
Разбор предложения по частям речи онлайн
Для начала разберемся с терминологией: для предложения существует только синтаксический разбор. В этом разборе указывается подлежащее, сказуемое и другие члены предложения. Указать часть речи можно только для слова. Тем не менее, в синтаксический разбор предложения часто входит задача указать часть речи для каждого слова. И есть сервисы, где можно ввести либо предложение целиком, либо по одному слову. И они дают вам информацию по частям речи для каждого слова.
Goldlit
В этом сервисе можно ввести предложение целиком и получить морфологический разбор каждого слова. В который, конечно же, входит и часть речи. Например:
 Разбор Goldlit
Разбор GoldlitКак видите, обнаруженное слово ставится в начальную форму и для него указывается:
- Начальная форма.
- Часть речи.
- Грамматика – что тут указывается зависит от части речи.
- Формы слова.
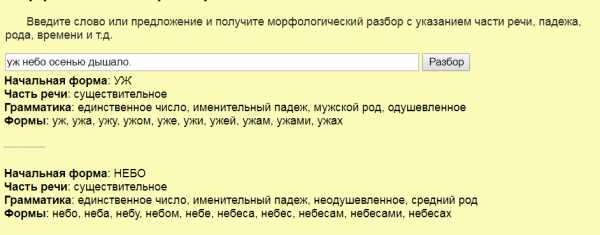
Возьмем другой пример, повествовательное предложение «Времени нет».
Что скажет нам Goldlit?
Начальная форма: ВРЕМЕНИТЬ
Часть речи: глагол в личной форме
Грамматика: второе лицо, действительный залог, единственное число, переходный, несовершенный вид, повелительное наклонение (императив)
То есть слово «времени» он понял как глагол «повремени». Что явно неправда. Дальше правда указывается второе значение:
Начальная форма: ВРЕМЯ
Часть речи: существительное
Грамматика: единственное число, неодушевленное, родительный падеж, средний род
Формы: время, времени, временем, времена, времён, временам, временами, временах
Это уже правильно, существительное. В общем будьте внимательны при использовании подобных сервисов.
Чтобы воспользоваться сервисом:
- Перейдите по адресу http://goldlit.ru/component/slog
- Введите предложение.
- Вы получите морфологический разбор каждого слова.
Викислово
Здесь вы можете указать только одно слово. При этом дополнительно вам скажут, каким членом предложения может быть это слово. Либо один вариант, либо, если их несколько, то так и пишут. Разбор слова «времени» выглядит примерно так же:

А вот разбор слова «добавив». Тут уже однозначно указан член предложения. Это обстоятельство. Потому что деепричастия всегда являются обстоятельствами.
Разбор слова в ВикисловоMorphologyonline
Этот сервис мне нравится даже больше: дизайн чище, рекламы меньше, работает не хуже.
Чтобы воспользоваться:
- Перейдите на сайт http://morphologyonline.ru/
- Введите слово в пустое поле.
- Щелкните кнопку «Разобрать».
Вы получите разбор:
 Разбор слова в Morphologyonline
Разбор слова в MorphologyonlineЗдесь третьей строкой идет «Синтаксическая роль». Это то же самое, что «Член предложения» в сервисе Викислово.
А второй строкой идут «Морфологические признаки», которые в первом сервисы обозначены как «Грамматика». Тут они прописаны лучше, так как разделены на постоянные и непостоянные. Имеется в виду, что в зависимости от формы слова, какие-то признаки могут меняться, а какие-то нет. Например, существительное «время» всегда нарицательное, неодушевленное, среднего рода и 2 склонения. Это постоянные признаки. А падеж и число могут меняться в зависимости от формы слова: «нет времени», «дай время», «с давних времен». Тут родительный, дательный, снова родительный падеж. И единственное, снова единственное и множественное число. Какую форму слова «время» употребишь, такой падеж и число и будет. Потому это непостоянные признаки.
Морфологический vs Морфемный
Морфологический разбор слова следует отличать от морфемного. В морфемный разбор слова входит определение корня, суффикса, окончания, основы слова. Для морфемного разбора тоже есть много сервисов, они описаны тут.
 Морфемный разбор слова
Морфемный разбор словаСинтаксический разбор предложения
Если вам надо определить не только части речи всех слов предложения, но и разобрать предложение в целом: по цели высказывания, подчеркнуть члены предложения, то используйте шпаргалки, коих полно в интернете. Кое-где можно даже поупражняться онлайн. Сравнение подобный сервисов у меня тут.
itlang.ru
Разбор предложения по частям речи онлайн
Часто пользователи ищут в Интернете способ разбора предложения по частям речи онлайн. Это необходимо не только школьникам при подготовке домашнего задания, но и людям, учащимся в университетах филологии и лингвистике. А также всем, кому каждый день приходится работать с текстом. Чтобы сделать синтаксический разбор предложения человек должен обладать необходимыми знаниями в этой области. Чтобы облегчить этот процесс можно обратиться к специальным онлайн сервисам. Ниже мы разберем несколько лучших сайтов по автоматическому разбору предложения на части речи.
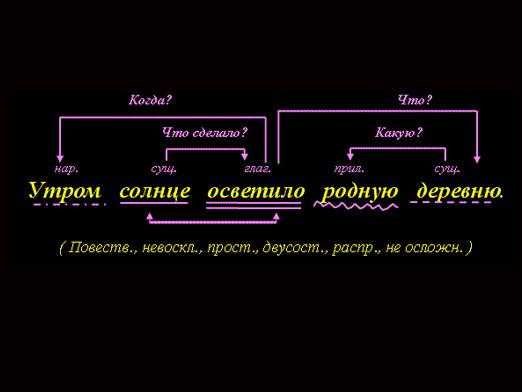 Пример анализа предложения
Пример анализа предложенияСодержание статьи:
Общие правила разбора предложения на части речи
Такой разбор в начальных и средних школах принято называть «разбор по членам предложения». Иногда говорят «разбор предложения по составу», но это выражение несколько некорректно, потому как по составу принято разбирать слова.
Чтобы сделать синтаксический разбор предложения:
Наличие синтаксических конструкций предложения, его параметров, а также богатство вариантов конструирования создают для разработчиков приложения большие преграды при создании оналйн сервиса по разбору предложения. Поэтому таких сервисов в сети не так уж и много. Но они все же есть.
Goldlit – сервис морфологического и синтаксического разбора предложения
Очень удобный сервис Goldlit. Простой дизайн и понятный интерфейс делают сайт доступным людям, с разным уровнем знания компьютера. В верхней строчке меню находятся 3 пункта с выпадающим списком.
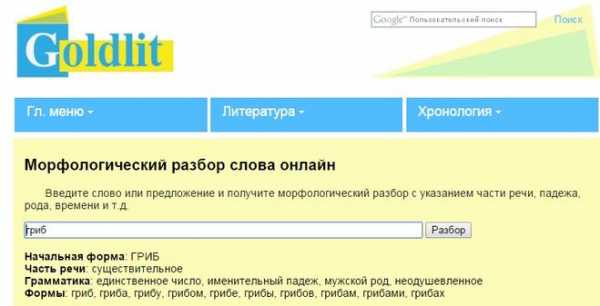 Онлайн сервис — goldlit.ru
Онлайн сервис — goldlit.ru- Главное меню – список из главных разделов сайта.
- Литература – в выпадающем меню список русской и зарубежной литературы, а также разбор стихотворений – что в них хочет сказать поэт.
- Хронология – литература, распложенная по столетиям.
Чтобы воспользоваться разбором предложения по частям речи на сервисе goldlit.ru:
- Перейдите на сайт — http://goldlit.ru/.
- Под меню находится строчка, в которую нужно ввести текст для разбора.
- Рядом с окном ввода текста находится кнопка «Разбор».
Сразу под строкой ввода текста, в желтом поле идут подряд вниз блоки с разбором. Каждый блок – это одно слово из предложения. Чередуются они в таком же порядке, как и чередуются слова в предложении. Части блока:
- Слово, которое стоит в начальной форме.
- Второй строкой выступает часть речи, которым является слово.
- Грамматика. Пишутся через запятую число, качество, одушевленная форма, род и т.д.
- Формы. Все существующие формы слова (с приставками, суффиксами, оконачаниями).
Seosin – сайт, который имеет сервис разбора предложения по частям речи
Один из известных ресурсов в Интернете, который предоставляет инструмент для синтаксического и морфологического разбора предложения в режиме онлайн. Помимо этого сайт предлагает и другие сервисы по работе с текстом, например – синонимайзер. А также по работе с другими файлами, такими как изображения и фотография. Сайт периодически имеет проблемы с доступом, хотя администратор пишет в объявлениях на сайте, что ситуация с сервером была исправлена. Поле ввода текста для анализа в seosin.ru
Поле ввода текста для анализа в seosin.ruЧтобы проверить текст в сервисе:
- Перейдите по этой ссылке – http://www.seosin.ru/.
- Введите текст для анализа в поле сервиса.
- Нажмите кнопку «Анализировать».
Через несколько секунд вам будет предоставлен разбор вашего текста с пояснениями.
Другие сайты и по разбору предложений по частям речи
Помимо автоматических сервисов онлайн существую также специальные сайты, на которых предоставляется вся необходимая информация, которая потребуется для синтаксического и морфологического разбора предложения. Одним из таких сайтов есть – сентябрята.рф. Для школьников он будет незаменим. Что касается русского языка, здесь вы найдете разделы:
- Слово – основные правописания слов с предлогами, частицами, перенос слов и т.д (онлайн проверка правописания).
- Вместе или раздельно – прилагательных, существительных, союзы, междометия.
- Безударные частицы «Не» и «Ни»
- Правила написания согласных – двойных «нн», «жж».
- Согласные, которые пишутся за шипящими – «ж, ч, ш, щ».
- Правописание гласных.
- Безударные главсные.
- Буквы «ь» и «ъ».
- Предложение.
- Аббревиатуры.
- Прописные буквы.
it-doc.info
Определение части речи слов в русском тексте (POS-tagging) на Python 3 / Хабр
Пусть, дано предложение “Съешьте еще этих мягких французских булок, да выпейте чаю.”, в котором нам нужно определить часть речи для каждого слова:[('съешьте', 'глаг.'), ('еще', 'нареч.'), ('этих', 'местоим. прил.'), ('мягких', 'прил.'), ('французских', 'прил.'), ('булок', 'сущ.'), ('да', 'союз'), ('выпейте', 'глаг.'), ('чаю', 'сущ.')]
Зачем это нужно? Например, для автоматического определения тегов для блог-поста (для отбора существительных). Морфологическая разметка является одним из первых этапов компьютерного анализа текста.
Существующие решения
Конечно, все уже придумано до нас. Существует mystem от Яндекса, TreeTagger с поддержкой русского языка, на питоне есть nltk, а также pymorphy от kmike. Все эти утилиты отлично работают, правда, у pymorphy нет поддержки питона 3, а у nltk поддержка третей версии питона только в бете (и там вечно что-то отваливается). Но реальная цель для создания модуля — академическая, понять как работает морфологический анализатор.
Алгоритм
Для начала разберемся, как обычный человек определяет к какой части речи относится слово.
- Обычно мы знаем к какой части речи относится знакомое нам слово. Например, мы знаем, что “съешьте” — это глагол.
- Если нам встречается слово, которое мы не знаем, то мы можем угадать часть речи, сравнивая с уже знакомыми словами. Например, мы можем догадаться, что слово “конгруэнтность” — это существительное, т.е. имеет окончание “-ость”, присущее обычно существительным.
- Мы также можем догадаться какая это часть речи, проследив за цепочкой слов в предложении: “
- Длина слова также может дать полезную информацию. Если слово состоит всего лишь из одной или двух букв, то скорее всего это предлог, местоимение или союз.
Конечно, для компьютера эта задача будет несколько сложнее, т.к. у него нет той базы знаний, которой обладает человек. Но мы постараемся смоделировать обучение компьютера, используя доступные нам данные.
Данные
Для обучения нашего скрипта я использовал национальный корпус русского языка. Часть корпуса, СинТагРус, представляет собой коллекцию текстов с размеченной информацией для каждого слова, такой как, часть речи, число, падеж, время глагола и т.д. Так выглядит часть корпуса в XML формате:
<se>
<w><ana lex="между" gr="PR"></ana>М`ежду</w>
<w><ana lex="то" gr="S-PRO,n,sg=ins"></ana>тем</w>
<w><ana lex="конкурент" gr="S,m,anim=pl,nom"></ana>конкур`енты</w>
<w><ana lex="наступать" gr="V,ipf,intr,act=pl,praes,3p,indic"></ana>наступ`ают</w>
<w><ana lex="на" gr="PR"></ana>на</w>
<w><ana lex="пятка" gr="S,f,inan=pl,acc"></ana>п`ятки</w> .
</se>
<se>
<w><ana lex="вот" gr="PART"></ana>Вот</w>
<w><ana lex="так" gr="ADV-PRO"></ana>так</w>,
<w><ana lex="за" gr="PR"></ana>з`а</w>
<w><ana lex="пять" gr="NUM=acc"></ana>пять</w>
<w><ana lex="минута" gr="S,f,inan=pl,gen"></ana>мин`ут</w>
<w><ana lex="до" gr="PR"></ana>до</w>
<w><ana lex="съемка" gr="S,f,inan=pl,gen"></ana>съёмок</w> ,
<w><ana lex="родиться" gr="V,pf,intr,med=m,sg,praet,indic"></ana>род`илс`я</w>
<w><ana lex="новый" gr="A=m,sg,nom,plen"></ana>н`овый</w>
<w><ana lex="персонаж" gr="S,m,anim=sg,nom"></ana>персон`аж</w> .
</se>
Предложения заключены в теги <se>, внутри которых расположены слова в теге <w>. Информация о каждом слове содержится в теге <ana>, аттрибут lex соответствует лексеме, gr — грамматические категории. Первая категория — это часть речи:
'S': 'сущ.',
'A': 'прил.',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.'
SVM
В качестве алгоритма обучения я выбрал метод опорных векторов (SVM). Если вы не знакомы с SVM или алгоритмами машинного обучения в общем, то представьте, что SVM это некий черный ящик, который принимает на вход характеристики данных, а на выходе классификацию по заранее заданным категориям. В качестве характеристик мы зададим, например, окончание слова, а в качестве категорий — части речи.

Чтобы черный ящик автоматически распознавал часть речи, для начала его нужно обучить, т.е. дать много характеристик примеров на вход, и соответствующие им части речи на выход. SVM построит модель, которая при достаточных данных будет в большинстве случаев корректно определять часть речи.
Даже в академических целях реализовать SVM лень, поэтому воспользуемся готовой библиотекой LIBLINEAR на С++, которая имеет обертку для питона. Для обучения модели используем функцию train(prob, param), которая принимает в качестве первого аргумента задачу: problem(y, x), где y — это массив частей речи для каждого примера из массива x. Каждый пример представлен в свою очередь вектором характеристик. Чтобы добиться такой постановки задачи, нам нужно сначала соотнести каждую часть речи и каждую характеристику с неким числовым номером. Например:
'''
съешьте - глагол
выпейте - глагол
чаю - сущ.
'''
x = [{1001: 1, 2001: 1, 3001: 1}, # 1001 - съешьте, 2001 - ьте, 3001 - те
{1002: 1, 2002: 1, 3001: 1}, # 1002 - выпейте, 2002 - йте, 3001 - те
{1003: 1, 2003: 1, 3002: 1}] # 1003 - чаю, 2003 - чаю, 3002 - аю
y = [1, 1, 2] # 1 - глагол, 2 - сущ.
import liblinearutil as svm
problem = svm.problem(y, x) # создаем задачу
param = svm.parameter('-c 1 -s 4') # параметры обучения
model = svm.train(prob, param) # обучаем модель
# используем модель для распознания слова 'съешьте'
label, acc, vals = svm.predict([0], {1001: 1, 2001: 1, 3001: 1}, model, '') # [0] - обозначает, что часть речи нам неизвестна
В итоге наш алгоритм такой:
- Читаем файл корпуса и для каждого слова определяем его характеристики: само слово, окончание (2 и 3 последних буквы), приставка (2 и 3 первые буквы), а также части речи предыдущих слов
- Каждой части речи и характеристике присваиваем порядковый номер и создаем задачу для обучения SVM
- Обучаем модель SVM
- Используем обученную модель для определения части речи слов в предложении: для этого каждое слово нужно опять представить в виде характеристик и подать на вход SVM модели, которая подберет наиболее подходящий класс, т.е. часть речи.
Реализация
С исходными кодами можете ознакомиться здесь: github.com/irokez/Pyrus/tree/master/src
Корпус
Для начала нужно получить размеченный корпус. Национальный корпус русского языка распространяется очень загадочным образом. На самом сайте корпуса можно только производить поиск по текстам, но при этом скачать целиком корпус нельзя:
“Оффлайновая версия корпуса недоступна, однако для свободного пользования предоставляется случайная выборка предложений (с нарушенным порядком) из корпуса со снятой омонимией объёмом 180 тыс. словоупотреблений (90 тыс. – пресса, по 30 тыс. из художественных текстов, законодательства и научных текстов)”.При этом в википедии написано
“The corpus will be made available off-line and distributed for non-commercial purposes, but currently due to some technical and/or copyright problems it is accessible only on-line.”
Хотя для наших целей пойдет и небольшая выборка из корпуса, доступная тут: www.ruscorpora.ru/download/shuffled_rnc.zip
Файлы в полученном архиве нужно пропустить через утилиту convert-rnc.py, которая переводит текст в UTF-8 и исправляет XML разметку. После этого, возможно, еще нужно пофиксить XML вручную (xmllint вам в помощь). Файл rnc.py содержит простой класс Reader для чтения нормализованных XML файлов нац. корпуса.
import xml.parsers.expat
class Reader:
def __init__(self):
self._parser = xml.parsers.expat.ParserCreate()
self._parser.StartElementHandler = self.start_element
self._parser.EndElementHandler = self.end_element
self._parser.CharacterDataHandler = self.char_data
def start_element(self, name, attr):
if name == 'ana':
self._info = attr
def end_element(self, name):
if name == 'se':
self._sentences.append(self._sentence)
self._sentence = []
elif name == 'w':
self._sentence.append((self._cdata, self._info))
elif name == 'ana':
self._cdata = ''
def char_data(self, content):
self._cdata += content
def read(self, filename):
f = open(filename)
content = f.read()
f.close()
self._sentences = []
self._sentence = []
self._cdata = ''
self._info = ''
self._parser.Parse(content)
return self._sentences
Метод Reader.read(self, filename) читает файл и выдает список предложений:
[[('Вод`итель', {'lex': 'водитель', 'gr': 'S,m,anim=sg,nom'}), ('дес`ятки', {'lex': 'десятка', 'gr': 'S,f,inan=sg,gen'}), ('кот`орую', {'lex': 'который', 'gr': 'A-PRO=f,sg,acc'}), ('прест`упники', {'lex': 'преступник', 'gr': 'S,m,anim=pl,nom'}), ('пойм`али', {'lex': 'поймать', 'gr': 'V,pf,tran=pl,act,praet,indic'}), ('у', {'lex': 'у', 'gr': 'PR'}), ('ВВЦ', {'lex': 'ВВЦ', 'gr': 'S,m,inan,0=sg,gen'}), ('оказ`ал', {'lex': 'оказать', 'gr': 'V,pf,tran=m,sg,act,praet,indic'}), ('им', {'lex': 'они', 'gr': 'S-PRO,pl,3p=dat'}), ('`яростное', {'lex': 'яростный', 'gr': 'A=n,sg,acc,inan,plen'}), ('сопротивл`ение', {'lex': 'сопротивление', 'gr': 'S,n,inan=sg,acc'}), ('за', {'lex': 'за', 'gr': 'PR'}), ('что', {'lex': 'что', 'gr': 'S-PRO,n,sg=acc'}), ('поплат`ился', {'lex': 'поплатиться', 'gr': 'V,pf,intr,med=m,sg,praet,indic'}), ('ж`изнью', {'lex': 'жизнь', 'gr': 'S,f,inan=sg,ins'})]]
Обучение и разметка текста
Библиотеку SVM можно скачать тут: http://www.csie.ntu.edu.tw/~cjlin/liblinear/. Чтобы обертка под питон заработала под 3-й версией я написал небольшой патч.
Файл pos.py содержит два основных класса: Tagger и TaggerFeatures. Tagger — это, собственно, класс, который осуществляет разметку текста, т.е. определяет для каждого слова его часть речи. Метод Tagger.train(self, sentences, labels) принимает в качестве аргументов список предложений (в том же формате, что и выдает rnc.Reader.read), а также список частей речи для каждого слова, после чего обучает SVM модель, используя библиотеку LIBLINEAR. Обученная модель впоследствии сохраняется (через метод Tagger.save), чтобы не обучать модель каждый раз. Метод Tagger.label(self, sentence) производит разметку предложения.
Класс TaggerFeatures предназначен для генерации характеристик для обучения и разметки. TaggerFeatures.from_body() возвращает характеристику по форме слова, т.е. возвращает ID слова в корпусе. TaggerFeatures.from_suffix() и TaggerFeatures.from_prefix() генерируют характеристики по окончанию и приставке слов.
Чтобы запустить обучение модели, был написан скрипт train.py, который читает файлы корпуса при помощи rnc.Reader, а затем вызывает метод Tagger.train:
import sys
import re
import rnc
import pos
sentences = []
sentences.extend(rnc.Reader().read('tmp/media1.xml'))
sentences.extend(rnc.Reader().read('tmp/media2.xml'))
sentences.extend(rnc.Reader().read('tmp/media3.xml'))
re_pos = re.compile('([\w-]+)(?:[^\w-]|$)'.format('|'.join(pos.tagset)))
tagger = pos.Tagger()
sentence_labels = []
sentence_words = []
for sentence in sentences:
labels = []
words = []
for word in sentence:
gr = word[1]['gr']
m = re_pos.match(gr)
if not m:
print(gr, file = sys.stderr)
pos = m.group(1)
if pos == 'ANUM':
pos = 'A-NUM'
label = tagger.get_label_id(pos)
if not label:
print(gr, file = sys.stderr)
labels.append(label)
body = word[0].replace('`', '')
words.append(body)
sentence_labels.append(labels)
sentence_words.append(words)
tagger.train(sentence_words, sentence_labels, True)
tagger.train(sentence_words, sentence_labels)
tagger.save('tmp/svm.model', 'tmp/ids.pickle')
После того, как модель обучена и сохранена, мы, наконец, получили скрипт для разметки текста. Пример использования показан в test.py:
import sys
import pos
sentence = sys.argv[1].split(' ')
tagger = pos.Tagger()
tagger.load('tmp/svm.model', 'tmp/ids.pickle')
rus = {
'S': 'сущ.',
'A': 'прил.',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.',
'INIT': 'инит',
'NONLEX': 'нонлекс'
}
tagged = []
for word, label in tagger.label(sentence):
tagged.append((word, rus[tagger.get_label(label)]))
print(tagged)
Работает так:$ src/test.py "Съешьте еще этих мягких французских булок, да выпейте же чаю"
[('Съешьте', 'глаг.'), ('еще', 'нареч.'), ('этих', 'местоим. прил.'), ('мягких', 'прил.'), ('французских', 'прил.'), ('булок,', 'сущ.'), ('да', 'союз'), ('выпейте', 'глаг.'), ('же', 'частица'), ('чаю', 'сущ.')]
Тестирование
Для оценки точности классификации работы алгоритма, метод обучения Tagger.train() имеет необязательного параметр cross_validation, который, если установлен как True, выполнит перекрестную проверку, т.е. данные обучения разбиваются на K частей, после чего каждая часть по очереди используется для оценки работы метода, в то время как остальная часть используется для обучения. Мне удалось добиться средней точности в 92%, что вполне неплохо, учитывая, что была использована лишь доступная часть нац. корпуса. Обычно точность разметки части речи колеблется в пределах 96-98%.
Заключение и планы на будущее
В общем, было интересно поработать с нац. корпусом. Видно, что работа над ним проделана большая, и в нем содержится большое количество информации, которую хотелось бы использовать в полной мере. Я послал запрос на получение полной версии, но ответа пока, к сожалению, нет.
Полученный скрипт разметки можно легко расширить, чтобы он также определял другие морфологические категории, например, число, род, падеж и др. Чем я и займусь в дальнейшем. В перспективе хотелось бы, конечно, написать синтаксический парсер русского языка, чтобы получить структуру предложения, но для этого нужна полная версия корпуса.
Буду рад ответить на вопросы и предложения.
Исходный код доступен здесь: github.com/irokez/Pyrus
Демо: http://vps11096.ovh.net:8080
habr.com
ПРОНОСИВШЕЙСЯ ЧАСТЬ РЕЧИ: Полный справочник для подготовки к ГИА читать онлайн бесплатно, автор М
Глагол – часть речи, обозначающая действие или состояние и отвечающая на вопросы: что делать? 6. Укажите, в каком ряду все прилагательные являются относительными. Союз – это служебная часть речи, которая служит для связи однородных членов предложения и простых предложений в составе сложного.
Отличается от причастия тем, что не имеет признаков залога, вида и времени. Наука о частях речи, морфология, – один из сложнейших разделов языкознания. Однако если отличить существительное от глагола бывает несложно, то с другими частями речи возникает множество вопросов.
Служебные части речи и междометие
Сервис онлайн определения частей речи поможет вам выпутаться из этого затруднительного положения. Точность. Вы можете полагаться на результаты онлайн определения частей речи. Эта программа вас не подведет. Простота. Вы получаете четкий ответ на поставленный вопрос: только часть речи, ничего лишнего. К 1-ому склонению относятся существительные ж.р. и м.р. с окончаниями а (-я) (книга).
Числительное – это часть речи, которая обозначает количество или порядок предметов при счете и отвечает на вопросы сколько? В изъявительном наклонении глаголы несовершенного вида имеют три времени: настоящее, прошедшее и будущее.
Одни лингвисты (В.В. Бабайцева) относят их к самостоятельным частям речи, так как они имеют ряд признаков, не свойственных глаголам, большинство же рассматривает их как особые формы глаголов. Причастие – это особая форма глагола, которая обозначает признак предмета по действию и отвечает на вопрос какой? Над бушующим (каким?
Грамматика. Морфология (В2-В4)
Наречие – часть речи, которая обозначает признак действия, предмета или другого признака (спорить горячо, говорить много, жить близко, не разобрать сослепу). К служебным частям речи относят предлоги, союзы, частицы.
Морфологические категории глагола различаются по составу охватываемых ими форм. Категории вида и залога присущи всем формам глагола, включая причастия и деепричастия
Предлог – это служебная часть речи, которая выражает зависимость существительного, прилагательного, местоимения от других слов в словосочетании и предложении. 7. Укажите предложения, в которых ПРИТОМ является союзом. Слова со столь различными лексическими значениями группируются в единую часть речи на основании общего для всех глаголов признака – категориального значения процессуальности.
Категория родасвойственна в единственном числе лишь формам прошедшего времени и сослагательного наклонения, а также причастиям. В учебнике «Русский язык» под ред. Л. Ю. Максимова (М., 19870) -чьквалифицируется как часть корня и суффикс, т. е. налицо наложение. 3. Современный русский язык. В 3-х ч. /Под ред. Н.М.Шанского.
Причастие – неспрягаемая глагольная форма, обозначающая действие или состояние как такой признак предмета, который может изменяться во времени. Деепричастие – неизменяемая форма глагола, обозначающая действие как признак другого действия, например: говорил, глядя в глаза; обессилев, присел на скамью. Связка – это оторвавшееся от парадигмы местоимения или глагола служебное слово. В его функции входит указание на синтаксические отношения между компонентами предложения.
Ну-ка, вы определите сходу, какой частью речи является слово в течение? Сделать это подчас сложно и дипломированным филологам. Несклоняемые существительные имеют для всех падежей одну и ту же форму (жюри). Каждый глагол имеет начальную форму, которая называется инфинитивом. Инфинитив – это неизменяемая форма глагола, которая отвечает на вопросы что делать?
Морфологические признаки глагола могут быть постоянными и непостоянными. Переходные глаголы – это глаголы, которые сочетаются с существительным или местоимением в В.п. без предлога (любить (что?) фрукты).
Спряжением глагола называется его изменение по лицам и числам. В русском языке таких глаголов – 4: хотеть, есть, дать, бежать. Глаголы в условном наклонении обозначают действия, желаемые или возможные при определенных условиях. Они образуются от основы начальной формы глагола при помощи суффикса – л и частицы бы (б), которая может стоять перед глаголом, после него или отделяться от глагола словами.
Словаловить и ловля имеют значение действия, но существительное ловля обозначает действие как предмет, а неопределенная форма ловить – как процесс
Глаголы совершенного вида – 2: прошедшее и будущее. Будущее время может быть простым и сложным. Глаголы, которые обозначают действия, совершаемые без действующего лица, называются безличными: Подморозило.
16. Укажите ряды, в которых все числительные количественные
2. Причастия имеют вид совершенный (написавший) и несовершенный (колотый). Наречие не изменяется, то есть не склоняется и не спрягается. 2. Укажите ряды, в которых встречаются только несклоняемые существительные. 10. Укажите, в каком ряду все глаголы относятся ко второму спряжению. 11. Укажите, в каких предложениях встречаются безличные глаголы. 15. Укажите, в каком ряду нет ошибок в образовании причастий и деепричастий. Все они не имеют лексического значения и не являются членами предложения.
Употребление неопределенной формы на–сть вне указанных случаев придает речи характер разговорный и просторечный: Всем домом правила Параша, поручено ей было счеты весть (А. Пушкин)
Все предлоги являются неизменяемыми. При этом понятие действия или состояния трактуется в грамматически обобщенном смысле. В Академической грамматике (1980) рассматриваются 3 класса форм: 1) спрягаемые формы; 2) инфинитив; 3) причастия и деепричастия. Инфинитив и деепричастия представлены одной формой. Спрягаемые формы глагола используются в синтаксической роли простого глагольного сказуемого (Здесь родилась я) и составного глагольного сказуемого (Дети могут спатьспокойно).
Так как причастия и деепричастия выступают в роли второстепенных членов, их называют атрибутивными. Инфинитив (лат. infinitivus– неопределенный) входит в систему глагольных форм, хотя и отличается весьма своеобразной структурой. Инфинитив обозначает действие в самом общем виде, без отнесения его к какому-либо субъекту. Все эти категории несловоизменительны, поэтому инфинитив – неизменяемая форма глагола.
Определение частей речи – чрезвычайно важное и полезное умение. Вопрос о месте причастия и деепричастия в системе частей речи решается неоднозначно.
Читайте также:
zvondrobyndl.ru
Первые шаги – подготовительные задания / Морфологический разбор / Русский на 5
Первые шаги – подготовительные задания
Текст:
Один раз в году бросаю все дела в шумном столичном городе и вырываюсь на природу, поближе к реке, к лесу, лугам, полям. За городом и небо яснее, и воздух чище. Друзья, знающие мои привычки, удивляются: «Куда же тебя несёт? Зачем тебе эта дыра? Ни удобств, ни привычных условий! Ведь ты городской человек!» Эх! Я и сама себя не понимаю, но сделать с собой ничего не могу. Я отвечаю им: «Попробуйте, сделать, как я. Только тогда вы меня поймёте».
Тема: Определение частей речи
Задание 1. Определите части речи в предложении:
Один раз в году бросаю все дела в шумном столичном городе и вырываюсь на природу, поближе к реке, к лесу, лугам, полям.
Ответ:
Один – числительное
раз – существительное
в – предлог
бросаю –глагол
все –местоимение
дела –существительное
в – предлог
шумном, столичном –прилагательные
городе – существительное
и – союз
вырываюсь – глагол
на–предлог
природу – существительное
поближе – наречие
к –предлог
реке , лесу, лугам, полям – существительное
Задание 2. Определите части речи в предложении:
За городом и небо яснее, и воздух чище.
Ответ:
За городом – наречие
и – союз
небо – существительное
яснее – прилагательное
и — союз
воздух – существительное
чище – прилагательное.
Задание 3. Определите части речи в предложениях:
Друзья, знающие мои привычки, удивляются: «Куда же тебя несёт? Зачем тебе эта дыра? Ни удобств, ни привычных условий! Ведь ты городской человек!»
Ответ:
Друзья — существительное
знающие – причастие (в альтернативном толковании: глагол)
мои — местоимение
привычки — существительное
удивляются — глагол
куда -наречие
же — частица
тебя — местоимение
несёт — глагол
зачем — наречие
тебе — местоимение
эта — местоимение
дыра — существительное
ни… ни — союз
удобств — существительное
привычных — прилагательное
условий — существительное
ведь — частица
ты — местоимение
городской — прилагательное
человек — существительное
Задание 4. Определите части речи в предложении:
Эх! Я и сама себя не понимаю, но сделать с собой ничего не могу.
Ответ:
Эх! — междометие
я — местоимение
и – союз
сама — местоимение
себя — местоимение
не -частица
понимаю — глагол
но -союз
сделать — глагол
с — предлог
собой — местоимение
ничего — местоимение
не — частица
могу -глагол
Задание 5. Определите части речи в предложении:
Я отвечаю им: «Попробуйте, сделать, как я. Только тогда вы меня поймёте».
Ответ:
Я — местоимение
отвечаю — глагол
им — местоимение
попробуйте — глагол
сделать -глагол
как -союз
я — местоимение
Только — частица
тогда –наречие
вы — местоимение
меня — местоимение
поймёте — глагол
Тема: Определение начальной формы.
Задание 1. Определите начальную форму (н.ф.) слов в предложении:
Один раз в году бросаю все дела в шумном столичном городе и вырываюсь на природу, поближе к реке, к лесу, лугам, полям.
Ответ:
Один, н.ф. — один
раз, н.ф. — раз
в , н.ф. нет
бросаю, н.ф. – бросать (не: бросить)
все, н.ф. — весь
дела, н.ф. — дело
в , н.ф. нет
шумном, столичном, н.ф. – шумный, столичный
городе, н.ф. — город
и, н.ф. нет
вырываюсь, н.ф. – вырываться (не: вырваться)
на , н.ф. нет
природу, н.ф. — природа
поближе, н.ф. нет
к , н.ф. нет
реке , лесу, лугам, полям, н.ф. – река, лес, лес, поле
Задание 2. Определите начальную форму (н.ф.) слов в предложении:
За городом и небо яснее, и воздух чище.
Ответ:
За городом, н.ф. нет
и , н.ф. нет
небо, н.ф. нет
яснее, н.ф. — ясный
и, н.ф. нет
воздух, н.ф. воздух
чище, н.ф. — чистый
Задание 3. Определите начальную форму (н.ф.) слов в предложении:
Друзья, знающие мои привычки, удивляются: «Куда же тебя несёт? Зачем тебе эта дыра? Ни удобств, ни привычных условий! Ведь ты городской человек!»
Ответ:
Друзья, н.ф. — друг
знающие, н.ф. – знающий (при альтернативном толковании: знать)
мои, н.ф. – мой
привычки, н.ф. — привычка
удивляются, н.ф. –удивляться (не: удивиться, не: удивлять)
куда, н.ф. нет
же, н.ф. нет
тебя, н.ф. — ты
несёт, н.ф. — нести (не: носить)
зачем, н.ф. нет
тебе, н.ф. — ты
эта, н.ф. — этот
дыра, н.ф. — дыра
ни… ни, н.ф. нет
удобств, н.ф. — удобство
привычных, н.ф. — привычный
условий, н.ф. — условие
ведь, н.ф. нет
ты, н.ф. — ты
городской, н.ф. — городской
человек, н.ф. — человек
Задание 4. Определите начальную форму (н.ф.) слов в предложении:
Эх! Я и сама себя не понимаю, но сделать с собой ничего не могу.
Ответ:
Эх! Н.ф. нет
я, н.ф. — я
и, н.ф. нет
сама, н.ф. — сам
себя, н.ф. – себя (формы И.п. у местоимения себя нет)
не, н.ф. нет
понимаю, н.ф. – понимать (не: понять)
но, н.ф. нет
сделать, н.ф. – сделать (не: делать)
с, н.ф. нет
собой, н.ф. – себя (формы И.п. у местоимения себя нет)
ничего, н.ф. — ничто
не, н.ф. нет
могу, н.ф. — мочь
Задание 5. Определите начальную форму (н.ф.) слов в предложении:
Я отвечаю им: «Попробуйте, сделать, как я. Только тогда вы меня поймёте».
Ответ:
Я, н.ф. — я
отвечаю, н.ф. – отвечать (не: ответить)
им, н.ф. — они
попробуйте, н.ф. – попробовать (не: пробовать)
сделать, н.ф. – сделать (не: делать)
как, н.ф. нет
я, н.ф. -я
Только, н.ф. -нет
тогда, н.ф. нет
вы, н.ф. — вы
меня, н.ф. — я
поймёте , н.ф. – понять (не: понимать)
Тема: Определение членов предложения.
Задание 1. Определите члены предложения:
Один раз в году бросаю все дела в шумном столичном городе и вырываюсь на природу, поближе к реке, к лесу, лугам, полям.
Ответ:
Один раз в году бросаю все дела в шумном столичном городе и вырываюсь на природу, поближе к реке, к лесу, лугам, полям.
Задание 2. Определите члены предложения:
За городом и небо яснее, и воздух чище.
Ответ:
За городом и небо яснее, и воздух чище .
Задание 3. Определите члены предложения:
Друзья, знающие мои привычки, удивляются: «Куда же тебя несёт? Зачем тебе эта дыра? Ни удобств, ни привычных условий! Ведь ты городской человек!»
Ответ:
Друзья, знающие мои привычки, удивляются: «Куда же тебя несёт? Зачем: тебе эта дыра? Ни удобств, ни привычных условий! Ведь ты городской человек!»
Задание 4. Определите члены предложения:
Эх! Я и сама себя не понимаю, но сделать с собой ничего не могу.
Ответ:
Эх! Я и сама себя не понимаю, но сделать с собой ничего не могу.
Задание 5. Определите члены предложения:
Я отвечаю им: «Попробуйте, сделать, как я. Только тогда вы меня поймёте».
Ответ:
Я отвечаю им: «Попробуйте сделать, как я. Только тогда вы меня поймёте».
Смотрите также
— Понравилась статья?:)Мой мир
Вконтакте
Одноклассники
Google+
russkiy-na-5.ru
Как определить часть речи в русском языке?
Все слова русского языка можно поделить на определенные классы, которые различаются между собой значением, морфологическими и синтаксическими признаками. В зависимости от значения выделим, например, слова, называющие предметы и отвечающими на вопросы: кто? что? Это существительные. Другие слова обозначают признак предмета и отвечают на вопрос quot;какой?quot; или его принадлежность (чей? братов, мамин, разбойничий). Это прилагательные.
Есть слова, обозначающие действие и отвечающие на вопросы: что делать? что сделать? Это глаголы. Вот так и определяем части речи по их основному значению и вопросу. Сюда подключаются морфологические признаки каждой части речи, которые изучает наука — морфология.
В русском языке существует три группы часей речи: самостоятельные, служебные и междометие. Самостоятельные части речи:
- Имя существительное. Оно отвечает на вопрос ы-кто-что- и обозначает предмет: кошка, дом.
- 2. Имя прилагательное. Оно отвечает на вопросы -какой, какая, какое, какие и обозначает признак предмета: красивый, красивая, красивое, красивые.
- Имя числительное. Оно отвечает на вопросы -сколько, который и обозначает количество или порядковый номер предмета: сорок, сороковой.
- Глагол. Одвечает на вопрос -что делать, что сделать и обозначает действие предмета: прыгать, перепрыгнуть.
- Наречие. Отвечает на вопросы -как, куда, где, откуда и обозначает признак действия: холодно, жарко.
- Местоимение-часть речи, которая указывает на предмет или его признак, не называя его: я, мы, он, вы, себя.
Служебные части речи: предлги(в, на, за от, на), они служат для связи слов в предложении; союзы(а,но,да в значении И. тоже, также и др.), они служат для того, чтобы связывать однородные члены предложения, части предложений. Союзы делят на соединительные, противительные и разделительные; частицы служат для придания оттенка различным словам, словосочетаниям, предложениям:бы, не, ни.
Междометие выступает как отдельная часть речи: Ах! Ох! Ой!. Эх!Ха! Браво! Служит для выражения человеческих эмоций.
Если хорошо знать этот материал, то можно очень просто определить часть речи в русском языке!
Слова, обозначающие предмет и отвечающие на вопросы кто? что?, называются существительными. Например, стол (что?), дерево(что?), мальчик(кто?).
Слова, обозначающие признак предмета и отвечающие на вопросы какой, какая?, какое?,
называются прилагательными. Например, красивый(какой?), большая(какая?),голубое(какое?).
Слова. обозначающие действие, и отвечающие на вопросы что делает, что сделает, называются глаголами. Например, играет(что делает?),побежит(что сделает?),смеются(что делают?).
Чтобы определить, к какой части речи относится слово, надо придумать с ним словосочетание и задать к этому слову вопрос. Например, Лес стоит загадочный.
Лес(кто?) — существительное.
Лес(какой?) — загадочный — прилагательное
Лес(что делает?) стоит — глагол.
Вот таким образом нас раньше обучали в школе определять и различать части речи. Есть и другие части речи, но думаю, об этом сейчас можно прочитать где угодно.
info-4all.ru