
Звуковой анализ слова ЛИСА | Презентация к уроку по обучению грамоте (старшая группа):
Слайд 1
Тема: « Звуковой анализ слова ЛИСА» Подготовила: учитель-логопед О.А. Абызова Автор шаблона: Фокина Л.П.Слайд 2
— А у нас гость! Хотите узнать кто? Отгадайте загадку. Мех пушистый, Хвост золотистый, По лесу гуляет, Зайчиков пугает. (Лиса) — Давайте назовем ее ласково (лисичка).
Слайд 4
-Лисичка очень любит греться на солнышке, давайте вместе с ней погреемся Самомассаж “ Солнышко ” Солнце с неба посылает Лучик, лучик, лучик (движения по лбу от середины к вискам). И им смело разгоняет Тучи, тучи, тучи (плавные зигзагообразные движения оп лбу). Лучик нежно согревает Щёчки, щёчки, щёчки (потирают щёчки). Солнышко на носик ставит Точки, точки, точки (постукивают пальцем по носу и щёчкам).
Слайд 6
— Лисичка, так же как и вы, ходит в лесной детский сад. Очень любит гулять, играть и выполнять разные задания. Но вот некоторые у нее не получаются. И она просит помочь ей. Поможем лисичке? — Ребята, что это такое? (звуковые схемы слов ) -Правильно!
Поможем лисичке? — Ребята, что это такое? (звуковые схемы слов ) -Правильно!
Слайд 8
-И мы научим сейчас нашу гостью составлять звуковую схему слова лиса. (Анализ и синтез слова, характеристика звуков и обозначение цветовыми символами)
Слайд 10
-Лисичка благодарит вас за помощь и приглашает на интересную игру! Динамическая пауза (самомассаж кистей рук). Ежик. Мы нашли колючий шарик, Нам его не удержать. Шарик крутится в ладошках, Шарик хочет убежать. (дети крутят между ладонями массажные мячи) Шарик наш живой и теплый, На кого же он похож? (смотрят на мяч, держа его в ладонях) Прыгнул шарик на дорожку — Оказалось…это еж! (дети слегка подбрасывают шарик, затем ловят его)
Слайд 12
Игра «Волшебный платочек» (образование множественного числа существительных) — Ребята, наша гостья с помощью волшебного платочка может превращать одни слова в другие, меня уже научила и я сейчас научу вас! Я буду называть слово и передавать вам волшебный платочек. Вы, взмахнув платочком , превращаете тот предмет, который я назову во множество таких же предметов и называете новое слово. Например: стол – столы, окно – окна Слова для игры: стул — стулья, дерево – деревья, роза– розы, ведро – ведра, носок – носки, петух – петухи, ребенок – дети, карандаш – карандаши, зеркало – зеркала, ботинок – ботинки, сухарь – сухари, пень – пни, олень – олени, мелок – мелки, кисть – кисти, нож – ножи, страна – страны, язык – языки, место – места, рама – рамы…
Например: стол – столы, окно – окна Слова для игры: стул — стулья, дерево – деревья, роза– розы, ведро – ведра, носок – носки, петух – петухи, ребенок – дети, карандаш – карандаши, зеркало – зеркала, ботинок – ботинки, сухарь – сухари, пень – пни, олень – олени, мелок – мелки, кисть – кисти, нож – ножи, страна – страны, язык – языки, место – места, рама – рамы…
Слайд 14
— Ребята, как вы думаете, нам удалось научить лисичку тому, что умеем сами? — Чему мы научили лисичку? -Ребята посмотрите, что нам оставила на память лисичка! Карточку со своим изображением. Только надо сначала обвести по контуру, потом раскрасить. И получится лисичка! Но мы с вами это сделаем, когда придем с прогулки!
Занятие по обучению грамоте в подготовительной к школе группы «Путешествие в сказочный лес»
Занятие по обучению грамоте в подготовительной к школе группы
«Путешествие в сказочный лес»
Н.А.Матвеева, воспитатель подготовительной к школе группы.
КГУ «Средняя школа № 42» г. Петропавловска СКО
Цели занятия:
Закрепление и систематизация знаний детей о гласных и согласных звуках;
Развитие умения производить полный звуковой анализ слов, чтение слогов, составление слов и предложений;
Воспитание у детей любви к чтению, развитие заинтересованности и творческой деятельности и самостоятельности на занятиях.
Методы: индивидуальный, фронтальный, групповой.
Демонстрационный материал: иллюстрированные сказочные герои, фишки для звукового анализа слов, соответствующие корзинки для звуков.
Раздаточный материал: фишки разных цветов, цветные карандаши, карточки для работы в парах (вставь букву в слово; допиши слово; соедини слоги)
Игровой момент: сказочные герои – лиса, белка, настольная игра «В гостях у сказки».
Ход занятия:
Организационный момент:
— Ребята, вы любите путешествовать? (Ответы детей)
— На чем можно путешествовать? (Ответы детей)
Сегодня мы отправимся в путешествие в сказочный лес! Там нас ждут удивительные встречи и невероятные приключения! Вы готовы? (Ответы детей) В путь!
2. На доске две корзинки для гласных и согласных звуков, лесная тропинка, на которой грибочки с буквами.
На доске две корзинки для гласных и согласных звуков, лесная тропинка, на которой грибочки с буквами.
— В лесу много разных деревьев, поют лесные птицы, дует легкий свежий ветерок… И вот перед нами тропинка…
— Что растет на этой тропинке? (грибы) А грибы эти не простые, а с буквами. Чем отличаются буквы от звуков? (Ответы детей) Ребята, мы своими ответами кого-то напугали! Вон он прячется за кустиком! Кто же это?
Рыщет кум в густом лесу,
Ищет кумушку …(лису).
— Правильно, ребята. Лисе нужно помочь, разложите грибочки в две корзинки, обратите внимание, на одной корзинке красный квадрат. Что он означает? Какие буквы мы будем складывать в эту корзинку? (Ответы детей)
А вторая корзинка – синий и зеленый квадратики, почему? (Ответы детей)
Как отличит согласный звук от гласного? (Ответы детей)
(Дети по очереди выходят к доске и раскладывают грибы-буквы в разные корзинки, объясняя свои действия.)
Игра «Зажги фонарики»
Потемнело в нашем лесу, давайте зажжем наши фонарики! Приготовили две фишки — синею и зеленую. Начинаем со слогов. Определяем первый звук: до, ми, ре, на, ку, ли, фа, зе. (Дети показывают соответствующую фишку). А теперь продолжаем играть, но задание становится труднее, надо определить первый звук не в слоге, а в слове: сом, река, дым, том, лес, гусь, белка. (Дети показывают соответствующую фишку). Вот какие мы молодцы, в нашем лесу стало светло и весело.
Начинаем со слогов. Определяем первый звук: до, ми, ре, на, ку, ли, фа, зе. (Дети показывают соответствующую фишку). А теперь продолжаем играть, но задание становится труднее, надо определить первый звук не в слоге, а в слове: сом, река, дым, том, лес, гусь, белка. (Дети показывают соответствующую фишку). Вот какие мы молодцы, в нашем лесу стало светло и весело.
Физмитунка.
«У медведя дом большой, а у зайки маленький,
Вот идет медведь домой, а за ним и заинька».
3. — Ребята, наша лиса призадумалась! О чем задумалась, лисичка? Помогите, ребята, разобрать это слово по звукам. (Слово «лиса» написано на доске, дети выходят и делают звуковой анализ слова, вспоминая правила об ударении и деления слова на слоги).
— А как её зовут, вы должны прочитать на своих листах с заданием «КУМА». Задание выполняется детьми самостоятельно. Кто правильно сделает задание – получает поощрительную фишку.
4. К нам ещё кто-то спешит, ловко скачет с ветки на ветку, прячется в дупле, гордится своим пушистым хвостиком, кто это? (Белка) Правильно, это маленький бельчонок Пушистик, который торопится тоже помочь вам, ребята. Но у него беда – по дороге рассыпались слова, слоги и буквы. Задания по рядам:
Но у него беда – по дороге рассыпались слова, слоги и буквы. Задания по рядам:
1 ряд – карточка на двоих детей с потерявшейся буквой О в словах: дом, кот, волк. Вставьте букву и прочитайте слова.
2 ряд – соединить слоги и прочитать слова
СО
БУК ВА
ТЫК
3 ряд – потерялся слог ЛОв словах: дуп…, жа…, мы… Вставьте слог и прочитайте слова.
Музыкальная физминутка «Осминожки»
5.А ещё у лисы есть одно задание. Это слова, их которых надо составить предложение и прочитать его, прочитав его, вы узнаете сюрприз, который вам приготовили наши гости из леса.
На доске слова: лиса, У, подарок.
Дети составляют предложение и получают подарок – настольную игру «В гостях у сказки».
6. Итог. Наше путешествие подошло к концу. С кем вы встречались? Что делали на занятии? (Ответы детей)
— Сегодня вы, ребята, были самые сообразительные и умные помощники-ученики.
Адрес публикации: https://www.prodlenka.org/metodicheskie-razrabotki/31911-zanjatie-po-obucheniju-gramote-v-podgotovitel
Конспект ООД в старшей группе «Пересказ сказки «Лиса и кувшин».
Конспект ООД в старшей группе «Пересказ сказки «Лиса и кувшин».
Цель: организовать коммуникативную деятельность, направленную на развитие связной монологической речи посредством знакомства со сказкой «Лиса и кувшин».
Задачи:
Образовательные:
- способствовать обучению детей рассказывать сказку без наводящих вопросов, выразительно, используя в качестве наглядной опоры – мнемотаблицу
- способствовать активизации и обогащения словарного запаса детей.
- способствовать обучению детей произносить предложения с разными оттенками интонации (сердитая, просительная, ласковая);
- способствовать развитию мышления, творческого воображения, связную диалогическую и монологическую речь, грамматическую, звуковую культуру речи.

- проводить звуковой анализ слова «лиса», состоящая из четырех звуков; соотносить слово с его звуковой моделью.
Развивающие:
- способствовать развитию у детей произвольного зрительного внимания и памяти, словесно – логического мышления, речи и активизировать словарь.
Воспитательные:
- воспитывать усидчивость, выдержку, умение выслушивать ответы товарищей.
Методические приемы:
- Рассматривание иллюстраций к сказке.
- Беседа, загадывание загадок, чтение и пересказ сказки, словарная работа.
Словарная работа:
«Жать», «подобралась», «вылакала», «кувшин не отстает».
Предварительная работа:
Чтение РНС, разучивание физкультминутки, беседа по прочитанным сказкам, «Доскажи словечко», «Угадай героя», «Назови правильно» и др
Средства реализации:
Демонстрационной материал:
Книга сказок, сундучок, конверт с запиской, иллюстрации к сказкам, мнемотаблица, мольберт.
Ход занятия
I часть. Организационный момент.
Воспитатель: посмотрите на своих соседей слева и справа, посмотрите на наших гостей и улыбнитесь им, а они улыбнутся вам.
Артикуляционная и мимическая гимнастика, развитие дыхания:
«Голодная лиса» — втянуть щеки
«Лиса лакает молоко» — полакать языком
«Лиса облизывается»
«Лисе нравится молоко» — почмокать губами
«Сытая лиса» — надуть щеки
Воспитатель: Я хочу пригласить вас в увлекательное путешествие в добрую сказочную страну чудес.
II часть. Основная часть.
Беседа с детьми.
Воспитатель: Посмотрите, что я нашла за дверью (показываю сундук) – это же волшебный сундук, а в нем книга и записка:
Уважаемые читатели!
Перед вами необычная книга. Она открывается не каждому, а только самому любознательному и сообразительному.
Она открывается не каждому, а только самому любознательному и сообразительному.
Чтобы сказку прочитать,
Её название сначала придётся угадать!
Название зашифровано в двух загадках. Вот первая загадка:
Хитрая плутовка,
Рыжая головка,
Хвост пушистый – краса,
А зовут её … (лиса)
Дети: Лиса.
(Выставить на мольберте изображение лисы, похвалить детей).
– А вот вам и вторая загадка:
Горлышко узкое,
Круглые бока.
Нужен нам для молока.
И даже в жаркий день всегда
В нём холодная вода. (Кувшин)
(Если загадка вызовет у детей затруднение, можно предложить подсказку: это посуда, в старину её делали из глины и хранили там молоко или квас, из этой посуды журавль лису окрошкой потчевал в сказке «Лиса и журавль». Выставить на мольберте изображение кувшина).
Воспитатель: перед нами и ответ. Вы догадались, как называется эта сказка? Дети: «Лиса и кувшин».
Воспитатель: Ребята, существует много сказок про лису. А какие сказки знаете вы, где лиса является главной героиней?
Дети: «Лиса и журавль», «Волк и лиса», «Заюшкина избушка», «Лиса и Кот» и др.
Воспитатель: Молодцы, много знаете сказок о лисе.
Воспитатель: (вопросы детям)
1. Как в сказках называют лису ласково?
Дети: Лисичка-сестричка, Лисонька, Лиса-Патрикеевна.
2. А какой лису в сказках изображает автор?
Дети: Хитрой, умной, ласковой, выдумщицей, смышленой.
3. Можно ли, лису назвать ласково лисенок?
Дети: Нельзя.
4. А почему?
Дети: Лисенок – это детеныш.
Воспитатель: Ребята, усаживайтесь удобнее, я прочитаю сказку «Лиса и кувшин». Вам в сказке встретятся незнакомые слова, чтобы они были понятны, я вам их сейчас объясню. (Словарная работа).
Вам в сказке встретятся незнакомые слова, чтобы они были понятны, я вам их сейчас объясню. (Словарная работа).
Чтение сказки.
Воспитатель: Понравилась вам сказка?
Дети: Да, понравилась.
Беседа по содержанию
Воспитатель: О ком была эта сказка?
Дети: Сказка была о Лисе.
Воспитатель: Кто пришел в поле?
Дети: В поле пришла Баба.
Воспитатель: Что делала баба в поле?
Дети: Жала рожь.
Воспитатель: Что, кроме серпа, принесла баба в поле?
Дети: Баба принесла кувшин.
Воспитатель: Что было в кувшине?
Дети: В кувшине было молоко.
Воспитатель: Для чего баба взяла в поле молоко?
Дети: Чтобы потом, когда сядет отдохнуть, попить молока.
Воспитатель: Куда баба поставила кувшин?
Дети: За снопы.
Воспитатель: Кто нашел кувшин?
Дети: Кувшин нашла лиса.
Воспитатель: Что сделала лиса?
Дети: вылакала молоко.
Воспитатель: Как лиса достала молоко из кувшина?
Дети: Всунула в кувшин голову.
Воспитатель: Что случилось с лисой?
Дети: Голова застряла в кувшине.
Воспитатель: Как лиса сначала разговаривала с кувшином, каким голосом?
Дети: Ласковым голосом.
Воспитатель: Какие слова она говорила?
Дети: «Отпусти меня, пошутил — и будет».
Воспитатель: Кувшин ответил лисе?
Дети: Нет.
Воспитатель: Почему он не ответил?
Воспитатель: Как стала потом разговаривать лиса, каким голосом?
Дети: Сердитым голосом.
Воспитатель: Какие слова она говорила?
Воспитатель: Чем заканчивается сказка?
Дети: Лиса сунула голову в реку и утонула вместе с кувшином.
Воспитатель: Дети, а как вы думаете, почему кувшин утонул?
Дети: Он наполнился водой и стал тяжелым.
Воспитатель: Можно сказать, что кувшин утонул, как камень и потянул за собой лису.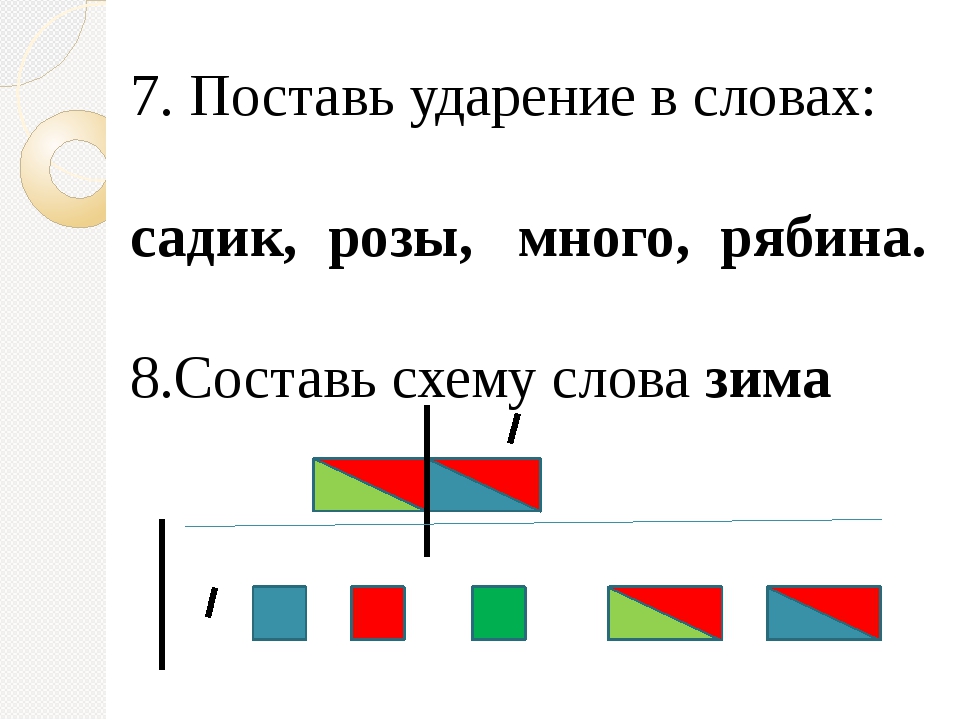
Физкультминутка «Лисонька».
Утром лисонька проснулась,
Лапкой вправо потянулась,
Лапкой влево потянулась,
Солнцу нежно улыбнулась
В кулачок все пальцы сжала,
Растирать все лапки стала –
Лапки, ножки и бока.
Вот какая красота!
А потом ладошкой
Пошлёпала немножко.
Ну, красавица – Лиса!
До чего же хороша!
Повторное чтение с установкой на запоминание.
Пересказ.
Воспитатель:: А сейчас я хочу, чтобы вы мне пересказали сказку. (3-4 человека). Пересказ с помощью мнемотаблицы.
Звуковой анализ слова.
Но в начал вспомним, какие бывают звуки.
Дети: согласные, гласные.
Воспитатель: А какие бывают согласные звуки?
Дети: Твердые, мягкие.
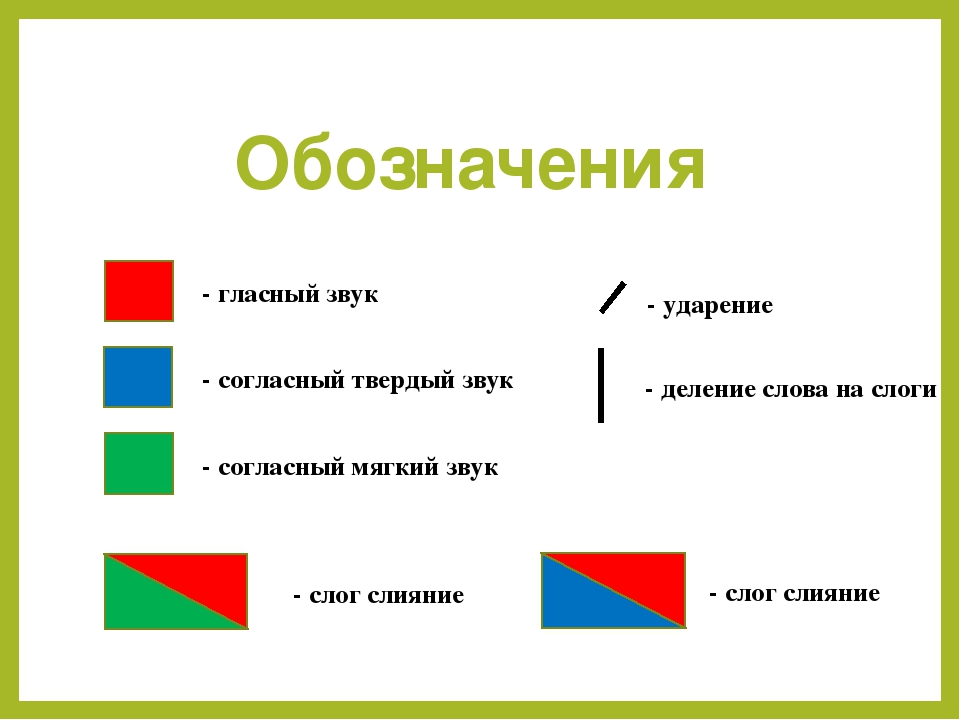
Воспитатель: Какими фишками обозначаем твердые согласные звуки?
Дети: Синими.
Воспитатель: Какими фишками обозначаем мягкие согласные звуки?
Дети: Зелеными.
Воспитатель: Какими фишками обозначаем гласные звуки?
Дети: Красными.
Воспитатель: Кто нарисован на картинке?
Дети: Лиса.
Воспитатель: Что обозначают клеточки?
Дети: Сколько звуков в слове «Лиса».
Воспитатель: Какой первый звук в слове «Лиса». Произнесем вместе.
Дети: «Ль»
Воспитатель: Что мешает во рту, когда произносим звук «Ль»?Дети: Язык.
Воспитатель: Какой он?
Дети: Согласный, мягкий.
Воспитатель: Какой фишкой обозначаем?
Дети: Зеленой.
Воспитатель: Какой второй звук в слове «Лиса». Произнесем вместе.
Произнесем вместе.
Дети: «И»
Воспитатель: Когда произносим звук «И», нам что-то мешает во рту?
Дети: Нет.
Воспитатель: Какой он?
Дети: Гласный.
Воспитатель: Какой фишкой обозначаем?
Дети: Красной.
Воспитатель: Какой третий звук в слове «Лиса». Произнесем вместе.
Дети: «С»
Воспитатель: Что мешает во рту, когда произносим звук
Дети: Язык, зубы.
Воспитатель: Какой он?
Дети: Согласный, твердый.
Воспитатель: Какой фишкой обозначаем?
Дети: Синей.
Воспитатель: Какой четвертый звук в слове «Лиса». Произнесем вместе.
Дети: «А»
Воспитатель: Когда произносим звук «А», нам что-то мешает во рту?
Дети: Нет.
Воспитатель: Какой он?
Дети: Гласный.
Воспитатель: Какой фишкой обозначаем?
Дети: Красной.
Воспитатель: Сколько звуков в слове «Ли-са»?
Дети: Четыре.
Воспитатель: Сколько слогов в слове «Лиса»?
Дети: Два слога.
Воспитатель: Какой первый слог?
Дети: «ли»
Воспитатель: Какой второй слог?
Дети: «са»
Воспитатель: Сколько гласных звуков в слове?
Дети: Два.
Воспитатель: Назовите их.
Дети: «И», «А».
Воспитатель: Сколько согласных звуков в слове?
Дети: Два.
Воспитатель: Назовите их.
Дети: «Ль», «С».
Воспитатель: Какое слово мы с вами разобрали?
Дети: Слово «Лиса».
III часть. Итог.
Воспитатель:
— С какой русской народной сказкой мы познакомились?
Дети: «Лиса и кувшин».
Воспитатель: Кто главные герои сказки?
Дети: Баба и лиса.
Воспитатель: Какой лиса оказалась в сказке?
Дети: Хитрая, жадная.
Воспитатель: Чему нас научила эта сказка?
Дети: Жадность до добра не доведет.
Воспитатель: На этом наше занятие закончилось. И чтобы оно вам запомнилось надолго, я дарю вам на память кадры из него. Но они черно- белые, и я думаю, вам не составит труда их раскрасить. Со сказкой мы прощаемся и в группу возвращаемся.
Задачи:
- познакомить детей с р.н. сказкой «Лиса и кувшин»;
- совершенствовать навыки пересказывания дошкольниками готовых текстов;
- расширять словарный запас детей;
- развивать умение детей произносить предложения с разными оттенками интонации
- (ласковая, просительная, сердитая);
- воспитывать усидчивость, выдержку, умение выслушивать ответы товарищей.
Предварительная работа: чтение сказок о лисе ( «Снегурушка и лиса», «Заюшкина избушка», «Петушок – золотой гребешок», «Лисичка-сестричка и серый волк», «Лиса и медведь» и др.);
– разъяснение слов «баба», «кувшин», «жать» на примере других сказок ( «Гуси-лебеди», «Лиса и журавль», «Медведь и собака»);
– театрализация сказок «Лиса и рак», «Лиса и журавль» и др.;
– рассматривание иллюстраций к сказкам;
– отгадывание загадок о животных;
– изготовление заготовок книжек-малышек.
Литература:
- Детство: Примерная основная общеобразовательная программа дошкольного образования/ Т.
 И. Бабаева, А. Г. Гогоберидзе, З. А. Михайлова и др. – ООО «ИЗДАТЕЛЬСТВО «ДЕТСТВО-ПРЕСС», 2011.
И. Бабаева, А. Г. Гогоберидзе, З. А. Михайлова и др. – ООО «ИЗДАТЕЛЬСТВО «ДЕТСТВО-ПРЕСС», 2011. - Развитие речи детей 5 – 7 лет. 2-е изд., перераб. и дополн. / Под ред. О. С. Ушаковой. – М.: ТЦ Сфера, 2012., с.88, 218.
Демонстрационный материал: предметные картинки: лиса, кувшин.
Раздаточный материал: наборы иллюстраций к сказке по количеству детей;
заготовки самодельных книжек-малышек по количеству детей;
наборы готовых форм для аппликации по количеству детей: баба, лиса, кувшин;
клей, кисточки, салфетки, клеёнка для намазывания клея, клеёнка для наклеивания аппликации по количеству детей.
Интеграция с областями: социализация, художественное творчество.
ХОД ЗАНЯТИЯ
I часть. Организационный момент
1. Воспитатель: (Вместе с детьми стоит на ковре в кругу). Девочки и мальчики, II часть. Основная
Воспитатель: Ребята, сегодня утром я нашла в группе книгу. Даже не знаю, как она к нам попала.
Даже не знаю, как она к нам попала.
(Воспитатель показывает книгу) Хотите, я сегодня вам её прочитаю? (Ответы детей) А что, в ней лежит? (ответы детей). А что нам делать с конвертом? (Ответы детей)
(Воспитатель и дети читают письмо)
Уважаемые читатели!
Перед вами необычная книга. Она открывается не каждому, а только самому любознательному и сообразительному.
Чтобы сказку прочитать,
Её название сначала придётся угадать!
Название зашифровано в двух загадках. Вот первая загадка:
Хитрая плутовка,
Рыжая головка,
Хвост пушистый – краса,
А зовут её … (лиса)
(Выставить на мольберте изображение лисы, похвалить детей).
– А вот вам и вторая загадка:
Горлышко узкое,
Круглые бока.
Нужен нам для молока.
И даже в жаркий день всегда
В нём холодная вода. (Кувшин)
(Кувшин)
(Если загадка вызовет у детей затруднение, можно предложить подсказку: это посуда, в старину её делали из глины и хранили там молоко или квас, из этой посуды журавль лису окрошкой потчевал в сказке «Лиса и журавль». Выставить на мольберте изображение кувшина).
Воспитатель: перед нами и ответ. Вы догадались, как называется эта сказка? Артём, как ты думаешь? (Никита, Лиза…, вы согласны?) Хотите я прочитаю вам сказку «Лиса и кувшин»?
Занимайте свои места и слушайте внимательно.
2. Чтение сказки
Воспитатель: понравилась вам сказка? Вам все слова были понятны, не услышали незнакомых слов?
(Если будут утвердительные ответы, попросить других детей разъяснить значение этих слов).
3. Беседа по содержанию
Вопросы к тексту:
- О ком была эта сказка? (Сеня, подскажи. Даша, правильно?)
- С чего сказка началась? (Настя, вспомни, пожалуйста.
 Арсений, ты согласен?)
Арсений, ты согласен?) - Что случилось с лисой? (Аня, скажи нам. Артём, ты согласен? Кто хочет добавить?)
- Как лиса сначала разговаривала с кувшином, каким голосом? (Ваня, как ты думаешь?)
- Какие слова она говорила? (Лиза, произнеси слова так, чтобы было понятно, что лиса говорит ласково)
- Кувшин ответил лисе? (Арина). Почему он не ответил? (Андрей, а как ты думаешь?)
- Как стала, потом разговаривать лиса, каким голосом? (Егор)
- Какие слова она говорила? (Никита, произнеси слова так, чтобы было понятно, что лиса говорит сердито.)
- Чем заканчивается сказка? (Андрюша. Маша, согласна?)
4. Физкультминутка «Весело в лесу»: (выполняется под музыку)
– А теперь я предлагаю вам немного поиграть.
Выходите на лужок,
Становитесь все в кружок.
Становитесь по порядку
На весёлую зарядку!
(Дети с воспитателем становятся в круг на ковре)
Воспитатель: Давайте покажем, что лисичка умеет делать.
Лисичка хвостиком следы заметает (наклоны туловища вправо и влево).
Лисичка принюхивается, ищет зайчат (наклоны вперёд с вытянутыми руками).
Лисичка крадётся (шагаем на месте с высоким подниманием коленей).
Лисичка прыгает за мышкой (прыжки на месте или с продвижением вперёд на двух ногах).
Лисичка грустит (тянемся за вытянутыми вверх руками, встаём на носочки).
Другой вариант:
Зайцы утром рано встали,
Весело в лесу играли.
По дорожкам прыг да прыг. (прыгают, подняв ладони над головой)
Кто к зарядке не привык?
Вот лиса идёт по лесу. (шагают на месте с высоким подниманием колен к ладоням)
Кто там скачет, интересно?
Чтоб ответить на вопрос,
Тянет лисонька свой нос. (наклоны вперёд с вытянутыми руками)
Но зайчата быстро скачут, (подскоки на месте)
Как же может быть иначе?
Тренировки помогают!
И зайчата убегают! (бег на месте)
Вот голодная лиса
Грустно смотрит в небеса. (тянутся на носочках вверх)
Тяжело вздыхает, (вдох носом, выдох ртом – 2 раза)
Садится, отдыхает. (садятся на ковёр, руку под щёку)
5. Дидактическая игра «Разложи по порядку»
Воспитатель: Мальчики и девочки, хотела я вам картинки к нашей сказке показать, да вот беда, перепутались они все между собой. Помогите мне, пожалуйста, разложить их по порядку. Пусть каждый из вас найдёт себе в пару помощника, с кем бы хотелось выполнить это задание. Выбирайте место, где вам будет удобно. (Дети расходятся для выполнения задания. Если ребёнок остался без пары, можно предложить в пару себя. После выполнения задания дети остаются на местах.)
А теперь давайте проверим, правильно ли выполнено задание.
- С чего началась сказка? Кто должен быть на первой картинке? (Аня, помогай). Выставляет на мольберте.
- Что случилось потом? Кто на второй картинке? (Гриша, что у тебя?) Выставляет на мольберте.
- Что произошло с лисой потом? Что на третьей картинке? (Даша и Лиза, что у вас получилось?) Выставляет на мольберте.
- Чем закончилась сказка? Что было на последней картинке? (Саша и Маша, как вы думаете?) Выставляет на мольберте.
(Дети проверяют свои варианты. Подбодрить детей, у которых задание не получилось.)
6. Изготовление книжек-малышек
Воспитатель: соберите картинки и подходите все ко мне (на ковёр). Помните, на прошлой неделе мы начали делать книжки-малышки (показать одну)? Но в книжках наших чего-то не хватает. Как вы думаете? (Выслушать ответы детей) Правильно, красивых, ярких картинок. Давайте их вклеим на страницы. Берите книжки, подходите к столу, берите фигурки для наклеивания (показать детям образцы). Вспомните, с чего начиналась сказка, а что происходило потом. Аккуратно пользуйтесь клеем и салфетками.
Кто закончил, занимайте места на стульчиках.
Теперь я прочитаю сказку ещё раз, а вы смотрите на картинки, слушайте внимательно и постарайтесь запомнить.
7. Повторное чтение сказки.
Воспитатель: Ребята, мы совсем забыли про наших гостей. Они, наверное, тоже хотят послушать сказку и посмотреть картинки.
Уважаемые гости, поднимите руку, кто хочет послушать сказку в исполнении наших детей.
Мальчики и девочки, смелее выбирайте, кому вы хотите рассказать свою сказку и показать картинки.
(Дети рассказывают зрителям. Нерешительных детей можно взять к себе на пересказ.)
А теперь возвращайтесь все ко мне. Дорогие гости, понравилась ли вам наша сказка? (Ответы гостей)
Вы все сегодня большие молодцы. Спасибо вам за работу. А не хотели бы вы рассказать сказку нашим малышам и подарить им несколько книжек-малышек. Я думаю, что они бы очень обрадовались.
(По желанию детей можно пройти в младшую группу и подарить книжки.)
Конспект занятия – игры со сказкой «Лиса и кувшин» для детей 4 – 5 лет (авторская идея и разработка) Цель: создание условий для знакомства со сказкой «Лиса и кувшин», развития речи и моторики речевого аппарата, обогащения активного словаря. Сценарий занятия: 1.Воспитатель читает сказку целиком. 2.Расмотреть вместе с детьми иллюстрации; предложить ответить на вопросы (так лучше запоминается сюжет и усваивается смысл прочитанной сказки); обсудить смысл сложных слов и словосочетаний; 3. Воспитатель зачитывает фрагмент из сказки: «…вышла баба на поле жать и спрятала за кусты кувшин с молоком…» Воспитатель задает вопросы: — Куда пошла баба? — Где баба спрятала кувшин с молоком? 4.Воспитатель показывает образец и предлагает детям собрать изображение кувшина из спичек. 5.Воспитатель предлагает посмотреть на рисунок, и сказать, кто оставил кувшин, а кто его нашел. 6. Воспитатель зачитывает фрагмент из сказки: «…подобралась к кувшину лиса, всунула в него голову, молоко вылакала; пора бы домой, да вот беда – головы из кувшина вытащить не может». Детям предлагаются вопросы: — Кто вылакал все молоко? — Что случилось с лисой? 7. Воспитатель зачитывает фрагмент из сказки: «…ходит лиса, головой мотает и говорит: «Ну, кувшин, пошутил, да и будет – отпусти же меня, кувшинушко! Полно тебе, голубчик, баловать – поиграл да и полно». После прочитанного отрывка детям задается вопрос: — Почему голова лисы застряла в кувшине? 8. 9. Воспитатель зачитывает фрагмент из сказки: «…побежала лиса к реке и давай кувшин топить. Кувшин – то утонуть утонул, да и лису за собой потянул». Предложить детям вопросы: — Как лиса решила избавиться от кувшина? — Чем закончилась сказка? — Смогла ли лиса обмануть кувшин? — Придумайте другой конец сказки. (Например, «Будь лиса поумнее, она бы разбила кувшин о камень, а бабе пришлось бы собирать кувшин по кусочкам». 10. Воспитатель обращается к детям с просьбой подарить бабе новый кувшин (дети на трафаретах кувшинов рисуют красивый узор и раскрашивают их). 11. Воспитатель предлагает придумать словосочетания по образцу: Лиса сердитая – лиса радостная Лиса жадная — … Лиса глупая — … У лисы настроение плохое — … 12. После выполненных игровых заданий предложить самостоятельно рассказать сказку с опорой на иллюстрации.
| < Предыдущая | Следующая > |
|---|
Путешествие в страну волшебных замков | Дошкольное образование
Путешествие в страну волшебных замков
Автор: Хрестина Надежда Анатольевна
Организация: МБДОУ »ЦРР — д/с »Сказка» ОП »Детский сад »Теремок» комбинированного вида»
Населенный пункт: Республика Мордовия, г. Ковылкино
Тема: «Путешествие в страну волшебных замков»
Цели:
Закрепить знания детей о гласных и согласных звуках, о различии согласных звуков по твердости и мягкости, о гласных буквах.
Закрепить умение определять гласный звук по немой артикуляции через игровую деятельность.
Учить отгадывать загадки.
Продолжить обучать звуковому анализу слов; совершенствовать умение делить слова на слоги, в определении ударения в слове.
Упражнять в составление и в анализе предложений.
Развивать логическое мышление.
Воспитывать доброжелательность, проявляя настойчивость, целенаправленность и взаимопомощь.
Демонстрационный материал и оборудование:
Музыкальная колонка, макет телевизора, Буратино, парта со скамеечкой для Буратино, «Замки для звуков», синий кубик пластмассовый, зеленый кубик поролоновый, гласные буквы, магнит (красный, синий, зеленый), картинка лиса, полоска с четырьмя клеточками, ящик с игрушками (кукла, машина, совок, кубик, дудка, буква, мяч, пирамидка, вилка, телефон, мишка, зеркало), 2 корзины, указка, карточки с мнемодорожкой для составления предложения.
Раздаточный материал:
Фишки (3 красного, 3 зеленого, 3 синего цвета), тарелочки, карточка с картинкой и схемой слова лиса, корзиночки с макаронами, бархатный картон, карточки с гласными буквами (а, о, у, ы, и, э).
Ход занятия
I. Организационный момент.
– Ребята, к нам сегодня на занятие пришли гости. Давайте с ними поздороваемся. (Здравствуйте).
Наши ушки на макушке,
Глазки хорошо открыты.
Слушаем, запоминаем,
Ни минуты не теряем.
– Для чего людям нужны уши? (Уши нужны для того, чтобы слышать).
– А для чего нам нужны глаза? (Глаза нужны, чтобы видеть).
– Что можно услышать ушами? (Правильно, ушами мы слышим разные звуки).
– А какие звуки вы сейчас слышите? (Тиканье часов, стук двери, звук работающей машины).
– Ребята, вы слышите, кто-то к нам спешит в гости?
Под музыку из кинофильма «Приключения Буратино» воспитатель вносит в группу куклу Буратино.
II. Основная часть
– Ребята, к нам пришел Буратино, но не с пустыми руками. Он принес рюкзачок, который ему передала Мальвина. Буратино говорит, что Мальвина любит всех воспитывать и учить. Она дает задания, которые он должен выполнить самостоятельно. К сожалению, Буратино не смог справиться с ними и просит нас помочь ему.
– Вы согласны? (Да).
– Буратино, ребята готовы тебе помочь. Но для начала я предлагаю вам отправиться в нашу волшебную страну звуков, где звуки живут в замках и вспомнить, что такое звук? (Звук – это то, что мы слышим и произносим).
– А что такое буква? (Буква – это то, что мы пишем и видим).
– Какими бывают звуки? (Звуки бывают гласными и согласными).
– Какие звуки мы называем гласными? (Звуки, которые тянутся, поются, произносятся протяжно, при произношении гласных звуков в ротике нет преграды).
– Каким цветом обозначаются гласные звуки? (Красным).
– Какие звуки мы называем согласными? (Звуки, при произношении которых в ротике есть преграда, это может быть губы, зубы и язычок).
– Какими бывают согласные звуки? (Твердые и мягкие).
– Каким цветом обозначаются твердые согласные звук? (Синим).
– Каким цветом обозначаются мягкие согласные звук? (Зеленым).
I Задание Игра «Сломанный телевизор»
(Воспитатель достает из рюкзачка листочек с I Заданием Игра «Сломанный телевизор»)
– Ребята, первое задание – поиграть в игру «Сломанный телевизор». Напоминаю правила игры: с помощью артикуляции, я буду без звука показывать вам гласные звуки, а вы должны определить его, произнести звук протяжно, а затем показать, какой буквой он обозначается.
– Молодцы! Справились и с этим заданием.
II Задание Игра «Кто внимательный»
– А теперь посмотрим кто самый внимательный из ребят.
– Итак, выберите и назовите гласные буквы, которые обозначают твердость предшествующих согласных звуков?
(Воспитатель ставит на магнитную доску синий магнит, а ребенок – выкладывает буквы).
Твердый согласный звук – а, о, э, у, ы.
– Какие гласные буквы обозначают мягкость предшествующих согласных звуков?
(Воспитатель ставит на магнитную доску зеленый магнит, а ребенок – выкладывает буквы).
Мягкий согласный звук – я, ё, е, ю, и.
III Задание «Наведи порядок»
– Сейчас постараемся выполнить следующее задание Мальвины. (Воспитатель достает из рюкзачка листочек со II Заданием «Наведи порядок»).
– Мальвина собрала игрушки в один ящик, их нужно разложить в две корзинки. В одну корзинку положить игрушки, названия которых начинаются с мягкого согласного звука, а в другую с твердого согласного звука.
– По очереди каждый из вас показывает игрушку, выделяете первый звук в слове и кладете в свою корзину.
Игрушки:
Твердый согласный звук – кукла, машина, совок, кубик, дудка, буква.
Мягкий согласный звук – мяч, пирамидка, вилка, телефон, мишка, зеркало.
(Дети берут по одной игрушке, показывают детям, выделяют первый звук в слове и кладут в свои корзины).
– Все разобрали, молодцы! Справились с этим заданием.
– Теперь давайте немного отдохнем и проведем физминутку «Буратино».
Буратино потянулся,
Раз – нагнулся, два – нагнулся,
Руки в стороны развел,
Видно ключик не нашел.
Чтобы ключик нам достать,
На носочки надо встать!
IV Задание «Звуковой анализ слова «Лиса»
– А теперь переходим к следующему заданию. Мальвина подготовила загадку, слушайте внимательно.
Посмотрите-ка, какая –
Вся горит, как золотая.
Ходит в шубке дорогой,
Хвост пушистый и большой.
(Лиса)
– Из скольких слогов состоит слово лиса? (Слово лиса состоит из 2 слогов).
– А из каких звуков, мы с вами определим. К доске выйдет Глеб Б. и проведет звуковой анализ слова лиса.
– Сколько звуков в слове лиса? (4).
– Сколько гласных звуков? (2).
– Назовите гласные звуки? (И, а).
– Какой гласный звук ударный? (Звук а).
– Уберите звук и, с, ударный звук а, ль.
V Задание Игра «Выложи гласную букву»
– Нам необходимо выложить из макарон гласную букву. Приступаем к работе.
– Молодцы, справились с заданием.
VI Задание «Работа с предложением»
– С помощью мнемодорожек нам необходимо составить предложение и его схему.
– Из скольких слов состоит предложение?
– Назовите мне 1, 2, 3 слово в предложении.
III. Итог занятия
– Ребята, что больше понравилось на занятии?
– Ребята, вы действительно, молодцы! Буратино говорит вам спасибо за помощь. Все старались, очень дружно выполняли сложные задания. Он хочет вас отблагодарить вкусным сладким ирисом «Золотой ключик».
– А сейчас ему пора возвращаться в школу к Мальвине. До свидания.
Приложения:
- file0.doc.. 46,5 КБ
Мультики про лис смотреть онлайн бесплатно
В любом государстве спокойные периоды нередко В любом государстве спокойные периоды нередко
Молодой рыжий Лисенок осознает, что ничего не умеет делать. Он пробует Молодой рыжий Лисенок осознает, что ничего не умеет делать. Он пробует
Обитатели птичьего двора решили устроить пир. Ворона с петухом танцевали под звуки балалайки, гусята Обитатели птичьего двора решили устроить пир. Ворона с петухом танцевали под звуки балалайки, гусята
Петух отправился в гости к своему другу Коту Котофеевичу. По дороге его схватила Лиса Петух отправился в гости к своему другу Коту Котофеевичу. По дороге его схватила Лиса
Маленький лисенок Рыжик отличается от своих родственников тем, что дружит со зверятами, на Маленький лисенок Рыжик отличается от своих родственников тем, что дружит со зверятами, на
Сегодня лесных обитателей ожидает грандиозное спортивное событие – велогонка. Десятки
Сегодня лесных обитателей ожидает грандиозное спортивное событие – велогонка. Десятки
В северных землях на краю Руси-матушки жил храбрый и благородный охотник. Защищал он род свой от В северных землях на краю Руси-матушки жил храбрый и благородный охотник. Защищал он род свой от
Последнее время у лисы все идет наперекосяк. Она не смогла вытащить из окна петушка, от нее сбежал Последнее время у лисы все идет наперекосяк. Она не смогла вытащить из окна петушка, от нее сбежал
Расстроен грозный Лев и огорчён – в его курятник повадились воришки. Дня не проходит, чтоб не пропала Расстроен грозный Лев и огорчён – в его курятник повадились воришки. Дня не проходит, чтоб не пропала
Однажды в семье лис появился долгожданный наследник – Людвиг Однажды в семье лис появился долгожданный наследник – Людвиг
Лиса решила разбогатеть, украв у деда с бабой курочку, несущую золотые яйца. Рыжая плутовка не Лиса решила разбогатеть, украв у деда с бабой курочку, несущую золотые яйца. Рыжая плутовка не
Был у зайца добротный лубяной домик, а у лисицы – ледяной, который с наступлением весны Был у зайца добротный лубяной домик, а у лисицы – ледяной, который с наступлением весны
Не найдя лекарства в аптеке, медведь, у которого заболела спина, вынужден идти к лисе. У нее всегда найдется Не найдя лекарства в аптеке, медведь, у которого заболела спина, вынужден идти к лисе. У нее всегда найдется
Зимой в лесу зверям приходится нелегко. Зная об этом, медведь заранее позаботился о теплом жилище Зимой в лесу зверям приходится нелегко. Зная об этом, медведь заранее позаботился о теплом жилище
Мультфильм создан по мотивам басен армянского поэта Вардана Айгекци, жившего в средние века. Кто Мультфильм создан по мотивам басен армянского поэта Вардана Айгекци, жившего в средние века. Кто
Программа старшей группы детского сада — МегаЛекции
Основная задача занятий по грамоте в старшей группе детского сада — обучение действию звукового анализа слов. Во время этого обучения дети знакомятся с гласными и согласными звуками, узнают о том, что согласные звуки бывают твердые и мягкие, узнают буквы, обозначающие гласные звуки.
Занятия в старшей группе воспитатель начинает, знакомя детей со схемой звукового анализа слова. Для этих занятий мы использовали содержание I части «Букваря» Д. Б. Эльконина на карточках. Таким образом, перед каждым ребенком на занятии лежит карточка, на которой нарисован предмет, слово — название которого будет предметом анализа, а под картинкой — схема звукового состава слова; такая же картинка в увеличенном масштабе висит на доске.
Кроме того, перед каждым ребенком стоит подносик с фишками. Фишки могут быть сделаны из любого материала — одинаковые кусочки картона, одинаковые пластмассовые пластинки какого-нибудь нейтрального цвета — белые, серые. Мы рекомендуем для каждого ребенка индивидуальный подносик, так как количество фишек для работы будет постепенно расти, достигая к концу занятий десятка, а такое количество разного материала, сложенного вместе для двух детей, неудобно для пользования. У каждого ребенка должна быть также маленькая указка — удобно использовать для этого счетные палочки.
Понятно, что на висящую на доске таблицу нельзя поставить фишку, поэтому материал для работы у доски имеет несколько иной вид. Таблица изготовлена из стандартного листа ватмана, нижний край его загнут и закреплен планкой. В образовавшийся таким образом карман ставят фишки — прямоугольные куски картона с зауженными нижними концами.
Познакомив детей со схемой звукового состава слова, воспитатель переходит к формированию действия звукового анализа слов. Если группой хорошо усвоен программный материал предыдущего года, дети легко понимают воспитателя. В том же случае, если воспитатель обнаруживает, что большая часть детей плохо справляется с интонационным выделением звуков в слове, надо немедленно прекратить занятия по формированию действия звукового анализа слова и вернуться к программе средней группы.
Нескольких занятий будет достаточно для повторения прошлого материала и перехода к новым заданиям.
Опираясь на отработанное ранее у детей умение интонационно выделять звуки в слове, воспитатель должен научить детей произносить анализируемое слово, одновременно ведя указкой по схеме звукового состава слова. Важно добиться полной синхронности в произнесении и движении, убедиться в том, что эта синхронность не случайна, что дети могут замедлять или убыстрять движение указки в зависимости от того, какой звук в слове интонационно подчеркивается.
Только убедившись в том, что дети ориентируются в схеме звукового состава, можно переходить к выделению в слове отдельных звуков. Мы уже показывали, что интонационное выделение является более простым способом моделирования звукового состава слова, чем схема звукового состава и фишки. Поэтому важно переходить к сложным формам моделирования только после усвоения более элементарных форм естественного натурального моделирования. Подготовленная группа детей легко усваивает способ звукового анализа слов с помощью интонационного выделения, схемы звукового состава слова и фишек. Однако не все дети начинают сразу работать одинаково успешно. Способ проведения звукового анализа слова, которому мы будем учить детей в течение всего года, одинаков для анализа любого слова, поэтому, давая для разбора все новые и новые слова (а это совершенно необходимо, чтобы исключить момент механического запоминания звуков в слове), воспитатель постепенно добивается усвоения всеми детьми группы программного материала. Вначале детям предлагаются для анализа трехзвуковые слова: мак, дом, сыр, кит, кот, шар, лук, жук, дым, нос, рак. На каждом занятии дети разбирают вначале одно новое слово. Однако это слово анализируется несколько раз разными способами. Сначала детям предлагается просто разобрать новое слово, например дом. Вся группа работает за столами, а к доске вызывается по одному ребенку для выделения в слове каждого звука. Слово произносится с интонационным выделением нужного звука, указка фиксирует этот звук на схеме, затем соответствующая клетка схемы заполняется фишкой.
Следующий этап — воспитатель предлагает убирать со схемы фишки в соответствии с называемыми им звуками. При этом звуки не следует называть в той последовательности, в какой они стоят в слове, лучше называть их вразбивку: «Уберите звук о, теперь звук м, какой звук остался?» Такого рода задания понуждают детей к повторному внимательному проведению звукового анализа, к обследованию звукового состава слова по схеме. Очень хорошо закреплять звуковой анализ в форме игры: к доске вызываются трое детей, каждый из них получает фишку и название звука («Ты будешь звук д»). Затем воспитатель вызывает к себе «звуки»: «Подойди ко мне звук д, теперь подойди звук м, подойди звук о». Дети должны встать в том же порядке, в каком стоят звуки в слове. Постепенно игра усложняется: воспитатель раздает детям звуки по номерам («Ты первый звук в слове, ты второй» и т. д.), а вызывает к себе по названиям звуков («Подойди звук м»). Для того чтобы выполнить такое задание, ребенок, получивший от воспитателя номер звука в слове, должен прочесть слово по схеме с интонационным выделением и таким образом узнать, какой же он звук в слове. Разные варианты игры такого типа дают возможность опросить на занятии большое количество детей и предложить им задания, соответствующие их возможностям. Воспитатель включает в занятия много заданий, развивающих у детей важнейшие мыслительные операции сравнения, сопоставления, анализа: найдите одинаковые звуки в словах дом и мак; найдите разные звуки в словах дом и дым; какие мы с вами разбирали слова, которые кончаются таким же звуком, с которого начинается слово кот, и т. д.
Задания могут быть самыми разнообразными, но, давая их, воспитатель должен обязательно учитывать индивидуальные возможности каждого ребенка. Очень важно добиться, чтобы на занятиях активно работали все дети группы. Но это возможно только в том случае, если воспитатель видит и знает каждого ребенка.
Самым активным и хорошо подготовленным детям могут быстро наскучить однообразные и легкие задания, поэтому воспитатель должен давать им для решения более сложные задачи (например, искать в словах разные звуки труднее, чем одинаковые). Можно дать и задание, которое не может быть выполнено: найди одинаковые звуки в словах дом и рак. Пассивных детей, напротив, могут отпугнуть непосильные для них задания, вселить в них еще большую неуверенность в своих силах. Мы рекомендуем заранее предупреждать таких детей о том, что их вызовут отвечать («Вот сейчас Костя кончит разбирать слово, а потом Марина напомнит нам, какой в этом слове второй звук»), это даст возможность ребенку внутренне собраться, подготовиться к выходу к доске.
После того как будут проанализированы все предлагаемые нами трехзвуковые слова и дети усвоят способ проведения звукового анализа, можно вводить в обучение новый момент — различение гласных и согласных звуков. Мы придаем большое значение тому, чтобы максимально большее количество «открытий» делали сами дети. Поэтому знакомство с гласными и согласными мы предлагаем проводить следующим образом.
Воспитатель вывешивает на доске знакомую уже детям таблицу, на которой нарисован мак, и предлагает отгадать загадку: «В этом слове есть один звук — необыкновенный. Этот звук можно очень громко крикнуть, можно пропеть, когда мы его произносим, ничто нам во рту не мешает — ни губы, ни зубы, ни язык. Угадайте, что это за звук?» Дети отгадывают, что это звук а. Так же они выбирают из слов звуки о (дом), у (жук), ы (дым), и (кит). Только после этого воспитатель объединяет все эти звуки в одну группу и говорит, что они называются гласными, в отличие от согласных, которые нельзя ни крикнуть, ни петь, ни сказать так, чтобы во рту при этом ничто не мешало. Детям предлагается назвать согласные звуки из слов, изображенных на таблицах.
Иногда дети допускают ошибки, называя в числе гласных звуков р, л и др. Каждый раз надо такую ошибку подробно анализировать, попытаться вместе с детьми этот звук громко прокричать, посмотреть, не мешает ли что-нибудь его произносить. Такое не выученное, а как бы самостоятельно сделанное определение гласных и согласных звуков прочно усваивается детьми, они легко оперируют своими знаниями.
С этого занятия все гласные звуки дети начинают обозначать красными фишками, а все согласные — синими, белые фишки убираются, больше ими дети не пользуются. Конечно, в дальнейшем, при разборе четырех- и пятизвуковых слов, дети еще не раз будут ошибаться, путать гласные и согласные, но легко исправят свои ошибки, вспомнив, как они сами разделили все звуки на гласные и согласные.
К анализу четырехзвуковых слов следует перейти сразу же после знакомства с гласными и согласными звуками. Мы предлагаем разобрать следующие слова: пила, луна, рыба, лиса, сани, мыло, гуси, бусы. Все эти слова очень легки для звукового анализа, дети их успешно разбирают. Усложнение в занятиях идет за счет звуковых игр. Знакомая нам игра со звуками только что разобранного слова заметно изменилась благодаря появлению нового различения гласных и согласных звуков. Теперь воспитатель, «раздав» детям звуки слова по номерам, может позвать их к себе как гласные и согласные звуки («Подойди ко мне, первый гласный звук в слове, теперь второй согласный» и т. д.), а на место посадить (поставить фишку обратно на схему), назвав их звуками (Встань на место звук а, встань на место звук н, и т. д.).
Понятно, что в такой форме эта игра требует хорошего овладения действием звукового анализа слов, свободной ориентации в звуковом составе слов, твердого знания всего пройденного материала. Выполнить задания воспитателя, опираясь только на запоминание, ребенок не может, он должен постоянно активно мыслить.
Вторая игра, которая была начата в средней группе детского сада, заключается в назывании слов, отвечающих какому-то условию, поставленному воспитателем. Если вначале задания были несложные, типа «Назови слово, в котором есть звук р», то постепенно они усложняются: «Назови слова, которые начинаются с третьего звука слова роза». Это игра-соревнование, за каждое правильно названное слово дети получают фишку, в конце игры при подсчете фишек определяется победитель.
Кроме того, в этот период воспитатель знакомит детей с новой игрой: называнием слов по модели звукового состава слова. Например, на доске ставятся фишки: синяя, красная, синяя; детям предлагается назвать слова, имеющие такой звуковой состав. Вначале слова называются неуверенно, в основном те, которые были проанализированы в группе, но постепенно дети осваиваются в этом новом для них виде работы и начинают называть много разных слов. Приведем в качестве примера слова, названные детьми по предложенной выше схеме в середине года: мак, кит, зал, газ, ток, лук, кот, дуб, шар, жук, дом, пар, лес, жар, сыр, дым, лак, пол, нож, дух, сон, бас, мяч, дот, лук (ребенок уточняет: «Не тот, который едят, а из которого стреляют»), бот, рог, шаг, пух, рад, шум, нос, лоб, рот, вол, лось, лом, Чук, Гек, чуб, пар, бей, зал, моль, щит, гам, там, таз, печь, сам, мел, сын, дочь, сом, сор, Мук, май, рожь и др.
Игры этого типа с постепенным усложнением модели по мере разбора новых слов продолжаются в течение всего года.
Следующий этап обучения — знакомство с мягкими и твердыми согласными.
Мы считали нужным вводить эти новые понятия так же, как ввели на предыдущем этапе гласные и согласные, т. е. дать возможность детям самим обнаружить разницу между согласными.
Для этого на занятии разбираются слова пила и лиса. После того как дети провели звуковой анализ этих слов, воспитатель предлагает им убрать одинаковые гласные звуки. Дети убирают со схем все красные фишки. Затем воспитатель просит снять со схем разные согласные звуки — дети убирают фишки, обозначающие звуки п и с. «Какие же звуки у нас остались?» — спрашивает воспитатель. «Звук л». — «А эти звуки одинаковые или разные?» — «Одинаковые», — «Давайте послушаем внимательно, как звучит звук л в слове пила и как он звучит в слове лиса: пила, лиса. Одинаково звучит?»
В каждой группе обязательно находятся несколько детей, которые отвечают, что звук л в этих словах звучит не одинаково: в слове пила — грубо, а в слове лиса — ласково. Воспитатель поддерживает этих детей, но меняет их формулировку: «Звук л звучит в слове пила твердо, а в слове лиса — мягко».
Затем воспитатель предлагает детям определять в парах называемых им слов, где один и тот же звук звучит твердо, а где — мягко. Все дети хорошо различают на слух твердые и мягкие согласные, хотя это, конечно, не означает, что в дальнейшем, анализируя новые слова и заполняя фишками схемы звукового состава слов (теперь мягкие согласные звуки дети обозначают зелеными фишками, а твердые — по-прежнему синими), дети не делают ошибок. Они часто забывают о новых дефинициях, но просьба воспитателя: «Послушай хорошенько, как звучит этот звук: мягко или твердо?» — неизменно приводит к исправлению ошибки.
Научившись различать гласные, твердые и мягкие согласные, дети переходят к разбору все более сложных слов со стечением гласных и согласных звуков: утки, паук, лист, аист, куст, игла, слон, волк, кукла, вишни, сумка, мишка, парта, мышка, тигр, арбуз, сахар и т. п.
На всех этих занятиях мы продолжаем отрабатывать у детей действие звукового анализа слов, добиваясь постепенно ото всех детей группы свободной ориентировки в разбираемом слове. Понятно, что с введением различения мягких и твердых согласных очень усложнились и все виды описанных выше игр: в игре «Звуки слова» воспитатель имеет возможность давать множество вариантов заданий детям, и, что важно, заданий очень различных по сложности.
Количество разбираемых на занятии слов постепенно увеличивается: дети разбирают 3—4 новых слова. Очень важно обращать внимание детей на различные модели звукового состава слова, сравнивать слова по моделям.
На вопрос воспитателя, на какое разобранное ранее слово похоже слово волк, дети уверенно отвечают: «На куст, там тоже сначала твердый согласный, потом гласный, а потом еще два согласных». Это способствует развитию игры, заключающейся в назывании слов по новым, сложным моделям.
К этому времени при разборе слов дети перестают пользоваться схемой звукового состава слова, выкладывают перед собой фишки прямо на столах. Мы подводим детей к отказу от схемы очень постепенно. Сначала мы предлагаем детям для анализа новое слово, не вывешивая перед ними соответствующую таблицу, схема на которой подсказывает детям количество звуков в слове.
Воспитатель медленно (но ни в коем случае не по слогам!) произносит слово и спрашивает детей: «Сколько клеточек вам нужно, чтобы разобрать это слово?» Очень быстро дети начинают определять количество звуков в слове (от 3 до 5) на слух и выбирать для работы схему с соответствующим количеством клеток (картинок дети больше не получают, каждый ребенок имеет набор схем из 3, 4, 5 клеточек). Вскоре и эти схемы становятся ненужными, дети выкладывают фишки на столах, постоянно проверяя себя, «прочитывая» анализируемое слово с указкой так, как мы учили их вначале. Надо отметить, что такое «чтение» с указкой и с интонационным выделением у детей сохраняется очень долго. Даже перейдя к «чтению» без подчеркнутого выделения каких-то звуков, дети в случае затруднений тут же снова начинают интонационно выделять нужный звук.
Неправильно было бы думать, что такого рода проговаривание является свидетельством недостаточной сформированности действия звукового анализа слов и что с этим надо бороться. Надо полагать, что для детей этого возраста полный отказ от моделирования звукового состава слова во внешнем плане вообще невозможен: даже наиболее подготовленные дети, разбирая «в уме» легкие слова (с открытыми слогами), возвращаются к проговариванию и действию с указкой при переходе к разбору слов со сложными стечениями согласных. Мы пробовали забрать у детей указку, они начинают использовать в качестве указки палец и продолжают шептать слово.
Наконец, последний этап работы в старшей группе детского сада — знакомство с гласными буквами. Каждая новая буква вводится одним и тем же способом. Покажем это на примере буквы а.
Детям предлагается разобрать несколько слов: марка, лампа, кран. Модели этих слов выложены перед детьми на столе и на доске. Затем воспитатель предлагает детям найти в проанализированных словах одинаковые гласные звуки. Дети определяют, что это звук а. Тогда воспитатель показывает букву а и, рассмотрев ее с детьми, просит заменить во всех словах соответствующий звук — красную фишку — буквой а. Дальше дети разбирают слова, всегда ставя букву а вместо звука. На каждом занятии детям давалась для ознакомления новая буква. Мы вводили детям гласные буквы парами: а — я, о — ё, у — ю и т. д. Как это делалось? На следующем занятии после изучения буквы а детям предлагались для разбора слова дыня, тряпка, мясо. Разбирая слово дыня, дети выкладывали его так: твердый согласный звук (синяя фишка), гласный звук (красная фишка), мягкий согласный звук (зеленая фишка), звук а (буква а). Воспитатель снимал со схемы букву а и говорил детям: «Запомните одно очень важное правило: после мягкого согласного звука никогда не пишется буква а, вместо нее пишется я. Как только буква а видит перед собой мягкий согласный звук, она убегает без оглядки, а вместо нее бежит буква «я». Надо заметить, что дети не сразу усваивают это правило, мы наблюдали случаи, когда отдельные наши воспитанники в течение нескольких занятий забывали, где и когда какая из букв пишется. Но мы повторяли новое сложное правило при разборе каждого слова, спрашивая детей: «А почему ты поставил здесь букву я? Я здесь слышу звук а».
Постепенно вес дети группы четко отвечали: «После мягкого согласного звук а обозначается буквой я. Букву а здесь писать нельзя».
Точно так же парами вводились и все остальные гласные. Для лучшего усвоения правила мы ввели специальную игру «Найди свое место». Игра заключается в следующем: каждый ребенок группы получает какую-нибудь гласную букву, два ребенка держат в руках зеленую и синюю фишки, означающие соответственно мягкий и твердый согласный звук. По сигналу воспитателя все буквы должны встать за своим звуком: буквы а, о, у, ы, э — за синей фишкой, буквы я, ё, ю, и, е — за зеленой. Игра помогает детям закрепить уже усвоенное правило, проходит очень весело.
На этом этапе обучения мы слегка модифицировали игру, заключающуюся в назывании слов по модели. Воспитатель выставляет на доске модель какого-либо слова и предлагает детям угадать, какое слово он задумал. Здесь уже недостаточно просто назвать любое слово с подобным звуковым составом, надо точно угадать слово, задуманное воспитателем. Для чего мы ввели такого рода изменения? При отгадывании загадки дети должны научиться ставить перед воспитателями вопросы, уточняющие ту область действительности, к которой принадлежит данное слово.
Приведем пример такой игры. Воспитатель выставляет на доске следующую модель: зеленая фишка, красная фишка, синяя фишка, красная фишка.
Дети начинают называть слова: Миша, Нина, лето, зима, мина, пила.
Э. Так вы долго не догадаетесь, нужно ведь сначала узнать, про что я загадала загадку.
И. Это человек или предмет?
Э. Не человек и не предмет.
И. Это птица?
Э. Нет.
И. Это животное?
Э. Да.
И. А какое животное: дикое или домашнее?
Э. Дикое.
И. Оно лесное?
Э. Да.
И. Лиса.
Загадка отгадана. Понятно, что приведенный пример отгадывания является своего рода образцом. Дети не сразу овладевают методом дедуктивных вопросов, их нужно этому специально учить.
На следующем этапе развития этой игры дети сами загадывают загадки, выкладывая на доске модели задуманных слов. В этом случае в отгадывание загадок включается и воспитатель. Надо заметить, что дети загадывают загадки несравненно более сложные, чем воспитатель, состоящие из большого количества звуков. Игра в загадки становится одной из любимых детских игр, они часто играют в нее.
Вообще к середине года дети помимо занятий часто самостоятельно играют в различные речевые игры. Внесение в кукольный уголок материалов, подобных тем, с которыми дети работают на занятиях по грамоте, способствует тому, что дети начинают играть «в школу», задавая друг другу слова для звукового анализа.
Наиболее подготовленные дети учат тех, кто отстал в занятиях.
Дети заканчивают программу старшей группы, обладая следующими знаниями и умениями:
1. Умеют провести звуковой анализ практически любого предложенного слова.
2. Различают гласные, твердые и мягкие согласные звуки.
3. Свободно ориентируются в звуковой структуре слова, подбирают слова по предложенным моделям.
4. Знают все гласные буквы и умеют объяснить правила написания гласных после мягких согласных звуков.
Занятия должны проводиться два раза в неделю. В начале года занятие рассчитано на 20 минут, в конце года оно увеличивается до 30 минут.
Рекомендуемые страницы:
Воспользуйтесь поиском по сайту:
разобрать слова на гласные,согл,твердые,мяг . Кот лиса слон арбуз
Помогите пожалуйста,задание на листочке
Составьте и запишите предложение, в состав которого входит обособленное обстоятельство и обособленное определение, подчеркните.
Помогите составить план для текста. Звено в цепи поколений Из чего вырастает огромная человеческая любовь к Родине? Это любовь, которую надо воспитыв … ать с детства. Любовь, которая вырастает из неразрывной связи поколений. Мы порой забываем о ней в повседневной суете, в заботах о хлебе насущном. Память о прошлом своей семьи, своего города, своей страны даёт почувствовать эту связь. И тогда ты не просто случайный человек, который почему-то родился в этой стране, и ничем с ней не связан. Ты – одно из звеньев в бесконечной цепи поколений. Тебе надо будет передать память следующим поколениям и так далее. Поэтому надо беречь всё, что сделали наши предки: храмы, и старинные постройки, изделия народных промыслов и шедевры живописи, древние книги и документы, могилы великих людей, героев, могилы дедов. Если понимать слово Родина таким образом, то все, что содержит это слово, –твоё, и ты в ответе за сохранение бесценного наследия.
Я на огэ забыл написать номер сочинения(9.1,9.2,9.3) Аннулируется или нет? У кого было?
237. Составьте сложноподчиненные предложения, дополнив данные предло- жения главной частью с глаголами со значением речи, мысли, чувства. Запиши- те с … оставленные предложения, вставьте пропущенные буквы, раскройте скобки. Прокомментируйте расстановку знаков препинания в них. 1. Главной пр. чиной возн.кновения гл..бальной энергетической проблемы следу…т …читать быстрый рост потр….бления м..нерального топлива. 2. (Tопливн…) энергетические р…сурсы постоя…о истощают- ся и через несколько сот лет могут вообще и. чезнуть.3. Гл.бальная энергетическая проблема это проблема об…спечения человечества топ- ливом и энергией сейчас и в об.зримом будущем. 4. Возн.кновение (энерг…) сырьевой проблемы объясня…ся прежде всего быстрым ростом потр…бления м…нерального топлива, сыр..я и м..штабами их добычи. 5. Энергетическая проблема объясня..ся растущим разрывом между высокими темпами развития (энерг) емких произво..ств и запасами невозобн.вляемых (энерг…) р..сурсов.
Запишите предложения расставляя знаки препинания. Подчеркни члены 1-го предложения. Обозначь орфограммы в выделенных словах. 1) Не было никакой возмож … ности уйти незаметно он вышел от крыто и шмыгнул в огород. 2) У дарил сильнейший гром задрожали все окна. 3) Лёд стал хрупким идти по реке опасно. 4)Быстро темнеет дорогу ты вряд(ли) различишь.
описание картинки велопоход всей семьёй!! СРОЧНО ПОМОГИТЕ ПОЖАЛУЙСТА
Русский язык Русский язык, 21.05.2020 12:59, Kubrex Спишите. Определите, чем осложнены предложения. Подпишите и выделите графически. Чувство вины не … самобичевание, а угрызение совести, стремление к нравственной незапятнанности и порядочности (В. Сухомлинский). 2. О Русь! Забудь былую славу! (В. Соловьев). 3. Весь купол твой, по слову очевидца, как на цепи, подвешен к небесам (О. Мандельштам). 4. Жизнь устроена так дьявольски искусно, что, не умея ненавидеть, невозможно искренне любить (М. Горький). 5. Кто-то воспринимал Есенина лишь как будоражащего воображение паренька из деревни (зачастую он сознательно притворялся таким) (М. Максимова). 6. Есенин тщится уже здесь, на Земле, а не где-то в далеком обетованном рае обрести утраченную гармонию (М. Максимова). 7. Он всеми силами души всегда желал одного – быть вполне хорошим (Л. Толстой). 8. Бог, считает Лермонтов, дал человеку страсти, но не спешит их утолить (Н. Зубков). 9. Между Буниным-прозаиком и Буниным-поэтом нет принципиальных различий: те же краткость (Бунин редко писал стихотворения длиннее двенадцати строк), пристальность, резкость (Д. Быков). 10. Но я люблю на дюнах казино, широкий вид в туманное окно и тонкий луч на скатерти измятой… (О. Мандельштам). 11. Некоторые казаки, и Лукашка в том числе, встали и вытянулись (Л. Толстой). 12. Огонь был новой важной силой в моей нынешней жизни, и силой В. Шаламов). 13. Тебя, Офелию мою, увел далеко жизни холод, и гибну, принц, в родном краю, клинком отравленным заколот (А. Блок).
Перестрой сложноподчинённое предложение с придаточной изъяснительной частью в сложное бессоюзное предложение. Запиши их, объясни постановку тире. 1) С … ветает, так что надо вставать. 2) Я хорошо изучил английский язык, так что свободно читаю английские книги. 3) наулице морозит, поэтому мы решили остаться дома.
237. Составьте сложноподчиненные предложения, дополнив данные предло- жения главной частью с глаголами со значением речи, мысли, чувства. Запиши- те с … оставленные предложения, вставьте пропущенные буквы, раскройте скобки. Прокомментируйте расстановку знаков препинания в них. 1. Главной пр. чиной возн.кновения гл..бальной энергетической проблемы следу…т …читать быстрый рост потр….бления м..нерального топлива. 2. (Tопливн…) энергетические р…сурсы постоя…о истощают- ся и через несколько сот лет могут вообще и. чезнуть.3. Гл.бальная энергетическая проблема это проблема об…спечения человечества топ- ливом и энергией сейчас и в об.зримом будущем. 4. Возн.кновение (энерг…) сырьевой проблемы объясня…ся прежде всего быстрым ростом потр…бления м…нерального топлива, сыр..я и м..штабами их добычи. 5. Энергетическая проблема объясня..ся растущим разрывом между высокими темпами развития (энерг) емких произво..ств и запасами невозобн.вляемых (энерг…) р..сурсов.
Лексическая категория— обзор
5.2.1 Обзор ресурсов, разработанных для обработки сербского языка
Многочисленные ресурсы, которые можно использовать для целей нашего исследования, были разработаны для обработки сербского языка, но многие из них имеют быть измененным или улучшенным. Большая часть этих ресурсов была разработана в системе Unitex [22], а часть из них была адаптирована для системы GATE [23].
Система Unitex — это система с открытым исходным кодом, разработанная Себастьяном Помье в Институте Гаспара-Монж при Университете Парижа в Марн-ла-Валле в 2001 году.Это система обработки корпуса, основанная на автоматизированной технологии, которая находится в постоянном развитии. Система используется во всем мире для задач НЛП, поскольку она обеспечивает поддержку ряда различных языков и многоязычных задач обработки.
Одной из основных частей системы являются электронные словари типа DELA (Dictionnaires Electroniques du Laboratoire d’Automatique Documentaire et Linguistique или электронные словари LADL), которые представлены на рис.2. Система состоит из словарей DELAS (простые формы DELA) и DELAF (DELA флективных форм). Словари DELAS — это словари простых слов, не изменяемых форм, в то время как словари DELAF содержат все изменяемые формы простых слов. С другой стороны, система содержит словари составных DELAC (DELA составных форм) и словари складываемых составных форм DELACF (DELA составных склонных форм).
Рис. 2. Система электронных словарей DELA.
Морфологические словари в формате DELA были предложены в Лаборатории автоматических документов и лингвистики под руководством Мориса Гросса. Формат словарей DELA подходит для решения задач сегментации текста и морфологической, синтаксической и семантической обработки текста. Подробнее о формате DELA можно найти в [24].
Морфологические электронные словари в формате DELA представляют собой простые текстовые файлы. Каждая строка в этих файлах содержит запись слова и измененную форму слова.Другими словами, каждая строка содержит лемму слова и некоторую грамматическую, семантическую и флективную информацию.
Пример записи из словаря DELAF на английском языке: « таблиц, таблица.N + Conc: p ». Флективная форма , таблицы является обязательной, таблица — лемма записи, а N + Conc — последовательность грамматической и семантической информации (N обозначает существительное, а Conc обозначает, что это существительное — конкретный объект), p — флективный код, который указывает на то, что существительное является множественным числом.
Словари этого типа для сербского языка разрабатываются группой НЛП на математическом факультете Белградского университета. Согласно [21], нынешний объем сербского морфологического словаря DELAS (простых слов) содержит 130 000 лемм. Большинство лемм из словаря DELAS относятся к общей лексике, а остальные относятся к разным видам простых имен собственных. Словарь DELAF содержит около 4 300 000 словоформ с заданными грамматическими категориями.Размер словарей DELAC и DELACF составляет примерно 10 500 и 54 000 лемм соответственно.
Аналогичный пример записи из сербского словаря простых словоформ с соответствующим грамматическим и семантическим кодом: padao, padati. V + Imperf + It + Iref: Gms, где словоформа padao является единственным (S) мужским родом (M) активного причастия прошедшего времени (G) глагола (V) padati «падать», который несовершенное (Imperf), непереходное (It) и рефлексивное (Iref).
Другой тип ресурсов, разработанный для сербского языка, — это различные типы конечных преобразователей. Конечные преобразователи используются для выполнения морфологического анализа, а также для распознавания и аннотирования фраз в текстах прогнозов погоды с соответствующими тегами XML, такими как ENAMEX, TIMEX и NUMEX, как мы объясняли ранее.
Пример графа конечного преобразователя для распознавания временных выражений и их аннотации с помощью тегов TIMEX представлен на рис. 3. Этот граф конечного преобразователя может распознавать последовательность « 14.01.2012 . » из текста нашего примера прогноза погоды и аннотируйте его тегом TIMEX, чтобы его можно было извлечь в форме «DATE_TIME: 14.01.2012.»
Рис. 3. Граф преобразователя с конечным числом состояний для извлечения и аннотирования временных выражений.
Другая система, которая больше подходит для решения проблемы IE (и CM), — это бесплатное программное обеспечение с открытым исходным кодом GATE (общая архитектура для текстовой инженерии). Система GATE или некоторые из ее компонентов уже используются для ряда различных задач НЛП на нескольких языках.Система GATE — это архитектура и среда разработки для приложений НЛП. GATE разрабатывается NLP Group Университета Шеффилда с 1995 года.
Архитектура GATE состоит из трех частей: языковые ресурсы, ресурсы обработки и визуальные ресурсы. Эти компоненты независимы, поэтому с системой могут работать разные типы пользователей. Программисты могут работать над разработкой алгоритмов для НЛП или настраивать внешний вид визуальных ресурсов для своих нужд, в то время как лингвисты могут использовать алгоритмы и языковые ресурсы без каких-либо дополнительных знаний о программировании.
Визуальные ресурсы, графический пользовательский интерфейс, останется в исходной форме для целей данного исследования. Это позволит визуализировать и редактировать языковые ресурсы и ресурсы обработки. Языковые ресурсы для этого исследования включают корпуса текстов прогнозов погоды на нескольких языках и концептуальную модель прогноза погоды, которая будет построена. Необходимые изменения Ресурсов обработки, особенно модификации для применения к обработке сербских текстов, представлены ниже.
Задача IE в GATE встроена в систему ANNIE (почти новое извлечение информации). Подробную информацию об ANNIE можно найти в [25]. Система ANNIE включает в себя следующие ресурсы обработки: Tokeniser, Sentence Splitter, POS (часть речи) tagger, Gazetteer, Semantic Tagger и Orthomatcher. Каждый из перечисленных ресурсов создает аннотации, необходимые для следующего ресурса обработки в списке:
- •
Tokeniser разбивает текст на токены (слова, числа, символы, белые шаблоны и знаки препинания).Токенизатор можно использовать для обработки текстов на разных языках с небольшими изменениями или без них.
- •
Разделитель предложений сегментирует текст на предложения, используя каскады преобразователей с конечным числом состояний. Он также не зависит от приложения и языка.
- •
POS Tagger назначает тег части речи (тег лексической категории, например, существительное, глагол) в форме аннотации к каждому слову. Английская версия POS Tagger, включенная в систему GATE, основана на тэггере Brill.Это не зависящий от приложения, но зависящий от языка ресурс, который должен быть полностью изменен для сербского языка.
- •
Другой ресурс, зависящий от языка, но зависящий от приложения, — это Gazetteer, который содержит списки городов, стран, личных имен, организаций и т. Д. Gazetteer использует эти списки для аннотирования появления элементов списка в текстах. .
- •
Semantic Tagger основан на языке JAPE (Java Annotations Pattern Engine) [26].JAPE выполняет конечную обработку аннотаций на основе регулярных выражений, и его важной характеристикой является то, что он может использовать концептуальные модели (онтологии).
Semantic Tagger включает набор грамматик JAPE, где каждая грамматика состоит из набора фаз, а каждая фаза представляет собой набор правил. Кроме того, правила содержат левую и правую стороны. Левая сторона (LHS) правила описывает шаблон аннотации, который обычно распознается на основе операторов регулярного выражения Клини.Правая сторона (RHS) правила описывает действие, которое должно быть предпринято после того, как LHS распознает шаблон, например, создание новой аннотации. Это ресурс, зависящий от приложения и языка.
- •
Orthomatcher идентифицирует отношения между именованными объектами, обнаруженными Semantic Tagger. Он создает новые аннотации на основе отношений между именованными объектами. Это независимый от приложения и языка ресурс.
Основная цель — разработать ресурсы, зависящие от языка или приложения (Gazetteer, POS Tagger и Semantic Tagger) для сербского языка.Путь, который мы выбрали для решения этой проблемы, — использовать ранее описанные ресурсы, разработанные для системы Unitex, и адаптировать их для использования в системе GATE. Изменение списков географического справочника — это простой процесс перевода с одного языка на другой. Построение грамматик JAPE с поддержкой онтологий для области прогноза погоды требует первоначальной разработки соответствующего подъязыка и концептуальной модели, которые будут обсуждаться в следующем подразделе в качестве предмета текущих исследований авторов.Проблема создания подходящего POS Tagger очень сложна и не будет здесь подробно описываться.
Вкратце, мы сделали оболочку для Unitex, чтобы ее можно было использовать непосредственно в системе GATE для создания электронных словарей для заданных текстов прогноза погоды и механизма для создания соответствующей аннотации POS Tagger для каждого слова. Это решение проблемы, хотя и имеет несколько недостатков, может стать хорошей основой для создания семантических тегов, основанных на концептуальных моделях и системах IE в целом.
3.2 Морфологический анализ
Цель морфологического анализа — выяснить, из каких морфем построено данное слово. Например, морфологический синтаксический анализатор должен уметь сказать нам, что слово cats является формой множественного числа от основы существительного cat , и что слово mice является формой множественного числа от основы существительного mouse . Таким образом, при вводе строки cats морфологический синтаксический анализатор должен выдать результат, похожий на cat N PL .Вот еще несколько примеров:
мышь | мышь N SG | |
мыши | мышь N PL | fox N PL |
Морфологический анализ дает информацию, которая полезна во многих приложениях НЛП. Например, при синтаксическом анализе это помогает узнать особенности согласования слов.Точно так же специалистам по проверке грамматики необходимо знать согласованную информацию, чтобы обнаруживать такие ошибки. Но морфологическая информация также помогает специалистам по проверке орфографии решить, является ли что-то возможным словом или нет, и при поиске информации она используется для поиска не только cats , если это вводит пользователь, но и cat .
Чтобы перейти от поверхностной формы слова к его морфологическому анализу, мы сделаем два шага. Во-первых, мы собираемся разделить слова на возможные составляющие.Итак, мы сделаем cat + s из cats , используя + для обозначения границ морфем. На этом этапе мы также учтем правила орфографии, так что есть два возможных способа разделить foxes , а именно foxe + s и fox + s . Первый предполагает, что foxe — это ствол, а s — суффикс, тогда как второй предполагает, что стержнем является fox и что e было введено из-за правила правописания, которое мы видели выше.
На втором этапе мы будем использовать словарь основ и аффиксов, чтобы найти категории основ и значения аффиксов. Итак, cat + s будет сопоставлен с cat NP PL , а fox + s — с fox N PL . Теперь мы также узнаем, что foxe не является юридической основой. Это говорит нам о том, что разделение foxe + s на foxe + s было на самом деле неправильным способом разделения foxe + s , от которого следует отказаться.Но обратите внимание, что для слова домов правильным является разделение его на домов .
Вот изображение, иллюстрирующее два шага нашего морфологического синтаксического анализатора с некоторыми примерами.
Теперь мы построим два преобразователя: один для преобразования формы поверхности в промежуточную форму, а другой — для преобразования промежуточной формы в нижележащую форму.
3.2.1 От поверхности к промежуточной форме
Для выполнения морфологического анализа этот преобразователь должен преобразовать поверхностную форму в промежуточную форму.А пока мы просто хотим рассмотреть случаи английских существительных единственного и множественного числа, которые мы видели выше. Это означает, что преобразователь может или не может вставлять границу морфемы, если слово заканчивается на s . Могут быть слова в единственном числе, оканчивающиеся на s (например, kiss ). Вот почему мы не хотим делать вставку границы морфемы обязательной. Если слово заканчивается на ses , xes или zes , оно может, кроме того, удалить e при введении границы морфемы.Вот преобразователь, который это делает. « Другая » дуга в этом преобразователе обозначает переход, который отображает все символы, кроме s, z, x , на себя.
Давайте посмотрим, как этот преобразователь работает с некоторыми из наших примеров. На следующих графиках показаны возможные последовательности состояний, которые может пройти преобразователь, учитывая, что на входных данных поверхность формирует кошек и лис .
3.2.2 От промежуточной формы к морфологической структуре
Теперь мы хотим взять промежуточную форму, которую мы создали в предыдущем разделе, и сопоставить ее с базовой формой.Ввод, который должен принимать этот преобразователь, может иметь одну из следующих форм:
корень обычного существительного, например cat
корень существительного + s, например cat + s
единственное число неправильное основание существительного, например мышь
множественное число неправильное основание существительного, например мышей
В первом случае преобразователь должен сопоставить все символы ствола себе, а затем вывести N и SG .Во втором случае он отображает все символы основы на себя, но затем выводит N и заменяет PL на s . В третьем случае он делает то же, что и в первом случае. Наконец, в четвертом случае преобразователь должен сопоставить неправильную основу существительного множественного числа с соответствующей основой единственного числа (например, мышей до мыши ), а затем он должен добавить N и PL . Итак, общая структура этого преобразователя выглядит следующим образом:
Что еще нужно указать, так это то, как точно выглядят части между состоянием 1 и состояниями 2, 3 и 4 соответственно.Здесь нам нужно распознать основы существительных и решить, правильные они или нет. Мы делаем это, кодируя лексикон следующим образом. Часть преобразователя, которая распознает cat , например, выглядит следующим образом:
И часть преобразователя, отображающая мыши — мышь , может быть указана следующим образом:
Подключив эти (частичные) преобразователи к преобразователю, указанному выше, мы получите преобразователь, который проверяет правильность формы ввода и добавляет информацию о категориях и числовых значениях.
3.2.3 Объединение двух преобразователей
Если теперь мы позволим двум преобразователям для отображения от поверхности к промежуточной форме и для сопоставления от промежуточной формы к нижележащей форме работать каскадом (т.е. мы позволим второму датчику работать на результат первого), мы можем провести морфологический анализ (некоторых) английских словосочетаний с существительными. Однако мы также можем использовать этот преобразователь для создания формы поверхности из формы, лежащей ниже. Помните, что мы можем изменить направление трансляции при использовании преобразователя в режиме трансляции.
Теперь рассмотрим ввод ягод . Что из этого сделают наши каскадные преобразователи? Первый вернет два возможных разделения, ягод и ягод , но тот, который нам нужен, ягод , не входит в их число. Причина в том, что здесь действует другое правило правописания, которое мы совсем не приняли во внимание. Это правило гласит, что « y меняется на , то есть до s ».Итак, на первом этапе может быть несколько правил правописания, которые все должны быть применены.
Есть два основных способа справиться с этим. Во-первых, мы можем сформулировать преобразователи для каждого из правил таким образом, чтобы их можно было запускать каскадом. Другая возможность — указать преобразователи таким образом, чтобы их можно было применять параллельно.
Существуют алгоритмы объединения нескольких каскадных преобразователей или нескольких преобразователей, которые предполагается использовать параллельно, в один преобразователь.Однако эти алгоритмы работают только в том случае, если отдельные преобразователи подчиняются некоторым ограничениям, поэтому мы должны проявлять осторожность при их указании.
3.2.4 Помещение его в Пролог
Если вы хотите реализовать небольшой морфологический синтаксический анализатор, который мы видели в предыдущем разделе, все, что вам действительно нужно сделать, это перевести спецификации преобразователя в формат Пролога, который мы использовали в последняя лекция. Затем вы можете использовать программу преобразователя из последней лекции, чтобы позволить им работать.
Мы не будем подробно показывать, как преобразователи выглядят в Prolog, но мы хотим быстро взглянуть на вставной преобразователь e , потому что он имеет одну интересную особенность; а именно переход другой .’): -!.
arc (6,1, X: X): -!.
Анализ простого языка разметки с помощью Haskell
Вы можете пойти дешевым и простым путем без надлежащего парсера. Важно понимать, что эта грамматика на самом деле довольно проста — в ней нет рекурсии или чего-то подобного. Это просто плоский список Str s и Explode s.
Итак, мы можем начать с разбивки строки на список, содержащий текст и разделители как отдельные значения. Нам нужен тип данных, чтобы отделить разделители ( %% ) от фактического текста (всего остального.)
Data ParserTokens = Сен | T Текст
Разрушение
Затем нам нужно разбить список на составляющие.
tokenise = вкрапление сен. карта Т. Text.splitOn "%%"
Это сначала разделит строку на %% , поэтому в вашем примере это будет
[«Шустрый коричневый», «лисица», «прыгает», «через себя», «ленивый», «собака».]
, затем мы сопоставляем с ним T , чтобы превратить его из [Text] в [ParserTokens] .Наконец, мы перемежаем сент. над ним, чтобы снова ввести разделители %% , но в форме, с которой легче иметь дело. Результат в вашем примере
[T "Быстрый коричневый", Sep, T "лисица", Sep, T "", Sep, T "прыгает", Sep, T "над", Sep, T "ленивый", Sep, T "собака . "]
Строим
После этого все, что осталось, — это преобразовать эту штуку в желаемую форму. Анализ этого сводится к нахождению удара 1-2-3 Sep – T «something» –Sep и замене его на Explode "something" .Для этого мы пишем рекурсивную функцию.
конструкция [] = []
construct (T s: rest) = Str s: построить отдых
construct (Sep: T s: Sep: rest) = Взрыв s: построить отдых
construct _ = error "Несоответствие '%%'!"
Преобразует T s в Str s и комбинацию разделителей и T s в Explode s . Если сопоставление с образцом не удается, это потому, что где-то был случайный разделитель, поэтому я просто установил его для сбоя программы.Возможно, вам понадобится лучшая обработка ошибок — например, перенос результата в Either String или что-то подобное.
После этого мы можем создать функцию
parseTemplate = конструкция. токенизировать
и в итоге, если запустить ваш пример через parseTemplate, мы получим ожидаемый результат
[Str "Быстрый коричневый", Explode "Лисица", Str "», Explode "Прыжки", Str "Over the", Explode "Ленивый", Str "собака"].
Какой звук на самом деле издает лиса?
Сообщение было обновлено.Первоначально он был опубликован 05.09.2013.
В 2013 году видеоклип норвежского дуэта Ylvis стал вирусным, потому что он был запоминающимся, странным, странным и про животных. Лирика проста: Борд Илвисокер и Вегард Илвисокер, люди, стоящие за Илвисом, описывают вокализацию различных обычных животных, от кошек до собак, от уток до коров, а затем в предварительном припеве задаются вопросом, какой звук издает лиса. Затем припев предлагает несколько вариантов, таких как «Геринг-динг-динг-динг-дингерингинг» и «Ва-па-па-па-па-па-пау».«Хорошие предложения, Борд Илвисокер и Вегард Илвисокер! Но я думаю, что мы можем придумать что-то более точное с научной точки зрения, когда дело доходит до звуков лисиц, а также смотреть много видео с животными, пока мы это делаем.
В Норвегии, откуда родом Илвис, водятся два вида лисиц: песец ( Vulpes lagopus ) и рыжий лис ( Vulpes vulpes ). Здесь, в Штатах, есть несколько других, например, серая лисица и лисица кит. У всех видов лисиц довольно много разных вокализаций, как у собак и кошек.Снизить, скажем, вокализацию собаки до «лая» несложно, но, как знает любой владелец, собаки могут визжать, ныть, выть, рычать и издавать всевозможные другие звуки. Лисицы собаки? Они определенно связаны, но их вокализации не так разнообразны.
Рыжая лисица, которая является наиболее распространенным видом лисиц во всем мире (и почти наверняка речь идет о разновидности лисиц Илвис; в Норвегии осталось всего около 120 песцов), очень шумно. Лисы — псовые, как собаки и волки, но не имеют близкого родства ни с одним из них; на самом деле, они охотятся больше как кошки, с низко-приземленной позой для преследования и сильно кусают острыми тонкими зубами, чтобы убить добычу (собаки и волки, как правило, имеют более тупые и большие зубы и используют «Способ убить»).В вокализации лисы не совсем похожи на собак.
Наиболее часто слышимые вокализации рыжей лисы — это серия быстрых лаев и кричащая вариация воя. Все вокализации лисы более высокие, чем собачьи, отчасти потому, что лисы намного меньше. Кора вроде ow-wow-wow-wow , но очень высокий, почти трепещущий. Его часто принимают за улюлюканье совы. Эта последовательность лая считается системой идентификации; исследования показывают, что лисы могут отличать друг друга по этому крику.
Кричащий вой чаще всего слышен в период размножения, весной. Это ужасно. Пронзительный, хриплый крик страдания, он больше всего похож на человеческий ребенок, подвергающийся физическим пыткам. Считается, что этот призыв используется лисицами (самками лисиц), чтобы заманить к себе самцов лисиц для спаривания, хотя было обнаружено, что самцы также иногда издают этот звук.
Лай и крик очень громкие, поэтому их часто можно услышать, но большинство других вокализаций лисы тихие и используются для общения между людьми, находящимися в непосредственной близости.Самый необычный называется «геккеринг»; это гортанная болтовня с периодическим визгом и завыванием, как ack-ack-ack-ackawoooo-ack-ack-ack . Геккеринга слышно среди взрослых в агрессивных схватках (которых много; рыжие лисы очень территориальны), а также среди молодых котят, играющих (или игровых боев). Также есть сигнал тревоги, который вблизи звучит как кашель, но издалека звучит как резкий лай, и в основном используется родителями лисиц, чтобы предупредить молодых людей об опасности.
[Связано: Лютые волки на самом деле мегалисы ледникового периода ]
Красные лисы, в отличие от других знакомых собак, таких как серый волк и койот, не образуют стай. В молодом возрасте они и мать могут образовывать небольшую семейную единицу, но в целом лисы живут поодиночке. Тем не менее, они иногда населяют одну и ту же территорию и поэтому имеют социальную иерархию, которая требует общения. Покорные лисы, приветствуя доминирующих лисиц, иногда издают пронзительный вой, который может усиливаться и превращаться в визг.Лисы общаются с котятами в основном с помощью телодвижений, но также издают фырканье и кашляющие звуки, а иногда и короткие кудахтанья, как обычная короткая форма геккеринга.
Вот какой звук издает лиса. Но не менее интересен тот факт, что большинство людей не знают , какой звук издает лиса. Это широко распространенный, чрезвычайно успешный и адаптивный вид, обитающий по всему миру, в самых разных климатических условиях, в лесах, в горах, в пригородах, а иногда даже в городах. Американцы и европейцы хорошо знакомы с рыжей лисой.И в отличие, скажем, от енота, это животное очень голосовое. Так почему же мы понятия не имеем, как это звучит?
Одна из основных причин в том, что это дикое животное. Детские игрушки, которые учат звуки животных, ориентированы на домашних животных, в основном домашний скот. Свинья, корова, овца, петух, утка, лошадь — это сельскохозяйственные животные, которые в коллективном аграрном прошлом Америки были членами домашнего хозяйства. Вы заметите, что на некоторых популярных игрушках вы не увидите ни одного из самых распространенных диких животных Северной Америки — ни енотов, ни койотов, ни оленей, ни малиновок, ни ястребов, ни лисиц.Какой звук издает олень? Черт, если я знаю.
Другая причина может заключаться в том, что лисий шум легко принять за звуки других животных. Обычный yow-wow-wow-wow больше похож на сову, чем на псов, а крик-вой звучит не столько как лиса, сколько саундтрек к кошмару. А лисы — ночные охотники, а это значит, что мы спим, когда они издают больше всего шума.
Тогда есть еще одна проблема. Лисы — обычное дело и милые, они фигурируют в мифах, и мы сделали все возможное, чтобы сделать их своими домашними животными, но издаваемые ими звуки… ужасны.У рыжей лисы нет сладкого голоса; даже когда он счастлив, это в основном звучит так, как будто его задушили. Было бы неловко учить вашего маленького ребенка, что корова мычит, лягушка квакает, а лиса идет ЯААГГАХХГХХХХХХХХХ !!!!!
Но! Теперь ты знаешь. Лисица идет yow-wow-wow , ack-ack-ackawoo-ack , и YAAGGAGHHGHHHHHAHHHH !!!!! .
Учебник по синтаксическому анализу (Rebol 2).
Введение
Если вы хотите извлекать данные из строк (например, HTML, TXT, CSV и т. Д.)) рассмотрим Parse. Если вы хотите просто проверить некоторые пользовательские данные на соответствие определенному формату, подумайте об использовании Parse. Если вы хотите проверить какое-то сообщение, написанное на вашем новом диалекте, используйте Parse. Разбор полезен. Разбор быстрый. Этот документ представляет собой очень грубую демонстрацию на примерах описания Parse с добавлением нескольких предупреждений. Я рекомендую вам прочитать его вместе с разделом (раздел 14) о Parse of REBOL Core User Guide.
Комментарии к бретту на codeconscious.com, пожалуйста.
Два режима разбора
Parse на самом деле, вероятно, имеет около пяти режимов работы, но выделяются две общие категории:
Анализ вводимой строки символов в режиме разделения строки. Разбор символьных строк или блоков с использованием правил (диалект синтаксического анализа).
Разделение строк на части — полезная функция синтаксического анализа, это удобная утилита.
Разбор входных данных в соответствии с правилами — более сложное использование Parse. При таком использовании Parse вы, скорее всего, каким-то образом интерпретируете ввод, наложив на него новое значение.То есть у вас есть строка или блок, и вы, возможно, идентифицируете поля записей или токены языка или даже идентифицируете разделы протокола сообщений.
Анализ входной строки символов (или двоичных данных)
Сначала вы должны решить, хотите ли вы, чтобы Parse обрабатывал пробельные символы за вас или вы обрабатываете их самостоятельно. По умолчанию Parse обрабатывает пробелы за вас. Если вы укажете / все уточнения Обработка пробелов в REBOL будет отключена./ «и пробел #» «.
Операции над строками
Parse может работать с вашими данными одним из трех способов. Вот режимы с использованием моей терминологии для их описания:
Режим разделения строк - разделители по умолчанию Режим разделения строк - указанные разделители Режим синтаксического анализа
Режим разделения строк — разделители по умолчанию
При таком использовании синтаксического анализа все, что вы действительно делаете, это вводите строку, и синтаксический анализ ее сломает. вверх согласно предопределенным разделителям.Эти разделители (я полагаю) следующие:
символы-разделители: {",;}
В этом режиме распознается текст в двойных кавычках. Так что, если синтаксический анализ обнаруживает двойные кавычки, он будет разделять текст следующей двойной кавычкой вместо того, чтобы говорить о разрыве запятой.
Если вы опустите уточнение / all, то пробел также будет считаться разделителем. Это может быть полезно для работы с некоторыми типами файлов с разделителями, такими как CSV (хотя для правильной работы с CSV-файлами, экспортированными с помощью MS Excel, требуется больше работы).
Примеры:
>> анализировать {123 "456 789" 012} нет
== ["123" "456 789" "012"]
>> анализировать {123,456, "789,012" 345} нет
== ["123" "456" "789 012" "345"]
Использование уточнения / all означает, что обработка пробелов отключена.
>> parse / all {123 "456 789" 012} нет
== [{123 "456 789" 012}]
>> parse / all {123,456, "789,012" 345} нет
== ["123" "456" "789 012" "345"]
String Breakapart mode — указанные разделители
В этом режиме вы указываете свои собственные разделители.Они заменят предопределенные разделители, и вы потеряете функцию двойных кавычек.
Примеры:
>> разобрать {123,456 * 789; 012} "*"
== ["123,456" "789; 012"]
>> parse / all {123,456 * 789; 012} "*"
== ["123,456" "789; 012"]
>> проанализировать {123, "456 * 789"; 012} "*"
== [{123, "456}" "{789"; 012}]
>> parse / all {123, "456 * 789"; 012} "*"
== [{123, "456} {789"; 012}]
>> разобрать {быстрая коричневая лисица} {aeiou}
== ["th" "q" "" "ck" "br" "wn" "f" "x"]
>> parse / all {быстрая коричневая лисица} {aeiou}
== ["th" "q" "" "" ck br "" wn f "" x "]
Разобрать диалект
В этом режиме вы даете синтаксический анализ блока правил, содержащий инструкции, которым нужно следовать.Эти инструкции позволяют использовать синтаксический анализ для интерпретации пользовательских внешних форматов или протоколов. Эти инструкции могут быть настолько простыми или сложными, насколько вам нужно. Простым примером может быть проверка того, что вводимые данные соответствуют формату почтового индекса. Изощренный пример — синтаксический анализатор XML REBOL. Он использует этот режим анализа для загрузки простых XML-документов. Я использовал этот режим синтаксического анализа для интерпретации сообщений электронной почты в формате MIME.
Инструкции написаны согласно диалекту синтаксического анализа. Инструкции говорят синтаксическому анализу, как читать введенные вами данные.Фактически, инструкции описывают шаблоны, которые должен принимать ввод. Parse пытается сопоставить ввод с вашими шаблонами. Parse вернет ИСТИННЫЙ результат, если ваши инструкции точно описывают ввод. Если ваши инструкции не описывают ввод (или если смотреть с другой стороны, ввод не соответствует вашим правилам), синтаксический анализ вернет FALSE. У вас также есть возможность выполнять обычные операции REBOL, поскольку синтаксический анализ проходит через ввод и ваши правила.
Очень важно понимать, что слова диалекта Parse интерпретируются Parse определенным образом и должны рассматриваться как отличающиеся по значению от слов REBOL при использовании на консоли.
В этом описании / учебнике я буду использовать примеры, предполагающие строковый ввод.
Начнем с конца
>> строка ввода: {}
>> синтаксический анализ строки ввода [конец]
== верно
А, успех! Здесь я разбираю пустую строку. Мое правило гласит, что при синтаксическом анализе «проверьте, что мы в конце». Результат, конечно, ИСТИНА, потому что строка изначально была пустой.
В обычном сценарии REBOL это похоже на:
>> хвост? строка ввода == верно
Детские ступеньки
Теперь давайте проверим, соответствует ли строка нашим ожиданиям:
>> строка ввода: "лиса" == "лиса" >> синтаксический анализ строки ввода [конец "лисы"] == верно
Мы успешно проверили, что ввод начинается с «fox», а затем завершается.Хорошо, ничего страшного. Но задумайтесь на мгновение. Это последовательность — сначала «лиса», затем КОНЕЦ. Когда синтаксический анализ проходит через вход и ваш блок правил, он отслеживает текущую позицию для обоих. Итак, в начале текущая позиция во входных данных находится в начале строки. После того, как правило «fox» было сопоставлено, текущая позиция во входной строке будет сразу после «x» в «fox». В этом примере это хвост строки, поэтому следующее правило соответствия END будет успешным.
Нам не всегда нужно указывать END в блоке правил.Вы можете опустить его в последнем примере, потому что Parse в любом случае эффективно вставляет один в конце.
>> синтаксический анализ строки ввода ["лиса"] == верно
Хотя вы можете сделать это для простых примеров, помните, что вам, вероятно, потребуется добавить это в явно для более сложных правил.
Хорошо, снова вернемся к примеру. В обычном сеансе REBOL приведенный выше пример аналогичен следующему:
>> строка ввода: найти / сопоставить строку ввода "лиса" == "" >> хвост? строка ввода == верно
Обратите внимание, что обычные примеры кода REBOL в этой статье предназначены для помощи в изучении PARSE.Между примерами Parse и обычными примерами кода достаточно важных различий, поэтому вы не можете всегда рассматривать их как полностью эквивалентные.
Неисправности / проблемы
Для контраста посмотрим на неудачный матч:
>> строка ввода: "собака" == "собака" >> синтаксический анализ строки ввода ["лиса"] == ложь
Смысл этого довольно очевиден. Погодите, что на самом деле происходит, когда Parse обнаруживает сбой в одном из правил? Что ж, он возвращает ввод до той точки, в которой он был, когда правило было запущено.Итак, в коде REBOL то, что происходит, на самом деле больше похоже на это:
строка ввода: "собака" Если позиция: Найти / сопоставить строку ввода "fox" [строка ввода: позиция] Хвост? строка ввода
Держите эту маленькую идею в глубине души, она станет более значимой с более сложными правилами.
Дополнительные правила сопоставления и составные правила
Что, если мы хотим проверить несколько распространенных альтернатив домашних животных? Возьмем «собаку», «кошку» или даже птицу:
>> строка ввода: "собака" == "собака" >> разобрать строку ввода ["собака" | «кот» | "птица"] == верно
В обычном REBOL это похоже на кодировку:
строка ввода: любая [
найти / сопоставить строку ввода "собака"
найти / сопоставить строку ввода "кошка"
найти / сопоставить строку ввода "птица"
]
хвост? строка ввода
Итак, REBOL может быть довольно кратким, а функция ANY определенно помогает в написании сжатого кода, но вы уже можете видеть, что диалект синтаксического анализа лучше подходит для сопоставления, чем обычный сценарий.
Размышляя над этим немного. У нас есть более интересное правило. Фактически у нас есть составное правило. Наше составное правило состоит из трех дополнительных правил. Каждое из трех дополнительных правил здесь очень простое, но им разрешено быть составными правилами. Базовые правила выполняют сопоставление входных данных на самом низком уровне, а составные правила проверяют общий шаблон (структуру / грамматику) ваших данных.
Вернуться к параметрам. А что насчет того, что может существовать, а может и не существовать? Используя OPT, мы можем указать, что собака может быть черной, или просто не указывать:
>> строка ввода: "черная собака" == "черная собака" >> синтаксический анализ строки ввода [opt "black" "dog"] == верно >> строка ввода: "собака" == "собака" >> синтаксический анализ входной строки [opt "black" "dog"] == верно
Повторение — известный диапазон повторений
Время для еще нескольких сложных правил.
Вот как проверить ровно двух собак.
>> разобрать "собака собака" [2 "собака"] == верно
Довольно круто, а? Таким же образом можно проверить ровно 30 собак. Подождите, вы можете возразить, между двумя собаками есть место! Верно, но действует обработка пробелов. Если вы используете уточнение / all, обработка пробелов не используется и пробел становится допустимым символом для проверки:
>> разобрать / все "собака собака" [2 "собака"] == ложь
Но теперь у нас есть не просто две собаки, у нас есть собака и собака:
>> parse / all "dog dog" ["dog" # "" "dog"] == верно
Для остальных вводных примеров я оставлю обработку пробелов включенной.
Также могу указать от 1 до 3 собак (включительно):
>> разобрать "собака" [1 3 "собака"] == верно >> разобрать "собака собака собака" [1 3 "собака"] == верно
Повторение снова 🙂 — количество повторений неизвестно
Что, если мы возьмем сеть и пойдем креветками? Мы можем не знать, сколько креветок поймано сетью, когда мы их ловим:
>> строка ввода: {} вставка / дублирование строки ввода {креветка} случайное 100
== ""
>> синтаксический анализ строки ввода [какая-то "креветка"]
== верно
Отлично, у нас есть креветки, но мы не знаем, сколько.Ключевое слово НЕКОТОРЫЕ означает «соответствие одному или нескольким из следующих». Опять же, это сложное правило, потому что я мог бы сделать это так же легко, если бы шел «дождь из кошек и собак»:
>> input-string: "собака собака кошка собака кошка кошка кошка собака кошка собака" == "собака собака кошка собака кошка кошка кошка собака кошка собака" >> проанализируйте строку ввода [some ["dog" | "Кот" ] ] == верно
Если наложен штраф:
>> строка ввода: {}
== ""
>> проанализируйте строку ввода [some ["dog" | "Кот" ] ]
== ложь
Возвращает false, потому что НЕКОТОРЫЕ требует сопоставления хотя бы одного экземпляра.Если, однако, нам все равно, получим мы что-то или нет, будем использовать ЛЮБОЙ:
>> строка ввода: {}
== ""
>> проанализируйте строку ввода [any ["dog" | "Кот" ] ]
== верно
>> строка ввода: {собака кошка}
== "собака кошка"
>> проанализируйте строку ввода [any ["dog" | "Кот" ] ]
== верно
Вот пример одного из тех слов REBOL с новым значением в контексте Parse. В обычном REBOL ANY — это функция, которая возвращает первое значение, отличное от false или none, в заданном блоке.В Parse, напротив, ANY — это ключевое слово, которое вводит составное правило, которое означает «соответствие нулю, одному или многим из следующих».
Повторное повторение
Теперь, когда я ввел правила повторения и составные правила, что произойдет, если я создам составное правило, состоящее из вложенных правил повторения? Хм, сложно.
В следующем примере Parse запускается в бесконечный цикл. Клавиша выхода не работает — попробуйте, только если знаете как убить процесс с помощью вашей операционной системы (например,g в NT4 используйте диспетчер задач). Версия, которую можно закрыть с помощью ключ выхода будет дан позже:
строка ввода: {}
синтаксический анализ строки ввода [любая [любая "собака"]]
Чтобы понять, что происходит этот бесконечный цикл, вам нужно знать, когда ЛЮБОЕ правило возвращает успех и когда оно завершается.
Вот главный ответ: ЛЮБОЙ ВСЕГДА возвращает успех. ANY будет продолжать вызывать свое субправило, пока это субправило возвращает успех. ЛЮБОЙ сдается при получении плохих новостей (неудача), но сам всегда возвращает успех.Теперь, если ЛЮБОЙ всегда получает успех, потому что это субправило на самом деле является другим ЛЮБЫМ … Ну, я думаю, это объясняет.
Помните OPT. Он всегда возвращает успех, как ЛЮБОЙ. Так что размещение OPT внутри ЛЮБОГО тоже обязательно приведет к неприятностям.
Дело в том, что ваши составные правила повторения должны быть тщательно написаны из-за возможности создания этих бесконечных циклов. Это не ошибка REBOL, это следствие наличия гибкого диалекта синтаксического анализа.
Иногда эти бесконечные циклы начинаются только после прохождения множества других сложных правил, и поэтому их трудно уловить.Я создаю эти петли реже, так как я начал думать, как я хочу, чтобы «точка внимания» Parse двигалась. При написании правил учитывайте, как вводимые данные потребляются правилами.
Это одна из причин, по которой я демонстрировал код REBOL, аналогичный различным примерам Parse.
Не все комбинации правил повторения создают бесконечные циклы:
>> строка ввода: {}
== ""
>> разобрать строку ввода [любая [какая-то "собака"]]
== верно
Этот последний пример подходит, потому что НЕКОТОРЫЕ не всегда возвращает успех.Если НЕКОТОРЫЕ не имеет хотя бы одного успеха, возвращает результат сбоя. Итак, вы можете видеть, что в какой-то момент, учитывая, что мы можем предположить, что ввод конечно, общее правило должно прекратиться.
Цитата Ладислава: «Опасные правила — это правила, которые не требуют ввода, но возвращают успех».
ВерсияREBOL, основанная на Core 2.5.3 и более поздних версиях, имеет другой способ обработки этого сценария бесконечного цикла — ключевое слово BREAK. BREAK отменяет правило при его обнаружении.Примеры см. В документации по изменениям REBOL.
Здесь ничего особенного
Проверьте это:
>> parse {} [нет]
== верно
Ключевое слово NONE ничего не делает, но всегда успешно. Кроме того, вы можете забыть об этом до тех пор, пока оно вам действительно не понадобится. О, и заключите NONE в ANY или SOME, и вы получите … много-много потраченных впустую циклов процессора.
Все эти персонажи
Кодировка. Обозначает набор символов. Это битсет, который, я считаю, делает его быстрым для операций сопоставления с образцом.
Допустим, вы хотите только проверить, что ваш ввод содержит цифры от 0 до 9.
цифра: charset [# "0" - # "9"]
Теперь синтаксический анализ может использовать это непосредственно как инструкцию сопоставления с образцом. Он будет соответствовать одному символу только из набора 0 — 9.
>> разобрать {1} [цифра]
== верно
Естественно, вы также можете использовать их в составных правилах:
Австралийский почтовый индекс состоит из 4 цифр, поэтому:
разобрать {2069} [4 цифры]
Может быть, вам нужно все, кроме цифр:
нецифровые: дополнительная цифра
>> синтаксический анализ {1} [не цифра]
== ложь
Наборы символов (битовые наборы) — это наборы, и вы можете применять объединение операций набора, пересечение, исключение и т. Д. на них:
letter: charset [# "a" - # "z" # "A" - # "Z"]
цифра: charset [# "0" - # "9"]
буква-или-цифра: объединенная буквенная цифра
допустимое-имя: [буква любая буква-или-цифра]
>> разобрать действительное имя {1abc}
== ложь
>> разобрать действительное имя {ребол}
== верно
>> разобрать действительное имя {xyz1234}
== верно
Идем дальше…
Иногда нам все равно, что находится между интересными вещами.
В этом примере не «пропустить c», а читается «сопоставить a, пропустить символ, сопоставить c, хвост?».
разобрать {abc} ["а" пропустить "с" конец]
Вы хотите пропустить 5 символов? Повторение использования:
синтаксический анализ {1234567890} ["123" 5 пропустить "90" конец]
Иногда мы не знаем, сколько находится между ними, но мы знаем, каков следующий интересный бит:
>> строка ввода: {1234 fox}
== "1234 лиса"
>> синтаксический анализ строки ввода [через конец "лисы"]
== верно
Это похоже на код REBOL:
>> строка ввода: найти / хвост строка ввода "лиса" == "" >> хвост? строка ввода == верно
Мы можем остановиться там, где начинается лиса:
>> строка ввода: "1234 лиса" == "1234 лиса" >> синтаксический анализ строки ввода [до конца "лиса" "лиса"] == верно
И код REBOL, который работает аналогично:
строка ввода: {1234 fox}
строка ввода: найти строку ввода "лиса"
строка ввода: найти / сопоставить строку ввода "лиса"
хвост? строка ввода
Можно пропустить и до конца:
>> разобрать {123456} ["123" до конца]
== верно
Здесь написано «совпадение 123, переход к хвосту, проверка хвоста».Совершенно очевидно, что мы получили бы истинный результат, если подумать об этом в этих терминах.
Пока мы здесь, как насчет еще одного предупреждения о повторении. Правило [до конца] переходит в хвост и сообщает успех каждый раз. Поместите ЛЮБОЙ или НЕКОТОРЫЕ вокруг него, и вы можете догадаться, что произойдет (подсказка, прочитайте раздел повторения несколько раз).
Но мне нужна информация!
До этого момента я сосредоточился на различных функциях сопоставления Parse. Конечно, вы хотите извлечь информацию из своих данных.Важное ключевое слово для этой цели — КОПИЯ. Также полезна возможность выполнять код REBOL в рамках правил синтаксического анализа и тем самым устанавливать и поддерживать переменные REBOL (например, счетчики) с использованием этого кода.
ОК КОПИРОВАТЬ.
Копировать действительно очень просто. Это составное правило, которое принимает два аргумента: переменную и подправило. Какой бы ввод не совпадал с подправилом, он копируется в переменную. Если подправило ничего не соответствует (не удается), COPY возвращает ошибку, но оставляет переменную без изменений.
Здесь субправило должно соответствовать «А», что явно не работает.
>> проанализируйте {123} [скопируйте какой-нибудь текст "A"]
== ложь
>> какой-то текст
** Ошибка скрипта: какой-то текст не имеет значения
** Где: остановка просмотра
** Рядом: какой-то текст
Здесь субправило — это простой пропуск:
>> разобрать {123} [скопировать конец пропуска текста]
== ложь
>> какой-то текст
== "1"
И здесь субправило — ничего не сопоставить NONE, что всегда успешно, поэтому copy копирует то, что было сопоставлено… Ну, возможно, это должна была быть пустая строка, но вот что происходит (по крайней мере, в REBOL / View 1.2.1):
>> проанализируйте "123" [скопировать какой-то текст нет] == ложь >> какой-то текст == нет
Принесите код
Обычный код REBOL может использоваться внутри диалекта синтаксического анализа с помощью «(» и «)», то есть Paren! серия:
>> parse {} [(выведите "только что выполненный код") конец]
какой-то код только что выполнен
== верно
Очевидно, это очень удобно.Лучше то, что он работает в соответствии с его положением в правиле. Однако обратите внимание, что даже если правило в конечном итоге не срабатывает, ваш код, возможно, уже запущен:
>> разобрать {123} [
[«1» (выведите «Найдено 1!»)
[«2» (выведите «найдено 2!»)
[«А» (выведите «А нашел А!»)
[ конец
[]
Найдено 1!
найдено 2!
== ложь
Итак, в результате вы можете поддерживать счетчики и предпринимать действия в соответствии с вашими правилами синтаксического анализа.
Еще одно интересное применение для Парена! это включить клавишу Escape для работы в ситуации с бесконечным циклом, описанной ранее, путем добавления внутри части цикла.
Взяв предыдущий пример и добавив Paren! ему дает:
строка ввода: {}
синтаксический анализ строки ввода [любая [() любая "собака"]]
Это будет циклически вращаться, пока вы не нажмете клавишу Escape (Esc).
Таким образом, во время разработки может быть полезно поместить в них операторы печати, позволяющие вам посмотрите, что происходит, и при необходимости воспользуйтесь клавишей Esc. Обратите внимание, что это возможно поведение может измениться в более поздней версии REBOL.
Текущий индекс и управление им
Parse поддерживает ссылку на ввод.Ссылка представляет собой серию и имеет текущий индекс.
Некоторый специальный синтаксис синтаксического диалекта позволяет вам получить и установить эту ссылку. Фактически вы используете синтаксис set-word и get-word соответственно.
В этом примере я установил слово «mark» для входной серии по текущему индексу, который имеет синтаксический анализ, не беспокойтесь о false — это просто говорит о том, что мы не прошли весь ввод:
>> проанализировать {123456} [метка "123":]
== ложь
>> отметка
== "456"
Я могу управлять текущим индексом, который тоже использует синтаксический анализ:
>> синтаксический анализ {1234567} [отметка "123": (отметка: следующая следующая отметка): отметка "67"]
== верно
Чтобы объяснить.Сначала сопоставляется «123», затем словесный знак устанавливается на ссылку. ~} строка ввода: «песец» parse / all input-string [[any ws «fox»] [any ws «dog»]]
Анализ загруженных значений
Этот режим используется, когда анализируемое значение на самом деле является блоком, а не строкой.Вы используете этот режим, когда вы уже загрузили данные в значения REBOL. Вы пишете инструкции синтаксического анализа в блоке правил, используя диалект синтаксического анализа, аналогично тому, как описано для синтаксического анализа строк, за исключением блоков синтаксического анализа, семантика отличается, и у вас есть еще пара ключевых слов для использования.
Это режим синтаксического анализа, который заслуживает внимания любого, кто использует REBOL. Причина в том, что вы можете хранить свои данные в форме, понятной вам и другим, но при этом читаемой компьютером.
Примером, показывающим, чего можно достичь, является пример операции с акциями Карла Сассенрата, который вы можете увидеть ниже. А что, если «продать 300 акций по 89,08 доллара» пришло по электронной почте?
Если вы изучите этот пример, вы увидите, что Карл на очень маленьком пространстве создал небольшой интерпретатор, который анализирует, проверяет и выполняет вычисления. Это очень мощная технология, которую легко недооценить, потому что она такая маленькая и простая.
правило: [
установить действие ['купить | 'продавать]
установить целое число!
"акции" в
установить цену в деньгах!
(либо действие = 'продать [
print [цена "доход" * число]
итого: итого + (цена * число)
] [
печать ["себестоимость" цена * число]
итого: итого - (цена * количество)
]
)
]
всего: 0
анализ [продать 100 акций по 123 доллара.45] правило
печать ["всего:" всего]
всего: 0
синтаксический анализ [
продать 300 акций по 89,08 доллара
купить 100 акций по $ 120,45
продать 400 акций по $ 270,89
] [какое-то правило]
печать ["всего:" всего]
Еще один яркий пример этого — VID-диалект REBOL / View. VID описывается в эффективный, но простой способ, что должно появиться на экране. VID — это фактически блок, использующий обычный Значения REBOL, такие как слова и строки. Функция LAYOUT REBOL / View принимает VID блок в качестве аргумента для создания визуальных объектов.Макет использует синтаксический анализ для обработки Спецификация VID.
Особые ситуации
Если вы НЕ хотите совпадать с шаблоном
Одна из ситуаций, в которой вы можете сделать это, — это когда у вас есть подправило, которое может «потреблять» что-то необходимое по правилу включения.
Я сталкивался с подобными проблемами несколько раз и благодарю Ладислава за показывая мне решение.
Для моего примера я буду разбирать блок, а не текст, но концепция все еще применяется.Я хочу разобрать следующий блок и распечатать каждое слово, но если я встречу «|» Распечатаю текст «**********»:
my-block: [быстрая коричневая лисица | прыгнул | над ленивым]
Следующий фрагмент кода не будет работать. Если вы попробуете, вы увидите, что там не напечатаны символы «*», вместо этого вы увидите «|»:
одно слово: [установить слово элемента! (элемент печатной формы)] фраза: [одно слово] parse my-block [фраза some ['| (выведите «**********») фраза]]
Следует отметить, что «|» это тоже слово.Следовательно, «|» «потребляется» по правилу, называемому ЕДИНОЕ СЛОВО. Так в одну сторону чтобы решить эту проблему, нужно дать ОДНОМУ СЛОВУ некоторое расстройство желудка (заставить его потерпеть неудачу), когда оно встречает «|». Для этого я буду использовать динамическое правило — правило, которое изменяется по мере выполнения синтаксического анализа.
Чтобы правило не сработало, убедитесь, что оно больше ни с чем не может соответствовать. Далеко чтобы убедиться, что это попытка пропустить после окончания ввода. Это никогда не может работать, если мы не в конце, он потерпит неудачу, если мы в конце, то пропустить не удастся.Таким образом, это правило гарантированно не срабатывает каждый раз:
всегда терпит неудачу: [конец пропустить]
Используя это, я теперь оборачиваю SINGLE-WORD правилом, которое я называю WORD-EXCEPT-BAR. В цель этого нового правила — потерпеть неудачу, если оно найдет «|» слово иначе это идет вперед и бежит SINGLE-WORD. Мне также нужно изменить PHRASE для вызова WORD-EXCEPT-BAR: динамическое правило, о котором я упоминал ранее, называется WEB. Здесь правила со сложным разделением на несколько строк для улучшения читаемость:
фраза: [какое-то слово-за исключением-бара]
word-except-bar: [
[
'| (web:: always-fails) | (Интернет:: однословно)
]
сеть
]
Другой способ описать правило PHRASE в том виде, в каком оно есть сейчас, — это «правило, которое соответствует ряду слов, не содержащему слова |.«
В завершение я создам функцию для вызова синтаксического анализа с правильным правилом и обернуть всю партию в предмет, чтобы навести порядок:
word-parsing-object: context [
всегда терпит неудачу: [конец пропустить]
одно слово: [установить слово элемента! (элемент печатной формы)]
word-except-bar: [
['| (web:: always-fails) | (Интернет:: одно слово)]
сеть
]
фраза: [какое-то слово-за исключением-бара]
set 'parse-words func [a-block [block!]] [
разобрать блок [фраза some ['| (выведите «**********») фраза]]
]
]
Вот тестовый прогон:
>> парс-слова [быстрая коричневая лиса | прыгнул | над ленивым] то быстро коричневый лиса ********** прыгнул ********** над то ленивый == верно
Таким образом, в этом разделе я продемонстрировал, как можно сопоставить определенный шаблон даже когда более общий образец (который включает конкретный образец) становится виден вход в первую очередь.
Почему ты просто не написал …
слова-синтаксического анализа: func [a-block [block!]] [
проанализировать a-блок [
некоторый [
'| (печать «**********») |
установить слово пункта! (элемент печатной формы)
]
]
]
Смысл в том, чтобы продемонстрировать [конец пропуска] и динамические правила, потому что бывают ситуации, когда они вам нужны.
Ключевое слово BREAK
Из документа RT об изменениях:
Когда в блоке правил встречается слово BREAK, блок немедленно завершается независимо от текущего указателя ввода.Выражения, следующие за BREAK в одном блоке правил, не будут быть оцененным.
В этом примере преждевременный выход из правила НЕКОТОРЫЕ:
>> проанализируйте "X" [некоторые [(print "* Break *") break] "X"] *Перерыв* == верно
Здесь снова НЕКОТОРЫЕ правило завершается досрочно, как и предыдущее. пример. В этом случае правило, которое обрабатывает НЕКОТОРЫЕ, обозначается словом:
>> разрушение правила: [(print "* Break *") break] == [(print "* Break *") break] >> проанализируйте "X" [некое нарушение правила "X"] *Перерыв* == верно
В этом случае получается бесконечный цикл.Потому что BREAK находится в подправиле правила, что НЕКОТОРЫЕ обрабатываются. BREAK не влияет на успех / неудачу status или указатель ввода — он просто выходит из правила раньше:
>> разрушение правила: [(print "* Break *") break] == [(print "* Break *") break] >> проанализируйте "X" [некоторые [нарушающие правила] "X"] *Перерыв* *Перерыв* ... *Перерыв* * Break * (побег)
Сопутствующий набор инструментов
Я написал «Набор инструментов анализа синтаксического анализа», чтобы помочь изучить и проанализировать, как работает синтаксический анализ.Функция Explain-parse набора инструментов должна помочь в изучении Parse. У скрипта есть соответствующая документация. Вы можете найти сценарий и ссылку на документацию по адресу:
parse-analysis.r (в библиотеке сценариев REBOL.org)
Основываясь на этом наборе инструментов, у меня есть визуальный маркер токенов. Скрипт и документация к нему находятся по адресу:
.parse-analysis-view.r (в библиотеке сценариев REBOL.org)
Снимок экрана Token Stepper, выделяющий правило ABNF с помощью abnf-parser.г:
Еще одна программа, которую я сделал, может возвращать дерево синтаксического анализа вашего ввода:
load-parse-tree.r (в библиотеке сценариев REBOL.org)
Комментарии
Parse — ключевой компонент REBOL. REBOL продвигается как мессенджер язык. Сообщения могут быть разных форматов (синтаксисов). Разбор позволяет вы должны определить синтаксис сообщения, чтобы вы могли интерпретировать сообщение и преобразовать это к чему-то другому или действовать в соответствии с этим напрямую. Это может показаться сложным, но на самом деле это не так.
Что такое сообщения? Многие вещи можно рассматривать как сообщения. В принципе, если вы можете поместите его в файл, и формат файла имеет какое-то правило, тогда я думаю, что у вас есть сообщение. Вам не нужно помещать его в файл, чтобы использовать синтаксический анализ. Сеть REBOL функции используют синтаксический анализ для интерпретации многих интернет-протоколов, которые предоставляет REBOL. доступ к.
С REBOL вы можете определить мини-язык (язык, разработанный для определенной цели). Parse помогает вам проверять и обрабатывать такие мини-языки.Вы можете захотеть спроектировать мини-язык для создания веб-страниц на вашем сайте. Или, возможно, для контроля специальное устройство, которое вы подключили к своему компьютеру.
Даже если вы не зайдете так далеко, режим разделения синтаксического анализа будет вам полезен как утилита string-breakapart.
Взлом языкового кода: нейронные механизмы, лежащие в основе анализа речи
Реферат
Сегментация слов, определение границ слов в непрерывной речи, является важным аспектом изучения языка.Предыдущие исследования на младенцах и взрослых показали, что поток речи можно легко сегментировать исключительно на основе статистических и речевых сигналов, предоставляемых входными данными. Используя функциональную магнитно-резонансную томографию (фМРТ), нейронный субстрат сегментации слов был исследован в режиме онлайн, когда участники слушали три потока сцепленных слогов, содержащих либо только статистические закономерности, статистические закономерности и речевые сигналы, либо никакие сигналы. Несмотря на неспособность участников явно обнаружить различия между речевыми потоками, нейронная активность значительно различалась в зависимости от условий, при этом увеличение леволатерализованного сигнала во височной коре головного мозга наблюдалось только тогда, когда участники слушали потоки, содержащие статистические закономерности, особенно поток, содержащий речевые сигналы.Во втором исследовании фМРТ, предназначенном для проверки того, что сегментация слов имела место неявно, участники слушали трехсложные комбинации, которые встречались с разной частотой в потоках речи, которые они только что слышали («слова» 45 раз; «частичные слова» 15 раз; «Не слов» — один раз). Достоверно большая активность левой нижней и средней лобных извилин наблюдалась при сравнении слов с частями и, в меньшей степени, при сравнении слов с неполными словами. Активность в этих регионах, взятая для индекса неявного обнаружения границ слов, положительно коррелировала с навыками быстрой обработки слуха участниками.Эти результаты обеспечивают нейронную подпись онлайн-сегментации слов в зрелом мозге и исходную модель, с помощью которой можно изучить изменения в нейронной архитектуре, участвующей в обработке речевых сигналов во время изучения языка.
Введение
Исследователи давно были очарованы тем, как младенцы и маленькие дети могут быстро «взломать» языковой код с гораздо большей легкостью, чем взрослые. Несмотря на то, что многочисленные поведенческие данные свидетельствуют о заметном снижении способности овладевать новым языком со знанием, аналогичным родному, после полового созревания (Johnson and Newport, 1989; Weber-Fox and Neville, 2001), мало что известно о нейронных коррелятах, лежащих в основе этого феномена.Непрерывный процесс нейронной приверженности статистическим и просодическим паттернам языка, испытанный в раннем возрасте, может объяснить соответствующее снижение способности к овладению другим языком позже (Kuhl, 2004). Однако механизмы, с помощью которых мозг кодирует эти статистические и просодические паттерны на начальных этапах изучения языка, до сих пор не исследовались на взрослых.
Предыдущие исследования функциональной нейровизуализации использовали несколько подходов для изучения различных аспектов изучения языка.В некоторых исследованиях изучались изменения в паттерне нейронной активности после периода интенсивного обучения новой лингвистической задаче (Friederici et al., 2002; Callan et al., 2003, 2005; Golestani and Zatorre, 2004). Хотя эти исследования могут затрагивать вопросы нейронной пластичности (поскольку они сосредоточены на нейронной реорганизации, которая возникает в результате обучения), они не предоставляют информации о нейронных системах, которые обслуживают сам процесс обучения. В других исследованиях изучалась нейронная основа изучения языка путем изучения изменений мозговой активности, которые происходят, когда участники изучают искусственную грамматику в сканере (Opitz and Friederici, 2003, 2004; Thiel et al., 2003; Хашимото и Сакаи, 2004 г.). Однако такие исследования включали языковую обработку в визуальной области и, таким образом, не могут пролить свет на нейронные механизмы, лежащие в основе изучения акустических свойств языка. Для исследования таких процессов использовалась функциональная магнитно-резонансная томография (фМРТ) для оценки связанных с обучением изменений в нейронной активности во время первоначального воздействия искусственных языков, представленных в слуховой модальности, когда слушатель сталкивается с непростой задачей определения границ слов в непрерывном потоке. речи.
Сегментация слов является фундаментальным аспектом изучения языка, потому что границы слов должны быть идентифицированы до того, как можно будет проводить любой дополнительный лингвистический анализ (Jusczyk, 2002; Saffran and Wilson, 2003). Хотя речь не содержит акустических сигналов, которые неизменно определяют границы слов, исследования показали, что младенцы в возрасте 7,5 месяцев могут использовать статистические закономерности, такие как большее совпадение слогов в словах, чем между словами, для успешного анализа непрерывного потока слов. речь (Saffran et al., 1996a; Aslin et al., 1998). В дополнение к этим переходным вероятностям, речевые сигналы, доступные во входных данных, такие как образцы ударения (т. Е. Более длительная, увеличенная амплитуда и более высокий тон некоторых слогов), также могут определять сегментацию слов (Johnson and Jusczyk, 2001; Thiessen and Saffran, 2003 ). Путем адаптации хорошо зарекомендовавшей себя парадигмы из детской поведенческой литературы, настоящее исследование изучило нейронные корреляты синтаксического анализа речи. В свете данных, указывающих на то, что способность обрабатывать быстрые акустические изменения в высокой степени предсказывает будущие языковые навыки (Benasich and Tallal, 2002), также была исследована взаимосвязь между нейронной активностью, индексирующей успешную сегментацию слов, и способностью быстрой обработки слуха.
Результаты
Поведенческие результаты
Точность и время реакции поведенческого теста на распознавание слов, проведенного сразу после сканирования фМРТ, представлены в таблице 1. Неудивительно, учитывая результаты предыдущих поведенческих исследований (Saffran et al., 1996b; Sanders et al., 2002), участники были неспособны явно распознать, какие трехсложные комбинации могли быть словами на искусственных языках, которые они слышали во время задания по выявлению речевого потока, о чем свидетельствуют оценки точности, не отличающиеся от случайных для ударных или безударных языковых условий.Точно так же не было значительных различий во времени реакции на элементы безударного языка, ударного языка или потоков случайных слогов.
Таблица 1.Поведенческие характеристики в задаче распознавания слов
Задача выявления речевого потока
Модели случайных эффектов использовались для выявления изменений в BOLD-сигнале, связанном с прослушиванием безударного языка, ударного языка и случайных слогов во время задачи раскрытия речевого потока.По сравнению с исходным уровнем покоя, прослушивание всех трех потоков непрерывной речи активировало крупномасштабную двустороннюю нейронную сеть, включая канонические языковые области в LH и их RH-аналогах, с обширной активацией во височной, лобной и теменной коре, а также в скорлупе. (Рис.3; Таблица 2). В целом, когда участники слушали искусственные языки (U + S), наблюдалась модель большей фокусной активности (то есть меньшая активация с точки зрения пространственной протяженности), чем когда они слушали поток случайных слогов (Таблица 2).Точно так же большая фокусная активность наблюдалась, когда участники слушали подчеркнутый язык, чем безударный (таблица 3), что указывает на то, что наличие статистических сигналов как в условиях искусственного языка, так и добавление просодических сигналов в подчеркнутом языке, предоставил более эффективную нейронную обработку.
Рисунок 3.Обширная активность височной, лобной и теменной коры, а также скорлупы наблюдалась, когда участники слушали поток случайных слогов ( A ), безударный языковой поток ( B ) и стрессовый языковой поток ( C ) по сравнению с исходным уровнем в состоянии покоя, при этом более фокусный паттерн активности наблюдается, когда в речевом потоке доступно больше сигналов.Карты активации отображаются с порогом t > 1,71 с поправкой на множественные сравнения на уровне кластера ( p, <0,05, исправлено).
Таблица 2.Пики активации во время воздействия речевых потоков
Таблица 3.Пики, в которых активность была выше во время воздействия безударного языкового потока, чем с подчеркнутым языковым потоком
Поскольку переходные вероятности и связанная с ними идентификация границ слов вычисляются в режиме онлайн в ходе условий активации, были исследованы области, в которых активность может возрастать в зависимости от воздействия речевых потоков.Статистическое контрастное моделирование увеличения активности искусственных языков с течением времени (U ↑ + S ↑) выявило значительное двустороннее увеличение сигнала в верхней височной извилине (STG) и поперечной височной извилине, распространяющееся на супрамаргинальную извилину (SMG) в LH (рис. .4 A , B ; Таблица 4). Анализ интересующей области показал, что эта возрастающая активность во время воздействия безударных и подчеркнутых языковых условий была достоверно сильнее в LH, чем в RH, на что указывает значительно большее количество вокселей, показывающих этот эффект в LH, чем в RH. RH (LH, 235 против RH, 180; F (1,26) = 4.622; p <0,05). Напротив, не наблюдалось достоверного увеличения сигнала с течением времени во время воздействия условия случайных слогов, что можно увидеть во временном ряду, показанном на Рисунке 4 B . Контраст, непосредственно сравнивающий увеличение сигнала, происходящее во время воздействия двух искусственных языков, с увеличением сигнала, происходящим во время воздействия условия случайных слогов [(U ↑ + S ↑) — R ↑], подтвердил, что активность в двусторонней средней височной извилине (MTG) и STG , а левый SMG показал значительно большее увеличение в зависимости от воздействия двух условий искусственного языка, чем условие случайных слогов (Таблица 4).Этот шаблон сохраняется при сравнении увеличения сигнала во время каждого условия искусственного языка по сравнению с условием случайных слогов (U ↑ — R ↑ и S ↑ — R ↑) (Рис. 5 A , B ; Таблица 5), с более сильным увеличением сигнала для сравнения ударного языка со случайными слогами, чем для безударного языка со случайными слогами [(S ↑ — R ↑) — (U ↑ — R ↑)] в левом STG и правом височно-теменном соединении (рис. 5 C ; Таблица 5).
Рисунок 4.Было обнаружено, что активность височной коры увеличивается в процессе прослушивания речевых потоков для обоих состояний искусственного языка (U ↑ + S ↑), пороговая величина которых составляет t > 1.71, с поправкой на множественные сравнения на уровне кластера ( p <0,05, исправлено) ( A ). Временной ряд, показывающий увеличение сигнала в височной коре во время воздействия трех речевых потоков, иллюстрирует значительное увеличение, наблюдаемое для безударных и подчеркнутых языковых состояний, но не для состояния случайных слогов ( B ).
Рисунок 5.Было обнаружено, что активность височной коры увеличивается во время воздействия безударного языкового потока ( A ) и ударного языкового потока ( B ) в большей степени, чем при воздействии потока случайных слогов (U ↑ — R ↑ и S ↑ — R ↑).Было обнаружено, что активность в левом STG и правом височно-теменном соединении увеличивается во время воздействия стрессового языкового потока в большей степени, чем во время воздействия безударного языкового потока (S ↑ — U ↑) ( C ). Карты активации отображаются с порогом t > 1,71 с поправкой на множественные сравнения на уровне кластера ( p, <0,05, исправлено).
Таблица 4.Пики активации для регионов, в которых активность увеличивалась в зависимости от воздействия обоих речевых потоков искусственного языка (ударные и безударные языки вместе)
Таблица 5.Пики активации для регионов, в которых активность увеличивалась в зависимости от воздействия безударных и подчеркнутых языковых речевых потоков
Статистическое контрастное моделирование снижения активности с течением времени для условий искусственного языка (U ↓ + S ↓) выявило активность в вентромедиальной префронтальной коре (координаты Талаираха 4, 56, 8; t = 5,26, с поправкой на множественные сравнения в кластере). уровень). Интересно, что при более либеральных порогах ( t > 1.71; p <0,05, без коррекции; минимальный размер кластера, 5 вокселей), снижение сигнала также наблюдалось в нескольких других областях (например, левая MTG, двусторонняя нижняя теменная долька (IPL), правая средняя и медиальная лобная извилины, передняя поясная извилина и левая скорлупа), в которых общая более высокая активность наблюдалось для случайных слогов по сравнению с условиями искусственного языка [(R - (S + U)]. И наоборот, при этих более либеральных порогах, большая активность наблюдалась для искусственных языков по сравнению с условием случайных слогов [(S + U) - R) ] в левой STG и IPL, то есть в тех регионах, в которых со временем наблюдался значительный рост искусственных языков.Для условия случайных слогов (R ↓) уменьшение сигнала со временем наблюдалось только в левой островке и IPL (координаты Талаираха -34, -24, -2, t = 5,3 и -50, -36, 50, t = 3,75 соответственно, оба исправлены на множественные сравнения на уровне кластера).
Корреляция с поведенческой точностью распознавания слов
Точность участников при различении слов в задаче распознавания слов по поведению после сканирования положительно коррелировала с активностью в левой STG, когда участники слушали ударные и безударные языки по сравнению со случайными слогами во время задачи выявления речевого потока (рис.6; Таблица 6). Важно отметить, что этот эффект наблюдался в том же регионе, демонстрируя возрастающую активность со временем при прослушивании искусственных языков.
Рисунок 6.Регрессионный анализ показал, что активность левой верхней височной извилины, связанная с прослушиванием искусственных языковых условий (по сравнению с условием случайных слогов) во время задания воздействия речевого потока, в значительной степени коррелировала со способностью участников различать слова, встречающиеся на искусственных языках, так как индексируется по их точности в поведенческой задаче распознавания слов после сканирования [пик в координатах Талаирах -50, -30, 14, предполагаемая область Бродмана 42; т = 2.94, с поправкой на множественные сравнения на уровне кластера ( p <0,05, исправлено)].
Таблица 6.Пики активации для регионов, в которых активность во время прослушивания речевых потоков была связана с точностью распознавания слов
Задача распознавания слов
Модели случайных эффектов использовались для идентификации изменений в BOLD-сигнале, связанном с прослушиванием слов, частей и неслов, представленных во время трех блоков задачи распознавания слов.Активность в ответ на прослушивание как слов, так и частей слов (которые произошли 45 и 15 раз, соответственно, во время задачи выявления речевого потока) суммировалась по безударным и подчеркнутым языковым блокам. (В соответствии с парадигмой предпочтения новизны поворота головы, используемой в развивающей литературе по сегментации слов, только 12 слов и 12 частичных слов были представлены в каждом языковом блоке. Сворачивание языковых блоков привело к 24 событиям для слов и 24 для частичных слов, которые нужно было сопоставить с 24 событиями для неслов из случайного блока слогов.) Активность для неслов соответствовала трехсложным комбинациям, представленным во время блока случайных слогов (эти комбинации произошли только один раз во время условия случайных слогов задачи раскрытия речевого потока). Статистический контраст, сравнивающий BOLD-сигнал, связанный с прослушиванием слов и неслов (W — NW), выявил значительно большую активность слов в левой нижней лобной извилине (IFG) и MFG (рис. 7 A ; таблица 7). Достоверно большая активность, хотя и в меньшей степени, также наблюдалась в тех же регионах при сравнении слов с частичными словами (W — PW) (рис.7 B ; Таблица 7) и частичные слова в сравнении с несловами (PW — NW) (Таблица 7). Сравнение неполных слов и не слов также выявило значительно большую активность в верхней теменной доле. Важно отметить, что не наблюдалось достоверно большей активности коры при любом из обратных статистических сравнений (NW — W, NW — PW и PW — W). Несмотря на ограниченное количество слов и частей слов в каждом языковом блоке, когда вышеупомянутый анализ проводился для ударных и безударных языковых блоков отдельно, наблюдалась практически идентичная картина результатов (хотя и с меньшим размером кластера).
Рисунок 7.Надежная активность наблюдалась в задней левой нижней и средней лобных извилинах, когда участники слушали слова по сравнению с несловыми (W — NW) ( A ) и частичными словами (W — PW) ( B ), с пороговыми значениями. при t > 2,48, с поправкой на множественные сравнения на уровне кластера ( p <0,05, исправлено). Гистограмма показывает оценки параметров активности в этих регионах, когда участники слушали слова, части и неслова ( C ).
Таблица 7.Пики активации в задаче распознавания слов
Был проведен дополнительный анализ, чтобы определить, будет ли наблюдаться различная активность, когда участники слушают слова, которые возникли в речевом потоке, когда были доступны как просодические, так и статистические сигналы для управления сегментацией слов (ударный язык), в отличие от слов, которые встречались в речевом потоке. речевой поток, содержащий только статистические подсказки (безударный язык).Сравнение активности, наблюдаемой во время языкового блока с ударением, с активностью, наблюдаемой во время языкового блока без ударения [S (W + PW) — U (W + PW)], показало, что левый MFG и правый IPL (координаты Талайраха -48, 12, 34, t = 2,85 и 36, -50, 38, t = 3,43, соответственно, с поправкой на множественные сравнения на уровне кластера) показал большую активацию, когда участники слушали слова и части слова из речевого потока, которые содержали дополнительные просодические сигналы (подчеркнутый язык), чем слова и частичные слова из потока, содержащего только статистические закономерности (безударный язык).При обратном сравнении [U (W + PW) — S (W + PW)] достоверной активности обнаружено не было.
Корреляция с навыками быстрой обработки слуха
Результативностьучастников в тесте на повторение талла положительно коррелировала с активностью левой MFG, в то время как участники слушали слова во время выполнения задания на распознавание слов (рис. 8). То есть, тем лучше у участников навыки быстрой обработки слуха, что определяется точностью на подшкале SM3Fast теста Tallal Repetition Test (среднее ± стандартное отклонение, 80.3 ± 19,6%), тем выше активность, наблюдаемая в левом MFG во время выполнения задания на распознавание слов при прослушивании трехсложных комбинаций, которые встречались 45 раз в стрессовых и безударных языковых условиях в задаче экспонирования речевого потока.
Рисунок 8.Регрессионный анализ показал, что активность средней лобной извилины, связанная с прослушиванием слов, в значительной степени коррелировала с навыками быстрой обработки слуха участников, что измерялось точностью теста Tallal Repetition (REP) [пик в координатах Талаирах -40, 36, 16, предположительно Площадь Бродмана 46; т = 4.37, с поправкой на множественные сравнения на уровне кластера ( p <0,05, исправлено)] ( A ). График разброса показывает положительную корреляцию между точностью теста REP и активностью в пределах левой средней лобной извилины ( r = 0,504; p <0,028) ( B ).
Обсуждение
В настоящем исследовании изучались нейронные корреляты сегментации слов, важный процесс на ранних этапах изучения языка.За последнее десятилетие важные исследования в литературе по поведению младенцев произвели революцию в наших представлениях о механизмах, лежащих в основе овладения языком, показав, что мозг обладает поразительными вычислительными способностями, которые позволяют младенцам быстро определять границы слов путем извлечения статистических и просодических паттернов в непрерывной речи ( Saffran et al., 1996a; Aslin et al., 1998; Johnson and Jusczyk, 2001; Thiessen and Saffran, 2003). Однако нейронная архитектура, лежащая в основе этого вычислительного навыка, еще не идентифицирована.Путем адаптации парадигмы, используемой в детской литературе, это исследование изучило, как мозг обрабатывает статистические и просодические речевые сигналы, доступные во входных данных, для взлома кода нового искусственного языка.
Несмотря на несколько необычный дизайн фМРТ, лобно-височные сети, активируемые, когда участники слушали потоки сцепленных слогов, соответствуют тем, которые наблюдались в предыдущих исследованиях, включающих представление похожих речевых стимулов и спектрально сложной акустической информации (Binder et al., 2000; Хикок и Поппель, 2000; Johnsrude et al., 2000; Scott et al .; 2000; Vouloumanos et al., 2001; Гандур и др., 2002; Янке и др., 2002; Zatorre et al., 2002; Гельфанд и Букхаймер, 2003; Скотт и Джонсруд, 2003; Dehaene-Lambertz et al., 2005) (рис.3; таблица 2). Наблюдаемая активность в областях моторной речи также согласуется с недавним исследованием, показывающим значительное перекрытие между областями, активными во время пассивного слушания слогов, и областями, активными во время явного производства слогов (Wilson et al., 2004). Более того, наш вывод об активности базальных ганглиев согласуется с предыдущими исследованиями, включающими обучение последовательности в различных модальностях (Poldrack et al., 2005; Doyon et al., 2003; Saint-Cyr, 2003; Van der Graaf et al., 2004). .
Более узконаправленный паттерн активности, наблюдаемый, когда участники слушали искусственные языки, в отличие от потока случайных слогов, предполагает, что статистические и просодические сигналы сегментации слов, присутствующие только в искусственных языках, способствовали синтаксическому анализу речевых потоков, таким образом обеспечение более эффективной нейронной обработки (таблица 2).Эта интерпретация согласуется с другими исследованиями, в которых сообщается о меньшей активности для более простых или лучше усваиваемых задач (Petersen et al., 1998; Landau et al., 2004; Casey et al., 2005; Kelly and Garavan, 2005). Общая более высокая активность, связанная с прослушиванием потока случайных слогов, в котором порядок появления слогов невозможно предсказать, также согласуется с исследованием, показывающим большую активность в верхней височной коре головного мозга в ответ на последовательности зрительных стимулов с низким временным интервалом. предсказуемость по сравнению с предсказуемостью с высокой степенью предсказуемости (Bischoff-Grethe et al., 2000).
Во время воздействия трех непрерывных потоков конкатенированных слогов леволатерализованный BOLD-сигнал увеличивается во временной и нижней теменной коре головного мозга только тогда, когда участники слушают два потока, содержащие статистические закономерности, в частности, поток, также содержащий просодические сигналы (рис. 4, 5; Таблицы 4, 5). Поскольку поток искусственных языков и случайных слогов различается только наличием признаков границ слов, увеличение сигнала, наблюдаемое для обоих искусственных языков вдоль верхних временных извилин, может отражать текущее вычисление переходных вероятностей (Blakemore et al., 1998; Bischoff-Grethe et al., 2000), тогда как увеличение активности в левой надмаргинальной извилине может отражать развитие фонологических представлений для «слов» в искусственных языках (Gelfand, Bookheimer, 2003; Xiao et al., 2005). . Более сильное усиление сигнала, наблюдаемое в этих областях, а также в первичной слуховой коре, для подчеркнутого языка по сравнению с безударным языком, предполагает, что наличие просодических сигналов действительно помогло синтаксическому анализу речи в соответствии с предыдущими поведенческими данными как у младенцев, так и у взрослых. (Johnson, Jusczyk, 2001; Thiessen, Saffran, 2003) (таблица 5).Хотя в нескольких исследованиях сообщалось о снижении активности по мере того, как участники учатся выполнять языковую задачу (Thiel et al., 2003; Golestani and Zatorre, 2004; Noppeney and Price, 2004), и, действительно, некоторое снижение также наблюдалось в настоящем исследовании, наши результаты согласуются с предыдущими сообщениями об увеличении активности как функции обучения в первичных и вторичных сенсорных и моторных областях, а также в регионах, участвующих в хранении связанных с заданием корковых репрезентаций (для обзора см. Kelly and Garavan, 2005). .
Наше открытие увеличения сигнала в височной и нижней теменной корках во время воздействия искусственных языков указывает на то, что произошла первоначальная сегментация слов, несмотря на тот факт, что в целом участники не могли надежно идентифицировать слова, используемые для создания речевых потоков в пост- сканировать поведенческий тест. Эта интерпретация убедительно подтверждается положительной взаимосвязью, обнаруженной между активностью в левой STG во время воздействия искусственных языков (по сравнению со случайным потоком слогов) и способностью участников различать слова в задаче поведенческого распознавания слов после сканирования (рис.6; Таблица 6). Кроме того, хотя нейровизуализационные исследования обучения обычно изучали изменения нейронной активности, связанные с наблюдаемыми поведенческими изменениями (индексируемыми явными или неявными измерениями), в нескольких других исследованиях сообщалось об изменениях нейронной активности, которые происходят в отсутствие каких-либо явных изменений в выполнении задания ( Shadmehr and Holcomb, 1997; Jaeggi et al., 2003; Landau et al., 2004; Kelly and Garavan, 2005). Нейронные изменения, которые предшествуют поведенческим изменениям, также были показаны в исследованиях связанного с событиями потенциала (ERP) при решении различных лингвистических задач (Shestakova et al., 2003; McLaughlin et al., 2004). Примечательно, что ERP-исследование сегментации слов также продемонстрировало, что, хотя взрослым требовалось длительное воздействие и обучение для явной идентификации слов в речевом потоке, они отображали увеличенный компонент N100 в начальных слогах слова (взятый для индексации неявного обнаружения границ слов) задолго до того, как появились доказательства явного знания (Sanders et al., 2002).
Результаты задачи распознавания слов, в которой участники подвергались трехсложным комбинациям, которые возникали с разной частотой в речевых потоках, предоставляют дополнительное свидетельство того, что сегментация слов неявно произошла во время задачи выявления речевого потока.Здесь большая активность наблюдалась в левых префронтальных областях в ответ на трехсложные комбинации с более высокой частотой встречаемости в речевых потоках и, таким образом, более высокой вероятностью перехода между слогами (рис. 7; таблица 7). В частности, прослушивание слов по сравнению с частичными словами (т. Е. Трехсложные комбинации, которые встречались 45 раз по сравнению с 15 раз в потоках искусственного языка) и неслов (т. Е. Трехсложные комбинации, которые встречались только один раз в потоке случайных слогов) вызывало большую активность в последнем , верхняя область левого IFG, простирающаяся в MFG, регионы, которые, как известно, важны для фонологического и последовательного процессинга (Gelfand and Bookheimer, 2003).Тот факт, что этот эффект был более выражен для слов из ударного языка, чем для безударного языка, снова предполагает, что участники смогли извлечь выгоду из наличия просодических сигналов, чтобы помочь сегментации слов во время задачи выявления речевого потока. Наблюдаемая левосторонняя префронтальная активность согласуется с множеством предыдущих исследований изображений, в которых эти области участвуют в нескольких аспектах фонологической обработки (см. Обзор в Bookheimer, 2002), включая фонематическую дискриминацию, временное упорядочение, артикуляционное перекодирование и поддержание акустической информация в рабочей памяти (Burton et al., 2000; Ньюман и Твиг, 2001; Гельфанд и Букхаймер, 2003; LoCasto et al., 2004; Xiao et al., 2005).
Интересно, что активность в левой MFG при прослушивании слов из ударных и безударных языков модулировалась навыками быстрой слуховой обработки участников, что было проиндексировано их выполнением теста Tallal Repetition Test (Tallal and Piercy, 1973) (рис. 8). ). Предыдущие исследования показали, что способность обрабатывать быстрые акустические изменения является очень важным предиктором будущих языковых результатов и вербального интеллекта, и что эта способность скомпрометирована у людей с нарушениями языкового обучения, такими как дислексия (Benasich and Tallal, 2002; Tallal, 2004). .Наблюдаемая взаимосвязь между активностью MFG (используемой для индексации успешной неявной сегментации слов) и индивидуальными различиями в навыках быстрой слуховой обработки дополнительно свидетельствует о важности этой области для изучения языка. Хотя другие исследования нейровизуализации связывают активность MFG с быстрой обработкой акустической информации на фонематическом уровне (Fiez et al., 1995; Temple et al., 2000; Poldrack et al., 2001; Temple, 2002), настоящие результаты указывают на то, что что навыки быстрой обработки слуха могут быть важны и для других аспектов изучения языка.
В заключение, текущее исследование подтверждает, что минимального воздействия непрерывного потока речи, содержащего статистические и просодические сигналы, достаточно для неявной сегментации слов и обеспечивает нейронную подпись сегментации слов в режиме онлайн в зрелом мозге. На прикладном уровне эта парадигма может быть полезна для выявления аномалий в нейронной архитектуре, способствующей изучению языка при нарушениях языка в процессе развития, и для изучения изменений в этой схеме после вмешательств.На теоретическом уровне, учитывая, что младенцы и взрослые могут сегментировать последовательности тонов так же хорошо, как и слоги (Saffran et al., 1999), сравнение нейронной активности во время анализа речи с анализом нелингвистических стимулов, таких как тоны, может позволить нам распутать предметно-зависимые от общих предметных механизмов, способствующих изучению языка. Что наиболее важно, настоящие результаты у взрослых могут служить конечной точкой развития нервной системы для исследования изменений в нейронной основе изучения языка, происходящих с возрастом и лингвистическим опытом, чтобы помочь ответить на давний вопрос о том, почему дети лучше изучают язык, чем взрослые.
Как кодировать текстовые данные для машинного обучения с помощью scikit-learn
Последнее обновление 28.06.2020
Текстовые данные требуют специальной подготовки, прежде чем их можно будет использовать для прогнозного моделирования.
Текст должен быть проанализирован для удаления слов, это называется токенизацией. Затем слова необходимо закодировать как целые числа или значения с плавающей запятой для использования в качестве входных данных для алгоритма машинного обучения, называемого извлечением признаков (или векторизацией).
Библиотека scikit-learn предлагает простые в использовании инструменты для выполнения токенизации и извлечения функций из ваших текстовых данных.
В этом руководстве вы узнаете, как именно подготовить текстовые данные для прогнозного моделирования в Python с помощью scikit-learn.
После прохождения этого руководства вы будете знать:
- Как преобразовать текст в векторы подсчета слов с помощью CountVectorizer.
- Как преобразовать текст в векторы частоты слов с помощью TfidfVectorizer.
- Как преобразовать текст в уникальные целые числа с помощью HashingVectorizer.
Начните свой проект с моей новой книги «Глубокое обучение для обработки естественного языка», включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
Как подготовить текстовые данные для машинного обучения с помощью scikit-learn
Фото Мартина Келли, некоторые права защищены.
Сумка со словами Модель
Мы не можем работать с текстом напрямую при использовании алгоритмов машинного обучения.
Вместо этого нам нужно преобразовать текст в числа.
Мы можем захотеть выполнить классификацию документов, чтобы каждый документ был « вход, », а метка класса — « выход, » для нашего алгоритма прогнозирования.Алгоритмы принимают в качестве входных данных векторы чисел, поэтому нам необходимо преобразовать документы в векторы чисел фиксированной длины.
Простая и эффективная модель анализа текстовых документов в машинном обучении называется Bag-of-Words Model или BoW .
Модель проста в том, что она отбрасывает всю информацию о порядке в словах и фокусируется на появлении слов в документе.
Это можно сделать, присвоив каждому слову уникальный номер.Тогда любой документ, который мы видим, можно закодировать как вектор фиксированной длины с длиной словаря известных слов. Значение в каждой позиции в векторе может быть заполнено счетчиком или частотой каждого слова в закодированном документе.
Это модель мешка слов, в которой нас интересуют только схемы кодирования, которые представляют, какие слова присутствуют или в какой степени они присутствуют в закодированных документах, без какой-либо информации о порядке.
Подробнее о модели мешка слов см. В руководстве:
Есть много способов расширить этот простой метод, как за счет лучшего разъяснения, что такое « слово », так и за счет определения того, что нужно кодировать для каждого слова в векторе.
Библиотека scikit-learn предоставляет 3 различных схемы, которые мы можем использовать, и мы кратко рассмотрим каждую.
Нужна помощь с глубоким обучением текстовых данных?
Пройдите бесплатный 7-дневный ускоренный курс по электронной почте (с кодом).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ ускоренный курс прямо сейчас
Количество слов с помощью CountVectorizer
CountVectorizer предоставляет простой способ как токенизировать коллекцию текстовых документов и создать словарь известных слов, так и кодировать новые документы с использованием этого словаря.
Вы можете использовать его следующим образом:
- Создайте экземпляр класса CountVectorizer .
- Вызовите функцию fit () для изучения словаря из одного или нескольких документов.
- Вызовите функцию transform () для одного или нескольких документов по мере необходимости, чтобы закодировать каждый как вектор.
Закодированный вектор возвращается с длиной всего словаря и целым числом, определяющим, сколько раз каждое слово появлялось в документе.
Поскольку эти векторы будут содержать много нулей, мы называем их разреженными. Python предоставляет эффективный способ обработки разреженных векторов в пакете scipy.sparse.
Векторы, возвращаемые вызовом transform (), будут разреженными векторами, и вы можете преобразовать их обратно в массивы numpy, чтобы посмотреть и лучше понять, что происходит, вызвав функцию toarray ().
Ниже приведен пример использования CountVectorizer для токенизации, создания словаря и последующего кодирования документа.
из sklearn.feature_extraction.text импорт CountVectorizer # список текстовых документов text = [«Быстрая коричневая лисица перепрыгнула через ленивого пса.»] # создаем преобразование vectorizer = CountVectorizer () # токенизация и создание словаря vectorizer.fit (текст) # подвести итоги печать (vectorizer.vocabulary_) # закодировать документ vector = vectorizer.transform (текст) # суммировать закодированный вектор печать (vector.shape) печать (тип (вектор)) печать (вектор.toarray ())
из sklearn.feature_extraction.text import CountVectorizer # список текстовых документов text = [«Быстрая коричневая лиса перепрыгнула через ленивую собаку.»] # создать преобразование векторизатор = CountVectorizer () # разметить и построить словарь vectorizer.fit (текст) # суммировать print (vectorizer.vocabulary_) # закодировать документ vector = векторизатор.transform (текст) # суммировать закодированный вектор print (vector.shape) print (type (vector)) print (vector.toarray ()) |
Выше вы можете видеть, что мы обращаемся к словарю, чтобы узнать, что именно было токенизировано, по телефону:
печать (vectorizer.vocabulary_)
печать (vectorizer.vocabulary_) |
Мы видим, что по умолчанию все слова были сделаны в нижнем регистре, а знаки препинания игнорировались.Эти и другие аспекты токенизации можно настроить, и я рекомендую вам просмотреть все параметры в документации API.
При выполнении примера сначала печатается словарь, а затем форма закодированного документа. Мы видим, что в словаре 8 слов, и поэтому длина закодированных векторов равна 8.
Затем мы можем видеть, что закодированный вектор является разреженной матрицей. Наконец, мы можем увидеть версию закодированного вектора в виде массива, показывающую количество вхождений 1 для каждого слова, кроме (индекс и идентификатор 7), для которого вхождение равно 2.
{‘dog’: 1, ‘fox’: 2, ‘over’: 5, ‘brown’: 0, ‘quick’: 6, ‘the’: 7, ‘lazy’: 4, ‘jumped’: 3} (1, 8) <класс 'scipy.sparse.csr.csr_matrix'> [[1 1 1 1 1 1 1 2]]
{‘dog’: 1, ‘fox’: 2, ‘over’: 5, ‘brown’: 0, ‘quick’: 6, ‘the’: 7, ‘lazy’: 4, ‘jumped’: 3 } (1, 8) [[1 1 1 1 1 1 1 2]] |
Важно отметить, что тот же векторизатор можно использовать для документов, содержащих слова, не включенные в словарь.Эти слова игнорируются, и в результирующем векторе не производится подсчет.
Например, ниже приведен пример использования векторизатора выше для кодирования документа с одним словом в словаре и одним словом без него.
# закодировать другой документ text2 = [«щенок»] вектор = vectorizer.transform (text2) печать (vector.toarray ())
# закодировать другой документ text2 = [«щенок»] вектор = векторизатор.преобразование (текст2) печать (vector.toarray ()) |
При выполнении этого примера печатается версия массива закодированного разреженного вектора, показывающая, что одно вхождение одного слова в словарь полностью игнорируется.
Закодированные векторы затем можно использовать напрямую с алгоритмом машинного обучения.
Word Frequency с TfidfVectorizer
Подсчет слов — хорошая отправная точка, но это очень просто.
Одна проблема с простым подсчетом состоит в том, что некоторые слова, такие как « the », будут появляться много раз, и их большое количество не будет иметь большого значения в закодированных векторах.
Альтернативой является вычисление частотности слов, и, безусловно, самый популярный метод называется TF-IDF. Это аббревиатура от « Term Frequency — Inverse Document » Frequency, которая является компонентом результирующих оценок, присваиваемых каждому слову.
- Частота термина : Суммирует, как часто данное слово появляется в документе.
- Обратная частота документа : уменьшает масштаб слов, которые часто встречаются в документах.
Не вдаваясь в математику, TF-IDF — это оценки частоты слов, которые пытаются выделить слова, которые более интересны, например часто встречается в документе, но не во всех документах.
TfidfVectorizer будет токенизировать документы, изучать словарный запас и обратную частоту взвешивания документов, а также позволит вам кодировать новые документы. В качестве альтернативы, если у вас уже есть изученный CountVectorizer, вы можете использовать его с TfidfTransformer, чтобы просто вычислить обратные частоты документов и начать кодирование документов.
Используется тот же процесс создания, подгонки и преобразования, что и для CountVectorizer.
Ниже приведен пример использования TfidfVectorizer для изучения словарного запаса и инверсии частот документов в 3 небольших документах, а затем для кодирования одного из этих документов.
из sklearn.feature_extraction.text import TfidfVectorizer # список текстовых документов text = [«Быстрая коричневая лиса перепрыгнула через ленивого пса.», «Собака.», «Лиса»] # создаем преобразование векторизатор = TfidfVectorizer () # токенизация и создание словаря векторизатор.соответствовать (текст) # подвести итоги печать (vectorizer.vocabulary_) печать (vectorizer.idf_) # закодировать документ vector = vectorizer.transform ([текст [0]]) # суммировать закодированный вектор печать (vector.shape) печать (vector.toarray ())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | из sklearn.feature_extraction.text import TfidfVectorizer # список текстовых документов text = [«Быстрая коричневая лиса перепрыгнула через ленивую собаку.», «Собака.», «Лисица»] # создать файл transform vectorizer = TfidfVectorizer () # tokenize and build vocab vectorizer.fit (text) # summarize print (vectorizer.vocabulary_) print (vectorizer.idf_) документ encode вектор = векторизатор.transform ([text [0]])# суммировать закодированный вектор print (vector.shape) print (vector.toarray ()) |
Словарь из 8 слов извлекается из документов, и каждому слову присваивается уникальный целочисленный индекс в выходном векторе.
Частоты обратных документов вычисляются для каждого слова в словаре, при этом наименьшая оценка 1,0 присваивается наиболее часто встречающемуся слову: « the » с индексом 7.
Наконец, первый документ закодирован как 8-элементный разреженный массив, и мы можем просмотреть окончательные оценки каждого слова с разными значениями для « the », « fox » и « dog » из другого слова в словарном запасе.
{‘fox’: 2, ‘lazy’: 4, ‘dog’: 1, ‘quick’: 6, ‘the’: 7, ‘over’: 5, ‘brown’: 0, ‘jumped’: 3} [1.69314718 1.28768207 1.28768207 1.69314718 1.69314718 1.69314718 1.69314718 1.] (1, 8) [[0,36388646 0,27674503 0,27674503 0,36388646 0,36388646 0,36388646 0,36388646 0,42983441]]
{‘fox’: 2, ‘lazy’: 4, ‘dog’: 1, ‘quick’: 6, ‘the’: 7, ‘over’: 5, ‘brown’: 0, ‘jumped’: 3 } [1.69314718 1.28768207 1.28768207 1.69314718 1.69314718 1.69314718 1.69314718 1.] (1, 8) [[0,36388646 0,27674503 0,27674503 0,36388646 0,36388000 0,49 0,36388646 0,36388646] 0,36388646] 0,36388646 |
Оценки нормализуются до значений от 0 до 1, а затем закодированные векторы документа можно использовать напрямую с большинством алгоритмов машинного обучения.
Хеширование с HashingVectorizer
Счетчики и частоты могут быть очень полезными, но одним из ограничений этих методов является то, что словарный запас может стать очень большим.
Это, в свою очередь, потребует больших векторов для кодирования документов и наложит большие требования на память и замедлит алгоритмы.
Умный обходной путь — использовать односторонний хэш слов для преобразования их в целые числа. Умная часть состоит в том, что словарный запас не требуется, и вы можете выбрать вектор произвольной длины фиксированной длины. Обратной стороной является то, что хэш является односторонней функцией, поэтому нет способа преобразовать кодировку обратно в слово (что может не иметь значения для многих контролируемых учебных задач).
Класс HashingVectorizer реализует этот подход, который может использоваться для последовательного хеширования слов, а затем токенизации и кодирования документов по мере необходимости.
В приведенном ниже примере демонстрируется HashingVectorizer для кодирования одного документа.
Был выбран произвольный размер вектора фиксированной длины, равный 20. Это соответствует диапазону хеш-функции, где небольшие значения (например, 20) могут привести к хеш-коллизиям. Вспоминая классы compsci, я считаю, что есть эвристики, которые вы можете использовать для выбора длины хэша и вероятности коллизии на основе предполагаемого размера словарного запаса.
Обратите внимание, что этот векторизатор не требует вызова для размещения в документах данных обучения. Вместо этого после создания его можно использовать непосредственно для начала кодирования документов.
из sklearn.feature_extraction.text import HashingVectorizer # список текстовых документов text = [«Быстрая коричневая лисица перепрыгнула через ленивого пса.»] # создаем преобразование vectorizer = HashingVectorizer (n_features = 20) # закодировать документ vector = vectorizer.transform (текст) # суммировать закодированный вектор печать (вектор.форма) печать (vector.toarray ())
из sklearn.feature_extraction.text import HashingVectorizer # список текстовых документов text = [«Быстрая коричневая лиса перепрыгнула через ленивого пса.»] # создать преобразование vectorizer = HashingVectorizer (n_features = 20 ) # кодировать документ vector = vectorizer.transform (text) # суммировать закодированный вектор print (vector.shape) print (vector.toarray ()) |
При выполнении примера образец документа кодируется как разреженный массив из 20 элементов.
Значения закодированного документа соответствуют нормализованному количеству слов по умолчанию в диапазоне от -1 до 1, но их можно сделать простыми целочисленными подсчетами, изменив конфигурацию по умолчанию.
(1, 20) [[0. 0. 0. 0. 0. 0.33333333 0. -0.33333333 0,33333333 0. 0. 0,33333333 0. 0. 0. -0.33333333 0. 0. -0,66666667 0.]]
(1, 20) [[0. 0. 0. 0. 0. 0.33333333 0. -0.33333333 0.33333333 0. 0. 0.33333333 0. 0. 0. -0.33333333 0. 0. -0.66666667 0.]] |
Дополнительная литература
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться.
Обработка естественного языка
sciki-learn
Класс API
Сводка
В этом руководстве вы узнали, как подготовить текстовые документы для машинного обучения с помощью scikit-learn.
В этих примерах мы коснулись лишь поверхности, и я хочу подчеркнуть, что существует множество деталей конфигурации для этих классов, которые влияют на токенизацию документов, которые стоит изучить.
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разрабатывайте модели глубокого обучения для текстовых данных уже сегодня!
Создавайте собственные текстовые модели за считанные минуты
… всего несколькими строками кода Python
Узнайте, как это сделать, в моей новой электронной книге:
Глубокое обучение для обработки естественного языка
Он предоставляет самоучителей по таким темам, как:
Пакет слов, встраивание слов, языковые модели, создание титров, перевод текста и многое другое.