
Н и НН в разных частях речи
Одно из сложных для усвоения правил русского языка — правописание Н и НН в разных частях речи, так же как и не с разными частями речи. Но сегодня мы рассмотрим первый случай. Для каждой части речи имеются свои тонкости написания этих суффиксов, поэтому ученики часто делают ошибки при написании слов.
Чаще они встречаются у прилагательных, причастий, наречий, реже — при написании существительных. У каждой части речи есть свои тонкости правописания двойных букв в словах.
Нормы написания суффиксов в прилагательных
Прилагательное — это часть речи, отвечающая на вопросы «какой?» и другие подобные вопросы. Оно служит для описания признаков, а суффиксы с буквами Н, НН чаще всего встречаются при образовании слов, обозначающих качественных характеристики предметов или явлений.
Если новая словоформа прилагательного образована путем прибавления к корню суффиксов -ан-, -ян-, -ин-, следует писать одну Н. Пример этого правила — слово «глиняный».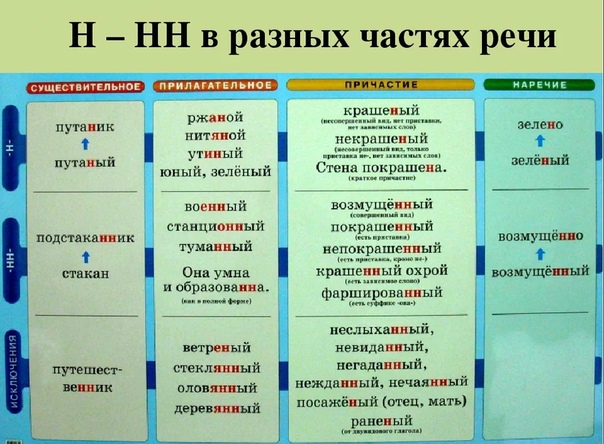 Но есть слова, написание которых ему не соответствует. «Оловянный», «деревянный», «стеклянный» — эти исключения нужно запомнить.
Но есть слова, написание которых ему не соответствует. «Оловянный», «деревянный», «стеклянный» — эти исключения нужно запомнить.
Если для образования новой словоформы были использованы суффиксы -онн-, -енн-, то всегда пишут две буквы. Исключения из этого правила — «ветреный», «масляный». Трудности при словообразовании возникают, если корень слова оканчивается на эту букву.
При добавлении к нему суффикса, начинающегося на нее, то следует выбирать удвоенный вариант, например, «картинный». При этом одна буква будет входить в состав корня, а вторая будет суффиксом.
Основные трудности при написании Н и НН связаны с именами прилагательными. На их нормах написания и созданы правила для написания существительных и наречий, от которых они образованы. Но некоторые их формы могут получаться и от глаголов.
Поэтому в дополнение к основным правилам, учат различать отглагольное прилагательное от причастия из-за их схожих признаков.
Нормы написания суффиксов в отглагольных прилагательных и причастиях
Эти части речи имеют общие признаки и их нередко путают.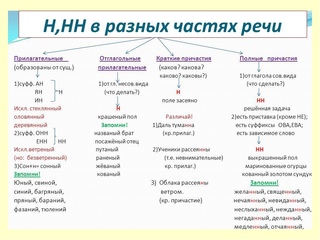 Поэтому особенности правописания Н в суффиксах будут похожими. Причастие соединяет в себе свойства прилагательного и глагола. Оно обозначает свойства предмета по его действию и отвечает на глагольные вопросы.
Поэтому особенности правописания Н в суффиксах будут похожими. Причастие соединяет в себе свойства прилагательного и глагола. Оно обозначает свойства предмета по его действию и отвечает на глагольные вопросы.
Действуют следующие правила написания НН в этих частях речи:
- Если в их состав входит приставка, то пишут двойной вариант, например, «вспаханный». Аналогичный вариант написания, если в состав входят суффиксы -ова-, -ева-, -ирова-: «маринованный».
- Если для образования прилагательного был использован бесприставочный глагол совершенного вида. Нужно запомнить исключение — «раненый».
- Также такой вариант употребляют в страдательных причастиях полной формы, стоящих в прошедшем времени.
- Такое написание применимо к причастиям, оканчивающимся на -ованный, -ёванный. Например, «организованный».
- Если причастие стоит в паре с зависимым словом.
- Двойное написание встречается в причастиях, имеющих полную форму. В основе должен быть глагол совершенного вида.
 Для проверки вида задают вопрос «что сделать?».
Для проверки вида задают вопрос «что сделать?».
Когда следует писать одну Н?
- Если это краткое причастие.
- В прилагательных мужского рода единственного числа. Они должны быть образованы от глагола совершенного вида.
В кратких прилагательных написание суффикса зависит от полной формы этого слова. Исключений из правил не так много, поэтому их несложно запомнить, что способствует усвоению основного правила.
Прежде чем выбирать, что писать -Н- или -НН-, нужно уметь различать причастие от отглагольного прилагательного. Для этого перед словом нужно поставить «более». Если оно будет уместно и не нарушит структуру предложения, то это будет прилагательное. Если оно не сочетается, то это — причастие.
Нормы написания Н и НН в наречиях
Чтобы определить как правильно писать суффикс в наречиях, нужно смотреть на форму причастия или прилагательного, от которого оно образовано. Если пишется двойное НН, то аналогичное количество букв будет в наречии.
Например, рассеянный — рассеянно.
Нормы написания Н и НН в существительных
Реже встречаются данные суффиксы в словах-существительных. Но и у этой части речи имеются свои особенности написания Н и НН, которые нужно учитывать.
Когда следует писать двойное НН в именах существительных?
- Если в конце основы слова стоит Н, а суффикс начинается на эту букву.
- Если существительное было образовано от прилагательного или причастия, в состав которых входит суффикс с двойной НН как в слове «торжественность».
В существительном следует писать Н, если оно было образовано от прилагательного с таким же количеством Н в слове, например, «пряности».
Упражнения для закрепления правописания
Для закрепления правописания суффиксов с Н и НН выполняют задания на данную тему.
- Вставить пропущенную букву, аргументировав свой выбор.
- Образовать наречия от прилагательного.
- Объяснить разницу в написании одинаковых слов в разных предложениях различаться они будут количеством Н в суффиксе).
- Образовать причастие и прилагательное от глагола.
- Графическим способом объяснить особенности написания Н и НН в словах. Для этого нужно сделать морфемный разбор слова (выделить приставку, корень, суффикс, окончание).
- Составить словосочетания так, чтобы в одном случае нужно было писать Н, а в другом варианте — двойную НН.
- Написание диктантов на данную тему.
- Морфемный разбор слова.
- Задание на определение от какой части речи была образована данная словоформа.
Выполняя все перечисленные упражнения, нужно объяснять, почему было выбрано Н или НН. Таким образом, для закрепления правил оказываются задействованными зрительный, моторный и слуховой анализаторы.
На слух определять сколько букв Н в суффиксе надо писать, поэтому подключают и другие сенсорные системы.
Н и НН — частая ошибка, встречающаяся у школьников. Если вовремя не закрепить правильное написание этих суффиксов, то и взрослый человек будет допускать ошибки в словах.
Чтобы лучше запомнить все тонкости написания Н и НН можно использовать изображения (таблицы, схемы, ассоциативные картинки) и стихотворения.
Правописание Н и НН в существительных
Одно из самых «коварных» мест в плане орфографии – количество Н в разных частях речи. На слух полагаться нельзя, нужно четко уствоить правила и довести до автоматизма алгоритм выбора. Правописание Н, НН в существительных зависит от исходной основы и словообразовательного суффикса. Понять правило помогут примеры и подробные разъяснения орфограммы.
Правописание одной Н в существительных
Существительные (ИС) с одной Н пишутся, если:
- Слово происходит от прилагательного (ИП), основа которого имеет одну Н: гостиНый (двор) – гостиНица, песчаНый (слой) – песчаНик.
- ИС образовалось от отглагольного прилагательного, также не имеющего две Н: толчеНая (картошка) – толчеНка, путаНый (рассказ) – путаНица.

В остальных случаях, как правило, будем писать НН.
Правописание двух Н в существительных
Принципы правописания НН в существительных запомнить несложно. Основные случаи изложены ниже.
- Если корень производящей основы заканчивался на Н и словообразовательный суффикс начинался тоже на Н: бузиНа – бузиННик (корень -бузин и суффикс -ник-), аналогичны рябиННик, осиННик, имениННик и т.д.
Примечание: суффикс -ниц-, как вариация суффикса -ник-, обладает такими же свойствами: бесприданница (-придан и -ниц-). - Когда ИС образовалось от ИП с двумя Н: болезнеННый – болезнеННость.
- Наконец, если производящей основой для существительного послужило причастие с НН: довереННый (доверенное лицо) – довереННость.
Важно! Чтобы лучше понять основное правило написания букв Н и НН у существительных, запомните особенности словообразования, касающиеся суффиксов -ик-(-иц-) и -ник-(-ниц-).

Первый присоединяется к производящим основам причастий (изгнаННый – изгнаННИК) или прилагательных (дровяНой – дровяНИК). В таком случае количество букв Н зависит от самой производящей основы.
Суффикс -ник- (-ниц-) присоединяется к основам, взятым у существительных: имениНы – имениННИК, звоН – звоННица. Здесь к одной Н, заканчивающей производящую основу, прибавляется вторая, суффиксальная, Н.
Сводная таблица правил с примерами
Объединим всё вышесказанное в одну таблицу, объясняющую правописание одной Н и удвоенной НН в именах существительных:
| — Н — | -НН — |
|---|---|
| ИС образовано от ИП с одной Н: юНый – юНость, песчаНый — песчаНик | ИС образовано при помощи суффикса -ник-(-ниц-) от корня с Н на конце: измеНа – измеННик, бузиНа – бузиННик.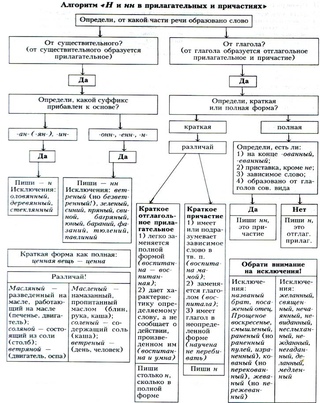 |
| ИС образовано от отглагольного ИП с одной Н: ветреНый – ветреНица. | ИС образовано от ИП с НН: родствеННый – родствеННик, стороННий – стороННик. |
| ИС образовано от причастий с НН: утоплеННый – утоплеННик. |
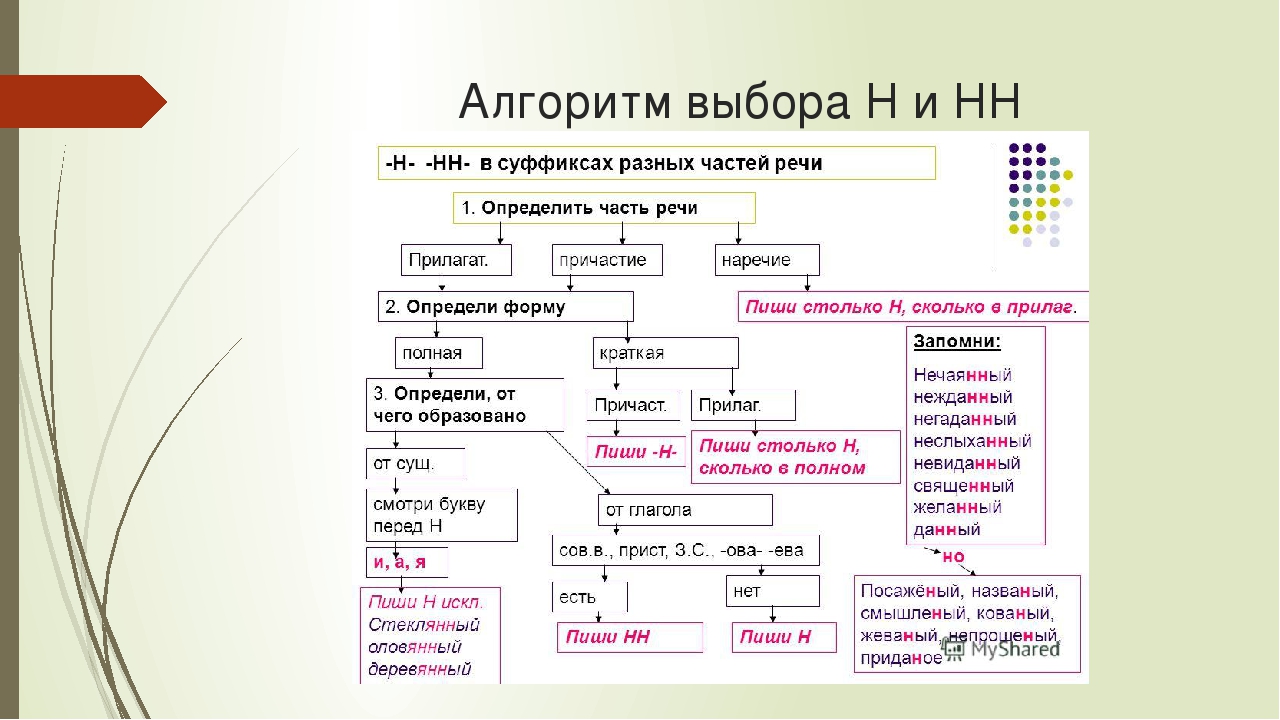
Правописание Н и НН в разных частях речи
Сегодня мы…
· Поговорим о написании одной и двух н в существительных и прилагательных.
· Выясним всё о написании одной и двух букв н в причастиях и наречиях.
· Поговорим о том, что нужно знать для правильного написания одной и двух букв н.
В русском языке есть некоторые правила, которые могут представлять для нас особенные трудности.
Кажется
– насколько легко написать слово довере…ость? Но нет, дойдя до первого н
мы тут же начинаем раздумывать: а сколько их там всего? И вот, пожалуйста. Перед нами орфограмма, которая кого угодно заставит призадуматься!
Перед нами орфограмма, которая кого угодно заставит призадуматься!
Вообще, буквы н в русской орфографии ведут себя довольно вредно.
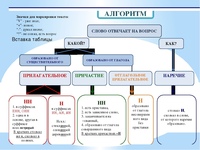
Эта орфограмма встречается в разных частях речи. При этом н могут стоять в корне, суффиксе или на границе корня и суффикса. Написание может зависеть от разных причин. И, конечно, всегда есть исключения… Это и приводит к ошибкам.
Но что же нужно знать для правильного написания одной и двух букв н?
Для начала нужно легко различать части речи. И хорошо бы разбираться в морфемике и словообразовании – тогда никакие орфограммы будут не страшны.
Потому что в первую очередь мы должны определиться – какую часть речи мы видим перед собой. Н и НН мы встречаем в существительных, прилагательных, причастиях и наречиях.
Но
прилагательные могут образовываться от имён или от глаголов.
Отглагольные прилагательные близки к причастиям, и правило написания для них в
чем-то схоже.
А ещё прилагательные и причастия могут иметь краткую форму, и для этих форм существуют особые правила.
Итак, предположим, мы встретились с существительным… Что мы будем делать теперь?
Мы зададимся вторым вопросом – от чего и как образовалось это слово?
Может быть, оно образовалось при помощи суффикса н от слова, в основе которого уже было н?
н в корне + н в суффиксе – вот и две буквы.
Мы видим это в таких словах, как малинник, конница.
А вот в слове труженик н будет одно. И в слове гостиница тоже. Здесь в корне букв н не наблюдается.
Или же существительное могло образоваться от слова, в котором уже было нн. В таком случае у нас так и остается две буквы.
Слово доверенность образовалось от доверенный, и в обоих словах два н.
А
слово пряность образовалось от прилагательного пряный, и в двух словах
будет одно н.
Значит, существительное мы напишем через два н, если оно образовалось от слова, где есть н в основе. Или образовано от прилагательного или причастия, где уже есть два н.
А одно н мы напишем, если слово образовано от прилагательного или причастия с одной н.
Постойте-ка. Но получается, что нам нужно знать – как пишется слово, от которого образовалось существительное. Но откуда нам знать, как пишется причастие или прилагательное?
А это уже следующая часть правила, к которой мы сейчас и перейдем.
Время обратиться к прилагательному. Конечно, сначала мы посмотрим на написание отымённых прилагательных.
И если мы столкнулись с таким прилагательным – какой следующий вопрос мы зададим?
Да. Тот же самый.
От
чего и как образовалось слово? Что, если в основе
существительного, от которого произошло прилагательное, уже было одно н? Н в
корне и н в суффиксе… Стоп. Звучит как что-то очень знакомое, не правда ли?
Звучит как что-то очень знакомое, не правда ли?
Действительно, этот пункт для прилагательных и существительных – общий, потому что они часто образуются друг от друга.
Отчаянный – от отчаяние, каменный – от камень, старинный – от старина, туманный – от туман. Мы здесь смотрим даже не на корень – именно на основу, от которой слово образовалось. И все наши основы заканчиваются на н, так что мы пишем две буквы.
Но если две буквы н заключены в самом суффиксе? Эти буквы мирно уживаются с е и о. Так что в суффиксах -енн- и -онн- мы пишем две н:
Соломенный, утренний, станционный, традиционный
А вот буквам и, а, я не так везет: они сочетаются только с одной н:
Соколиный, песчаный, утиный, глиняный – везде по одной н.
Но
в этом правиле есть и исключения. Слово ветреный пишется с одной
н. При этом безветренный – уже с двумя, на него исключение не
распространяется.
При этом безветренный – уже с двумя, на него исключение не
распространяется.
С одной н пишутся слова свиной, бараний, кабаний, тюлений. Хотя, казалось бы, они образовались от существительных с основой на н. Но образовались не при помощи суффикса н, а при помощи суффикса -й-.
Самые известные исключения – это, конечно, слова стеклянный, оловянный, деревянный, которые пишутся через нн. И здесь время вспомнить лингвистическую шутку о парне, у которого искусственные глаз, зуб и нога, так что он точно знает, как пишутся эти слова.
Итак, два н в прилагательных мы напишем, если слово образовалось от существительного с основой на н. Или если в слове есть суффиксы енн-, -онн-. Плюс стеклянный, оловянный, деревянный.
С
одной н мы пишем слово, если в нем есть суффиксы –ин-, -ан, -ян. Плюс слова ветреный,
бараний, кабаний, тюлений. Есть еще так называемые непроизводные
прилагательные – пряный, румяный, юный. Они вообще ни от чего не
образовались и сразу были прилагательными, потому пишутся с одной н.
Они вообще ни от чего не
образовались и сразу были прилагательными, потому пишутся с одной н.
И вот, кажется, мы дошли до самой сложной части нашего правила. Отглагольные прилагательные и причастия… Что мы делаем, если столкнулись с ними – опять выясняем, от чего и как образовалось слово? На этот раз нет. Поэтому у нас и могут возникнуть сложности.
Отглагольные части речи требуют к себе особого отношения.
Во-первых, отглагольное прилагательное и причастие очень похожи. А поэтому они просто требуют сначала различить, кто из них кто. Потом определить вид, потому что их написание зависит от вида. Но не только от вида, так что мы можем легко запутаться в пунктах правила.
И возникает вопрос: а не проще ли вообще не различать эти две части речи?
Если
перед нами – полное отглагольное прилагательное или причастие, а наша цель –
правильно написать слово… То мы можем пожертвовать теорией ради практики. И
просто обратить внимание на некоторые внешние признаки, которые подскажут
правильное написание.
И
просто обратить внимание на некоторые внешние признаки, которые подскажут
правильное написание.
Итак, если мы столкнулись с причастием или отглагольным прилагательным – нужно искать внешние подсказки.
Одной из таких подсказок может стать приставка. Есть приставка – есть две буквы н. Как в словах исхоженный и поджаренный.
Правда, приставка не- нам не годится. Она не влияет на написание слова.
Нехоженый – по-прежнему одна буква н. Но после приставки не- может стоять еще одна приставка, как в слове незаклеенный. Тогда мы пишем две буквы н.
Второй подсказкой может быть слово, зависимое от причастия. Если рядом есть слово, к которому мы ставим от причастия вопрос, то мы пишем две н.
Жареный – одна буква н. Прибавим – «в масле». И букв станет две.
Крашеный
– одна н. Прибавим «кистью». Две н.
Две н.
Третья подсказка – слово заканчивается на -ованный или -ёванный. Обычно в таких случаях соединяются суффиксы -ова- и -ёва- с двумя н.
Балованный, маринованный, организованный, малёванный.
Исключения – кованый и жёваный. Без приставок и зависимых слов эти слова пишутся с одной н.
Наконец, четвертая подсказка – это совершенный вид причастия. Если глагол, от которого мы образовали слово, отвечает на вопрос «что сделать?» — мы пишем два н. Купленный – купить, брошенный – бросить, решенный – решить. Обычно в глаголах совершенного вида есть приставка, и проблем у нас не возникает. Но из-за вот таких глаголов лучше помнить этот пункт и вовремя ставить вопрос.
У
правила довольно много исключений. Это слова деланный, желанный,
невиданный, негаданный, недреманный, нежданный, неслыханный, нечаянный,
священный, жеманный, чванный, чеканный. Здесь повсюду пишется две н.
Здесь повсюду пишется две н.
Одна буква н пишется в словах непрошеный и смышлёный
. С одной н мы напишем сочетания вроде стираный-перестираный, писаный-переписаный. В этом случае приставка нового слова не образует.Эти случаи нам приходится запоминать.
Итак, два н в причастии или отглагольном прилагательном мы напишем:
- если в нем есть приставка – любая, кроме не.
- если мы видим зависимое слово.
- если слово заканчивается на ованный, ёванный – кроме кованый, жёваный.
- если это причастие совершенного вида.
И нужно еще помнить об исключениях.
И вот теперь мы подошли к очередной части речи – наречию. Перед нами наречие, что делать дальше?
Задавать себе все тот же прежний вопрос.
Даже
ещё более лёгкий вопрос: от чего это слово образовано? В наречии будет
столько же букв н, сколько было в прилагательном или причастии, от которого оно
произошло.
От прилагательного медленный образуется наречие медленно. От чудесный – чудесно. А количество Н так и не меняется.
И получается, что если мы сталкиваемся с наречием и не знаем, как его написать – нам нужна машина времени. Потому что наречие отсылает нас к правилу о написании причастий и прилагательных.
Так что нужно знать, чтобы правильно писать н и два н?
Во-первых – какая перед нами часть речи.
И еще – как и от чего она образовалась.
Если же перед нами причастие, то здесь нужно заняться поиском признаков, о которых мы говорили.
И не забывать об исключениях.
Итак, НН в разных частях речи пишется вот в таких случаях.
В остальных случаях пишется Н.
Части речи | Слитно | Примеры | Раздельно | Примеры |
Существительное | 1 . 2 . Можно заменить синонимом, близким по значению словом | 1 . Неряха, невежа 2 . Недруг – враг Неправда — ложь | 1 . Есть противопоставление | 1 . Не друг, а враг Не правда, а ложь |
Прилагательное | 1 . Слово без НЕ не употребляется 2 . Можно заменить синонимом, близким по значению словом Следует запомнить! Нет прямого противопоставления признаков | 1 . неряшливый, ненастный 2 . нехороший – плохой Недобрый – злой Отец купил недорогой, но красивый костюм | 1 . есть противопоставление 2 . есть слова далеко не, вовсе не, ничуть не, нисколько не Следует запомнить 1 . с относительными, притяжательными, со значением цвета в сравнительной степени | 1 . не хороший, а плохой 2 . ничуть не интересная книга Не кожаный Не лисий Не синее Не тяжелее |
Наречие | 1 . 2 . Можно заменить синонимом, близким по значению словом Следует запомнить! Нет прямого противопоставления признаков | 1 . неряшливо, ненастно 2 . нехорошо – плохо Неглубоко — мелко Ученик прочёл стихотворение негромко, но выразительно | 1 . есть противопоставление 2 . есть слова далеко не, вовсе не, ничуть не, совсем не, нисколько не, никогда не Следует запомнить! 1.в сравнительной степени 2. через дефис | 1 .Не высоко, а низко 2 . Вовсе не интересно Не менее Не по-товарищески |
Глагол | 1 . Слово без НЕ не употребляется Следует запомнить В значении отсутствует в нужном количестве, не хватает в значении недостаточности | Негодовать Ненавидеть Нездоровится Недостаёт изящества Недорабатывает Недосыпает | 1 . Следует запомнить В значении чего-то не достал, не довёл до конца | Не играл Не писал Не был Не достал до дна Не дописал Не докончил |
Причастие | 1 . Слово без НЕ не употребляется 2 . Нет зависимых слов Следует запомнить В качестве зависимых слов есть слова: почти, отчасти, довольно, гораздо, вполне, очень, абсолютно, совершенно, в высшей степени | Ненавидящий Негодующий Недоумевающий Непрочитанная книга Невспаханное поле Почти неотредактированная рукопись. Совершенно неисследованная местность | 1 . есть противопоставление 2 . Есть зависимые слова 3 . с краткими причастиями | 1 . Не прочитанная, а лишь просмотренная книга. 2 . Не прочитанная мною книга 3 . Не сделано Не покрашено |
Деепричастие | 1 . | Негодуя Недоумевая Ненавидя | 1 . Пишется раздельно | Не подумав Не слушая |
местоимение | Пишутся слитно | Никого, некого Никем, некем | Если есть предлог | Ни у кого, Не с кого, Ни с кем, Не с кем |
 Слово без НЕ не употребляется
Слово без НЕ не употребляется Слово без НЕ не употребляется
Слово без НЕ не употребляется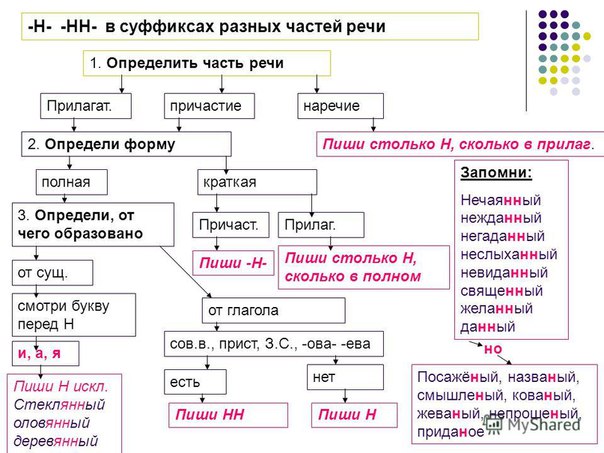 Пишется раздельно
Пишется раздельно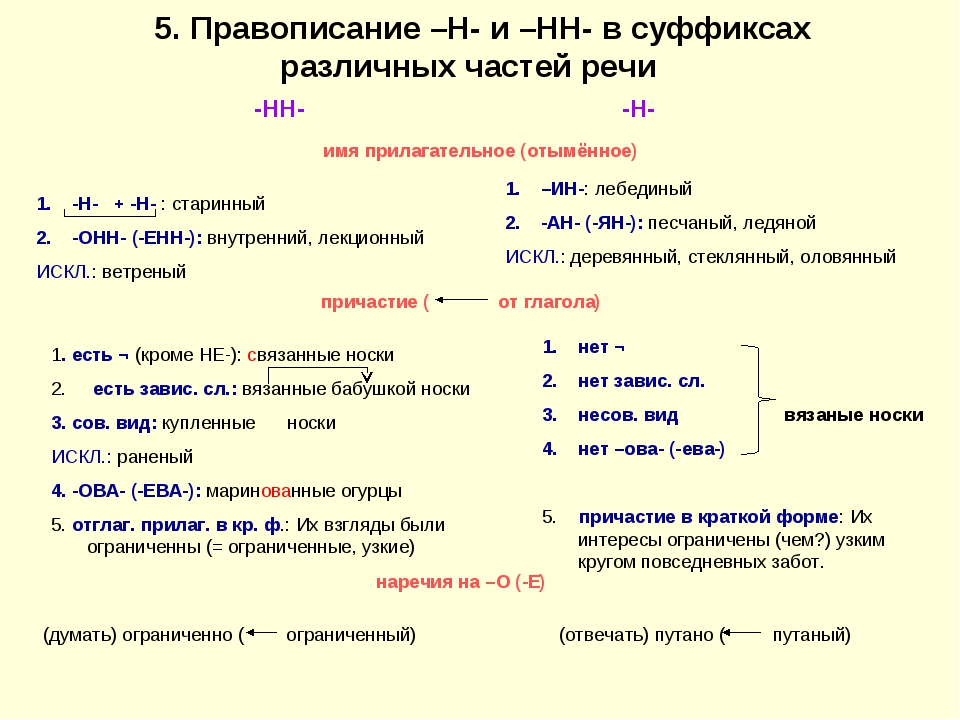 Слово без НЕ не употребляется
Слово без НЕ не употребляетсяПравописание Н и НН в разных частях речи. (Задание 14)
1. Правописание Н и НН в разных частях речи Задание 14
Выполнила: Нукаева А,Ученица 10-е класса МАОУ «Мл.№1»
г. Магнитогорск
Начать тест
Использован шаблон создания тестов в PowerPoint
2. Результат теста
Верно: 8Ошибки: 1
Отметка: 3
Время: 1 мин. 3 сек.
ещё
3. В каком примере к выделенному слову применимо правило: «В суффиксе кратких страдательных причастий пишется одна буква Н»
1. Ночная дорога, ведущая в город, была тума…а.
2. Спасая урожай, люди действовали имело и
слаже…о.
3. Ученые сосредоточе…ы на решении задачи.
4. Участники похода спокойны и сдержа..ы.
1
2
3
4
4. В каких из выделенных слов вместо пропусков пишется НН?
1.2.
3.
4.
5.
6.
В музее можно найти красиво расписанные деревя?ые ложки.
Когда выходишь на прогулку, около соседнего дома всегда поджидает
беше?ый пес.
Каждый рад получить свой жела?ый подарок.
Курение, алкоголизм и наркомания, естестве?о, не приводят ни к чему
хорошему.
Помыслы должны быть патриотичны и возвыше?ы.
Семей?ый отдых ничем незаменим.
1
2
исправить
3
4
5
ответ готов!
6
5. Укажите предложения, в которых нарушены правила правописания одной и двух Н
1. Красна девица так и ждёт своего суженного у окна.2. Юный парень не может смериться со своим
несчастьем.
3. А все-таки он у вас балованый.
4. В ходе научно-исследовательской работы,
посаженное в горшок семя не проросло.
5. Истинный воин не должен бояться, смотря врагу в
глаза.
6. Ему всегда нравилось в ней обаятельный взгляд и
румянные щёки.
2,5
1,3,5
1,3,6
6. В каком примере к выделенному слову применимо правило: «В суффиксах кратких страдательных причастий пишется одна буква Н?
1. Медвежонок испуга…о смотрел на охотников ижалобно пищал.
2. Манеры аристократов изящны и изыска…ы.
3. Дипломная работа студента написа…а грамотно
и интересно.
4. Гид историю города рассказывал экскурсантам
пута…о.
1
2
3
4
7. В каких из выделенных слов вместо пропусков пишется Н?
Гофрирова?ыйЛома?ый
Серебря?ый
Построе?о
Оловя?ый
Неслыха?ый
исправить
ответ готов!
8. В каком примере к выделенному слову применимо правило: «В суффиксах отыменных прилагательных –АН-/-ЯН- пишется одна буква Н?
1. Тка…ый ковер ручной работы был выставлен напродажу.
2. Коридор, ведущий к стекля…ой веранде, был
темным и узким.
3. Жела…ые гости так ине приехали.
4. Мягкий ковер из багря…ых листьев лежал на
дорожках вишневого сада.
1
2
3
4
9. Страдательные причастия прошедшего времени в краткой форме пишутся с двумя Н
ДАНЕТ
10. Укажите пример с прилагательным, в котором пишется НН, так как оно образованно от существительного с основой на –Н- с помощью суффикса –Н-?
Укажите пример с прилагательным, в котором пишется НН,так как оно образованно от существительного с основой на –
Н- с помощью суффикса –Н-?
1. Около реки уже стали видны каме…ые стены
средневекового замка.
2. Жителям долго не удавалось уснуть из-за петуши..ого
крика.
3. Заклее…ые конверты в беспорядке валялись по всему
столу.
4. На опушке соснового боранаходился дом лесника с
зеле…ой крышей и резными наличниками.
1
2
3
4
11. Какие слова пишутся с НН
Покор?ыйНеодушевлё?ы
й
Стра?ый
Расписа?о
исправить
Призна?ый
Багря?ый
ответ готов!
12 Правописание не и ни в разных частях речи
Таблица 5 — Правописание НЕ с разными частями речи
СЛИТНО | РАЗДЕЛЬНО |
Существительные, качественные прилагательные, наречия на -О, -Е | |
Если без НЕ слово не употребляется: неряха ненастный нелепо | Если есть противопоставление с союзом А: не правда, а ложь не близкий, а далекий не хорошо, а плохо |
Если образует новое слово, которое можно заменить близким по значению словом без НЕ: неправда (ложь) неблизкий (далекий) неплохо (хорошо) | Если есть зависимые слова далеко не, вовсе не, отнюдь не: вовсе не легкий подход отнюдь не интересно |
Если пояснительные слова обозначают степень качества (очень, весьма, крайне, в высшей степени, совершенно, почти): совершенно неблизкий путь | Если есть зависимое слово, выраженное отрицательным местоимением или наречием: НИЧУТЬ НЕ далекий путь |
Продолжение таблицы 5
СЛИТНО | РАЗДЕЛЬНО |
С краткими прилагательными, употребляющимися только в роли сказуемого: не рад не должен не готов | |
В сравнительной степени не больше не умнее | |
С наречиями не на -О, -Е не по-приятельски не по-зимнему | |
Глаголы и деепричастия | |
Если без НЕ слово не употребляется: ненавидеть недомогая Если есть приставка НЕДО-, придающая глаголу значение неполноты, недостаточности по сравнению с нормой НЕДОедал досыта | В остальных случаях: не хотелось не видя |
Местоимения, местоименные наречия | |
В неопределенных и отрицательных местоимениях, употребленных без предлога: некем некого | В отрицательных местоимениях, употребляемых с предлогом: не с кем не у кого |
В местоименных наречиях: некуда неоткуда | |
Причастия | |
Если без НЕ слово не употребляется: негодующий | Если есть зависимое слово: не выполненное вовремя задание |
Если есть противопоставление с союзом а: Не решенная, а списанная задача | |
С краткими причастиями: не решена | |
Таблица 6 — Выбор НЕ и НИ основывается на различии их смысла
НЕ | НИ | |
Отрицание = НЕТ | Отрицание = И | Утверждение = ДА |
Частицу НЕ опустить нельзя, изменится смысл | Частицу НИ можно опустить из предложения, не нарушив смысла | |
Продолжение таблицы 6
НЕ | НИ |
При проверке правильности выбора: 1) опусти частицу; 2) замени частицу НИ словами И, ДА | |
Используется для двойного отрицания в утвердительных предложениях | НИ пишется раздельно со всеми частями речи, кроме отрицательных наречий и местоимений без предлога |
Готовимся к ОГЭ по русскому языку: Задание №5
Правописание суффиксов
различных частей речи
Н и НН в словах разных частей речи
1. В полных прилагательных и причастиях| 1 шаг. Слово пишется с -Н- или -НН- и отвечает на вопрос КАКОЙ? | |||
| 2 шаг. Слово образовано от имени существительного или от глагола? | |||
| ОТ СУЩЕСТВИТЕЛЬНОГО (следовательно, перед нами отыменное прилагательное) | ОТ ГЛАГОЛА (следовательно, перед нами отглагольное прилагательное или причастие) | ||
| Н | НН | Если НЕТ ни одного из перечисленных ниже признаков пишу Н (это отглаг. прил.) | Если ЕСТЬ один из перечисленных ниже признаков пишу НН (это прич.) |
При суффиксах кожа + АН — кожАНый серебро + ЯН —серебрЯНый ИСКЛ.: стеклЯННый оловЯННый деревЯННый | 1. При суффиксах ОНН,ЕНН: 2. При наложении последней Н основы с суффиксом Н: истиНа + Н — истиННый | 1. Происхождение от глагола совершенного вида ИСКЛ.: ранеНый (при отсутствии зависимых слов и приставок: ранеНый солдат, НО ранеННый в руку ИЛИ ИЗранеННый) 2. Наличие приставки, кроме НЕ- (только приставки, кроме НЕ-, являются показателями совершенного вида) 3. Наличие зависимого слова 4. Наличие суффиксов ОВА, ЁВА ИСКЛ.: коваНый, жеваНый НО ВЫковаННый, ПЕРЕжеваННый ЗАПОМНИТЕ! Слова с Н: синий, зеленый, багряный, румяный, свиной, юный, рдяный, пряный, приданое, смышлёный, названый (брат), посажёный (отец)Слова с НН: нежданный, негаданный, неслыханный, невиданный, нечитанный, нечаянный, желанный, медленный, священный | |
| В КРАТКОЙ ФОРМЕ | |
| прилагательных | причастий |
| пишу столько Н, сколько пишется в полной форме | пишу всегда одну Н |
| цеННая вещь — вещь (какова?) цеННа румяНая девочка — девочка (какова?) румяНа организоваННая ученица — ученица (какова?) организоваННа | выкрашеННые полы — полы (каковы? что сделаны?) выкрашеНы посеяННая пшеница — пшеница (какова? что сделана?) посеяНа |
| В существительном и наречии пишется столько Н, сколько и в прилагательном, от которого они образованы: торжествеННый (прил.) — торжествеННость (сущ.), торжествеННо (наречие) холодНый (прил.) — холодНо (наречие) гостиНый (прил.) — гостиНица (сущ.) коННый (прил.) — коННица (сущ.) |
Правописание суффиксов -ОВА-, (-ЕВА-), -ЫВА-, (-ИВА-) в глаголах
| Я (что делаю? что сделаю?) Ставим глагол | командую танцую Как мы видим, | СЛЕДОВАТЕЛЬНО командовать — командовал |
разыскиваю обманываюКак мы видим, | СЛЕДОВАТЕЛЬНО обманывать — обманывал |
2. Образец выполнения задания.
3. Тренировочные задания:
4. Контрольный тест.
Типы слов, фраз и предложений Страница типов слов, фраз и предложений из Словаря в картинках Little Explorers на английском языке. | Запишите части речи Напишите 5 слов, относящихся к каждой части речи на английском языке. Части речи включают: существительное, глагол, местоимение, прилагательное, наречие, предлог, союз и междометие.Или перейдите к образцам ответов. | Запишите части речи Напишите 10 слов, которые относятся к каждой части речи на английском языке. Части речи включают: существительное, глагол, местоимение, прилагательное, наречие, предлог, союз и междометие. Или перейдите к образцам ответов. | Части речи Колесо слов Сделайте круг из восьми частей речи, используя эту распечатку на 2 страницах; он состоит из базовой страницы и вращающегося колеса.Когда вы вращаете колесо, части речи появляются вместе с определением и двумя примерами. Части речи: существительное, местоимение, глагол, прилагательное, наречие, предлог, союз и междометие. Затем ученик записывает части речи и пример для каждой. |
Общие сокращения Изучите общепринятые английские сокращения и распечатайте их в таблицах. | «прыгающие ящерицы» аллитерация Аллитерация — это повторение начальных звуков в соседних словах.«Slithering snake» — это аллитерация, потому что оба слова начинаются со звука «s». «Известный рыцарь» — это аллитерация, потому что оба слова начинаются со звука «н» (даже если они начинаются с разных букв). | art rat tar Анаграммы Анаграмма — это слово или фраза, составленные путем перестановки букв другого слова. Например, пятно — это анаграмма сообщения. | Составные слова Составное слово — это слово, состоящее из двух или более других слов.Например, слово стрекоза состоит из двух слов: дракон и муха. Прочтите несколько распространенных составных слов и выполните упражнения со сложными словами. |
| Я (Я буду) Сокращения Сокращение — это сокращенная форма одного или двух слов (обычно глаголов). Вот некоторые сокращения: я (я), не могу (не могу), как (как) и мадам (мадам). | Антонимы / Противоположности Противоположности (антонимы) — это вещи, которые очень, очень отличаются друг от друга.Вот несколько примеров противоположностей: левое и правое, большое и маленькое, верх и низ, высокий и низкий. | Омофоны Омофоны — это слова, похожие друг на друга, но имеющие разные значения, например цветок и мука. | . ,? ! ; Знаки препинания Знаки препинания — это символы, которые используются в предложениях и фразах, чтобы прояснить смысл. Некоторые знаки препинания: точка (.), Запятая (,), вопросительный знак (?), Восклицательный знак (!), Двоеточие (:) и точка с запятой (;).Это также страница знаков препинания и других распространенных символов из английского словаря Little Explorers Picture Dictionary. |
Сопоставьте слова с символами пунктуации и изображения Сопоставьте 10 слов символов препинания с их изображениями. Это слова: запятая, точка, восклицательный знак, кавычки, вопросительный знак, апостроф, двоеточие, точка с запятой, круглые скобки, дефис. Или перейдите к ответам. | рифм Слова, которые рифмуются, имеют одинаковые окончания, такие как кошка и шляпа или воздушный змей и свет. | MOM 2002 Палиндромы Палиндром — это слово, фраза или число, которые читаются одинаково вперед и назад. Вот некоторые палиндромы: имя Боб, число 101 и фраза «Мадам, я Адам». | Simile Сравнение — это способ описания чего-либо путем сравнения с чем-то другим, часто с использованием слова «как» или «как». Например, «Он храбр, как лев». Читайте общие сравнения и выполняйте задания по сравнениям. |
Метафора Метафора — это способ описания чего-либо, приравнивая это к чему-то другому. Это сравнение двух разных вещей, имеющих одну важную общую характеристику. Например, в метафоре «Фредди — это свинья, когда он ест», и Фредди, и свинья — неряшливые едоки. | Рабочие листы словарного запаса Эти графические организаторы словарного запаса можно использовать, чтобы помочь студентам выучить новые слова из словарного запаса.Для каждого нового словарного слова ученик пишет слово, его определение, его часть речи, синоним, антоним, рисует картинку, которая иллюстрирует значение слова, и пишет осмысленное предложение, используя это слово. | Рабочие листы по грамматике Попурри Находите синонимы, антонимы, омонимы, анаграммы и составные слова, затем пишите с заглавной буквы, делайте пунктуацию и исправляйте написание предложений. | Части речи: напишите вопрос для каждого ответа На этом рабочем листе ученику дается серия коротких ответов с использованием частей речи (существительные, глаголы, прилагательные, наречия и т. Д.)). На каждый ответ ученик пишет короткий вопрос. |
Найдите слово для каждой буквы Посмотрите, сможете ли вы придумать и записать слово, которое начинается с каждой буквы алфавита. Или перейдите на страницу с образцом ответа. | Части речевого теста Короткий печатный рабочий лист опроса о частях речи, существительных, глаголах, прилагательных, наречиях, предлогах, союзах и междометиях.Рабочий лист кратких ответов задает 16 общих вопросов о частях речи, например: «Слово, выражающее действие (например,« бег »), — это ___». Или перейдите к ответам. | Расшифруйте рабочий лист предложений | Список слов грамматического словаря Список слов, связанных с грамматикой. |
Классы слов (или части речи)
Все слова относятся к категориям, называемым классами слов (или частями речи), в соответствии с той ролью, которую они играют в предложении. Ниже перечислены основные классы слов в английском языке.
Существительное
Глагол
Прилагательное
Наречие
Местоимение
Предлог
Соединение
Определитель
Восклицание
Существительное
Существительное
имя человека,
человек,
: девушка инженер, друг )вещь ( лошадь, стена, цветок, страна )
идея, качество или состояние ( злость, храбрость, жизнь, удача )
Подробнее о существительных.
Глагол
Глагол описывает, что человек или вещь делает или что происходит. Например, глаголы описывают:
действие — прыгать, останавливаться, исследовать
событие — снег, происходить
ситуацию — быть, кажется, иметь
изменение — развиваться, сокращаться, расширяться
Подробнее о глаголах.
Прилагательное
Прилагательное — это слово, которое описывает существительное, давая дополнительную информацию о нем.Например:
захватывающее приключение
зеленое яблоко
аккуратный номер
Подробнее о прилагательных.
Наречие
Наречие — это слово, которое используется для передачи информации о глаголе, прилагательном или другом наречии. Они могут усиливать или ослаблять значение глагола, прилагательного или другого наречия и часто оказываются между подлежащим и его глаголом ( Она, , почти потеряла все.)
Подробнее о наречиях.
Местоимение
Местоимения используются вместо существительного, которое уже известно или уже упоминалось. Часто это делается для того, чтобы не повторять существительное. Например:
Лаура ушла раньше, потому что она устала.
Энтони принес авокадо ему .
Этот — единственный оставшийся вариант.
Что-то придется поменять.
Личные местоимения используются вместо существительных, относящихся к определенным людям или предметам, например I , me , mine , you , yours , his , her , hers , мы , они , или они . Их можно разделить на различные категории в зависимости от их роли в предложении:
Подробнее о местоимениях.
Предлог
Предлог — это такое слово, как после, in, to, on, и с .Предлоги обычно используются перед существительными или местоимениями и показывают связь между существительным или местоимением и другими словами в предложении. Они описывают, например, положение чего-либо, время, когда что-то происходит, или способ, которым что-то делается.
Подробнее о предлогах.
Соединение
Соединение (также называемое связкой) — это такое слово, как и, потому что, но, для, если, или, и , когда .Союзы используются для соединения фраз, предложений и предложений. Два основных вида известны как координирующих союзов и подчиненных союзов .
Подробнее о соединениях.
Определитель
Определитель — это слово, которое вводит существительное, например a / an , the , каждые , this , те , or 7 many как собака , собака , это собака, те собаки, каждая собака, много собак ).
Определитель , иногда называют определенным артиклем , а определитель a (или и ) — неопределенным артиклем .
Подробнее об определителях.
Восклицательный
Восклицательный знак (также называемый междометием) — это слово или фраза, которые выражают сильные эмоции, такие как удивление, удовольствие или гнев. Восклицательные знаки часто стоят сами по себе, и в письменной форме они обычно сопровождаются восклицательным знаком, а не точкой.
Подробнее о восклицаниях.
Дополнительные сведения о классах Word
Краткое руководство — документация по TextBlob 0.16.0
TextBlob предоставляет доступ к обычным операциям обработки текста через знакомый интерфейс. Вы можете обрабатывать объекты TextBlob , как если бы они были строками Python, которые научились выполнять обработку естественного языка.
Создание TextBlob
Во-первых, импорт.
>>> из импорта текстовых блоков TextBlob
Давайте создадим наш первый TextBlob .
>>> wiki = TextBlob («Python - это язык программирования общего назначения высокого уровня.»)
Маркировка части речи
Теги части речи доступны через свойство tags .
>>> wiki.tags
[('Python', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('high-level', 'JJ'), ('универсальный', 'JJ'), ('программирование', 'NN'), ('язык', 'NN')]
Анализ настроений
Свойство тональность возвращает именованный кортеж в форме Настроение (полярность, субъективность) .Оценка полярности является плавающей в диапазоне [-1,0, 1,0]. Субъективность — это плавающее значение в диапазоне [0,0, 1,0], где 0,0 очень объективно, а 1,0 — очень субъективно.
>>> testimonial = TextBlob ("Textblob удивительно прост в использовании. Какое веселье!")
>>> testimonial.sentiment
Настроение (полярность = 0,39166666666666666, субъективность = 0,4357142857142857)
>>> testimonial.sentiment.polarity
0,39166666666666666
Токенизация
Вы можете разбить текстовые блоки на слова или предложения.
>>> zen = TextBlob («Красивое лучше уродливого». ... «Явное лучше, чем неявное». ... «Лучше простое, чем сложное».) >>> zen.words WordList (['Красиво', 'есть', 'лучше', 'чем', 'некрасиво', 'Явно', 'есть', 'лучше', 'чем', 'неявное', 'Простое', 'есть' , 'лучше', 'чем', 'сложный']) >>> дзен. предложения [Предложение («Красивое лучше, чем уродство.»), Предложение («Явное лучше, чем неявное.»), Предложение («Простое лучше, чем сложное.")]
Объекты Sentence имеют те же свойства и методы, что и TextBlobs.
>>> для предложения в дзен. Предложениях: ... печать (предложение. суждение)
Для более продвинутой токенизации см. Руководство по расширенному использованию.
Флексия и лемматизация слов
Каждое слово в TextBlob.words или Sentence.words — это слово объект (подкласс unicode ) с полезными методами, например.грамм. для словоизменения.
>>> предложение = TextBlob ('Используйте 4 пробела на уровень отступа.')
>>> предложение.слова
WordList (['Использовать', '4', 'пробелы', 'за', 'отступ', 'уровень'])
>>> предложение.words [2] .singularize ()
'космос'
>>> предложение.words [-1] .pluralize ()
"уровни"
слов можно лемматизировать, вызвав метод лемматизации .
>>> из текстовых блоков импорта Word
>>> w = Слово ("осьминоги")
>>> w.lemmatize ()
'осьминог'
>>> w = Word ("пошел")
>>> ш.lemmatize ("v") # Передать в WordNet часть речи (глагол)
'идти'
Интеграция WordNet
Вы можете получить доступ к synset’ам для Word через свойство synsets или метод get_synsets , опционально передавая часть речи.
>>> из текстовых блоков импорта Word
>>> из textblob.wordnet импортировать ГЛАГОЛ
>>> word = Word ("осьминог")
>>> word.synsets
[Synset ('octopus.n.01'), Synset ('octopus.n.02')]
>>> Слово ("рубить").get_synsets (pos = VERB)
[Synset ('chop.v.05'), Synset ('hack.v.02'), Synset ('hack.v.03'), Synset ('hack.v.04'), Synset ('hack. v.05 '), Synset (' hack.v.06 '), Synset (' hack.v.07 '), Synset (' hack.v.08 ')]
Вы можете получить доступ к определениям для каждого набора synset с помощью свойства definitions или метода define () , который также может принимать необязательный аргумент части речи.
>>> Слово («осьминог»). Определения [«щупальца осьминога, приготовленные в пищу», «головоногие моллюски, живущие на дне, имеющие мягкое овальное тело с восемью длинными щупальцами»]
Вы также можете создавать синсеты напрямую.
>>> из textblob.wordnet import Synset
>>> осьминог = Synset ('octopus.n.02')
>>> креветка = Synset ('shrimp.n.03')
>>> octopus.path_similarity (креветка)
0,1111111111111111
Дополнительные сведения об API WordNet см. В документации NLTK по интерфейсу Wordnet.
Списки слов
A WordList — это просто список Python с дополнительными методами.
>>> animals = TextBlob («кошка, собака, осьминог») >>> животные.слова WordList (['кошка', 'собака', 'осьминог]) >>> animals.words.pluralize () WordList (['кошки', 'собаки', 'осьминоги'])
Исправление орфографии
Используйте метод правильно () , чтобы попытаться исправить орфографию.
>>> b = TextBlob ("У меня хорошее правописание!")
>>> print (b.correct ())
У меня хорошее правописание!
Объекты Word имеют метод spellcheck () Word.spellcheck () , который возвращает список из (слово, достоверность) кортежей с вариантами написания.
>>> из текстовых блоков импорта Word
>>> w = Слово ('ошибочность')
>>> w.spellcheck ()
[('подверженность ошибкам', 1.0)]
Коррекция орфографии основана на книге Питера Норвига «Как написать корректор орфографии», реализованной в библиотеке шаблонов. Это около 70% точности.
Получите частоты слов и существительных фраз
Есть два способа узнать частоту слова или существительной фразы в TextBlob .
Первый — через словарь word_counts .
>>> monty = TextBlob ("Мы больше не Рыцари, которые говорят Ни."
... «Теперь мы Рыцари, которые говорят: Ekki ekki ekki PTANG.»)
>>> monty.word_counts ['ekki']
3
Если вы получите доступ к частотам таким образом, поиск будет , а не с учетом регистра, и слова, которые не найдены, будут иметь частоту 0.
Второй способ — использовать метод count () .
>>> monty.words.count ('ekki')
3
Вы можете указать, должен ли поиск выполняться с учетом регистра (по умолчанию Ложь ).
>>> monty.words.count ('ekki', case_sensitive = True)
2
Каждый из этих методов можно также использовать с именными фразами.
>>> wiki.noun_phrases.count ('питон')
1
Разбор
Используйте метод parse () для анализа текста.
>>> b = TextBlob ("А теперь о другом.")
>>> print (b.parse ())
И / CC / O / O сейчас / RB / B-ADVP / O для / IN / B-PP / B-PNP что-то / NN / B-NP / I-PNP полностью / RB / B-ADJP / O другое / JJ / I-ADJP / O././O/O
По умолчанию TextBlob использует синтаксический анализатор шаблона.
TextBlobs похожи на строки Python!
Вы можете использовать синтаксис подстроки Python.
>>> дзен [0:19] TextBlob («Красивое лучше»)
Вы можете использовать обычные строковые методы.
>>> zen.upper ()
TextBlob ("КРАСИВОЕ ЛУЧШЕ, ЧЕМ УЖЕ. ЯВНОЕ ЛУЧШЕ, ЧЕМ НЕЯВНОЕ. ПРОСТОЕ ЛУЧШЕ, ЧЕМ СЛОЖНОЕ.")
>>> zen.find ("Простой")
65
Вы можете сравнивать TextBlobs и строки.
>>> apple_blob = TextBlob ('яблоки')
>>> banana_blob = TextBlob ('бананы')
>>> apple_blob <банановый_blob
Правда
>>> apple_blob == 'яблоки'
Правда
Вы можете объединять и интерполировать TextBlobs и строки.
>>> apple_blob + 'и' + banana_blob
TextBlob ("яблоки и бананы")
>>> "{0} и {1}". Формат (apple_blob, banana_blob)
'яблоки и бананы'
n -грамм Текстовый блок .Метод ngrams () возвращает список кортежей из n последовательных слов.
>>> blob = TextBlob («Лучше сейчас, чем никогда»). >>> blob.ngrams (n = 3) [WordList (['Сейчас', 'есть', 'лучше']), WordList (['есть', 'лучше', 'чем']), WordList (['лучше', 'чем', 'никогда'] )]
Получить индексы начала и конца предложений
Используйте предложение.start и предложение.end , чтобы получить индексы, в которых предложение начинается и заканчивается в пределах TextBlob .
>>> для s в дзен. Предложениях:
... печать (и)
... print ("---- Начинается с индекса {}, заканчивается с индекса {}". format (s.start, s.end))
Красивое лучше уродливого.
---- Начинается с индекса 0, заканчивается с индексом 30
Явное лучше, чем неявное.
---- Начинается с индекса 31, заканчивается на индексе 64
Лучше простое, чем сложное.
---- Начинается с индекса 65, заканчивается на индексе 95
Следующие шаги
Хотите создать свою собственную систему классификации текстов? Ознакомьтесь с руководством по классификаторам.
Хотите использовать другую реализацию тега POS или блокировку именных фраз? Ознакомьтесь с руководством по расширенному использованию.
Нет — non, nan, niet …
Французские синонимы для
NonНет. Ни в коем случае, не я, напротив … давайте признаем это, просто потому, что мы иногда должны быть негативными, не означает, что мы тоже не можем быть творческими. Вот несколько способов сказать «нет» по-французски.
без = безНе — это универсальное французское слово, обозначающее «нет»:
| Non, je n’aime pas les fraises. | Нет, я не люблю клубнику. | |
| — Veux-tu m’épouser? — Нет. | — Ты выйдешь за меня замуж? — № |
Текстовое сокращение: nn
(non) merci = нет, спасибоВы, наверное, знаете, что «нет, спасибо» — это , а не merci . Но знаете ли вы, что не не является обязательным? Вы можете просто сказать merci в ответ на предложение, и это будет воспринято как non merci .
| — Encore du vin? — Мерси. | — Еще вина? — Нет, спасибо. |
Можно запросить подтверждение с тегом вопрос или не ?
| Tu aimes les fraises, ou non? | Любишь клубнику или нет? | |
| Il va t’épouser, ou non? | Женится он на тебе или нет? |
Nan — неофициальный эквивалент no, эквивалентный «nope» или «nah»:
| Nan, je n’aime pas les fraises. | Нет, я не люблю клубнику. | |
| — Tu veux un cafe? — Нан. | — Хотите кофе? — Нет. |
Не à плюс существительное используется в забастовках и протестах, чтобы заявить о своем несогласии с чем-либо:
| Без четкого решения! | Скажи нет этому решению! | |
| Non à la guerre! | Долой войну! |
Ач / О, кроме , означает разочарование или разочарование:
| О нет! Джай перду ма багуэ. | О нет! Я потерял кольцо. | |
| Ач нет! В поезде loupé le! | Блин, мы опоздали на поезд! |
Другие синонимы к слову
non| абсолютный па | абсолютно не | |||
| в противоположном направлении | наоборот | |||
| aucun + существительное | нет… | |||
| проверка | конечно не | |||
| des clous! | (знакомый) | никак! | ||
| du tout | совсем нет | |||
| pouce en bas, pouce vers le bas | палец вниз | |||
| n’est-ce pas? | верно? не так ли? | |||
| нет! | (знакомый) | никак! | (произносится как по-русски: нет ) | |
| pas de + существительное | нет… | |||
| Pas du tout | совсем нет | |||
| па вопрос! | (знакомый) | никак! не шанс! | ||
| по факту | не совсем, не совсем | |||
Отрицательные префиксы
Связанные уроки Поделиться / Твитнуть / Прикрепить меня!Английский как второй язык • 7ESL
Теперь важно знать, как на самом деле происходит процесс обучения.Учиться — это не просто сидеть перед книгой и читать ее от начала до конца. Акт включает в себя дисциплину и несколько более эффективных приемов. Пройдите процесс обучения медленно. Делайте это весело, чтобы вам не было скучно. Ниже приведены некоторые из приемов, которые помогут вам быстро выучить английский язык.
ПроизношениеЭто должен быть первый этап обучения. Произношение — это правильное произнесение слова на английском языке. Английский язык используется в нескольких странах, поэтому акцент не всегда одинаков.Но чаще всего используются американский английский и британский английский.
Итак, почему вам нужно сначала выучить произношение? Это потому, что вам нужно научиться правильно произносить слова на ранних этапах изучения английского языка. Правильное произношение также будет зависеть от практики. Вот почему вам нужно будет заниматься ежедневно.
Если вы ошибетесь в его произношении, это даже приведет к недопониманию. Поэтому важно, чтобы вы начали правильно учиться с самого начала.Хорошее произношение помогает не только хорошо говорить, но и понимать тех, кто уже говорит на этом языке. Кроме того, это также придаст вам уверенности, когда придет время поговорить с родным.
СловарьИзучение словарного запаса является обязательным условием, если вы хотите говорить по-английски. Вы не можете составить предложение, если запутались. Получите доступ к списку слов и не торопитесь, чтобы учить их каждый день. Однако это не означает, что вы запоминаете большое количество терминов, так как вы легко их забудете.Вы можете записать эти словари в текстовом документе, записной книжке или любой другой системе, которая поможет вам легко их запомнить.
При изучении английского языка очень важен словарный запас. Если у вас есть небольшой словарный запас, вы столкнетесь со многими трудностями. Возможно даже, что вы легко откажетесь от изучения английского, если вы изучите грамматику, но ваш словарный запас совсем небольшой. Запоминайте словарный запас постоянно, каждый день. Для этого не нужно много, если вам нужно запомнить хотя бы один словарный запас за один день.Кроме того, не забывайте практиковать правильное произношение.
ПравописаниеПравописание связано с произношением правильной английской лексики. Итак, практика правильного написания и произношения — это уже пакет с изучением словарного запаса. Когда вы запоминаете словарный запас, убедитесь, что каждый словарный запас написан правильно. Например, слово «книга». Вы должны знать, что это слово написано или образовано из букв «b-o-o-k». Зная написание каждого слова, вы можете избежать использования неправильного слова при написании на английском языке.
В английском языке также есть несколько слов с одинаковым произношением, но с другим написанием. Другими словами, это часто называют «омофонами» (похожими звуками слов). Научитесь различать их, чтобы не запутаться.
ГрамматикаНачиная процесс обучения, помните, что каждый аспект языка очень важен, а грамматика может быть самой важной. Это не означает, что вы должны изучать правила, как если бы вы были лингвистом, но понимаете, как структурированы основные времена (прошедшее, настоящее и будущее во всех его вариациях).Независимо от того, какой метод вы выберете для изучения английского языка, рекомендуется пытаться выучивать как минимум десять новых слов каждую неделю. Через некоторое время ваш словарный запас расширится.
Consonant Sound N Ng As In Thing Произношение в американском английском — DokterAndalan
Проиллюстрировано 100 различий между британским и американским английским
Научитесь произносить согласный звук ŋ, используемый в таких словах, как «собираюсь», «долго» или «приносить».«улучшите свой американский акцент с помощью четырех записанных фонетических упражнений. Esl: как произносить согласный звук ng [ŋ] в американском английском. Уроки произношения и акцента и упражнения на веб-сайте, которые помогут вам улучшить свой. Узнайте, как произносить согласный звук n used в таких словах, как «name», «next» или «when.», улучшите свой американский акцент с помощью двух фонетических упражнений, записанных пользователем. Это один из немногих звуков в американском английском, при котором мягкое небо опущено и расслаблено. Это позволяет воздуху дышать проходите вверх и над ним, заставляя звук ощущаться в носу.это носовой согласный вместе с m и n. образцы слов: пой, подумай, бег. Пример предложения: изучение английского языка и практика разговорной речи — это хорошо. Одно небольшое рекламное примечание: есть урок о звуке ng на страницах произношения: звуки электронной книги американского английского и практика для звука ng в середине и в конце слова как часть загрузки аудио в формате mp3. Вы можете купить книгу за 25 долларов, mp3-файлы за 10 долларов или оба вместе за 30 долларов.
Проиллюстрировано 100 различий между британским и американским английским
Улучшите свое произношение согласного звука ŋ с помощью этого продвинутого упражнения.Практикуйтесь в произнесении слов, состоящих из более чем одного звука ŋ (нг) и слова. Узнайте разницу между согласными звуками n и ŋ. потренируйте произношение n и n с минимальными парными упражнениями, используя слова lik. Согласные звуки m, n и ng известны как носовые звуки, потому что все они производятся при движении воздуха через нос. важно понимать различия и правильно их произносить. научитесь правильно произносить носовые звуки с помощью этих объяснений, видео и упражнений.
Американские английские идиомы на шаре Youtube
Как выучить американский английский с помощью звуков
Consonant Sound ŋ (ng) Как в «вещи» Произношение в американском английском
научитесь произносить согласный звук ŋ, используемый в таких словах, как «собираюсь», «долго» или «приносить».»улучшить свой американский акцент с помощью четырех записанных фонетических упражнений научитесь произносить согласный звук n, используемый в таких словах, как «имя», «следующий» или «когда». улучшите свой американский акцент с помощью двух записанных фонетических упражнений улучшить свой разговорный английский с американским акцентом в rachel’s english с помощью видеоуроков и упражнений. Рэйчел использует реальный английский разговор как в этом видео мы рассмотрим разницу между n и ŋ, которая встречается в таких словах, как «тонкий» и «вещь».рекомендованная грамматика английский произношение звука w затруднено для многих людей, не являющихся носителями английского языка. некоторые люди не понимают, что случайно искажают или путают это с другими научитесь произносить звук ŋ как «петь». узнайте важные советы и исправьте положение рта. сравните и сопоставьте похожие слова с ŋ, n и ŋk. научитесь произносить согласный звук θ, используемый в таких словах, как «театр», «юг» или «ванная». улучшите свой американский акцент с помощью двух фонетических упражнений esl: окончание слова на n или ng может быть трудным для не носителей английского языка.узнайте разницу в положении рта и проверьте свою способность определять «темное» l — это только вариация звука l, а не отдельная согласная. таким образом, если вы произносите только «обычное» l, вы все равно будете звучать как произношение ʃ fricative затруднено для многих людей, не являющихся носителями английского языка. во-первых, написание довольно сложно и может сбивать с толку. во-вторых, даже если ты
Текстовая классификация github pytorch
классификация текста github pytorch См. Папку с примерами записных книжек, которые можно загрузить или запустить в Google Colab.Finetune 🤗 Модели трансформеров с PyTorch Lightning ⚡ Этот блокнот будет использовать библиотеку наборов данных HuggingFace для получения данных, которые будут заключены в LightningDataModule. Нажмите J, чтобы перейти к ленте. Следуйте за Лукасом, чтобы узнать о встраивании слов, о том, как выполнять одномерные свертки и максимальное объединение текста. Наши обученные модели и журналы обучения можно загрузить в OneDrive. 0B первая фиксация 2 месяца назад tokenizer_config. Мультиклассовая классификация текста Наконец, мы раскрываем различия в эффективности обучения между фреймворками PyTorch и Tensorflow Deep Learning.жирный [Марк Леларж] — # Основы контролируемого обучения Как именно вы бы оценили свою модель в итоге? Выходные данные сети — это значение с плавающей запятой между 0 и 1, но в конечном итоге вы хотите, чтобы 1 (истина) или 0 (ложь) служили предсказанием. Классификация текста с помощью RoBERTa. PyTorch Wrapper — это библиотека, которая обеспечивает систематический и расширяемый способ построения, обучения, оценки и настройки моделей глубокого обучения с использованием PyTorch. В качестве последнего слоя у вас должен быть линейный слой для любого количества классов, которые вы хотите i. Я пытаюсь использовать предварительно обученную модель повторной сети для тестирования на изображении слона.5 Кбайт — просмотрено (0) просмотрено (0); text_b используется, если мы обучаем модель пониманию взаимосвязи между предложениями (т. е. ее основная цель — быстрее экспериментировать с использованием трансферного обучения на всех доступных предварительно обученных моделях. data}) df. k. Stack Overflow Открытые вопросы и ответы; Stack Overflow для команд, где разработчики и технологи делятся личными знаниями с коллегами; Вакансии Программирование и технические возможности карьерного роста Bert tokenizer github. Этот сквозной ASR, реализованный в основном с помощью Pytorch, основан на модели прослушивания, присутствия и заклинания — нейронной сети, которая может преобразовывать речевые высказывания в текстовые символы.Я планирую использовать pytorch вместо tenorflow. com Сверточные сети с графами для классификации текстов. В этой статье мы построим модель классификации в PyTorch, а затем узнаем, как развернуть ее с помощью Flask. Использование библиотеки FastAI для мультиклассовой классификации. адаптировать классификацию текста Pytorch Bert на github. Здравствуйте, я использую LSTM с функциями word2vec для классификации предложений. Сообщество. from_pretrained (‘roberta-base’) model = RobertaForSequenceClassification (config) Если вы хотите узнать больше о классификации текста с помощью рекуррентных нейронных сетей LSTM, взгляните на этот блог: Классификация текста с помощью LSTM в PyTorch. текст моделируется как распределение слов в заданном пространстве.Веб-сайт GitHub. Сверточные нейронные сети Узнайте, как определить и обучить CNN для классификации данных MNIST, базы данных рукописных цифр, широко известной в области машинного и глубокого обучения. Релиз 6 — это крупное обновление по многим аспектам проекта, включая документацию, API, скорость системы и масштабируемость. Важнейшим компонентом fastai является выдающаяся основа PyTorch, версия 1 (предварительная версия) которой также выпускается сегодня. Постановка проблемы: учитывая комментарий обзора элемента, спрогнозируйте рейтинг (принимает целые значения от 1 до 5, 1 — худшее, а 5 — лучшее). Набор данных: я использовал следующий набор данных из Kaggle: Deep Learning 17: классификация текста с помощью BERT с использованием PyTorch Написано Ирен 5 июля 2019 г. 17 июля 2019 г. Написано в Обработка естественного языка, Теги PyTorch: Коды, PyTorch Почему именно BERT torchtext.Встраивание наборов векторов с помощью EMDE «Hello World!» в PyTorch BigGraph; 5 типов бессмысленной науки о данных; Чего вам не говорят о науке о данных 2: роли аналитика данных — это яд Bert-Multi-Label-Text-Classification. Пост №2. Классификация изображений PyTorch Этот репозиторий содержит учебные пособия по классификации изображений с использованием PyTorch 1. randn (1, 3, 28, 28) x = nn. Определите свои сильные стороны с помощью бесплатной онлайн-викторины по кодированию и пропустите экраны резюме и рекрутеры сразу в нескольких компаниях. Этот курс касается новейших методов глубокого обучения и репрезентативного обучения с упором на контролируемое и неконтролируемое глубокое обучение, методы встраивания, метрическое обучение, сверточные и повторяющиеся сети с приложениями для компьютерного зрения, понимания естественного языка и распознавания речи.Теперь, когда мы рассмотрели некоторые интересные вещи, которые может делать spaCy в целом, давайте рассмотрим более крупное практическое применение некоторых из этих техник обработки естественного языка: классификацию текста. В конце записной книжки есть упражнение, которое вы можете попробовать, в котором вы научите мультиклассовый классификатор предсказывать The Data Science Lab. Он работает на стандартном стандартном оборудовании. основной. Мы обсудили извлечение таких функций из текста в Feature Engineering; здесь мы будем использовать функции разреженного подсчета слов из корпуса 20 групп новостей, чтобы продемонстрировать глубокое обучение для классификации текста.Нажмите вопросительный знак, чтобы изучить остальные сочетания клавиш. Unsupervised OpenIE (NLP, PyTorch, flair) — Project Link. Перво-наперво, нам нужно импортировать RoBERTa из pytorch-transformers, убедившись, что мы используем последнюю версию 1. Станьте инженером-программистом в ведущих компаниях. Привет, у меня есть степень магистра информатики. Этот код запускает эксперимент GAN-BERT над набором данных TREC для задачи детальной классификации вопросов. Используйте оптимизацию гиперпараметров, чтобы добиться от модели большей производительности.Размер входного изображения для сети будет 256 × 256. v0. Одним из наиболее многообещающих достижений является Тонкая настройка универсальной языковой модели для классификации текста (ULMFiT), созданная Джереми Ховардом и Себастьяном Рудером. Размер изображения должен составлять не менее 640 × 320 пикселей (для наилучшего отображения — 1280 × 640 пикселей). Примером текстовых данных является коллекция сообщений электронной почты, отправленных сотрудниками GitHub — a7b23 / text-classification-in-pytorch-using-lstm Hot github. Поддерживаемые архитектуры CIFAR-10 / CIFAR-100. Это демонстрируется в FastText — бесплатной, облегченной библиотеке с открытым исходным кодом, которая позволяет пользователям изучать текстовые представления и текстовые классификаторы.Тип модели. md, чтобы продемонстрировать производительность модели. Модели (бета) Находите, публикуйте и повторно используйте предварительно обученные модели dataset_collator_gpt2_text_classification. 127. Список литературы; 1. Просмотрите код на GitHub CNN для классификации текста: полная реализация Мы просмотрели много информации, и теперь я хочу подвести итог, объединив все эти концепции. # Бинарная классификация текста с несбалансированными классами # Сравнение CNN с традиционными моделями (TFIDF + логистическая регрессия и SVM) # Прогнозирование искренности вопроса на Quora # Наборы данных: Набор данных — вопросы Quora из конкурса Kaggle.токены представляют собой тензор после числовой обработки строковых токенов. Сверточные нейронные сети Узнайте, как определить и обучить CNN для классификации данных MNIST, базы данных рукописных цифр, широко известной в области машинного и глубокого обучения. Вот подробное руководство, которое поможет вам быть в курсе последних событий: Всеобъемлющее руководство по пониманию и реализации классификации текста в Python. Современная обработка естественного языка для PyTorch и TensorFlow 2. randn (28, 28)) [0]. autograd import Переменная из torchvision.В этом руководстве демонстрируется классификация текста, начиная с простых текстовых файлов, хранящихся на диске. К счастью, существует множество ресурсов, которые могут помочь вам выполнить этот процесс, независимо от того, используете ли вы инструменты с открытым исходным кодом или SaaS. 9%), а лучший способ начать работу с fastai (и глубоким обучением) — это прочитать книгу и пройти бесплатный курс. 6 Отпустите выделение. грамм. 🤗 Transformers предоставляет тысячи предварительно обученных моделей для выполнения таких задач с текстами, как классификация, извлечение информации, ответы на вопросы, обобщение, перевод, создание текста и т. Д. На более чем 100 языках.Этот репозиторий основан на библиотеке Pytorch-Transformers от HuggingFace. 0/9. грамм. Обновление: одни и те же значения параметров (включая желаемый текст) могут (и, по-видимому, обычно так и есть) приводить к разным выходным изображениям в разных прогонах. Эти архитектуры дополнительно адаптированы для обработки данных разных размеров, форматов и разрешений при применении к нескольким областям в медицинской визуализации, автономном вождении, финансовых услугах и других. Сообщество. Реализации популярных трансформеров НЛП в PyTorch.com. Этапы установки; По желанию; При работе с пакетами Python рекомендуется всегда использовать виртуальные среды. импорт моделирования BertPreTrainedModel. Он предоставляет следующие возможности: Определение конвейера предварительной обработки текста: токенизация, низкое вычисление и т. Д. Недавно я начал с конкурса НЛП на Kaggle под названием Quora Question неискренность. Я просто хочу поэкспериментировать с моделью BERT самым простым способом, чтобы предсказать результат классификации нескольких классов, чтобы я мог сравнить результаты с более простыми моделями классификации текста, которыми мы являемся Ignite Posters с конференции разработчиков Pytorch: 2019; 2018; Примеры учебников.from_pretrained (‘roberta-base’) tokenizer = RobertaTokenizer. Библиотеки с открытым исходным кодом для классификации текста Загрузите изображение, чтобы настроить предварительный просмотр вашего репозитория в социальных сетях. com Классификация китайского текста с CNN и RNN. Это бесплатно, конфиденциально, включает в себя бесплатные лучшие проекты GitHub по машинному обучению. модели импортируют resnet50 из PIL import Image net = resnet50 (pretrained = True Multiclass). Классификация изображений — обычная задача в компьютерном зрении, где мы классифицируем изображение с помощью изображения.Давайте создадим фрейм данных, состоящий из текстовых документов и соответствующих им ярлыков (названий групп новостей). Включает готовый код для моделей BERT, XLNet, XLM и RoBERTa. Эта библиотека является частью проекта PyTorch. com-649453932-Chinese-Text-Classification-Pytorch _-_ 2019-08-02_02-38-13 Пример игрушки в pytorch для двоичной классификации. Вот функция, которую я придумал, которая выполняет вычисления за меня и проверяет заданную форму вывода: Python и PyTorch: реализация PyTorch «Обобщенных сквозных потерь для проверки громкоговорителей» Ван, Ли и др.В этом руководстве вы познакомитесь с ключевыми идеями программирования с глубоким обучением с использованием Pytorch. Если вы хотите быстро освежить в памяти PyTorch, вы можете прочитать статью ниже: С помощью преобразователей Pytorch мы можем использовать предварительно обученную языковую модель Берта для классификации последовательностей. Сообщение Reddit о CLIP. Библиотека для быстрого представления и классификации текста. davidefiocco / классификация текста в pytorch-to-refactor-with-pytorch-lightning. К сожалению, я какой-то нуб с pytorch, и даже читая исходный код потерь, я не могу понять, делает ли одна из уже существующих потерь именно то, что я хочу, или я должен создать новую потерю. , и если это так, я действительно не знаю, как это сделать.Место для обсуждения кода PyTorch, проблем, установки, исследования. Измените текст в приведенной выше записной книжке в разделе Params с «красивый Валуиджи» на желаемый текст. . Подумал, что поделюсь реализацией CNN Юна Кима, которую я реализовал в PyTorch 1. Кроме того, индуктивное передающее обучение сильно повлияло на компьютерное зрение, но существующие подходы в НЛП по-прежнему требуют модификаций для конкретных задач и обучения с нуля. 7. Скрипт на гитхабе с именем Классификация текста с использованием LSTM.а. Мы сообщаем о серии экспериментов со сверточными нейронными сетями (CNN), обученными на основе предварительно обученных векторов слов для задач классификации на уровне предложений. Последняя активность: 22 февраля 2021 г. Текстовый конвейер преобразует текстовую строку в список целых чисел на основе таблицы поиска, определенной в словаре. Джеймс Маккаффри из Microsoft Research начинает серию из четырех статей, в которых представлен полный комплексный пример двоичной классификации производственного качества с использованием нейронной сети PyTorch, включая полный пример кода Python и файлы данных.Предварительно подготовленные модели для классификации текста мы рассмотрим Ресурсы для разработчиков. Цель состоит в том, чтобы классифицировать документы по фиксированному количеству предопределенных категорий с учетом переменной длины текстовых тел. Место для обсуждения кода PyTorch, проблем, установки, исследования. III — Классификация текста с использованием Transformer (реализация Pytorch): слишком просто использовать ClassificationModel из simpletransformes: загрузите исходный код с нашего github. PyTorch-Transformers (NLP) Скажу честно — мощь обработки естественного языка (NLP) просто поражает меня.py выполняет обучение модели. Прогнозирование повторяющихся вакансий (FastAI, PyTorch) — ссылка на проект. 👾 PyTorch-Трансформеры. MultiheadAttention (28, 2) x (inp [0], torch. Классификация Cnn-текста: это реализация статьи Кима о сверточных нейронных сетях для классификации предложений в PyTorch. Пожалуйста, обратитесь к этой статье Medium для получения дополнительной информации о том, как этот проект работает . Это экспериментальная установка для создания базы кода для PyTorch. Используйте comd из pytorch_pretrained_bert. Как получить имя класса после получения идентификатора класса.Бинарная классификация с использованием PyTorch: подготовка данных. . Этот CLI принимает в качестве входных данных контрольную точку TensorFlow (три файла, начинающиеся с bert_model. Была реализована базовая модель для классификации текста с использованием нейронных сетей LSTM в качестве ядра модели, аналогично, модель была закодирована с использованием преимуществ PyTorch как фреймворк для моделей глубокого обучения. Awesome Open Source не связан с юридическим лицом, владеющим организацией Shawn1993. В этом руководстве показано, как быстро и эффективно использовать библиотеки Pytorch BERT и HuggingFace, чтобы приблизить модель Fine-Tune к самая продвинутая классификация предложений.И: pip install pytorch_tabular для самого необходимого. Мы импортируем Pytorch для построения модели, torchText для загрузки данных, matplotlib для построения графиков и sklearn для оценки. ) к распределенным большим данным. Просто и практично с предоставленным примером кода. Реализация Tensorflow Vision Transformer (ViT), представленная в An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, где авторы показывают, что преобразователи, применяемые непосредственно к патчам изображений и предварительно обученные на больших наборах данных, действительно хорошо работают при классификации изображений.Исходники pytorch_tabular можно скачать с Github repo_. Вывод солнца или дождя (fastai, torchvision, Image Recognition) — Project Link GAN-BERT можно использовать в задачах классификации последовательностей (также с использованием текстовых пар). 8k участников сообщества mlclass. Это репо содержит реализацию PyTorch предварительно обученной модели BERT для классификации текста с несколькими метками. json 112. В предыдущем разделе описывалось, как представить классификацию 2 классов с помощью логистической функции.Keras нацелен на быстрое прототипирование. PyTorch Мгновенно делитесь кодом, заметками и фрагментами. В этом руководстве дано пошаговое объяснение реализации вашей собственной модели LSTM для классификации текста с помощью Pytorch. 0. Это простой и легкий метод классификации текста, использование этой библиотеки pytorch требует лишь небольшой предварительной обработки. Anaconda / Miniconda — это менеджер пакетов, который позволяет вам создавать виртуальные среды и легко управлять установкой пакетов. Полный код доступен на Github.тестирование. В Fast R-CNN, даже несмотря на то, что вычисление для классификации 2000 предложений области было совместным, часть алгоритма, генерирующая предложения области, не разделяла никаких вычислений с частью, которая выполняла классификацию изображений. В последние годы появилось несколько архитектур нейронных сетей, предназначенных для решения конкретных задач, таких как обнаружение объектов, языковой перевод и механизмы рекомендаций. Аргументы: Vocab: объект словаря, используемый для набора данных. Размер ([28, 3, 1]) как правильно использовать MultiHeadAttention для изображений? работает ли это multiheadattention что-то под капотом — pytorch v1.Базовые параметры для классификации текста. Размер входного изображения для сети будет 256 × 256. В этом руководстве показано, как быстро и эффективно использовать библиотеки BERT и HuggingFace Pytorch, чтобы модель Fine-Tune приблизилась к самой сложной классификации предложений. 3 и scikit-learn 0. Чтобы повысить производительность, я хотел бы попробовать механизм внимания. randn (28, 28), факел. Мы также можем доработать предварительно обученную языковую модель Берта в соответствии с нашей задачей, а затем использовать ее. Эта записная книжка классифицирует обзоры фильмов как положительные или отрицательные, используя текст обзора.Мы используем сверточные нейронные сети для данных изображений … PyTorch — это библиотека машинного обучения с открытым исходным кодом на основе Torch для обработки естественного языка с использованием Python. Автор: Роберт Гатри. Не полностью переведен, только для одноклассников, которые читают по-английски, английский хорошо видеть исходный текст прямо в CLOAB. 1. Последние сообщения. Это правильный подход? импортная горелка импортная torchvision. Мы сообщаем о серии экспериментов со сверточными нейронными сетями (CNN), обученными на основе предварительно обученных векторов слов для задач классификации на уровне предложений.Также мы применяем более или менее стандартный набор аугментаций во время тренировок. Он будет охватывать: Токенизацию и создание словаря из текстовых данных. Руководство от А до Я о том, как вы можете использовать Google BERT для задач двоичной классификации текста с помощью Python и Pytorch. Введение в PyTorch. Глубокое обучение для НЛП с Pytorch. Вэйдун Сюй, Зею Чжао, Тяньнин Чжао. Присоединяйтесь к сообществу разработчиков PyTorch, чтобы вносить свой вклад, учиться и получать ответы на свои вопросы. Слой внедрения преобразует индексы слов в векторы слов.Например, text_pipeline (‘вот пример’) >>> [475, 21, 2, 30, 5286] label_pipeline (’10 ‘) >>> 9.. Описание модели. предварительная обработка. Функции, описанные в этой документации, классифицируются по статусу выпуска: Стабильный: эти функции будут поддерживаться в течение длительного времени, и, как правило, в документации не должно быть серьезных ограничений производительности или пробелов. PyTorch, с другой стороны, создает динамический вычислительный граф, который определяется во время выполнения, полный список см. На носителе.Бумага: повышение точности и ускорение классификации изображений документов с помощью параллельных систем. Узнайте, как загружать, настраивать и оценивать задачи классификации текста с помощью библиотеки Pytorch-Transformers. Вы научите бинарный классификатор выполнять анализ тональности набора данных IMDB. Это стандартная модель PyTorch. Эта библиотека содержит 9 модулей, каждый из которых можно использовать независимо в существующей кодовой базе или объединить вместе для полного рабочего процесса обучения / тестирования. Английский -> Французский) перевести ранее переведенный текст на исходный язык (например,Прежде чем полностью реализовать иерархическую сеть внимания, я хочу построить иерархическую сеть LSTM в качестве базовой линии. Сверточные нейронные сети на уровне символов для классификации текста в PyTorch. Классификация текста pytorch lstm предоставляет учащимся исчерпывающий и исчерпывающий способ увидеть прогресс после окончания каждого модуля. com / pytorch / text 102328 всего загрузок class: center, middle, title-slide count: false # Модуль 3: ## Функции потерь для классификации в глубоком обучении
.Мы выяснили, что bi-LSTM обеспечивает приемлемую точность для обнаружения фальшивых новостей, но еще есть возможности для улучшения. Классификация текста pytorch rnn предоставляет учащимся исчерпывающий и исчерпывающий способ увидеть прогресс после окончания каждого модуля. предсказывает следующие 100 слов после. Если вы перешли к этой части и хотите запустить код, вот Github. Сверточные нейронные сети Узнайте, как определить и обучить CNN для классификации данных MNIST, базы данных рукописных цифр, широко известной в области машинного и глубокого обучения.Создает сеть на основе архитектуры DeepSpeech3, обученную с помощью функции активации CTC. Реализация некоторых алгоритмов школьного машинного обучения для классификации текста. Форумы. переведите этот текст на язык временного назначения (например, предварительно обученные модели. жирный шрифт [Marc Lelarge] — # Основы контролируемого обучения В этой статье я расскажу о 6 современных предварительно обученных моделях классификации текста. воспроизводимость, быстрое экспериментирование и повторное использование кодовой базы, чтобы вы могли создать что-то новое, а не писать еще один цикл поезда.GoogLeNet был основан на архитектуре глубокой сверточной нейронной сети под кодовым названием «Начало», которая отвечала за создание нового уровня техники для классификации и обнаружения в ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). Этот коммит включает скрипт для преобразования контрольной точки Megatron-BERT, загруженной из NVIDIA GPU Cloud. Многие концепции (такие как абстракция графа вычислений и автоградиент) не являются уникальными для Pytorch и относятся к любому набору инструментов глубокого обучения.zero_grad #flatten входные данные для соответствия линейной модели y_hat = model Введение в PyTorch: узнайте, как создавать нейронные сети в PyTorch и использовать предварительно обученные сети для современных классификаторов изображений. В этой записной книжке мы увидим, как настроить одну из моделей 🤗 Transformers для задачи классификации текста теста GLUE Benchmark. com Пыторч-Трансформаторы-Классификация. Однако недавно, когда появилась возможность поработать над мультиклассовой классификацией изображений, я решил использовать PyTorch.Найдите ресурсы и получите ответы на вопросы. Я предлагаю добавить линейный слой, поскольку необработанный текст, загруженный tfds, необходимо обработать, прежде чем его можно будет использовать в модели. 01] -epochs N количество эпох для поезда [по умолчанию: 10]-dropout вероятность выпадения [по умолчанию: 0. категоризация текста или тегирование текста) — задача назначения набора предопределенных категорий для открытого текста. 8. Это достигается за счет использования сверточных нейронных сетей (CNN). Классификация текста с использованием иерархической LSTM.трансформируется как трансформируется из факела. Я провел классификацию узлов, кластеризацию узлов и классификацию графов в мозговых сетях с использованием геометрических библиотек DGL и Pytorch. Я пытаюсь написать нейронную сеть для двоичной классификации в PyTorch, и меня смущает функция потерь. Набор данных, используемый в этой модели, был взят из конкурса Kaggle. Место для обсуждения кода PyTorch, проблем, установки, исследования. Напишите TensorFlow или PyTorch с кодом Spark для распределенного обучения и вывода.примечание: для нового пакета pytorch-pretrained-bert. Реализуйте ячейку ConvLSTM / ConvGRU с помощью Pytorch. Гиперпараметры — это параметры, которые контролируют процесс обучения моделей, такие как скорость обучения, размер пакета и уменьшение веса. 2. Введение. Я пробовал это на основе репозитория pytorch-pretrained-bert на GitHub и видео на Youtube. py -h или. PyTorch — это среда машинного обучения с открытым исходным кодом. — zhulf0804 / GCN. ipynb. форму придает факел. ) Обучение с подкреплением; Ниже приведены некоторые подробные ресурсы, если вы хотите узнать о PyTorch с нуля: Руководство для начинающих по PyTorch и как он работает с нуля; Создайте модель классификации изображений с помощью сверточных нейронных сетей в PyTorch Analytics. Zoo бесшовно масштабирует TensorFlow, Keras и PyTorch для распределенных больших данных (с использованием Spark, Flink & Ray).GAN-BERT может использоваться в задачах классификации последовательностей (включая текстовые пары). Не стесняйтесь присылать м Подробнее. HuggingFace выпускает новую библиотеку PyTorch: Accelerate для пользователей, которые хотят использовать несколько графических процессоров или TPU без использования абстрактного класса, которым они не могут легко управлять или настраивать. 2k участников в сообществе tensorflow. . PyTorch Text — это пакет PyTorch с набором утилит для обработки текстовых данных, он позволяет выполнять базовые задачи НЛП в PyTorch. Этот код запускает эксперимент GAN-BERT над набором данных TREC для задачи детальной классификации вопросов.shape [0] # PyTorch хранит градиенты в изменяемой структуре данных. Это учебник PyTorch по классификации текста. github. Предскажите класс текста с помощью обученной модели преобразователя. Это вызов НЛП по классификации текстов, и поскольку проблема стала более ясной после прохождения конкурса, а также изучения бесценных ядер, предложенных экспертами kaggle, я подумал о том, чтобы поделиться своими знаниями. Я также вижу, что выходной слой из N выходов для N возможных классов является стандартным для общей классификации.Он также предоставляет несколько готовых к использованию модулей и функций для быстрой разработки моделей. В последние годы появилось несколько архитектур нейронных сетей, предназначенных для решения конкретных задач, таких как обнаружение объектов, языковой перевод и механизмы рекомендаций. Модель, представленная в документе, обеспечивает хорошую производительность классификации для ряда задач классификации текста (например, анализа настроений) и с тех пор стала стандартной базовой линией для новых архитектур классификации текста. Сверточные нейронные сети Узнайте, как определить и обучить CNN для классификации данных MNIST, базы данных рукописных цифр, широко известной в области машинного и глубокого обучения.В этом пакете мы предоставляем код, а также данные для проведения эксперимента с использованием 2% маркированного материала (109 примеров) и 5343 немаркированного класса: центр, средний, количество заголовков и слайдов: false # Регрессии, классификация и основы PyTorch
. Он полностью функционален, но многие настройки в настоящее время жестко запрограммированы, и он требует серьезного рефакторинга, прежде чем он сможет быть достаточно полезным для сообщества. Обновление (23 января 2020 г.) Реализация сверточных нейронных сетей в Pytorch для классификации предложений.NFNets и Adaptive Gradient Clipping для SGD реализованы в PyTorch. randn (28, 28)) [1]. Это простой и легкий способ классификации текста с минимальным объемом предварительной обработки с использованием этой библиотеки PyTorch. С интеграцией UIS-RNN. Я стажер в области науки о данных, вообще не имеющий опыта глубокого обучения. srviest / char-cnn-text-classification-pytorch Включите уценку в верхней части файла README на GitHub. LSTM — это основная обучаемая часть сети — реализация PyTorch имеет механизм стробирования, реализованный внутри ячейки LSTM, который может изучать длинные последовательности данных.Это учебник PyTorch по классификации текста. Давайте теперь посмотрим на применение LSTM. Я серьезно не настраивал гиперпараметры для SST. Я предполагаю, что вы знаете, что такое классификация текста. Реализация классификации текста с помощью Python может быть сложной задачей, особенно при создании классификатора с нуля. Ссылка на GitHub. Размер изображения должен составлять не менее 640 × 320 пикселей (для наилучшего отображения — 1280 × 640 пикселей). Найдите ресурсы и получите ответы на вопросы. Если вы хотите проверить свои знания, попробуйте использовать Vision-Transformer-Keras-Tensorflow-Pytorch-Examples.# В противном случае он будет иметь старую информацию от оптимизатора предыдущей итерации. Присоединяйтесь к сообществу разработчиков PyTorch, чтобы вносить свой вклад, учиться и получать ответы на свои вопросы. /основной. Описание. В этом руководстве показано, как быстро и эффективно использовать библиотеки BERT и HuggingFace Pytorch, чтобы модель Fine-Tune приблизилась к самой сложной классификации предложений. Узнайте, почему вложения слов полезны и как можно использовать предварительно обученные вложения слов. 0: из pytorch_transformers импортировать RobertaModel, RobertaTokenizer из pytorch_transformers импортировать RobertaForSequenceClassification, RobertaConfig config = RobertaConfig.Учебники на GitHub. Помимо набора данных, мы даем базовые результаты, используя современные методы для трех задач: распознавание символов (максимальная точность 80. до (device) batch_size = input. Присоединяйтесь к сообществу разработчиков PyTorch, чтобы вносить свой вклад, учиться и получите ответы на свои вопросы. def __init__ (self, voiceab, data, labels): «» «Инициировать набор данных классификации текста. Точная настройка BERT для классификации спама. Я выполнил удобочитаемую реализацию PyTorch CNN классификации настроений, которая рассматривает обзоры фильмов как входные данные и создает метку класса (положительную или отрицательную) как изображения (обнаружение, классификация и т. д.)При реализации исходной статьи (Kim, 2014) в PyTorch мне нужно было собрать множество частей, чтобы завершить проект. Реализована задача классификации в pytorch для моей собственной архитектуры. Изучение векторов для конкретных задач с помощью тонкой настройки дает дополнительный выигрыш в производительности. Берт. gpt2_classificaiton_collator = Gpt2ClassificationCollator (use_tokenizer = tokenizer, «Cnn Text Classification Pytorch» и другие слова, потенциально защищенные товарными знаками, изображения, защищенные авторским правом, и содержимое readme, защищенное авторским правом, вероятно, принадлежат юридическому лицу, которому принадлежит организация «Shawn1993».Тест GLUE — это группа из девяти задач классификации предложений или пар предложений, а именно: Китайский текст-Классификация-Pytorch 中文 文本 分类 , TextCNN , TextRNN , FastText , TextRCNN , BiLSTM_Attention, DPCNN, Transformer, 基于 pytorch , 开箱 即。 介绍 模型 介绍 、 数据 流动 过程 : 我 的 博客 数据 以 字 为 单位 输入 模型 , 预 使用 搜 Слово + символ 300d , 点 这里 下载 环境 21. для входного изображения размером 3x28x28 inp = torch . Он широко используется в сентиментальном анализе (классификация обзоров IMDB, YELP), сентиментальном анализе фондового рынка и в умных ответах по электронной почте GOOGLE.Я начал работать в области науки о данных несколько лет назад, и масштабы, в которых НЛП выросло и изменило то, как мы работаем с текстом, почти не поддаются описанию. Таким образом, у меня есть несколько вопросов: возможно ли / полезно ли уделять внимание простым классификациям? Классификация Is Text является основной проблемой для многих приложений, таких как обнаружение спама, анализ тональности или умные ответы. Классификация текста с использованием сверточных нейронных сетей; Вариационные автоэнкодеры; Сверточные нейронные сети для классификации Fashion-MNISTDataset; Цикл обучения — GAN на лошадях toZebras с Nvidia / Apex — журналы на входах W&B = входы.Прогноз продаж Россманна (FastAI) — ссылка на проект. Голые кости CNN. Все слова, включая неизвестные, которые инициализированы нулем, остаются статичными, и изучаются только другие параметры модели. Это пример бинарной или двухклассовой классификации, важной и широко применяемой задачи машинного обучения. Pytorch-text-classifier Реализация классификации текста в pytorch с использованием CNN / GRU / LSTM. В корне проекта вы увидите: Введение в PyTorch: узнайте, как создавать нейронные сети в PyTorch и использовать предварительно обученные сети для современных классификаторов изображений.Size ([3, 28, 28]) while x (inp [0], torch. Overview¶. Cuda. Узнайте о классификации текста Python с помощью Keras. Создайте слой и передайте текст набора данных в слой. Создание пакетов и наборов данных , и разбивая их на (обучение, проверка, тест) GitHub — raghakot / keras-text: Библиотека классификации текста Hot github. py генерирует файл для отправки в тестовом наборе, который можно отправить по ссылке https cnn текстовой классификации github предоставляет всеобъемлющую и комплексная программа, позволяющая учащимся увидеть прогресс после окончания каждого модуля.Ресурсы для разработчиков. Пройдите свой путь от модели набора слов с логистической регрессией к более продвинутым методам, ведущим к сверточным нейронным сетям. 8, matplotlib 3.. Сверточные нейронные сети Узнайте, как определить и обучить CNN для классификации данных MNIST, базы данных рукописных цифр, широко известной в области машинного и глубокого обучения. Мы применяем BERT, популярную модель Transformer, для обнаружения фейковых новостей с помощью Pytorch. 0B первая фиксация 2 месяца назад PyTorch Wrapper. rand: все слова инициализируются случайным образом, а затем изменяются во время обучения.Форумы. 5 Кбайт — просмотрено (0) просмотрено (0); text_b используется, если мы обучаем модель для понимания взаимосвязи между предложениями (я вижу, что BCELoss — это общая функция, специально предназначенная для двоичной классификации. С командой чрезвычайно преданных и квалифицированных преподавателей классификация текста pytorch rnn будет не только быть местом для обмена знаниями, а также для того, чтобы помочь учащимся вдохновиться исследованием и открытием для себя многих решений PyTorch. Полный список см. на github. data: список кортежей меток / токенов.Вы можете либо клонировать общедоступный репозиторий: загрузите изображение, чтобы настроить предварительный просмотр вашего репозитория в социальных сетях. В вашем случае, поскольку вы выполняете классификацию да / нет (1/0), у вас есть два ярлыка / класса, поэтому у линейного слоя есть два класса. Этот коммит включает скрипт для преобразования контрольной точки Megatron-BERT, загруженной из NVIDIA GPU Cloud. to (устройство) метки = метки. Последняя версия DGL 0. изменила файл конфигурации, подробности см. В каталоге Config. 1 МБ первая фиксация 2 месяца назад special_tokens_map.жирный [Марк Леларж] — # Обзор 137 голосов, 15 комментариев. Французский -> Английский). Остальная часть этого совета покажет вам, как реализовать обратный перевод с помощью библиотеки трансформеров MarianMT и Hugging Face. fastai не заменяет и скрывает API PyTorch, а предназначен для его расширения и улучшения. Теперь мы настроим модель BERT для выполнения классификации текста с помощью библиотеки Transformers. Модели (бета) Обнаружение, публикация и повторное использование предварительно обученных моделей Классификация текста — обычная задача в обработке естественного языка (NLP).Классификация текста. В настоящее время библиотека содержит реализации PyTorch, предварительно обученные веса моделей, сценарии использования и утилиты преобразования для следующих моделей: Классификация текста — очень классическая проблема. Модели (бета) Обнаружение, публикация и повторное использование предварительно обученных моделей Классификация текста широко используется в реальных бизнес-процессах, таких как обнаружение спама в электронной почте, классификация заявок в службу поддержки или рекомендации контента на основе тем текста. io / blog / MMOCR — это набор инструментов с открытым исходным кодом, основанный на PyTorch и mmdetection для обнаружения текста, распознавания текста и соответствующих последующих задач, включая извлечение ключевой информации.Установка На этой странице. Мы также вкратце рассмотрели тензорные элементы — основную структуру данных, используемую в PyTorch. FloatTensor [1, 512]], который является выходом 0 SelectBackward, находится в версии 2; ожидаемая версия 1 вместо Учебного пособия Dropout в PyTorch Tutorial: Dropout as Regularization and Bayesian Approximation. Задача бинарной классификации — предсказать выходное значение, которое может быть одним из двух возможных дискретных значений, например, «мужской» или «женский». Awesome Open Source не связан с юридическим лицом, которому принадлежит организация «Медвежья лапа». .Это очень похоже на нейронный переводчик и на последовательное обучение. json 361. 6 марта 2019 г. • Дэн Сало. В предыдущем посте мы обсудили PyTorch, его сильные стороны и почему вам стоит его изучить. ckpt) и связанный файл конфигурации (bert_config. 0. g. С 5 строками кода, добавленными в необработанный обучающий цикл PyTorch, сценарий запускается как локально, так и на любом распределенном se Не полностью переведен, только для одноклассников, которые читают английский, английский хорошо видеть исходный текст прямо в CLOAB.Классификация текста — одна из важных и распространенных задач машинного обучения. Классификация текста pytorch предоставляет учащимся исчерпывающий и исчерпывающий способ увидеть прогресс после окончания каждого модуля. # ПРИМЕЧАНИЕ. При этом предполагается, что ваша модель ожидает, что текст будет токенизирован # с «input_ids» и «token_type_ids» — что верно для некоторых популярных моделей трансформаторов, например. com · text — классификация -in-pytorch -using- lstm классификация набора данных большого обзора фильмов imdb достигает точности 88.Берт токенизатор github. Раньше я всегда использовал Keras для проектов компьютерного зрения. Единственные новые параметры, добавленные во время точной настройки, — это forBert для классификации текста в SST; Требование PyTorch: 1. «Классификация Pytorch» и другие слова, потенциально защищенные товарными знаками, изображения, защищенные авторским правом, и защищенное авторским правом содержимое readme, вероятно, принадлежат юридическому лицу, которому принадлежит организация «Bearpaw». PyTorch-Transformers (ранее известная как pytorch-pretrained-bert) — это библиотека современных предварительно обученных моделей для обработки естественного языка (NLP).Нет комментариев к классификации мультиклассового текста с использованием LSTM в Pytorch. Прогнозирование рейтингов элементов на основе отзывов клиентов. Человеческий язык полон двусмысленности, во многих случаях одна и та же фраза может иметь несколько интерпретаций в зависимости от контекста и даже может сбивать с толку людей. Найдите ресурсы и получите ответы на вопросы. Это часть проекта OpenMMLab. В конце записной книжки есть упражнение, которое вы можете попробовать, в котором вы научите мультиклассовый классификатор предсказывать класс: центр, середина, количество заголовков и слайдов: false # Регрессии, классификация и основы PyTorch
.e 10, если вы выполняете классификацию цифр, как в MNIST. Однако я могу найти ресурсы только о том, как привлечь внимание к моделям от последовательности к последовательности, а не к моделям от последовательности к фиксированному выходу. print («Этот текст принадлежит к классу% s»% DBpedia_label [предсказать (ex_text_str3, model, vocab, 2)]) Таким образом, мы используем torchtext для реализации классификации текста на несколько классов. Наивные байесовские классификаторы — это набор алгоритмов контролируемого обучения, основанных на применении теоремы Байеса, но с сильными предположениями о независимости между функциями, заданными значением переменной класса (следовательно, наивным).Последние достижения в области глубокого обучения значительно повысили производительность задач обработки естественного языка (NLP), таких как классификация текста. Если вам нужно введение в нейронные сети и «длинную версию» того, что это такое и что она делает, прочтите мой пост в блоге. Этот аргумент придает вес положительной выборке для каждого класса, поэтому, если у вас 270 классов, вы должны передать факел. Речь идет о присвоении класса всему, что связано с текстом. 1 питон: 3. python3 main. Экосистема Catalyst В этой записной книжке мы увидим, как настроить одну из моделей 🤗 Transformers для задачи классификации текста теста GLUE Benchmark.Мультиклассовая классификация текста — прогнозирование оценок на основе комментариев к обзорам. Я могу сделать эту работу за тебя. Также мы применяем более или менее стандартный набор аугментаций во время тренировок. Загрузчики данных и абстракции для текста и НЛП. Он предназначен в качестве отправной точки для всех, кто хочет использовать модели Transformer в задачах классификации текста. Я знаю, что это старый вопрос, но я снова наткнулся на него при работе с нестандартными размерами ядра, расширениями и т. Д. В этом руководстве мы описываем, как создать классификатор текста с помощью инструмента fastText.Используя кодировщик LSTM, мы намерены закодировать всю информацию текста в последнем выводе рекуррентной нейронной сети перед запуском сети прямого распространения для классификации. Прежде чем мы углубимся в подробности, давайте кратко познакомимся с PyTorch. py -h Вы получите: Классификатор текста CNN Необязательные аргументы: -h, —help показать это справочное сообщение и выйти -batch-size Размер пакета N для обучения [по умолчанию: 50] -lr Начальная скорость обучения LR [по умолчанию: 0. Благодаря команде чрезвычайно преданных своему делу и качественных преподавателей классификация текста pytorch lstm будет не только местом для обмена знаниями, но и поможет студентам вдохновиться исследовать и открыть для себя множество бесплатных программ для классификации текста Берта и сразу же использовать Pytorch для классификации текстов Bert. получите скидку% или $ или бесплатную доставку Deep Learning API и сервер на C ++ 11 Поддержка Caffe, Caffe2, PyTorch, TensorRT, Dlib, NCNN, Tensorflow, XGBoost и TSNE машинное обучение caffe сервер глубокого обучения tensorflow gpu rest api xgboost классификация изображений обнаружение объектов dlib сегментация изображений tsne нейронные сети deepdetect caffe2 ncnn detectron Сквозная структура PyTorch для классификации изображений и видео.Смотрите полный список на github. Мы показываем, что простая CNN с небольшой настройкой гиперпараметров и статическими векторами дает отличные результаты на нескольких тестах. DataFrame ({‘label’: набор данных. Мы реализуем нейронную сеть для классификации обзоров фильмов по настроениям. Требование pyorch: 1. Наш метод HuggingFace выпускает новую библиотеку PyTorch: Accelerate для пользователей, которые хотят использовать мульти-графические процессоры или TPU без используя абстрактный класс, которым они не могут легко управлять или настраивать.Это основная задача обработки естественного языка.Если вы хотите более конкурентоспособных результатов, ознакомьтесь с моей предыдущей статьей о классификации текста BERT! Наша модель классификации текста использует предварительно обученную модель BERT (или другие модели, подобные BERT), за которой следует уровень классификации на выходе первого токена ([CLS]). · Классификация текста с помощью Keras и сообщение в блоге TensorFlow здесь. Тест GLUE Benchmark представляет собой группу из девяти задач классификации предложений или пар предложений, а именно: Это руководство демонстрирует классификацию текста, начиная с простых текстовых файлов, хранящихся на диске.Классификация видео. С 5 строками кода, добавленными в необработанный цикл обучения PyTorch, сценарий запускается как локально, так и в любой распределенной установке. глубокое обучение сентимент-анализ текст-классификация pytorch наивный-байес-классификатор svm-classifier сентимент-классификация rcnn китайский-текст-классификация knn-classifier lstm-Внимание самовнимание cnn-pytorch Помощник для обучения двоичной классификации в PyTorch — binary_classification_utils. Текстовые классификаторы можно использовать для организации, структурирования и категоризации практически любого текста — от документов, медицинских исследований и файлов, а также по всему Интернету.. Conda Files; Этикетки; Значки; Лицензия: BSD Home: https: // github. В этом посте я попытаюсь провести вас через Jarvx / text-classification-pytorch. Включите уценку вверху вашего GitHub README. Текстовая классификация. bin 422. Форумы. Он предназначен для написания меньшего количества кода, позволяя разработчику сосредоточиться на других задачах, таких как подготовка данных, обработка, очистка и т. Д. PyTorch нацелен на реализацию набора данных Pytorch для NUS-WIDE, является стандартной и очень похожей на любую реализацию набора данных для классификации. набор данных.Тензор с формой (270,), определяющей вес для каждого класса. Analytics Zoo предоставляет унифицированную платформу для анализа данных и искусственного интеллекта, которая органично объединяет программы TensorFlow, Keras, PyTorch, Spark, Flink и Ray в интегрированный конвейер, который может прозрачно масштабироваться от ноутбука до больших кластеров для обработки больших производственных данных. com / castorini / Castor. RuntimeError: одна из переменных, необходимых для вычисления градиента, была изменена внутренней операцией: [torch. Введение в PyTorch: узнайте, как создавать нейронные сети в PyTorch и использовать предварительно обученные сети для современных классификаторов изображений.Эта статья служит полным руководством для CNN по задачам классификации предложений, сопровождаемым советами для практиков. Ресурсы для разработчиков. 24%. 5 Узнайте о функциях и возможностях PyTorch. Конвейер меток преобразует метку в целые числа. Простые преобразователи — мультиклассовая классификация текста с помощью BERT, RoBERTa, XLNet, XLM и DistilBERT. Весь исходный код доступен в репозитории Github. После открытия новостного веб-сайта и выбора настроения в результате чтения страницы есть ли какая-либо связь между настроением людей и различными частями новостей? pytorch_text_classification.Ресурсы для разработчиков. Существует множество приложений классификации текста, таких как фильтрация спама, анализ тональности, тегирование речи, определение языка и многое другое. Самый простой способ обработать текст для обучения — использовать экспериментальный. Классификация коротких текстов на основе RNN. Этот слой имеет много возможностей, но в этом руководстве используется поведение по умолчанию. Это четвертое в серии руководств, которые я планирую написать о самостоятельной реализации классных моделей с помощью замечательной библиотеки PyTorch.Catalyst является частью экосистемы PyTorch. Чтобы увидеть, что возможно с fastai, взгляните на Quick Start, в котором показано, как использовать около 5 строк кода для создания классификатора изображений, модели сегментации изображений, модели тональности текста, системы рекомендаций и табличной модели. . Используемые технологии — PyTorch, TorchText, ScikitLearn, Matplot, Numpy. Они действительно раздвигают границы, чтобы сделать новейшие и лучшие алгоритмы доступными для более широкого сообщества, и действительно здорово видеть, как их проект быстро растет в github (в то время Пишу, они уже превзошли более 10к на github для репозитория pytorch-transformer, например).Звезды. «Эта статья является третьей в серии из четырех статей, в которых представлен полный комплексный пример бинарной классификации производственного качества с использованием нейронной сети PyTorch. Ну, на самом деле я просмотрел документацию, и вы действительно можете просто использовать pos_weight. 0 (поддержка ускорения cuda, можно выбрать) Использование. Полная ссылка на документ. Сквозной конвейер для применения моделей ИИ (TensorFlow, PyTorch, OpenVINO и т. Д. Классификация текста CNN с использованием Pytorch; Время присоединиться к сообществу! Поздравляем с завершением этот учебник по записной книжке! Если вам понравилось и вы хотите присоединиться к движению к сохранению конфиденциальности, децентрализованному владению ИИ и цепочкой поставок ИИ (данными), вы можете сделать это следующими способами! Star PySyft на GitHub Узнайте о функциях PyTorch и возможности.Эти архитектуры дополнительно адаптированы для обработки данных разных размеров, форматов и разрешений при применении к нескольким областям в медицинской визуализации, автономном вождении, финансовых услугах и других. Языковая модель Bert и использование PyTorch После первой части, посвященной обзору синтаксисов Keras и PyTorch, это вторая часть о том, как переключаться между Keras и PyTorch. У вас должно быть базовое понимание определения, обучения и оценки моделей нейронных сетей в PyTorch. Если у вас есть проблемы или вопросы, pytorch_model.Структура кода. Для мультиклассовой классификации существует расширение этой логистической функции, называемое функцией softmax, которое используется в полиномиальной логистической регрессии. Этот токенизатор выполняет базовую очистку, а затем разбивает текст на пробелы и знаки препинания. В этом посте мы реализуем модель, аналогичную сверточным нейронным сетям Ким Юна для классификации предложений. Далее будет объяснена функция softmax и способы ее получения. json) и создает модель PyTorch для этой конфигурации, загружает веса из контрольной точки TensorFlow в модель PyTorch и сохраняет полученную модель в стандартном файле сохранения PyTorch, который может быть Image Source: Fast R-CNN paper by Ross Girshich 2.py # Создать подборщик данных для кодирования текста и меток в числа. Вы научите бинарный классификатор выполнять анализ тональности набора данных IMDB. Логотип PyTorch. Доступ Узнайте о функциях и возможностях PyTorch. Довольно часто мы можем столкнуться с набором текстовых данных, которые мы хотели бы классифицировать по некоторым параметрам. Реализация набора данных Pytorch для NUS-WIDE является стандартной и очень похожа на любую реализацию набора данных для набора данных классификации. Весь код можно найти в общем репозитории Github ниже.В этой статье мы перейдем к некоторым практическим примерам использования предварительно обученных сетей, которые присутствуют в модуле TorchVision для классификации изображений. Благодаря команде чрезвычайно преданных своему делу и качественных лекторов, github для классификации текста cnn станет не только местом для обмена знаниями, но и поможет студентам вдохновиться исследовать и открыть для себя многие Введение в PyTorch: узнайте, как создавать нейронные сети в PyTorch и использовать предварительные версии. обученные сети для современных классификаторов изображений. Ссылка на проект прогнозирования кредитного дефолта (Scikit-Learn).Как правило, в CN N набор изображений сначала умножается на ядро свертки в режиме скользящего окна, а затем выполняется объединение свернутых выходных данных, а затем изображение выравнивается и передается на линейный слой для 4. Это представляет собой сложный набор данных с хорошим разнообразием, содержащий плоский текст, выпуклый текст, текст при плохом освещении, удаленный текст, частично скрытый текст и т. д. Эта реализация находится в стадии разработки. GitHub Gist: мгновенно делитесь кодом, заметками и фрагментами.Благодаря… print («Этот текст принадлежит классу% s»% DBpedia_label [предсказать (ex_text_str3, model, vocab, 2)]) Таким образом, мы реализовали мультиклассовую классификацию текста с помощью TorchText. Позже модели можно уменьшить в размерах, чтобы они поместились даже на мобильных устройствах. Библиотека для глубокого изучения графиков. Текстовые данные: текстовые данные могут использоваться для различных задач обработки естественного языка, таких как классификация обзоров фильмов, обнаружение фальшивых новостей, обобщение, ответы на вопросы, обнаружение тем, обобщение стенограммы и обнаружение элементов действий из электронных писем и т. Д.Поскольку размер изображений в наборе данных CIFAR составляет 32×32, популярные сетевые структуры для ImageNet нуждаются в некоторых модификациях для адаптации этого входного размера. 5k участников сообщества pytorch. static: модель с предварительно обученными векторами из word2vec. форму придает факел. Мы предоставляем в этом пакете код, а также данные для проведения эксперимента с использованием 2% маркированного материала (109 примеров) и 5343 немаркированного материала. Не полностью переведен, только для одноклассников, которые читают по-английски, английский язык подходит для просмотра исходного текста. прямо в CLOAB.Клонирование голоса в реальном времени: d-вектор: Python и PyTorch: Реализация «Переноса обучения от проверки динамика на синтез речи с несколькими динамиками» (SV2TTS) с вокодером, который работает в pytorch-pfn-extras (ppe) pytorch- Модуль pfn-extras Python (называемый PPE или «ppe» (имя модуля) в этом документе) предоставляет различные дополнительные компоненты для PyTorch, включая API, подобные Chainer, e. Модули Extensions, Reporter, Lazy (автоматически определяют форму параметров). Пошаговое руководство по использованию моделей трансформаторов для задач классификации текста.Сообщение Reddit №1 о СИРЕНЕ. Сообщество. Изучение векторов для конкретных задач с помощью тонкой настройки дает дополнительный выигрыш в производительности. PyTorch — это библиотека на основе Python, которая обеспечивает гибкость в качестве платформы разработки для глубокого обучения. Мы дополнительно github. Также я не уверен, что правильно выполняю предварительную обработку. Классификация текста с помощью библиотеки torchtext Набор примеров pytorch в Vision, Text, Reinforcement Learning и т. Д. Этот набор данных состоит из твитов. deepspeech3: Реализация DeepSpeech3 с использованием Baidu Warp-CTC.7, torchvision 0. Доктор. Итак, нам нужно установить его в чистое состояние, прежде чем использовать. Разработчики SpaCy назвали spaCy самой быстрой системой в системе. После того, как вы установили Pytorch, просто используйте: pip install pytorch_tabular [all], чтобы установить полную библиотеку с дополнительными зависимостями. Мы предлагаем тонкую настройку универсальной языковой модели (ULMFiT), эффективный метод трансферного обучения, который может быть применен к любой задаче в НЛП, и представляем методы, которые являются ключевыми для точной настройки языковой модели. Этот токенизатор выполняет базовую очистку, а затем разбивает текст на пробелы и знаки препинания.Инструменты классификации текста с Python. 24, с Python 3. PyTorch Text — это пакет PyTorch с набором утилит для обработки текстовых данных, он позволяет выполнять базовые задачи НЛП в PyTorch. TensorFlow — это библиотека машинного интеллекта с открытым исходным кодом для численных вычислений с использованием нейронных сетей. a-PyTorch-Tutorial-to-Text-Classification. 4 Более быстрый детектор объектов R-CNN. PyTorch Реализация CNN для классификации текста. Фреймворк PyTorch для исследований и разработок в области глубокого обучения. текст-классификация tensorflow rnn-tensorflow siamese-network textcnn textrnn cnn-text-Classification tensorflow-text-classifiers Обновлено 6 марта 2018 г. Python Введение в PyTorch: узнайте, как создавать нейронные сети в PyTorch и использовать предварительно обученные сети для проверки состояния -художественные классификаторы изображений.Этот проект частично основан на работе Castorini на https: // github. Мы показываем, что простая CNN с небольшой настройкой гиперпараметров и статическими векторами дает отличные результаты на нескольких тестах. Теперь мы почти готовы настроить класс набора данных для предварительного обучения BERT. Место для обсуждения кода PyTorch, проблем, установки, исследования. Аннотация: Это руководство призвано дать читателям полное представление о выпадении, которое включает в себя реализацию выпадения (в PyTorch), как использовать выпадение и почему это полезно.Рекуррентные нейронные сети в основном используются в PyTorch для машинного перевода, классификации, генерации текста, тегов и других задач НЛП. Слой TextVectorization. md, чтобы продемонстрировать производительность модели. Прервите цикл — используйте катализатор! Узнайте больше о нашем видении в Манифесте проекта. 5%), обнаружение символов (AP 70. Классификация текста (a. Мы увидим, как мы можем использовать языковую модель XLNet для задачи классификации текста. Target, ‘text’: dataset. задача машинного обучения / глубокого обучения, в которой мы классифицируем изображения на основе помеченных людьми данных определенных классов.грамм. Найдите объяснение на tourdeml. 6 cuda: 8. df = pd. randn (28, 28), факел. Модель определяется в файле конфигурации, в котором объявляется несколько важных разделов. 204 тыс. Участников сообщества Learnmachinelearning. shape (11314, 2) Мы преобразуем это в задачу двоичной классификации, выбрав только 2 из 20 меток, присутствующих в наборе данных. Автор: HuggingFace Team. py PyTorch Metric Learning¶ Примеры Google Colab¶. Применение. ) Текст (классификация, генерация и т. Д.). Чтобы реализовать это, мне нужно создать ввод данных как 3D, а не как 2D в предыдущих двух сообщениях.Классификация текста Char Cnn Pytorch. https: // github. Преимущества PyTorch: 1) простая библиотека, 2) динамический вычислительный граф, 3) лучшая производительность, 4) собственный Python; PyTorch использует Tensor для каждой переменной, аналогично ndarray numpy, но с поддержкой вычислений GPU. com PyTorch-Transformers. Предполагается базовое знание PyTorch, рекуррентных нейронных сетей. Мы начнем с реализации многослойного перцептрона (MLP), а затем перейдем к архитектурам, использующим сверточные нейронные сети (CNN).Затем мы пишем класс для выполнения классификации текста для любого набора данных из теста GLUE Benchmark. метка — целое число. PyTorch-Transformers (ранее известная как pytorch-pretrained-bert) — это библиотека современных предварительно обученных моделей для обработки естественного языка (NLP). С командой чрезвычайно преданных своему делу и качественных лекторов классификация текста pytorch станет не только местом для обмена знаниями, но и поможет студентам вдохновиться исследовать и открывать для себя множество творческих тегов: cnn pytorch, CNN, сверточные нейронные сети, Классификация изображений, NumPy , python, pytorch, tensors Следующая статья Добавьте блеска в свое резюме по науке о данных с помощью этих 8 амбициозных проектов на GitHub Одно из мест, где полиномиальный наивный байесовский метод часто используется, — это классификация текста, где функции связаны с количеством слов или частотой в быть классифицированным.