
Как разобрать слово по составу — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
1. Измени слово по числам или по команде одного-двух вопросов, выдели изменяемую часть – окончание. Отметь основу слова (это часть слова без окончания).
2. Объясни значение слова с помощью слова-родственника, подбери ещё одно-два однокоренных, выдели их общую часть – корень.
3. Определи и укажи часть слова перед корнем – приставку, постарайся объяснить её работу.
4. Определи и укажи часть слова после корня перед окончанием – суффикс, подумай о его работе.
5. Проверь, все ли части слова выделены.
Укажем состав имени существительного подставка.
1. Изменю слово по числам: подставки – подставка (изменилось -а, это окончание). Основа подставк-
2. Объясню значение слова: подставка – подставляют, ставят под что-то; подставить. Корень –став.
3. под – приставка
под – приставка
4. -к- – суффикс (называет существительное со значением действия)
Разберём по составу имя прилагательное радостный.
1. радостный– радостная, радостные (изменилось -ый, это окончание)
Основа радостн-.
2. радостный – полный радости, радуюсь, рад
Корень -рад-.
3. суффиксы -ост-, -н-
Укажем состав глагола подумаем.
1. подумаем – подумаю (изменилось -ем, это окончание)
Основа подума-.
2. однокоренные слова – дума, раздумье, думать
Корень дум-.
3. приставка по-
4. суффикс -а-
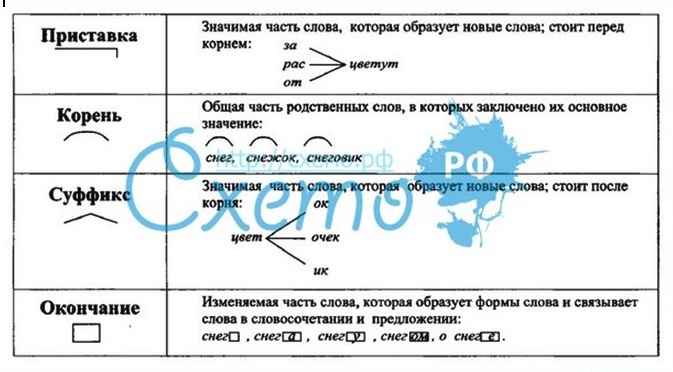
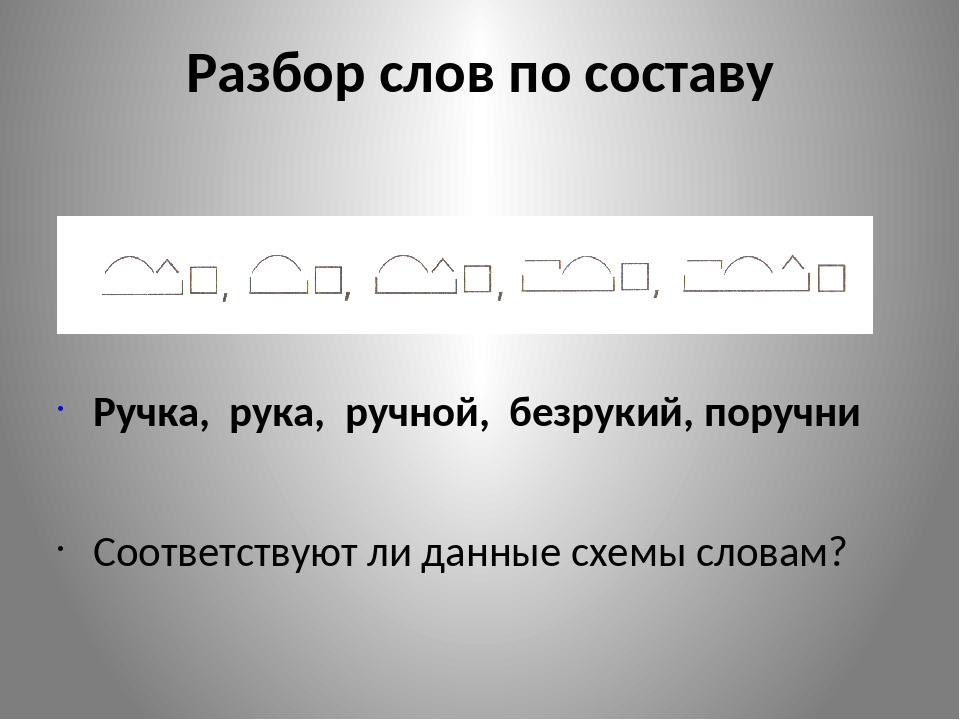
Составьте и запишите слова по схемам с корнем -мор-.
Вам помогут приставка при-, суффикс -ск-.
Море, морской, приморский, приморье.
1. Основа может состоять только из корня: мор-е.
2. В основу может входить, кроме корня, суффикс: мор-ск-ой.
3. В основу могут входить, кроме корня, приставка и суффикс: при-мор-ск-ий.
4. В основу может входить, кроме корня, приставка: при-морь-е.
Чтобы не делать ошибок в разборе слова по составу, нужно учитывать значение слова и значение части слова.
Окончание нулевое, основа лётчик-, мячик-.
В существительном мячик выделяем суффикс -ик-, который придаёт слову значение «маленький» (мячик – это маленький мяч).
А существительное лётчик не имеет значения «маленький». В этом слове другой суффикс -чик-. Существительное обозначает профессию человека. Такое значение придаёт суффикс -чик-
Окончание нулевое, основа дружок-, урок-.
В существительном дружок выделяем суффикс -ок-, который имеет уменьшительно-ласкательное значение (друг – дружок).
А существительное урок не имеет такого значения, потому что в нём нет такого суффикса. Корень -урок- (родственное слово урочный)
Побегу – окончание -у, изменим слово: побегут. Основа побег-.
Основа побег-.
Победа – окончание -а, изменим слово: победы. Основа побед-.
В глаголе побегу приставка по- указывает на начало движения. Корень -бег-.
В существительном победа нет такой приставки, корень -побед- (однокоренные слова: победить, победитель)
Сделаю – сделаем, окончание -ю. Основа сдела-.
Однокоренные слова: дело, поделка. Корень -дел-, приставка с-, суффикс -а-.
Смешу – смешим, окончание -у. Основа смеш-.
Смешу – вызываю смех, корень -смеш-, -смех-, в корне есть чередование согласных х//ш.
Листики – листика, окончание -и. Основа листик-.
Листики – это маленькие листы. Корень -лист-, суффикс -ик-.
Ластики – ластикам, окончание -и. Основа ластик-.
В этом существительном нет суффикса -ик-, корень -ластик- (однокоренное слово ластиковый).
Ухожу – уходим, окончание -у. Основа ухож-.
Ухо – уха, окончание -о, основа ух-.
В глаголе ухожу выделяем приставку у-, которая имеет значение «удаляться». Корень -хож- (родственные слова: ход, ходьба, чередование д//ж в корне).
В существительном ухо нет приставки у-. Однокоренные слова: ушастый, ушки, корень -ух-, -уш-, чередование х//ш.
Удвоенные согласные на стыке приставки и корня:
Попробуйте самостоятельно разобрать слова по составу: касса, рассада, рассольник, рассказ.
В словах рассказ, рассада и рассольник последняя буква приставки и первая буква корня одинаковые.
В слове касса удвоенные согласные в корне.
вернуться на страницу «Русский язык 3 класс» >>>
Если Вам понравилось — поделитесь с друзьями :
Русский язык с репетиторами онлайнПрактичные советы по изучению русского языка
Мы в соцсетях:Морфемный разбор слова онлайн – ТОП-5 сервисов
В школе часто задают выполнить морфемный разбор слова: найти основу, корень, суффикс, окончание Существуют онлайн-сервисы для морфемного разбора.
Я проверила их корректность и выбрала лучший.
МорфемОнлайн
Самый лучший сервис, два следующих просто копируют результаты из него в сокращенном виде.
- Красиво и полно представлены результаты разбора по составу.
- Нет рекламы.
- Есть шпаргалка по разбору слова по составу – теория описана кратко и просто.
- Современный и полный словарь слов.
По поводу полноты словаря: это единственный сайт, на котором слово «онлайн» представлено аж в трех лексических значениях, и все значения прояснены. И соответственно разобрано слово тоже в трех вариантах. На большинстве сайтов этого слова либо нет, либо дано только одно значения. Не считая сайтов-копий, которые я поставила на 2-е и 3-е место соответственно. Но если честно, нет ни единой причины предпочитать другие сайты этому.
Для того, чтобы выбрать ответ, надо только определить часть речи и лексическое значение. Ведь одно и то же слово может быть сразу несколькими частями речи в зависимости от контекста.
Существительное:
Я сижу в онлайне.
Я сижу в кафе.
Наречие:
Я смотрю фильм онлайн.
Я сижу давно.
Есть шпаргалка по разбору слова по составуСоставСлова
Урезанная копия morphemeonline, где не объясняется лексическое значение слова «онлайн». Кроме того, есть реклама. Как я уже сказала, ни единой причины использовать этот сайт по сравнению с предыдущим нет.
Результат работы сервиса СоставСловаЛексическое значение слов «онлайн» не объяснено, хотя оно не очевидно. Ведь есть существительное «онлайн», в котором можно сидеть. Есть наречие «онлайн»: например, смотреть «онлайн». И есть наречие «онлайн» в противоположность «офлайн», будет приставка. Во всех трех случаях разбор по составу разный.
Но не пугайтесь, если не понимаете разницу, в школьных домашних заданиях слова для разбора обычно попроще. Этот пример приведен для того, чтоб вы поняли преимущества первого сайта.
Как видите, скриншот даже не вмещает все три разбора из-за наличия рекламы.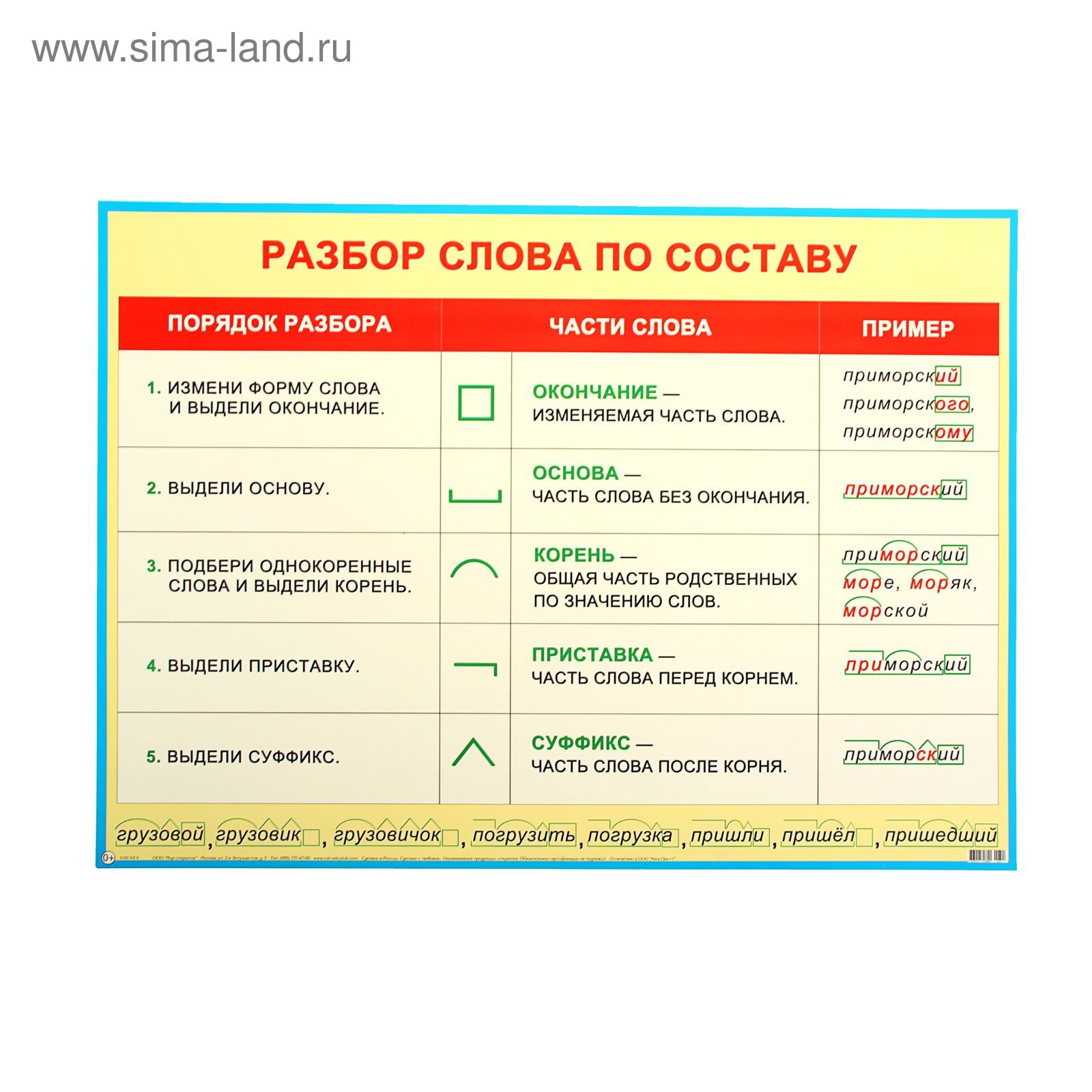
ВикиСлово
Тоже урезанная копия morphemeonline, где не объясняется лексическое значение. Кроме того, урезано описание морфем – только картинка.
Есть дополнительный сервисы: фонетический, морфологический разбор.
ВикиСлово
Но в этом сервисе, как и во всех, кроме самого первого, больше минусов, чем плюсов. Один из них реклама.
Есть навязчивая реклама
УдарениеРу
Словарь не полностью представлен, найдено только одно значение слова «онлайн». Разбор слова по составу представлен некрасиво, описание с сокращениями, нет картинок.
Как видите, найдено только одно основное значение слова:
Результат работы сервиса УдарениеСловОнлайн
Очень ограниченный словарь, слово «онлайн» не найдено вообще. Разбор по составу представлен некрасиво. Есть реклама, интерфейс устаревший неудобный.
Ужасный интерфейс СловОнлайнТрудно пользоваться, при поиске надо не забыть выбрать «Разбор по составу (Морфемный)» и потом щелкнуть найденное слово. Тут много словарей, но устаревших, так как наше слово в них все равно не найдено.
Тут много словарей, но устаревших, так как наше слово в них все равно не найдено.
Разница между морфемный и морфологическим разбором
И напоследок разъясню разницу между морфемным и морфологическим разбором слова.
Морфемный разбор – это разбор по составу, тут ручкой отмечают корень, суффикс, окончание.
Что такое морфемный разбор словаА при морфологическом разборе ручкой ничего не отмечают, это просто определение склонения, рода и других (зависит от слова) характеристик части речи.
Что такое морфологический разбор слова
Разбор слова по составу — Штрих-код: 9785944550866
Результаты поиска Штрих-код: 9785944550866
Наши пользователи определили следующие наименования для данного штрих-кода:
| № | Штрих-код | Наименование | Единица измерения | Рейтинг* |
|---|---|---|---|---|
| 1 | 9785944550866 | РАЗБОР СЛОВА ПО СОСТАВУ | ШТ. |
3 |
| 2 | 9785944550866 | СЛОВАРЬ РАЗБОР СЛОВА ПО СОСТАВУ.СЛОВАРИК ШКОЛЬН. | ШТ. | 1 |
| 3 | 9785944550866 | РАЗБОР СЛОВА ПО СОСТАВУ СЛОВАРИК ШКОЛЬНИКА / 978-5-94455-086-6, ШТ (1 ШТ)) | ШТ. | 1 |
| 4 | 9785944550866 | РАЗБОР СЛОВА ПО СОСТАВУ СЛОВАРИК ШКОЛЬНИКА / 978-5-94455-086-6 | ШТ. | 1 |
| 5 | 9785944550866 | СЛОВАРИК ШКОЛЬНИКА»РАЗБОР СЛОВА ПО СОСТАВУ» | ШТ. | 1 |
* Рейтинг — количество пользователей, которые выбрали это наименование, как наиболее подходящее для данного штрих-кода
Поиск: Разбор слова составу
морфемного разбора слова, разбора по составу (корневой суффикс, префикс, окончание). Разбор состава (морфемы) слова «sloppy» Морфемный разбор слова sloppy
Разбор слова по составу один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе это также называется синтаксический анализ морфемы … Сайт с практическими рекомендациями поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
В школьной программе это также называется синтаксический анализ морфемы … Сайт с практическими рекомендациями поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово?
При синтаксическом разборе морфем соблюдайте определенную последовательность выделения значимых частей.
Начните с того, чтобы «убрать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумных разделений. Определите значения морфем и выберите одинаковые корневые слова, чтобы подтвердить правильный анализ.- Запишите слово так же, как и в домашнем задании. Прежде чем приступить к разборке сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи он относится. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (имеет окончание) или неизменный (не имеет окончания)
- есть ли у него формирующий суффикс?
- Найдите концовку.
 Для этого склоняйтесь по регистру, меняйте число, пол или человека, спрягайте — переменная часть будет окончанием.Помните об изменяемых словах с нулевым окончанием, обязательно укажите, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
Для этого склоняйтесь по регистру, меняйте число, пол или человека, спрягайте — переменная часть будет окончанием.Помните об изменяемых словах с нулевым окончанием, обязательно укажите, если оно есть: sleep (), friend (), audibility (), gratitude (), ate (). - Выделите основу слова как часть без окончания (и формирующего суффикса).
- Обозначьте префикс в базе (если есть). Для этого сравните одинаковые корневые слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки сопоставьте слова с разными корнями и с одним и тем же суффиксом, чтобы они выражали одно и то же значение.
- Найдите корень в основании. Для этого сравните несколько связанных слов. Их общая часть — это корень. Запомните одни и те же корневые слова с чередующимися корнями.
- Если в слове два (или более) корня, обозначьте соединяющую гласную (если есть): листопад, звездолет, садовник, пешеход.
- Отметьте формирующие суффиксы и постфиксы (если есть)
- Еще раз проверьте синтаксический анализ и выберите все значимые части с помощью значков
В начальной школе разобрать слово — означает выделить окончание и основу, затем обозначить префикс суффиксом, подобрать одинаковые корневые слова и затем найти их общую часть: корень, и все.
* Примечание: Минобрнауки России рекомендует для общеобразовательных школ три учебных комплекса по русскому языку в 5-9 классах. У разных авторов морфемный анализ по составу отличается подходом. Чтобы избежать проблем с домашним заданием, сравните приведенный ниже порядок анализа с вашим учебником.
Порядок полного синтаксического анализа морфем по составу
Во избежание ошибок предпочтительно связывать синтаксический анализ морфем с деривационным синтаксическим анализом.Такой анализ называется формально-семантическим.
- Определите часть речи и проведите графический морфемный анализ слова, то есть обозначьте все доступные морфемы.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы словоформы (если есть)
- Запишите основу слова (без формирующих морфем: окончаний и формирующих суффиксов)
- Найдите морфемы. Выпишите суффиксы и префиксы, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный.
 Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание». - Запишите корень, подберите одинаковые корневые слова, укажите возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного синтаксического анализа глагола «спал»:
- окончание «а» указывает на женскую форму глагола, единственного числа, прошедшего времени, сравните: проспал;
- основание гандикапа «проспал»;
- два суффикса: «a» — суффикс основы глагола, «l» — этот суффикс, образует глаголы прошедшего времени,
- приставку «pro» — действие со значением потери, неудобства, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «cn» — в родственных словах возможны чередования cn // cn // sleep // syp.
 Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
Неаккуратная схема парсинга:
Неряшливая
Разбор словесной композиции.
Состав слова «sloppy»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова sloppy
carelessДетальный разбор слова в a неосторожный способ.Слово cope, префикс, суффикс и окончание слова. Мофема разбор слова неаккуратна, его схема и часть слова (морфология).
- Схема морфем: sloppy / n / a
- Структура слова по морфемам: корень / суффикс / окончание
- Схема (построение) слова sloppy по составу: корень sloppy + суффикс n + окончание th
- Список морфем в слове коряво:
- небрежно — корень
- n — суффикс
- th — конец
- Типы морфов и их количество в слове неаккуратное:
- доставка: отсутствует — 0
- королева: небрежно — 1
- соединение лед: отсутствует — 0
- cyffix: n — 1
- постфикс: отсутствует — 0
- конец: th — 1
Все морфемы в слове: 3.
Производный синтаксический анализ слова sloppy
- Основа слова: небрежно ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс n , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образуется в 1 (один) способ .
См. Также другие словари:
Однокорневые слова … это слова с корнем … принадлежащие к разным частям речи, и в то же время близкие по значению… Слова с тем же корнем, что и у слова sloppy
Как будет слово sloppy в единственном и множественном числе. Словенский дословно
Полный морфологический анализ слова «небрежный»: часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, где это слово изучается … Морфологический разбор sloppy
Ударение в слове небрежно: какой слог ударен и как … Слово «небрежный» правильно пишется как… Ударение в слове sloppy
Синонимов к слову sloppy. Онлайн-словарь синонимов: найдите синонимы к слову «небрежный». Синонимические слова, похожие слова и похожие выражения в … Синонимы к небрежному
Онлайн-словарь синонимов: найдите синонимы к слову «небрежный». Синонимические слова, похожие слова и похожие выражения в … Синонимы к небрежному
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи … Антонимы к небрежному
Анаграммы (составьте анаграмма) к слову sloppy, смешивая буквы … Анаграммы для слова sloppy
Морфемический разбор слова sloppy
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфемы (части слова), входящие в данное слово.
Морфемный синтаксический анализ слова sloppy очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.
 Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова; - Следующий шаг — поиск корня слова. Подбираем родственные слова для неосторожных (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Остальные морфемы мы находим, выбирая другие слова, образованные таким же образом.
Как видите, синтаксический анализ морфемы выполняется просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Морфемный синтаксический анализ слова (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбораНеаккуратная схема парсинга:
небрежная
Разбор словесной композиции.
Состав слова «небрежно»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова случайно
случайно Подробная разбивка слова небрежно составленный. Слово cope, префикс, суффикс и окончание слова. Мофема небрежное расположение слова, его схема и части слова (морфология).
Слово cope, префикс, суффикс и окончание слова. Мофема небрежное расположение слова, его схема и части слова (морфология).
- Схема морфем: небрежный / н / о
- Структура слова по морфемам: корень / суффикс / суффикс
- Схема (построение) слова небрежно в составе: корень небрежный + суффикс n + суффикс o
- Список морфем словом случайно:
- небрежный — корень
- n — суффикс
- o — суффикс
- Типы морфов и их количество в слове неаккуратно:
- доставка: отсутствует — 0
- королева: небрежно — 1
- соединение ледяное: отсутствует — 0
- cyffix: но — 2
- постфикс: отсутствует — 0
- конец: нулевое окончание.–0
Все морфемы в слове: 3.
Производный синтаксический анализ слова неаккуратно
- Основа слова: случайно ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс но , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образуется в 1 (один) способ .

См. Также другие словари:
Однокорневые слова… это слова с корнем … принадлежащие к разным частям речи, и в то же время близкие по значению … Однокорневые слова к слову случайно
Какое слово в слово случайно в единственном и множественном числе . Склонение слова «небрежно» в падежах
Полный морфологический анализ слова «небрежно»: часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, где изучается слово … Неосторожный морфологический разбор
Ударение в слове невнимательное: на какой слог ударение и как… Слово «небрежно» написано правильно как … Ударение в слове неосторожно
Синонимы к слову «небрежно». Онлайн-словарь синонимов: найдите синонимы к слову «небрежно». Синонимы, похожие слова и похожие выражения в … Синонимы к неосторожному
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи … Антонимы к случайному
Анаграммы анаграмма) к слову случайно, путём смешивания букв . .. Анаграммы для слова случайно
.. Анаграммы для слова случайно
Неосторожный разбор морфемного слова
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем ( части слова), входящие в данное слово.
Морфемный разбор слова обычно выполняется очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- Следующий шаг — поиск корня слова. Родственные слова подбираем по неаккуратности (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Остальные морфемы мы находим, выбирая другие слова, образованные таким же образом.

Как видите, синтаксический анализ морфемы выполняется просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Морфемный синтаксический анализ слова (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбора(PDF) Разбор GLR с несколькими грамматиками для запросов естественного языка
Разбор GLR с несколькими грамматиками для запросов естественного языка • 143
Транзакции ACM по обработке информации на азиатских языках, Vol. 1, No. 2, June 2002.
работает с соответствующим субпарсером.Мы объединяем выходы субпарсеров
вместе, чтобы сформировать общий синтаксический анализ входной строки. Наши экспериментальные результаты показывают, что
разбиение грамматики может уменьшить общий размер таблицы синтаксического анализа на порядок,
по сравнению с использованием одной контекстно-свободной грамматики, полученной из обучающих наборов ATIS
. Полный анализ синтаксического анализа одного синтаксического анализатора GLR такой же, как подходы для синтаксического анализа
Полный анализ синтаксического анализа одного синтаксического анализатора GLR такой же, как подходы для синтаксического анализа
. Однако композиция синтаксического анализатора может производить частичный синтаксический анализ, и
, таким образом, достигает более высокой точности понимания.Мы также сравнили две стратегии составления синтаксического анализатора
: каскадирование и прогнозирующее сокращение. Каскадирование применяет субпарсеры в каждой позиции
во входной строке (или решетке) в порядке, указанном вызывающим графом коллекции субграмматик
. Мы использовали алгоритм кратчайшего пути, чтобы найти лучший путь
через несколько выходов подпарсера, чтобы охватить всю входную строку. Predictive
pruning следует ограничениям предсказания левого угла при вызове различных подпараметров
и, следовательно, более эффективен с точки зрения вычислений, чем каскадирование.Дополнительные вычисления
в каскаде (по сравнению с прогнозирующим сокращением) расходуются на производство
дополнительных частичных синтаксических анализов, поскольку каскадирование позволяет синтаксическим деревьям начинаться и заканчиваться во всех местах
входного предложения. Текущая работа включает в себя разработку подхода к композиции гибридного анализатора
Текущая работа включает в себя разработку подхода к композиции гибридного анализатора
, встроенного в архитектуру мультипарсера, которая может составлять
различных синтаксических анализаторов (синтаксический анализатор GLR, синтаксический анализатор Эрли и т. Д.). Мы также экспериментируем с
с автоматическими методами разбиения грамматик. для замены ручного процесса, а также
, поскольку включает вероятности ранжирования альтернативных деревьев синтаксического анализа в выходных данных данных WSJ
в Penn Treebank.
БЛАГОДАРНОСТЬ
Мы хотели бы поблагодарить нескольких анонимных рецензентов за их комментарии и предложения.
СПИСОК ЛИТЕРАТУРЫ
ЭБНИ, С. 1991. Разбор по частям. В «Принципиальный синтаксический анализ: вычисления и психолингвистика», R. C.
Berwick et al., Eds. Kluwer Academic Publishers, 1991.
AHO, A., SETHI, I, R. и ULLMAN, J. 1986. Компиляторы: принципы, методы и инструменты. Addison-Wesley,
Reading, MA: 1986.
AMTRUP, J.1995. Параллельный анализ: разные схемы распределения диаграмм. В материалах 4-го международного семинара
по технологиям синтаксического анализа (ACL / SIGPARSE, сентябрь 1995 г.), 12-13.
EARLEY, J. 1968. Эффективный контекстно-свободный алгоритм синтаксического анализа. Кандидат наук. диссертация, Университет Карнеги-Меллона,
Питтсбург, Пенсильвания, 1968.
ХИЛЛИЕР Ф. С. и ЛИБЕРМАН Г. Дж. 1995. Введение в исследования операций. 6-е изд. McGraw-Hill, 1995.
ДЖОНСОН, С.С. 1975. YACC: еще один компилятор компилятора.Tech. Rep. CSTR 32, Bell Laboratories,
Murray Hill, NJ., 1975.
KITA, K., MORIMOTO, T. и SAGAYAMA, S. 1993. Анализ LR с тестом достижимости категорий, примененный к распознаванию речи
. IEICE Trans. Инф. Syst. Е 76-Д, 1 (1993), 23-28.
KITA, K., TAKEZAWA, T., HOSAKA, J., EHARA, T. и MORIMOTO, T. 1990. Распознавание непрерывной речи
с использованием двухуровневого анализа LR. В материалах Международной конференции по разговорному языку
Processing, 21.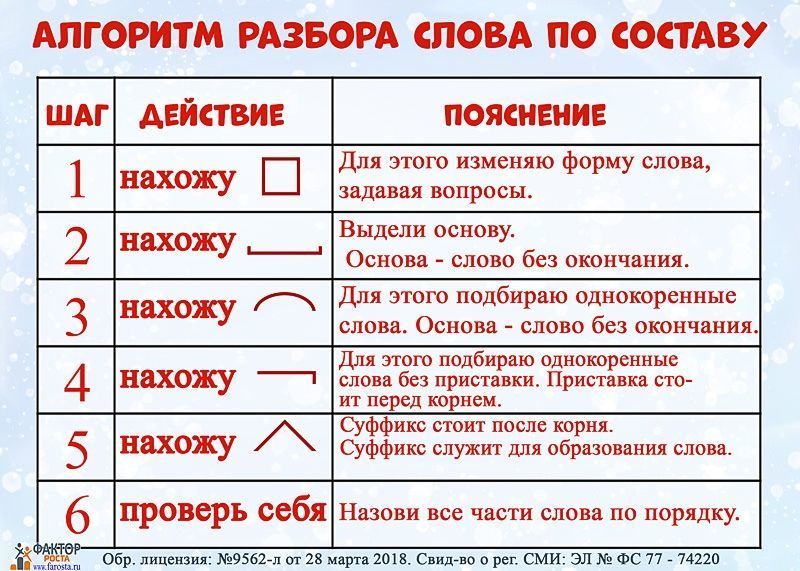 3.1, 905-908.
3.1, 905-908.
КИТА, К., ТАКЕЗАВА, Т. и МОРИМОТО, Т. 1991. Распознавание непрерывной речи с использованием двухуровневого анализа LR.
IEICE Пер. Е 74, 7 (1991), 1806-1810.
КОРЕНЯК А. 1969. Практический метод построения LR (k). Commun. ACM 12, 11 (ноябрь 1969).
LUK, P. C., MENG, H., and WENG, F. 2000. Грамматическое разбиение и состав синтаксического анализатора для понимания естественного языка.
. В материалах Международной конференции по обработке разговорной речи (Пекин,
2000).
Добросовестная морфема. Разбор состава (морфемы) слова «прилежный». Как найти морфему в слове
Разбор словесной композиции.
Состав слова «усердный»:
Морфемный разбор слова усердный
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфемы данного слова (части слова ).
Морфемный разбор слова прилежный очень прост.Для этого достаточно соблюдать все правила и порядок разбора.
Давайте сделаем синтаксический анализ морфемы правильным, но для этого достаточно пройти 5 шагов:
- определение части речи слова прилежный — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.
 Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова; - Следующий шаг — поиск корня слова. Подбираем родственные слова для усердных (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Остальные морфемы для усердного мы находим, выбирая другие слова, образованные таким же образом, как и усердный.
Как видите, синтаксический анализ морфемы усердно проделан просто.Теперь давайте определимся с основными морфемами слова прилежный и проясним.
См. Также другие словари:
Какое слово означает прилежный в единственном и множественном числе …. Прилежный
Полный морфологический анализ слова «прилежный»: часть речи, начальная форма, морфологические признаки и словоформы. Направление науки о языке, где изучается слово … Морфологический разбор прилежный
Ударение в слове прилежное: на какой слог ударение и как… Слово «прилежный» правильно пишется как… Ударение в слове прилежный
Синонимы слова «прилежный». Онлайн-словарь синонимов: найдите синонимы к слову «прилежный». Слова-синонимы, похожие слова и похожие выражения в … Синонимы к слову прилежный
Онлайн-словарь синонимов: найдите синонимы к слову «прилежный». Слова-синонимы, похожие слова и похожие выражения в … Синонимы к слову прилежный
Разбор словесной композиции.
Состав слова «усердно»:
Морфемный разбор слова усердно
Морфемный разбор слова обычно называется разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова выполняется старательно очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте сделаем морфемный синтаксический анализ правильно, и для этого нам достаточно пройти 5 шагов:
- Прилежное определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец.
 Это будет основой слова;
Это будет основой слова; - Следующий шаг — поиск корня слова. Мы старательно подбираем родственные слова для (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Мы находим остальные морфемы для усердно, выбирая другие слова, которые сформированы таким же образом, как усердно.
Как видите, парсинг морфемы старательно делается просто.Теперь давайте тщательно определим основные морфемы слова и проанализируем их.
См. Также другие словари:
Что означает слово «усердно» в единственном и множественном числе. Склонение слова усердно
Полный морфологический анализ слова «усердно»: часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово … Морфологический разбор усердно
Ударение в слове старательное: на какой слог падает ударение и как… Слово «прилежно» правильно написано как … Ударение в слове прилежное
Разбор слова по составу один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе это также называется разбор морфем … Сайт с практическими рекомендациями поможет вам правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
В школьной программе это также называется разбор морфем … Сайт с практическими рекомендациями поможет вам правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово?
При синтаксическом разборе морфем соблюдайте определенную последовательность выделения значимых частей … Начните с того, чтобы «убрать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумных разделений. Определите значения морфем и выберите одинаковые корневые слова, чтобы подтвердить правильный анализ.
- Запишите слово так же, как и в домашнем задании. Прежде чем приступить к разборке композиции, выясните ее лексическое значение (значение).
- Определите из контекста, к какой части речи он относится. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (имеет окончание) или неизменный (не имеет окончания)
- есть ли у него формирующий суффикс?
- Найдите концовку.
 Для этого в склонении по падежу измените число, пол или лицо, спрягите — переменная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
Для этого в склонении по падежу измените число, пол или лицо, спрягите — переменная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate (). - Выделите основу слова как часть без окончания (и формирующего суффикса).
- Обозначьте префикс в базе (если есть). Для этого сравните одинаковые корневые слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки сопоставьте слова с разными корнями и с одним и тем же суффиксом, чтобы они выражали одно и то же значение.
- Найдите корень в основании. Для этого сравните несколько связанных слов. Их общая часть — это корень. Запомните одни и те же корневые слова с чередующимися корнями.
- Если в слове два (или более) корня, обозначьте соединяющую гласную (если есть): листопад, звездолет, садовник, пешеход.
- Отметьте формирующие суффиксы и постфиксы (если есть)
- Еще раз проверьте синтаксический анализ и выберите все значимые части с помощью значков
В первичных классах разобрать слово — означает выделить окончание и основу, затем обозначить префикс суффиксом, выбрать одинаковые корневые слова и затем найти их общую часть: корень, и все.
* Примечание: Минобрнауки России рекомендует для общеобразовательных школ три учебных комплекса по русскому языку в 5-9 классах. У разных авторов морфемный анализ по составу отличается подходом. Чтобы избежать проблем с выполнением домашнего задания, сравните приведенный ниже порядок синтаксического анализа с вашим учебником.
Порядок полного синтаксического анализа морфем по составу
Во избежание ошибок предпочтительно связывать синтаксический анализ морфем с деривационным синтаксическим анализом.Такой анализ называется формально-семантическим.
- Определите часть речи и проведите графический морфемический анализ слова, то есть обозначьте все доступные морфемы.
- Запишите окончание, определите его грамматическое значение. Укажите суффиксы словоформы (если есть)
- Запишите основу слова (без формирующих морфем: окончаний и формирующих суффиксов)
- Найдите морфемы. Выпишите суффиксы и префиксы, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный.
 Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание». - Запишите корень, подберите одинаковые корневые слова, укажите возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного синтаксического анализа глагола «спал»:
- окончание «а» указывает на форму глагола женского рода, единственного числа, прошедшего времени, сравните: проспал;
- основание гандикапа «проспал»;
- два суффикса: «a» — суффикс основы глагола, «l» — этот суффикс, образует глаголы прошедшего времени,
- приставку «pro» — действие со значением потери, неудобства, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «cn» — в родственных словах возможно чередование cn // sn // sleep // syp.
 Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
синонимов, антонимов и парсинговых слов. Как пишется слово «дольше»?
К какой части речи относится слово «длиннее»? Ответ на этот вопрос вы узнаете из материалов этой статьи.Кроме того, мы расскажем, как разобрать такую лексическую единицу по ее составу, какой синоним можно заменить и так далее.
Общая информация
Как правильно написать слово «длиннее» знает почти каждый. Но не все знают, к какой части речи идет речь. В связи с этим предлагаем начать нашу статью с разъяснения именно этого вопроса.
Определить часть речи
Чтобы определить, какая часть речи принадлежит слову «длиннее», его следует указать в его исходной форме — «длинный».Далее требуется задать подходящий вопрос: «что?» — длинный. Следовательно, это имя — прилагательное. Но здесь возникает новый вопрос: почему слово «более длинный» оканчивается не на -е или -е, а на -е? Для этого необходимо вспомнить особенности названий прилагательных.
Степени сравнения прилагательных
Все качественные прилагательные имеют такой вариативный морфологический признак, как степень сравнения. Из школьной программы мы знаем, что в русском языке есть две степени:
Рассмотрим их подробнее.
Превосходная степень
Такой знак указывает на наименьшую или наибольшую степень проявления признака (например, самая высокая гора) или на очень маленькую или большую степень проявления признака (например, на самого доброго человека).
Следует особо отметить, что отличная степень прилагательных образуется путем добавления к основным словам суффиксов -yush- или -aish-, приставок большинства, а также дополнительных лексических единиц «самый», «самый», «наименее», «все» или «все».
Как мы выяснили выше, слово «длиннее» — это прилагательное имени. Однако он не стоит в высшей степени, поскольку не показывает суффиксы -yesh- или -aish-, префиксы большинства, а также дополнительные лексические единицы «большинство», «большинство», «меньше всего», «все» или «всего».
сравнительный
Такой знак названий прилагательных указывает (например, Маша выше Саши, это озеро глубже того) или на этот предмет, но в другом случае (Маша выше, чем была в прошлом году, здесь озеро глубже, чем в том).
Следует отметить, что сравнительная степень формируется на основе названий прилагательных с помощью суффиксов типа -sh / -e-ee (-e) и -e (например, выше, быстрее, раньше, глубже), префиксов (например, новее), а также из других основ (например, хорошо — лучше, хуже — хуже) или дополнительных лексических единиц (более или менее).
Из всего вышесказанного мы можем с уверенностью сказать, что слово «дольше» является прилагательным в сравнительной степени. Он будет состоять из основания слова long и суффикса her.
Как пишется слово «дольше»?
О том, как написано это слово, знает практически каждый. Хотя некоторые люди на момент написания все же могут ошибаться. Например, довольно часто в письме встречается выражение: «Посмотрим, у кого нос длиннее». Это ошибочное написание слова. В конце концов, его следует использовать только с двумя буквами «n». Чтобы доказать это утверждение, приведем соответствующее правило русского языка.
Это ошибочное написание слова. В конце концов, его следует использовать только с двумя буквами «n». Чтобы доказать это утверждение, приведем соответствующее правило русского языка.
Слово «более длинный» образовано от начальной формы прилагательного «длинный».Как видите, в нем две буквы «n». Ведь, в свою очередь, такая лексическая единица произошла от существительного «длина» с добавлением суффикса -n-. Следовательно, и «длинный», и «длинный» пишутся только с двойным «n». Приведем наглядный пример:
- Ее платье длиннее моего.
- Она намного длиннее своей подруги.
- Дольше трассы я не видел в жизни.
- Он был настолько длинным, что с трудом поместился в машине.
Кстати, в этой лексической единице некоторые сомневаются в правильности написания буквы «и».Например, часто в тексте можно встретить слово «еще». Как в этом случае это проверить? Для этого следует применить правило, которое применяется к безударным гласным в корне слова. То есть к представленной лексической единице требуется выбрать такое проверочное слово, в котором сомнительная буква будет находиться в ударной позиции. Например, «длина». Как видите, буква «и» в этом слове подчеркнута. Поэтому правильнее будет быть «длиннее».
Например, «длина». Как видите, буква «и» в этом слове подчеркнута. Поэтому правильнее будет быть «длиннее».
Морфемный анализ слова
Нередко учителя просят своих учеников произвести разбор слова по композиции.«Лонгер» — лексическая единица, которую довольно проблематично подвергнуть морфемическому анализу. Однако мы рассмотрели выше, как образовано это слово. Поэтому разобрать его по составу несложно.
Итак, проведем морфемный анализ названия прилагательного «длиннее», которое стоит в сравнительной степени:
- Определим окончание. В данном случае это ноль.
- Определяем приставку. В нашем случае префикс отсутствует.
- Определите суффикс.Сравнительный суффикс в этом слове — -e-. Также есть суффикс -n-, относящийся к основанию.
- Определить корень. Корень этого слова — «длина».
- Определяем основу. Основа имени прилагательного — «длиннее» — «долго».
Подбираем синоним
Синонимами в русском языке называют слова одной части речи, разные по написанию и звучанию, но имеющие схожее лексическое значение. Приведем наглядный пример:
Приведем наглядный пример:
- small — малый;
- large — большой;
- beautiful — красиво;
- некрасиво — ужасно;
- хочу — желание;
- talk — разговор;
- большой — большой;
- create — создать;
- вещь объект;
- die — погибнуть;
- to keep — защелкнуть;
- холодный — не теплый;
- медленно — медленно и так далее.
Таким образом, синоним слова «длиннее» должен быть названием прилагательного и по возможности стоять в сравнительной степени. Например:
- длиннее — удлиненная;
- длиннее — длиннее;
- длиннее — растянуто;
- длиннее — более продолжительное;
- длиннее — выше;
- длиннее — длиннее и тд.
Однако следует отметить, что синонимы к этому слову следует подбирать так, чтобы в контексте они выглядели естественно.Было бы ошибкой сказать: «Он длиннее его», так как нужно сказать: «Он выше ее».
Подбираем антонимы
Антонимами в русском языке называют слова одной и той же части речи, которые отличаются по написанию и звучанию, но имеют прямо противоположные лексические значения.
- true False;
- красиво — некрасиво;
- говори — молчи;
- холодный — горячий;
- длинный короткий;
- морозно-горячий;
- большой маленький;
- fast — медленный;
- бегать — стоять;
- добрый злой;
- высокий Низкий;
- плохо хорошо и тд.
Итак, попробуем найти антоним слову «длиннее»:
- long — короче;
- длиннее — меньше.
Аналогичным образом можно выбрать синонимы и антонимы для начальной формы прилагательного «длинный». Например: высокий, длинный, удлиненный и короткий, лаконичный, короткий и так далее.
Земной суффикс. «Земля» — морфемный анализ слова, анализ композиции (корень soffix, приставка, окончание)
Схема анализа состава Земля:
земля
Продам слова в композиции.
Состав слова «земля»:
Соединительные гласные: отсутствует
POCTFICC: отсутствует
Морфемы — части слова Земля
земля Подробная PAZBOP Calway Earth Po Cost. Коппи, префикс, суффикс и конечные слова. MOPFEM PAZBOP CERVA EARTH, EGO CXEMA и МИНУСЫ (MOPFEM).
Коппи, префикс, суффикс и конечные слова. MOPFEM PAZBOP CERVA EARTH, EGO CXEMA и МИНУСЫ (MOPFEM).
- Схема морфем: Земля / I
- Структура слова Морфема: Корень / Окончание
- Схема (дизайн) Слова Земля в составе: земля корень + конец
- Список морфем в слове Земля:
- Bid MopFEM и их число в слове Земля:
- собственно
- : отсутствует — 0
- copa: земля — 1
- cOEDINITE HLACHNA: отсутствует — 0
- cyFFICC: отсутствует -0
- pOCTFICC: отсутствует — 0
- выезд: и — 1
BCEGO MORFEM в CLA: 2.
Словообразующее слово Слово
- Основа слова: основание ;
- Аффиксы образования: префикс отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Образование пищи: или непроизводное, то есть не образованное из другого отдельного слова; или образовано методом бессфиксации: отсечение суффикса от основы прилагательного или глагола ;
- Способ образования:
или непроизводное, то есть не образованное от другого отдельного слова; или образовано методом бессфиксации: отсечение суффикса от основания прилагательного или глагола
.
См. Также в других словарях:
Отдельные слова … Это слова, имеющие корень … принадлежащие к разным частям речи, и в то же время близкие по значению … Отдельные слова к слову Земля
Заглушите слово Земля для падежей в единственном и кратном числе …. Склонение слова Земля для Пада
Полный морфологический анализ слова «Земля»: часть речи, исходная форма, морфологические признаки и форма слова. Направление языкознания, где изучается слово… Морфологический анализ земля
Ударение в слове Земля: на какой слог падает ударение и как … слово «земля» правильно пишется как … Курс земли
Синонимы «Земля». Словарь синонимов онлайн: Подберите синонимы к слову «земля». Пел синонимы, похожие слова и близкие по смыслу выражения в … Кононимы к слову Земля
Антонимы … имеют противоположное значение, разные по звучанию, но относятся к одной и той же части речи … Антонимы для слово Земля
Анаграммы (составьте анаграмму) к слову Земля с помощью движущихся букв…. Анаграмма к слову Земля
Анаграмма к слову Земля
Слово из букв составляют анаграмму. Вы ввели буквы «Земля», можете составить следующие слова из … Составьте слова из заданных букв земля
К чему снится земля толкование снов, узнайте бесплатно в нашем соннике, что означает мечта о земле. … увиденная во сне земля означает, что … Сонник: К чему снится земля
Разбор слова Морфем
Анализ слова Морфем принято называть анализом слов по составу — это поиск и анализ Морфам входит в указанное слово (части слова).
Морфемный анализ слов Земля очень прост. Для этого соблюдайте все правила и порядок проведения анализа.
Сделайте это анализ морфемы Это верно, и для этого мы просто пройдем через 5 шагов:
- определение слова «речь» — это первый шаг;
- второй — выделяем окончание: для изменяющихся слов мы прячем или склоняем, для неизменяемого (глагольные духи, наречия, некоторые имена существительных и имена прилагательных, официальные части речи) — окончания не являются ;
- дальше ищем основу.
 Это самая легкая часть, ведь для определения основы нужно просто отрезать конец. Это будет основой слова;
Это самая легкая часть, ведь для определения основы нужно просто отрезать конец. Это будет основой слова; - На следующем шаге нужно найти корень слова. Подбираем родственные слова для Земли (их еще называют одноручными), тогда корень слова будет очевиден;
- Мы находим оставшиеся морфемы, выбирая другие слова, образованные таким же образом.
Как видите, анализ морфем Делается просто.Теперь определимся с основными морфемами слова и проведем его разбор.
* Morphem word parsing (анализ слов в композиции) — поиск корня, консолей, суффикса, конца и основы слов Анализ слов по составу на сайте сайта производится по словарю морфемного анализа.земля
Состав слова «земля» :
корень — [Земля], окончание — [I]
Предлагает со словом «Земля»
И он пришел внезапно: за его спиной ничего нет , край, земля рушится, и только тьма у стены, звезды, вечный холод.
Но вторая рука Рубахина, швартовная машина на земле, взобралась на него и с изрезанным ртом с красивыми губами и легким дрожащим вздохом.
Так, наверное, старый дуб нащупывает свою кукурузу, шаркая корнями из земли.
Планер получает достаточно энергии, чтобы оторваться от земли и взлететь с холма.
Дед снимает ощущение сырости кожи, вытряхивает из них мелкие камешки, землю, потом выдавливает оттуда пучки бархатистой специальной альпийской травы, которую для мягкости закладывают в сенсоры.
Кроме того, эта же техника позволит быстро и засыпать землю под кустарники и клумбы.
Однако сделать это им не удалось: над тоннелем Stater слой льда и суши.
Вот кубанцев, скажем так, можно сортировать, потому что земля у них голая, как пальма …
Текст этой лекции стал популярным, но министерство образования одной из земель ФРГ запретило ее вузам.
Слово разбирать по составу, что это значит?
Свернуть слова в композиции Один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе также называется морфемный анализ . Сайт HOW-TO-ALL поможет вам правильно разобрать в составе онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, глагол, наречие, числительное.
В школьной программе также называется морфемный анализ . Сайт HOW-TO-ALL поможет вам правильно разобрать в составе онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, глагол, наречие, числительное.
План: как слово разобрать?
При проведении морфемного анализа соблюдайте определенную последовательность выделения значимых частей. Начнем с того, чтобы «отстрелять» морфемы с конца, метод «сдирания корня». Подходите к анализу осмысленно, избегайте необдуманных разделений.Определите значения морфемы и выберите односторонние слова, чтобы подтвердить правильность анализа.
- Напишите слово в той же форме, что и в домашнем задании. Прежде чем приступить к разборке сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи он применяется. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (есть) или неизменный (нет конца)
- есть ли у него формирующий суффикс?
- Найди конец.
 Для этого подкрадитесь к корпусу, измените номер, род или грань, спрайты — вариативная часть будет завершением. Помните об изменении слов с нулевым окончанием, обязательно укажите, если это возможно: sleep (), friend (), слышание (), спасибо (), при попытке ().
Для этого подкрадитесь к корпусу, измените номер, род или грань, спрайты — вариативная часть будет завершением. Помните об изменении слов с нулевым окончанием, обязательно укажите, если это возможно: sleep (), friend (), слышание (), спасибо (), при попытке (). - Выбрать основу слова — часть без конца (и образующий суффикс).
- Обозначить префикс (если он есть). Для этого сравните одноручные слова с консолями и без.
- Определите суффикс (если есть).Чтобы проверить, выберите слова с другими корнями и с тем же суффиксом, чтобы они выражали то же значение.
- Находим рут. Для этого сравните несколько связанных слов. Их общая часть — это корень. Помните о однокоренных словах с чередующимися корнями.
- Если в слове два (и более) корня, обозначьте соединительные гласные (если есть): листопад, звездчатый, садовник, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если есть)
- Повторный анализ и значки выделяют все значимые части
В первичных классах разобрать слово — Означает выделить окончание и основание, после обозначения префикса суффиксом подобрать отдельные слова, а затем найти их общую часть: корень — и все.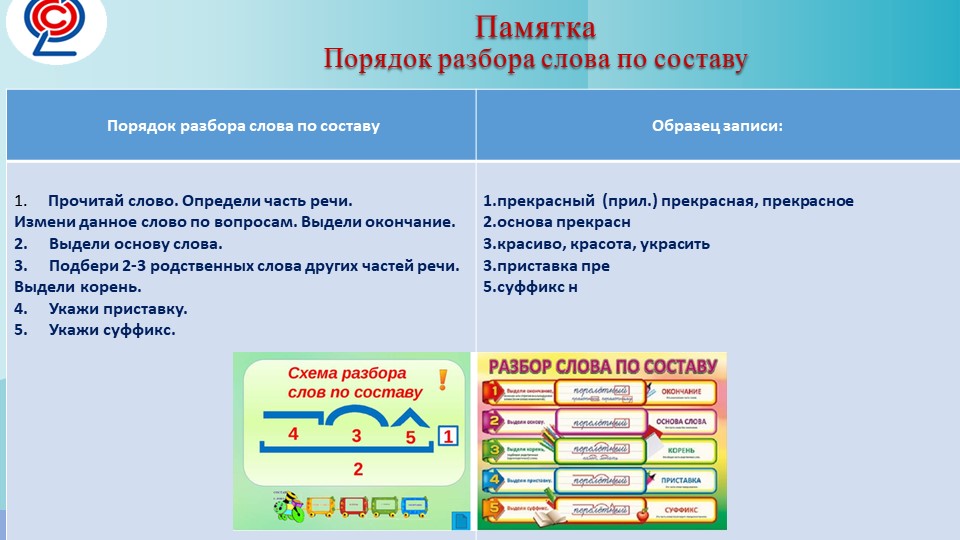
* Примечание: Минобразования РФ рекомендует три учебных комплекса на русском языке в 5-9 классах общеобразовательных школ. З. разных авторов morphem Диффузный подход. Чтобы избежать проблем при выполнении домашнего задания, сравните описанную ниже процедуру с вашим учебным пособием.
Порядок полного морфемного анализа композиции
Во избежание ошибок морфемный анализ предпочтительнее ассоциировать с словообразованием. Этот анализ называется формально семантическим.
- Задать часть речи и выполнить графический морфемный анализ слов, то есть обозначить все доступные морфемы.
- Запишите окончание, определите его грамматические значения. Укажите суффиксы, образующие формулы (если есть)
- Запишите основу слова (без образования морфем: окончания и формирующие суффиксы)
- Найдите морфемы. Запишите суффиксы и консоли, обоснуйте их назначение, объясните их значения
- Root: Free or connected.Для слов со свободными корнями составьте словообразовательную цепочку: «Ине-ах → Писать», «сухой (ой) → dry-art () → dry-ar-nice — (но)».
 Для слов со связным корнем выберите слова с одной структурой: «Оденься и раздай маскировку».
Для слов со связным корнем выберите слова с одной структурой: «Оденься и раздай маскировку». - Напишите корень, выберите отдельные слова, укажите возможные варианты, чередование гласных или согласных звуков в корнях.
Как найти морфинг в слове?
Пример полной морфемы pavement глагола «спал»:
- конец «А» указывает на форму глагола женский, единицы, прошедшее время, ср .: Pospel-and;
- основа формы — «проспек»;
- два суффикса: «А» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «Про» — действие со смыслом потери, нечувствительный, ср: По заплатить, проиграть, проникнуть;
- лечебная цепочка: Сон — Сон — Сон;
- корень «ИП» — по родственным словам есть чередования СП // СН // Сон // Сыр.Отдельные слова: сон, сон, сонливость, недосыпание, бессонница.
Как разобрать слово «земля»?
- Именительный падеж (какой?) — Земля;
- Родительский корпус (нет Что?) — Земля;
- Токопроводящий падеж (до чего дошел?) — На землю
- Винительный падеж (я вижу что?) — Земля;
- Сертификатный футляр (чем устраивает?) — Земля;
- Предлагаемый футляр (о чем говорили?) — Про Землю.

Анализ состава (или морфемный анализ) слова земля
Наша земля — одна из планет солнечной системы.
Земля — существительное женского рода с окончанием I:
земля, земля, земля, земля, земля, земля.
Основа слова земля.
Теперь найдите в слове основную его часть — корень.
Вспомните одноручные слова: землянка, земляне, земля, экскаватор, земля.
Итак, корень будет частью слова Земля // Земля.
Существительное земля различается по падежам и числам:
край земли и уходят в землю e. , найдите Z e. мл, далеко от эл. мл.
Итак, буква и Виноград выражается — окончание.
специальный, Zagora-Lh?
Чтобы не ошибиться при определении корневых границ существительного quot; landquot;, обращаемся за помощью к родственникам:
земля, земляне, земляк, земляк, земляне, земля.
Как видим, общая часть всех этих слов, связанных с одним значением, — это часть Земли.
Подведем итог:
земля — корень / окончание.
Земля — существительное женского рода в единственном числе. Это довольно простое и очень известное слово, тем не менее, вам нужно уметь разбирать и тому подобное.
Это довольно простое и очень известное слово, тем не менее, вам нужно уметь разбирать и тому подобное.
Чтобы правильно найти конец, нужно нарисовать слово: Земля, земля, земля. Переменная часть и будет концом, в данном случае это так. Соответствует окончанию существительных первого заката.
Мы преодолеем ряд однозначных слов, чтобы точно знать, как выглядит корень: приземлился, земля, заземление, земляк, земляне. Деталь не меняется — значит будет рут. Основа слова выглядит так же — круглая.
Итого у нас земля / I — корень / окончание.
Слово земля Существительные женского рода в единственном числе (во множественном числе будет слово — quot; landquot;] в именительном падеже.
Осуществляем анализа морфем (анализ состава) слов quot; landquot;:
Для определения конца слова определите слово по падежу:
Итак, в существительном женского рода kind quot; landquot; Конец.
Выберем несколько отдельных слов: земля, земля, земля и так далее.
Слово укоренено.
Основой слова будет земля.
Разберем слово:
1) в слове quot; землетрясение; Приставка отсутствует;
2) корень слова quot; landquot; будет quot; earthquot ;;
3) в слове quot; landquot; Суффикс отсутствует;
4) конец в слове quot; землетрясение; Будет: quot; yquot ;;
5) основание слова quot; landquot; Будет: quot; earthquot ;.
Слово quot; землетрясение; Это одно из простых слов, чтобы отказаться от композиции. Ибо есть только две морфемы:
-Zele — (Земля, земля, раскопки) Root Morphem,
— есть окончание морфемы;
в основе слова quot; Земля quot; — Земля.
слов Morphem quot; landQuot; Начнем с поиска конца. Для этого следует запланировать прокачку кейсов таким образом: Земля и , земля и , земля эл., земля ю. , земля ей , земля эл. . Вариативная часть слова, как видите, Morphem quot; —Quot; Что будет в конце. Остальное слово является его основанием: quot; земля-quot; . Префикс в слове quot; землетрясение; Суффиксов нет. И корень морфа является частью слова: quot; земля-quot; . Крупные слова quot; landQuot; Композиция окончена.
, земля ей , земля эл. . Вариативная часть слова, как видите, Morphem quot; —Quot; Что будет в конце. Остальное слово является его основанием: quot; земля-quot; . Префикс в слове quot; землетрясение; Суффиксов нет. И корень морфа является частью слова: quot; земля-quot; . Крупные слова quot; landQuot; Композиция окончена.
Земля — существительное женского рода, единственное число указывает на третью планету от Солнца, земли и территориально-административной единицы Германии.
Морфемный (по составу) Отдельные слова Земля:
корень: Земля (проверка по словам земля, земля, земля, земля)
окончание: I.
основа: Земля
Консоли, суффиксы и постфикс нет .
Существительное женского рода земля применяется к первому закату и в его составе необходимо выделить окончание — I: Земля-Земля-Земля-Земля. Отдельные слова — земля-земля-земля-земля-земля-подземелье-подземелье — редкоземельный. Корень земли — это корень, в котором возможно как чередование, так и возникновение беглого гламура E.
Получаем: Земля (корень-конец), основу слова земля.
На первом этапе анализа слов в композиции нужно поменять числа, падежи, лица, затем найти конец в слове. Словом. Определяем основу слова. Шаг найдет корень в ворде.
В слове Земля: конец меня, основа слова земля, корнем тоже будет земля, консоли не будет, суффикса тоже нет.
Количество слов образца текста
Для каждой текстовой коллекции D — это количество документов, W — количество слов в словаре, а N — общее количество слов в коллекции (ниже NNZ — количество ненулевых считается в сумке со словами).После токенизации и удаления игнорируемых слов словарь уникальных слов был усечен за счет сохранения только тех слов, которые. Этот инструмент анализа текста предоставляет информацию о читабельности и сложности текста, а также статистику по частоте слов и количеству символов. Может помочь переводчикам при расчете расценок для клиентов. Введите или вставьте текст для анализа в поле ниже, затем нажмите GO (Number Words) — НОВИНКА! Этот рабочий лист для печати содержит множество объектов, чтобы сделать урок более интересным.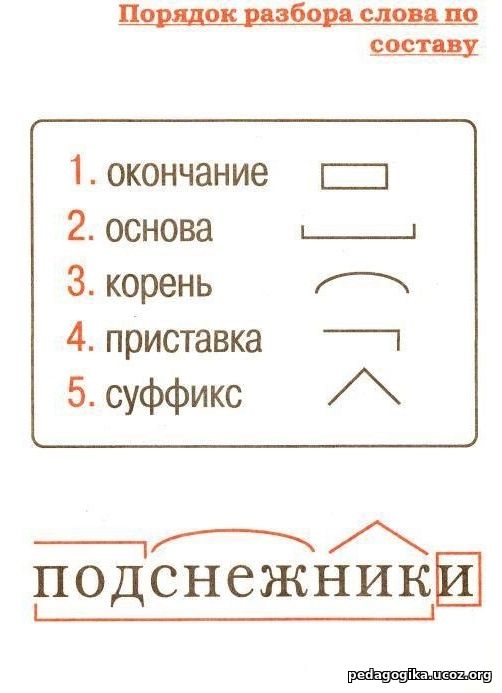 Задача рабочих листов — научить детей считать, сколько предметов, и обводить правильное числовое слово. Рабочий лист доступен на следующих языках: английском, французском, итальянском и испанском. Просмотрите образец страницы «Сколько?». Диаграмма кластера слов Автор: Джефф Кларк Дата: понедельник, 18 апреля 2011 г. Несколько лет назад я представил идею кластерных облаков слов, которые используют размер слова для обозначения частоты, но также используют расположение и цвет слов для группировки слов, которые сильно коррелировали в текст.Я думаю, это работает достаточно хорошо. PySpark — подсчет слов. В этом примере подсчета слов PySpark мы узнаем, как подсчитывать количество уникальных слов в текстовой строке. Конечно, мы изучим Map-Reduce, основной шаг в изучении больших данных. Бесплатный онлайн-подсчет слов и бесплатные онлайн-инструменты для подсчета символов Если вы веб-мастер и вам когда-либо требовалось отправить свою ссылку в онлайн-каталог или обмен ссылками, который ограничивает количество символов или количество слов, которые вы можете использовать для своего сайта описание, вы наверняка знаете, насколько неприятно складывать слова или символы! Следующие шесть победителей документальных фильмов, посвященных Национальному дню истории, получили награду Next Generation Angels Awards 2020 от Общества лучших ангелов.
Задача рабочих листов — научить детей считать, сколько предметов, и обводить правильное числовое слово. Рабочий лист доступен на следующих языках: английском, французском, итальянском и испанском. Просмотрите образец страницы «Сколько?». Диаграмма кластера слов Автор: Джефф Кларк Дата: понедельник, 18 апреля 2011 г. Несколько лет назад я представил идею кластерных облаков слов, которые используют размер слова для обозначения частоты, но также используют расположение и цвет слов для группировки слов, которые сильно коррелировали в текст.Я думаю, это работает достаточно хорошо. PySpark — подсчет слов. В этом примере подсчета слов PySpark мы узнаем, как подсчитывать количество уникальных слов в текстовой строке. Конечно, мы изучим Map-Reduce, основной шаг в изучении больших данных. Бесплатный онлайн-подсчет слов и бесплатные онлайн-инструменты для подсчета символов Если вы веб-мастер и вам когда-либо требовалось отправить свою ссылку в онлайн-каталог или обмен ссылками, который ограничивает количество символов или количество слов, которые вы можете использовать для своего сайта описание, вы наверняка знаете, насколько неприятно складывать слова или символы! Следующие шесть победителей документальных фильмов, посвященных Национальному дню истории, получили награду Next Generation Angels Awards 2020 от Общества лучших ангелов. ПОЖАЛУЙСТА, ОБРАТИТЕ ВНИМАНИЕ: следующие документальные проекты размещены на Google Диске. Средний читатель в пять раз медленнее, чем хороший читатель. Еще хуже, если принять во внимание не только скорость чтения, но и эффективность чтения. Эффективность чтения — это скорость чтения, взвешенная по степени понимания прочитанного, и она составляет 200 x 60% или 120 эффективных слов в минуту (ewpm) для среднего читателя и 1000 x 85% или 850 ewpm для лучших читателей. Textbox.io — первый редактор HTML WYSIWYG, разработанный для настольных и мобильных устройств.Его революционный мобильный пользовательский интерфейс, подобный приложениям, обеспечивает оптимизированный интерфейс для пользователей планшетов и мобильных телефонов. Легко добавляйте и загружайте изображения с помощью камеры устройства или галереи, используйте преобразование текста в речь для ввода содержимого и наслаждайтесь легким редактированием форматированного текста из любого места. Методика состоит в том, чтобы предсказать контекст слова с учетом самого слова, тогда как цель моделей CBOW и vLBL — предсказать слово с учетом его контекста.
ПОЖАЛУЙСТА, ОБРАТИТЕ ВНИМАНИЕ: следующие документальные проекты размещены на Google Диске. Средний читатель в пять раз медленнее, чем хороший читатель. Еще хуже, если принять во внимание не только скорость чтения, но и эффективность чтения. Эффективность чтения — это скорость чтения, взвешенная по степени понимания прочитанного, и она составляет 200 x 60% или 120 эффективных слов в минуту (ewpm) для среднего читателя и 1000 x 85% или 850 ewpm для лучших читателей. Textbox.io — первый редактор HTML WYSIWYG, разработанный для настольных и мобильных устройств.Его революционный мобильный пользовательский интерфейс, подобный приложениям, обеспечивает оптимизированный интерфейс для пользователей планшетов и мобильных телефонов. Легко добавляйте и загружайте изображения с помощью камеры устройства или галереи, используйте преобразование текста в речь для ввода содержимого и наслаждайтесь легким редактированием форматированного текста из любого места. Методика состоит в том, чтобы предсказать контекст слова с учетом самого слова, тогда как цель моделей CBOW и vLBL — предсказать слово с учетом его контекста. Посредством оценки задачи аналогии со словом эти модели продемонстрировали способность изучать лингвистические паттерны как линейные отношения между векторами слов.В отличие от матричной факторизации … Что это такое: TeXcount — это Perl-скрипт для подсчета слов в документах LaTeX. Он анализирует действительные документы LaTeX, считая слова, заголовки, формулы (математические) и группы с плавающей запятой / начало-конец. Как его запустить: Чтобы запустить сценарий, вы можете либо загрузить его и запустить на своем компьютере, либо использовать веб-интерфейс. Информация о переносе по словам Автор: Рон Корвинг Лицензия: FPDF Описание Если вы хотите обернуть какой-либо текст без его рендеринга, вы можете использовать эту простую функцию.int WordWrap (string & text, float maxwidth) Возвращает общее количество строк, из которых состоит строка. Текстовый параметр перезаписывается (вызов по ссылке) новым обернутым текстом. Определите количество. count синонимов, count произношение, count перевод, определение слова count в английском словаре.
Посредством оценки задачи аналогии со словом эти модели продемонстрировали способность изучать лингвистические паттерны как линейные отношения между векторами слов.В отличие от матричной факторизации … Что это такое: TeXcount — это Perl-скрипт для подсчета слов в документах LaTeX. Он анализирует действительные документы LaTeX, считая слова, заголовки, формулы (математические) и группы с плавающей запятой / начало-конец. Как его запустить: Чтобы запустить сценарий, вы можете либо загрузить его и запустить на своем компьютере, либо использовать веб-интерфейс. Информация о переносе по словам Автор: Рон Корвинг Лицензия: FPDF Описание Если вы хотите обернуть какой-либо текст без его рендеринга, вы можете использовать эту простую функцию.int WordWrap (string & text, float maxwidth) Возвращает общее количество строк, из которых состоит строка. Текстовый параметр перезаписывается (вызов по ссылке) новым обернутым текстом. Определите количество. count синонимов, count произношение, count перевод, определение слова count в английском словаре. … Текст; А; А; А; А; … Совокупность конкретных элементов … 29 мая 2017 г. · Показать общее количество раз, когда слово foo встречается в файле с именем bar.txt. Синтаксис: grep -c строка имя_файла grep -c foo bar.txt Примеры выходных данных: 3. Чтобы подсчитать общее количество вхождений слова в файле с именем / etc / passwd root с помощью grep, выполните: grep -c root / etc / passwd Чтобы проверить это, выполните: grep —color root / etc / passwd Подсчет слов важен, потому что он влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи. С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).Тезаурус и инструменты для творчества. Найдите слово, которое вы ищете! Выберите из предложенного списка 15-25 слов, которые вам неизвестны. Найдите и запишите определение, часть речи и используйте новое слово в предложении из более чем 6 слов.
… Текст; А; А; А; А; … Совокупность конкретных элементов … 29 мая 2017 г. · Показать общее количество раз, когда слово foo встречается в файле с именем bar.txt. Синтаксис: grep -c строка имя_файла grep -c foo bar.txt Примеры выходных данных: 3. Чтобы подсчитать общее количество вхождений слова в файле с именем / etc / passwd root с помощью grep, выполните: grep -c root / etc / passwd Чтобы проверить это, выполните: grep —color root / etc / passwd Подсчет слов важен, потому что он влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи. С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).Тезаурус и инструменты для творчества. Найдите слово, которое вы ищете! Выберите из предложенного списка 15-25 слов, которые вам неизвестны. Найдите и запишите определение, часть речи и используйте новое слово в предложении из более чем 6 слов. Попрактикуйтесь в использовании нового слова. Напишите рассказ, открытку, письмо или создайте запись в дневнике, используя 15-25 слов в контексте. Приблизительный способ подсчета слов в тексте на английском языке — это предположить, что стандартная отформатированная страница с шрифтом Courier 12 pt и строками с двойным интервалом составляет 250 слов.[4] Из-за форматирования количество страниц может изменяться в зависимости от шрифта, стиля, форматирования или размера бумаги опубликованной работы и не может считаться надежным показателем длины … Например, в Microsoft Word нажмите Инструменты -> Количество слов в общей сложности. Если вы использовали пишущую машинку, предположите, что одна страница с одинарным интервалом, с обычным шрифтом и полями содержит около 500 слов (если через два интервала — 250 слов). Если количество слов или страниц не указано, стремитесь к 250-500 словам — достаточно длинным, чтобы показать глубину, и достаточно коротким, чтобы удержать интерес.Вот сколько раз слово встречается в документе.
Попрактикуйтесь в использовании нового слова. Напишите рассказ, открытку, письмо или создайте запись в дневнике, используя 15-25 слов в контексте. Приблизительный способ подсчета слов в тексте на английском языке — это предположить, что стандартная отформатированная страница с шрифтом Courier 12 pt и строками с двойным интервалом составляет 250 слов.[4] Из-за форматирования количество страниц может изменяться в зависимости от шрифта, стиля, форматирования или размера бумаги опубликованной работы и не может считаться надежным показателем длины … Например, в Microsoft Word нажмите Инструменты -> Количество слов в общей сложности. Если вы использовали пишущую машинку, предположите, что одна страница с одинарным интервалом, с обычным шрифтом и полями содержит около 500 слов (если через два интервала — 250 слов). Если количество слов или страниц не указано, стремитесь к 250-500 словам — достаточно длинным, чтобы показать глубину, и достаточно коротким, чтобы удержать интерес.Вот сколько раз слово встречается в документе. Шаг 4: Создайте текстовую таблицу частот. После создания таблицы подсчета следующим шагом будет поиск таблицы частотности текста. Чтобы найти его, вы разделите значение каждой ячейки документа на общее количество слов в документе. Например, если у вас есть три слова в документе с каждой ячейкой …
Шаг 4: Создайте текстовую таблицу частот. После создания таблицы подсчета следующим шагом будет поиск таблицы частотности текста. Чтобы найти его, вы разделите значение каждой ячейки документа на общее количество слов в документе. Например, если у вас есть три слова в документе с каждой ячейкой …
9 декабря 2009 г. · 2. Запустите Word или любую другую программу обработки текста, которую вы используете. 3. Откройте файл резюме. Дважды проверьте орфографию и грамматику, особенно если вы внесли какие-либо изменения.4. Выделите весь текст в …
Ожидания по классам Понимание прочитанного с закрытой книгой имеет решающее значение! Классы K и 1 должны пересказать историю, установить связь с его / ее жизнью или другой книгой, рассказать любимую часть и почему. Ученики 2 и выше должны пересказать, рассказать урок, который преподает автор, рассказать о самом важном событии и почему. Как только ваш ребенок переходит на уровень I (конец первого класса), скорость (слов в минуту) составляет …
Выберите область, в которую следует вставить счетчик слов, особенно над аннотацией и под данными об авторе; Нажмите «Вставить», затем «Быстрая часть» и «Поле»; Выберите NumWords из списка названий полей и нажмите ОК, и вот оно что; Опять же, как я уже сказал, это маловероятно, поскольку профессор увидит ваш подсчет слов, как только откроет ваш документ.
Следующие два образца статей были опубликованы в аннотированном формате в Руководстве по публикациям и представлены здесь для удобства пользования. Аннотации привлекают внимание к соответствующему содержанию и форматированию и предоставляют пользователям соответствующие разделы Руководства по публикациям (7-е изд.), Чтобы получить дополнительную информацию.
Количество слов важно, потому что оно влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи.С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).
20 мая 2019 г. · В kbenoit / LIWCalike: Анализ текста, аналогичный примерам формата использования описания лингвистического запроса и подсчета слов (LIWC). Описание. Некоторые образцы коротких документов в текстовом формате для тестирования с помощью liwcalike.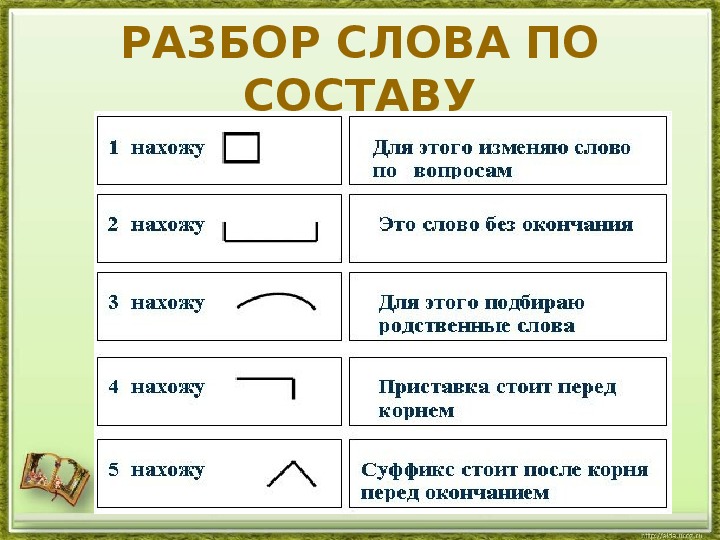 Использование
Использование
26 апреля 2019 г. · Создание случайного текста с помощью формулы Rand. Если вы хотите использовать случайный (но согласованный) текст в качестве содержимого-заполнителя в документе Word, вы можете использовать формулу генерации случайного содержимого, предоставленную Word.Однако при использовании этой функции следует сделать несколько примечаний, в зависимости от того, сколько текста вам нужно.
Одной из наиболее важных задач является обобщение разговорного текста при прослушивании PTE. Подготовьте задание с образцами вопросов здесь.
Примеры подсчета слов Эти строки из «Печали Вертера» были созданы на сайте blindtextgenerator.com, чтобы дать представление о том, как разные подсчеты слов выглядят на экране. 50 слов Чудесная безмятежность овладела всей моей душой, как это сладкое весеннее утро, которым я наслаждаюсь всем сердцем.
Пример схемы академического чтения Завершение (выделение слов из текста) [Примечание: это отрывок из текста Части 3 о влиянии низкокалорийной диеты на …
Для этого задания вы будете напишите программу, которая подсчитывает, сколько раз встречаются слова во входном текстовом файле. Структура WordCount Определите структуру C ++ с именем WordCount, которая содержит следующие элементы данных: Массив из 31 символа с именем word Целое число с именем count Функции Напишите следующие функции: int main (int argc, char * argv []) Эта функция должна объявлять массив 200…
Структура WordCount Определите структуру C ++ с именем WordCount, которая содержит следующие элементы данных: Массив из 31 символа с именем word Целое число с именем count Функции Напишите следующие функции: int main (int argc, char * argv []) Эта функция должна объявлять массив 200…
Например, давайте выберем файл примера TXT для подсчета слов с текстом: «Le Petit Prince est une œuvre de langue française, la plus connue d’Antoine de Saint-Exupéry. Publié en 1943 à New York simultanément à sa an traduction anglaise, c’est une œuvre poétique et Философский sous l’apparence d’un contra pour enfants.
11 июля 2020 г. · Выражения могут включать буквальное сопоставление текста, повторение, композицию шаблонов, ветвление и другие сложные правила. Большое количество проблем синтаксического анализа легче решить с помощью регулярного выражения, чем путем создания специального лексического анализатора и анализатора.Регулярные выражения обычно используются в приложениях, требующих обработки большого количества текста.
9 октября 2019 г. · Например, строка «Java Example.Hello» вернет количество слов как 2 с использованием шаблона «\\ s +», поскольку «Example» и «Hello» разделены не пробелом, а точкой. В то время как шаблон «\\ w +» вернет счетчик слов как 3, поскольку он соответствует словам, указанным ниже.
Теперь, когда мы знаем, что чтение файла csv или файла json возвращает идентичные фреймы данных, мы можем использовать один метод для вычисления количества слов в текстовом поле.Идея здесь состоит в том, чтобы разбить слова на токены для каждой записи строки в фрейме данных и вернуть счетчик 1 для каждого токена (строка 4). Эта функция возвращает список списков, каждый из которых …
Инструмент подсчета символов — счетчик символов отслеживает и сообщает количество символов и слов в тексте, который вы вводите, в режиме реального времени. Таким образом, он подходит для написания текста с ограничением количества слов / символов. Ограничение количества слов / символов встречается во многих случаях. Например: Twitter: 280, SMS: 160, Reddit Title: 300, Ebay Title: 80, Yelp Post: 5000, LinkedIn Summary: 2000, Pinterest Description: 500, описание Blogspot: 500, статус Facebook: 63 206, тег заголовка в HTML : отображать только 70 символов…
Например: Twitter: 280, SMS: 160, Reddit Title: 300, Ebay Title: 80, Yelp Post: 5000, LinkedIn Summary: 2000, Pinterest Description: 500, описание Blogspot: 500, статус Facebook: 63 206, тег заголовка в HTML : отображать только 70 символов…
Примеры WordCount демонстрируют, как настроить конвейер обработки, который может читать текст, преобразовывать текстовые строки в отдельные слова и выполнять подсчет частоты для каждого из этих слов. Пакеты SDK Beam содержат серию из этих четырех последовательно более подробных примеров WordCount, которые дополняют друг друга.
Потребность в онлайн-сравнении текста со временем возрастает, и мы поняли, насколько распространено сравнение текста, будь то текстовый документ или огромный абзац кодов и числовых данных.Хотя существует множество существующих инструментов, которые обещают предложить аналогичные услуги, но не были специально созданы для быстрого и точного сравнения!
Возвращает количество слогов в тексте. Для английских слов подсчет слогов является точным и ищется из словаря произношения CMU из словаря слогов по умолчанию data_int_syllables. Для любого слова, которого нет в словаре, количество слогов оценивается путем подсчета кластеров гласных. data_int_syllables — это предоставленный квантом объект данных, состоящий из именованного числового вектора…
Для любого слова, которого нет в словаре, количество слогов оценивается путем подсчета кластеров гласных. data_int_syllables — это предоставленный квантом объект данных, состоящий из именованного числового вектора…
4 июня, 2017 · min_count = 1 — пороговое значение для слов. В модель будут включены только слова с более высокой частотой. size = 300 — количество измерений, в которых мы хотим представить наше слово. Это размер вектора слов. worker = 4 — используется для распараллеливания. # using модель
Count-words.com — это бесплатный онлайн-инструмент, который позволяет подсчитывать слова и символы в тексте. Введите свой текст в форму ниже, и вы увидите анализ количества слов и символов в реальном времени.Для более глубокого анализа и очень длинных текстов нажмите кнопку «Анализировать текст». Там вы увидите подробную информацию о подсчитываемых словах и символах, а также о плотности каждого слова в вашем тексте.
Облака слов заголовка Версия 2.6 Автор Ян Феллоуз Сопровождающий Иэн Феллоуз Описание Функциональные возможности для создания красивых облаков слов, визуализации различий и сходства между документами, а также предотвращения чрезмерного рисования на точечных диаграммах с текстом. Лицензия LGPL-2.1 LazyLoad да Зависит от методов, RColorBrewer Imports Rcpp (> = 0.9.4)
Лицензия LGPL-2.1 LazyLoad да Зависит от методов, RColorBrewer Imports Rcpp (> = 0.9.4)Помните, что в среднем одна страница с интервалом обычно содержит около 3000 символов или 500 слов. В зависимости от форматирования текста количество слов на странице может составлять от 200 (крупный шрифт) до 600 слов (учебная книга). Подсчитайте символы и слова с помощью инструмента AnyCount, чтобы получить точную оценку и получить каждый заработанный цент.
Напишите программу C для подсчета общего количества слов в строке с примером.Программа на C для подсчета общего количества слов в строке. Пример 1. Эта программа позволяет пользователю вводить строку (или массив символов) и символьное значение. Затем он подсчитает общее количество слов, присутствующих в этой строке, с помощью цикла For Loop. ics заключается в том, что текст по своей природе имеет большие размеры. Предположим, что у нас есть образец документов, каждый из которых состоит из w слов, и предположим, что каждое слово взято из словаря, содержащего p возможных слов. Тогда уникальное представление этих документов имеет размерность p w.Выборка сообщений Twitter из тридцати слов, которые используют только тысячу больше всего. Этот инструмент анализа текста предоставляет информацию о читабельности и сложности текста, а также статистику по частоте слов и количеству символов. Может помочь переводчикам при расчете расценок для клиентов. Введите или вставьте текст для анализа в поле ниже, затем нажмите GO. Эта утилита генерирует алфавитный список уникальных слов с несколькими вариантами форматирования.
Тогда уникальное представление этих документов имеет размерность p w.Выборка сообщений Twitter из тридцати слов, которые используют только тысячу больше всего. Этот инструмент анализа текста предоставляет информацию о читабельности и сложности текста, а также статистику по частоте слов и количеству символов. Может помочь переводчикам при расчете расценок для клиентов. Введите или вставьте текст для анализа в поле ниже, затем нажмите GO. Эта утилита генерирует алфавитный список уникальных слов с несколькими вариантами форматирования.
Станислав Сливко: «Триумфальная ложь» — зачем хабаровчан вводят в заблуждение? : Аналитика Накануне.RU
Станислав Сливко: «Триумфальная ложь» — зачем хабаровчан вводят в заблуждение?
Станислав СливкоМоя статья об установке в Хабаровске «триумфальной арки» в честь царской семьи вызвала определенный резонанс, из-за чего руководитель инициативной группы по установке арки А. Никонов счел нужным ее прокомментировать, «разложив все по полочкам». Что ж, у А. Никонова это получилось, за что я ему очень благодарен. Ведь теперь для меня стало окончательно ясно, какую тактику избрала инициативная группа, чтобы достичь своей цели. Предлагаю разобрать аргументы А. Никонова.
Никонов счел нужным ее прокомментировать, «разложив все по полочкам». Что ж, у А. Никонова это получилось, за что я ему очень благодарен. Ведь теперь для меня стало окончательно ясно, какую тактику избрала инициативная группа, чтобы достичь своей цели. Предлагаю разобрать аргументы А. Никонова.
1. Первым делом А. Никонов предпочел заявить, что истинная цель установления арки – «восстановить историческую справедливость и воссоздать частичку дореволюционного прошлого Хабаровска». И, дескать, он никогда и нигде не говорил о том, что цель установки арки – призыв к покаянию за свержение самодержавия и убийство царской семьи. Однако, сам Никонов в речи при открытии памятного камня в честь установленной в 1891 году арки сказал следующее: «На Триумфальной арке будут размещены лики святых мучеников царской семьи, которые будут смотреть в сторону города». Вряд ли А. Никонову неизвестно, что основным мотивом канонизации и почитания семьи Николая II был мотив покаяния.
Насчет исторической справедливости и воссоздания «частички дореволюционного прошлого Хабаровска». На аутентичной арке, установленной в Хабаровске 1891 году, не было изображения «святых мучеников царской семьи». Прежде всего потому, что никакой семьи Николая тогда не было и в помине – цесаревич побывал в Хабаровске, будучи неженатым. Его женитьба состоялась только в 1894 году, а в 1895 году на свет появилась первая дочь Ольга. Смысл арки, установленной в 1891 году – приветствие наследника престола. Смысл той, которую пытается навязать хабаровчанам «инициативная группа» – покаяние за убийство царской семьи и «революционные грехи». Разница в смыслах колоссальная.
Не было на арке и «композиции Покрова Пресвятой Богородицы», которую также планирует там разместить инициативная группа во главе с А. Никоновым. Более того, сама арка стояла в том месте, где сейчас проходит проезжая часть, а установить новодел нам предлагают в 10-20 метрах от ее прежнего расположения. Вместо дерева «инициаторы» предлагают антивандальный сверхпрочный материала, а сам предполагаемый облик арки лишь отдаленно напоминает то сооружение, что было воздвигнуто к визиту цесаревича. Где же тут частичка истории и восстановление справедливости? Их здесь нет. Поскольку цель совсем другая.
Никоновым. Более того, сама арка стояла в том месте, где сейчас проходит проезжая часть, а установить новодел нам предлагают в 10-20 метрах от ее прежнего расположения. Вместо дерева «инициаторы» предлагают антивандальный сверхпрочный материала, а сам предполагаемый облик арки лишь отдаленно напоминает то сооружение, что было воздвигнуто к визиту цесаревича. Где же тут частичка истории и восстановление справедливости? Их здесь нет. Поскольку цель совсем другая.
В 2017 году, когда инициативную группу по установке арки возглавлял не А. Никонов, а Е. Казакова, которая и сейчас состоит в группе, предложение об установке «покаянной арки» обсуждалось на заседании Президиума Хабаровского краевого совета Всероссийского общества охраны памятников истории и культуры (ВООПИиК). Мне довелось присутствовать на этом заседании. Е. Казакова обратилась к ВООПИиК с просьбой поддержать установку арки и изложила свои аргументы именно в том смысле, о котором написано выше. А именно – арку планировалось установить к 100-летию расстрела царской семьи, чтобы успеть к участию во всероссийской акции памяти и покаяния.
2. А. Никонов предпочел откреститься от организации «Двуглавый орел» (ныне «Царьград») – дескать, сейчас он не возглавляет местное отделение этой организации. Но если открыть сайт «Царьграда», то мы увидим имя и контакты А. Никонова в разделе «Регионы» напротив Хабаровского края. А на страничке Хабаровского отделения «Двуглавого орла» в ВК именно А.
3. Далее А. Никонов заявляет: «Если мы будем решать судьбу памятников по принципу того, вызывает данная историческая личность споры или нет, то нам придется снести все памятники Ленину в России, которые стоят на каждом шагу». Налицо попытка подменить понятия и сместить фокус внимания. Памятники Ленину, установленные в советское время, принадлежат советской эпохе и олицетворяют ее, это памятники истории и культуры советского времени. Иными словами, это объекты культурного наследия советской эпохи. Вопрос об их сносе, демонтаже или уничтожении не стоит в повестке дня. Более того, есть соответствующий федеральный закон об охране объектов культурного наследия. Между тем, А. Никонов и его коллеги предлагают нам установить новый монумент с вполне определенным идеологическим подтекстом. Это не исторический памятник, а обычный новодел. И это уже дело современности, а не прошлого. Хотя, слова А. Никонова и огромное количество материалов/заявлений/акций общества «Двуглавый орел» («Царьград») дают нам понять, что и он сам, и его коллеги готовы без тени сомнения стереть любое упоминание о Ленине из нашей топонимики, а памятники Ленину уничтожить. Что ж, не они первые. Этим занимались многие — от гитлеровцев на оккупированных территориях СССР до украинских националистов, устроивших «Ленинопад» в 2014-2015 годах.
Налицо попытка подменить понятия и сместить фокус внимания. Памятники Ленину, установленные в советское время, принадлежат советской эпохе и олицетворяют ее, это памятники истории и культуры советского времени. Иными словами, это объекты культурного наследия советской эпохи. Вопрос об их сносе, демонтаже или уничтожении не стоит в повестке дня. Более того, есть соответствующий федеральный закон об охране объектов культурного наследия. Между тем, А. Никонов и его коллеги предлагают нам установить новый монумент с вполне определенным идеологическим подтекстом. Это не исторический памятник, а обычный новодел. И это уже дело современности, а не прошлого. Хотя, слова А. Никонова и огромное количество материалов/заявлений/акций общества «Двуглавый орел» («Царьград») дают нам понять, что и он сам, и его коллеги готовы без тени сомнения стереть любое упоминание о Ленине из нашей топонимики, а памятники Ленину уничтожить. Что ж, не они первые. Этим занимались многие — от гитлеровцев на оккупированных территориях СССР до украинских националистов, устроивших «Ленинопад» в 2014-2015 годах.
4. Рассуждения А. Никонова о правительственном терроре в период правления Николая II, причинах и предпосылках российских революций, красном и белом терроре в период Гражданской войны, о личности Николая II выдают в нем человека, который не знаком с ключевыми научными публикациями по этим темам (говоря языком профессионалов, с историографией этих научных проблем), комплексами исторических источников и методологией истории. Это не случайно, поскольку А. Никонов не историк, а юрист по образованию. Но, я полагаю, А. Никонову необходимо знать, что история – это наука. И ее научный статус ничуть не меньше, чем у физики, химии, филологии, юриспруденции. Чтобы «разбираться в истории», мало прочесть учебник или статью в интернете, посмотреть видео на You-tube или интересную книгу. Для этого надо учиться и весьма серьезно. Если у А. Никонова есть желание, факультет востоковедения и истории Пединститута ТОГУ проводит прием абитуриентов и на бакалавриат, и в магистратуру.
5. Самое интересное во всей этой истории, что А. Никонов не удосужился вникнуть в суть мною написанного и понять, что цель моей статьи – вовсе не в том, чтобы ни под каким видом не допустить установки арки в честь Николая II в Хабаровске. Напоминаю А. Никонову, что я считаю вполне приемлемым установление точной копии той арки, которая была возведена к моменту визита Николая в Хабаровск в 1891 году, но на территории исторического парка, который должен быть создан для размещения копий тех историко-культурных объектов, которые на настоящий момент утрачены, в том числе и относящихся к советскому времени. Например, памятников И.В. Сталину, демонтированных после ХХ съезда КПСС. И арка в честь приезда цесаревича, и православные храмы Хабаровска, и памятники И.В. Сталину, и снесенное не так давно старое здание аэропорта – все это и многое другое было в истории нашего города, значительно влияя на его историко-культурный ландшафт. И хабаровчане вправе знать, как выглядели эти культурные объекты. Это элементарная объективность. Но из всей этой идеи А.
Никонов не удосужился вникнуть в суть мною написанного и понять, что цель моей статьи – вовсе не в том, чтобы ни под каким видом не допустить установки арки в честь Николая II в Хабаровске. Напоминаю А. Никонову, что я считаю вполне приемлемым установление точной копии той арки, которая была возведена к моменту визита Николая в Хабаровск в 1891 году, но на территории исторического парка, который должен быть создан для размещения копий тех историко-культурных объектов, которые на настоящий момент утрачены, в том числе и относящихся к советскому времени. Например, памятников И.В. Сталину, демонтированных после ХХ съезда КПСС. И арка в честь приезда цесаревича, и православные храмы Хабаровска, и памятники И.В. Сталину, и снесенное не так давно старое здание аэропорта – все это и многое другое было в истории нашего города, значительно влияя на его историко-культурный ландшафт. И хабаровчане вправе знать, как выглядели эти культурные объекты. Это элементарная объективность. Но из всей этой идеи А.
6. И, наконец, самое «горячее», а именно – политика. Сразу в нескольких местах своей заметки А. Никонов упоминает, что я коммунист (причем в некоторых местах почему-то «экс-коммунист»). И, следовательно, все, сказанное мной, неизбежно несет на себе печать идеологии и политическую ангажированность. Информирую А. Никонова, что Н.М. Карамзин был монархистом, П.Н. Милюков либералом, М.Н. Покровский коммунистом и все вместе они были выдающимися российскими историками. Следовательно, есть профессионализм и научная квалификация, а есть политические убеждения. Всё-таки это разные вещи. Каждый ученый, в том числе и историк, может быть коммунистом/анархистом/либералом/монархистом, но отнюдь не каждый коммунист/анархист /либерал /монархист может быть историком.
Своих политических убеждений я никогда ни от кого не скрывал. Да, я коммунист. Но все мои соображения, изложенные в статье – это, прежде всего, взгляд историка на проблему сохранения историко-культурного наследия г. Хабаровска. А эта проблема колоссальна. И сохранить исторический облик Хабаровска, на мой взгляд, можно только так:
1. Реставрируя существующие памятники истории и культуры и бережно их сохраняя
2. Создавая копии безвозвратно утраченных памятников истории и культуры, размещая их в специально созданном историческом парке.
Этот подход признан и поддержан представителями профессионального сообщества историков Хабаровска.
Но без поддержки государства всё это невозможно реализовать. Историки могут бесконечно говорить об этом, но без деятельного участия органов государственной власти сохранить памятники истории и культуры Хабаровска нельзя. У самих историков нет для этого ни полномочий, ни средств.
У самих историков нет для этого ни полномочий, ни средств.
И вот здесь хотелось бы затронуть еще один любопытный момент. А. Никонов – член «Единой России». Он избирался от этой партии в Хабаровскую городскую думу в 2014 году и до 2019 года был депутатом. Обладая властью, А. Никонов и пальцем не пошевелил для того, чтобы памятники архитектуры дореволюционного времени были сохранены для потомков. Я внимательно изучил сайт Хабаровской городской думы, городские и краевые электронные СМИ, интернет-ресурсы партийных отделений «Единой России» в Хабаровске и Хабаровском крае, но ни одной инициативы А. Никонова в этом направлении не обнаружил! Ни одного голоса в защиту этих действительных свидетелей эпохи от депутата А. Никонова не раздалось. И этот факт еще одно свидетельство в пользу того, что для А. Никонова «сохранение исторического облика города» – обычная ширма для реализации своих политических амбиций? Поскольку, имея в своих руках рычаги власти, никаких реальных шагов для сохранения этого облика за 5 лет своего депутатства А. Никонов не сделал? Впрочем, свою оценку депутатской деятельности А. Никонову дали избиратели 6 одномандатного округа г. Хабаровска. В 2014 году за него на округе проголосовали 1523 человека, а в 2019 году – 596 человек. Утратить доверие 2/3 избирателей и не избраться по тому же округу в городскую думу – это тоже результат деятельности.
Никонов не сделал? Впрочем, свою оценку депутатской деятельности А. Никонову дали избиратели 6 одномандатного округа г. Хабаровска. В 2014 году за него на округе проголосовали 1523 человека, а в 2019 году – 596 человек. Утратить доверие 2/3 избирателей и не избраться по тому же округу в городскую думу – это тоже результат деятельности.
И все же, если А. Никонов и его коллеги всерьез озаботятся сохранением исторического облика Хабаровска и перестанут вводить хабаровчан в заблуждение, пытаясь под видом «восстановления исторический справедливости» реализовать свои политические цели, они всегда найдут в моем лице человека, готового им в этом помочь. Сохранение памятников истории и культуры должно быть общим делом – это моя принципиальная позиция.
Станислав Сливко, кандидат исторических наук, доцент кафедры Отечественной и всеобщей истории Пединститута ТОГУ, член Президиума Хабаровского краевого Совета ВООПИиК
Станислав Устенко, генеральный директор медиахолдинга С-Media
М.
 СПИРИДОНОВ: Добрый день, коллеги. Вы слушаете 213-й выпуск программы «Рунетология», запись от 12 ноября 2013 года. Меня зовут Максим Спиридонов. Эту беседу я веду из Москвы, мой собеседник также находится в столице.
СПИРИДОНОВ: Добрый день, коллеги. Вы слушаете 213-й выпуск программы «Рунетология», запись от 12 ноября 2013 года. Меня зовут Максим Спиридонов. Эту беседу я веду из Москвы, мой собеседник также находится в столице.Небольшое объявление от наших коллег
Команда облачного контент-фильтра SkyDNS ищет ведущего аналитика по информационной безопасности.
Команда проекта входит в двадцатку лучших стартапов России по версии ИД Коммерсант и журнала Секрет Фирмы. В этом году SkyDNS вышел на западный рынок и запустил линейку продуктов для больших корпораций и операторов связи.
Если вы желаете присоединиться к большой истории и работать с Big Data – пишите по адресу [email protected]
М.СПИРИДОНОВ: Пожалуй, главная тема, которая волнует сегодня людей, работающих с контентом в разных его проявлениях, с текстовым контентом в частности – это вопрос, на какие платформы, какие среды распространения делать ставку. Не успели утихнуть споры о необходимости срочного ухода от бумажного носителя, как набирает силу мнение, что и в интернете издателям уже особо делать нечего, и что нужно идти в мобильные устройство, в Smart TV.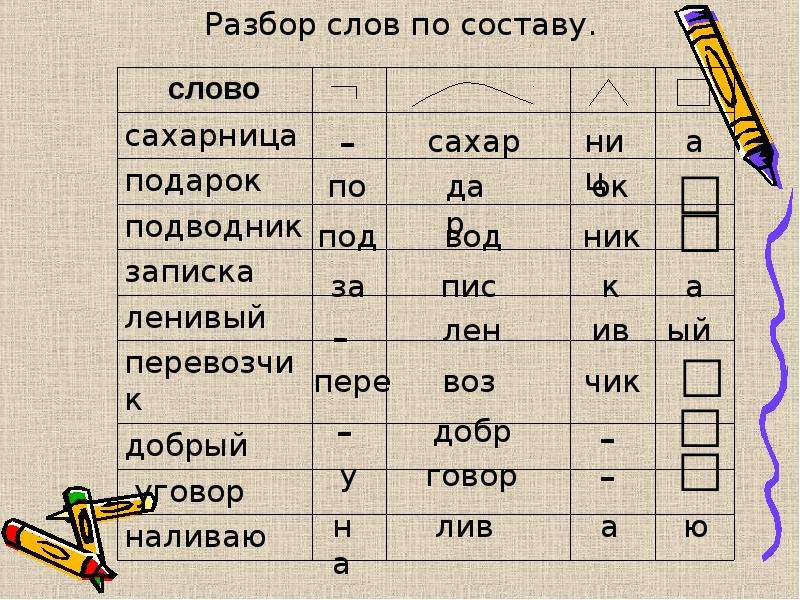 Надеюсь, что в этом выпуске мы сможем основательно разобрать как тему жизни и выживания контентных проектов в сегодняшних реалиях, так и вопросы построения бизнеса вокруг них. У нас в гостях генеральный директор медиа-холдинга С-Media Стас Устенко. Приветствую, Стас.
Надеюсь, что в этом выпуске мы сможем основательно разобрать как тему жизни и выживания контентных проектов в сегодняшних реалиях, так и вопросы построения бизнеса вокруг них. У нас в гостях генеральный директор медиа-холдинга С-Media Стас Устенко. Приветствую, Стас.
С.УСТЕНКО: Здравствуйте!
М.СПИРИДОНОВ: Стас, правда, что пару лет назад ты выпустил фантастический роман?
С.УСТЕНКО: Да, это скорее не фантастический роман. Издательство ему присвоило титул «Социальный триллер». Наверное, он ближе к этому жанру.
М.СПИРИДОНОВ: Вот как! О чем он?
С.УСТЕНКО: Рассказывать, о чем книга – это самое неблагодарное дело.
М.СПИРИДОНОВ: Расскажи в двух словах.
С.УСТЕНКО: Там много всего намешано. В ней много сатиры на современное общество, рассматривается развитие личности.
М.СПИРИДОНОВ: Для тебя это был программный шаг? Это не было просто хобби, возникшим постольку – поскольку?
С.УСТЕНКО: Это скорее хобби, но прорывное. Я последние 5 лет хотел написать книгу, но всё не шло. Я садился, писал 2 странички, смотрел на них и отправлял в корзину. Потом я начал писать и понял, что я пошел в нужном направлении. Где-то за полгода я написал книгу.
Я последние 5 лет хотел написать книгу, но всё не шло. Я садился, писал 2 странички, смотрел на них и отправлял в корзину. Потом я начал писать и понял, что я пошел в нужном направлении. Где-то за полгода я написал книгу.
М.СПИРИДОНОВ: Роман издан?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Какой тираж?
С.УСТЕНКО: 5000.
М.СПИРИДОНОВ: Сейчас его можно купить?
С.УСТЕНКО: Да, на Озоне, Литресе он есть. Издательство «Поколение» сделало достаточно хорошую выкладку. Он был во всех крупных магазинах и очень неплохо продался.
М.СПИРИДОНОВ: Мы коротко скажем об этом чуть позже. У нас получился нетематический эпиграф, мы отошли в сторону, дальше мы будем говорить об электронных медиа и их различных проявлениях, в частности об С-Media. Сейчас краткий рассказ о нашем госте, и мы продолжим разговор.
Досье
Стас Устенко родился 28 июня 1975 года в Москве. В 1997 году окончил Московский Государственный Институт Стали и Сплавов, кафедру экономики и менеджмента. С 1999 по 2003 гг. разрабатывал различные интернет-проекты – такие, как dvdspecial.ru, участвовал в запуске журнала Total DVD. С 2003 по 2006 гг. – издатель, главный редактор журнала «DVD Эксперт», член финансового комитета ИД Game(land). С 2006 по 2008 гг. – коммерческий директор, издатель ИД C-Media. C 2008 г. – генеральный директор медиа-холдинга C-Media. В 2010 году написал фантастический роман «Наблюдатель». Увлекается кино, йогой, гаджетами. Живет и работает в Москве.
С 1999 по 2003 гг. разрабатывал различные интернет-проекты – такие, как dvdspecial.ru, участвовал в запуске журнала Total DVD. С 2003 по 2006 гг. – издатель, главный редактор журнала «DVD Эксперт», член финансового комитета ИД Game(land). С 2006 по 2008 гг. – коммерческий директор, издатель ИД C-Media. C 2008 г. – генеральный директор медиа-холдинга C-Media. В 2010 году написал фантастический роман «Наблюдатель». Увлекается кино, йогой, гаджетами. Живет и работает в Москве.
М.СПИРИДОНОВ: Громко звучит название института, особенно в сборе с профессией, которую ты получил. Ты окончил Институт Стали и Сплавов и учился там менеджменту и экономике.
С.УСТЕНКО: Это очень хороший институт, очень хорошая кафедра. Профиль, который я получил – это маркетинг. Я специалист по менеджменту на предприятии, специалист по маркетингу, и это я активно использую.
М.СПИРИДОНОВ: По отзывам и инсайдам о тебе ты оправдываешь название собственного института. Говорят, что ты довольно жесткий, «стальной» управленец.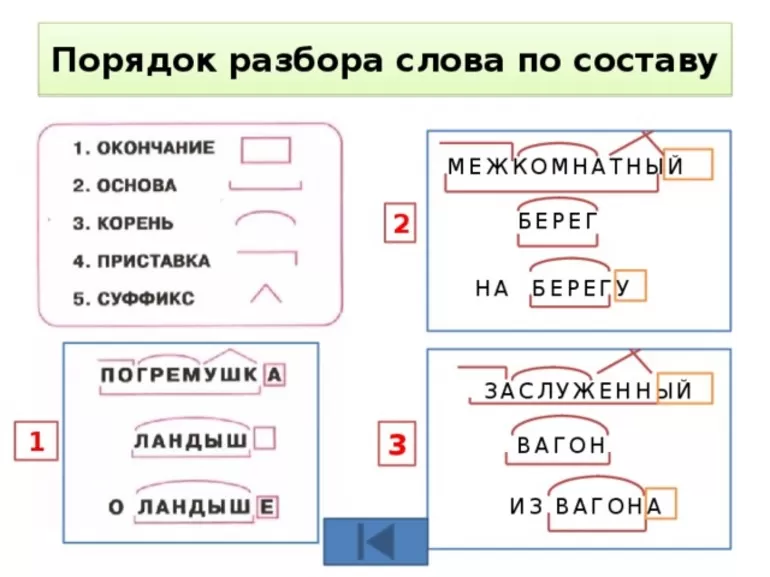
С.УСТЕНКО: Мне кажется, что я очень демократичный управленец, но в компании меня иногда за глаза называют Сталиным.
М.СПИРИДОНОВ: Ок. Каким-то образом в свое время ты оказался сначала в издательском деле, а потом в интернете.
С.УСТЕНКО: Нет, сначала я оказался в интернете. Все мои электронные увлечения и дела привели к тому, что в начале 2000-х годов мы стали заниматься сайтами. Поскольку после схлопывания пузыря доткомов этот рынок стал не слишком привлекательным на какое-то время, я переориентировался в сторону печатных СМИ, то есть на запуск DVD Эксперта и так далее. Где-то в 2008 году мы в C-Media приняли решение об отказе от концепции Издательского дома, который занимается печатными журналами, и переходе к цифровой форме медиа-компании.
М.СПИРИДОНОВ: Ты забегаешь немного вперед. Давай последовательно разберем твою карьеру. Занимаясь сайтами, ты строил проекты, которые уже можно было называть медиа, правильно? Это были журналы?
С. УСТЕНКО: Мы вступаем на грань, которая была обозначена в начале передачи. Что такое контент, и что такое носитель информации? На мой взгляд, носитель информации может быть любым. Это может быть печатный журнал, сайт, мобильное приложение и так далее. Главное – это то, что в нем размещено. Нужно размещать информацию там, где это востребовано аудиторией.
УСТЕНКО: Мы вступаем на грань, которая была обозначена в начале передачи. Что такое контент, и что такое носитель информации? На мой взгляд, носитель информации может быть любым. Это может быть печатный журнал, сайт, мобильное приложение и так далее. Главное – это то, что в нем размещено. Нужно размещать информацию там, где это востребовано аудиторией.
М.СПИРИДОНОВ: То, что ты делал первично в интернет-проектах, было носителями контента?
С.УСТЕНКО: Да, конечно.
М.СПИРИДОНОВ: Последующий переход из интернета в бумагу был органичен? Ничего принципиально нового не приходилось узнавать?
С.УСТЕНКО: Безусловно, пришлось разбираться с продажей тиражей, работой с сетями и так далее. Определенная мишура на костяк навешивалась, но костяк и фундамент был неизменен. Он был, есть и будет всегда. Если мы производим контент, который востребован аудиторией, мы сможем его продать, и он будет потребляться аудиторией. Если мы производим что-то непонятное, то в какую угодно обертку контент не заворачивай, он никому не будет нужен.
М.СПИРИДОНОВ: Меня всегда интересовало, что очень большое количество проектов, которые могли бы называться журналами, сайтами, носителями контента, появлялось на заре Рунета, то есть в конце 90-х – начале 2000-х. Подавляющее большинство из них не становились медиа в более-менее высоком смысле этого слова, их авторы не сумели поднять их на уровень, когда бы это становилось чем-то за пределами свободного времяпрепровождения. Они делают какие-то сайты про собственные увлечения рыбалкой, но это ресурс, на котором не появляются рекламодатели, или случайно появляются и тут же убегают. Они делают ресурсы, касающиеся праздничной темы, например, собирают стихи, на них есть аудитория, но нет медиа-продукта. Что позволило тебе отличиться от них, выйти из этого множества и суметь профессионализироваться?
С.УСТЕНКО: Наверное, то, что мы изначально стояли на позиции производства профессионального контента. Мы растили авторов, и всеми людьми, с которыми я работал, я горжусь, и я горжусь тем, чего они добились.
М.СПИРИДОНОВ: Ты же не был профессионалом в этой области, ты не журналист.
С.УСТЕНКО: У меня образование «Маркетинг». Я не позиционирую себя как гениального писателя, я позиционирую себя как менеджера, а задача менеджера – это растить кадры, и это мы делаем достаточно успешно. На сегодняшний день наши площадки во многих отраслях являются непререкаемыми авторитетами. Проблема, которая была на заре интернета, которая очень сильно проявилась в 2008-2009 годах – это разграничение профессионального и непрофессионального контента. Интернет – это средство неограниченной свободы. Человек заходит и может делать всё, что угодно. Раз может, значит, и знает, что и как делать. Глобальная ошибка заключается в том, что люди считают, что пользовательский контент сможет подменить профессиональный. Мы это проходили в конце 2008-2009 годов, когда стартовало много проектов, и все они говорили, что редакции не нужны, что они будут создавать контент, опираясь на комьюнити вовлеченных людей. К сожалению, это невозможно. Комьюнити будет работать именно как комьюнити, как сообщество, блоги, форумы, площадки по обмену мнениями, но на базе комьюнити невозможно сделать качественный и профессиональный контент.
К сожалению, это невозможно. Комьюнити будет работать именно как комьюнити, как сообщество, блоги, форумы, площадки по обмену мнениями, но на базе комьюнити невозможно сделать качественный и профессиональный контент.
М.СПИРИДОНОВ: Справедливости ради скажу, что были единичные успешные попытки. Можно вспомнить ХабраХабр, Dirty, Лепра. Это коллективные блоги.
С.УСТЕНКО: Вы считаете, что они успешны с коммерческой точки зрения?
М.СПИРИДОНОВ: ХабраХабр с коммерческой точки зрения успешен. Там всё в порядке. Там более полумиллиона уникальных пользователей в сутки, и у этой аудитории очень хорошая покупаемость в силу того, что она конкретная и понятная, понятно, кому ее продавать. Что касается Лепры и Dirty, то это другая история. Они не за деньги, они за идею.
С.УСТЕНКО: Да, я говорил про Лепру и Dirty. Есть один-два прорыва в этой отрасли, но они не являются системными. Если мы возьмем пример любой другой площадки с посещаемостью 500 тысяч людей в сутки, которые генерят определенное количество контента, посмотрим на маржинальность, заработок и так далее, и сравним с площадкой, где продается эксклюзивный профессиональный контент, сделанный на высочайшем уровне, то у второй площадки будут большие обороты, большая прибыль, большая востребованность и вовлеченность аудитории. Сейчас можно зарабатывать очень большие деньги и на производстве печатных журналов, но мы этого не делаем по причине того, что считаем, что данное приложение сил не самое перспективное. Прикладывать силы нужно там, где рынок растет.
Сейчас можно зарабатывать очень большие деньги и на производстве печатных журналов, но мы этого не делаем по причине того, что считаем, что данное приложение сил не самое перспективное. Прикладывать силы нужно там, где рынок растет.
М.СПИРИДОНОВ: Что касается бумаги и электронных медиа, у вас был интересный переход. Его я увидел, когда рассматривал историю Издательского Дома и твою карьерную историю. Ты пришел в C-Media, когда он был преимущественно бумажным, и постепенно переконвертировал его преимущественно в электронный, верно?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Можешь рассказать о том, как это решение принималось? Почему вы так сделали? Какие бренды были убиты? Как принимались решения о том, что какие-то бренды должны покинуть эту бренную землю?
С.УСТЕНКО: Ничего убито не было, это вопрос производства контента и его распределения через ту платформу, которая востребована. На рубеже 2008 года мы по отзывам экспертов и общению с клиентами поняли, что печатный рынок идет вниз. В кризис бумажные журналы упали сильнее всего, а интернет за год вырос на 10%, не смотря на то, что бушевал кризис. Это стало и точкой принятия решения. Какой смысл расшибаться в лепешку и играть там, где рынок схлопывается? Естественно, он не схлопнется до 0,. Всё точно также, как в сравнении кино и театра. Кино не уничтожило театр, но…
В кризис бумажные журналы упали сильнее всего, а интернет за год вырос на 10%, не смотря на то, что бушевал кризис. Это стало и точкой принятия решения. Какой смысл расшибаться в лепешку и играть там, где рынок схлопывается? Естественно, он не схлопнется до 0,. Всё точно также, как в сравнении кино и театра. Кино не уничтожило театр, но…
М.СПИРИДОНОВ: Сделало его более элитарным искусством.
С.УСТЕНКО: Да, и схлопнуло эту нишу. Мы же не сравниваем Аватар и какой-то мюзикл. Понятное дело, что разница будет в несколько порядков. В 2009 году мы окончательно решили, что мы хотим стать цифровой компанией, медиа-холдингом, избавиться от приставки «Издательский дом» и заниматься цифровыми проектами. С 2009 по 2011 год мы сформировали довольно большой портфель площадок, баннерообменных сетей, агентств и так далее, нам удалось аккумулировать порядка 30 миллионов человек, и это позволило нам очень гибко перевести большую часть клиентов, сохранив с ними отношения, и перевести большую часть нашей аудитории.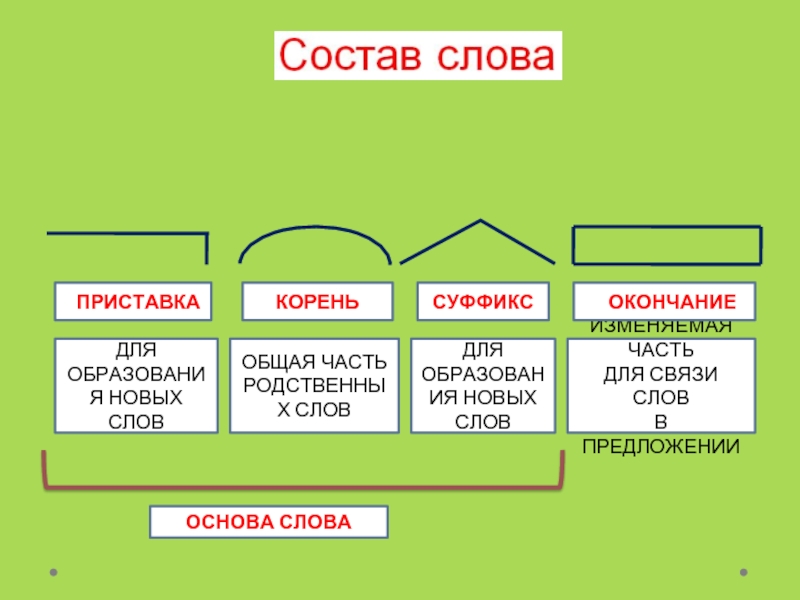 В 2012 году мы со спокойной душой смогли отказаться от ряда наших печатных журналов.
В 2012 году мы со спокойной душой смогли отказаться от ряда наших печатных журналов.
М.СПИРИДОНОВ: Бренды остались, а сами журналы перешли в интернет?
С.УСТЕНКО: У нас был журнал Hi-fi и сайт Hi-Fi.ru. На сегодняшний день Hi-Fi.ru существует в электронном виде для платформ iOS и Андроид, а в печатном виде его нет. Количество установок сейчас выше, чем тираж печатной версии. Таким образом, мы ничего не потеряли, плюс избавились от сложностей, связанных с сетями распространения, типографией, растаможкой и так далее. Сейчас есть фиксированные платежи за скачивание платформы.
М.СПИРИДОНОВ: Получается, рентабельность заметно выросла?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Стоимость номера сильно отличается от той, что была в бумаге?
С.УСТЕНКО: На 10%.
М.СПИРИДОНОВ: Пойдем дальше. Я думаю, что сейчас будет целесообразно вставить справку о медиа-холдинге.
Справка о компании
Медиа-холдинг C-Media основан в 2006 году Олегом Чаминым. Среди активов компании 9 крупных тематических интернет-проектов Рунета – Film.ru, Hi-fi.ru, CARS.ru, Zvezdi.ru, Paparazzi.ru, Newsland.com, Sportliga.com, Maxpark.com и iWorker.ru, а также электронные журналы EMPIRE, Hi-Fi.ru; печатные журналы EMPIRE, «Аудиомагазин». В состав медиа-холдинга входят коммуникационное SMM-агентство Social Craft, баннерообменная сеть «Союз Журналистов», агентство мультиформатной видео-рекламы MediaToday, международная выставка HI FI & HIGH END SHOW. Ежемесячный охват аудитории на тематических веб-площадках – более 9 млн. уникальных пользователей. Суммарная ежемесячная аудитория всех проектов холдинга – более 30 млн. уникальных посетителей.
Среди активов компании 9 крупных тематических интернет-проектов Рунета – Film.ru, Hi-fi.ru, CARS.ru, Zvezdi.ru, Paparazzi.ru, Newsland.com, Sportliga.com, Maxpark.com и iWorker.ru, а также электронные журналы EMPIRE, Hi-Fi.ru; печатные журналы EMPIRE, «Аудиомагазин». В состав медиа-холдинга входят коммуникационное SMM-агентство Social Craft, баннерообменная сеть «Союз Журналистов», агентство мультиформатной видео-рекламы MediaToday, международная выставка HI FI & HIGH END SHOW. Ежемесячный охват аудитории на тематических веб-площадках – более 9 млн. уникальных пользователей. Суммарная ежемесячная аудитория всех проектов холдинга – более 30 млн. уникальных посетителей.
М.СПИРИДОНОВ: Довольно пестрая и удивительная с точки зрения разнообразия представленных продуктов подборка. Попробуем разобраться. Холдинг основан Олегом Чаминым, верно?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Олег Чамин – разнообразный бизнесмен, он занимался, в том числе сетью «Вулкан», одиозно известной. Что подтолкнуло его создать медиа-холдинг?
Что подтолкнуло его создать медиа-холдинг?
С.УСТЕНКО: Я боюсь, что получится испорченный телефон, и я не думаю, что стоит эту тему активно обсуждать. Изначально была идея выстраивания структуры в составе большого вертикально-ориентированного холдинга, куда входило несколько разных компаний. На рубеже 2008 года мы полностью пересмотрели ситуацию и сфокусировались на медиа-компании.
М.СПИРИДОНОВ: Проекты покупались или создавались с нуля?
С.УСТЕНКО: Ряд проектов был создан с нуля, некоторые проекты были куплены, причем мы покупали проекты с 10-летней историей на рынке.
М.СПИРИДОНОВ: Куплены были в основном электронные издания?
С.УСТЕНКО: Да. Например, Film.ru, Hi-fi.ru.
М.СПИРИДОНОВ: Film.ru должен был стать конкурентом Кинопоиска?
С.УСТЕНКО: Нет. Мы никогда не планировали делать из Film.ru конкурента Кинопоиска. Film.ru базируется не на пользовательской информации и не на обсуждении кинематографа пользователями, а исключительно на профессиональном контенте профессиональных кинокритиков, в том числе там много материалов от британской редакции EMPIRE, которая имеет прямой доступ на все съемочные площадки на несколько месяцев раньше, чем другие СМИ. Это информационное поле для вовлеченных людей, которые хотят читать информацию о кино от профессионалов. То же самое и с Hi-fi.ru. Не смотря на то, что на Hi-fi.ru есть огромный форум и огромное комьюнити вовлеченных пользователей, ядром сайта являются профессиональные рецензии, тесты, техники и так далее.
Это информационное поле для вовлеченных людей, которые хотят читать информацию о кино от профессионалов. То же самое и с Hi-fi.ru. Не смотря на то, что на Hi-fi.ru есть огромный форум и огромное комьюнити вовлеченных пользователей, ядром сайта являются профессиональные рецензии, тесты, техники и так далее.
М.СПИРИДОНОВ: Возникновение SMM-агентства, баннерообменной сети – это инфраструктурные инструменты для того чтобы эффективнее монетизировать трафик на контентных ресурсах?
С.УСТЕНКО: Не совсем. Мы просто видим ниши, которые развиваются, и стараемся их активно закрывать. Если мы говорим о MediaToday, то в систему включено 1250 сайтов, поэтому наши 9 площадок там не играют особой роли.
М.СПИРИДОНОВ: Откуда такой активный поход в инструменты? Обычно если холдинг занимается чем-то профильным, то он этим и занимается. Он создает, поглощает, покупает, развивает контентные ресурсы, и это его главный профиль, а продажи рекламы нередко вынесены за пределы, а у вас не только свои продажи, но есть и свои дополнительные инструменты, которые вы транслируете и на другие ресурсы. Почему вы туда направились? Что к этому подтолкнуло?
Почему вы туда направились? Что к этому подтолкнуло?
С.УСТЕНКО: Мы посчитали, что эти сектора будут очень быстро развиваться, и так оно и получилось. Темпы роста по нашей баннерообменной сетке очень впечатляющие, и это один из способов диверсификации нашего портфеля. Портфель нашей компании сильно диверсифицирован, и мы считаем, что это большой плюс.
М.СПИРИДОНОВ: Баннерообменная сеть растет, в то время как другие баннерообменные сети потихоньку уходят?
С.УСТЕНКО: Я никогда не слышал о том, что баннерообменные сети куда-то уходят. Наоборот, они очень активно прирастают. С внедрением мобильных инструментов они будут прирастать и дальше.
М.СПИРИДОНОВ: Насчет мобильных инструментов я не буду утверждать, но то, что баннерообменные сети в их классическом виде отошли, это точно, или я чего-то не понимаю?
С.УСТЕНКО: Я не знаю.
М.СПИРИДОНОВ: Союз журналистов – это сеть, которая классическим образом позволяет меняться трафиком сайтам одного профиля?
С.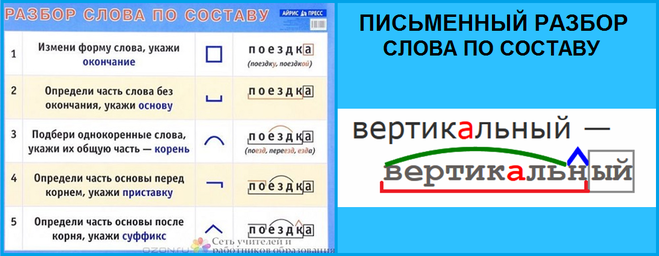 УСТЕНКО: Меняться трафиком, покупать и продавать его.
УСТЕНКО: Меняться трафиком, покупать и продавать его.
М.СПИРИДОНОВ: Какие ресурсы туда входят? То, что я видел в классическим виде, и то, что знают большинство, например, RLE и подобные проекты, почили в бозе.
С.УСТЕНКО: Союз журналистов не почил. Какие сети почили в бозе, и вообще почему к этому рынку иногда скептически относятся? Потому что на нем работало много продуктов с использованием не слишком качественного трафика. Я не буду углубляться в эту тему, но по факту так и было. Союз журналистов – это баннерообменная сеть в смокинге, то есть мы продаем очень хороший и качественный трафик дорогим клиентам. Этот сегмент у нас активно растет, и мы считаем, что это одно из лучших наших вложений.
М.СПИРИДОНОВ: Назови клиентов.
С.УСТЕНКО: На сайте обозначена большая часть клиентов, и она ротируется. Если мы сейчас зайдем туда, то мы увидим 3DFiles, NEWSru.com.
М.СПИРИДОНОВ: Ок. SMM-агентство – это тоже отклик на зов времени?
С. УСТЕНКО: Да.
УСТЕНКО: Да.
М.СПИРИДОНОВ: Оно занимается выполнением внешних заказов?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Как поживает видео-реклама MediaToday?
С.УСТЕНКО: Мы считаем, что MediaToday – один из лидеров российского рынка в этом направлении, и мы очень активно это направление развиваем и делаем на него очень большие ставки. Это продукт завтрашнего дня.
М.СПИРИДОНОВ: В чем специфичность этого продукта? Я тебя пытаю не для того чтобы что-то выведать, я просто хочу, чтобы для наших слушателей, которые не знакомы с твоими проектами, вырисовалась картинка.
С.УСТЕНКО: Я никаких секретов не открою. У MediaToday есть 3 направления: видео-клик, Videointeractive, видео-ролл. В следующем году мы планируем из 3 основных инструментов сделать 10, но пока забегать вперед рано. Видео-клик – это всплывающий ролик при наведении курсора мыши на выделенное в тексте слово. Videointeractive – это всевозможные интерактивные спецпроекты, то есть баннеры, которые при наведении курсора расхлопываются в видеоряд и так далее. Видео-ролл – это вставка ролика перед видео-потоком.
Видео-ролл – это вставка ролика перед видео-потоком.
М.СПИРИДОНОВ: Вставка в ваш плеер, или она интегрируется в любой видео-хостинг?
С.УСТЕНКО: Интегрируется.
М.СПИРИДОНОВ: Она должна встать внутрь? Ее нельзя вставить, скажем, в ролики Youtube, или можно?
С.УСТЕНКО: В ролики Youtube нельзя вставить, но если на площадке есть свой плеер, то туда можно вставить.
М.СПИРИДОНОВ: Вернемся к истории C-Media. Он сегодня стал набором разных проектов. Я чуть позже коснусь этой разности в их презентации и тематике. Какие были этапы построения? Каким образом вы их между собой интегрировали? Я знаю, что на фоне кризиса было принято решение срезать косты. Как это делалось? Мог бы рассказать об истории построения холдинга и его доведения до сегодняшнего состояния?
С.УСТЕНКО: Мы обрисовали ряд секторов, которые считали перспективными для роста и понятными в плане компетенций для нас. Если мы не самые большие специалисты в fashion, то мы и не вкладывались в площадки, которые освещают эту тему. Если наши специалисты хорошо понимают технику, то мы решаем приобрести Hi-fi.ru. По такому принципу мы сформировали определенный набор секторов, которые решили закрыть. Мы считаем, что мы это выполнили. На этом и базировалась наша стратегия. Мы оценивали перспективы роста сектора и наличие в этом секторе свободных ниш или проектов, которые мы можем купить за адекватные деньги. После того как весь набор продуктов был создан, мы сделали кросс-промо, но пересечение аудитории не является ключевым преимуществом. Мы специалисты выращивания и выведения на прибыль проектов. У нас есть понимание того, что им нужно для развития, какой персонал нужен для обеспечения контента, какие шаги нужно сделать, чтобы их развить, чтобы они стали особенными, уникальными и очень хорошо воспринимались аудиторией, и мы знаем, как продавать на них рекламу. У нас стоят всевозможные таргетинги, то есть мы можем вычленить человека практически по любому профилю и показывать рекламу именно ему.
М.СПИРИДОНОВ: Мне кажется, реклама распределяется очень неравномерно. На отдельных ресурсах ее зримо много, то есть она бросается в глаза, причем в буквальном смысле этого слова, потому что она делает это с помощью раскрывающихся окон.
На отдельных ресурсах ее зримо много, то есть она бросается в глаза, причем в буквальном смысле этого слова, потому что она делает это с помощью раскрывающихся окон.
С.УСТЕНКО: Например?
М.СПИРИДОНОВ: Zvezdi.ru, Paparazzi.ru. Как мне показалось, там рекламы в избытке.
С.УСТЕНКО: Мы сейчас активно не развиваем Zvezdi.ru, Paparazzi.ru. Проекты работают на перепродаже трафика, а не на традиционной медийной рекламе.
М.СПИРИДОНОВ: Они стали расстрельной командой?
С.УСТЕНКО: Нет. Аудитория на них активно растет. Просто мы не увидели больших перспектив в росте этого сегмента, который нам достался в наследство, и мы немного сместили с них фокус усилий.
М.СПИРИДОНОВ: Вы решили, что нужно его максимально замостить рекламой и забыть о развитии?
С.УСТЕНКО: Развитие идет, но не такое, как в Film.ru, например.
М.СПИРИДОНОВ: Какие сейчас приоритеты у холдинга?
С.УСТЕНКО: Это все наши баннерообменные сетки и наши профильные площадки, то есть Film, Hi-fi, CARS, Newsland.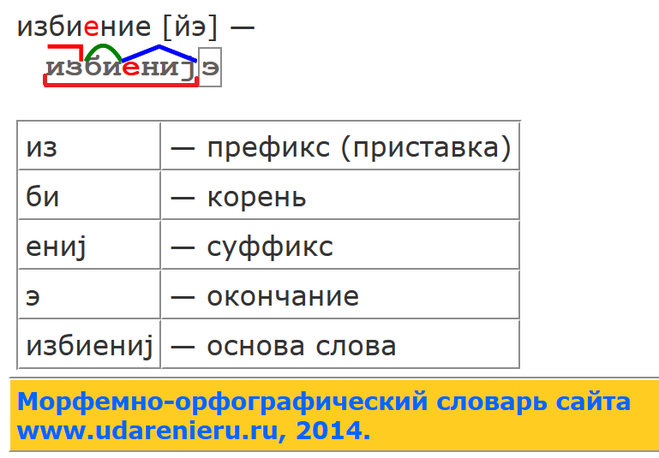
М.СПИРИДОНОВ: Именно там создается профессиональный контент в регулярном режиме?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Видимо, я не с того места начал знакомство с вашими продуктами, потому что Zvezdi.ru и Paparazzi.ru являются пестренькими, мягко говоря.
С.УСТЕНКО: Да, они пестренькие.
М.СПИРИДОНОВ: Про желтенькие не я сказал, но суть такая. СпортЛига тоже является одним из профильных активов?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Как построена работа по ним? Насколько автономны редакции? Насколько они регулируются и направляются холдингом?
С.УСТЕНКО: Мы не сторонники того, чтобы говорить редакциям, что им делать. Если мы будем стоять над каждым автором, то непонятно, зачем нужна такая редакция. У каждой площадки есть свой руководитель, которого мы называем издателем. Издатель отвечает за бизнес-процессы в проекте. Он утверждает бизнес-план и общую концепцию того, как проект развивается и как он должен выглядеть. За подачу материала и контентное развитие отвечает главный редактор. В проекте идет работа издателя и главного редактора над формированием того потока информации, который будет максимально востребован.
За подачу материала и контентное развитие отвечает главный редактор. В проекте идет работа издателя и главного редактора над формированием того потока информации, который будет максимально востребован.
М.СПИРИДОНОВ: Какого размера у вас редакция? Есть какой-то средний размер, или люди неравномерно распределены в проектах?
С.УСТЕНКО: Очень неравномерно. Это зависит от нагрузки. Скажем, тестовая лаборатория в Hi-fi со своим измерительным стендом, фотолабораторией и так далее требует больших усилий, чем Film, где сходил в кино, посмотрел и написал рецензию.
М.СПИРИДОНОВ: В среднем от 2-3 человек до десятков?
С.УСТЕНКО: От нескольких до 10 человек.
М.СПИРИДОНОВ: Всё это объединено в рамках одного местоположения, или они распределены?
С.УСТЕНКО: По большей части редакция объединена в одном месте, а сети могут находиться в других офисах.
М.СПИРИДОНОВ: Каким образом вы определяете преимущества в плане доставки? У вас всё еще есть бумага, электронные журналы в десктопном вебе и мобильные приложения.
С.УСТЕНКО: Надо понимать, что никогда нельзя быть на 100% уверенным в чем-то. Если бы мы на 100% знали, что какой-то инструмент заработает, то мы бы только в нем и сидели. Мы активно общаемся с аудиторией, пытаемся спросить у нее, мы выпускаем тестовые разработки и пытаемся по ним оценить востребованность. Скажем, электронный журнал. На начало этого года очень мало кто прогнозировал значимый процент скачиваний электронного журнала для iPhone. Все потребляли журналы исключительно на планшетах, потому что там есть картинки, анимация, всё красиво крутится и так далее. Как его можно смотреть на 4-дюймовом экране? Сейчас у нас темпы роста iPhone-версии раз в 5 выше, чем темпы роста iPad-версии. Я думаю, что к следующему году объемы если не сравняются, то они будут сравнимы. Получается, что на начало этого года люди не хотели читать журналы на iPhone, потому что им не хватало размера экрана и так далее, а через год темп жизни настолько ускорился, что это становится одним из векторов. Я еду в метро, стою в пробке на машине, и мне неохота доставать планшет, я лучше не экране смартфона, который всегда со мной, посмотрю информацию.
Я еду в метро, стою в пробке на машине, и мне неохота доставать планшет, я лучше не экране смартфона, который всегда со мной, посмотрю информацию.
М.СПИРИДОНОВ: С чем это связано? Это глобальная смена привычек, или это просто увеличение диагонали экрана?
С.УСТЕНКО: Я бы не сказал, что очень сильно увеличилась диагональ экрана для iPhone. В 5 и 5S одинаковая диагональ.
М.СПИРИДОНОВ: У 4 и 5 разные диагонали.
С.УСТЕНКО: Это было в прошлом году. Я сомневаюсь, что это так сильно сказалось. Тем более, 0,3 дюйма – это не так много. Это скорее ускорение ритма жизни.
М.СПИРИДОНОВ: Просто люди обживаются в мобильном пространстве и чувствуют себя там более комфортно?
С.УСТЕНКО: Да, люди обживаются в мобильном пространстве, и люди живут всё в более высоком ритме. Если раньше можно было подойти к компьютеру, взять печатный журнал, то потом стало удобнее дома работать на планшете, и зачем тогда мне дома еще за компьютер садиться, если я на работе за ним сижу? Я могу сесть на диван, взять iPad, и мне будет удобно. Сейчас планшеты не успевают за этими темпами, и всё сосредоточивается на смартфоне. Например, я стою в очереди в магазине, достаю iPhone и читаю статью. У нас на порталах порядка 9 миллионов уникальных юзеров в месяц. На начало этого года мобильная аудитория составляла 400 тысяч человек, и это был очень неплохой показатель на начало 2013 года. Мы в течение года не предпринимали никаких усилий по росту мобильного трафика, то есть рост был исключительно органический. На сентябрь 2013 года у нас был миллион мобильного трафика. Я думаю, что к концу года будет 1 200 000, то есть за год мобильный трафик увеличился в 3 раза.
Сейчас планшеты не успевают за этими темпами, и всё сосредоточивается на смартфоне. Например, я стою в очереди в магазине, достаю iPhone и читаю статью. У нас на порталах порядка 9 миллионов уникальных юзеров в месяц. На начало этого года мобильная аудитория составляла 400 тысяч человек, и это был очень неплохой показатель на начало 2013 года. Мы в течение года не предпринимали никаких усилий по росту мобильного трафика, то есть рост был исключительно органический. На сентябрь 2013 года у нас был миллион мобильного трафика. Я думаю, что к концу года будет 1 200 000, то есть за год мобильный трафик увеличился в 3 раза.
М.СПИРИДОНОВ: Мобильный трафик у вас полностью монетизируется или частично?
С.УСТЕНКО: У нас весь трафик монетизируется частично. Я сомневаюсь, что на рынке много площадок, которые монетизируют 100% своего трафика.
М.СПИРИДОНОВ: Какие модели вы используете? Это только продажа приложений?
С.УСТЕНКО: Это трафик порталов, а не приложений, то есть люди смотрят сайты с телефонов. Трафик портала полностью монетизировать на каких-то площадках невозможно. Самые низколиквидные баннеры всё равно будут отдаваться под баннерообмен, крутилки или что-то еще, а не продаваться.
М.СПИРИДОНОВ: Как вы смотрите на мобильного пользователя? Раз на веб-порталах такой высокий мобильный трафик, может быть, и не нужно развивать мобильные приложения?
С.УСТЕНКО: Наоборот. Как раз больше всего и нужно развивать мобильные приложения. Сайты достаточно неплохо выглядят и на экранах современных смартфонов.
М.СПИРИДОНОВ: Можно делать адаптивные сайты, как многие говорят, и успокоиться.
С.УСТЕНКО: Адаптивный сайт – это термин, который под собой мало, что несет.
М.СПИРИДОНОВ: Это сайт, который адаптируется под платформу.
С.УСТЕНКО: Ваш сайт адаптивный?
М.СПИРИДОНОВ: Если брать сайт Нетологии, то частично.
С.УСТЕНКО: Давай возьмем какой-нибудь неадаптивный сайт. Современная платформа Андроид или iOs позволит достаточно комфортно потребить сайт на экране смартфона.
М.СПИРИДОНОВ: Если не сделано грубой ошибки верстки, то да.
С.УСТЕНКО: Если рубрикатор не поплывет на текст, вы спокойно всё это отмасштабируете пальцами, всё прочитаете и будете вполне довольны, но мобильные приложения – это как раз средство отличаться от этого, ведь в нашем ритме играют роль даже мельчайшие отличия. То, что не надо куда-то заходить, масштабировать, что-то искать, тыкать в рубрикатор – это важно, и это дает революционное преимущество отдельному мобильному приложению. Также важна сама подача информации. Как ни крути, подача информации в журнале и интернете отличается, и подача информации на сайте и в мобильном приложении тоже отличается, и она обязана отличаться.
М.СПИРИДОНОВ: В чем эти отличия?
С.УСТЕНКО: Это нюансы каждой платформы, нельзя назвать конкретные отличия. Прежде всего, короче тексты, ярче выводы, нагляднее и понятнее верстка, в мобильных приложениях совершенно другое оформление иллюстраций, отсутствие одной рекламы и присутствие другой рекламы, отсутствие определенных инструментов, утяжеляющих интерфейс, которые необходимы в традиционном вебе. На мой взгляд, в адаптивную верстку всё это вложить невозможно. Мне кажется, путь развития – это развитие мобильных приложений.
На мой взгляд, в адаптивную верстку всё это вложить невозможно. Мне кажется, путь развития – это развитие мобильных приложений.
М.СПИРИДОНОВ: Иными словами, ты планируешь все проекты, которые не отправлены в отстойник истории, например, Zvezdi и Paparazzi, развивать в мобильных приложениях?
С.УСТЕНКО: В отстойник истории у нас никто не отправлен, мы просто концентрируемся на том, что на сегодня максимально быстро растет. Zvezdi и Paparazzi чувствуют себя прекрасно, они живут и обновляются.
М.СПИРИДОНОВ: Если быть честным, там тяжело находиться, потому что там избыток рекламы. Складывается ощущение, что это могила.
С.УСТЕНКО: К сожалению, это финансовая модель, которой живут эти проекты. Можно убрать рекламу, и тогда сайт не будет обновляться или будет обновляться гораздо реже.
М.СПИРИДОНОВ: Для вас важно, чтобы проект окупался?
С.УСТЕНКО: Да, конечно. К сожалению, это данность. Люди жалуются, что они покупают глянцевый журнал и на первых 20 страницах видят рекламу. На это главный редактор отвечает: «Если бы не эти 20 страниц рекламы, никакой редакции бы не было». В случае с Paparazzi то же самое. Как можно на это жаловаться?
На это главный редактор отвечает: «Если бы не эти 20 страниц рекламы, никакой редакции бы не было». В случае с Paparazzi то же самое. Как можно на это жаловаться?
М.СПИРИДОНОВ: Ок. Все твои глянцевые проекты выйдут в мобайл?
С.УСТЕНКО: Поэтапно да. Я не берусь сейчас ставить какие-то сроки, но у нас есть четкие планы.
М.СПИРИДОНОВ: При этом десктопные версии останутся?
С.УСТЕНКО: Да, конечно.
М.СПИРИДОНОВ: В мобайле монетизация будет преимущественно за оплату приложений, подписку, или будет рекламная модель?
С.УСТЕНКО: Мы пока не планируем вводить оплату за приложения, скорее будет модель free-to-pay, когда в приложение встроены какие-то инструменты покупки эксклюзивного контента, но, прежде всего, будет базовая модель заработка на рекламе.
М.СПИРИДОНОВ: Как и в бумаге, в электронных версиях будет продажа внимания читателя рекламодателю?
С.УСТЕНКО: Да.
М.СПИРИДОНОВ: Хорошо. Нам нужно двигаться к финалу, осталось всего несколько минут. Впереди будет одна небольшая рубрика. Будем закрывать разговор об индустрии. Какие ты видишь тренды развития электронного контента, контента с точки зрения потребления и бизнеса? О чем ты как управленец думаешь, когда наблюдаешь за тем, как развивается отрасль и твоя компания?
Нам нужно двигаться к финалу, осталось всего несколько минут. Впереди будет одна небольшая рубрика. Будем закрывать разговор об индустрии. Какие ты видишь тренды развития электронного контента, контента с точки зрения потребления и бизнеса? О чем ты как управленец думаешь, когда наблюдаешь за тем, как развивается отрасль и твоя компания?
С.УСТЕНКО: Прежде всего, я думаю о скорости. Если раньше горизонт планирования был очень далеким и легко прогнозируемым, то сейчас он сокращается. Скорость жизни настолько возрастает, что чтобы стоять на одном месте, приходится бежать всё быстрее и быстрее, а мы стоять на одном месте не любим, поэтому нам приходится бежать очень быстро. Самое главное – это обилие информации, и проникновение информации, которое есть сегодня, будет расти и дальше. Информационное поле диктует определенные законы, и при этом мы не можем четко сказать, как будет меняться это поле с введением новых инструментов. В следующем году выходят Google Glass, и пока комментарии экспертов сильно разнятся. Кто-то говорит, что аудитории не будут очень интересны эти очки, а кто-то говорит, что это будет революцией, сравнимой с выходом первого iPhone. Если это будет революцией, то система потребления информации сильно изменится.
Кто-то говорит, что аудитории не будут очень интересны эти очки, а кто-то говорит, что это будет революцией, сравнимой с выходом первого iPhone. Если это будет революцией, то система потребления информации сильно изменится.
М.СПИРИДОНОВ: Ты не рассматриваешь платформу Smart TV как возможность для текстово-графических медиа?
С.УСТЕНКО: Smart TV – это прекрасное направление, и мы его очень любим. Мало того, мы очень любим технику. Это одно из направлений, это очень удобно. У меня тоже телевизор подключен к Wi-fi.
М.СПИРИДОНОВ: Мне кажется логичным, что глянцевые журналы, журналы, касающиеся автомобилей, спорта, те журналы, которые имеют большие иллюстрации, будут на больших экранах.
С.УСТЕНКО: На мой взгляд, это совсем нелогично. Никому в голову не может прийти смотреть журнал на экране телевизора. Это из серии «есть не вилкой, а лопатой». Наверное, тоже можно, но, сомневаюсь, что нужно.
М.СПИРИДОНОВ: А как еще смотреть большие фотографии?
С. УСТЕНКО: Там же не только фотографии. Любой электронной контент – это, прежде всего, текст. Под Smart TV нужно или перекладывать текстовый контент в видео-поток, чтобы были нарезка фотографий и проговаривание текста, или создавать отдельные подкасты и видео-каналы. Просто рассматривать фотки на экране – это абсолютный тупик, а формирование видеоряда под это дело и транслирование этого видеоряда – это замечательно. Например, я прочитал журнал на электронном устройстве, а когда пришел домой, передо мной транслируется красивый видеоряд, и проговаривается текст, это здорово.
УСТЕНКО: Там же не только фотографии. Любой электронной контент – это, прежде всего, текст. Под Smart TV нужно или перекладывать текстовый контент в видео-поток, чтобы были нарезка фотографий и проговаривание текста, или создавать отдельные подкасты и видео-каналы. Просто рассматривать фотки на экране – это абсолютный тупик, а формирование видеоряда под это дело и транслирование этого видеоряда – это замечательно. Например, я прочитал журнал на электронном устройстве, а когда пришел домой, передо мной транслируется красивый видеоряд, и проговаривается текст, это здорово.
М.СПИРИДОНОВ: Можно представить, что в будущем ведущие бренды будут представлять номер в версии десктопа, бумажную версию в красивом и дорогом представлении, также будет мобильное приложение, которое имеет свои бенефиты, и видеоверсия для Smart TV.
С.УСТЕНКО: Как вариант. Мне кажется, в этом есть определенный вектор, более живой, нежели трансляция текстовой версии в Smart TV, но это пальцем в небо.
М.СПИРИДОНОВ: Да, мы и пытаемся нарисовать образ будущего. Бумага останется, и она будет еще долго и уверенно жить, просто в каком-то небольшом сегменте?
С.УСТЕНКО: Долго, уверенно и счастливо. Может быть, она будет жить в нормальном сегменте. Просто там не будет солидных темпов роста и солидных прорывов. Это консервативный рынок, как театр. Он будет жить еще 100 лет и никуда не денется. Например, вы сели в самолет, вас попросили выключить все электронные устройства, вы достали журнал и читаете его.
М.СПИРИДОНОВ: Сейчас, кстати, в Америке в отдельных авиакомпаниях перестали просить выключать их, и говорят, что это дальше пойдет. Боюсь, это убьет бумагу.
С.УСТЕНКО: Посмотрим. Значит, будут читать в других местах.
М.СПИРИДОНОВ: Осталось единственное место – туалет, хотя туда тоже многие ходят с гаджетами. Сейчас будет последняя рубрика «Бизнес-цитата». В ней мы зачитываем интересные и порой парадоксальные мысли знаменитых людей, это могут быть предприниматели, мыслители, герои кинофильмов, и предлагаем гостю прокомментировать цитату. До этого мы предлагаем выбрать одного из отобранных нами героев. Сегодня у нас есть Томас Джефферсон, 3-ий президент США, Генри Форд, основатель Ford Motors и Рой Эш, основатель Litton Industries.
До этого мы предлагаем выбрать одного из отобранных нами героев. Сегодня у нас есть Томас Джефферсон, 3-ий президент США, Генри Форд, основатель Ford Motors и Рой Эш, основатель Litton Industries.
С.УСТЕНКО: Форд.
М.СПИРИДОНОВ: Генри Форд любил и умел говорить рублеными фразами. Однажды он сказал: «Богатство, как и счастье никогда не достигается напрямую. Оно приходит как побочный продукт предоставления услуг». Согласен с этим?
С.УСТЕНКО: Безусловно. Главное – это заниматься любимым делом и делать его со страстью, а всё остальное – побочные продукты.
М.СПИРИДОНОВ: Что важнее – счастье или богатство, с твоей точки зрения?
С.УСТЕНКО: Счастье складывается из множества компонентов.
М.СПИРИДОНОВ: Возможно счастье без богатства?
С.УСТЕНКО: Я не отвечу на этот вопрос, потому что счастье состоит из множества факторов. Счастье – это здоровье, любовь, богатство, любимое дело, силы, увлечения, друзья и так далее. Счастлив ли богатый, но больной человек? Сомневаюсь.
Счастлив ли богатый, но больной человек? Сомневаюсь.
М.СПИРИДОНОВ: На этом закончим. Если есть, чем зафиналить, я предлагаю тебе сказать резюме к нашей беседе. Если нет, то я поставлю точку.
С.УСТЕНКО: Мы живем в очень интересное время в очень интересном мире, который очень быстро меняется, и это здорово.
М.СПИРИДОНОВ: Надо поспевать быть счастливым, быть и с друзьями, и с богатством. На этом всё. Вы слушали программу «Рунетология», у нас в гостях был генеральный директор медиа-холдинга C-Media Стас Устенко. Редакция выпуска – Андрей Митрохин, Станислав Жураковский, Юрий Берингов, Надежда Гусарова. Вел программу Максим Спиридонов. Пока.
границ | ULTRA: Universal Grammar как универсальный синтаксический анализатор
Введение
Одним из наиболее значительных недавних достижений в лингвистической теории является появление высококачественных наборов данных по всему спектру межъязыковых вариаций. В прошлом генеративные исследования обычно основывались на подробном изучении одного или нескольких языков для освещения синтаксических механизмов. Хотя этот подход, безусловно, плодотворен, накопление информации о большом количестве языков открывает новые возможности для улучшения понимания.
Хотя этот подход, безусловно, плодотворен, накопление информации о большом количестве языков открывает новые возможности для улучшения понимания.
В генеративной грамматике значительное внимание уделяется рекурсии как (или даже ) фундаментальному свойству языка (обсуждение см. в Berwick and Chomsky, 2016). Это формализовано в основной операции, называемой слиянием, объединяющей два синтаксических объекта (в конечном итоге построенных из лексических элементов) в набор, содержащий оба. Рекурсия следует из способности Merge применять к своему собственному выводу. Слияние также фиксирует важный факт, что предложения имеют внутреннюю структуру (заключенные в скобки группы), каждый слой соответствует применению слияния.
Вопреки этой схеме, я утверждаю, что рассматривать предложения как группы (будь то наборы или что-то еще) лексических единиц является концептуальной ошибкой. Ошибка заключается в том, что лексические единицы рассматриваются как связные единицы, существующие на одном уровне. Это приводит к мысли о предложениях как об одноуровневых репрезентациях. Слова, проще говоря, не вещей ; они представляют собой пару процессов, растянутых во времени. В контексте понимания важными процессами являются узнавание слова и интеграция его значения в интерпретацию.Я развиваю новый взгляд на структуру предложений с точки зрения этих двух видов процессов. Важно отметить, что их относительная последовательность определяется нетривиальной взаимосвязью: одно слово может встречаться раньше другого в поверхностном порядке, но его значение может быть интегрировано позже. Рассмотрение предложений как унифицированных, вневременных репрезентаций, построенных на непроницаемых лексических атомах, оставляет нас неспособными уловить вовлеченные фундаментально временные явления, в которых два аспекта каждого слова не связаны вместе, а процессы для разных слов переплетаются.
Это приводит к мысли о предложениях как об одноуровневых репрезентациях. Слова, проще говоря, не вещей ; они представляют собой пару процессов, растянутых во времени. В контексте понимания важными процессами являются узнавание слова и интеграция его значения в интерпретацию.Я развиваю новый взгляд на структуру предложений с точки зрения этих двух видов процессов. Важно отметить, что их относительная последовательность определяется нетривиальной взаимосвязью: одно слово может встречаться раньше другого в поверхностном порядке, но его значение может быть интегрировано позже. Рассмотрение предложений как унифицированных, вневременных репрезентаций, построенных на непроницаемых лексических атомах, оставляет нас неспособными уловить вовлеченные фундаментально временные явления, в которых два аспекта каждого слова не связаны вместе, а процессы для разных слов переплетаются.
В этой статье предлагается новая модель грамматических механизмов, называемая ULTRA (Универсальный реактивный автомат линейной трансдукции). Внутри локальных синтаксических доменов, образующих расширенную проекцию лексического корня (например, глагола или существительного), ULTRA использует алгоритм сортировки стека Кнута (1968) для прямого сопоставления поверхностных порядков слов с лежащей в основе базовой структурой. Отображение успешно только для 213-избегающих заказов. Это интригующий результат, поскольку 213-избегание, возможно, ограничивает вариации нейтрального порядка слов в разных языках в различных синтаксических областях.Хотя локальные звуковые и смысловые представления в этой модели представляют собой последовательности, тем не менее иерархическая структура возникает в динамическом действии отображения. Структуры в квадратных скобках, найденные здесь, хотя и являются эпифеноменальными, очень похожи на структуры, построенные Merge, с некоторыми важными отличиями (возможно, в пользу настоящей теории).
Внутри локальных синтаксических доменов, образующих расширенную проекцию лексического корня (например, глагола или существительного), ULTRA использует алгоритм сортировки стека Кнута (1968) для прямого сопоставления поверхностных порядков слов с лежащей в основе базовой структурой. Отображение успешно только для 213-избегающих заказов. Это интригующий результат, поскольку 213-избегание, возможно, ограничивает вариации нейтрального порядка слов в разных языках в различных синтаксических областях.Хотя локальные звуковые и смысловые представления в этой модели представляют собой последовательности, тем не менее иерархическая структура возникает в динамическом действии отображения. Структуры в квадратных скобках, найденные здесь, хотя и являются эпифеноменальными, очень похожи на структуры, построенные Merge, с некоторыми важными отличиями (возможно, в пользу настоящей теории).
Сортировка стека оказывается эффективной процедурой для связывания порядка слов и иерархической интерпретации, включая линеаризацию, смещение, композицию и помеченные скобки. Теория предполагает реализацию в виде процесса производительности в реальном времени. Стремление к этому осознанию значительно перекраивает границы между производительностью и компетентностью. Примечательно, что ULTRA не требует никаких языковых параметров; инвариантный алгоритм служит грамматическим средством для всех языков. Проще говоря, я полагаю, что Universal Grammar является универсальным синтаксическим анализатором.
Теория предполагает реализацию в виде процесса производительности в реальном времени. Стремление к этому осознанию значительно перекраивает границы между производительностью и компетентностью. Примечательно, что ULTRA не требует никаких языковых параметров; инвариантный алгоритм служит грамматическим средством для всех языков. Проще говоря, я полагаю, что Universal Grammar является универсальным синтаксическим анализатором.
Тем не менее, стековая сортировка — слишком ограниченный механизм для описания всех явлений человеческого синтаксиса. Остаются три вида эффектов: неограниченная рекурсия, ненейтральные порядки и существование явно различных языков.Более того, понимание сортировки стека как системы обработки сталкивается с двумя очевидными проблемами: это однонаправленный синтаксический анализатор, не обратимый для производства тривиально; и это противоречит убедительным доказательствам пословной инкрементальности в понимании.
Хотя построение полной модели синтаксиса и обработки выходит далеко за рамки данной статьи, проблемы, возникающие при построении модели синтаксического анализатора как грамматики на основе сортировки стека, заслуживают рассмотрения. Я обращаюсь к различию между реактивными и прогнозирующими процессами, рассматривая сортировку стека как универсальную реактивную процедуру.Отдельный модуль прогнозирования играет решающую роль в производстве и в появлении четких, относительно жестких порядков слов. Прогнозирование также помогает согласовать ULTRA с инкрементальной интерпретацией. Я обращаюсь к свойствам памяти для решения дальнейших проблем, предполагая, что первичная память (отличная от памяти последнего времени, лежащей в основе сортировки стека) является источником другого кластера синтаксических свойств, включая перемещение на большие расстояния, перекрестные зависимости и особый синтаксис «левая периферия».Наконец, я предполагаю, что эпизодическая память — независимо иерархическая структура у людей — играет ключевую роль в лингвистической рекурсии.
Я обращаюсь к различию между реактивными и прогнозирующими процессами, рассматривая сортировку стека как универсальную реактивную процедуру.Отдельный модуль прогнозирования играет решающую роль в производстве и в появлении четких, относительно жестких порядков слов. Прогнозирование также помогает согласовать ULTRA с инкрементальной интерпретацией. Я обращаюсь к свойствам памяти для решения дальнейших проблем, предполагая, что первичная память (отличная от памяти последнего времени, лежащей в основе сортировки стека) является источником другого кластера синтаксических свойств, включая перемещение на большие расстояния, перекрестные зависимости и особый синтаксис «левая периферия».Наконец, я предполагаю, что эпизодическая память — независимо иерархическая структура у людей — играет ключевую роль в лингвистической рекурсии.
Структура этой статьи следующая. В разделе Linear Base утверждается, что «базовая» структура в каждом локальном синтаксическом домене представляет собой последовательность. Раздел *213 в нейтральном порядке слов исследует обобщение, что 213-избегание ограничивает возможности информационно-нейтрального порядка слов в разных языках. В разделе «Сортировка стека как грамматический механизм» предлагается процедура сортировки стека для фиксации 213-избегания в порядке слов.Раздел Stack-Sorting: Linearization, Displacement, Composition и Labeled Brackets показывает, как дальнейшие синтаксические эффекты следуют из стековой сортировки. Раздел «Сравнение с существующими учетными записями Universal 20» сравнивает ULTRA с существующими учетными записями 213-avoidance в порядке слов, уделяя особое внимание Universal 20. Раздел «Универсальная грамматика как универсальный синтаксический анализатор» преследует реализацию сортировки стека в режиме реального времени. В разделе «Возможные расширения более полной теории синтаксиса» рассматриваются проблемы, связанные с принятием сортировки стека в качестве ядра универсальной грамматики, и намечаются некоторые возможные расширения.
Раздел *213 в нейтральном порядке слов исследует обобщение, что 213-избегание ограничивает возможности информационно-нейтрального порядка слов в разных языках. В разделе «Сортировка стека как грамматический механизм» предлагается процедура сортировки стека для фиксации 213-избегания в порядке слов.Раздел Stack-Sorting: Linearization, Displacement, Composition и Labeled Brackets показывает, как дальнейшие синтаксические эффекты следуют из стековой сортировки. Раздел «Сравнение с существующими учетными записями Universal 20» сравнивает ULTRA с существующими учетными записями 213-avoidance в порядке слов, уделяя особое внимание Universal 20. Раздел «Универсальная грамматика как универсальный синтаксический анализатор» преследует реализацию сортировки стека в режиме реального времени. В разделе «Возможные расширения более полной теории синтаксиса» рассматриваются проблемы, связанные с принятием сортировки стека в качестве ядра универсальной грамматики, и намечаются некоторые возможные расширения.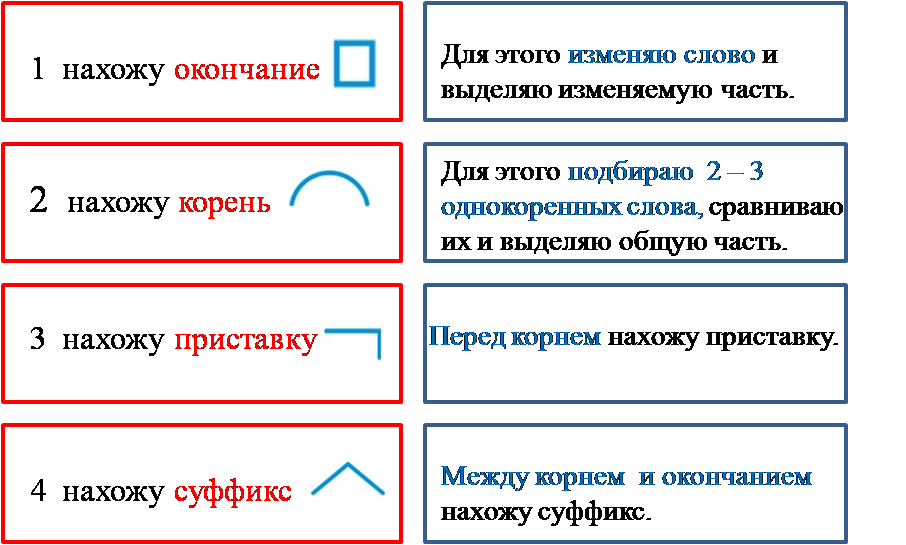 Заключение раздела.
Заключение раздела.
Линейная база
Синтаксическая комбинация может принимать различные формы. Появляется мнение, что комбинация в значительной степени соответствует отношениям «голова-дополнение» (Starke, 2004; Jayaseelan, 2008). В этом контексте термин «голова» имеет как минимум два разных значения. Во-первых, в любой комбинации двух синтаксических объектов один из них является «более центральным» для составного значения. Назовем это понятие головы корнем , отметив, что в расширенных проекциях существительных и глаголов семантически доминирует корень лексического существительного или глагола.Другой смысл головы касается того, какой элемент определяет комбинаторное поведение композита; назовем это понятие головы меткой .
В более старых теориях структуры фраз два значения заголовка (корень и ярлык) сходились на одном и том же элементе; например, существительное в сочетании со всеми его модификаторами в именной фразе. Таким образом, головокружение сопоставляется с иерархическим доминированием; корень спроецировал свою метку выше своих иждивенцев. Для иллюстрации комбинация прилагательного и существительного, например красных книг , будет представлена следующим образом.
Для иллюстрации комбинация прилагательного и существительного, например красных книг , будет представлена следующим образом.
Этот традиционный вывод о взаимосвязи зависимости и иерархии опровергается современной синтаксической картографией (Rizzi, 1997; Cinque, 1999 и последующие работы). Картографические подходы предполагают, что синтаксическая комбинация следует строгой, кросс-лингвистически единообразной иерархии в каждой расширенной проекции. Эта иерархия включает в себя последовательность функциональных головок, лицензионное сочетание с различными модификаторами в строгом порядке. Фраза красных книг представляется следующим образом.
Здесь прилагательное является спецификатором специальной функциональной головки (F), которая маркирует композит, определяя его комбинаторное поведение. В картографических изображениях головы равномерно расположены на ниже их иждивенцев, которые появляются выше по позвоночнику.
Возникают вопросы по поводу этих репрезентаций, постулирующих обилие непроизносимого материала. Любопытное наблюдение заключается в том, что функциональные головы и их спецификаторы, по-видимому, не встречаются вместе явно, как это формализовано в Купмановском (2000) Generalized Double-Filled Comp Filter.
Любопытное наблюдение заключается в том, что функциональные головы и их спецификаторы, по-видимому, не встречаются вместе явно, как это формализовано в Купмановском (2000) Generalized Double-Filled Comp Filter.
Starke (2004) развивает наблюдение Купмана дальше, утверждая, что головы и спецификаторы не встречаются одновременно, потому что они представляют собой токенов одного и того же типа , конкурирующих за одну позицию. Штарке переделывает картографический корешок как абстрактную функциональную последовательность ( fseq ), позиции которой могут быть в равной степени разряжены лексическим или фразовым материалом. Следуя концепции Штарке, сочетание прилагательного и существительного будет представлено, как показано ниже.
Опять же, мы перевернули традиционные выводы об иерархии глав и подчиненных.Тем не менее, понятие корня (выбор существительного) по-прежнему имеет решающее значение, поскольку модификаторы встречаются в иерархическом порядке, определяемом и fseq.
Синтаксическая комбинация такого рода является последовательной, внутри каждой расширенной проекции. Эти «базовые» последовательности кодируют восходящую композицию, поэтому естественно расположить последовательность таким же образом (снизу вверх). База (т. е. fseq, картографический корешок) считается единообразной для разных языков и выражает «тематическое», информационно-нейтральное значение (в отличие от дискурсивно-информационной структуры).
Грамматика, по чьей-либо теории, определяет формальное отображение, связывающее звук и значение (точнее, внешнюю и внутреннюю форму, допускающую неслуховые модальности). Эта спецификация может принимать различные формы. Последовательное представление базы позволяет удивительно просто сформулировать звуковое значение отображения. Эта переформулировка дает принципиальное описание класса универсалий порядка слов. Более того, в то время как объекты интерфейса (порядки слов и базовые деревья), участвующие в отображении, представляют собой последовательности, иерархическая структура в квадратных скобках возникает как динамический эффект.
Существуют различные способы концептуализации отношений между базовым и поверхностным порядком слов. Обычный взгляд состоит в том, что база упорядочивает ввод в производное, давая поверхностный порядок слов в качестве вывода. Эта направленность подразумевается терминами, используемыми для описания отношения иерархия-порядок: линеаризация , экстернализация и т. д. В этой статье используется другая точка зрения, согласно которой поверхностные порядки слов являются входными данными для алгоритма, пытающегося собрать базу в качестве выходных данных. Примечательно, что единственными входами, которые сходятся на единой основе в этом процессе, являются 213-избегающие; все порядки слов, содержащие 213, приводят к отклонению вывода.
*213 В нейтральном порядке слов
213-avoidance, вероятно, отражает возможности информационно-нейтрального порядка слов в различных синтаксических областях в разных языках. Под 213-избеганием я подразумеваю запрет на поверхностный порядок … b…a…c …, для элементов a ≫ b ≫ c , где ≫ указывает c-команду в стандартных древовидных представлениях базы ( то же самое, доминирование в деревьях Старке). Другими словами, нейтральный порядок слов, по-видимому, избегает (под)последовательности элементов из одной fseq средней-высокой-низкой.Элементы, образующие этот запрещенный контур, не обязательно должны быть соседними в порядке поверхности или в базовой fseq.
Другими словами, нейтральный порядок слов, по-видимому, избегает (под)последовательности элементов из одной fseq средней-высокой-низкой.Элементы, образующие этот запрещенный контур, не обязательно должны быть соседними в порядке поверхности или в базовой fseq.
213-avoidance ограничивает варианты упорядочения кластеров глаголов, хорошо известных в западногерманских языках (см. обзор Wurmbrand, 2006). Обширный обзор голландских диалектов, проведенный Barbiers et al. (2008), обнаружил очень мало примеров такого порядка; Немецкие диалекты, кажется, также избегают этого порядка. Тем временем Zwart (2007) анализирует 213 порядка в кластерах голландских глаголов как предполагающие экстрапозицию конечного элемента.
Наиболее изученным доменом, поддерживающим избегание 213 в порядке слов, является Универсальный 20 Гринберга, описывающий порядок словосочетаний существительных.
«Когда какой-либо или все элементы (указательное, числительное и описательное прилагательное) предшествуют существительному, они всегда находятся в этом порядке. Если они следуют, порядок либо такой же, либо прямо противоположный» (Гринберг, 1963, стр. 87).
Если они следуют, порядок либо такой же, либо прямо противоположный» (Гринберг, 1963, стр. 87).
Последующая работа улучшила эту картину. Cinque (2005) сообщает, что только 14 из 24 логически возможных порядков этих элементов засвидетельствованы как информационно нейтральные порядки (таблица 1).
Таблица 1 . Возможные порядок словосочетаний. Cinque (2005, стр. 319–320) отчет о количестве языков, демонстрирующих каждый порядок, обозначен числом: 0 = не подтверждено; 1 = очень мало языков; 2 = несколько языков; 3 = много языков; 4 = очень много языков.
Чинкве описывает эти факты с ограничением движения от единой базы. В частности, он предлагает, чтобы все движения перемещали существительное или что-то, содержащее его, влево (раздел «Сравнение с существующими отчетами Universal 20» подробно описывает теорию Чинкве и связанные с ней отчеты).Что запрещено, так это остаточное движение.
Порядки словосочетаний подчиняются простому обобщению: засвидетельствованные порядки — это все и только 213-избегающие перестановки. Все неподтвержденные заказы имеют 213 подобных подпоследовательностей. Например, неподтвержденный * Num Dem Adj N содержит подпоследовательности Num Dem Adj … и Num Dem Adj … N , представляющие средние-высокие-низкие контуры по отношению к fseq.
Все неподтвержденные заказы имеют 213 подобных подпоследовательностей. Например, неподтвержденный * Num Dem Adj N содержит подпоследовательности Num Dem Adj … и Num Dem Adj … N , представляющие средние-высокие-низкие контуры по отношению к fseq.
Stack-Sorting как грамматический механизм
Существует особенно простая процедура, которая сопоставляет 213-избегающий порядок слов с единой базой, называемую сортировкой стека.Я описываю адаптацию алгоритма сортировки стека Кнута (Knuth, 1968), который использует память «последний пришел — первый ушел» (стек) для сортировки элементов по их относительному порядку в базе. Это частичный алгоритм сортировки: он достигает желаемого результата только для некоторых входных заказов.
(4) S АЛГОРИТМ СОРТИРОВКИ ПО ПРИЦЕПКЕ D EFINITIONS
Пока ввод не пуст, I: следующий элемент ввода.
Если I ≫ S, Pop. S: элемент на вершине стека.
S: элемент на вершине стека.
Еще Нажмите. x ≫ y: x c-команды y в
основание (например, Dem ≫ N).
Пока стек не пуст, Push: перемещает I из ввода
в стек.
Поп. Pop: перемещает S из стека
для вывода.
(4) отображает все и только 213-избегающие порядки слов в 321-подобную иерархию, соответствующую основе. Заказы, содержащие 213, сопоставляются с девиантным выходом, отличным от базового. По условию, именно поэтому такие порядки типологически недоступны: они автоматически сопоставляются с неинтерпретируемым порядком композиции. Это объясняет паттерн Universal 20 (табл. 2, 3).
Таблица 2 . Результат сортировки стека логически возможных порядков из 4 элементов в формате ввод → вывод.
Таблица 3 . Вычисления сортировки стека для 4-х порядков.
Давайте проиллюстрируем, как (4) анализирует некоторые порядок словосочетаний существительных: Dem-Adj-N, N-Dem-Adj, *Adj-Dem-Num.
(5) Dem-Adj-N: PUSH(Dem), PUSH(Adj), PUSH(N),
POP(N), POP(Adj), POP(Dem).
(6) N-Dem-Adj: PUSH(N), POP(N), PUSH(Dem), PUSH(Adj),
POP(прил.), POP(дем.).
Для аттестованных заказов номинальные категории POP в порядке
(7) *Adj-Dem-N: PUSH(Adj), POP(Adj), PUSH(Dem),
PUSH(N), POP(N), POP(Dem).
Для неподтвержденного 213-подобного порядка элементы POP в отклоняющемся порядке *
Это хорошо: (4) сопоставляет подтвержденные приказы с их универсальным значением, одновременно исключая неподтвержденные приказы. Но помимо такого сопоставления адекватная грамматика должна объяснять другие аспекты знания языка, включая скобки поверхностной структуры. Если грамматика рассматривает поверхностные порядки и базовые структуры как последовательности (локально), откуда может взяться такая структура в квадратных скобках?
Если грамматика рассматривает поверхностные порядки и базовые структуры как последовательности (локально), откуда может взяться такая структура в квадратных скобках?
Stack-Sorting: линеаризация, смещение, композиция и маркированные скобки
В этом разделе я покажу, что сортировка стека эффективно включает в себя линеаризацию, смещение и композицию, а также назначение скобок с однозначной маркировкой и без поиска. Более того, он делает все это без языковых параметров.
В стандартном представлении («Y-модель») линеаризация и композиция являются отдельными интерфейсными операциями, интерпретирующими структуры, построенные в автономном синтаксическом модуле Merge.В ULTRA линеаризация идет в другом направлении, загружая поверхностный порядок слов поэлементно в память и собирая его в порядке композиционной интерпретации.
Смещение — естественное свойство грамматики сортировки стека
Смещение — естественная особенность сортировки стека; с одной точки зрения, это основное свойство системы. В стандартных отчетах составляющие, которые составляют вместе в интерпретации, должны казаться соседними в поверхностном порядке. Такое расположение обусловлено грамматиками структуры фраз.Смещение, при котором элементы, составляющие вместе, разделяются промежуточными элементами в порядке поверхности, всегда казалось удивительным свойством, нуждающимся в объяснении.
В стандартных отчетах составляющие, которые составляют вместе в интерпретации, должны казаться соседними в поверхностном порядке. Такое расположение обусловлено грамматиками структуры фраз.Смещение, при котором элементы, составляющие вместе, разделяются промежуточными элементами в порядке поверхности, всегда казалось удивительным свойством, нуждающимся в объяснении.
В ULTRA все работает иначе. Ключевое предположение представления на основе слияния отброшено: нет уровня представления, охватывающего порядок слов и fseq в унифицированном объекте более высокого порядка. Вместо этого порядок слов и базовая иерархия представляют собой несвязные последовательности, связанные динамически. Несмежные входные элементы вполне могут оказаться смежными в выходных данных.Смещение — это не исключение, а правило; каждый элемент в поверхностном порядке «трансформируется», проходя через память перед извлечением для интерпретации.
Скобки и метки без элементарного округа
Алгоритм (4) неявно присваивает помеченную структуру в квадратных скобках каждому порядку поверхности, почти точно совпадая со структурами, назначенными такими отчетами, как Cinque (2005). Явно, нажатие (сохранение порядка слов в стек) соответствует левой скобке, а извлечение (извлечение из стека для интерпретации) — правой скобке.Эти операции применяются к одному элементу за раз; естественно думать об этом элементе как о маркировке соответствующей скобки. См. Таблицу 4, в которой представлены вычисления сортировки стека для всех перестановок поверхностей трехэлементной базы.
Явно, нажатие (сохранение порядка слов в стек) соответствует левой скобке, а извлечение (извлечение из стека для интерпретации) — правой скобке.Эти операции применяются к одному элементу за раз; естественно думать об этом элементе как о маркировке соответствующей скобки. См. Таблицу 4, в которой представлены вычисления сортировки стека для всех перестановок поверхностей трехэлементной базы.
Таблица 4 . Вычисления сортировки стека для порядков из 3 элементов.
При рассмотрении этих скобок последовательность операций push и pop (сохранение и извлечение) для каждого порядка неявно определяет дерево, как показано на рисунке 1. Это так называемые деревья Дайка, набор всех упорядоченных корневых деревьев с фиксированным числом. узлов (здесь 4).Сравните их с деревьями с бинарными ветвлениями, назначенными в соответствии с отчетом Cinque (2005), с неостаточным движением влево, влияющим на правоветвящееся основание (рис. 2). Скобки почти идентичны, как и их этикетки, допуская некоторые вольности с техническими деталями аккаунта Чинкве.
Рисунок 1 . Скобки и соответствующие деревья push-pop для принятых (сортируемых стеком) порядков из трех элементов. Это просто деревья Дайка с 4 узлами.
Рисунок 2 .Бинарно-ветвящиеся деревья для получения подтвержденных порядков из трех элементов без движения остатков с соответствующим заключением в скобки. Лексический корень (например, N в именной группе) показан черным треугольником, а структуры с окончанием и следом движения представлены двойной ветвью ||. Деревья представлены таким образом, чтобы подчеркнуть соответствие с деревьями Дайка для этих порядков, полученных в результате сортировки стека.
Отложив на данный момент 321 дерево (дерева), деревья Дайка представляют собой систематические сжатые без потерь деревья Чинкве, где каждое поддерево, представляющее собой гребенку с правым ветвлением в дереве Чинкве, заменено линейным деревом (см. Jayaseelan, 2008) в дереве Дайка.Для этого соответствия, которое равносильно удалению всех терминалов в двоичном дереве, лексический корень (например, существительное в DP) не должен быть удален. Элементы из поверхностного порядка связаны с каждым узлом дерева Дайка, кроме самого высокого, с линейным порядком, читаемым слева направо среди сестринских узлов и сверху вниз по одинарным ветвящимся путям. Например, для поверхностного порядка 132 1 связан с единственным узлом бинарного ветвления в его дереве Дайка, 3 и 2 — с его левой и правой дочерними элементами (рис. 3).
Элементы из поверхностного порядка связаны с каждым узлом дерева Дайка, кроме самого высокого, с линейным порядком, читаемым слева направо среди сестринских узлов и сверху вниз по одинарным ветвящимся путям. Например, для поверхностного порядка 132 1 связан с единственным узлом бинарного ветвления в его дереве Дайка, 3 и 2 — с его левой и правой дочерними элементами (рис. 3).
Рисунок 3 .Два представления в квадратных скобках 132 порядка поверхности и соответствующие деревья. Слева показана структура, найденная при чтении операций сортировки стека как скобок; Элементы поверхности отождествляются с каждым узлом (кроме самого верхнего, отмеченного пунктиром). Линейный порядок считывается сверху вниз по одинарным ветвям и слева направо среди сестринских узлов. В соответствующем бинарно-ветвящемся дереве, представляющем его производное движением (справа) , ярко выраженные элементы отождествляются только с конечными узлами.
Между тем, 321 порядок, присвоенный троичному дереву путем сортировки стека, имеет два производных, исключающих движение остатка. В одном возможном выводе 3 переворачивается с 2 сразу после слияния 2, затем комплекс 32 проходит мимо 1 после слияния 1. В другом возможном выводе полная базовая структура сначала объединяется, затем 23 хода влево, а затем движение влево всего на 3.
Ключевой эмпирический вопрос заключается в том, демонстрируют ли 321 порядок две отдельные структуры, заключенные в скобки, как позволяет обработка бинарного ветвления, или только единственную, «плоскую» структуру, предсказанную здесь.Проблема еще более остра для 4 элементов, как в Universal 20, где существует до 5 различных производных Merge для 4321 порядка. К счастью, это ( N Adj Num Dem ) самый распространенный порядок словосочетаний; будущие исследования должны осветить этот вопрос.
Резюме раздела
Stack-sorting захватывает удивительное количество синтаксических механизмов, обычно разделенных между различными модулями. В обычном представлении автономный генеративный механизм строит составляющие структуры, интерпретируемые на интерфейсах дальнейшими процессами линеаризации и композиции.В ULTRA линеаризация и композиция представляют собой единую процедуру. Составляющая структура не является примитивной, но записывает этапы хранения и поиска, с помощью которых сортировка стека собирает интерпретацию. Это создает поверхностную структуру в квадратных скобках, помеченную соответствующим образом, в значительной степени идентичную структуре в квадратных скобках в счетах, постулирующих движение (внутреннее слияние) из единой базы (сформированной внешним слиянием). Однако там, где стандартные теории допускают множественные производные для некоторых поверхностных порядков (и неоднозначную бинарно-ветвящуюся структуру), в настоящем отчете присваивается уникальная внебинарная скобка.Примечательно, что особенности языка не играют роли в управлении движением. Смещение обрабатывается автоматически путем сортировки стека и фактически является его основной функцией.
В обычном представлении автономный генеративный механизм строит составляющие структуры, интерпретируемые на интерфейсах дальнейшими процессами линеаризации и композиции.В ULTRA линеаризация и композиция представляют собой единую процедуру. Составляющая структура не является примитивной, но записывает этапы хранения и поиска, с помощью которых сортировка стека собирает интерпретацию. Это создает поверхностную структуру в квадратных скобках, помеченную соответствующим образом, в значительной степени идентичную структуре в квадратных скобках в счетах, постулирующих движение (внутреннее слияние) из единой базы (сформированной внешним слиянием). Однако там, где стандартные теории допускают множественные производные для некоторых поверхностных порядков (и неоднозначную бинарно-ветвящуюся структуру), в настоящем отчете присваивается уникальная внебинарная скобка.Примечательно, что особенности языка не играют роли в управлении движением. Смещение обрабатывается автоматически путем сортировки стека и фактически является его основной функцией.
Сравнение с существующими учетными записями Universal 20
В этом разделе сравнивается учетная запись Universal 20 для сортировки стека с существующими учетными записями на основе слияния (Cinque, 2005; Steddy and Samek-Lodovici, 2011; Abels and Neeleman, 2012). Я утверждаю, что учетная запись с сортировкой стека проще, и в то же время позволяет избежать проблем, возникающих в каждой из этих существующих альтернатив.
Счет Cinque (2005)
Cinque предлагает единообразную для разных языков базовую иерархию, отражающую фиксированный порядок внешнего слияния. Он предполагает, что движение (внутреннее слияние) равномерно направлено влево, а основание имеет правое ответвление, в соответствии с LCA Кейна (1994). Он оговаривает, что остаточное движение в именной группе запрещено: каждое движение влияет на существительное или составляющую, содержащую его. Его базовая структура именной группы — (8).
Открытые модификаторы — это спецификаторы выделенных функциональных головок (например,г. , Х 0 ), ниже согласовываются фразы, предусматривающие посадочные площадки для движения. Эта структура и его предположения о движении порождают все и только засвидетельствованные приказы. Похожий на английский порядок Dem-Num-Adj-N появляется без движения; все остальные приказы включают некоторую последовательность движений NP или что-то ее содержащее.
, Х 0 ), ниже согласовываются фразы, предусматривающие посадочные площадки для движения. Эта структура и его предположения о движении порождают все и только засвидетельствованные приказы. Похожий на английский порядок Dem-Num-Adj-N появляется без движения; все остальные приказы включают некоторую последовательность движений NP или что-то ее содержащее.
Отчет Абеля и Нилмана (2012)
Abels and Neeleman (2012) модифицируют анализ Cinque, отбрасывая элементы, введенные для соответствия LCA (включая фразы соглашения и выделенные функциональные главы).Они утверждают, что LCA не играет объяснительной роли; все, что требуется, это чтобы движение было влево, а остаточное движение было заблокировано. Они допускают свободную линеаризацию родственных узлов, используя значительно более простую базовую структуру (9). Они опускают метки для нетерминальных узлов как не относящиеся к их анализу (Abels and Neeleman, 2012: 34).
Согласно их теории, восемь засвидетельствованных порядков могут быть получены без движения путем изменения линейного порядка сестер. Остальные засвидетельствованные заказы требуют движения влево, без остатка.В принципе, их система допускает расширенный набор выводов Cinque (2005); некоторые порядки могут быть получены посредством выбора линеаризации или посредством движения. Однако, ограничивая внимание строго необходимыми операциями и предполагая, что свободная линеаризация проще движения, их вывод вообще проще, чем вывод Чинкве.
Остальные засвидетельствованные заказы требуют движения влево, без остатка.В принципе, их система допускает расширенный набор выводов Cinque (2005); некоторые порядки могут быть получены посредством выбора линеаризации или посредством движения. Однако, ограничивая внимание строго необходимыми операциями и предполагая, что свободная линеаризация проще движения, их вывод вообще проще, чем вывод Чинкве.
Отчет Стедди и Самек-Лодовичи (2011)
Steddy and Samek-Lodovici (2011) предлагают еще один вариант анализа Cinque (2005).Они предлагают теоретико-оптимальное объяснение, сохраняя базовую структуру Чинкве (8). Линейный порядок регулируется набором ограничений Align-Left (10), по одному для каждого открытого элемента.
(10) а. N-L — Выровнять (NP, L, AgrWP, L)
Выровняйте левый край NP с левым краем AgrWP.
б. A-L — Выровнять (AP, L, AgrWP, L)
Выровняйте левый край точки доступа с левым краем AgrWP.
c. NUM-L — Выровнять (NumP, L, AgrWP, L)
Выровняйте левый край NumP с левым краем AgrWP.
d. DEM-L — Выровнять (DemP, L, AgrWP, L)
Выровняйте левый край DemP с левым краем AgrWP.
(Из Steddy and Samek-Lodovici, 2011: 450).
Эти ограничения выравнивания подвергаются нарушению для каждого явного элемента или трассы, отделяющей соответствующий элемент от левого края домена, и ранжируются по-разному в зависимости от языка. Аттестованные заказы являются оптимальными кандидатами при ранжировании с некоторыми ограничениями. Неподтвержденные порядки исключаются, потому что они «гармонически ограничены»: какой-то другой кандидат подвергается меньшему количеству нарушений более высокого ранга при любом ранжировании ограничений.Следовательно, они могут отказаться от ограничений движения, принятых Cinque (2005) и Abels and Neeleman (2012). Левонаправленный, непостоянный характер движения вместо этого выпадает из принципов выравнивания.
Проблемы с существующими учетными записями
Хотя эти учетные записи различаются в деталях, у них есть некоторые общие проблемы. Во-первых, все они охватывают модель порядка слов на трех уровнях объяснения: (i) единая базовая структура, (ii) синтаксическое движение и (iii) принципы линеаризации.Во всех трех учетных записях (i) описывает порядок внешнего слияния. Детали (ii) и (iii) варьируются в зависимости от счета. Для Cinque (2005 г.) и Steddy and Samek-Lodovici (2011 г.) все заказы, кроме Dem-Num-Adj-N , связаны с перемещением; Abels and Neeleman (2012) требуют движения только для шести засвидетельствованных заказов. Что касается линеаризации, Cinque (2005) использует LCA Kayne (1994); Абельс и Нилеман (2012) имеют равномерное движение влево, но сестры, порожденные базой, свободно линеаризуются на основе языка; Стедди и Самек-Лодовичи (2011) имеют ранжирование языковых ограничений.
Все эти учетные записи требуют разных грамматик для разных порядков. В системе Cinque (2005) необходимо изучить особенности, управляющие определенными движениями. То же самое верно для Abels and Neeleman (2012) с дополнительным изучением порядка для сестринских узлов. Стедди и Самек-Лодовичи (2011) требуют изучения ранжирования ограничений, которое приводит к возникновению каждого заказа. Таким образом, все эти отчеты сталкиваются с проблемами из-за того, что языки допускают свободу порядка в DP; по сути, они должны допускать недоопределенные или конкурирующие грамматики, чтобы охватить разные порядки.
Наконец, все эти сообщения имеют некоторую степень структурной или грамматической двусмысленности для некоторых порядков. Согласно Cinque (2005), один вид двусмысленности возникает при выборе, следует ли переместить функциональную категорию или включающую ее фразу Соглашения; этот выбор не имеет явного рефлекса. Хотя его теория резко ограничивает количество и место приземления возможных движений, эти ограничения несколько искусственны; мало что изменилось бы по существу, если бы мы постулировали дополнительные молчащие функциональные слои для размещения дальнейших движений или разрешили несколько спецификаторов.В пределе это позволяет использовать весь спектр неоднозначных выводов, обсуждавшихся в разделе Сортировка стека: линеаризация, смещение, композиция и скобки с метками. Подход Абельса и Нилмана (2012) допускает эту неоднозначность среди различных производных движений, а также получение многих порядков посредством движения или переупорядочения сестринских узлов. Наконец, Стедди и Самек-Лодовичи (2011) столкнулись с другой проблемой неоднозначности: некоторые порядки согласуются с ранжированием нескольких ограничений (таким образом, с несколькими грамматиками).
Сравнение с учетной записью Stack-Sorting
Учетная запись сортировки стека справляется с этими проблемами лучше. Вместо того, чтобы постулировать отдельные уровни принципов основания, движения и линеаризации, соответствующий механизм реализуется в одном алгоритмическом процессе. Алгоритм сортировки является универсальным, он избегает особенностей языка для управления движением, упорядочивания сестринских узлов или ограничений ранжирования. Такая теория идеально подходит для объяснения феномена свободного порядка слов.Кроме того, каждый заказ вызывает уникальную последовательность операций хранения и поиска, отслеживая уникальную скобку. В доменах, характеризующихся нейтральным порядком слов и единственным fseq, нет ложной структурной или грамматической двусмысленности для любого порядка слов.
Универсальная грамматика как универсальный синтаксический анализатор
В этом разделе развивается мнение о том, что сортировка стека может стать основой для инвариантного механизма производительности, реализующего Universal Grammar как универсальный синтаксический анализатор. Это изменяет традиционные выводы о компетентности и производительности, обеспечивая при этом новый взгляд на то, что такое грамматика.
Переосмысление компетенции и производительности
В генеративных отчетах существует фундаментальное разделение между компетентностью и производительностью (Chomsky, 1965). Компетенция включает в себя знание языка, понимаемого как абстрактное вычисление, определяющее структурную декомпозицию бесконечного множества предложений. Отдельные системы производительности получают доступ к знаниям системы компетенций во время обработки в реальном времени. В терминах трехуровневого описания систем обработки информации Marr (1982) компетентность соответствует высшему, вычислительному уровню, определяющему , что делает система, и , почему .Производительность довольно приблизительно соответствует нижнему алгоритмическому уровню, описывающему пошаговое выполнение вычислений.
Конечно, иерархия Марра применима к обработке информации в языке как в соответствии с настоящей теорией, так и любой другой. Однако разделение труда между этими компонентами здесь существенно перерисовано, и гораздо большее бремя объяснения ложится на исполнение. Принципиальное отличие состоит в том, что в ULTRA структура в квадратных скобках не входит в компетенцию.Вместо этого такая структура возникает при взаимодействии компетенции с алгоритмом сортировки стека, во время парсинга в реальном времени. Знания, приписываемые грамматике компетенций, проще, включая врожденный fseq в качестве основного компонента. В некотором смысле это согласуется с точкой зрения недавней работы Хомского, в которой компетентность в основном ориентирована на вычисление интерпретаций, а экстернализация является «вспомогательной».
Универсальный синтаксический анализатор
Новое утверждение ULTRA заключается в том, что для всех языков существует единый синтаксический анализатор.Это отходит от почти универсального предположения, что синтаксические анализаторы интерпретируют специфические для языка грамматики. Но даже в рамках этого традиционного взгляда была признана привлекательность универсальных механизмов.
«Ключевым моментом, который необходимо сделать, является то, что поиск должен быть поиском универсалий, даже — и, возможно, особенно — в области обработки. Ибо может показаться, что самая сильная теория синтаксического анализа — это та, которая утверждает, что интерпретатор грамматики сам по себе является универсальным механизмом, т.11).
Идея о том, что «парсер — это грамматика», имеет долгую историю; см. Phillips (1996, 2003), Kempson et al. (2001) и статьи в Fodor and Fernandez (2015) для недавней точки зрения. Фодор называет это представлением грамматики производительности только (PGO).
«Теория PGO вступает в игру с одним мощным преимуществом: должны быть психологические механизмы для речи и понимания, и соображения простоты, таким образом, возлагают бремя доказательства на любого, кто утверждает, что есть нечто большее» (Fodor, 1978, стр.470).
Однако, допуская, что это влечет за собой более простую теорию, Фодор отвергает эту идею, не находя мотивов для движения вне автономной грамматики ( там же ., 472). Это предполагает, что движение принципиально сложно для разбора механизмов (которые должны предпочесть фразеоструктурные механизмы трансформационным). Однако в ULTRA смещение не является усложнением более простых механизмов; смещение — это основного механизма.
Смещение не уникально для человеческого языка
Часто говорят, что смещение уникально для человеческого языка, а искусственные коды избегают этого свойства.Но смещение появляется в языках программирования точно в том же смысле, что и в ULTRA. Простой пример иллюстрирует: порядок, в котором пользователи нажимают клавиши на калькуляторе, не является порядком, в котором выполняются соответствующие вычисления. На практике калькуляторы компилируют входные данные в обратную польскую нотацию для машинного использования с помощью алгоритма маневровой станции Дейкстры (SYA).
Пример не праздный; алгоритм сортировки стека (4) практически идентичен алгоритму SYA. Лексические главы (существительные и глаголы) «отводятся» непосредственно на интерпретацию, как числовые константы в калькуляторе.При этом спутники, образующие их расширенные проекции, сортируются стопкой в соответствии с их относительным рангом, точно так же, как арифметические операторы. В этой аналогии картографический порядок соответствует порядку старшинства арифметических операторов.
На самом деле, хотя это свойство мало используется, SYA является протоколом сортировки; многие входные заказы приводят к одному и тому же внутреннему расчету. Как пользователи калькулятора, мы используем одну схему ввода (инфиксную нотацию), но подойдут и другие. Стандартизированный порядок ввода для калькуляторов имеет тот же статус, что и отдельные языки по отношению к ULTRA: пользователи могут придерживаться узких привычек упорядочения, но алгоритм автоматически обрабатывает многие другие порядки.
Грамматичность и неграмматичность
Одной из центральных задач, приписываемых грамматикам, является различение грамматических предложений языка от неграмматических строк. В ULTRA знание грамматики сильно отличается от знания грамматики и . Первый вид знания в основном связан с вычислением интерпретаций. Но инвариантный процесс, интерпретирующий поверхностный порядок одного языка, может в равной степени интерпретировать порядок других языков. С этой точки зрения существует только один Я-язык и единственная грамматика исполнения, которая его обеспечивает.Хотя этот вывод кажется привлекательным, остается важный вопрос: откуда берутся отдельные языки с очевидно разными грамматиками?
Возможные расширения более полной теории синтаксиса
В этом разделе рассматриваются два типа проблем, возникающих при интерпретации сортировки стека как средства повышения производительности. Первый касается согласования теории с тем, что известно об обработке языка в реальном времени; второй касается расширения модели на свойства синтаксиса, которые остались необъясненными.Даже подробное обсуждение этих проблем, не говоря уже об обосновании каких-либо решений, выходит за рамки данной статьи. Цель состоит в том, чтобы просто обрисовать проблемы и указать направления для дальнейшей работы.
Реакция против предсказания: инкрементальность и жесткий порядок слов
Что касается обработки, одна проблема заключается в том, что этому подходу, по-видимому, противоречат убедительные доказательства пословной инкрементальности в понимании (особенно в парадигме визуального мира; см. Tanenhaus and Trueswell, 2006).ULTRA является «пешеходным» в том смысле, против которого предостерегает Stabler (1991). Внутри каждого домена восходящая интерпретация не может начаться до тех пор, пока не встретится лексический корень fseq.
Одна из возможностей согласования ULTRA с инкрементальностью основана на различии между реактивными процессами, такими как процедура сортировки стека, и прогнозирующей обработкой (см. Braver et al., 2007; Huettig and Mani, 2016). Идея состоит в том, что сортировка стека — это реактивный механизм восприятия языка; это контрастирует с возможностями прогнозирования, связанными с нисходящей обработкой и производством, и обязательно дополняется ими.Только последняя система содержит выученные, специфические для языка грамматические знания. Это предложение перекликается с другими подходами с двухэтапным процессом синтаксического анализа, такими как Frazier and Fodor’s (1978) Sausage Machine. ULTRA напоминает их Preliminary Phrase Packager (PPP), быстрый низкоуровневый конструктор структуры, отличающийся от крупномасштабного решения проблем их Sentence Structure Supervisor (SSS). Маркус выражает аналогичную точку зрения, описывая синтаксический анализатор как «быстрый, «тупой» черный ящик» (Marcus, 1980: 204), производящий частичный анализ, дополненный интеллектуальным решением проблем для построения крупномасштабной структуры.
Я полагаю, что доказательства пословной инкрементальности можно согласовать с настоящей теорией через взаимодействие между реакцией и предсказанием, используя понятие «гиперактивности» (Momma et al., 2015). Идея состоит в том, что понимание может проскальзывать вперед, создавая видимость постепенности, если лексический корень (существительное или глагол) предоставляется заранее путем предсказания. Что-то вроде этого кажется правдой.
«Появляется все больше свидетельств того, что понимающие часто выстраивают структурные позиции в своих разборах, прежде чем встречают слова во входных данных, которые фонологически реализуют эти позиции […] Возьмем только один пример: в языке, завершающем начало, таком как японский, может быть необходимо для система построения структуры, чтобы создать позицию для заголовка фразы до того, как она завершит аргументы и дополнения, предшествующие заголовку» (Филлипс и Льюис, 2013, стр.19).
Дополнительная система прогнозирования может помочь решить еще две проблемы для ULTRA: объяснить, как возможно производство, и почему существуют разные языки с разным, относительно жестким порядком слов. Алгоритм сортировки стека представляет собой однонаправленный синтаксический анализатор; нет тривиального способа «повернуть поток вспять» для производства. Столкнувшись с этой неопределенностью, было бы естественно полагаться на прогнозирование для обеспечения порядка слов в производстве. Чтобы упростить производство, полезно, чтобы порядок слов был предсказуемым; в свою очередь, эта система может изучать тенденции порядка слов в языковой среде.Это предполагает петлю обратной связи и вероятный путь появления и расхождения относительно жестких порядков слов.
Первенство против новизны и двойственность семантики
Остается невыясненным ряд важных синтаксических свойств. Чтобы расширить предложение до отдаленно адекватной теории, эти свойства должны быть каким-то образом рассмотрены. К ним относятся, во-первых, группа синтаксических свойств, относящихся к синтаксису A-bar, и так называемая двойственность семантики. Я предполагаю, что этот отличительный вид синтаксиса связан с важным различием в кратковременной памяти, между первичностью и недавностью, основанной на модели начала-конца (SEM) Хенсона (1998).В модели Хенсона первичность и новизна являются различными эффектами, отражающими адресованное по содержанию кодирование двух аспектов последовательного положения.
Актуальность естественным образом связана со стековой памятью (последним пришел, первым ушел). Первичность, с другой стороны, естественным образом описывается памятью очереди (первым поступил, первым обслужен). Помимо оптимального порядка доступа, существует еще одно важное различие между эффектами первичности и недавности. Проще говоря, первый элемент в последовательности остается первым элементом, независимо от того, сколько еще элементов следует за ним; сигнатура первенства данного элемента относительно стабильна во временном масштабе, относящемся к синтаксическому анализу.Давность отличается: каждый элемент в последовательности является новым правым краем, подавляющим доступ к памяти на основе давности всего, что ему предшествует. Таким образом, мы ожидаем своего рода давление «используй или потеряешь» в памяти недавнего времени, но не в памяти первичности.
Предварительно я хотел бы предположить, что в основе двойственности семантики и разделения между А-чертеном и А-синтаксисом лежат различные коды первичности и новизны памяти. Актуальность, связанная со стеком, является основой для нейтральной к информации локальной перестановки, обычно характеризующейся вложенными зависимостями.Если предположить, что первичность играет решающую роль в ненейтральном синтаксисе, то синтаксис типа A-bar предполагает объяснение группы удивительных свойств. Наиболее очевидна ассоциация дискурсивно-информационных эффектов с «левой периферией»: левый край доменов — это то место, где, как мы ожидаем, первичная память будет играть значительную роль. Участие первичной памяти также предполагает анализ эффектов превосходства в множественных конструкциях белых движений. В теориях, основанных на слиянии, такие конструкции (демонстрирующие пересечение зависимостей) проблематичны и требуют условных устройств, таких как вывод Ричардса (1997) «Tucking-In».Думая об эффектах как о первичной памяти, можно предположить более простое объяснение: упорядочивание нескольких wh-фраз — это вопрос доступа по принципу «первым пришел — первым обслужен» (память очереди). Последним свойством этой альтернативной синтаксической системы, которое можно рационализировать, является перемещение на большие расстояния. Возможно, доступность дальних перемещений для отношений A-bar является следствием стабильности первичной памяти, делающей элементы, встречающиеся на левой периферии, доступными для последующего припоминания без особых затруднений, в отличие от недавней памяти (которая может поддерживать только короткие, локальные отзывать).Хотя это наводит на размышления, обращение к обширной литературе по синтаксису A-bar должно быть оставлено для будущих исследований.
Что насчет рекурсии?
Последняя проблема, вырисовывающаяся на заднем плане, — это рекурсия. ULTRA работает в пределах синтаксических доменов, характеризующихся одной fseq. Это требует некоторого комментария, поскольку рекурсия является фундаментальным свойством синтаксиса. Для рекурсии также могут иметь решающее значение свойства памяти и вмешательство дополнительной прогностической системы. Интересно, что эпизодическая память человека имеет независимую иерархическую структуру, возможно, в отличие от родственных животных (Tulving, 1999; Corballis, 2009).В модели SEM эпизодические маркеры создаются для групп внутри сгруппированных последовательностей (Henson, 1998). Лингвистическая рекурсия требует некоторого дополнительного механизма для обработки маркера группы, соответствующего одной последовательности, как маркера элемента в другой последовательности.
Как обсуждалось в разделе «Сравнение с существующими учетными записями Universal 20», в ULTRA структурная неоднозначность не возникает без двусмысленности значения в отдельных доменах. Однако неизбежно возникает структурная неопределенность, когда присутствует несколько доменов, с точки зрения того, какой домен встраивается в другой или где прикрепить элемент, который может занимать позиции в двух разных доменах.Здесь «быстрый и глупый черный ящик» беспомощен и должен обращаться к другим ресурсам. Одним из очевидных источников помощи в объединении нескольких доменов является отдельная система прогнозирования с доступом к нисходящим знаниям о правдоподобных значениях в контексте. Постоянная проблема разрешения двусмысленности встраивания также мотивирует к жесткому порядку слов, что резко снижает возможности прикрепления.
Важным моментом является то, что скобки определяются относительно конкретной fseq.Рекурсивное встраивание одного домена в другой (например, имени в качестве аргумента глагола) включает проецирование скобки, соответствующей всей вложенной фразе, внутри домена встраивания. Рассмотрим следующий пример.
(11) Собака погналась за мячиком.
Здесь есть три области сортировки: две номинальные проекции, встроенные в третью, вербальную проекцию (отбрасывая возможность того, что предложения содержат две области, фазы vP и CP). Их брекетинг ULTRA показан ниже.
(12) NP1 = [ [ собака собака ] ]
NP2 = [ a [ шар шар ] a ]
VP = [ NP1 [ гоняемый ] [ NP2 NP2 ] NP1 ]
Этот пример иллюстрирует неоднозначность, сопровождающую внедрение. Вопрос в том, как связать именные фразы с позициями в fseq глагола (т. е. с тета-ролями). Поскольку тета-роли не выражаются открыто (маркировка регистра — ненадежный ориентир), реактивный синтаксический анализатор должен использовать внешние средства (например, специфические для языка привычки упорядочения или предсказания правдоподобных интерпретаций).
Последний пункт о рекурсии возвращается к вопросу о том, как работают калькуляторы с помощью алгоритма маневровой станции Дейкстры. Такие вычисления являются рекурсивными. Но алгоритм синтаксического анализа не обрабатывает рекурсию; скорее, оно возникает на уровне интерпретации, где частичные результаты арифметических операций используются в дальнейших вычислениях. Аналогичный вывод (рекурсия является семантической, а не синтаксической) возможен в рамках настоящей структуры, учитывая сходство между ULTRA и SYA. Примечательно, что обе процедуры компилируют входные данные в обратную польскую нотацию, так называемый конкатенативный язык программирования, однозначно выражающий рекурсивные иерархические операции в последовательном формате.
Нужен ли нам алгоритм?
Я показал, как особенно простой алгоритм фиксирует ряд синтаксических явлений. Но вопрос, почему этот алгоритм ? Другие процедуры сортировки в принципе возможны и приведут к другим профилям предотвращения перестановок. Как мы можем обосновать выбор сортировки стека в качестве подходящей процедуры для синтаксического отображения?
Есть три важных ингредиента. Во-первых, это ориентация системы как парсера, отображающего звук в смысл.Это не является логически необходимым; это просто один из разумных вариантов. Второй фактор — линейная природа звука и смысла. Это просто для звуковых последовательностей, но гораздо меньше для интерпретаций, где это просто смелая гипотеза. Третий ингредиент — выбор стековой памяти. Вероятно, это можно связать с эффектом модальности: разборчивый речевой ввод порождает необычайно сильный эффект новизны (Surprenant et al., 1993). Кажется небольшим шагом предположить, что формальный стек, используемый в алгоритме, может просто (и грубо) отражать преобладание эффектов новизны в памяти для лингвистического материала.
До сих пор сортировка стека была реализована с помощью явного алгоритма. Это может быть ненужным. Вместо того, чтобы думать о сортировке стека как о наборе явных инструкций, мы могли бы переформулировать ее как антиконфликтную предвзятость между доступностью элементов в памяти с точки зрения эффекта давности и поиском для жесткой последовательности интерпретации. Если это верно, то, возможно, для объяснения этих эффектов не потребовалось никакого нового когнитивного механизма. Остается понять, откуда берется сам порядок интерпретаций (fseq), на чем я не буду здесь размышлять.
Заключение
Подводя итог, можно сказать, что простой алгоритм (4) отображает 213-избегающие порядки слов в восходящую композиционную последовательность, а 213-содержащие порядки отображают в девиантные последовательности. Хотя ввод и вывод отображения представляют собой последовательности, присутствует иерархическая структура: алгоритмические шаги реализуют левые и правые скобки почти точно там, где их размещают стандартные учетные записи. Аккаунт отличается от стандартных аккаунтов назначением однозначного брекетинга всем заказам.
Эта модель улучшает существующие учетные записи ограничений порядка слов, которые требуют дополнительных условий (например,г., ограничения на движение вместе с принципами линеаризации), помимо построения основной синтаксической структуры. В ULTRA эти эффекты выпадают из единого процесса реального времени. В свою очередь, синтаксическое замещение, долгое время считавшееся любопытным усложнением, становится фундаментальным грамматическим механизмом. Изучение особенностей языка не требуется; одна грамматика интерпретирует множество порядков.
Должно быть ясно, что описанная здесь система является лишь частью синтаксического познания. Эта система строит одну расширенную проекцию за раз; требуются дополнительные механизмы для встраивания одного домена в другой.Однако это может быть достоинством: заманчиво идентифицировать области действия для этой архитектуры с фазами, которые, таким образом, являются особыми по принципиальным причинам.
Более того, сортировка стека работает только с нейтральной к информации структурой. При этом игнорируется другой важный компонент синтаксиса, так называемая информационная структура дискурса, связанная с потенциально отдаленными зависимостями A-bar. Этот недостаток также может быть достоинством, предлагающим принципиальную основу для двойственности семантики.Я предположил, что первичная память играет центральную роль в этих эффектах, потенциально объясняя несколько любопытных свойств (левота, дальность и пересечение).
Подняв наш взгляд, можно сделать более широкий вывод: большая часть механизма синтаксического познания может сводиться к эффектам, не специфичным для языка. Излишне говорить, что это всего лишь программный набросок; будущие исследования определят, можно ли и каким образом сортировку стека ULTRA интегрировать в более полную модель языка.
Вклад авторов
Автор подтверждает, что является единственным автором данной работы и одобрил ее публикацию.
Заявление о конфликте интересов
Автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Части этой работы были впервые разработаны на семинаре для выпускников Университета Аризоны (2015 г.) и представлены на симпозиуме POL в Токио (2016 г.), LCUGA 3 (2016 г.) и ежегодном собрании LSA (2017 г.).Я благодарен зрителям на этих площадках и многочисленным коллегам за полезные обсуждения. В знак благодарности я хотел бы выделить следующих: Клауса Абельса, Дэвида Адджера, Боба Бервика, Тома Бевера, Эндрю Карни, Ноама Хомского, Гульельмо Чинкве, Дженнифер Калбертсон, Сэндивэй Фонг, Томаса Графа, Джона Хейла, Хайди Харли, Норберта Хорнштейна, Майкл Джарретт, Ричард Кейн, Хильда Купман, Диего Кривохен, Марко Кульманн, Массимо Пиаттелли-Палмарини, Колин Филлипс, Пол Пьетроски, Маркус Саерс, Йосуке Сато, Дэн Сиддики, Доминик Спортиш, Хуан Уриагерека, Элли ван Гельдерен, Эндрю Ведель и Стивен Уилсон.Я особенно благодарен аспирантам, которые участвовали в моей исследовательской группе Stack-Sorting (2015-2016). Конечно, все ошибки и недоразумения в этой статье мои собственные.
Сноски
Ссылки
Абельс, К., и Нилеман, А. (2012). Линейные асимметрии и LCA. Синтаксис 15, 25–74. doi: 10.1111/j.1467-9612.2011.00163.x
Полнотекстовая перекрестная ссылка | Академия Google
Барбьерс, С., ван дер Ауэра, Дж., Беннис, Х., Боеф, Э., де Вогелаер, Г., и ван дер Хам, М. (2008). Синтаксический атлас голландских диалектов, Vol. II , Амстердам: Издательство Амстердамского университета.
Академия Google
Бервик, Р., и Хомский, Н. (2016). Почему только мы: язык и эволюция . Кембридж, Массачусетс: MIT Press.
Академия Google
Брейвер, Т.С., Грей, Дж.Р., и Берджесс, Г.К. (2007). «Объяснение многих разновидностей вариаций рабочей памяти: двойные механизмы когнитивного контроля», в «Вариации рабочей памяти », под редакцией А.Конвей, К. Джаррольд, М. Кейн, А. Мияке и Дж. Тоуз (Нью-Йорк, штат Нью-Йорк: издательство Оксфордского университета), 76–106.
Академия Google
Чези, К., и Моро, А. (2015). «Тонкая зависимость между компетентностью и производительностью», в 50 лет спустя: размышления об аспектах Хомского , ред. Дж. Гальего и Д. Отт (Кембридж, Массачусетс: Рабочие документы Массачусетского технологического института по лингвистике), 33–46.
Академия Google
Хомский, Н. (1965). Аспекты теории синтаксиса .Кембридж, Массачусетс: MIT Press.
Академия Google
Хомский, Н. (1995). Минималистская программа . Кембридж, Массачусетс: MIT Press.
Академия Google
Чинкве, Г. (1999). Наречия и функциональные заголовки: межъязыковая перспектива . Оксфорд: Издательство Оксфордского университета.
Академия Google
Чинкве, Г. (2005). Получение универсальных 20 Гринберга и их исключений. Лингвистическое исследование 36, 315–332. дои: 10.1162/00243896917
Полнотекстовая перекрестная ссылка | Академия Google
Делл, Г. С., и Чанг, Ф. (2014). P-цепь: связь производства предложений и их нарушений с пониманием и усвоением. Фил. Транс. Р. Соц. В 369:20120394. doi: 10.1098/rstb.2012.0394
Реферат PubMed | Полный текст перекрестной ссылки | Академия Google
Фодор, JD (1978). Стратегии синтаксического анализа и ограничения на преобразования. Лингвистическое исследование 9, 427–473.
Академия Google
Фодор, Дж. Д., и Фернандес, Э. (2015). Спецвыпуск по грамматикам и парсерам: к единой теории знания и использования языка. Ж. Психолингвист. Рез. 44, 1–5. doi: 10.1007/s10936-014-9333-3
Полнотекстовая перекрестная ссылка
Фрейзер, Л., и Фодор, Дж. Д. (1978). Колбасная машина: новая двухступенчатая модель разбора. Познание 6, 291–325. дои: 10.1016/0010-0277(78)
-1
Полнотекстовая перекрестная ссылка | Академия Google
Гринберг, Дж.(1963). «Некоторые грамматические универсалии с особым упором на порядок значимых элементов», в универсалиях языка , изд. Дж. Гринберг (Кембридж, Массачусетс: MIT Press), 73–113.
Академия Google
Хюттиг, Ф., и Мани, Н. (2016). Необходимо ли предсказание для понимания языка? Возможно нет. Ланг. Познан. Неврологи. 31, 19–31. дои: 10.1080/23273798.2015.1072223
Полнотекстовая перекрестная ссылка | Академия Google
Джаясилан, К.А.(2008). Голая структура фразы и синтаксис без спецификаторов. Биолингвистика 2, 87–106.
Академия Google
Джоши, А. К. (1990). Обработка перекрестных и вложенных зависимостей: автоматный взгляд на результаты психолингвистики. Ланг. Познан. Процесс 5, 1–27. дои: 10.1080/0169096
02095
Полнотекстовая перекрестная ссылка | Академия Google
Кейн, Р. (1994). Антисимметрия синтаксиса . Кембридж, Массачусетс: MIT Press.
Академия Google
Кемпсон, Р., Мейер-Виол, В., и Габбай, Д. (2001). Динамический синтаксис . Оксфорд: Блэквелл.
Академия Google
Кнут, Д. (1968). Искусство компьютерного программирования, Vol. 1: Основные алгоритмы . (Рединг, Массачусетс: Аддисон-Уэсли).
Купман, Х. (2000). Синтаксис спецификаторов и заголовков . Лондон: Рутледж.
Маркус, член парламента (1980). Теория синтаксического распознавания естественных языков . Кембридж, Массачусетс: MIT Press.
Академия Google
Марр, Д.(1982). Видение: компьютерное исследование человеческого представления и обработки визуальной информации . Нью-Йорк, штат Нью-Йорк: WH Freeman.
Момма, С., Слевц, Л. Р., и Филлипс, К. (2015). «Время планирования глаголов в активном и пассивном построении предложений», в плакате , представленном на 28-й ежегодной конференции CUNY по обработке человеческих предложений (Лос-Анджелес, Калифорния).
Академия Google
Филлипс, К., и Льюис, С. (2013). Деривационный порядок в синтаксисе: доказательства и архитектурные последствия. Шпилька. Линг. 6, 11–47.
Академия Google
Ричардс, Н. (1997). Что перемещается, где и когда на каком языке? Докторская диссертация, Массачусетский технологический институт.
Ричардс, Н. (2010). Издающиеся деревья . Кембридж, Массачусетс: MIT Press.
Академия Google
Рицци, Л. (1997). «Тонкая структура левой периферии», в Elements of Grammar: Handbook in Generative Syntax , изд. Л. Хегеман (Дордрехт: Kluwer), 281–337.
Академия Google
Шмид, Т., и Фогель, Р. (2004). Диалектные вариации в немецких кластерах из 3 глаголов: поверхностно-ориентированный учет ОТ. J. Сравн. германский линг. 7, 235–274. doi: 10.1023/B:JCOM.0000016639.53619.94
Полнотекстовая перекрестная ссылка
Шихан М., Биберауэр Т., Робертс И., Песецкий Д. и Холмберг А. (2017). Последнее-над-финальным условием: синтаксическая универсалия, Vol. 76 , Кембридж, Массачусетс: MIT Press.
Стейблер, Э.П. младший (1991). «Избегайте парадокса пешехода», в «Разбор на основе принципов: вычисления и психолингвистика », редакторы Р. Бервик, С. Эбни и К. Тенни (Дордрехт: Клювер), 199–237.
Академия Google
Starke, M. (2004). «Об отсутствии спецификаторов и природе головок», в The Cartography of Syntactic Structures, Vol. 3: Structures and Beyond , под ред. А. Беллетти. (Нью-Йорк, штат Нью-Йорк: издательство Оксфордского университета), 252–268.
Стедди, С.и Самек-Лодовичи, В. (2011). О неграмматичности остаточного движения в словообразовании универсалия Гринберга 20. Linguistic Inquiry 42, 445–469. doi: 10.1162/LING_a_00053
Полнотекстовая перекрестная ссылка | Академия Google
Стидман, М. (2000). Синтаксический процесс . Кембридж, Массачусетс: MIT Press.
Академия Google
Таненхаус, М.К., и Трусвелл, Дж.К. (2006). «Движения глаз и понимание разговорной речи», в Справочнике по психолингвистике , под редакцией М.Тракслер и М.А. Гернсбахер (Нью-Йорк, штат Нью-Йорк: Elsevier Academic Press), 863–900.
Академия Google
Тульвинг, Э. (1999). «Об уникальности эпизодической памяти», в Cognitive Neuroscience of Memory , eds L. Nilsson and HJ Markowitsch (Ashland, OH: Hogrefe and Huber), 11–42.
Академия Google
Вурмбранд, С. (2006). «Группы глаголов, повышение глаголов и реструктуризация», в The Blackwell Companion to Syntax , Vol. V, редакторы М. Эверарт и Х.ван Римсдейк (Оксфорд: Блэквелл), 227–341.
Академия Google
Zwart, CJ (2007). Несколько замечаний о происхождении и распространении IPP-эффекта. Groninger Arbeiten zur Germanistischen Linguistik 45, 77–99.
Академия Google
Дерево синтаксического анализа для предложения «Фильм очень интересный», построенное…
В этой диссертации основное внимание уделяется двум задачам обработки естественного языка, которые требуют извлечения семантической информации из необработанных текстов: анализу тональности и суммированию текста.В этой диссертации обсуждаются проблемы и делается попытка улучшить нейронные модели для обеих задач, которые стали доминирующей парадигмой за последние несколько лет. Соответственно, эта диссертация состоит из двух частей: первая часть (нейронный анализ настроений) посвящена компьютерному изучению мнений и чувств людей, а вторая часть (нейронное суммирование текста) пытается извлечь существенную информацию из сложного предложения и переписать ее. в удобочитаемой форме. Нейронный анализ настроений. Подобно компьютерному зрению, многочисленные глубокие сверточные нейронные сети были адаптированы для анализа настроений и задач классификации текста.Однако, в отличие от области изображений, эти исследования проводятся на разных типах входных данных и на разных наборах данных, что затрудняет понимание того, действительно ли нужна глубокая сеть. В этой диссертации мы пытаемся найти элементы для ответа на этот вопрос, то есть должны ли нейронные сети вычислять глубокие иерархии функций для текстовых данных так же, как они это делают в зрении. Таким образом, мы предлагаем новую адаптацию самой глубокой сверточной архитектуры (DenseNet) для классификации текста и изучаем важность глубины в сверточных моделях с различными уровнями атомов (слова или символа) ввода.Мы показываем, что глубокие модели действительно дают лучшую производительность, чем неглубокие сети, когда вводимый текст представлен в виде последовательности символов. Однако простая неглубокая и широкая сеть превосходит модели глубокой DenseNet со словесными входами. Кроме того, для дальнейшего совершенствования классификаторов настроений и их контекстуализации мы предлагаем моделировать их совместно с диалоговыми актами, которые являются фактором объяснения и коррелируют с настроениями, но тем не менее часто игнорируются. Мы вручную аннотировали как диалоги, так и настроения в социальной среде, похожей на Twitter, и обучили многозадачную иерархическую рекуррентную сеть совместному распознаванию настроений и диалоговых действий.Мы показываем, что трансферное обучение может быть эффективно достигнуто между обеими задачами, и дополнительно анализируем некоторые конкретные корреляции между настроениями и диалогами в социальных сетях. Обобщение нейронного текста. Выявление настроений и мнений из больших цифровых документов не всегда позволяет пользователям таких систем принимать обоснованные решения, поскольку отсутствует другая важная семантическая информация. Людям также нужны основные аргументы и подтверждающие доводы из исходных документов, чтобы по-настоящему понять и интерпретировать документ.Чтобы собрать такую информацию, мы стремимся сделать модели обобщения нейронного текста более объяснимыми. Мы предлагаем модель, обладающую лучшими свойствами объяснимости и достаточно гибкую, чтобы поддерживать различные модули неглубокого синтаксического анализа. В частности, мы линеаризуем синтаксическое дерево в виде перекрывающихся текстовых сегментов, которые затем выбираются с помощью обучения с подкреплением (RL) и регенерируются в сжатую форму. Следовательно, предлагаемая модель способна обрабатывать как экстрактивное, так и абстрактное обобщение.Кроме того, мы наблюдаем, что модели на основе RL становятся все более распространенными для многих задач суммирования текста. Мы заинтересованы в лучшем понимании того, какие виды информации учитываются такими моделями, и предлагаем изучить этот вопрос с синтаксической точки зрения. Таким образом, мы предоставляем подробное сравнение подходов, основанных на RL и синтаксисе, а также их комбинации по нескольким параметрам, которые относятся к воспринимаемому качеству сгенерированных резюме, таким как количество повторений, длина предложения, распределение тегов части речи. , релевантность и грамматичность.Мы показываем, что при ограничении ресурсов (вычислений и памяти) разумно обучать модели только с RL и без какой-либо синтаксической информации, поскольку они дают почти такие же хорошие результаты, как модели с учетом синтаксиса, с меньшим количеством параметров и более быстрой сходимостью обучения.
5 Принципы визуального дизайна в UX
Глядя на визуальный элемент, мы обычно сразу можем сказать, нравится он или нет. (Потому что они часто разыгрываются на интуитивном уровне в модели эмоционального дизайна Дона Нормана.) Однако немногие могут объяснить, почему макет визуально привлекателен. Графика, основанная на принципах хорошего визуального дизайна, может привлечь внимание и повысить удобство использования.
Принципы визуального дизайна информируют нас о том, как элементы дизайна, такие как линия, форма, цвет, сетка или пространство, сочетаются друг с другом для создания хорошо продуманных и продуманных визуальных эффектов.
В этой статье определяются 5 принципов визуального дизайна, влияющих на UX:
- Шкала
- Визуальная иерархия
- Весы
- Контраст
- Гештальт
Соблюдение этих 5 принципов визуального дизайна может повысить вовлеченность и удобство использования.
1. Весы
Этот принцип широко используется: он используется почти в каждом хорошем визуальном дизайне.
Определение: Принцип шкалы относится к использованию относительного размера для обозначения важности и ранга в композиции.
Другими словами, при правильном использовании этого принципа самые важные элементы в дизайне больше, чем менее важные. Причина этого принципа проста: когда что-то большое, его скорее заметят.
В визуально приятном дизайне обычно используется не более 3 разных размеров. Наличие ряда элементов разного размера не только внесет разнообразие в ваш макет, но и установит визуальную иерархию (см. следующий принцип) на странице. Обязательно подчеркните наиболее важные аспекты вашего дизайна, сделав их самыми большими.
При правильном использовании принципа масштабирования и подчеркивании правильных элементов пользователи легко разберут визуальный элемент и узнают, как его использовать.
Medium для iPhone: популярные статьи визуально больше, чем другие статьи. Шкала направляет пользователей к потенциально более интересной статье. В этом гараже в Кракове самая важная часть информации (зона H — где вы сейчас находитесь в гараже) — самая большая по размеру. (Источник изображения: www.behance.com)2. Визуальная иерархия
Макет с хорошей визуальной иерархией будет легко понятен вашим пользователям.
Определение : Принцип визуальной иерархии относится к направлению взгляда на страницу таким образом, чтобы он обращал внимание на различные элементы дизайна в порядке их важности.
Визуальная иерархия может быть реализована с помощью вариаций масштаба, значения, цвета, интервалов, размещения и множества других сигналов.
Визуальная иерархия управляет доставкой опыта. Если вам трудно понять, где искать на странице, более чем вероятно, что в ее макете отсутствует четкая визуальная иерархия.
Чтобы создать четкую визуальную иерархию, используйте 2–3 размера шрифта, чтобы указать пользователям, какие части контента являются наиболее важными или находятся на самом высоком уровне в мини-информационной архитектуре страницы.Или рассмотрите возможность использования ярких цветов для важных предметов и приглушенных цветов для менее важных.
Масштабтакже может помочь определить визуальную иерархию, поэтому используйте различные масштабы для различных элементов дизайна. Общее эмпирическое правило заключается в том, чтобы включать в проект мелкие, средние и крупные компоненты.
Среднее мобильное приложение: существует четкая визуальная иерархия заголовка, подзаголовка и основного текста. Каждый компонент статьи имеет размер шрифта, равный его важности. Мобильное приложение Uber: четкая визуальная иерархия в мобильном приложении Uber.Экран разделен пополам между картой и формой ввода (нижняя половина экрана), что навязывает мысль о том, что эти компоненты одинаково важны для пользователя. Сразу бросается в глаза Куда? поле из-за его серого фона, а затем в недавние местоположения под ним, размер шрифта которых немного меньше. Мобильное приложение Dropbox: визуальная иерархия менее четкая в мобильном приложении Dropbox. Несмотря на то, что пояснительный текст меньше по размеру, чем имя файла, его трудно различить между разными файлами.Миниатюры представляют собой дополнительный уровень иерархии, но их наличие зависит от доступных типов файлов. В конечном итоге пользователям приходится много анализировать и читать, чтобы найти нужную папку или файл.3. Весы
Балансировка похожа на качели: вместо веса вы уравновешиваете элементы дизайна.
Определение : Принцип баланса относится к удовлетворительному расположению или соотношению элементов дизайна. Баланс возникает, когда количество визуального сигнала равномерно распределено (но не обязательно симметрично) по обе стороны от воображаемой оси, проходящей через середину экрана.Эта ось часто вертикальна, но может быть и горизонтальной.
Как и при балансировке веса, если бы у вас был один маленький элемент дизайна и один большой элемент дизайна с двух сторон от оси, дизайн выглядел бы немного несбалансированным. При создании баланса важна площадь, занимаемая элементом дизайна, а не только количество элементов.
Воображаемая ось, которую вы устанавливаете на своем визуальном элементе, будет отправной точкой для организации вашего макета и поможет вам понять текущее состояние баланса вашего визуального элемента.В сбалансированном дизайне ни одна область не привлекает ваше внимание настолько сильно, что вы не можете видеть другие области (даже если некоторые элементы могут иметь больший визуальный вес и быть фокусами). Баланс может быть:
Тип баланса, который вы используете в своем изображении, зависит от того, что вы хотите передать. Асимметрия динамична и привлекательна. Это создает ощущение энергии и движения. Симметрия спокойна и статична. Радиальный баланс всегда будет приводить взгляд к центру композиции.
The Hub Style Exploration: композиция кажется стабильной, что особенно уместно, когда вы ищете любимую работу.Баланс здесь симметричный. Если вы проведете воображаемую вертикальную ось по центру веб-сайта, элементы будут равномерно распределены по обеим сторонам оси. (Источник изображения: dribbble.com) Nike: эта страница асимметрично сбалансирована, создавая ощущение энергии и движения, что соответствует бренду Nike. Если бы вы провели вертикальную ось по центру этого визуального элемента, количество элементов было бы примерно одинаковым с обеих сторон оси. Однако разница в том, что они не идентичны и находятся в одних и тех же местах.Несмотря на то, что технически на левой стороне обуви немного больше текста, он уравновешивается более крупным текстом справа, который занимает больше места и визуального веса, что делает их довольно похожими. Наручные часы Brathwait: эти классические часы имеют радиальную балансировку. Взгляд немедленно притягивается к центру циферблата, и весь визуальный вес распределяется равномерно, независимо от того, где нарисована воображаемая ось. Этот редакционный разворот не сбалансирован.Если бы вы провели вертикальную ось вниз по странице, элементы не были бы равномерно распределены по обеим сторонам оси. (Источник изображения: www.behance.net)4. Контраст
Это еще один широко используемый принцип, который выделяет определенные части вашего дизайна для ваших пользователей.
Определение : Принцип контраста относится к сопоставлению визуально непохожих элементов, чтобы передать тот факт, что эти элементы различны (например, принадлежат к разным категориям, имеют разные функции, ведут себя по-разному).
Другими словами, контраст обеспечивает глазу заметную разницу (например, в размере или цвете) между двумя объектами (или между двумя наборами объектов), чтобы подчеркнуть их различие.
Принцип контраста часто применяется через цвет. Например, красный часто используется в дизайне пользовательского интерфейса, особенно на iOS, для обозначения удаления. Яркий цвет сигнализирует о том, что красный элемент отличается от остальных.
Приложение «Напоминания» для iOS: красный цвет, сильно контрастирующий с окружающим контекстом, зарезервирован для удаления.Часто в UX слово «контраст» ассоциируется с контрастом между текстом и его фоном. Иногда дизайнеры намеренно уменьшают контрастность текста, чтобы не выделять менее важный текст. Но такой подход опасен — снижение контраста текста также снижает читаемость и может сделать ваш контент недоступным. Используйте средство проверки цветового контраста, чтобы убедиться, что ваш контент все еще может быть прочитан всеми вашими целевыми пользователями.
Greenhouse Juice Co. Четкость текста на бутылке зависит от цвета сока.Хотя контраст прекрасно работает для некоторых соков, этикетки на бутылках со светлыми соками почти невозможно прочитать. (Источник изображения: www.instagram.com)5. Гештальт-принципы
Это набор принципов, установленных в начале двадцатого века гештальт-психологами. Они показывают, как люди понимают изображения.
Определение : Гештальт-принципы объясняют, как люди упрощают и организуют сложные образы, состоящие из множества элементов, подсознательно организуя части в организованную систему, создающую целое, а не интерпретируя их как ряд разрозненных элементов.Другими словами, принципы гештальта отражают нашу склонность воспринимать целое, а не отдельные элементы.
Существует несколько гештальт-принципов, в том числе сходство, продолжение, замыкание, близость, общая область, фигура/фон, а также симметрия и порядок. Близость особенно важна для UX — она означает, что элементы, которые визуально ближе друг к другу, воспринимаются как часть одной группы.
Именно принцип замыкания гештальта позволяет нам увидеть две целующиеся фигуры вместо случайных фигур на картине Пикассо.Наш мозг заполняет недостающие части, чтобы создать две фигуры. Мы также часто видим применение гештальт-теории в логосе. На логотипе NBC павлина в белом пространстве нет, но наш мозг понимает, что он есть. В форме регистрации Uber используется гештальт-принцип близости: метки полей располагаются рядом с соответствующими текстовыми полями, что упрощает понимание того, какую информацию вводить в какие поля. Если бы между полем и последующей меткой (для следующего поля) было бы меньше места, пользователям было бы сложно понять, что к чему относится. Налоговая форма США 2017 г.: из-за отсутствия места между полями ее заполнение усложняется. Вы можете легко пропустить то, к чему относится второе поле «Фамилия». Использование гештальт-принципа близости для различения полей, относящихся к себе и супругу, принесло бы пользу UX.Почему важны принципы визуального дизайна
Почему мы должны заботиться о принципах визуального дизайна и понимать их? Помимо того, что что-то «выглядит красиво», их понимание и использование в своих интересах служит:
- Повышение удобства использования. Следование этим принципам визуального дизайна часто приводит к созданию простых в использовании макетов. Например, золотое сечение, которое часто используется для создания красивых произведений искусства, также использовалось в наборе текста для создания визуально приятного соотношения между размером шрифта, высотой строки и шириной строки. Результат обычно приводил к сокращению длины строки, что создавало баланс (через пустое пространство) на веб-странице и облегчало чтение текста. В сочетании с сильным интерактивным дизайном визуальный дизайн повысит успешность выполнения задач и вовлеченность пользователей.
- Вызывайте эмоции и восторг. Красивые вещи вызывают положительные эмоции. (На самом деле, эффект эстетики и удобства использования говорит о том, что когда люди находят дизайн визуально привлекательным, они могут быть более снисходительны к незначительным ошибкам юзабилити.) Следуя принципам хорошего визуального дизайна, дизайнеры могут создавать пользовательские интерфейсы, которые хорошо выглядят и, таким образом, побуждают пользователей хорошо себя чувствовать.
- Укрепление восприятия бренда. Сильная визуальная система повышает доверие и интерес пользователей к продукту, а также надлежащим образом представляет и укрепляет бренд.
Каталожные номера
Луптон, Э. (2008). Графический дизайн: новые основы. Нью-Йорк: Принстонская архитектурная пресса.
Пулен, Р. (2018). Язык графического дизайна. Беверли: Quarto Publishing Group USA, Inc.
КОД 128 и GS1-128 | Основы штрих-кодов | Информация о штрих-коде и советы
В мире существует около 100 видов штрих-кодов. Ниже представлено введение в штрих-коды CODE128 и GS1-128.
Единственное руководство, которое вам нужно, чтобы узнать все о штрих-кодах !
В этом руководстве представлены простые для понимания структуры и стандарты одномерных кодов, таких как EAN, CODE39 и CODE128.
Скачать
CODE 128 — это штрих-код, разработанный Computer Identics Corporation (США) в 1981 году.
CODE 128 может представлять все 128 символов кода ASCII (цифры, прописные/строчные буквы, символы и управляющие коды). Поскольку он может представлять все символы (кроме японских кандзи, хираганы и катаканы), которые можно использовать с клавиатурой компьютера, этот штрих-код удобен для компьютера.
Основной состав следующий:
- А
- Стартовый код
- Б
- Контрольная цифра (Модуль 103)
- С
- Код остановки
- Существует 4 размера стержня.
- Один символ представлен 3 штрихами и 3 пробелами (всего шесть элементов).
- Начальный символ имеет три типа; «КОД-А», «КОД-В» и «КОД-С». Тип начального символа определяет состав последующих символов. (См. здесь таблицу состава символов. Например, когда CODE A используется в качестве начального символа, могут быть представлены символы в столбце CODE-A.)
- А
- Начните с кода C
- Б
- Изменить на КОД-А
- При использовании кода CODE-C двузначные числа могут быть представлены одним типом штрихового рисунка.Это обеспечивает очень высокую плотность данных.
- Когда используются символы набора кодов (КОД-A, КОД-B и КОД-C), штрих-код, начинающийся с начального символа КОДА-A, можно изменить, чтобы использовать символы в столбце КОД-B или КОД-C в середина обработки штрих-кода.
- При использовании «SHIFT» только один символ рядом с SHIFT может быть заменен на символ в следующем столбце (A на B, B на C, C на A). (Аналогично действию клавиши SHIFT на клавиатуре компьютера)
- «Модуль 103» используется как контрольная цифра.
- Штрих-код CODE 128 может включать все 128 символов кода ASCII (включая управляющие коды, такие как [ESC], [STX], [ETX], [CR] и [LF]).
- Когда в качестве начального символа используется CODE-C, одна полоса может представлять собой двузначные числа. Это позволяет очень эффективно составлять штрих-коды. Если данные штрих-кода состоят из 12 или более цифр, CODE 128 обеспечивает меньший размер, чем ITF.
- Поскольку в CODE 128 используются 4 типа размера прутка, требуются принтеры с высоким качеством печати. CODE 128 не подходит для печати на матричных и струйных принтерах FA, а также для флексографской печати на гофрированном картоне.
Использование CODE-C в качестве начального кода позволяет CODE 128 обеспечивать штрих-код с очень высокой плотностью данных, если обрабатываются только числа.
GS1-128 использует характеристики CODE 128 и в настоящее время используется во многих промышленных приложениях.При использовании GS1-128 в штрих-код включаются различные данные, такие как дата изготовления продукта, дата открытия, вес, размер, номер партии, пункт назначения, счет клиента и т. д.
КОД 128 используется в следующих отраслях:
- Швейная промышленность США
- Пищевая промышленность США
- США Производство лекарств и медицинского оборудования
- Пищевая промышленность Австралии и Новой Зеландии
- Европейская фармацевтическая промышленность и производство медицинских инструментов
GS1-128 — это штрих-код, который предоставляет различные данные, включая данные о распределении и бизнес-транзакциях, в дополнение к данным, предоставляемым кодом JAN и стандартным кодом распределения (ITF), доступным в настоящее время.
В штрих-код GS1-128 могут быть включены следующие данные:
- Номер упаковки
- Количество в упаковке
- Масса, грузоподъемность и кубатура
- Дата изготовления и подтверждение качества
- Номер лота
- Номер места (пункт назначения)
- Код счета клиента
- Номер заказа клиента
Необходимые данные используются для формирования этикетки со штрих-кодом для различных приложений.
Например, покупка/заказ в режиме онлайн с использованием EDI (система обмена электронными данными между компаниями), управление открытой датой для продуктов питания, управление сроком годности лекарств, упрощение работы по проверке входящих продуктов, сортировка посылок по каждому пункту назначения и т.д. .. (Следующая этикетка представляет собой образец от производителя продуктов питания.)
- А
- Код изделия
- Б
- Срок действия качества (27 августа 1999 г.)
- С
- Количество поставки
- Д
- Масса нетто
- Е
- Номер лота
- Ф
- Серийный номер
JAN и стандартный код распределения (ITF) являются штрих-кодами для обозначения самого продукта и его количества, а не для таких данных, как дата изготовления, номер упаковки, действительность качества и номер заказа.
Хотя CODE 39 позволяет включать такие данные в штрих-код, обмен такими данными между компаниями не допускается, поскольку определение и количество цифр данных различаются.
GS1-128 установлен как всемирный универсальный штрих-код для общего использования, при этом элементы и количество цифр данных, а также тип штрих-кода стандартизированы.
Базовый состав ГС1-128 следующий:
- В качестве штрих-кода используется код 128.
- Чтобы разделить необходимые данные, такие как вес и открытые данные, добавляется «идентификатор приложения (AI)», за которым следуют данные. Если представлено несколько данных, все данные должны быть связаны.
- А
- А.И. указать код контейнера доставки
- Б
- А.И. для указания достоверности качества
- С
- А.I. указать объем поставки
Хотя идентификаторы приложений заключены в скобки, они не включаются в данные штрих-кода. Они используются только для презентации.
В приведенном выше примере после идентификатора приложения «01» присваивается 14-значный код для идентификации контейнера доставки (минимальная единица упаковки для коробок из гофрокартона). После идентификатора приложения «15» данные, отражающие достоверность качества (действительность потребления или действительность лекарственного средства), указываются на 27 августа 1995 года.После последнего идентификатора приложения «30» данные, представляющие количество поставки, указываются для показа 3 штук.
Существует около 100 идентификаторов приложений, кроме указанных выше. Необходимые данные выбираются и включаются в штрих-коды пользователями.
GS1-128 не предназначен для представления фиксированных данных, но данные выбираются пользователем. Следовательно, для последовательного использования GS1-128 среди компаний стандарты для системы штрих-кода с доступными данными должны быть подготовлены соответствующей отраслью и участвующими группами компаний.
- Чтобы отличить GS1-128 от CODE 128, необходимо ввести [FNC 1] (функция 1) после кода запуска (CODE-A — C).
- Даже если количество цифр для данных, следующих за идентификатором приложения, имеет переменную длину, [FNC 1] используется для разделения данных.
- А
- Код запуска C
- Б
- [FNC 1] для сигнала GS1-128
- С
- Данные 1 (фиксированной длины)
- Д
- Данные 2 (переменной длины)
- Е
- [FNC 1] для разделения данных
- Ф
- Данные 3 (переменной длины)
- Г
- Контрольная цифра
- Х
- Код остановки
- С добавлением GS1-128 к коду EAN и стандартному коду распределения (ITF) его можно использовать в качестве кода для добавления дополнительных данных.
GS1-128 предназначен для представления идентификаторов приложений и относительных данных о продуктах или данных транзакций компаний, использующих КОД 128.
Другими словами, GS1-128 является стандартом для приложений, представляющих различные данные. CODE 128 является стандартом только для самого штрих-кода. Разница между GS1-128 и CODE 128 заключается в том, представляет ли он приложение или нет.
Поскольку GS1-128 использует состав штрих-кода CODE 128, любой считыватель штрих-кода, который может считывать CODE 128, можно использовать для считывания данных GS1-128.
Существует 100 типов идентификаторов приложений, которые можно классифицировать следующим образом. Некоторые данные, следующие за каждым идентификатором приложения, имеют фиксированное количество цифр (стандартный идентификатор коробки, дата и единица измерения), в то время как другие имеют неопределенное количество цифр (номер партии, серийный номер, количество в упаковке, количество и номер заказа). ).
| Классификация | Содержание | Идентификатор приложения |
|---|---|---|
| Тип упаковки |
| 00 «Стандартный идентификатор коробки» |
| Управление продуктами |
| 01 «Код контейнера доставки» |
| 20 | |
| 11~17 | |
| 10 | ||
| 21 | ||
| Индикатор измерения |
| 310~369 |
| Администрация | 400 | |
| 401 | |
| 410~421 | |
| 90~99 |
| Идентификатор приложения | Содержание | Число цифр данных |
|---|---|---|
| 00 | Стандартная коробка ID | Номера с 18 цифрами |
«00» — это идентификатор, который дает серийный номер упаковки каждой коробке из гофрокартона и поддону для доставки.Поэтому каждой доставке присваивается разный номер.
Данные состоят из 18 цифр следующего состава:
| Тип упаковки | 1 цифра |
| Универсальный код компании | 7 цифр |
| Серийный номер упаковки для каждой поставки | 9 цифр |
| Контрольная цифра (модуль 10/3 веса) | 1 цифра |
«Тип упаковки» выглядит следующим образом:
| Тип упаковки | |
|---|---|
| 0 | Футляр или коробка |
| 1 | Поддон (больше ящика и коробки) |
| 2 | Контейнер (больше поддона) |
| 3 | Любой тип упаковки, кроме указанного выше |
| 4 | По внутренним требованиям (для внутреннего пользования) |
| 5 | По взаимным требованиям заинтересованных компаний |
| 6~9 | Использование запрещено |
«Универсальный код компании» обозначается «код страны» + «код производителя» для компаний, зарегистрировавших JAN.Для компаний, которые не зарегистрировали JAN, необходимо получить универсальный код бизнес-счета.
«Стандартный идентификатор коробки» называется SSCC-18 (серийный код транспортной тары) в Европе и Америке.
| Идентификатор приложения | Содержание | Число цифр данных |
|---|---|---|
| 01 | Код контейнера доставки | Номера с 14 цифрами |
Тот же состав стандартного кода распределения (ITF) обычно применяется к «01».Он состоит из кода EAN упакованного продукта и индикатора упаковки, указывающего количество продукта.
| Индикатор упаковки | 1 цифра |
| Код EAN | 12 цифр |
| Контрольная цифра (Модуль 10/3 веса) | 1 цифра |
«Индикатор пакета» выглядит следующим образом:
| Индикатор упаковки | |
|---|---|
| 0 | Коробки из гофрированного картона, содержащие смешанные продукты |
| 1~8 | Коробка из гофрированного картона для одного предмета в одинаковом количестве.Настройка в диапазоне от 1 до 8. Во многих случаях устанавливается 1. |
| 9 | Коробка из гофрированного картона, содержащая разное количество для одной позиции |
Поскольку «код контейнера доставки» имеет тот же состав данных, что и код EAN и код стандартной дистрибуции, его можно использовать только при условии, что коды EAN и стандартной дистрибуции не печатаются на коробках из гофрокартона.
«Код контейнера доставки» называется SCC-14 (код контейнера доставки) в Европе и Америке.
- А
- Идентификатор (01 — код контейнера доставки.)
- Б
- Код контейнера доставки
- С
- Идентификатор (17 означает действительность для продажи.)
- Д
- Срок действия для продажи (30 августа 1998 г.)
- Е
- Идентификатор (10 — номер партии.)
- Ф
- Номер партии
| Идентификатор приложения | Содержание | Формат |
|---|---|---|
| 10 | Номер партии или номер партии | В пределах 20 буквенно-цифровых символов |
«10» — идентификатор приложения для указания номера партии и номера партии продукта.Доступно 20 буквенно-цифровых символов (переменной длины) или менее.
| Идентификатор приложения | Содержание | Формат |
|---|---|---|
| 11 | Дата изготовления (ГГММДД) | Номера с 6 цифрами |
| 13 | Дата упаковки (ГГММДД) | Номера с 6 цифрами |
| 15 | Срок действия качества (ГГММДД) | Номера с 6 цифрами |
| 17 | Срок действия для продажи (ГГММДД) | Номера с 6 цифрами |
Указаны данные разных дат.
Для достоверности качества указаны важные данные, необходимые для управления. Например, «дата открытия» пищевых продуктов и «действительность лекарств» лекарств.
| Идентификатор приложения | Содержание | Формат |
|---|---|---|
| 400 | Номер администрации (номер заказа клиента) | В пределах 30 буквенно-цифровых символов |
| 411 | Номер места (код клиента) | Номера с 13 цифрами |
Это идентификаторы приложений для указания административных данных, таких как «номер заказа» клиентов и «код счета клиента».
| Идентификатор приложения | Содержание | Формат |
|---|---|---|
| 410 | Номер места (код пункта назначения) | Номера с 13 цифрами |
| 420 | Номер места (почтовый индекс места назначения) | В пределах 9 буквенно-цифровых символов |
Используются для сортировки товаров по местам назначения.«410» — это идентификатор приложения, который позволяет сортировать каждую компанию с используемым кодом компании EAN.
«420» — это идентификатор приложения, который позволяет выполнять сортировку для каждого пункта назначения доставки с использованием почтовых номеров.
ИНДЕКС
Организация аргументации // Purdue Writing Lab
Сводка:
На этой странице представлены три исторических метода аргументации со структурными шаблонами для каждого из них.
Как я могу эффективно представить свой аргумент?
Чтобы ваши аргументы были убедительными, в них должна использоваться организационная структура, которую аудитория воспринимает как логичную и легко поддающуюся анализу. Три аргументативных метода — Метод Тулмина , Классический метод и Роджерианский метод — дают представление о том, как организовать пункты в аргументе.
Обратите внимание, что это только три самые популярные модели организации спора.Альтернативы существуют. Обязательно проконсультируйтесь со своим инструктором и/или прислушайтесь к указаниям вашего задания, если вы не уверены, что использовать (если таковые имеются).
Метод Тулмина
Метод Тулмина – это формула, которая позволяет писателям создавать прочную логическую основу для своих аргументов. Впервые предложенный автором Стивеном Тулмином в The Uses of Argument (1958), метод Тулмина делает упор на построение тщательной структуры поддержки для каждого из ключевых утверждений аргумента.
Основной формат для метода Тулмина следующий:
Утверждение: В этом разделе вы объясняете свой общий тезис по этому вопросу.Другими словами, вы приводите свой главный аргумент.
Данные (основания): Вы должны использовать доказательства в поддержку претензии. Другими словами, предоставьте читателю факты, доказывающие силу ваших аргументов.
Ордер (мост): В этом разделе вы объясняете, почему и как ваши данные подтверждают претензию. В результате основное предположение, на котором вы строите свои аргументы, основано на разуме.
Поддержка (фонд): Здесь вы предоставляете любую дополнительную логику или аргументацию, которая может потребоваться для поддержки ордера.
Встречный иск: Вы должны предвидеть встречный иск, который опровергает основные положения вашего аргумента. Не избегайте аргументов, противоречащих вашим собственным. Вместо этого ознакомьтесь с противоположной точкой зрения. Если вы отвечаете на встречные претензии, вы кажетесь беспристрастным (и, следовательно, зарабатываете уважение своих читателей). Вы даже можете включить несколько встречных утверждений, чтобы показать, что вы тщательно изучили тему.
Опровержение: В этом разделе вы включаете свои собственные доказательства, которые не согласуются со встречным иском.Очень важно включить тщательное обоснование или мост, чтобы усилить аргументацию вашего эссе. Если вы представляете данные своей аудитории, не объясняя, как они подтверждают ваш тезис, ваши читатели могут не установить связь между ними или сделать разные выводы.
Пример метода Тулмина
:Утверждение: Гибридные автомобили — эффективная стратегия борьбы с загрязнением окружающей среды.
Data1: Вождение личного автомобиля является наиболее загрязняющим воздух занятием типичного горожанина.
Ордер 1: В связи с тем, что автомобили являются крупнейшим источником частного (а не промышленного) загрязнения воздуха, переход на гибридные автомобили должен повлиять на борьбу с загрязнением.
Данные 2: Каждый произведенный автомобиль будет находиться в эксплуатации примерно от 12 до 15 лет.
Ордер 2: Автомобили, как правило, имеют длительный срок службы, а это означает, что решение о переходе на гибридный автомобиль окажет долгосрочное влияние на уровень загрязнения.
Данные 3: Гибридные автомобили сочетают в себе бензиновый двигатель и электродвигатель с батарейным питанием.
Ордер 3: Комбинация этих технологий приводит к меньшему загрязнению.
Встречный иск: Вместо того, чтобы сосредотачиваться на автомобилях, которые по-прежнему поощряют неэффективную культуру вождения, хотя и сокращают загрязнение окружающей среды, нация должна сосредоточиться на создании и поощрении использования систем общественного транспорта.
Опровержение: Хотя общественный транспорт — это идея, которую следует поощрять, она неосуществима во многих сельских и пригородных районах или для людей, которым приходится добираться до работы.Таким образом, гибридные автомобили являются лучшим решением для большей части населения страны.
Роджерианский метод
Роджерианский метод (названный в честь влиятельного американского психотерапевта Карла Р. Роджерса, но не разработанный им) – популярный метод решения спорных вопросов. Эта стратегия направлена на то, чтобы найти точки соприкосновения между сторонами, заставляя аудиторию понять точки зрения, выходящие за рамки (или даже противоречащие) позиции автора. В большей степени, чем другие методы, он делает акцент на повторении аргумента оппонента к его или ее удовлетворению.Убедительная сила Роджерианского метода заключается в его способности определять термины аргумента таким образом, что:
- Ваша позиция кажется разумным компромиссом.
- вы кажетесь сострадательным и чутким.
Основной формат Роджерианского метода следующий:
Введение: Расскажите аудитории о проблеме, стараясь оставаться максимально объективной.
Противоположная точка зрения : Непредвзято объясните позицию другой стороны.Когда вы обсуждаете контраргументы без осуждения, противоположная сторона может видеть, что вы напрямую не отвергаете точки зрения, противоречащие вашей позиции.
Заявление о достоверности (понимание): В этом разделе обсуждается, как вы признаете, что точки зрения другой стороны могут быть действительными при определенных обстоятельствах. Вы определяете как и почему их точка зрения имеет смысл в конкретном контексте, но при этом приводите свои собственные аргументы.
Изложение вашей позиции: К этому моменту вы продемонстрировали, что понимаете точку зрения другой стороны.В этом разделе вы объясняете свою позицию.
Заявление о контексте : Исследуйте сценарии, в которых ваша должность заслуживает внимания. Когда вы объясняете, как ваша аргументация наиболее подходит для определенных контекстов, читатель может понять, что вы признаете несколько способов рассматривать сложную проблему.
Заявление о преимуществах: В заключение вы должны объяснить противоположной стороне почему они выиграют, если примут вашу позицию. Объясняя преимущества своего аргумента, вы заканчиваете на положительной ноте, не игнорируя полностью точку зрения другой стороны.
Пример метода Роджера:
Введение: Вопрос о том, должны ли дети носить школьную форму, является предметом споров.
Противоположная точка зрения: Некоторые родители считают, что лучше требовать, чтобы дети носили форму.
Заявление о достоверности (понимание): Те родители, которые поддерживают форму, утверждают, что, когда все учащиеся носят одну и ту же форму, у них может развиться единое чувство гордости за школу и причастность к ней.
Заявление о вашей позиции : От учащихся не требуется носить школьную форму. Обязательная форма запрещает выбор, который позволяет учащимся проявлять творческий подход и выражать себя через одежду.
Положение о контекстах: Однако, даже если униформа гипотетически может способствовать инклюзивности, в большинстве реальных контекстов администраторы могут использовать унифицированные политики для обеспечения соответствия. Студенты должны иметь возможность исследовать свою личность через одежду, не опасаясь быть подвергнутыми остракизму.
Заявление о преимуществах: Хотя обе стороны стремятся отстаивать интересы учащихся, от учащихся не следует требовать ношения школьной формы. Предоставляя учащимся свободу выбора, учащиеся могут исследовать свою самоидентификацию, выбирая, как представить себя своим сверстникам.
Классический метод
Классический метод структурирования аргумента — еще один распространенный способ систематизировать свои аргументы. Первоначально разработанные греческим философом Аристотелем (а затем развитые римскими мыслителями, такими как Цицерон и Квинтилиан), классические аргументы, как правило, сосредоточены на вопросах определения и тщательного применения доказательств.Таким образом, основное предположение классической аргументации состоит в том, что, когда все стороны прекрасно понимают проблему, правильный курс действий будет ясен.
Основной формат классического метода следующий:
Введение (Exordium): Расскажите о проблеме и объясните ее значение. Вы также должны установить свой авторитет и легитимность темы.
Предыстория (повествование): Предоставьте зрителям важную контекстуальную или историческую информацию, чтобы они лучше поняли проблему.Поступая таким образом, вы предоставляете читателю практические знания по теме, не зависящие от вашей собственной позиции.
Предложение (Propositio): После того, как вы предоставите читателю контекстуальные знания, вы готовы заявить о своих утверждениях, которые относятся к информации, которую вы предоставили ранее. В этом разделе излагаются основные моменты для читателя.
Доказательство (Confirmatio): Вы должны объяснить читателю свои причины и доказательства. Не забудьте тщательно обосновать свои причины.В этом разделе при необходимости можно указать дополнительные доказательства и подпункты.
Опровержение (Refuatio): В этом разделе вы рассматриваете ожидаемые контраргументы, которые не согласуются с вашим тезисом. Хотя вы признаете точку зрения другой стороны, важно доказать , почему ваша позиция более логична.
Заключение (Peroratio): Вы должны обобщить основные моменты. Заключение также соответствует эмоциям и ценностям читателя.Использование пафоса здесь делает читателя более склонным к рассмотрению вашего аргумента.
Пример классического метода
:Введение (Exordium): Миллионы рабочих по всей стране получают фиксированную почасовую оплату. Федеральная минимальная заработная плата стандартизирована, чтобы защитить работников от слишком низкой оплаты. Исследования указывают на многие точки зрения на сколько платить этим рабочим. Некоторые семьи не могут позволить себе поддерживать свои домохозяйства на текущую заработную плату, предусмотренную для выполнения работы с минимальной заработной платой.
Предыстория (рассказ): В настоящее время миллионы американских рабочих пытаются свести концы с концами на минимальную заработную плату. Это создает нагрузку на личную и профессиональную жизнь работников. Некоторые работают на нескольких работах, чтобы обеспечить свои семьи.
Предложение (Propositio): Текущая федеральная минимальная заработная плата должна быть увеличена, чтобы лучше удовлетворить миллионы переутомленных американцев. Подняв минимальную заработную плату, работники могут тратить больше времени на обеспечение средств к существованию.
Доказательство (Confirmatio): По данным Министерства труда США, 80,4 миллиона американцев работают за почасовую оплату, но почти 1,3 миллиона получают заработную плату ниже федерального минимума. Повышение заработной платы снимет стресс этих работников. Их жизнь выиграет от этого повышения, потому что оно затрагивает несколько областей их жизни.
Опровержение (Refuatio): Есть некоторые свидетельства того, что повышение федеральной заработной платы может увеличить стоимость жизни.Однако другие данные противоречат этому или предполагают, что увеличение не будет большим. Кроме того, опасения по поводу роста стоимости жизни должны быть уравновешены преимуществами предоставления необходимых средств миллионам трудолюбивых американцев.
Заключение (Peroratio): Если бы федеральная минимальная заработная плата была повышена, многие работники могли бы частично облегчить свое финансовое бремя. В результате их эмоциональное благополучие в целом улучшится. Хотя некоторые утверждают, что стоимость жизни может увеличиться, преимущества перевешивают потенциальные недостатки.
Программа просмотра Google Ngram
Что делает средство просмотра Ngram?
Когда вы вводите фразы в Google Books Ngram Viewer, отображается график, показывающий, как эти фразы встречались в корпусе книг (например, «Британский английский», «Английская художественная литература», «Французский») над выбранным годы. Давайте посмотрим на образец графика:
Это показывает тенденции в трех ngrams с 1960 по 2015 год: «питомник школа» ( 2-грамм или биграмма ), «детский сад» ( 1-грамм или униграмм ) и «уход за детьми» (другой биграмма).Ось Y показывает следующее: из всех содержащихся биграмм в нашей выборке книг, написанных на английском языке и опубликованных в Соединенных Государства, какой процент из них составляют «детские сады» или «присмотр за детьми»? Какой процент из всех униграмм относится к «детским садам»? Здесь вы можете видеть, что использование фразы «уход за детьми» начало расти. в конце 1960-х, обогнав «детский сад» примерно в 1970-х, а затем «детский сад» примерно в 1973 году. Он достиг своего пика вскоре после 1990 года и был неуклонно падает с тех пор.
(Интересно, что результаты заметно отличаются, когда корпус переведен на британский английский.)
Вы можете навести курсор на линейный график ngram, который подсветит его. С участием щелчок левой кнопкой мыши по линейному графику позволяет сфокусироваться на конкретной энграмме, затемнение других энграмм на диаграмме, если таковые имеются. На последующем слева щелчки по другим линейным графикам на диаграмме, несколько энграмм могут быть сосредоточенным. Вы можете дважды щелкнуть любую область диаграммы, чтобы восстановить все энграммы в запросе.
Вы также можете указывать подстановочные знаки в запросах, искать перегибы, выполнять поиск без учета регистра, искать определенные части речи или складывать, вычитать и делить энграммы.Подробнее о тех, кто находится в разделе «Расширенное использование».
Расширенное использование
Некоторые функции Ngram Viewer могут понравиться пользователям, которые хотят копать немного глубже в использование фразы: поиск по подстановочным знакам , поиск с перегибом , поиск без учета регистра , теги части речи и составы ngram .
Поиск подстановочных знаков
Когда вы поставите * вместо слова, Ngram Viewer отобразит десять первых замен.Например, чтобы найти самые популярные слова после «Университет», выполните поиск «Университет *».
Вы можете щелкнуть правой кнопкой мыши любую из замещающих энграмм, чтобы свернуть их все в исходный запрос с подстановочными знаками, в результате чего будет получена сумма замен за год. Последующий щелчок правой кнопкой мыши расширяет запрос с подстановочными знаками до всех замен. Обратите внимание, что Ngram Viewer поддерживает только один * на ngram.
Обратите внимание, что первые десять замен вычисляются для указанного диапазона времени.Поэтому вы можете получить разные замены для разных диапазонов лет. Мы отфильтровали знаки пунктуации из списка первых десяти, но для слов, которые часто начинают или заканчивают предложения, вы можете увидеть один из символов границы предложения (_START_ или _END_) в качестве одной из замен.
Поиск перегиба
Инфлексия — это модификация слова для представления различных грамматических категорий, таких как вид, падеж, род, наклонение, число, лицо, время и залог. Вы можете искать их, добавляя _INF к ngram.Например, поиск «book_INF a hotel» отобразит результаты для «book», «booked», «books» и «booking»:
.Щелчок правой кнопкой мыши по любому изгибу сворачивает все формы в их сумму. Обратите внимание, что Ngram Viewer поддерживает только одно ключевое слово _INF для каждого запроса.
Предупреждение: Вы не можете свободно смешивать поиск с подстановочными знаками, перегибы и поиск без учета регистра для одной конкретной энграммы. Однако вы можете искать с помощью любой из этих функций отдельные ngram в запросе: «book_INF a hotel, book * hotel» — это нормально, а «book_INF * hotel» — нет.
Поиск без учета регистра
По умолчанию Ngram Viewer выполняет поисковых запросов с учетом регистра : использование заглавных букв имеет значение. Вы можете выполнить поиск без учета регистра, установив флажок «без учета регистра» справа от поля запроса. Затем Ngram Viewer отобразит годовую сумму наиболее распространенных вариантов без учета регистра. входного запроса. Вот две нечувствительные к регистру ngram, «Fitzgerald» и «Dupont»:
Щелчок правой кнопкой мыши по любой сумме за год приводит к раскрытию наиболее распространенных вариантов без учета регистра.Например, щелчок правой кнопкой мыши на «Dupont (All)» приводит к появлению следующих четырех вариантов: «DuPont», «Dupont», «duPont» и «DUPONT».
Теги части речи
Рассмотрим слово браться за , которое может быть глаголом («заниматься проблема») или существительное («рыболовная снасть»). Можно различать эти разные формы, добавив _VERB или _СУЩЕСТВИТЕЛЬНОЕ:
Полный список тегов выглядит следующим образом:
| _СУЩЕСТВИТЕЛЬНОЕ_ | Эти метки могут либо стоять в одиночку (_PRON_) или могут быть добавлены к слову (she_PRON) | |
| _VERB_ | ||
| _ADJ_ | прилагательное | |
| _ADV_ | Наречие | |
| _PRON_ | местоимений | |
| _DET_ | определитель или изделие | |
| _ADP_ | позиция объявления: либо предлог или постпозиция | |
| _NUM_ | позици | |
| _CONJ_ | конъюнкции | |
| _PRT_ | частица | |
| _ROOT_ | корень дерева разбора | Эти теги должны стоять отдельно (например,г., _START_) |
| _START_ | начало предложения | |
| _END_ | конец предложения |
вы можете использовать тег DET для поиска прочитать книгу , прочитать книгу , прочитать эту книгу , прочитать эту книгу , и так далее:
Если вы хотите узнать, каковы наиболее распространенные определители в этом контексте, вы можете комбинировать подстановочные знаки и теги части речи для read * _DET book :
Чтобы получить все различные варианты слова книга , за которыми следуют СУЩЕСТВИТЕЛЬНОЕ в корпусе вы можете выполнить запрос book_ INF _NOUN_:
Наиболее часто встречающиеся части речи для слова могут быть извлечены с помощью функции подстановочных знаков.Рассмотрим запрос cook_* :
.Ключевое слово склонения также можно комбинировать с тегами частей речи. Например, рассмотрим запрос cook _INF, cook _VERB_INF ниже, который выделяет интонации глагольного значения «повар»:
Средство просмотра Ngram помечает границы предложений, позволяя вам идентифицировать ngram в начале и конце предложений с помощью тегов START и END:
Иногда полезно думать о словах с точки зрения зависимостей а не узоры.Допустим, вы хотите знать, как часто вкусно модифицирует десерт . То есть вы хотите количество упоминаний о вкусных замороженных десертах , хрустящих, вкусных десерт , вкусный но дорогой десерт , и все остальные случаи, когда слово вкусный применяется к десерт . Для этого Ngram Viewer предоставляет отношения зависимости с оператор =>:
Каждое проанализированное предложение имеет _ROOT_. в отличие от других теги, _ROOT_ не обозначает конкретное слово или позицию в предложении.Это корень дерева синтаксического анализа, построенного анализ синтаксиса; вы можете думать об этом как о заполнителе для того, что основной глагол предложения является изменением. Итак, как определить как часто будет главным глаголом в предложении:
Приведенный выше график будет включать предложение Ларри будет принять решение. , а не Ларри сказал, что он решит , Поскольку will не является основным глаголом в этом предложении.
Зависимости можно комбинировать с подстановочными знаками.Например, рассмотрим запрос drink=>*_ NOUN ниже:
«Чистые» части речи можно свободно смешивать с обычными словами в 1, 2, 3, 4 и 5 граммах (например, тосты _ADJ_ или _DET_ _ADJ_ тост).
Композиции Ngram
Ngram Viewer предоставляет пять операторов, которые можно использовать для объединения ngrams: +, -, /, * и :.
| + | Суммирует выражения с обеих сторон, позволяя объединить несколько временных рядов ngram в один. |
| — | Вычитает выражение справа из выражения слева, давая вам возможность измерить один ngram относительно другого. Поскольку пользователям часто нужно искать фразы, написанные через дефис, ставьте пробелы по обе стороны от знака -. |
| / | Делит выражение слева на выражение справа, что полезно для выделения поведения одной энграммы по отношению к другой. |
| * | Умножает выражение слева на число справа, что упрощает сравнение энграмм с очень разными частотами.(Обязательно заключайте всю ngram в круглые скобки, чтобы * не интерпретировался как подстановочный знак.) |
| : | Применяет ngram слева к корпусу справа, позволяя сравнивать ngram в разных корпусах. . |
Средство просмотра Ngram попытается угадать, применять ли эти поведение. Вы можете использовать круглые скобки, чтобы принудительно включить их, и возвести в квадрат скобы, чтобы принудительно их снять. Пример: и/или будет разделить и на или ; для измерения использования фраза и/или , используйте [и/или].И из лучших побуждений будет искать фраза из лучших побуждений ; если вы хотите вычесть смысл из колодца, использовать (в хорошем смысле).
Чтобы продемонстрировать оператор +, вот как можно найти сумму игра , спорт и игра :
При определении того, писали ли люди больше о выборе, чем о лет, ты мог сравнить выбор , выбор , вариант , и альтернатива , указав формы существительных, чтобы избежать формы прилагательных (т.г., выбор лакомства , альтернатива музыка ):
ВычитаниеNgram дает вам простой способ сравнить один набор ngrams с другим:
Вот как вы можете комбинировать + и /, чтобы показать, как слово яблочное пюре расцвело за счет яблочного пюре :
Оператор * полезен, когда вы хотите сравнить энграммы с широким диапазоном частот, например, скрипка и более эзотерический терменвокс :
Оператор выбора :corpus позволяет сравнивать энграммы в разные языки, или американский против британского английского (или художественная литература), или между версиями сканов наших книг 2009, 2012 и 2019 годов.Вот чат на английском и тот же униграмм на французском:
Когда мы создали исходный корпус Ngram Viewer в 2009 году, наш OCR не был так хорош, как сегодня. Особенно это было заметно в английский язык до 19 века, где удлиненная медиальная буква s (ſ) была часто интерпретируется как f , поэтому часто читается best как перед . Вот свидетельство улучшений, которые мы сделали с тех пор затем, используя оператор корпуса, сравнить версии 2009, 2012 и 2019:
Сравнивая художественную литературу со всем английским, мы видим, что из мастера вообще английский в последнее время набирает по сравнению с использованием в художественной литературе:
Корпус
Ниже приведены описания корпусов, которые можно искать с помощью Средство просмотра Ngram для Google Книг.Все корпуса созданы в июле 2009 г., июль 2012 г. и февраль 2020 г.; мы будем обновлять эти корпуса как нашу книгу сканирование продолжается, и обновленные версии будут иметь четкие постоянные идентификаторы. Книги с низким качеством OCR и сериалы были исключены.
| Неформальное название корпуса | Стенограмма | Постоянный идентификатор | Описание |
| Американский английский 2019 | eng_us_2019 | googlebooks-eng-us-20200217 | Книг преимущественно на английском языке, изданных в США. |
| Американский английский 2012 | eng_us_2012 | googlebooks-eng-us-all-20120701 | |
| Американский английский 2009 | eng_us_2009 | googlebooks-eng-us-all-200 | |
| Британский английский 2019 | eng_ru_2019 | googlebooks-eng-gb-20200217 | Книг преимущественно на английском языке, изданных в Великобритании. |
| Британский английский 2012 | eng_ru_2012 | googlebooks-eng-gb-all-20120701 | |
| Британский английский 2009 | eng_gb_2009 | googlebooks-eng-gb-all-200 | |
| Английский 2019 | eng_2019 | googlebooks-eng-20200217 | Книг преимущественно на английском языке, изданных в любой стране. |
| Английский 2012 | eng_2012 | googlebooks-eng-all-20120701 | |
| Английский 2009 | eng_2009 | googlebooks-eng-all-200 | |
| Английская художественная литература 2019 | eng_fiction_2019 | googlebooks-eng-fiction-20200217 | Книги преимущественно на английском языке, которые библиотека или издатель определили как художественную литературу. |
| Английская художественная литература 2012 | eng_fiction_2012 | googlebooks-eng-fiction-all-20120701 | |
| Английская художественная литература 2009 г. | eng_fiction_2009 | googlebooks-eng-fiction-all-200 | |
| Английский Один миллион | eng_1m_2009 | googlebooks-eng-1M-200 | «Гугл Миллион».Все на английском языке с датами от с 1500 по 2008 год. Было отобрано не более 6000 книг из год, что означает, что все отсканированные книги ранних лет настоящее время, а книги более поздних лет выбираются случайным образом. Случайный выборки отражают предметные распределения за год (поэтому есть больше компьютерных книг в 2000 г., чем в 1980 г.). |
| Китайский 2019 | chi_sim_2019 | гуглбукс-чи-сим-20200217 | Книги преимущественно на упрощенном китайском языке. |
| Китайский 2012 | chi_sim_2012 | googlebooks-chi-sim-all-20120701 | |
| Китайский 2009 | chi_sim_2009 | googlebooks-chi-sim-all-200 | |
| Французский 2019 | fre_2019 | googlebooks-fre-20200217 | Книги преимущественно на французском языке. |
| Французский 2012 | fre_2012 | googlebooks-fre-all-20120701 | |
| Французский 2009 | fre_2009 | googlebooks-fre-all-200 | |
| Немецкий 2019 | ger_2019 | googlebooks-ger-20200217 | Книги преимущественно на немецком языке. |
| Немецкий 2012 | ger_2012 | googlebooks-ger-all-20120701 | |
| Немецкий 2009 | ger_2009 | googlebooks-ger-all-200 | |
| Иврит 2019 | heb_2019 | googlebooks-heb-20200217 | Книги преимущественно на иврите. |
| Иврит 2012 | heb_2012 | googlebooks-heb-all-20120701 | |
| Иврит 2009 | heb_2009 | googlebooks-heb-all-200 | |
| Испанский 2019 | spa_2019 | googlebooks-spa-20200217 | Книги преимущественно на испанском языке. |
| Испанский 2012 | спа_2012 | googlebooks-spa-all-20120701 | |
| Испанский 2009 | spa_2009 | googlebooks-spa-all-200 | |
| Русский 2019 | рус_2019 | googlebooks-rus-20200217 | Книг преимущественно на русском языке. |
| Русский 2012 | рус_2012 | гуглбукс-рус-все-20120701 | |
| Русский 2009 | rus_2009 | googlebooks-rus-all-200 | |
| Итальянский 2019 | ита_2019 | googlebooks-ita-20200217 | Книги преимущественно на итальянском языке. |
| Итальянский 2012 | ита_2012 | googlebooks-ita-all-20120701 |
По сравнению с версиями 2009 года версии 2012 и 2019 годов имеют больше книг, улучшенное распознавание текста, улучшенная библиотека и издатель метаданные. Версии 2012 и 2019 годов также не образуют энграммы, которые перекрещивают предложения. границы, и формируют ngrams через границы страницы, в отличие от версии 2009 года.
В корпусах 2012 и 2019 токенизация также улучшилась с использованием набор правил, придуманных вручную (за исключением китайского, где статистическая система используется для сегментации).В корпусах 2009 г. токенизация основывалась просто на пробелах.
Поиск в Google Книгах
Под графиком мы показываем «интересные» диапазоны лет для вашего запроса. условия. При нажатии на них ваш запрос будет отправлен непосредственно в Google. Книги. Обратите внимание, что Ngram Viewer чувствителен к регистру, но Google Книги результаты поиска , а не .
Эти поиски дадут фразы на языке любого выбранный вами корпус, но результаты возвращаются из полного Google Корпус книг.Поэтому, если вы используете Ngram Viewer для поиска французского фразу во французском корпусе, а затем перейдите в Google Книги, этот поиск будет вестись по той же французской фразе, которая может встречаться в книга преимущественно на другом языке.
Часто задаваемые вопросы
Почему я не вижу ожидаемых результатов?
Возможно, по одной из следующих причин:
- Средство просмотра Ngram чувствительно к регистру. Попробуйте написать запрос с заглавной буквы или установите флажок «без учета регистра». поле справа от окна поиска.
- Вы ищете в неожиданном корпусе. Например, Франкенштейн не встречается в русских книгах, поэтому, если вы выполните поиск в русском корпусе, вы увидите прямую линию. Вы можете выбрать корпус через раскрывающееся меню под окном поиска или с помощью оператора выбора корпуса, например, Frankenstein:eng_2019.
- Ваша фраза содержит запятую, плюс, дефис, звездочку, двоеточие, или косая черта в нем. Они имеют особое значение для Ngram Зритель; см. Расширенное использование.Попробуйте заключить фразу в квадратные скобки (хотя это не поможет с запятыми).
Как Ngram Viewer обрабатывает пунктуацию?
Мы применяем набор правил токенизации, характерных для конкретного язык. В английском языке сокращения становятся двумя словами (они становится биграммой они, мы будем мы буду и так далее). Притяжательный ‘s также отделяется, но R’n’B остается одним токеном. Отрицания (n’t) нормализовано так, что не становится не. На русском, диакритическое ё нормализуется к е и т.д.Такие же правила применяется для разбора как ngrams, введенных пользователями, так и ngrams извлечены из корпусов, а это значит, что если вы ищете ибо не пугайтесь того факта, что Ngram Viewer переписывает его, чтобы этого не делать; это точно изображает обычаи как нет, так и нет в корпусе. Однако это означает, что нет возможности явно искать конкретный формы не могут (или не могут): вы получаете не может и не может и не может все сразу.
Как просмотреть примеры использования в контексте?
Под диаграммой Ngram Viewer мы предоставляем таблицу предопределенных Поиски в Google Книгах, каждый из которых сужен до определенного диапазона лет.Мы выбираем диапазоны в зависимости от интереса: если ngram имеет огромный пик в определенный год, который появится сам по себе как поиск, с другие поиски, охватывающие более длительные периоды.
В отличие от корпуса Ngram Viewer 2019 года, корпус Google Книг не помечены частью речи. Нельзя искать, скажем, форму глагола из приветствовать в Google Книгах. Таким образом, любые ngrams с частью речи теги (например, cheer_VERB) исключаются из таблицы Google Поиски книг.
В Ngram Viewer есть корпуса 2009, 2012 и 2019 годов, но Google Книги так не работает.Когда вы ищете в Google Книгах, вы поиск всех доступных в настоящее время книг, так что могут быть некоторые различия между тем, что вы видите в Google Книгах, и тем, что вы ожидайте увидеть данную диаграмму Ngram Viewer.
Почему в первые годы я вижу больше всплесков и плато?
Издание было относительно редким событием в 16 и 17 вв. веков. (Есть издано всего около 500 000 книг на английском языке до 19 века.) Поэтому, если фраза встречается в одной книге в одной году, но не в предыдущие или последующие годы, что создает более высокий шип, чем в последующие годы.
Плато обычно представляют собой просто сглаженные шипы. Изменить сглаживание до 0.
Что означает «сглаживание»?
Часто тенденции становятся более очевидными, когда данные рассматриваются как движущиеся средний. Сглаживание 1 означает, что данные за 1950 год будут среднее значение необработанного счета за 1950 год плюс 1 значение с каждой стороны: («счет за 1949 год» + «счет за 1950 год» + «счет за 1951 год»), деленное на 3. Таким образом, сглаживание 10 означает, что будет усреднено 21 значение: 10 на с обеих сторон плюс целевое значение в центре.
На левом и правом краях графика меньше значений. усредненный. При сглаживании 3 самое левое значение (представьте, это 1950 год) будет рассчитываться как («количество за 1950» + «количество за 1951 год» + «счет за 1952 год» + «счет за 1953 год»), деленное на 4.
Сглаживание, равное 0, означает полное отсутствие сглаживания: только необработанные данные.
В современные годы издается гораздо больше книг. Разве это не перекос результаты?
Было бы, если бы мы не нормализовали количество книг, изданных в каждый год.
Почему вы показываете плоскую линию 0%, когда я знаю фразу в моем запрос возник хотя бы в одной книге?
При большой нагрузке Ngram Viewer иногда возвращает плоская линия; перезагрузите, чтобы подтвердить, что на самом деле нет хитов для фраза. Кроме того, мы учитываем только те энграммы, которые встречаются не менее чем в 40 книги. В противном случае набор данных раздулся бы в размерах, и мы бы не в состоянии предложить их все.
Насколько точна маркировка частей речи?
Прогнозируются частичные теги и отношения зависимости автоматически.Оценка точности этих прогнозов сложно, но для современного английского языка мы ожидаем точности теги части речи должны быть около 95%, а точность зависимости отношения около 85%. На старом английском тексте и для других языков точность ниже, но, вероятно, выше 90% для тегов части речи и выше 75% для зависимостей. Это предполагает значительное количество ошибки, которые следует учитывать при рисовании выводы.
Теги части речи созданы на основе небольшого обучающего набора (просто миллион слов для английского).Это будет иногда недооценивают необычные употребления, такие как зеленый или собака или запишите как глаголы, или спросите как существительное.
Дополнительное примечание о китайском языке: до 20 века классический Китайский язык традиционно использовался для всех письменных коммуникация. Классический китайский язык основан на грамматике и словарь древнекитайского языка, а синтаксические аннотации будут поэтому ошибаются чаще, чем правы.
Также обратите внимание, что корпуса 2009 года не были частью речи. помечен.
Я пишу статью на основе ваших результатов. Как я могу процитировать вашу работу?
Если вы собираетесь использовать эти данные для научной публикации, пожалуйста, укажите оригинал статьи:
Жан-Батист Мишель*, Юань Куй Шен, Авива Прессер Эйден, Адриан Верес, Мэтью К. Грей, Уильям Брокман, команда Google Книги, Джозеф П. Пикетт, Дейл Хойберг, Дэн Клэнси, Питер Норвиг, Джон Орвант, Стивен Пинкер, Мартин А. Новак и Эрез Либерман Эйден*. Количественный анализ культуры с использованием миллионов оцифрованных Книги . Science (опубликовано в Интернете до печати: 16 декабря 2010 г.)
У нас также есть статья о нашей маркировке частей речи:
Юрий Лин, Жан-Батист Мишель, Эрез Либерман Эйден, Джон Орвант, Уильям Брокман, Слав Петров. Синтаксические аннотации для корпуса Google Книг Ngram . Производство 50-го ежегодного собрания Ассоциации компьютерной лингвистики Том 2: Демонстрационные документы (ACL ’12) (2012)
Могу ли я загрузить ваши данные для проведения собственных экспериментов?
Да! Данные ngram доступны для Скачать здесь.Чтобы сделать размеры файлов управляемы, мы сгруппировали их по начальной букве, а затем сгруппированы различные размеры ngram в отдельные файлы. Нграммы внутри каждый файл не отсортирован по алфавиту.
Для создания машиночитаемых имен файлов мы транслитерировали ngrams для языков, использующих нелатинское письмо (китайский, иврит, русский) и использовал начальную букву транслитерированного ngram для определить имя файла. Тот же подход был применен к персонажам например, ä на немецком языке.Обратите внимание, что транслитерация была используется только для определения имени файла; фактические ngrams закодированы в UTF-8 с использованием алфавита для конкретного языка.
Я хочу опубликовать график Ngram в своей книге/журнале/блоге/презентации. Каковы ваши условия лицензирования?
Графики и данные Ngram Viewer можно свободно использовать для любых целей, однако мы приветствуем упоминание Google Books Ngram Viewer в качестве источника и включение ссылки на http://books.google.com/ngrams.
Наслаждайтесь!
Команда Google Ngram Viewer, часть Google Research
Как написать идеальное эссе для языкового экзамена AP
Если вы планируете сдавать экзамен AP Language (или AP Lang), вы, возможно, уже знаете, что 55% вашего общего балла за экзамен будут основаны на трех эссе. Первое из трех эссе, которое вам нужно будет написать на экзамене AP Language, называется «обобщающее эссе». Если вы хотите получить максимальное количество баллов за эту часть экзамена AP Lang, вам нужно знать, что такое обобщающее эссе и какие навыки оцениваются в обобщающем эссе AP Lang.
В этой статье мы объясним различные аспекты обобщающего эссе А. П. Ланга, в том числе, какие навыки вам необходимо продемонстрировать в ответе на обобщающее эссе, чтобы получить хороший балл. Мы также дадим вам полную разбивку настоящей подсказки об обобщении эссе А.П. Ланга, предоставим анализ примера обобщающего эссе А.П. Ланга и дадим вам четыре совета о том, как написать обобщающее эссе.
Давайте начнем с более подробного изучения того, как работает синтетическое эссе А. П. Ланга!
2021 Изменения в тестах AP в связи с COVID-19
Из-за продолжающейся пандемии коронавируса COVID-19 тесты AP теперь будут проводиться в течение трех разных сессий в период с мая по июнь. Даты ваших тестов, а также то, будут ли ваши тесты онлайн или бумажными, будут зависеть от вашей школы. Чтобы узнать больше о том, как все это будет работать, и получить самую свежую информацию о датах тестирования, онлайн-обзоре AP и о том, что эти изменения означают для вас, обязательно ознакомьтесь с нашей статьей часто задаваемых вопросов AP COVID-19 2021 года.
Обобщающее эссе AP Lang: что это такое и как это работает
Обобщающее эссе AP Lang является первым из трех эссе, включенных в раздел Free Response экзамена AP Lang.
Часть обобщающего эссе AP Lang раздела Free Response длится в общей сложности один час . Этот час состоит из рекомендуемого 15-минутного периода чтения и 40-минутного периода записи. Имейте в виду, что эти временные рамки являются просто рекомендациями, и экзаменуемые могут использовать отведенные 60 минут для завершения обобщающего эссе по своему усмотрению.
А вот как выглядит структура обобщающего эссе А. П. Ланга. Экзамен представляет от шести до семи источников, которые организованы вокруг определенной темы (например, альтернативная энергия или выдающаяся область, которые являются темами прошлых экзаменов по синтезу).
Из этих шести-семи источников по крайней мере два являются визуальными , включая по крайней мере один количественный источник (например, график или круговую диаграмму). Остальные четыре-пять источников основаны на печатном тексте, и каждый из них содержит примерно 500 слов.
В дополнение к шести-семи источникам экзамен AP Lang предоставляет письменную подсказку, состоящую из трех абзацев. В подсказке будет кратко объяснена тема эссе, а затем представлено утверждение, на которое учащиеся ответят в эссе, в котором синтезируется материал как минимум из трех предоставленных источников.
Вот пример подсказки, предоставленной Советом колледжей:
Направления : Следующая подсказка основана на сопровождающих шести источниках.
Этот вопрос требует, чтобы вы объединили различные источники в связное, хорошо написанное эссе. Обратитесь к источникам, подтверждающим вашу позицию; избегайте простого перефразирования или резюме. Ваш аргумент должен быть центральным; источники должны поддерживать этот аргумент .
Не забывайте указывать как прямые, так и косвенные цитаты.
Введение
Телевидение оказывает влияние на президентские выборы в США с 1960-х годов. Но что это за влияние и как оно повлияло на избранных? Сделало ли оно выборы более справедливыми и доступными или переместило кандидатов от решения проблем к погоне за имиджем?
Назначение
Внимательно прочтите следующие источники (включая любую вводную информацию). Затем в эссе, обобщающем как минимум три источника поддержки, займите позицию, которая защищает, оспаривает или уточняет утверждение о том, что телевидение оказало положительное влияние на президентские выборы.
Ссылаться на источники как Источник A, Источник B и т. д.; названия включены для вашего удобства.
Источник A (Campbell)
Источник B (Hart and Triece)
Источник C (Menand)
Источник D (диаграмма)
Источник E (Ranney)
Источник F (Koppel)
Как мы упоминали ранее, эта подсказка дает вам тему, которая кратко объясняется, а затем просит вас занять позицию. В этом случае вам придется выбрать позицию в отношении того, повлияло ли телевидение на U положительно или отрицательно.С. выборы. Вам также предоставляется шесть источников для оценки и использования в вашем ответе. Теперь, когда у вас есть все, что вам нужно, теперь ваша задача — написать потрясающее обобщающее эссе.
Но что именно означает «синтезировать»? Согласно CollegeBoard, когда в подсказке к эссе вас просят синтезировать, это означает, что вы должны «объединить различные точки зрения из источников, чтобы сформировать поддержку последовательной позиции» в письменной форме. Другими словами, в обобщающем эссе вас просят изложить ваше утверждение по теме, а затем выделить взаимосвязь между несколькими источниками, поддерживающими ваше утверждение по этой теме. Кроме того, вам нужно будет привести конкретные доказательства из ваших источников, чтобы доказать свою точку зрения.
За обобщающее эссе можно получить шесть баллов на экзамене AP Lang . Учащиеся могут получить 0-1 балл за написание тезиса в эссе, 0-4 балла за включение доказательств и комментариев и 0-1 балл за изощренность мысли и продемонстрированное комплексное понимание темы.
Ваша оценка будет основываться на том, насколько эффективно вы сделаете следующее в своем обобщающем эссе AP Lang:
Напишите диссертацию, которая отвечает на вопрос экзамена с защитной позицией
Предоставьте конкретные доказательства в поддержку всех заявлений в вашей аргументации из по крайней мере трех предоставленных источников, а также четко и последовательно объясните, как доказательства, которые вы включаете, подтверждают вашу аргументацию
Демонстрировать изощренность мысли, создавая вдумчивый аргумент, помещая аргумент в более широкий контекст, объясняя ограничения аргумента
Сделайте риторический выбор, который укрепит ваши аргументы, и/или используйте яркий и убедительный стиль на протяжении всего эссе.
Если ваше обобщающее эссе соответствует указанным выше критериям, , то есть большая вероятность, что вы наберете хорошие баллы за эту часть экзамена AP Lang!
Если вам нужна дополнительная информация о подсчете баллов, совет колледжей разместил на своем веб-сайте рубрику оценивания AP Lang Free Response. (Вы можете найти его здесь.) Мы рекомендуем внимательно изучить его, так как он включает дополнительные сведения о подсчете баллов за обобщающее эссе.
Не пугайтесь….мы научим вас, как разобрать даже самую сложную подсказку для синтеза AP.
Полное описание настоящей подсказки AP Lang для синтеза эссе
В этом разделе мы научим вас анализировать и отвечать на приглашение для синтеза эссе за пять простых шагов, включая рекомендуемые временные рамки для каждого этапа процесса.
Шаг 1. Анализ подсказки
Самое первое, что нужно сделать, когда часы заработают, это прочитать и проанализировать подсказку. Чтобы продемонстрировать, как это сделать, мы рассмотрим приведенный ниже пример синтезирующего эссе А. П. Ланга. Это приглашение взято прямо из экзамена AP Lang 2018 года:
.Выдающееся владение — это власть правительства приобретать собственность у частных владельцев для общественного пользования. Обоснование выдающихся владений заключается в том, что правительства имеют большую юридическую власть над землями в пределах своих владений, чем частные владельцы. Eminent домен был установлен так или иначе во всем мире в течение сотен лет.
Внимательно прочитайте следующие шесть источников, включая вводную информацию для каждого источника. Затем синтезируйте материал как минимум из трех источников и включите его в последовательное, хорошо разработанное эссе, которое защищает, оспаривает или уточняет представление о том, что выдающаяся область продуктивна и полезна.
Ваш аргумент должен быть в центре вашего эссе. Используйте источники, чтобы развить свою аргументацию и объяснить ее аргументацию. Избегайте простого обобщения источников.Четко указывайте, из каких источников вы черпаете информацию, будь то прямая цитата, перефразирование или краткое изложение. Вы можете указывать источники как Источник A, Источник B и т. д. или использовать описания в скобках.
При первом чтении вы можете нервничать по поводу того, как ответить на это приглашение… особенно если вы не знаете, что такое выдающийся домен! Но если вы разобьете подсказку на куски, вы сможете понять, что подсказка просит вас сделать в кратчайшие сроки.
Чтобы получить полное представление о том, что эта подсказка хочет от вас, вам нужно определить наиболее важные детали в этой подсказке, абзац за абзацем. Вот что требует от вас каждый абзац:
- Абзац 1: Подсказка представляет и кратко объясняет тему , по которой вы будете писать обобщающее эссе. Этой темой является концепция выдающегося домена.
- Параграф 2: В этом абзаце подсказка представляет конкретное утверждение о концепции выдающегося домена: Выдающийся домен является продуктивным и полезным. В этом абзаце вам предлагается решить, хотите ли вы защитить, оспорить или уточнить это утверждение в своем обобщающем эссе , и использовать для этого материалы как минимум из трех предоставленных источников.
- Пункт 3: В последнем абзаце подсказки экзамен дает вам четкие инструкции о том, как подходить к написанию обобщающего эссе . Во-первых, сделайте свой аргумент в центре эссе. Во-вторых, используйте материал как минимум из трех источников, чтобы развить и объяснить свою аргументацию. В-третьих, комментируйте материалы, которые вы включаете, и давайте надлежащие цитаты, когда вы включаете цитаты, парафразы или резюме из предоставленных источников.
Таким образом, вы должны согласиться, не согласиться или уточнить утверждение, указанное в подсказке, а затем использовать как минимум три источника для обоснования своего ответа. Так как вы, вероятно, мало что знаете о выдающемся домене, вы, вероятно, определитесь со своей позицией после того, как прочтете предоставленные источники.
Чтобы эффективно использовать свое время на экзамене, вы должны потратить около 2 минут на чтение подсказки и записать, что она просит вас сделать.Это оставит вам достаточно времени, чтобы прочитать предоставленные источники, что является следующим шагом к написанию обобщающего эссе.
Шаг 2. Внимательно прочитайте исходники
После того, как вы внимательно прочитаете подсказку и запишете наиболее важные детали, вам необходимо прочитать все предоставленные источники. Заманчиво пропустить один или два источника, чтобы сэкономить время, но мы не рекомендуем этого делать. Это потому, что вам потребуется полное понимание темы, прежде чем вы сможете точно ответить на приглашение!
Для приведенного выше примера приглашения на экзамен предусмотрено шесть источников.Мы не собираемся включать все источники в эту статью, но вы можете просмотреть шесть источников из этого вопроса на экзамене AP Lang 2018 здесь. Источники включают пять источников печатного текста и один визуальный источник, представляющий собой мультфильм.
Когда вы читаете исходники, важно читать быстро и внимательно. Не торопись! Держите карандаш в руке, чтобы быстро отметить важные отрывки, которые вы, возможно, захотите использовать в качестве доказательства в своем обобщении. Пока вы читаете источники и отмечаете отрывки, вы хотите подумать о том, как информация, которую вы читаете, влияет на вашу позицию по проблеме (в данном случае — на выдающуюся область).
Когда вы закончите чтение, потратьте несколько секунд, чтобы резюмировать во фразе или предложении, защищает ли источник, оспаривает или уточняет, выгоден ли выдающийся домен (что является утверждением в подсказке) . Хотя может показаться, что у вас нет на это времени, важно сделать себе эти заметки о каждом источнике, чтобы вы знали, как вы можете использовать каждый из них в качестве доказательства в своем эссе.
Вот что мы имеем в виду: скажем, вы хотите оспорить идею о том, что выдающийся домен полезен.Если вы сделали заметки о каждом источнике и о чем он говорит, вам будет легче включить соответствующую информацию в план и эссе.
Итак, сколько времени вы должны потратить на чтение предоставленных источников? Экзамен AP Lang рекомендует уделить 15 минут чтению исходников . Если вы потратите около двух из этих минут на чтение и разбор подсказки эссе, , имеет смысл потратить оставшиеся 13 минут на чтение и аннотирование источников.
Если вы закончите чтение и аннотирование раньше, вы всегда можете перейти к составлению сводного эссе.Но убедитесь, что вы не торопитесь и внимательно читаете! Лучше потратить немного больше времени на чтение и понимание источников сейчас, чтобы вам не пришлось возвращаться и перечитывать источники позже.
Сильный тезис сделает большую работу в вашем эссе. (Видите, что мы там делали?)
Шаг 3. Напишите сильный тезис
После того, как вы проанализировали подсказку и внимательно прочитали источники, следующее, что вам нужно сделать, чтобы написать хорошее обобщающее эссе, это написать сильное тезисное утверждение .
Хорошая новость о написании тезисов для этого обобщающего эссе заключается в том, что у вас под рукой есть все инструменты, необходимые для этого. Все, что вам нужно сделать, чтобы написать тезис, это решить, какова ваша позиция по отношению к заданной теме.
В приведенном ранее примере подсказки вам, по сути, предоставляется три варианта того, как сформулировать ваше тезисное утверждение: вы можете защищать, оспаривать или квалифицировать утверждение, которое было предоставлено в подсказке, что выдающаяся область является продуктивной и выгодно .Вот что это означает для каждого варианта:
Если вы решите защищать претензию, ваша задача будет состоять в том, чтобы доказать, что претензия верна . В этом случае вам придется показать, что выдающийся домен — это хорошо.
Если вы решите оспорить претензию, вы будете утверждать, что претензия неверна. Другими словами, вы будете утверждать, что элитный домен не является продуктивным или полезным.
Если вы решите соответствовать требованиям, это означает, что вы согласны с частью претензии, но не согласны с другой частью претензии. Например, вы можете возразить, что элитное доменное имя может быть продуктивным инструментом для правительства, но не выгодно для владельцев собственности. Или, может быть, вы утверждаете, что именитый домен полезен в одних обстоятельствах, но не в других.
Когда вы решите, хотите ли вы, чтобы ваше обобщающее эссе защищало, оспаривало или уточняло это утверждение, вам необходимо четко выразить эту позицию в своем тезисе. Вы хотите избежать простого повторения утверждения, представленного в подсказке, суммирования проблемы без последовательного утверждения или написания тезиса, который не отвечает на подсказку.
Вот пример тезиса, получившего максимальные баллы за выдающееся эссе по синтезу предметной области:
Хотя выдающееся владение может быть использовано не по назначению в личных интересах за счет граждан, оно является жизненно важным инструментом любого правительства, которое намерено иметь какое-либо влияние на землю, которой оно управляет, за пределами писаного закона.
Этот тезис получил высшие баллы, потому что он излагает достойную защиты позицию и устанавливает линию рассуждений по вопросу о выдающемся домене. В нем излагается позиция автора (что некоторые части выдающихся владений хороши, а другие плохи), затем дается объяснение, почему автор считает, что (это хорошо, потому что позволяет правительству выполнять свою работу, но плохо потому что правительство может злоупотреблять своей властью.)
Поскольку в этом примере тезиса излагается защищаемая позиция и устанавливается линия рассуждений, его можно развить в основной части эссе с помощью дополнительных утверждений, подтверждающих доказательств и комментариев.Веский аргумент — это ключ к тому, чтобы получить шесть баллов за обобщающее эссе для AP Lang!
Нужна помощь в подготовке к экзамену AP?
Наши индивидуальные услуги онлайн-репетиторов AP помогут вам подготовиться к экзаменам AP. Найди лучшего репетитора, получившего высокий балл на экзамене, к которому ты готовишься!
Шаг 4. Создайте базовый план эссе
После того, как вы подготовили тезис, у вас есть основа, необходимая для разработки основного плана вашего обобщающего эссе.Разработка плана может показаться пустой тратой вашего драгоценного времени, но , если вы хорошо разработаете план, это на самом деле сэкономит вам время, когда вы начнете писать эссе.
Имея это в виду, мы рекомендуем потратить от 5 до 10 минут на наброски вашего обобщающего эссе . Если вы используете базовый план, подобный приведенному ниже, помечая каждую часть контента, которую вам нужно включить в черновик эссе, вы сможете разработать наиболее важные части синтеза еще до того, как набросаете собственно эссе.
Чтобы помочь вам увидеть, как это может работать в день тестирования, мы создали для вас образец схемы. Вы даже можете запомнить этот план, чтобы помочь вам в день экзамена! В приведенном ниже плане вы найдете места для заполнения тезисов, предложений по темам основного абзаца, доказательств из предоставленных источников и комментариев :
- Введение
- В нескольких предложениях представьте контекст, связанный с темой эссе (это хорошее место, чтобы использовать то, что вы узнали об основных мнениях или разногласиях по теме из ваших источников).
- Напишите простой, четкий и краткий тезис, в котором излагается ваша позиция по теме
- Корпус
- Основная часть Параграф № 1
- Тематическое предложение, представляющее первый аргумент или утверждение
- Доказательство № 1
- Комментарий к доказательствам №1
- Доказательство №2 (при необходимости)
- Комментарий к улике №2 (при необходимости)
- Основной абзац № 2
- Тематическое предложение, представляющее второй аргумент или утверждение
- Доказательство № 1
- Комментарий к доказательствам №1
- Доказательство №2 (при необходимости)
- Комментарий к улике №2 (при необходимости)
- Основной абзац № 3
- Тематическое предложение, представляющее три аргумента или утверждение
- Доказательство № 1
- Комментарий к доказательствам №1
- Доказательство №2 (при необходимости)
- Комментарий к улике №2 (при необходимости)
- Основная часть Параграф № 1
- Заключительный пункт
- Суммируйте основную аргументацию, которую вы разработали и защищали на протяжении всего эссе
- Повторяет тезис
Если вы потратите время на то, чтобы разработать эти важные части синтеза в общих чертах, это даст вам карту для вашего окончательного эссе.Если у вас есть карта, писать эссе будет намного проще.
Шаг 5. Составьте ответ на эссе
Самое замечательное в том, что вы потратите несколько минут на разработку плана, это то, что вы сможете превратить его в черновик эссе. После того, как вы потратите от 5 до 10 минут на набросок своего обобщающего эссе, , вы можете использовать оставшиеся 30–35 минут, чтобы набросать эссе и просмотреть его.
Поскольку вы составите план своего эссе до того, как начнете его набрасывать, написание эссе должно быть довольно простым.Вы уже будете знать, сколько абзацев вы собираетесь написать, какова будет тема каждого абзаца и какие цитаты, парафразы или резюме вы собираетесь включить в каждый абзац из предоставленных источников. Вам просто нужно заполнить одну из самых важных частей вашего синтеза — ваш комментарий.
Комментарии — это ваше объяснение того, почему ваши доказательства подтверждают аргумент, изложенный вами в диссертации. Ваш комментарий — это место, где вы на самом деле излагаете свои аргументы, поэтому это такая важная часть вашего обобщающего эссе.
Думая о том, что сказать в своем комментарии, помните одну вещь, указанную в подсказке AP Lang для синтеза эссе: не просто суммируйте источники. Вместо этого, когда вы комментируете доказательства, которые вы включили, вам необходимо объяснить, как эти доказательства подтверждают или подрывают ваш тезис . Вы должны включить комментарий, который предлагает вдумчивый или новый взгляд на доказательства из ваших источников, чтобы развить свою аргументацию.
При составлении эссе следует помнить одну очень важную вещь — указывать источники.Подсказка для синтеза эссе экзамена AP Lang указывает, что вы можете использовать общие метки для предоставленных источников (например, «Источник 1», «Источник 2», «Источник 3» и т. д.). В приглашении к экзамену будет указано, какая метка соответствует какому источнику, поэтому вам нужно убедиться, что вы обращаете внимание и точно цитируете источники. Вы можете цитировать свои источники в предложении, где вы вводите цитату, резюме или парафраз, или вы можете использовать цитату в скобках. Ссылка на ваши источники влияет на вашу оценку за обобщающее эссе, поэтому важно помнить об этом.
Одной из наиболее важных частей вашего заявления в колледж является то, какие предметы вы выберете в старшей школе (в сочетании с тем, насколько хорошо вы успеваете по этим предметам). Наша команда экспертов по приему в школу PrepScholar собрала свои знания в этом едином руководстве по планированию расписания занятий в старшей школе. Мы посоветуем вам, как сбалансировать свое расписание между обычными курсами и курсами с отличием/AP/IB, как выбрать дополнительные занятия и какие занятия вы не можете позволить себе не посещать.
Продолжайте читать, чтобы увидеть реальный пример отличного ответа на синтезированное эссе AP!
Пример эссе синтеза AP из реальной жизни и анализ
Если вы все еще не знаете, как написать обобщающее эссе, вам помогут примеры реальных эссе из прошлых экзаменов AP Lang. Эти ответы студентов на обобщающее эссе из реальной жизни могут помочь вам понять, как написать обобщающее эссе, которое поразит первоклассников.
Несмотря на то, что в Интернете есть несколько примеров эссе, мы выбрали один из них, чтобы рассмотреть его поближе. Мы собираемся дать вам краткий анализ одного из этих примеров студенческих эссе синтеза из экзамена AP Lang 2019 ниже!
Пример синтеза эссе AP Lang Response
Для начала давайте посмотрим на официальную подсказку к сводному эссе 2019 года:
В ответ на растущий спрос нашего общества на энергию крупномасштабная ветроэнергетика привлекла внимание правительств и потребителей как потенциальная альтернатива традиционным материалам, питающим наши энергосистемы, таким как уголь, нефть, природный газ, вода или даже более новые материалы. источников, таких как ядерная или солнечная энергия.Тем не менее, создание крупномасштабных ветряных электростанций коммерческого уровня часто вызывает споры по целому ряду причин.
Внимательно прочитайте шесть источников, найденных на экзамене AP English Language and Composition 2019 (вопрос 1), включая вводную информацию для каждого источника. Напишите эссе, в котором будет синтезирован материал как минимум из трех источников и изложена ваша позиция в отношении наиболее важных факторов, которые следует учитывать частному лицу или агентству при принятии решения о создании ветряной электростанции.
Источник A (фото)
Источник B (Лейтон)
Источник C (Зельтенрих)
Источник D (Браун)
Источник E (Правило)
Источник F (Молла)
В своем ответе вы должны сделать следующее:
- Ответьте на запрос с тезисом, представляющим защищаемую позицию.
- Выберите и используйте доказательства как минимум из 3 предоставленных источников, чтобы поддержать свою линию рассуждений. Четко указывайте использованные источники посредством прямой цитаты, перефразирования или краткого изложения. Источники могут быть указаны как Источник A, Источник B и т. д., или используя описание в скобках.
- Объясните, как доказательства подтверждают вашу линию рассуждений.
- Используйте правильную грамматику и пунктуацию при передаче аргумента.
Теперь, когда вы точно знаете, что подсказка попросила студентов сделать на обобщающем эссе AP Lang 2019 года, вот пример обобщающего эссе AP Lang, написанный реальным студентом на экзамене AP Lang в 2019 году:
[1] Ситуация известна уже много лет, и до сих пор делается очень мало: альтернативная энергия — единственный способ обеспечить надежное питание меняющегося мира.Энергопотребление, поступающее от промышленности и частной жизни, превосходит существующие источники невозобновляемой энергии, а в связи с сокращением запасов ископаемого топлива выход из эксплуатации электростанций, работающих на угле и газе, является лишь вопросом времени. Таким образом, одной из жизнеспособных альтернатив является энергия ветра. Но, как и во всем, есть плюсы и минусы. Основными факторами, которые энергетические компании должны учитывать при строительстве ветряных электростанций, являются экологические, эстетические и экономические факторы.
[2] Экологические преимущества использования энергии ветра хорошо известны и доказаны.Энергия ветра, согласно определению Источника B, бесспорно чистая и возобновляемая. От того, что для их производства требуется очень мало опасных материалов, до отсутствия топлива, помимо того, что происходит естественным путем, энергия ветра на сегодняшний день является одним из наименее вредных для окружающей среды доступных источников энергии. Кроме того, энергия ветра с помощью редуктора и усовершенствованных материалов для лопастей имеет самый высокий процент удержания энергии. Согласно источнику F, энергия ветра удерживает 1164% энергии, поступающей в систему, а это означает, что она увеличивает энергию, преобразованную из топлива (ветра) в электричество в 10 раз! Ни один другой метод производства электроэнергии не эффективен даже вполовину.Важно учитывать эффективность и чистоту энергии ветра, особенно потому, что они вносят экономический вклад в энергетические компании.
[3] С экономической точки зрения энергия ветра является одновременно и благом, и костяком для электрических компаний и других пользователей. Для потребителей энергия ветра очень дешева, что приводит к меньшим счетам, чем из любого другого источника. Потребители также получают косвенное возмещение в виде налогов (источник D). В одном из техасских городков, МакКейми, налоговые поступления увеличились на 30% благодаря возведению в городе ветряной электростанции.Это помогает финансировать улучшения в городе. Но нет никаких сомнений в том, что энергия ветра также наносит ущерб энергетическим компаниям. Хотя с точки зрения возобновляемых источников энергии ветер невероятно дешев, он все же значительно дороже, чем ископаемое топливо. Таким образом, хотя это помогает сократить выбросы, это обходится электрическим компаниям дороже, чем традиционные электростанции, работающие на ископаемом топливе. Хотя общая экономическая тенденция положительна, есть некоторые препятствия, которые необходимо преодолеть, прежде чем энергия ветра станет действительно более эффективной, чем ископаемое топливо.
[4] Эстетика может быть самой большой неудачей для энергетических компаний. Хотя ветроэнергетика может принести значительную экономическую и экологическую выгоду, люди всегда будут бороться за сохранение чистой, нетронутой земли. К сожалению, мало что можно сделать для улучшения визуальной эстетики турбин. Белая краска является наиболее распространенным выбором, потому что она «ассоциируется с чистотой». (Источник Е). Но это может сделать его выделяющимся, как больной палец, и сделать гигантские машины более неуместными.Сайт также не может быть изменен, потому что это влияет на генерирующие мощности. Звук едва ли не хуже беспокойства, потому что он прерывает личную продуктивность, нарушая режим сна людей. Одна вещь, которую энергетические компании должны рассмотреть, — это работа с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку.
[5] Как и в большинстве случаев, у энергии ветра нет простого ответа. Компании, строящие их, несут ответственность за взвешивание преимуществ и последствий.Но, соблюдая баланс между экономикой, эффективностью и эстетикой, энергетические компании могут создать решение, которое уравновешивает влияние человека и сохранение окружающей среды.
А это пример полного синтеза эссе AP Lang, написанного в ответ на настоящую подсказку экзамена AP Lang! Важно помнить, что подсказки для синтеза эссе на экзамене AP Lang всегда имеют одинаковую структуру и формулировку, и учащиеся часто отвечают примерно таким же количеством абзацев, как вы видите в приведенном выше примере ответа на эссе.
Далее, давайте проанализируем это примерное эссе и поговорим о том, что оно делает эффективно, где его можно улучшить и какие баллы ему присудили участники прошлых экзаменов.
Анализ
Чтобы начать анализ образца эссе, , давайте посмотрим на комментарий о подсчете баллов, предоставленный Советом колледжей:
- За разработку дипломной работы, реферат получил 1 балл из 1 возможных
- За доказательства и комментарии сочинение получило 4 балла из 4 возможных
- За изощренность мысли сочинение получило 0 баллов из 1 возможных.
Это означает, что окончательная оценка этого примерного сочинения составила 5 из 6 возможных баллов . Давайте более внимательно посмотрим на содержание примерного эссе, чтобы понять, почему оно получило такую разбивку баллов.
Разработка диссертации
Тезис — это одна из трех основных категорий, которые учитываются при начислении баллов за эту часть экзамена. Этот образец эссе получил 1 из 1 общего количества баллов.
А теперь вот почему: в тезисе четко и лаконично изложена позиция по теме, представленной в подсказке – альтернативной энергетике и ветроэнергетике – и определены наиболее важные факторы, которые энергетические компании должны учитывать при принятии решения о создании ветропарка. .
Доказательства и комментарии
Второй ключевой категорией, принимаемой во внимание при оценке сводных экзаменов, является включение доказательств и комментариев. Этот образец получил 4 балла из 4 возможных за эту часть сводного эссе.Как минимум, этот образец эссе соответствует требованию, упомянутому в подсказке, что автор должен включать доказательства как минимум из трех предоставленных источников.
Вдобавок ко всему, автор проделывает хорошую работу по соединению включенных свидетельств с утверждением, сделанным в тезисе, с помощью эффективного комментария. Комментарий в этом образце эссе эффективен, потому что он выходит за рамки простого обобщения того, что говорят предоставленные источники. Вместо этого он объясняет и анализирует доказательства, представленные в выбранных источниках, и связывает их с поддерживающими точками, которые автор делает в каждом абзаце основного текста.
Наконец, автор эссе также получил баллы за доказательства и комментарии, потому что автор разработал и поддерживал последовательную линию рассуждений на протяжении всего эссе . Эта линия рассуждений резюмируется в четвертом абзаце в следующем предложении: «Одна вещь, которую должны рассмотреть энергетические компании, — это работать с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку».
Поскольку автор проделал хорошую работу, постоянно развивая свои аргументы и приводя доказательства, они получили высшие баллы в этой категории.Все идет нормально!
Изощренность мысли
Итак, мы знаем, что это сочинение получило 5 баллов из 6 возможных, а место, где автор потерял балл, было на основании сложности мысли, за что автор получил 0 баллов из 1. Это потому, что в этом образце эссе делается несколько обобщений и расплывчатых утверждений, хотя вместо этого можно было бы сделать конкретные утверждения , поддерживающие более сбалансированный аргумент.
Например, в следующем предложении из 5-го абзаца образца эссе автор упускает возможность указать конкретные возможности, которые энергетические компании должны учитывать в отношении ветровой энергии .Вместо этого автор двусмыслен и ни к чему не обязывает, говоря: «Как и в большинстве случаев, у ветроэнергетики нет простого ответа. Компании, строящие их, несут ответственность за взвешивание преимуществ и последствий».
Если автор этого эссе заинтересован в том, чтобы попытаться получить этот 6-й балл в ответе на обобщающее эссе, он может подумать о том, чтобы сделать более конкретные заявления. Например, они могут указать конкретных преимуществ и последствий , которые энергетические компании должны учитывать при принятии решения о создании ветряной электростанции.Сюда могут входить такие вещи, как воздействие на окружающую среду, экономическое воздействие или даже плотность населения!
Несмотря на потерю одного балла в последней категории, этот пример обобщающего эссе является сильным. Он хорошо разработан, продуманно написан и продвигает аргументацию по теме экзамена, используя доказательства и поддержку повсюду.
4 совета по написанию обобщающего эссе
AP Lang — это экзамен с ограничением по времени, поэтому вам нужно выбирать, на чем вы хотите сосредоточиться, за то ограниченное время, которое вам дается на написание обобщающего эссе.Продолжайте читать, чтобы получить наш экспертный совет о том, на чем следует сосредоточиться во время экзамена.
Совет 1. Сначала прочитайте подсказку
Это может показаться очевидным, но когда у вас мало времени, легко растеряться. Просто помните: когда придет время писать обобщающее эссе, сначала прочтите подсказку !
Почему так важно прочитать подсказку перед чтением исходников? Потому что, когда вы знаете, на какой вопрос вы пытаетесь ответить, вы сможете более стратегически читать источники. Подсказка поможет вам понять, какие утверждения, пункты, факты или мнения следует искать при чтении источников.
Чтение исходников без предварительного прочтения подсказки похоже на попытку вести машину с завязанными глазами: возможно, вы сможете это сделать, но вряд ли это закончится хорошо!
Совет 2. Делайте заметки во время чтения
В течение 15-минутного периода чтения в начале обобщающего эссе вы будете читать источники как можно быстрее.В конце концов, вы, вероятно, очень хотите начать писать!
Хотя, безусловно, важно эффективно использовать свое время, также важно читать достаточно внимательно, чтобы понимать источники. Внимательное чтение позволит вам определить части источников, которые также помогут вам поддержать ваш тезис в вашем эссе.
Когда вы читаете исходники, отмечайте полезные отрывки звездочкой или галочкой на полях экзамена , чтобы знать, какие части текста следует быстро перечитать при составлении обобщающего эссе.Вы также можете суммировать ключевые моменты или положение каждого источника в предложении или нескольких словах, когда закончите чтение каждого источника в течение периода чтения. Это поможет вам узнать позицию каждого источника по заданной теме и поможет вам выбрать три (или более!), которые подкрепят ваш обобщающий аргумент.
Совет 3: начните с тезиса
Если вы не начнете свое обобщающее эссе с сильного тезиса, вам будет сложно написать эффективное обобщающее эссе. Как только вы закончите читать и аннотировать предоставленные источники, вам нужно будет написать сильную тезисную формулировку.
В соответствии с рекомендациями CollegeBoard по выставлению оценок за обобщающее эссе А. П. Ланга, на подсказку будет отвечать сильное тезисное утверждение — , а не , переформулируйте или перефразируйте подсказку. Хороший тезис будет занимать четкую, доказуемую позицию по теме, представленной в подсказке, и по источникам.
Другими словами, чтобы написать четкое тезисное утверждение, которое будет служить ориентиром для остальной части вашего обобщающего эссе, вам нужно обдумать свою позицию по рассматриваемой теме, а затем сделать заявление по этой теме на основе вашего должность. Эта позиция будет защищать, оспаривать или уточнять утверждение, сделанное в подсказке эссе.
Защитимая позиция, которую вы устанавливаете в своем тезисе, будет направлять ваши аргументы в остальной части эссе, поэтому важно сделать это в первую очередь. Как только у вас будет сильный тезис, вы можете приступить к изложению своего эссе.
Совет 4. Сосредоточьтесь на своем комментарии
Очень важно написать вдумчивый, оригинальный комментарий, объясняющий ваши аргументы и ваши источники.На самом деле, если вы сделаете это хорошо, вы получите четыре балла (из шести)!
AP Ланг предоставляет вам от шести до семи источников на экзамене, и вы должны будете включить цитаты, парафразы или резюме по крайней мере из трех из этих источников в свое обобщающее эссе и интерпретировать эти доказательства для читателя.
Хотя включение доказательств очень важно, чтобы получить дополнительный балл за «сложность мысли» в обобщающем эссе, важно уделять больше времени размышлениям о вашем комментарии к доказательствам, которые вы решите включить.Комментарий — это ваш шанс продемонстрировать оригинальное мышление, сильные риторические навыки и четко объяснить, как доказательства, которые вы включили, подтверждают позицию, изложенную вами в вашем тезисе.
Чтобы получить 6-й возможный балл за обобщающее эссе, убедитесь, что ваш комментарий демонстрирует тонкое понимание исходного материала, объясняет это тонкое понимание и размещает доказательства, полученные из источников, в диалоге друг с другом.Для этого убедитесь, что вы избегаете расплывчатых выражений. Будьте конкретны, когда можете, и всегда связывайте свой комментарий с тезисом!
Что дальше?
Экзамен AP Language включает в себя гораздо больше, чем просто обобщающее эссе. Обязательно ознакомьтесь с нашим экспертным руководством по всему экзамену, а затем узнайте больше о сложном разделе с несколькими вариантами ответов.
Экзамен AP Lang сложный или легкий? Посмотрите, как он сочетается с другими тестами AP в нашем списке самых сложных экзаменов AP.
Знаете ли вы, что технически существует два экзамена AP по английскому языку? В этой статье вы можете узнать больше о втором тесте AP по английскому языку, экзамене AP по литературе.