема пищи, например, понемногу уменьшая порции по вечерам или увеличивая их за завтраком. И тем самым постепенно приучая организм к более сбалансированному плану питания.
1. Генотип как целостная система
Взаимодействие генов — это совместное действие нескольких генов, в результате которого появляется признак, которого нет у родителей, или усиливается проявление уже имеющегося признака.
Для объяснения результатов взаимодействия генов важно понимать механизм формирования признаков.
Ген — это участок ДНК, в котором закодирована информация об одном белке. В простейшем случае формирование признака может происходить в результате действия одного белка, синтез которого определяется одним геном:
— но обычно признак формируется в результате сложных биохимических процессов. В клетке происходит взаимодействие между белками-ферментами, синтез которых определяется генами, или между веществами, которые образуются под влиянием этих ферментов.
В клетке происходит взаимодействие между белками-ферментами, синтез которых определяется генами, или между веществами, которые образуются под влиянием этих ферментов.
Возможны следующие типы проявления генов в фенотипе:
- один признак формируется в результате взаимодействия нескольких белков, синтез которых определяется несколькими генами:
- один ген определяет синтез белка, который влияет на формирование нескольких признаков:
— как показано на схеме.
Возможно взаимодействие как между аллельными генами, так и между неаллельными.
Аллельные гены расположены в одинаковых участках гомологичных хромосом и определяют один признак. Примеры взаимодействия аллельных генов:
- полное доминирование;
- неполное доминирование.
(Сведения о взаимодействии аллельных генов изложены в предыдущих подтемах.)
Неаллельные гены расположены в разных участках негомологичных хромосом. Формы взаимодействия неаллельных генов:
Формы взаимодействия неаллельных генов:
- комплементарность;
- эпистаз;
- полимерия.
Комплементарность, эпистаз и полимерия — это взаимодействия, при которых несколько генов определяют один признак.
Наследование, при котором один ген влияет на формирование нескольких признаков, называется плейотропия (или множественное действие гена).
Анализ hcv определение генотипа – сдать по цене 1100 руб. в Москве
Вирус гепатита С (ВГС), вызывающий развитие посттрансфузионных гепатитов, является РНК содержащим гепатотропным вирусом, относящимся к семейству Flaviviridae. Геном вируса представлен одноцепочечной молекулой РНК. Подобно другим РНК-содержащим вирусам, для популяции ВГС характерен широкий полиморфизм нуклеотидных последовательностей. Отличительной особенностью ВГС является способность к длительной персистенции в организме, что обуславливает высокий процент хронизации инфекции до 80% случаев.
Основным путем передачи ВГС является посттрансфузионный путь. Доля ВГС-позитивных среди больных посттрансфузионным гепатитом составляет 60-90%. Доля перинатального и полового путей передачи ВГС не велика и составляет 5%.
В современной лабораторной диагностике вирусного гепатита С основная роль отводится выявлению серологических маркеров-антител к ВГС и выявлению геномной РНК вируса. Обнаружение в крови РНК ВГС является основным арбитражным критерием, характеризующим вирусемию, свидетельствующую о продолжающейся активной репликации ВГС в гепатоцитах.
При мониторинге ВГС инфекции существенную роль играют количественная оценка содержания вируса в сыворотке или плазме крови больного и принадлежность его к тому или иному генотипу. Показано, что наиболее благоприятный прогноз течения заболевания и ответа на противовирусную терапию имеют лица с невысоким титром вируса в крови или генотипом 2 или 3.
Генотипы вируса гепатита С:
Существенной особенностью характеристики HCV является его генетическая неоднородность, соответствующая быстрой замещаемости нуклеотидов. В результате образуется большое число разных генотипов и субтипов. По классификации Simmonds разграничивают 11 типов (генотипы 1-11), подразделяющихся, в свою очередь, на 70 подтипов HCV (например: 1а, 1в, 1с). Для клинической практики достаточно разграничивать пять субтипов HCV: 1а, 1в, 2а, 2в, 3а.
Установлены существенные географические различия в распространении разных генотипов. Так, в Японии, на Тайване, частично в Китае регистрируются преимущественно генотипы 1в, 2а, 2в. Тип 1в даже называется «японским». В США преобладает «американский» генотип 1а. В европейских странах преобладает генотип HCV- 1а, в Южной Европе заметно возрастает доля 1в генотипа. На территории России преобладающим генотипом является 1в (80%), далее с убывающей частотой- 3а, 1а, 2а.
Тип 1в даже называется «японским». В США преобладает «американский» генотип 1а. В европейских странах преобладает генотип HCV- 1а, в Южной Европе заметно возрастает доля 1в генотипа. На территории России преобладающим генотипом является 1в (80%), далее с убывающей частотой- 3а, 1а, 2а.
Показано, что больные, инфицированные ВГС, принадлежащим к генотипам 2а, имеют менее тяжелый характер течения заболевания, как правило, менее низкий уровень виремии и существенно лучше поддаются традиционной противовирусной терапии (интерферонотерапии), чем больные, инфицированные ВГС генотипа 1в или 1а. Генотипирование ВГС имеет прогностическую значимость и способствует назначению адекватной интерферонотерапии (в частности, выбора дозы интерферона).
В отличие от гепатита В, при котором могут быть определены антигены вируса и антитела к ним, при гепатите С методом ИФА улавливаются только антитела. Антигены HCV, если и попадают в кровь, то в количествах, которые практически не улавливаются. Наличие антител Анти-HCV не свидетельствуют о продолжающейся репликации вируса, и могут являться признаком как текущей, так и перенесенной инфекции.
Ведущую роль в лабораторной диагностике инфекции HCV занимают методы генодиагностики, позволяя: непосредственно выявить генетический материал вируса в сыворотке крови и тканях человеческого организма; оценить репликативную активность вируса в тканях; количественно определить концентрацию вируса в сыворотке крови; установить генотип вируса и вести наблюдение за изменчивостью HCV. Обнаружение в сыворотке крови РНК HCV является “золотым стандартом” диагностики, свидетельствующем о продолжающейся репликации HCV.
Анализ на генетический код в лаборатории «ЛИТЕХ»
- Полимераная цепная реакция (ПЦР) (выявление специфического фрагмента РНК вируса)
- Качественное определение HСV РНК.

- Количественное определение HСV РНК. Анализ проводится после положительного качественного исследования.
- Определение генотипа HCV. Анализ проводится после положительного качественного исследования
Сыворотка крови. Только в одноразовой пластиковой пробирке с плотно завинчивающейся крышкой.
Серологические исследования: определение специфических антител к вирусу гепатита С : Anti-HCV
Метод исследования: иммуноферментный анализ (ИФА). Материал для исследования: сыворотка крови. Только в одноразовой пластиковой пробирке с плотно завинчивающейся крышкой.
Сеть лабораторий «Литех» предлагает вам сдать анализ на определение генотипа вируса гепатита C по доступной цене. Чтобы определить, сколько полностью стоит проведение лабораторного исследования на генотипирование гепатита C, оформите заявку через форму на сайте или по телефону 8-800-700-45-82.
Памятка для пациентов: Гепатиты С и В
Когда вирус гепатита С (сокращенное название — HCV) проникает в организм, иммунная система вырабатывает специальные белки, которые кровь разносит по организму, что бы помочь побороть вирус гепатита С. Они называются антителами. Если у вас обнаружены антитела HCV — это предполагает, что у вас был контакт с HCV. Но это не означает, что у вас гепатит С в активной стадии. У некоторых людей (у 2-3 из 10) иммунная система способна самостоятельно избавиться от вируса, но у остальных 7-8 человек организм не может побороть вирус.
Они называются антителами. Если у вас обнаружены антитела HCV — это предполагает, что у вас был контакт с HCV. Но это не означает, что у вас гепатит С в активной стадии. У некоторых людей (у 2-3 из 10) иммунная система способна самостоятельно избавиться от вируса, но у остальных 7-8 человек организм не может побороть вирус.
Есть два вида тестов, используемых для диагностирования состоявшегося контакта с вирусом гепатита С – ИФА (иммуноферментный анализ) и ЭХЛ (электрохемилюминисцентный анализ). Чувствительность и специфичность ИФА при этом составляет около 90%, а ЭХЛ – около 98%, поэтому в крайне редких случаях возможны ложноположительные и ложноотрицательные результаты.
Для определения наличия и активности вируса гепатита С вам понадобится сделать дополнительно соответствующие тесты.
Важно помнить:
· Даже если у вас был контакт с вирусом гепатита С, ваш организм мог избавиться от вируса самостоятельно. Поэтому важно сделать дополнительные тесты.
· Попробуйте не волноваться, даже если ваш анализ на антитела положительный, и активный гепатит С подтвердился дополнительными тестами. Обычно, требуется от 10 до 40 лет для того, чтобы вирус повредил вашу печень. Кроме того, существует очень много вещей, которые вы можете сделать для того, чтобы ваша печень оставалась здоровой.
· Только ваш врач может интерпретировать Ваши индивидуальные результаты тестирования и устанавливать клинический диагноз.
Для уточнения активности вируса ваш доктор, с целью детального обследования, назначит несколько дополнительных анализов крови, что бы узнать точно, что происходит внутри вас. Эти анализы называются ПЦР — полимеразная цепная реакция, с помощью которого обнаруживают генетический материал вируса гепатита С, присутствующий в крови. Один из анализов даст ответ на наличие вируса у вас. Другой — позволит определить какой генотип у вируса (HCV имеет несколько генотипов). Еще один анализ определит вирусную загрузку — как много у вас вируса гепатита С и насколько активен этот вирус.
Если у вас есть вирус гепатита С, то он не остается только в клетках печени, он также может быть обнаружен в вашей крови. HCV очень активен и производит много копий самого себя. Анализ на вирусную загрузку — это единственный способ измерить сколько HCV присутствует у вас.
Анализ на Вирусную загрузку очень важен по нескольким причинам:
Первая: Анализ на вирусную загрузку скажет вам присутствует ли у вас вирус или вы уже освободились от него.
Вторая: Если вы беременная женщина, риск передачи вируса вашему ребенку очень низок, но если вы беременная женщина с высокой вирусной загрузкой, риск передачи вируса ребенку будет несколько выше.
Третья: Если вы решите пройти терапию интерфероном, анализ на вирусную загрузку поможет доктору узнать действует ли терапия и как долго требуется ее продолжать.
ПОМНИТЕ: Всегда делайте ваши анализы в одной лаборатории. Это позволит делать правильные оценки при сравнении получаемых результатов.
Что такое генотипирование?
Вирус гепатита С (сокращенно HCV) имеет несколько разновидностей. Фактически, есть шесть разных видов HCV. Эти виды называются генотипами и нумеруются от 1 до 6. Некоторые генотипы имеют дальнейшие разделения называемые субтипами (например 1a и 1b).
Для лечащего доктора очень важно знать генотип вашего вируса, так как разные вирусы с разными генотипами по разному поддаются лечению (отвечают на терапию). Например, генотип 1 немного сложнее лечить, чем генотипы 2 или 3. И терапия 1-го типа HCV требует доз препаратов, отличных от применяемых при терапии с генотипами 2 или 3.
Наличие у вас определенного генотипа не означает, что вы больны больше или меньше. Но некоторые генотипы (например, 3) могут быть связаны с определенными состояниями печени, такими как ожирение.
Важно помнить, что у большинства людей гепатит С вообще не проявляется в виде каких либо симптомов — независимо от генотипа вируса.
Знание генотипа вируса важно по нескольким причинам:
Во первых: Если вы решите пойти на терапию, тест на генотип позволит предсказать ваши шансы на избавления от вируса.
Во вторых: тест на генотип вируса поможет вашему доктору определить необходимые дозы препаратов и длительность вашей терапии.
ПОМНИТЕ: Что наличие у вас вируса того или иного генотипа не значит, что вы больны легче или тяжелее.
Важная информация:
Статистика для 100 человек, заражённых гепатитом C (HCV)
Приблизительно у 80 из 100 человек, с выявленным вирусом гепатита С (HCV), заболевание перейдёт в хроническую форму: другие 20 человек, инфицированных HCV, освободятся от вируса самостоятельно. Это связано с тем, что организм некоторых людей в состоянии справиться с HCV естественным путем.
Приблизительно у 20 человек, полученная хроническая инфекция, будет прогрессировать и разовьется за десятилетия в серьезную болезнь: Только у около 20 из первоначальных 100 человек, инфицированных HCV, гепатит разовьется в серьезную, опасную для жизни болезнь (цирроз). Обычно, у человека с гепатитом С печень становится действительно больной в течение 40 и более лет.
Приблизительно у 2-3 человек, с хронической инфекцией гепатита С, разовьётся рак печени: Только 2-3 человека из первоначальных 100 человек, у которых было установлено инфицирование вирусом гепатита С, заболевают раком печени. Происходит это только после того, как печень будет поражена циррозом в значительной степени.
Гепатит В
Существуют различные анализы крови для диагностики гепатита B. Можно сделать общий тест или серию исследований. Ниже приведены некоторые из основных тестов и их расшифровка.
Основной тест на выявление гепатита В — Поверхностный антиген (HBsAg, HBs антиген, HBs Ag, австралийский антиген). Он является поверхностным белком вируса гепатита В и может быть обнаружен в крови при остром или хроническом гепатите, а так же при носительстве вируса гепатита В. Есть два вида тестов, используемых для обнаружения HBsAg – ИФА (иммуноферментный анализ) и ЭХЛ (электрохемилюминисцентный анализ). Чувствительность и специфичность ИФА при этом составляет около 90%, а ЭХЛ – около 98%, поэтому в крайне редких случаях возможны ложноположительные и ложноотрицательные результаты.
С целью подтверждения наличия и выявления активности вируса гепатита В ваш доктор, с целью детального обследования, назначит несколько дополнительных анализов крови, что бы узнать точно, что происходит внутри вашего организма. Эти анализы называются ПЦР — полимеразная цепная реакция, с помощью которого обнаруживают генетический материал вируса гепатита B, присутствующий в крови. Один из анализов даст ответ на наличие вируса у вас. Другой — определит вирусную загрузку — как много у вас вируса гепатита B насколько активен этот вирус.
Положительный ПЦР-тест означает, что вирус активно размножается в организме человека и такой человек несет потенциальную опасность заражения гепатитом. Если человек имеет хронический гепатит вирусной этиологии, наличие вирусной ДНК, также, означает, что человек, возможно, подвергается повышенному риску повреждения печени.
Отрицательный ПЦР-тест означает отсутствие вируса гепатита В в крови либо его крайне низкую активность.
Важно! Только Ваш врач может интерпретировать Ваши индивидуальные результаты тестирования и устанавливать клинический диагноз.
Диагностика наследственных заболеваний методом высокопроизводительного секвенирования
В соответствии с особенностями методов и спецификой практических и научных задач в лаборатории организованы 3 направления клинической диагностики:
Запись на прием осуществляется через отдел платных услуг: 437-11-00, +7-911-766-97-70 по рабочим дням с 09-00 до 17-00.
Диагностика наследственных заболеваний методом высокопроизводительного секвенирования
Наследственные заболевания являются актуальной проблемой современного здравоохранения. По данным ВОЗ оценочное число наследственных болезней может достигать 10000, а количество больных – 10% всего населения земного шара.
Первостепенная задача, стоящая перед лечащим врачом, состоит в исключении или подтверждении генетической природы заболевания, что позволяет определить тактику лечения, дать прогноз жизни и здоровья больному и его родственникам.
Постановка клинического диагноза редкого заболевания часто бывает затруднена, особенно у новорожденных. В таких случаях молекулярная диагностика имеет определяющее значение.
В таких случаях молекулярная диагностика имеет определяющее значение.
В зависимости от конкретной клинической задачи требуется исследование разных по размеру участков генома – от одного нуклеотида до всего генома. Решение об объеме проводимого генетического тестирования принимается индивидуально для каждого пациента и требует комплексного подхода.
В генетической лаборатории СПб ГБУЗ ГБ№40 возможно проведение молекулярно-генетического тестирования методом высокопроизводительного секвенирования на приборе MiSeq Illumina. Данный метод дает возможность определять нуклеотидную последовательность как отдельных генов, так и все экзома (все кодирующие последовательности) или генома.
Консультация врача-генетика перед молекулярно-генетическим тестированием позволяет уточнить показания к проведению теста и объем исследования. По результатам анализа выдается письменное заключение с развернутой интерпретацией. Рекомендации и разъяснения по результатам можно получить у врача-генетика или лечащего врача.
Генетический паспорт
В будущем генетический паспорт станет самым достоверным носителем всех персональных данных человека. Сейчас петербургские ученые уже разработали методику определения генетических возможностей и рисков на основе ДНК.
Технология этого процесса проста. Практически из любого биоматериала (соскоба со щеки или капли крови) выделяют молекулу. Она содержит, по последним данным, 22 тысячи генов. Однако для наиболее точного анализа используют около 100 генов. Каждый из них несет свою информацию, по которой оценивают как вашу предрасположенность к болезням, например, патологии сердца и сосудов, так и к другим показателям: выносливости, полноте, агрессии, непереносимости молока, злаковых или алкоголя.
Затем специалисту достаточно взглянуть на «картину» и сказать, какие опасности вас ждут впереди, выдать определенные рекомендации по образу жизни и питанию. Например: при возможности возникновения диабета – уменьшить потребление сахара и жира; чтобы снизить риск инфаркта или инсульта – укреплять слабые сосуды.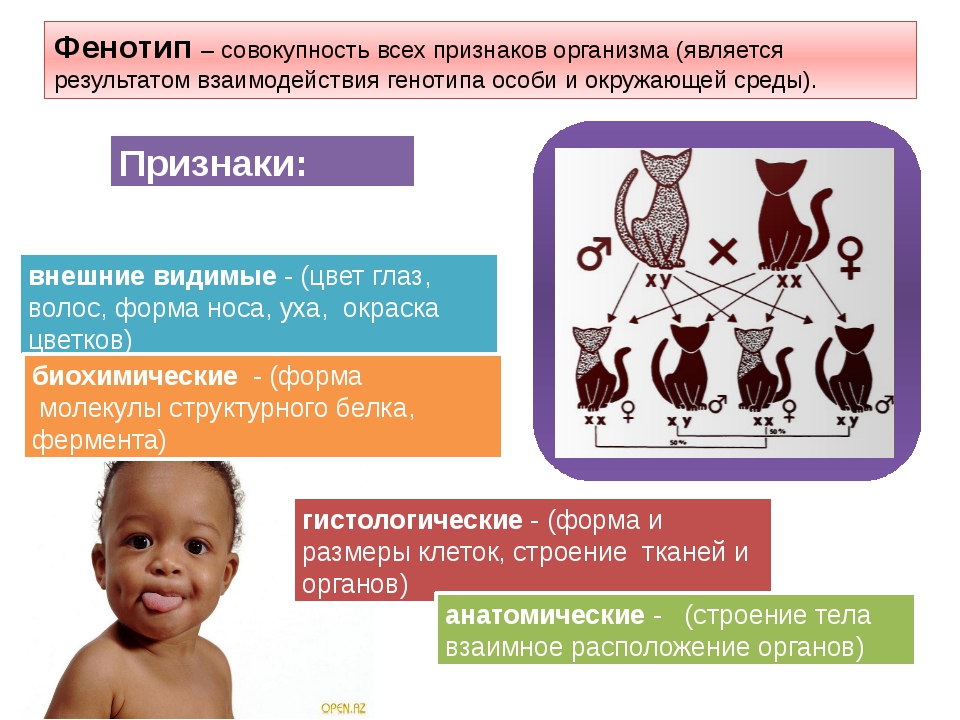 То есть даже при генетической предрасположенности к тому или иному заболеванию можно предотвратить его развитие или снизить риск возникновения тяжелых осложнения.
То есть даже при генетической предрасположенности к тому или иному заболеванию можно предотвратить его развитие или снизить риск возникновения тяжелых осложнения.
Еще один плюс – ваши гены «подскажут» наиболее эффективное лечение при случившемся недуге. Обычно для врача человек, пришедший за лечением – среднестатистический пациент, и при заболевании он рекомендует Вам стандартное лекарство. Но на кого-то оно подействует хорошо, а кому-то поможет мало – все зависит от генов. Если врач заглянет в генетический паспорт, то сможет подобрать лечение, исходя из ваших особенностей – наиболее эффективное именно для вашего организма.
Кроме того, можно предсказать, получится ли из конкретного человека хороший спортсмен, вплоть до вида спорта, гениальный ученый или музыкант.
Пока основные потребители «генетического паспорта» – будущие мамы, желающие родить и родить здорового малыша. Для них разработаны специальные генетические программы по планированию беременности, профилактике осложнений беременности, снижению осложнений при родах и др.
- Каждая пятая супружеская пара в России бесплодна и более 30% женщин имеют серьезные нарушения во время беременности, с высоким риском тяжелых осложнений для матери и будущего ребенка
- Одной из причин невынашивания и бесплодия может является наличие у супругов сбалансированных хромосомных перестроек, которые никоим образом не влияют на состояние здоровья носителя. Хромосомные перестройки в кариотипе одного из родителей могут приводить к появлению несбалансированного кариотипа у плода, что является причиной остановки развития беременности и формированию пороков. Стандартное кариотипирование, проводимое в лаборатории, позволяет выявить носителей хромосомных перестроек, что даст возможность выбрать корректную и оптимальную тактику планирования и ведения беременности.
- Значительная часть нарушений связана с наследственной предрасположенностью женщины к таким частым заболеваниям как эндометриоз, гестоз, привычное невынашивание беременности, диабет, бронхиальная астма, тромбофилия и др.

Разработанная сотрудниками Лаборатории «Генетическая карта репродуктивного здоровья» позволяет еще до беременности выявить женщин высокого риска этих заболеваний и начать их своевременную профилактику. Она также предусматривает генетическое консультирование семьи, планирующей рождение ребенка, анализ кариотипа супругов и генетическое тестирование родителей для исключения носительства мутаций, приводящих к тяжелым наследственным болезням (муковисцидоз, фенилкетонурия, спинальная мышечная дистрофия, адрено-генитальный синдром и др).
Для проведения полного или выборочного генетического обследования на наследственную предрасположенность к этим болезням, на скрытое носительство мутаций и хромосомных аберраций у родителей будущего ребенка следует:
- на приеме у врача-генетика лаборатории получить направление на необходимое именно Вашей семье обследование;
- сдать кровь на генетическое тестирование;
- по результатам генетического тестирования получить заключение специалиста и рекомендации врача-генетика.

Генетические тесты и рекомендации
Генетические анализы и анализ ДНК — важная необходимость при планировании беременности
В настоящее время стал доступен генетический анализ на предрасположенность ко многим мультифакториальным заболеваниям. Различные генетические центры и лаборатории предлагают либо проведение анализа на ряд заболеваний по рекомендации врача генетика, либо проведение анализа ДНК по всем доступным лаборатории маркерам мультифакториальных заболеваний с последующим составлением генетического паспорта. Кроме информации о предрасположенности к мультифакториальным заболеваниям такой генетический паспорт может содержать данные о носительстве наследственных заболеваний, рекомендации по коррекции образа жизни и профилактике тех мультифакториальных заболеваний, к которым обнаружилась предрасположенность.
Тромбофилия наследственная и при беременности (патологическое состояние, обуславливающее повышенную склонность к внутрисосудистому тромбообразованию).
Рекомендуется проводить анализ на предрасположенность к тромбофилии всем женщинам, планирующим беременность (рекомендация ВОЗ от 8 декабря 2005 года), особенно, если были осложнения в предыдущие беременности (как тромбозы, так и акушерские кровотечения, причины которых были коагулопатии). Также рекомендуется анализ женщинам с бесплодием и женщинам, имеющим близких родственников с тромбофилиями.
Какую информацию может дать анализ на предрасположенность к тромбофилии? Данный анализ может выявить генетические причины бесплодия, выявить повышенный риск к развитию осложнений во время беременности (гестозы, привычное невынашивание, внутриутробная гибель плода, задержка внутриутробного развития, преждевременная отслойка плаценты, повторные неудачи ЭКО, акушерские кровотечения, тромбоз сосудов малого таза, варикозная болезнь и т.д. ).
Что может рекомендовать ваш врач при наличии предрасположенности к тромбофилии? Медикаментозную профилактику тромбозов и коагулопатий с целью профилактики осложнений во время беременности. Коррекцию тактики лечения бесплодия.
Коррекцию тактики лечения бесплодия.
Варикозная болезнь (паталогический процесс поражения вен, для которого характерно увеличение диаметра просвета, истончение венозной стенки, образование «узлов» и нарушение венозного кровотока).
Рекомендуется проводить анализ на предрасположенность к варикозной болезни всем женщинам, планирующим беременность, особенно, если есть случаи этого заболевания у близких родственников (особенно у матери).
Какую информацию может дать анализ на предрасположенность к варикозной болезни? Данный анализ выявляет повышенный риск развития варикозной болезни (варикозное расширение вен нижних конечностей и геммороидальных узлов). Беременность является предрасполагающим фактором для развития варикоза, поэтому при наличии генетической предрасположенности к этому заболеванию следует обратить особое внимание на его профилактику.
Что может рекомендовать ваш врач при наличии предрасположенности к варикозной болезни? Комплекс мер по профилактике данного заболевания во время беременности.
Эндометриоз (гинекологическое заболевание, при котором клетки эндометрия (внутреннего слоя стенки матки) разрастаются за пределами матки. Поскольку эндометриоидная ткань имеет рецепторы к гормонам, в ней возникают те же изменения, что и в нормальном эндометрии, проявляющиеся ежемесячными кровотечениями, болезненностью, приводик к воспалению окружающих тканей).
Рекомендуется проводить анализ на предрасположенность к эндометриозу женщинам с бесплодием, диагностированным эндометриозом, в случаях наличия близких родственниц с эндометриозом.
Какую информацию может дать анализ на предрасположенность к эндометриозу? Данный анализ позволяет выявить возможную причину бесплодия. В случае диагностированного эндометриоза, наличие генетической предрасположенности к этому заболеванию может потребовать коррекцию проводимой терапии.
Что может рекомендовать ваш врач при наличии предрасположенности к эндометриозу? Коррекцию проводимой терапии уже диагностированного эндометриоза. Лапароскопию для подтверждения или исключения эндометриоза, как причины бесплодия. Профилактические мероприятия для предупреждения развития данного заболевания (профилактические осмотры, лечение хронических очагов инфекции мочеполовой системы, контроль гормонального фона).
Лапароскопию для подтверждения или исключения эндометриоза, как причины бесплодия. Профилактические мероприятия для предупреждения развития данного заболевания (профилактические осмотры, лечение хронических очагов инфекции мочеполовой системы, контроль гормонального фона).
Привычное невынашивание беременности (патология беременности, характеризуется повторяющейся самопроизвольной остановкой развития беременности).
Рекомендуется проводить анализ на предрасположенность к привычному невынашиванию беременности женщинам планирующим беременность, особенно тем, у кого были случаи невынашивания беременности, а также имеющим близких родственниц с привычным невынашиванием беременности.
Какую информацию может дать анализ на предрасположенность к привычному невынашиванию? Данный анализ позволяет выявить генетически обусловленный риск невынашивания беременности, выявить вероятные генетические причины в случаях диагностированного привычного невынашивания беременности.
Что может рекомендовать ваш врач при наличии предрасположенности к невынашиванию беременности? Ряд профилактических мероприятий для предотвращения прерывания беременности с учетом генетических особенностей пациента.
Гестоз (осложнение второй половины беременности, характеризующиеся повышением артериального давления, отеками, наличием белка в моче, при неблагоприятном течении приводит к развитию полиорганной недостаточности).
Рекомендуется проводить анализ на предрасположенности к гестозу всем женщинам, планирующим беременности, особенно тем, кто имеет близких родственниц со случаями данного осложнения беременности, а так же с имеющимися соматическими заболеваниями (Сахарный диабет 1 и 2 типа, гипертоническая болезнь, заболевания почек, заболевания щитовидной железы).
Какую информацию может дать анализ на предрасположенность к гестозу? Данный анализ позволяет выявить генетически обусловленный риск гестоза с целью его профилактики во время беременности.
Что может рекомендовать ваш врач при наличии предрасположенности к гестозу? Комплекс мер по профилактике гестоза во время беременности, повышенное внимание к беременной.
Гипертоническая болезнь (заболевание сердечно-сосудистой системы, главным проявлением которого является повышение артериального давления).
Рекомендуется проводить анализ на предрасположенность к гипертонической болезни всем женщинам, планирующим беременность, особенно тем, кто имеет близких родственников с гипертонической болезнью.
Какую информацию может дать анализ на предрасположенность к гипертонической болезни? Генетическая предрасположенность к гипертонической болезни связана с повышенным риском развития гестоза во время беременности.
Что может рекомендовать ваш врач при наличии предрасположенности к гипертонической болезни? Комплекс мер по профилактике гестоза и гипертонии во время беременности.
Рак молочной железы и рак яичников.
Рекомендуется проводить анализ на предрасположенность к раку молочной железы и яичников всем женщинам, особенно имеющим близких родственниц с такими заболеваниями.
Какую информацию может дать анализ на предрасположенность к раку молочной железы и яичников? Риск заболеть раком молочной железы или раком яичников в течение жизни для женщин, имеющих генетическую предрасположенность к этим заболеваниям, достигает 80-90%. При этом риск заболеть в молодом возрасте (до 30 лет) достигает 10%. Для успешного лечения онкологических заболеваний очень важно обнаружение опухоли на ранней стадии, еще до появления симптомов. Поэтому наличие генетической предрасположенности к раку молочной железы и яичников очень серьезное показание для регулярного обследования (раз в полгода, минимум раз в год) с целью обнаружения заболевания на ранней стадии.
Что может рекомендовать ваш врач при наличии предрасположенности к раку молочной железы и яичников? Регулярные обследования, которые обычно включают анализ крови на наличие опухолевых маркеров, УЗИ малого таза, УЗИ молочной железы или маммография.
Предрасположенность к незарощению невральной трубки и синдрому Дауна у плода.
Рекомендуется проводить анализ на предрасположенность к незарощению невральной трубки и синдрому Дауна у плода всем женщинам, планирующим беременность.
Какую информацию может дать анализ? Некоторые генетически обусловленные особенности обмена гомоцистеина у женщины способны провоцировать врожденные патологии развития у будущего ребенка. Анализ на предрасположенность к незарощению невральной трубки и синдрому Дауна у плода выявляет наличие этих особенностей.
Что может рекомендовать ваш врач при наличии предрасположенности к незарощению невральной трубки и синдрому Дауна у плода? Прием повышенных доз фолиевой кислоты и витаминов группы В в период планирования беременности значительно уменьшают риски врожденных патологий у плода.
Носительство моногенных наследственных заболеваний (муковисцидоз, фенилкетонурия, спинальная амиотрофия, нейросенсорная тугоухость и другие).
Рекомендуется проводить анализ всем семейным парам, планирующим ребенка, особенно тем, в чьих семьях были случаи генетических заболеваний.
Какую информацию может дать анализ? Анализ позволяет выявить носительство моногенных заболеваний у будущих родителей. В случае обнаружения носительства заболевания у обоих супругов требуется консультация генетика до наступления или на самых ранних сроках беременности.
Что может рекомендовать врач генетик при обнаружении носительства заболевания у обоих супругов? Перенатальную диагностику плода на наличие заболевания.
Кариотипирование
Рекомендовано поводить анализ обоим супругам в случае невынашивания беременности.
Какую информацию дает анализ? Анализ позволяет выявлять сбалансированные хромосомные перестройки, которые могут быть причиной невынашиваемости беременности.
Что может рекомендовать ваш врач при наличии сбалансированных хромосомных перестроек? Перенатальное кариотипирование плода в I триместре беременности для коррекции тактики ведения беременности.
Общие понятия по мультифакториальным заболеваниям
Генетическая информация в сочетании с влиянием внешней среды определяют уникальность каждого человека. Под «внешней средой» мы здесь понимаем совокупность множества факторов влияющих на жизнь человека таких, как вредные привычки, воспитание, профессиональная деятельность, физическая активность и многих, многих других.
Генетическая информация + Внешняя среда = Уникальный человек
Генетическая (или наследственная) информация содержится в нуклеотидной последовательности ДНК. Нить ДНК плотно упакована (скручена) в хромосомы. Каждая клетка человеческого организма содержит 23 пары хромосом. В каждой паре одна хромосома от матери, одна от отца. Исключение составляют половые клетки (яйцеклетки и сперматозоиды), которые содержат по одной хромосоме из каждой пары. После оплодотворения яйцеклетки сперматозоидом, получается зародыш с 23 парами хромосом, из которого развивается человек с полным объемом генетической информации.
Молекула ДНК представляет собой последовательность нуклеотидов («букв»). Эта последовательность нуклеотидов кодирует наследственную информацию. В результате международной программы «Геном человека» в 2003 году была расшифрована такая последовательность для всех хромосом человека (за исключением ряда участков, чья расшифровка затруднена в связи с их структурными особенностями).
Расшифровка генома человека показала, что генетическая информация двух людей, не связанных родством, совпадает всего лишь на 99%. Оставшийся 1% в совокупности с «внешней средой» отвечает за многообразие внешности, способностей, характера, за все отличия людей друг от друга.
Кроме внешности, характера или способностей человек наследует также особенности своего здоровья – устойчивость к стрессам, способность переносить физические нагрузки, особенности обмена веществ, переносимость медикаментов. Уникальность наследственной информации проявляется в особенностях функционирования организма на молекулярном уровне. Например, у одного человека определенный фермент может быть более активен, чем у другого, а у третьего этот фермент может вообще отсутствовать. Такие вариации могут приводить к различным заболеваниям, причем эти заболевания делятся на наследственные и мультифакториальные.
Например, у одного человека определенный фермент может быть более активен, чем у другого, а у третьего этот фермент может вообще отсутствовать. Такие вариации могут приводить к различным заболеваниям, причем эти заболевания делятся на наследственные и мультифакториальные.
В случае наследственных заболеваний изменения в геноме (мутации) напрямую ведут к развитию заболевания. То есть если мутацию передал один из родителей, то человек становится носителем заболевания, если мутацию передали оба родителя, то человек заболеет. К самым распространенным генетическим (или наследственным) заболеваниям относят муковисцидоз, фенилкетонурию, гемофилию, дальтонизм и другие.
Наследственные заболевания достаточно редкое явление, в основном вариации в геноме связаны с мультифакториальными заболеваниями.
Мультифакториальные заболевания.Мультифакториальные заболевания – это заболевания, возникающие при неблагоприятном сочетании ряда факторов: генетических особенностях (генетической предрасположенности) и влияния «внешней среды» — вредных привычек, образа жизни, профессиональной деятельности и других. За генетическую предрасположенность чаще всего отвечают так называемые SNP (single nucleotide polymorphism – однонуклеотиные полиморфизмы или замены). То есть замена одной буквы в нити ДНК на другую.
За генетическую предрасположенность чаще всего отвечают так называемые SNP (single nucleotide polymorphism – однонуклеотиные полиморфизмы или замены). То есть замена одной буквы в нити ДНК на другую.
В случае наследственных заболеваний мы использовали термин «мутация», а в случае мультифакториальных заболеваний – «полиморфизм». С молекулярной точки зрения это одно и то же: количественные и качественные изменения в структуре ДНК. Основные их различия состоят в частоте встречаемости и последствиях для организма. Внутри популяции определенная мутация встречается с частотой 1-2%. Они либо не совместимы с жизнью либо обязательно приводят к развитию заболевания. Полиморфизмы встречаются с частотой больше 1-2%. Они могут быть нейтральными (никак не воздействовать на организм), предрасполагать к заболеваниям при определенных условиях либо, наоборот, в некоторой степени защищать от развития заболевания.
То есть само наличие генетической предрасположенности к заболеванию не обязательно приведет к развитию этого заболевания.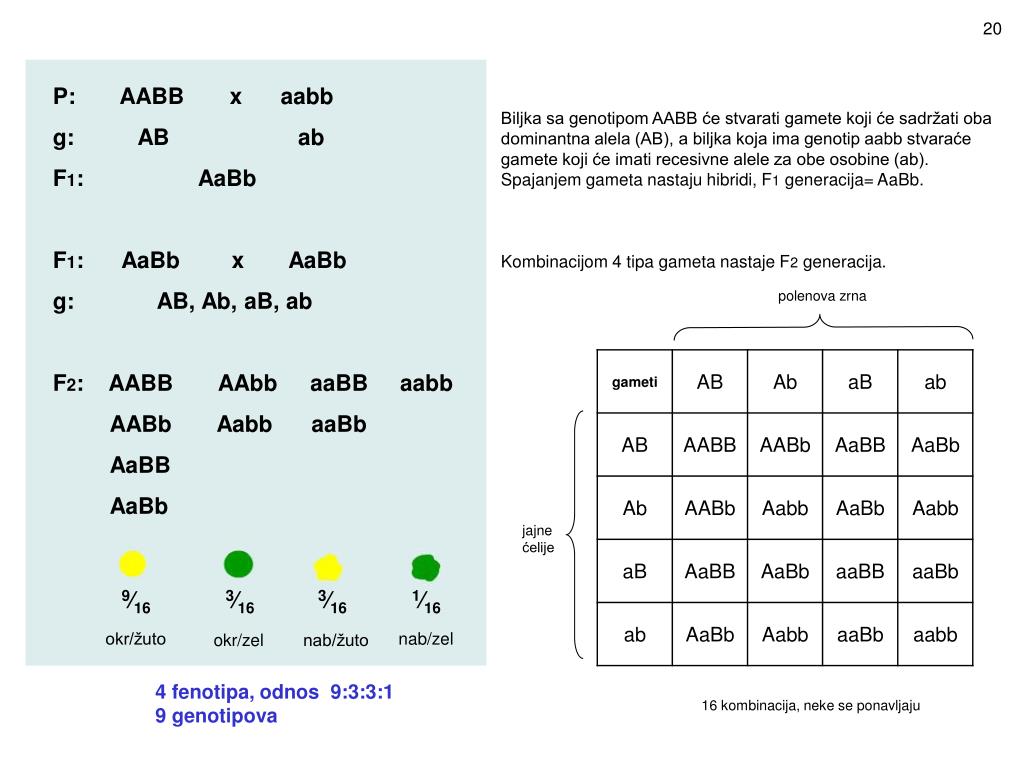 Однако при наличии неблагоприятных факторов «внешней среды», человек с наследственной предрасположенностью имеет значительно большую вероятность заболеть, чем люди, не имеющие такой предрасположенности.
Однако при наличии неблагоприятных факторов «внешней среды», человек с наследственной предрасположенностью имеет значительно большую вероятность заболеть, чем люди, не имеющие такой предрасположенности.
В качестве наглядного примера можно привести предрасположенность к раку легкого и такой фактор «внешней среды», как курение. Всем известно о вреде курения и о том, что эта вредная привычка может привести к раку. Однако от курильщиков в качестве опровержения вреда курения часто можно услышать истории про то, как кто-либо курил всю жизнь по две пачки сигарет в день и прожил до 90 лет. Да, такое случается, только это не опровергает вред курения, это говорит о том, что одни люди предрасположены генетически к развитию рака легкого, а другие нет. И в сочетании с таким фактором «внешней среды», как курение, наследственная предрасположенность с большой вероятностью приведет к развитию рака.
Что же нам может дать знание о том, что мы генетически предрасположены к какому-либо заболеванию?
Часто можно услышать такое мнение, что лучше не знать о своей предрасположенности к различным заболеваниям – все равно ведь ничего не изменить, только лишний повод понервничать. Но это не так!
Но это не так!
Во-первых, давайте вспомним, что заболевание возникает при наличии неблагоприятных факторов «внешней среды». Влияние этих факторов во многих случаях можно исключить. Например, наличие предрасположенности к раку легкого – весомый довод в пользу отказа от этой вредной привычки.
Во-вторых, в ряде случаев существуют эффективные методы профилактики заболевания, к которому есть генетическая предрасположенность. Например, при предрасположенности к тромбоэмболии, регулярный прием малых доз аспирина значительно снижает риск тромбозов.
В-третьих, гораздо легче лечить болезни на ранней стадии. Но в это время заболевание зачастую протекает бессимптомно. Мало у кого хватает желания, временных и финансовых ресурсов для регулярного полного обследования своего организма. Если мы знаем особенности своего генома, знаем конкретный перечень заболеваний, к которым мы предрасположены, нам будет легче отследить эти заболевания на ранней стадии.
В-четвертых, наличие генетической предрасположенности к определенному заболеванию может повлиять на схему лечения данного заболевания. Например, регуляция кровяного давления – достаточно сложный процесс, за который отвечает большое количество генов. В зависимости от того, изменение в каком именно гене ведет к развитию артериальной гипертензии, врач может назначить наиболее эффективное лечение.
Например, регуляция кровяного давления – достаточно сложный процесс, за который отвечает большое количество генов. В зависимости от того, изменение в каком именно гене ведет к развитию артериальной гипертензии, врач может назначить наиболее эффективное лечение.
Установление (определение) отцовства, родства и идентификация личности
Генетическая экспертиза по определению отцовства всегда была и остается дорогостоящей, хлопотной и психологически травматичной процедурой: необходимо обратиться в суд, добиться решения суда о назначении экспертизы, всем членам семьи явиться в назначенный судом медико генетический центр, с соблюдением юридических процедур сдать кровь и обычно достаточно долго дожидаться результата.
Мы предлагаем Вам, используя наши возможности (основанные на достижениях научно-технического прогресса в области медицины и лабораторной диагностики), провести генетическое исследование по установлению отцовства и биологического родства.
Технологически процедура выполнения исследования, а соответственно и полученные результаты идентичны проведению экспертизы определения отцовства.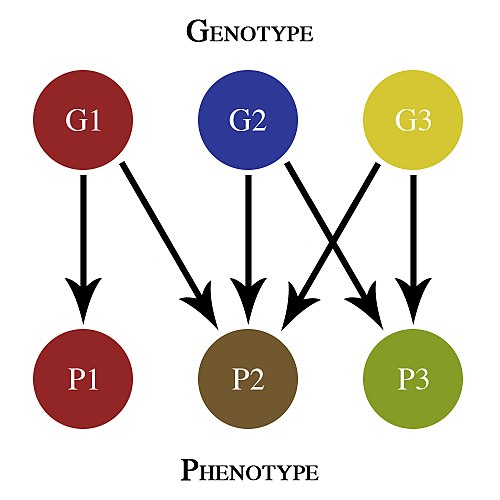 Однако используя тот факт, что клетки любых тканей человека содержат абсолютно идентичную ДНК с клетками крови, мы имеем возможность упростить процедуру взятия материала, не потеряв в достоверности исследования.
Однако используя тот факт, что клетки любых тканей человека содержат абсолютно идентичную ДНК с клетками крови, мы имеем возможность упростить процедуру взятия материала, не потеряв в достоверности исследования.
Для этого всего лишь необходимо произвести отбор материала (соскоба эпителия с внутренней поверхности щеки) для исследований у ребенка и предполагаемого отца в строгом соответствии с инструкцией (забор слюны, забор крови), то есть соблюсти правила взятия материала, порядок маркировки, условия хранения и доставки в регистратуру лаборатории больницы.
Лаборатория проводит сравнительный анализ ДНК из полученных от заказчика образцов. Заказчику выдается заключение, содержащее описание методик и тест-систем, использованных в исследовании, перечень исследованных участков ДНК (локусов), генотипы («генетические портреты») ребенка и родителя, все расчеты сравнения этих генотипов, то есть достоверную объективную информацию, которая может быть воспроизведена (проверена) в любой оснащенной специализированной лаборатории с получением идентичного результата.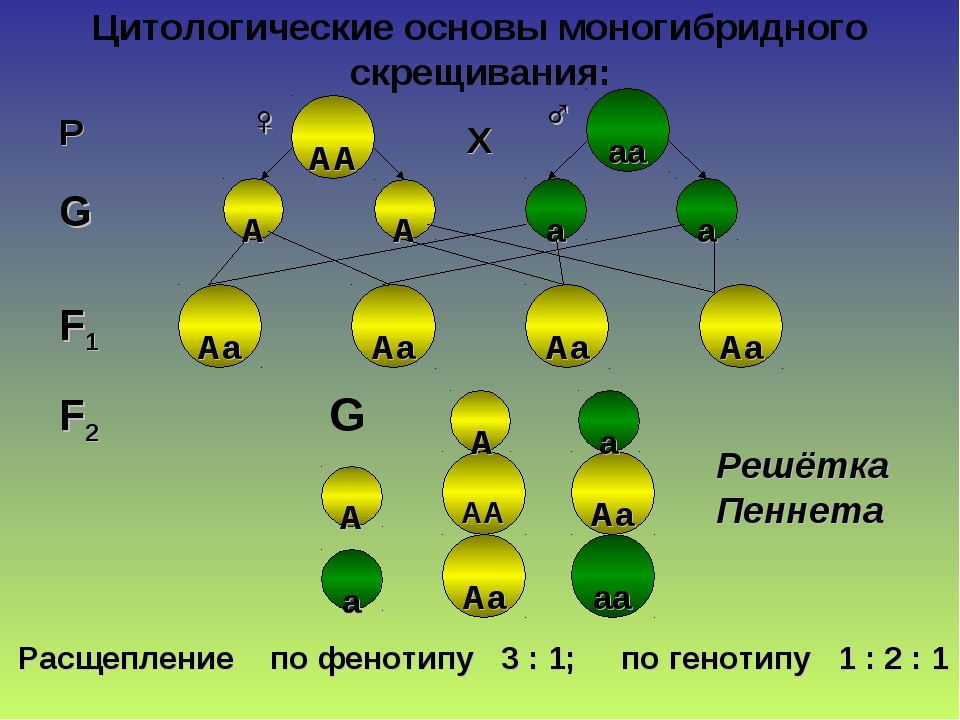 Точность отрицательного заключения («не является отцом») – 100 %, точность положительного («является отцом») – не менее 99,99 %.
Точность отрицательного заключения («не является отцом») – 100 %, точность положительного («является отцом») – не менее 99,99 %.
Спортивная генетика и генетический паспорт
Анализируя результаты последних крупных мировых соревнований, в том числе Олимпийских игр в Пекине, становится очевидным, что успехи спортивной науки и практики во многом связаны с использованием современных научных достижений генетики.
Спортивная генетика, и связанные с ней генетические тестирования абсолютно безопасны в отличие от применения допинга и учитывает индивидуальные особенности организма человека лучше любых других существующих методов. Более того, генетическое тестирование на любом этапе спортивной подготовки может дать первичную информацию тренерам для отбора в спортивные секции и выбора индивидуального подхода к тренировкам при «занятии для себя». С другой стороны, не меньшее значение имеет индивидуальный подход к процедурам восстановления. Известно, что разные люди по-разному и с разной скоростью воспринимают тренировочные нагрузки. Кому-то свойственна быстрая адаптация, кто-то восстанавливается медленнее. Большинство из этих процессов, так или иначе, обусловлено генетическими механизмами, именно эти процесы изучаются в разделе спортивная генетика
Кому-то свойственна быстрая адаптация, кто-то восстанавливается медленнее. Большинство из этих процессов, так или иначе, обусловлено генетическими механизмами, именно эти процесы изучаются в разделе спортивная генетика
Показателен пример четкой зависимости уровня артериального давления от работы некоторых генов. Если человек, обладающий геном “повышенного давления”, получит высокую дозу нагрузки после перерыва, то резко возрастает вероятность инфаркта миокарда. С другой стороны, такие люди быстрее восстанавливаются при небольших и регулярных нагрузках. Наращивание мышечной массы также находиться в прямой зависимости от генов – некоторым из нас для «накачки мышц» достаточно нескольких тренировок, другим нужно много и долго тренироваться. Все это обусловлено Вашей генетикой.
В последнее время среди мирового Спортивного сообщества и в различных видах спорта (футбол, тяжелая атлетика, теннис, бокс и т.д.) отчетливо формируется интерес к спортивной генетике, а в частности к использованию молекулярно-генетических методов и технологий в практике подготовки спортсменов.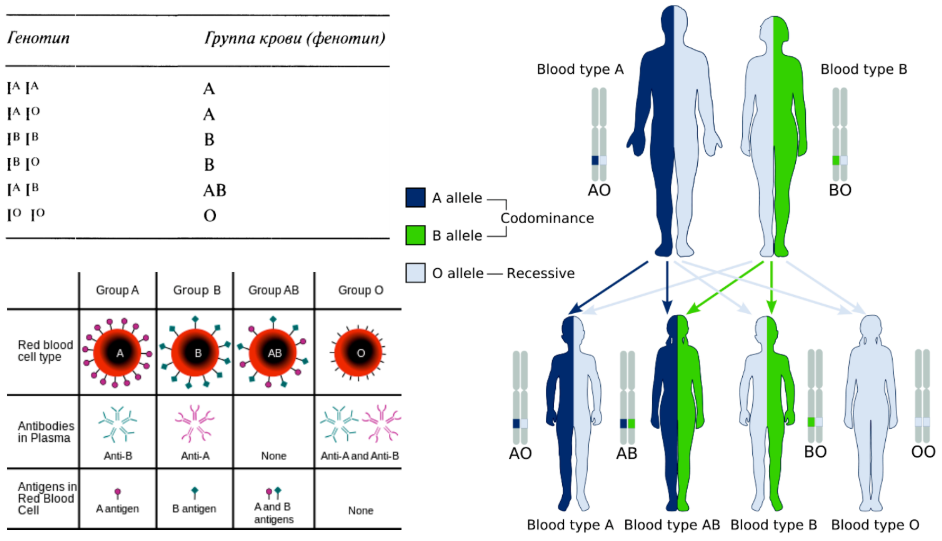 При этом, генетические технологии применяются как для отбора наиболее перспективных по наследственным качествам кандидатов, так и в целях индивидуализации и повышения адекватности тренировочного процесса, в целом способствующих повышению результативности самого спортсмена и спорта в целом.
При этом, генетические технологии применяются как для отбора наиболее перспективных по наследственным качествам кандидатов, так и в целях индивидуализации и повышения адекватности тренировочного процесса, в целом способствующих повышению результативности самого спортсмена и спорта в целом.
Сегодня генетический паспорт спортсмена имеют уже многие футболисты и теннисисты сборной России, профессиональные боксеры и другие известные и уважаемые спортсмены.
Орфанные заболевания в РоссииВ России редкими предложено считать заболевания с «распространенностью не более 10 случаев на 100 000 человек».
В список орфанных болезней специалисты Минздравсоцразвития РФ в 2012 году внесли 230 наименований, однако в случае выявления новых болезней список будет пополняться. По данным Формулярного комитета Российской академии медицинских наук (РАМН), россиян с этими болезнями насчитывается около 300 тысяч человек.
Орфанные, или «сиротские», заболевания представляют собой группу редких болезней. На данный момент описано около 7 000 их разновидностей.
На данный момент описано около 7 000 их разновидностей.
Орфанные заболевания встречаются у небольшой части населения, их распространенность составляет около 1 : 2 000 и реже. Данная статистика весьма условна, так как одно и то же заболевание может быть редким в одном регионе и частым в другом. Например, проказа часто встречается в Индии, но редко в Европе.
Откуда берутся орфанные болезни?
Примерно половина орфанных заболеваний обусловлена генетическими отклонениями. Симптомы могут быть очевидны с рождения или проявляться в детском возрасте. В то же время более 50% редких заболеваний проявляются уже во взрослом возрасте.
Реже встречаются токсические, инфекционные или аутоиммунные «сиротские» болезни. Причинами их развития могут быть наследственность, ослабление иммунитета, плохая экология, высокий радиационный фон, вирусные инфекции у мамы и у самих детей в раннем возрасте.
Большинство орфанных заболеваний – хронические. Они в значительной мере ухудшают качество жизни человека и могут стать причиной летального исхода. Для большинства таких болезней не существует эффективного лечения. Основа терапии таких больных – улучшение качества и увеличение продолжительности жизни пациентов.
Для большинства таких болезней не существует эффективного лечения. Основа терапии таких больных – улучшение качества и увеличение продолжительности жизни пациентов.
В настоящее время в развитых странах ведется активное изучение орфанных заболеваний. Оно затрудняется малым количеством пациентов, недостаточным для проведения полноценного исследования. Однако на базе научных изысканий синтезируются новые препараты и выстраиваются схемы лечения больных.
Диагностика орфанных болезней
Единственный сегодня способ поиска причин редких заболеваний – это ДНК диагностика. В случае если заболевание хорошо изучено, то его диагностику осуществляют по разработанным протоколам обычными генетическими методами, если природа заболевания не понятна, или нет мажорных (частых) мутаций, то диагностику в таких семьях проводят методом полногеномного секвенирования с последующей верификацией другими методами.
Классный урок на «Радио России – Тамбов», эфир 28 апреля 2020 года
Автор ГТРК «ТАМБОВ» На чтение 16 мин. Просмотров 149 Опубликовано
Просмотров 149 Опубликовано
Урок биологии для десятиклассников на канале «Радио России» в рамках совместного проекта ГТРК «Тамбов», Управления образования и науки Тамбовской области и ТГУ имени Г.Р. Державина ведут сегодня педагоги университета и 13-го Центра образования Тамбова. Татьяна Николаевна Киселева рассказывает о цитоплазматической наследственности и генотипическом определении пола. А Инна Вячеславовна Баженова — о взаимодействии неаллейных генов.
БИОЛОГИЯ ДЛЯ ДЕСЯТИКЛАССНИКОВ
Предмет: Биология (для 10 класса)
Педагог: Инна Вячеславовна Баженова – учитель биологии МАОУ «Центр образования №13 им. Н.А. Кузнецова»
Тема: Взаимодействие неаллейных генов.
Генотип – это не простая совокупность генов, а система сложного взаимодействия между ними Если развитие признака контролируется более чем одной парой генов, то это означает, что он находится под полигенным контролем.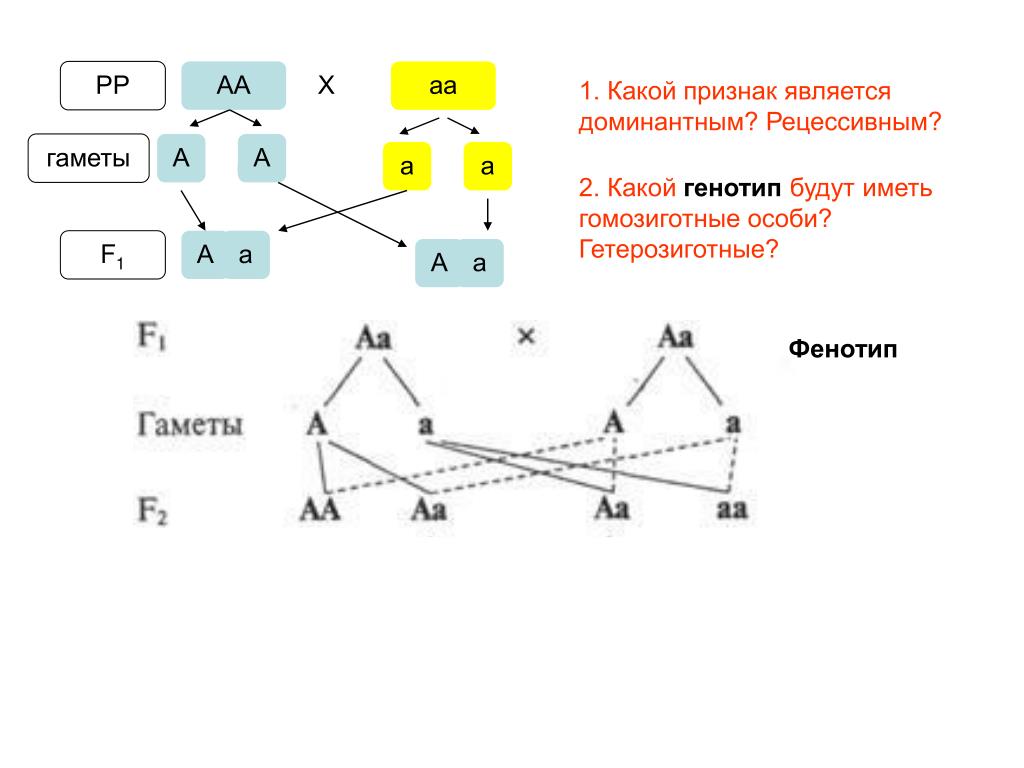 Взаимодействие генов — это совместное действие нескольких генов, в результате которого появляется признак, которого нет у родителей, или усиливается проявление уже имеющегося признака. Первый случай неаллельного взаимодействия был описан в качестве примера отклонения от законов Менделя английскими учеными У. Бетсоном и Р. Пеннетом в 1904 г. при изучении наследования формы гребня у кур. Для объяснения результатов взаимодействия генов важно понимать механизм формирования признаков. Ген — это участок ДНК, в котором закодирована информация об одном белке. В простейшем случае формирование признака может происходить в результате действия одного белка, синтез которого определяется одним геном: — но обычно признак формируется в результате сложных биохимических процессов. В клетке происходит взаимодействие между белками-ферментами, синтез которых определяется генами, или между веществами, которые образуются под влиянием этих ферментов. Возможны следующие типы проявления генов в фенотипе:
Взаимодействие генов — это совместное действие нескольких генов, в результате которого появляется признак, которого нет у родителей, или усиливается проявление уже имеющегося признака. Первый случай неаллельного взаимодействия был описан в качестве примера отклонения от законов Менделя английскими учеными У. Бетсоном и Р. Пеннетом в 1904 г. при изучении наследования формы гребня у кур. Для объяснения результатов взаимодействия генов важно понимать механизм формирования признаков. Ген — это участок ДНК, в котором закодирована информация об одном белке. В простейшем случае формирование признака может происходить в результате действия одного белка, синтез которого определяется одним геном: — но обычно признак формируется в результате сложных биохимических процессов. В клетке происходит взаимодействие между белками-ферментами, синтез которых определяется генами, или между веществами, которые образуются под влиянием этих ферментов. Возможны следующие типы проявления генов в фенотипе:- один признак формируется в результате взаимодействия нескольких белков, синтез которых определяется несколькими генами:
- один ген определяет синтез белка, который влияет на формирование нескольких признаков:
 Возможно взаимодействие как между аллельными генами, так и между неаллельными. Неаллельные гены — это гены, расположенные в различных участках (локусах) хромосом и кодирующие неодинаковые белки. Формы взаимодействия неаллельных генов:
Возможно взаимодействие как между аллельными генами, так и между неаллельными. Неаллельные гены — это гены, расположенные в различных участках (локусах) хромосом и кодирующие неодинаковые белки. Формы взаимодействия неаллельных генов:- комплементарность;
- эпистаз;
- полимерия.
 При скрещивании двух растений с белыми цветками у гибридов F1 цветки оказались пурпурными. При самоопылении растений из F1 в F2 наблюдалось расщепление растений по окраске цветков в отношении, близком к 9:7. Пурпурные цветки были обнаружены у 9/16 растений, белые у 7/16. Объяснение такого результата состоит в том, что каждый из доминантных генов не может вызвать появление окраски, определяемой пигментом антоцианом. У душистого горошка есть ген А, обусловливающий синтез бесцветного предшественника пигмента — пропигмента. Ген В определяет синтез фермента, под действием которого из пропигмента образуется пигмент. Цветки душистого горошка с генотипом ааВВ и ААbb имеют белый цвет: в первом случае есть фермент, но нет пропигмента, во втором — есть пропигмент, но нет фермента, переводящего пропигмент в пигмент. Проведем скрещивание двух растений душистого горошка с белыми цветками. В одной из линий, АAbb, есть доминантный аллель А, а у другой, ааBB, есть доминантный аллель В. У растений, имеющих доминантные гены А и В одновременно, есть и пропигмент (обеспечиваемый А), и фермент (обеспечиваемый В), необходимые для образования пурпурного пигмента.
При скрещивании двух растений с белыми цветками у гибридов F1 цветки оказались пурпурными. При самоопылении растений из F1 в F2 наблюдалось расщепление растений по окраске цветков в отношении, близком к 9:7. Пурпурные цветки были обнаружены у 9/16 растений, белые у 7/16. Объяснение такого результата состоит в том, что каждый из доминантных генов не может вызвать появление окраски, определяемой пигментом антоцианом. У душистого горошка есть ген А, обусловливающий синтез бесцветного предшественника пигмента — пропигмента. Ген В определяет синтез фермента, под действием которого из пропигмента образуется пигмент. Цветки душистого горошка с генотипом ааВВ и ААbb имеют белый цвет: в первом случае есть фермент, но нет пропигмента, во втором — есть пропигмент, но нет фермента, переводящего пропигмент в пигмент. Проведем скрещивание двух растений душистого горошка с белыми цветками. В одной из линий, АAbb, есть доминантный аллель А, а у другой, ааBB, есть доминантный аллель В. У растений, имеющих доминантные гены А и В одновременно, есть и пропигмент (обеспечиваемый А), и фермент (обеспечиваемый В), необходимые для образования пурпурного пигмента. У гибридов F1 генотип AaBb, есть оба доминантных гена, поэтому они имеют пурпурные цветки. При самоопылении этих растений получаем F2. Результаты отражены в решётке Пеннета, розовым выделены генотипы тех растений, которые будут иметь пурпурные цветки.
У гибридов F1 генотип AaBb, есть оба доминантных гена, поэтому они имеют пурпурные цветки. При самоопылении этих растений получаем F2. Результаты отражены в решётке Пеннета, розовым выделены генотипы тех растений, которые будут иметь пурпурные цветки.| гаметы | AB | Ab | aB | ab |
| AB | AABB | AABb | AaBB | AaBb |
| Ab | AABb | AAbb | AaBb | Aabb |
| aB | AaBB | AaBb | aaBB | aaBb |
| ab | AaBb | Aabb | aaBb | aabb |
 В этом случае расщепление будет 9:6:1. Например, это наблюдается при наследовании формы плодов у тыквы: Возможно и возникновение четырёх фенотипов. Например, при скрещивании кур с различной формой гребня. А_В_ — ореховидный А_bb — гороховидный aaB_ — розовидный aabb — простой (листовидный) Чтобы успешно решать задачи, надо помнить, что такое явление, как комплементарность, в принципе, возможно, и быть внимательным при написании генотипов особей и их гамет. Пример решения задачи Наследование слуха у человека определяется двумя доминантными генами из разных аллельных пар, один из которых детерминирует развитие слухового нерва, а другой – улитки. Определить вероятность рождения глухих детей, если оба родителя глухие, но по разным генетическим причинам (у одного отсутствует слуховой нерв, у другого улитка). По генотипу оба родителя являются дигомозиготными. Здесь проявляется I закон Менделя — закон единообразия гибридов первого поколения. Возможен только один вариант генотипа ребенка от такого брака.
В этом случае расщепление будет 9:6:1. Например, это наблюдается при наследовании формы плодов у тыквы: Возможно и возникновение четырёх фенотипов. Например, при скрещивании кур с различной формой гребня. А_В_ — ореховидный А_bb — гороховидный aaB_ — розовидный aabb — простой (листовидный) Чтобы успешно решать задачи, надо помнить, что такое явление, как комплементарность, в принципе, возможно, и быть внимательным при написании генотипов особей и их гамет. Пример решения задачи Наследование слуха у человека определяется двумя доминантными генами из разных аллельных пар, один из которых детерминирует развитие слухового нерва, а другой – улитки. Определить вероятность рождения глухих детей, если оба родителя глухие, но по разным генетическим причинам (у одного отсутствует слуховой нерв, у другого улитка). По генотипу оба родителя являются дигомозиготными. Здесь проявляется I закон Менделя — закон единообразия гибридов первого поколения. Возможен только один вариант генотипа ребенка от такого брака. У ребенка будет развит и слуховой нерв, и улитка — ребенок не будет глухим, в отличие от родителей. Эпистаз Эпистаз — взаимодействие неаллельных генов, при котором один из них подавляется другим. Подавляющий ген называется эпистатичным, супрессором, подавляемый — гипостатичным. Если эпистатичный ген не имеет собственного фенотипического проявления, то он называется ингибитором и обозначается буквой I. Эпистатическое взаимодействие неаллельных генов может быть доминантным и рецессивным. Доминантный эпистаз При доминантном эпистазе проявление гипостатичного гена (В, b) подавляется доминантным эпистатичным геном (I > В, b). Примером доминантного эпистаза служит наследование окраски шерсти у лошадей и окраски плодов у тыквы. Расщепление по фенотипу при доминантном эпистазе может происходить в соотношении 12:3:1, 13:3. Последний вариант возникает, когда рецессивная гомозигота по гипостатичному гену фенотипически неотличима от фенотипа I (например, обе формы неокрашены).
У ребенка будет развит и слуховой нерв, и улитка — ребенок не будет глухим, в отличие от родителей. Эпистаз Эпистаз — взаимодействие неаллельных генов, при котором один из них подавляется другим. Подавляющий ген называется эпистатичным, супрессором, подавляемый — гипостатичным. Если эпистатичный ген не имеет собственного фенотипического проявления, то он называется ингибитором и обозначается буквой I. Эпистатическое взаимодействие неаллельных генов может быть доминантным и рецессивным. Доминантный эпистаз При доминантном эпистазе проявление гипостатичного гена (В, b) подавляется доминантным эпистатичным геном (I > В, b). Примером доминантного эпистаза служит наследование окраски шерсти у лошадей и окраски плодов у тыквы. Расщепление по фенотипу при доминантном эпистазе может происходить в соотношении 12:3:1, 13:3. Последний вариант возникает, когда рецессивная гомозигота по гипостатичному гену фенотипически неотличима от фенотипа I (например, обе формы неокрашены). Наследование окраски шерсти у собак (пример доминантного эпистаза): A — черная окраска, а — коричневая, I — подавляет окраску, i — не подавляет. Рецессивный эпистаз Рецессивный эпистаз — это подавление рецессивным аллелем эпистатичного гена в гомозиготном состоянии аллелей гипостатичного гена (ii > В, b). Расщепление по фенотипу может идти в соотношении 9:3:4, 9:7. Последний вариант возникает, когда рецессивная гомозигота по гипостатичному гену фенотипически неотличима от фенотипа ii (например, обе формы неокрашены). Рецессивный эпистаз проявляется при наследовании окраски шерсти у домовых мышей. А — окраска агути (рыжевато-серая) а — черная окраска В — способствует проявлению окраски b — супрессор (подавляет действие А и а) Мыши с генотипом А-bb и ааbb имеют одинаковый фенотип — все белые. Широко известным примером рецессивного эпистаза является Бомбейский феномен, названный так в результате зафиксированного случая в индийском городе Бомбеи.
Наследование окраски шерсти у собак (пример доминантного эпистаза): A — черная окраска, а — коричневая, I — подавляет окраску, i — не подавляет. Рецессивный эпистаз Рецессивный эпистаз — это подавление рецессивным аллелем эпистатичного гена в гомозиготном состоянии аллелей гипостатичного гена (ii > В, b). Расщепление по фенотипу может идти в соотношении 9:3:4, 9:7. Последний вариант возникает, когда рецессивная гомозигота по гипостатичному гену фенотипически неотличима от фенотипа ii (например, обе формы неокрашены). Рецессивный эпистаз проявляется при наследовании окраски шерсти у домовых мышей. А — окраска агути (рыжевато-серая) а — черная окраска В — способствует проявлению окраски b — супрессор (подавляет действие А и а) Мыши с генотипом А-bb и ааbb имеют одинаковый фенотип — все белые. Широко известным примером рецессивного эпистаза является Бомбейский феномен, названный так в результате зафиксированного случая в индийском городе Бомбеи. Доктор Бхенде обнаружил, что у людей рецессивных по гену h (hh) на поверхности эритроцитов не синтезируются агглютиногены — в результате этого они могут быть универсальными донорами. Говоря проще о Бомбейском феномене: у людей с генотипом hh всегда обнаруживается первая группа крови при любом генотипе — IAIA, IBIB, IAIB. Ген h подавляет гены IA и IB — на поверхности эритроцитов не образуются агглютиногены A и B. Пример решения задачи «Редкий рецессивный ген (h) в гомозиготном состоянии обладает эпистатическим действием по отношению к генам IA, IB и изменяет их действие до I группы крови (бомбейский феномен). Определите возможные группы крови у детей, если у мужа II гомозиготная, у жены IV и оба родителя гетерозиготны по эпистатическому гену». Вероятность рождения детей с i(0) группой крови в данном случае равна 2/8, или 1/4 (25%). Генотипами, у которых будет i(0) группа крови являются: IAIAhh и IAIBhh.
Доктор Бхенде обнаружил, что у людей рецессивных по гену h (hh) на поверхности эритроцитов не синтезируются агглютиногены — в результате этого они могут быть универсальными донорами. Говоря проще о Бомбейском феномене: у людей с генотипом hh всегда обнаруживается первая группа крови при любом генотипе — IAIA, IBIB, IAIB. Ген h подавляет гены IA и IB — на поверхности эритроцитов не образуются агглютиногены A и B. Пример решения задачи «Редкий рецессивный ген (h) в гомозиготном состоянии обладает эпистатическим действием по отношению к генам IA, IB и изменяет их действие до I группы крови (бомбейский феномен). Определите возможные группы крови у детей, если у мужа II гомозиготная, у жены IV и оба родителя гетерозиготны по эпистатическому гену». Вероятность рождения детей с i(0) группой крови в данном случае равна 2/8, или 1/4 (25%). Генотипами, у которых будет i(0) группа крови являются: IAIAhh и IAIBhh. Эпистатический рецессивный ген hh в гомозиготном состоянии всегда приводит к i(0) группе крови. Полимерия Полимерия — взаимодействие неаллельных генов, при котором степень проявления признака зависит от количества генов. Полимерные гены обозначаются одинаковыми буквами, а аллели одного гена имеют одинаковый нижний индекс , в соответствии с числом неаллельных генов. Полимерный тип взаимодействия был впервые установлен Г. Нильсеном-Эле при изучении наследования окраски зерна у пшеницы Например, у пшеницы А — тёмно-красный цвет зёрен, а — белый цвет зёрен. За цвет отвечают два гена — 1 и 2. Первый ген может быть представлен аллелями А1 и а1, второй — аллелями А2 и а2. В зависимости от того, каких аллелей больше — А или а, оттенок зёрен будет изменяться. Полимерное взаимодействие неаллельных генов может быть кумулятивным и некумулятивным. При кумулятивной (накопительной) полимерии степень проявления признака зависит от числа доминантных аллелей всех генов.
Эпистатический рецессивный ген hh в гомозиготном состоянии всегда приводит к i(0) группе крови. Полимерия Полимерия — взаимодействие неаллельных генов, при котором степень проявления признака зависит от количества генов. Полимерные гены обозначаются одинаковыми буквами, а аллели одного гена имеют одинаковый нижний индекс , в соответствии с числом неаллельных генов. Полимерный тип взаимодействия был впервые установлен Г. Нильсеном-Эле при изучении наследования окраски зерна у пшеницы Например, у пшеницы А — тёмно-красный цвет зёрен, а — белый цвет зёрен. За цвет отвечают два гена — 1 и 2. Первый ген может быть представлен аллелями А1 и а1, второй — аллелями А2 и а2. В зависимости от того, каких аллелей больше — А или а, оттенок зёрен будет изменяться. Полимерное взаимодействие неаллельных генов может быть кумулятивным и некумулятивным. При кумулятивной (накопительной) полимерии степень проявления признака зависит от числа доминантных аллелей всех генов. Чем больше доминантных аллелей генов, тем сильнее выражен тот или иной признак. У человека полимерное действие генов заложено в наследовании количественных признаков таких как рост, масса тела, интеллектуальные особенности, склонность к повышению артериального давления, устойчивость к инфекционным заболеваниям и других. Пример решения задачи «Цвет кожи у мулатов наследуется по типу полимерии. При этом данный признак контролируется 2 аутосомными несцепленными генами. Сын белой женщины и негра женился на белой женщине. Может ли этот ребенок быть темнее своего отца?» В данном случае полимерия проявляется в том, что чем больше доминантных генов в генотипе (A и B), тем более темный цвет кожи имеет человек. Это правило мы и применим для решения. В результате первого брака (вспоминаем закон единообразия Менделя) получается AaBb — средний мулат. По условиям задачи он берет в жены белую женщину aabb. Очевидно, что в этой семье ребенок не может быть темнее своего отца: дети могут быть или же средними мулатами (AaBb), как отец, либо белыми, как мать (aabb).
Чем больше доминантных аллелей генов, тем сильнее выражен тот или иной признак. У человека полимерное действие генов заложено в наследовании количественных признаков таких как рост, масса тела, интеллектуальные особенности, склонность к повышению артериального давления, устойчивость к инфекционным заболеваниям и других. Пример решения задачи «Цвет кожи у мулатов наследуется по типу полимерии. При этом данный признак контролируется 2 аутосомными несцепленными генами. Сын белой женщины и негра женился на белой женщине. Может ли этот ребенок быть темнее своего отца?» В данном случае полимерия проявляется в том, что чем больше доминантных генов в генотипе (A и B), тем более темный цвет кожи имеет человек. Это правило мы и применим для решения. В результате первого брака (вспоминаем закон единообразия Менделя) получается AaBb — средний мулат. По условиям задачи он берет в жены белую женщину aabb. Очевидно, что в этой семье ребенок не может быть темнее своего отца: дети могут быть или же средними мулатами (AaBb), как отец, либо белыми, как мать (aabb). При некумулятивной полимерии признак проявляется при наличии хотя бы одного из доминантных аллелей полимерных генов. Количество доминантных аллелей не влияет на степень выраженности признака. Расщепление по фенотипу происходит в соотношении 15:1 для двух генов, 63:1 для трёх генов и т.д. К взаимодействию неаллельных генов относят также явление плейотропии — множественного действия гена, влияния его на развитие нескольких признаков. Плейотропное действие генов является результатом серьезного нарушения обмена веществ, обусловленного мутантной структурой данного гена. Летальный эффект при переходе в гомозиготное состояние характерен для многих плейотропных мутаций. Так, у лисиц доминантные гены, контролирующие платиновую и беломордую окраски меха, не оказывающие летального действия в гетерозиготе, вызывают гибель гомозиготных зародышей на ранней стадии развития. Аналогичная ситуация имеет место при наследовании серой окраски шерсти у овец породы ширази и недоразвития чешуи у зеркального карпа.
При некумулятивной полимерии признак проявляется при наличии хотя бы одного из доминантных аллелей полимерных генов. Количество доминантных аллелей не влияет на степень выраженности признака. Расщепление по фенотипу происходит в соотношении 15:1 для двух генов, 63:1 для трёх генов и т.д. К взаимодействию неаллельных генов относят также явление плейотропии — множественного действия гена, влияния его на развитие нескольких признаков. Плейотропное действие генов является результатом серьезного нарушения обмена веществ, обусловленного мутантной структурой данного гена. Летальный эффект при переходе в гомозиготное состояние характерен для многих плейотропных мутаций. Так, у лисиц доминантные гены, контролирующие платиновую и беломордую окраски меха, не оказывающие летального действия в гетерозиготе, вызывают гибель гомозиготных зародышей на ранней стадии развития. Аналогичная ситуация имеет место при наследовании серой окраски шерсти у овец породы ширази и недоразвития чешуи у зеркального карпа. Летальный эффект мутаций приводит к тому, что животные этих пород могут быть только гетерозиготными и при внутрипородных скрещиваниях дают расщепление в соотношении 2 мутанта : 1 норма. Схема наследования платиновой окраски у лис F1
Летальный эффект мутаций приводит к тому, что животные этих пород могут быть только гетерозиготными и при внутрипородных скрещиваниях дают расщепление в соотношении 2 мутанта : 1 норма. Схема наследования платиновой окраски у лис F1| A | a | |
| A | AA погибают | Aa платин. |
| a | Aa платин. | aa черн. |
 Такое нарушение приводит к тому, что у человека формируются вывих хрусталика глаза, пороки клапана сердца, длинные и тонкие пальцы, пороки развития сосудов и частые вывихи суставов. Синдром Марфана назван по имени педиатра, который наблюдал девочку с этим заболеванием на протяжении 20 лет. Имеется много интересных фактов о людях, имеющих характерные признаки патологии. Первая манекенщица (Лесли Хорнби – «Твигги»), которая была прототипом для всех чрезмерно худых моделей, болела синдромом Марфана. Наиболее известные личности, о которых есть подобные сведения: президент А. Линкольн, скрипач Н. Паганини, писатель Г. Х. Андерсен, композитор С. Рахманинов.
Такое нарушение приводит к тому, что у человека формируются вывих хрусталика глаза, пороки клапана сердца, длинные и тонкие пальцы, пороки развития сосудов и частые вывихи суставов. Синдром Марфана назван по имени педиатра, который наблюдал девочку с этим заболеванием на протяжении 20 лет. Имеется много интересных фактов о людях, имеющих характерные признаки патологии. Первая манекенщица (Лесли Хорнби – «Твигги»), которая была прототипом для всех чрезмерно худых моделей, болела синдромом Марфана. Наиболее известные личности, о которых есть подобные сведения: президент А. Линкольн, скрипач Н. Паганини, писатель Г. Х. Андерсен, композитор С. Рахманинов. Предмет: Биология (для 10 класса)
Педагог: Татьяна Николаевна Киселева – ассистент кафедры довузовской подготовки ТГУ им. Г.Р.Державина
Тема: Цитоплазматическая наследственность. Генотипитическое определение пола.
Цитоплазматическая наследственность.
Генетическое определение пола.
 Пластидная наследственность – выявлена при наследовании пестролистной окраски. Связана с наличием в клетках только окрашенных, только бесцветных или их смеси пластид. Плазмидная наследственность – связана с генами, расположенными в плазмидах (коротких кольцевых молекул ДНК, находящихся вне нуклеотида бактериальной клетки), обеспечивает наследование устойчивости бактерий к действию лекарственных препаратов благодаря защитным белкам. Характерной чертой цитоплазматической наследственности является наследование по линии матери. Это связано с тем, что в яйцеклетке и пластид, и митохондрий очень много, а в мужских гаметах этих органоидов практически нет (так как эти клетки практически лишены цитоплазмы). В сперматозоидах присутствуют митохондрии, но они все равно не проникают в яйцеклетку, так как при слиянии гамет в яйцеклетку попадает только ядро сперматозоида, содержащее генетический материал. Таким образом, все митохондрии и пластиды зиготы достаются ей в наследство только от материнского организма.
Пластидная наследственность – выявлена при наследовании пестролистной окраски. Связана с наличием в клетках только окрашенных, только бесцветных или их смеси пластид. Плазмидная наследственность – связана с генами, расположенными в плазмидах (коротких кольцевых молекул ДНК, находящихся вне нуклеотида бактериальной клетки), обеспечивает наследование устойчивости бактерий к действию лекарственных препаратов благодаря защитным белкам. Характерной чертой цитоплазматической наследственности является наследование по линии матери. Это связано с тем, что в яйцеклетке и пластид, и митохондрий очень много, а в мужских гаметах этих органоидов практически нет (так как эти клетки практически лишены цитоплазмы). В сперматозоидах присутствуют митохондрии, но они все равно не проникают в яйцеклетку, так как при слиянии гамет в яйцеклетку попадает только ядро сперматозоида, содержащее генетический материал. Таким образом, все митохондрии и пластиды зиготы достаются ей в наследство только от материнского организма.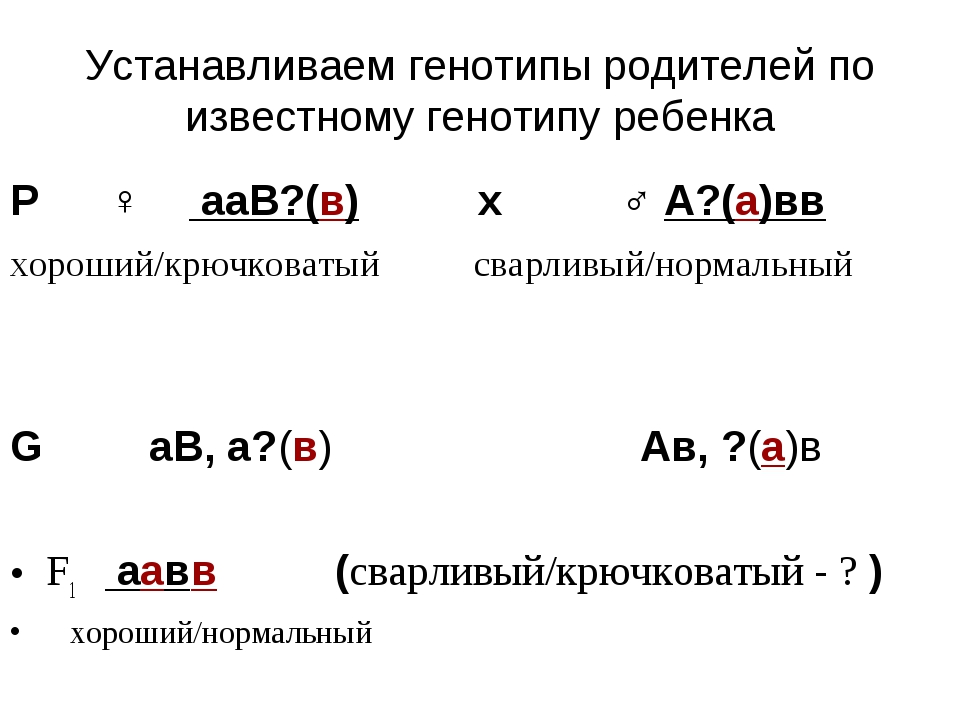 Показано, что хромосомная и нехромосомная наследственность могут взаимодействовать, приводя к сложным случаям наследования. Например, большинство белков митохондрий закодировано в ядерных генах и наследуется по правилам Менделя, а оставшиеся белки кодируются в ДНК самих митохондрий, которые передаются только по материнской линии. Генетическое определение пола Мы знаем, что большинство животных и двудомных растений являются раздельнополыми организмами, причем внутри вида количество особей мужского пола приблизительно равно количеству особей женского пола. Другими словами, каждому виду, имеющему четкое деление на мужские и женские особи, свойственно определенное соотношение полов, близкое 1:1. Проблема происхождения половых отличий, механизм определения пола и поддержание определенного соотношения полов в группах животных организмов важна как для практической, так и для теоретической биологии. Пол у животных чаще всего определяется в момент оплодотворения – сингамный тип определения пола.
Показано, что хромосомная и нехромосомная наследственность могут взаимодействовать, приводя к сложным случаям наследования. Например, большинство белков митохондрий закодировано в ядерных генах и наследуется по правилам Менделя, а оставшиеся белки кодируются в ДНК самих митохондрий, которые передаются только по материнской линии. Генетическое определение пола Мы знаем, что большинство животных и двудомных растений являются раздельнополыми организмами, причем внутри вида количество особей мужского пола приблизительно равно количеству особей женского пола. Другими словами, каждому виду, имеющему четкое деление на мужские и женские особи, свойственно определенное соотношение полов, близкое 1:1. Проблема происхождения половых отличий, механизм определения пола и поддержание определенного соотношения полов в группах животных организмов важна как для практической, так и для теоретической биологии. Пол у животных чаще всего определяется в момент оплодотворения – сингамный тип определения пола. Это – генетическое определение пола, так как зависит от баланса хромосом. Довольно часто его называют хромосомным определением пола. Если определение пола происходит еще до оплодотворения в процессе созревания яйцеклеток, то такое определение пола называют прогамным (т.е. перед оплодотворением, до слияния гамет). Характерно для тли, коловраток… Если определение пола происходит после оплодотворения, то подобный тип определения пола называют эпигамным (т.е. после слияния гамет). У ряда многоклеточных организмов определение пола происходит вне связи с оплодотворением. Это партеногенез (пример: дафнии – в зависимости от условий существования образуются потомки мужского или женского пола). Поскольку у большинства живых организмов пол чаще определяется в момент оплодотворения, то важнейшая роль в генетическом определении пола принадлежит хромосомному набору зиготы. Таким образом, определение пола обычно связывают с наличием одной пары хромосом, по которой отличается женский пол от мужского.
Это – генетическое определение пола, так как зависит от баланса хромосом. Довольно часто его называют хромосомным определением пола. Если определение пола происходит еще до оплодотворения в процессе созревания яйцеклеток, то такое определение пола называют прогамным (т.е. перед оплодотворением, до слияния гамет). Характерно для тли, коловраток… Если определение пола происходит после оплодотворения, то подобный тип определения пола называют эпигамным (т.е. после слияния гамет). У ряда многоклеточных организмов определение пола происходит вне связи с оплодотворением. Это партеногенез (пример: дафнии – в зависимости от условий существования образуются потомки мужского или женского пола). Поскольку у большинства живых организмов пол чаще определяется в момент оплодотворения, то важнейшая роль в генетическом определении пола принадлежит хромосомному набору зиготы. Таким образом, определение пола обычно связывают с наличием одной пары хромосом, по которой отличается женский пол от мужского. И одинаковые по внешнему виду хромосомы в клетках раздельнополых организмов называют аутосомами, а пару различающихся хромосом, неодинаковых у самца и самки называют половыми хромосомами. Общее число, размер и форма хромосом – кариотип. Вспомните например, хромосомный набор человека (кариотип). В наборе хромосом зиготы содержатся парные – гомологичные хромосомы. В женском кариотипе все хромосомы парные, в мужском имеется одна крупная равноплечая непарная хромосома, другая маленькая палочковидная, встречающаяся у мужчин. Таким образом, кариотип женщин содержит 22 пары хромосом — аутосом, одинаковые у мужчин и женщин. И одну пару хромосом, по которой различны оба пола — гетерохромосомы. Половые хромосомы у женщин одинаковы – X-хромосомы. Диплоидные (соматические) клетки женского организма содержат 2 X – хромосомы и в процессе овогенеза образуют яйцеклетки, имеющие по одной X – хромосоме. Пол, образующий гаметы, одинаковые по половой хромосоме, называют гомогаметным.
И одинаковые по внешнему виду хромосомы в клетках раздельнополых организмов называют аутосомами, а пару различающихся хромосом, неодинаковых у самца и самки называют половыми хромосомами. Общее число, размер и форма хромосом – кариотип. Вспомните например, хромосомный набор человека (кариотип). В наборе хромосом зиготы содержатся парные – гомологичные хромосомы. В женском кариотипе все хромосомы парные, в мужском имеется одна крупная равноплечая непарная хромосома, другая маленькая палочковидная, встречающаяся у мужчин. Таким образом, кариотип женщин содержит 22 пары хромосом — аутосом, одинаковые у мужчин и женщин. И одну пару хромосом, по которой различны оба пола — гетерохромосомы. Половые хромосомы у женщин одинаковы – X-хромосомы. Диплоидные (соматические) клетки женского организма содержат 2 X – хромосомы и в процессе овогенеза образуют яйцеклетки, имеющие по одной X – хромосоме. Пол, образующий гаметы, одинаковые по половой хромосоме, называют гомогаметным. У мужчин в диплоидных клетках имеется 1 X- хромосома и 1 Y – хромосома. При сперматогенезе получаются гаметы 2-х сортов (X и Y). Пол, который формируют гаметы, неодинаковые по половой хромосоме называют гетерогаметным. Таким образом, у человека хромосомный набор выглядит так: Женский: 2×2 + XX Мужской: 2×2 + XY Т.е. женский пол – гомогаметен, а мужской – гетерогаметен. У бабочек, птиц гомогаметным полом является мужской пол, т.е. петух будет иметь XX набор хромосом, а курица XY. Y-хромосома определяет развитие семенников, а в дальнейшем развитие мужских половых признаков. Подводя итог занятию, благодаря наличию ДНК не только в ядрах, но и в органеллах цитоплазмы живые организмы получают определенное преимущество в процессе эволюции. Дело в том, что ядро и хромосомы отличаются генетически обусловленной высокой устойчивостью к меняющимся условиям окружающей среды. В то же время хлоропласты и митохондрии развиваются до некоторой степени независимо от клеточного деления, непосредственно реагируя на воздействие окружающей среды.
У мужчин в диплоидных клетках имеется 1 X- хромосома и 1 Y – хромосома. При сперматогенезе получаются гаметы 2-х сортов (X и Y). Пол, который формируют гаметы, неодинаковые по половой хромосоме называют гетерогаметным. Таким образом, у человека хромосомный набор выглядит так: Женский: 2×2 + XX Мужской: 2×2 + XY Т.е. женский пол – гомогаметен, а мужской – гетерогаметен. У бабочек, птиц гомогаметным полом является мужской пол, т.е. петух будет иметь XX набор хромосом, а курица XY. Y-хромосома определяет развитие семенников, а в дальнейшем развитие мужских половых признаков. Подводя итог занятию, благодаря наличию ДНК не только в ядрах, но и в органеллах цитоплазмы живые организмы получают определенное преимущество в процессе эволюции. Дело в том, что ядро и хромосомы отличаются генетически обусловленной высокой устойчивостью к меняющимся условиям окружающей среды. В то же время хлоропласты и митохондрии развиваются до некоторой степени независимо от клеточного деления, непосредственно реагируя на воздействие окружающей среды. Таким образом, они имеют потенциальную возможность обеспечить быстрые реакции организма на изменение внешних условий. Домашнее задание: решить задачи на сцепленное с полом наследование. Задача 1. Мужчина с нормальным зрение женился на женщине-дальтонике (рецессивный ген d сцеплен с Х-хромосомой). Определите генотипы родителей, соотношение фенотипов и генотипов в потомстве. Задача 2. Мужчина, больной гемофилией вступает в брак с нормальной женщиной, отец которой страдал гемофилией. Определите вероятность рождения здоровых детей? Задача 3. У кур встречается сцепленный с полом летальный ген (а), вызывающий гибель эмбрионов, гетерозиготы по этому гену жизнеспособны. Скрестили нормальную курицу с гетерозиготным по этому гену петухом (у птиц гетерогаметный пол — женский). Составьте схему решения задачи, определите генотипы родителей, пол и генотип возможного потомства и вероятность вылупления курочек от общего числа жизнеспособного потомства. Задача 4. У человека наследование альбинизма не сцеплено с полом (А – наличие меланина в клетках кожи, а – отсутствие меланина в клетках кожи – альбинизм), а гемофилии – сцеплено с полом (XН – нормальная свёртываемость крови, Xh – гемофилия).
Таким образом, они имеют потенциальную возможность обеспечить быстрые реакции организма на изменение внешних условий. Домашнее задание: решить задачи на сцепленное с полом наследование. Задача 1. Мужчина с нормальным зрение женился на женщине-дальтонике (рецессивный ген d сцеплен с Х-хромосомой). Определите генотипы родителей, соотношение фенотипов и генотипов в потомстве. Задача 2. Мужчина, больной гемофилией вступает в брак с нормальной женщиной, отец которой страдал гемофилией. Определите вероятность рождения здоровых детей? Задача 3. У кур встречается сцепленный с полом летальный ген (а), вызывающий гибель эмбрионов, гетерозиготы по этому гену жизнеспособны. Скрестили нормальную курицу с гетерозиготным по этому гену петухом (у птиц гетерогаметный пол — женский). Составьте схему решения задачи, определите генотипы родителей, пол и генотип возможного потомства и вероятность вылупления курочек от общего числа жизнеспособного потомства. Задача 4. У человека наследование альбинизма не сцеплено с полом (А – наличие меланина в клетках кожи, а – отсутствие меланина в клетках кожи – альбинизм), а гемофилии – сцеплено с полом (XН – нормальная свёртываемость крови, Xh – гемофилия). Определите генотипы родителей, а также возможные генотипы, пол и фенотипы детей от брака дигомозиготной нормальной по обеим аллелям женщины и мужчины альбиноса, больного гемофилией. Составьте схему решения задачи. Задача 5. Глухота — аутосомный признак; дальтонизм – признак, сцепленный с полом. В браке здоровых родителей родился ребёнок глухой дальтоник. Составьте схему решения задачи. Определите генотипы родителей и ребёнка, его пол, генотипы и фенотипы возможного потомства, вероятность рождения детей с обеими аномалиями. Какие законы наследственности проявляются в данном случае? Ответ обоснуйте.
Определите генотипы родителей, а также возможные генотипы, пол и фенотипы детей от брака дигомозиготной нормальной по обеим аллелям женщины и мужчины альбиноса, больного гемофилией. Составьте схему решения задачи. Задача 5. Глухота — аутосомный признак; дальтонизм – признак, сцепленный с полом. В браке здоровых родителей родился ребёнок глухой дальтоник. Составьте схему решения задачи. Определите генотипы родителей и ребёнка, его пол, генотипы и фенотипы возможного потомства, вероятность рождения детей с обеими аномалиями. Какие законы наследственности проявляются в данном случае? Ответ обоснуйте.Темные секреты ДНК. Ученые рассказали об опасности «чистоты крови»
https://ria.ru/20200806/1575417295.html
Темные секреты ДНК. Ученые рассказали об опасности «чистоты крови»
Темные секреты ДНК. Ученые рассказали об опасности «чистоты крови» — РИА Новости, 06.08.2020
Темные секреты ДНК. Ученые рассказали об опасности «чистоты крови»
Ученые секвенировали геном мужчины, захороненного в гробнице каменного века Ньюгрейндж в Ирландии, и выяснили, что он родился в результате инцеста.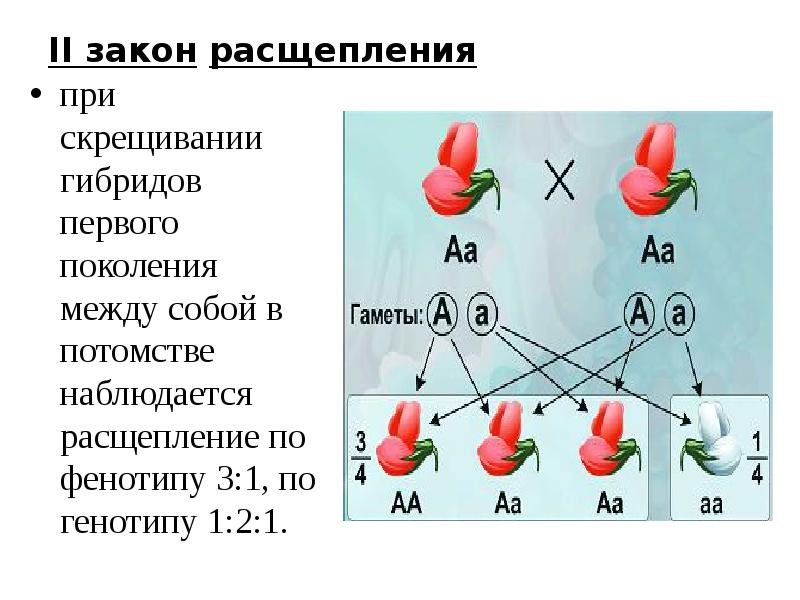 Браки между… РИА Новости, 06.08.2020
Браки между… РИА Новости, 06.08.2020
2020-08-06T08:00
2020-08-06T08:00
2020-08-06T12:27
наука
открытия — риа наука
здоровье
биология
генетика
проект 5-100
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdnn21.img.ria.ru/images/07e4/08/05/1575414311_0:131:2730:1667_1920x0_80_0_0_5ceba64bc96b0140a1e2708e92f9e49f.jpg
МОСКВА, 6 авг — РИА Новости, Татьяна Пичугина. Ученые секвенировали геном мужчины, захороненного в гробнице каменного века Ньюгрейндж в Ирландии, и выяснили, что он родился в результате инцеста. Браки между близкими родственниками запрещали практически всегда из-за угрозы вырождения. Однако есть риск случайного кровосмешения. Насколько это опасно с точки зрения генетики — в материале РИА Новости. Власть, скрепленная кровьюПо биологическим и культурным причинам инцест табуирован с древнейших времен. Нарушали запрет в исключительных случаях ради укрепления власти.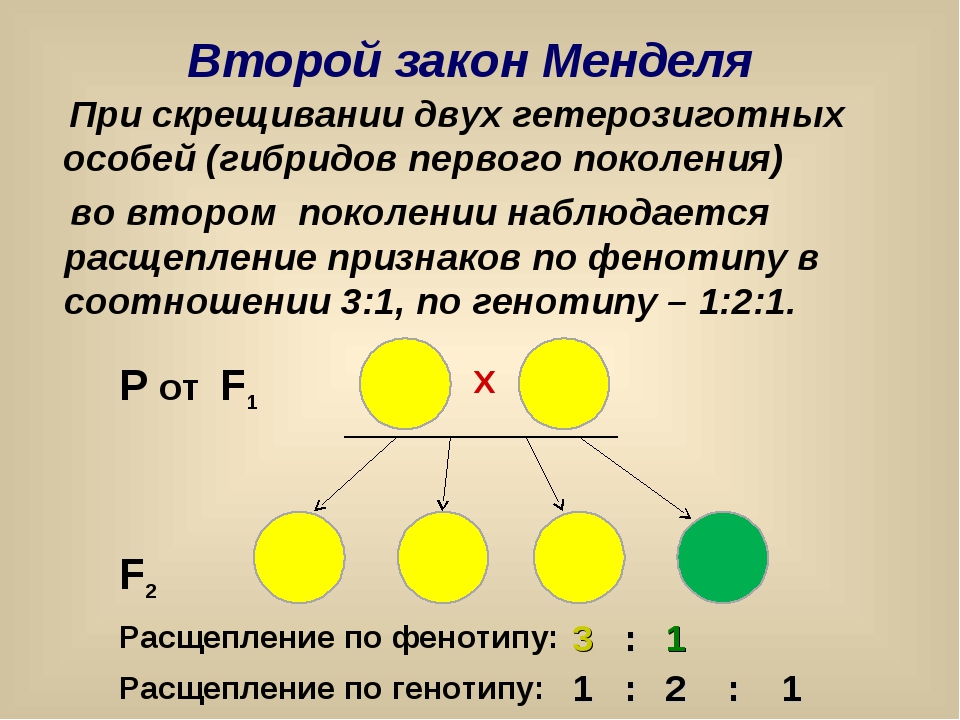 Вероятно, открытие ирландских ученых в Ньюгрейндже связано именно с этим — со становлением правящей элиты в доисторическом обществе.Династические браки между родными и двоюродными заключали в Древнем Египте, империи инков, в королевских семействах Гавайского архипелага. Некогда это символизировало чистоту крови. Большинство 360-тысячного населения Исландии — потомки нескольких групп викингов, обосновавшихся на острове в IX веке. Популяция генетически очень однородная. Несколько лет назад местная компания deCode Genetics даже выпустила приложение на основе базы данных ДНК-тестов, чтобы молодые люди не заключили случайно брак с близким родственником.ДНК спешит на помощьРазработаны компьютерные программы, сравнивающие набор определенных участков генома и определяющие степень родства. Генеалогических исследования вообще сейчас очень популярны. Люди делают ДНК-тесты, загружают результаты в публичные базы данных, такие как Ancestry и Gedmach, и находят родственников. Прежде всего те, кто не знает своего происхождения: выросшие в детских домах, усыновленные.
Вероятно, открытие ирландских ученых в Ньюгрейндже связано именно с этим — со становлением правящей элиты в доисторическом обществе.Династические браки между родными и двоюродными заключали в Древнем Египте, империи инков, в королевских семействах Гавайского архипелага. Некогда это символизировало чистоту крови. Большинство 360-тысячного населения Исландии — потомки нескольких групп викингов, обосновавшихся на острове в IX веке. Популяция генетически очень однородная. Несколько лет назад местная компания deCode Genetics даже выпустила приложение на основе базы данных ДНК-тестов, чтобы молодые люди не заключили случайно брак с близким родственником.ДНК спешит на помощьРазработаны компьютерные программы, сравнивающие набор определенных участков генома и определяющие степень родства. Генеалогических исследования вообще сейчас очень популярны. Люди делают ДНК-тесты, загружают результаты в публичные базы данных, такие как Ancestry и Gedmach, и находят родственников. Прежде всего те, кто не знает своего происхождения: выросшие в детских домах, усыновленные.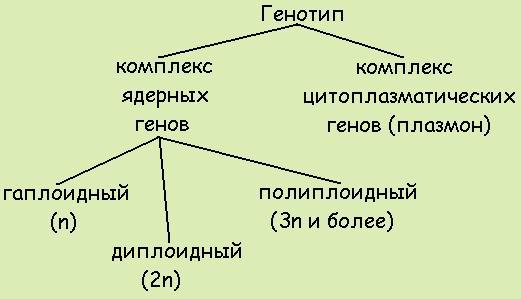 Иногда подобные изыскания преподносят неприятные сюрпризы. Так, американка подарила мужу на день рождения ДНК-тест. Результаты повергли супругов в шок: они оказались кузенами первого порядка по отцу. Причем у пары уже был двухлетний ребенок. Об этом женщина рассказала год назад в подкасте американского издания Slate. Ученые сразу предупреждали, что донорство спермы чревато случайными инцестами, и рекомендовали строго ограничивать число зачатых одним донором детей. В 2011-м The New York Times сообщала о 150 полукровных братьях и сестрах. В 2017 году в британской прессе поднимали вопрос о таких странах, как Нигерия, где законодательное регулирование этой области слабое. В прошлом году в США широко обсуждали историю доктора Клайна, который обманом оплодотворял собственной спермой клиенток репродуктивной клиники. Почти пять десятков его биологических детей нашли друг друга через публичные базы данных ДНК-тестирования. Насколько опасны «династийные узы»Дети кровосмесительных браков в два раза чаще получают наследственную патологию, считает Мадина Азова, доктор биологических наук, профессор, заведующая кафедрой биологии и общей генетики медицинского института РУДН (участника Проекта 5-100).
Иногда подобные изыскания преподносят неприятные сюрпризы. Так, американка подарила мужу на день рождения ДНК-тест. Результаты повергли супругов в шок: они оказались кузенами первого порядка по отцу. Причем у пары уже был двухлетний ребенок. Об этом женщина рассказала год назад в подкасте американского издания Slate. Ученые сразу предупреждали, что донорство спермы чревато случайными инцестами, и рекомендовали строго ограничивать число зачатых одним донором детей. В 2011-м The New York Times сообщала о 150 полукровных братьях и сестрах. В 2017 году в британской прессе поднимали вопрос о таких странах, как Нигерия, где законодательное регулирование этой области слабое. В прошлом году в США широко обсуждали историю доктора Клайна, который обманом оплодотворял собственной спермой клиенток репродуктивной клиники. Почти пять десятков его биологических детей нашли друг друга через публичные базы данных ДНК-тестирования. Насколько опасны «династийные узы»Дети кровосмесительных браков в два раза чаще получают наследственную патологию, считает Мадина Азова, доктор биологических наук, профессор, заведующая кафедрой биологии и общей генетики медицинского института РУДН (участника Проекта 5-100). У них выше риск редких генетических болезней (орфанных), вызываемых рецессивными аллелями — вариантами генов, чья активность обычно подавлена.»Рецессивный мутантный аллель оба супруга могут унаследовать от общего предка. Они здоровы, но у них гетерозиготный генотип, то есть с данным аллелем. Вероятность того, что у такой пары родится больной ребенок с гомозиготным генотипом, составляет 25 процентов», — поясняет исследователь. В этом случае необходимо медико-генетическое консультирование, чтобы снизить риск передачи генетической патологии ребенку. Специалисты учитывают все: степень родства, состояние здоровья членов семьи, другие родственные браки в предыдущих поколениях, этническую принадлежность, так как некоторые наследственные заболевания накапливаются в определенных этнических группах. «Во время беременности можно пройти пренатальную генетическую диагностику, чтобы получить наиболее точные данные о генетическом материале ребенка», — отмечает Азова. Между тем, по разным оценкам, около миллиарда человек живут в закрытых общинах, где близкородственные браки нередки и даже поощряются.
У них выше риск редких генетических болезней (орфанных), вызываемых рецессивными аллелями — вариантами генов, чья активность обычно подавлена.»Рецессивный мутантный аллель оба супруга могут унаследовать от общего предка. Они здоровы, но у них гетерозиготный генотип, то есть с данным аллелем. Вероятность того, что у такой пары родится больной ребенок с гомозиготным генотипом, составляет 25 процентов», — поясняет исследователь. В этом случае необходимо медико-генетическое консультирование, чтобы снизить риск передачи генетической патологии ребенку. Специалисты учитывают все: степень родства, состояние здоровья членов семьи, другие родственные браки в предыдущих поколениях, этническую принадлежность, так как некоторые наследственные заболевания накапливаются в определенных этнических группах. «Во время беременности можно пройти пренатальную генетическую диагностику, чтобы получить наиболее точные данные о генетическом материале ребенка», — отмечает Азова. Между тем, по разным оценкам, около миллиарда человек живут в закрытых общинах, где близкородственные браки нередки и даже поощряются. Например, в Египте мужчины могли жениться, только если у них был дом. Соответственно, проблема решалась браком между родственниками, проживающими под одной крышей, — как правило, двоюродными. «На юге Индии более 52 процентов браков — между двоюродными и троюродными братьями и сестрами. Многие народности живут так тысячелетиями и до сих пор не исчезли с лица земли из-за рецессивного редкого гена, ассоциированного с каким-либо заболеванием», — комментирует Дмитрий Сосин, молекулярный биолог, начальник Центра биотехнологий, доцент кафедры внутренних болезней медицинского факультета ИАТЭ НИЯУ МИФИ.Человек способен адаптироваться практически в любой ситуации, полагает Сосин. Самые серьезные патологии, не совместимые с жизнью, отсеиваются еще на стадии зиготы — при слиянии половых клеток или нескольких первых делений зародыша. Если же патология не смертельна, ребенок может родиться. «Самый известный пример у нас — царская семья Гольштейн-Готторп-Романовых, в которой цесаревич Алексей Николаевич оказался носителем гена гемофилии, как и многие его родственники — потомки королевы Виктории.
Например, в Египте мужчины могли жениться, только если у них был дом. Соответственно, проблема решалась браком между родственниками, проживающими под одной крышей, — как правило, двоюродными. «На юге Индии более 52 процентов браков — между двоюродными и троюродными братьями и сестрами. Многие народности живут так тысячелетиями и до сих пор не исчезли с лица земли из-за рецессивного редкого гена, ассоциированного с каким-либо заболеванием», — комментирует Дмитрий Сосин, молекулярный биолог, начальник Центра биотехнологий, доцент кафедры внутренних болезней медицинского факультета ИАТЭ НИЯУ МИФИ.Человек способен адаптироваться практически в любой ситуации, полагает Сосин. Самые серьезные патологии, не совместимые с жизнью, отсеиваются еще на стадии зиготы — при слиянии половых клеток или нескольких первых делений зародыша. Если же патология не смертельна, ребенок может родиться. «Самый известный пример у нас — царская семья Гольштейн-Готторп-Романовых, в которой цесаревич Алексей Николаевич оказался носителем гена гемофилии, как и многие его родственники — потомки королевы Виктории. Большинство вариантов гемофилии связано с рецессивным геном в X-хромосоме, то есть женщина заболеет, только когда носителями являются оба родителя, что бывает крайне редко», — продолжает ученый.И приводит еще один пример — Турцию, где браки между двоюродными братом и сестрой весьма распространены. Младенческая смертность там высокая, а среди пожилых людей — обычная для стран со сходным уровнем доходов и социального обеспечения. Этот феномен получил название «турецкой головоломки», или «турецкого пазла». «В 1968 году 27 процентов браков в Турции заключили близкие родственники. В 2008-м — 24. Исследования показали, что в целом близкородственные браки первой степени, то есть между двоюродными братом и сестрой, повышают младенческую смертность на 45 процентов. Это еще одна страховка, посредством которой природа убирает из уравнения жизни детей, не способных существовать физически полноценно», — говорит Дмитрий Сосин.Однако выводить некую среднюю величину риска патологий в близкородственных браках некорректно.
Большинство вариантов гемофилии связано с рецессивным геном в X-хромосоме, то есть женщина заболеет, только когда носителями являются оба родителя, что бывает крайне редко», — продолжает ученый.И приводит еще один пример — Турцию, где браки между двоюродными братом и сестрой весьма распространены. Младенческая смертность там высокая, а среди пожилых людей — обычная для стран со сходным уровнем доходов и социального обеспечения. Этот феномен получил название «турецкой головоломки», или «турецкого пазла». «В 1968 году 27 процентов браков в Турции заключили близкие родственники. В 2008-м — 24. Исследования показали, что в целом близкородственные браки первой степени, то есть между двоюродными братом и сестрой, повышают младенческую смертность на 45 процентов. Это еще одна страховка, посредством которой природа убирает из уравнения жизни детей, не способных существовать физически полноценно», — говорит Дмитрий Сосин.Однако выводить некую среднюю величину риска патологий в близкородственных браках некорректно.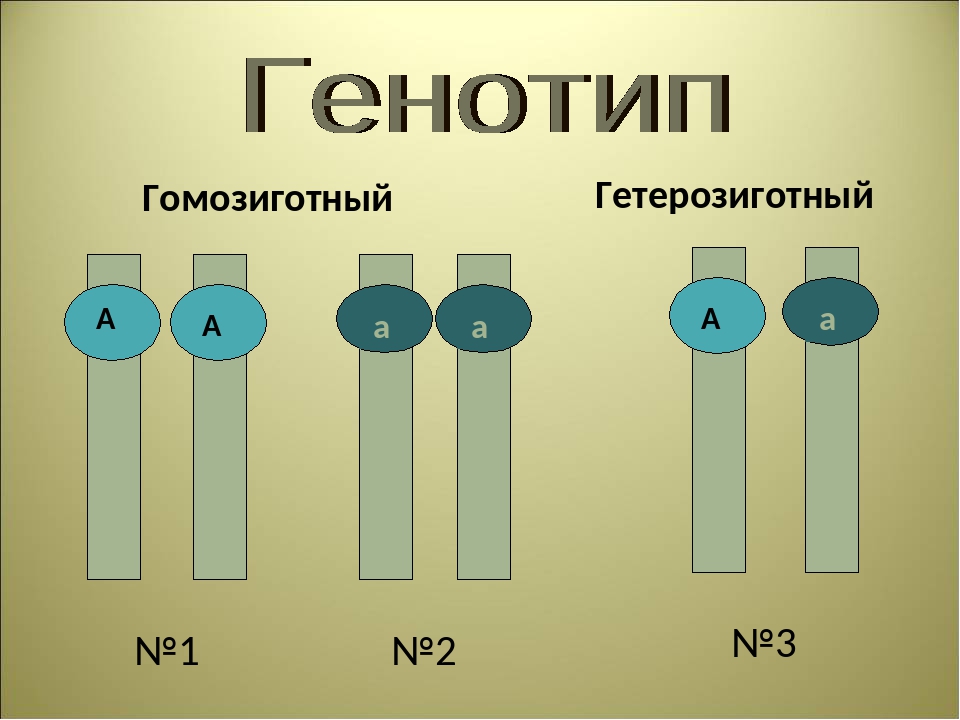 Каждый случай уникален. Особенно сложно с мультифакторными заболеваниями, причины которых остаются невыясненными. Они могут быть, кстати, и экологическими, корениться в образе жизни. Например, шизофрения. У родителей с этим диагнозом риск передачи патологии ребенку — 29 процентов, если они при этом близкие родственники — 41 процент. По некоторым данным, у детей, рожденных в браке между двоюродными братом и сестрой, немного хуже показатели IQ (на 0,8-1,3 пункта). В интернете пишут, что в близкородственных браках чуть ли не половина детей — с наследственными патологиями. На самом деле, подчеркивает Сосин, гораздо меньше. По разным оценкам, от одного до девяти процентов, если речь идет о родителях, которые приходятся друг другу двоюродными братом и сестрой в первом поколении.
Каждый случай уникален. Особенно сложно с мультифакторными заболеваниями, причины которых остаются невыясненными. Они могут быть, кстати, и экологическими, корениться в образе жизни. Например, шизофрения. У родителей с этим диагнозом риск передачи патологии ребенку — 29 процентов, если они при этом близкие родственники — 41 процент. По некоторым данным, у детей, рожденных в браке между двоюродными братом и сестрой, немного хуже показатели IQ (на 0,8-1,3 пункта). В интернете пишут, что в близкородственных браках чуть ли не половина детей — с наследственными патологиями. На самом деле, подчеркивает Сосин, гораздо меньше. По разным оценкам, от одного до девяти процентов, если речь идет о родителях, которые приходятся друг другу двоюродными братом и сестрой в первом поколении.
https://ria.ru/20200219/1564930704.html
https://ria.ru/20190402/1552300297.html
https://ria.ru/20190529/1555014395.html
https://ria.ru/20191203/1561868639.html
https://ria.ru/20180826/1527190793. html
html
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2020
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
https://cdnn21.img.ria.ru/images/07e4/08/05/1575414311_0:0:2730:2048_1920x0_80_0_0_ef776dcd1aaae2439234929aae22a292.jpgРИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og. xn--p1ai/awards/
xn--p1ai/awards/
открытия — риа наука, здоровье, биология, генетика, проект 5-100
МОСКВА, 6 авг — РИА Новости, Татьяна Пичугина. Ученые секвенировали геном мужчины, захороненного в гробнице каменного века Ньюгрейндж в Ирландии, и выяснили, что он родился в результате инцеста. Браки между близкими родственниками запрещали практически всегда из-за угрозы вырождения. Однако есть риск случайного кровосмешения. Насколько это опасно с точки зрения генетики — в материале РИА Новости.
Власть, скрепленная кровью
По биологическим и культурным причинам инцест табуирован с древнейших времен. Нарушали запрет в исключительных случаях ради укрепления власти. Вероятно, открытие ирландских ученых в Ньюгрейндже связано именно с этим — со становлением правящей элиты в доисторическом обществе.
Династические браки между родными и двоюродными заключали в Древнем Египте, империи инков, в королевских семействах Гавайского архипелага. Некогда это символизировало чистоту крови. Большинство 360-тысячного населения Исландии — потомки нескольких групп викингов, обосновавшихся на острове в IX веке. Популяция генетически очень однородная. Несколько лет назад местная компания deCode Genetics даже выпустила приложение на основе базы данных ДНК-тестов, чтобы молодые люди не заключили случайно брак с близким родственником.19 февраля 2020, 08:00НаукаУченые объяснили, какие мутации могут помешать браку
Большинство 360-тысячного населения Исландии — потомки нескольких групп викингов, обосновавшихся на острове в IX веке. Популяция генетически очень однородная. Несколько лет назад местная компания deCode Genetics даже выпустила приложение на основе базы данных ДНК-тестов, чтобы молодые люди не заключили случайно брак с близким родственником.19 февраля 2020, 08:00НаукаУченые объяснили, какие мутации могут помешать бракуДНК спешит на помощь
Разработаны компьютерные программы, сравнивающие набор определенных участков генома и определяющие степень родства. Генеалогических исследования вообще сейчас очень популярны. Люди делают ДНК-тесты, загружают результаты в публичные базы данных, такие как Ancestry и Gedmach, и находят родственников. Прежде всего те, кто не знает своего происхождения: выросшие в детских домах, усыновленные.
Иногда подобные изыскания преподносят неприятные сюрпризы. Так, американка подарила мужу на день рождения ДНК-тест. Результаты повергли супругов в шок: они оказались кузенами первого порядка по отцу. Причем у пары уже был двухлетний ребенок. Об этом женщина рассказала год назад в подкасте американского издания Slate.
Причем у пары уже был двухлетний ребенок. Об этом женщина рассказала год назад в подкасте американского издания Slate.
Насколько опасны «династийные узы»
Дети кровосмесительных браков в два раза чаще получают наследственную патологию, считает Мадина Азова, доктор биологических наук, профессор, заведующая кафедрой биологии и общей генетики медицинского института РУДН (участника Проекта 5-100). У них выше риск редких генетических болезней (орфанных), вызываемых рецессивными аллелями — вариантами генов, чья активность обычно подавлена.
У них выше риск редких генетических болезней (орфанных), вызываемых рецессивными аллелями — вариантами генов, чья активность обычно подавлена.
«Рецессивный мутантный аллель оба супруга могут унаследовать от общего предка. Они здоровы, но у них гетерозиготный генотип, то есть с данным аллелем. Вероятность того, что у такой пары родится больной ребенок с гомозиготным генотипом, составляет 25 процентов», — поясняет исследователь.
В этом случае необходимо медико-генетическое консультирование, чтобы снизить риск передачи генетической патологии ребенку. Специалисты учитывают все: степень родства, состояние здоровья членов семьи, другие родственные браки в предыдущих поколениях, этническую принадлежность, так как некоторые наследственные заболевания накапливаются в определенных этнических группах.
«Во время беременности можно пройти пренатальную генетическую диагностику, чтобы получить наиболее точные данные о генетическом материале ребенка», — отмечает Азова.
Между тем, по разным оценкам, около миллиарда человек живут в закрытых общинах, где близкородственные браки нередки и даже поощряются. Например, в Египте мужчины могли жениться, только если у них был дом. Соответственно, проблема решалась браком между родственниками, проживающими под одной крышей, — как правило, двоюродными. 29 мая 2019, 08:00Наука»Наука не может объяснить». Тайна, неподвластная технологиям»На юге Индии более 52 процентов браков — между двоюродными и троюродными братьями и сестрами. Многие народности живут так тысячелетиями и до сих пор не исчезли с лица земли из-за рецессивного редкого гена, ассоциированного с каким-либо заболеванием», — комментирует Дмитрий Сосин, молекулярный биолог, начальник Центра биотехнологий, доцент кафедры внутренних болезней медицинского факультета ИАТЭ НИЯУ МИФИ.
Например, в Египте мужчины могли жениться, только если у них был дом. Соответственно, проблема решалась браком между родственниками, проживающими под одной крышей, — как правило, двоюродными. 29 мая 2019, 08:00Наука»Наука не может объяснить». Тайна, неподвластная технологиям»На юге Индии более 52 процентов браков — между двоюродными и троюродными братьями и сестрами. Многие народности живут так тысячелетиями и до сих пор не исчезли с лица земли из-за рецессивного редкого гена, ассоциированного с каким-либо заболеванием», — комментирует Дмитрий Сосин, молекулярный биолог, начальник Центра биотехнологий, доцент кафедры внутренних болезней медицинского факультета ИАТЭ НИЯУ МИФИ.Человек способен адаптироваться практически в любой ситуации, полагает Сосин. Самые серьезные патологии, не совместимые с жизнью, отсеиваются еще на стадии зиготы — при слиянии половых клеток или нескольких первых делений зародыша. Если же патология не смертельна, ребенок может родиться.
«Самый известный пример у нас — царская семья Гольштейн-Готторп-Романовых, в которой цесаревич Алексей Николаевич оказался носителем гена гемофилии, как и многие его родственники — потомки королевы Виктории. Большинство вариантов гемофилии связано с рецессивным геном в X-хромосоме, то есть женщина заболеет, только когда носителями являются оба родителя, что бывает крайне редко», — продолжает ученый.
Большинство вариантов гемофилии связано с рецессивным геном в X-хромосоме, то есть женщина заболеет, только когда носителями являются оба родителя, что бывает крайне редко», — продолжает ученый.

Однако выводить некую среднюю величину риска патологий в близкородственных браках некорректно. Каждый случай уникален. Особенно сложно с мультифакторными заболеваниями, причины которых остаются невыясненными. Они могут быть, кстати, и экологическими, корениться в образе жизни. Например, шизофрения. У родителей с этим диагнозом риск передачи патологии ребенку — 29 процентов, если они при этом близкие родственники — 41 процент. По некоторым данным, у детей, рожденных в браке между двоюродными братом и сестрой, немного хуже показатели IQ (на 0,8-1,3 пункта).
В интернете пишут, что в близкородственных браках чуть ли не половина детей — с наследственными патологиями. На самом деле, подчеркивает Сосин, гораздо меньше. По разным оценкам, от одного до девяти процентов, если речь идет о родителях, которые приходятся друг другу двоюродными братом и сестрой в первом поколении.
26 августа 2018, 08:00НаукаЛихой детектив: как русские распоряжаются своим генетическим материаломфенотип | генетика | Британика
фенотип , все наблюдаемые характеристики организма, возникающие в результате взаимодействия его генотипа (полное генетическое наследование) с окружающей средой. Примеры наблюдаемых характеристик включают поведение, биохимические свойства, цвет, форму и размер.
Примеры наблюдаемых характеристик включают поведение, биохимические свойства, цвет, форму и размер.
Фенотип может постоянно меняться на протяжении всей жизни человека из-за изменений окружающей среды и физиологических и морфологических изменений, связанных со старением.Различные условия могут влиять на развитие унаследованных признаков (например, на размер влияет доступная пища) и изменять экспрессию сходных генотипов (например, близнецы, созревающие в разных семьях). В природе влияние окружающей среды составляет основу естественного отбора, который первоначально воздействует на особей, способствуя выживанию тех организмов, фенотипы которых лучше всего подходят для их текущей среды. Преимущество в выживании, предоставляемое особям с такими фенотипами, позволяет этим особям размножаться с относительно высокими показателями успеха и, таким образом, передавать успешные генотипы последующим поколениям.Однако взаимодействие между генотипом и фенотипом удивительно сложно. Например, все наследуемые возможности в генотипе не выражены в фенотипе, потому что некоторые являются результатом латентных, рецессивных или заторможенных генов.
Три типа естественного отбора, показывающие влияние каждого из них на распределение фенотипов в популяции. Стрелки вниз указывают на те фенотипы, против которых действует отбор. Стабилизирующий отбор (левый столбец) действует против фенотипов на обоих концах распределения, способствуя размножению промежуточных фенотипов.Направленный отбор (центральный столбец) действует только против одной крайности фенотипов, вызывая сдвиг в распределении в сторону другой крайности. Диверсифицирующий отбор (правый столбец) действует против промежуточных фенотипов, создавая разделение в распределении в сторону каждой крайности.
Британская энциклопедия, Inc.Подробнее по этой теме
наследственность
…генотип противопоставляется фенотипу , который представляет собой внешний вид организма и результат его развития…
Одним из первых, кто различал элементы, передающиеся от одного поколения к другому («зародышевая» плазма), и организмы, развившиеся из этих элементов («сома»), был немецкий биолог Август Вейсман в конце 19 века. Позже зародышевую плазму отождествили с ДНК, которая несет в себе схемы синтеза белков и их организации в живое тело — сому. Однако современное понимание фенотипа во многом основано на работах датского ботаника и генетика Вильгельма Людвига Йохансена, который в начале 20 века ввел термин фенотип для описания наблюдаемых и измеримых явлений организмов.(Йоханнсен также ввел термин генотип по отношению к наследственным единицам организмов.)
Позже зародышевую плазму отождествили с ДНК, которая несет в себе схемы синтеза белков и их организации в живое тело — сому. Однако современное понимание фенотипа во многом основано на работах датского ботаника и генетика Вильгельма Людвига Йохансена, который в начале 20 века ввел термин фенотип для описания наблюдаемых и измеримых явлений организмов.(Йоханнсен также ввел термин генотип по отношению к наследственным единицам организмов.)
Различие генотип-фенотип — обзор
Введение
Методы идентификации можно разделить на две группы: фенотипические и генотипические. Различие генотип-фенотип проводится в генетике. «Генотип» — это полная наследственная информация организма, даже если она не выражена. «Фенотип» — это реально наблюдаемые свойства организма, такие как морфология, развитие или поведение (Sutton and Cundell, 2004).
Наиболее распространены фенотипические методы из-за их относительно низкой стоимости для многих лабораторий. Однако следует признать, что проявления микробного фенотипа, т. е. размер и форма клеток, спорообразование, клеточный состав, антигенность, биохимическая активность, чувствительность к антимикробным агентам и т. д., часто зависят от среды и условий роста, которые был использован.
Однако следует признать, что проявления микробного фенотипа, т. е. размер и форма клеток, спорообразование, клеточный состав, антигенность, биохимическая активность, чувствительность к антимикробным агентам и т. д., часто зависят от среды и условий роста, которые был использован.
Эти условия будут включать такие переменные, как температура, pH, окислительно-восстановительный потенциал и осмоляльность, а также, возможно, менее известные переменные, такие как истощение питательных веществ, доступность витаминов и минералов, цикл роста, активность воды в твердых средах, статическая или вращающаяся жидкая культура и культура твердых сред по сравнению с жидкими, а также плотность колоний на чашке.Поэтому требуется определенная осторожность при интерпретации результатов микробиологической идентификации и анализе тенденций данных.
Еще одним ограничением фенотипических методов является размер и тип базы данных фенетической классификации. Что касается типа базы данных, многие базы данных ориентированы на клинические приложения и не обязательно хорошо подходят для промышленного применения. С точки зрения размера базы данных ограничены из-за относительно небольшого числа охарактеризованных микроорганизмов (Stager and Davis, 1992).
С точки зрения размера базы данных ограничены из-за относительно небольшого числа охарактеризованных микроорганизмов (Stager and Davis, 1992).
Классическая схема идентификации бактерий биохимическими методами зависит от того, может ли чистая культура интересующего микроорганизма расти в чашке с агаром, скошенном агаре, бульоне, бумажной полоске или другом вспомогательном материале, содержащем специализированные стимуляторы роста или ингибиторы в присутствии ферментируемого или разлагаемого соединения, что приводит к изменению цвета среды, образованию газа, образованию флуоресцентного соединения и другим проявлениям метаболической активности.Если поведение известных культур в этих средах известно, неизвестная культура может быть сопоставлена с этими характеристиками, и на основе наиболее близкого совпадения с базой данных аналитик может идентифицировать неизвестную культуру. Этот процесс утомителен, отнимает много времени и требует много труда, материалов, времени и энергии для проведения испытаний. Кроме того, умение аналитика интерпретировать реакции и прийти к правильному суждению делает этот процесс субъективным и часто ненадежным (Kalamaki et al., 1997).
Кроме того, умение аналитика интерпретировать реакции и прийти к правильному суждению делает этот процесс субъективным и часто ненадежным (Kalamaki et al., 1997).
Генотипические методы не зависят от среды выделения или характеристик роста микроорганизма. Генотипические методы значительно расширили базы данных различных видов микроорганизмов. До появления генотипических методов микробиологи предполагали, что существует ряд таксонов, которые невозможно культивировать (так называемые жизнеспособные, но не культивируемые штаммы). Генотипические методы открыли совершенно новый набор видов и подвидов, а также переклассифицировали виды и родственные виды (таким образом, таксоны, которые часто сходно группируются фенотипическими методами, на самом деле являются полифилетическими группами, т. е. содержат организмы с разной эволюционной историей, которые гомологически несходные организмы, объединенные в группы).
Еще одним преимуществом генотипических методов является их точность и более быстрое получение результатов (поскольку микроорганизмы не нужно выращивать на питательных средах). Однако они относительно дороги.
Однако они относительно дороги.
Для полной идентификации можно провести множество тестов, как показано в таблице 1.
Таблица 1. Информация, необходимая для идентификации патогенов пищевого происхождения (Fung, 1995).
| Макроскопическая морфология на агарных пластинах | ||||||||||||||||||||||||||||||||||||||||||||||||
| Морфология при микроскопическом увеличении | ||||||||||||||||||||||||||||||||||||||||||||||||
| грамма реакция (положительный, отрицательный или переменной) и специальные свойства окрашивания | ||||||||||||||||||||||||||||||||||||||||||||||||
| биохимическая активность профильные и специальные ферментные системы | ||||||||||||||||||||||||||||||||||||||||||||||||
| Производство пигментов, биолюминесценция, хемилюминесценция и производство флуоресцентных соединений | ||||||||||||||||||||||||||||||||||||||||||||||||
| Требования к питательным веществам и факторам роста | ||||||||||||||||||||||||||||||||||||||||||||||||
| Требования к температуре и pH и толерантность | продукция||||||||||||||||||||||||||||||||||||||||||||||||
| Характеристика чувствительности к антибиотикам (антибиограмма) | ||||||||||||||||||||||||||||||||||||||||||||||||
| Потребность в газах и переносимость | ||||||||||||||||||||||||||||||||||||||||||||||||
| Клеточная стенка, клеточная мембрана и клеточные компоненты | ||||||||||||||||||||||||||||||||||||||||||||||||
| Константа скорости роста И время поколения | ||||||||||||||||||||||||||||||||||||||||||||||||
| моторика и споры | ||||||||||||||||||||||||||||||||||||||||||||||||
| Генотипические характеристики | ||||||||||||||||||||||||||||||||||||||||||||||||
| Генетический профиль: ДНК / РНК-последовательности и отпечатки пальцев | ||||||||||||||||||||||||||||||||||||||||||||||||
| Информация, связанная с микроорганизмом | Патогенность к животным и людям | серология и фаг | Экологическая ниша и способность выживания | | BMC BioinformaticsСмешанная модель Мы подгоняем смешанные модели к сигналам ответа, чтобы классифицировать маркеры по одному из пяти классов генотипов, соответствующих пяти возможным дозировкам аллелей у тетраплоидов. Пусть пара s a и с б представляют собой измеренные уровни сигналов аллелей a и b для индивидуума. Анализируем дробь с а /( с а + с б ).Поскольку выгодно иметь гомоскедастический отклик в смешанной модели, а рассчитанная доля показывает неоднородность дисперсии с меньшими вариациями для дробей, близких к 0 и 1, мы берем преобразованную дробь из корня арксинуса ( asr ) для стабилизации дисперсии . Для преобразованной дроби y подбирается нормальная (или гауссовская) смешанная модель [18]: с f j плотность нормального распределения со средним μ j и общее стандартное отклонение σ . Одним из принципов статистического моделирования является экономия: удаление избыточных параметров модели для повышения стабильности и интерпретируемости результатов.
с C 1 = A 0 / A 1 , C 2 = B 0 / A 1 и R = б 1 / а 1 .Следовательно, параметры с 1 и с 2 пропорциональны фоновым сигналам, а r — отношению чувствительности мощностей сигналов а и b к дозам аллелей. Если уровни фонового сигнала a и b равны, для получения модели 2 можно использовать общий параметр c = c 1 = c 2 : (2) Предположение о линейной зависимости между силой сигнала и дозой аллеля может быть слишком ограничительным.Таким образом, модель для отдельных мощностей сигналов расширяется до предположения о равной кривизне для обоих сигналов, отображая третью модель (3) с d = а 2 / а 1 . Модель 3 может быть упрощена до модели 4 путем приравнивания уровней фонового сигнала: (4) Модели (1) — (4) сформулированы для доли средних уровней сигналов.Однако, поскольку ответ представляет собой преобразованную переменную asr- y , модели также необходимо преобразовать. Преобразованная модель (1) для ожидания y равна μ y = ASR ( C 1 + x ) / ( C 1 + C 2 + R (4 — x ))) , а также для остальных трех моделей. С моделями есть две небольшие сложности:
Подводя итог, используются два приближения: E ( asr ( s a /( с а + с б ))) ≈ аср ( E ( с а /( с а + с б ))) ≈ аср ( E ( с а )/( E ( с а ) + Е ( с б ))). Для сравнения различных моделей, напр. модели без ограничений и модели с ограничениями HWE можно сравнить -2 логарифмические правдоподобия (-2LL) с по определению меньшим -2LL для модели без ограничений (большей). Чтобы сбалансировать соответствие модели и ее повышенную сложность, мы используем байесовский информационный критерий (BIC), который добавляет штраф к -2LL на основе количества параметров k в модели (и n количества людей): БИК = -2LL+ k ln( n ) [19]. Различные смешанные модели подгоняются к преобразованным фракциям с использованием максимального правдоподобия (ML). Для нахождения ML-оценок используется EM-алгоритм [20]. ЭМ-алгоритму нужны начальные значения параметров. Далее повторяются Е- и М-шаги. На шаге E, учитывая текущие значения параметров, рассчитываются апостериорные вероятности индивидуума иметь дозировку каждой из пяти аллелей, за которым следует шаг M, на котором смешанные вероятности π j оцениваются, а μ j и σ взвешенным нелинейным методом наименьших квадратов. Выбор модели и маркераВыбор подходящей смешанной модели для данного маркера является результатом многоступенчатого процесса, разработанного эмпирическим путем. Перед началом самого выбора модели необходимо удалить недостоверные наблюдения. В случае анализа Illumina GoldenGate мы удалили все наблюдения с общей интенсивностью сигнала менее 3200 (обоснование этого порога см. в разделе Наборы данных). На первом этапе устанавливаются восемь различных моделей смеси. Каждая модель состоит из 5 распределений компонентов. Средние значения распределений компонентов ограничены пятью возможными отношениями аллелей, используя один параметр для отношения внутренней силы сигнала для обоих аллелей, и дополнительно один или два параметра для фона сигнала и отсутствие или один коэффициент для квадратичного члена в отклик сигнала (уравнения 1-4). Сравниваются BIC 16 результатов и выбирается результат с минимальным BIC. Используя выбранную модель, для каждой выборки рассчитываются вероятности принадлежности к каждому из пяти распределений. Если разница в отклике между двумя аллельными сигналами велика (параметр r намного меньше или больше 1), между нуллиплексным или квадруплексным пиком и следующим пиком возникает широкий разрыв, в то время как остальные четыре пика близко разнесены. В таких случаях может случиться так, что EM-алгоритм не находит оптимальную подгонку, а вместо этого подбирает симплексный или триплексный пик в широком промежутке. Чтобы обнаружить и исправить такие несоответствия, на втором этапе проверяется, имеют ли симплексные или триплексные пики более низкую пропорцию смешивания или меньшее количество отсчетов, назначенных по сравнению с пиками с обеих сторон. Для каждой установленной модели выполняется проверка на наличие более низкого пика между более высокими пиками. Ни в перекрестном потомстве, ни в популяции в равновесии Харди-Вайнберга такой закономерности не ожидается. Поэтому по умолчанию алгоритм включает третий шаг, который отбрасывает все подходящие решения, в которых встречается такой шаблон; однако эту проверку можно отключить. Если во всех подогнанных моделях более низкие пики встречаются между более высокими пиками или если эта проверка отключена, на этом шаге никакие решения не отбрасываются. После этих начальных шагов выбирается подобранная модель с наименьшим BIC среди неотклоненных решений. Снова для каждой выборки рассчитываются вероятности принадлежности к каждому из пяти распределений и назначаются генотипы с использованием того же критерия, что и на этапе 1. На последнем этапе маркеры могут быть отклонены на основании нескольких дополнительных критериев. Если меньше минимальной доли (по умолчанию 60%) образцов соответствует генотип, это указывает на нечеткую картину пика.Этот параметр взаимодействует с параметром, определяющим минимальный уровень вероятности, необходимый для присвоения генотипа, как описано выше. Также пиковая дисперсия выше определенного порога (по умолчанию 0,1 по преобразованной шкале) приводит к отклонению маркера; опять же, это отфильтровывает нечеткие модели пиков. Этот параметр может быть уменьшен, когда общий уровень шума хорошо работающих анализов низкий. Третьим критерием отклонения маркера является превышение максимальной доли (по умолчанию 85%) назначенных образцов в одном и том же пике. Рекомендуется попробовать несколько разных значений параметров на основе приведенных выше рекомендаций и проверить результаты для подмножества маркеров, прежде чем выбирать значения для применения ко всему набору данных. Программа Алгоритм подбора и подбора модели реализован в пакете R fitTetra [21], который включен в виде Дополнительных файлов 1 и 2.FitTetra выдает выходные данные в табличной форме, включая (1) спецификацию подобранной модели с a.o. средние значения и пропорции смешивания компонентов смеси и (2) список образцов, их вероятности принадлежности к каждому из компонентов смеси и присвоенные им генотипы. Кроме того, он создает графическое представление с гистограммой распределения отношения сигналов аллелей, подобранной модели и генотипов, присвоенных образцам. Типичный графический вывод fitTetra . Верхняя панель: гистограмма отношений сигналов: аллель а/(аллель а + аллель b) набора тетраплоидных сортов картофеля (белые столбцы) и потомство диплоидного скрещивания (серые столбцы) для маркера PotSNP016. Указана модель, приспособленная к тетраплоидным сортам (зеленая линия). Нижняя панель: генотип (от 0 до 4 для нуллиплекса к квадруплексу), присвоенный тетраплоидным образцам в отношении отношения сигналов.Неназначенные образцы показаны внизу красным цветом. Диплоидные образцы совпадают с пиками нуллиплекса, дуплекса и квадруплекса тетраплоидных образцов. FitTetra 2.0 — улучшенный генотип, требующий тетраплоидов с поддержкой нескольких популяций и родительских данных | BMC BioinformaticsОбзор fitTetra R-пакет fitTetra [2] представляет собой программу определения генотипа SNP-маркеров у тетраплоидных видов с использованием нормальных смешанных моделей. Функция CodomMarker позволяет накладывать ограничения на параметры μ j и π j .Параметры π j могут быть свободными или ограниченными, чтобы следовать равновесию Харди-Вайнберга. Параметры μ j могут быть ограничены таким образом, что 1) фоновые сигналы для a и b (для двух аллелей SNP) равны или не равны; 2) связь между отношением сигналов и дозой аллеля является линейной или квадратичной. Эти ограничения позволяют средствам μ j располагаться асимметрично в диапазоне 0 — π/2. Гистограмма генотипа, требующая probe_1028 (из тестового набора данных fitTetra 2.0), пример, когда результаты fitTetra 2.0 отличаются от fitTetra 1.0. Присутствуют две популяции: ассоциативная панель с надписью «ПАНЕЛЬ» и семейство FS с двумя родительскими генотипами (оба реплицированы). Предполагается, что панель ассоциации находится в равновесии Харди-Вайнберга. Распространение на несколько популяций быть указано, тогда как fitTetra 1.0 рассматривал все наблюдения как происходящие из одной единственной популяции. При использовании нескольких совокупностей параметры модели для средних значений μ j (т. е. положения пиков) и дисперсии σ 2 (т. В фиттетра 1.5{\pi}_j=1 \); 2) равновесие Харди-Вайнберга («p.HW»), где оценивается только частота аллелей, а пропорции смешивания являются функцией пропорций, основанных на равновесии Харди-Вайнберга, что часто приемлемо для ассоциативных панелей; 3) фиксированные пропорции («p.fixed»), т. е. π j остаются фиксированными на своих заданных значениях во время EM-алгоритма (используется, когда значения известны из другого источника). В новой версии программы мы добавили новый вид ограничения на пропорции смешивания, с.type = “p.F1” для популяции F1. Учитывая родительские генотипы, оцененные в предыдущей итерации алгоритма EM, пропорции «p.F1» рассчитываются как ожидаемые коэффициенты тетрасомной сегрегации потомства F1 этих двух родителей. Эти коэффициенты сегрегации предполагают случайные двухвалентные пары и отсутствие двойной редукции и показаны в таблице 1. EM-алгоритм используется для нахождения оценок максимального правдоподобия параметров смешанной модели с несколькими группами населения. В этом алгоритме Е-шаги (Ожидание) и М-шаги (Максимизация) повторяются до тех пор, пока вероятность не сойдется. На шаге Е при текущих оценках параметров рассчитываются вероятности того, что наблюдение принадлежит каждому из пяти компонентов смеси. На М-этапе на основе этих рассчитанных вероятностей рассчитываются новые средние компоненты и дисперсия по всем наблюдениям.Затем рассчитываются новые пропорции смешивания для каждой совокупности в зависимости от типа ограничений на пропорции смешивания, как обсуждалось выше. В fitTetra 2.0 функция «CodomMarker» (и, как следствие, функция-оболочка «fitTetra» и вспомогательная функция «saveMarkerModels») выдает тот же тип вывода, что и fitTetra 1. Поддержка данных родительского генотипа Когда доступна дополнительная родительская информация, ее можно использовать для дальнейшего облегчения вызова генотипа. Пользовательские массивы SNP, наиболее популярные средства генотипирования тетраплоидов, часто основаны на исследованиях открытий, в которых родителей популяции секвенируют, чтобы разработать массив для самой популяции [5, 11]. Пользователь может предоставить эту информацию и установить тип вероятности «p.фиксированный» для родительских популяций. Это зафиксирует пропорции смешивания для родительских популяций во время выполнения алгоритма. Более того, если родители анализировались в том же цикле, что и семейство FS, их дозировки также используются для назначения стартовых средств для одного или двух компонентов смешивания. Когда у родителей разные дозы, известны два начальных средних значения, а оставшиеся три оцениваются с использованием простой модели линейной регрессии.Это может быть не совсем точным, поскольку зависимость между дозировкой и интенсивностью не обязательно является линейной, но, по нашему опыту, это обеспечивает лучший старт, чем простое группирование образцов. При измерении нескольких популяций в одном цикле средние значения распределения пяти генотипов/дозировок распределяются между популяциями. Поскольку fitTetra 2.0 может обрабатывать несколько популяций одновременно, использование известных дозировок родителей приносит пользу генотипу не только для их потомков F1, но и для всех других популяций, даже если они не связаны с этими родителями. Тем не менее, начальные дозировки родительского компонента могут быть неверными, и применение этих данных в качестве начальных значений может привести к неправильным вызовам или вообще к несоответствию какой-либо модели. Пример этого показан в нашем предыдущем исследовании открытия SNP [5], в котором мы разработали массив с производительностью RNA-Seq. Когда родительские дозы оцениваются по данным RNA-Seq, на них может влиять дифференциальная экспрессия аллелей (например, если истинный родительский генотип — AABB, а аллель A экспрессируется в три раза больше, чем аллель B, массив SNP будет сообщать о генотипе AABB, но количество прочтений RNA-Seq предполагает наличие AAAB).Чтобы учесть это, алгоритм подходит для ряда моделей как без данных о родительской дозировке, так и с ними; выбирается наилучшая модель (наименьшее значение байесовского информационного критерия). Для краткости мы будем называть fitTetra 2.0 без использования родительских данных fitTetra2NP, а fitTetra 2.0, где родительские генотипы использовались для фиксации пропорций смешивания и расчета начальных средних значений, позже будем называть fitTetra2P. Количественная неопределенность в вызовах генотипа | БиоинформатикаАннотацияМотивация: Полногеномные ассоциативные исследования (GWAS) используются для обнаружения генов, лежащих в основе сложных наследственных заболеваний, для которых в прошлом не удавались менее эффективные схемы исследований.В последнее время количество GWAS резко возросло, и результаты исследований были опубликованы в ведущих журналах и основных средствах массовой информации. Микрочипы являются предпочтительной технологией определения генотипа в GWAS, поскольку они позволяют одновременно исследовать более миллиона однонуклеотидных полиморфизмов (SNP). Отправной точкой для статистического анализа, используемого GWAS для определения связи между локусами и заболеванием, является определение генотипа (AA, AB или BB). Однако необработанные данные, интенсивности зондов микрочипов, тщательно обрабатываются перед поступлением на эти вызовы.Были предложены различные сложные статистические процедуры для преобразования необработанных данных в вызовы генотипа. Мы обнаружили, что изменчивость качества вывода микрочипов в разных SNP, разных массивах и разных партиях образцов оказывает существенное влияние на точность вызовов генотипа, сделанных существующими алгоритмами. Отсутствие учета этих источников изменчивости может отрицательно сказаться на качестве результатов, сообщаемых GWAS. Результаты: Мы разработали метод, основанный на расширенной версии многоуровневой модели, используемой CRLMM версии 1.Два ключевых отличия заключаются в том, что теперь мы учитываем вариативность между партиями и улучшаем оценку каждого вызова для каждого вызова. Новая модель позволяет разрабатывать показатели качества для SNP, образцов и партий образцов. Используя три независимых набора данных, мы демонстрируем, что CRLMM версии 2 превосходит CRLMM версии 1 и алгоритм, предоставленный Affymetrix, Birdseed. Основное преимущество нового подхода заключается в том, что он позволяет выявлять некачественные SNP, образцы и партии. Доступность: Программная реализация метода, описанного в этой статье, доступна в виде свободного и открытого исходного кода в пакете crlmm R/BioConductor. Контактное лицо: [email protected] Дополнительная информация: Дополнительные данные доступны по адресу Биоинформатика онлайн. 1 ВВЕДЕНИЕОднонуклеотидный полиморфизм (SNP) представляет собой однонуклеотидную вариацию ДНК, встречающуюся в геномах особей одного и того же вида.Для большинства SNP наблюдаются только два основания. Две возможности обозначаются как аллели . Как правило, один встречается реже и называется минорным аллелем . В этой статье мы будем ссылаться на два аллеля в любом SNP как на аллели A и B . Поскольку у нас есть две копии каждой аутосомной хромосомы (материнская и отцовская), возможны три комбинации аллелей в каждом SNP: AA , AB и BB .Их называют генотипами . Вариации в ДНК имеют большое значение, поскольку они могут объяснить, например, как у людей развиваются болезни и как они реагируют на лечение. Ассоциативные исследования позволяют проверить взаимосвязь между аллелями и фенотипами, т.е. статус болезни. В прошлом ассоциативные исследования отбирали сотни SNP, тщательно отобранных, чтобы быть рядом с генами-кандидатами. Сегодня технология микрочипов позволяет проводить скрининг миллионов SNP по всему геному и произвела революцию в этих исследованиях, которые теперь называются полногеномными ассоциативными исследованиями (GWAS). Результаты большого GWAS для таких заболеваний, как биполярное расстройство, ишемическая болезнь сердца, болезнь Крона, гипертония, ревматоидный артрит, диабет 1 и 2 типа (Консорциум Wellcome Trust Case Control, 2007), диабетическая нефропатия (Mueller et al. , 2006) и дисфункцию почек (Bash et al. , 2009), привлекли большое внимание. За последние два года мы наблюдаем значительный рост этих исследований, и многие другие находятся в стадии разработки. В настоящее время типичная процедура анализа данных заключается в генотипировании большого количества (тысяч) случаев и контролей с использованием микрочипов и поиске SNP, которые статистически связаны с заболеванием.Однако процесс преобразования необработанных интенсивностей в вызовы генотипа состоит из сложной статистической обработки зашумленных данных, и многие вызовы генотипа являются неопределенными. Обычный подход к анализу заключается в простом выполнении χ 2 -тестов для оценки ассоциации заявленных генотипов и болезни без учета неопределенности. Как показано Ruczingi et al. (http://www.bepress.com/jhubiostat/paper181) с помощью моделирования, неспособность должным образом учесть неопределенность генотипа может привести к неэффективным или недействительным ассоциациям.Конечно, правильная количественная оценка неопределенности является необходимым условием для ее использования в ассоциативных исследованиях, и мы сосредоточимся на этом аспекте. В разделе 2 мы обрисовываем статистическую проблему и описываем предыдущие работы по генотипированию, уделяя особое внимание CRLMM версии 1, модель которой является отправной точкой для результатов, которые мы сообщаем в этой статье. В разделе 3 мы обрисовываем в общих чертах модель и описываем процедуры оценки. В разделе 4 мы демонстрируем полезность нашей методологии с тремя наборами данных. Наконец, в разделе 5 мы подводим итоги и обсуждаем наши выводы. 2 ПРЕОБРАЗОВАНИЕ НЕОБРАБОТАННЫХ ИНТЕНСИВНОСТЕЙ В ВЫЗОВЫ ГЕНОТИПОВНа первом этапе, называемом предварительной обработкой, исходные интенсивности микрочипов преобразуются в количества, пропорциональные количеству ДНК в целевом образце, связанному с каждым аллелем A и B для каждого SNP. Обозначим эти суммарные интенсивности через I A и I B . Мы не рассматриваем этот первый шаг и отсылаем читателя к Carvalho et al. (2007 г.), Affymetrix (2006 г.), Affymetrix (2007 г.) и Korn et al. (2008 г.) для получения подробной информации. Мы сосредоточимся на втором этапе (генотип , вызывающий ): отображение наблюдаемых интенсивностей ( I A , I B ) в апостериорные вероятности (type 202 0AA 3 0AA ) трех возможных генотипов. , AB и BB ) и, таким образом, обеспечить меру достоверности, которую можно использовать для принятия решения о том, какие призывы опускать или вводить соответствующую неопределенность генотипа при оценке ассоциации. Наивный подход к генотипированию состоит в том, чтобы установить доверительные пороги и назвать генотипы на основе того, что I выше или ниже этих порогов. Например, чтобы назвать генотип AA , можно потребовать, чтобы I A − I B > C . К сожалению, эффект зондирования, подробно описанный в литературе по микрочипам (Irizarry et al. , 2003; Li and Wong, 2001a, b; Naef and Magnasco, 2003; Wu et al., 2004), для каждого SNP требуется разное пороговое значение. Это требование проистекает из того факта, что распространенность каждого аллеля SNP измеряется с помощью разных зондов, имеющих разные последовательности и, следовательно, разные свойства гибридизации, что приводит к большой изменчивости SNP к SNP в распределении интенсивностей I A и I B (рис. 1; цветная версия на сайте). Конкурирующие алгоритмы определения генотипа используют разные стратегии для определения этих SNP-специфических пороговых значений.Многие используют неконтролируемую кластеризацию, например, алгоритм на основе динамической модели (DM) (Di et al. , 2005) и CHIAMO (Консорциум по управлению делами Wellcome Trust, 2007). Более успешные алгоритмы обучаются на данных, для которых известны генотипы, например, BRLMM (Affymetrix, 2006), CRLMM версии 1 (Carvalho et al. , 2007), BRLMM-P (Affymetrix, 2007) и Birdseed (Korn ). и др. , 2008). Для большинства SNP в этих обучающих массивах у нас есть независимые вызовы генотипа для 270 образцов HapMap (The International HapMap Consortium, 2003).Эти вызовы основаны на согласованных результатах различных технологий и считаются золотым стандартом. Рис. 1. Интенсивность обоих аллелей нанесена относительно друг друга, т. е. I A против I B для четырех случайно выбранных SNP. Три круга иллюстрируют распределение данных для каждого генотипа (AA: зеленый; AB: оранжевый; BB: фиолетовый) для первого SNP. Обратите внимание, что эти регионы несовместимы с данными для трех других SNP.На этом рисунке показано, что вариабельность SNP к SNP намного больше, чем вариабельность внутри SNP, и что наивные алгоритмы генотипирования, определяющие глобальные пороги, не подходят. Рис. 1. Интенсивности обоих аллелей нанесены друг против друга, т. е. I A против I B SNPs, для четырех случайно выбранных SNP. Три круга иллюстрируют распределение данных для каждого генотипа (AA: зеленый; AB: оранжевый; BB: фиолетовый) для первого SNP.Обратите внимание, что эти регионы несовместимы с данными для трех других SNP. На этом рисунке показано, что вариабельность SNP к SNP намного больше, чем вариабельность внутри SNP, и что наивные алгоритмы генотипирования, определяющие глобальные пороги, не подходят. Плотность микрочипов SNP значительно увеличилась за последние 5 лет, увеличившись с нескольких тысяч до примерно одного миллиона SNP на чип. В настоящее время нередко можно найти GWAS, которые нацелены на тысячи образцов одновременно, и алгоритмы генотипирования претерпели серьезные модификации, чтобы приспособиться к таким изменениям.CRLMM версии 1 был одним из примеров таких разработок, поскольку он расширил идеи, доступные в то время, чтобы предоставить средства для эффективного учета различных эффектов, связанных с партиями, превосходящие конкурирующие алгоритмы (Lin et al. , 2008). Мы относимся к нему как к ведущему алгоритму генотипирования и используем его модель в качестве отправной точки для нашей работы. CRLMM использует вызовы HapMap для определения известных генотипов, что, в свою очередь, позволяет нам определить обучающую выборку. Имея данные для обучения, Carvalho et al. (2007) описывают контролируемый подход к обучению, основанный на двухэтапной иерархической модели. В отличие от других алгоритмов, CRLMM моделирует M ≡ log 2 ( I A / I B ) вместо пары интенсивностей. Этот выбор делает CRLMM более устойчивым к эффектам зондирования, потому что зондирующие эффекты двух аллельных зондов имеют схожие аддитивные эффекты и, таким образом, частично компенсируются. Это показано на рис. 2. Для учета хорошо описанного (Affymetrix, 2006, 2007; Carvalho et al. , 2007) зависимость M от общей интенсивности , Carvalho et al. (2007) подгоняют сплайны, используя смешанную модель, и корректируют смещение с помощью подобранных кривых. Затем для заданного SNP распределение M , обусловленное генотипом, моделируется как гауссово. Чтобы учесть оставшийся эффект зондирования, каждый SNP i =1,…, I имеет разные средние значения μ i и стандартное отклонение (SD) σ i . Выборочные средние и стандартные отклонения из обучающих данных используются для оценки μ i с и σ i с.Однако из-за низких частот минорных аллелей даже этот большой обучающий набор данных дает относительно мало точек данных для редкого генотипа в некоторых SNP. Рис. 2. Преимущество моделирования М вместо ( I A , I B ): здесь построены те же данные 3, что и для S показано на рисунке 1. Вариабельность SNP меньше для M , чем для S .Однако эффект зондирования не полностью устранен, как видно из SNP на нижней правой панели. Отметим, что для этого SNP центры кластеров существенно смещены. Рис. 2. Преимущество моделирования M вместо ( I , I , I I B ): Здесь мы сюжет м против S для тех же данных как показано на рисунке 1. Вариабельность SNP меньше для M , чем для S .Однако эффект зондирования не полностью устранен, как видно из SNP на нижней правой панели. Отметим, что для этого SNP центры кластеров существенно смещены. Иерархическая модель используется для повышения точности параметров модели для этих SNP. Карвальо и др. (2007) используют эмпирический байесовский подход, в котором средние значения, зависящие от генотипа, подчиняются многомерному нормальному распределению, а дисперсии подчиняются обратному гамма-распределению. Этот подход позволяет CRLMM заимствовать силу у других SNP.Чтобы сделать вызовы, CRLMM обрабатывает оценочные параметры как известные и вычисляет апостериорные вероятности для каждого генотипа с учетом наблюдаемого логарифмического отношения M . Затем апостериорные значения используются в качестве меры достоверности. Лин и др. (2008 г.) обнаружил, что меры достоверности, предоставляемые CRLMM версии 1, не были оптимальными, и предложил специальную корректировку , основанную на подходе к обучению. CRLMM версии 1 использует эти скорректированные меры достоверности. Стратегии, используемые для обучения алгоритму генотипирования, предложенному Carvalho et al. (2007 г.) и тот, что представлен в этой статье, требуют вмешательства специалиста. В настоящее время нет автоматического решения этой проблемы, но возможно расширение алгоритма на другие платформы, как это сделали Ritchie et al. (2009 г.) для чипов illumina infinium beadChips. 3 МОДЕЛЬ3.1 МотивацияПроцедуры, используемые в ассоциативных исследованиях, очень подвержены проблемам из-за неточностей, вызванных процедурами генотипирования.В доступных в настоящее время алгоритмах генотипирования отсутствуют методы идентификации SNP и партий, которые, если их не использовать на ранних стадиях исследования, могут неблагоприятно повлиять на результаты. Текущий подход к определению связи между SNP и заболеванием заключается в проведении теста на связь между генотипами и исходами, т.е. a χ 2 — критерий для дискретных исходов. SNP со слишком низкими показателями достоверности «отбрасываются», но порог достоверности является весьма произвольным и может повлиять на результаты.Важно отметить, что из-за большей неопределенности, связанной с гетерозиготными вызовами (AB), чем с гомозиготными вызовами (AA, BB), указание одного порога для обоих (текущая практика) может привести к систематической ошибке из-за отсутствия информации. Поскольку CRLMM версии 1 и другие алгоритмы вызова основаны на моделях, как и оценки ассоциации, естественным расширением является разработка тестов ассоциации, основанных на вероятностях генотипа, а не на жестких вызовах. Марчини и др. (2007) и Plagnol и др. (2007 г.) используют такие вызовы на основе вероятности для объединения результатов на разных платформах. Ручинки и др. (http://www.bepress.com/jhubiostat/paper181) демонстрируют, что использование вероятностных вызовов повышает эффективность GWAS. Апостериорные вероятности, предоставленные CRLMM версии 1, имеют три важных ограничения:
Рис. 3. Пример SNP с тремя четкими кластерами: вызовы, полученные с помощью алгоритма, представлены цветами (AA: зеленый; AB: оранжевый и BB: фиолетовый). Наблюдение с красным кружком вокруг него было неправильно названо BB, и при нормальном предположении об остатках апостериорное значение составило 0,999. При допущении, что остатки следуют распределению t , апостериорная доля была снижена до 0,500. Рис. 3. Пример SNP с тремя четкими кластерами: вызовы, полученные по алгоритму, представлены цветами (AA: зеленый; AB: оранжевый и BB: фиолетовый).Наблюдение с красным кружком вокруг него было неправильно названо BB, и при нормальном предположении об остатках апостериорное значение составило 0,999. При допущении, что остатки следуют распределению t , апостериорная доля была снижена до 0,500. Третий пункт особенно проблематичен. Логистическая проблема с этими большими GWAS заключается в том, что гибридизации необходимо обрабатывать партиями. Поскольку образцы ДНК хранятся в 96-луночных планшетах, а роботы позволяют одновременно обрабатывать все образцы в планшете, планшеты обычно путают со временем гибридизации.Что еще хуже, GWAS редко рандомизирует или контролирует планшеты при хранении образцов. Таким образом, часто пластинка и интересующий результат, по крайней мере, частично смешиваются. Следовательно, если алгоритмы генотипирования не будут должным образом оценивать эти пакетные эффекты, будет трудно, если вообще возможно, отличить настоящие ассоциации от искусственных. Новые методы, представленные в этой статье, успешно обнаруживают проблемные партии, просто проверяя некоторые из оцененных параметров модели. Чтобы устранить эти недостатки, мы разработали усовершенствование модели, используемой в версии 1 CRLMM, которая обеспечивает значительно улучшенные апостериорные вероятности и мощный вероятностный подход к обнаружению проблемных SNP и пакетов. Мы демонстрируем, что эти SNP и показатели качества партии в сочетании с улучшенными показателями достоверности могут эффективно выявлять элементы низкого качества и значительно повышать точность вызовов генотипа, которые будут использоваться в последующих анализах. 3.2 Усовершенствованная иерархическая модельМы структурируем наш анализ с помощью иерархической модели, (1) Индекс i =1,…, I представляет SNP, j =1,…, J представляет партию, k =1,…, K представляет собой образец, а г = AA , AB или BB представляет собой генотип. Z «являются ненаблюдаемыми, истинными генотипами, м » являются наблюдаемыми коэффициентами журнала, μ I = (μ IAA , μ IAB , μ , μ IBB ) ‘) ‘ представляет собой сдвиги для SNP I , λ IJ IJAA , λ IJAB , λ IJBB ) ′ обозначает пакетные эффекты, связанные с SNP i и пакетом j , σ ig 2 представляет собой специфическую для SNP дисперсию для генотипа g и объясняет тот факт, что разные масштабы вариаций SNP имеют разные вокруг предсказанных центров кластеров d g являются степенями свободы, связанными с дисперсией s 2 g типичного SNP.И d g , и s 2 g оцениваются на основе обучающих данных с использованием эмпирического байесовского подхода, описанного в Smyth (2004).Исследование данных показывает, что для больших и малых значений интенсивности M для генотипов AA и BB уменьшаются до 0 (рис. 8 в Carvalho et al. , 2007). Как это сделано Carvalho et al. (2007), мы учитываем эту интенсивно-зависимую смещение с детерминированной функцией F JKG , требующие, чтобы F 4 JKAB 7 = 0 и F JKAA = — f jkBB для всех j , k .Различия между генотипами (например, M для AA в среднем больше, чем M для AB ) поглощаются f . Эти функции оцениваются на отдельном этапе, как подробно описано Carvalho et al. (2007), и считаются известными.Модель, используемая в версии 1 CRLMM, предполагает, что ϵ ijkg имеет нормальное распределение. Масштабный коэффициент σ ig необходим, потому что логарифмические отношения для разных SNP представляют разные уровни вариации вокруг центров предсказанных областей.Поскольку для некоторых генотипов некоторые SNP имеют очень мало наблюдений, для заимствования информации из других SNP применяется эмпирический байесовский подход. Априор, используемый для σ ig , является обратным χ 2 с d g степенями свободы. Это удобный априор, который обеспечивает решения в закрытой форме. Оценка выполняется, как описано Smyth (2004). Недавно мы заметили, что выбросы были обычным явлением, и, как следствие, оценки достоверности CRLMM версии 1 были чрезмерно оптимистичными.Чтобы избежать подгонки различных моделей ошибок к каждому SNP, мы адаптировали подход к анализу данных, изменив распределение ϵ ijkg со стандартного нормального на t с 6 степенями свободы. Модель и процедура подбора коэффициента масштабирования остались такими же, как и в версии 1 CRLMM. Мы использовали обучающие данные, чтобы выбрать шесть, и это хорошо сработало в тестовых наборах. Обратите внимание, что если есть член ошибки и нужно добавить коэффициент масштабирования, в эмпирическом байесовском контексте необходимо оценить его распределение.Независимо от выбора модели результирующая случайная величина представляет собой отношение (или произведение) двух других. Использование обратного распределения χ 2 удобно и эффективно; другие варианты, обеспечивающие достаточную гибкость, дадут аналогичные результаты. 3.3 Оценка параметровЗаметим, что модель (1) имеет I × (2+ J ) × 3 + 12 параметров. При I = 906 600 SNP это слишком много, чтобы процедура глобальной оценки была практичной.В этом разделе мы опишем эффективную аппроксимативную модульную процедуру. На первом этапе мы используем существующие обучающие данные для оценки μ . Затем для каждой новой партии j мы рассматриваем μ как известные и оцениваем λ j . Оба шага реализуют двухэтапный подход, при котором производятся надежные оценки параметров методом наименьших квадратов вместе с их стандартными ошибками, а затем они передаются на второй этап, который сокращается для повышения точности.Наш подход позволил нам получить априорные значения без использования нелинейного алгоритма. Это было важной особенностью, учитывая размер типичных наборов данных: один миллион SNP и несколько сотен образцов, распределенных по десяткам пакетов. Этот подход привел к мощному программному инструменту, который превосходит алгоритм по умолчанию по скорости вычислений. 3.3.1 Оценка сдвигов, специфичных для SNPДля оценки V мы используем эмпирический байесовский подход (Louis and Carlin, 2009).Мы начинаем с получения надежных версий выборочных средних и дисперсий обучающих данных для оценки μ и σ с помощью и . Эти надежные оценки используются для учета t -распределенных ошибок. Поскольку набор обучающих данных считается эталоном, от которого отклоняются партии, мы предполагаем, что λ = 0, и, таким образом, и являются несмещенными оценками. Затем V оценивается выборочной дисперсией-ковариацией , что дает . Обратите внимание, что некоторые генотипы будут иметь очень мало доступных точек в обучающих данных для использования при оценке μ и σ, и оценка будет неточной.Теперь, чтобы заимствовать силу SNP, мы используем для сокращения использование формулы апостериорного распределения для многомерного гауссова: (2) с W i диагональная матрица с элементами s 2 g 3 3 / N ig , g =1,…, 3 и N ig количество точек, доступных в обучающих данных для оценки Точно так же мы уменьшаем оценки дисперсии (Smyth, 2004), что защищает от систематических ошибок, которые могут быть вызваны ситуациями с небольшим размером выборки: 2 .В этих вычислениях используются обучающие данные, и большинство пользователей не имеют к ним доступа. Поэтому мы сохраняем ‘s и N ig и включаем их как часть программного обеспечения, реализующего CRLMM версии 2.3.3.2 Оценка смен для конкретных партийЗдесь мы описываем двухэтапный подход, используемый для оценки λ j для каждой партии j =1,…, J . Общая идея состояла в том, чтобы использовать предварительно оцененные параметры сдвига, специфичные для SNP, ‘s и ‘s, для получения предварительных апостериорных значений для каждого генотипа.Они были использованы для создания псевдообучающего набора данных . Затем были оценены λ ij в соответствии с процедурой, аналогичной той, которая использовалась для оценки µ . Далее следуют некоторые подробности. Первый шаг — получить начальные значения для апостериорных значений, предполагая, что сдвиг, специфичный для партии, отсутствует, λ = 0, и известны сдвиги μ, характерные для SNP: Затем мы присваиваем генотип каждому SNP для каждой выборки в пакет, просто максимизируя эти апостериорные значения: с помощью этих вызовов был создан набор псевдообучающих данных.Ожидаемая стоимость м IJK обусловлено Z IJK = G F JKG ( S IJK 7) + μ IG +λ ijg . Поэтому мы предполагаем, что среднее (на практике мы вычисляем надежное среднее) отклонение с и N ijg (0) есть количество элементов в X ijg , является несмещенной оценкой λ ijg .На втором этапе оценивается U j с выборочной дисперсией-ковариацией . Имея на месте Û j оценку U j , мы уменьшаем, как в (2): (3) с W i как3.4 Изготовление задних зубовПри использовании CRLMM версии 1 апостериорные вызовы были особенно самоуверенными. Это согласуется с тем фактом, что оценки считаются известными.Мы разработали процедуру, которая позволяет нам учитывать неопределенность, связанную с оценкой сдвигов SNP и партий. В этом разделе мы проиллюстрируем эту идею, демонстрируя подход, когда сдвигов, характерных для партии, нет, а ϵ распределены нормально. В дополнительных материалах мы описываем детали, необходимые для полной модели, включая смены для конкретных партий и предположение о распределении t . 3.5 Показатели качестваКарвальо и др. (2007) представляют мощную процедуру обнаружения проблемных массивов на основе оценки f . Здесь мы представляем процедуру оценки качества SNP и гибридизационных партий. Качество партии j можно количественно оценить по диагональным записям Û j . Мы продемонстрируем полезность этого подхода в разделе 4. Для SNP мы можем количественно оценить качество, назначив апостериорную вероятность быть выбросом для каждой смены, т. е. μ i или λ ij .Используя установленные предыдущие распределения для μ I I и I I I , мы вводим плотность H 0 для отдаленного μ и вычислить заднюю вероятность: с φ ( μ )=(2π) −3/2 | В | −1/2 exp( μ ′ В −1 μ ). Практическим выбором для h является трехмерное равномерное распределение, охватывающее все возможные значения μ .Выполняем аналогичные вычисления для λ ij для каждой партии j . Чтобы проиллюстрировать преимущество эмпирического байесовского подхода, мы построили графики зависимости λ ijAA от λ ijAB и λ ijAA от λ ijBB (рис. 3BB ). Большое количество SNP позволило нам позаимствовать силу у SNP. Ненулевые корреляции позволили нам заимствовать силу между генотипами.Рис. 4. Рис. 4. 3.6 Программное обеспечениеОписанная здесь методология доступна в пакете crlmm R/BioConductor. Чтобы продемонстрировать его эффективность, мы сравнили CRLMM версии 2 с Birdseed, стандартным инструментом генотипирования для массивов SNP 6.0, на 270 образцах HapMap. В этом наборе максимальный объем памяти, используемый CRLMM версии 2 во время предварительной обработки, составлял 3,2 ГБ. После предварительной обработки использование памяти было уменьшено до 2 ГБ.CRLMM версии 2 требовалось 52 минуты для выполнения задачи. Birdseed использовал 845 МБ для большей части процесса, постепенно увеличиваясь до 900 МБ, что заняло 150 минут. Сравнения проводились на четырехпроцессорной системе (двухъядерный процессор AMD Opteron 2222 с частотой 3 ГГц) с 32 ГБ ОЗУ. Реализация этого алгоритма соответствует стандартам, используемым CRLMM версии 1: он обеспечивает определение парного генотипа и показатель достоверности для каждого образца при каждом доступном SNP и не выполняет никакой автоматической фильтрации, которая остается на усмотрение исследователя. 4 РЕЗУЛЬТАТАМы оценили производительность CRLMM версии 2 в сравнении с CRLMM версии 1 и Birdseed, алгоритм по умолчанию предоставляется производителем. Мы используем три набора данных: Мы использовали образцы HapMap, потому что знание «правды» позволило нам эффективно оценить нашу методологию. Обратите внимание, что, несмотря на те же образцы, используемые здесь гибридизации не были такими же, как набор, используемый для обучения нашего алгоритма. Набор данных C представлял собой большой набор из 34 различных партий, определяемых 96-луночным планшетом, в котором хранились образцы.Чтобы оценить производительность с этим набором данных, мы вычислили соответствие между вызовами, полученными при запуске алгоритма на всех выборках, и вызовами, полученными при пакетном запуске алгоритмов. Мы получили вызовы для каждого набора данных с Birdseed, CRLMM версии 1 и CRLMM версии 2.
Основными дополнениями, представленными в CRLMM версии 2 и описанными ниже, являются (A) набор показателей для оценки SNP (раздел 4.1) и качества партии (раздел 4.2) и (B) хорошо откалиброванные показатели достоверности. Эти показатели в сочетании с отношением сигнал-шум или SNR (Carvalho et al. , 2007) предлагают мощный набор инструментов для оценки качества процедуры генотипирования.Затем исследователь может пометить низкокачественные SNP, образцы и партии. Надлежащее использование этих инструментов повышает производительность и надежность алгоритма определения генотипа, как демонстрируют вышеупомянутые разделы в дополнение к разделам 4.3 и 4.4. 4.1 Показатели качества SNPДля наборов данных A и B мы рассчитали баллы контроля качества (QC) SNP, как описано ранее. А именно, для каждого SNP мы рассчитали апостериорную вероятность того, что оцененное λ не будет выбросом.Это имеет большое значение для исследователей, так как позволяет идентифицировать SNP, чьи генотипические вызовы очень точны. На практике это означает, что если исследователь использует SNP с более высокими баллами, маловероятно, что будет обнаружено много ошибок. Чтобы продемонстрировать полезность этой метрики, мы разделили SNP по показателю качества, представленному для наборов данных A и B, и построили графики зависимости точности от частоты выпадения (ADR) для каждой страты, показанные на рисунке 5. Обратите внимание, что, ограничивая внимание SNP с Баллы КК выше 0.25, мы получили почти идеальные результаты. Для наборов данных A и B 98,63% и 99,18% SNP превзошли этот предел, как показано в таблице 1. Рис. 5. Графики ADR для наборов данных A и B. SNP были стратифицированы по их показателям качества, и для каждой страты были построены кривые ADR. Показано, что баллы успешно идентифицируют SNP с более низкой точностью. Удаление таких SNP значительно повышает точность метода. Рис. 5. Графики ADR для наборов данных A и B.SNP были стратифицированы по их показателям качества, и для каждой страты были построены кривые ADR. Показано, что баллы успешно идентифицируют SNP с более низкой точностью. Удаление таких SNP значительно повышает точность метода. Таблица 1.Распределение SNP по стратам: примерно 99% SNP превышают предложенный порог SNP QC (0,25)
Распределение SNP по стратам: примерно 99% SNP превышают предложенный порог SNP QC (0,25) . Набор данных А
. | Набор данных B
. | 0.00-0.01 0,0063 0,0027 | 0,01-0,05 0,0027 0,0016 | 0,05-0,25 0,0047 0,0039 | 0.25-1.00 0,9863 | 0,9918 | |
 Этот тип классификации часто называют кластеризацией на основе моделей, поскольку для ответов используется статистическая модель. Описываем модель здесь.
Этот тип классификации часто называют кластеризацией на основе моделей, поскольку для ответов используется статистическая модель. Описываем модель здесь. Вероятности смешивания π j — априорные вероятности маркера иметь дозу аллеля j , где Σ j π j = 1. В модели, описанной выше, пять компонентов определены для пяти дозировок аллеля (0,..,4 ), но в других ситуациях может потребоваться меньше или больше компонентов. В случае пяти компонентов необходимо оценить десять параметров модели: пять средних μ j (для средних ответов пяти дозировок аллелей), одно стандартное отклонение σ (измерение общего разброса индивидуальных ответов с одной и той же дозировкой аллелей) и четыре вероятности π j (измерение доли лиц, имеющих дозу аллеля j th ), с пятой вероятностью, следующей из четырех других.
Вероятности смешивания π j — априорные вероятности маркера иметь дозу аллеля j , где Σ j π j = 1. В модели, описанной выше, пять компонентов определены для пяти дозировок аллеля (0,..,4 ), но в других ситуациях может потребоваться меньше или больше компонентов. В случае пяти компонентов необходимо оценить десять параметров модели: пять средних μ j (для средних ответов пяти дозировок аллелей), одно стандартное отклонение σ (измерение общего разброса индивидуальных ответов с одной и той же дозировкой аллелей) и четыре вероятности π j (измерение доли лиц, имеющих дозу аллеля j th ), с пятой вероятностью, следующей из четырех других. Здесь может оказаться полезным наложить ограничения на две группы параметров:
Здесь может оказаться полезным наложить ограничения на две группы параметров: Сначала мы предполагаем, что мощности сигналов с a и с б линейно зависят от дозировки аллеля: при x дозировка аллеля а и 4- x дозировка аллеля b, модель указывает на среднюю силу сигнала s a и с б , где a 0 и b 0 — мощность фонового сигнала для аллелей a и b.Дробь содержит лишний параметр и может быть упрощена до модели 1:
Сначала мы предполагаем, что мощности сигналов с a и с б линейно зависят от дозировки аллеля: при x дозировка аллеля а и 4- x дозировка аллеля b, модель указывает на среднюю силу сигнала s a и с б , где a 0 и b 0 — мощность фонового сигнала для аллелей a и b.Дробь содержит лишний параметр и может быть упрощена до модели 1:
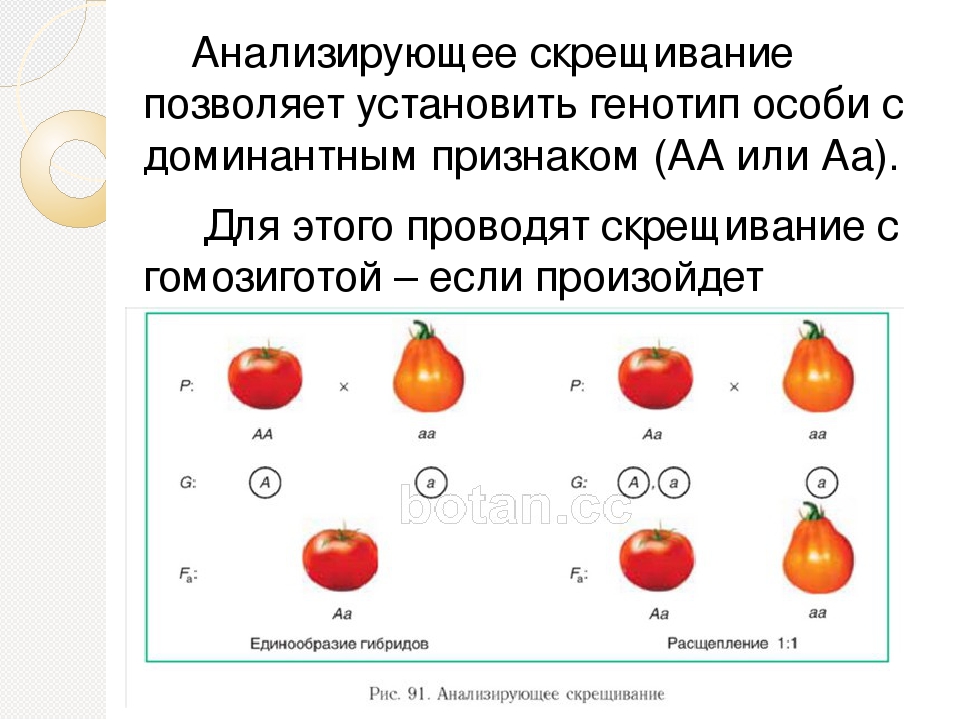
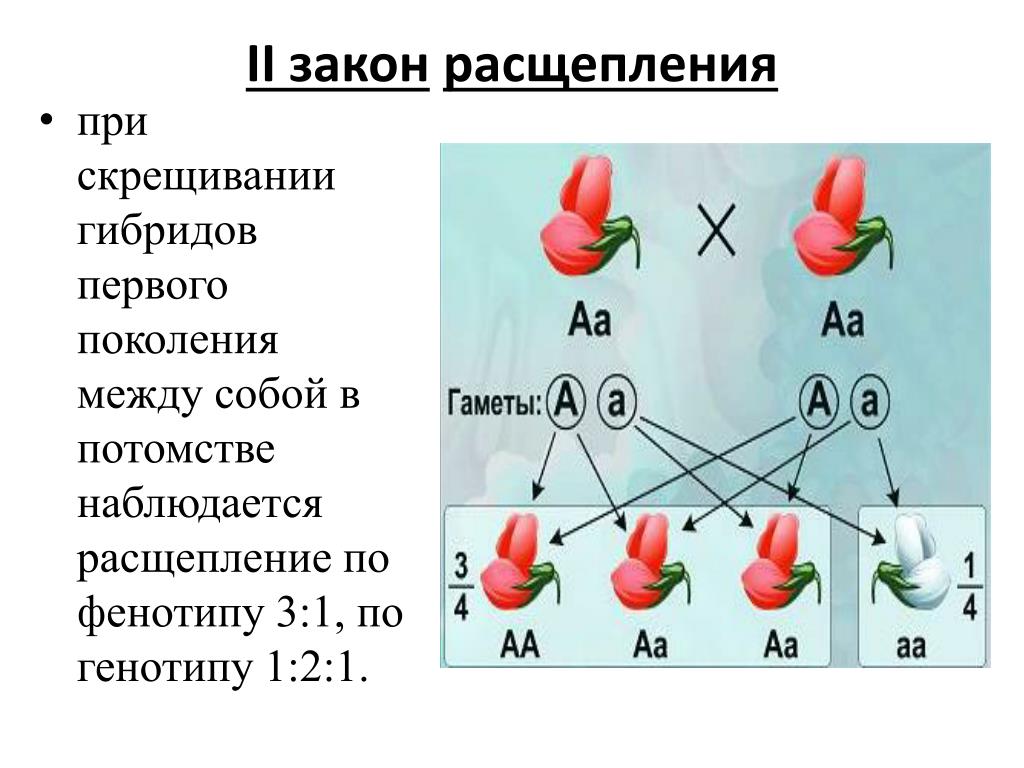 Анализируем аср — преобразованное отношение интенсивностей /( с а + с б )), составляя модель для ожидания E ( y ).Это математическое ожидание приблизительно, но не точно, равно asr ( E ( y )).
Анализируем аср — преобразованное отношение интенсивностей /( с а + с б )), составляя модель для ожидания E ( y ).Это математическое ожидание приблизительно, но не точно, равно asr ( E ( y )).
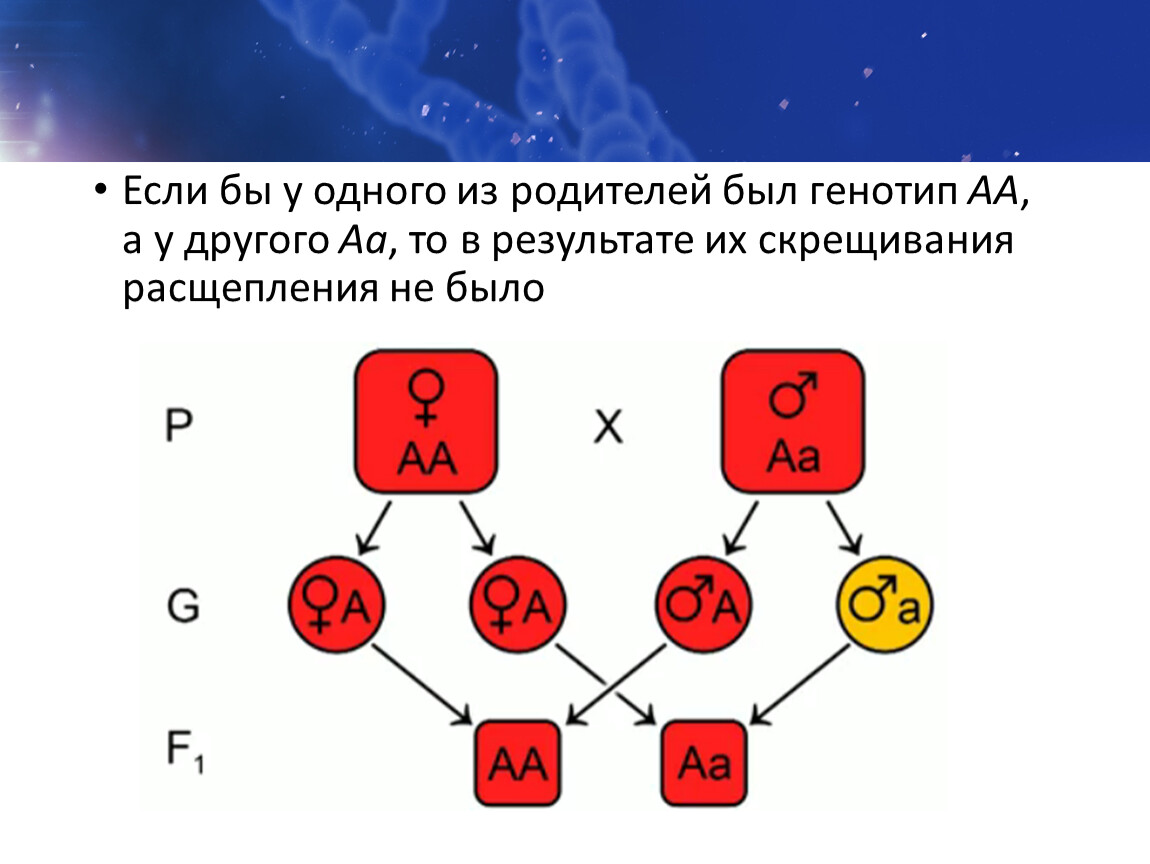 Подгонка выполняется с помощью R [21]. Более подробное описание смешанных моделей для маркерного генотипирования и алгоритма EM см. в [17].
Подгонка выполняется с помощью R [21]. Более подробное описание смешанных моделей для маркерного генотипирования и алгоритма EM см. в [17]. Это приводит к четырем возможным моделям для средних распределений компонентов.Каждая из этих моделей сочетается с двумя моделями пропорций смешивания: (а) пропорции смешивания не ограничены или (б) пропорции смешивания ограничены отношениями равновесия Харди-Вайнберга (HWE). Ограничение HWE часто помогает идентифицировать пики, даже если фактические отношения немного отличаются от HWE. Поскольку EM-алгоритм не всегда находит глобальный максимум из заданной начальной конфигурации значений параметров, EM-алгоритм для этих восьми моделей запускается с двумя различными конфигурациями средних значений: одна, где пять исходных средних получаются из иерархической кластеризации коэффициенты сигнала, и тот, где они установлены в равноудаленных положениях на преобразованной шкале от 0.от 142 до 1,429 (соответствует 0,02 и 0,98 по исходной шкале).
Это приводит к четырем возможным моделям для средних распределений компонентов.Каждая из этих моделей сочетается с двумя моделями пропорций смешивания: (а) пропорции смешивания не ограничены или (б) пропорции смешивания ограничены отношениями равновесия Харди-Вайнберга (HWE). Ограничение HWE часто помогает идентифицировать пики, даже если фактические отношения немного отличаются от HWE. Поскольку EM-алгоритм не всегда находит глобальный максимум из заданной начальной конфигурации значений параметров, EM-алгоритм для этих восьми моделей запускается с двумя различными конфигурациями средних значений: одна, где пять исходных средних получаются из иерархической кластеризации коэффициенты сигнала, и тот, где они установлены в равноудаленных положениях на преобразованной шкале от 0.от 142 до 1,429 (соответствует 0,02 и 0,98 по исходной шкале). Только если максимальная вероятность превышает определенный порог (по умолчанию 0,99), образцу присваивается соответствующий класс генотипа. Этот порог влияет на надежность показателей генотипа; высокий порог (такой как значение по умолчанию) приводит к высокой надежности, но к менее вызываемым генотипам; и если процент вызванных генотипов падает ниже определенного уровня (см. ниже), SNP вообще не учитывается.
Только если максимальная вероятность превышает определенный порог (по умолчанию 0,99), образцу присваивается соответствующий класс генотипа. Этот порог влияет на надежность показателей генотипа; высокий порог (такой как значение по умолчанию) приводит к высокой надежности, но к менее вызываемым генотипам; и если процент вызванных генотипов падает ниже определенного уровня (см. ниже), SNP вообще не учитывается. Если это так, восемь моделей снова подгоняются к третьей начальной конфигурации для средств распределения: если триплексный пик оказывается вписанным в зазор, средние дуплексные, симплексные и нульплексные пики переназначаются триплексным, дуплексным и симплексный пик; для нуллиплексного пика назначается новое среднее значение, находящееся посередине между (новым) симплексным средним значением и 0,0. Аналогичная перестановка выполняется, если симплексный пик оказывается помещенным в зазор. Используя эту новую начальную конфигурацию средств, ЭМ-алгоритм для восьми моделей запускается снова.
Если это так, восемь моделей снова подгоняются к третьей начальной конфигурации для средств распределения: если триплексный пик оказывается вписанным в зазор, средние дуплексные, симплексные и нульплексные пики переназначаются триплексным, дуплексным и симплексный пик; для нуллиплексного пика назначается новое среднее значение, находящееся посередине между (новым) симплексным средним значением и 0,0. Аналогичная перестановка выполняется, если симплексный пик оказывается помещенным в зазор. Используя эту новую начальную конфигурацию средств, ЭМ-алгоритм для восьми моделей запускается снова.
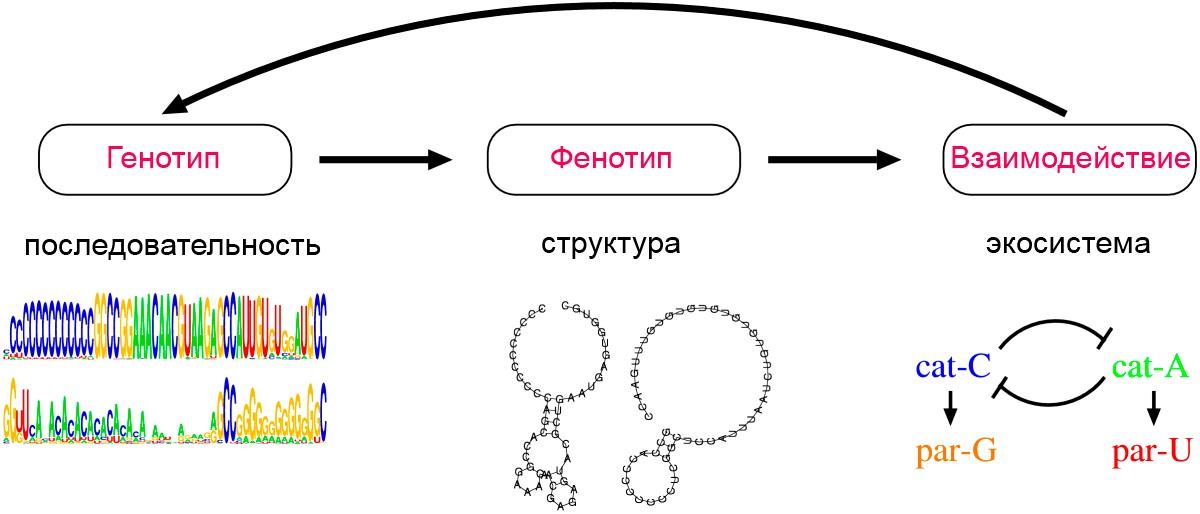 Этот параметр может быть увеличен для наборов данных с большим количеством выборок, если имеется достаточно выборок за пределами основного пика для надежной подгонки остальных компонентов распределения смеси.
Этот параметр может быть увеличен для наборов данных с большим количеством выборок, если имеется достаточно выборок за пределами основного пика для надежной подгонки остальных компонентов распределения смеси. Если также доступны данные о диплоидных образцах, гистограмма с отношениями сигналов этих образцов показана наложенной на тетраплоидную гистограмму для визуального сравнения; диплоидные образцы не используются при подборе или выборе модели.Типичный пример показан на рис. 1.
Если также доступны данные о диплоидных образцах, гистограмма с отношениями сигналов этих образцов показана наложенной на тетраплоидную гистограмму для визуального сравнения; диплоидные образцы не используются при подборе или выборе модели.Типичный пример показан на рис. 1. 5{\pi}_j{f}_j\left({y}_i\right) \) ( j = 1,..,5), которые описывают вероятности того, что выборка принадлежит каждому из пяти распределений. Если один из p ij больше установленного пользователем порогового значения (например, 0,9), генотип будет называться j-1 (поскольку распределение для j = 1 соответствует оценка дозы 0).
5{\pi}_j{f}_j\left({y}_i\right) \) ( j = 1,..,5), которые описывают вероятности того, что выборка принадлежит каждому из пяти распределений. Если один из p ij больше установленного пользователем порогового значения (например, 0,9), генотип будет называться j-1 (поскольку распределение для j = 1 соответствует оценка дозы 0). Пример гистограммы, полученной с помощью fitTetra для SNP для тетраплоидного картофеля, показан на рис. 1. Темные столбцы на гистограмме представляют соотношение диплоидных генотипов картофеля, включенных в это исследование. Соотношения аллелей для диплоидных гомозигот равны соотношениям для гомозигот (нуллиплекс и квадруплекс) в тетраплоидах, а соотношение для диплоидных гетерозигот такое же, как соотношение для дуплексных генотипов в тетраплоидах. Таким образом, положение диплоидного распределения по сравнению с тетраплоидным может служить дополнительной проверкой качества призыва.
Пример гистограммы, полученной с помощью fitTetra для SNP для тетраплоидного картофеля, показан на рис. 1. Темные столбцы на гистограмме представляют соотношение диплоидных генотипов картофеля, включенных в это исследование. Соотношения аллелей для диплоидных гомозигот равны соотношениям для гомозигот (нуллиплекс и квадруплекс) в тетраплоидах, а соотношение для диплоидных гетерозигот такое же, как соотношение для дуплексных генотипов в тетраплоидах. Таким образом, положение диплоидного распределения по сравнению с тетраплоидным может служить дополнительной проверкой качества призыва. Правильно : Вызов с помощью fitTetra 2.0 (используя данные родительского генотипа). Установлено, что родительские генотипы являются дуплексными (2) и квадруплексными (4), что приводит к схеме сегрегации 0:0:1:4:1, которая показана на верхней панели. Левый : Вызов с помощью fitTetra 1.0. Без информации о структуре популяции родительские образцы генотипированы как симплексные (1) и триплексные (3). Такая комбинация должна привести к шаблону 0:1:2:1:0 в семействе FS. Однако, если мы просто рассмотрим образцы из семейства FS, результаты вызова предполагают шаблон 0:1:4:1:0, который не соответствует какой-либо родительской комбинации
Правильно : Вызов с помощью fitTetra 2.0 (используя данные родительского генотипа). Установлено, что родительские генотипы являются дуплексными (2) и квадруплексными (4), что приводит к схеме сегрегации 0:0:1:4:1, которая показана на верхней панели. Левый : Вызов с помощью fitTetra 1.0. Без информации о структуре популяции родительские образцы генотипированы как симплексные (1) и триплексные (3). Такая комбинация должна привести к шаблону 0:1:2:1:0 в семействе FS. Однако, если мы просто рассмотрим образцы из семейства FS, результаты вызова предполагают шаблон 0:1:4:1:0, который не соответствует какой-либо родительской комбинации е. ширина пиков на шкале арксинус-квадратного корня) являются общими для разных популяций, в то время как пропорции смешивания π j могут быть разными для каждой популяции.
е. ширина пиков на шкале арксинус-квадратного корня) являются общими для разных популяций, в то время как пропорции смешивания π j могут быть разными для каждой популяции. Ожидается, что двойная редукция будет происходить с относительно низкой частотой, даже когда иногда возникают поливалентные пары. Родительские выборки указаны как отдельные популяции.
Ожидается, что двойная редукция будет происходить с относительно низкой частотой, даже когда иногда возникают поливалентные пары. Родительские выборки указаны как отдельные популяции.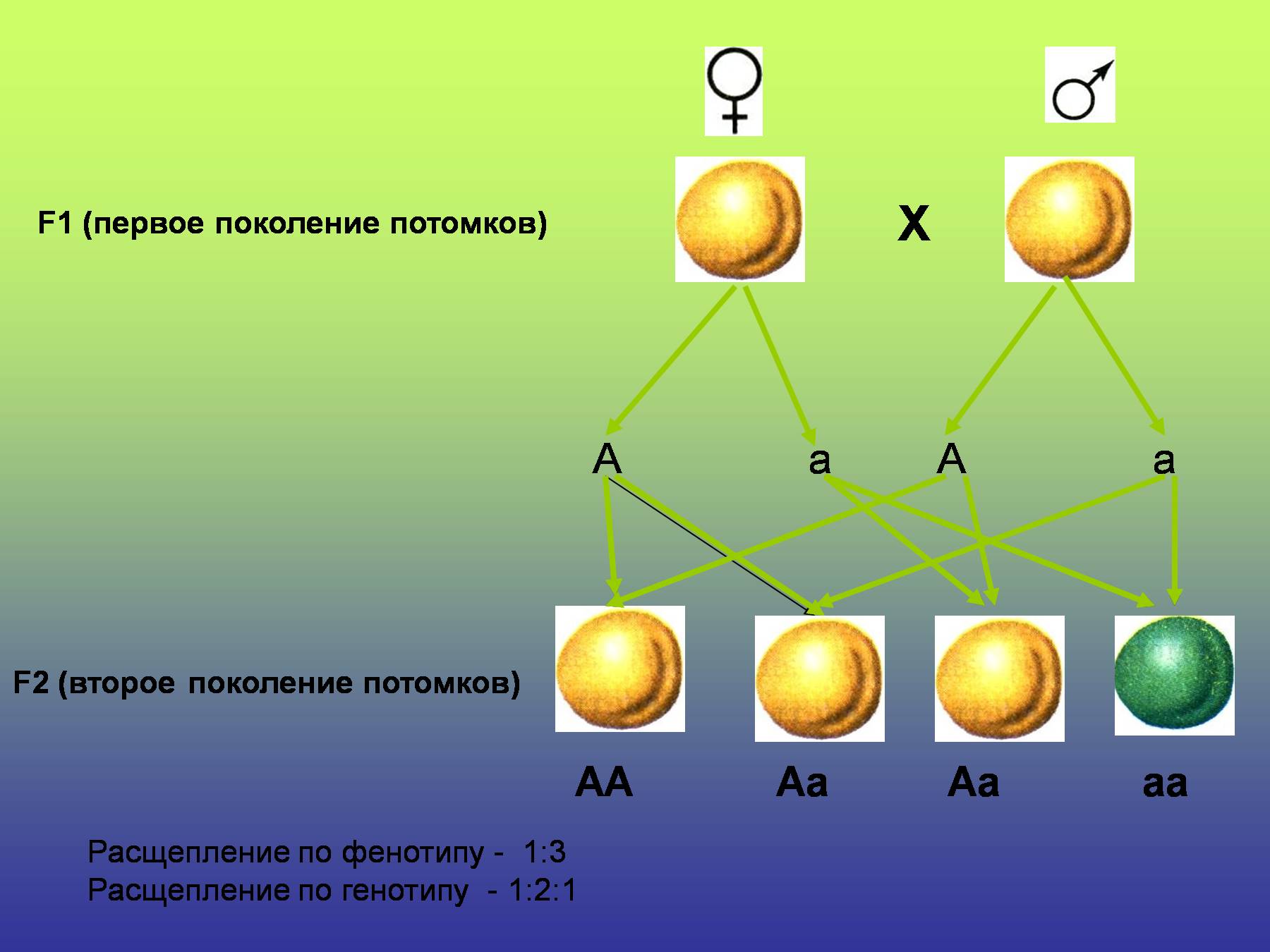 0, за исключением вывода вероятностей пяти распределения, которые теперь зависят от популяции. При необходимости строится массив гистограмм, показывающий для каждой совокупности (для ассоциативных панелей и для FS) гистограмму отношений с подобранной смешанной моделью.Родительские данные показаны отдельными цветными символами на гистограммах для соответствующего семейства ФС (рис. 1).
0, за исключением вывода вероятностей пяти распределения, которые теперь зависят от популяции. При необходимости строится массив гистограмм, показывающий для каждой совокупности (для ассоциативных панелей и для FS) гистограмму отношений с подобранной смешанной моделью.Родительские данные показаны отдельными цветными символами на гистограммах для соответствующего семейства ФС (рис. 1). Соответственно будут рассчитаны вероятности (коэффициенты расщепления) соответствующего потомства F1. Возможно, что родительские генотипы ошибочны (например, если они были получены из RNA-Seq, на них может повлиять дифференциальная экспрессия генов). Чтобы избежать потери маркеров только из-за этого, fitTetra 2.0 всегда будет пытаться подогнать модель, в которой вместо «p.free» используется «p.free».исправлено», и будет выбрана модель с лучшим показателем BIC. Если родительские генотипы, предоставленные пользователем, верны, прогон с «p.fixed» должен давать модель не хуже, чем с «p.free».
Соответственно будут рассчитаны вероятности (коэффициенты расщепления) соответствующего потомства F1. Возможно, что родительские генотипы ошибочны (например, если они были получены из RNA-Seq, на них может повлиять дифференциальная экспрессия генов). Чтобы избежать потери маркеров только из-за этого, fitTetra 2.0 всегда будет пытаться подогнать модель, в которой вместо «p.free» используется «p.free».исправлено», и будет выбрана модель с лучшим показателем BIC. Если родительские генотипы, предоставленные пользователем, верны, прогон с «p.fixed» должен давать модель не хуже, чем с «p.free».
| СНП КК . | Набор данных А . | Набор данных B . 91 755 |
|---|---|---|
| 0.00-0.01 0,0063 0,0027 | ||
| 0,01-0,05 0,0027 0,0016 | ||
| 0,05-0,25 0,0047 0,0039 | ||
| 0.25-1.00 0,9863 | 0,9918 |
4.2 Показатели качества партии
Для набора данных C у нас нет эталонных вызовов для сравнения, как для образцов, являющихся частью HapMap.Поэтому мы генерировали вызовы двумя способами: (i) с использованием и (ii) игнорированием пакетной информации. Затем мы рассчитали соответствие между этими двумя наборами вызовов для каждой партии после исключения вызовов, показатели достоверности которых были ниже 5-го процентиля. Эти соответствия представлены на оси y рис. 6А и В. Мы считали партии с более низким соответствием проблематичными. Процент выборок с отношением сигнал/шум, как определено Carvalho et al. (2007 г.), значение ниже пяти было лучшим предиктором низкокачественных партий, как показано на рис. 6А.Следующим значительным улучшением, внесенным в CRLMM версии 2, стала оценка качества партии, которая также предсказывала низкое качество, как показано на рисунке 6B.
Рис. 6.
Графики пакетного качества. ( A ) Соответствие с коэффициентом отбрасывания 5% наносится на график в зависимости от процента выборки, помеченной оценкой SNR. ( B ) Соответствие с коэффициентом отбрасывания 5% нанесено на график в зависимости от нашей оценки качества партии.
Рис. 6.
Графики пакетного качества.( A ) Соответствие с коэффициентом отбрасывания 5% наносится на график в зависимости от процента выборки, помеченной оценкой SNR. ( B ) Соответствие с коэффициентом отбрасывания 5% нанесено на график в зависимости от нашей оценки качества партии.
Наша оценка качества партии также эффективно предсказала различия в точности, наблюдаемые на рис. 7. Обратите внимание, что наборы данных A и B имели оценки качества партии 0,0337 и 0,0745 соответственно.
Рис. 7.
Графики ADR для наборов данных A и B.Для первого набора CRLMM версии 2 превосходит как Birdseed, так и CRLMM версии 1. Для второго набора он превосходит два других метода примерно с коэффициентом отбрасывания 6%. Также обратите внимание, что точность второго набора данных ниже по сравнению с первым, что указывает на значительные различия в качестве двух наборов.
Рис. 7.
Графики ADR для наборов данных A и B. Для первого набора CRLMM версии 2 превосходит как Birdseed, так и CRLMM версии 1. Для второго набора он превосходит два других метода примерно при частоте выпадения 6 %.Также обратите внимание, что точность второго набора данных ниже по сравнению с первым, что указывает на значительные различия в качестве двух наборов.
Для каждого SNP мы подсчитываем, сколько образцов было отнесено к каждому кластеру генотипов, и обозначаем это как N ijg . Используя и N ijg , мы оцениваем сдвиг, который может быть приписан каждому наблюдению в этом кластере, с помощью (7), где член ( N ijg +1) используется, чтобы избежать деления на нуль.Отметив, что для фиксированной партии j отдельные сдвиги в уравнении (7) могут быть обозначены матрицей Δ j , мы создаем подмножество Δ j q 3 3 , которое содержит только строки Δ j , связанные с SNP, показатель качества которых ниже q . Метрика качества партии затем определяется средней дисперсией Δ j q , (8) для которой мы рекомендуем порог q = 0.70.4.3 Общая точность
Затем мы сравнили общую точность с использованием наборов данных A и B. Мы рассчитали точность, т. е. долю правильных вызовов, для вызовов с оценкой достоверности выше заданного порога. Рассматривались различные отсечки. Затем мы построили график зависимости точности от доли вызовов ниже порога достоверности. Графики ADR, рис. 7, продемонстрировали, что в целом CRLMM версии 2 превосходит два других алгоритма.
4.4 Задняя часть
Чтобы оценить достоверность апостериорных данных, мы сравнили наблюдаемую точность с зарегистрированными апостериорными данными.В частности, мы разделили вызовы по связанным с ними апостериорным показателям и для каждого слоя вычислили долю правильных вызовов. Затем мы нанесли их друг на друга, ожидая, что они попадают на линию тождества. Хотя CRLMM версии 1 не использует апостериорные значения в качестве меры достоверности, мы получили апостериорные значения, изменив его код. CRLMM версии 2 улучшил апостериорные значения, предоставленные CRLMM версии 1, которые явно были оптимистичными (рис. 8).
Рис.8.
Для набора данных A вызовы были стратифицированы по связанным с ними апостериорным данным. Для каждой страты наблюдаемая точность была рассчитана путем сравнения с вызовами золотого стандарта HapMap. CRLMM версии 2 сравнивают с CRLMM версии 1, что явно слишком оптимистично. Пунктирные линии представляют собой гомозиготы, пунктирные линии — гетерозиготы, а сплошные линии — общую точность.
Рис. 8.
Для набора данных A вызовы были стратифицированы по связанным с ними апостериорным данным. Для каждой страты наблюдаемая точность была рассчитана путем сравнения с вызовами золотого стандарта HapMap.CRLMM версии 2 сравнивают с CRLMM версии 1, что явно слишком оптимистично. Пунктирные линии представляют собой гомозиготы, пунктирные линии — гетерозиготы, а сплошные линии — общую точность.
5 ОБСУЖДЕНИЕ
Мы представили многоуровневое усовершенствование модели CRLMM, описанное Carvalho et al. (2007 г.). Наша единственная цель состоит в том, чтобы предоставить точные вызовы генотипа, откалиброванные оценки достоверности и показатели качества, основанные на наблюдаемой интенсивности зондов SNP и наборе оценок параметров (местоположение и масштаб), полученных из обучающего набора данных.Эта стратегия не использует какую-либо другую информацию, такую как известные области количества копий. Наша модель учитывает три уровня изменчивости данных массива SNP: (i) сдвиги, специфичные для SNP, (ii) сдвиги пакетов гибридизации для каждого SNP и (iii) ошибка измерения с тяжелыми хвостами. За счет явного моделирования этих источников неопределенности оцениваемые апостериорные вероятности значительно улучшаются по сравнению с теми, которые предлагаются в версии 1 CRLMM. Мы также учитываем изменчивость, связанную с оценкой параметров модели, с обучающими данными.Наш подход позволил получить априорные значения с более высокими свойствами, чем те, которые были созданы CRLMM версии 1. Уточнения повысят точность последующих результатов, полученных из тестов на основе вероятностных ассоциаций, таких как описанный Ruczingi et al. (http://www.bepress.com/jhubiostat/paper181).
Мы также описали методологию, полезную для обнаружения проблемных SNP и партий гибридизации. Мы находим последний вклад особенно важным. Адаптация инструментов анализа для работы с эффектами пакетной гибридизации должна быть приоритетом групп анализа, работающих с данными GWAS.Из-за экспериментальной логистики GWAS редко контролируют или рандомизируют луночный планшет, например, при использовании внешних контролей. Следовательно, необнаруженная проблемная партия может затруднить, если не сделать невозможным, отличить зарегистрированные ассоциации от искусственных, например, вызванных партиями гибридизации. Мы представили мощное решение, которое прогнозирует проблемные партии и может быть легко включено в любой конвейер анализа.
БЛАГОДАРНОСТИ
Мы благодарим Информационную сеть генетической ассоциации (GAIN) и Джеймса Варрама за данные GoKinD; Саймон Коули, Affymetrix и Дэн Аркинг для данных HapMap; Нэнси Кокс, Ануар Конкашбаев, Эрин М.Ramos и Lisa J. McNeil за помощь в получении и понимании данных GoKinD; Ingo Ruczinksi за полезные комментарии; а также Марвину Ньюхаусу и Джионг Янг за помощь в управлении данными. Исследование «Генетика почек при диабете» (GoKinD) изначально поддерживалось Фондом исследования ювенильного диабета в сотрудничестве с Диабетическим центром Джослина и Университетом Джорджа Вашингтона, а также Центрами США по контролю и профилактике заболеваний; постоянную поддержку GoKinD оказывает Национальный институт диабета, болезней органов пищеварения и почек (NIDDK).Коллекция ДНК GoKinD была генотипирована в рамках программы GAIN при поддержке FNIH и NIDDK. Набор данных, использованный для анализов, описанных в этой рукописи, был получен из базы данных генотипа и фенотипа (dbGaP), найденной на http://www.ncbi.nlm.nih.gov/gap, под номером доступа dbGaP phs000018.v1.p1.
Финансирование : Гранты Национального института здравоохранения R01GM083084 от Национального института общей медицины; 5R01RR021967 Национального центра исследовательских ресурсов; R01 DK061662 Национального института диабета; Заболевания органов пищеварения и почек; R01 HL0 Национального института сердца, легких и крови; R01 GM083084, грант CTSA для медицинских учреждений Джона Хопкинса; докторская стипендия, присуждаемая Бразильским агентством по финансированию CAPES (Coordenação de Aprimoramento Pessoal de Nível Superior).
Конфликт интересов : не объявлено.
ССЫЛКИ
Affymetrix
BRLMM: Улучшенный метод вызова генотипа для Genechip Change Appropting 500K Набор
,Технический отчет
,2006
Affymetrix
Affymetrix
Affymetrix
BRLMM-P: Метод вызова генотипа для массива SNP 5.0
,Технический отчет
,2007
Affymetrix
, и др.Воспаление, гемостаз и риск снижения функции почек при риске атеросклероза в сообществах (aric) исследование
,Am.Дж. Почки Дис.
,2009
, том.53
(стр.572
—575
) и др.Исследование, нормализация и определение генотипа данных массива олигонуклеотидов SNP высокой плотности
8
(стр.485
—499
), и др.Алгоритмы на основе динамических моделей для скрининга и генотипирования более 100 тыс. SNP на олигонуклеотидных микрочипах
21
(стр.1958
—1963
) и др.Исследование, нормализация и обобщение данных уровня зонда массива олигонуклеотидов высокой плотности
4
(стр.249
—264
), и др.Интегрированный анализ определения генотипа и ассоциации SNP, полиморфизма распространенных номеров копий и редких cnvs
,Nat. Жене.
,2008
, том.40
(стр.1253
—1260
), .Модельный анализ массивов олигонуклеотидов: вычисление индекса экспрессии и обнаружение выбросов
,Proc. Натл акад. науч. США
,2001
, том.98
(стр.31
—36
), .Модельный анализ массивов олигонуклеотидов: проверка модели, вопросы дизайна и применение стандартной ошибки
,Genome Biol.
,2001
, том.2
, и др.Валидация и расширение эмпирического метода Байеса для SNP с использованием микрочипов Affymetrix
,Genome Biol.
,2008
, том.9
стр.R63
, .Байесовские методы анализа данных
Новый многоточечный метод полногеномных ассоциативных исследований путем вменения генотипов
,Nat. Жене.
,2007
, том.39
(стр.906
—913
) и др.Исследование генетики почек при диабете (Гокинд): коллекция генетических данных для выявления факторов генетической предрасположенности к диабетической нефропатии при диабете 1 типа
,J.Являюсь. соц. Нефрол.
,2006
, том.17
(стр.1782
—1790
), .Решение загадки ярких несоответствий: мечение и эффективное связывание в массивах олигонуклеотидов
,Phys. Rev. E, Stat., Nonlin., Soft Matter Phys.
,2003
, том.68
Часть 1
стр.011906
, и др.Метод устранения дифференциальной систематической ошибки при генотипировании в крупномасштабных ассоциативных исследованиях
,PLoS Genet.
,2007
, том.3
стр.e74
, и др.Программное обеспечение R/Bioconductor для чипов Illumina infinium для полногеномного генотипирования
,Биоинформатика
,2009
, том.25
(стр.2621
—2623
).Линейные модели и эмпирические байесовские методы для оценки дифференциальной экспрессии в экспериментах с микрочипами
,Stat. заявл. Жене. Мол. биол.
,2004
, том.3
Международный консорциум HapMap
Международный проект HapMap
,Nature
,2003
, vol.426
(стр.789
)796
)Wellcome Trust Counter Control Consortium
Геном-ассоциация Изучение 14 000 случаев семи распространенных заболеваний и 3000 общих ресурсов
,Nature
,2007
, Vol.447
(стр.661
—678
) и др.Основанная на модели корректировка фона для массивов экспрессии олигонуклеотидов
,J. Am. Стат. доц.
,2004
, том.99
(стр.909
—917
)Примечания автора
© Автор, 2009 г. Опубликовано Oxford University Press. Все права защищены. Чтобы получить разрешение, отправьте электронное письмо по адресу: [email protected]
.Что означают буквы в генотипе? | Образование
Когда вы были зачаты, половые клетки ваших родителей предоставили такое же количество генетической информации, чтобы описать физические черты, которые вы продемонстрируете миру.В биологии эти внешние физические черты называются фенотипом, а лежащий в основе генетический код называется генотипом. Ученые используют определенные буквы для обозначения различных типов генов, известных как аллели, которые объединяются для создания генотипа. Каждая из этих букв и то, как она пишется, имеет особое значение.
Что делать с аллелями?
Аллели для генов — то же, что цвета для футболок. Точно так же, как вы можете зайти в магазин и купить одну и ту же футболку разных цветов, в генетическом пуле человека существует несколько вариаций одного и того же гена.Эти вариации называются аллелями. Ученые используют определенные буквы для обозначения аллелей и их характеристик.
Не одно стандартное представление
Разные ученые и научные учреждения используют разные стандарты для представления аллелей. Некоторые ученые используют буквы с надстрочными и нижними индексами для обозначения генотипа и фенотипа признака соответственно. Однако многие ученые также используют прописные и строчные буквы для обозначения доминантных и рецессивных генов соответственно.Эти буквы, как правило, относятся к рассматриваемому признаку, например, буква B обозначает карий цвет глаз как доминантный аллель.
Верхние и нижние индексы
Некоторые ученые используют нижние индексы для представления фенотипов и верхние индексы для представления генотипов. Лучше всего это можно понять на таком примере, как цвет шубы. Скажем, в генетике волка есть аллель белого и коричневого меха. Аллель белой шубы будет представлена буквой F (для «меха») с нижним индексом «W», а аллель коричневой шубы будет представлена буквой F с нижним индексом «B».Буквы «W» и «B» будут нижними индексами, потому что они являются фенотипами или физическими представлениями цвета шубы.
Прописные и строчные буквы
Многие ученые используют прописные буквы для обозначения доминантного аллеля и строчные буквы для обозначения рецессивного аллеля. Например, предположим, что ученый собирается завести ребенка со своим мужем, и она хочет предсказать, какого цвета будут глаза ее новорожденного. Предположим, что у нее карие глаза и оба ее аллеля относятся к карим глазам, а также предположим, что глаза ее мужа зеленые, и у него есть два аллеля для зеленых глаз.Она представила бы свой генотип как «BB», а генотип своего мужа как «gg», потому что карие глаза являются доминантным признаком, а зеленые глаза — рецессивным признаком. Нарисовав квадрат Пеннета (см. ссылку в разделе «Ресурсы»), она будет знать, что у ее ребенка будет один аллель для карих глаз и один аллель для зеленых глаз, поэтому генотип ребенка будет представлен «Bg».
Ссылки
Ресурсы
Писатель Био
Розмари Питерс имеет степень бакалавра наук в области электротехники и степень магистра наук в области научных коммуникаций.Она работала над редакционным и дизайнерским контентом для нескольких изданий, в том числе «Маяк» и «Международные инновации». Она также работала в отделе научного радио BBC.
Аллели, генотип и фенотип | Science Primer
Генетика — это наука об организации, выражении и передаче наследуемой информации. Способность информации передаваться от поколения к поколению требует механизма. Живые организмы используют ДНК. ДНК представляет собой цепь или полимер нуклеиновых кислот.Отдельные полимеры ДНК могут содержать сотни миллионов молекул нуклеиновых кислот. Эти длинные нити ДНК называются хромосомами. Порядок отдельных нуклеиновых кислот в цепи содержит информацию, используемую организмами для роста и размножения. Использование ДНК в качестве информационной молекулы является универсальным свойством всего живого на Земле. Наш клеточный механизм считывает эту генетическую информацию, позволяя нашему телу синтезировать множество ферментов и белков, необходимых для жизни
.На иллюстрации исследуется взаимосвязь между наличием различных аллелей в определенном локусе и генотипом и фенотипом организма.Организм в модели – растение. Он диплоидный, и признак — цвет цветка. Ниже приведено видео на YouTube, демонстрирующее использование иллюстрации и набора задач, которые вы можете использовать, чтобы проверить свое понимание этих концепций.
Генетическая информация хранится в дискретных единицах, называемых генами. Каждый ген содержит информацию, необходимую для синтеза отдельных клеточных компонентов, необходимых для выживания. Скоординированная экспрессия множества различных генов отвечает за рост и активность организма.
В пределах отдельного вида гены встречаются в определенных местах на хромосомах. Это позволяет определить их местонахождение. Положение определенного гена на хромосоме называется его локусом.
Вариации порядка расположения нуклеиновых кислот в молекуле ДНК позволяют генам кодировать достаточно информации для синтеза огромного разнообразия различных белков и ферментов, необходимых для жизни. Помимо различий между генами, расположение нуклеиновых кислот может различаться между копиями одного и того же гена.Это приводит к различным формам отдельных генов. Различные формы гена называются аллелями.
Организмы, размножающиеся половым путем, получают по одной полной копии своего генетического материала от каждого родителя. Наличие двух полных копий их генетического материала делает их диплоидными. Совпадающие хромосомы от каждого родителя называются гомологичными хромосомами. Совпадающие гены от каждого родителя встречаются в одном и том же месте на гомологичных хромосомах.
Диплоидный организм может иметь либо две копии одного и того же аллеля, либо по одной копии каждого из двух разных аллелей.Люди, у которых есть две копии одного и того же аллеля, считаются гомозиготными по этому локусу. Люди, которые получают разные аллели от каждого родителя, считаются гетерозиготными по этому локусу. Аллели, которые человек имеет в локусе, называются генотипом. Генотип организма часто выражается буквами. Видимое выражение генотипа называется фенотипом организма.
Аллели не созданы равными. Одни аллели маскируют присутствие других. Аллели, которые маскируются другими, называются рецессивными аллелями.Рецессивные аллели экспрессируются только тогда, когда организм гомозиготен по этому локусу. Аллели, экспрессирующиеся независимо от присутствия других аллелей, называются доминантными.
Если один аллель полностью маскирует присутствие другого в том же локусе, говорят, что этот аллель проявляет полное доминирование. Однако доминирование не всегда является полным. В случаях неполного доминирования возможны промежуточные фенотипы.
Взаимодействия генов могут быть довольно сложными. Приведенный выше пример демонстрирует простую ситуацию, в которой отдельному признаку соответствует один ген.В более сложных случаях несколько генов могут влиять на отдельный признак. Это называется полигенным наследованием. В этих ситуациях связь между конкретными аллелями и характеристиками не так однозначна.
В своих знаменитых исследованиях растений гороха Мендель изучил семь признаков, обладающих характеристиками, необходимыми для наблюдения за наследованием отдельных признаков.