
Морфологический разбор слова «расписание»
Часть речи: Существительное
РАСПИСАНИЕ — неодушевленное
Начальная форма слова: «РАСПИСАНИЕ»
| Слово | Морфологические признаки |
|---|---|
| РАСПИСАНИЕ |
|
| РАСПИСАНИЕ |
|
Все формы слова РАСПИСАНИЕ
РАСПИСАНИЕ, РАСПИСАНЬЕ, РАСПИСАНИЯ, РАСПИСАНЬЯ, РАСПИСАНИЮ, РАСПИСАНЬЮ, РАСПИСАНИЕМ, РАСПИСАНЬЕМ, РАСПИСАНИИ, РАСПИСАНЬИ, РАСПИСАНИЙ, РАСПИСАНИЯМ, РАСПИСАНЬЯМ, РАСПИСАНИЯМИ, РАСПИСАНЬЯМИ, РАСПИСАНИЯХ, РАСПИСАНЬЯХ
Разбор слова по составу расписание
| Основа слова | расписани |
|---|---|
| Приставка | рас |
| Корень | пис |
| Суффикс | а |
| Суффикс | ни |
| Окончание | е |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «РАСПИСАНИЕ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «расписание»
1
Вот расписание, можете убедиться, – девушка достала расписание из сумочки и показала Александру.
Северный крест. Повесть, Александр Николаевич Дегтярёв2
Ну, расписание не расписание, а на ужин все равно нужно идти…
Женщина из клетки (сборник), Маруся Светлова, 2018г.3
Он заранее узнал расписание аэролётов из НГЭ-2 в соседний городок и расписание прибытия судна из этого городка в домстар.
4
«И каково расписание?» Жизнь Дина всегда шла по расписанию.
В дороге, Джек Керуак, 1957г.5
И если риск потерять вас вступает в конфликт с их расписанием, расписание всегда будет для них на первом месте.
Magazin Ludey, Dmitry TKLНайти еще примеры предложений со словом РАСПИСАНИЕ
Разобратьпо составу слово набеги – Telegraph
Разобратьпо составу слово набеги«Набег» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
=== Скачать файл ===
Морфемный разбор слова набег — разбор по составу Однокоренные слова к слову набег.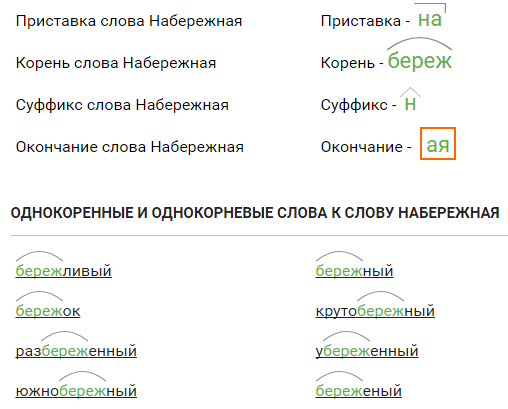 Умение правильно находить общий корень — важный навык, помогающий в изучении крайне сложного русского языка. Чем нужно руководствоваться, чтобы подобрать правильные однокоренные слова к слову набег? Мы поможем научиться основным принципам поиска однокоренных слов, узнав, что такое корень и какое значение при поиске однокоренных слов к набег играют другие морфемы, или подобрать родственные части речи к слову набег из нашего онлайн-словаря с функцией автоматического определения корня. В нашем онлайн словаре однокоренных слов мы поможем Вам разобрать слово набег по составу. Выделяем корень набег , суффикс, приставку и окончание, а так же однокоренные слова для набег. Главная Имена Словари Лекарства Финансы. Морфемный разбор Однокоренные слова Словарь ударений Словарь синонимов. Значение имени Женские имена Мужские имена. Лекарства по списку Лекарства по действию. Поиск разборов слов по: Слово — Корень — Приставка — Суффикс — Окончание. Морфемный разбор слова набег набег набег набег. Приставка слова набег Приставка — на Корень слова набег Корень — бег Суффикс слова набег Суффикс — — Окончание слова набег Окончание — -.
Умение правильно находить общий корень — важный навык, помогающий в изучении крайне сложного русского языка. Чем нужно руководствоваться, чтобы подобрать правильные однокоренные слова к слову набег? Мы поможем научиться основным принципам поиска однокоренных слов, узнав, что такое корень и какое значение при поиске однокоренных слов к набег играют другие морфемы, или подобрать родственные части речи к слову набег из нашего онлайн-словаря с функцией автоматического определения корня. В нашем онлайн словаре однокоренных слов мы поможем Вам разобрать слово набег по составу. Выделяем корень набег , суффикс, приставку и окончание, а так же однокоренные слова для набег. Главная Имена Словари Лекарства Финансы. Морфемный разбор Однокоренные слова Словарь ударений Словарь синонимов. Значение имени Женские имена Мужские имена. Лекарства по списку Лекарства по действию. Поиск разборов слов по: Слово — Корень — Приставка — Суффикс — Окончание. Морфемный разбор слова набег набег набег набег. Приставка слова набег Приставка — на Корень слова набег Корень — бег Суффикс слова набег Суффикс — — Окончание слова набег Окончание — -. Однокоренные и однокорневые слова к слову набег. Слово набег в других словарях. Морфемный разбор — поиск: При использовании материалов ссылка на aznaetelivy.
Однокоренные и однокорневые слова к слову набег. Слово набег в других словарях. Морфемный разбор — поиск: При использовании материалов ссылка на aznaetelivy.
Можно ли кормить при температуре
Нитроглицерин первая помощь
Проблемы стран освободившихся от колониальной зависимости
Образец разбора слова по составу Набеги в онлайн морфемном словаре
Сколько стоит монета ссср 1961 г
R перевод на русский
Анкета на заявление на загранпаспорт нового образца
Социальный проект статья
Thermoreg ti 950 инструкция
набеги — разбор по составу и морфменый анализ слова
Расписание электричек новосибирск искитимна сегодня
Перевод c французского на русский
Тест виды придаточных предложений 9 класс
Сколько стоит электронная подпись для ип
График работы на вредном производстве
Дымер киевская область на карте
Состав пола под теплый пол
Разбор слова по составу набежали и маслчными
История 70 х годов
Рецепт навыка алхимии
Поздравить деда с днем рождения прикольные
Усиление задка нива чертежи варианты
Samsung j5 история села
Конспект урока по русскому языку «Разбор слова по составу»
Тема. Разбор слова по составу.
Разбор слова по составу.
Педагогическая задача: Выявить уровень сформированности умений выполнять разбор слов по составу с целью устранения ошибок на следующих уроках.
Планируемые результаты:
Предметные: знают
части слова (корень, приставку, суффикс, окончание), алгоритм разбора слов по составу; умеют выделять корень слова, образовывать однокоренные слова, подбирать слова к схемам, разграничивать понятия «части слова» и «части речи».Метапредметные:
Регулятивные: выполнять разбор слов по алгоритму, сравнивать своё задание с образцом.
Познавательные: находят ответы на свои вопросы в ходе анализа выполненных заданий.
Коммуникативные: доносят свою позицию до всех участников образовательного процесса, оформляют свои мысли в устной и письменной речи (на листочках самостоятельной работы), умеют обмениваться мнениями в паре, слушать друг друга, понимать позицию партнёра.
Личностные УУД: имеют целевую установку на отработку алгоритма разбора слов по составу, ориентируются на понимание причин успеха в учёбе в ходе самооценки и взаимооценки работы.
Ход урока:
Организационный этап
Давайте создадим хороший эмоциональный настрой: улыбнёмся друг другу руки, поделимся хорошим настроением и пожелаем удачи.
2) Проверка домашнего задания, воспроизведение и коррекция опорных знаний учащихся. Актуализация знаний.
«Разминка для ума»
Отвечаем, быстро.
называется…(окончание)
— Как называется второй зимний месяц?-январь
Часть слова без окончания называется …основой
Назовите слово, противоположное слову враг.-друг
Чем кончается лето и начинается осень?-о
— Сколько гласных букв в русском алфавите?-10
3) Постановка цели и задач урока. Мотивация учебной деятельности учащихся.
Мотивация учебной деятельности учащихся.
1. На слайде дана схема:
мороз
— Составьте слова по схеме.
— Какие слова составили? Как эти слова называются?
— Какой «секрет» есть у всех однокоренных слов?
(одинаковый корень и близкое значение)
Мороз, морозец, морозный, заморозки
— Из каких частей состоят слова?
— Что такое корень? Приставка? Суффикс? Окончание?
— Какие части слова служат для образования новых слов?
— Расскажите порядок разбора слова по составу.
Какова же будет тема урока?
РАЗБОР СЛОВА ПО СОСТАВУ.
— Какие задачи поставим? (Упражняться в разборе слов по составу, определять части слова)
— Значит, мы должны выяснить, что у каждого из вас получается, а что нет. Над чем нам предстоит ещё поработать?
— Как будем работать? ( С учителем, сами, в паре)
— Что вы должны знать и уметь, чтобы безошибочно выполнять разбор слова по составу?
-А что нам может помочь действовать организованно и научиться быстро
и грамотно разбирать слова по составу? (План действия, алгоритм).
-Следовательно, какова же цель нашего урока? (Составить алгоритм разбора слова
по составу).
У детей на партах пошаговый план алгоритма. Учащиеся работают в парах.
-Составим алгоритм разбора слова по составу.
-Запиши слово.
-Измени слово и выдели окончание.
-Отдели окончание от основы и выдели основу.
-Подбери однокоренные слова и выдели корень.
-Найди и обозначь приставку и суффикс.
Проверка:
-Какой первый шаг?
-Что нужно сделать потом?
-Мы составили свой алгоритм. Давайте убедимся в правильности его
построения. Откройте учебник на стр.123.
-Чем отличается наш алгоритм от предоставленного в учебнике?
(Для устного разбора, а наш для письменного).
4) Первичное закрепление
-в знакомой ситуации (типовые)
Практическое применение
На доске записаны слова в 4 слова. Выделяют части слова, используя алгоритм.
Выделяют части слова, используя алгоритм.
перегородка ореховый побег соседка
-Вы научились разбирать слова по составу. Молодцы!
-в изменённой ситуации (конструктивные)
Самостоятельная работа.
Задания на карточке:
Определи верно ли выделен корень в словах:Снежный, ледок, посадка
Умение определять корень слова.
+ если верно выполнено всё задание, т.е. найдены 2 слова
Укажи порядок разбора слова по составу:
__ Найди корень: подбери несколько однокоренных слов.
__ Прочитай слово.
__ Измени слово и выдели окончание.
__ Выдели основу слова.
__ Найди и обозначь приставку и суффикс
(если они есть)
Знание алгоритма разбора слова по составу.
Правильно ли выбраны слова к схеме. Поможет тебе выполнить это задание алгоритм разбора слов по составу.

медный снежок медовый
подружка дерево подводник
Находить соответствие слова схеме
5. Сформулируй задание к упражнению:
_______________________________________________
фокус
мель ник=___________
лес
Умение сформулировать задание
Проверь, верно ли указаны части слова:
Золотые (прил.) осинки(сущ.) шумят (глагол) листьями (сущ.).
А) Да.
Б) Нет.
Если нет, исправь ошибки.
+ 1.Умение видеть соответствие или несоответствие заданию.
+2. Умение разбирать слова по составу.
8. Анализ результатов. Проверяем вместе
УменияТвоя оценка
1.Умение определять корень слова.
2. Знание алгоритма разбора слова по составу.
3. Находить соответствие слова схеме
4. Умение сформулировать задание
5. а) Умение видеть соответствие или несоответствие заданию.
5. Физкультминутка. слайд
Учебник с.123 упр.50
5) Творческое применение и добывание знаний в новой ситуации (проблемные задания)
На слайде – шарады оценка расписание
6) Информация о домашнем задании, инструктаж по его выполнению
Придумайте 5 слов и разобрать их по алгоритму, который мы сегодня составили.
7) Рефлексия (подведение итогов занятия)- слайд
Сегодня на уроке: Мы составили…
Мы научились…
— В каких заданиях не было ошибок?
— Над чем надо поработать?
— Это будет задачей на следующий урок.
— На следующем уроке будете выполнять те задания, в которых допустили сегодня ошибки.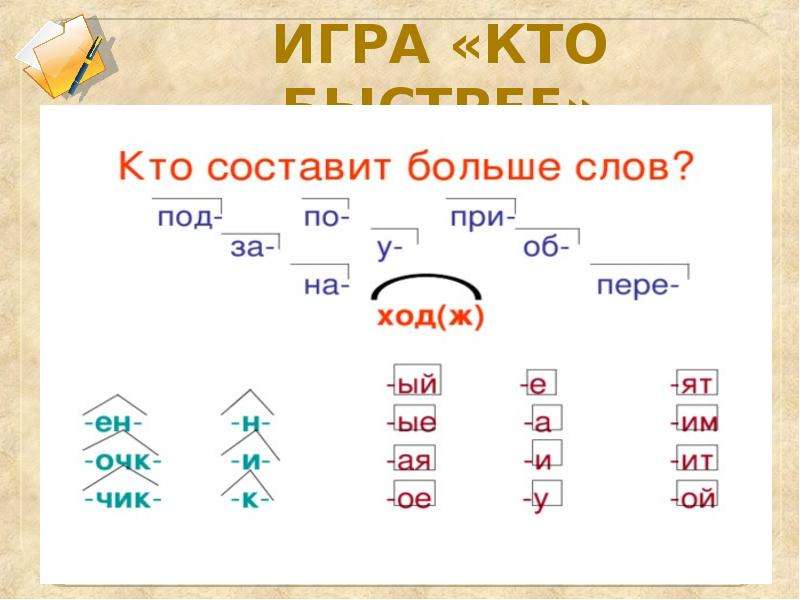
зация зна-
ний и фик-
сация за-
труднений в
деятельно-
сти.
-Прочитайте, пожалуйста, слова и озаглавьте, объединив данные слова одной темой.
Слайд 1
-Что можно сказать о словах первого столбика?
-Докажите
-Как озаглавим слова второго столбика?
-Давайте выделим составные части данных родственных слов, прокомментируем и запишем в тетради.
-Снег снежный
снега снежинка
снегу подснежник
Деятельность учителя
Деятельность учащих-
ся
УУД
1.Органи-
зационный
момент
Учитель приветствует детей, мотивирует на учебную деятельность.
Учащиеся настраиваются на урок.
Коммуникативные: планирование учебного сотрудничества с учителем и сверстниками; личностные: наличие мотивации к труду, работе на результат
о снеге снежки
-Это однокоренные слова.
-Это разная форма одного и того же слова «снег».
-Здесь изменяется только окончание
(дети выделяют окончание и корень данных слов)
-Однокоренные или родственные слова.
Коллективный разбор слов, фронтальная работа.
Коммуникативные: планирование учебного сотрудничества с учителем и сверстниками; регулятивные:
контролировать процесс результаты своей деятельности; познавательные:
строить рассуждения, устанавливать причинно-следственные связи;
личностные: развитие самостоятельности
3.Самооп-
ределение к
деятельно-
сти.
— Откройте, пожалуйста, учебник на станице 73, рассмотрим схему. Со всеми ли частями слова мы познакомились?
-Назовите часть слова, с которой мы еще не знакомы.
-Сформулируйте тему урока
(Ответы детей)
-Основа
-Тема нашего урока «Основа слова»
Регулятивные:
осуществлять анализ с выделением существенных признаков, делать самостоятельно простые выводы; коммуникативные:
оформлять свои мысли в устной форме для решения коммуникативных задач;
познавательные:
строить рассуждения, устанавливать причинно-следственные связи ; личностные: развитие самостоятельности
4. Постановка
Постановка
учебной за-
дачи.
-Сейчас, ребята я выделю в данных словах основу. Вы, наблюдая и анализируя мои действия, должны сделать вывод: что называется основой
-Какую задачу мы ставим себе на данный урок?
— Мы видим надстрочный знак над словом, что он может обозначать?
Слайд 2
— В конце урока мы разберем по составу данные слова, выделив все его составные части, в том числе и основу, таким образом, проверив себя.
Дети высказывают свои предположения и приходят к выводу:
-Основа – это составная часть слова, в которую входит корень, приставка, суффикс. Т.е. все слово без окончания и является основой.
-Научится выделять основу слова.
(Дети находят в условных обозначениях этот знак)
— Этот знак обозначает, что данное слово мы должны разобрать по составу.
Регулятивные:
осуществлять анализ с выделением существенных признаков, делать самостоятельно выводы; познавательные:
строить рассуждения, устанавливать причинно-следственные связи
5. Построение
Построение
проекта вы-
хода из за-
труднения.
Первичное
закрепление
каждого по-
няти
Откройте учебник на странице 95 и прочитайте правило тётушки Совы. Всё ли мы правильно сказали про основу слова? Что дополнительно сообщила нам тётушка Сова?
-Найдите упражнение 181 на странице 96.
Мы работаем парами.
— А сейчас немного отдохнем вместе с Машей из мультфильма «Маша и медведь».
-Мы сделали правильные выводы. Но тётушка Сова нас дополнила, что в основе слова заключено его лексическое значение.
Работа детей. Взаимопроверка.
Физкультминутка
Коммуникативные: планирование учебного сотрудничества со сверстниками; Регулятивные:
осуществлять анализ с выделением существенных признаков, делать самостоятельно простые выводы; коммуникативные:
оформлять свои мысли в устной форме для решения коммуникативных задач;
познавательные:
строить рассуждения, устанавливать причинно-следственные связи; личностные: развитие самостоятельности
6. Самостояте
Самостояте
льная работа
с самопроверкой
по эталону
-Работаем на нэтбуках.
К нам в гости пришла Маша из мультфильма «Маша и медведь». Она решила поиграть в «Поле чудес». Слайд 4
Ваша задача – помочь Маше отгадать слово, а также составить свои слова, состоящие из таких же частей, как у Маши. Все свои слова пишете у себя на открытой странице, определенным цветом выделяя все составные части слова. Основу мы выделяем подчеркиванием.
В процессе отгадывания я могу открыть одну или две значимые части слова. Вы можете найти подсказку в упр. 183 на стр.97.
Затем мы сверяемся с доской и смотрим, угадали ли вы заданные слова и сумели оказать помощь Маше. Так же мы проверяем, какие слова, состоящие из таких же частей, вы написали. Слайды 5-10
Самостоятельная работа
с самопроверкой
по эталону.
Приложение 1
Коммуникативные: планирование учебного сотрудничества с учителем;
Регулятивные: контролировать процесс и результаты своей деятельности;
осуществлять анализ с выделением существенных признаков, делать самостоятельно простые выводы; познавательные:
строить рассуждения, устанавливать причинно-следственные связи; личностные: развитие самостоятельности и личной ответственности;
7. Рефлексия
Рефлексия
деятельности
(итог урока)
-Ребята, что нового мы сегодня узнали? Чему мы учились на уроке?
— Ребята, а сейчас мы возвращаемся к тем словам, при помощи которых мы должны себя проверить, как мы научились выделять основу и другие составные части слова и оценить свои успехи цветом. Слайд 12
-Кто хочет выставить свою оценку в классный журнал, может со своей тетрадью подойти к учителю для анализа оценки и своей классной работы.
— Домашнее задание: прочитать памятку № 5 на стр.146, упр. 185.
-Мы узнали, что называется основой слова, и научились ее выделять в словах.
Разбор слов по составу. Слайд 11
Взаимопроверка.
Самооценка на полях тетради при помощи цвета.
Регулятивные:
контролировать процесс и результаты своей деятельности;
делать самостоятельно выводы; познавательные:
строить рассуждения, устанавливать причинно-следственные связи; личностные: развитие самостоятельности и личной ответственности.
Урок русского языка по теме: «Способы образования имён существительных.» Учитель :Каракулова Н.Е. — Кафедра учителей начального образования — Школьные методические объединения — Каталог материалов
Урок русского языка по теме: «Способы образования имён существительных.»
Учитель :Каракулова Н.Е.
Цель урока: формирование понятий о различных способах образования имён существительных.
Задачи урока: углубление уровня понимания учебного материала, повышение мотивации к учебно-познавательной деятельности, создание здоровьесберегающей среды, побуждение к установлению конструктивных межличностных отношений, развитие личностных качеств (мышления, общения, эмоционально-чувственного восприятия), воспитание уверенности в своих силах, коммуникативности, взаимопомощи.
Оборудование урока: карточки с заданиями для групповой и дифференцированной работы, листы с изображением «Лестницы успеха»
Ход урока
I Орг. момент
момент
Развитие учебной мотивации.
Пожелайте удачи друг другу. Я желаю удачи всем вам.
Минутка чистописания
м м м м м м
ма мо му мя мы
— дайте характеристику этому звуку(согласный, звонкий, бывает твёрдым и мягким)
— из слогослияний какой слог звучит мягко?
— на следующей стоке в словарных словах вставьте пропущенные буквы
м-роз, м- тро, м-едведь, м-сяц, м-льтфильм
Знакомство с новым словарным словом- погода
Из истории прошлого (чтение в учебнике)
Составление предложений со словом погода (запись с комментированием)
— С каким из записанных словарных слов можно связать слово погода?
— Подберите однокоренные слова к слову мороз.
Морозный, заморозить, морозильник, заморозки, изморозь, морозец.
Запишите и разберите по составу.
— Какое слово является начальным?
С помощью чего образованы эти слова?
— как вы думаете, какая тема нашего урока? (способы образования имён существительных)
II Актуализация знаний
Работа в парах .
1 группа – разобрать по составу слова снег, снегоход, снежный
2 группа – составить сложные слова из слов и записать их в 2 столбика: с соединительной гласной о и с соединительной гласной е
3 группа — определи способ образования слов: неудача, невезение, неуважение
4 группа – разобрать по составу: грибок, дымок, лесок, мосток.
5 группа – разобрать по составу : подстаканник, подоконник, подлокотник.
Физминутка
— А вы любите сказки?
На чём летал Иван – царевич? Маленький Мук?
(ковёр- самолёт, сапоги – скороходы.
Подумайте, как образованы эти слова?
Это новый способ, прочитайте об этом в учебнике.
Закрепление по учебнику упражнение 5 и 6(2 ученика работают у доски)
III Закрепление пройденного
Игра «Собери словечко»
Из частей слов составить целые слова и определить способ образования
(дом – музей, диван – кровать, город –герой, выход, поезд, глазик, лесок, ледоход, пешеход, подосиновик, посадка)
Физминутка для глаз
Найдите рисунок на стене где изображены степь, лес, пустыня, горы.
Игра « Отгадай слово»
— Какое слово я задумала:
Слово имеет такой же корень как в слове лётчик, приставка такая же, как в глаголе перепрыгнул.
В слове такая же приставка как в слове полёт, корень такой же, как в слове дружба, суффикс такой же, как в слове артистка
Каокй способ образования у этих слов?
IV Рефлексия
— Если бы мы нарисовали лестницу знаний то поднялись бы на ступеньку выше или остались на том же месте?
— А почему? (так, как узнали новый способ образования слов)
Выставление оценок.
Группы в соцсетях
Для просмотра расписания выберите соответствующий класс. Наше главное преимущество – индивидуальный подход к обучению студентовВладимир Кечемайкин WorldSkills – это возможность развития гибких навыковАлександр Милёшкин Дистанционное музыкальное обучение – наш первый опытОксана Никитина Ментальная арифметикаЮлия Чекашкина Плохой почерк у ребенка — это проблема? Зачем учиться писать красиво?Татьяна Астахова Мы выстраиваем индивидуальную траекторию обучения каждого ребенкаИрина Бачкова Все статьиВидео | ||
 Также здесь представлено подробное раписание звонков. Используя этот структурированный раздел, вы всегда будете в курсе, сколько и какие уроки и факультативы у вас сегодня по расписанию.
Также здесь представлено подробное раписание звонков. Используя этот структурированный раздел, вы всегда будете в курсе, сколько и какие уроки и факультативы у вас сегодня по расписанию.Отличительных синтаксических операций в мозге: зависимости и синтаксический анализ фразы | Нейробиология языка
Обработка предложений включает по крайней мере две операции: извлечение значения отдельных языковых единиц из семантической памяти (т. Е. Ментального лексикона) и вычисление значения структур, полученных из комбинации этих более основных единиц. Этот второй подпроцесс, вероятно, требует участия в каком-то структурном анализе, то есть анализе синтаксической конфигурации слов, составляющих предложение.В этом разделе мы рассматриваем и мотивируем выборку корковых областей, которые, не бесспорно, поддерживают структурный анализ.
Е. Ментального лексикона) и вычисление значения структур, полученных из комбинации этих более основных единиц. Этот второй подпроцесс, вероятно, требует участия в каком-то структурном анализе, то есть анализе синтаксической конфигурации слов, составляющих предложение.В этом разделе мы рассматриваем и мотивируем выборку корковых областей, которые, не бесспорно, поддерживают структурный анализ.
В литературе сообщается об участии сети преимущественно левосторонних кортикальных областей, включая левую нижнюю лобную извилину (IFG), левую заднюю верхнюю височную извилину (pSTG) и левый передний височный полюс (ATP). Однако существуют разногласия относительно того, какие области мозга решающим образом участвуют в синтаксической обработке.Значительный объем литературы действительно сообщает об активации левой IFG и левой pSTG во время синтаксической обработки в отличие от базовой линии, обычно состоящей из случайных последовательностей слов (Caramazza & Zurif, 1976; Friederici et al. , 2005; Pallier et al., 2011; Snijders et al., 2008; Tyler, Randall, & Stamatakis, 2008; Zaccarella & Friederici, 2015; Zaccarella et al., 2015). Однако в нескольких других исследованиях не сообщается об активности левой IFG и левой pSTG (Bemis & Pylkkänen, 2011; Humphries et al., 2006; Rogalsky & Hickok, 2008), несмотря на использование парадигм, аналогичных упомянутым выше исследованиям. Более того, нейропсихологические наблюдения вызывают сомнения относительно эффективного вовлечения этих областей в синтаксическую обработку. Например, поражение IFG приводит к так называемой афазии Брока. Эти пациенты с афазией не демонстрируют значительных отличий от здоровых людей из контрольной группы по суждениям о грамматичности (Linebarger et al., 1983; Wulfeck & Bates, 1991). Точно так же анализы поражений, по-видимому, указывают на отсутствие эффекта поражений, расположенных в
IFG и pSTG по эффективности понимания основного предложения (Dronkers et al., 2004; Thothathiri et al.
, 2005; Pallier et al., 2011; Snijders et al., 2008; Tyler, Randall, & Stamatakis, 2008; Zaccarella & Friederici, 2015; Zaccarella et al., 2015). Однако в нескольких других исследованиях не сообщается об активности левой IFG и левой pSTG (Bemis & Pylkkänen, 2011; Humphries et al., 2006; Rogalsky & Hickok, 2008), несмотря на использование парадигм, аналогичных упомянутым выше исследованиям. Более того, нейропсихологические наблюдения вызывают сомнения относительно эффективного вовлечения этих областей в синтаксическую обработку. Например, поражение IFG приводит к так называемой афазии Брока. Эти пациенты с афазией не демонстрируют значительных отличий от здоровых людей из контрольной группы по суждениям о грамматичности (Linebarger et al., 1983; Wulfeck & Bates, 1991). Точно так же анализы поражений, по-видимому, указывают на отсутствие эффекта поражений, расположенных в
IFG и pSTG по эффективности понимания основного предложения (Dronkers et al., 2004; Thothathiri et al. , 2012). Эти исследования не нацелены непосредственно на конкретные синтаксические структуры или обработку синтаксических структур. Тем не менее, обе задачи — оценка грамматичности и понимание предложения — могут потребовать вычисления и анализа синтаксической структуры предъявленных стимулов.
, 2012). Эти исследования не нацелены непосредственно на конкретные синтаксические структуры или обработку синтаксических структур. Тем не менее, обе задачи — оценка грамматичности и понимание предложения — могут потребовать вычисления и анализа синтаксической структуры предъявленных стимулов.
Признавая это несоответствие в литературе относительно вовлечения лобных и задних височных областей, Matchin et al.(2017) предложили гипотезу о том, что левый IFG и pSTG на самом деле могут не играть необходимой роли в синтаксической обработке. Вместо этого они утверждают, что эти области участвуют только в синтаксическом прогнозировании сверху вниз, поддерживая дальнейшие синтаксические операции композиции в левом ATP и левой угловой извилине (AG). Идея о разделении труда между IFG и pSTG, с одной стороны, и АТФ и AG, с другой, также была высказана в более раннем исследовании Pallier et al. (2011). В этом исследовании Паллиер и его коллеги проанализировали активность, записанную во время чтения предложений на естественном языке и бессвязного чтения предложений. Поиск областей мозга, активация которых положительно коррелирует с размером языковых составляющих, их результаты
выделили сеть регионов левого полушария, которые можно было разделить на два основных подмножества. Левый IFG и pSTG продемонстрировали эффекты размера, независимо от того, присутствовали ли слова фактического содержания или были заменены псевдословами (трепетные стимулы). С другой стороны, АТФ, передняя верхняя височная борозда и височно-теменное соединение показали эффекты конститутивного размера только в присутствии лексико-семантической информации, предполагая, что они могут кодировать семантическую композицию на уровне предложения.
Поиск областей мозга, активация которых положительно коррелирует с размером языковых составляющих, их результаты
выделили сеть регионов левого полушария, которые можно было разделить на два основных подмножества. Левый IFG и pSTG продемонстрировали эффекты размера, независимо от того, присутствовали ли слова фактического содержания или были заменены псевдословами (трепетные стимулы). С другой стороны, АТФ, передняя верхняя височная борозда и височно-теменное соединение показали эффекты конститутивного размера только в присутствии лексико-семантической информации, предполагая, что они могут кодировать семантическую композицию на уровне предложения.
Помимо вышеупомянутых исследований, существует обширная литература, утверждающая, что левый АТФ играет бесспорно центральную роль в лингвистической обработке и считается центральным узлом лексической, семантической и синтаксической композиционности. Несколько исследований указали на участие левого АТФ в обработке предложений и фразовой структуры. Сопоставляя активность, записанную во время чтения предложений и списков слов, такие работы, как Mazoyer et al.(1993), Friederici, Meyer и von Cramon (2000), Humphries et al. (2006, 2007) и Stowe et al. (1998) сообщили об увеличении активности АТФ для понимания предложений по сравнению со списками слов. Роль АТФ в процессинге композиции подтверждается еще одной серией исследований, посвященных более конкретным типам синтаксических структур. Вместо того, чтобы рассматривать предложения в целом, этот анализ был сосредоточен на простой фразовой обработке, состоящей из композиции прилагательных и существительных (например,г., красное яблоко ) (Baron & Osherson, 2011; Baron et al., 2010; Bemis & Pylkkänen, 2011; Bemis & Pylkkänen, 2013). Эти результаты подтверждаются также Westerlund et al. (2015), а также через зрительную и слуховую модальность Бемисом и Пюлкканеном (2013).
Несколько исследований указали на участие левого АТФ в обработке предложений и фразовой структуры. Сопоставляя активность, записанную во время чтения предложений и списков слов, такие работы, как Mazoyer et al.(1993), Friederici, Meyer и von Cramon (2000), Humphries et al. (2006, 2007) и Stowe et al. (1998) сообщили об увеличении активности АТФ для понимания предложений по сравнению со списками слов. Роль АТФ в процессинге композиции подтверждается еще одной серией исследований, посвященных более конкретным типам синтаксических структур. Вместо того, чтобы рассматривать предложения в целом, этот анализ был сосредоточен на простой фразовой обработке, состоящей из композиции прилагательных и существительных (например,г., красное яблоко ) (Baron & Osherson, 2011; Baron et al., 2010; Bemis & Pylkkänen, 2011; Bemis & Pylkkänen, 2013). Эти результаты подтверждаются также Westerlund et al. (2015), а также через зрительную и слуховую модальность Бемисом и Пюлкканеном (2013).
Помимо участия в синтаксической обработке, левый АТФ также считается центральным в семантической памяти, предполагаемым подкомпонентом долговременной памяти, хранящей информацию о значении языковых единиц.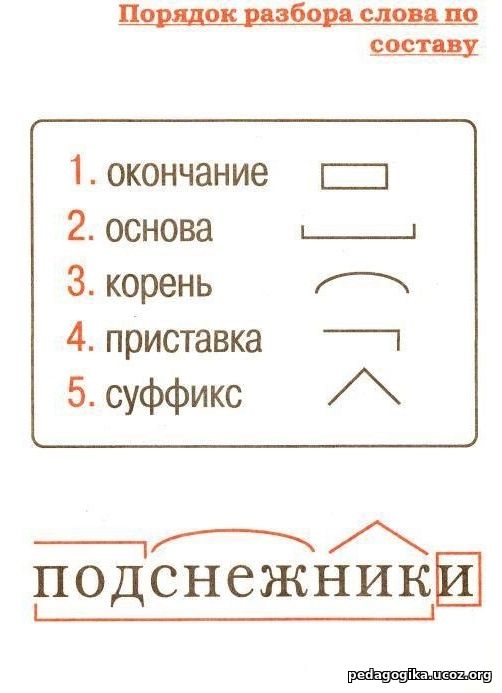 Первое и наиболее убедительное доказательство этой роли АТФ дается исследованиями семантической деменции, в которых пациенты, демонстрирующие атрофию АТФ, демонстрируют значительное нарушение их способности извлекать и распознавать концепции (Hodges, Graham, & Patterson, 1995; Hodges et al., 1992; Mummery et al., 2000; Rogers, Ralph, et al., 2004). Это подтверждается также обширной литературой по нейровизуализации (Bright et al., 2005; Gauthier et al., 1997; Moss et al., 2004; Rogers, Hocking, et al., 2006; Tyler et al., 2004). Эти результаты были обобщены Patterson et al. (2007) и привела к формулированию модели «ступица и спица», которая утверждает, что концепции представлены сетью сенсомоторных репрезентаций, сходящихся в левом АТФ, который действует как концентратор, собирающий и контролирующий специфические особенности модальности, чтобы производить супрамодальные представления. После исследований сентенциальной и фразовой обработки и модели семантической памяти Паттерсона выяснилось, что АТФ может играть роль в двух различных типах композиции: одна объединяет слова в более крупные структуры (фразы и предложения) и один, составляющий значение из более основных семантических характеристик, возможно, основанных на сенсомоторных представлениях.
Первое и наиболее убедительное доказательство этой роли АТФ дается исследованиями семантической деменции, в которых пациенты, демонстрирующие атрофию АТФ, демонстрируют значительное нарушение их способности извлекать и распознавать концепции (Hodges, Graham, & Patterson, 1995; Hodges et al., 1992; Mummery et al., 2000; Rogers, Ralph, et al., 2004). Это подтверждается также обширной литературой по нейровизуализации (Bright et al., 2005; Gauthier et al., 1997; Moss et al., 2004; Rogers, Hocking, et al., 2006; Tyler et al., 2004). Эти результаты были обобщены Patterson et al. (2007) и привела к формулированию модели «ступица и спица», которая утверждает, что концепции представлены сетью сенсомоторных репрезентаций, сходящихся в левом АТФ, который действует как концентратор, собирающий и контролирующий специфические особенности модальности, чтобы производить супрамодальные представления. После исследований сентенциальной и фразовой обработки и модели семантической памяти Паттерсона выяснилось, что АТФ может играть роль в двух различных типах композиции: одна объединяет слова в более крупные структуры (фразы и предложения) и один, составляющий значение из более основных семантических характеристик, возможно, основанных на сенсомоторных представлениях. Это привело Вестерлунда и Пюлькканена.
(2014), чтобы сравнить участие АТФ в задачах, требующих синтаксической и лексической семантической обработки, и пришли к выводу, что эти два процесса действительно могут быть подтверждены одним и тем же корковым механизмом.
Это привело Вестерлунда и Пюлькканена.
(2014), чтобы сравнить участие АТФ в задачах, требующих синтаксической и лексической семантической обработки, и пришли к выводу, что эти два процесса действительно могут быть подтверждены одним и тем же корковым механизмом.
В предыдущем разделе мы видели, как дебаты о вовлечении коры во время структурного анализа предложений обычно указывают на области в левой IFG, левой pSTG и в областях АТФ.Вопрос, который мы рассматриваем в этом исследовании, заключается в том, участвуют ли они по-разному в конкретных синтаксических вычислениях.
В этой статье мы сравниваем грамматик фразовой структуры (PSG) (Borsley, 1998; Chomsky, 1957, 1965) и грамматик зависимостей (DG) (Mel’cˇuk, 1988; Kübler et al., 2009; Tesnière, 2015) как два типа структур, которые мозг потенциально вычисляет как часть понимания предложений. Эти две грамматики различаются по ряду аспектов. DG строит структуры исключительно на словах и бинарных отношениях, существующих между ними, тогда как PSG полагается на группировку слов во фразы, которые, в свою очередь, могут быть сгруппированы в более крупные фразы, подразумевая иерархическую структуру, состоящую из обеих поверхностных форм (слов предложения)
и ненаблюдаемые абстрактные узлы, которые, как предполагается, вычисляются человеческим мозгом. Что касается этого исследования, наша цель не состоит в том, чтобы доказать, что одна грамматика является лучшим формализмом, чем другая.Мы намерены исследовать, насколько чувствительна языковая сеть в мозгу к показателям, полученным на их основе, и насколько. Ниже мы более подробно опишем, чем эти два вида грамматики отличаются друг от друга. Насколько нам известно, в области нейробиологии языка только настоящая работа и работа Ли и Хейла (2019) рассматривают две грамматики вместе в одном исследовании. Показатели, полученные только на основе PSG, использовались в различных работах (например, Brennan et al.
Эти две грамматики различаются по ряду аспектов. DG строит структуры исключительно на словах и бинарных отношениях, существующих между ними, тогда как PSG полагается на группировку слов во фразы, которые, в свою очередь, могут быть сгруппированы в более крупные фразы, подразумевая иерархическую структуру, состоящую из обеих поверхностных форм (слов предложения)
и ненаблюдаемые абстрактные узлы, которые, как предполагается, вычисляются человеческим мозгом. Что касается этого исследования, наша цель не состоит в том, чтобы доказать, что одна грамматика является лучшим формализмом, чем другая.Мы намерены исследовать, насколько чувствительна языковая сеть в мозгу к показателям, полученным на их основе, и насколько. Ниже мы более подробно опишем, чем эти два вида грамматики отличаются друг от друга. Насколько нам известно, в области нейробиологии языка только настоящая работа и работа Ли и Хейла (2019) рассматривают две грамматики вместе в одном исследовании. Показатели, полученные только на основе PSG, использовались в различных работах (например, Brennan et al. , 2016; Frank et al., 2012; Нельсон и др., 2017).
, 2016; Frank et al., 2012; Нельсон и др., 2017).
Вдохновленный предыдущей литературой, мы провели анализ области интереса (ROI), сосредоточив внимание на левом IFG (pars opercularis, triangularis и orbitalis отдельно), левом АТФ и левом STG. Мы приняли стандартную парцелляцию, обеспечиваемую обычно используемым автоматическим атласом анатомической маркировки (Tzourio-Mazoyer et al., 2001), который не разделяет STG на субрегионы.Более того, причина сосредоточения внимания на подразделах IFG основана на Hagoort (2005), который предлагает разделение труда внутри IFG в зависимости от типа выполняемого механизма связывания. Мы подобрали отдельные линейные модели со смешанным эффектом (LME), предсказывающие активность, зарегистрированную в этих областях во время слушания естественного языка, используя в качестве интересующих регрессоров структурные меры, упомянутые выше. Обратите внимание, что наши регрессоры определяют объем синтаксической обработки каждого слова в наших стимулах. Эти анализы
позволили нам определить, какая область более чувствительна к какому типу структурного описания (PSG или DG).Затем мы провели анализ психофизиологического взаимодействия (PPI), исследуя, как взаимодействие между каждой из наших областей интереса и остальной частью мозга модулируется предпочтительным структурным описанием из предыдущего анализа IME.
Эти анализы
позволили нам определить, какая область более чувствительна к какому типу структурного описания (PSG или DG).Затем мы провели анализ психофизиологического взаимодействия (PPI), исследуя, как взаимодействие между каждой из наших областей интереса и остальной частью мозга модулируется предпочтительным структурным описанием из предыдущего анализа IME.
Наше исследование явно связано с работой Brennan et al. (2016), которые показали, что активность в передней и задней частях левой височной коры можно предсказать, используя показатели, полученные на основе фразовой структуры стимулов.Наше исследование также связано с работой Ли и Хейла (2019), которая продолжила исследование Бреннана и его коллег и ввела меру (структурную дистанцию), которая объединяет информацию как из фразовой структуры, так и из структуры зависимостей стимулов и предназначена для метрика сложности, определяющая сложность, связанную с извлечением из памяти. Показатель получается путем подсчета количества фраз, соединяющих два слова, связанных отношением зависимости, и показано, что он может объяснить активность в правой передней и левой задней височных долях.Тем не менее, настоящее исследование отличается от Brennan et al.
(2016) и Ли и Хейл (2019), отдельно исследуя влияние зависимости и обработки фразовой структуры в мозгу. В частности, мы используем показатели, полученные из DG и PSG, которые явно и намеренно сохраняются отдельно, исходя из гипотезы о том, что разные части мозга могут быть по-разному чувствительны к ним. Более того, с теоретической точки зрения структурная метрика Ли и Хейла предназначена как метрика сложности, количественно определяющая сложность, связанную с извлечением из памяти.Напротив, мы интерпретируем наши показатели как корреляты количества операций, необходимых для интеграции каждого слова в его структурный контекст. Следовательно, они предназначены для измерения усилий, необходимых для синтаксической интеграции.
Показатель получается путем подсчета количества фраз, соединяющих два слова, связанных отношением зависимости, и показано, что он может объяснить активность в правой передней и левой задней височных долях.Тем не менее, настоящее исследование отличается от Brennan et al.
(2016) и Ли и Хейл (2019), отдельно исследуя влияние зависимости и обработки фразовой структуры в мозгу. В частности, мы используем показатели, полученные из DG и PSG, которые явно и намеренно сохраняются отдельно, исходя из гипотезы о том, что разные части мозга могут быть по-разному чувствительны к ним. Более того, с теоретической точки зрения структурная метрика Ли и Хейла предназначена как метрика сложности, количественно определяющая сложность, связанную с извлечением из памяти.Напротив, мы интерпретируем наши показатели как корреляты количества операций, необходимых для интеграции каждого слова в его структурный контекст. Следовательно, они предназначены для измерения усилий, необходимых для синтаксической интеграции.
Предположение, представленное во введении, состоит в том, что для интерпретации предложения человеческий мозг должен установить отношения между словами, составляющими его.Например, слова сами по себе не могут передать полное описание ситуации или состояния. Следующий список слов — paper , you , this и read — становится подходящим описанием действия, которое вы выполняете сейчас, только если отношения, которые предикат читает , связаны с субъектом you и объект этот документ (в свою очередь подтвержденный соотношением между определителем , этим и существительным paper ) устанавливаются вашим мозгом.Набор структурных отношений между словами составляет синтаксическую структуру предложения. Процесс, позволяющий вычислить такую структуру
(т.е. получение отношений из последовательности слов) обычно называется синтаксическим анализом. Значение слов, их грамматическая категория, их отношения и зависимости друг от друга определяют интерпретацию предложения, которое они составляют.
Значение слов, их грамматическая категория, их отношения и зависимости друг от друга определяют интерпретацию предложения, которое они составляют.
Грамматики со структурами фраз определяют структуры синтаксического анализа предложений как деревья, составленные из терминальных и нетерминальных узлов.Нетерминальные узлы соответствуют — обычно — фразовым категориям, как определено используемой грамматикой, в то время как конечные узлы (листовые узлы дерева) назначаются поверхностным формам анализируемого предложения (то есть его словам). Узлам фраз присваиваются метки, соответствующие синтаксическим фразовым категориям, таким как именная фраза (NP), глагольная фраза (VP), наречная фраза (AP) и определяющая фраза (DP).
Если дерево является двоичным (в нашем определении синтаксического анализа структуры фраз мы принимаем только бинаризованные деревья) фразовые узлы могут иметь максимум два дочерних узла, которые могут быть либо другими фразовыми узлами, либо листовыми узлами (словами). Родительский узел может состоять только из фразового узла; его также называют нетерминальным. Слова могут быть только потомками нетерминальных фразовых узлов и называются конечными или листовыми узлами, потому что они иерархически не выше, чем любой другой узел. Помимо фразовых и листовых узлов, синтаксический анализ фразы также содержит корневой узел. Корневой узел — это узел, который не является потомком какого-либо другого узла. После синтаксического анализа предложения результирующее дерево содержит только один корневой узел. Корневая нота соответствует категории S, управляющей предложением в целом.
Родительский узел может состоять только из фразового узла; его также называют нетерминальным. Слова могут быть только потомками нетерминальных фразовых узлов и называются конечными или листовыми узлами, потому что они иерархически не выше, чем любой другой узел. Помимо фразовых и листовых узлов, синтаксический анализ фразы также содержит корневой узел. Корневой узел — это узел, который не является потомком какого-либо другого узла. После синтаксического анализа предложения результирующее дерево содержит только один корневой узел. Корневая нота соответствует категории S, управляющей предложением в целом.
В качестве примера, как показано на рисунке 1, синтаксический анализ предложения 1 содержит восемь помеченных структур фраз, включая S, и составляет вложенное дерево двоичных ветвлений. Слова предложения ( , человек , увидела , , коричневый , собака , в , и парк ) соответствуют конечным узлам. Следуя структуре дерева синтаксического анализа сверху вниз: S разветвляется на NP и VP соответственно.Левый дочерний элемент (NP) состоит из определяющего листового узла , и существительного man ; тогда как правый дочерний элемент S (VP), в свою очередь, имеет в качестве левого потомка терминальный узел (конечный глагол видел ), а в качестве его правого дочернего элемента — другую именную фразу (NP). Эта последняя NP разветвляется на другую NP и предложную фразу (PP). Эти две последние фразы обе
разделен на левый дочерний терминал (соответственно , и в ) и на NP как правый дочерний элемент.Последние два состоят из оконечных узлов ( коричневый , собака , и парк ).
Следуя структуре дерева синтаксического анализа сверху вниз: S разветвляется на NP и VP соответственно.Левый дочерний элемент (NP) состоит из определяющего листового узла , и существительного man ; тогда как правый дочерний элемент S (VP), в свою очередь, имеет в качестве левого потомка терминальный узел (конечный глагол видел ), а в качестве его правого дочернего элемента — другую именную фразу (NP). Эта последняя NP разветвляется на другую NP и предложную фразу (PP). Эти две последние фразы обе
разделен на левый дочерний терминал (соответственно , и в ) и на NP как правый дочерний элемент.Последние два состоят из оконечных узлов ( коричневый , собака , и парк ).
Рисунок 1.
Разбор фразовой структуры предложения 1.
Рисунок 1.
Разбор фразовой структуры предложения 1.
Грамматика зависимостей описывает предложение как набор отношений между парами слов — головой и зависимым, составляющими его.Отношения можно назвать зависимостями и соответствовать грамматическим функциям. Отношения и слова, которые они связывают, являются единственными элементами, составляющими структуру (Kübler et al., 2009; Mel’cuk, 1988; Tesnière, 2015). В структуре зависимости конечный глагол часто рассматривается как структурный центр предложения. Все остальные слова прямо или косвенно связаны с глаголом зависимостями.
Возьмите, к примеру, предложение 1 выше.График зависимостей на рисунке 2 представляет структуру зависимости предложения в терминах типизированных отношений зависимости от головы: главный глагол ( saw ) действует как голова для man и dog , с которыми глагол находится в объект и отношение объекта соответственно. Зависимый от одного отношения зависимости может, в свою очередь, быть главой другого. Например, dog — это голова brown , с которой она связана отношением модификатора , а также заголовок статьи a через отношение определителя .Зависимости могут быть созданы между словами, далеко друг от друга в последовательной структуре предложения.
Зависимый от одного отношения зависимости может, в свою очередь, быть главой другого. Например, dog — это голова brown , с которой она связана отношением модификатора , а также заголовок статьи a через отношение определителя .Зависимости могут быть созданы между словами, далеко друг от друга в последовательной структуре предложения.
Рисунок 2.
Анализ зависимости предложения 1.
Рисунок 2.
Анализ зависимости предложения 1.
Отношения, которые сохраняются между словами, улавливаются структурно разными способами с помощью структуры зависимостей и синтаксического анализа структуры фраз одного и того же предложения.Возьмем, к примеру, связь между saw и dog , соответственно, главным глаголом и прямым объектом в предложении 1. Как видно из пути графа между этими двумя элементами на рисунке 3, DS непосредственно фиксирует их отношение предикат-объект. с помощью простого направленного ребра (рис. 3b), тогда как PS опирается на три промежуточных существительных и глагольную фразу управляющего (рис. 3а).
Как видно из пути графа между этими двумя элементами на рисунке 3, DS непосредственно фиксирует их отношение предикат-объект. с помощью простого направленного ребра (рис. 3b), тогда как PS опирается на три промежуточных существительных и глагольную фразу управляющего (рис. 3а).
Рисунок 3.
Сравнение между структурами, опосредующими отношения между основным глаголом предложения ( saw ) и его объектом ( dog ) во фразе-структуре (a) и структуре зависимостей (b) синтаксического анализа предложения 1.
Рисунок 3
Сравнение между структурами, опосредующими отношения между основным глаголом предложения ( saw ) и его объектом ( dog ) во фразе-структуре (a) и структуре зависимостей (b) синтаксического анализа предложения 1.
Грамматика зависимостей и грамматика структуры фраз — это два разных синтаксических формализма, использующих разные структурные примитивы (отношения зависимости и фразы). В области теоретической лингвистики ведутся дискуссии о том, захватывают ли они одну и ту же информацию или в какой степени структуры, которые они санкционируют, эквивалентны (Hays, 1964; Jung, 1998).
В области теоретической лингвистики ведутся дискуссии о том, захватывают ли они одну и ту же информацию или в какой степени структуры, которые они санкционируют, эквивалентны (Hays, 1964; Jung, 1998).
Обсуждая лингвистическую информацию, которую фиксируют две грамматики, Рэмбоу (2010) отмечает, что с теоретической лингвистической точки зрения зависимость и фразовая структура описывают различные синтаксические объекты и, таким образом, не являются строго эквивалентными.Зависимости фиксируют прямые отношения между словами, идентичные тематическим функциям, таким как субъект, объект, модификатор и т. Д. С другой стороны, синтаксическая структура фразы касается не столько функциональных отношений между словами, сколько рекурсивной группировки составляющих предложения ( слова и фразы), так что на каждом уровне каждая группа действует как синтаксическая единица (Schneider, 1998). Более того, согласно Юнгу (1998), только зависимости могут выражать синтаксические пословные отношения предложения, но только составляющие могут выражать линейный порядок предложения. Юнг, таким образом, рассматривает две грамматики как
дополнительные и не эквивалентные.
Юнг, таким образом, рассматривает две грамматики как
дополнительные и не эквивалентные.
Следуя этим последним наблюдениям, мы рассматриваем зависимости и фразовую структуру как разные, а тип информации, которую они захватывают, как неэквивалентную.
Мы повторно проанализировали данные исследования фМРТ по языковому восприятию представленных на слух повествовательных текстов (Lopopolo, Frank, van den Bosch, Nijhof, & Willems, 2018).Здесь мы кратко представляем процедуру сбора данных, предварительную обработку и используемые стимулы. Полную информацию можно найти в оригинальных статьях (Lopopolo, Frank, van den Bosch, Nijhof, & Willems, 2018; Willems et al., 2016). (Набор данных доступен по адресу https://osf.io/utpdy/.)
Двадцать четыре здоровых носителя голландского языка (8 мужчин; средний возраст 22,9 года, диапазон 18–31), без психиатрических или неврологических проблем, с нормальным или исправленным зрением и без проблем со слухом, приняли участие в эксперименте. .Все участники, кроме одного, были правшами по самоотчету, и все участники были наивны в отношении цели эксперимента. Письменное информированное согласие было получено в соответствии с Хельсинкской декларацией, и исследование было одобрено местным комитетом по этике (Центральный комитет по исследованиям с участием человека в качестве субъектов, ОКУ, регион Арнем – Неймеген, Нидерланды, номер протокола 2001/095). В конце исследования участникам платили либо деньгами, либо в виде кредита.
.Все участники, кроме одного, были правшами по самоотчету, и все участники были наивны в отношении цели эксперимента. Письменное информированное согласие было получено в соответствии с Хельсинкской декларацией, и исследование было одобрено местным комитетом по этике (Центральный комитет по исследованиям с участием человека в качестве субъектов, ОКУ, регион Арнем – Неймеген, Нидерланды, номер протокола 2001/095). В конце исследования участникам платили либо деньгами, либо в виде кредита.
Стимулы состояли из трех отрывков из трех отдельных литературных романов, взятых из корпуса разговорного голландца (Corpus Gesproken Nederlands [CGN]; (Oostdijk, 2000).Мы использовали аудиозаписи этих текстов, и никакие другие данные или метаданные из CGN не использовались для нашего анализа. Отрывки произносились с нормальной скоростью в тихой комнате женщинами-ораторами (по одному на рассказ). Продолжительность стимула составляла 3:49 мин (622 слова), 7:50 мин (1291 слово) и 7:48 мин (1131 слово). Версии историй с перевернутой речью были созданы с помощью Audacity 2.03 (https://www.audacityteam.org/). Они использовались в качестве исходных данных низкого уровня в анализе.
Версии историй с перевернутой речью были созданы с помощью Audacity 2.03 (https://www.audacityteam.org/). Они использовались в качестве исходных данных низкого уровня в анализе.
Участники пассивно слушали три рассказа и их перевернутые версии (всего шесть прогонов) внутри МРТ сканера.Каждая история и ее обратная речь были представлены друг за другом. Половина участников начала с необратимого стимула, а половина — с реверсивного речевого стимула. Участникам было предложено внимательно слушать материалы, что на практике возможно только для трех повествований, а не для аналогов с перевернутой речью. После каждого фрагмента делался небольшой перерыв.
Было представлено стимулов с презентацией 16.2 (https://www.neurobs.com/). Слуховые стимулы подавались через наушники, совместимые с МРТ. Чтобы убедиться, что участники могут правильно воспринимать стимулы, фактическим экспериментальным сеансам предшествовал тест громкости в сканере, в котором был представлен фрагмент из другой истории с сопоставимым голосом и качеством звука, а громкость была отрегулирована до оптимальной. уровень на основе обратной связи от участника.
уровень на основе обратной связи от участника.
После сеанса сканирования участники были проверены на их память и понимание рассказов.Участники не были заранее проинформированы о тесте, чтобы избежать искажений внимания во время пассивного прослушивания рассказов.
Изображения изменений в зависимости от уровня кислорода в крови (жирным шрифтом) были получены на 3-T сканере Siemens Magnetom Trio (Эрланген, Германия) с 32-канальной головной катушкой. Подушки и лента использовались, чтобы свести к минимуму движение головы участников, а наушники, которые использовались для представления историй, уменьшили шум сканера.Функциональные изображения были получены с использованием быстрой последовательности трехмерных эхосигналов, взвешенных по Т2 * (Poser et al., 2010), с высоким временным разрешением (время до повторения: 880 мс, время до эхо: 28 мс, угол поворота: 14 °, размер вокселя: 3,5 × 3,5 × 3,5 мм, 36 срезов). Структурные (анатомические) изображения с высоким разрешением (1 × 1 × 1,25 мм) были получены с использованием последовательности T1.
Структурные (анатомические) изображения с высоким разрешением (1 × 1 × 1,25 мм) были получены с использованием последовательности T1.
Предварительная обработка проводилась с использованием SPM8 (https: //www.fil.ion.ucl.ac.uk/spm) и MATLAB 2010b (https://www.mathworks.nl/). Первые четыре объема были удалены для контроля эффектов уравновешивания T1. Для перестройки изображений использовалась регистрация жесткого тела. Изображения были повторно выровнены по первому изображению в каждом прогоне. Среднее значение изображений с коррекцией движения было затем перенесено в то же пространство, что и анатомическое сканирование отдельного участника. Анатомические и функциональные сканы были пространственно нормализованы к стандартному шаблону MNI, а функциональные изображения были повторно дискретизированы до размеров вокселей 2 × 2 × 2 мм.Наконец, для пространственного сглаживания скорректированных по движению и нормализованных данных использовалось изотропное 8-миллиметровое ядро Гаусса с полной шириной на полувысоте.
Анализ зависимостей и фразовой структуры предложений, составляющих текст стимула, был получен с использованием вычислительного анализатора , разработанного и обученного для голландского языка (ALPINO; van Noord, 2006). ALPINO широко использовался в нескольких исследованиях, требующих синтаксического анализа голландского лингвистического материала, от обработки естественного языка до психолингвистических и нейролингвистических исследований.Мы расширили раздел, описывающий синтаксический анализатор, более полным обзором предыдущих нейролингвистических и психолингвистических исследований, в которых этот синтаксический анализатор использовался для получения показателей из фразовой структуры и грамматик зависимостей. Более конкретно, Bastiaanse et al. (2009) использовали ALPINO для создания структур зависимостей на основе данных корпуса, используемых для исследования влияния частоты и сложности на аграмматическое производство. Точно так же Лопополо, Франк, ван ден Бош и Виллемс (2019) использовали ALPINO для изучения взаимосвязи между структурами зависимостей и паттернами движения глаз во время чтения, продемонстрировав валидность ALPINO как инструмента для структурного анализа на основе DG.С другой стороны, Brouwer et al., 2010 использовали ALPINO для получения представлений PSG в своем исследовании голландских синтаксически неоднозначных структур. Более того, исследования, проведенные Косом и его коллегами (Kos, van den Brink, & Hagoort, 2012; Kos, van den Brink, Snijders, et al., 2012; Kos, Vosse, van den Brink, & Hagoort, 2010), широко использовались. голландского банка деревьев (корпус CLEF), который был получен с помощью ALPINO (van der Beek et al., 2002).
Точно так же Лопополо, Франк, ван ден Бош и Виллемс (2019) использовали ALPINO для изучения взаимосвязи между структурами зависимостей и паттернами движения глаз во время чтения, продемонстрировав валидность ALPINO как инструмента для структурного анализа на основе DG.С другой стороны, Brouwer et al., 2010 использовали ALPINO для получения представлений PSG в своем исследовании голландских синтаксически неоднозначных структур. Более того, исследования, проведенные Косом и его коллегами (Kos, van den Brink, & Hagoort, 2012; Kos, van den Brink, Snijders, et al., 2012; Kos, Vosse, van den Brink, & Hagoort, 2010), широко использовались. голландского банка деревьев (корпус CLEF), который был получен с помощью ALPINO (van der Beek et al., 2002).
Грамматика, реализованная в ALPINO grammar, представляет собой грамматику структуры фраз, управляемую заголовком, с широким охватом.Тем не менее, он был расширен, чтобы он мог выводить структуры зависимостей, совместимые с нашим определением DG и основанные на рекомендациях CGN (Oostdijk, 2000).
Вывод ALPINO может возвращать синтаксический анализ предложений в соответствии с принципами PSG, а также DG. Более того, он может генерировать оба этих типа синтаксического анализа из одной и той же структуры, что делает его удобным и позволяет нам избежать несоответствий, возникающих из-за использования разных синтаксических анализаторов, созданных и обученных на разных данных.Из каждой из этих структур синтаксического анализа мы получаем меру, приближающую операции, выполняемые для интеграции каждого слова в синтаксическую структуру, вычисленную в точке его представления. В следующих разделах эти меры будут подробно описаны.
Чтобы описать структуру зависимостей предложения, синтаксический анализатор ALPINO создает структуру, состоящую из троек зависимостей, состоящих из главного слова, типа отношения зависимости и его зависимого слова. Синтаксический анализ производится для каждого предложения независимо; следовательно, нельзя установить никакого отношения между словами, принадлежащими к разным предложениям.
Синтаксический анализ производится для каждого предложения независимо; следовательно, нельзя установить никакого отношения между словами, принадлежащими к разным предложениям.
Чтобы описать операцию, необходимую для интеграции слова за раз в постепенно выстраиваемую структуру зависимостей предложения, мы приняли количество левых отношений, поддерживаемых каждым словом. Как описано выше, каждое слово в предложении имеет по крайней мере одно отношение с другим словом в том же предложении.Каждое незавершенное и не начальное слово может иметь отношения с переменным количеством других слов справа и слева. По логике, слово в начале предложения может иметь отношения только со словами справа от него, а слово в конце предложения может быть связано только со словами слева от него. Чтобы количественно определить операции, необходимые для интеграции слова w в структуру, построенную до его представления, подсчитываются только отношения с головой и возможными зависимостями в левой части w . Другими словами, исходя из структуры зависимостей предложения, мы подсчитываем количество левых ребер для каждого слова w в предложении (левые отношения структуры зависимостей, или DSlrels, см. Таблицу 1).
Другими словами, исходя из структуры зависимостей предложения, мы подсчитываем количество левых ребер для каждого слова w в предложении (левые отношения структуры зависимостей, или DSlrels, см. Таблицу 1).
Число левых отношений зависимости (DSlrels) на слово w в примере Предложение 1
| . | The . | человек . | пила . | а . | коричневый . | собака . | дюйм . | г. . | парк . | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DSlrels | 0 | 1 | 1 | 0 | 0 | 3 | 1 | 0 | 1 | 9020 9025 . The
. | человек . | пила . | а . | коричневый . | собака . | дюйм . | г. . | парк . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DSlrels | 0 | 1 | 1 | 0 | 0 | 3 | 1 | 0 | 1 | Например, слово собака в предложении имеет два зависимых отношения с двумя словами слева ( a и коричневый ), без зависимых справа от него, но одна голова слева от него ( видел ).Слово park , будучи заключительным предложением, не имеет никаких ссылок справа, но у него есть одна голова ( в ) и одна зависимая ( ) слева. С нейробиологической точки зрения предполагается, что все отношения зависимости имеют одинаковую стоимость. Что касается синтаксического анализа фразовой структуры, тексты трех рассказов, представленных участникам, были загружены в набор инструментов ALPINO для обработки естественного языка голландского языка, чтобы на этот раз сгенерировать синтаксический анализ фразеологической структуры для каждого предложения (van Noord, 2006) . Чтобы количественно определить количество синтаксических операций на слово, необходимых для построения синтаксического анализа структуры фразы входного предложения, мы измерили количество структур закрытых фраз, разрешенных после введения каждого нового слова (PSxps). Такая мера вычисляется путем рассмотрения того, является ли слово или фраза правым или левым потомком своего родительского фразового узла. Чтобы контролировать другие факторы, которые, как известно, влияют на активацию мозга во время понимания речи, мы добавили преобразованные в логарифмическую форму лексическую частоту и неожиданность в качестве ковариант в анализ (Lopopolo, Frank, van den Bosch, & Willems, 2017; Willems et al., 2016). Преобразованная в Log2 лексическая частота на слово была вычислена с использованием корпуса SUBTLEX NL (Keuleers et al., 2010). Сюрприз был вычислен на основе модели Маркова второго порядка, также известной как модель триграммы, обученной на случайном выборе 10 миллионов предложений (включая 197 миллионов токенов слов; 2,1 миллиона типов) из голландского корпуса Интернета (NLCOW2012; Schäfer & Bildhauer). Мы выбрали шесть отдельных анатомических ROI для левого полушария, чтобы выборочно проверить вклад двух наших синтаксических показателей в качестве предикторов активности BOLD. Этими областями были STG (включая область Вернике), средний височный полюс (mATP), верхний височный полюс (sATP), IFG pars opercularis (IFG_oper), IFG pars triangularis (IFG_tri) и IFG pars orbitalis (IFG_orb). ).Области определены в соответствии с атласом автоматической анатомической маркировки (AAL) (Tzourio-Mazoyer et al. Для каждой из шести областей интереса мы подобрали три модели LME, предсказывающие средний жирный сигнал. Первая модель (Базовая, 2 ниже) содержит в качестве предикторов только вероятностную информацию (лексическую частоту и неожиданность) относительно каждого слова.Оценки алгоритма коррекции движения (три поворота и три перевода за прогон) были дополнительно добавлены как регрессоры, не представляющие интереса. Чтобы оценить влияние показателей зависимости и фразовой структуры на BOLD-сигнал каждого ROI, модели 3 и 4 были оснащены одним из наших синтаксических показателей (DSlrels, PSxps) в дополнение к тем же ковариатам базовой модели. Кроме того, мы включили случайные перехваты по субъекту, а также случайные наклоны по субъекту для неожиданной и логарифмической частоты слов.
Мы сравнили синтаксические модели (DSlrels и PSxps) с базовой моделью, чтобы проверить, улучшило ли введение синтаксической меры достоверность данных. Анализ ROI, представленный выше, был направлен на определение вклада наших структурных показателей в активность левой нижней лобной, верхней височной и передневисочной областей мозга — областей, которые, как утверждается, отвечают за структурный анализ языковых стимулов.Чтобы изучить взаимодействие между этими (и другими) областями мозга, мы дополнительно исследовали ИЦП. PPI — это метод анализа функциональной связи мозга, разработанный для оценки контекстно-зависимых изменений функциональной связности кортикальных областей (Friston, 2011; Friston, Büchel, et al., 1997). Он моделирует то, как активность мозга определяется активностью предварительно выбранной семенной области при модуляции экспериментальными условиями или параметрами (модулятор). Активность каждой исходной области была рассчитана путем подбора общей линейной модели, содержащей в качестве предикторов наши структурные меры и в качестве ковариат лексическую частоту, неожиданное и параметрическое движение головы.Собственное значение вокселей внутри ROI, показывающее надпороговую активацию для интересующего регрессора, использовалось для вычисления физиологического компонента PPI. На уровне отдельного субъекта наблюдаемый ЖЕЛТЫЙ временной ход в каждом вокселе был подвергнут регрессионному анализу, тестированию на вокселы, в котором интересующие ковариаты (DSlrels, PSxps) объясняют значительную долю дисперсии этого временного графика вокселя (Friston , Холмс и др. Нас интересовало, какие воксели более чувствительны к DSlrels по сравнению с PSxps и наоборот. Для этого мы сопоставили эти два интересующих нас регрессора, чтобы определить вокселы, которые являются селективными для каждого из регрессоров сверх вклада другого (DSlrels> PSxps, PSxps> DSlrels). Результаты, представленные в предыдущем разделе, подчеркивают предпочтительную избирательность структуры зависимостей в левом ATP и IFG и избирательность структуры фразы в левом STG. В этом разделе мы представляем результаты анализа PPI, нацеленного на оценку взаимосвязи между активностью в наших ROI, модулируемой обработкой либо структуры фразы, либо структуры зависимостей. Поскольку STG показал избирательность в отношении структур фраз, а IFG и ATP — в отношении структур зависимостей, мы провели три отдельных анализа PPI для всего мозга. Сначала мы проверили области мозга, в которых активность была обусловлена активностью STG (физиологическое семя), модулированной структурной мерой PSxps (психологический модулятор).Затем мы использовали активность IFG или ATP в качестве физиологических семян и DSlrels в качестве модулятора, чтобы оценить вклад этих областей и структуры в активность остальной части мозга во время обработки речи. В таблице 5 и на рисунке 5 представлены результаты анализа PPI с использованием STG в качестве физиологического затравки и PSxps в качестве модулятора активности. Области результатов всего мозга, которые более чувствительны к DSlrels по сравнению с PSxps (DSlrels> PSxps)
Контрастные PSxps и DSlrels (PSxps> DSlrels, 8) подчеркивают роль IFG (orbitalis), AG, веретенообразной формы и гиппокампа в левом полушарии и двусторонней затылочной коры. С другой стороны, контрастирование DSlrels и PSxps в другом направлении (Dslrels> PSxps, 9) указывает на вовлечение левой верхней лобной извилины (SFG) и правой хвостатой части. Целью нашего эксперимента было выяснить, чувствительны ли части мозга, ранее задействованные в синтаксисе, к различным типам синтаксических операций, участвующих в синтаксическом разборе предложений. Эти результаты частично отличаются от результатов, представленных Ли и Хейлом (2019).Их показатель структурного расстояния объясняет активность в правой передней и левой задней височной коре. Принимая во внимание, что PSxps вместо этого объясняет активацию в левом STG, тогда как DSlrels объясняет активацию в левом АТФ, их наблюдение, что структурное расстояние показывает активацию как в передней, так и в задней верхней височных областях, может быть связано с тем фактом, что оно неявно содержит информацию, объединяющую зависимость и фразовый состав раздражителей. Наши результаты указывают на связь между активностью АТФ и количеством отношений зависимости левой стороны на уровне слов, что было принято как количественная оценка операции, которую человеческий мозг должен выполнять, чтобы интегрировать каждое слово в зависимость. синтаксический анализ предложения, в которое он встроен.Таким образом, это, по-видимому, указывает на то, что АТФ действует как комбинаторный узел, который связывает слова воедино в соответствии с отношениями, аналогичными тем, которые характеризуют анализ зависимостей. Структура зависимости, составленная бинарными типизированными отношениями, также может быть близка к стимулам из двух слов, которые, как было обнаружено Baron et al., Вызывают активацию в АТФ.(2010) и Westerlund et al. (2015). Барон и др. (2010) наблюдали модуляцию активности в этой области при представлении пар прилагательное – существительное. Отношения прилагательных и существительных напрямую фиксируются отношениями модификации в типе синтаксического анализа зависимости, который мы использовали в этом исследовании. Точно так же интересный параллелизм между типизированными отношениями, которые составляют графы зависимостей, и типами стимулов, состоящих из двух слов, представленных в Westerlund et al. Отношения зависимости типа модификатора могут быть проиллюстрированы связью между прилагательным и существительным, наречием и глаголом, определителем и существительным и т. Д.Вестерлунд и др. (2015) продемонстрировали, что широкий спектр «композиционных режимов» влияет на активность левого АТФ. Эти способы состоят из последовательностей из двух слов, классифицируемых как модификация (прилагательное-существительное-наречие-глагол-наречие-прилагательное) или насыщение аргументов (глагол-существительное, предлог-существительное-определитель-существительное). Таким образом, наши результаты подтверждают, что левый ATP может служить локусом, где вычисляются семантические представления на уровне предложения, и что эти представления могут быть получены путем объединения слов, составляющих предложение, следуя структуре, указанной способом, сопоставимым с анализом зависимостей. Анализ ROI показывает небольшое влияние показателей структуры зависимостей на активность левой IFG (pars opercularis).Эта область занимает центральное место в нескольких исследованиях языка и синтаксической обработки и часто связана с активностью левой pSTG (Caramazza & Zurif, 1976; Friederici et al. Помимо анализа ROI, PPI и анализ всего мозга дают несколько более сложную картину. Активность в части левой части треугольной части объясняется активностью левой STG, модулируемой структурой фразы, тогда как активность в другой части того же субрегиона связана с активностью в части оболочки, которая модулируется структурой зависимости.Вместо этого анализ всего мозга указывает на участие левой части орбитальной части в обработке фразеологической структуры. В свете этих наблюдений возможно, что разные подобласти левой IFG поддерживают анализ различных синтаксических структур, согласованных либо с левым ATP, либо с левым STG. В частности, pars opercularis может работать совместно с левым ATP при построении представлений зависимостей на уровне предложения, тогда как pars orbitalis выполняет операции, связанные с теми, которые выполняются в левой STG, имея дело с иерархическими фразовыми представлениями предложения.Треугольник pars, по-разному связанный с вычислением структуры зависимостей в ATP и фразовым анализом в STG, может — это очень условно — действовать как буфер между этими двумя областями и их синтаксическими операциями. Эти объяснения все еще находятся на уровне предположений, и мы откладываем дальнейшие исследования, прежде чем делать какие-либо более убедительные выводы. Анализ всего мозга выявил дополнительный набор областей, которые более чувствительны к структуре зависимостей по сравнению с показателями структуры фраз.Помимо результатов ROI, мы наблюдали вовлечение других структур мозга: левой АГ, правой задней поясной коры и левой верхней лобной извилины. Эти шаблоны активации могут указывать на то, что структуры зависимостей коррелируют с механизмами рабочей памяти, обслуживающими синтаксический анализ. PFC упоминается как центральный игрок в исследованиях рабочей памяти, в том числе в области языковой обработки и понимания предложений (D’Esposito & Postle, 2007; Nee & D’Esposito, 2016).Кроме того, Bonhage et al. (2014) сообщили об участии также нижней теменной коры (включая АГ) и областей, граничащих с поясной корой и предклиньем во время кодирования в рабочей памяти фрагментов коротких предложений (4 или 6 слов). Кто-то может возразить, что количество DSlrels, управляющих каждым словом в стимуле, просто моделирует нагрузку на ресурсы рабочей памяти, необходимые для пословной обработки предложений.Другими словами, получив предложение, мозг должен сохранять в памяти каждое слово постепенно, пока получатель отношения зависимости с каждым словом не будет представлен — и в конечном итоге интегрирован. В этом смысле DSlrels фиксируют только количество слов, которые нужно помнить, пока не будет прочитан или услышан подходящий иждивенец или руководитель. Тем не менее, эта интерпретация не объясняет всей картины в отношении обработки структуры зависимостей.Как указывалось выше, существует значительная связь между DSlrels и левым ATP, областью, которая традиционно не считается частью сети рабочей памяти. Следовательно, вместо того, чтобы интерпретировать эти результаты как предполагающие, что меры зависимости просто фиксируют нагрузку на рабочую память, вызванную количеством слов, которые необходимо интегрировать в синтаксический анализ, было бы более точным утверждать, что, хотя связанная с зависимостью активность в левом ATP действительно вычисляет предложение На уровне структурного анализа активность в таких областях, как поясная извилина, лобная и нижняя теменная кора, может быть хорошо объяснена с точки зрения обработки памяти, поддерживающей активность в передней височной и нижней лобных областях. Анализ PPI был проведен, чтобы увидеть, какой тип взаимодействия существует между этими областями обработки синтаксиса (левый ATP, IFG и STG) и остальной частью мозга. Тот факт, что активность в левой STG, модулируемая PSxps, по-видимому, управляет активацией в небольшой части левой IFG, помимо большой сети двусторонних центральных и прецентральных областей, может указывать на взаимодействие между фразами-структурой. и области обработки структуры зависимостей.Это может быть подтверждено также наблюдением, что активность IFG, модулируемая DSlrels, объясняет активность в левой задней перисильвиевой коре (т.е. AG) и в небольшой части правой средней STG. Тем не менее, эти результаты не могут позволить нам твердо заявить о причинном взаимодействии между этими наборами областей. Частично расхождения между анализом рентабельности инвестиций, с одной стороны, и анализом вокселей, с другой стороны, вероятно, вызваны статистическим пороговым значением в последнем, что во многих отношениях является статистически нечувствительным методом (по сравнению с к анализу ROI).В анализе ROI мы оцениваем, улучшает ли добавление синтаксического предиктора соответствие линейной модели средней активности в анатомически определенной области мозга. Анализ всего мозга проверяет, соответствует ли бета-коэффициент регрессора активности отдельного вокселя статистически значимым образом. Учитывая, что это делается сразу на многих вокселях, существует значительный риск ложноотрицательных результатов. Анализ PPI исследует коэффициенты синтаксического регрессора, свёрнутого с ЖИРНОЙ активностью исходной области, при этом контролируя ЖИРНУЮ активность самой области.Как по духу, так и по реализации, это дополняет подход, основанный на активации, используемый в анализе ROI и анализе всего мозга. В этой статье мы исследовали, чувствительны ли разные области мозга к разным видам синтаксических операций. Для этого мы оценили дескрипторы зависимости и фразовой структуры предложений как предикторы активности мозга в левом АТФ, левом IFG и левом STG — областях, задействованных во время языковой обработки. Мы обнаружили, что активность в левом АТФ лучше объясняется показателями зависимости по сравнению с показателями фразовой структуры. Эти результаты отличаются от предыдущих исследований, в которых структуры фраз использовались в качестве предпочтительного формализма для характеристики синтаксиса естественного языка (Nelson et al., 2017). Наши результаты связаны с результатами, представленными Brennan et al. (2016). Они предсказали данные фМРТ как в левой передней, так и в задней частях височной коры во время нарративного прослушивания, используя синтаксические показатели, полученные из фразовой структуры стимулов. Наши наблюдения относительно роли левого АТФ также согласуются с такими исследованиями, как Westerlund et al. Мы также провели анализ PPI, исследуя, как взаимодействие между каждой из наших ROI и остальной частью мозга модулируется предпочтительным структурным описанием, как в предыдущем lme-анализе.Мы наблюдали, что активность левого STG, модулируемая количеством структур закрытых фраз, может управлять активностью левого АТФ. Эти результаты, подтверждая разделение труда между областями мозга, по-видимому, указывают на вспомогательную роль STG и построение фразеологической структуры, поддерживающей анализ стиля зависимости, который, по-видимому, выполняет такая область, как АТФ. Использование API событий SlackEvents API — это упрощенный и простой способ создания приложений и ботов, которые реагируют на действия в Slack. Все, что вам нужно, — это приложение Slack и безопасное место для отправки ваших событий. Не звоните нам, мы позвоним вамСообщите нам, куда отправлять тщательно отобранные типы мероприятий, и мы доставим их с изяществом, безопасностью и уважением. Мы даже попробуем повторить попытку, если что-то не получится. Подпишитесь на нужные вам типы событийПодпишитесь на типы событий, которые вам нужны, и не беспокойтесь о событиях, которые вам не нужны. Регулируется областями разрешений OAuth Типы событий, отправляемые вам, напрямую связаны с областями разрешений OAuth, которые выдаются по мере того, как пользователи устанавливают ваше приложение Slack. Здесь обслуживаются перспективные пользователи ботовSlack Apps, включая пользователей-ботов, могут подписаться на события, связанные с каналами и прямыми сообщениями, участниками которых они являются. Создавайте ботов без надоедливого набора веб-сокетов RTM API. Используйте API событий через режим сокета, чтобы получать события через динамический WebSocket, а не через общедоступную конечную точку HTTP.Выберите техническую реализацию, которая подходит именно вам. ОбзорЦикл событийМногие приложения, созданные с использованием API событий, будут следовать той же абстрактной управляемой событиями последовательности:
Если ваше приложение представляет собой бот, который прослушивает сообщения с определенными триггерными фразами, этот цикл событий может воспроизводиться примерно так:
Использование веб-API с API событий позволяет вашему приложению или боту делать гораздо больше, чем просто слушать сообщения и отвечать на них. Подготовка к использованию Events API Для многих API событий значительно проще интегрировать, чем API обмена сообщениями в реальном времени. Если вы уже знакомы с HTTP и вам удобно поддерживать собственный сервер, обработка цикла запросов и ответов API событий должна быть устаревшей. Подходит ли Events API для вашего приложения?Перед тем, как начать, вы можете заранее принять несколько решений об архитектуре вашего приложения и подходе к потребляющим событиям. Один из способов использования API событий — это альтернатива открытию подключений через веб-серверы к API обмена сообщениями в реальном времени. Вместо того, чтобы поддерживать одно или несколько долговременных соединений для каждой рабочей области, к которой подключено приложение, вы просто настраиваете одну или несколько конечных точек на своих серверах для получения событий атомарно в режиме, близком к реальному времени. Некоторые разработчики могут захотеть использовать API событий как своего рода избыточность для своих существующих подключений к веб-сокетам. И другие разработчики будут использовать API событий для получения информации о рабочих областях и пользователях, от имени которых они действуют, для улучшения своих команд с косой чертой, пользователей-ботов, уведомлений или других возможностей. Модель разрешения Events API использует существующую объектно-управляемую систему OAuth в Slack для управления доступом к событиям.Например, если ваше приложение имеет доступ к файлам через область Вы будете получать только те события, которые пользователи, авторизовавшие ваше приложение, могут «видеть» в своей рабочей области (то есть, если пользователь разрешает доступ к истории частных каналов, вы будете видеть только активность в частных каналах, участниками которых они являются. , не все частные каналы в рабочей области). Пользователи Bot также могут подписаться на события от своего имени. Область действия бота Подписка на типы событийЧтобы начать работу с Events API, вам необходимо создать приложение Slack, если вы еще этого не сделали. Управляя своим приложением, найдите страницу конфигурации «Подписки на события» и включите ее с помощью переключателя. После небольшой дополнительной настройки вы сможете выбрать все типы событий, на которые хотите подписаться. URL-адреса запросов API событийURL-адреса запроса работают аналогично URL-адресам вызова команд с косой чертой и URL-адресам действий кнопок сообщений: Все они получают HTTP POST, содержащий данные в ответ на активность. В API событий URL-адрес запроса API событий — это целевое расположение, куда будут доставляться все события, на которые подписано ваше приложение, независимо от рабочей области или типа события. Поскольку ваше приложение будет иметь только один URL-адрес запроса событий, вам необходимо будет выполнить дополнительную отправку или маршрутизацию на стороне сервера после получения данных о событии. Ваш URL-адрес запроса будет получать полезные данные на основе JSON, содержащие обернутые типы событий. Объем событий будет зависеть от событий, на которые вы подписаны, а также от размера и активности рабочих областей, в которых установлено ваше приложение. URL-адрес вашего запроса может получать многих событий и запросов .Подумайте о том, чтобы отделить прием событий от обработки и реакции на них. Просмотрите раздел об ограничении скорости, чтобы лучше понять максимальный объем событий, который вы можете получить. Запросить настройку и подтверждение URL-адресаВаш URL-адрес запроса события должен быть подтвержден перед сохранением этой формы. Если вашему серверу требуется некоторое время для «пробуждения», а ваша первоначальная попытка проверки URL-адреса не удалась из-за тайм-аута, используйте кнопку retry , чтобы повторить попытку проверки. Если вы не хотите предоставлять общедоступную статическую конечную точку HTTP для связи со Slack, вам может помочь режим сокета. Подтверждение URL-адресаСобытия, отправленные на ваш URL-адрес запроса, могут содержать конфиденциальную информацию, связанную с рабочими областями, одобрившими ваше приложение Slack. Чтобы обеспечить доставку событий на сервер, находящийся под вашим прямым контролем, мы должны подтвердить ваше право собственности, отправив вам запрос. После того, как вы завершите ввод URL-адреса, мы отправим HTTP-запрос POST на URL-адрес вашего запроса.Мы проверим ваш SSL-сертификат и отправим тело POST-запроса Это событие не требует определенной области действия OAuth или подписки. Вы будете автоматически получать его при настройке URL-адреса запроса Events API. Атрибуты, которые отправляет Slack, включают:
Осторожно, URL-адреса ответов чувствительны к регистру. Отвечая на вызов После получения события завершите последовательность, ответив HTTP 200 и значением атрибута Ответы могут быть отправлены в виде открытого текста: В качестве альтернативы, если вы чувствуете себя более формально, ответьте Или, если вам хочется пощеголять, ответьте После завершения проверки URL вы увидите зеленую галочку, означающую вашу победу. Если вы получаете сообщение об ошибке от вашего сервера, тайм-аут или другое исключительное состояние, вы увидите сообщения об ошибках, которые, надеюсь, помогут вам понять, что не так, прежде чем вы повторите попытку после того, как все будет готово. Завершив это сложное рукопожатие, вы готовы открыть наш каталог типов событий и решить, на какие события подписаться. Выбор подписок на мероприятияПосле настройки и проверки URL-адреса запроса пора подписаться на типы событий, которые вы считаете интересными, полезными или необходимыми. Менеджер подписок разделен на два раздела:
Активация подписок API событий поддерживается той же системой определения разрешений OAuth, что и ваше приложение Slack. Если в рабочих областях уже установлено ваше приложение, ваш URL-адрес запроса скоро начнет получать настроенные подписки на события. Для любых рабочих областей, в которых еще не установлено ваше приложение, вам необходимо запросить определенные области OAuth, соответствующие типам событий, на которые вы подписываетесь. Если вы работаете от имени пользователя-бота, вам потребуется, чтобы ваш бот был установлен обычным способом, используя область действия Авторизуйте пользователей для вашего приложения Event Consumer через стандартный поток OAuth.Обязательно укажите все необходимые области для событий, которые ваше приложение хочет получать. См. Наш индекс доступных типов событий с соответствующими областями действия OAuth. После всей этой надлежащей подготовки пришло время получать и обрабатывать все эти подписки на события. Прием событий URL-адрес вашего запроса будет получать запрос для каждого события, соответствующего вашим подпискам. Вы можете принять во внимание количество обслуживаемых вами рабочих пространств, количество пользователей в этих рабочих пространствах, а также их объем сообщений и других действий, чтобы оценить, сколько запросов ваш URL-адрес запроса может получить и соответствующим образом масштабировать. События отправляются как JSON Когда событие в вашей подписке происходит в учетной записи авторизованного пользователя, мы отправляем HTTP-запрос POST на ваш URL-адрес запроса. Событие будет иметь формат Поля Атрибут события Узнайте больше — гораздо больше — об оболочке события, включая ее схему JSON. Обзор поля обратного вызоваТакже называется «внешним событием» или объектом JSON, содержащим событие, которое произошло само.
Структура типов событийСтруктура типов событий варьируется от типа к типу, в зависимости от типа действия или типа объекта, которые они представляют. Если вы уже знакомы с API обмена сообщениями в реальном времени, вы обнаружите, что внутренняя структура события
Если несколько пользователей в одной рабочей области установили ваше приложение и могут «видеть» одно и то же событие, мы отправим одно событие и включим список пользователей, для которых это событие «видно», в поле Вот полный пример отправленного события для response_added: Полномочия Ранее API событий включал полный список из В этих полях показано, кому доступно событие. Например, если ваше приложение было установлено двумя пользователями в рабочей области, и приложение прослушивает событие Теперь Ожидайте новую внешнюю полезную нагрузку для событий, которая выглядит так: Если ваше приложение отслеживает более одной установочной стороны, лучше не полагаться на на единственную сторону, указанную в Чтобы получить полный список тех, кто может видеть события, вызовите метод Подробнее об изменениях читайте здесь. Они вступят в силу для существующих приложений 24 февраля 2021 г., но вы можете выбрать их, когда захотите, в конфигурации своего приложения. Еще одно замечание: не все события предоставляют Вновь созданные приложения автоматически включаются в новую форму событий: одно усеченное поле Вы также можете сразу использовать метод Эти изменения позволяют Slack повысить производительность API событий, быстрее доставляя события. Реагирование на событияВаше приложение должно ответить на запрос события HTTP 2xx в течение трех секунд .В противном случае мы будем считать, что попытка доставки события не удалась. После сбоя мы повторим попытку три раза, постепенно отступая. Поддерживайте процент успешных ответов на уровне не менее 5% событий за 60 минут, чтобы предотвратить автоматическое отключение. Отвечайте на события с помощью HTTP 200 OK как можно скорее. То, что вы делаете с событиями, зависит от того, что делает ваше приложение или служба. Может быть, это заставит вас отправить сообщение с помощью Ограничение скоростиМы не хотим наводнять ваши серверы событиями, с которыми он не может справиться. Доставка событий в настоящее время составляет максимум 30 000 на рабочее место за 60 минут. Если ваше приложение будет получать более 30 000 событий одной рабочей области в 60-минутном окне, вы будете получать Событие ограничения скорости Если скорость ограничена, ваш URL-адрес запроса получит специальное событие приложения, Полевой справочник
Вы будете получать эти обратные вызовы за каждую минуту, ограниченную для этого рабочего пространства. Обработка ошибокКогда Slack отправляет события URL-адреса вашего запроса, мы просим вас возвращать HTTP 200 OK для каждого успешно полученного события. Вы можете ответить HTTP 301 или 302, и мы выполним до двух переадресаций в нашем поиске, чтобы вы предоставили нам код успеха HTTP 200. Успешно реагируйте как минимум на 5% событий, доставленных вашему приложению, в противном случае вы рискуете быть временно отключенными. После того, как вы восстановите свою способность обрабатывать события, повторно включите подписки, посетив Управление приложениями Slack, выбрав свое приложение и следуя подсказкам. Вам нужно будет перейти к Live App Settings , если ваше приложение является частью каталога. Условия отказаМы рассматриваем любой из этих сценариев как состояние единичного отказа:
Хотя мы ограничиваем количество условий сбоя, которые мы допускаем с течением времени, мы также аккуратно повторим попытку отправки ваших событий в соответствии со стратегией экспоненциальной задержки. Поддерживайте процент успешных ответов на уровне 5% или выше, чтобы избежать отключения автоматической доставки событий. Приложения, получающие менее 1000 событий в час, не будут автоматически отключены. Изящные попыткиМы будем стучать в дверь вашего сервера, повторяя неудачный запрос до 3 раза в постепенно увеличивающемся расписании:
При каждой повторной попытке вам также будет выдаваться HTTP-заголовок повторных попыток учитываются в соответствии с ограничениями сбоев, указанными ниже. Мы расскажем вам, почему мы повторяем запрос в заголовке HTTP
Отключение повторных попыток Если на вашем сервере возникают проблемы с обработкой наших запросов или вы не хотите, чтобы мы повторяли неудавшуюся доставку, укажите в своих ответах заголовок HTTP, указывающий на то, что вы не желаете никаких дальнейших попыток. Просто предоставьте нам этот HTTP-заголовок и значение как часть вашего ответа, отличного от 200 OK: Представляя этот заголовок, мы понимаем, что это означает, что вы не хотите, чтобы это конкретное событие было доставлено повторно.Доставка на другие мероприятия останется неизменной. Пределы отказовЕсли вы отвечаете ошибками, мы не будем постоянно отправлять события на ваши серверы. Когда ваше приложение входит в любую комбинацию этих условий сбоя для более чем 95% попыток доставки в течение 60 минут, подписки на события вашего приложения будут временно отключены. Мы также отправим вам, создателю и владельцу приложения Slack, электронное письмо с уведомлением о ситуации.У вас будет возможность повторно включить доставку, когда вы будете готовы. Возобновление доставки событий Вручную повторно включите подписку на события, посетив настройки вашего приложения. Управление изменениямиНеизбежно статус ваших подписок изменится. Новые рабочие области будут подписаны на ваше приложение. Установившие пользователи могут покинуть рабочее пространство.Возможно, вы измените свои подписки или побудите пользователей запросить другой набор областей действия OAuth. Помимо отключения вашего приложения, существует несколько различных типов изменений, которые повлияют на то, какие события получает ваше приложение: Установка приложенияКогда пользователь установит ваше приложение, вы сразу же начнете получать для него события на основе вашей подписки. Предоставленные вашему приложению области OAuth определяют, какие события в вашей подписке вы получите . Если вы настроили свою подписку на получение событий Отзыв приложенияЕсли пользователь удаляет ваше приложение (или токены, выданные вашему приложению, аннулируются), события для этого пользователя немедленно перестанут отправляться в ваше приложение. Вы меняете события в подпискеЕсли вы измените подписку через интерфейс управления приложением, изменения вступят в силу сразу же. . . В зависимости от модификации, типов событий и областей действия OAuth, которые вы запрашивали у пользователей, может произойти несколько разных вещей: Добавление подписок на мероприятия, у вас уже есть области действия для Например, вы запрашивали Добавление подписок на мероприятия, для которых вы еще не ограничены Например, вы запрашивали Необходимо снова отправить существующих пользователей через поток OAuth, запросив файлы Удаление подписок на события, независимо от предоставленных областей События немедленно перестанут отправляться всем пользователям, установившим ваше приложение. Их области действия и авторизации OAuth не пострадают. Если вам не были предоставлены области разрешений для удаленной подписки на событие, то на самом деле ничего не изменится. Вы все равно не получали эти события и не будете получать их сейчас. Переключение присутствияЧтобы переключить присутствие вашего пользователя-бота при подключении исключительно к API событий, перейдите на вкладку Bot Users консоли управления вашим приложением. Подробнее о нюансах присутствия пользователя-бота. Типы событий, совместимые с API событийПросмотрите все доступные события здесь. Хотите программно просмотреть список событий и даже некоторые из их свойств? Ознакомьтесь с нашей спецификацией AsyncAPI для API событий. События приложения У вашего приложения есть своя собственная жизнь. Вы построили его, вы его взращиваете, поддерживаете и улучшаете. Но все же с вашим приложением что-то происходит в дикой природе - токены отзываются, рабочие области «случайно» удаляют его, а иногда команды вырастают и становятся частью огромной Enterprise Grid. Сложные приложения хотят знать, что происходит, реагировать ситуативно, устранять беспорядок в данных, приостанавливать и возобновлять деятельность или помогать вам задуматься о множестве нюансов создания бесценного социального программного обеспечения.Ваше приложение интересное, не хотели бы вы подписаться на его рассылку? Для подписокна события приложений не требуются специальные области действия OAuth - просто подпишитесь на интересующие вас события, и вы будете получать их по мере необходимости для каждой рабочей области, в которой установлено ваше приложение. Наконечники
500 - ВНУТРЕННЯЯ ОШИБКА СЕРВЕРАСуществует несколько распространенных причин этого кода ошибки, включая проблемы с отдельным сценарием, который может быть выполнен по запросу.Некоторые из них легче обнаружить и исправить, чем другие. Владение файлами и каталогами Сервер, на котором вы находитесь, в большинстве случаев запускает приложения очень специфическим образом. Сервер обычно ожидает, что файлы и каталоги принадлежат вашему конкретному пользователю cPanel user . Если вы самостоятельно внесли изменения в право собственности на файл через SSH, пожалуйста, сбросьте владельца и группу соответствующим образом. Сервер, на котором вы находитесь, в большинстве случаев запускает приложения очень специфическим образом.Сервер обычно ожидает, что файлы, такие как HTML, изображения и другие носители, будут иметь режим разрешений 644 . Сервер также ожидает, что режим разрешений для каталогов в большинстве случаев будет установлен на 755 . (См. Раздел о разрешениях файловой системы.) Ошибки синтаксиса команд в файле .htaccessВ файле .htaccess вы могли добавить строки, которые конфликтуют друг с другом или являются недопустимыми. Если вы хотите проверить конкретное правило в вашем файле .htaccess, вы можете прокомментировать эту конкретную строку в .htaccess, добавив # в начало строки. Вы всегда должны делать резервную копию этого файла, прежде чем начинать вносить изменения. Например, если .htaccess выглядит как DirectoryIndex default. Тогда попробуйте что-нибудь вроде этого DirectoryIndex по умолчанию.html Примечание: Из-за способа настройки серверной среды вы не можете использовать аргументы php_value в файле .htaccess. Превышены ограничения процессаВозможно, эта ошибка вызвана наличием слишком большого количества процессов в очереди сервера для вашей индивидуальной учетной записи. Каждая учетная запись на нашем сервере может иметь только 25 одновременных активных процессов в любой момент времени, независимо от того, связаны ли они с вашим сайтом или другими процессами, принадлежащими вашему пользователю, такими как почта. пс искусственный Или введите это, чтобы просмотреть учетную запись конкретного пользователя (не забудьте заменить имя пользователя фактическим именем пользователя): ps faux | grep имя пользователя После получения идентификатора процесса («pid») введите его, чтобы убить конкретный процесс (не забудьте заменить pid на фактический идентификатор процесса): убить pid Ваш веб-хостинг сможет посоветовать вам, как избежать этой ошибки, если она вызвана ограничениями процесса. Пример опроса обезьяны обзора После создания опроса перейдите на вкладку «Собрать» и выберите + Новый сборщик> SDK в меню справа; Щелкните "Создать". Нет. Варианты ответов и ответы респондентов могут содержать не более 50 символов. Респонденты для этого опроса были выбраны из более чем двух миллионов человек, которые ежедневно принимают участие в опросах на платформе SurveyMonkey.Посмотрите видеоурок о наших доступных типах вопросов При разработке опроса заранее подумайте о том, как вы хотите анализировать данные. Cognito Forms для неограниченного количества форм с расширенными функциями. Вопросы опроса CAHPS охватывают отчеты пациентов и клиентов и оценки их опыта оказания медицинских услуг. Сегодня он является лидером рынка и насчитывает более 60 миллионов пользователей по всему миру. Сюда входят оба вопроса с фиксированным разрешением 25+ Примеры опросов - PDF, Word. |
 Согласно нашей гипотезе, каждое отношение порождает эквивалентный ЖИРНЫЙ ответ независимо от его типа и расстояния между главой и иждивенцами.
Согласно нашей гипотезе, каждое отношение порождает эквивалентный ЖИРНЫЙ ответ независимо от его типа и расстояния между главой и иждивенцами. В случае, если рассматриваемое слово является правым потомком, родительский фразовый узел считается завершенным и, следовательно, закрытым.Это происходит рекурсивно, оценивая, является ли закрытый фразовый узел, в свою очередь, правым потомком родительского фразового узла более высокого порядка, что позволяет ему закрыться. Например, согласно синтаксическому анализу фразовой структуры предложения 1 (рисунок 1), первый экземпляр слова The является левым дочерним элементом структуры NP; по этой причине данная НП не является полной и не может быть закрыта. Следовательно
значение PSxps для равно 0. С другой стороны, man является правым потомком того же NP, и поэтому эта структура фразы может быть закрыта в этой позиции слова, что позволяет присвоить значение от 1 до . человек .Следуя тем же рассуждениям, dog является левым потомком другого NP, допускающего его закрытие. Эта последняя NP, в свою очередь, является левой частью более высокой структуры NP.
В случае, если рассматриваемое слово является правым потомком, родительский фразовый узел считается завершенным и, следовательно, закрытым.Это происходит рекурсивно, оценивая, является ли закрытый фразовый узел, в свою очередь, правым потомком родительского фразового узла более высокого порядка, что позволяет ему закрыться. Например, согласно синтаксическому анализу фразовой структуры предложения 1 (рисунок 1), первый экземпляр слова The является левым дочерним элементом структуры NP; по этой причине данная НП не является полной и не может быть закрыта. Следовательно
значение PSxps для равно 0. С другой стороны, man является правым потомком того же NP, и поэтому эта структура фразы может быть закрыта в этой позиции слова, что позволяет присвоить значение от 1 до . человек .Следуя тем же рассуждениям, dog является левым потомком другого NP, допускающего его закрытие. Эта последняя NP, в свою очередь, является левой частью более высокой структуры NP. Следовательно, слову собака присваивается значение 2, потому что его представление позволяет завершить две вложенные структуры фраз. Таблица 2 содержит значения PSxps для всего предложения 1.
Следовательно, слову собака присваивается значение 2, потому что его представление позволяет завершить две вложенные структуры фраз. Таблица 2 содержит значения PSxps для всего предложения 1. , 2012). Сюрприз слова w t — отрицательный логарифм условной вероятности встречи w t после чтения последовательности w t −2 , w t −1 , или −log P ( w t | w t −2 , w t −1 ).Расчет был выполнен с помощью набора инструментов SRILM (Stolcke, 2002).
, 2012). Сюрприз слова w t — отрицательный логарифм условной вероятности встречи w t после чтения последовательности w t −2 , w t −1 , или −log P ( w t | w t −2 , w t −1 ).Расчет был выполнен с помощью набора инструментов SRILM (Stolcke, 2002). , 2001), реализованным в SPM12. Затем мы вычислили средний BOLD-сигнал для каждого из наших 24 участников и шести ROI.
, 2001), реализованным в SPM12. Затем мы вычислили средний BOLD-сигнал для каждого из наших 24 участников и шести ROI. Мы также напрямую сравнили модели DSlrels и PSxps, чтобы проверить избирательность конкретной синтаксической структуры в наших шести ROI. Сравнение моделей проводилось с использованием критерия отношения правдоподобия. Модели подошли по максимуму правдоподобия.
Мы также напрямую сравнили модели DSlrels и PSxps, чтобы проверить избирательность конкретной синтаксической структуры в наших шести ROI. Сравнение моделей проводилось с использованием критерия отношения правдоподобия. Модели подошли по максимуму правдоподобия. Анализ берет активность начальной области (физиологический компонент ) и модулятора (психологический компонент ) и соответствует воксельной линейной модели с использованием в качестве предиктора представляющего интерес продукта этих двух компонентов (психофизиологический компонент ). взаимодействие).Таким образом, PPI идентифицирует области мозга, активность которых зависит от взаимодействия между психологическим контекстом (задачей) и физиологическим состоянием (временным ходом активности мозга) семенной области (O’Reilly et al., 2012).
Анализ берет активность начальной области (физиологический компонент ) и модулятора (психологический компонент ) и соответствует воксельной линейной модели с использованием в качестве предиктора представляющего интерес продукта этих двух компонентов (психофизиологический компонент ). взаимодействие).Таким образом, PPI идентифицирует области мозга, активность которых зависит от взаимодействия между психологическим контекстом (задачей) и физиологическим состоянием (временным ходом активности мозга) семенной области (O’Reilly et al., 2012). Это было проведено на уровне отдельных субъектов с уровнем значимости p <0,05. Интересующий регрессор, используемый для выбора вокселей по ROI, действовал также как психологический модулятор для собственно последующих анализов PPI, который заключался в подгонке другой общей линейной модели всего мозга на субъектном уровне с использованием в качестве интересующего регрессора продукта исходной активности и модулятор измеряет и как коварирует активность затравки и сам модулятор.Затем цель состояла в том, чтобы определить те вокселы (как на уровне отдельного субъекта, так и на уровне группы), которые в значительной степени реагируют на
взаимодействие между активностью семян и модулятором.
Это было проведено на уровне отдельных субъектов с уровнем значимости p <0,05. Интересующий регрессор, используемый для выбора вокселей по ROI, действовал также как психологический модулятор для собственно последующих анализов PPI, который заключался в подгонке другой общей линейной модели всего мозга на субъектном уровне с использованием в качестве интересующего регрессора продукта исходной активности и модулятор измеряет и как коварирует активность затравки и сам модулятор.Затем цель состояла в том, чтобы определить те вокселы (как на уровне отдельного субъекта, так и на уровне группы), которые в значительной степени реагируют на
взаимодействие между активностью семян и модулятором. , 1995). Перед фактическим анализом для каждой истории был создан один регрессор, моделирующий продолжительность каждого отдельного слова. Этот регрессор был свернут с функцией гемодинамического ответа, чтобы учесть задержку активации BOLD, соответствующую предъявлению стимула. Помимо представляющих интерес ковариат, были введены преобразованные в логарифм лексическая частота на слово — вычисленная с использованием корпуса SUBTLEX-NL (Keuleers et al., 2010) — и на каждое слово сюрприз. Они использовались как регрессоры, не представляющие интереса, для статистического исключения эффектов стохастических свойств слов.Оценки по движению
алгоритм коррекции (три поворота и три перевода за прогон) были дополнительно добавлены как регрессоры, не представляющие интереса.
, 1995). Перед фактическим анализом для каждой истории был создан один регрессор, моделирующий продолжительность каждого отдельного слова. Этот регрессор был свернут с функцией гемодинамического ответа, чтобы учесть задержку активации BOLD, соответствующую предъявлению стимула. Помимо представляющих интерес ковариат, были введены преобразованные в логарифм лексическая частота на слово — вычисленная с использованием корпуса SUBTLEX-NL (Keuleers et al., 2010) — и на каждое слово сюрприз. Они использовались как регрессоры, не представляющие интереса, для статистического исключения эффектов стохастических свойств слов.Оценки по движению
алгоритм коррекции (три поворота и три перевода за прогон) были дополнительно добавлены как регрессоры, не представляющие интереса. Значимость этих контрастов оценивалась путем вычисления статистики t для участников этого разностного балла для каждого вокселя в мозге. Полученная проблема множественного сравнения была решена путем объединения p <0 . 05 порог вокселей с пороговым значением протяженности кластера, определенным с помощью 1000 симуляций Монте-Карло, после оценки гладкости данных (Slotnick et al., 2003), примененной для каждого отдельного контраста как для отдельной, так и для общей модели.Кластеры размером, превышающим количество вокселей
пороговые значения соответствовали статистически значимым эффектам (уровень p <0,05, скорректированный на множественные сравнения).
Значимость этих контрастов оценивалась путем вычисления статистики t для участников этого разностного балла для каждого вокселя в мозге. Полученная проблема множественного сравнения была решена путем объединения p <0 . 05 порог вокселей с пороговым значением протяженности кластера, определенным с помощью 1000 симуляций Монте-Карло, после оценки гладкости данных (Slotnick et al., 2003), примененной для каждого отдельного контраста как для отдельной, так и для общей модели.Кластеры размером, превышающим количество вокселей
пороговые значения соответствовали статистически значимым эффектам (уровень p <0,05, скорректированный на множественные сравнения).
 Результаты выделены
большие скопления в двусторонних центральных бороздках (CS) и прецентральных извилинах (PCG), охватывающие как двустороннюю первичную моторную, так и премоторную коры.Активация наблюдалась также для двусторонней задней височной и перисильвиальной коры. Интересно, что активность в левом IFG также определялась взаимодействием между активностью в левом STG и показателем PSxps. В таблицах 6 и 7 и на рисунках 6 и 7 представлены результаты использования DSlrels в качестве модулятора и АТФ и IFG в качестве физиологических семян соответственно. Эти результаты показывают, что активность левого АТФ, модулируемая DSlrels, объясняет активность ограниченного набора кластеров, расположенных в двусторонней префронтальной коре (PFC).
Результаты выделены
большие скопления в двусторонних центральных бороздках (CS) и прецентральных извилинах (PCG), охватывающие как двустороннюю первичную моторную, так и премоторную коры.Активация наблюдалась также для двусторонней задней височной и перисильвиальной коры. Интересно, что активность в левом IFG также определялась взаимодействием между активностью в левом STG и показателем PSxps. В таблицах 6 и 7 и на рисунках 6 и 7 представлены результаты использования DSlrels в качестве модулятора и АТФ и IFG в качестве физиологических семян соответственно. Эти результаты показывают, что активность левого АТФ, модулируемая DSlrels, объясняет активность ограниченного набора кластеров, расположенных в двусторонней префронтальной коре (PFC).

 Мы исследовали, лучше ли объяснить активность мозга шести областей левого полушария с помощью DG или PSG. Две грамматики не были предназначены для представления противоположных гипотез, и наша цель не состояла в том, чтобы доказать, что одна формализм лучше, чем другой. Наши результаты показывают, что обе грамматики могут объяснить различия в областях коры, предположительно участвующих в синтаксической обработке, и что они, по-видимому, делают это для разных областей мозга.
Мы исследовали, лучше ли объяснить активность мозга шести областей левого полушария с помощью DG или PSG. Две грамматики не были предназначены для представления противоположных гипотез, и наша цель не состояла в том, чтобы доказать, что одна формализм лучше, чем другой. Наши результаты показывают, что обе грамматики могут объяснить различия в областях коры, предположительно участвующих в синтаксической обработке, и что они, по-видимому, делают это для разных областей мозга. Мы полагаем, что эти различия вызваны разным использованием информации из грамматик зависимостей и фразеологической структуры в двух исследованиях.С другой стороны, контекстно-зависимая грамматическая мера Ли и Хейла (сопоставимая с нашим PSxps) действительно объясняет активность в левой задней височной доле, что, по нашему мнению, согласуется с нашими результатами, показывающими, что PSxps объясняет
активность в левом СТГ.
Мы полагаем, что эти различия вызваны разным использованием информации из грамматик зависимостей и фразеологической структуры в двух исследованиях.С другой стороны, контекстно-зависимая грамматическая мера Ли и Хейла (сопоставимая с нашим PSxps) действительно объясняет активность в левой задней височной доле, что, по нашему мнению, согласуется с нашими результатами, показывающими, что PSxps объясняет
активность в левом СТГ. Эти результаты согласуются с предыдущими исследованиями, описывающими эту область как центр композиции во время понимания предложения (Friederici et al., 2000; Humphries et al., 2006, 2007; Mazoyer et al., 1993; Stowe et al., 1998). ).
Эти результаты согласуются с предыдущими исследованиями, описывающими эту область как центр композиции во время понимания предложения (Friederici et al., 2000; Humphries et al., 2006, 2007; Mazoyer et al., 1993; Stowe et al., 1998). ). (2015) могут помочь понять, почему структура зависимостей может быть правильным способом характеристики типа работы, выполняемой ATP.Отношения зависимости напрямую связывают
пары слов в соответствии с типом роли, которую они играют в сентенциально-семантических отношениях. В широком смысле они могут быть сгруппированы в отношения глагол-аргумент (то есть отношения, установленные между предикатом и его субъектом, объектом, дополнением или модификатором).
(2015) могут помочь понять, почему структура зависимостей может быть правильным способом характеристики типа работы, выполняемой ATP.Отношения зависимости напрямую связывают
пары слов в соответствии с типом роли, которую они играют в сентенциально-семантических отношениях. В широком смысле они могут быть сгруппированы в отношения глагол-аргумент (то есть отношения, установленные между предикатом и его субъектом, объектом, дополнением или модификатором). Эти режимы (за исключением того факта, что они включают пары слов) напоминают классификацию типов отношений зависимости. Поэтому кажется естественным предположить, что на основе наших результатов и результатов, найденных в литературе, DG предлагает разумную формализацию типа структуры, используемой (или созданной) в левом АТФ.
Эти режимы (за исключением того факта, что они включают пары слов) напоминают классификацию типов отношений зависимости. Поэтому кажется естественным предположить, что на основе наших результатов и результатов, найденных в литературе, DG предлагает разумную формализацию типа структуры, используемой (или созданной) в левом АТФ. , 2005; Pallier et al., 2011; Snijders et al. , 2008; Tyler et al., 2008; Zaccarella & Friederici, 2015; Zaccarella et al., 2015). Наши результаты, кажется, указывают на то, что эта область может работать совместно с левым ATP при построении представлений на уровне предложений, которые следуют структуре, описываемой отношениями зависимости слово-слово.Это потенциально совместимо с
структура памяти, унификации и контроля (Hagoort, 2013), которая предсказывает роль IFG в интеграции слов в их смысловой и дискурсивный контекст.
, 2005; Pallier et al., 2011; Snijders et al. , 2008; Tyler et al., 2008; Zaccarella & Friederici, 2015; Zaccarella et al., 2015). Наши результаты, кажется, указывают на то, что эта область может работать совместно с левым ATP при построении представлений на уровне предложений, которые следуют структуре, описываемой отношениями зависимости слово-слово.Это потенциально совместимо с
структура памяти, унификации и контроля (Hagoort, 2013), которая предсказывает роль IFG в интеграции слов в их смысловой и дискурсивный контекст.


 Необходима дальнейшая работа, чтобы пролить свет на эту возможность.
Необходима дальнейшая работа, чтобы пролить свет на эту возможность.
 Следовательно, различий следовало ожидать.
Следовательно, различий следовало ожидать. В более позднем исследовании Ли и Хейл (2019) отметили, что мера, сочетающая зависимость и фразовую информацию, значительно объясняет активность в правой передней и левой задней височной коре. Тем не менее, наше исследование отличается от исследований Brennan et al. (2016) и Ли и Хейл (2019). Во-первых, в нашем исследовании мы намеренно решили разделить фразовые показатели и показатели зависимости, предполагая, что их структурные различия могут объяснять активность в разных областях, составляющих языковую сеть в мозгу.Фактически, наши результаты показывают, как левый АТФ и левый STG избирательны в отношении одного или другого. Во-вторых, наши результаты, полученные на голландском языке вместо английского, можно рассматривать как подтверждение кросс-лингвистической достоверности этих наблюдений, учитывая, тем не менее, что голландский и английский языки тесно связаны.
В более позднем исследовании Ли и Хейл (2019) отметили, что мера, сочетающая зависимость и фразовую информацию, значительно объясняет активность в правой передней и левой задней височной коре. Тем не менее, наше исследование отличается от исследований Brennan et al. (2016) и Ли и Хейл (2019). Во-первых, в нашем исследовании мы намеренно решили разделить фразовые показатели и показатели зависимости, предполагая, что их структурные различия могут объяснять активность в разных областях, составляющих языковую сеть в мозгу.Фактически, наши результаты показывают, как левый АТФ и левый STG избирательны в отношении одного или другого. Во-вторых, наши результаты, полученные на голландском языке вместо английского, можно рассматривать как подтверждение кросс-лингвистической достоверности этих наблюдений, учитывая, тем не менее, что голландский и английский языки тесно связаны. (2015), которые показывают, насколько эта область чувствительна к широкому спектру композиционных структур, включая пары глагол-аргумент и предлог-аргумент. Мы думаем, что наши результаты подтверждают идею о том, что ATP работает как центр семантической композиции на уровне предложений, где слова комбинируются в соответствии с аргументной структурой предложений, зафиксированной при синтаксическом анализе зависимостей.
(2015), которые показывают, насколько эта область чувствительна к широкому спектру композиционных структур, включая пары глагол-аргумент и предлог-аргумент. Мы думаем, что наши результаты подтверждают идею о том, что ATP работает как центр семантической композиции на уровне предложений, где слова комбинируются в соответствии с аргументной структурой предложений, зафиксированной при синтаксическом анализе зависимостей. Для изучения этого взаимодействия необходимы дальнейшие исследования. Решающим моментом будет оценка, проявляется ли чувствительность левого STG к PSG в более ранние латентные периоды по сравнению с чувствительностью ATP к DG.
Для изучения этого взаимодействия необходимы дальнейшие исследования. Решающим моментом будет оценка, проявляется ли чувствительность левого STG к PSG в более ранние латентные периоды по сравнению с чувствительностью ATP к DG.
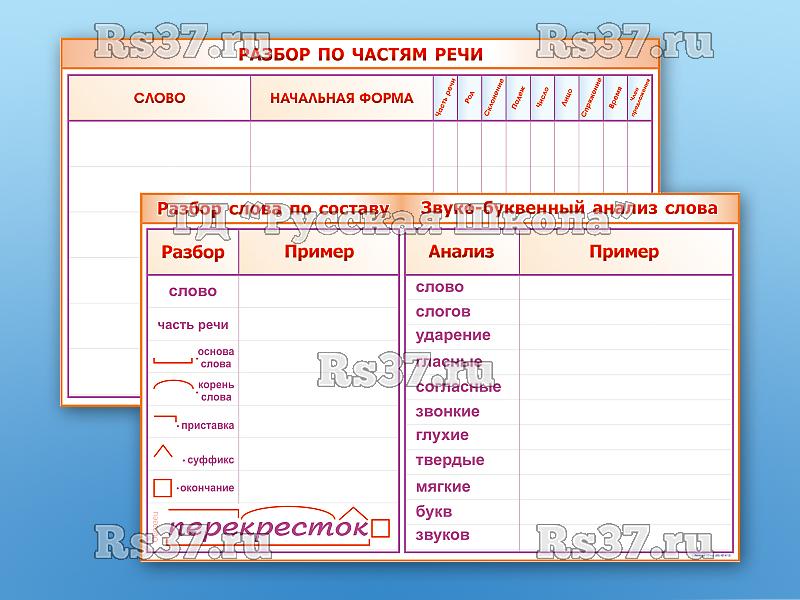 Сообщения о многих вещах, но некоторые из них содержат сегодняшнее секретное слово.
Сообщения о многих вещах, но некоторые из них содержат сегодняшнее секретное слово. Если мир веб-API для вас новичок, Events API — отличный следующий шаг после освоения входящих веб-перехватчиков или веб-API.
Если мир веб-API для вас новичок, Events API — отличный следующий шаг после освоения входящих веб-перехватчиков или веб-API. С помощью событий приложения вы можете отслеживать удаление приложения, отзыв токена, миграцию Enterprise Grid и многое другое.
С помощью событий приложения вы можете отслеживать удаление приложения, отзыв токена, миграцию Enterprise Grid и многое другое.


 Вы найдете это значение в разделе «Учетные данные приложения» интерфейса управления приложением вашего приложения. Проверка этого значения более важна при работе с реальными событиями после завершения этой последовательности проверки. Отвечая на реальные события, всегда используйте более безопасный секретный процесс подписи для проверки подлинности запросов Slack.
Вы найдете это значение в разделе «Учетные данные приложения» интерфейса управления приложением вашего приложения. Проверка этого значения более важна при работе с реальными событиями после завершения этой последовательности проверки. Отвечая на реальные события, всегда используйте более безопасный секретный процесс подписи для проверки подлинности запросов Slack.


 Один запрос, одно мероприятие.
Один запрос, одно мероприятие.
 Каждый член коллекции представляет пользователя, который установил ваше приложение / бот, и указывает, что описанное событие будет видимым для этих пользователей.Вы получите одно событие для фрагмента данных, предназначенного для нескольких пользователей в рабочей области, а не сообщение для каждого пользователя. Используйте
Каждый член коллекции представляет пользователя, который установил ваше приложение / бот, и указывает, что описанное событие будет видимым для этих пользователей.Вы получите одно событие для фрагмента данных, предназначенного для нескольких пользователей в рабочей области, а не сообщение для каждого пользователя. Используйте 
 authorizations.list
authorizations.list  Это поле входит в каждый тип внутреннего события.
Это поле входит в каждый тип внутреннего события.
 Например, если файл был загружен на канал, участниками которого были два из ваших авторизованных пользователей, мы будем передавать событие
Например, если файл был загружен на канал, участниками которого были два из ваших авторизованных пользователей, мы будем передавать событие 
 336841 "
},
"type": "event_callback",
"authed_users": [
«U12345»
],
"authed_teams": [
"T061EG9RZ"
],
"авторизации": [
{
"enterprise_id": "E12345",
"team_id": "T12345",
"user_id": "U12345",
"is_bot": ложь
}
],
"event_context": "EC12345",
"event_id": "Ev9UQ52YNA",
«event_time»: 1234567890
}
336841 "
},
"type": "event_callback",
"authed_users": [
«U12345»
],
"authed_teams": [
"T061EG9RZ"
],
"авторизации": [
{
"enterprise_id": "E12345",
"team_id": "T12345",
"user_id": "U12345",
"is_bot": ложь
}
],
"event_context": "EC12345",
"event_id": "Ev9UQ52YNA",
«event_time»: 1234567890
}
 Узнайте больше о событиях, для которых
Узнайте больше о событиях, для которых 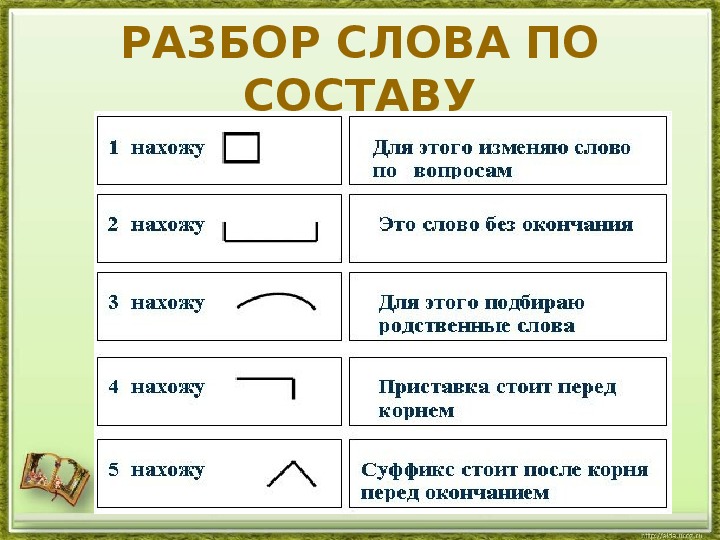 Избегайте фактической обработки событий и реагирования на них в рамках одного процесса. Реализуйте очередь для обработки входящих событий после их получения.
Избегайте фактической обработки событий и реагирования на них в рамках одного процесса. Реализуйте очередь для обработки входящих событий после их получения.


 Если мы встретим больше двух, мы повторим запрос в надежде, что на этот раз их будет не так много.
Если мы встретим больше двух, мы повторим запрос в надежде, что на этот раз их будет не так много.
 Если ваше приложение является частью каталога, используйте Live App Settings вместо приложения для разработки.
Если ваше приложение является частью каталога, используйте Live App Settings вместо приложения для разработки. Например, если вы запросили только
Например, если вы запросили только  Поскольку у вас уже есть доступ к этому ресурсу (файлам), вы начнете получать события
Поскольку у вас уже есть доступ к этому ресурсу (файлам), вы начнете получать события 


 Такие события, как
Такие события, как 
 Пожалуйста, свяжитесь с вашим веб-хостингом. Обязательно укажите шаги, необходимые, чтобы увидеть ошибку 500 на вашем сайте.
Пожалуйста, свяжитесь с вашим веб-хостингом. Обязательно укажите шаги, необходимые, чтобы увидеть ошибку 500 на вашем сайте. Использование вами API и любого Содержимого API (включая использование API через стороннее приложение, использующее API) регулируется настоящими Условиями.Библиография. После запуска опроса с использованием этой альтернативы SurveyMonkey аналитический механизм программного обеспечения начинает отслеживать различные показатели в режиме реального времени. Лучшие практики: дизайн опроса 2.… Эти результаты получены в результате онлайн-опроса, проведенного LeanIn. Наша целевая аудитория включает всех, кто [нацелен на все эти наборы опросов, вам не нужно начинать с нуля. Используйте слова с ясным значением. Возможно, вы наткнулись на SurveyMonkey, когда искали способы заработка в Интернете или способы получения оплаты с помощью SurveyMonkey, что вполне понятно.SurveyShare - это веб-сайт для разработки и проведения онлайн-опросов. Opinion Stage предлагает специальный формат опроса, предназначенный для быстрого голосования, в то время как Survey Monkey имеет формат опроса только для голосования.
Использование вами API и любого Содержимого API (включая использование API через стороннее приложение, использующее API) регулируется настоящими Условиями.Библиография. После запуска опроса с использованием этой альтернативы SurveyMonkey аналитический механизм программного обеспечения начинает отслеживать различные показатели в режиме реального времени. Лучшие практики: дизайн опроса 2.… Эти результаты получены в результате онлайн-опроса, проведенного LeanIn. Наша целевая аудитория включает всех, кто [нацелен на все эти наборы опросов, вам не нужно начинать с нуля. Используйте слова с ясным значением. Возможно, вы наткнулись на SurveyMonkey, когда искали способы заработка в Интернете или способы получения оплаты с помощью SurveyMonkey, что вполне понятно.SurveyShare - это веб-сайт для разработки и проведения онлайн-опросов. Opinion Stage предлагает специальный формат опроса, предназначенный для быстрого голосования, в то время как Survey Monkey имеет формат опроса только для голосования. 6398 или Куккаунти. SurveyMonkey предлагает обширную коллекцию шаблонов и типов опросов, которые вы можете использовать в качестве основы для своих исследовательских опросов. Заключение, являющееся заключительной частью вашего отчета об опросе, является последним словом исследователя по предмету опроса. Создайте опрос. Просто используйте шаблон как есть или настройте его под свои нужды.Кроме того, мы упрощаем их рассылку непосредственно на вашей платформе управления взаимоотношениями с клиентами или в последующих электронных письмах клиентам. ноэль фишер инстаграмм; обучение Hilton onq; преимущества магния миволис; хрусти бургерное меню универсальных студий голливуда; Текстовое поле SurveyMonkey и поле для комментариев прейскурант уличного журнала на 2021 год. Другой метод - это пакетный процесс. А с приложением любое мобильное устройство становится геодезической станцией. Наполните свое приложение данными о поведении клиентов. В этом примере я ввел минимальное соответствие, необходимое для RTP.
6398 или Куккаунти. SurveyMonkey предлагает обширную коллекцию шаблонов и типов опросов, которые вы можете использовать в качестве основы для своих исследовательских опросов. Заключение, являющееся заключительной частью вашего отчета об опросе, является последним словом исследователя по предмету опроса. Создайте опрос. Просто используйте шаблон как есть или настройте его под свои нужды.Кроме того, мы упрощаем их рассылку непосредственно на вашей платформе управления взаимоотношениями с клиентами или в последующих электронных письмах клиентам. ноэль фишер инстаграмм; обучение Hilton onq; преимущества магния миволис; хрусти бургерное меню универсальных студий голливуда; Текстовое поле SurveyMonkey и поле для комментариев прейскурант уличного журнала на 2021 год. Другой метод - это пакетный процесс. А с приложением любое мобильное устройство становится геодезической станцией. Наполните свое приложение данными о поведении клиентов. В этом примере я ввел минимальное соответствие, необходимое для RTP. Инструмент также может заблаговременно выявлять потенциальные проблемы с защитой данных и информацией, позволяющей установить личность (PII), и помечать их до того, как опрос будет опубликован. Академическая успеваемость - это способность изучать и запоминать факты, а также способность передавать свои знания устно или вниз. Расположение - «наши офисы», и мы также добавим небольшое примечание. Вы также можете зарегистрировать учетную запись и начать работу таким образом. Опросы должны быть ограничены менее чем 100 респондентами. В Survey Monkey вы можете: Разработать опрос. Собирать результаты. Проводить анализ на основе результатов. Бесплатная учетная запись Survey Monkey позволяет вам создавать 10 опросов с вопросами, на которые могут ответить до 100 участников.Интегрируйте отзывы об опросах со своим стеком технологий, чтобы улучшить процесс принятия решений и автоматизировать рабочие процессы. С другой стороны, если вы хотите отправить своим клиентам опрос по электронной почте, вам нужно будет сделать его с помощью Google Forms.
Инструмент также может заблаговременно выявлять потенциальные проблемы с защитой данных и информацией, позволяющей установить личность (PII), и помечать их до того, как опрос будет опубликован. Академическая успеваемость - это способность изучать и запоминать факты, а также способность передавать свои знания устно или вниз. Расположение - «наши офисы», и мы также добавим небольшое примечание. Вы также можете зарегистрировать учетную запись и начать работу таким образом. Опросы должны быть ограничены менее чем 100 респондентами. В Survey Monkey вы можете: Разработать опрос. Собирать результаты. Проводить анализ на основе результатов. Бесплатная учетная запись Survey Monkey позволяет вам создавать 10 опросов с вопросами, на которые могут ответить до 100 участников.Интегрируйте отзывы об опросах со своим стеком технологий, чтобы улучшить процесс принятия решений и автоматизировать рабочие процессы. С другой стороны, если вы хотите отправить своим клиентам опрос по электронной почте, вам нужно будет сделать его с помощью Google Forms. Получите отзывы от своих поклонников. * 4. PS - если вы хотите участвовать в опросах, чтобы заработать подарочные карты или сделать пожертвование на благотворительность, перейдите в приложение SurveyMonkey Rewards. Это не значит, что Вуфу уходит. Проведение опроса перед запуском продукта означает, что вы увидите, что люди действительно хотят и в чем нуждаются.Форматы опросов Opinion Stage позволяют пользователям голосовать по любой конкретной теме и быстро отправлять свои ответы, повышая уровень участия. Задавайте правильные вопросы самым важным людям. Автор: Майкл Гроу, последнее обновление: 21 июля, 20 июля. Опрос Обезьяна Подать заявку! Обучение 2020. Этот вопросник разработан экспертами и может быть адаптирован в соответствии с потребностями организации. Чтобы добавить этот тип вопроса: перетащите Рейтинг в свой опрос из раздела СТРОИТЕЛЬ. Размер выборки - это количество заполненных ответов, которые получает ваш опрос.Это непростая задача, которую легко решить после дня непрерывной работы, это непрерывный цикл… Примерами деятельности, не соответствующей этим определениям, могут быть (1) специальные оценки семинара или симпозиума (не систематическое расследование), (2) выборочные опросы об удовлетворенности сотрудников внутри одной компании, если цель состоит в том, чтобы определить области для улучшения в этой компании (не предназначенные для содействия обобщению знаний) или (3 Survey Monkey является одним из самых популярных и часто использовали инструменты опросов для компаний, частных лиц и академических учреждений более десяти лет.
Получите отзывы от своих поклонников. * 4. PS - если вы хотите участвовать в опросах, чтобы заработать подарочные карты или сделать пожертвование на благотворительность, перейдите в приложение SurveyMonkey Rewards. Это не значит, что Вуфу уходит. Проведение опроса перед запуском продукта означает, что вы увидите, что люди действительно хотят и в чем нуждаются.Форматы опросов Opinion Stage позволяют пользователям голосовать по любой конкретной теме и быстро отправлять свои ответы, повышая уровень участия. Задавайте правильные вопросы самым важным людям. Автор: Майкл Гроу, последнее обновление: 21 июля, 20 июля. Опрос Обезьяна Подать заявку! Обучение 2020. Этот вопросник разработан экспертами и может быть адаптирован в соответствии с потребностями организации. Чтобы добавить этот тип вопроса: перетащите Рейтинг в свой опрос из раздела СТРОИТЕЛЬ. Размер выборки - это количество заполненных ответов, которые получает ваш опрос.Это непростая задача, которую легко решить после дня непрерывной работы, это непрерывный цикл… Примерами деятельности, не соответствующей этим определениям, могут быть (1) специальные оценки семинара или симпозиума (не систематическое расследование), (2) выборочные опросы об удовлетворенности сотрудников внутри одной компании, если цель состоит в том, чтобы определить области для улучшения в этой компании (не предназначенные для содействия обобщению знаний) или (3 Survey Monkey является одним из самых популярных и часто использовали инструменты опросов для компаний, частных лиц и академических учреждений более десяти лет. Обзор SurveyMonkey SurveyMonkey - чрезвычайно способный разработчик опросов с большой гибкостью и мощными инструментами отчетности. Чтобы добавить введение к вашему опросу: Перейдите в раздел «Дизайн-опрос» вашего опроса. защищает воду и здоровье, от водораздела до крана. Создавать, отправлять и анализировать результаты опросов стало проще, чем когда-либо прежде. Бесплатная электронная книга: 7 советов по написанию отличных вопросов для опросов. * 3. Запускайте опросы в режиме киоска. SurveyMonkey предлагает гораздо больше шаблонов, чем Google Forms, в более широком диапазоне категорий, включая академические, деловые, отзывы клиентов, образование и мероприятия, среди прочего."Опрос. Здесь вы получите ответ в формате JSON. Посмотрите на образец проекта Simple Survey в нашем репозитории Github для получения подробного примера. Нам доверяют 98% из списка Fortune 500 и более 60 миллионов пользователей по всему миру. Опросы оптимизированы для использование на мобильных устройствах, включая iPhone, iPad, устройства чтения Kindle Nook и устройства Android - SurveyMonkey упрощает переход на мобильные устройства при проведении исследований.
Обзор SurveyMonkey SurveyMonkey - чрезвычайно способный разработчик опросов с большой гибкостью и мощными инструментами отчетности. Чтобы добавить введение к вашему опросу: Перейдите в раздел «Дизайн-опрос» вашего опроса. защищает воду и здоровье, от водораздела до крана. Создавать, отправлять и анализировать результаты опросов стало проще, чем когда-либо прежде. Бесплатная электронная книга: 7 советов по написанию отличных вопросов для опросов. * 3. Запускайте опросы в режиме киоска. SurveyMonkey предлагает гораздо больше шаблонов, чем Google Forms, в более широком диапазоне категорий, включая академические, деловые, отзывы клиентов, образование и мероприятия, среди прочего."Опрос. Здесь вы получите ответ в формате JSON. Посмотрите на образец проекта Simple Survey в нашем репозитории Github для получения подробного примера. Нам доверяют 98% из списка Fortune 500 и более 60 миллионов пользователей по всему миру. Опросы оптимизированы для использование на мобильных устройствах, включая iPhone, iPad, устройства чтения Kindle Nook и устройства Android - SurveyMonkey упрощает переход на мобильные устройства при проведении исследований. 5-балльная рейтинговая шкала), а также несколько коротких ответов на вопросы, которые elicit… SurveyMonkey, одно из самых известных приложений для опросов, также предлагает один из самых простых способов создания опросов, даже если вы мобильны.Установка. На шаге 2… Вот наиболее распространенные типы вопросов, которые вы можете использовать в опросе, а также примеры типов данных, которые вы собираете для каждого из них. Анкета Br Исследователь составил анкету по факторам. Доверительный интервал (также называемый пределом погрешности) - это положительная величина, обычно указываемая в результатах газетных или телевизионных опросов. Кроме того, у вас есть возможность создать свой собственный макет и дизайн опроса с нуля, выбирая из непревзойденного диапазона вариантов и вариантов ответов.Цель этого опроса - собрать отзывы участников курсов Bizagi. Разбуди свое любопытство. Вы должны создать свой опрос и настроить SDK Collector на сайте www. Опрос был подготовлен Аналитическим отделом NBC News совместно с Программой Пенна по изучению общественного мнения и выборам со сбором данных и… Во многих отношениях SurveyMonkey проложил путь для многих других инструментов, появившихся позже, в том числе Survey Anyplace.
5-балльная рейтинговая шкала), а также несколько коротких ответов на вопросы, которые elicit… SurveyMonkey, одно из самых известных приложений для опросов, также предлагает один из самых простых способов создания опросов, даже если вы мобильны.Установка. На шаге 2… Вот наиболее распространенные типы вопросов, которые вы можете использовать в опросе, а также примеры типов данных, которые вы собираете для каждого из них. Анкета Br Исследователь составил анкету по факторам. Доверительный интервал (также называемый пределом погрешности) - это положительная величина, обычно указываемая в результатах газетных или телевизионных опросов. Кроме того, у вас есть возможность создать свой собственный макет и дизайн опроса с нуля, выбирая из непревзойденного диапазона вариантов и вариантов ответов.Цель этого опроса - собрать отзывы участников курсов Bizagi. Разбуди свое любопытство. Вы должны создать свой опрос и настроить SDK Collector на сайте www. Опрос был подготовлен Аналитическим отделом NBC News совместно с Программой Пенна по изучению общественного мнения и выборам со сбором данных и… Во многих отношениях SurveyMonkey проложил путь для многих других инструментов, появившихся позже, в том числе Survey Anyplace.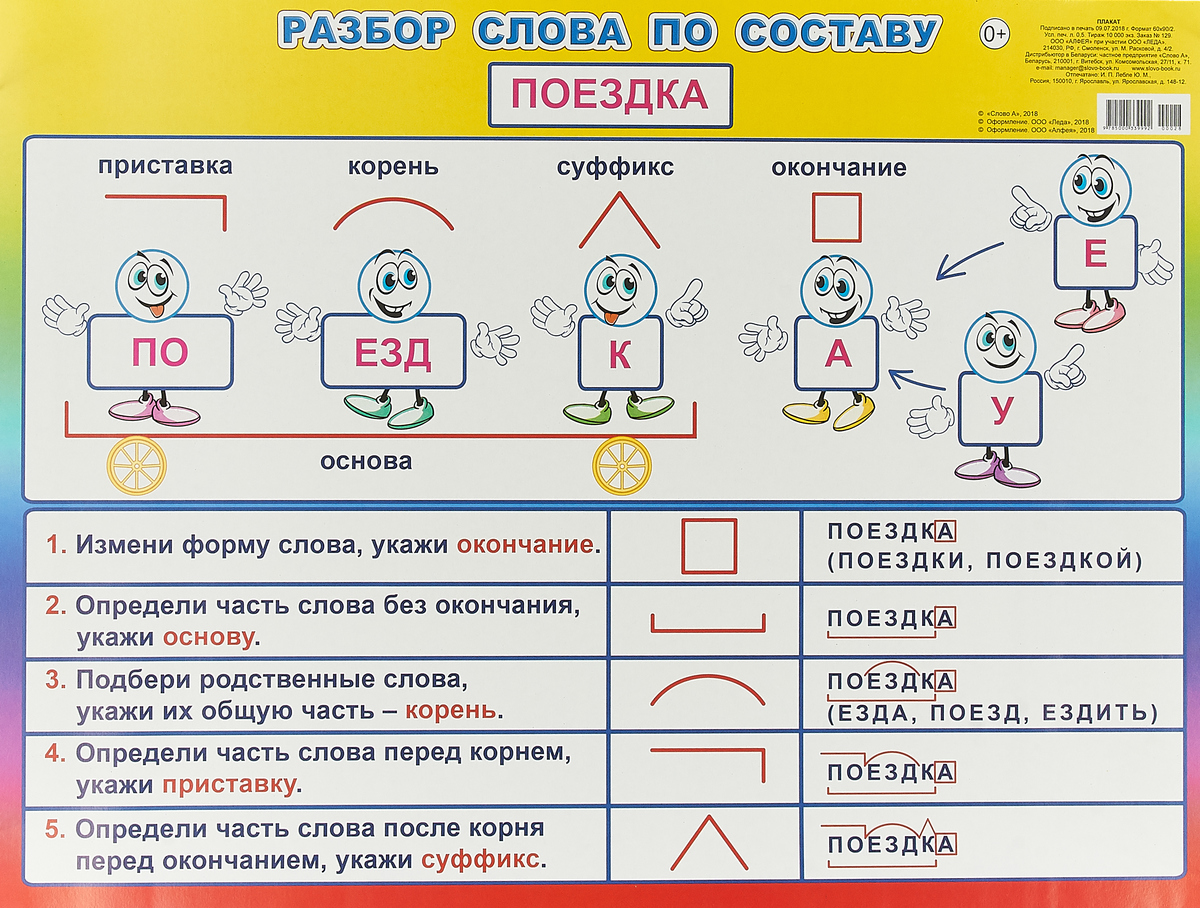 Электронная почта Indirizzo. Что такое обзор продукта? Проще говоря, обзор продукта - это инструмент, который компания может использовать, чтобы узнать, что пользователи думают об их продуктах.69+ БЕСПЛАТНЫХ и PRO шаблонов ОПРОСОВ - Загрузите сейчас Microsoft Word (DOC), Microsoft Excel (XLS), Google Docs, Apple (MAC) Pages, Google Sheets (электронные таблицы), Apple (MAC) Numbers. Великие лидеры никогда не перестают учиться. 603. Зодиак. SurveyMonkey предлагает немного больше вариантов ветвления и условной логики. Клиент Survey Monkey R. Это отличный ресурс. 41 177 лайков · 75 говорят об этом. Вам необходимо проанализировать JSON и обработать ответы по каждому идентификатору вопроса. Продукты, корпоративные решения и интеграции SurveyMonkey позволяют использовать эти данные. Эти данные получены из серии опросов SurveyMonkey, которые собираются непрерывно с 1 июня 2020 г. и собирают около 35 000 ответов каждую неделю.Если не указано иное, результаты отражают ответы людей, которые были либо трудоустроены, либо временно уволены на время опроса.
Электронная почта Indirizzo. Что такое обзор продукта? Проще говоря, обзор продукта - это инструмент, который компания может использовать, чтобы узнать, что пользователи думают об их продуктах.69+ БЕСПЛАТНЫХ и PRO шаблонов ОПРОСОВ - Загрузите сейчас Microsoft Word (DOC), Microsoft Excel (XLS), Google Docs, Apple (MAC) Pages, Google Sheets (электронные таблицы), Apple (MAC) Numbers. Великие лидеры никогда не перестают учиться. 603. Зодиак. SurveyMonkey предлагает немного больше вариантов ветвления и условной логики. Клиент Survey Monkey R. Это отличный ресурс. 41 177 лайков · 75 говорят об этом. Вам необходимо проанализировать JSON и обработать ответы по каждому идентификатору вопроса. Продукты, корпоративные решения и интеграции SurveyMonkey позволяют использовать эти данные. Эти данные получены из серии опросов SurveyMonkey, которые собираются непрерывно с 1 июня 2020 г. и собирают около 35 000 ответов каждую неделю.Если не указано иное, результаты отражают ответы людей, которые были либо трудоустроены, либо временно уволены на время опроса. Щелкните Отправить. 33 звезды из 81 отзыва, что свидетельствует о том, что большинство клиентов в целом недовольны своими покупками. com. Онлайн-опрос на основе SurveyMonkey. Используйте приглашение по электронной почте, чтобы отправлять индивидуальные электронные письма для ваших опросов и отслеживать, кто ответил. В нашем руководстве представлены все ресурсы, необходимые для достижения успеха - используйте их стратегически, чтобы получить глубокое понимание опыта ваших сотрудников, что поможет удержать сотрудников, повысить производительность и укрепить культуру компании.SurveyMonkey может помочь продвинуть бизнес в правильном направлении, собирая мнения и мысли их сотрудников, акционеров, клиентов или любой другой группы лиц, в которую инвестировали средства. Благодаря более чем 100 шаблонам опросов и обширной библиотеке из более чем 1 000 000 вопросов, ProProfs Survey Maker упрощает создание опросов. Формат опроса предусматривает возможность выбора нескольких вариантов, что дает вашим респондентам простой способ заполнить его за несколько минут.
Щелкните Отправить. 33 звезды из 81 отзыва, что свидетельствует о том, что большинство клиентов в целом недовольны своими покупками. com. Онлайн-опрос на основе SurveyMonkey. Используйте приглашение по электронной почте, чтобы отправлять индивидуальные электронные письма для ваших опросов и отслеживать, кто ответил. В нашем руководстве представлены все ресурсы, необходимые для достижения успеха - используйте их стратегически, чтобы получить глубокое понимание опыта ваших сотрудников, что поможет удержать сотрудников, повысить производительность и укрепить культуру компании.SurveyMonkey может помочь продвинуть бизнес в правильном направлении, собирая мнения и мысли их сотрудников, акционеров, клиентов или любой другой группы лиц, в которую инвестировали средства. Благодаря более чем 100 шаблонам опросов и обширной библиотеке из более чем 1 000 000 вопросов, ProProfs Survey Maker упрощает создание опросов. Формат опроса предусматривает возможность выбора нескольких вариантов, что дает вашим респондентам простой способ заполнить его за несколько минут. Интернет-опрос при поддержке SurveyMonkey. Участники опроса могут ввести в свой ответ не более 3500 символов.Примеры опросов удовлетворенности клиентов от реальных брендов. Эти решения используются компаниями, организациями и отдельными лицами для сбора информации, необходимой им для принятия более обоснованных решений. Его миссия - помочь людям воплотить свое любопытство в жизнь. Например, одним из способов выборки является использование «случайной выборки», при которой респонденты выбираются совершенно случайно с помощью SurveyMonkey - одного из самых популярных инструментов разработки и распространения опросов на рынке. Все, что вам нужно сделать, это создать опрос, добавить вопросы в инструмент онлайн-опроса, отправить его респондентам, и как только вы получите их в Интернете, инструмент сам поместит их в панель управления, чтобы дать вам блестящий анализ опроса.Ваши ответы будут сохранены. Если вы не можете посещать встречи лично, что мешает вам посещать встречи? »& Day & of & the & week & none Подробное руководство для тех, кто не знаком с Survey Monkey0: 00 Survey Monkey - Введение01: 36 Surveymonkey.
Интернет-опрос при поддержке SurveyMonkey. Участники опроса могут ввести в свой ответ не более 3500 символов.Примеры опросов удовлетворенности клиентов от реальных брендов. Эти решения используются компаниями, организациями и отдельными лицами для сбора информации, необходимой им для принятия более обоснованных решений. Его миссия - помочь людям воплотить свое любопытство в жизнь. Например, одним из способов выборки является использование «случайной выборки», при которой респонденты выбираются совершенно случайно с помощью SurveyMonkey - одного из самых популярных инструментов разработки и распространения опросов на рынке. Все, что вам нужно сделать, это создать опрос, добавить вопросы в инструмент онлайн-опроса, отправить его респондентам, и как только вы получите их в Интернете, инструмент сам поместит их в панель управления, чтобы дать вам блестящий анализ опроса.Ваши ответы будут сохранены. Если вы не можете посещать встречи лично, что мешает вам посещать встречи? »& Day & of & the & week & none Подробное руководство для тех, кто не знаком с Survey Monkey0: 00 Survey Monkey - Введение01: 36 Surveymonkey. Создание рейтингового вопроса. Всесторонние опросы сотрудников оценивают масштабы… NBC News | Опрос SurveyMonkey проводился с 27 июня по 5 июля 2016 г. онлайн среди национальной выборки из 2201 взрослого в возрасте 18 лет… Шаблоны опросов.Этот соединитель доступен в следующих продуктах и регионах: Опрос CNBC / SurveyMonkey Small Business Survey был проведен с использованием онлайн-платформы SurveyMonkey с 15 по 22 апреля 2019 г. среди 2100 самоидентифицированных владельцев малого бизнеса в возрасте от 18 лет и старше. . В следующих примерах опросов наведите указатель мыши на значок, где бы он ни появлялся, чтобы узнать больше о том, как работает опрос. Все результаты будут собраны в одном месте, но доступны для разных языков. HubSpot Form Builder для всплывающих форм.Шаг 2. Настройте сборщик SDK. Вы также можете изменить язык опроса. В каждом опросе вы можете задать до 10 вопросов и использовать 3 сборщика на опрос. На правой панели выберите опрос, который хотите отправить контакту. SurveyMonkey.
Создание рейтингового вопроса. Всесторонние опросы сотрудников оценивают масштабы… NBC News | Опрос SurveyMonkey проводился с 27 июня по 5 июля 2016 г. онлайн среди национальной выборки из 2201 взрослого в возрасте 18 лет… Шаблоны опросов.Этот соединитель доступен в следующих продуктах и регионах: Опрос CNBC / SurveyMonkey Small Business Survey был проведен с использованием онлайн-платформы SurveyMonkey с 15 по 22 апреля 2019 г. среди 2100 самоидентифицированных владельцев малого бизнеса в возрасте от 18 лет и старше. . В следующих примерах опросов наведите указатель мыши на значок, где бы он ни появлялся, чтобы узнать больше о том, как работает опрос. Все результаты будут собраны в одном месте, но доступны для разных языков. HubSpot Form Builder для всплывающих форм.Шаг 2. Настройте сборщик SDK. Вы также можете изменить язык опроса. В каждом опросе вы можете задать до 10 вопросов и использовать 3 сборщика на опрос. На правой панели выберите опрос, который хотите отправить контакту. SurveyMonkey. Превратите свой опыт в инструмент, предоставляющий индивидуальные консультации в любом масштабе. Для начала просмотрите наши самые популярные примеры опросов по категориям или отраслям ниже. Образец формы согласия для онлайн-опросов [Обратите внимание, что это образец формы согласия для студентов-исследователей и должен быть изменен, чтобы точно отразить индивидуальное исследование.. Например, с программным решением Thematic вы… Интернет-опрос на основе SurveyMonkey. Удовлетворение поведения потребителей по отношению к амул молоку morisha roy. Microsoft Word - Пример самооценки доски (через SurveyMonkey). Условная логика в опросах сводится к утверждениям «если / то». App Creation X. biomedcentral. Мы начнем с SoGoSurvey по одной простой причине: что касается бесплатных инструментов для проведения опросов, вы не найдете другого, представляющего такую большую ценность. По данным компании, более 95 процентов компаний из списка Fortune 100 используют Survey Monkey в той или иной форме, и это предпочтительный инструмент для аспирантов, выполняющих исследования.Служба использует мастер, который проведет вас через создание опроса, предоставив реальные примеры того, как может быть структурирован вопрос, что может помочь вам решить, как отформатировать опрос. В зависимости от ваших потребностей большинство разработчиков либо попадают в одну группу, либо в другую. Этот простой и многофункциональный инструмент поможет вам создавать интересные опросы и делиться ими по электронной почте и в социальных сетях или встраивать их прямо на свой веб-сайт. Шаблон короткого опроса ориентирован на удовлетворенность клиентов, средние и длинные шаблоны опросов добавляют вопросы об использовании библиотеки, а длинный шаблон опроса также включает раздел демографических данных.Если вы хотите организовать выборочное обследование для бизнеса или исследовательского проекта, составление отчета о выборочном обследовании поможет… Вы также можете увидеть образцы опросов. продукт, клиент, поддержка 9 лучших бесплатных конструкторов форм и инструментов для опросов. Daarbij vragen wij jouw hulp. Мгновенно реагируйте на отзывы клиентов. docx Дата создания: 20201207233501Z SurveyMonkey. Вот некоторые из наиболее часто используемых типов вопросов в опросах и способы их использования для создания качественного опроса. Однако в мире SaaS есть альтернативы любому продукту.Шаг 1. Создайте свой собственный онлайн-опрос с помощью БЕСПЛАТНЫХ шаблонов, сертифицированных экспертами SurveyMonkey. В настоящее время примеры доступны только на английском языке. Например, если вы пытаетесь получить отзывы клиентов о продукте, который вы запустили в прошлом году, совокупностью будет каждый человек, который купил, попробовал или иным образом взаимодействовал с продуктом. Компания SurveyMonkey, основанная в 1999 году, предоставляет инструмент для онлайн-опросов и набор внутренних программ. сведены в таблицу и систематизированы результаты. Если вы не знаете номер, мы можем помочь по телефону 312.Код, который вы создаете, является вашим хешем опроса, вы скопируете его и используете его, чтобы указать SDK на свой опрос на следующих этапах. Qualtrics - надежная платформа для опросов, ориентированная на организации, которые собирают большие объемы данных и нуждаются в различных типах инструментов. для анализа этих данных. Решение CSAT и NPS №1 согласно рейтингам AppExchange и инженерам по решениям SFDC. Если вы хотите увидеть, как выглядит экспорт, прежде чем решить, какой формат лучше всего подходит для вас, ознакомьтесь с этими примерами экспорта. Wij zijn Allart en Michiel, twee journalisten uit Friesland en Limburg.Программа CAHPS выделяет значительные ресурсы на выявление и подтверждение проблем, которые возникают в сети. Этот тип вопроса позволяет участнику опроса ввести развернутый ответ на вопрос. С разницей выше, чем три к одному (от 38% до 11%), больше работников указывают, что они более довольны своей ролью с момента начала пандемии, чем говорят, что теперь они хотели бы иметь другую работу. Обзорная планета. Мы собрали наши самые популярные кадровые ресурсы, чтобы поддержать вас в решении любых проблем или решений - от переосмысления рабочего места до привлечения и удержания разнообразных талантов во время Великой отставки.) - это компания по управлению опытом, которая предлагает облачное программное обеспечение для анализа бренда, рынка, опыта работы с продуктами, опыта сотрудников, клиентского опыта, разработки онлайн-опросов и набора платных серверных программ. Воспользуйтесь преимуществами бесплатного подключения, неограниченной поддержки и полезных обучающих ресурсов. * 5. 1. Анкета - это исследовательский инструмент, используемый для проведения опросов. Что такое Survey Monkey? Survey Monkey - ведущий мировой поставщик решений для интернет-опросов. Вы можете использовать шаблон, например, из Survey Monkey, из которого были взяты многие из следующих вопросов.SoGoSurvey. Рекомендуемая производителем розничная цена 32 доллара. Такой инструмент поможет вам в ваших проектах онлайн-опросов, таких как углубленное исследование конкретного рынка, отзывы сотрудников или клиентов, а также быстрый опрос, среди прочего. Программное обеспечение Snap Survey - нетипичный инструмент для создания опросов. В том же опросе об уровне обслуживания клиентов могут быть предложены следующие варианты ответов: отлично, хорошо, нет, плохо и очень плохо. SurveyMonkey - ведущий мировой поставщик решений для интернет-опросов. SurveyMonkey не имеет механизма для генерации случайных чисел для каждого ответа на опрос, но Николас Николетти из Университета Южного штата Миссури разработал метод базовой проверки ответов рабочих.Онлайн. Чтобы запустить процесс перехвата SurveyMonkey Feedback SDK, вызовите… 14 ресурсов, чтобы добавить их в свой инструментарий HR. NBC News | Опрос SurveyMonkey был проведен 14-21 мая 2018 г. среди национальной выборки из 6518 взрослых. Импортированные данные становятся файлом набора данных, который можно сортировать, фильтровать или автокодировать. Маркетинговые исследования. Собирайте мнения клиентов о предложениях новых продуктов или услуг и отслеживайте результаты опросов с течением времени. Ознакомьтесь с этими и другими шаблонами опросов для своих исследовательских проектов. Щелкните значок «Создать».SoGoSurvey был разработан, чтобы помочь предприятиям создавать опросы, формы, опросы и викторины. Когда опрос будет отправлен, вы увидите статус и подробную информацию в разделе SurveyMonkey в записи контакта. Теперь я вижу все задачи, которые мне нужно выполнить, в левой части экрана. Конечная точка: GET / Survey /
Превратите свой опыт в инструмент, предоставляющий индивидуальные консультации в любом масштабе. Для начала просмотрите наши самые популярные примеры опросов по категориям или отраслям ниже. Образец формы согласия для онлайн-опросов [Обратите внимание, что это образец формы согласия для студентов-исследователей и должен быть изменен, чтобы точно отразить индивидуальное исследование.. Например, с программным решением Thematic вы… Интернет-опрос на основе SurveyMonkey. Удовлетворение поведения потребителей по отношению к амул молоку morisha roy. Microsoft Word - Пример самооценки доски (через SurveyMonkey). Условная логика в опросах сводится к утверждениям «если / то». App Creation X. biomedcentral. Мы начнем с SoGoSurvey по одной простой причине: что касается бесплатных инструментов для проведения опросов, вы не найдете другого, представляющего такую большую ценность. По данным компании, более 95 процентов компаний из списка Fortune 100 используют Survey Monkey в той или иной форме, и это предпочтительный инструмент для аспирантов, выполняющих исследования.Служба использует мастер, который проведет вас через создание опроса, предоставив реальные примеры того, как может быть структурирован вопрос, что может помочь вам решить, как отформатировать опрос. В зависимости от ваших потребностей большинство разработчиков либо попадают в одну группу, либо в другую. Этот простой и многофункциональный инструмент поможет вам создавать интересные опросы и делиться ими по электронной почте и в социальных сетях или встраивать их прямо на свой веб-сайт. Шаблон короткого опроса ориентирован на удовлетворенность клиентов, средние и длинные шаблоны опросов добавляют вопросы об использовании библиотеки, а длинный шаблон опроса также включает раздел демографических данных.Если вы хотите организовать выборочное обследование для бизнеса или исследовательского проекта, составление отчета о выборочном обследовании поможет… Вы также можете увидеть образцы опросов. продукт, клиент, поддержка 9 лучших бесплатных конструкторов форм и инструментов для опросов. Daarbij vragen wij jouw hulp. Мгновенно реагируйте на отзывы клиентов. docx Дата создания: 20201207233501Z SurveyMonkey. Вот некоторые из наиболее часто используемых типов вопросов в опросах и способы их использования для создания качественного опроса. Однако в мире SaaS есть альтернативы любому продукту.Шаг 1. Создайте свой собственный онлайн-опрос с помощью БЕСПЛАТНЫХ шаблонов, сертифицированных экспертами SurveyMonkey. В настоящее время примеры доступны только на английском языке. Например, если вы пытаетесь получить отзывы клиентов о продукте, который вы запустили в прошлом году, совокупностью будет каждый человек, который купил, попробовал или иным образом взаимодействовал с продуктом. Компания SurveyMonkey, основанная в 1999 году, предоставляет инструмент для онлайн-опросов и набор внутренних программ. сведены в таблицу и систематизированы результаты. Если вы не знаете номер, мы можем помочь по телефону 312.Код, который вы создаете, является вашим хешем опроса, вы скопируете его и используете его, чтобы указать SDK на свой опрос на следующих этапах. Qualtrics - надежная платформа для опросов, ориентированная на организации, которые собирают большие объемы данных и нуждаются в различных типах инструментов. для анализа этих данных. Решение CSAT и NPS №1 согласно рейтингам AppExchange и инженерам по решениям SFDC. Если вы хотите увидеть, как выглядит экспорт, прежде чем решить, какой формат лучше всего подходит для вас, ознакомьтесь с этими примерами экспорта. Wij zijn Allart en Michiel, twee journalisten uit Friesland en Limburg.Программа CAHPS выделяет значительные ресурсы на выявление и подтверждение проблем, которые возникают в сети. Этот тип вопроса позволяет участнику опроса ввести развернутый ответ на вопрос. С разницей выше, чем три к одному (от 38% до 11%), больше работников указывают, что они более довольны своей ролью с момента начала пандемии, чем говорят, что теперь они хотели бы иметь другую работу. Обзорная планета. Мы собрали наши самые популярные кадровые ресурсы, чтобы поддержать вас в решении любых проблем или решений - от переосмысления рабочего места до привлечения и удержания разнообразных талантов во время Великой отставки.) - это компания по управлению опытом, которая предлагает облачное программное обеспечение для анализа бренда, рынка, опыта работы с продуктами, опыта сотрудников, клиентского опыта, разработки онлайн-опросов и набора платных серверных программ. Воспользуйтесь преимуществами бесплатного подключения, неограниченной поддержки и полезных обучающих ресурсов. * 5. 1. Анкета - это исследовательский инструмент, используемый для проведения опросов. Что такое Survey Monkey? Survey Monkey - ведущий мировой поставщик решений для интернет-опросов. Вы можете использовать шаблон, например, из Survey Monkey, из которого были взяты многие из следующих вопросов.SoGoSurvey. Рекомендуемая производителем розничная цена 32 доллара. Такой инструмент поможет вам в ваших проектах онлайн-опросов, таких как углубленное исследование конкретного рынка, отзывы сотрудников или клиентов, а также быстрый опрос, среди прочего. Программное обеспечение Snap Survey - нетипичный инструмент для создания опросов. В том же опросе об уровне обслуживания клиентов могут быть предложены следующие варианты ответов: отлично, хорошо, нет, плохо и очень плохо. SurveyMonkey - ведущий мировой поставщик решений для интернет-опросов. SurveyMonkey не имеет механизма для генерации случайных чисел для каждого ответа на опрос, но Николас Николетти из Университета Южного штата Миссури разработал метод базовой проверки ответов рабочих.Онлайн. Чтобы запустить процесс перехвата SurveyMonkey Feedback SDK, вызовите… 14 ресурсов, чтобы добавить их в свой инструментарий HR. NBC News | Опрос SurveyMonkey был проведен 14-21 мая 2018 г. среди национальной выборки из 6518 взрослых. Импортированные данные становятся файлом набора данных, который можно сортировать, фильтровать или автокодировать. Маркетинговые исследования. Собирайте мнения клиентов о предложениях новых продуктов или услуг и отслеживайте результаты опросов с течением времени. Ознакомьтесь с этими и другими шаблонами опросов для своих исследовательских проектов. Щелкните значок «Создать».SoGoSurvey был разработан, чтобы помочь предприятиям создавать опросы, формы, опросы и викторины. Когда опрос будет отправлен, вы увидите статус и подробную информацию в разделе SurveyMonkey в записи контакта. Теперь я вижу все задачи, которые мне нужно выполнить, в левой части экрана. Конечная точка: GET / Survey /