
Правописание Н и НН в разных частях речи
Сегодня мы…
· Поговорим о написании одной и двух н в существительных и прилагательных.
· Выясним всё о написании одной и двух букв н в причастиях и наречиях.
· Поговорим о том, что нужно знать для правильного написания одной и двух букв н.
В русском языке есть некоторые правила, которые могут представлять для нас особенные трудности.
Кажется – насколько легко написать слово довере…ость? Но нет, дойдя до первого н мы тут же начинаем раздумывать: а сколько их там всего? И вот, пожалуйста. Перед нами орфограмма, которая кого угодно заставит призадуматься!
Вообще, буквы н в русской орфографии ведут себя довольно вредно.
Эта
орфограмма встречается в разных частях речи. При этом н могут стоять в корне,
суффиксе или на границе корня и суффикса.
Но что же нужно знать для правильного написания одной и двух букв н?
Для начала нужно легко различать части речи. И хорошо бы разбираться в морфемике и словообразовании – тогда никакие орфограммы будут не страшны.
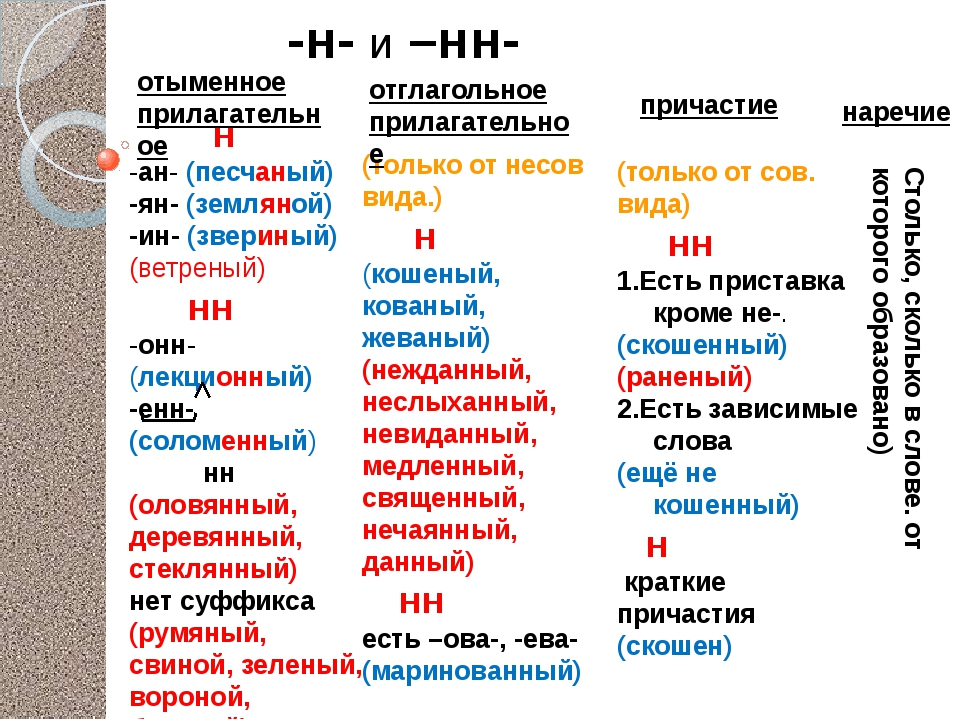
Потому что в первую очередь мы должны определиться – какую часть речи мы видим перед собой. Н и НН мы встречаем в существительных, прилагательных, причастиях и наречиях.
Но прилагательные могут образовываться от имён или от глаголов. Отглагольные прилагательные близки к причастиям, и правило написания для них в чем-то схоже.
А ещё прилагательные и причастия могут иметь краткую форму, и для этих форм существуют особые правила.
Итак, предположим, мы встретились с существительным… Что мы будем делать теперь?
Мы зададимся вторым вопросом – от чего и как образовалось это слово?
Может быть, оно образовалось при помощи суффикса н от слова, в основе которого уже было н?
н
в корне + н в суффиксе – вот и две буквы.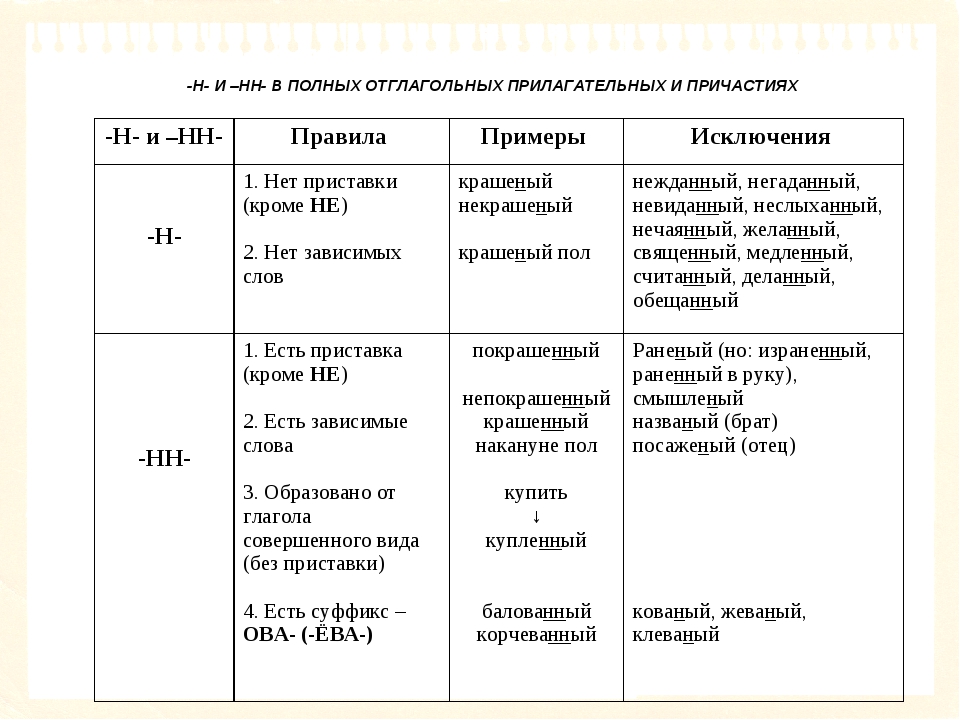
Мы видим это в таких словах, как малинник, конница.
А вот в слове труженик н будет одно. И в слове гостиница тоже. Здесь в корне букв н не наблюдается.
Или же существительное могло образоваться от слова, в котором уже было нн. В таком случае у нас так и остается две буквы.
Слово доверенность образовалось от доверенный, и в обоих словах два н.
А слово пряность образовалось от прилагательного пряный, и в двух словах будет одно н.
Значит, существительное мы напишем через два н, если оно образовалось от слова, где есть н в основе. Или образовано от прилагательного или причастия, где уже есть два н.
А одно н мы напишем, если слово образовано от прилагательного или причастия с одной н.
Постойте-ка.
Но получается, что нам нужно знать – как пишется слово, от которого
образовалось существительное. Но откуда нам знать, как пишется причастие или
прилагательное?
Но откуда нам знать, как пишется причастие или
прилагательное?
А это уже следующая часть правила, к которой мы сейчас и перейдем.
Время обратиться к прилагательному. Конечно, сначала мы посмотрим на написание отымённых прилагательных.
И если мы столкнулись с таким прилагательным – какой следующий вопрос мы зададим?
Да. Тот же самый.
От чего и как образовалось слово? Что, если в основе существительного, от которого произошло прилагательное, уже было одно н? Н в корне и н в суффиксе… Стоп. Звучит как что-то очень знакомое, не правда ли?
Действительно, этот пункт для прилагательных и существительных – общий, потому что они часто образуются друг от друга.
Отчаянный
– от отчаяние, каменный – от камень,
старинный – от старина, туманный – от туман. Мы
здесь смотрим даже не на корень – именно на основу, от которой слово
образовалось.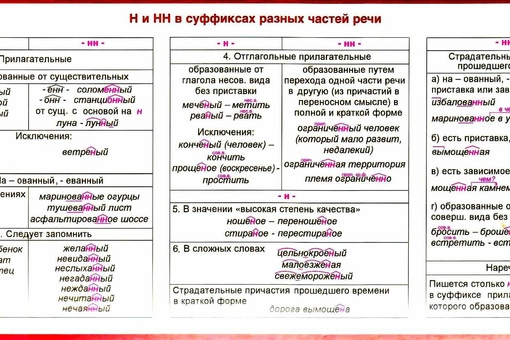 И все наши основы заканчиваются на н, так что мы пишем две буквы.
И все наши основы заканчиваются на н, так что мы пишем две буквы.
Но если две буквы н заключены в самом суффиксе? Эти буквы мирно уживаются с е и о. Так что в суффиксах -енн- и -онн- мы пишем две н:
Соломенный, утренний, станционный, традиционный.
А вот буквам и, а, я не так везет: они сочетаются только с одной н:
Соколиный, песчаный, утиный, глиняный – везде по одной н.
Но в этом правиле есть и исключения. Слово ветреный пишется с одной н. При этом безветренный – уже с двумя, на него исключение не распространяется.
С одной н пишутся слова свиной, бараний, кабаний, тюлений. Хотя, казалось бы, они образовались от существительных с основой на н. Но образовались не при помощи суффикса н, а при помощи суффикса -й-.
Самые
известные исключения – это, конечно, слова стеклянный, оловянный,
деревянный, которые пишутся через нн. И здесь время вспомнить
лингвистическую шутку о парне, у которого искусственные глаз, зуб и нога, так
что он точно знает, как пишутся эти слова.
И здесь время вспомнить
лингвистическую шутку о парне, у которого искусственные глаз, зуб и нога, так
что он точно знает, как пишутся эти слова.
Итак, два н в прилагательных мы напишем, если слово образовалось от существительного с основой на н. Или если в слове есть суффиксы енн-, -онн-. Плюс стеклянный, оловянный, деревянный.
С одной н мы пишем слово, если в нем есть суффиксы –ин-, -ан, -ян. Плюс слова ветреный, бараний, кабаний, тюлений. Есть еще так называемые непроизводные прилагательные – пряный, румяный, юный. Они вообще ни от чего не образовались и сразу были прилагательными, потому пишутся с одной н.
И
вот, кажется, мы дошли до самой сложной части нашего правила. Отглагольные
прилагательные и причастия… Что мы делаем, если столкнулись с ними – опять выясняем,
от чего и как образовалось слово? На этот раз нет. Поэтому у нас и могут
возникнуть сложности.
Отглагольные части речи требуют к себе особого отношения.
Во-первых, отглагольное прилагательное и причастие очень похожи. А поэтому они просто требуют сначала различить, кто из них кто. Потом определить вид, потому что их написание зависит от вида. Но не только от вида, так что мы можем легко запутаться в пунктах правила.
И возникает вопрос: а не проще ли вообще не различать эти две части речи?
Если перед нами – полное отглагольное прилагательное или причастие, а наша цель – правильно написать слово… То мы можем пожертвовать теорией ради практики. И просто обратить внимание на некоторые внешние признаки, которые подскажут правильное написание.
Итак, если мы столкнулись с причастием или отглагольным прилагательным – нужно искать внешние подсказки.
Одной
из таких подсказок может стать приставка. Есть приставка – есть две
буквы н. Как в словах исхоженный и поджаренный.
Правда, приставка не- нам не годится. Она не влияет на написание слова.
Нехоженый – по-прежнему одна буква н. Но после приставки не- может стоять еще одна приставка, как в слове незаклеенный. Тогда мы пишем две буквы н.
Второй подсказкой может быть слово, зависимое от причастия. Если рядом есть слово, к которому мы ставим от причастия вопрос, то мы пишем две н.
Жареный – одна буква н. Прибавим – «в масле». И букв станет две.
Крашеный – одна н. Прибавим «кистью». Две н.
Третья подсказка – слово заканчивается на -ованный или -ёванный. Обычно в таких случаях соединяются суффиксы -ова- и -ёва- с двумя н.
Балованный, маринованный, организованный, малёванный.
Исключения –
Наконец,
четвертая подсказка – это совершенный вид причастия.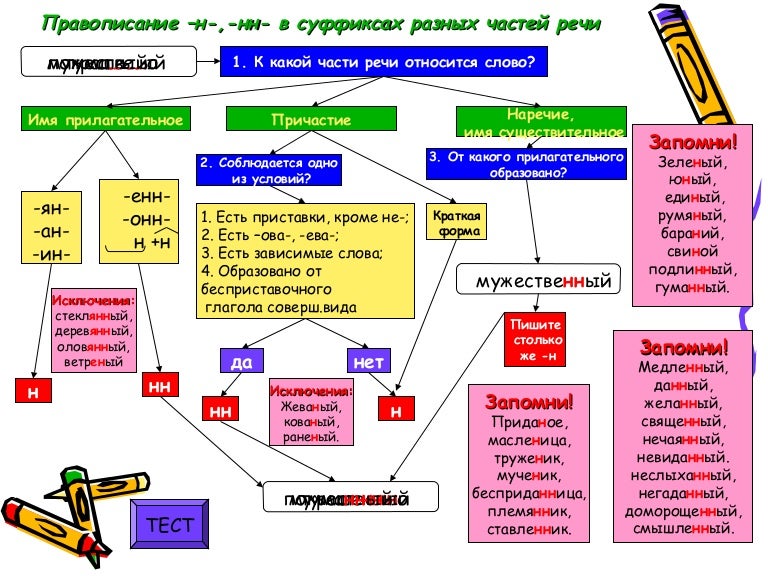 Если глагол,
от которого мы образовали слово, отвечает на вопрос «что сделать?» — мы пишем
два н. Купленный – купить, брошенный – бросить, решенный – решить.
Обычно в глаголах совершенного вида есть приставка, и проблем у нас не возникает.
Но из-за вот таких глаголов лучше помнить этот пункт и вовремя ставить вопрос.
Если глагол,
от которого мы образовали слово, отвечает на вопрос «что сделать?» — мы пишем
два н. Купленный – купить, брошенный – бросить, решенный – решить.
Обычно в глаголах совершенного вида есть приставка, и проблем у нас не возникает.
Но из-за вот таких глаголов лучше помнить этот пункт и вовремя ставить вопрос.
У правила довольно много исключений. Это слова деланный, желанный, невиданный, негаданный, недреманный, нежданный, неслыханный, нечаянный, священный, жеманный, чванный, чеканный. Здесь повсюду пишется две н.
Одна буква н пишется в словах непрошеный и смышлёный. С одной н мы напишем сочетания вроде стираный-перестираный, писаный-переписаный. В этом случае приставка нового слова не образует.
Эти случаи нам приходится запоминать.
Итак, два н в причастии или отглагольном прилагательном мы напишем:
-
если в нем есть приставка – любая, кроме не.
- если мы видим зависимое слово.
- если слово заканчивается на ованный, ёванный – кроме кованый, жёваный.
- если это причастие совершенного вида.
И нужно еще помнить об исключениях.
И вот теперь мы подошли к очередной части речи – наречию. Перед нами наречие, что делать дальше?
Задавать себе все тот же прежний вопрос.
Даже ещё более лёгкий вопрос: от чего это слово образовано? В наречии будет столько же букв н, сколько было в прилагательном или причастии, от которого оно произошло.
От прилагательного медленный образуется наречие медленно. От чудесный – чудесно. А количество Н так и не меняется.
И
получается, что если мы сталкиваемся с наречием и не
знаем, как его написать – нам нужна машина времени. Потому что наречие отсылает
нас к правилу о написании причастий и прилагательных.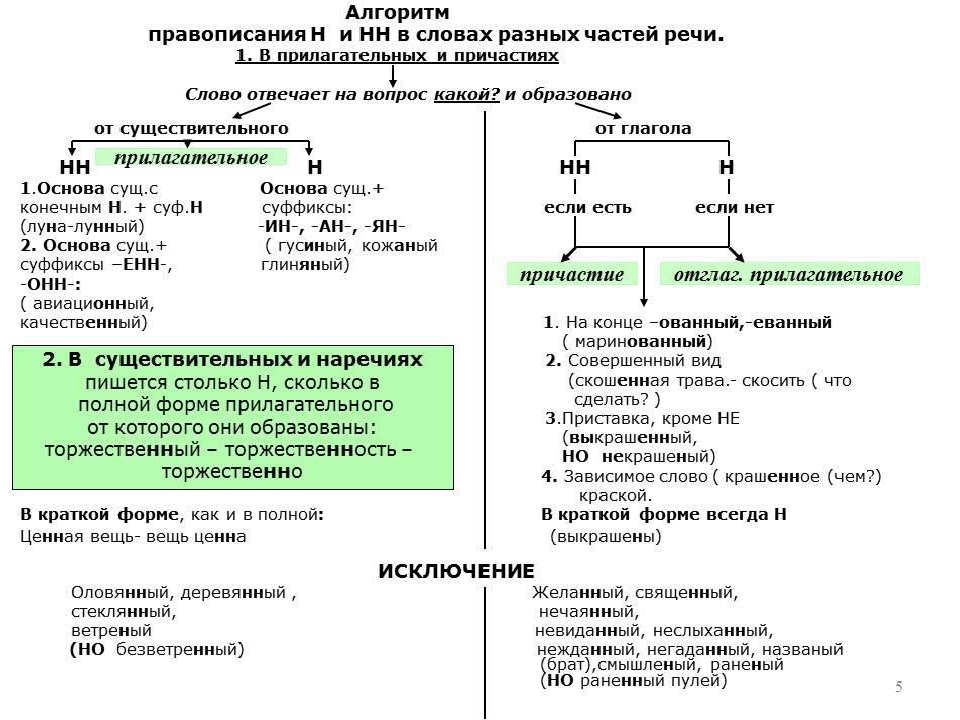
Так что нужно знать, чтобы правильно писать н и два н?
Во-первых – какая перед нами часть речи.
И еще – как и от чего она образовалась.
Если же перед нами причастие, то здесь нужно заняться поиском признаков, о которых мы говорили.
И не забывать об исключениях.
Итак, НН в разных частях речи пишется вот в таких случаях.
В остальных случаях пишется Н.
Если образовано от прилагательного с -Н- : Багряница (багряный), ветреник (ветреный), торфяник (торфяной), масленица (масленый), копчености (копченый) и др. | Если образовано от существительного с основой на -Н-: Дружинник (от дружина) Если образовано от прилагательного с -НН-: Болезненность (от болезненный) | В ОТЫМЕННЫХ ПРИЛАГАТЕЛЬНЫХ | Если образовано от существительного с помощью суффиксов –ИН-/ -АН-/-ЯН- Голубиный (от голубь), кожаный (от кожа), дровяной (от дрова) ЗАПОМНИТЬ: стеклянный, оловянный, деревянный. | Если образовано от существительного с помощью –ЕНН-/ -ОНН- : Искусственный (от искусство), дискуссионный (от дискуссия) и др. ЗАПОМНИТЬ: ветреный Если образовано от прилагательных с помощью –ЕНН- (со значением «высокая степень признака») : Высоченный (от высокий), широченный (от широкий) и т. д. Если образовано от существительного с основой на –Н- : Истинный (от истина), старинный (от старина). Если образовано от существительных на –МЯ при помощи –ЕНН- : Временный (от время), пламенный (от пламя) и др. | В ПРИЧАСТИЯХ | В кратких страдательных причастиях: Сочинение написано | Если образовано от приставочного глагола (совершенного вида): Наклеенный (от наклеить), покрашенный (от покрасить). Если образовано от бесприставочного глагола (несовершенного вида) и есть зависимое слово: Мощенная булыжником дорога, недавно кошенный луг. Груженная песком баржа, крашенный масляной краской пол. | В ОТГЛАГОЛЬНЫХ ПРИЛАГАТЕЛЬНЫХ | Если образовано от бесприставочного глагола (несовершенного вида) и нет суффиксов –ованн-/ -еванн- : Бешеная собака (от бесить), вареный картофель (от варить), сушеная ягода (от сушить) Если образовано от бесприставочного глагола (несовершенного вида) и нет зависимого слова: Крашеный пол, груженая баржа. !!! В кратких прилагательных сохраняется столько Н, сколько было в полных !!! ЗАПОМНИТЬ: приданое, посаженый отец, прощеное воскресение, названый брат. | Если есть суффиксы –ованн-/ -еванн-: Окольцованный, бронированный. ЗАПОМНИТЬ: нежданный, негаданный, неслыханный, невиданный, деланный, желанный, нечаянный, священный, жеманный, чванный, чеканный, окаянный, медленный, считанный, недреманное (око) и др. |


Н и НН в прилагательных и причастиях 📕
Особенности правописания Н и НН в прилагательных и причастиях
В русском языке правописание Н и НН в прилагательных и причастиях зависит от способа образования конкретного прилагательного и его грамматических особенностей.
Примеры Н и НН в прилагательных, образованных от существительных: песчаный пляж, лиственный лес, вечерняя прогулка, девочка грустна.
Примеры Н и НН в отглагольных прилагательных и причастиях: кованое изделие, нарисованный портрет, убранная комната, задача решена.
Н и НН в прилагательных, образованных от существительных
В прилагательных, образованных от существительных НН пишется в случаях:
- Если прилагательное образовано при помощи суффиксов – онн – .
 . Исключения – масленый, ветреный. Если прилагательное образовано при помощи суффикса – н – от существительного с основой на – н.
. Исключения – масленый, ветреный. Если прилагательное образовано при помощи суффикса – н – от существительного с основой на – н.Одна буква Н пишется:
- Если прилагательное образовано с помощью суффиксов – ин-, – ан – . Исключения – оловянный, стеклянный, деревянный.
В кратких прилагательных правописание Н и НН аналогично правописанию в полных прилагательных.
Н и НН в причастиях и отглагольных прилагательных
Написание
Н и НН в суффиксах прилагательных и причастий, зависит от степени сравнения глаголов, от которых они образованы, а также наличия или отсутствия в слове приставок.НН пишется:
- В отглагольных прилагательных и полных причастиях, образованных от глаголов совершенного вида. Исключения – крещеная мать, раненый солдат, смышленый ребенок, названая сестра и др. В страдательных причастиях прошедшего времени, которые образованы от глаголов несовершенного вида и имеют зависимые слова. В прилагательных и причастиях, образованных от глаголов с приставками кроме не – .
 Исключения – непуганый, незваный, нечищеный и др.
Исключения – непуганый, незваный, нечищеный и др.- В причастиях и прилагательных на – ованный.
Н пишется:
- Если отглагольное прилагательное образовано от глагола несовершенного вида без приставки при помощи суффиксов – ен-, – н – и не имеет зависимых слов. Исключения – деланный, желанный, действенный и др. В некоторых причастиях, образованных от глаголов несовершенного вида.
В кратких причастиях всегда пишется одна Н.
Н и НН в прилагательных и причастиях
Блог 6-го издания в стиле APA: Грамматика математики: запись о переменных
Челси Ли
В социальных науках миры грамматики и математики пересекаются, поскольку авторы должны не только проводить статистические тесты, но и четко и последовательно описывать их результаты. Чтобы помочь в достижении этой цели, этот пост посвящен некоторым грамматикам математики: как вводить и использовать статистические термины в тексте, когда вы сообщаете о своих результатах.
В шестом издании Publication Manual приводится список многих математических переменных и терминов, которые обычно встречаются в документах APA Style (см. Таблицу 4.5 на стр. 119–123). В приведенной ниже таблице приведены некоторые из наиболее распространенных статистических данных, показывающие их письменные и сокращенные формы как в единственном, так и во множественном числе. После этого мы обсудим все тонкости их использования в документе APA Style.
Письменная форма | Аббревиатура/символ | ||
Единственное число | Множественное число | Единственное число | Множественное число |
Коэна d | Коэна d s | г | д с |
степень свободы | степени свободы | дф | дф с |
F статистика или F значение | F статистика или F значения | Ф | Ф с |
означает | означает | М | М с |
размер выборки (подвыборки) | размеров выборки (подвыборки) | п | н с |
размер выборки (полная выборка) | размеры выборки (полная выборка) | Н | Н с |
р значение | p значений | р | р с |
r значение | r значения | р | р с |
Ч 2 значение | R 2 значения | Р 2 | Ч 2 с |
стандартное отклонение | стандартные отклонения | SD | SD с |
стандартная ошибка | стандартные ошибки | SE | SE с |
т значение | t значения | т | т с |
z оценка | z баллов | я | з с |
Альфа Кронбаха | Альфа Кронбаха | Кронбаха α | αs Кронбаха |
бета | бета | β | βs |
хи-квадрат | хи-квадрата | х 2 | х 2 с |
дельта | дельты | Δ | Δs |
Единственное и множественное число
- Синтаксис вашего предложения определяет, нужно ли использовать переменную в единственном или во множественном числе.

- Все аббревиатуры множественного числа образуются путем добавления некурсивной строчной буквы «s». Не используйте апостроф плюс «s», курсивную «s» или заглавную «S».
- Правильно: p с < 0,05; М с = 3,70 и 4,22; степени свободы.
- Неверно: пс < 0,05, пс < 0,05; Ms= 3,70 и 4,22; Средние значения = 3,70 и 4,22; степени свободы.
Письменная форма в сравнении с сокращенной формой
- Использовать письменную форму переменной в прозе; используйте этот символ в сочетании со всеми математическими операторами (такими как знак равенства или знаки больше/меньше).
- Как обычно, используйте единственное или множественное число в зависимости от контекста.
Курсив в сравнении с обычным шрифтом
- Переменные выделены курсивом.
- Надстрочные числа не выделены курсивом (например, R 2 ).

- Идентификаторы (которые могут быть надстрочными или подстрочными словами, буквами или цифрами) не выделяются курсивом. Например, если М девочек = 4,22 и М мальчиков = 3.78 символ среднего значения выделен курсивом, но неизменяемые идентификаторы (здесь идентифицирующие две группы, «девочки» и «мальчики») курсивом не выделены.
Пример
Средние значения и стандартные отклонения приведены в таблице 1. Мы рассчитали альфа Кронбаха как статистику надежности, а затем провели тест хи-квадрат. Группа чтения вслух ( M = 4,55, SD = 0,65) и группа чтения молча ( M = 2,72, SD = 0.53) достоверно различались по тесту на понимание прочитанного, χ 2 (1, 50) = 4,25, p < 0,05. Мальчики и девочки достоверно не отличались ( М девочки = 4,22 и М мальчики = 3,78). Размер выборки для каждой группы тестирования составлял 25 человек, но у нескольких участников в каждой группе (90 007 n 90 008 s = 5 и 6 соответственно) отсутствовали данные по последнему вопросу, и они были заменены средним баллом участника. На надежность это не повлияло (α Кронбаха = .83).
На надежность это не повлияло (α Кронбаха = .83).
Законы экспонентов
Экспоненты также называются Степенями или Индексами
Показатель степени числа говорит , сколько раз использовать число при умножении .
В этом примере: 8 2 = 8 × 8 = 64
Прописью: 8 2 можно назвать «8 во второй степени», «8 во второй степени» или просто «8 в квадрате»
Попробуйте сами:
изображения/экспонента-расч.js
Таким образом, экспонента избавляет нас от записи большого количества умножений!
Пример: а
7а 7 = а × а × а × а × а × а × а = ааааааа
Обратите внимание, как мы написали буквы вместе, чтобы означать умножение? Мы будем делать это много здесь.
Пример: x
6 = xxxxxxКлюч к законам
Написание всех букв — ключ к пониманию Законов
Пример: x
2 x 3 = (xx)(xxx) = xxxxx = x 5Что показывает, что x 2 x 3 = x 5 , но об этом позже!
Итак, если вы сомневаетесь, просто не забудьте записать все буквы (столько, сколько вам говорит показатель степени) и посмотреть, сможете ли вы понять это.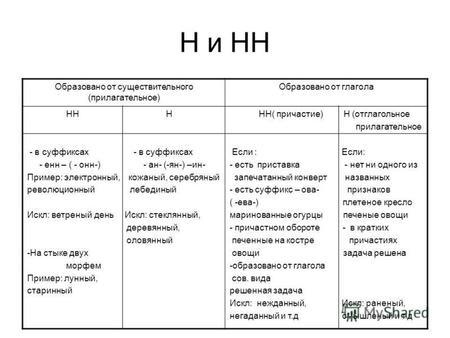
Все, что вам нужно знать…
«Законы экспонентов» (также называемые «Правилами экспонентов») исходят из трех идей :
| Показатель степени говорит сколько раз использовать число в умножении . | |
| Отрицательный показатель степени означает, что делят , потому что противоположным умножению является деление | |
Если вы их понимаете, то понимаете и экспоненты!
И все законы ниже основаны на этих идеях.
Законы показателей
Вот законы (пояснения следуют):
| Право | Пример |
|---|---|
| х 1 = х | 6 1 = 6 |
| х 0 = 1 | 7 0 = 1 |
| х -1 = 1/х | 4 -1 = 1/4 |
| | |
| х м х п = х м+п | х 2 х 3 = х 2+3 = х 5 |
| x м /x н = х м-н | x 6 /x 2 = x 6-2 = x 4 |
| (х м ) н = х мн | (х 2 ) 3 = х 2×3 = х 6 |
| (ху) н = х н у н | (ху) 3 = х 3 у 3 |
| (x/y) n = x n /y n | (х/у) 2 = х 2 / у 2 |
| x -n = 1/x n | х -3 = 1/х 3 |
| И закон о дробных показателях: | |
| х м/н =
п√х м = (n√x) м | х 2/3 =
3√х 2 = (3√х) 2 |
Объяснение законов
Первые три вышеприведенных закона (x 1 = x, x 0 = 1 и x -1 = 1/x) являются лишь частью естественной последовательности показателей степени.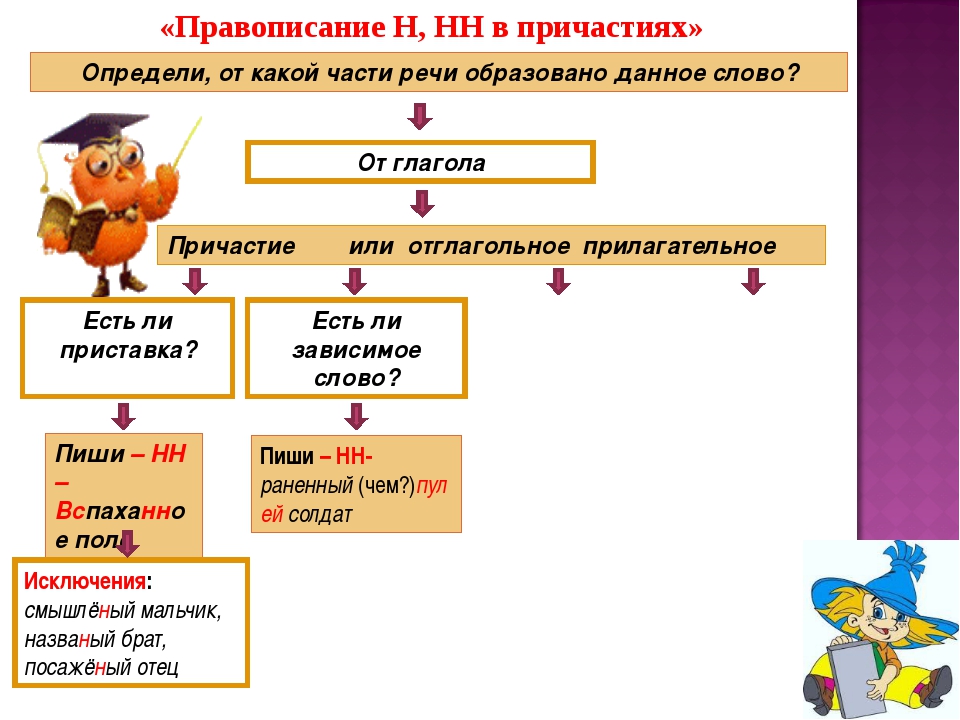 Взгляните на это:
Взгляните на это:
| Пример: Степени числа 5 | |||
|---|---|---|---|
| .. и т.д.. | |||
| 5 2 | 1 × 5 × 5 | 25 | |
| 5 1 | 1 × 5 | 5 | |
| 5 0 | 1 | 1 | |
| 5 -1 | 1 ÷ 5 | 0.2 | |
| 5 -2 | 1 ÷ 5 ÷ 5 | 0,04 | |
| .. и т.д.. | |||
Некоторое время посмотрите на эту таблицу. .. обратите внимание, что положительный, нулевой или отрицательный показатель степени на самом деле являются частью одного и того же шаблона, то есть в 5 раз больше (или в 5 раз меньше) в зависимости от того, увеличивается (или уменьшается) показатель степени.
.. обратите внимание, что положительный, нулевой или отрицательный показатель степени на самом деле являются частью одного и того же шаблона, то есть в 5 раз больше (или в 5 раз меньше) в зависимости от того, увеличивается (или уменьшается) показатель степени.
Закон, что x
m x n = x m+nС x m x n , сколько раз мы должны умножить «x»? Ответ: первых «m» раз, затем еще «n» раз, всего «m+n» раз.
Пример: x
2 x 3 = (xx)(xxx) = xxxxx = x 5Итак, х 2 х 3 = х (2+3) = х 5
Закон, что х
m /x n = x m-nКак и в предыдущем примере, сколько раз нам нужно умножить «x»? Ответ: «m» раз, тогда уменьшите это в «n» раз (потому что мы делим), итого в «m-n» раз.
Пример: x
4 /x 2 = (xxxx) / (xx) = xx = x 2Итак, х 4 /х 2 = х (4-2) = х 2
(Помните, что x / x = 1, поэтому каждый раз, когда вы видите x «над чертой» и одну «под чертой», вы можете отменить их. )
)
Этот закон также может показать вам, почему x 0 = 1 :
Пример: x
2 /x 2 = x 2-2 = x 0 =1Закон того, что (x
m ) n = x mnСначала вы умножаете «m» раз.Тогда у вас есть , чтобы сделать это «n» раз , всего m×n раз.
Пример: (x
3 ) 4 = (xxx) 4 = (xxx)(xxx)(xxx)(xxx) = xxxxxxxxxxxx = x 12Так (х 3 ) 4 = х 3×4 = х 12
Закон того, что (xy)
n = x n y nЧтобы показать, как это работает, просто подумайте о перестановке всех «x» и «y», как в этом примере:
Пример: (xy)
3 = (xy)(xy)(xy) = xyxyxy = xxxyyy = (xxx)(yyy) = x 3 y 3Закон того, что (x/y)
n = x n /y nАналогично предыдущему примеру, просто переставьте «x» и «y»
Пример: (x/y)
3 = (x/y)(x/y)(x/y) = (xxx)/(yyy) = x 3 /y 3Закон, который х
м/н = п√х м знак равно (n√x) мХорошо, это немного сложнее!
Я предлагаю вам сначала прочитать дробные экспоненты, так это имеет больше смысла.
В любом случае, важная идея заключается в том, что:
x 1/ n = n- -й корень из x
Таким образом, дробная экспонента, такая как 4 3/2 , на самом деле говорит о том, что нужно сделать из куба (3) и извлечь квадратный корень из из (1/2) в любом порядке.
Просто запомните из дробей, что m/n = m × (1/n) :
Пример: x
( м n ) = x (м × 1 n ) = (x м ) 1/n = п√х мПорядок не имеет значения, поэтому он также работает для m/n = (1/n) × m :
Пример: x
( м n ) = x ( 1 n × m) = (x 1/n ) м = (n√x) мЭкспоненты экспонентов .
 ..
..Что насчет этого примера?
4 3 2
Мы делаем показатель степени в top first , поэтому мы вычисляем его следующим образом:
| Начните с: | 4 3 2 | |
| 3 2 = 3×3: | 4 9 | |
| 4 9 = 4×4×4×4×4×4×4×4×4: | 262144 |
Вот и все!
Если вам трудно запомнить все эти правила, то запомните это:
, вы сможете понять их, когда поймете
три идеи в верхней части этой страницы:
- Показатель степени говорит сколько раз использовать число при умножении
- A отрицательный показатель степени означает деление
- Дробная экспонента, такая как 1/n , означает, что берет корень n-й степени : х ( 1 п ) = п√х
О, еще кое-что .
 .. Что если х = 0?
.. Что если х = 0?| Положительный показатель степени (n>0) | 0 n = 0 | |
| Отрицательная экспонента (n<0) | 0 -n равно undefined (поскольку деление на 0 не определено) | |
| Показатель степени = 0 | 0 0 … ммм … см. ниже! |
Странная история 0
0Существуют разные аргументы для правильного значения 0 0
0 0 может быть 1 или, возможно, 0, поэтому некоторые люди говорят, что это действительно «неопределенно»:
| х 0 = 1, значит … | 0 0 = 1 | |
0 n = 0, значит.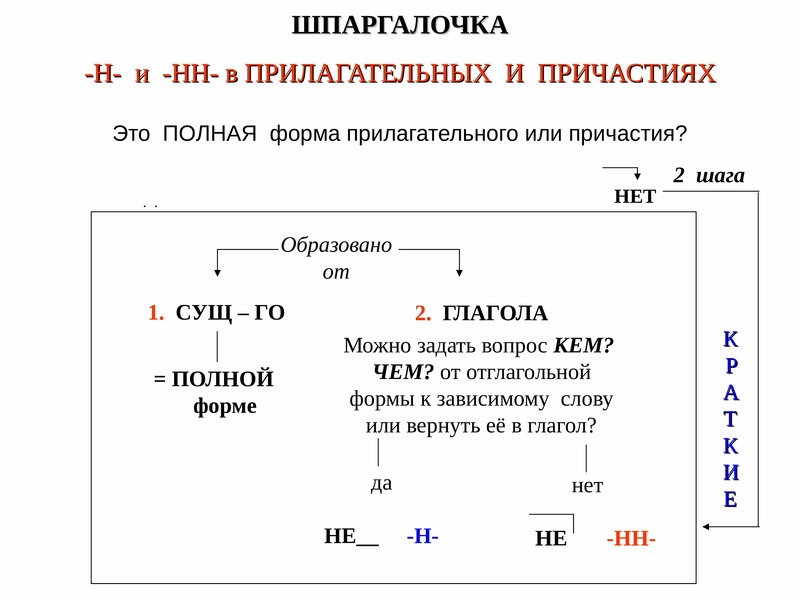 .. .. | 0 0 = 0 | |
| Если есть сомнения… | 0 0 = «неопределенный» |
323, 2215, 2306, 324, 2216, 2307, 371, 2217, 2308, 2309
Создание связей таблиц «многие ко многим» в обзоре Microsoft Dataverse — Power Apps
- Статья
- 2 минуты на чтение
Пожалуйста, оцените свой опыт
да Нет
Любая дополнительная обратная связь?
Отзыв будет отправлен в Microsoft: при нажатии кнопки отправки ваш отзыв будет использован для улучшения продуктов и услуг Microsoft. Политика конфиденциальности.
Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Связи таблиц «один ко многим» (1:N) устанавливают иерархию между строками. В отношениях «многие ко многим» (N:N) нет явной иерархии. Нет столбцов подстановки или поведения для настройки. Строки, созданные с использованием отношений «многие ко многим», могут считаться одноранговыми, и эти отношения являются взаимными.
Один пример отношения «многие ко многим» определен между двумя стандартными таблицами, включенными в приложение Dynamics 365 Sales. Таблица возможностей имеет связь N:N с таблицей конкурентов. Это позволяет добавить несколько конкурентов к возможности и несколько возможностей, связанных с одним и тем же конкурентом.
С отношениями «многие ко многим» таблица отношений (или пересечений) хранит данные, которые связывают таблицы. Эта таблица имеет связь «один ко многим» с обеими связанными таблицами и хранит только те значения, которые необходимы для определения связи.Вы не можете добавлять настраиваемые столбцы в таблицу отношений, и она никогда не отображается в пользовательском интерфейсе.
Эта таблица имеет связь «один ко многим» с обеими связанными таблицами и хранит только те значения, которые необходимы для определения связи.Вы не можете добавлять настраиваемые столбцы в таблицу отношений, и она никогда не отображается в пользовательском интерфейсе.
Для создания отношения «многие ко многим» необходимо выбрать две таблицы, которые вы хотите использовать в отношении. Для приложений, управляемых моделями, вы можете решить, как вы хотите, чтобы соответствующие списки были доступны в навигации для каждой таблицы. Это те же параметры, которые используются для основной таблицы в связях таблиц 1:N. Дополнительные сведения: Элемент области навигации для основной таблицы
Не все таблицы можно использовать с отношениями «многие ко многим».Если таблица недоступна для выбора в конструкторе, вы не сможете создать новую связь «многие ко многим» с этой таблицей. Дополнительные сведения: Документация разработчика: право на связь между таблицами
Существует два конструктора, которые можно использовать для создания и редактирования отношений 1:N (один ко многим) или N:1 (многие к одному):
Примечание
Вы также можете создать новую связь таблицы «многие ко многим» (N:N) в своей среде, используя следующее:
Информация в этом разделе поможет вам выбрать конструктор, который вы можете использовать.
Вы должны использовать портал Power Apps для создания и редактирования отношений таблиц «многие ко многим» (N:N), если вам не нужно выполнять какое-либо из следующих требований:
- Настройка параметров панели навигации для приложений на основе модели.
- Скрыть взаимосвязь из расширенного поиска в приложениях на основе моделей.
См. также
Создание и изменение связей между таблицами
Создание связей таблиц «многие ко многим» в Dataverse с помощью портала Power Apps
Создание связей таблиц N:N (многие ко многим) в Dataverse с помощью обозревателя решений
Документация для разработчиков: настройка метаданных отношений таблиц
Документация разработчика: право на связь между таблицами
Статистические отчеты в стиле APA — Статистические инструкции
Стиль APA может быть привередливым.Попытка запомнить очень специфические правила для пробелов, курсива и других правил форматирования может быть непосильной, если вы также пишете довольно техническую статью.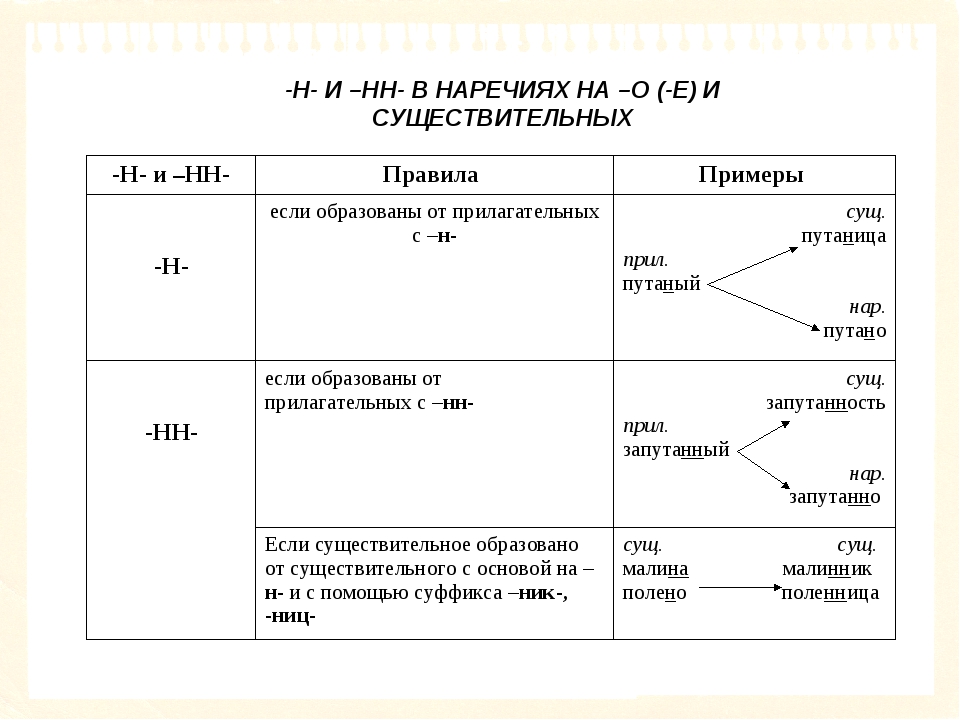 Мой лучший совет — написать статью, а затем отредактировать ее по грамматике. Не беспокойтесь о представлении статистики в стиле APA, пока ваша статья не будет почти готова к публикации. Затем просмотрите свою статью и сделайте второе редактирование статистической записи на основе этого списка.
Мой лучший совет — написать статью, а затем отредактировать ее по грамматике. Не беспокойтесь о представлении статистики в стиле APA, пока ваша статья не будет почти готова к публикации. Затем просмотрите свою статью и сделайте второе редактирование статистической записи на основе этого списка.
Общие рекомендации смотрите в видео:
Видео не видно? Кликните сюда.
1. Общие советы по составлению статистических отчетов в стиле APA
2. Отчет по конкретной статистике в стиле APA
Выдержка из профессионального журнала.
Доверительные интервалы : Для доверительных интервалов используйте скобки: 95% ДИ [2,47, 2,99], [-5,1, 1,56] и [-3,43, 2,89]. Если вы сообщаете список статистических данных в круглых скобках, вам не нужно использовать скобки в круглых скобках. Например:
Если вы сообщаете список статистических данных в круглых скобках, вам не нужно использовать скобки в круглых скобках. Например:
( SD = 1,5, CI = -5, 5)
Используйте круглые скобки, чтобы заключить степеней свободы .Например, t(10) = 2,16.
Значения вероятности: сообщают точное значение p, если оно не меньше 0,001. Если меньше этой суммы, принято сообщать об этом как: p < 0,001.
Примечание. Я написал здесь «Значения вероятности» по одной причине: символ нижнего регистра не может быть написан с заглавной буквы в начале предложения или в заголовке таблицы, поскольку прописные и строчные буквы имеют значение.
Среднее значение, стандартное отклонение (и аналогичные единичные статистические данные): используйте круглые скобки: ( M = 22, SD = 3.4).
Существительные (p-значение, z-тест, t-тест) не пишутся через дефис, но в качестве прилагательного они являются: результаты t-теста, оценка z-теста.
В начале раздела результатов повторно сформулируйте свою гипотезу, а затем укажите, подтверждают ли ее ваши результаты. За этим должны следовать данные и статистика, подтверждающие или опровергающие нулевую гипотезу.
Односторонний/двусторонний Дисперсионный анализ : Укажите степени свободы между группами, затем укажите степени свободы внутри групп, а затем F-статистику и уровень значимости.Например: «Основной эффект был значительным, F (1, 149) = 2,12, p = 0,02».
Критерий независимости хи-квадрат: В скобках укажите степени свободы и размер выборки, затем значение хи-квадрат и уровень значимости. Например:
«Реакция животных на стимулы не различалась по видам, х 2 (1, N = 75) = 0,89, p = 0,25».
t-тесты : Запишите значение t и уровень значимости следующим образом: t (54) = 5.43,
р < 0,001. То, что вы вложите в формулировку, будет немного отличаться в зависимости от того, есть ли у вас t-тест для одной выборки или t-тест для групп. Примеры:
Примеры:
- Один образец: «Подростки младшего возраста просыпались раньше ( M = 7:30, SD = 0,45), чем подростки в целом, t (33) = 2,10, p = 0,31″
- Зависимые/независимые выборки: «Подростки младшего возраста отдавали предпочтение видеоиграм ( M = 7,45, SD = 2.51), чем книги ( M = 4,22, SD = 2,23), t (15) = 4,00, p < 0,001».
Отчет корреляций со степенями свободы (N-2), за которыми следует уровень значимости. Например: «Два набора результатов экзаменов сильно коррелированы, r(55) = 0,49, p < 0,001».
Спасибо Марку Саггсу за вклад в эту статью.
Ссылки:
Американская психологическая ассоциация.(2019). Руководство по публикации Американской психологической ассоциации (7-е изд.).
Милан, JE, Уайт, AA. Влияние адаптированного к этапу интернет-вмешательства на использование поливитаминов, содержащих фолиевую кислоту, студентками колледжа. Am J Health Promot. 2010 июль-август; 24(6):388-95. doi: 10.4278/ajhp.071231143.
Am J Health Promot. 2010 июль-август; 24(6):388-95. doi: 10.4278/ajhp.071231143.
Шелдон. (2013). Словарь статистики и методов исследования APA (справочники APA), 1-е издание. Американская психологическая ассоциация (АПА).
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Оставьте комментарий на нашей странице в Facebook .
Применение правил письма к веб-страницам: статья Якоба Нильсена
Введение
Наши более ранние исследования того, как люди читают в Интернете [1], показали, что они: предпочитают сканировать, а не читать, хотят, чтобы текст был кратким и содержательным, и ненавидят чрезмерно разрекламированные рекламные тексты («маркетологизм»).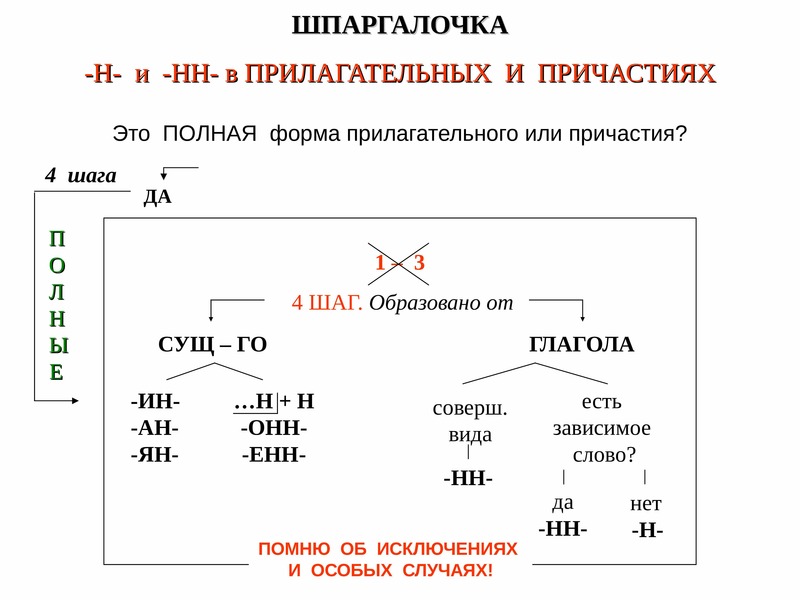 Мы обнаружили улучшения в юзабилити для новых версий сайта, которые были сканируемыми, краткими или объективными (а не рекламными) по стилю. Когда все три улучшения стиля письма были объединены в финальную версию сайта, удобство использования увеличилось на 124%. Эти результаты побудили нас применить улучшения к страницам веб-сайта Sun.
Мы обнаружили улучшения в юзабилити для новых версий сайта, которые были сканируемыми, краткими или объективными (а не рекламными) по стилю. Когда все три улучшения стиля письма были объединены в финальную версию сайта, удобство использования увеличилось на 124%. Эти результаты побудили нас применить улучшения к страницам веб-сайта Sun.
Применение правил письма
Общим связующим звеном между краткостью, удобочитаемостью и объективностью является то, что каждый из них снижает когнитивную нагрузку пользователя, что приводит к более быстрой и эффективной обработке информации.(Краткий текст содержит меньше информации для обработки, сканируемый текст привлекает внимание к ключевой информации, а сомнение в достоверности рекламных заявлений, по-видимому, отвлекает пользователей от осмысления смысла, как показали наши предыдущие исследования.) Таким образом, наша цель состояла в том, чтобы переработать существующие веб-страницы таким образом, чтобы что они сведут к минимуму когнитивную нагрузку и повысят скорость и эффективность.
Мы взяли два технических документа (один по обработке новых медиа и один по Java) с веб-сайта Sun и использовали их для создания двух версий учебного веб-сайта.Выдержки из обеих версий сайта доступны по адресу: http://www.nngroup.com/articles/downloadable-files-to-replicate-web-reading-study/.
Первоначальная версия тестового сайта состояла из трех страниц и использовала существующие технические документы с небольшими изменениями: для технических документов были созданы специальная домашняя страница и баннер, а внешние гипертекстовые ссылки были удалены, чтобы оценщики могли сосредоточиться только на этом сайте. .
Переписанная версия сайта состояла из восьми страниц, которые в среднем были намного короче (не считая главной страницы, каждая страница содержала в среднем 346 слов по сравнению с 2232 в оригинале).Общее количество слов на сайте составило 2425 слов, что составляет 54% длины исходной версии.
Краткий : Это было самым трудным для выполнения правилом, потому что мы боялись вырезать «слишком много». Мы начали с того, что разделили технические документы, используя, казалось бы, естественные разрывы разделов. Затем мы сокращаем, пытаясь найти баланс между сохранением полезной информации и упрощением и быстротой чтения технических документов. Для этого требовалось не только ужесточение формулировок, но и сокращение слишком подробной информации.Вот пример текста с каждого сайта:
Мы начали с того, что разделили технические документы, используя, казалось бы, естественные разрывы разделов. Затем мы сокращаем, пытаясь найти баланс между сохранением полезной информации и упрощением и быстротой чтения технических документов. Для этого требовалось не только ужесточение формулировок, но и сокращение слишком подробной информации.Вот пример текста с каждого сайта:
Оригинал:
Средства управления также предвещают высокий рост. Безусловно, сегодня микропроцессоры можно найти в электронных термостатах, системах внутренней связи, автоматических спринклерных системах, автономных таймерах освещения и системах сигнализации, которые сами связаны с центральной станцией наблюдения. Но представьте себе домашнюю сеть, которая объединяет все эти вещи и многое другое в скоординированную систему управления окружающей средой…..
Переписано:
Управление объектами также будет полагаться на новые устройства. Электронные термостаты, системы внутренней связи, автоматические спринклерные системы и системы сигнализации будут объединены в скоординированную систему управления, связанную с центральной системой мониторинга.
…
Scannable : Внесено несколько изменений, чтобы обобщить и привлечь внимание к важным частям текста. Мы добавили оглавления и резюме разделов, поскольку пользователи в предыдущих исследованиях сочли их особенно полезными.Мы также включили маркеры, нумерованные списки, полужирный и цветной текст, чтобы выделить ключевые слова, дополнительные заголовки и более короткие абзацы. Эти изменения было относительно легко сделать, и они придали страницам более чистый и открытый дизайн.
Задача : Удалить рыночный вариант из текста было несложно. Мы удалили прилагательные (например, «великий» и «подавляющий»), модные словечки (например, «парадигма») и утверждения, не подтвержденные доказательствами. Конечно, может быть невозможно (или нежелательно) удалить все рекламные тексты с корпоративного веб-сайта.Как и в случае с краткостью, мы иногда пытались найти то, что считали разумным балансом.
Оценка сайтов
Чтобы оценить оригинальные и переписанные веб-сайты, 21 технический пользователь принял участие в эксперименте между субъектами с двумя условиями (исходный или переписанный сайт). Должности пользователей включали системного администратора, системного аналитика, разработчика программного обеспечения и старшего программиста.
Должности пользователей включали системного администратора, системного аналитика, разработчика программного обеспечения и старшего программиста.
Первые две задачи участника заключались в поиске конкретных фактов на сайте.Например, одна задача заключалась в том, чтобы выяснить: «Согласно веб-сайту, как в будущем пользователи нового медиа рабочего стола будут воспринимать интерфейс LAN/WAN?» Следующей была задача на оценку, предложенная [2], в которой участник должен был найти соответствующую информацию, а затем вынести о ней суждение. Вопрос звучал так: «В официальном документе «Market for Java» упоминается несколько характеристик Java. Как вы думаете, какая характеристика упоминается наиболее важная? Почему вы так думаете?» За этим заданием последовала анкета.
Затем участник провел 8 минут, просматривая страницы веб-сайта, готовясь к короткому экзамену. Например, один из вопросов гласил: «По данным сайта, какая область применения сетевых вычислений наименее развита? а) правительство, б) торговля, в) потребитель, г) образование».
Результаты
Как и предполагалось, переписанная версия сайта превзошла исходную версию по всем четырем основным параметрам, как показали данные тестирования t (см. таблицу).
| Состояние | Время задачи | Ошибки задачи | Память | Субъективное удовлетворение |
|---|---|---|---|---|
| Оригинал (контрольное состояние) | 637 | 0,91 | 0,33 | 4,9 |
| (315) | (0,70) | (0,35) | (2.5) | |
| Переписано | 315** | 0,10** | 0,65** | 6,7* |
| (110) | (0,32) | (0,19) | (1,4) |
Таблица показывает, что переписанная версия превзошла оригинал по всем параметрам. В таблице показаны средние баллы для следующих показателей (стандартные отклонения указаны в скобках):
В таблице показаны средние баллы для следующих показателей (стандартные отклонения указаны в скобках):
Время задачи
количество секунд, которое потребовалось пользователям для выполнения трех задач
Ошибки задачи
процентная оценка, основанная на количестве неправильных ответов, данных в двух поисковых заданиях
Память
включает в себя показатели узнавания (баллы за вопросы с несколькими вариантами ответов) и припоминания (процент припоминаемых характеристик Java) из экзамена
.Субъективное удовлетворение
средний балл (по 10-балльной шкале) оценок, выставленных пользователями по четырем показателям из анкеты: качество сайта, простота использования, привлекательность сайта и воздействие на пользователя.
Чтобы определить, насколько лучше или хуже в процентном отношении была переписанная версия сайта по сравнению с исходной, мы нормализовали все средние баллы по основным показателям. Для каждой меры средний балл исходного состояния был установлен равным 100, а средний балл переписанного состояния был преобразован (путем деления) относительно контроля. Данные показали, что переписанная версия сайта была «лучше» по всем четырем параметрам: время выполнения задачи (лучше на 80%), ошибки в задаче (809%), память (100%) и субъективное удовлетворение (37%).
Данные показали, что переписанная версия сайта была «лучше» по всем четырем параметрам: время выполнения задачи (лучше на 80%), ошибки в задаче (809%), память (100%) и субъективное удовлетворение (37%).
Общая оценка удобства использования была рассчитана для каждой версии сайта, взяв среднее геометрическое нормализованных оценок для четырех показателей. Что касается общего удобства использования, переписанная версия была на 159% лучше, чем исходная версия .
Комментарии пользователей также подтвердили их предпочтение переписанной версии. Пользователи особенно оценили изменения, упростившие просмотр текста. Типичным комментарием было: «Основные идеи продолжают появляться у вас. Стрела. Очень легко следовать.»
Выводы
Это исследование показало, что переработка некоторых веб-страниц Sun (чтобы текст был удобочитаемым, кратким и объективным) привела к значительным положительным изменениям в производительности и субъективном удовлетворении технических пользователей, а также в общем удобстве использования.
Конечно, «Насколько лаконично слишком лаконично?» нелегко ответить. Мы сделали переписанную версию на 54% длиннее оригинала. Мы старались вырезать аккуратно, но вполне вероятно, что часть вырезанной информации могла оказаться полезной для некоторых пользователей.Однако пользователи предпочли более короткую версию и даже подумали, что она на больше, чем оригинал. (На вопрос «Насколько полно тема представлена на сайте?», переписанная версия набрала 7 баллов из 10 по сравнению с 6 баллами оригинала.) Таким образом, краткое изложение не противоречит исчерпывающему изложению.
Результаты ошибок задачи впечатляют. Основываясь на наблюдениях за участниками, мы считаем, что ошибки в значительной степени связаны с нетерпением пользователей оригинальной версии и нежеланием пробираться через длинные блоки текста, предпочитая вместо этого угадывать ответ.Наконец, наши исследования показывают, что во многих случаях можно удвоить юзабилити веб-сайта, просто переписав исходный текст автора:
- Наше первое исследование повысило удобство использования сайта с туристической информацией на 124%
- Текущее тематическое исследование повысило удобство использования технических документов на 159 %
Первое исследование просто сделало текст кратким, удобочитаемым и объективным; второе исследование следовало этим рекомендациям, а также нескольким другим, включая использование гипертекста для разделения длинного текста на более мелкие и более целенаправленные страницы.
Каталожные номера
- Моркес, Дж., и Нильсен, Дж. (1997). Кратко, сканируемо и объективно: как писать для Интернета. http://www.nngroup.com/articles/how-users-read-on-the-web/ и http://www.nngroup.com/articles/concise-scannable-and-objective-how-to-write -для Интернета/
- Спул, Дж. М., Скэнлон, Т., Шредер, В., Снайдер, К., и ДеАнджело, Т. (1997). Юзабилити веб-сайта: руководство для дизайнеров. Северный Андовер, Массачусетс: разработка пользовательского интерфейса.
Передовой опыт управления отношениями «многие ко многим»
Списки смежности — это шаблон проектирования, полезный для моделирования отношений «многие ко многим». в Amazon DynamoDB.В более общем смысле они обеспечивают способ представления данных графа (узлов и ребер) в ДинамоДБ.
Шаблон проектирования списка смежности
Когда между различными объектами приложения существует отношение «многие ко многим»,
отношение может быть смоделировано как список смежности. В этом шаблоне все объекты верхнего уровня
(синоним узлов в графовой модели) представлены с помощью ключа раздела. Любой
отношения с другими сущностями (ребрами на графике) представлены как элемент внутри
раздел, задав значение ключа сортировки для идентификатора целевого объекта (целевого узла).
В этом шаблоне все объекты верхнего уровня
(синоним узлов в графовой модели) представлены с помощью ключа раздела. Любой
отношения с другими сущностями (ребрами на графике) представлены как элемент внутри
раздел, задав значение ключа сортировки для идентификатора целевого объекта (целевого узла).
К преимуществам этого шаблона относятся минимальное дублирование данных и упрощенные шаблоны запросов для поиска всех объектов (узлов), связанных с целью объект (имеющий ребро к целевому узлу).
Примером из реальной жизни, где этот шаблон был полезен, является система выставления счетов, в которой
счета-фактуры содержат несколько счетов. Один счет может принадлежать нескольким счетам. Ключ раздела
в этом примере это либо InvoiceID , либо BillID . Разделы BillID имеют все атрибуты, характерные для счетов. Идентификатор счета-фактуры разделы имеют элемент, в котором хранятся атрибуты, относящиеся к счету-фактуре, и элемент для каждого BillID , который суммируется со счетом.
Схема выглядит следующим образом.
Используя предыдущую схему, вы можете видеть, что все счета для счета могут быть запрошены с помощью первичный ключ в таблице. Чтобы найти все счета, которые содержат часть счета, создайте глобальный вторичный индекс по ключу сортировки таблицы.
Прогнозы глобального вторичного индекса выглядят следующим образом.
Шаблон материализованного графа
Многие приложения построены на понимании ранжирования среди аналогов, общих отношения между объектами, состояние соседнего объекта и другие типы стиля графика рабочие процессы. Для этих типов приложений рассмотрите следующий дизайн схемы шаблон.
На предыдущей схеме показана структура данных графа, которая определяется набором данных
разделы, содержащие элементы, определяющие ребра и узлы графа.Пограничные элементы
содержат атрибут Target и Type . Эти атрибуты используются как
часть имени составного ключа «TypeTarget» для идентификации элемента в разделе в первичном
таблице или во втором глобальном вторичном индексе.
Эти атрибуты используются как
часть имени составного ключа «TypeTarget» для идентификации элемента в разделе в первичном
таблице или во втором глобальном вторичном индексе.
Первый глобальный вторичный индекс строится на основе атрибута данных . Этот
атрибут использует глобальную вторичную перегрузку индекса, как описано ранее, для индексации нескольких
различные типы атрибутов, а именно Даты , Имена , Места ,
и Навыки .Здесь один глобальный вторичный индекс эффективно индексирует четыре
разные атрибуты.
Когда вы вставляете элементы в таблицу, вы можете использовать интеллектуальную стратегию сегментирования для
распределить наборы элементов с большими агрегациями (дата рождения, навык) по как можно большему количеству логических
разделы в глобальных вторичных индексах по мере необходимости, чтобы избежать горячего чтения/записи
проблемы.
Результатом такого сочетания шаблонов проектирования является надежное хранилище данных для эффективные графические рабочие процессы в реальном времени.Эти рабочие процессы могут обеспечить высокую производительность состояние объекта и запросы агрегирования краев для механизмов рекомендаций, социальных сетей приложения, ранжирование узлов, агрегирование поддеревьев и другие распространенные варианты использования графов.
Если ваш вариант использования не чувствителен к согласованности данных в реальном времени, вы можете использовать запланированный Процесс Amazon EMR для заполнения ребер релевантными агрегированными сводками графа для ваших рабочих процессов. Если вашему приложению не нужно немедленно знать, когда к графу добавляется ребро, вы может использовать запланированный процесс для агрегирования результатов.
Чтобы обеспечить некоторый уровень согласованности, проект может включать Amazon DynamoDB Streams и
AWS Lambda для обработки периферийных обновлений. Он также может использовать задание Amazon EMR для проверки результатов на
регулярный интервал. Этот подход иллюстрируется следующей диаграммой. Обычно используется
в приложениях социальных сетей, где стоимость запроса в реальном времени высока и необходимо
сразу узнайте, что отдельных пользовательских обновлений мало.
Он также может использовать задание Amazon EMR для проверки результатов на
регулярный интервал. Этот подход иллюстрируется следующей диаграммой. Обычно используется
в приложениях социальных сетей, где стоимость запроса в реальном времени высока и необходимо
сразу узнайте, что отдельных пользовательских обновлений мало.
Приложения для управления ИТ-услугами (ITSM) и обеспечения безопасности обычно должны реагировать в реальном времени. время до изменения состояния объекта, состоящего из сложных агрегаций ребер.Такие приложения нуждаются в система, которая может поддерживать агрегацию нескольких узлов второго и третьего уровня в режиме реального времени. отношения или сложные обходы ребер. Если ваш вариант использования требует этих типов графических рабочих процессов запроса, мы рекомендуем вам рассмотреть возможность использования Amazon Neptune для управления этими рабочими процессами.
Функция fwrite — RDocumentation
Использование
fwrite(x, file = "", append = FALSE, quote = "auto",
sep = ",", sep2 = c("","|",""),
эол = если (. Платформа$OS.type=="windows") "\r\n" иначе "\n",
na = "", dec = ".", row.names = FALSE, col.names = TRUE,
qmethod = c ("двойной", "побег"),
logical01 = getOption("datatable.logical01", FALSE), # из-за изменения на TRUE; см. НОВОСТИ
logicalAsInt = logical01, # устарело
scipen = getOption('scipen', 0L),
dateTimeAs = c ("ISO", "сквош", "эпоха", "write.csv"),
buffMB = 8L, nThread = getDTthreads (подробный),
showProgress = getOption ("datatable.showProgress", интерактивный()),
сжать = c("авто", "нет", "gzip"),
ямл = ЛОЖЬ,
Бом = ЛОЖЬ,
verbose = getOption("datatable.verbose", FALSE))
Платформа$OS.type=="windows") "\r\n" иначе "\n",
na = "", dec = ".", row.names = FALSE, col.names = TRUE,
qmethod = c ("двойной", "побег"),
logical01 = getOption("datatable.logical01", FALSE), # из-за изменения на TRUE; см. НОВОСТИ
logicalAsInt = logical01, # устарело
scipen = getOption('scipen', 0L),
dateTimeAs = c ("ISO", "сквош", "эпоха", "write.csv"),
buffMB = 8L, nThread = getDTthreads (подробный),
showProgress = getOption ("datatable.showProgress", интерактивный()),
сжать = c("авто", "нет", "gzip"),
ямл = ЛОЖЬ,
Бом = ЛОЖЬ,
verbose = getOption("datatable.verbose", FALSE)) Примеры
# NOT RUN {
DF = data.frame(A=1:3, B=c("foo","A,Name","baz"))
fwrite(ДФ)
write.csv(DF, row.names=FALSE, quote=FALSE) # то же самое fwrite(DF, row.names=ИСТИНА, цитата=ИСТИНА)
write.csv(DF) # то же самое DF = data.frame(A=c(2.1,-1.234e-307,pi), B=c("foo","A,Name","bar"))
fwrite(DF, quote='auto') # Просто DF[2,2] автоматически цитируется
write.csv(DF, row.names=FALSE) # такое же числовое форматирование DT = data. table(A=c(2,5.6,-3),B=list(1:3,c("foo","A,Name","bar")),round(pi*1:3 ,2)))
fwrite(ДТ)
fwrite(DT, sep="|", sep2=c("{",",","}")) # }
# НЕ РАБОТАТЬ {
набор.семена(1)
DT = as.data.table( lapply(1:10, образец,
x=as.numeric(1:5e7), size=5e6)) # 382 МБ
system.time(fwrite(DT, "/dev/shm/tmp1.csv")) # 0,8 с
system.time(write.csv(DT, "/dev/shm/tmp2.csv", # 60,6 с
цитата = ЛОЖЬ, row.names = ЛОЖЬ))
system("diff /dev/shm/tmp1.csv /dev/shm/tmp2.csv") # идентичны set.seed(1)
N = 1e7
DT = данные.таблица(
str1=sample(sprintf("%010d",sample(N,1e5,replace=TRUE)), N, replace=TRUE),
str2=sample(sprintf("%09d",sample(N,1e5,replace=TRUE)), N, replace=TRUE),
str3 = образец (sapply (образец (2:30, 100, ИСТИНА), функция (n)
paste0 (образец (БУКВЫ, n, ИСТИНА), свернуть = "")), N, ИСТИНА),
str4 = sprintf («% 05d», образец (образец (1e5,50), N, ИСТИНА)),
num1=sample(round(rnorm(1e6,mean=6.5,sd=15),2), N, заменить=ИСТИНА),
num2=sample(round(rnorm(1e6,mean=6.5,sd=15),10), N, replace=TRUE),
str5 = образец (с ("Y", "N"), N, ИСТИНА),
str6 = образец (с ("M", "F"), N, ИСТИНА),
int1 = образец (потолок (rexp (1e6)), N, заменить = ИСТИНА),
int2=выборка(N,N,заменить=ИСТИНА)-N/2
) # 774 МБ
system.
table(A=c(2,5.6,-3),B=list(1:3,c("foo","A,Name","bar")),round(pi*1:3 ,2)))
fwrite(ДТ)
fwrite(DT, sep="|", sep2=c("{",",","}")) # }
# НЕ РАБОТАТЬ {
набор.семена(1)
DT = as.data.table( lapply(1:10, образец,
x=as.numeric(1:5e7), size=5e6)) # 382 МБ
system.time(fwrite(DT, "/dev/shm/tmp1.csv")) # 0,8 с
system.time(write.csv(DT, "/dev/shm/tmp2.csv", # 60,6 с
цитата = ЛОЖЬ, row.names = ЛОЖЬ))
system("diff /dev/shm/tmp1.csv /dev/shm/tmp2.csv") # идентичны set.seed(1)
N = 1e7
DT = данные.таблица(
str1=sample(sprintf("%010d",sample(N,1e5,replace=TRUE)), N, replace=TRUE),
str2=sample(sprintf("%09d",sample(N,1e5,replace=TRUE)), N, replace=TRUE),
str3 = образец (sapply (образец (2:30, 100, ИСТИНА), функция (n)
paste0 (образец (БУКВЫ, n, ИСТИНА), свернуть = "")), N, ИСТИНА),
str4 = sprintf («% 05d», образец (образец (1e5,50), N, ИСТИНА)),
num1=sample(round(rnorm(1e6,mean=6.5,sd=15),2), N, заменить=ИСТИНА),
num2=sample(round(rnorm(1e6,mean=6.5,sd=15),10), N, replace=TRUE),
str5 = образец (с ("Y", "N"), N, ИСТИНА),
str6 = образец (с ("M", "F"), N, ИСТИНА),
int1 = образец (потолок (rexp (1e6)), N, заменить = ИСТИНА),
int2=выборка(N,N,заменить=ИСТИНА)-N/2
) # 774 МБ
system.