
Морфологический разбор слова «стройка»
Часть речи: Существительное
СТРОЙКА — неодушевленное
Начальная форма слова: «СТРОЙКА»
| Слово | Морфологические признаки |
|---|---|
| СТРОЙКА |
|
Все формы слова СТРОЙКА
СТРОЙКА, СТРОЙКИ, СТРОЙКЕ, СТРОЙКУ, СТРОЙКОЙ, СТРОЙКОЮ, СТРОЕК, СТРОЙКАМ, СТРОЙКАМИ, СТРОЙКАХ
Разбор слова по составу стройка
| Основа слова | стройк |
|---|---|
| Корень | строй |
| Суффикс | к |
| Окончание | а |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СТРОЙКА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «стройка»
1
Все знали, что «стройка» – это не неопределённое понятие где-то там, в новых районах, «стройка» – именно недостроенные руины плавательного бассейна.
Пасынки отца народов. Мне спустит шлюпку капитан. Квадрология. Книга вторая, Александрос Бурджанадзе2
Стройка ждёт, великая стройка коммунизма.
Вижу сердцем, Александр Сергеевич Донских3
Практически речь здесь идет сразу о нескольких стройках: проспект Победы Социализма, Дом науки, стройка Министерства национальной обороны.
4
Стройкастройкой – бетономешалка, лопаты, кирпичи и вёдра.
T-Shirtoлогия. Общая теория футболки. Полутрикотажный роман, Bandy Sholtes, 2015г.5
Жизнь рядом со стройкой – удовольствие невеликое, а в том, что за забором развернется великая стройка, сомневаться не приходилось.
Железный характер, Лариса Райт, 2015г.Найти еще примеры предложений со словом СТРОЙКА
Карточки с заданиями по русскому языку по теме «Разбор слова по составу»
Карточки для индивидуальной работы по русскому языку
для учащихся 3 класса
Карточки
можно использовать на этапе закрепления и диагностики темы «Разбор слова по
составу».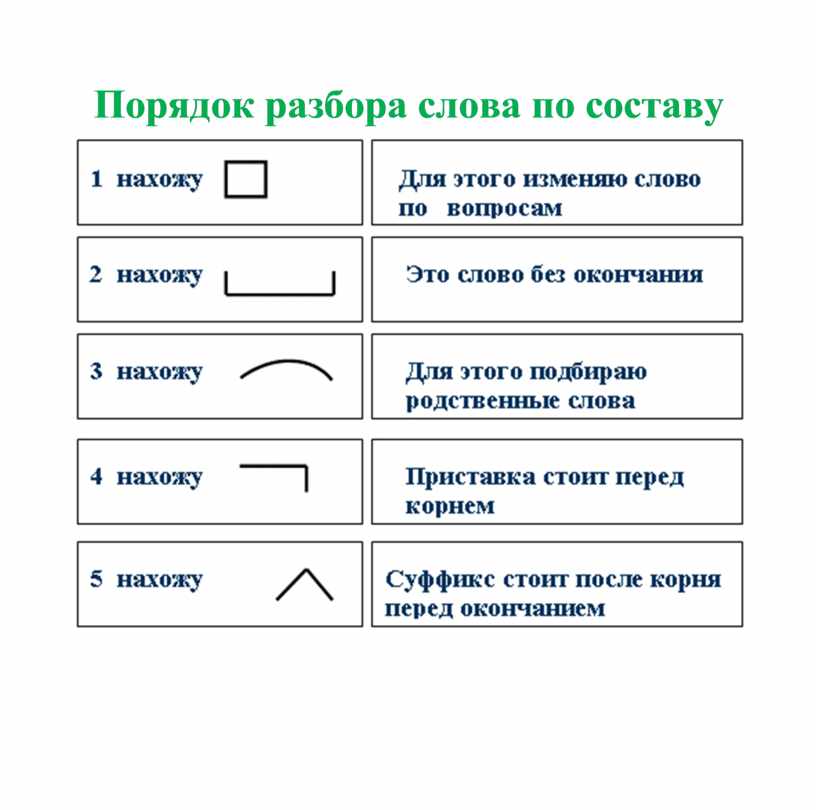 Задания в карточках предложены двух уровней: (1)- базовый, (2)-
повышенный.
Задания в карточках предложены двух уровней: (1)- базовый, (2)-
повышенный.
Карточка №1
1(1) Разобрать слова по составу.
Снежинка, переносить, заморозить, рыбка, мореход, лётчик, кустик, корешок.
2(2) Распределите слова в соответствующие столбики, соответственно схемам. Разберите слова по составу.
Банька, снежный, добежать, учение, ответить, разговор, ночь, черный.
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Карточка №2
1(2)Разбери слова по составу. Запиши слова в соответствующие столбики.
Сад , переход, медовый, улететь, залез,
выходной, белый.
слова, называющие предметы | слова, называющие действия | слова, называющие признаки |
|
|
|
|
|
|
|
|
|
|
|
|
2(2) Разбери слова по составу. Найди слова с одинаковым составом и выпиши их ниже парами.
Прибрежный, ключик, небесный, подушка, подосиновик, осиная, читать, учить, дорисовать, кленовый.
____________________________________________________________________________________________________________________________________
Карточка №3
1(2) Разбери слова по составу.
Листочек, школьник, держать, бой, купить, снежок, подорожник, учение, долететь.
Придумайте слово с таким же составом как слово- ПОДОРОЖНИК.
____________________________________________________________________________________________________________________________________
2(2) Отгадайте слово и разберите его по составу.
| Приставка как, в слове …
| Корень как, в слове …
| Суффикс как, в слове …
| Окончание как, в слове … | Получилось слово… |
1 | понес | бегать | читать | летать |
|
2 |
| посадить | мостовая | серая |
|
3 | залетать | полёт | смотреть | ходить |
|
4 | почитать | дорожка | подснежник | конь |
|
5 |
| ветреная | снежок | стул |
|
Карточка №4
1(1)
Разобрать слова по составу.
Дубовый, длинный, мяч, перелётная, подбежать, осмотреться, подъехать, улей.
2(2) Распределите слова в соответствующие столбики, соответственно схемам. Разберите слова по составу.
Стена, ручной, море, ключик, звонкий, подвозить, зимушка, осенняя, переход, школьный.
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Карточка №5
1(2)Разбери слова по составу. Запиши слова в соответствующие столбики.
Стройка, цветник, ворона, кочка, снеговой, бежать, дубовая, стульчик, слоненок, береговая.
слова, называющие предметы | слова, называющие действия | слова, называющие признаки |
|
|
|
|
|
|
|
|
|
|
|
|
2(2) Разбери слова по составу. Найди слова
с одинаковым составом и выпиши их ниже парами.
Найди слова
с одинаковым составом и выпиши их ниже парами.
Стенка, травяной, бумажка, прибрежная, город, глазик, лесник, посадить, листовой, чай , кофе.
____________________________________________________________________________________________________________________________________
Карточка №6
1(2) Разбери слова по составу.
Крот, девица, ученик, весёлый, листочек, ученица, молочный, метро, желтый.
Придумайте слово с таким же составом как слово- молочный.
____________________________________________________________________________________________________________________________________
2(2) Отгадайте слово и разберите его по составу.
| Приставка как, в слове …
| Корень как, в слове …
| Суффикс как, в слове …
| Окончание как, в слове … | Получилось слово… |
1 | донести | бежать | читать | учить |
|
2 |
| садик | медовый | белая |
|
3 | захочет | летчик | смотреть | ходить |
|
4 | порулить | дорожная | подснежник | лес |
|
5 |
| круглый | дружок | пень |
|
Карточки по теме «Состав слова»(3 класс)
Карточки
«Состав слова». 3класс
3класс
Соловьева Анна Сергеевна,
учитель начальных классов
МОБУ СОШ №7 города Тынды
Карточка №1.
1.Разбери слова по составу:
Травинка, написала, прабабушка, подорожник, поварешка, придворный, полюшко, березовый, пуховый, лисенок, северное, самокат, белохвостый
2.Подбери 3 слова к схеме:
Карточка №2.
1.Разбери слова по составу:
Известные, подбородок, перекличка, тяжелый, быстроходный, предгрозовая, дедушка, прадед, прабабушка, речушка, охотники, полотно, предрассветная
2. Подобрать однокоренные слова с корнем -враг- -лес-
Карточка №3.
1. Разбери слова по составу
Интересная, предгрозовая, чистильщик, золотая, пришкольный, подсвечник, дымоход, близкий заварка, солонка, головушка, теплоход, охотники.
2.Подбери слова к схемам:
а) приставка + корень + окончание
б) приставка + корень + суффикс
Карточка №4.
1. Разбери слова по составу
Иголочка, журавлиная, садик, выдумка, замазка, выходной, липовый, стройка, звонок, цветной, ласточка, тёмный, ночка, снеговой
2.Подчеркни в каждой строке лишнее слово. Выдели корень в однокоренных словах.
Родина, родной, род, огород.
Моржи, моряк, морской, море.
Дело, деловой, делить, делать.
Песня, песок, песочек, песочный.
Лук, луч, луковый, лучок.
Карточка №5.
1. Разбери слова по составу
Примерка, северный, сладкий, поднос, тёплый, вырубка, говоришь, карандаш, избушка, беленький, сиреневый, зверёк, звёздочка
2. Образуй слова с помощью данных приставок: под- от- при- у-
Образуй слова с помощью данных приставок: под- от- при- у-
Ползти-………………, бежать-…………….., тащить-……………….., гнать-………………….., нести-………………., плыть-…………………, водить-……………………., лететь-…………………………….
Карточка №6.
Поездка, лисёнок, приморский, снежок, зимнее, дорожки, денёк, подруга, река, строитель, учитель, школьник, садовник, подъезды, побелка, листья,
2. Образуй слова с помощью суффикса –к-.
печь — ____________________________________________
ночь — ___________________________________________
дача- _____________________________________________
дочь — _____________________________________________
река — ______________________________________________
рука — ______________________________________________
Карточка №7.
1.Разбери слова по составу
Вылет, ёлочные, ёлочка, вырез, пробежка, хлебный, посадка, кораблик, завязка, приход, машинный, излом, подарок, звёздочка, река, ночной, облака,
2. Спишите слова. Выделите основу и окончание.
Парта, партой, у парты; высокая, высокий, высокое.
Карточка №8.
11. Составь и запиши слово. Разбери полученное слово по составу.Корень от слова одеяло
суффикс от слова школьник
приставка от слова подъезд
окончание от слова ушки _________________________________________
2. Распредели слова на три группы.
Записка, молчаливый, листва, выходит, приморский, залепят
Карточка №9
1. Разбери слова по составу.
Подосиновик, пришкольный, ореховый, лисёнок, переходит.
2. Выпиши слова в три столбика: дерево, грибок, сова, пальто, адрес, шоссе
Выпиши слова в три столбика: дерево, грибок, сова, пальто, адрес, шоссе
Слова с нулевым окончанием
Слова, не имеющие окончания
Карточка №10
Найди в каждом столбике «лишнее» слово и зачеркни его. Допиши по два своих примера с данными приставками и суффиксами.
над-
-к-
-ов-
отвар
надомный
берёзка
персиковый
отрезок
надломить
козочка
садовый
отцовский
надпись
травка
беловатый
2. Составь и запиши слово. Разбери полученное слово по составу.
Разбери полученное слово по составу.
Корень от слова моряк
суффикс от слова школьник
приставка от слова городской
окончание от слова синий _______________________________
Карточка №11
Распредели слова на три группы.
Ранний, пробежка, переходы, беленький, настенный, отцветёт
Разбери слова по составу.
Золотистый, подберёзовик, пушистая, улетит, солнышко.
Вход на сайт
Красивая природа
Конец формы
Друзья сайта
.
Непроизносимые согласные в корне слова — Правила русского языка
Учащиеся часто пропускают непроизносимые согласные или вставляют лишние буквы, потому что У многих не выработан навык образования нужных форм слова, подбора однокоренных слов.
При работе над этой темой можно использовать те же методические приемы, что и при изучении сомнительных согласных.
Упражнения на правописание слов с непроизносимыми согласными дают большой материал для работы по лексике и словообразованию, помогают учащимся разобраться в семантике целого ряда трудных слов, поупражняться в разборе слов по составу.
В результате этой работы, учащиеся убеждаются, как важно правильно выделять корень и подбирать родственные слова.
Повторение различных приемов проверки написания непроизносимых согласных приводится в процессе выполнения упражнений.
1. Подобрать в качестве проверочного слова глагол: поздний — опоздать, хрустнуть — хрустеть.
Запасной, громоздкий, свистнуть, пастбище, ужасный, лестный, расчистка, повестка, верстка, хлестнуть.
2. Подобрать в качестве проверочного слова существительное: тростник.- трости, древесный — древесина.
Чудесница, местность, грустный, здравствовать, страстный, тяжеловесный, агентство, известный, редкостный, шотландский, завистливый, голландский, усердный, фашистский. честный, доблестный.
честный, доблестный.
3. Проверить прилагательное существительным с предлогом: безжалостный — без жалости, безучастный — без участия.
Бессовестный, бесхитростный, безвластный, бескорыстный, безрадостный, беспристрастный, безлесный, бесчестный, безопасный, безвкусный.
4. Написать, от каких слов образованы данные сложные слова; подчеркнуть проверочное слово: сенокосный — косить сено.
Добросовестный, злосчастный, полновластный, буревестник, ‘Тяжеловесный, двухъярусный, жизнерадостный, ежечасный, победоносный, кровеносный, сорокаградусный, орденоносный, рукописный.
5. В один столбик выписать словосочетания, в которых есть слова с непроизносимой согласной, в другой — словосочетания, в которых таких слов нет. Доказать, что вы выписали правильно.
Ужасное зрелище, корыстные цели, захолустный город, вкусный обед, гигантская стройка, опасная дорога, безвестный поэт, чудесный день, окрестные места, согласный звук, уездный лекарь, поверхностный взгляд, запасной выход, грустная улыбка, целостное впечатление, безмолвствующая толпа, несносный характер, чествовать юбиляра, участвовать в спектакле.
6. Разобрать слова по составу.
Безмолвствовать, чувствительность, бескорыстный, бесхитростный, завистливый, тяжеловесный, предшественник, бесчувственный, шефствовать, происшествие, искусственный, здравствовать, объездчик, громоздкий, бесстрастный, безрадостный, безвластный, крепостной, доблестный, искусный, напутственный, безучастный, неуместный.
7. К прилагательным в данных словосочетаниях подобрать синонимы с непроизносимой согласной.
Неглубокая рецензия (поверхностная) ,огромное здание (гигантское), жестокий враг (безжалостный), печальный взгляд (грустный), храбрый воин (доблестный), тяжелая мебель (громоздкая), равнодушный (бесстрастный).
8. Подобрать антонимы с непроизносимой согласной.
Веселый (грустный), счастливый (несчастный), печальный (радостный), знакомый (неизвестный), хитрый (бесхитростный).
Приводим материал для словарных диктантов.
1. Безопасная дорога, завистливый взгляд, древесная кора, чудесная сенокосная пора, гигантский метеор, редкостные ковры, добросовестный труд; горестная повесть, устный счет, небесный.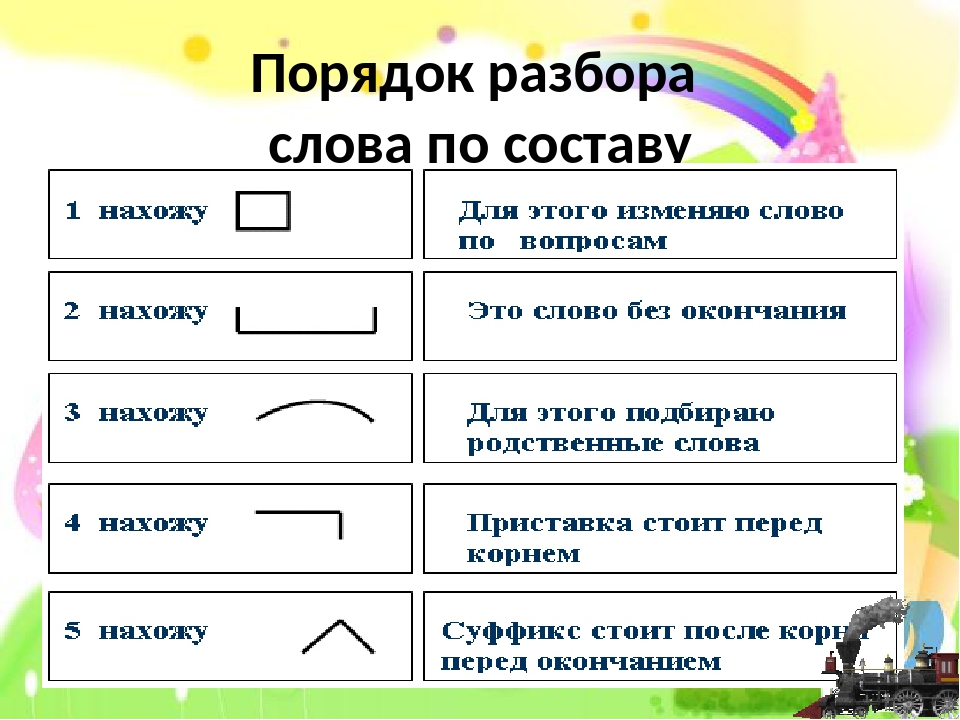 свод, капустные листья, отличный наездник, тягостное молчание, безвестные села. .
свод, капустные листья, отличный наездник, тягостное молчание, безвестные села. .
2. Предчувствовать опасность, радостный праздник, чествовать героя, тягостная поездка, удивительные яства, сочувствовать ровеснику, доблестные участники, ужасное происшествие, присутствовать на празднике.
Творческая работа в группе «Собери слова из морфем»
Жумагулова Улдай Айнадиновна учительница русского языка и литературы средней школы №16 им. М.Горького г.Казалинска Кызылординской областиТема: Приставка и суффикс как способ образования новых слов.
Цели: 1. закрепить знания учащихся об особенностях частей слова — приставки и суффикс, уметь правильно писать их;
2. развивать логику, внимание, память; способствовать формированию навыков грамотного письма, расширению и обогащению словарного запаса учащихся;
3. способствовать воспитанию ответственного отношения к обучению.
Тип урока: изучение нового материла
Оборудование: интерактивная доска, опорная схема, презентация к уроку, распечатка цветка ромашки, кроссворд, карточки с заданиями.
Ход урока
І.Организационный момент
Приветствие. Сообщение темы и целей урока.
ІІ.Проверка домашнего задания.
1.Работа по опорной схеме. Мозговая атака.
(Класс разделен на три группы)
Ребята, давайте вспомним о чем мы с вами говорили на прошлых уроках? (Верно). Из каких частей состоит слово? Что называется корнем слова? Что такое приставка? Что такое суффикс? Что такое окончание? Что входит в состав основы слова?
ІІІ. Изучение нового материала
1 Посмотрите на пары слов. От каких слов и при помощи чего образованы данные слова.
Танк – танкист читать – прочитать
Школа – школьный ходить – приходить
Помощь – помощник писать – написать
Окно – подоконник
Давайте сделаем вывод: одни слова образованы от других слов с помощью суффиксов, одни слова образованы при помощи приставок, есть слова образованные одновременно при помощи приставок и суффиксов.
2 Работа с учебником. Упр. 3 стр. 69
Упр. 3 стр. 69
Задание: Определите, от каких слов и при помощи чего они образованы
Подоконник, подснежник, подсолнечник, поездка, разведка, покупка, записка.
Разобрать слова по составу.
3. Творческая работа в группе «Собери слова из морфем»
Задание: На доске морфемы: рас-, -сказ-, -чик; зим-, -н-, ий; у-, чи-,
-тель; раз-, -вед-, -чик; по-, -сад-, -ка.
Из них нужно собрать пять слов (рассказчик, зимний, учитель, разведчик, посадка) и разобрать по составу.
4.Физминутка. Под музыку из мультфильма упражнения для нормализации мозгового кровообращения.
5. Работа в группе. Игра «Ромашка».
Задание: Каждая группа получает листок бумаги с изображенной на ней ромашкой, внутри которой записан глагол (носить, возить,ехать, ходить). В лепестки вам нужно вписать приставки, которые могут сочетаться с данным глаголом и образовать новые слова.
Побеждает тот, кто первый справится с задачей быстрее и правильно.
6. Упражнение «Развиваем память».
Упражнение «Развиваем память».
Задание. Составьте словосочетания. Прибавьте к глаголам из ромашки существительные и запишите в тетрадь.
Приносить дрова, отвозить на санках, приходить в школу…
7. Разноуровневое задание
1 уровень
Задание : выписать слова, образованные при помощью приставки или суффикса
Галчонок неожиданно для всех научился самостоятельно есть.
Задание: Выдели главные члены предложения
Строители создают новые города.
2 уровень
Задание: разбери слова по составу.
Грустный, разъезд, заморозки, погода, полет, грибник, вырубка.
3 уровень
Задание: Образуй новые слова при помощи приставок и суффисов
Стройка — школа —
Ходит – футбол —
Писал —
8.Творческое задание: расшифровать телеграмму, составив из морфем слова.
ВЫ- …
1-ое слово.Приставка как в слове прехорошенькая,
Корень как в слове красавица,
Суффикс как в слове вольный,
Окончание как в слове счастливые;
Вы прекрасные
2-ое слово.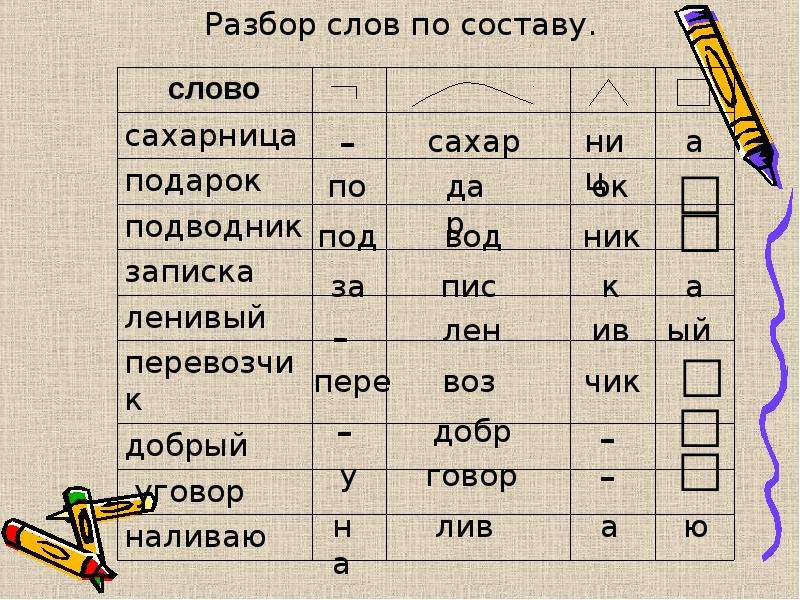 Корень как в слове ученый,
Корень как в слове ученый,
Суффикс как последний суффикс в слове певуче,
Суффикс как в слове лесник
Окончание как в слове рыбаки;
ученики
3-е слово. Корень как в слове вера,
Суффикс как в слове летняя,
Окончание как в слове любимые;
и верные
4-ое слово. Корень как в слове подружка (ж// з),
Окончание как в слове семья.
друзья
Вы прекрасные ученики и верные друзья!
ІҮ.Подведения итогов.
Решить кроссворд.
По горизонтали: 1. Изменяемая часть слова. 5. Главная значимая часть слова, в которой заключено общее значение всех однокоренных слов.
По вертикали: 2. Часть слова без окончания. 3. Часть слова, которая находится перед корнем и обычно служит для образования слов. 4. Часть слова, которая находится после корня и обычно служит для образования слов.
Ү.Комментированное выставление оценок.
— Перед вами лежат фрукты яблоки, бананы, груши. С помощью этих фруктов оцениваете свою работу на уроке.
Яблоко – у меня все получилась, я доволен своей работой на уроке.
Бананы – у меня были затруднения
Груши – у меня ничего не получилось, я не доволен своей работой
ҮІ. Домашнее задания
Упражнение 4 стр. 69
разделить черточками для переноса. стройка, мойка, скамейка, линейка, ручейки, чайник, сойка, просьба, коньки, пеньки, зверьки, огоньки, топольки,
10-11 класс
школьник.
Asslovesu 06 янв. 2016 г., 4:00:32 (5 лет назад) савачка06 янв. 2016 г., 5:20:06 (5 лет назад)
Строй-ка, мой-ка, ска-мей,ка, ли-ней-ка, ру-чей-ки, чай-ник, сой-ка, прось-ба, конь-ки, пень-ки, зверь-ки, огонь-ки, то-поль-ки, школь-ник.
Iukshctgshsygdh06 янв. 2016 г., 7:33:52 (5 лет назад)
строй-ка, мой-ка, ска-мей-ка, ли-ней-ка, ру-чей-ки,чай-ник,сой-ка,прось-ба, конь-ки,пень-ки,зверь-ки,о-гонь-ки, то-поль-ки, школь-ник
Ответить
Другие вопросы из категории
Mansur2001 / 30 дек. 2015 г., 15:42:01
2015 г., 15:42:01
(на)чисто,закрыл (на)глух…,(перво)(на)перво,остановился (на)миг,узнал (в)первые,принять(в)штыки,заметил (во)первых,сделал (по)моему,всё (чин)чином,пойдем (в)круговую,пришли (не)(к)стати,жили (бок)(о)бок,перевязал (крест)(на)крест,прийти (в)упадок,звал (по)(имени)отчеству,ступал (по)медвежьи,остался (в)накладе,(на)завтр… о нем забыли,заговорили (на)перебой,работал (на)износ.
Читайте также
Ssmpak1 / 08 окт. 2013 г., 6:01:35
КОМПЬЮТЕР, САМОЛЕТ, ПАРОВОЗ, маленький, кроссворд, обезьяна, варенье, вьюга, хоккей, апрельский (день).Запишите слова. Разделяйте их черточкой для переноса там, где он возможен.
О б р а з е ц : Ком-пью-тер…
Вы находитесь на странице вопроса «разделить черточками для переноса. стройка, мойка, скамейка, линейка, ручейки, чайник, сойка, просьба, коньки, пеньки, зверьки, огоньки, топольки,«, категории «русский язык«. Данный вопрос относится к разделу «10-11» классов. Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта.
Данный вопрос относится к разделу «10-11» классов. Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта.
NLP1
NLP1Обзор НЛП: проблемы и стратегии
доменов приложений НЛП:
- обработка текста — обработка текста, электронная почта, орфография и грамматика шашки
- интерфейсов к базам данных — языки запросов, поиск информации, интеллектуальный анализ данных, резюмирование текста
- экспертные системы — объяснения, диагностика болезней
- лингвистика — машинный перевод, контент-анализ, помощники писателей, поколение языка
Инструменты для НЛП:
- Языки программирования и программное обеспечение — Пролог , ALE , Lisp / Схема, C / C ++
- Статистические методы — Марковские модели, вероятностные грамматики, на основе текста анализ
- абстрактных моделей — контекстно-свободные грамматики (BNF), грамматики атрибутов, Исчисление предикатов и другие семантические модели, основанные на знаниях и онтологические методы
Лингвистическая организация НЛП
- Грамматика и лексика — правила построения хорошо структурированных предложений, и слова, составляющие эти предложения
- Морфология — образование слов из корней, префиксов и суффиксов
E.г., есть + s = ест
- Синтаксис — набор всех правильно построенных предложений на языке и правила их формирования
- Семантика — значения всех правильно построенных предложений в языке
- Прагматика (мировое знание и контекст) — влияние чего мы знаем о реальном мире по смыслу предложения. Например, » воздушный шар роза «позволяет сделать вывод, что он должен быть заполнен вещество легче воздуха.
- Влияние контекста дискурса (например, роли говорящего-слушающего в разговоре) о значении предложения
- Неопределенность
- лексический — выбор значений слов (например, летает )
- синтаксис — выбор структуры предложения (например, Она увидела человек на холме с телескопом .) Семантика
- — выбор значения предложения (например, Они летают самолеты.)
Грамматика и синтаксический анализ
Синтаксические категории (общие обозначения) в NLP
- np — именная фраза
- vp — глагольная фраза
- с — предложение
- det — определитель (артикул)
- n — имя существительное
- tv — переходный глагол (принимает объект)
- iv — непереходный глагол
- преп — предлог
- п.
 п. — предложная фраза
п. — предложная фраза - прил. — прилагательное
Контекстно-свободная грамматика (CFG) — это список правил, определяющих набор всех правильно построенных предложений на языке.У каждого правила есть левая сторона, которая определяет синтаксическую категорию, и правую часть, который определяет его альтернативные составные части, читая слева направо.
Предложение на языке, определенном CFG, представляет собой серию
слов, которые могут быть получены с помощью
, систематически применяя правила, начиная с правила, которое
s с левой стороны.Анализ
предложения представляет собой серию приложений правил
в котором синтаксическая категория заменяется
правой частью правила, имеющего эту категорию на своей
слева, и последнее применение правила
дает само предложение. Например, анализ
фраза «мечта жирафа»:
Например, анализ
фраза «мечта жирафа»:
s => np vp => det n vp => n vp => жираф vp => жираф iv => жираф мечты
Удобный способ описать синтаксический анализ — показать его
Дерево синтаксического анализа , которое представляет собой просто графическое отображение
синтаксического анализа.На рисунке 1 показано дерево синтаксического анализа для предложения.
«жираф мечтает». Обратите внимание на
, что корень каждого поддерева имеет грамматическую категорию, которая
появляется в левой части правила
, и дочерние элементы этого корня идентичны элементам
в правой части этого правила.
 язык в 1960 году.
язык в 1960 году.Цели лингвистических грамматик
- Разрешить двусмысленность — убедиться, что в предложении есть все возможные анализирует (например, «плодовые мушки, как яблоко» на рис. 2)
- Ограничение грамматики — например, требуется согласование количества, напряжение, пол, лицо. Запретить «жираф ест яблоко» (рис. 1)
- Обеспечение осмысленности — E.g., запретить «яблоко съедает жираф »(рисунок 1)
NLP против PLP (обработка языков программирования):
Есть некоторые параллели и некоторые фундаментальные различия между цели и методы обработки языка программирования (дизайн и компилятор стратегии) и обработки естественного языка. Вот краткое изложение:| | НЛП | PLP |
| область дискурса | широкий: что можно выразить | узкий: что можно вычислить |
| словарь | большой / сложный | малый / простой |
| грамматические конструкции | много и разнообразно — декларативная — вопросительная — фрагменты и т.  Д. Д. | несколько — декларативная — императивная |
| значения выражения | многие | одна |
| инструменты и методы | морфологический анализ синтаксический анализ семантический анализ интеграция мировых знаний | лексический анализ контекстно-свободный синтаксический анализ генерация / компиляция кода интерпретация |
Ссылки
- Мэтьюз, Клайв, Введение в обработку естественного языка через Пролог , Лонгман, 1998.
- Аллен, Джеймс, Понимание естественного языка 2e, Бенджамин Каммингс, 1995.
- Уилкс, Йорик, «Обработка естественного языка», Связь с ACM 39, 1 (январь 1996 г.
 ),
60-62.
),
60-62. - Ковингтон, Майкл, Обработка естественного языка для программистов на прологе , Прентис Холл, 1994.
- Мэннинг, К. и Х. Шутце, Основы статистической
Обработка естественного языка , MIT Press, 1999.
Что такое трансформатор BERT: внимание — это еще не все, что вам нужно | Дэмиен Силео | synapse_dev
Фреймворк синтаксического анализа / композиции для понимания Transformers
BERT — это новейшая модель обработки естественного языка, которая показала новаторские результаты во многих задачах, таких как ответы на вопросы, логический вывод естественного языка и обнаружение перефразирования.Поскольку он находится в открытом доступе, он стал популярным в исследовательском сообществе.
На следующем графике показана эволюция баллов по тесту GLUE — среднее значение баллов в различных оценочных задачах НЛП.
Хотя неясно, являются ли все задачи GLUE очень значимыми, общие модели, основанные на кодировщике с именем Transformer (Open-GPT, BERT и BigBird), сократили разрыв между моделями, предназначенными для конкретных задач, и производительностью человека и в пределах менее год.
Однако, как отмечает Йоав Голдберг, мы не до конца понимаем, как Transformer кодирует предложения.
[Трансформаторы] в отличие от RNN — полагаются исключительно на механизмы внимания и не имеют явного понятия порядка слов, кроме маркировки каждого слова его вложением абсолютной позиции. Эта зависимость от внимания может привести к тому, что можно ожидать снижения производительности в задачах, чувствительных к синтаксису, по сравнению с моделями RNN (LSTM), которые напрямую моделируют порядок слов и явно отслеживают состояния в предложении.
В нескольких статьях подробно рассматриваются технические аспекты BERT. Здесь мы постараемся предоставить некоторые новые идеи и гипотезы, которые могли бы объяснить сильные возможности BERT.
Способ понимания языка людьми — давний философский вопрос. В 20-м веке два дополнительных принципа пролили свет на эту проблему:
- Принцип композиционности гласит, что значение словосочетаний происходит от значения отдельных слов и от того, как эти слова сочетаются.
 Согласно этому принципу значение словосочетания «плотоядные растения» может быть получено из значения «плотоядные» и значения «растение» посредством процесса, названного составом.[Szabó 2017]
Согласно этому принципу значение словосочетания «плотоядные растения» может быть получено из значения «плотоядные» и значения «растение» посредством процесса, названного составом.[Szabó 2017] - Другой принцип — это иерархическая структура языка. В нем говорится, что посредством анализа предложения можно разбить на простые структуры, такие как предложения. Предложения можно разбить на глагольные и существительные, и так далее.
Анализ иерархических структур и рекурсивное извлечение значения из их компонентов до тех пор, пока не будет достигнут уровень предложения, является привлекательным рецептом для понимания языка. Рассмотрим предложение «Барт наблюдал за белкой в бинокль» .Хороший компонент синтаксического анализа может дать следующее дерево синтаксического анализа:
Дерево синтаксического анализа на основе избирательных округов предложения «Барт наблюдал за белкой в бинокль» Значение предложения может быть получено из последовательных композиций (составляющих «а», и «Белка» , «наблюдали» с «белкой », « смотрели белку» и «в бинокль» ) до тех пор, пока не будет получено значение предложения.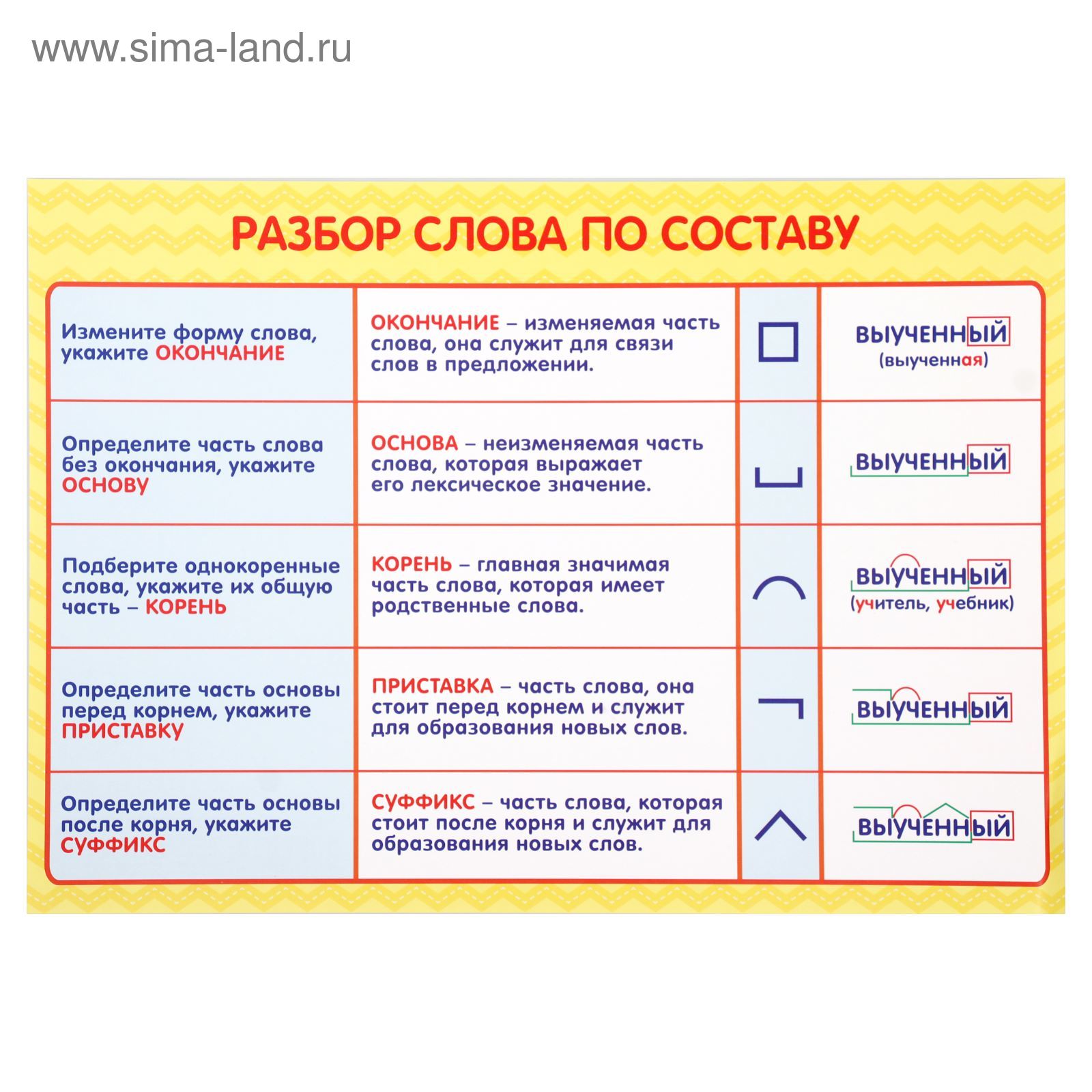
Векторные пространства (как при встраивании слов) могут использоваться для представления слов, фраз и других составляющих.Композицию можно представить в виде функции f, которая будет составлять ( «a» , «белка» ) в значимое векторное представление «белка» = f ( «a» , «белка» ). [Baroni 2014]
Однако композиция и синтаксический анализ — сложные задачи, и они нуждаются друг в друге.
Очевидно, что композиция полагается на результат синтаксического анализа, чтобы определить, что должно быть составлено. Но даже при правильном вводе композиция — сложная проблема.Например, значение прилагательных меняется в зависимости от слова, которое они характеризуют: цвет «белое вино» на самом деле желтоватый, а белый кот на самом деле скорее белый. Это явление известно как со-композиция. [Pustejovsky 2017]
Представления «белого вина» и «белого кота» в двухмерном семантическом пространстве (с цветовыми измерениями) Для композиции также может потребоваться более широкий контекст. Например, способ составления слов в строке «зеленый свет» зависит от ситуации.Зеленый свет может обозначать авторизацию или фактический зеленый свет. Значение некоторых идиоматических выражений требует формы запоминания, а не композиции как таковой. Таким образом, выполнение этих композиций в векторном пространстве требует мощных нелинейных функций, таких как глубокая нейронная сеть (которая также может запоминать [Arpit 2017]).
Например, способ составления слов в строке «зеленый свет» зависит от ситуации.Зеленый свет может обозначать авторизацию или фактический зеленый свет. Значение некоторых идиоматических выражений требует формы запоминания, а не композиции как таковой. Таким образом, выполнение этих композиций в векторном пространстве требует мощных нелинейных функций, таких как глубокая нейронная сеть (которая также может запоминать [Arpit 2017]).
И наоборот, операция синтаксического анализа, возможно, требует композиции для работы в некоторых случаях. Рассмотрим следующее дерево синтаксического анализа того же предыдущего предложения: « Барт наблюдал за белкой в бинокль ».
Другое дерево синтаксического анализа на основе избирательного округа предложения «Барт наблюдал за белкой в бинокль». Хотя синтаксически это верно, этот синтаксический анализ приводит к странной интерпретации предложения, в котором Барт наблюдает (невооруженным глазом) за белкой, держащей бинокль. Тем не менее, необходимо использовать некоторую форму композиции, чтобы понять, что появление белки в бинокль — маловероятное событие.
Тем не менее, необходимо использовать некоторую форму композиции, чтобы понять, что появление белки в бинокль — маловероятное событие.
В более общем плане, многие разрешения неоднозначности и интеграции базовых знаний должны продолжаться до того, как будут получены соответствующие структуры.Но этот вывод может быть также достигнут с помощью некоторых форм синтаксического анализа и композиции.
Несколько моделей пытались применить на практике комбинацию синтаксического анализа и композиции [Socher 2013], однако они полагались на ограничительную настройку с вручную аннотированными стандартными деревьями синтаксического анализа и уступили гораздо более простым моделям.
Мы предполагаем, что трансформеры в значительной степени полагаются на эти две операции новаторским способом: поскольку композиция требует синтаксического анализа, а синтаксический анализ требует композиции, трансформаторы используют итерационный процесс с последовательными этапами синтаксического анализа и композиции для решения проблемы взаимозависимости. Действительно, Трансформеры состоят из нескольких составных слоев (также называемых блоками). Каждый блок состоит из уровня внимания, за которым следует нелинейная функция, применяемая к каждому токену.
Действительно, Трансформеры состоят из нескольких составных слоев (также называемых блоками). Каждый блок состоит из уровня внимания, за которым следует нелинейная функция, применяемая к каждому токену.
Мы постараемся выделить связь между этими компонентами и фреймворком синтаксического анализа / композиции.
В BERT механизм внимания позволяет каждому токену из входной последовательности (например, предложениям, состоящим из токенов слов или подслов) фокусироваться на любом другом токене.
В целях иллюстрации мы используем инструмент визуализации из этой статьи, чтобы углубиться в головы внимания и проверить нашу гипотезу на предварительно обученной базовой модели BERT без корпуса. На следующей иллюстрации головы внимания слово «оно», относится ко всем остальным фишкам и, кажется, фокусируется на «улица», и «животное».
Визуализация значений внимания на слое 0, заголовок №1, для токена «оно».
BERT использует 12 отдельных механизмов внимания для каждого уровня.Таким образом, на каждом уровне каждый токен может фокусироваться на 12 различных аспектах других токенов. Поскольку в Трансформаторах используется множество различных головок внимания (12 * 12 = 144 для базовой модели BERT), каждая голова может фокусироваться на различных типах комбинаций составляющих.
Мы проигнорировали значения внимания, относящиеся к токенам «[CLS]» и «[SEP]» . Мы пробовали использовать несколько предложений, и трудно не переоценить результаты, поэтому вы можете смело проверять нашу гипотезу на этой записной книжке с разными предложениями.Обратите внимание, что на рисунках левая последовательность соответствует правой последовательности.
На втором уровне голова №1 внимания, кажется, формирует составляющие на основе родства.
Разбор строки в Swift | Swift by Sundell
Практически каждая программа на планете так или иначе имеет дело со строками, поскольку текст играет фундаментальную роль в том, как мы общаемся и представляем различные формы данных. Но обработка и анализ строк одновременно надежным и эффективным способом может иногда быть действительно трудным.Хотя некоторые строки имеют очень строгий и удобный для компьютера формат, например JSON или XML, другие строки могут быть гораздо более хаотичными .
Но обработка и анализ строк одновременно надежным и эффективным способом может иногда быть действительно трудным.Хотя некоторые строки имеют очень строгий и удобный для компьютера формат, например JSON или XML, другие строки могут быть гораздо более хаотичными .
На этой неделе давайте рассмотрим различные способы синтаксического анализа и извлечения информации из таких строк, а также то, как разные методы и API приведут к разному набору компромиссов.
Bitrise: Мой любимый сервис непрерывной интеграции. Автоматически создавайте, тестируйте и распространяйте свое приложение при каждом запросе на слияние, а также используйте новый мощный набор надстроек для визуализации результатов тестирования, упрощения доставки приложения и добавления в проект мониторинга сбоев и производительности.Начни бесплатно.
В некотором смысле Swift заработал репутацию немного сложного в работе, когда дело доходит до синтаксического анализа строк. Хотя это правда, что реализация Swift String не предлагает такого же удобства , как многие другие языки (например, вы не можете просто произвольно получить доступ к заданному символу с помощью целого числа, например, string [7] ), это облегчает написание правильного кода синтаксического анализа строки .
Потому что, хотя приятно иметь возможность произвольного доступа к любому заданному символу в строке на основе его воспринимаемой позиции, многоязычный (или, возможно, эмодзи-язычный ?) Мир, в котором мы живем сегодня, делает такие API очень подверженными ошибкам , поскольку способ представления символа в текстовом пользовательском интерфейсе во многих случаях сильно отличается от того, как на самом деле хранит в строковом значении.
В Swift строка состоит из набора значений символов , хранящихся с использованием кодировки UTF-8 . Это означает, что если мы перебираем строку (например, используя цикл для ), каждый элемент будет символом , который может быть буквой, смайликом или какой-либо другой формой символа. Чтобы идентифицировать группы символов (например, буквы или цифры), мы можем использовать CharacterSet , который можно передать в несколько различных API на String и связанных с ним типах.
Допустим, мы работаем над приложением, которое позволяет нескольким разным пользователям совместно работать над документом, и мы хотим реализовать функцию, которая позволяет пользователям упоминать других людей, используя синтаксис @mention , похожий на Twitter.
Выявление пользователей, упомянутых в данной строке, — это задача, которая на самом деле очень похожа на то, что компилятор Swift должен делать при идентификации различных частей в строке кода — процесс, известный как lexing или tokenizing — только то, что наша реализация будет на несколько порядков проще, так как нам нужно искать только одного вида токена.
Начальная реализация может выглядеть примерно так — вычисляемое свойство на String , в котором мы разбиваем строку на основе @ символов, отбрасываем первый элемент (так как это будет текст перед первым @ — sign), а затем compactMap поверх результата — идентификация строк непустых буквенных символов:
extension String {
var упомянутоUsernames: [String] {
let parts = split (разделитель: "@"). dropFirst ()
пусть delimiterSet = CharacterSet.буквы. перевернутые
return parts.compactMap {часть в
let name = part.components (separatedBy: delimiterSet) [0]
return name.isEmpty? ноль: имя
}
}
}
dropFirst ()
пусть delimiterSet = CharacterSet.буквы. перевернутые
return parts.compactMap {часть в
let name = part.components (separatedBy: delimiterSet) [0]
return name.isEmpty? ноль: имя
}
}
} Вышеупомянутая реализация довольно проста и использует некоторые действительно хорошие функции Swift, такие как изменение коллекций, использование compactMap для отбрасывания значений nil и так далее. Но у него есть одна проблема — для требуется три итерации , одна для разделения строки на основе символов @ , одна для итерации по всем этим частям, а затем одна для разделения каждой части на основе небуквенных символов.
Хотя каждая итерация меньше предыдущей (поэтому сложность нашего алгоритма не совсем O (3N) ), несколько итераций чаще всего приводят к некоторым формам узких мест по мере роста входного набора данных. В нашем случае это может стать проблемой, поскольку мы планируем применить этот алгоритм к документам любого размера (возможно, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), Так что давайте посмотрим, сможем ли мы что-то сделать. чтобы оптимизировать его.
В нашем случае это может стать проблемой, поскольку мы планируем применить этот алгоритм к документам любого размера (возможно, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), Так что давайте посмотрим, сможем ли мы что-то сделать. чтобы оптимизировать его.
Вместо того, чтобы разбивать нашу строку на компоненты, а затем повторять эти компоненты, давайте вместо этого сделаем один проход через нашу строку — путем итерации по ее символам.Хотя для этого потребуется немного больше кода ручного синтаксического анализа, это позволит нам сократить наш алгоритм до одной итерации, например:
extension String {
var упомянутоUsernames: [String] {
var partialName: Строка?
var names = [String] ()
func parse (символ _: символ) {
if var name = partialName {
guard character.isLetter else {
if! name.isEmpty {
имена. добавить (имя)
}
partialName = nil
возвратный синтаксический анализ (символ)
}
name.append (символ)
partialName = имя
} else if character == "@" {
partialName = ""
}
}
forEach (синтаксический анализ)
если let lastName = partialName,! lastName.isEmpty {
names.append (фамилия)
}
вернуть имена
}
}
добавить (имя)
}
partialName = nil
возвратный синтаксический анализ (символ)
}
name.append (символ)
partialName = имя
} else if character == "@" {
partialName = ""
}
}
forEach (синтаксический анализ)
если let lastName = partialName,! lastName.isEmpty {
names.append (фамилия)
}
вернуть имена
}
} Обратите внимание, что приведенный выше API isLetter для символа был добавлен в Swift 5.
Хотя вышеупомянутая реализация намного сложнее, чем наша первоначальная, она примерно в два раза быстрее (в среднем), что дает нам первый четкий компромисс : выбираем ли мы более простое решение по потенциальной цене производительности — или мы выберем более сложный, а также более эффективный алгоритм?
Обсуждение того, какой компромисс принять, становится еще более интересным по мере того, как наш список требований растет. Предположим, что после успешного развертывания функции упоминания для наших пользователей мы начали получать запросы на добавление поддержки для хэштегов, и мы решили сделать именно это.
Предположим, что после успешного развертывания функции упоминания для наших пользователей мы начали получать запросы на добавление поддержки для хэштегов, и мы решили сделать именно это.
Поскольку обнаружение имен пользователей и хэштегов — это одна и та же проблема (отличается только ведущий символ — @ и # ), имеет смысл использовать одну и ту же реализацию для обнаружения обоих. Для этого давайте сначала определим тип Symbol , который мы будем использовать для представления упоминания или хэштега:
struct Symbol {
enum Kind {упоминание о регистре, хэштег}
пусть добрые: добрые
var строка: Строка
} Хотя мы, , могли бы вместо использовать перечисление со связанными строковыми значениями — поскольку и упоминания, и хэштеги имеют одну и ту же структуру, это упростит наш алгоритм, если мы будем использовать структуру.Однако, чтобы разрешить использование Symbol в стиле , подобном перечислению , мы также можем добавить некоторые статические фабричные методы, чтобы упростить создание значений с использованием точечного синтаксиса:
extension Symbol {
упоминание статической функции (_ строка: Строка) -> Символ {
символ возврата (вид: упоминание, строка: строка)
}
хэштег static func (_ строка: String) -> Symbol {
символ возврата (вид: хэштег, строка: строка)
}
} С учетом вышеизложенного, давайте обновим наш упомянутый ранее алгоритм Usernames для обнаружения символов, а не только имен пользователей:
extension String {
var symbols: [Symbol] {
var partialSymbol: Символ?
var symbols = [Symbol] ()
func parse (символ _: символ) {
if var symbol = partialSymbol {
охранник. isLetter else {
if! symbol.string.isEmpty {
symbols.append (символ)
}
partialSymbol = nil
возвратный синтаксический анализ (символ)
}
symbol.string.append (символ)
partialSymbol = символ
} еще {
переключить символ {
дело "@":
partialSymbol = .mention ("")
дело "#":
partialSymbol =.хэштег("")
По умолчанию:
перерыв
}
}
}
forEach (синтаксический анализ)
если let lastSymbol = partialSymbol,! lastSymbol.string.isEmpty {
symbols.append (lastSymbol)
}
символы возврата
}
}
isLetter else {
if! symbol.string.isEmpty {
symbols.append (символ)
}
partialSymbol = nil
возвратный синтаксический анализ (символ)
}
symbol.string.append (символ)
partialSymbol = символ
} еще {
переключить символ {
дело "@":
partialSymbol = .mention ("")
дело "#":
partialSymbol =.хэштег("")
По умолчанию:
перерыв
}
}
}
forEach (синтаксический анализ)
если let lastSymbol = partialSymbol,! lastSymbol.string.isEmpty {
symbols.append (lastSymbol)
}
символы возврата
}
} С указанным выше изменением разница между нашей первоначальной реализацией на основе разделения строк и нашим последним алгоритмом становится еще больше — поскольку, если бы мы токенизировали и имена пользователей, и хэштеги путем разделения строк, нам потребовалось бы 6 различных итераций ( 2 раза по 3) — два из которых будут полными проходами через исходную строку.
Однако было бы неплохо, если бы мы смогли найти какую-то золотую середину между простотой нашей первоначальной реализации и мощностью нашего ручного алгоритма. Одним из способов сделать это может быть введение абстракции, которая отделяет часть нашего алгоритма токенизации от логики фактического обращения с любыми найденными токенами.
Для этого давайте переместим основную часть нашего последнего алгоритма в метод tokenize , который принимает словарь обработчиков, хэшированных в зависимости от того, какой символ они обрабатывают, например:
extension String {
func tokenize (с использованием обработчиков: [Character: (String) -> Void]) {
var parsingData: (символ: String, обработчик: (String) -> Void)?
func parse (символ _: символ) {
if var data = parsingData {
охранник.isLetter else {
if! data.symbol.isEmpty {
data.handler (data.symbol)
}
parsingData = nil
возвратный синтаксический анализ (символ)
}
data.symbol.append (символ)
parsingData = данные
} еще {
guard let handler = handlers [персонаж] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
forEach (синтаксический анализ)
если пусть lastData = parsingData,! lastData.symbol.isEmpty {
lastData.handler (lastData.symbol)
}
}
} Вышеупомянутое не только немного очищает нашу реализацию, но также дает нам гораздо больше гибкости — поскольку теперь мы можем повторно использовать один и тот же алгоритм токенизации во многих различных контекстах и выбирать, как каждый токен должен обрабатываться на сайте вызова. .
Теперь мы можем сократить наш код синтаксического анализа символов с предыдущего до следующего:
extension String {
var symbols: [Symbol] {
var symbols = [Symbol] ()
tokenize (используя: [
"@": {символы.append (.mention ($ 0))},
"#": {symbols.append (.hashtag ($ 0))}
])
символы возврата
}
} Очень красиво и чисто! 👍 Но, как и раньше, здесь есть ряд компромиссов. Хотя абстракции — отличный способ скрыть сложную логику за гораздо более красивым API, они не бесплатны. Фактически, нашей последней версии требуется примерно на 40% больше времени для выполнения по сравнению с тем, когда алгоритм был встроен в свойство символов . Тем не менее, это примерно в два раза быстрее, чем делать то же самое при разделении строк, так что на самом деле это может быть та хорошая золотая середина, которую мы искали.
До сих пор мы в основном сравнивали итерацию вручную по символам строки с разбиением ее на компоненты, но, как и во многих других случаях, есть и другие варианты, которые следует учитывать.
Одним из таких вариантов является использование типа Scanner от Foundation для непрерывного сканирования строки для идентификации искомых токенов. Как и в нашей предыдущей реализации, он позволяет нам полагаться на абстракцию (на этот раз предоставленную Apple) для обработки большей части «тяжелой работы» нашего алгоритма.Вот как может выглядеть такая реализация:
extension String {
var symbols: [Symbol] {
let scanner = Сканер (строка: self)
let symbolSet = CharacterSet (charactersIn: "@ #")
var symbols = [Symbol] ()
var symbolKind: Тип символа?
while! scanner.isAtEnd {
if let kind = symbolKind {
symbolKind = nil
var результат: NSString?
scanner.scanCharacters (от:.буквы, в: & результат)
guard let string = result else {
Продолжать
}
symbols.append (Символ (вид: вид, строка: строка как строка))
} еще {
scanner.scanUpToCharacters (от: symbolSet, в: nil)
if scanner.scanString ("@", into: nil) {
symbolKind = .mention
} else if scanner.scanString ("#", into: nil) {
symbolKind =.хэштег
}
}
}
символы возврата
}
} В то время как «Objective-C-ness» из Scanner может сделать наш код немного менее «Swifty» , это допустимый вариант для такого рода проблем — и его характеристики производительности включены -par с нашей ручной реализацией на основе итераций из прошлого. Можно также утверждать, что использование Scanner дает немного более читаемый код, поскольку его API-интерфейсы явно заявляют, что мы сканируем на заданную строку в каждой части алгоритма, но это будет очень субъективно.
Давайте рассмотрим еще одно место для оптимизации — использование ленивых коллекций . До этого момента все реализации, которые мы исследовали, имели одну общую черту — все они немедленно анализировали всю строку. Хотя это вполне нормально для случаев использования, которые также будут использовать все результаты немедленно, мы потенциально могли бы еще оптимизировать вещи, вместо этого выполняя синтаксический анализ более ленивым образом .
Как мы рассмотрели в «Быстрые последовательности: искусство быть ленивым» , отсрочка вычисления элемента в последовательности до тех пор, пока он действительно не понадобится , иногда может дать нам повышение производительности — особенно если вызывающий будет только потреблять подмножество нашей последовательности.
Давайте обновим нашу последнюю реализацию на основе Scanner , чтобы она выполнялась лениво. Для этого мы обернем наш алгоритм в AnySequence и AnyIterator , что позволяет нам формировать ленивые последовательности, не требуя от нас реализации нового типа с нуля:
extension String {
символы var: AnySequence {
let symbolSet = CharacterSet (charactersIn: "@ #")
вернуть AnySequence {() -> AnyIterator в
let scanner = Сканер (строка: self)
var symbolKind: Символ.Своего рода?
func iterate () -> Символ? {
guard! scanner.isAtEnd else {
вернуть ноль
}
guard let kind = symbolKind else {
scanner.scanUpToCharacters (от: symbolSet, в: nil)
if scanner.scanString ("@", into: nil) {
symbolKind = .mention
} else if scanner.scanString ("#", into: nil) {
symbolKind = .hashtag
}
вернуть итерацию ()
}
symbolKind = nil
var результат: NSString?
сканер.scanCharacters (из: букв в: & результат)
guard let string = result else {
вернуть итерацию ()
}
символ возврата (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (итерация)
}
}
} С указанным выше изменением мы теперь получаем довольно значительный прирост производительности для такого кода, который выполняет итерацию только по нашей последовательности символов до заданной точки:
let firstHashtag = string.symbols.first {$ 0.kind == .hashtag} И это представляет нам последний компромисс для этой статьи — готовы ли мы принять дополнительную сложность (и, возможно, немного более сложную отладку), чтобы сделать более короткие итерации более производительными?
Bitrise: Мой любимый сервис непрерывной интеграции. Автоматически создавайте, тестируйте и распространяйте свое приложение при каждом запросе на слияние, а также используйте новый мощный набор надстроек для визуализации результатов тестирования, упрощения доставки приложения и добавления в проект мониторинга сбоев и производительности.Начни бесплатно.
Как и при написании любых алгоритмов, какая именно реализация будет наиболее подходящей, в значительной степени зависит как от того, с какой проблемой мы имеем дело, насколько велики наборы данных, на которых мы планируем ее запускать, так и от того, как результат будет израсходован.
Есть, конечно, также много других способов синтаксического анализа строк в Swift, которые эта статья не охватывала — например, использование регулярных выражений или погружение в анализ вещей на базовом уровне Unicode — но, надеюсь, это дало вам обзор , около инструментов и методов, имеющихся в нашем распоряжении, и различных компромиссов, с которыми все они связаны.
Мой личный подход почти всегда заключается в том, чтобы начинать с простейшей возможной реализации и, постоянно измеряя результаты и характеристики производительности моих алгоритмов, увеличивать масштаб по мере необходимости — точно так же, как в этой статье. В следующей статье мы также подробнее рассмотрим, как точно измерять наш код с помощью различных показателей производительности.
Что вы думаете? У вас есть любимый способ синтаксического анализа строк в Swift, или вы попробуете один из методов из этой статьи в следующий раз, когда столкнетесь с подобной проблемой? Дайте мне знать — вместе со своими вопросами, комментариями и отзывами — в Twitter @johnsundell или связавшись со мной.
Спасибо за чтение! 🚀
ios — Разделение текста на массив с сохранением пунктуации в Swift
Чтобы объяснить из моего комментария … Думайте о регулярных выражениях как о способе красивого поиска шаблонов в строках. В вашем случае шаблон — это слова (группы букв) с другими возможными символами (знаками препинания) между ними.
Возьмите регулярное выражение в моем комментарии (который я здесь немного расширил), например: ([, \. \: \ "]) * ([A-Za-z0-9 \ '] *) ([ , \. \: \ "]) *
Там у нас 3 групп .Первый ищет любые символы (например, начальную кавычку). Второй — поиск букв, цифр и апострофа (потому что людям нравится объединять слова, например «Я»). а третья группа ищет любые конечные знаки препинания.
Отредактируйте, чтобы отметить: группы в приведенном выше списке обозначены круглыми скобками (и), а квадратные скобки [и] обозначают допустимые символы для поиска. Так, например, [A-Z] говорит, что все буквы верхнего регистра от A до Z допустимы. [A-Za-z] позволяет получать как верхнее, так и нижнее значение, а [A-Za-z0-9] включает все буквы и цифры от 0 до 9. Конечно, есть сокращенные версии этого написания, но те, которые вы обнаружите в будущем.
Итак, теперь у нас есть способ разделить все слова и знаки препинания, теперь вам нужно его использовать, делая что-то вроде:
func find (value: NSString) выбрасывает -> [NSString] {
let regex = try NSRegularExpression (шаблон: "([, \\.\\: \\\ "]) * ([A-Za-z0-9 \\ '] *) ([, \\. \\: \\\"]) * ") // Обратите внимание, что вам нужно бежать значения в коде
пусть результаты = regex.matches (in: value, range: NSRange (location: 0, length: nsString.length))
вернуть results.map ({value.substring (with: $ 0.range)}). filter ({$ 0! = nil})
}
Это должно дать вам каждую ненулевую группу, найденную в строковом значении, которое вы передаете методу.
Конечно, этот последний метод фильтрации может и не понадобиться, но я недостаточно знаком с тем, как Swift обрабатывает регулярные выражения, чтобы знать наверняка.
Но это определенно должно указать вам правильное направление …
Ура ~
бетон | Определение, состав, использование и факты
Бетон , в строительстве, конструкционный материал, состоящий из твердого, химически инертного твердого вещества, известного как заполнитель (обычно песок и гравий), который скреплен между собой цементом и водой.
бетонСтроители заливают бетон.
© Дмитрий Калиновский / Shutterstock.comПодробнее по этой теме
Строительство: Ранние бетонные конструкции
Одним из самых ранних сохранившихся примеров этой бетонной конструкции является Храм Сибиллы (или Храм Весты) в Тиволи, построенный в …
У древних ассирийцев и вавилонян в качестве связующего вещества чаще всего использовалась глина. Египтяне разработали вещество, более напоминающее современный бетон, используя известь и гипс в качестве связующих.Известь (оксид кальция), полученная из известняка, мела или (если возможно) раковин устриц, продолжала оставаться основным пуццолановым или цементирующим агентом до начала 1800-х годов. В 1824 году английский изобретатель Джозеф Аспдин сжег и измельчил смесь известняка и глины. Эта смесь, называемая портландцементом, остается основным вяжущим веществом, используемым в производстве бетона.
Заполнители обычно обозначаются как мелкие (размером от 0,025 до 6,5 мм [от 0,001 до 0.25 дюймов]) или крупными (от 6,5 до 38 мм [0,25 до 1,5 дюймов] или больше). Все материалы заполнителя должны быть чистыми и не содержать примесей с мягкими частицами или растительными веществами, потому что даже небольшие количества органических соединений почвы приводят к химическим реакциям, которые серьезно влияют на прочность бетона.
Бетон характеризуется типом используемого заполнителя или цемента, конкретными качествами, которые он проявляет, или методами, используемыми для его производства. В обычном конструкционном бетоне характер бетона во многом определяется соотношением воды и цемента.Чем ниже содержание воды при прочих равных условиях, тем прочнее бетон. В смеси должно быть ровно столько воды, чтобы гарантировать, что каждая частица заполнителя полностью окружена цементным тестом, чтобы промежутки между заполнителем были заполнены, и чтобы бетон был достаточно жидким, чтобы его можно было заливать и эффективно растекать. Другой фактор долговечности — это количество цемента по отношению к заполнителю (выраженное в трехкомпонентном соотношении — цемент, мелкий заполнитель и крупный заполнитель). Там, где требуется особо прочный бетон, заполнителя будет относительно меньше.
Получите подписку Britannica Premium и получите доступ к эксклюзивному контенту. Подпишитесь сейчасПрочность бетона измеряется в фунтах на квадратный дюйм или килограммах на квадратный сантиметр силы, необходимой для раздавливания образца определенного возраста или твердости. На прочность бетона влияют факторы окружающей среды, особенно температура и влажность. Если позволить ему высохнуть преждевременно, он может испытывать неравные растягивающие напряжения, которым невозможно противостоять в недостаточно затвердевшем состоянии. В процессе, известном как отверждение, бетон остается влажным в течение некоторого времени после заливки, чтобы замедлить усадку, возникающую при затвердевании.Низкие температуры также отрицательно сказываются на его прочности. Чтобы компенсировать это, к цементу примешивают такую добавку, как хлорид кальция. Это ускоряет процесс схватывания, который, в свою очередь, выделяет тепло, достаточное для противодействия умеренно низким температурам. Большие бетонные формы, которые невозможно покрыть должным образом, не заливают при отрицательных температурах.
бетонРабочие гладят свежеуложенный бетон мастерками.
Помощник фотографа 2-го класса Эрик Пауэлл / У.S. NavyБетон, затвердевший на заделанном металле (обычно стали), называется железобетонным или железобетонным. Его изобретение обычно приписывают Жозефу Монье, парижскому садовнику, который сделал садовые горшки и кадки из бетона, армированного железной сеткой; он получил патент в 1867 году. Арматурная сталь, которая может иметь форму стержней, стержней или сетки, способствует прочности на разрыв. Обычный бетон с трудом выдерживает нагрузки, такие как воздействие ветра, землетрясения, вибрации и другие изгибающие силы, и поэтому не подходит для многих строительных конструкций.В железобетоне прочность на разрыв стали и прочность на сжатие бетона делают элемент способным выдерживать большие нагрузки всех видов на значительных пролетах. Текучесть бетонной смеси позволяет размещать сталь в точке или около того места, где ожидается наибольшая нагрузка.
Еще одно новшество в каменном строительстве — это использование предварительно напряженного бетона. Это достигается либо предварительным, либо последующим натяжением. При предварительном натяжении отрезки стальной проволоки, тросов или канатов укладываются в пустую форму, а затем растягиваются и закрепляются.После заливки и схватывания бетона анкеры освобождаются, и по мере того, как сталь стремится вернуться к своей исходной длине, она сжимает бетон. В процессе последующего натяжения сталь пропускается через каналы, образованные в бетоне. Когда бетон затвердеет, сталь прикрепляется к внешней стороне элемента каким-либо захватным устройством. Приложив к стали отмеренное растягивающее усилие, можно тщательно отрегулировать степень сжатия, передаваемого бетону.Предварительно напряженный бетон нейтрализует растягивающие силы, которые могут привести к разрыву обычного бетона, сжимая область до точки, в которой не возникает никакого напряжения, пока не будет преодолена прочность сжатой секции. Поскольку он обеспечивает прочность без использования тяжелой стальной арматуры, он с большим успехом используется для строительства более легких, мелких и элегантных конструкций, таких как мосты и огромные крыши.
Помимо огромной прочности и первоначальной способности адаптироваться практически к любой форме, бетон является огнестойким и стал одним из самых распространенных строительных материалов в мире.
Разделенные инфинитивы: они все еще табу?
Политика защиты данных
Get It Write Online
Последнее обновление 29.01.19
Определения
Бизнес означает Get It Write Online.
GDPR означает Общий регламент по защите данных.
Ответственное лицо означает Нэнси Тутен.
Реестр систем означает реестр всех систем или контекстов, в которых персональные данные обрабатываются Бизнесом.
1. Принципы защиты данных
Компания обязуется обрабатывать данные в соответствии со своими обязанностями в соответствии с GDPR.
Статья 5 GDPR требует, чтобы персональные данные были
a. обрабатываются законным, справедливым и прозрачным образом по отношению к физическим лицам;
г. собираются для определенных, явных и законных целей и не обрабатываются в дальнейшем способом, несовместимым с этими целями; дальнейшая обработка в целях архивирования в общественных интересах, научных или исторических исследованиях или статистических целях не считается несовместимой с первоначальными целями;
г.адекватные, актуальные и ограниченные тем, что необходимо в отношении целей, для которых они обрабатываются;
г. точные и, при необходимости, актуальные; должны быть предприняты все разумные шаги для обеспечения того, чтобы персональные данные, которые являются неточными, с учетом целей, для которых они обрабатываются, были удалены или исправлены без промедления;
e. хранятся в форме, позволяющей идентифицировать субъектов данных, не дольше, чем это необходимо для целей, для которых обрабатываются персональные данные; Персональные данные могут храниться в течение более длительных периодов времени, поскольку персональные данные будут обрабатываться исключительно для целей архивирования в общественных интересах, в целях научных или исторических исследований или в статистических целях при условии реализации соответствующих технических и организационных мер, требуемых GDPR для того, чтобы защищать права и свободы человека; и
ф.обрабатываются таким образом, который обеспечивает надлежащую безопасность персональных данных, включая защиту от несанкционированной или незаконной обработки, а также от случайной потери, уничтожения или повреждения, с использованием соответствующих технических или организационных мер ».
2. Общие положения
a. Эта политика применяется ко всем личным данным, обрабатываемым Бизнесом.
г. Ответственное лицо несет ответственность за постоянное соблюдение Компанией этой политики.
г. Эта политика должна пересматриваться не реже одного раза в год.
г. Компания должна зарегистрироваться в Управлении Уполномоченного по информации в качестве организации, обрабатывающей персональные данные.
3. Законная, справедливая и прозрачная обработка данных
a. Чтобы обеспечить законную, справедливую и прозрачную обработку данных, Компания должна вести Реестр систем.
г. Реестр систем должен пересматриваться не реже одного раза в год.
г. Физические лица имеют право на доступ к своим личным данным, и любые такие запросы, поступающие в адрес Бизнеса, должны обрабатываться своевременно.
4. Законные цели
a. Все данные, обрабатываемые Бизнесом, должны выполняться на одной из следующих законных оснований: согласие, договор, юридическое обязательство, жизненно важные интересы, общественная задача или законные интересы (дополнительную информацию см. В руководстве по ICO).
г. Компания должна указать соответствующую правовую основу в Реестре систем.
г. Если согласие рассматривается как законное основание для обработки данных, подтверждение согласия сохраняется вместе с личными данными.
г. Если сообщения отправляются физическим лицам на основании их согласия, должна быть четко доступна возможность отозвать свое согласие, и должны быть созданы системы, обеспечивающие точное отражение такого отзыва в системах Бизнеса.
5. Минимизация данных: Компания должна гарантировать, что персональные данные адекватны, актуальны и ограничены тем, что необходимо в отношении целей, для которых они обрабатываются.
6. Точность
а. Компания должна принимать разумные меры для обеспечения точности персональных данных.
г. Если это необходимо для законной основы обработки данных, должны быть приняты меры для обеспечения актуальности персональных данных.
7. Архивирование / удаление
a. Чтобы гарантировать, что личные данные хранятся не дольше, чем это необходимо, Компания должна внедрить политику архивирования для каждой области, в которой обрабатываются личные данные, и ежегодно проверять этот процесс.
г. Политика архивирования должна учитывать, какие данные должны / должны храниться, как долго и почему.
8. Безопасность
a. Бизнес должен обеспечить безопасное хранение личных данных с использованием современного программного обеспечения, которое поддерживается в актуальном состоянии.
г. Доступ к личным данным должен быть ограничен персоналом, которому необходим доступ, и должна быть обеспечена соответствующая безопасность, чтобы избежать несанкционированного обмена информацией.
г. Когда личные данные удаляются, это следует делать безопасно, чтобы данные нельзя было восстановить.
г. Должны быть в наличии соответствующие решения для резервного копирования и аварийного восстановления.
9. Нарушение
В случае нарушения безопасности, ведущего к случайному или незаконному уничтожению, потере, изменению, несанкционированному раскрытию или доступу к личным данным, Компания должна незамедлительно оценить риск для прав и свобод людей, и если соответствующий отчет об этом нарушении в ICO (более подробная информация на сайте ICO).
КОНЕЦ ПОЛИТИКИ
Как улучшить структуру предложения
Структура предложения определяет, как соединяются различные части предложения, от пунктуации до порядка слов.Помимо соблюдения основных правил порядка слов, вы должны учитывать множество других вещей, чтобы писать правильно и четко структурированные предложения.
Есть две особенно распространенные ошибки построения предложений:
- Повторяющиеся предложения : неправильная пунктуация, используемая для соединения разных частей предложения
- Фрагменты предложения : отсутствуют необходимые компоненты для формирования полного грамматически правильного предложения
Структура предложения зависит не только от грамматики, но также от стиля и последовательности.В сильном академическом письме используются предложения различной длины и структуры. Важно избегать слишком длинных предложений, которые могут сбить читателя с толку, но слишком много очень коротких предложений могут сделать ваш текст неровным и несвязным.
Избегайте повторения приговоров
Независимое предложение — это группа слов, которая сама по себе может стоять как полное предложение. Существуют различные способы соединения независимых предложений, но если они соединены без правильной пунктуации, возникает дополнительное предложение.
Продолжение предложений зависит от грамматики, а не от длины — даже относительно короткие предложения могут содержать эту ошибку. Есть две распространенные ошибки, из-за которых предложения становятся нескончаемыми.
Соединитель запятой
Два независимых предложения не могут быть соединены одной запятой. Эта форма предложения называется соединением запятой.
- Проект перевыполнен, обработка данных была обширной.
Есть три способа исправить эту ошибку. Вы можете разделить предложения на два отдельных предложения.
- Проект перевыполнен. Обработка данных была обширной.
Вы можете заменить запятую точкой с запятой или (при необходимости) двоеточием.
- Проект перевыполнен; обработка данных была обширной.
В качестве альтернативы вы можете использовать союз для создания связи между предложениями.
- Срок выполнения проекта истек, поскольку обработка данных была обширной.
Соединения запятыми могут также появляться в более длинных предложениях с несколькими предложениями.В этом контексте они особенно часто вызывают путаницу.
- Джимми любит добавлять в кофе сливки и сахар, когда он пьет его теплым, ему нравится черный кофе.
Здесь не ясно, какая часть предложения должна быть связана с клаузулой , когда он выпил ее теплым. Ему нравятся сливки и сахар, когда он пьет теплый кофе, или ему нравится черный кофе, когда он пьет его теплым? Точка с запятой, точка или союз поясняют значение предложения, значение которого меняется в зависимости от места расположения знаков препинания.
- Джимми любит добавлять в кофе сливки и сахар; когда он пьет его теплым, ему также нравится черный.
- Джимми любит добавлять в кофе сливки и сахар, когда он пьет его теплым. Еще ему нравится черный цвет.
- Джимми любит добавлять в кофе сливки и сахар, но когда он пьет его теплым, ему нравится черный кофе.
Отсутствует запятая при координационном соединении
В английском языке существует семь координирующих союзов: for, and, nor, but, or, still, so (вы можете запомнить их по аббревиатуре FANBOYS).Когда вы используете одно из этих союзов для соединения двух независимых предложений, вам необходимо поставить перед ним запятую.
- Данные были собраны с помощью анкет, и отдельные респонденты приняли участие в интервью.
Отсутствующая запятая приводит к продолжению предложения и, как и соединение запятой, часто может вызвать путаницу. Поскольку мы используем эти союзы так часто и для многих целей, полезно знать, как они используются, когда мы с ними сталкиваемся.
Запятая помогает читателю ориентироваться в предложении, сигнализируя о том, что следующая часть является новой, связанной и законченной мыслью.
- Данные были собраны с помощью анкет, и отдельные респонденты участвовали в интервью.
Избегайте фрагментов предложения
Фрагмент — это группа слов, не содержащая всех компонентов грамматически правильного предложения. Чтобы строка слов считалась предложением, она должна содержать подлежащее и сказуемое.
Обратите внимание, что фрагменты предложений часто стилистически используются в журналистике и творческом письме, но они редко уместны в академическом или другом формальном письме.
Субъекты и предикаты
Предикат в предложении сообщает нам о человеке или предмете, который действует, а предикат говорит нам о том, что субъект делает или чем является. Другими словами, подлежащее — это существительная часть предложения, а сказуемое — это глагольная часть.
Некоторые предложения содержат более одной комбинации подлежащее-сказуемое, но позиция подлежащего всегда стоит на первом месте. Независимо от того, сколько пар субъект-предикат входит в предложение, соотношение всегда 1: 1 — каждому субъекту нужен предикат, а каждому предикату — субъект.
Примеры субъект-предикат
Утки летают.
Хаггардские и пожилые утки и гуси летают медленнее, ниже и осторожнее.
Хаггард, пожилые утки и гуси летают медленнее, ниже и осторожнее, возможно, из-за ревматизма.
Хаггард, пожилые утки и гуси летают медленнее, ниже и осторожнее, возможно, потому, что им мешает ревматизм.
Утки летают; собаки гуляют.
Утки летают быстрее гусей, когда собаки бегают и лают.
Собака ловит мяч.
Собака ловит мяч, покрытый слюной.
Собака ловит мяч, который мы купили.
Мяч пойман.
Теперь мяч имеет следующие характеристики: скользкость, запах и жевательность.
Мяч теперь имеет следующие характеристики: он скользкий, вонючий и жевательный.
Мяч теперь имеет следующие характеристики: он скользкий, вонючий и жевательный.
Отсутствует предикат
Простейшая форма фрагмента предложения — это предложение, в котором отсутствует главный глагол.Сама по себе именная фраза не является предложением — ей нужно сказуемое, чтобы быть грамматически правильным.
- После того, как они уладили спор, они стали друзьями. Удачный поворот событий.
Фрагмент можно изменить, используя соответствующую пунктуацию, чтобы присоединить его к предыдущему предложению, или переписав предложение, включив в него предикат.
- После того, как они уладили спор, они стали друзьями: удачный поворот событий.
- После того, как они уладили спор, они стали друзьями.Это был удачный поворот событий.
Зависимая оговорка сама по себе
Зависимое предложение имеет подлежащее и сказуемое, но оно не выражает целостной мысли. Он должен быть добавлен к отдельной статье, чтобы составить полное предложение.
Зависимые предложения часто образуются с подчиненными союзами, которые включают такие слова, как when, after, Since, while, Хотя, if, if, because, while , and while . Когда одно из этих слов добавляется в начало независимого предложения, оно превращается в зависимое предложение.
- Берег был чист.
- Когда берег был свободен.
Первое предложение — это независимое предложение, которое само по себе может стоять как полное предложение. Подчиняющий союз , когда преобразует его в зависимое предложение. Сам по себе это фрагмент предложения. Его необходимо правильно связать с другим предложением, чтобы сформировать полное предложение.
- Они пойдут в безопасное место. Когда берег был свободен.
- Они пойдут в безопасное место; , когда берег был свободен.
- Они уйдут в безопасное место, когда берег будет свободен.
- Когда берег станет чистым, они уйдут в безопасное место.
Обратите внимание, что эти предложения нельзя соединять точкой с запятой. Точка с запятой может соединять только два независимых предложения.
Злоупотребление настоящим причастием
Причастие настоящего времени — это форма глагола, который заканчивается на -ing (например, работает, исследует, является ). Иногда его неправильно используют, когда вместо этого следует использовать простую форму настоящего или прошедшего времени.Глагол -ing сам по себе может быть частью модификатора, который относится к другой части предложения, но не может отмечать начало сказуемого.
Наиболее распространенным глаголом, которым злоупотребляют при этой ошибке, является , чтобы быть , который спрягается, как , это , когда он должен быть спряжен, это или было .
- Спорил всю ночь. Дело в том, что важно.
Важно — это фрагмент предложения.Он должен быть связан с другим предложением или исправлен с помощью правильно спрягаемого глагола.
- Спорил всю ночь. Дело было важным.
- Он спорил всю ночь, причем важно.
Получите отзывы о языке, структуре и макете
Профессиональные редакторы корректируют и редактируют вашу статью, уделяя особое внимание:
- Академический стиль
- Расплывчатые предложения
- Грамматика
- Единообразие стиля
См. Пример
Разбивать слишком длинные предложения
Иногда длинное предложение грамматически правильно, но его длина затрудняет понимание.Чтобы ваш текст был более четким и читаемым, избегайте использования слишком большого количества слишком длинных предложений.
Средняя длина предложения составляет около 15-25 слов. Если ваше предложение начинает превышать 30-40 слов, вы можете подумать о его пересмотре. Устранение дублирования и преувеличенных фраз — хороший способ начать, но если все слова в предложении важны, попробуйте разбить его на более короткие предложения.
Поскольку раннее детство, определяемое как первые пять лет жизни, является критическим временем с точки зрения не только физического, но и социального развития, исследования сосредоточили значительное внимание на этом периоде, и в этом разделе обсуждаются ключевые выводы исследователей. и их значение для текущего исследования.
В этом предложении нет грамматических ошибок, но информацию можно представить более четко, изменив ее структуру.
Раннее детство, определяемое как первые пять лет жизни, является критическим временем с точки зрения как физического, так и социального развития. Следовательно, исследования сосредоточили значительное внимание на этом периоде. В этом разделе обсуждаются основные выводы исследователей и их значение для текущего исследования.
Еще одна проблема, на которую следует обратить внимание, — это слишком длинные вводные фразы или предложения.Если ваше предложение начинается с повторения уже представленного материала, оно может скрыть новую информацию, которую вы хотите передать.
В отличие от того, что можно было предположить в предыдущем разделе о сборе, анализе, интерпретации и применении данных, ни один из выводов не был значительным.
Суть предложения состоит в том, что ни один из выводов не был значительным , но длинная вводная фраза отвлекает нас от этой информации. Чтобы прояснить суть и сократить предложение, сосредоточьтесь на сокращении повторений.
В отличие от того, что можно было предположить в предыдущем разделе, ни один из результатов не был значительным.
Соедините вместе слишком короткие предложения
Более короткие предложения обычно более ясны и читабельны, но использование слишком большого количества очень коротких предложений может сделать текст прерывистым, несвязным или повторяющимся. Попробуйте использовать предложения различной длины и слова перехода, чтобы помочь читателям увидеть, как ваши идеи сочетаются друг с другом.
Исходные данные были собраны в первый день. Данные также были собраны через неделю.Измерения проводились в 9 утра. Это делалось каждый день.
Хотя все это грамматически правильные предложения, текст читается более плавно, если они объединены.
Исходные данные были собраны в первый день и через одну неделю. Измерения проводились в 9 утра каждый день.
Другие подсказки по структуре предложения
Помимо этих основных правил, есть еще несколько приемов, которые можно использовать для улучшения структуры предложения.