
Урок «Состав и функции белков»
Состав и функции белков
Цель урока: продолжить углубление и расширение знаний о химическом составе клетки, раскрыв состав и функции белков
Задачи урока:
Образовательные:
Расширить и углубить знания учащихся о важнейших органических веществах в клетке на основе изучения строения и функции белков.
Раскрыть состав и строение белков.
Раскрыть функции белков, показать их разнообразие и значимость для жизнедеятельности живых организмов.
Развивающие:
Сформировать у учащихся познавательный интерес к процессу изучения функций белков в клетке и организме.
Продолжить формирование умений выявлять связь между строением и функциями
Тип урока: урок изучения нового материала.
Форма проведения: групповая работа.
Методы: фронтальная беседа, проблемные вопросы.
Оборудование: штативы, пробирки, реактивы: растворы гидроксида натрия, хлорида натрия, сульфата меди, глицин, глутаминовая кислота, лизин, лакмусовая бумага, мультимедийный проектор, презентация (приложение 1)
Ход урока:
1. Приветствие. Здравствуйте! Я очень рада видеть вас в этой аудитории. Меня зовут Чернова Ольга Геннадьевна. Я учитель биологии средней школы №33.
2. Мотивация учебной деятельности. Начать урок я хочу словами Сергея Яковлевича Надсона: (слайд 1)
Меняя каждый миг свой образ прихотливый
Капризна, как дитя, и призрачна, как дым,
Кипит повсюду ЖИЗНЬ в тревоге суетливой,
Великое смешав с ничтожным и смешным
Что такое жизнь? Откуда она взялась на Земле? Эти вопросы давно интересовали людей в разные времена.
Академик Опарин говорил:«Путь к живым организмам лежит через белки. Жизнь и белки – понятия неотделимые одно от другого»
Белок — основа жизни, верно ли это? Вот основной проблемный вопрос нашего урока.
Поэтому тема нашего урока – Состав и функции белка. (слайд 2)
3. Новый материал. Белки – это сложные органические вещества, состоящие из углерода, кислорода, водорода, азота. В некоторых молекулах белков содержится железо, сера, фосфор, цинк, медь и др. Белки, или протеины – это биополимеры, нерегулярные полимеры.
Белков в клетках больше, чем каких бы то ни было других органических веществ. На их долю приходится в среднем около 50 % общей массы клетки. Так, например, в мышцах на долю белка приходится 80%, в коже-63%, печени – 57%, мозге — 45%, костях — 28%. Интересны формулы некоторых белков. Так, формула всем нам известного гемоглобина, белка крови, C (слайд 3)
(слайд 3)
4. Итак, вернемся к нашему проблемному вопросу. Для ответа на этот вопрос мы проведем небольшое исследование. Любое исследование всегда подразумевает изучение теории, т.е. изучение литературы на эту тему. Мы с вами пойдем от противного, и начнем разговор с функций. В течение всего урока мы работаем на рабочих листах, которые перед вами. (приложение 2)
Давайте вспомним, какие функции выполняют белки в клетке?
(Рассказ о функциях или фронтальная беседа). (слайды 4-14)Функции белков
Белки выполняют чрезвычайно важные и многообразные функции. Всего функций белков насчитывается около 30. Мы рассмотрим лишь главные из них.
1. Структурная или строительная. Белки являются основой всех биологических мембран, всех органоидов клетки. Многие белки образуют волокна, перевитые друг с другом или уложенные плотным слоем. Они выполняют опорную или защитную функцию, скрепляя биологические структуры и придавая им прочность. Так, коллаген является важным составным компонентом соединительной ткани (хрящей и сухожилий), кератин – компонентом перьев, волос, ногтей, эластин – эластичный компонент связок, стенок кровеносных сосудов.
Они выполняют опорную или защитную функцию, скрепляя биологические структуры и придавая им прочность. Так, коллаген является важным составным компонентом соединительной ткани (хрящей и сухожилий), кератин – компонентом перьев, волос, ногтей, эластин – эластичный компонент связок, стенок кровеносных сосудов.
3. Важное значение имеет транспортная функция. Так, гемоглобин переносит кислород из легких к клеткам других тканей и органов. Транспортные белки в наружной мембране клеток переносят различные вещества из окружающей среды в цитоплазму. Белки сыворотки крови способствуют переносу липидов и жирных кислот, различных биологически активных веществ.
Белки сыворотки крови способствуют переносу липидов и жирных кислот, различных биологически активных веществ.
4. Специфические белки выполняют защитную функцию. Они предохраняют организм от вторжения чужеродных белков и микроорганизмов. Так, антитела, вырабатываемые лимфоцитами, блокируют чужеродные белки; фибрин и тромбин предохраняют организм от кровопотери.
5. Регуляторная функция присуща белкам – гормонам. Они поддерживают постоянные концентрации веществ в крови и клетках, участвуют в росте, размножении и других жизненно важных процессах. Например, инсулин регулирует содержание сахара в крови.
6. Рецепторная. С помощью этих белков клетка воспринимает информацию о состоянии внешней среды, сигналы от низкомолекулярных физиологически активных веществ. Они играют важную роль при передаче нервного возбуждения
7.Энергетическая. Белки могут служить источником энергии для клетки.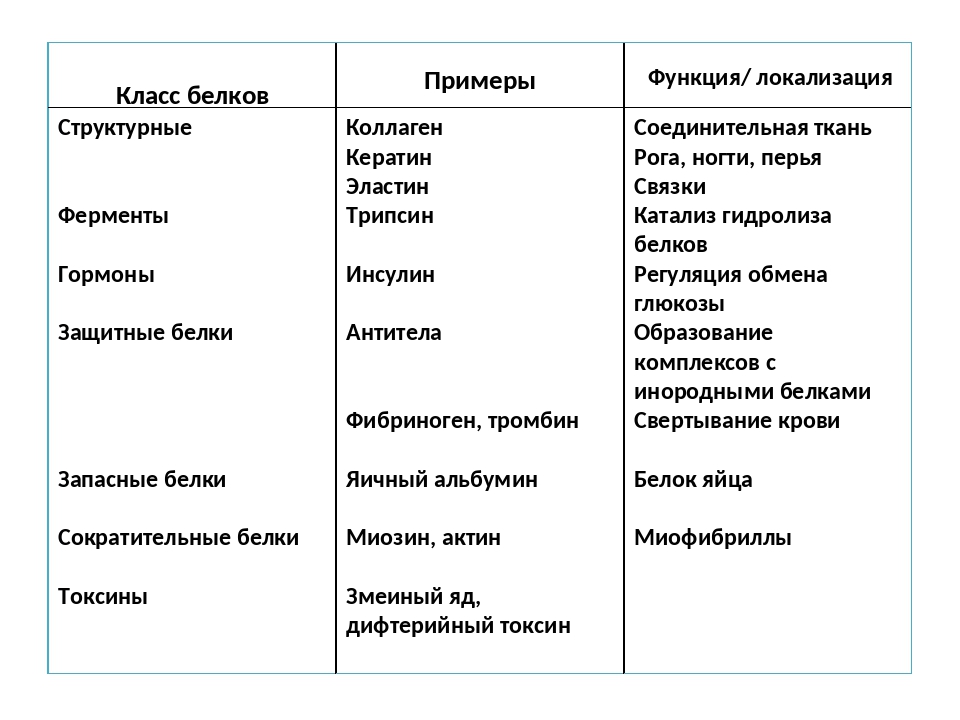
8. Токсическая. Многие живые организмы для обеспечения защиты выделяют белки – токсины, которые в большинстве случаев являются сильными ядами.
9.Ферментативная. В каждой живой клетке непрерывно происходят сотни биохимических реакций, в ходе которых идут распад и окисление поступающих извне питательных веществ. Клетка использует энергию, полученную вследствие их окисления, продукты расщепления служат для синтеза необходимых клетке органических соединений. Быстрое протекание реакций обеспечивают биокатализаторы – ферменты. Известно более двух тысяч ферментов, каждый из которых способен осуществлять от тысячи до сотен тысяч реакций в минуту. В ходе биохимических превращений ферменты не расходуются. Они соединяются с реагирующими веществами, ускоряет их превращения и выходит из реакции неизменным.
9.Запасающая. В семенах многих растений запасены пищевые белки, потребляемые зародышем на первых стадиях развития. Наиболее известны такие белки в семенах кукурузы, пшеницы, риса.
5. Как мы видим, белки выполняют огромное количество функций. Как вы думаете, с чем это связано? Почему такое многообразие функций? Вот еще один проблемный вопрос.
Для его решения проведем небольшую практическую работу. Для этого делимся на 3 группы по рядам. Первая выясняет состав белковой молекулы. Вторая — её структуру. Третья – изучает свойства белков. Перед вами информационные листы (приложение 3) Внимательно изучите алгоритм работы. В своем рабочем листе отобразите основные моменты вашей работы. Затем, мы посмотрим, что у нас получилось.
6. Итоги работы в группах
1 группа.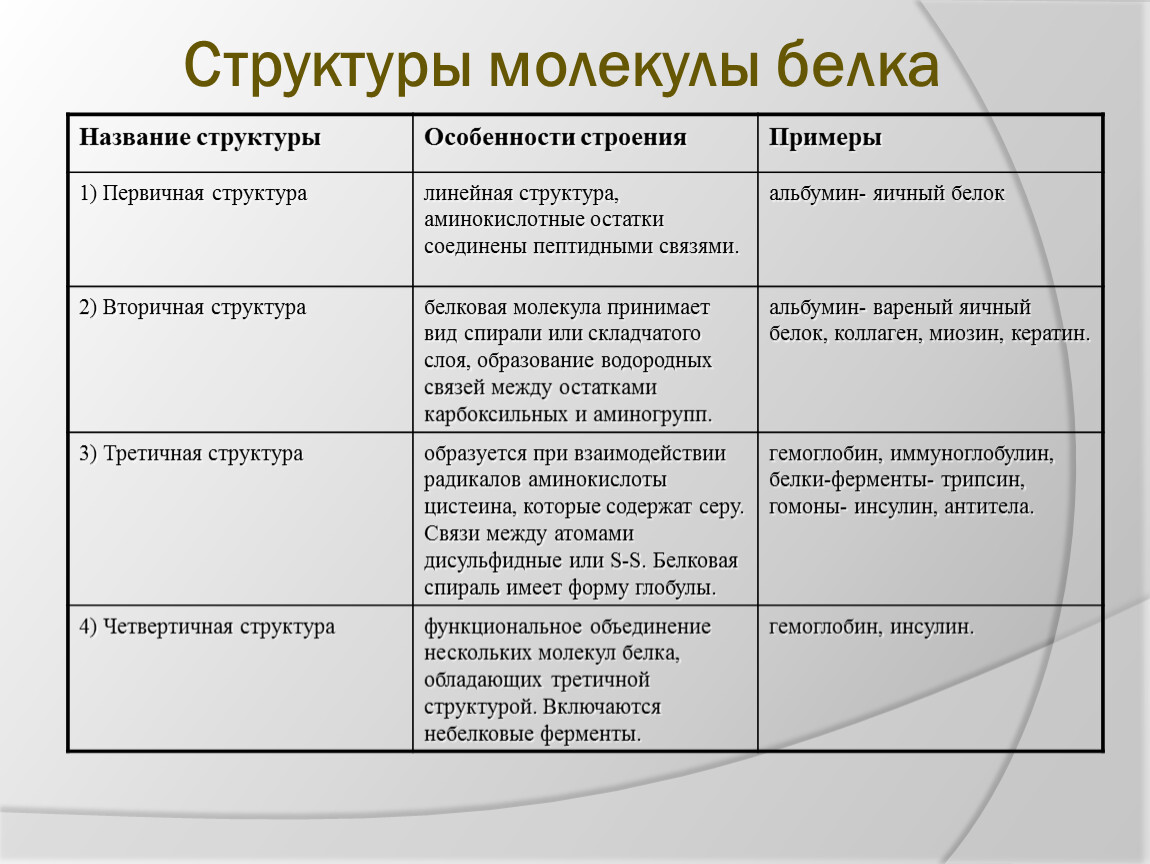 Выводы: мономеры белков – аминокислоты, строение. Амфотерность. 20 аминокислот Рассказ об опыте.
Выводы: мономеры белков – аминокислоты, строение. Амфотерность. 20 аминокислот Рассказ об опыте.
Есть АК с основными свойствами (лизин; 2 аминогруппы), есть с кислотными (глутаминовая кислота; 2 карбоксильные группы)
2 группа. Пептидная связь.
Доказательства пептидной связи. Рассказ об опыте
Структуры белка.
Вывод: белки очень разнообразны, так как каждый из них характеризуется специфической последовательностью аминокислот. Свойства белков зависят от химического строения.
3 группа Денатурация. Её значение. Повышенная температура тела, спирт и т.д. Денатурация приводит к нарушению антигенной чувствительности белка, а иногда к полному блокированию иммунных реакций, к инактивации ферментов, нарушению обмена веществ. Ученые предполагают, что процессы старения связаны с медленной денатурацией.
Рассказ об опыте.
7. Строение изучили, изучили и функции. Давайте вернемся к нашему проблемному вопросу. Белки – основа жизни?
Строение изучили, изучили и функции. Давайте вернемся к нашему проблемному вопросу. Белки – основа жизни?
Понятия жизнь и белок неразрывно связаны. Чтобы ответить на вопрос «Что такое жизнь»? надо знать, что такое белки. Насколько многообразны белки, настолько сложна, многолика и загадочна жизнь. Подтверждением этого может стать высказывание Гёте: «Я всегда говорил и не устаю повторять, что мир бы не мог существовать, если бы был так просто устроен»
Если остается время: либо тест, либо ответ на вопрос:
Строение и функции белков
Урок изучения нового материала в 10-м классе. Данный материал учащиеся уже
изучали в 9 классе, поэтому некоторые понятия им уже известны. Соответственно с
ребятами ведется диалог о строении и функциях белков. С помощью учителя учащиеся
узнают о классификации ферментов.
Соответственно с
ребятами ведется диалог о строении и функциях белков. С помощью учителя учащиеся
узнают о классификации ферментов.
Для того, чтобы активизировать деятельность учащихся на уроке, приводятся интересные факты о белках, которые помогают ребятам и нацеливают их на дальнейшее усвоение нового материала. Так же для этих целей предлагается провести лабораторную работу. На данном уроке основная масса изучаемого материала записывается в виде таблиц, схемы, которые учитель строит в ходе урока вместе и учениками. Качество изучаемого материала проверяется в виде фронтального опроса. Урок рассчитан как на детей-аудиалов, так и визуалов.
Цель урока: дать представление о строении и функции белков.
Задачи: продолжить расширение и углубление знаний важнейших органических
веществах клетки на основе изучения строения и функции белков, сформировать
знания функциях белков и их важнейшей роли в органическом мире, продолжить
формирование умения выявлять связи между строением и функциями веществ.
Основные понятия: белки, протеины, протеиды, пептид, пептидная связь, простые и сложные белки, первичная, вторичная, третичная и четвертичная структуры белков денатурация.
Средства обучения: таблицы по общей биологии, иллюстрирующие строение молекул белков; лабораторное оборудование для проведения лабораторной работы “Расщепление пероксида водорода с помощью ферментов, содержащихся в плетках листа элодеи”.
Ход урока
I. Изучение нового материала.
1. Рассказ учителя (или фрагмент лекции) об особенностях строения молекул белков как биополимеров, состоящих из большого количества разных аминокислот, между которыми происходит полимеризация на основе пептидной связи. Зарисовка и запись на доске и в тетрадях учащихся.
2. Самостоятельное изучение учащимися текста учебника (С.42) о классификации белков.
3. Беседа об уровнях организации белковой молекулы и химической основы
каждого из четырех уровней (структур) этой молекулы, о денатурации как утрате
белковой молекулы своей природной структуры.
Структура белковой молекулы.
| Структура белка | Характеристика | Тип связи | Схема (учащиеся рисуют самостоятельно) |
| Первичная | Линейная структура – последовательность аминокислот в полипептидной цепи, которая определяет все другие структуры молекулы, а также свойства и функции белка. | Пептидная. | |
| Вторичная | Закручивание полипептидной цепи в
спираль или складывание в “гармошку”. |
Водородные связи. | |
| Третичная | Глобулярный белок: упаковка вторичной
структуры в глобулу; фибриллярный белок: несколько вторичных структур, уложенных параллельными слоями, или скручивание нескольких вторичных структур наподобие каната в суперспираль. |
Ионные, водородные, дисульфидные, гидрофобные. | |
| Четвертичная | Встречается редко. Комплекс из нескольких третичных структур органической природы и неорганическое вещество, например, гемоглобин. | Ионные, водородные, гидрофобные. |
4.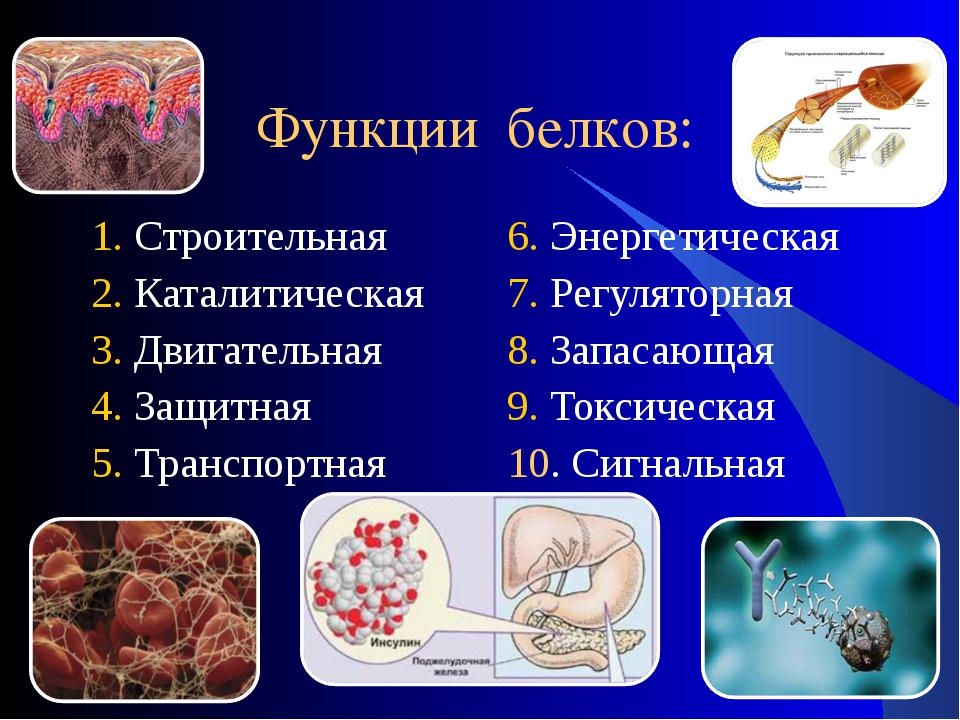 Рассказ учителя о многообразии функций белков с краткой записью в тетрадях
сущности функций: структурной, ферментативной, транспортной, защитной,
регуляторной, энергетической, сигнальной.
Рассказ учителя о многообразии функций белков с краткой записью в тетрадях
сущности функций: структурной, ферментативной, транспортной, защитной,
регуляторной, энергетической, сигнальной.
5. Лабораторная работа “Расщепление пероксида водорода с помощью ферментов, содержащихся в клетках листа элодеи”.
Ход работы:
а. Приготовьте микропрепарат листа элодеи и рассмотрите его под микроскопом.
б. Капните на микропрепарат немного пероксида водорода и еще раз рассмотрите, в
каком состоянии находятся клетки листа элодеи.
в. Объясните, с чем связано выделение пузырьков из теток листа, что это за газ,
на какие вещества может расщепиться пероксид водорода, какие ферменты участвуют
в этом процессе?
г. Капните каплю пероксида на предметное стекло и, рассмотрев его под
микроскопом, опишите наблюдаемую, картину. Сравните состояние пероксида водорода
в листе элодеи и на стекле, сделайте выводы.
По завершении лабораторной работы следует провести беседу о биохимических реакциях, протекающих при участии белковых катализаторов-ферментов как основе жизнедеятельности клеток и организмов.
Химические свойства белков обусловлены их различным аминокислотным составом. Существуют белки хорошо растворимые в воде и совершенно нерастворимые, химически активные и устойчивые к действию различных агентов, способные укорачиваться и растягиваться и т. д.
Под влиянием различных факторов – высокой температуры, действия химических
веществ, облучения, механического воздействия – может произойти разрушение
структур белковой молекулы. Нарушение природной структуры белка называется
денатурацией. Если воздействие перечисленных факторов было недолгим и несильным,
то белок может вернуть свою природную структуру – обратимая денатурация (ренатурация),
если же воздействие было долгим или сильным, то происходит нарушение не только
третичной и вторичной структур, но и первичной – необратимая денатурация (рис. 3).
3).
Функции белков.
| Функция | Характеристика |
| 1. Строительная (структурная). | Входят в состав клеточных мембран и органоидов клетки (липопротеиды и гликопротеиды), участвуют в образовании стенок кровеносных сосудов, хрящей, сухожилий (коллаген) и волос (кератин). |
| 2. Двигательная | Обеспечивается сократительными белками (актин и миозин), которые обуславливают движение ресничек и жгутиков, сокращение мышц, перемещение хромосом при делении клетки, движение органов растений. |
| 3. Транспортная. | Связывают и переносят с током крови
многие химические соединения, например, гемоглобин и миоглобин
транспортируют кислород, белки сыворотки крови переносят гормоны, липиды
и жирные кислоты, различные биологически активные вещества. |
| 4. Защитная. | Выработка антител (иммуноглобулинов) в ответ на проникновение в нее чужеродных веществ (антигенов), которые обеспечивают иммунологическую защиту; участие в процессах свертывания крови (фибриноген и протромбин). |
| 5, Сигнальная (рецепторная). | Прием сигналов из внешней среды и передача команд в клетку за счет изменения третичной структуры встроенных в мембрану белков в ответ на действие факторов внешней среды. Например, гликопротеины (встроены в гликокал икс), опсин (составная часть светочувствительных пигментов родопсина и йодопсина), фитохром (светочувствительный белок растений). |
| 6. Регуляторная. | Белки-гормоны оказывают влияние на
обмен веществ, т. е. обеспечивают гомеостаз, регулируют рост,
размножение, развитие и другие жизненно важные процессы. Например,
инсулин регулирует уровень глюкозы в крови, тироксин – физическое и
психическое развитие и т.д. е. обеспечивают гомеостаз, регулируют рост,
размножение, развитие и другие жизненно важные процессы. Например,
инсулин регулирует уровень глюкозы в крови, тироксин – физическое и
психическое развитие и т.д. |
| 7. Каталитическая (ферментативная). | Белки-ферменты ускоряют биохимические процессы в клетке. |
| К. Запасающая | Резервные белки животных: альбумин (яйца) запасает воду, ферритин – железо в клетках печени, селезенки; миоглобин – кислород в мышечных волокнах, казеин (молоко) и белки семян – источник питания для зародыша. |
| 9. Пищевая (основной источник аминокислот). | Белки пищи – основной источник
аминокислот (особенно незаменимых) для животных и человека; казеин
(белок молока) – основной источник аминокислот для детенышей
млекопитающих. |
| 10. Энергетическая. | Являются источником энергии – при окислении 1 г белка выделяется 17,6 кДж энергии, но организм использует белки в качестве источника энергии очень редко, например, при длительном голодании. |
Ферменты (энзимы) – это специфические белки, которые присутствуют во всех живых организмах и играют роль биологических катализаторов.
Химические реакции в живой клетке протекают при умеренной температуре,
нормальном давлении и нейтральной среде. В таких условиях реакции синтеза или
распада веществ протекали бы очень медленно, если бы не подвергались воздействию
ферментов. Ферменты ускоряют реакцию без изменения ее общего результата за счет
снижения энергии активации. Это означает, что в их присутствии требуется
значительно меньше энергии для придания реакционной способности молекулам,
которые вступают в реакцию. Ферменты отличаются от химических катализаторов
высокой степенью специфичности, т. е. фермент катализирует только одну реакцию
или действует только на один тип связи. Скорость ферментативных реакций зависит
от многих факторов – природы и концентрации фермента и субстрата, температуры,
давления, кислотности среды, наличия ингибиторов и т.д.
Ферменты отличаются от химических катализаторов
высокой степенью специфичности, т. е. фермент катализирует только одну реакцию
или действует только на один тип связи. Скорость ферментативных реакций зависит
от многих факторов – природы и концентрации фермента и субстрата, температуры,
давления, кислотности среды, наличия ингибиторов и т.д.
Классификация ферментов.
| Группа | Катализируемые реакции, примеры |
| Оксидоредуктазы. | Окислительно-восстановительные
реакции: перенос атомов водорода (Н) и кислорода (О) или электронов от
одного вещества к другому, при этом окисляется первый и
восстанавливается второй. Участвуют во всех процессах биологического
окисления, например, вдыхании: АН + В А
ВН (окисленный)
или А + О АО
(восстановленный). |
| Трансферазы. | Перенос группы атомов (метильной,
ацильной, фосфатной или аминогруппы) от одного вещества к другому.
Например, перенос остатков фосфорной кислоты от АТФ на глюкозу или
фруктозу под действием фототрансфераз: АТФ + глюкоза глюкозо-6-фосфат + АДФ. |
| Гидролазы. | Реакции расщепления сложных
органических соединений на более простые путем присоединения молекул
воды в месте разрыва химической связи (гидролиз). Например, амилаза (гидролизирует
крахмал), липаза (расщепляет жиры), трипсин (расщепляет белки) и др.: АВ + Н20 АОН + ВН. |
| Лиазы | Негидролитическое присоединение к
субстрату или отщепление от него группы атомов.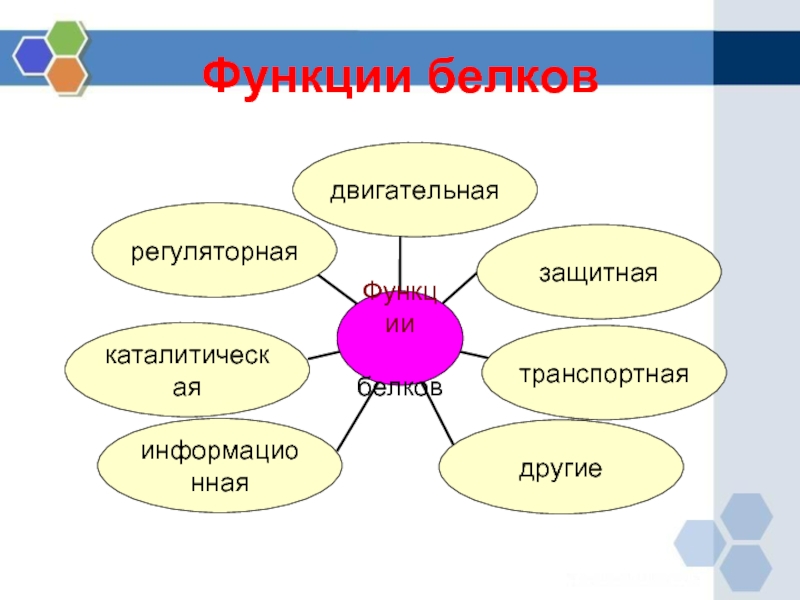 При этом могут
разрываться связи С-С, C-N, С-О, C-S. Например, декарбоксилаза отщепляет
карбоксильную группу: При этом могут
разрываться связи С-С, C-N, С-О, C-S. Например, декарбоксилаза отщепляет
карбоксильную группу: |
| Изомеразы | Внутримолекулярные перестройки,
превращение одного изомера в другой (изомеризация): глюкозо-6-фосфат глюкозо-1-фосфат. |
| Лигазы (синтетазы) | Реакции соединения двух молекул с
образованием новых связей С–О, С–S, С–N, С–С, с использованием энергии
АТФ. Например, фермент валин-тРНК-синтетаза, под действием которого
образуется комплекс валин– тРНК: АТФ + валин + тРНК АДФ + Н3Р04 + валин-тРНК. |
Механизм действия фермента представлен на рис. 4. В молекуле каждого фермента
имеется активный центр – это один или более участков, в которых происходит
катализ за счет тесного контакта между молекулами фермента и специфического
вещества (субстрата).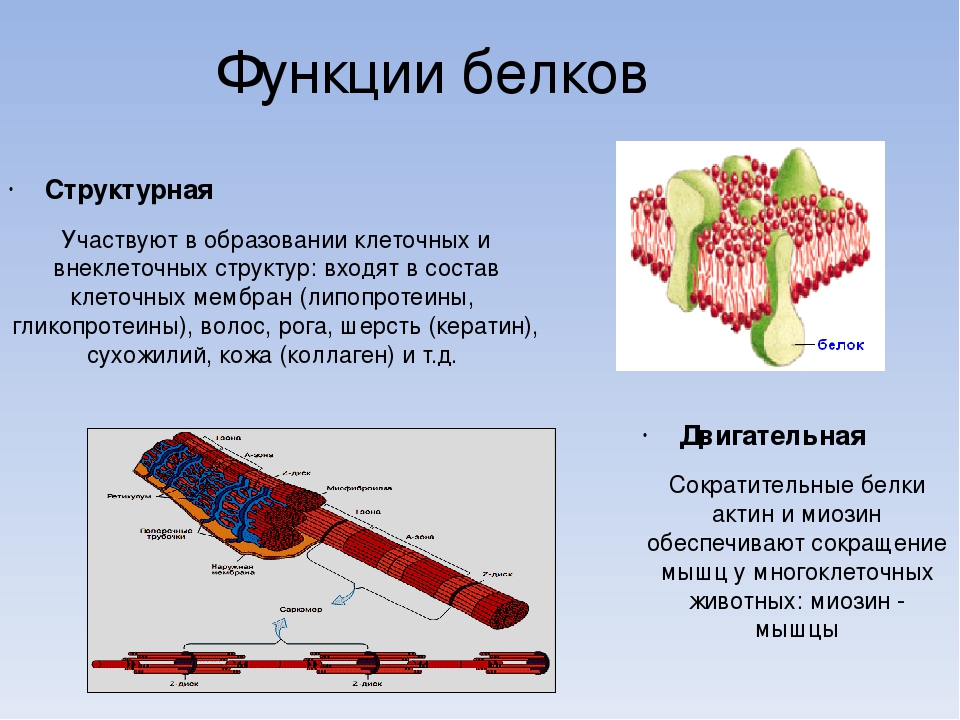 Активным центром выступает или функциональная группа
(например, ОН-группа), или отдельная аминокислота. Активный центр может
формироваться связанными с ферментом ионами металлов, витаминами и другими
соединениями небелковой природы – коферментами или кофакторами. Форма и
химическое строение активного центра таковы, что с ним могут связываться только
определенные субстраты в силу их идеального соответствия (комплементарности)
друг другу.
Активным центром выступает или функциональная группа
(например, ОН-группа), или отдельная аминокислота. Активный центр может
формироваться связанными с ферментом ионами металлов, витаминами и другими
соединениями небелковой природы – коферментами или кофакторами. Форма и
химическое строение активного центра таковы, что с ним могут связываться только
определенные субстраты в силу их идеального соответствия (комплементарности)
друг другу.
Молекула фермента изменяет глобулярную форму молекулы субстрата. Молекула субстрата, присоединяясь к ферменту, тоже в определенных пределах изменяет свою конфигурацию для увеличения реакционности функциональных групп центра.
На заключительном этапе химической реакции фермент-субстратный комплекс распадается с образованием конечных продуктов и свободного фермента. Освободившийся при этом активный центр может принимать новые молекулы субстрата.
II. Обобщающая беседа об основополагающей роли белков как самых
необходимых химических соединений для жизней деятельности всего живого на Земле.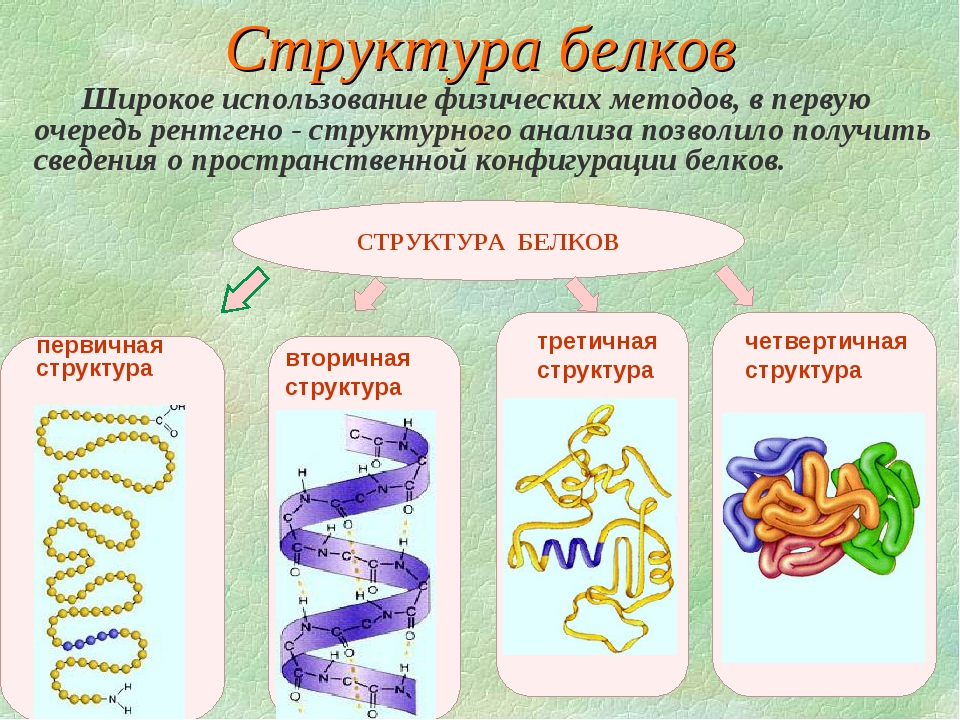
III. Закрепление знаний в процессе беседы с помощью следующих вопросов:
- Какие органические вещества клетки можно назвать самыми важными?
- Каким образом создается бесконечное разнообразие белков?
- Что собой представляют мономеры биополимера белка?
- Как формируется пептидная связь?
- Что собой представляет первичная структура белка?
- Каким образом происходит переход первичной структуры молекул белка во вторичную, а затем– в третичную и четвертичную?
- Какие функции могут выполнять белковые молекулы?
- Чем обусловлено многообразие функций белковых молекул?
- Приведите примеры белков, выполняющих самые разные функции. При ответе можно использовать следующую схему:
Биологические функции белков.
Это интересно.
Многие молекулы очень велики и по длине, и по молекулярной массе. Так,
молекулярная масса инсулина – 5700, белка-фермента рибонуклеазы – 127 ООО,
яичного альбумина – 36 ООО, гемоглобина – 65 ООО. В состав различных белков
входят самые разные аминокислоты. Набор всех двадцати видов аминокислот
содержит: казеин молока, миозин мышц и альбумин яйца. В белке-ферменте
рибонуклеазе – 19, в инсулине – 18 аминокислот. Коллективу ученых под
руководством академика Ю.А. Овчинникова удалось расшифровать сложную структуру
белка родопсина, ответственного за процесс зрительного восприятия.
Так,
молекулярная масса инсулина – 5700, белка-фермента рибонуклеазы – 127 ООО,
яичного альбумина – 36 ООО, гемоглобина – 65 ООО. В состав различных белков
входят самые разные аминокислоты. Набор всех двадцати видов аминокислот
содержит: казеин молока, миозин мышц и альбумин яйца. В белке-ферменте
рибонуклеазе – 19, в инсулине – 18 аминокислот. Коллективу ученых под
руководством академика Ю.А. Овчинникова удалось расшифровать сложную структуру
белка родопсина, ответственного за процесс зрительного восприятия.
Кровь осьминогов, моллюсков и пауков имеет голубой цвет, потому что переносчиком кислорода у них служит не красный гемоглобин, содержащий атомы железа, а гемоцианин с атомами меди.
Почти половина необходимых нам белков, углеводов, 70–80% витаминов, значительное количество минеральных солей, аминокислот и других питательных элементов содержится в хлебе.
Американские ученые выделили из растения (семейство Пентадипландовых),
произрастающего в Западной Африке, белок, который слаще сахара в 2 тыс. раз.
Этот шестой известный науке сладкий белок, названный бразеином, содержится в
плодах, которые с большой охотой поедают местные обезьяны. Биохимики
расшифровали строение молекул сладкого белка, в каждой из них содержится 54
аминокислотных остатка.
раз.
Этот шестой известный науке сладкий белок, названный бразеином, содержится в
плодах, которые с большой охотой поедают местные обезьяны. Биохимики
расшифровали строение молекул сладкого белка, в каждой из них содержится 54
аминокислотных остатка.
IV. Домашнее задание: Изучить § 11, ответить на вопросы на с. 46. Приготовить сообщения или рефераты на темы: “Белки – биополимеры жизни”, “Функции белков – основа жизнедеятельности каждого организма на Земле”, “Денатурация и ренатурация, ее практическое значение”, “Многообразие ферментов, их роль в жизнедеятельности клеток и организмов” и др.
Используемые ресурсы:
- Каменский А.А.Общая биология 10–11: учеб.для общеобразоват. учреждений.– М.:Дрофа, 2006.
- Козлова Т.А. Тематическое и поурочное планирование по биологии к
учебнику А.А.Каменского и др. “Общая биология 10–11”. – М.: Издательство
“Экзамен”, 2006.

- Биология. Общая биология. 10–11 классы: рабочая тетрадь к учебнику Каменского А.А. и др. “Общая биология 10–11”– М.: Дрофа, 2011.
- Кириленко А.А. Молекулярная биология. Сборник заданий для подготовки к ЕГЭ: уровни А,В,С: учебно-методическое пособие. – Ростов н/Д: Легион, 2011.
Органические вещества в составе клетки, биологические молекулы (Таблица)
Справочная таблица содержит органические вещества в составе клетки (или биологические молекулы), такие как углеводы, нуклеиновые кислоты и нуклеотиды, липиды, аминокислоты и белки, витамины
Биологические молекулы — в основе их строения лежит способность атомов углерода образовывать ковалентные связи, обычно с атомами углерода, кислорода, водорода или азота. Молекулы могут иметь форму длинных цепей или же формировать различные кольцевые структуры.
|
Органические вещества клетки |
Функции в клетках |
Структура и свойства |
|
Углеводы |
— являются основным источником энергии для организма — компонент соединительных тканей — защитная функция (слизь, гепарин) — запасные питательные вещества (полисахариды) |
Эти органические вещества клетки обычно состоят только из С, Н и О Эмпирическая формула — СnН2nОn Для определения простейших углеводов (редуцирующих сахаров) обычно используется нагревание с реактивом Бенедикта Многие углеводы растворимы в воде Делятся на три основных класса: моносахариды, олигосахариды и полисахариды. |
|
Нуклеиновые кислоты и нуклеотиды |
— синтез белка — хранение наследственной информации клетки — запас и накопление энергии в клетках |
Нуклеиновые кислоты — биополимеры, мономерами которых являются нуклеотиды. Содержат С, Н, О, N и Р Фосфатная группа дает КИСЛУЮ РЕАКЦИЮ После гидролиза сахар пентоза дает позитивную РЕАКЦИЮ БЕНЕДИКТА |
|
Липиды |
— источник энергии — компоненты клеточных мембран — защитная функция клеток — транспортная функция — роль запасных веществ |
Липиды — это различные соединения, отличающихся своей гидрофобностью. Большая часть липидов это жиры. Обычно не растворяются в воде, но растворимы в органических растворителях Обычно состоят только из С, Н и О, при этом содержание О меньше, чем в углеводах Определяют, как правило, с помощью физической реакции — эмульсионной пробы |
|
Аминокислоты и белки |
— структурная функция — каталитическая (ферменты) — транспортная функция (гемоглобин) — защитная функция (антитела) — энергетическая функция |
Аминокислоты — это соединения, в составе которых есть карбоксильная группа и аминогруппа Биологические молекулы белков состоят из С, Н, О, N и иногда S Эти органические вещества обычно растворимы в воде Белки дают положительную биуретовую реакцию |
|
Коферменты |
Основная функция — энергетическая! |
Коферменты — это молекулы не белковой природы, соединяются с белками (апоферментами) и играют роль активного центра. Коферменты используются для переноса функциональных групп между ферментами, которые катализируют химические реакции. К ним относят витамины, АТФ, Ацетил-КоА. АТФ (аденозинтрифосфат) центральный кофермент, универсальный источник энергии клеток. |


_______________
Источник информации:
1. Биология человека в диаграммах / В.Р. Пикеринг — 2003.
2. Общая биология / Левитин М. Г. — 2005.
Ответ § 6. Белки и нуклеиновые кислоты
Важнейшими химическими веществами клетки и всей живой природы являются белки и нуклеиновые кислоты. Белки — биологический полимеры, мономерами которых являются аминокислоты. Особенности химического строения нуклеиновых кислот обеспечивают возможность хранения и реализации наследственной информации.
1) Заполните таблицу «Особенности строения белковой молекулы».
-
Ответ:
Структура молекулы белка Особенности строения Первичная структура Длинная нить последовательной присоединенных друг к другу аминокислот Вторичная Спирально скрученная нить молекулы Третичная Многократное скручивание нити молекулы — глобула Четвертичная Более сложная форма, состоящая из нескольких глобул
2) Известно, что вторичная структура молекулы белка представляет собой спираль. Благодаря чему возможная такая конструкция?
Благодаря чему возможная такая конструкция?
3) Заполните пропуски в предложениях.
-
Ответ: Потерю своих качеств и частичное изменение структуры белковой молекулы называют денатурация белка. Этот процесс обратим в тех случаях, когда затронута только вторичная структура или третичная структура. При этом могут восстановиться функции белка.
4) Как проявляется ферментативная функция белковых молекул? Что означает выражение «специфичность действия фермента»?
5) Заполните таблицу «Основные функции белков».
-
Ответ:
Функции белков Значение Ферментативная Химические реакции Транспортная Доставляют кислород и питательные вещества Структурная Образуют соединительную ткань Защитная Защита от вредных веществ
6) Используя текст учебника, заполните таблицу «Особенности нуклеиновых кислот».
-
Ответ:
Признаки ДНК РНК 1 2 3 Состав Дезоксирибоза Рибозы Структура 2 полунуклеотидные цепочки 1 полинуклеотидная цепочка Место в клетке Ядро и органоиды Ядро, цитоплазма Функция Носитель наследственной информации иРНК, тРНК, рРНК, участие в синтезе белка
7) Какой процесс называют репликацией ДНК?
Перерисуйте фрагмент ДНК и смоделируйте репликацию этого фрагмента. Обозначьте черточками число водородных связей.
-
Ответ:
8) Какие функции в клетке выполняют нуклеиновые кислоты?
-
Ответ: ДНК хранит наследственную информацию, а РНК учавствует в процессах, связанных с передачей генетической информации.

список продуктов, таблица продуктов. Преимущество растительного белка
Что представляет собой белок
Одним из трех нутриентов, важных для полноценной жизнедеятельности организма, является белок. Большинство тканей содержит его в большом количестве, особенно, мышечная. Это высокомолекулярное соединение состоит из 22 аминокислот. На них он распадается в кишечном тракте под воздействием ферментов. Аминокислоты делятся на три большие группы:
- Заменимые — их организм синтезирует самостоятельно.
- Незаменимые — самостоятельный синтез невозможен. Поэтому важно, чтобы меню состояло из тех продуктов, которые их содержат.
- Условно заменимые — их источником также является пища. Но необходимы организму они в определенных случаях, например, при стрессе или болезни.
Важно питаться правильно, сбалансировано, чтобы аминокислоты могли оказывать комплексное воздействие с целью создания прочной структуры организма.
Для расщепления протеина организм затрачивает немалое количество времени и энергии.Ежедневно клеткам организма для обновления, а также восстановления, необходимо получать суточную норму белка. А она составляет 1,5 г на килограмм массы тела. При белковом дефиците организм начинает использовать запасы протеина, хранящегося в мышечной ткани. Постепенно развивается дистрофия: теряются мышцы, кожа становится дряблой, слабой. Подобную потерю веса можно назвать не только бесполезной, но и губительной для здоровья.
Польза растительного белка
Растительные пептиды поступают в организм из злаков, зелени и плодов. Чтобы поддерживать функции на должном уровне, нужно выбирать такие сочетания продуктов, чтобы ограничивать порции по массе, не увеличивая нагрузку на пищеварительную систему.
Белок растительного происхождения:
- Усваивается легче. В нем практически нет холестерина, небольшое количество липидов. Благодаря этому уменьшается вероятность появления аллергических реакций и развития следующих заболеваний — варикоза, тромбофлебита, атеросклероза, инсульта.

- Имеет высокое количество клетчатки и пищевых волокон, поэтому оказывает благотворное воздействие на состояние пищеварительных органов. У людей, придерживающихся вегетарианской диеты, рак толстого кишечника возникает в 5 раз реже, чем у мясоедов.
- Способствует похудению, не дает сформироваться жировой прослойке.
Благодаря поступлению протеинов из растений все органические функции поддерживаются в полном объеме. Нормализуется работа репродуктивной системы, обеспечиваются обменные процессы, непрерывно формируются новые клетки, сохраняется баланс кишечной микрофлоры. Иммунный статус организма остается стабильным, и риск развития сахарного диабета снижается.
Нужно обратить внимание еще на один аспект. Вегетарианская диета — это экологично, не истощает ресурсы Земного шара. Получить хороший урожай намного легче, чем восстановить поголовье скота. К тому же метан, который вырабатывается на фермах, загрязняет атмосферу.
Кроме того, стоит учитывать и моральную составляющую. Многие люди переходят на вегетарианскую диету по убеждениям — они не хотят чувствовать себя «убийцами».
Многие люди переходят на вегетарианскую диету по убеждениям — они не хотят чувствовать себя «убийцами».
Почему так важен белок
Почему он важен? Потому что, как уже сказалось выше, при расщеплении белок распадается на аминокислоты, основные действия которых заключаются в следующем:
- формировании мышечной ткани;
- сопровождении окислительно-восстановительных клеточных процессов;
- поддержании здорового вида волос, ногтей, кожи.
Особенно необходим белок детям в период активного роста. Спортсмены или просто те, кто мечтает улучшить фигуру, также нуждаются в достаточном поступлении белка.
Виды белков
Принято разделять белки по аминокислотному составу, по степени их усвояемости, происхождению. О третьей классификации поговорим более подробно. Делятся они на растительные и животные протеины.
Животный белок считается полноценным, потому что содержит все незаменимые аминокислоты, что отличает его от растительного. Но при сочетании разных продуктов — источников растительного протеина, вполне можно «собрать в кучу» все необходимые компоненты.
Но при сочетании разных продуктов — источников растительного протеина, вполне можно «собрать в кучу» все необходимые компоненты.
Растительный белок богат на содержание минералов и витаминов, но калорий он содержит существенно меньше, чем в противоположном органическом соединении. Высокой жирностью обладают только орехи, семечки.
В больших количествах растительные продукты содержат клетчатку, которая оказывает очищающее действие на кишечный тракт. Поэтому растительный белок усваивается организмом всего на 70%, ведь пища просто долго не задерживается в кишечнике. Придется съесть гораздо больше таких продуктов, чтобы восполнить суточную норму белка.
Питание подобной пищей неплохо подходит для худеющих или больных сахарным диабетом. Причиной тому имеет низкий гликемический индекс и малое содержание калорий. Их применение рекомендуется людям, страдающим повышенным давлением и заболеваниями сердечно-сосудистой системы, так как не повышают уровень холестерина в крови.
Противопоказания и вред растительного белка
Геоботаническими продуктами наесться труднее, чем животными, и неограниченное поступление протеинов этого типа может оказать негативное влияние на организм. Кишечные петли перерастягиваются, увеличивается метеоризм. К тому же придется тратить больше времени на коррекцию фигуры.
Кишечные петли перерастягиваются, увеличивается метеоризм. К тому же придется тратить больше времени на коррекцию фигуры.
Ценность растительного белка высока, однако полностью переходить на него не рекомендуется. Подобная диета оказывает негативное влияние на организм. Если снизится уровень гемоглобина в крови, может развиться железодефицитная анемия, мочекаменная болезнь и артрит, ухудшиться самочувствие.
Большинство продуктов с высоким количеством протеинов в составе также имеет высокое количество фитогормонов. На женский организм это может оказать негативное влияние — из-за гормонального сбоя нарушается менструальный цикл.
Существует теория, что мужчины, употребляющие пищу подобного типа для пополнения запаса питательных веществ в организме, приобретают «женские черты». У них могут увеличиться молочные железы, жировая прослойка начнет откладываться по женскому типу — на бедрах. Чтобы получить все необходимые аминокислоты в полном объеме, необходимо научиться правильно сочетать растительные ингредиенты.
Существует и прямая опасность для строгих веганов. Геоботанические продукты не содержат витамина В12 — кобальтсодержащего биологически активного комплекса, состоящего из метилкобаламина, кобамамида, цианокобаламина и гидроксокобаламина. Поэтому в рацион нужно включать хотя бы изредка животные компоненты. Чтобы получить яйца, цельное молоко и кисломолочные продукты, не придется уничтожать животных. А значит, моральные убеждения не пострадают.
Еще один минус растительных протеинов: завтрак или обед, в который входят все полезные вещества, необходимые организму в течение дня, может стоить намного дороже, чем бутерброд с колбасой.
Список продуктов с растительным белком
Сочетая геоботанические продукты различных видов, можно не только восстановить энергетический ресурс, но и скорректировать некоторые проблемы со здоровьем. Белок в растительных продуктах нормализует обменные процессы. Этому помогают дополнительные составляющие.
Соя
На вопрос, какая растительная пища является хорошим источником белка, смело можно ответить — соя.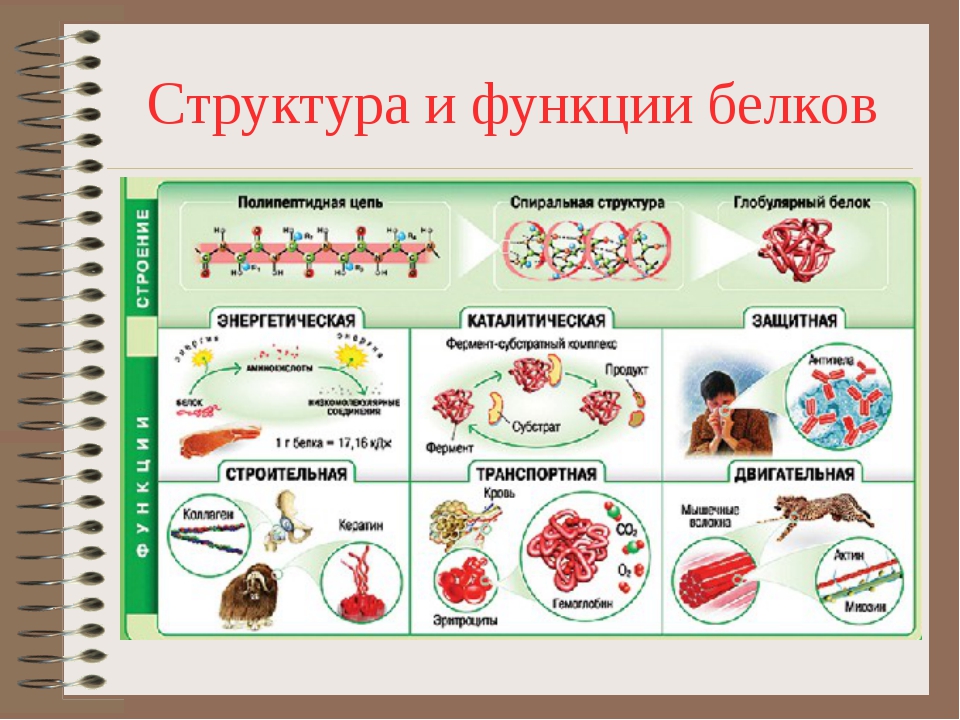 Это растение из семейства Бобовых. Количество белка в сое на 100 г — до 12 г.
Это растение из семейства Бобовых. Количество белка в сое на 100 г — до 12 г.
Несмотря на высокое содержание протеина, нужно учитывать, что его биологическая ценность ниже животного, так как метионина малое количество. А без этой серосодержащей аминокислоты глутатион (антиоксидант, защищающий клетки от повреждений) не вырабатывается. То есть обеспечить нужный уровень антиоксидантной активности трудно.
Зато в сое высокое количество железа, кальция и фитоэстрогена изофлавона, который по структуре напоминает гормон, вырабатываемый женским организмом — эстроген. Поэтому при переходе в менопаузу количество бобовых этого вида в рационе рекомендуется увеличить.
Из сои изготавливают популярные продукты с высоким содержанием белка — тофу, эдемам, темпех. Их едят самостоятельно и добавляют в салаты. В сырах количество белка на 100 г достигает 19 г.
Однако злоупотребление соей опасно. Высокое содержание изофлавонов может спровоцировать онкологические заболевания репродуктивных органов и аутоиммунные заболевания. Употребление полноценного белкового, но неферментированного соевого продукта может нанести вред.
Употребление полноценного белкового, но неферментированного соевого продукта может нанести вред.
Чечевица
Этот продукт также относится к бобовым, используется для приготовления каш, салатов, супов. Количество белка в чечевице на 100 г — 7,5 г. Кроме того, эта порция на 30% пополняет рекомендуемое количество клетчатки. Также в составе зерен высокое количество железа, марганца и фолиевой кислоты.
Пищевые волокна повышают иммунитет, поддерживают жизнедеятельность полезных бактерий в толстом кишечнике, уменьшают вероятность развития рака, сердечно-сосудистых заболеваний, ожирения. А регулярное употребление чечевицы снижает уровень сахара в крови.
Овсянка
Каждый день следует начинать с богатого протеинами завтрака. В этом вам поможет овсянка – идеальный выбор для завтрака или перекуса. Овес является превосходным источником высококачественного протеина, но если вы хотите увеличить его содержание в каше, приготовьте ее на молоке с высоким содержанием белка.
Однако для тех, кто не хочет употреблять молочные продукты, существует идеальное решение – соевое или миндальное молоко. А если вы еще добавите столовую ложку молотого льняного семени или польете кашу вашим любимым фруктовым или ореховым маслом, то вы получите идеальный протеиновый завтрак.
Греческий йогурт
Греческий йогурт – еще один прекрасный продукт для повышения уровня белка. Обычный йогурт фильтруется для устранения сыворотки, и благодаря этому греческий йогурт более густой и имеет характерный вкус. Поскольку он более «концентрированный», в нем содержится больше протеина чем в обычном йогурте(в 150 граммах — 10 грамм).
Такой йогурт будет сытным и здоровым перекусом. Невероятно вкусно добавлять греческий йогурт в смузи или смешивать его с фруктами на завтрак. Вместо ароматизированных, выбирайте простой, так как первые содержат большое количество углеводов и ненужного сахара. Чего же вы ждете? Вперед, в магазин!
Творог
В 100 г содержится 14-16 г протеина.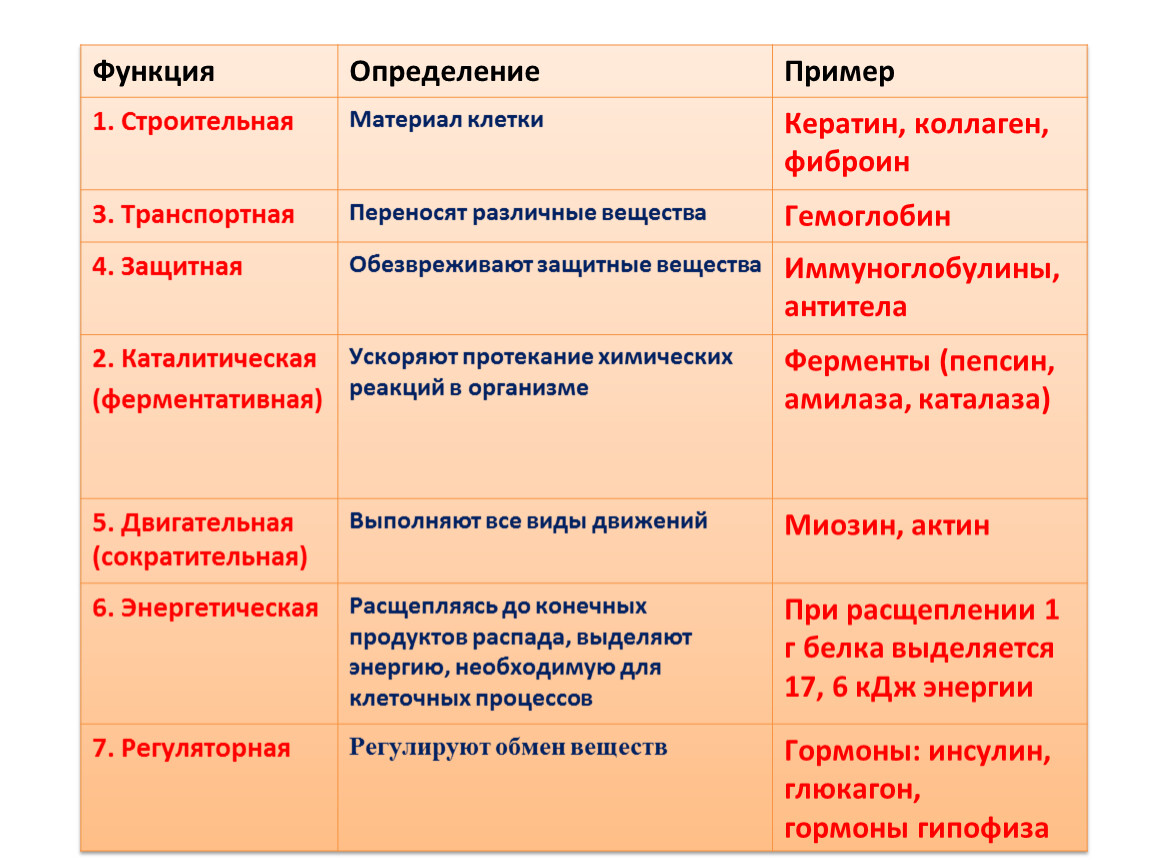 При соблюдении белковой диеты стоит отдать предпочтение обезжиренному творогу.
При соблюдении белковой диеты стоит отдать предпочтение обезжиренному творогу.
Козий сыр
Продукт содержит 22 г белка на 100 г. Также в состав сыра входит комплекс витаминов и микроэлементов, он благоприятствует интенсивному росту мышц благодаря богатому протеинами составу.
Йогурт (греческий, обезжиренный)
На 100 г приходится 10 г белка. Греческий йогурт помогает сжечь жир, увеличить скорость роста мускулатуры. Также продукт содержит пробиотики — бактерии, которые, заселяясь в кишечнике, участвуют в переваривании пищи и формировании иммунитета.
Киноа
Хлебная зерновая культуры киноа, произрастающая на склонах Анд в Южной Америке, не содержит глютена. Киноа – один из немногих растительных продуктов, который является полноценным белком, содержащим все девять незаменимых аминокислот. Известно, что регулярное употребление киноа предотвращает ожирение.
Для вегетарианцев и веганов это отличный источник протеина( в 1 стакане — 8,14 г). Данный злак можно употреблять как кашу на завтрак или смолоть в муку для выпечки. Вы также можете использовать киноа вместо риса в соленых и острых блюдах.
Сыр фета
В 100 г сыра 14 г протеина. Молочный продукт часто используют в качестве ингредиента для салатов.
Сыр (Пармезан)
Пармезан — полноценный источник белка для вегетарианцев. В 100 г продукта содержится 38 г протеинов.
Молоко (сухое/обезжиренное)
В 100 г сухого молока 26 г белка. Используется для похудения, а также набора мышечной массы. Сухое молоко на 80% состоит из казеина, поэтому используется спортсменами в качестве медленного протеина. Также продукт применяют для похудения.
Обезжиренное молоко
Обезжиренное молоко – это продукт с высоким содержанием питательных элементов, в том числе высококачественного белка и всех необходимых аминокислот.
На 1 стакан обезжиренного молока приходится 8 грамм белка.Такое молоко содержит более чем на 40 процентов меньше калорий, чем цельное. Если вы не переносите лактозу, можно пить соевое молоко, ведь протеина в нем содержится столько же сколько и в цельном.
Яйца
Существует огромное множество людей, которые не едят баранину или курицу, но спокойно едят яйца. Такие яйцееды (англ. Eggitarians) называют себя вегетарианцами. Яйца, пожалуй, самый простой и очевидный источник белка. Они содержат все незаменимые аминокислоты, и именно поэтому обеспечивают организм полноценным протеином.
See AlsoНа куриное яйцо среднего размера приходится около 6-7 граммов белка. Причем он содержится не только в белке, но и в желтке. Если вы хотите получить как можно больше пользы, ешьте яйцо целиком. Помимо впечатляющего содержания белка, яйца, как известно, помогают сбросить вес, так как они содержат мало калорий и обладают высоким содержанием питательных веществ.
Зеленый горошек
Белок в 100 г – 5,4 г
7,9 г в чашке
Соотношение калорий – 15 ккал на 1 г
Ростки пшеницы и пшеничные отруби
Белок в 100 г – 23,2 г
26,6 г в чашке
Соотношение калорий – 16 ккал на 1 г
Лимская фасоль (вареная)
Белок в 100 г – 8 г
14,6 г в филе
Соотношение калорий – 16 ккал на 1 г
Тофу
Тофу еще называют соевым творогом. Он является не только важным источником белка, но и содержит огромное количество железа,кальция, магния, меди, цинка и витамина В1. На порцию в 100 грамм приходится 9 грамм протеина. Данный низкокалорийный продукт без глютена помогает поддерживать оптимальный вес. И помните, чем тверже тофу, тем выше в нем содержание белка.
Норма потребления белка
Следует знать, какой объем белков необходим в течение дня. Белок состоит из 20-ти аминокислот. Некоторые из них вырабатываются организмом, но большая их часть поступает исключительно с пищей. Существуют средние нормы потребления протеинов, исходя из возраста и пола.
Таблица 1. Норма потребления протеинов.
| Возраст | Норма потребляемого белка (граммов) |
| 0 – 6 месяцев (на 1 кг веса) | 2,4 на кг |
| 6 – 12 месяцев (на 1 кг веса) | 2,1 на кг |
| 1 – 3 года (на 1 кг веса) | 2,1 – 2,95 на кг |
| 4 – 6 лет | 30 – 35 |
| 7 – 9 лет | 35 – 40 |
| 10 – 12 лет | 45 — 50 |
| 11 – 13 мальчики | 56 |
| 11 – 13 девочки | 51 |
| 14 – 17 мальчики | 60 |
| 14 – 17 девочки | 54 |
| Взрослые мужчины | 120 |
| Взрослые женщины | 90 |
| Беременные | 109 |
| Женщины в период лактации | 120 |
Важно!
Для правильного питания необходимо соблюдать нормы потребления протеинов. Лучший рацион – это тот, который полностью удовлетворяет потребностям организма в белках, жирах и углеводах. Веганам и вегетарианцам, в рационе которых преобладает растительная пища, сложно соблюдать такой рацион в силу жизненной позиции. Вегетарианский образ жизни вынуждает их искать альтернативные способы поддержания нормальной жизнедеятельности и включать в свое меню продукты, содержащие белок в большом количестве.
Белок в питании вегетарианцев и веганов
Вегетарианцы – это люди, отказавшиеся от употребления мяса и рыбы. Веганы – приверженцы более строгого питания. Они отказались не только от мяса и рыбы, но и от молочных продуктов, меда и всех производных животного происхождения. Поэтому им рекомендованы продукты для веганов как источники растительного белка, а также прием специальных заменителей животных белков и регулярное медицинское обследование.
Белки выполняют несколько функций:
- Строительную. Участвует в процессе регенерации клеток.
- Защитную. Помогает иммунной системе производить антитела.
- Транспортную. Участвует в переносе питательных веществ по кровеносным сосудам.
- Регулирующую. Поддерживает оптимальный гормональный фон.
- Энергетическую. Поддерживает физическую активность в течение дня.
- Белок также необходим для создания цепочек ДНК и РНК.
Веганы и вегетарианцы, соблюдая растительную диету, получают намного меньше белка, чем это требует организм. При смене питания проблемы со здоровьем появляются не сразу. Но в дальнейшем на фоне растительной диеты возникает дефицит железа. На это указывают следующие симптомы:
- Излишняя утомляемость. Чувство разбитости при пробуждении.
- Побледнение кожи. Сначала бледнеют веки, затем — остальные кожные покровы.
- Одышка. Возникает из-за низкого уровня гемоглобина в крови.
- Частые головокружения и мигрени.
- Тахикардия. Из-за дефицита железа сердце начинает работать в ускоренном темпе, чтобы лучше снабдить внутренние органы необходимым объемом кислорода и питательных веществ.
- Сухость волос и кожи. При серьезном дефиците железа начинают выпадать волосы.
- Появление язв и отеков в полости рта. В тяжелых случаях развивается анемия.
- Синдром беспокойных ног. Синдром не полностью изучен. Характеризуется болезненными ощущениями и желанием постоянно изменять положение нижних конечностей. Особенно сильно это проявляется ночью.
- Хрупкие ногти. Основная составляющая ногтей — белок кератин. При его дефиците, рост ногтей замедляется, и на их поверхности проявляются белые пятна. Кератин также участвует в обновлении кожных покровов и в росте волос.
- Отечность. В результате дефицита необходимых элементов, мочевыделительная система замедляет свою работу, задерживая жидкость в организме и таким образом провоцируя образование отеков нижних конечностей.
- Снижение веса. Особенно резко сокращается мышечная масса.
Мы перечислили основные симптомы, свидетельствующие о том, что на фоне растительного питания организм страдает от недостатка железа.
Внимание!
Длительный дефицит белка приводит к сбою в работе всех систем организма. Он может вызвать крайнюю степень физического истощения, когда масса тела составляет менее 60% от нормы. При этом в организме происходят необратимые процессы. Возможно развитие квашиоркора — тяжёлой дистрофии из-за недостатка белковых продуктов в пищевом рационе на фоне растительного питания. Кожа становится грубой, появляется отечность во всем теле. Не исключены нарушения психики, когнитивных функций и развитие социопатии.
Таким образом, для предотвращения развития вышеназванных проблем со здоровьем, веганам и вегетарианцам нужно придерживаться в питании богатых белками растительных продуктов.
Другие источники белка
Существуют альтернативные источники белка животного и растительного типа. В растениях содержится веганский белок, поэтому рацион веганов может быть не менее сбалансирован. Где брать белок? Белок для веганов содержится в следующих продуктах:
- Семена Чиа или испанский шалфей. В России эти семена мало популярны. Семена чиа — природный антиоксидант, богатый растительным белком. Также семена чиа – богатый источник кальция, клетчатки и жирных аминокислот. При употреблении в пищу, семена чиа способствуют стабильной работе организма.
- Грибы. Это натуральное «лесное мясо». Это богатый источник протеинов (до 35 граммов на 100 граммов продукта). А еще в них 18 аминокислот, 8 из которых не вырабатываются организмом. Это один из самых богатых растительным белком продуктов.
- Сейтан. Это продукт питания, производимый из пшеничного белка. Благодаря высокому содержанию белка, а также внешним свойствам и текстуре, сейтан — это всемирно известный растительный заменитель мяса.
- Витаминные комплексы и биологически активные добавки (БАД), которые сегодня представлены в широком ассортименте в любой аптеке. Такие препараты разработаны с учетом покрытия суточной нормы употребления необходимых для организма элементов. Уже после первого месяца приема, как правило, улучшается метаболизм и общее самочувствие.
- Микроводоросли. На сегодняшний день существует много биологически активных добавок на основе переработанных водорослей. Водоросли очищены от болезнетворных бактерий, но при этом сохраняют свои полезные свойства. Содержат белки растительного происхождения.
- Микроорганизмы. Продаются компаниями — производителями БАД. В данном случае каждый сам решает, являются ли они частью фауны или же их можно отнести к флоре и с чистой совестью употреблять в пищу.
- Растительное мясо. Это современный продукт, который на российском рынке представлен слабо, но пользуется популярностью в США и в Европе.
- Протеиновые коктейли. Обеспечивают суточную потребность человека в протеине. Продаются в специализированных магазинах.
Итак, мы с вами рассмотрели, чем веганы заменяют белок.
Сегодня растительное питание стремительно набирает популярность. В XXI веке можно найти продукты для вегетарианцев и веганов в качестве альтернативы животным белкам. В магазинах представлен достаточный выбор растительных продуктов по доступным ценам. Если ежедневно готовить новые блюда (даже из одних и тех же продуктов), то растительная диета вряд ли надоест. Более того, вегетарианство и веганство позволят предотвратить развитие ряда опасных заболеваний, риск появления которых с возрастом увеличивается.
аминокислоты БАДы белок белок для вегетарианцев веганство вегетарианская диета вегетарианский образ жизни вегетарианство витамины гемоглобин грибы дефицит белка дефицит железа животные белки здоровое питание здоровый образ жизни здоровый образ питания здоровье источники белка кератин мед отказ от меда микроводоросли микроорганизмы микроэлементы молочные продукты мясо отказ от животных белков отказ от молочных продуктов отказ от мяса отказ от рыбы потребление белка правильное здоровое питание правильное питание продукты с высоким содержанием белка протеиновые коктейли протеины растительная диета растительное мясо растительное питание растительные белки рыба сейтан семена чиа симптомы недостатка железа содержание белка
Источники
- https://doctorbormental.ru/kb/produkty/rastitelnye-belki/
- https://tutknow.ru/meal/11883-v-kakih-produktah-soderzhatsja-rastitelnye-belki.html
- https://FitZdrav.com/pitanie/istochniki-belka-dlya-vegetariantsev.html
- https://cross.expert/zdorovoe-pitanie/produkty-pitaniya/belok-dlya-vegetarianca-i-vegana.html
- https://MinusKilo.com/pitanie/produkty/belok-dlya-vegetariantsev.html
- https://vegatlas.ru/food/belok-dlya-vegetariantsev-chem-zamenit-zhivotnye-belki
[свернуть]
Содержание белка в продуктах таблица
Спортсменам белок важен, прежде всего, для роста мышц. Если в рационе мало протеина, то мечты о красивом, рельефном теле так и останутся мечтами. Поможет узнать содержание белка в продуктах таблица, где указано количество белка на 100 г. В спортивном клубе «Мультиспорт» вы можете получить консультацию по тренировкам и питанию. Также здесь можно записаться на занятия к опытным тренерам, которые помогут вам построить тело, о котором вы давно мечтали.
Функции белка в организме
Белок – один из трех главных макронутриентов, жизненно необходимых человеку. В отличие от двух остальных, жиров и углеводов, белки выполняют строительную функцию в организме, а значит, отвечают за внешний вид человека. Недостаток протеина негативно влияет на здоровье ногтей, волос и кожи, а для мышц он и вовсе губителен. Людям, которые хотят нарастить мышцы, диетологи и тренеры советуют следить за нормой протеина. Подробнее о норме читайте ниже, а пока рассмотрим, за что еще отвечает белок в организме. Основные функции белка:
- Строительная – из белка состоят мембраны всех клеток.
- Каталитическая – благодаря белкам-ферментам возможно пищеварение и другие химические реакции в организме.
- Двигательная – за эту функцию отвечает миозин.
- Транспортная – транспортировка полезных веществ через кровь, этим занимается гемоглобин.
- Защитная – белки-антитела противодействуют вирусам и бактериям.
- Гормональная – белки гормонов отвечают за нормальные функции систем организма, например, инсулин регулирует сахар в крови.
- Пластическая – коллаген и эластин защищают соединительные ткани от разрушения.
- Рецепторная – белки имеют огромное значение в передаче сигналов между клетками.
- Энергетическая – увеличивают продуктивность.
Недостаток белка провоцирует преждевременное старение и появление аутоиммунных заболеваний. Чтобы этого не допустить, человеку необходимо употреблять индивидуальную норму протеина каждый день.
Норма белка для человека
Стандартная норма белка для человека – 0,8-1 г на килограмм тела. Это значит, что девушка массой 52 кг должна употреблять минимум 41 г белка в день, а мужчина весом 85 кг – 68 г белка. Для спортсменов этот показатель должен увеличиться до 1,5 г на 1 кг веса.
А если вы работаете на рост мышц, то необходимо употреблять минимум 2 г белка на 1 кг веса.
Больше всего белка содержится в продуктах питания животного происхождения: мясе, рыбе, твороге, сыре, яйцах. Но есть и растительные продукты, богатые белком: бобы, орехи, зерновые.
Содержание белка в продуктах питания
Посмотрим, сколько белка содержится в растительных и животных продуктах на 100 г веса.
- Сыр «Пармезан» – 35,7 г;
- Тунец – 24,4 г;
- Творог нежирный – 22 г;
- Арахис – 26,3 г;
- Горох сырой лущеный – 23 г;
- Брынза – 22,1 г;
- Фасоль сырая – 21 г;
- Молоко – 2,9 г;
- Скумбрия – 18 г;
- Курица – 18, 2 г;
- Свинина – 14,3 г;
- Говяжья печень – 17,9 г;
- Миндаль – 18,6 г;
- Гречка сырая – 10,8 г;
- Яйцо куриное – 12,7 г.
Меньше всего белка вы найдете в овощах и фруктах, в среднем, 0,5-1 г на 100 г.
Если вас интересует содержание белка в продуктах таблица, то приходите в фитнес-клуб «Мультиспорт». Здесь работают опытные специалисты, которые расскажут вам о построении правильного рациона питания для похудения, рельефа и роста мышц. А если остались вопросы, то звоните или пишите, здесь вам всегда рады!
Поделиться:
Cell Surface Receptor Identification Using Genome-Scale CRISPR/Cas9 Genetic Screens
Секвенирование данных с двух репрезентативных экранов нокаута генома для идентификации связывающего партнера человека TNFSF9 и P. falciparum RH5, выполненных в NCI-SNU-1 и HEK293, соответственно, предоставляются(Дополнительная таблица 1). На связывающее поведение RH5 повлияли как гепарановый сульфат, так и его известный рецептор BSG24(Рисунок 3C),в то время как TNFRSF9 специально связан со своим известным рецептором TNFSF9 и не терял привязки при преинкубации растворимым гепарином. Белок 3 на рисунке 3B представляет TNFRSF9.
Для обеих клеточных линий, распределение GRNAs в библиотеке контрольных мутантов после 3 дней (9, 14, и 16 дней посттрансдукции) также предусмотрены(Дополнительная таблица 1). Распределение gRNA показало, что сложность библиотеки сохранялась на протяжении всего эксперимента(рисунок 5А). Генетический экран для идентификации лиганда для TNFSF9 был выполнен на день 14 posttransduction, тогда как то для RH5 было выполнено день 9 posttransduction. Техническое качество экранов было оценено путем изучения распределения наблюдаемых складных изменений гРНК, нацеленных на справочный набор несущественных генов по сравнению с распределением для эталонного набора основных генов22(рисунок 5B). Кроме того, обогащение на уровне путей также показало, что ожидаемые основные пути были выявлены и значительно обогащены в популяции «выпадения» при сравнении контрольной выборки с оригинальной плазмидной библиотекой. Пример с образцом дня 14 NCI-SNU-1 изображен на рисунке 5C.
Распределение gRNA в контрольной и отсортированной популяции с использованием -тестовой функции MAGeCK (см. Дополнительную таблицу 1 для вывода сводковых генов от MAGeCK) использовалось для идентификации рецептора из фенотипических экранов. Измененная оценка RRA, зарегистрированная MAGeCK в анализе уровня генов, построена на основе генов, ранжированных по значениям p. Оценка RRA в MAGeCK обеспечивает меру, в которой gRNAs ранжируются стабильно выше, чем ожидалось. На экране для TNFRSF9, топ хит был TNFSF9, который является известным связующим партнером TNFRSF9 (Рисунок 5D). Кроме того, был также выявлен ряд генов, связанных с пути TP53. В случае RH5, в дополнение к известным рецептором (BSG) и ген, необходимый для производства сульфатных GAGs(SLC35B2), дополнительный ген (SLC16A1) также был определен(Рисунок 5E). SLC16A1 является сопровождающим, необходимым для торговли BSG на поверхность ячеек25. Вместе эти результаты демонстрируют способность экрана идентифицировать непосредственно взаимодействующие рецепторы и клеточные компоненты, необходимые для того, чтобы этот рецептор выражался на поверхности клеток в функциональной форме.
Рисунок 1: Обзор генетического подхода к скринингу для выявления рецепторов поверхности клеток. Этот анализ состоит из трех основных шагов: Во-первых, рекомбинантные белки, представляющие эктодоин рецепторов поверхности клеток, выражены в клеточной линии, которая может добавить структурно критические постпереводные изменения, такие как клетки HEK293. Мономерный белок эктодоменов олигомеризированы путем спряжения стрептавидин-PE, чтобы увеличить их связывания алчность. Во-вторых, эти алчный зонды используются в клеточной связывания анализы, где яркие окрашивания на клеточных линий, указанные видные сдвиг в PE флуоресценции (зеленый) по сравнению с отрицательным протеином контроля (в черном) демонстрирует наличие клеточной поверхности связывающего партнера. В-третьих, выбираются рецепторно-положительные клеточные линии Cas9 и проводится скрининг генома с использованием гРНК, ориентированных на подавляющее большинство генов, кодирующих белок. При генерации библиотек мутантов, обычно используется 30% эффективности трансдукции, которая основана на вероятности распределения Пуассона, которая гарантирует, что каждая клетка получает один gRNA таким образом, что результирующий фенотип приписывается конкретному нокауту. Маркер BFP, выраженный трансиндуцированными клетками, используется для выбора клеток, содержащих ГРНК с помощью FACS. Фенотипические экраны выполняются между 9-16 дней посттрансдукции. В день экрана общая популяция клеток мутантов делится на две части. Одна половина хранится в качестве контрольной популяции, а другая половина отбирается для рекомбинантного связывания белка. Клетки из библиотеки мутантов, которые больше не в состоянии связать рекомбинантный белок, сортируются с помощью FACS, и обогащение gRNA в отсортированной и контрольной популяции используется для определения генов, необходимых для связывания поверхности клетки помеченного алчного зонда. Указаны шаги в протоколе, которые требуют значительного времени. Эта цифра была изменена из Шарма и др.19. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Рисунок 2: Установление соотношений биотинилапопрома белка к стрептавидину-PE с помощью метода на основе ELISA. Пример стратегии спряжения стрептавидина-ПЭ, используемой для генерации алчный зонд из биотинилапотного мономерного белка. Против фиксированной концентрации стрептавидина была инкубирована серия разбавления биотинители. Минимальное разбавление, при котором не может быть обнаружено избыток биотинители, было определено ELISA. ELISA была выполнена с или без preincubating диапазон разбавления белка с 10 нг стрептавидин-PE. При наличии стрептавидина-PE, минимальное разбавление, при котором не было выявлено сигнала (кружевной черный) и количество белка, необходимого для насыщения, было рассчитано на генерацию 10-x запасного раствора с 4 мкг/мл стрептавидина-PE. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Рисунок 3: Представительная привязка белков к клеточным линиям. (A) Протеина связывания клеточных линий было четкое увеличение клеточной флуоресценции по сравнению с контрольным образцом. Тепловая обработка (80 градусов по Цельсию в течение 10 мин) рекомбинантного белка отменяла все переплеты обратно к отрицательному контролю, демонстрируя, что связывающее поведение зависит от правильно сложенного белка. (B) Различные классы поведения связывания белка к поверхностям клетки; зависимость от ГАГ. Слева направо, белки могут быть классифицированы на три типа: Белок типа 1 только адсорбы в HS. Эти белки теряют свои связывания после преинкубации с концентрацией гепарина более 0,2 мг/мл. Белок типа 2 связывается с ГС в дополнение к конкретному рецептору. Эти белки теряют частичную связывание в предблокирующих экспериментах. Белок типа 3 не связывает HS. Эти белки не теряют связывания по сравнению с родительскими линиями. (C) Пример белка (т.е., RH5), который связывается с ГС и специфическим рецептором в аддитивной манере. Ориентация либо на рецептор (т.е. BSG) или ферменты, необходимые для синтеза СГ (например, SLC35B2, EXTL3) лишь частично снижает связывание RH5 с клетками относительно контроля. Трансиндуцированные поликлональные линии могут быть использованы в таких экспериментах для установления связывающего поведения. Эта цифра была изменена из Шарма и др.19. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Рисунок 4: Выбор клональных клеточных линий с высокой активностью Cas9. Эффективность редактирования генома как поликлональных, так и клонированных линий клеточных линий NCI-SNU-1 оценивалась с помощью системы репортеров GFP-BFP, в которой клеточные линии переводились вирусами с помощью плазмидного плазмида, нацелившегося на гфальтари или без (т.е. «пустой»). Изображена схема. Цитометрия потока использовалась для проверки экспрессии BFP и GFP после трансдукции и сравнивалась с неинфицированным контролем. Выражение GFP использовалось в качестве прокси для деятельности Cas9, в то время как выражение BFP с пометкой трансиндуцированных ячеек. Профиль для неинфицированных и пустых инфицированных клеток выглядел одинаково для всех клонов. Профили представителей изображены на левой панели. Все пять клонов клеточной линии NCI-SNU-1 показали более высокую потерю GFP по сравнению с поликлональной линией (правая панель), при этом клон 4 показывает самую высокую эффективность с самой низкой огнеупорной популяцией. Эта цифра была изменена из Шарма и др.19. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Рисунок 5: Представитель результаты генетических экранов для идентификации клеточной поверхности связывания партнеров. (A) Совокупные участки функции распределения сравнения изобилия gRNA в плазмидной библиотеке к библиотекам мутантов HEK-293-E и NCI-SNU-1 на 9, 14 и 16 дней посттрансдукции. Для любого данного числа функция кумулятивной плотности сообщает процент точек данных, которые были ниже этого порога. Небольшой сдвиг популяции мутантных клеток по сравнению с первоначальной популяцией плазмидных представляет собой истощение в подмножестве гРНК по сравнению с плазмидной библиотекой. (B) Распределение изменений в журнале, которые ранее были классифицированы как существенные (красные) или несущественные (черные) в HEK293 и NCI-SNU-1 клеточных линий. Распределение складных изменений для несущественных генов сосредоточено на 0, в то время как для основных генов сместился влево в сторону отрицательных изменений складок. (C) Значительно обогащенные пути в генах истощены в NCI-SNU-1 мутант контроля населения 14 дней послетрансдукции. Были выявлены известные клеточные пути. (D) Robust Rank Algorithm (RRA) — оценка для генов, которые были обогащены в отсортированных клетках, которые потеряли способность связывать зонд TNFRSF9. Гены были ранжированы в соответствии с RRA-счет. Известный партнер по взаимодействию TNFSF9 и гены, связанные с пути TP53 (помечены красным цветом) были определены на экране. (E) Rank-ordered RRA-оценки для генов, идентифицированных из анализа обогащения gRNA, необходимых для связывания RH5 к клеткам HEK293 (левая панель). SLC35B2 и SLC16A1 были выявлены в пределах порога ложного обнаружения (FDR) в 5%. Два дополнительных гена в пути биосинтеза HS (т.е., EXTL3 и NDST1)были определены в пределах ФДР 25%. Схематическая изображение общего пути биосинтеза GAG с соответствующими генами, отображаемыми на соответствующие шаги (панель 2). Гены, необходимые для принятия обязательств по биогене зуфору хондроитин (т.е. CSGALNACT1/2)не были идентифицированы на экране. Эта цифра была изменена из Шарма и др.19. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
| Плазмида имя | Плазмидные # | Использовать |
| Конструкция экспрессии протеина: CD200RCD4d3’4-био-linker-его | Адген: 36153 | Производство рекомбинантного белка с CD4d3’4, биотином и 6-его тегами. |
| pMD2.G | Адген: 12259 | Конверт VSV-G, выражающий плазмид; производство лентивирусной |
| psPAX2 | Аддген: 12260 | Лентивирусная упаковка плазмида, производство лентивирусного |
| Cas9-конструкция: pKLV2-EF1a-Cas9Bsd-W | Аддген: 68343 | Производство составно выражающей линии Cas9 |
| конструкция выражения gRNA: pKLV2-U6gRNA5 (BbsI)-PGKpuro2ABFP-W | Добавление: 67974 | Вектор экспрессии CRISPR gRNA с улучшенными эшафотами и маркерами puro/BFP |
| Улучшенная геномная библиотека Knockout CRISPR | Аддген: 67989 | Библиотека gRNA против 18 010 человеческих генов, предназначенных для использования в лентивирусе. |
| Конструкция GFP-BFP: pKLV2-U6gRNA5 (gGFP)-PGKBFP2AGFP-W | Аддген: 67980 | Cas9 деятельности репортера с BFP и GFP. |
| Пустая конструкция: pKLV2-U6gRNA5 (пустой)-PGKBFP2AGFP-W | Адген: 67979 | Cas9 деятельности репортера (контроль) с BFP и GFP. |
Таблица 1: Плазмиды, используемые в этом подходе.
| Имя буфера | Компоненты |
| HBS (10X) | 1.5 M NaCl и 200 мМ HEPES в воде Милич, приспособите к рН 7.4 |
| PBS (10X) | 80 г NaCl, 2 г KCl, 14,4 г Na2HPO4 и 2,4 г KH2PO4 в воде Мили, приспосабливайте к рН 7,4 |
| Фосфатный буфер натрия (80м) | 7.1 g Na2HPO4.2H2O, 5.55 g2PO4,отрегулировать к pH 7.4 |
| Его очистка связывающий буфер | 20 мМ фосфатный буфер натрия, 0,5 М NaCl и 20 мМ Имидазол, приспосабливаться к рН 7,4 |
| Буфер его очищения elution | 20 мМ фосфатный буфер натрия, 0.5M NaCl и 400 mM Имидазол, приспосабливайте к pH 7.4 |
| Дитаноламин буфер | 10% дизтанноламина и 0,5 мМ MgCl2 в воде Мили, приспосабливайся к рН 9.2: |
| D10 | DMEM, 1% пенициллин-стрептомицин (100 единиц/мл) и 10% теплоинактивированный FBS |
Таблица 2: Буферы, необходимые для этого исследования.
| Компоненты | 10-сантиметровое блюдо | 6-хорошая тарелка |
| 293FT-клетки | 70-80% слияние | 70-80% слияние |
| Трансфектии совместимые носители (Opti-MEM) (Шаг 5.1.2) | 3 мл | 500 л |
| Трансфектии совместимые носители (Opti-MEM) (Шаг 5.1.4) | 5 мл | 2 мл |
| Вектором передачи лентивир | 3 мкг | 0,5 мкг |
| psPax2 (см. таблицу 1) | 7,4 мкг | 1,2 мкг |
| pMD2.G (см. таблицу 1) | 1,6 мкг | 0,25 мкг |
| Plus реагент | 12 зл | 2 л |
| Липофектамин LTX | 36 зл | 6 зл |
| D10 (Шаг 7.1.7) | 5 мл | 1,5 мл |
| D10 (Шаг 7.1.8 и 7.1.10) | 8 мл | 2 мл |
Таблица 3: Объемы и объемы реагентов для лентивирусной упаковки.
Таблица 4: Праймер последовательности для усиления gRNA и NGS. Пожалуйста, нажмите здесь, чтобы просмотреть этот файл (Право нажмите, чтобы скачать).
| Реагента | Объем на одну реакцию | Мастер-микс (x38) |
| No 5 Горячий старт высокой верности 2x | 25 зл. | 950 л |
| Смесь праймер (L1/U1) (по 10 км) | 1 зл | 38 зл |
| Геномная ДНК (1 мг/мл) | 2 л | 72 Зл |
| H2O | 22 зл. | 1100 л |
| Общая | 50 зл | 1900 г. Л. |
Таблица 5: ПЦР для усиления ГРНК из образцов высокой сложности.
| Номер цикла | Денатурная | Отжига | Расширение |
| 1 | 98 кв.с. | ||
| 2-24 | 98 кв.с. | 61 КК, 15с | 72 КК, 20s |
| 25 | 72 КК, 2 мин |
Таблица 6: Условия ПЦР для первого ПЦР.
| Реагента | Объем на одну реакцию |
| KAPA HiFi HotStart ReadyMix | 25 зл. |
| Смесь primer (PE1.0/index primer) (по 5 мкм каждый) | 2 л |
| Первый продукт ПЦР (40 пг/л) | 5 зл |
| H2O | 18 зл |
| Общая | 50 зл |
Таблица 7: ПЦР для индексирования sgRNA с генетических экранов.
| Номер цикла | Денатурная | Отжига | Расширение |
| 1 | 98 кв.с. | ||
| 2-15 | 98 кв.с. | 66 кв.м, 15с | 72 КК, 20s |
| 16 | 72 КК, 5 мин |
Таблица 8: Условия ПЦР для второго ПЦР.
Дополнительная диаграмма S1: Руководство по рисованию ворот для сортировки неимеющей обязательной популяции. (A) Идеальный кандидат белка для скрининга должны иметь четкий сдвиг связывающей популяции по сравнению с контрольной популяции и связывание должно быть сохранено на клетках, не имеющих механизмов для биосинтеза HS. Эксперимент по блокированию гепарина может быть использован вместо тестирования на целевых клеточных линиях SLC35B2. (B) Клетки, не имеющие поверхности окрашивания из белка эктодона, но выражая BFP флуоресценции от лентивирусной трансдукции были собраны. Клетки отображаются с экрана для идентификации рецептора для GABBR222. Эта цифра была изменена из Шарма и др.19. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Дополнительная диаграмма S2: Клеточный поверхности гликопротеина транскриптомики на основе PCA участок с использованием РНК-сек данных из более чем 1000 раковых клеток линий. Сотовые линии из Cell Model Passport27 были сгруппированы с использованием K-средств кластеризации в соответствии с значениями FPKM 1500 клеточных гликопротеинов поверхности. Помечены представительные клеточные линии из каждого кластера. Кластер 5 полностью состоял из клеточных линий гематопоиетического происхождения (также см. Дополнительную таблицу 2). Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Дополнительная цифра S3: Essentiality оценки для KEGG-аннотации белка экспорта и N-связанных гликозиловых генов из результатов проекта. Скорректированные баллы Байеса-существенности для линий клеток в 330 фунтов (столбцы, не помечены) построены для генов экспорта белков и N-связанных гликозилата пути (X-оси). Результаты выше 0 представляют собой значительное истощение популяции мутантов по сравнению с оригинальной плазмидной библиотекой. Гены могут быть разделены на три различных кластера, которые представляют различные уровни существенности в клеточных линиях. Эта кластеризация может быть использована для решения дня сортировки. Если экран выполняется в конце времени (день 16), вполне возможно, что гены, которые, как известно, имеют важное значение для клеток (кластеры 1 и 3) не будут определены. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
Дополнительная таблица 1: Сырье кол-files для и MAGeCK программного обеспечения, генерируемого gene_summary файлов, связанных с репрезентативными генетическими экранами. Пожалуйста, нажмите здесь, чтобы просмотреть этот файл (Право нажмите, чтобы скачать).
Дополнительная таблица 2: Кластеризация клеточных линий в зависимости от выражения рецепторов поверхности клетки. Пожалуйста, нажмите здесь, чтобы просмотреть этот файл (Право нажмите, чтобы скачать).
Структурная функция белка | Протокол
4.15: Структурная функция белка
Структурные белки — это категория белков, отвечающих за различные функции, от формы и движения клеток до поддержки основных структур, таких как кости, хрящи, волосы и мышцы. В эту группу входят такие белки, как коллаген, актин, миозин и кератин.
Коллаген, самый распространенный белок у млекопитающих, содержится во всем теле.В соединительной ткани, такой как кожа, связки и сухожилия, он обеспечивает прочность на разрыв и эластичность. В костях и зубах он минерализуется с образованием твердых тканей и способствует их несущей способности. Помимо структурной поддержки, коллаген также может взаимодействовать с рецепторами клеточной поверхности и другими промежуточными молекулами для регулирования клеточных процессов, таких как рост и миграция, которые включают изменения формы клеток и тканей.
Структурные белки составляют основу цитоскелета клетки.Цитоскелет состоит из трех типов нитей, микрофиламентов, промежуточных нитей и микротрубочек, каждый из которых состоит из различных структурных белков. Микрофиламент образуется, когда актин самополимеризуется в длинные повторяющиеся структуры. Эти актиновые филаменты вносят вклад в форму и организацию клеток; Кроме того, микрофиламенты также могут способствовать перемещению и делению клеток, когда они действуют вместе с миозином. Состав промежуточных волокон варьируется в зависимости от типа клетки.Существует около 70 различных генов, кодирующих различные промежуточные филаменты. Промежуточные филаменты в эпителиальных клетках содержат кератин, периферические нейроны содержат периферин, а саркомеры в мышечных клетках содержат десмин. Основная структурная функция этих нитей — укреплять клетки и организовывать их в ткани. Микротрубочки состоят из структурных белков, называемых тубулинами. Тубулины самоорганизуются с образованием микротрубочек, которые способствуют организации цитоплазмы, включая расположение органелл.Микротрубочки также необходимы для митоза и деления клеток.
Поскольку структурные белки широко распространены, мутация в гене, кодирующем любой из этих белков, может иметь серьезные пагубные последствия. Например, мутация в гене, кодирующем коллаген, может привести к состоянию, известному как несовершенный остеогенез, которое характеризуется слабостью костей и деформациями соединительных тканей. Различные мутации в гене коллагена могут привести к синдрому Альпорта, который характеризуется проблемами в таких органах, как почки, глаза и уши.
Рекомендуемая литература
- Лодиш, Х., Берк, А., Зипурски, С. Л., Мацудаира, П., Балтимор, Д., и Дарнелл, Дж. (2000). Молекулярная клеточная биология 4-е издание. Национальный центр биотехнологической информации, книжная полка .
- Рикар-Блюм, С. (2011). Семейство коллагена. Колд-Спринг-Харбор: биологические перспективы , 3 (1), a004978.
- Домингес, Р., и Холмс, К.С. (2011). Структура и функции актина. Годовой обзор биофизики , 40 , 169-186.
- Даунинг, К. Х., & Ногалес, Э. (1998). Строение тубулина и микротрубочек. Текущее мнение в области клеточной биологии , 10 (1), 16-22.
- Гейслер Ф. и Лейбе Р. Э. (2016). Эпителиальные промежуточные нити: защитники от микробной инфекции ?. Ячейки , 5 (3), 29. doi: 10.3390 / Cell5030029
PROFESS: база данных функций, развития, структуры и последовательности PROtein | База данных
Абстрактные
Распространение биологических баз данных и легкий доступ к ним через Интернет оказывают благотворное влияние на биологические науки и трансформируют методы проведения исследований.В Интернете разбросано около 1100 баз данных по молекулярной биологии. Чтобы помочь в функциональном, структурном и эволюционном анализе большого количества новых белков, постоянно идентифицируемых в результате полногеномного секвенирования, мы вводим базу данных PROFESS (PROtein Function, Evolution, Structure and Sequence). Наша база данных разработана так, чтобы быть универсальной и расширяемой, и она не будет ограничивать анализ уже существующим набором взаимосвязей данных. Фундаментальным компонентом этого подхода является разработка интуитивно понятной системы запросов, которая включает в себя множество функций подобия, способных генерировать отношения данных, не заданные во время создания базы данных.Полезность PROFESS демонстрируется анализом структурного дрейфа гомологичных белков и идентификацией потенциальных терапевтических мишеней рака поджелудочной железы на основе наблюдения сетей белок-белкового взаимодействия.
URL базы данных: http://cse.unl.edu/∼profess/
Введение
Существует около 1100 баз данных по молекулярной биологии в открытом доступе в Интернете (1,2). Эти базы данных составляют объем наших знаний, связанных с геномикой, протеомикой, метаболомикой и структурной геномикой.Большинство из них служат хранилищами данных с простыми интерфейсами для поиска данных (3). Для решения более сложных вопросов биологам обычно требуется разрабатывать новые базы данных путем фильтрации информации из существующих баз данных (4). Несмотря на то, что это крайне неэффективно, растет число специализированных баз данных, разработанных для отдельных тем. К сожалению, это просто усиливает основную проблему: неспособность использовать данные вне ограничений, налагаемых разработчиками базы данных (5).Использование потенциала биологической информации требует разработки базы данных нового поколения, которая позволит биологам исследовать биологические данные по-новому. Ключом к решению этой проблемы является смещение фокуса дизайна со структуры базы данных (предопределенные отношения между полями) на жидкую ассоциацию, которая может быть адаптирована к вопросам биолога (6) без перепроектирования базовой структуры данных. Однако существуют препятствия для связывания отдельных баз данных из-за разных форматов и структуры данных (7, 8).Таким образом, для этих усилий было важно реализовать новый подход к интеграции различных биологических баз данных (9).
Большая часть работы по интеграции баз данных сосредоточена на бизнес-данных и пространственно-временных данных (10, 11). Удовлетворительные, общие и практические решения оказались труднодостижимыми для этих сложных источников данных, которые на самом деле просты по сравнению с биологическими данными. Тем не менее, наиболее универсальным решением является использование отдельного адаптера или «оболочки» (рис. 1) для каждой исходной базы данных (12).«Оболочки» обеспечивают упрощенное «представление» исходной базы данных, представленное в форме, более простой в использовании, чем исходная исходная база данных. Фактически, некоторые части исходных данных могут быть полностью опущены в этой переупакованной презентации, оставив только те части данных, которые необходимы предприятию, которое хочет их использовать. Преимущество подхода «ответы на запросы с использованием представлений» к проблеме интеграции базы данных состоит в том, что он сводит проблему интеграции к двум этапам: (i) создание оболочек исходных баз данных, тем самым обеспечивая простые «представления», и (ii) применение стандартных запросы к базе данных по представлениям.Таким образом, реализация оболочек позволяет создать надежную систему запросов, которая включает в себя множество функций подобия, способных генерировать взаимосвязи данных, не задуманные во время создания базы данных. Это позволит пользователю выйти за рамки простых текстовых запросов. Таким образом, база данных PROFESS (PROtein Function, Evolution, Structure and Sequence) использует обертки для помощи в структурном, функциональном и эволюционном анализе большого количества новых белков, постоянно идентифицируемых в результате полногеномного секвенирования.
Рисунок 1.
Два решения проблемы интеграции данных. (A) Программное обеспечение ETL извлекает, преобразует и загружает источники данных в хранилище. ( B ) Более гибкий метод local-as-view определяет виртуальную базу данных, которая взаимодействует с источниками данных через оболочки, которые обеспечивают упрощенное представление исходных баз данных.
Рисунок 1.
Два решения проблемы интеграции данных. (A) Программное обеспечение ETL извлекает, преобразует и загружает источники данных в хранилище.( B ) Более гибкий метод local-as-view определяет виртуальную базу данных, которая взаимодействует с источниками данных через оболочки, которые обеспечивают упрощенное представление исходных баз данных.
Содержание базы данных
Четырнадцать источников данных были интегрированы для создания PROFESS (таблица 1) с использованием модульного подхода local-as-view (LAV) (рисунок 1B) (подробности см. В разделе «Метод интеграции данных»). Модульная функциональность PROFESS в сочетании с удобными для пользователя возможностями поиска делает PROFESS особенно полезным для задания ряда вопросов о последовательности, структуре и функциональных отношениях эволюционных и функционально связанных белков.Пользователь взаимодействует с PROFESS через веб-интерфейс, используя язык запросов функционального стиля, который переведен на язык запросов структуры (SQL) для интеллектуального анализа данных PROFESS (рисунок 2A). Ядро PROFESS установило взаимосвязь между Protein Data Bank (PDB) (13) и базами данных eggNOG (14, 15) (Рисунок 2B). Связь между eggNOG и PDB была установлена с использованием регистрационных номеров белков UniProt и службы UniProt Mapping (16).
Рисунок 2.
Схема базы данных ПРОФЕСС. ( A ) Связь пользовательского интерфейса с системой функциональных запросов (зеленый) с базами данных PROFESS; и ( B ) основные базы данных, интегрированные в PROFESS. Центральная связь eggNOG-PDB показана красным цветом, двойные стрелки указывают на интенсивное взаимодействие, синие прямоугольники представляют базы данных, доступные в Интернете, а фиолетовые прямоугольники обозначают другие базы данных, которые будут интегрированы в будущем. Каждый дополнительный набор данных взаимодействует с ядром PROFESS посредством использования программ-оболочек, чтобы сделать язык запросов единообразным.
Рисунок 2.
Структура базы данных PROFESS. ( A ) Связь пользовательского интерфейса с системой функциональных запросов (зеленый) с базами данных PROFESS; и ( B ) основные базы данных, интегрированные в PROFESS. Центральная связь eggNOG-PDB показана красным цветом, двойные стрелки указывают на интенсивное взаимодействие, синие прямоугольники представляют базы данных, доступные в Интернете, а фиолетовые прямоугольники обозначают другие базы данных, которые будут интегрированы в будущем. Каждый дополнительный набор данных взаимодействует с ядром PROFESS посредством использования программ-оболочек, чтобы сделать язык запросов единообразным.
Таблица 1.базовых баз данных, которые в настоящее время интегрированы в PROFESS
Таблица 1.базовых баз данных, которые в настоящее время интегрированы в PROFESS
Для упрощения интерфейса каждое семейство ортологичных белков имеет четыре вкладки, содержащие информацию о: функции, эволюции, структуре и последовательности. Дополнительная вкладка, болезни, показывает связи между человеческими белками и информацией, взятой из баз данных, посвященных функциональной геномике и протеомике конкретных заболеваний.Каждый белок аннотируется его исходным организмом с использованием базы данных таксономии UniProtKB (16). Каждый уровень базы данных PROFESS собирает информацию из всех интегрированных баз данных и предоставляет пользователю исчерпывающие таблицы с аннотациями (рисунок 3). Таблицы определены как независимые модули, каждый из которых обеспечивает уникальное представление интегрированных данных. Каждый модуль можно активировать или деактивировать в зависимости от конкретных потребностей пользователя. PROFESS не ограничен размером или типом данных, которые могут быть включены из-за подхода LAV в сочетании с модульным интерфейсом.Это позволяет интегрировать биологические данные для быстрой идентификации биологически значимых сходств или различий между различными функциями белков.
Рисунок 3.
Скриншот страницы результатов для prNOG04586. Краткое описание кластера отображается (вверху) вместе со статистикой. Подробные данные показаны для каждого уровня (функция, эволюция, структура, последовательность и болезнь). На каждом уровне данные дополнительно группируются в разные модули, каждый из которых обеспечивает уникальное представление данных.Каждый модуль может быть активирован или деактивирован в зависимости от потребностей пользователя. На снимке экрана показан модуль, суммирующий функциональные аннотации белков в prNOG04586. Данные берутся из классификации ферментов, базы данных семейств белков и онтологии генов. Для каждой базы данных PROFESS показывает записи, относящиеся к белкам в кластере prNOG04586. Круговые диаграммы представляют относительную частоту каждой записи в базе данных в ортологическом кластере.
Рисунок 3.
Скриншот страницы результатов для prNOG04586.Краткое описание кластера отображается (вверху) вместе со статистикой. Подробные данные показаны для каждого уровня (функция, эволюция, структура, последовательность и болезнь). На каждом уровне данные дополнительно группируются в разные модули, каждый из которых обеспечивает уникальное представление данных. Каждый модуль может быть активирован или деактивирован в зависимости от потребностей пользователя. На снимке экрана показан модуль, суммирующий функциональные аннотации белков в prNOG04586. Данные берутся из классификации ферментов, базы данных семейств белков и онтологии генов.Для каждой базы данных PROFESS показывает записи, относящиеся к белкам в кластере prNOG04586. Круговые диаграммы представляют относительную частоту каждой записи в базе данных в ортологическом кластере.
Функция
Вкладка «Функция» программы PROFESS обобщает биологическую функцию ортологичного кластера. Для трех основных описаний функции белков вычисляется количество белков в каждом классе (в текущем ортологическом кластере), а распределения представлены в виде круговых диаграмм.Это позволяет пользователю быстро отличать соответствующие классы от выбросов. Классы сортируются по убыванию количества белков. Чем темнее цвет на круговой диаграмме, тем больше белков. В качестве примера поиска «коллагеназы» были получены 34 различных ортологичных группы, одна группа (prNOG04586) показана на рисунке 3.
Вкладка «Функция» также содержит три уникальных субмодуля, которые описывают основную биологическую функцию кластера ортологов. Первый модуль, Functions , представляет собой таблицу функциональных аннотаций для структуры белка, взятой из PDB, включая семейства белков (PFAM) (17), онтологию генов (GO) (18) и номер комиссии по ферментам (EC). (19).Пользователю предоставляется возможность изучить комбинацию аннотаций, чтобы оценить ее общую согласованность и выявить возможные неправильные аннотации. Функцию белка также можно описать с помощью партнеров по взаимодействию с белками, поэтому два дополнительных модуля (лиганды , и взаимодействия с белками, ) перечисляют лиганды и белки, которые, как экспериментально показано, взаимодействуют с членами семейства eggNOG. Модуль Ligands отображает подробную информацию о лигандах, которые, как известно, связывают белок, на основе связанных с лигандом структур в PDB, а также перекрестные ссылки на Киотскую энциклопедию генов и геномов (KEGG) (20).Общие буферы, детергенты, ионы и растворители перечислены отдельно, чтобы обеспечить быстрый доступ к биологически значимым данным. Модуль взаимодействия белков перечисляет взаимодействия белков, обнаруженные в Escherichia coli (21). Взаимодействия коррелировали с соответствующим идентификатором PDB путем сопоставления генов приманки и жертвы с их репрезентативным кластером eggNOG. Модуль взаимодействия белков также объединяет 69 171 вручную курируемое взаимодействие белок / белок (по состоянию на апрель 2010 г.) у 274 организмов из базы данных взаимодействующих белков (22).
Evolution
Вкладка «Эволюция» в PROFESS отображает таблицу основных генов, а также филогенетические деревья на основе последовательностей и структур. Дерево последовательностей показывает некорневое филогенетическое дерево, созданное из файлов дерева, загруженных из базы данных eggNOG (14, 15). Окончательное изображение было создано с помощью DrawTree из пакета Phylip (23, 24). Деревья последовательностей содержат множество ветвей и узлов и обеспечивают обзор общей кустистой природы кластера, более подробное дерево можно найти, выполнив поиск в конкретном кластере с использованием базы данных eggNOG (14, 15).
Структурное дерево показывает некорневое филогенетическое дерево, созданное с использованием белковых структур PDB. Структуры были выровнены с помощью MAMMOTH-mult (25), а выравнивание последовательностей на основе структуры было использовано для вычисления деревьев и изображения. Длины ветвей для каждого выравнивания структуры из MAMMOTH-mult (25) были измерены нашим собственным программным обеспечением и минимизированы с помощью программы объединения соседей, реализованной в Phylip (24). Окончательное изображение было сгенерировано таким же образом, как дерево последовательностей .
Модуль существенных генов уровня эволюции показывает, является ли белок в ортологическом кластере существенным, и был получен из базы данных эссенциальных генов (DEG) (26). Начиная с версии 5.4, DEG включает 5260 основных прокариотических генов и 5040 эукариотических генов, извлеченных из литературы. Гены отображаются с соответствующими белковыми структурами из PDB (см. Модуль «Сходства последовательностей» для получения более подробной информации об ассоциативном гене / структуре). Как и все базы данных, DEG не следует рассматривать как исчерпывающий или полный список всех основных генов, а только как незавершенную работу.Например, общепринятые и очевидно важные гены не могут быть включены в DEG, потому что он сосредоточен на современной литературе. Поскольку PROFESS постоянно обновляется и расширяется, список классифицированных основных генов будет продолжать расширяться по мере проведения новых исследований и по мере того, как DEG все глубже проникает в старую литературу.
Структура
Вкладка структуры PROFESS содержит все структуры, связанные с кластером eggNOG, и связаны между собой их номерами доступа Uniprot.Следовательно, доступность структуры в PROFESS ограничена уже существующей связью Uniprot-eggNOG. Если связь Uniprot-eggNOG не существует для запрашиваемой структуры, то эта структура отсутствует в PROFESS и не будет отображаться в сводке результатов. Вкладка структуры также содержит сводную таблицу данных из баз данных CATH (27) и SCOP (28). Из-за ограничений авторского права ссылки предоставляются для получения данных с веб-сайта SCOP, а не для воспроизведения данных SCOP на наших страницах.
Вкладка «Структура» предназначена для облегчения поиска всех ортологичных кластеров с определенной складкой. Это достигается прямым или итеративным поиском определенного идентификатора CATH. Метод прямого поиска — ввести известный CATH ID в PROFESSor, чтобы найти коррелированные ортологические кластеры. При итеративном поиске пользователь сначала ищет структуру белка с помощью PROFESSor, чтобы идентифицировать ортологичную группу, находит CATH ID на вкладке структуры, а затем ищет выбранный CATH ID с помощью PROFESSor.Оба метода поиска будут генерировать список ортологичных кластеров, которые содержат интересующую белковую складку.
Структура Уровень также содержит все попарные выравнивания структур ортологичного кластера. Инструмент парного сравнения структур DaliLite (29, 30) был использован для измерения сходства структуры остова белков в пределах каждого ортологичного кластера, определенного в базе данных eggNOG. Парные структурные сравнения «все против всех» были выполнены для всех 224 847 NOG с 401 967 сравнениями общей структуры.Расчеты конструкции были выполнены с помощью Голландского вычислительного центра Университета Небраски-Линкольн.
Баллы Dali Z были нормализованы для расчета оценки дробного структурного сходства (FSS): FSS = Z AB / Z AA , где Z AB — это Dali Z -оценка, когда белок B сравнивается с белком A, и Z AA — это Z -оценка, когда белок A сравнивается с самим собой.Таким образом, Z AA представляет собой максимальный балл Z , который может быть достигнут для идеального сходства. FSS обеспечивает простую нормализованную и количественную меру расстояния, на которое два белка разошлись в своих структурах.
Последовательность
На вкладке последовательности PROFESS перечислены все белковые последовательности в ортологическом кластере. На вкладке последовательности также представлены номера доступа Uniprot, молекулярная масса, длина последовательности и, если возможно, структура.Список всех последовательностей из каждой ортологической группы можно загрузить в формате FASTA, и каждую последовательность можно отдельно скопировать и вставить в текстовый документ в формате FASTA.
Болезни
Вкладка болезней PROFESS зарезервирована для информации о генах и белках, идентифицированных во всей литературе как участвующие в различных заболеваниях человека. В настоящее время PROFESS включает информацию о генах и белках, участвующих в раке поджелудочной железы, но этот уровень PROFESS будет быстро расти по мере включения новых данных.
Система запросов для интеллектуального анализа данных
ПРОФЕССОР
Основной функцией поиска PROFESS является PROFESSor (рисунок 4), унифицированное текстовое поле, которое поможет пользователю легко уточнить сложные запросы, динамически предлагая записи из любой интегрированной базы данных. PROFESSor помогает пользователю, исправляя орфографические ошибки, используя метрики Левенштейна, а также предоставляя определяемую пользователем функцию ориентированного просмотра. Например, после ввода запроса «коллагеназа» PROFESSor возвращает раскрывающийся список белковых складок и функций, которые имеют известную связь с коллагеназой (рис. 4).Если пользователь выбирает вариант свертки (CATH), PROFESS вернет все функциональные кластеры, которые, как известно, содержат эту свертку. Таким же образом PROFESSor ищет все другие источники данных в PROFESS. Например, за один поиск пользователь может идентифицировать другие функции белка с такой же складкой, схожими лигандами или клеточными локализациями.
Рисунок 4.
Система запросов PROFESSor. PROFESSor — это инструмент динамического поиска, созданный из основных баз данных, чтобы помочь пользователю уточнить сложные запросы.Используя PROFESSor, пользователям предлагаются предложения по расширению их поисковых слов / фраз, которые помогают им быстро и точно находить всю функциональную, структурную и последовательную информацию о конкретном белке и ее связи с другими функциями белка, складками или лигандами.
Рисунок 4.
Система запросов PROFESSor. PROFESSor — это инструмент динамического поиска, созданный из основных баз данных, чтобы помочь пользователю уточнить сложные запросы. Используя PROFESSor, пользователям предлагаются предложения по расширению их поисковых слов / фраз, которые помогают им быстро и точно находить всю функциональную, структурную и последовательную информацию о конкретном белке и ее связи с другими функциями белка, складками или лигандами.
PROFESSor также может быть запрошен с использованием множества ключевых слов из нескольких баз данных с использованием логической логики. Используя регулярные выражения, общий синтаксис запросов определяется следующим образом: KEY зависит от базы данных и может быть одним из следующих (обратите внимание, что этот список будет расти вместе с количеством основных баз данных): ALL, CATH, EC, GO, LIGAND, NOG, PDB, PFAM, TAXON или UNIPORT. По умолчанию все ключевые слова после [KEY] рассматриваются как уникальная строка для запроса. Верхние индексы 0, 1 и * означают, что не используется, используется только один раз и используется произвольное количество раз, соответственно.Это поведение можно изменить, добавив к ключевым словам префикса [OR]. В запросе можно использовать символы подстановки% (любое число n символов, при n> 0) и _ (ровно один символ). Логические И выполняются между разными ключами.Расширенная система запросов
Хотя стандартные представления призваны предоставить широкий обзор функций, эволюции, структур и последовательностей белков, пользователям может потребоваться создать свой собственный модуль — или представление — для анализа только тех фрагментов данных, которые необходимы для ответа на конкретный запрос.Новые представления могут быть легко реализованы с помощью запросов SQL, которые предоставляют пользователям полный доступ к любым данным, интегрированным в PROFESS. Пример запроса SQL показан на рисунке 5A и обсуждается ниже в разделе «Приложения». Диаграмма сущность-взаимосвязь, описывающая структуру PROFESS, представлена в онлайн-документации и поможет пользователям разрабатывать запросы SQL. Как и другие модули, данные, отображаемые в настраиваемом представлении, можно при необходимости сортировать и кластеризовать. Данные также можно загрузить в формате CSV для дальнейшего анализа.
Рисунок 5.
Идентификация потенциальных мишеней для лекарств от рака поджелудочной железы. ( A ) Пример SQL-запроса, используемого для синтаксического анализа PROFESS для создания сетей белок-белкового взаимодействия между белками, связанными с раком поджелудочной железы. Выберите (зеленый) только ту информацию, которая имеет отношение к решению поставленного вопроса из динамического объединения соответствующих представлений из PROFESS (синий). Затем результаты фильтруются, чтобы выявить только взаимодействия с интересующими белками (красный).Части запроса, относящиеся к первому взаимодействующему элементу, показаны более темным цветом, тогда как разделы запроса, относящиеся ко второму взаимодействующему элементу, показаны более светлым цветом. ( B ) SQL-запрос к PROFESS привел к списку белок-белковых взаимодействий между набором белков, связанных с раком поджелудочной железы. Сети взаимодействия отображали с помощью Cytoscape (55). Идентификация белков, которые являются частью более крупной сети, обеспечивает один метод определения приоритетности потенциальных терапевтических целей среди набора белков, связанных с раком поджелудочной железы.
Рисунок 5.
Идентификация потенциальных мишеней для лекарств от рака поджелудочной железы. ( A ) Пример SQL-запроса, используемого для синтаксического анализа PROFESS для создания сетей белок-белкового взаимодействия между белками, связанными с раком поджелудочной железы. Выберите (зеленый) только ту информацию, которая имеет отношение к решению поставленного вопроса из динамического объединения соответствующих представлений из PROFESS (синий). Затем результаты фильтруются, чтобы выявить только взаимодействия с интересующими белками (красный). Части запроса, относящиеся к первому взаимодействующему элементу, показаны более темным цветом, тогда как разделы запроса, относящиеся ко второму взаимодействующему элементу, показаны более светлым цветом.( B ) SQL-запрос к PROFESS привел к списку белок-белковых взаимодействий между набором белков, связанных с раком поджелудочной железы. Сети взаимодействия отображали с помощью Cytoscape (55). Идентификация белков, которые являются частью более крупной сети, обеспечивает один метод определения приоритетности потенциальных терапевтических целей среди набора белков, связанных с раком поджелудочной железы.
Функциональная система запросов
Фундаментальный компонент запросов PROFESS — дать пользователям возможность включать множество новых функций, которые принимают на входе набор параметров и выдают на выходе четко определенное значение или набор значений.Такие определяемые пользователем функции естественным образом возникают во многих приложениях. Например, мы определили функцию подобия CPASS, которая способна генерировать новые взаимосвязи данных между белками на основе сходства последовательности и структуры в сайтах связывания лиганда (31). В качестве другого примера можно запросить связь между базами данных PFAM и eggNOG, даже если это отношение явно не определено в базе данных PROFESS. Первая атомарная функция, которую нужно интегрировать, — это BLAST, которая будет добавлена в ближайшее время.Это позволит пользователям извлекать ортологичные кластеры белков, связанные с интересующей белковой последовательностью. Входные последовательности будут сопоставлены со всеми последовательностями из базы данных eggNOG. Затем пользователю будут возвращены кластеры NOG, соответствующие значительным совпадениям. Предоставляя библиотеку стандартных элементарных функций, таких как BLAST, пользователи смогут составлять элементарные функции в сложные запросы функционального стиля. Запрос функционального стиля определяется как конвейер любой из элементарных функций, где выходные данные функции служат входными данными следующей функции в конвейере.Полное описание текущего набора функций в PROFESS будет доступно в онлайн-документации.
Метод интеграции данных
Традиционные методы интеграции данных включают хранилище данных, где база данных извлекает, преобразует и загружает (ETL) данные из различных источников в единую схему, которую легко запросить (рисунок 1A). Однако методам ETL не хватает гибкости, поскольку они требуют, чтобы схема хранилища была тесно связана с источниками данных.В результате интеграция новых источников данных требует значительных усилий, поскольку необходимо переопределить все хранилище и последующие запросы. Схему хранилища также может потребоваться изменить, если одна из схем источников данных изменится после обновления.
Метод LAV
Чтобы решить проблемы гибкости широко используемых методов ETL, база данных PROFESS была разработана с использованием гибкого метода LAV (12, 32), как показано на рисунке 1B. Методы LAV включают оболочки, которые обеспечивают уровень абстракции для каждого набора данных.Оболочки — это программное обеспечение, которое переводит источники данных и обеспечивает абстрактное упрощенное представление об интегрированных источниках данных. Несмотря на то, что ранее предпринимались попытки интеграции структурных данных и функциональных источников данных, система PROFESS имеет уникальный подход. Он создает две внутренние оболочки: одну для интегрированных функциональных данных, а другую — для интегрированных структурных данных. Затем он применяет новые функции для связи между этими двумя оболочками. Этот подход многоэтапной интеграции сначала объединяет источники данных, которые легче интегрировать, а затем объединяет источники данных, которые труднее интегрировать.Неполная и неверная информация в источнике данных — одна из основных трудностей при интеграции данных. Благодаря первому слиянию тесно связанных источников данных наш метод увеличивает вероятность того, что данные из разных источников будут дополнять и исправлять друг друга. Все аннотации сообщаются пользователю, который затем может использовать их для оценки возможных неправильных аннотаций. Таким образом, PROFESS поможет пользователям преодолеть такие проблемы, как неполные и вводящие в заблуждение аннотации данных. Структурные и функциональные данные часто трудно интегрировать из-за разных идентификационных номеров, разных функциональных определений и отсутствия прямой связи между двумя источниками данных.Наш подход к многоуровневой интеграции сначала связывает всю промежуточную информацию либо с центральной функциональной оболочкой (как определено базой данных eggNOG), либо с центральной структурной оболочкой (как определено базой данных PDB). Затем мост PDB-eggNOG служит посредником для связывания функциональной и структурной оберток. Если эта связь не существует, то белок не включен в PROFESS.
Последним шагом к достижению наших целей гибкости и расширяемости была нормализация структуры нашей базы данных.Нормализация базы данных была введена Коддом в 1970 году (33). Это систематический процесс, гарантирующий, что структура базы данных не будет подвержена аномалиям после вставки, обновления и удаления, которые могут привести к потере целостности данных (34). Нормализация данных также полезна для уменьшения потребности в реструктуризации коллекции отношений по мере появления новых типов данных. В настоящее время существует пять нормальных форм. Чем выше нормальная форма, тем надежнее структура базы данных против несоответствий.ПРОФЕСС был разработан с использованием пятой нормальной формы, предложенной Фэгиным (35). Результирующая диаграмма «сущность-взаимосвязь» показана на рисунке 1.
Однако впоследствии была выполнена выборочная денормализация по соображениям производительности (36). В частности, PROFESSor запрашивает данные из таблицы precalc_professor включает предварительно вычисленные соединения между отношениями вместо использования динамического представления. Для обеспечения согласованности данных вместе с оболочками были реализованы процедуры для регенерации этой таблицы всякий раз, когда новые данные вставляются в PROFESS.
Приложения
Сравнение структуры гомологичных белков
PROFESS был первоначально создан для проверки гипотезы о том, что белки испытывают однородный структурный дрейф после расхождения от общего предка. Целью этого исследования было разрешить очевидный парадокс структурной биологии. Белковые структуры обычно считаются инвариантными для поддержания функции (37), но последовательность определяет структуру, а изменения последовательности являются основным детерминантом эволюции (38, 39).Следовательно, каково влияние на структуру генетического дрейфа последовательности белка? Ответ на этот вопрос концептуально прост и просто требует структурного сравнения функционально идентичных белков из разных типов. Поскольку PDB наиболее богата бактериальными белками, очевидным выбором были функционально и эволюционно схожие белковые структуры двух наиболее населенных бактериальных филумов, Proteobacteria и Firmicutes . Таким образом, ключевым компонентом этого анализа была идентификация и выделение белковых структур Proteobacteria и Firmicutes из PDB с идентичной функциональной классификацией.Поскольку PDB является классическим примером базы данных хранилища с ограниченными возможностями запросов, получить эту информацию напрямую из PDB было невозможно, и это послужило стимулом для разработки PROFESS. Затем PROFESS был использован для связывания структур PDB как с eggNOG (эволюционная генеалогия генов: неконтролируемые ортологичные группы), так и с классификациями типов. Из этого набора данных мы идентифицировали 281 уникальный NOG, который содержал минимум два Firmicutes организмов и два Proteobacteria организмов с общим количеством 3047 бактериальных белков (1066 Firmicutes и 1981 Proteobacteria ).Этот набор был подвергнут парному структурному сравнению между структурами Proteobacteria – Proteobacteria , структурами Firmicutes – Firmicutes и структурами Proteobacteria – Firmicutes . Результатом стало большее различие между структурами Proteobacteria – Firmicutes , что согласуется с древним разделением между двумя типами. Результаты были внесены в базу данных PROFESS.
Идентификация потенциальных терапевтических мишеней рака поджелудочной железы
Рак поджелудочной железы имеет самую низкую пятилетнюю выживаемость (5.5%) среди онкологических заболеваний и является четвертой по значимости причиной смерти от рака в США (40, 41). Только три препарата были одобрены FDA для лечения рака поджелудочной железы: 5-фторурацил (42), гемцитабин (43) и эрлотиниб (44), при этом эти препараты обычно минимально эффективны и существенно не продлевают жизнь (45). Таким образом, реальный прогресс в лечении рака поджелудочной железы требует выявления действительно новых, но поддающихся лекарственным средствам белковых мишеней (46). Один из подходов заключается в продвижении существующих исследований в области геномики и протеомики, которые широко используются в литературе.Использование этих существующих наборов данных может предоставить механизм для определения потенциальных целей открытия лекарств. Пять отдельных протеомных исследований классифицировали в общей сложности 802 уникальных белка, которые дифференциально экспрессировались в различных клеточных линиях рака поджелудочной железы (47–51). Аналогичным образом, недавний геномный анализ частоты мутаций в 24 клеточных линиях рака поджелудочной железы выявил 1331 ген, по крайней мере, с одним генетическим изменением (52).
Чтобы продемонстрировать легкость, с которой новые данные могут быть интегрированы в PROFESS, и гибкость PROFESS для выявления ранее неизвестных взаимосвязей, PROFESS был использован для проверки гипотезы о том, что протеомный и функциональный геномный анализ клеток рака поджелудочной железы может быть использован для выявления потенциальных мишени для открытия новых лекарств.Несмотря на то, что изменения профилей экспрессии или высокая частота мутаций недостаточны для подтверждения того, что белок связан с заболеванием или имеет терапевтическое значение (53, 54), возможно, что открытие сетей белок-белковых взаимодействий может очень хорошо привести к возможные мишени для лекарств среди набора данных белков, связанных с раком поджелудочной железы.
Отобранные вручную данные «omics» клеток поджелудочной железы (PCOD) были интегрированы в PROFESS путем реализации оболочки и создания новой взаимосвязи в базе данных.Первая проблема заключалась в том, что записи PCOD были идентифицированы с помощью идентификаторов UniProt, а гены из базы данных взаимодействующих белков (DIP) идентифицированы с помощью GI. Использование стандартного метода ETL потребовало бы, чтобы программа создала новую таблицу, содержащую данные из PCOD, DIP и сопоставление между идентификаторами UniProt ID и GI. Подобные таблицы должны быть созданы для любых дополнительных взаимосвязей, представляющих интерес для PCOD, что приведет к экспоненциальному росту числа таблиц. Вместо этого наша база данных PROFESS может использовать любые данные, которые уже были интегрированы в базу данных.В частности, отображение UniProtKB между идентификаторами UniProt ID и GI можно использовать в запросах SQL для создания новых динамических представлений. Таким образом, PROFESS был добыт для создания представления kog_interacting_cancer_protein, функциональных кластеров взаимодействующих белков, связанных с раком поджелудочной железы, с использованием оператора SQL, показанного на рисунке 5A. Сеть взаимодействия белков была быстро визуализирована (рис. 5В) путем импорта вывода запроса PROFESS SQL в Cytoscape (55). После того, как представление было создано пользователем, оно будет автоматически обновляться всякий раз, когда обновляются соответствующие таблицы, хранящие данные из DIP и PCOD.Полученные в результате сети взаимодействия белков иллюстрируют быстрый анализ данных, который может быть достигнут с использованием полностью интегрированной и гибкой базы данных, основанной на функциях и структуре белков. Используя наш подход, основанный на LAV, представление о функциональных кластерах взаимодействующих белков, связанных с раком поджелудочной железы, было получено менее чем за четыре часа. Получение эквивалентной таблицы с использованием метода ETL потребовало бы значительных дополнительных усилий.
Доступ к данным
PROFESS находится в свободном доступе по URL-адресу http: // cse.unl.edu/∼profess и через наш веб-сайт http://bionmr-c1.unl.edu/. Данные могут быть загружены в виде анализируемых файлов в формате значений, разделенных запятыми (CSV), из веб-интерфейса или с помощью HTTP-запросов RESTful, которые могут быть объединены в сценарии. Последовательности и филогенетические деревья можно загрузить в форматах FASTA и PHYLIP соответственно.
Реализация
База данных PROFESS полагается на систему управления базами данных MySQL. Оболочки реализованы в Java 1.6 и не зависят от платформы.Пользовательский веб-интерфейс реализован на PHP, динамическом HTML и общих средах асинхронного Javascript и XML (AJAX), разработанных Yahoo! (http://developer.yahoo.com/yui/) и ExtJS (http://extjs.com). PROFESS работает под Open SuSE Linux 11.0 на нашем новом сервере SunFire x4600, который оснащен 8 четырехъядерными процессорами AMD (32 ядра) и 64 ГБ памяти.
Будущие направления
Первоначальная реализация PROFESS была сосредоточена на интеграции данных и развитии базовых возможностей поиска.Дальнейшее развитие PROFESS будет сосредоточено на реализации более надежных и удобных для пользователя возможностей поиска для дополнения запросов PROFESSor и SQL. Кроме того, мы продолжим расширять PROFESS, добавляя другие базы данных, которые содержат информацию, относящуюся к структуре, функциям и эволюции белков и их связи с заболеваниями человека. Идентификация функциональных отношений зависит от этой важной информации, и ожидается, что наши новые возможности подобия и поиска сделают ассоциации не так очевидными в исходных наборах данных.Кроме того, для создания надежного инструмента для функциональной аннотации в PROFESS будет интегрирована база данных CPASS (56) и результаты функционального скрининга новых белков с помощью технологии функциональной аннотации с помощью ЯМР (FAST-NMR) (57, 58). Наконец, PROFESS предоставляет прекрасные возможности в качестве исходных данных для многих новейших алгоритмов интеллектуального анализа данных и классификации данных, специально разработанных для крупномасштабных биологических данных (59).
Финансирование
Работа частично поддержана Национальным институтом аллергии и инфекционных заболеваний (номер гранта R21AI081154), предоставленным R.P., а также грантами Фонда развития биомедицинских исследований табачного поселения Небраски для R.P .; грант исследовательского совета Небраски на междисциплинарные исследования для R.P .; стипендия Милтона Э. Мора для T.T .; и стипендия Фулбрайта П.Р.Исследование проводилось в помещениях, отремонтированных при поддержке Национальных институтов здравоохранения (номер гранта RR015468-01). Финансирование платежей в открытом доступе: Национальный институт аллергии и инфекционных заболеваний (номер гранта R21AI081154) R.P.
Конфликт интересов . Ничего не объявлено.
Работа по сравнению структур была завершена с использованием вычислительного центра Голландии Университета Небраски-Линкольн. Авторы несут полную ответственность за содержание, которое не обязательно отражает официальную точку зрения Национального института аллергии и инфекционных заболеваний.
Список литературы
1« и др.DoD2007: 1082 баз данных по молекулярной биологии
,Биоинформация
,2007
, т.2
(стр.64
—67
) 2,.Nucleic Acids Research, ежегодный выпуск базы данных и коллекция онлайновой базы данных молекулярной биологии NAR в 2009 г.
,Nucleic Acids Res.
,2009
, т.37
(стр.D1
—D4
) 3« и др.От биологических баз данных до платформ для биомедицинских открытий
,Trends Biotechnol.
,2003
, т.21
(стр.263
—268
) 4.Создание нации биоинформатики
,Nature
,2002
, vol.417
(стр.119
—120
) 5,,.Сбор и сбор биологических данных: информационные системы GPCRDB и NucleaRDB
,Nucleic Acids Res.
,2001
, т.29
(стр.346
—349
) 6,,,.Классификация задач по биоинформатике
,Биоинформатика
,2001
, т.17
(стр.180
—188
) 7.Технологии интеграции биологических данных
,Краткий Биоинформ.
,2002
, т.3
(стр.389
—404
) 8,,.Проблемы интеграции источников биологических данных
,J. Comp. Биол.
,1995
, т.2
(стр.557
—572
) 9,.Модельный организм как система: интеграция наборов данных «омикс»
,Nature Rev.Мол. Cell Biol.
,2006
, т.7
(стр.198
—210
) 10,. ,Proceedings of the 2003 IEEE / WIC International Conference on Web Intelligence
,2003
Washington, DC; Галифакс, Канада
Компьютерное общество IEEE
(стр.301
—309
) 11,.Реклассификация линейно классифицированных данных с использованием баз данных ограничений
,Труды Двенадцатой восточноевропейской конференции по развитию баз данных и информационных систем
,2008
Пори, Финляндия
Springer LNCS 5207
(стр.231
—245
) 12.Ответы на запросы с использованием представлений: обзор
,VLDB J .: Very Large Data Bases
,2001
, vol.10
(стр.270
—294
) 13« и др.Банк данных по белкам
,Nucleic Acids Res.
,2000
, т.28
(стр.235
—242
) 14« и др.eggNOG: автоматизированное построение и аннотация ортологичных групп генов
,Nucleic Acids Res.
,2008
, т.36
(стр.D250
—D254
) 15« и др.eggNOG v2.0: расширение эволюционной генеалогии генов с расширенными неконтролируемыми ортологическими группами, видами и функциональными аннотациями
,Nucleic Acids Res.
,2010
, т.38
(стр.D190
—D195
) 16Консорциум UniProt
Универсальный белковый ресурс (UniProt) 2009
,Nucleic Acids Res.
,2009
, т.37
(стр.D169
—D174
) 17« и др.База данных семейств белков Pfam
,Nucleic Acids Res.
,2008
, т.36
(стр.D281
—D288
) 18Консорциум генных онтологий
Проект Gene Ontology (GO) в 2006 г.
,Nucleic Acids Res
,2006
, vol.34
(стр.D322
—D326
) 19. ,Номенклатура ферментов 1992: Рекомендации Номенклатурного комитета Международного союза биохимии и молекулярной биологии по номеру (номенклатура ферментов)
,1992
Сан-Диего, Калифорния
Academic Press
20,,, et al.KEGG для связывания геномов с жизнью и окружающей средой
,Nucleic Acids Res.
,2008
, т.36
(стр.D480
—D484
) 21« и др.Масштабная идентификация белок-белкового взаимодействия Escherichia coli K-12
,Genome Res.
,2006
, т.16
(стр.686
—691
) 22« и др.База данных взаимодействующих белков: обновление 2004 г.
,Nucleic Acids Res.
,2004
, т.32
(стр.D449
—D451
) 23.Филогенетический анализ с использованием PHYLIP
,Methods Mol. Биол.
,2000
, т.132
(стр.243
—258
) 24.PHYLIP — Пакет вывода филогении (версия 3.2)
,Cladistics
,1989
, vol.5
(стр.164
—166
) 25,,.Новый прогрессивно-итерационный алгоритм для множественного выравнивания структур
,Bioinformatics
,2005
, vol.21
(стр.3255
—3263
) 26,.DEG 5.0, база данных основных генов прокариот и эукариот
,Nucleic Acids Res.
,2009
, т.37
(стр.D455
—D458
) 27« и др.Пересмотр классификации CATH — рассмотрены архитектуры и новые способы характеристики структурной дивергенции в суперсемействах
,Nucleic Acids Res.
,2009
, т.37
(стр.D310
—D314
) 28« и др.Рост данных и его влияние на базу данных SCOP: новые разработки
,Nucleic Acids Res.
,2008
, т.36
(стр.D419
—D425
) 29,,,.Поиск в базах данных структуры белков с помощью DaliLite v.3
,Bioinformatics
,2008
, vol.24
(стр.2780
—2781
) 30,.Инструмент DaliLite для сравнения структуры белков
,Bioinformatics
,2000
, vol.16
(стр.566
—567
) 31« и др.Сравнение структур активных центров белков для функциональной аннотации белков и дизайна лекарств
,БЕЛКИ: Struct. Функц. Биоинформатика
,2006
, т.65
(стр.124
—135
) 32,.MiniCon: масштабируемый алгоритм ответа на запросы с использованием представлений
,The VLDB J.
,2001
, vol.10
(стр.182
—198
) 33.Реляционная модель для больших общих банков данных
,Commun. АСМ
,1970
, т.13
(стр.377
—387
) 34. ,Реляционная модель для управления базами данных: версия 2
,1990
Бостон, Массачусетс, США
Addison-Wesley Longman Publishing Co. Inc.
35.Обычная форма для реляционных баз данных, основанная на доменах и ключах
,ACM Trans. Системы баз данных
,1981
, т.6
(стр.387
—415
) 36. ,База данных в подробностях: теория отношений для практиков
,2005
Севастополь, Калифорния, США
O’Reilly Media Inc.
37,,, et al.Функциональные идеи структурной геномики
,J. Struct. Функц. Геномика
,2007
, т.8
(стр.37
—44
) 38,.Связь между расхождением последовательности и структуры в белках
,Embo J.
,1986
, т.5
(стр.823
—826
) 39.Сумеречная зона выравнивания последовательностей белков
,Protein Eng.
,1999
, т.12
(стр.85
—94
) 40,,.Рак поджелудочной железы: патогенез, профилактика и лечение
,Toxicol. Прил. Pharmacol.
,2007
, т.224
(стр.326
—336
) 41« и др.Статистика рака, 2009 г.
,CA Cancer J.Clin.
,2009
, т.59
(стр.225
—249
) 42,,.Четыре десятилетия непрерывных инноваций с фторурацилом: текущие и будущие подходы к химиолучевой терапии фторурацилом
,J. Clin. Онкол.
,2004
, т.22
(стр.2214
—2232
) 43,.Гемцитабин: обзор его использования в лечении рака поджелудочной железы
,Am. J. Cancer
,2005
, т.4
(стр.395
—416
) 44,.Новые терапевтические направления при распространенном раке поджелудочной железы: воздействие на эпидермальный фактор роста и пути фактора роста эндотелия сосудов
,Онколог
,2008
, vol.13
(стр.289
—298
) 45,,.Вклад цитотоксической химиотерапии в 5-летнюю выживаемость при злокачественных новообразованиях у взрослых
,Clin. Онкол.
,2004
, т.16
(стр.549
—560
) 46.Определение лекарственной устойчивости
,Нат. Rev. Drug Discovery
,2007
, vol.6
стр.187
47« и др.Протеомный профиль клеточных линий рака поджелудочной железы, соответствующих канцерогенезу и метастазам
,J. Proteomics Bioinf.
,2009
, т.2
(стр.001
—018
) 48« и др.Профили экспрессии белка при аденокарциноме поджелудочной железы по сравнению с нормальной тканью поджелудочной железы и тканью, пораженной панкреатитом, по данным двумерного гель-электрофореза и масс-спектрометрии
,Cancer Res.
,2004
, т.64
(стр.9018
—9026
) 49« и др.Протеом рака поджелудочной железы: белки, лежащие в основе инвазии, метастазирования и иммунологического ускользания
,Гастроэнтерология
,2005
, vol.129
(стр.1187
—1197
) 50« и др.Протеомный анализ хронического панкреатита и аденокарциномы поджелудочной железы
,Гастроэнтерология
,2005
, т.129
(стр.1454
—1463
) 51« и др.Мета-анализ микроматриц рака поджелудочной железы определяет набор обычно нерегулируемых генов
,Онкоген
,2005
, vol.24
(стр.5079
—5088
) 52« и др.Основные сигнальные пути при раке поджелудочной железы человека, выявленные глобальным геномным анализом
,Science
,2008
, vol.321
(стр.1801
—1806
) 53,.Применение зондов на основе активности для изучения ферментов, участвующих в прогрессировании рака
,Curr. Opin. Genet. Dev.
,2008
, т.18
(стр.97
—106
) 54,,,.Нацеливание на мутации потери функции в генах-супрессорах опухолей как стратегия разработки терапевтических агентов против рака
,Семин. Онкол.
,2006
, т.33
(стр.513
—520
) 55« и др.Cytoscape: программная среда для интегрированных моделей сетей биомолекулярного взаимодействия
,Genome Res.
,2003
, т.13
(стр.2498
—2504
) 56« и др.Сравнение структур активных центров белков для функциональной аннотации белков и дизайна лекарств
,Proteins
,2006
, vol.65
(стр.124
—135
) 57« и др.FAST-ЯМР: технология скрининга функциональных аннотаций с использованием ЯМР-спектроскопии
,J.Являюсь. Chem. Soc.
,2006
, т.128
(стр.15292
—15299
) 58,,.Применение FAST-ЯМР для идентификации новых лекарств.
,Drug Discov. Сегодня
,2008
, т.13
(стр.172
—179
) 59,.Интеграция классификации и переклассификация с использованием баз данных ограничений
,Artif. Intell. Med.
,2010
, т.49
(стр.79
—91
) 60« и др.GenBank
,Nucleic Acids Res.
,2009
, т.37
(стр.D26
—D31
) 61,.База данных последовательностей белков SWISS-PROT и дополнение к ней TrEMBL в 2000
,Nucleic Acids Res.
,2000
, т.28
(стр.45
—48
)Заметки автора
© Автор (ы) 2010.Опубликовано Oxford University Press.
Это статья в открытом доступе, распространяемая в соответствии с условиями некоммерческой лицензии Creative Commons Attribution (http://creativecommons.org/licenses/by-nc/2.5), которая разрешает неограниченное некоммерческое использование, распространение и воспроизведение на любом носителе при условии правильного цитирования оригинальной работы.
Глава 18: аминокислоты, белки и ферменты
- Белки — полимеры аминокислот.
- Пример, Алкогольдегидрогеназа (фермент)
- Таблица функций белков
- Обзор функций белков
- Аминокислоты
- Хиральные цвиттерионы
- Группы боковой цепи
- Общий рисунок склеивания: N-вывод на C-вывод
- Волокнистый vs.Глобулярные белки
- Волокнистый: похож на волокна, не растворим в воде. Например, кератин: в волосах, внешнем слое кожи.
- Шаровидные: многие из них имеют несколько сферическую форму (не волокнистые), растворимы в воде. Пример: химотрипсин, пищеварительный фермент.
- Первичная структура: аминокислотная последовательность (например, ala-pro-ser-ser-gly-ala …)
- Вторичная структура: специфически фиксированные расположения полипептида
позвоночник
- α-Спираль и β-Лист: модели водородных связей
- α-Helix и β-Sheet: рисунки лент
- Третичная структура: Общая трехмерная форма одиночного полипептида:
Пример амилазы
- Силы, поддерживающие структуру
- Четвертичная структура: способ сборки нескольких полипептидов (некоторые белки): гемоглобин пример.
- Определение катализатора: любое вещество, увеличивающее скорость или скорость химической реакции без изменения или расходуется в реакции.
- Классы ферментов
- Действие фермента: Модель замка и ключа (специфичность подложки)
- Действие фермента: Модель индуцированной подгонки
- Некоторые препараты являются ингибиторами ферментов
- Ацикловир (противовирусный препарат, обратимое ингибирование)
- Схема обратимого торможения («соревновательная»)
- Необратимое торможение, пример пенициллина
- Неорганические кофакторы — это ионы металлов, такие как ионы цинка и меди.
- Органические кофакторы называются «коферментами», и большинство из них — витамины.
- Витамины — это органические соединения, которые необходимы в очень маленьких количества для поддержания нормального обмена веществ.Они вообще не могут быть синтезированы организмом на адекватном уровне и должны полученные из рациона.
- Одним из примеров является кофермент, NAD , г. витамин B 3 (ниацин)
- Пропустить Раздел 18.2: Реакции аминокислот
- Пропустить таблицу 18.6: Классификационные номера ферментов
- Пропустить Раздел 18.7: Ферментативная активность
- Пропустить запрет на участие в соревнованиях и подавление с обратной связью
Белки тяжелого острого респираторного синдрома Коронавирус-2 (SARS CoV-2 или n-COV19), причина COVID-19
Li X, Zai J, Wang X, Li Y (2020) Возможность крупномасштабной передачи вируса 2019-nCoV от человека к человеку «первого поколения». J Med Virol 92: 448–454
CAS PubMed PubMed Central Статья Google Scholar
Гралински Л.Е., Менахери В.Д. (2020) Возвращение коронавируса: 2019-nCoV. Вирусы 12: 135
Статья PubMed Central Google Scholar
Chan JF-W, Kok K-H, Zhu Z, Chu H, To KK-W, Yuan S, Yuen K-Y (2020) Геномная характеристика нового патогенного для человека коронавируса 2019 года, выделенного у пациента с атипичной пневмонией после посещения Ухани. Emerg Microb Infect 9: 221–236
CAS Статья Google Scholar
Wang C, Liu Z, Chen Z, Huang X, Xu M, He T, Zhang Z (2020) Создание эталонной последовательности для SARS-CoV-2 и вариационный анализ.J Med Virol 92: 667–674
CAS Статья PubMed Google Scholar
Хайланы Р.А., Сафдар М., Озаслан М. (2020) Геномная характеристика нового SARS-CoV-2. Gene Rep 19: 100682
PubMed Central Статья Google Scholar
Андерсен К.Г., Рамбаут А., Липкин В.И., Холмс Э.К., Гарри Р.Ф. (2020) Проксимальное происхождение SARS-CoV-2. Nat Med 26: 450–455
CAS PubMed Статья Google Scholar
Li Y-H, Hu C-Y, Wu N-P, Yao H-P, Li L-J (2019) Молекулярные характеристики, функции и связанная патогенность белков MERS-CoV. Инженерное дело 5: 940–947
CAS PubMed Статья Google Scholar
Сонг З., Сюй И, Бао Л., Чжан Л., Ю П, Цюй Й, Чжу Х, Чжао В., Хань И, Цинь С. (2019) От SARS до MERS, привлекающие внимание к коронавирусу. Вирусы 11:59
CAS Статья PubMed Central Google Scholar
Hilgenfeld R (2014) От SARS до MERS: кристаллографические исследования коронавирусных протеаз позволяют создавать противовирусные препараты. FEBS J 281: 4085–4096
CAS PubMed PubMed Central Статья Google Scholar
Calligari P, Bobone S, Ricci G, Bocedi A (2020) Молекулярное исследование белков SARS-CoV-2 и их взаимодействия с противовирусными препаратами. Вирусы 12: 445
PubMed Central Статья CAS Google Scholar
Liu DX, Fung TS, Chong KK-L, Shukla A, Hilgenfeld R (2014) Дополнительные белки SARS-CoV и других коронавирусов. Antiviral Res 109: 97–109
CAS PubMed PubMed Central Статья Google Scholar
Prajapa M, Sarma P, Shekhar N, Avti P, Sinha S, Kaur H, Kumar S, Bhattacharyya A, Kumar H, Bansal S, Medhi B (2020) Цели в отношении лекарств для вируса короны: систематический обзор . Indian J Pharmacol 52: 56–65
Статья Google Scholar
Zhou P, Yang XL, Wang XG, Hu B, Zhang L, Zhang W, Si HR, Zhu Y, Li B, Huang CL, Chen HD, Chen J, Luo Y, Guo H, Jiang RD, Liu MQ, Chen Y, Shen XR, Wang X, Zheng XS, Zhao K, Chen QJ, Deng F, Liu LL, Yan B, Zhan FX, Wang YY, Xiao GF, Shi ZL (2020) Вспышка пневмонии, связанная с новым коронавирусом вероятной летучая мышь происхождения. Nature 579: 270–273
CAS PubMed PubMed Central Статья Google Scholar
Cagliani R, Forni D, Clerici M, Sironi M (2020) Вычислительный вывод отбора, лежащий в основе эволюции нового коронавируса, SARS-CoV-2. J Virol. https://doi.org/10.1128/JVI.00411-20
Артикул PubMed Google Scholar
Huang C, Lokugamage KG, Rozovics JM, Narayanan K, Semler BL, Makino S (2011) Белок nsp1 коронавируса SARS индуцирует зависимое от матрицы эндонуклеолитическое расщепление мРНК: вирусные мРНК устойчивы к индуцированному nsp1 расщеплению РНК.PLoS Pathog 7: e1002433
CAS PubMed PubMed Central Статья Google Scholar
Madeira F, Park YM, Lee J, Buso N, Gur T, Madhusoodanan N, Basutkar P, Tivey ARN, Potter SC, Finn RD, Lopez R (2019) Инструменты поиска и анализа последовательности EMBL-EBI API в 2019 году. Nucleic Acids Res 47: W636 – W641
CAS PubMed PubMed Central Статья Google Scholar
Cornillez-Ty CT, Liao L, Yates JR, Kuhn P, Buchmeier MJ (2009) Неструктурный белок 2 коронавируса тяжелого острого респираторного синдрома взаимодействует с комплексом белков-хозяев, участвующих в митохондриальном биогенезе и внутриклеточной передаче сигналов. J Virol 83: 10314–10318
CAS PubMed PubMed Central Статья Google Scholar
Sakai Y, Kawachi K, Terada Y, Omori H, Matsuura Y, Kamitani W (2017) Изменение двух аминокислот в nsp4 коронавируса SARS отменяет репликацию вируса.Вирусология 510: 165–174
CAS PubMed PubMed Central Статья Google Scholar
Lei J, Kusov Y, Hilgenfeld R (2018) Nsp3 коронавирусов: структуры и функции большого многодоменного белка. Antiviral Res 149: 58–74
CAS PubMed Статья Google Scholar
Baez-Santos YM, St. John SE, Mesecar AD (2015) Папаин-подобная протеаза SARS-коронавируса: структура, функция и ингибирование разработанными противовирусными соединениями.Antiviral Res 115: 21–38
CAS PubMed Статья Google Scholar
Tomar S, Johnston ML, St. John SE, Osswald HL, Nyalapatla PR, Paul LN, Ghosh AK, Denison MR, Mesecar AD (2015) Лиганд-индуцированная димеризация коронавируса респираторного синдрома Ближнего Востока (MERS) Значение протеазы nsp5 (3CL pro ) для регуляции nsp5 и разработки противовирусных препаратов. J. Biol. Chem. 290: 19403–19422
CAS PubMed PubMed Central Статья Google Scholar
Cottam EM, Whelband MC, Wileman T (2014) Коронавирус NSP6 ограничивает распространение аутофагосом. Аутофагия 10: 1426–1441
CAS PubMed PubMed Central Статья Google Scholar
Angelini MM, Akhlaghpour M, Neuman BW, Buchmeier MJ (2013) Неструктурные белки 3, 4 и 6 коронавируса тяжелого острого респираторного синдрома индуцируют двойные мембранные везикулы. mBio 13: e00524 – e1513
Google Scholar
te Velthuis AJ, van de Worm SH, Snijder EJ (2012) Комплекс SARS-коронавирус nsp7 + nsp8 — это уникальная мультимерная РНК-полимераза, способная как к инициации de novo, так и к удлинению праймера. Nucleic Acids Res 40: 1737–1747
Статья CAS Google Scholar
Гао Й, Янь Л., Хуан И, Лю Ф, Чжао И, Цао Л., Ван Т., Сунь Ц., Мин З, Чжан Л., Гэ Дж, Чжэн Л., Чжан И, Ван Х, Чжу Ю. , Zhu C, Hu T, Hua T, Zhang B, Yang X, Li J, Yang H, Liu Z, Xu W., Guddat LW, Wang Q, Lou Z, Rao Z (2020) Структура РНК-зависимой РНК-полимеразы от вируса COVID-19.Наука. https://doi.org/10.1126/science.abb7498
Артикул PubMed PubMed Central Google Scholar
Zhao S, Ge X, Wang X, Liu A, Guo X, Zhou L, Yu K, Yang H (2015) DEAD-box РНК-геликаза 5 положительно регулирует репродукцию репродуктивной системы свиней и респираторный синдром. вирус путем взаимодействия с вирусным Nsp9 in vitro . Virus Res 195: 217–224
CAS PubMed Статья Google Scholar
Ma Y, Wu L, Shaw N, Gao Y, Wang J, Sun Y, Lou Z, Yan L, Zhang R, Rao Z (2015) Структурная основа и функциональный анализ комплекса nsp14-nsp10 коронавируса SARS. Proc Natl Acad Sci USA 112: 9436–9441
CAS PubMed Статья Google Scholar
Wang Y, Sun Y, Wu A, Xu S, Pan R, Zeng C, Jin X, Ge X, Shi Z, Ahola T, Guo D (2015) Метилтрансфераза коронавируса nsp10 / nsp16 может стать мишенью для Производный от nsp10 пептид in vitro и in vivo для уменьшения репликации и патогенеза.J Virol 89: 8416–8427
CAS PubMed PubMed Central Статья Google Scholar
Subissi L, Posthuma CC, Collet A, Zevenhoven-Dobbe JC, Gorbalenya AE, Decroly E, Snijder EJ, Canard B, Imbert I (2014) Один белковый комплекс коронавируса тяжелого острого респираторного синдрома объединяет процессивную РНК-полимеразу и экзонуклеазная активность. Proc Natl Acad Sci USA 111: E3900 – E3909
CAS PubMed Статья Google Scholar
Jang K-J, Jeong S, Kang DY, Sp N, Yang YM, Kim D.-E (2020) Высокая концентрация АТФ усиливает кооперативную транслокацию геликазы nsP13 коронавируса SARS при раскручивании дуплексной РНК. Научный представитель 10: 4481
CAS PubMed PubMed Central Статья Google Scholar
Jia Z, Yan L, Ren Z, Wu L, Wang J, Guo J, Zheng L, Ming Z, Zhang L, Lou Z, Rao Z (2019) Тонкая структурная координация тяжелого острого респираторного синдрома коронавирус Nsp13 при гидролизе АТФ.Нуклеиновые кислоты Res 47: 6538–6550
CAS PubMed PubMed Central Статья Google Scholar
Иванов К.А., Тиль В., Доббе Дж. К., ван дер Меер Ю., Снайдер Э. Дж., Зибур Дж. (2004) Множественная ферментативная активность, связанная с хеликазой коронавируса тяжелого острого респираторного синдрома. J Virol 78: 5619–5632
CAS PubMed PubMed Central Статья Google Scholar
Case JB, Ashbrook AW, Dermody TS, Denison MR (2016) Мутагенез S -аденозил-1-метионин-связывающих остатков в N7-метилтрансферазе коронавируса nsp14 демонстрирует различные требования к трансляции генома и устойчивости к врожденному иммунитету. J Virol 90: 7248–7256
CAS PubMed PubMed Central Статья Google Scholar
Jin X, Chen Y, Sun Y, Zeng C, Wang Y, Tao J, Wu A, Yu X, Zhang Z, Tian J, Guo D (2013) Характеристика активности гуанин-N7 метилтрансферазы коронавирус nsp14 на нуклеотиде GTP.Virus Res 176: 45–52
CAS PubMed PubMed Central Статья Google Scholar
Bouvet M, Debarnot C, Imbert I, Selisko B, Snijder EJ, Canard B, Decroly E (2010) Восстановление метилирования cap мРНК SARS-коронавируса in vitro. PLoS Pathog 6: e1000863
PubMed PubMed Central Статья CAS Google Scholar
Накагава К., Локугамаге К.Г., Макино С. (2016) Трансляция вирусной и клеточной мРНК в клетках, инфицированных коронавирусом.Adv Virus Res 96: 165–192
CAS PubMed PubMed Central Статья Google Scholar
Bhardwaj K, Sun J, Holzenburg A, Guarino LA, Kao CC (2006) Распознавание и расщепление РНК эндорибонуклеазой коронавируса SARS. J Mol Biol 361: 243–256
CAS PubMed PubMed Central Статья Google Scholar
Hackbart M, Deng X, Baker SC (2020) Эндорибонуклеаза коронавируса нацелена на вирусные полиуридиновые последовательности, чтобы избежать активации сенсоров хозяина.Proc Natl Acad Sci USA 117: 8094–8103
CAS PubMed Статья Google Scholar
Bhardwaj K, Palaninathan S, Ortiz Alcantara JM, Li Yi L, Guarino L, Sacchettini JC, Cheng Kao C (2008) Структурный и функциональный анализ эндорибонуклеазы Nsp15 коронавируса тяжелого острого респираторного синдрома. J Biol Chem 283: 3655–3664
CAS PubMed Статья Google Scholar
Kim Y, Jedrzejczak R, Maltseva NI, Wilamowski M, Endres M, Godzik A, Michalska K, Joachimiak A (2020) Кристаллическая структура эндорибонуклеазы Nsp15 NendoU из SARS-CoV-2. Protein Sci. https://doi.org/10.1002/pro.3873
Артикул PubMed PubMed Central Google Scholar
Bhardwaj K, Guarino L, Kao CC (2004) Белок Nsp15 коронавируса тяжелого острого респираторного синдрома представляет собой эндорибонуклеазу, которая предпочитает марганец в качестве кофактора.J Virol 78: 12218
CAS PubMed PubMed Central Статья Google Scholar
Deng X, Baker SC (2018) «Старый» белок с новой историей: эндорибонуклеаза коронавируса важна для уклонения от противовирусной защиты хозяина. Вирусология 517: 157–163
CAS PubMed PubMed Central Статья Google Scholar
Decroly E, Imbert I, Coutard B, Bouvet M, Selisko B, Alvarez K, Gorbalenya AE, Snijder EJ, Canard B (2008) Неструктурный белок коронавируса 16 — это связывающий кэп-0 фермент, обладающий (нуклеозид- 2’O) -метилтрансферазная активность.J Virol 82: 8071–8084
CAS PubMed PubMed Central Статья Google Scholar
Decroly E, Debarnot C, Ferron F, Bouvet M, Coutard B, Imbert I, Gluais L, Papageorgiou N, Sharff A, Bricogne G, Ortiz-Lombardia M, Lescar J, Canard B (2011) Crystal структурный и функциональный анализ комплекса sars-коронавирусная РНК cap 2′-O-метилтрансфераза nsp10 / nsp16. PLoS Pathog 7: e1002059
CAS PubMed PubMed Central Статья Google Scholar
Lan J, Ge J, Yu J, Shan S, Zhou H, Fan S, Zhang Q, Shi X, Wang Q, Zhang L, Wang X (2020) Структура границы домена связывания шипа SARS-CoV-2 к рецептору ACE2. Природа. https://doi.org/10.1038/s41586-020-2180-5s
Артикул PubMed Google Scholar
Шан Дж, Йе Г, Ши К., Ван И, Луо С., Айхара Х, Гэн Кью, Ауэрбах А., Ли Ф (2020) Структурная основа распознавания рецепторов SARS-CoV-2. Природа. https: // doi.org / 10.1038 / s41586-020-2179-y
Артикул PubMed Google Scholar
Walls AC, Park Y-J, Tortorici MA, Wall A, McGuire AT, Vessler D (2020) Структура, функция и антигенность гликопротеина шипа SARS-CoV-2. Cell 180: 281–292
Статья CAS Google Scholar
Siu KL, Yuen KS, Castano-Rodriguez C, Ye ZW, Yeung ML, Fung SY, Yuan S, Chan CP, Yuen KY, Enjuanes L, Jin DY (2019) Тяжелый острый респираторный синдром, коронавирусный белок ORF3a активирует воспаление NLRP3, стимулируя TRAF3-зависимое убиквитинирование ASC.FASEB J 33: 8865–8877
CAS PubMed PubMed Central Статья Google Scholar
Verdia-Baguena C, Nieto-Torres JL, Alcaraz A, DeDiego ML, Torres J, Aguilella VM, Enjuanes L (2012) Белок коронавируса E образует ионные каналы с функционально и структурно задействованными мембранными липидами. Вирусология 432: 485–494
CAS PubMed PubMed Central Статья Google Scholar
Schoeman D, Fielding BC (2019) Белок оболочки коронавируса: текущие знания. Virol J 16:69
PubMed PubMed Central Статья CAS Google Scholar
Лим К.П., Лю Д.Х. (2001) Недостающее звено в сборке коронавируса: удержание белка оболочки вируса инфекционного бронхита птичьего коронавируса в компартментах пре-Гольджи и физическое взаимодействие между белками оболочки и мембраны. J Biol Chem 276: 17515–17523
CAS PubMed Статья Google Scholar
Ruch TR, Machamer CE (2012) Белок коронавируса E: сборка и не только. Вирусы 4: 363–382
CAS PubMed PubMed Central Статья Google Scholar
Weiss SR, Navas-Martin S (2005) Патогенез коронавируса и новый возбудитель тяжелого острого респираторного синдрома коронавирус. Microbiol Mol Biol Rev 69: 635–664
CAS PubMed PubMed Central Статья Google Scholar
Neuman BW, Kiss G, Kunding AH, Bhella D, Baksh MF, Connelly S, Droese B, Klaus JP, Makino S, Sawicki SG, Siddell SG, Stamou DG, Wilson IA, Kuhn P, Buchmeier MJ (2011) Структурный анализ белка М в сборке и морфологии коронавируса. J Struct Biol 174: 11–22
CAS PubMed Статья Google Scholar
Tsoi H, Li L, Chen ZS, Lau K-F, Tsui SKW, Chan HYE (2014) Мембранный белок коронавируса SARS индуцирует апоптоз путем вмешательства в передачу сигналов PDK1-PKB / Akt.Biochem J 464: 439–447
CAS PubMed Статья Google Scholar
Siu YL, Teoh KT, Lo J, Chan CM, Kien F, Escriou N, Tsao SW, Nicholls JM, Altmeyer R, Peiris JSM, Bruzzone R, Nal B (2008) The M, E, and Структурные белки N коронавируса тяжелого острого респираторного синдрома необходимы для эффективной сборки, транспортировки и высвобождения вирусоподобных частиц. J Virol 82: 11318–11330
CAS PubMed PubMed Central Статья Google Scholar
Kumar P, Gunalan V, Liu B, Chow VTK, Druce J, Birch C, Catton M, Fielding BC, Tan YJ, Lal SK (2007) Неструктурный белок 8 (nsp8) коронавируса SARS взаимодействует с его дополнительным белком ORF6 . Вирусология 366: 293–303
CAS PubMed PubMed Central Статья Google Scholar
Zhao J, Falcon A, Zhou H, Netlan J, Enjuanes L, Brena PP, Perlman S (2009) Для оптимальной репликации требуется белок коронавируса 6 тяжелого острого респираторного синдрома.J Virol 83: 2368–2373
CAS PubMed Статья Google Scholar
Nelson CA, Pekosz A, Lee CA, Diamond MS, Fremont DH (2005) Структура и внутриклеточное нацеливание дополнительного белка Orf7a коронавируса SARS. Структура 13: 75–85
CAS PubMed PubMed Central Статья Google Scholar
Schaecher SR, Mackenzie JM, Pekosz A (2007) Белок ORF7b коронавируса тяжелого острого респираторного синдрома (SARS-CoV) экспрессируется в инфицированных вирусом клетках и включается в частицы SARS-CoV.J Virol 81: 718–731
CAS PubMed Статья Google Scholar
Le TM, Wong HH, Tay FPL, Fang S, Keng CT, Tan YJ, Liu DX (2007) Экспрессия, посттрансляционная модификация и биохимическая характеристика белков, кодируемых субгеномной мРНК8 тяжелого острого респираторного синдрома коронавирус. FEBS J 274: 4211–4222
CAS PubMed PubMed Central Статья Google Scholar
Wong HH, Fung TS, Fang S, Huang M, Le MT, Liu DX (2018) Дополнительные белки 8b и 8ab коронавируса тяжелого острого респираторного синдрома подавляют путь передачи сигналов интерферона, опосредуя убиквитин-зависимую быструю деградацию фактора регуляции интерферона 3. Вирусология 515: 165–175
CAS PubMed Статья Google Scholar
Grunewald ME, Fehr AR, Athmer J, Perlman S (2018) Нуклеокапсидный белок коронавируса является ADP-рибозилированным.Вирусология 517: 62–68
CAS PubMed Статья Google Scholar
Mu J, Xu J, Zhang L, Shu T, Wu D, Huang M, Ren Y, Li X, Geng Q, Xu Y, Qiu Y, Zhou X (2020) SARS-CoV-2- кодируемый белок нуклеокапсида действует как вирусный супрессор РНК-интерференции в клетках. Наука, Китай Наука о жизни 63:10
Google Scholar
Surjit M, Liu B, Chow VTK, Lal SK (2006) Нуклеокапсидный белок тяжелого острого респираторного синдрома-коронавирус подавляет активность циклин-циклин-зависимого киназного комплекса и блокирует прогрессирование S-фазы в клетках млекопитающих.J Biol Chem 281: 10669–10681
CAS PubMed Статья Google Scholar
Gordon DE, Jang GM, Bouhaddou M, Xu J, Obernier K, White KM, O’Meara MJ, Rezelj VV, Guo JZ, Swaney DL, Tummino TA, Huettenhain R, Kaake RM, Richards AL, Тутункуоглу Б., Фуссар Х, Батра Дж., Хаас К., Модак М., Ким М., Хаас П., Полакко Б. Дж., Браберг Х, Фабиус Дж. М., Экхардт М., Соучрей М., Беннетт М. Дж., Чакир М., МакГрего М. Дж., Ли К., Мейер Б. , Roesch F, Vallet T, Mac Kain A, Miorin L, Moreno E, Naing ZZC, Zhou Y, Peng S, Shi Y, Zhang Z, Shen W, Kirby IT, Melnyk JE, Chorba JS, Lou K, Dai SA, Баррио-Эрнандес I, Мемон Д., Эрнандес-Армента К., Лю Дж., Мэти С.Дж., Перика Т., Пилла КБ, Ганесан С.Дж., Зальцберг Д.Д., Ракеш Р., Лю Х, Розенталь С.Б., Кальвиелло Л., Венкатараманан С., Либой-Луго Дж. , Lin Y, Huang XP, Liu Y, Wankowicz SA, Bohn M, Safari M, Ugur FS, Koh C, Savar NS, Tran QD, Shengjuler D, Fletcher SJ, O’Neal MC, Cai Y, Chang JCJ, Broadhurst DJ , Klippsten S, Sharp PP, Wenzell NA, Kuzuoglu D, Wang HY, Trenker R, Young JM, Cavero DA, Hiatt J, Roth TL, Rathore U, Subramanian A, Noack J, Хуберт М., Страуд Р.М., Франкель А.Д., Розенберг О.С., Верба К.А., Агард Д.А., Отт М., Эмерман М., Юра Н., фон Застров М., Вердин Э., Эшворт А., Шварц О, д’Энферт С., Мукерджи С., Якобсон М., Малик Х.С., Фухимори Д.Г., Идекер Т., Крайк С.С., Флор С.Н., Фрейзер Дж. Шокат К.М., Шойчет Б.К., Кроган Н.Дж. (2020) Карта взаимодействия белков SARS-CoV-2 выявляет цели для перепрофилирования лекарств.Природа. https://doi.org/10.1038/s41586-020-2286-9
Артикул PubMed Google Scholar
Rancurel C, Khosravi M, Dunker AK, Romero PR, Karlin D (2009) Перекрывающиеся гены производят белки с необычными свойствами последовательности и дают представление о создании белков de novo. J Virol 83: 10719–10736
CAS PubMed PubMed Central Статья Google Scholar
Шукла А., Хильгенфельд Р. (2015) Приобретение новых белковых доменов коронавирусами: анализ перекрывающихся генов, кодирующих белки N и 9b, в коронавирусе SARS. Гены вирусов 50: 29–38
CAS PubMed Статья Google Scholar
Wu A, Peng Y, Huang B, Ding X, Wang X, Niu P, Meng J, Zhu Z, Zhang Z, Wang J, Sheng J, Quan L, Xia Z, Tan W, Cheng G , Jiang T (2020) Состав генома и расхождение нового коронавируса (2019-nCoV), происходящего из Китая.Клеточный микроб-хозяин 27: 325–328
CAS PubMed PubMed Central Статья Google Scholar
Firth AE, Brierley I (2012) Неканоническая трансляция в РНК-вирусах. J Gen Virol 93: 1385–1409
CAS PubMed PubMed Central Статья Google Scholar
Hussain S, Pan J, Chen Y, Yang Y, Xu J, Peng Y, Wu Y, Li Z, Zhu Y, Tien P, Guo D (2005) Идентификация новых субгеномных РНК и инициация неканонической транскрипции сигналы тяжелого острого респираторного синдрома коронавируса.J Virol 79: 5288–5295
CAS PubMed PubMed Central Статья Google Scholar
Quan PL, Firth C, Street C, Henriquez JA, Petrosov A, Tashumukhamedova A, Hutchison SK, Egholm M, Osinubi MOV, Niezgoda M, Ogunkoya AB, Briese T, Rupprecht CE, Lipkin WI (2010) Выявление коронавирусоподобного вируса тяжелого острого респираторного синдрома у летучей мыши-листоноса в Нигерии. МмБио 1: 00208–00210
Google Scholar
Wu F, Zhao S, Yu B, Chen YM, Wang W, Song ZG, Hu Y, Tao ZW, Tian JH, Pei YY, Yuan ML, Zhang YL, Dai FH, Liu Y, Wang QM, Zheng JJ, Xu L, Holmes EC, Zhang YZ (2020) Новый коронавирус, связанный с респираторным заболеванием человека в Китае. Nature 579: 265–269
CAS PubMed PubMed Central Статья Google Scholar
Янг Д., Лейбовиц Дж. Л. (2015) Структура и функции геномных 3 ’и 5’ концов коронавируса.Virus Res 206: 120–133
CAS PubMed PubMed Central Статья Google Scholar
Jean S-S, Lee P-I, Hsueh P-R (2020) Варианты лечения COVID-19: реальность и проблемы. J Microbiol. https://doi.org/10.1016/j.jmii.2020.03.034
Артикул Google Scholar
Costanzo M, De Giglio MAR, Roviello GN (2020) SARS-CoV-2: недавние отчеты о противовирусных методах лечения на основе лопинавира / ритонавира, дарунавира / умифеновира, гидроксихлорохина, ремдесивира, фавипиравира и других препаратов для лечения нового коронавируса.Curr Med Chem 27: 32297571
Артикул Google Scholar
Цзэн QL, Yu ZJ, Gou JJ, Li GM, Ma SH, Zhang GF, Xu JH, Lin WB, Cui GL, Zhang MM, Li C, Wang ZS, Zhang ZH, Liu ZS (2020) Влияние плазменной терапии выздоравливающих на выделение вируса и выживаемость пациентов с COVID-19. J Infect Dis. https://doi.org/10.1093/infdis/jiaa228
Артикул PubMed PubMed Central Google Scholar
Caly L, Druce JD, Catton MG, Jans DA, Wagstaff KM (2020) Одобренный FDA препарат ивермектин подавляет репликацию SARS-CoV-2 in vitro . Antiviral Res 178: 104787
CAS PubMed PubMed Central Статья Google Scholar
Esposito S, Noviello S, Pagliano P (2020) Последняя информация о лечении COVID-19: продолжающиеся исследования между многообещающими и разочаровывающими результатами. Le Infezioni Med 2: 198–211
Google Scholar
Купфершмидт К., Коэн Дж. (2020) Гонка за методами лечения COVID-19 ускоряется. Наука 367: 1412–1413
CAS PubMed Статья Google Scholar
Сигел Д., Доерффлер Е., Кларк МО, Чун К., Чжан Л., Невилл С., Карра Е., Лью В., Росс Б., Ван К., Вулф Л., Джордан Р., Соловьева В., Нокс Дж., Перри Дж. , Perron M, Stray KM, Barauskas O, Feng JY, Xu Y, Lee G, Rheingold AL, Ray AS, Bannister R, Strickley R, Swaminathan S, Lee WA, Bavari S, Cihlar T, Lo MK, Warren TK, Mackman RL (2017) Открытие и синтез фосфорамидатного пролекарства пирроло [2,1-f] [триазин-4-амино] аденин C-нуклеозида (GS-5734) для лечения лихорадки Эбола и новых вирусов.J Med Chem 60: 1648–1661
CAS PubMed PubMed Central Статья Google Scholar
Gordon CJ, Tchesnokov EP, Woolner E, Perry JK, Feng JY, Porter DP, Götte M (2020) Ремдесивир — это противовирусный препарат прямого действия, который ингибирует РНК-зависимую РНК-полимеразу от тяжелого острого респираторного синдрома, вызванного коронавирусом 2. с высокой потенцией. J Biol Chem. https://doi.org/10.1074/jbc.RA120.013679
Артикул PubMed PubMed Central Google Scholar
Meyerowitz EA, Vannier AGL, Friesen MGN, Schoenfeld S, Gelfand JA, Callahan MV, Kim AY, Reeves PM, Poznansky MC (2020) Переосмысление роли гидроксихлорохина в лечении COVID-19. FASEB J 34 (5): 6027–6037
CAS PubMed Статья PubMed Central Google Scholar
Touret F, de Lamballerie X (2020) Хлорохина и COVID-19. Antiviral Res 177: 104762
CAS PubMed PubMed Central Статья Google Scholar
Wong YK, Yang J, He Y (2020) Осторожность и ясность, необходимые при использовании хлорохина для COVID-19. Lancet Rehumatol 2: 255
Артикул Google Scholar
Джойс Э., Фабр А., Махон Н. (2012) Кардиотоксичность гидроксихлорохина, проявляющаяся как быстро развивающаяся бивентрикулярная кардиомиопатия: ключевые диагностические особенности и обзор литературы. Eur Heart J 2: 77–83
Google Scholar
Geleris J, Sun Y, Platt J, Zucker J, Baldwin M, Hripcsak G, Labella A, Manson D, Kubin C, Barr RG, Sobieszczyk ME, Schluger NW (2020) Оберзационное исследование гидроксихлорохина у госпитализированных пациентов с Covid-19 . N Engl J Med. https://doi.org/10.1056/NEJMoa2012410
Артикул PubMed PubMed Central Google Scholar
Pati ML, Hornick JR, Niso M, Berardi F, Spitzer D, Abate C, Hawkins W. (2017) Производные агонистов рецептора сигма-2 1-циклогексил-4- [3- (5-метокси- 1,2,3,4-тетрагидронафталин-1-ил) пропил] пиперазин (PB28) вызывает гибель клеток за счет выработки митохондриального супероксида и активации каспазы при раке поджелудочной железы.BMC Рак 17:51
PubMed PubMed Central Статья CAS Google Scholar
Рива Л., Юань С., Инь Х, Мартин-Санчо Л., Мацунага Н., Бургшталлер-Мюльбахер С., Паш Л., Де Хесус П.П., Халл М.В., Чанг М., Чан Дж.Ф.-В, Цао Дж., Пун ВК-М, Герберт К., Нгуен Т.Т., Пу И, Нгуен С., Рубанов А., Мартинес-Собридо Л., Лю В.К., Миорин Л., Уайт К.М., Джонсон-младший, Беннер С., Сан Р., Шульц П.Г., Су А., Гарсия- Састре А., Чаттерджи А.К., Юен К.Ю., Чанда С.К. (2020) Крупномасштабное исследование по репозиционированию лекарств для противовирусных препаратов SARS-CoV-2.bioRxiv. https://doi.org/10.1101/2020.04.16.044016
Артикул PubMed PubMed Central Google Scholar
Xu J, Zhang Y (2020) Лечение COVID-19 традиционной китайской медициной. Дополнение Ther Clin Pract 39: 101165
PubMed Статья PubMed Central Google Scholar
Chen CH, Dickman KG, Moriya M, Zavadil J, Sidorenko VS, Edwards KL, Gnatenko DV, Wu L, Turesky RJ, Wu XR, Pu YS, Grollman AP (2012) Уротелиальный рак, связанный с аристолоховой кислотой в Тайване.Proc Natl Acad Sci USA 109: 8241–8246
CAS PubMed Статья Google Scholar
Дуань Л., Го Л., Ван Л., Инь К., Чжан С.-М. и др. (2018) Применение метаболомики в оценке токсичности традиционных китайских лекарств. Чин Мед 13:60
CAS PubMed PubMed Central Статья Google Scholar
Lv W, Piao J-H, Jiang J-G (2012) Типичные токсичные компоненты в традиционной китайской медицине.Мнение эксперта по наркотикам Saf 11: 985–1002
CAS PubMed Статья Google Scholar
Wassenaar TM, Zou Y (2020) 2019_nCoV / SARS-CoV-2: быстрая классификация вирусов бета-короны и идентификация традиционной китайской медицины как потенциального источника зоонозных коронавирусов. Lett Appl Microbiol 70: 342–348
CAS PubMed PubMed Central Статья Google Scholar
Lurie N, Saville M, Hatchett R, Halton J (2020) Разработка вакцин против Covid-19 со скоростью пандемии. N Engl J Med. https://doi.org/10.1056/NEJMp2005630
Артикул PubMed Google Scholar
Brown BL, McCullough J (2020) Лечение новых вирусов: плазма выздоравливающих и COVID-19. Transfus Apher Sci. https://doi.org/10.1016/j.transci.2020.102790
Артикул PubMed PubMed Central Google Scholar
Xu S, Li Y (2020) Остерегайтесь второй волны COVID-19. Ланцет 395: 1321–1322
CAS PubMed PubMed Central Статья Google Scholar
Леунг К., Ву Дж.Т., Лю Д., Люн Г.М. (2020) Передача и серьезность первой волны COVID-19 в Китае за пределами провинции Хубэй после мер контроля и планирование сценария второй волны: оценка воздействия моделирования. Ланцет 395: 1382–1393
CAS PubMed PubMed Central Статья Google Scholar
Ceraolo C, Giorgi FM (2020) Геномная дисперсия коронавируса 2019-nCoV. J Med Virol 92: 522–528
CAS PubMed PubMed Central Статья Google Scholar
https://swissmodel.expasy.org/repository/species/2697049. По состоянию на 26 апреля 2020 г., 6:05
Геномные мутации и изменения вторичной структуры белка и доступность растворителя SARS-CoV-2 (вирус COVID-19)
Ген S
Спайковый белок S содержит 1273 АК.Количество записей GenBank, содержащих полные CDS белка S, составляет 4434 с 259 уникальными последовательностями AA. Среди них 1156 последовательностей не имеют мутаций или синонимичных мутаций, в то время как другие 3278 последовательностей имеют делеционные или несинонимичные мутации. Нет инсерционной мутации среди 4434 последовательностей белка S. Имеется 34 делеционные мутации, встречающиеся в шести последовательностях с и 28 уникальными делециями . Последовательности в записях MT012098 (Индия: штат Керала, 27 января 2020 г.) и MT412290 (США: Вашингтон, 01 апреля 2020 г.) имеют по одной делеции Y145-.Последовательность в MT621560 (Гонконг в 2020-03 гг.) Имеет десять делеций непрерывно, состоящих из N679-, S680-, P681-, R682-, R683-, A684-, R685-, S686-, V687- и A688-. Последовательность в MT479224 (Тайвань, 18.03.2020) имеет 14 делеций, распределенных по двум сегментам делеций. Первый сегмент включает девять делеций I68-, H69-, V70-, S71-, G72-, T73-, N74-, G75- и T76-, а второй включает пять делеций Q675-, T676-, Q677-, T678-. и N679-. Последовательности MT474127 и MT460124 (обе собраны в США: CA 27 марта 2020 года и 28 апреля 2020 года соответственно) аналогичным образом имеют четыре делеции L141-, G142-, V143- и Y144-.Передача вируса могла произойти между этими двумя изолятами, но это требует дальнейшего изучения. Выравнивание этих последовательностей показано на рис. 9.
Рисунок 9Делеции в белке S, которые все находятся за пределами области RBD (319–541), предполагая, что RBD, возможно, был эволюционно оптимизирован с целью связывания с клетка-хозяин. Цифры вверху показывают положения остатков в белке. Слева представлены регистрационные номера GenBank, даты сбора и названия изолятов.
Количество несинонимичных мутаций в гене S составляет 3711, с 240 отдельными мутациями. Мутации, которые происходят в 10 или более случаях, представлены в таблице 10. Число синонимичных мутаций составляет 670, что составляет соотношение между несинонимичными и синонимичными мутациями на уровне 5,54. Среди несинонимичных мутаций чрезвычайно распространена мутация D614G , поскольку это происходит в 3089 последовательностях, в основном собранных в США (2340), Индии (210) и Австралии (132). Дата первого сбора данных мутации D614G не может быть идентифицирована точно, потому что некоторые последовательности, депонированные в NCBI GenBank, не записали полную дату.Текущие данные показывают, что сначала была собрана одна из следующих последовательностей с мутацией D614G: MT326173 в США в 2020 г. или MT270104, MT270105, MT270108 и MT270109 все в Германии: Bavaria в 2020-01 гг. Или MT503006 в Таиланде в 2020-01-04. Однако важно отметить, что первый пациент, имеющий мутацию D614G, и его / ее местонахождение могут никогда не быть известны, поскольку геном этого пациента не может быть секвенирован и не зарегистрирован. Таким образом, информация, представленная здесь, может помочь в дальнейшем расследовании.
С другой стороны, в Таиланде встречается 37 мутаций A829T. Первый случай этой мутации был зарегистрирован 23 января 2020 года, а последний — 07 апреля 2020 года. Это может указывать на то, что первый случай, вероятно, был передан другим пациентам с той же мутацией A829T в Таиланде. Альтернативно, мутации h246Y (24 случая), V483A (11 случаев), E554D (14 случаев), P681L (16 случаев) и S939F (11 случаев) встречаются только в США, или мутация L8V (4 случая) встречается только в Гонконге ( см. данные электронной таблицы, которые можно найти в разделе «Доступность данных»).
Таблица 10 Ген S — несинонимичные мутации, встречающиеся в 10 или более последовательностях.Мы идентифицируем область RBD в диапазоне остатков Arg319-Phe541 белка S на основе исследования в 38 . Только в области RBD количество несинонимичных мутаций составляет 53, а количество синонимичных — 46, что составляет соотношение 1,15. Это намного меньше, чем соотношение 5,54 для всего гена S, предполагая, что область RBD могла быть оптимизирована для связывания с рецептором клетки-хозяина.Это дополняется фиг. 9, на которой показаны все делеционные мутации в гене S, находящиеся за пределами области RBD. Обратите внимание, что различие этих соотношений частично связано с большим количеством мутаций D614G (3089), которые находятся за пределами области RBD.
В таблице 11 приведены несинонимичные мутации в области RBD, встречающиеся в 2 или более последовательностях. Заметной мутацией в этой области является V483A, встречающаяся в 11 изолятах, собранных в США. Даты первого и последнего сбора этих изолятов были соответственно 5 марта 2020 г. и 05 апреля 2020 г., что позволяет предположить, что первый изолят мог распространиться среди других, имеющих ту же мутацию V483A.Аналогичным образом мутация G476S встречается в 6 изолятах, собранных в США: Вашингтон с 10 марта по 25 марта 2020 года. В качестве альтернативы мутация Y453F встречается в 5 последовательностях всех в Нидерландах, но первая дата сбора была 25 апреля 2020 года, а самая последняя дата сбора — 29 апреля 2020 года. Эти даты слишком близки, что указывает на то, что все зарегистрированные случаи Y453F могли быть инфицированы от другого случая, чей геном не был секвенирован и не был зарегистрирован в NCBI GenBank. Важно отметить, что все последствия передачи требуют дальнейшего изучения с дополнительными данными по другим аспектам, таким как история поездок, физические контакты и так далее.
Таблица 11 Ген S — только область RBG — несинонимичные мутации, встречающиеся в 2 или более последовательностях.В гене S 164 несинонимичные мутации (69 уникальных), вероятно, вносят изменения во вторичную структуру белка. В регионе RBD: S477G [CBCTT (S )CCCC → CBCTT (S) CCCEC], P479L [CTTSC (C) CCCCC → CTTSC (C) CECCC], V483A [CCCCC (C) CTTTC → CCCCC (C) CCTTC], и F486L [CCCCT (T) TCBCS → CCCEC (T) TCBCS] — четыре мутации, обладающие потенциалом изменения структуры белка.
С другой стороны, 184 несинонимичные мутации (58 уникальных) обладают потенциалом относительного изменения доступности растворителя.Из них только три мутации находятся в области RBD: V483A [eebbb (b) bebeb → eebbb (b) bbbeb], G485R [bbbbb (e) bebee → bbbbb (b) bebee] и F486L [bbbbe (b) ebeeb → bbbbb (e) ebeeb]. Две мутации , V483A и F486L , таким образом, вероятно, изменяют как вторичную структуру белка, так и относительную доступность растворителя в области RBD.
Для всего белка S 134 несинонимичные мутации (48 уникальных) имеют потенциал изменения как структуры, так и доступности растворителя. Эти мутации, встречающиеся в 2 или более последовательностях, представлены в Таблице 12. Мутация h246Y встречается в 24 случаях, а мутация P681L встречается в 16 случаях, все они собраны в США. Наиболее распространенная мутация D614G не обладает потенциалом изменять ни вторичную структуру белка, ни относительную доступность растворителя.
Таблица 12 Ген S — несинонимичные мутации, которые имеют потенциал изменения структуры и доступности растворителя, происходящий в 2 или более последовательностях.Ген E
Белок оболочки E содержит 75 AA, обнаруженных в 5852 записях GenBank с 15 уникальными последовательностями AA.Среди них 5824 последовательности не имеют мутаций или имеют только синонимичные мутации, а 28 последовательностей имеют несинонимичные мутации. Таким образом, ген E относительно стабилен и может быть использован для разработки вакцин и лекарств. Это подтверждается тем фактом, что не обнаруживает инсерционных или делеционных мутаций в гене E. Существует 14 различных несинонимичных мутаций в гене E, и те, которые встречаются в 2 или более последовательностях, представлены в таблице 13.
Пять отдельных несинонимичных мутаций мутации в гене E обладают потенциалом изменения структуры белка: S68C, S68F, P71L, D72Y и L73F.Альтернативно, 4 различные мутации могут изменить относительную доступность растворителя: L37H, L37R, D72Y и L73F. Следовательно, D72Y и L73F представляют собой две мутации в гене E, которые могут изменять как структуру белка, так и доступность растворителя.
Таблица 13 Ген E — несинонимичные мутации, встречающиеся в 2 или более последовательностях.Ген M
Белок M имеет 222 AA, и его полный CDS фигурирует в 5677 записях GenBank с 37 уникальными последовательностями AA. Есть 5557 последовательностей, не имеющих мутаций или только синонимичных мутаций, в то время как другие 120 последовательностей имеют несинонимичные мутации. В гене M не обнаружены инсерционные или делеционные мутации . Число отдельных несинонимичных мутаций в гене M составляет 37, причем те, которые встречаются в 5 или более последовательностях, показаны в таблице 14. Среди них 10 мутаций, вероятно, приведут к изменениям в белке. вторичная структура: C64F, A69S, A69V, V70F, N113B, R158L, V170I, D190N, D209Y и S214I. Альтернативно, 6 мутаций имеют потенциал изменения доступности растворителя: N113B, P123L, P132S, h255Y, D190N и T208I. Таким образом, N113B и D190N представляют собой две мутации, способные изменить как структуру белка, так и доступность растворителя в гене M.
Таблица 14 Ген М — несинонимичные мутации, встречающиеся в 5 или более последовательностях.Ген N
Белок N имеет 419 AA, и его полный CDS присутствует в 5281 изоляте с 178 уникальными последовательностями AA. Среди них 4315 последовательностей не имеют мутаций или имеют только синонимичные мутации, в то время как остальные 966 последовательностей имеют делеции или несинонимичные мутации. В гене N нет вставки . Последовательность в MT434815 (собрана в США: Нью-Йорк, 09.03.2020) имеет три последовательных делеции в Q390-, T391- и V392-, в то время как последовательность в MT370992 (США: NY on 2020-03-20) имеет шесть последовательных делеций в T366-, E367-, P368-, K369-, K370- и D371-.Две другие последовательности MT605818 и MT560525 (обе собраны в Турции 16 апреля 2020 г.) имеют три последовательные делеции в R195-, N196- и S197-. Существует 1927 несинонимичных мутаций, из которых 156 различных, и те, которые встречаются в 10 или более последовательностях, представлены в таблице 15. Заметными мутациями являются R203K, встречающиеся в 871 последовательностях, и G204R, встречающиеся в 433 последовательностях. В этом белке есть 15 мутаций, способных изменить как структуру белка, так и доступность растворителя, включая G18V, D22Y, G34W, R40C, R40L, R185C, A211S, P365H, T391I, T393I, A398S, D399E, D399H, D401Y и D402Y.
Таблица 15 Ген N — несинонимичные мутации, встречающиеся в 10 или более последовательностях.Глубокая аннотация функции белков различных бактерий из мутантных фенотипов
Предпосылки
Были секвенированы десятки тысяч бактериальных геномов, что позволило выявить предсказанные аминокислотные последовательности миллионов различных белков. Напротив, только небольшая часть этих белков была изучена экспериментально, и для большинства предполагаемые функции можно предсказать только по их сходству с экспериментально охарактеризованными белками.Однако около трети бактериальных белков недостаточно похожи на какие-либо охарактеризованные белки, чтобы их можно было аннотировать с помощью этого подхода. Кроме того, эти прогнозы часто неверны, поскольку гомологичные белки могут иметь различную субстратную специфичность 1 . Этот разрыв между последовательностью и функцией представляет собой растущую проблему для микробиологии, потому что новые бактериальные геномы секвенируются с постоянно возрастающей скоростью, в то время как экспериментальная характеристика белков остается относительно медленной 2 .
Одним из подходов к определению функции неизвестного белка является оценка последствий мутации потери функции соответствующего гена в большом количестве условий 3-6 . Мутагенез транспозонов с последующим секвенированием (TnSeq) позволяет применять этот принцип более систематически и выявлять мутантные фенотипы в масштабе всего генома. В этом подходе транспозон используется для создания сложной библиотеки мутантных штаммов, каждый из которых имеет свой сайт случайной вставки в геном.Если вставка находится внутри гена, кодирующего белок, она нарушает функцию соответствующего белка. Секвенирование ДНК может определить место вставки каждого транспозона и количественно оценить численность каждого мутантного штамма. Важно отметить, что пулы из сотен тысяч различных мутантов могут быть выращены вместе, что позволяет проводить измерения фенотипов и функции белков в масштабе всего генома в одном эксперименте 7,8 . Сочетание подхода к случайному штрих-кодированию ДНК (RB-TnSeq) отдельных мутантов дополнительно увеличивает эффективность, облегчая оценку данной библиотеки мутантов в большом количестве экспериментальных условий 9 .Здесь мы используем RB-TnSeq для непосредственного устранения разрыва между последовательностью и функцией путем систематического изучения фенотипов тысяч белков из 25 бактерий в сотнях экспериментальных условий ( Fig. 1a ).
Рис. 1. Высокопроизводительная генетика для 25 бактерий.(A) Наш подход к измерению приспособленности генов. (B) Обзор наших данных. Для каждой бактерии мы показываем количество мутантных штаммов, которые мы использовали для оценки пригодности для типичного белка (методы), типы условий, которые мы изучали, и сколько белков имело мутантные фенотипы.Сильный фенотип определяется как приспособленность <-2. (C) Пригодность генов во время использования двух источников углерода в Cupriavidus basilensis . Подробную информацию о выделенных генах см. В дополнительной таблице 5 . Данные 4-934 гидроксибензоата являются средним значением для двух биологических повторностей. (D) Мы классифицировали белки от всех бактерий по тому, насколько информативными были их аннотации (методы), и для каждого класса мы показываем, сколько белков имеют каждый тип фенотипа.
Результаты
Компендиум мутантной пригодности для 25 бактерий
Для проведения систематической оценки функций белков в филогенетически разнообразном наборе бактерий мы выбрали 25 генетически поддающихся трактовке бактерий, представляющих пять различных бактериальных отделов и 16 различных родов.Помимо модельной бактерии Escherichia coli и 22 других аэробных гетеротрофов, мы изучили строго анаэробную сульфатредуцирующую бактерию ( Desulfovibrio vulgaris ) и строго фотосинтезирующую цианобактерию ( Synechococcus elongatus ) (14, рис. 1b, ), рис. Мы создали библиотеку мутантных транспозонов с произвольными штрих-кодами для каждой из 25 бактерий, семь из которых были ранее описаны 9-11 . Для каждой мутантной популяции мы использовали TnSeq для создания полногеномных карт мест вставки транспозонов (методы).Мутантные популяции были очень сложными: от 28 252 до 504 158 вставок транспозонов с уникальным штрих-кодом на геном, что соответствует от 5 до 66 вставок для типичного (медианного) гена, кодирующего белок. Гены с очень небольшим количеством вставок транспозонов или без них, вероятно, будут важны для жизнеспособности в условиях, которые использовались для отбора мутантов. Мы идентифицировали от 289 до 614 незаменимых белков на каждую бактерию (6–23% генов в каждой), всего 10 766 незаменимых белков (Методы; Дополнительная таблица 1; Дополнительное примечание 1 ).Чтобы оценить, сколько из этих важных белков плохо аннотировано, мы классифицировали все существующие аннотации белков для каждого генома как «Подробная роль TIGR» (для подсемейств, которые аннотированы функциональными ролями с помощью TIGRFAM), «Прочие подробные» (для других функциональных аннотаций) , «Нечеткие» (для аннотаций типа «транспортер») или «Гипотетические» (для функционально неинформативных аннотаций) (Методы, Дополнительный рис. 1 ). Среди 25 бактерий мы идентифицировали 667 гипотетических белков и 480 белков с расплывчатыми аннотациями, которые были важны ( Дополнительная таблица 1 ).
Чтобы определить условия, подходящие для определения профиля приспособленности мутантов, мы протестировали рост бактерий дикого типа в широком диапазоне условий, включая использование 94 различных источников углерода и 45 различных источников азота, а также их ингибирование 55 стрессовыми соединениями, включая антибиотики, поверхностно-активные вещества и тяжелые металлы ( Дополнительные таблицы 2-4 ). Если мы определили использование или ингибирование, то мы провели эксперимент по пригодности для всего генома, используя соответствующую библиотеку мутантов.В типичном эксперименте мы вырастили пул мутантов для 4-8 поколений и использовали секвенирование штрих-кода ДНК (BarSeq) 12 для сравнения численности мутантов до и после роста ( Fig. 1a ). Для каждого гена мы определили приспособленность гена как log 2 изменения численности мутантов в этом гене во время эксперимента (методы, , рис. 1а, ).
Для каждой бактерии мы успешно оценили приспособленность в 27-129 различных экспериментальных условиях ( Рис.1b ), всего 2035 комбинаций бактерий и состояний. Эти условия включали условия роста, описанные выше, а также рост при различных pH, температуре и подвижности на чашках с агаром. Включая реплики, мы провели в общей сложности 3903 эксперимента по пригодности для всего генома, которые соответствовали нашим критериям биологической и внутренней согласованности 9 , и мы получили 14,9 миллиона значений пригодности генов для 96 024 различных несущественных генов, кодирующих белок. Условия и фитнес-данные можно просмотреть в фитнес-браузере (http: // fit.genomics.lbl.gov/). Взятые вместе, наши результаты представляют собой карты пригодности для всего генома с высоким разрешением для всех 25 исследованных бактерий.
Чтобы установить согласованность наших данных с известными функциями белков, мы изучили данные о пригодности для трех наиболее распространенных классов экспериментов: использование углерода, использование азота и стресс. Гены без фенотипов имеют значения пригодности около 0, гены, которые важны для приспособленности, имеют значения приспособленности меньше 0, а гены, вредные для приспособленности, имеют значения приспособленности больше 0 ( рис.1с ). Для использования D-фруктозы или 4-гидроксибензоата в качестве единственного источника углерода в Cupriavidus basilensis данные пригодности идентифицируют ожидаемые белки для катаболизма каждого субстрата ( Fig. 1c ). Сходным образом идентифицированы ключевые ферменты и переносчики, необходимые для использования D-аланина или цитозина в качестве единственного источника азота в Azospirillum brasilense ( Supplementary Fig. 2a ). Наконец, в Shewanella loihica ортологи откачивающего насоса тяжелых металлов CzcCBA 13 и чувствительного к цинку регулятора ZntR важны для фитнеса в присутствии повышенного содержания цинка ( Дополнительный рис.2б ). Помимо идентификации ожидаемых белков, во всех представленных примерах мы также идентифицировали белки, о которых ранее не было известно об участии в соответствующем процессе, включая отводящий насос, важный для утилизации 4-гидроксибензоата C. basilensis ( Рис. 1c , Дополнительная таблица 5 ). Таким образом, эти примеры подчеркивают, как данные о пригодности могут подтверждать аннотации белков и идентифицировать новые белки, участвующие в различных биологических процессах.
Мы идентифицировали значимый мутантный фенотип (уровень ложного обнаружения <5%) по крайней мере в одном состоянии для 28 674 из 96 024 (30%) несущественных белков, для которых мы собрали данные ( Рис. 1b ). Белки с высоким или умеренным сходством с другим белком в том же геноме (паралоги, оценка выравнивания выше 30% от оценки самовыравнивания) с меньшей вероятностью будут иметь фенотип (25% против 31%, P <10 — 15 ; Supplementary Fig. 3 ), что, вероятно, отражает генетическую избыточность.18% всех белков с измерениями пригодности были вредными для приспособленности по крайней мере в одном состоянии ( Supplementary Fig. 3 ), что согласуется с предыдущими сообщениями о том, что многие белки вредны в некоторых условиях 3,14 . Белки, аннотированные подробным описанием роли TIGR, с особой вероятностью обладали фенотипами, при этом более половины (52%) белков с данными приспособленности демонстрировали значительный фенотип ( Fig. 1d ). Напротив, белки, которые не имеют подробных аннотаций (расплывчатые или гипотетические аннотации), с меньшей вероятностью будут иметь фенотипы (27% или 19% соответственно).Тем не менее, наши анализы идентифицировали фенотипы для 4585 гипотетических белков и для 3902 других белков с расплывчатыми аннотациями ( Fig. 1d ). Они включают 2828 белков, которые не принадлежат ни к одному из охарактеризованных семейств ни в Pfam, ни в TIGRFAM 15,16 . В целом, мы идентифицировали мутантные фенотипы для 8 487 белков, которые в настоящее время не аннотированы детальной функцией, подчеркивая, что значительная часть до сих пор нечетко аннотированных или гипотетических белков выполняет критические функции у бактерий.
Консервированные фенотипы являются точными предикторами функции белков
Чтобы осветить биологическую функцию отдельных белков с использованием данных о пригодности для всего генома от множества бактерий в большом количестве экспериментальных условий, мы использовали два основных подхода: (1) Идентификация «специфических» »Фенотипы, которые наблюдаются только при одном или небольшом количестве условий; (2) Паттерны «соответствия», когда несколько белков демонстрируют одинаковые профили приспособленности во всех условиях.Кроме того, мы идентифицировали консервативные специфические фенотипы и консервативную совместимость, сравнивая данные по 25 бактериям; и мы проверили надежность этих консервативных ассоциаций для аннотирования функции белка.
Для определения конкретных фенотипов мы идентифицировали белки, которые имели значительный и заметный фенотип (| пригодность |> 1) только при одном или очень нескольких условиях (методы). Например, отток фторидного белка CrcB 17 необходим для приспособленности к повышенному фторидному стрессу у нескольких бактерий, но не для приспособленности ни в одном из сотен других экспериментальных условий, которые мы тестировали ( Рис.2а ). Среди всех генов со значительным фенотипом при любых условиях 34% имеют определенный фенотип (9 905 белков), в то время как остальные гены имеют либо слабые, но значимые фенотипы (| приспособленность | <1), либо сложные фенотипические паттерны.
Рисунок 2. Идентификация консервативных фенотипов.(A) Пример консервативного и специфического фенотипа. Каждая точка показывает пригодность crcB в эксперименте, при этом эксперименты с фторидным стрессом выделены красным. Значения меньше -4 показаны как -4.Ось Y случайна. (B) Фракция белков E. coli с определенным фенотипом в определенных средах, которые «непосредственно» участвуют в поглощении или катаболизме соединения. Консервативный указывает на то, что ортолог белка E. coli из другой бактерии важен для приспособленности во время роста с тем же соединением (приспособленность <-1). (C) Сколько белков каждого типа имели консервативный конкретный фенотип или определенный фенотип. (D) Сравнение значений пригодности для ptsP и npr из E.coli и S. oneidensis во всех испытанных условиях. Эксперименты обозначены цветом по типу. (E) Использование подролей TIGR для проверки точности ассоциаций ген-ген. (F) Сколько белков каждого типа имело по крайней мере одну ассоциацию от консервативной cofitness ( r > 0,6 у обеих бактерий) или еще от cofitness ( r > 0,8).
Чтобы оценить, являются ли определенные фенотипы полезными индикаторами функции белков, мы использовали наше понимание E.coli физиологии и спросил, можно ли использовать определенные фенотипы у этой бактерии для точного определения белков «прямой» ферментативной, регуляторной или транспортной функции в катаболическом пути. Например, все 4 белка в E. coli со специфическим фенотипом во время роста на D-ксилозе непосредственно участвуют в его утилизации ( xylABFR ). В более широком смысле, мы вручную исследовали 101 экспериментально охарактеризованный белок в соответствии с базой данных EcoCyc 18 с конкретными фенотипами по отдельным источникам углерода и азота и обнаружили, что 67% имеют известную прямую функцию либо в поглощении, либо в катаболизме этого соединения, либо в активация генов, которые являются ( Дополнительная таблица 6 ).Мы также ожидали, что если конкретный фенотип будет сохранен (ортологичный белок другой бактерии имеет заметный фенотип в том же состоянии, см. Методы), ассоциация будет более надежной. Действительно, среди тех же 101 белков E. coli мы обнаружили, что 87% белков с консервативными специфическими фенотипами напрямую участвовали в утилизации, по сравнению с 35% белков со специфическими фенотипами, которые не были консервативными ( Рис. 2b ; P <10 −4 , точный критерий Фишера; Дополнительная таблица 6 ).Таким образом, если белок имеет определенный фенотип в определенной среде, он, вероятно, будет непосредственно участвовать в использовании этого субстрата, и, следовательно, может быть назначена функция белка, и вероятность выше, если фенотип сохраняется у другой бактерии.
В целом, мы идентифицировали специфические фенотипы и консервативные специфические фенотипы для белков всех классов аннотаций ( Fig. 2c ). В частности, определенные фенотипы связали 2970 белков с неопределенными или гипотетическими аннотациями с более чем 100 различными состояниями, включая 79 источников углерода, 42 источника азота и 54 стресса.К ним относятся консервативные специфические фенотипы и, следовательно, ассоциации с высокой степенью достоверности для 733 таких плохо аннотированных белков.
Наша вторая стратегия определения роли белка была основана на наблюдении, что белки со связанными функциями часто имеют сходные паттерны приспособленности в различных условиях, что мы называем «совместимостью» 3,4 . Например, Npr и PtsP системы азот-фосфотрансферазы (PTS) в E. coli проявляют высокую совместимость ( Fig. 2d, ), что согласуется с известной ролью PtsP в фосфорилировании и активации Npr 19 .Воспользовавшись нашим всеобъемлющим набором данных о пригодности для 25 бактерий, мы теперь можем систематически выяснять, является ли сохраненная совместимость более сильным показателем функции, чем совместимость одной бактерии. Напр., Ортологи Npr и PtsP также имеют высокую совместимость с S. oneidensis ( Fig. 2d ).
Сначала мы идентифицировали все пары белков с сильно коррелированными фенотипами в организме (cofit-белки) и их подмножество с ортологичными парами белков, которые cofit у двух или более организмов (консервативные cofit-белки).Чтобы проверить, насколько точно cofitness или консервативная cofitness связывает вместе функционально связанные белки, мы затем идентифицировали пары белков с существующими подробными функциональными аннотациями (подроль TIGR из базы данных TIGRFAMs семейств белков 16 ) и определили частоту, с которой аннотация подроли белок точно «предсказывается» на основе белка cofit с наивысшей оценкой, который не находится поблизости (подробности см. в разделе «Методы»). Высокая совместимость у одной бактерии приводит к предсказаниям субролей TIGR, которые в основном верны, но точность быстро снижается по мере уменьшения оценки совместимости ( рис.2д ). Напротив, для сохраненной кофитности распад происходит намного медленнее ( Рис. 2e ). Кроме того, консервативная совместимость значительно более точна для заданного числа прогнозов: например, верхние 2000 прогнозов на основе совместимости ( r > 0,81 для пар генов от одной бактерии) имеют 62% -ное согласие, в то время как верхние 2000 прогнозов на основе сохраненной совместимости ( r > 0,56 для пар генов от обеих бактерий) имеют 69% совпадение ( P <10 -5 , точный критерий Фишера).Используя пороги r > 0,8 для cofitness или r > 0,6 для консервативной cofitness, мы идентифицировали по крайней мере одну ассоциацию cofitness или консервативной cofitness для 15% генов с данными приспособленности и для 45% генов со значительными фенотипами. Мы идентифицировали ассоциации для всех типов белков ( Fig. 2f ), в том числе для 1934 гипотетических белков и для 1674 других нечетко аннотированных белков. Когда ассоциации связывают белки, у которых отсутствуют подробные аннотации к белкам, с подролами TIGR, роли верхнего уровня разнообразны, причем наиболее распространенная роль («клеточные процессы») составляет всего 21% из них.
Комбинируя специфические фенотипы и функциональные ассоциации, основанные на совместимости, мы идентифицировали функциональную взаимосвязь для 19 962 белков, включая 5 512 белков с неопределенными или гипотетическими аннотациями. Для 1914 из этих плохо аннотированных белков мы идентифицировали консервативные ассоциации, которые, как ожидается, будут особенно надежными предикторами функции белка ( Supplementary Table 7 ). Эти результаты демонстрируют полезность конкретных фенотипов и совместимости для выяснения разнообразных ролей тысяч плохо аннотированных белков и подчеркивают преимущества сбора данных о пригодности для всего генома для множества бактерий.
Генетические обзоры биологических процессов в различных бактериях
Профили мутантной пригодности по всему геному филогенетически разнообразных бактерий в широком диапазоне биологических условий обеспечивают всесторонний генетический обзор каждого изученного биологического состояния. Чтобы проиллюстрировать это, мы исследовали белки с консервативными, специфическими и важными фенотипами (приспособленность <0) во время стресса цисплатином ( Fig. 3a ). Цисплатин реагирует с ДНК с образованием перекрестных связей, которые блокируют репликацию ДНК, поэтому мы ожидали, что белки репарации ДНК будут важны для роста в этом состоянии 3 .Действительно, из 57 семейств белков, которые были особенно важны для устойчивости к цисплатину у более чем одной бактерии, 28, как известно, участвуют в репарации ДНК, включая комплекс эксцизионной репарации нуклеотидов UvrABC и путь гомологичной рекомбинации RecFOR ( Рис. 3a, , ). Дополнительная таблица 8 ). Кроме того, 6 других охарактеризованных семейств, которые обладают консервативной чувствительностью к цисплатину, участвуют в делении клеток или сегрегации хромосом ( Fig. 3a ), что актуально, потому что повреждение ДНК может ингибировать репликацию ДНК и приводить к нитчатым клеткам 20 .
Рис. 3. Генетические обзоры состояния или класса белков.(A) Обзор консервативных специфических фенотипов при стрессе цисплатина у бактерий. Данные представляют собой среднее значение для всех успешных экспериментов с цисплатином для каждой бактерии до 5 различных концентраций. (B) Обзор конкретных фенотипов использования D-ксилозы в качестве источника углерода у 8 бактерий. В окислительном пути названия генов xylABCDX взяты из Stephens et al. 27 и не следует путать с E.coli xylAB , которые не связаны между собой. Кроме того, предполагаемые ортологи включаются в тепловую карту, даже если они не важны для утилизации D-ксилозы. Например, ксилонолактоназа связана с другими лактоназами, которые важны для катаболизма других сахаров. Данные представляют собой среднее значение 1-2 повторных экспериментов для каждой бактерии. Цветовая шкала такая же, как у панели (A). (C) Резюме улучшений аннотаций для транспортеров ABC на основе анализа конкретных фенотипов.
Мы прогнозируем, что 11 из оставшихся 23 семейств с консервативными фенотипами цисплатина также участвуют в репарации ДНК либо потому, что они содержат ДНК-родственные домены, либо потому, что аналогичные белки регулируются регулятором реакции на повреждение ДНК LexA у некоторых бактерий 21-23 .Три предполагаемых новых гена репарации ДНК ( endA, yejH, yhgF ) присутствуют в хорошо изученной бактерии E. coli, , и все 3 важны для устойчивости к ионизирующему излучению, которое также повреждает ДНК 24 . Это убедительно свидетельствует о том, что их фенотипы вызваны повреждением ДНК. Мы также подтвердили, что штамм E. coli , который имеет удаленный конец endA , чувствителен к цисплатину (дополнительный рисунок , ). Остальные 12 семейств, вероятно, косвенно играют роль в репарации ДНК, включая 3 гена, участвующих в метаболизме тРНК или рРНК.В целом, наши эксперименты с цисплатином предоставляют обзор белков, участвующих в репарации ДНК у различных бактерий, включая 28 семейств белков с известной ролью и 11 семейств белков, предполагаемая роль которых в репарации ДНК еще не изучена.
Подобные генетические обзоры систематически получали для широкого спектра изученных метаболических процессов. Чтобы проиллюстрировать это, мы идентифицировали по крайней мере один белок с консервативным, специфическим и важным фенотипом в 67 источниках углерода и 39 источниках азота.В качестве наглядного примера мы исследовали катаболизм D-ксилозы, который мы проанализировали как единственный источник углерода в 8 бактериях. Мы обнаружили, что XylAB необходим в E. coli и в 6 других бактериях, подтверждая его центральную и консервативную роль в катаболизме D-ксилозы ( Fig. 3b ). Напротив, хорошо охарактеризованный регулятор XylR E. coli и переносчик XylF не требуются для каждой из других 6 бактерий: две псевдомонады используют альтернативные транспортные белки для D-ксилозы, тогда как Phaeobacter ингибирует и Sinorhizobium meliloti требуется lacI-подобный регулятор для утилизации D-ксилозы, как предсказывалось ранее 9,25 .В отличие от 7 бактерий, которые используют канонический путь XylAB, мы обнаружили, что Sphingomonas koreensis использует альтернативный окислительный путь для утилизации D-ксилозы 26,27 . Данные о пригодности и сравнительный анализ аналогичного пути у архей 26,28 позволяют предположить, что xylX кодирует необходимый фермент 2-кето-3-дезоксилонатдегидратазу в S. koreensis ( Дополнительная таблица 9 ). Наш анализ также выявил дополнительные гены, включая lon , galM и iclR -подобный регулятор, которые демонстрируют консервативные фенотипы утилизации D-ксилозы у множества бактерий, но чьи точные роли в катаболизме D-ксилозы еще предстоит выяснить.Этот сравнительный фенотипический анализ D-ксилозы как единственного источника углерода представляет собой лишь один из более чем 100 изученных экспериментов с источниками углерода и азота и подчеркивает силу нашего подхода к проверке и открытию новых белков и путей, участвующих в основных метаболических процессах.
Точные аннотации отдельных семейств белков
Крупномасштабные данные о приспособленности мутантов также могут быть использованы для улучшения нашего понимания белков, аннотированных с общей биохимической функцией, но не обладающих специфичностью к субстрату.Чтобы проиллюстрировать это, мы использовали данные о приспособленности мутантов для систематического повторного аннотирования субстратной специфичности белков семейства 101 ABC-транспортеров, которые имеют сильные и специфические фенотипы (приспособленность <-2 и статистически значимая) во время использования различных источников углерода или азота ( рис. 3c ; Дополнительная таблица 10 ). 20 из 101 белка имеют только расплывчатые аннотации, и для них мы сделали новые прогнозы субстрата, основанные на данных о конкретном фенотипе.Например, Dshi_0548 и Dshi_0549 из Dinoroseobacter shibae аннотированы без субстратной специфичности, но важны для использования ксилита. Для еще 31 белка с умеренно специфичными субстратными аннотациями, такими как «аминокислоты», мы предсказали специфический субстрат в этой группе соединений. Например, Ac3h21_2942 и Ac3h21_2943 из Acidovorax sp. 3h21 обозначены как транспортирующие «различные полиолы», тогда как наши данные показывают, что они важны для использования полиола D-сорбита, но не полиола D-маннита.Еще 14 белков имели неправильные аннотации: например, в трех Pseudomonads переносчик L-карнитина неправильно аннотирован как переносчик холина. В 10 случаях конкретные фенотипы указывают на то, что белок транспортирует субстрат, который не был включен в аннотацию, вместе с ожидаемым субстратом. Например, PS417_12705 из P. simiae аннотируется как транспортирующий D-маннит, но этот белок также важен для использования D-сорбита и D-маннозы.24 белка имели правильные аннотации, что подтверждено нашими данными; они включали 22 случая, в которых конкретный фенотип (ы) ожидался с учетом аннотации, и 2 случая, в которых ген имел ожидаемый мутантный фенотип (ы), но ассоциация с конкретным состоянием вводила в заблуждение. Данные по оставшимся 2 белкам трудно интерпретировать. В целом, наши данные о пригодности предоставили улучшенные аннотации для 75 из 101 исследованного транспортера. Этот анализ также подчеркивает, насколько подробные вычислительные аннотации часто вводят в заблуждение: для 24 из 50 транспортеров ABC, которые были аннотированы субстратом (48%), предсказанная специфичность была ошибочной или неполной.
Аннотация не охарактеризованных семейств белков
Чтобы оценить полезность данных о пригодности для выяснения функций полностью не охарактеризованных семейств белков, мы идентифицировали консервативную совместимость или консервативный специфический фенотип для 288 белков, которые представляют 77 различных доменов с неизвестной функцией (DUF) из база данных Pfam 15 ( Дополнительная таблица 11 ). Мы вручную исследовали фенотипы этих 77 DUF и предлагаем широкие функциональные аннотации для 13 из них и конкретные молекулярные функции для дополнительных 8 ( Supplementary Note 2 ).Например, белки, содержащие UPF0126, особенно важны для утилизации глицина пятью бактериями ( Fig. 4a ). Поскольку предполагается, что это семейство является мембранным белком, мы предполагаем, что это более конкретно переносчик глицина. В качестве второго примера мы обнаружили, что члены семейства предсказанных трансмембранных белков UPF0060 обладают консервативным специфическим фенотипом в присутствии повышенного содержания таллия у трех бактерий ( Fig. 4b ). Следовательно, мы предполагаем, что белки, содержащие UPF0060, могут функционировать как таллий-специфический насос оттока.В качестве третьего примера мы обнаружили, что у трех бактерий белки, содержащие DUF2849, являются совместными с соседним геном сульфитредуктазы ( cysI ) ( Fig. 4c ). Сульфитредуктаза важна для приспособления в большинстве определенных условий среды, потому что она участвует в ассимиляции сульфата, который был единственным источником серы в нашей базовой среде, и DUF2849, по-видимому, также участвует в этом процессе. У этих трех бактерий отсутствует cysJ , который обычно является источником электронов для cysI , а другие бактериальные геномы, содержащие DUF2849, также содержат cysI , но не cysJ .На основании этих данных мы предполагаем, что DUF2849 является альтернативным источником электронов для сульфитредуктазы.
Рисунок 4. Аннотация белков из не охарактеризованных семейств.(A, B) Консервированные специфические фенотипы белков с неизвестной функцией. Каждая точка представляет пригодность белка в отдельном эксперименте. Значения меньше -4 показаны как -4. Ось Y случайна. (C) Тепловая карта данных пригодности для cysI (сульфитредуктаза) и DUF2849 у трех бактерий. (D) Тепловая карта фитнес-данных для yeaG , yeaH и ycgB от трех разных бактерий.Выделены некоторые экспериментальные условия со значительными фенотипами. Цветовая шкала такая же, как на рис. 3а.
Консервативная фенотипическая ассоциация также может использоваться для идентификации более сложных путей, содержащих неохарактеризованные белки. Например, неохарактеризованные белки YeaH и YcgB и плохо охарактеризованная протеинкиназа YeaG 29 имели высокую совместимость с шестью разными бактериями (, рис. 4d, показывает данные для трех из этих бактерий; все r> 0.7 ). Интересно, что хотя эти три белка более согласованы друг с другом, чем с любым другим белком в каждой из шести бактерий, фенотипы не сохраняются у разных видов ( Fig. 4d ). Мы подтвердили некоторые из этих ключевых фенотипов в анализах роста с отдельными мутантами. Эти эксперименты подтвердили, что в E. coli мутанты по всем трем генам имеют преимущество в росте, когда L-аргинин является источником азота ( Дополнительный рис. 5, ), тогда как в S.oneidensis , мутанты во всех трех генах растут медленно, когда источником углерода является N-ацетилглюкозамин (, дополнительный рисунок 6, ). Основываясь на этих данных и активности протеинкиназы YeaG, мы предполагаем, что эти три белка действуют вместе в консервативном сигнальном пути, который необходим для различных клеточных функций у разных бактерий. Взятые вместе, наши данные показывают, как исчерпывающие данные о пригодности могут быть использованы для создания новых экспериментальных аннотаций для не охарактеризованных семейств белков и путей.
Релевантность для всех бактерий
Помимо 25 бактерий, экспериментально изученных в настоящем исследовании, объединение данных о пригодности со сравнительной геномикой дает возможность назначить аннотации белков, полученные из фенотипа, во всех секвенированных бактериальных геномах. Чтобы решить эту проблему, мы сосредоточились на полезности нашего набора данных для освещения функций гипотетических или неопределенно аннотированных белков из филогенетически разнообразных бактериальных геномов ( методы ). Для плохо аннотированных белков из этих бактериальных геномов 14% имеют предполагаемый ортолог (с сходством последовательностей не менее 30%) со значительным фенотипом в нашем наборе данных ( рис.5а ). Более того, для 11% плохо аннотированных белков мы можем связать ортолог (сходство более 30%) с конкретным состоянием или с другим белком с совместимостью ( Fig. 5a ). Даже при 30% сходстве наши данные должны предоставить функциональное представление о многих плохо охарактеризованных бактериальных белках. Подтверждая это, используя аннотации генной онтологии, подтвержденные экспериментальными данными, Кларк и Радивояк проанализировали сходство молекулярных функций между гомологичными белками и обнаружили 60-70% функциональную консервацию для гомологов от 30-100% идентичности 30 .Неудивительно, что вероятность найти ортолог с функциональной ассоциацией в нашем наборе данных намного выше для плохо аннотированных белков из бактериальных подразделений, которые мы изучали у нескольких представителей (α, β, γ-Proteobacteria), чем для таких белков из других бактерий ( 21% против 6%). Для бактерий из этих трех подразделений мы предоставляем предполагаемые ортологи с функциональными ассоциациями примерно для 330 плохо аннотированных белков на средний геном (3913 белков на геном * 40% плохо аннотированных * 21%).Чтобы обеспечить быстрый доступ к фенотипам и функциональным ассоциациям гомологов интересующего белка, мы предоставляем веб-сервис Fitness BLAST (http://fit.genomics.lbl.gov/images/fitblast_example.html). Результаты Fitness BLAST доступны на страницах, посвященных белкам: IMG / M 31 и MicrobesOnline 32 . Мы также предоставляем веб-страницу для сравнения всех белков в бактерии с данными о пригодности. В целом, наши данные предоставляют функциональную информацию по гомологии для 14% плохо аннотированных белков для всех секвенированных бактерий.
Рис. 5. Актуальность для всех бактерий.Мы выбрали гипотетические или нечетко аннотированные белки из различных видов бактерий, мы сравнили их с генами, для которых у нас есть данные о пригодности (с использованием белка BLAST), и мы определили потенциальные ортологи как наилучшие совпадения, которые были гомологичны не менее 75% каждого из них. длина белка. Мы показываем долю этих белков, у которых есть ортолог с каждым типом фенотипа и которая превышает заданный уровень сходства последовательностей. Сходство определялось как отношение битовой оценки выравнивания к оценке выравнивания запроса с самим собой.
Обсуждение
Мы показали, что высокопроизводительная генетика может обеспечить мутантные фенотипы и функциональные ассоциации для тысяч неопределенно аннотированных и гипотетических бактериальных белков. Многие из этих функциональных ассоциаций были сохранены, что увеличивает надежность этих ассоциаций. Эти ассоциации могут также выявить ошибки в текущих вычислительных аннотациях, как мы продемонстрировали для транспортеров ABC. Кроме того, наши сравнительные данные обеспечивают беспристрастный функциональный обзор биологических процессов путем выявления белков, которые важны для пригодности в одних и тех же условиях у нескольких бактерий, как показано на примере использования D-ксилозы и стресса цисплатина.
Основной проблемой при распространении наших результатов на все бактериальные белки является их невероятное разнообразие. Хотя мы идентифицировали функциональные ассоциации для 19 962 белков и 5 512 белков, которые не имеют подробных аннотаций, они включают предполагаемые ортологи только 11% бактериальных белков, которые не имеют подробных аннотаций. Улучшение этого охвата потребует больших усилий для создания мутантов у более разнообразных бактерий: в наше исследование были включены представители только 5 из 40 подразделений бактерий, которые культивировались до сих пор.Другой задачей будет улучшение вывода о функции белка по фенотипу. Многие из нечетко аннотированных или неправильно аннотированных белков принадлежат к охарактеризованным семействам ферментов или переносчиков, и основная неопределенность в отношении их функции заключается в том, на какой субстрат они действуют. Мы предложили функциональные ассоциации для 64% белков, которые имеют значительные фенотипы, и в принципе эти ассоциации могут использоваться для автоматической идентификации физиологического субстрата для многих из этих белков.
Для тысяч белков, ранее не имевших информативной аннотации, наши мутантные фенотипы и производные от них функциональные ассоциации предоставляют богатый ресурс для проведения дальнейших исследований. Чтобы облегчить это, мы разработали веб-сайт Fitness Browser (http://fit.genomics.lbl.gov) для просмотра данных о пригодности для интересующего гена или состояния. Этот сайт также поддерживает сравнение данных о пригодности бактерий и включает инструменты для аннотации на основе последовательностей. Таким образом, наше исследование демонстрирует масштаб, с которым могут быть собраны крупномасштабные данные о пригодности у различных бактерий, и полезность этих данных для получения представления о функциях тысяч белков, тем самым помогая ликвидировать разрыв между последовательностями и функциями в организме. микробиология.
Методы
Бактерии
Бактерии, мутагенизированные в этом исследовании, перечислены в дополнительной таблице 12 . Семь бактерий были выделены из подземных вод, собранных из различных мониторинговых скважин в Центре полевых исследований Национальной лаборатории Окриджа (FRC; http://www.esd.ornl.gov/orifrc/), и пять бактерий ранее не описывались: Acidovorax sp. GW101-3h21, Pseudomonas fluorescens FW300-N1B4, P. fluorescens FW300-N2E3, P.fluorescens FW300-N2C3 и P. fluorescens GW456-L13. Acidovorax sp. GW101-3h21 выделяли в виде отдельной колонии на чашке с агаром Лурия-Бертани (LB), выращенной при 30 ° C с использованием посевного материала из лунки FRC GW101. P. fluorescens FW300-N1B4, P. fluorescens FW300-N2E3 и P. fluorescens FW300-N2C3 были изолированы при 30 ° C в условиях анаэробной денитрификации с ацетатом, пропионатом и бутиратом в качестве источника углерода. соответственно, используя посевной материал из лунки FRC FW300. Pseudomonas fluorescens GW456-L13 выделяли из лунки FRC FW456 при анаэробной инкубации на чашке с агаром LB. Ранее мы описали выделение Pseudomonas fluorescens FW300-N2E2 33 и Cupriavidus basilensis 4G11 34 . Мы также изучили отдельные мутанты нескольких организмов. Для E. coli BW25113 мы использовали делеции одного гена из коллекции Keio 35 . Для S. oneidensis MR-1 мы использовали мутанты транспозонов, которые были секвенированы индивидуально 4 .
Среды и стандартные условия культивирования
Полный список сред, используемых в этом исследовании, и их компонентов приведен в дополнительной таблице 13 . Обычно мы культивировали Acidovorax sp. GW101-3h21, Azospirillum brasilense Sp245, Burkholderia phytofirmans PsJN, Escherichia coli BW25113, все Pseudomonads и Shewanellae , Sinorhizobium meliloti , Sinorhizobium meliloti, , Sinorhizobium, , DS Cupriavidus basilensis 4G11 обычно культивировали в среде R2A. Dechlorosoma suillum PS культивировали в среде ALP 11 . Desulfovibrio vulgaris Miyazaki F выращивали анаэробно на лактат-сульфатной (MOLS4) среде, как описано ранее 36,37 . Мы использовали морской бульон (Difco 2216) для стандартного культивирования Dinoroseobacter shibae DFL-12, Kangiella aquimarina SW-154T, Marinobacter adhaerens HP15 и Phaeobacter ignens BS107. Synechococcus elongatus PCC 7942 обычно культивировали в среде BG-11 с мощностью 7000 или 9250 люкс. Все бактерии обычно культивировали при 30 ° C, за исключением Escherichia coli BW25113 и Shewanella amazonensis SB2B, которые культивировали при 37 ° C, а P. ингибирует BS107, который выращивали при 25 ° C. Штамм конъюгации E.coli WM3064 культивировали в LB при 37 ° C с добавлением диаминопимелиновой кислоты (DAP) до конечной концентрации 300 мкМ.
Высокопроизводительные анализы роста бактерий дикого типа
Для оценки фенотипических возможностей 23 аэробных гетеротрофных бактерий и определения условий, подходящих для профилирования мутантной приспособленности, мы отслеживали рост бактерий дикого типа в 96-луночном микропланшете. проба.Эти предварительные анализы роста выполняли на микропланшетном ридере Tecan (Sunrise или Infinite F200) с измерением оптической плотности (OD 600 ) каждые 15 минут. Все анализы роста на 96-луночных микропланшетах содержали 150 мкл объема культуры на лунку при исходной OD 600 0,02. Мы использовали пакет grofit в R 38 для анализа всех данных кривой роста в этом исследовании. Для использования источников углерода и азота мы протестировали 94 и 45 возможных субстратов, соответственно, в определенной среде ( дополнительных таблиц 2 и 3 ).Мы классифицировали бактерию как положительную для использования определенного субстрата, если (1) максимальная OD 600 на субстрате была по крайней мере в 1,5 раза больше, чем среднее значение для водных контролей, а интеграл под кривой (сплайн. Интеграл) составлял 10 % больше, чем в среднем для контролей с водой, или (2) успешный анализ пригодности для всего генома собирали на субстрате, как описано ниже. Мы включили второй критерий, потому что наша автоматическая оценка кривых роста дикого типа была консервативной и не включала все условия, используемые для полногеномных анализов пригодности.
Кроме того, для каждой из 23 гетеротрофных бактерий мы определили ингибирующие концентрации для 39-55 различных стрессовых соединений, включая антибиотики, биоциды, металлы, фураны, альдегиды и оксианионы. Для каждого соединения мы выращивали бактерии дикого типа в 1000-кратном диапазоне концентраций ингибитора в богатой среде. Мы использовали параметр spline.integral для grofit, чтобы подогнать кривые доза-ответ и рассчитать значения полумаксимальной ингибирующей концентрации (IC 50 ) для каждого соединения ( Дополнительная таблица 4) .Для Desulfovibrio vulgaris Miyazaki F и Synechococcus elongatus PCC 7942 мы не проводили эти предварительные анализы роста, скорее, мы просто проводили анализы приспособленности мутантов в широком диапазоне концентраций ингибиторов.
Секвенирование генома
Мы секвенировали Acidovorax sp. GW101-3h21 и пять псевдомонад с использованием комбинации Illumina и Pacific Biosciences. Для сборки Illumina-first мы использовали scythe (https: // github.com / vsbuffalo / scythe) и серп (https://github.com/najoshi/sickle) для обрезки и очистки чтения Illumina, мы собрали с помощью SPAdes 3.0 39 , мы выполнили гибридную сборку Illumina / PacBio на SMRTportal с использованием AHA 40 , мы использовали BridgeMapper на SMRTportal для исправления неправильно собранных контигов, мы сопоставили чтения Illumina с новой сборкой с помощью bowtie 2 41 , и мы использовали pilon для исправления локальных ошибок 42 . Для Acidovorax sp. GW101-3h21, вместо этого мы использовали A5 43 для сборки считывателей Illumina, а для объединения контигов мы использовали AHA.Для сборки PacBio-first мы использовали HGAP3 на SMRTportal, мы использовали Circlator, чтобы найти дополнительные соединения 44 , и мы снова использовали bowtie 2 и pilon для исправления локальных ошибок. См. Дополнительную таблицу для получения сводки этих геномных сборок и их регистрационных номеров. Кроме того, Sphingomonas koreensis DSMZ 15582 было секвенировано для этого проекта Объединенным институтом генома с использованием Pacific Biosciences.
Конструирование пулов мутантов транспозонов с произвольными штрих-кодами
Библиотеки мутантов транспозонов для семи бактерий были описаны ранее 9-11 .Другие 18 бактерий были мутагенизированы плазмидами с произвольным штрих-кодом, содержащими транспозон mariner или Tn 5, зависимый от pir- условный ориджин репликации и маркер устойчивости к канамицину, с использованием векторов, которые мы описали ранее 9 . Плазмиды были доставлены путем конъюгации с E. coli WM3064, который является ауксотрофом диаминопимелата и представляет собой pir + . Условия мутагенизации каждого организма описаны в дополнительной таблице № 15 .Как правило, мы конъюгировали донор WM3064, выращенный в средней логарифмической фазе (либо mariner, донорская плазмидная библиотека APA752, либо Tn 5, донорская плазмидная библиотека APA766) и клетки-реципиенты на 0,45 мкМ нитроцеллюлозных фильтрах (Millipore), наложенных на чашки с агаром с богатой средой с добавлением DAP . Мы использовали богатую среду, предпочитаемую получателем ( Дополнительная таблица 15, ). После конъюгации фильтры ресуспендировали в среде реципиента с обогащенной средой и помещали на чашку с агаром с обогащенной средой реципиента с добавлением канамицина.После роста мы соскребали вместе колонии, устойчивые к канамицину, в среду, богатую реципиентом, с канамицином, снова разбавляли культуру до исходного значения OD 600 0,2 в 50-100 мл среды, обогащенной реципиентом с канамицином, и выращивали мутантную библиотеку до конечного значения OD. 600 от 1,0 до 2,0. Мы добавили глицерин до конечного объема 10%, сделали несколько 1 или 2 мл смеси для замораживания при -80 ° C и собрали осадок клеток для извлечения геномной ДНК для TnSeq. Для Desulfovibrio vulgaris Miyazaki F мы отобрали мутанты-транспозоны, устойчивые к G418, в жидких средах без стадии посева ( Дополнительная таблица 15, ).
Секвенирование сайта вставки транспозона (TnSeq)
Учитывая пул мутантов, мы выполнили TnSeq только один раз, чтобы амплифицировать и секвенировать соединение транспозона и связать штрих-коды с местом в геноме 9 . Мы считали, что штрих-код надежно сопоставлен с местоположением, если это сопоставление поддерживалось как минимум 10 чтениями. (Для Shewanella sp. ANA-3 порог составлял 8 считываний.) Количество уникальных штрих-кодов (штаммов), картированных в каждой мутантной библиотеке, показано в дополнительной таблице 15 .При таком отображении численность штаммов в каждом образце можно определить с помощью более простого и дешевого протокола: амплификации штрих-кодов с помощью ПЦР с последующим секвенированием штрих-кода 12 .
Идентификация основных генов
Гены, в которых отсутствуют вставки или которые имеют очень низкий охват в исходных образцах, вероятно, будут важны или важны для роста в богатой среде, за исключением Synechococcus elongatus , были получены пулы мутантов и восстановлен в среде, содержащей дрожжевой экстракт.Мы использовали ранее опубликованные эвристические методы 10 , чтобы отличить наиболее важные гены от генов, которые слишком короткие или слишком повторяющиеся для картирования вставок. Вкратце, для каждого гена, кодирующего белок, мы вычислили общую плотность чтения в TnSeq (читается / нуклеотидов по всему гену) и плотность сайтов вставки в центральных 10-90% каждого гена (сайты / нуклеотиды). Затем мы исключили гены, в которые может быть трудно картировать вставки внутри, потому что они очень похожи на другие части генома (оценка BLAT выше 50), а также очень короткие гены менее 100 нуклеотидов.Учитывая среднюю плотность вставок и среднюю длину оставшихся генов, мы спросили, насколько коротким может быть ген, и при этом вероятность того, что он вообще не будет случайно вставлен, вообще не будет ( P <0,02, распределение Пуассона). Гены короче этого порога были исключены; порог варьировал от 100 нуклеотидов для Phaeobacter ингибирует до 600 нуклеотидов для Desulfovibrio vulgaris Miyazaki. Для остальных генов мы нормализовали плотность чтения по содержимому GC путем деления на текущую медиану плотности чтения в окне из 201 гена (отсортированных по содержимому GC).Мы нормализовали плотность вставки так, чтобы среднее значение гена составляло 1. Гены, кодирующие белок, считались важными или важными для роста, если мы не оценивали значения приспособленности для гена, и как нормализованная плотность вставки, так и нормализованная плотность считывания были ниже 0,2. Подтверждение данного подхода описано в дополнительном примечании № 1 № .
Анализы приспособленности мутантов
Для каждой библиотеки мутантов мы провели конкурентные анализы приспособленности мутантов при большом количестве условий роста, которые были выбраны на основе результатов высокопроизводительных анализов роста бактерий дикого типа (см. Выше).Полный список экспериментов, выполненных для каждой мутантной библиотеки, доступен на http://fit.genomics.lbl.gov. Наш анализ включает 385 успешных экспериментов Wetmore et al. 9 и 36 успешных экспериментов Мельника et al. 11 . Другие 3482 успешных теста на пригодность описаны здесь впервые. В общем, все анализы роста с источниками углерода, источниками азота и ингибиторами проводили, как описано ранее 9 .Вкратце, аликвоту мутантной библиотеки размораживали и инокулировали в 25 мл богатой среды с канамицином и выращивали до середины логарифмической фазы в колбе. В зависимости от мутантной библиотеки это восстановление роста заняло от 3 до 24 часов. После извлечения мы собрали осадок для экстракции геномной ДНК и секвенирования штрих-кода (BarSeq) входного или «стартового» образца. Мы использовали оставшиеся клетки для создания множественных анализов пригодности мутантов с различными источниками углерода и азота в определенных средах и различными ингибиторами в богатых средах, все при начальной OD 600 0.02. Кроме того, для большинства бактерий мы профилировали рост мутантной библиотеки при разном pH и различных температурах. После того, как мутантная библиотека выросла до насыщения в условиях селективного роста (обычно от 4 до 8 удвоений популяции), мы собрали осадок клеток для экстракции геномной ДНК и BarSeq «конечного» образца. Как описано ниже, мы вычисляем приспособленность гена по количеству штрих-кодов конечной выборки относительно начальной.
Мы использовали ряд различных форматов роста и сред для анализа мутантной пригодности 25 бактерий.Полные метаданные для всех анализов мутантной пригодности для каждой бактерии доступны на вспомогательном веб-сайте. Полный список составных компонентов для каждой питательной среды содержится в дополнительной таблице 13 . Многие анализы пригодности проводили в 48-луночных микропланшетах (Greiner) с объемом культуры 700 мкл на лунку и выращивали в планшет-ридере Tecan Infinite F200 с измерениями OD 600 каждые 15 минут. Для этих тестов с 48-луночным микропланшетом мы объединили культуры из двух репликативных лунок перед экстракцией геномной ДНК (общий объем эксперимента = 1.4 мл). Для экспериментов с 24-луночным микропланшетом мы использовали планшеты с глубокими лунками с общим объемом культуры 1,5 мл (для ингибиторов) или 2 мл (для источников углерода и азота) на лунку. Все эксперименты с 24-луночным микропланшетом выращивали в инкубационном шейкере Multitron (Innova). Для экспериментов с 24-луночным микропланшетом мы обычно отбирали OD 600 каждой культуры каждые 12–24 часа в считывающем устройстве для планшетов Tecan (после переноса клеток в 96-луночный микропланшет Greiner). Более 1000 экспериментов, в первую очередь экспериментов с источниками углерода и температурой, были проведены в стеклянных пробирках с объемом культивирования 5 мл.Для экспериментов с пробирками мы контролировали OD 600 каждые 12–24 часа с помощью стандартного спектрофотометра и кювет.
Для стрессовых экспериментов мы пытались использовать концентрацию каждого соединения, которая позволяет расти (потому что, если нет роста, то численность штаммов не изменится), но значительно подавляет рост (или, в противном случае, паттерн приспособленности может быть как если бы соединение не добавлялось). В идеале концентрация должна быть такой, чтобы скорость роста сократилась вдвое.Для аэробных гетеротрофов мы измерили рост по нескольким порядкам концентраций каждого стрессового соединения, как описано выше. Это дало приблизительную оценку того, какую концентрацию использовать. Затем, когда мы проводили тесты пригодности, мы использовали несколько различных концентраций, чтобы попытаться зафиксировать ингибирующую, но сублетальную концентрацию. Для анализов, проведенных в 48-луночных микропланшетах и выращенных на планшет-ридере Tecan Infinite F200, мы могли подтвердить, что культура была ингибирована по сравнению с контролем отсутствия стресса.Для стресс-тестов в 24-луночных, глубоколуночных микропланшетах и выращивании в шейкере Multitron мы снимали показания OD примерно каждые 12 часов, чтобы оценить, какие культуры были ингибированы. На практике мы часто проводили несколько анализов пригодности мутантов с разными концентрациями одного и того же ингибитора. Мы также собрали данные о пригодности в простых мультимедийных материалах без добавления ингибирующего соединения.
Для некоторых экспериментов с источниками углерода в Desulfovibrio vulgaris Miyazaki F, который является строго анаэробным, мы выращивали пул мутантов в трубках с подвесом 18 × 150 мм с бутилкаучуковой пробкой и алюминиевым обжимным уплотнением (Chemglass Life Sciences, Vineland, NJ ) с объемом культуры 10 мл и свободным пространством около 15 мл.Для оставшейся части фитнес-экспериментов Desulfovibrio vulgaris мы выращивали пул мутантов в 24-луночных микропланшетах внутри анаэробной камеры. Мы использовали измерения OD 600 , чтобы определить, какие культуры ингибировались различными концентрациями стрессовых соединений. Точно так же у шести других гетеротрофов мы измерили приспособленность генов во время анаэробного роста. Все анаэробные среды были приготовлены в анаэробной камере Коя с атмосферой примерно 2% H 2 , 5% CO 2 и 93% N 2 .
Для Synechococcus elongatus PCC 7942, который является строго фотосинтетическим, мы извлекли библиотеку из морозильной камеры в среде BG-11 при уровне освещенности 7000 люкс и провели фитнес-тесты при 9250 люксах. Мы использовали OD 750 для измерения роста S. elongatus . Большинство анализов пригодности мутанта S. elongatus проводили в лунках 12-луночного микропланшета (Falcon) с объемом культуры 5 мл.
В дополнение к тестам на рост в жидкой среде, мы успешно изучили подвижность 12 бактерий с помощью теста на мягком агаре.Для анализа подвижности пул мутантов инокулировали в центр чашки со средой, богатой 0,3% агаром, и «внешние» образцы с подвижными клетками удаляли бритвой через 24-48 часов. Во многих случаях мы также удаляли «внутренний» образец клеток вблизи места инокуляции. Не все бактерии, которые мы исследовали, были подвижными в этом анализе с мягким агаром, а другие были подвижными, но не дали результатов приспособленности мутантов, которые соответствовали нашим критериям качества.
Мы также оценили выживаемость четырех бактерий. В этих анализах пул мутантов подвергался стрессовым условиям (либо длительная стационарная фаза, либо низкая температура 4 ° C) в течение определенного периода; Затем, чтобы определить, какие штаммы все еще жизнеспособны, они были восстановлены в мультимедийной среде в течение нескольких поколений.После восстановления в богатой среде клетки собирали для экстракции геномной ДНК и BarSeq.
Секвенирование со штрих-кодом (BarSeq)
Экстракцию геномной ДНК и ПЦР со штрих-кодом проводили, как описано ранее 9 . Большинство экстракций геномной ДНК проводилось в 96-луночном формате с использованием робота для обработки жидкостей QIAcube HT (QIAGEN). Мы использовали протокол 98 ° C BarSeq PCR 9 , который менее чувствителен к высокому содержанию GC. В целом мы мультиплексировали 48 образцов на полосу Illumina HiSeq.Для E. coli вместо этого мы секвенировали 96 образцов на дорожку.
Вычисление значений пригодности
Данные пригодности анализировались, как описано ранее 9 . Вкратце, значение пригодности каждого штамма (индивидуальный мутант транспозона) представляет собой нормализованный логарифм 2 (количество штрих-кода штамма в конце эксперимента / количество штрих-кода штамма в начале эксперимента). Значение приспособленности каждого гена представляет собой средневзвешенное значение приспособленности его штаммов; Включены только штаммы, которые имеют достаточное количество начальных считываний и находятся в пределах 10-90% центрального гена.Среднее количество пригодных для использования штаммов на ген в каждой бактерии показано на рис. 1b. Затем значения приспособленности гена были нормализованы, чтобы исключить влияние вариации количества копий генов: медиана для каждого каркаса устанавливается равной нулю, а для больших каркасов вычитается текущая медиана значений пригодности гена. Кроме того, для больших каркасов пик распределения значений пригодности генов устанавливается равным нулю. Например, значение пригодности гена -2 означает, что штаммы со вставками мутанта транспозона в этот ген были в среднем на 25% от их исходной численности в конце эксперимента.
Фитнес-эксперименты были признаны успешными с использованием показателей качества, которые мы описали ранее. 9 . Эти показатели гарантируют, что типичный ген имеет достаточный охват, что значения приспособленности независимых вставок в один и тот же ген согласованы и что нет систематической ошибки GC 9 . Эксперименты, которые не соответствовали этим пороговым значениям, были исключены из нашего анализа. Остальные эксперименты показывают хорошее соответствие между биологическими повторами со средней корреляцией 0.88 для значений пригодности генов из определенных экспериментов со средой. Стресс-эксперименты иногда имеют слабый биологический сигнал, поскольку они обычно проводятся в богатой среде, а мутанты генов, важных для роста в богатой среде, могут отсутствовать в пулах. Тем не менее, средняя корреляция между повторными стрессовыми экспериментами составила 0,68.
Чтобы оценить надежность значения приспособленности для гена в конкретном эксперименте, мы используем статистику теста t , которая представляет собой приспособленность гена, деленную на стандартную ошибку 9 .Стандартная ошибка — это максимум двух оценок. Первая оценка основана на постоянстве пригодности штаммов в этом гене. Вторая оценка основана на количестве считываний гена.
Даже умеренные фенотипы были вполне стабильными между повторными экспериментами, если они были статистически значимыми. Например, если ген имел мягкий, но значимый фенотип в одной реплике (0,5 <| приспособленность | <2 и | t |> 4), то знак значения приспособленности был таким же в другой реплике 95.5% случаев. Поскольку это сравнение могло быть предвзятым, если бы две реплики сравнивались с одним и тем же контрольным образцом, были включены только реплики с независимыми контролями.
Гены со статистически значимыми фенотипами
Мы усреднили значения пригодности из повторных экспериментов. Мы объединили t баллов в повторных экспериментах с двумя разными подходами. Если реплики не использовали исходную выборку и были полностью независимыми, то мы использовали t comb = сумма ( t ) / sqrt ( n ), где n — количество реплик.Но если бы реплики использовали одну и ту же начальную выборку, этот показатель был бы смещенным. Чтобы исправить это, мы предположили, что начальная и конечная выборки имеют одинаковое количество шума. Это консервативно, потому что мы обычно секвенировали стартовые образцы с помощью более чем одной ПЦР и с разными тегами мультиплексирования. Учитывая это предположение и учитывая, что дисперсия (A + B) = дисперсия (A) + дисперсия (B), если A и B являются независимыми случайными величинами, легко показать, что приведенная выше оценка t comb должна быть уменьшена на коэффициент sqrt (( n ** 2 + n ) / (2 * n )), где n — количество повторов.
Наш стандартный порог значимого фенотипа был | пригодность | > 0,5 и | комбинированные т | > 4, но это было увеличено для некоторых бактерий, чтобы поддерживать уровень ложного обнаружения (FDR) менее 5%. Мы используем минимальный порог | фитнес | а также | т | чтобы учесть несовершенную нормализацию или другие небольшие отклонения в значениях пригодности. Для оценки количества ложноположительных результатов мы использовали контрольные эксперименты, то есть сравнения между разными измерениями разных аликвот одной и той же стартовой пробы.Однако мы не использовали некоторые ранее опубликованные контрольные сравнения (из 9 ), которые использовали старые настройки ПЦР и имели сильное смещение GC (чтобы исключить их, мы использовали те же пороговые значения, которые мы использовали для удаления смещенных экспериментов). Предполагаемое количество ложноположительных генов представляло собой количество контрольных измерений, превышающих пороговые значения, умноженное на количество условий и разделенное на количество контрольных экспериментов. В качестве второго подхода к оценке количества ложных срабатываний мы использовали количество ожидаемых ложных срабатываний, если значения t comb следуют стандартному нормальному распределению (2 * P ( z > t ) * #experiments * #genes).Если любая из оценок уровня ложного обнаружения превышала 5%, мы повышали наши пороговые значения для обоих | пригодности | и | т гребенчатая | с шагом 0,1 и 0,5, соответственно, до FDR <5%. Самыми высокими пороговыми значениями были | пригодность | > 0,9 и | t | > 6. Кроме того, для Pseudomonas fluorescens m FW300-N1B4 мы идентифицировали шесть генов с большими различиями между контрольными образцами (| пригодность | ≈ 2 и | t | ≈ 6). Эти гены группируются на хромосоме в две группы и тесно связаны друг с другом, а некоторые из генов аннотированы как участвующие в синтезе капсульного полисахарида.Поскольку эта бактерия довольно липкая, мы подозреваем, что мутанты по этим генам менее адгезивны и были обогащены в некоторых контрольных образцах из-за недостаточного перемешивания, поэтому эти шесть генов были исключены при оценке количества ложноположительных результатов.
Анализ последовательности
Чтобы назначить гены Pfams 15 или TIGRFAM 16 , мы использовали HMMer 3.1b1 45 и надежный предел оценки для каждой семьи. Мы использовали Pfam 28.0 и TIGRFAM 15.0. Мы использовали только тщательно отобранные семьи в Pfam («Pfam A»).
Чтобы идентифицировать предполагаемые ортологи между парами геномов, мы использовали двунаправленные совпадения наилучшего белка BLAST с как минимум 80% покрытием выравнивания в обоих направлениях. Мы не использовали какое-либо ограничение сходства, поскольку сходство фенотипа может показать, что отдаленные гомологи имеют консервативные функции.
Чтобы измерить актуальность наших данных о пригодности для различных бактерий, мы начали с 1752 бактериальных геномов из MicrobesOnline 32 . Мы сгруппировали тесно связанные геномы, если они были отделены от общего предка менее чем на 0.01 замен на сайт в высококонсервативных белках (с использованием дерева видов MicrobesOnline). Эти группы примерно соответствуют видам. Мы случайным образом выбрали по одному представителю из каждой группы, что дало нам 1236 различных бактериальных геномов. Мы выбрали 5 белков случайным образом, независимо от их аннотации, из каждого из этих геномов, чтобы сформировать нашу выборку генов, кодирующих бактериальные белки. Лучшее попадание в одну из 25 исследованных бактерий рассматривалось как потенциальный ортолог, если охват выравнивания составлял 75% или более; мы использовали диапазон пороговых значений схожести, но мы рекомендуем отсечение, чтобы отношение балла согласования BLAST к самооценке было выше 0.3 (как в 46 ).
Для оценки эволюционных взаимоотношений бактерий, которые мы изучали ( Рис. 1b ), мы использовали Amphora2 47 для идентификации 31 высококонсервативного белка в каждом геноме и для их выравнивания, мы объединили 31 выравнивание белков и мы использовали FastTree 2.1.8 48 для вывода дерева.
Специфические фенотипы
Мы определили специфический фенотип для гена в эксперименте как: | приспособленность | > 1 и | т | > 5 в этом эксперименте; | фитнес | <1 как минимум в 95% экспериментов; и значение пригодности в этом эксперименте заметно более экстремально, чем большинство других значений пригодности (| пригодность |> 95-й процентиль (| пригодность |) + 0.5).
Мы считали, что конкретный фенотип сохраняется, если потенциальный ортолог имел конкретный фенотип с тем же знаком в аналогичном эксперименте с тем же источником углерода, источником азота или стрессорным соединением (но не обязательно с использованием той же базовой среды или той же самой среды). концентрация соединения). Для специфически важных фенотипов мы также считали, что специфический фенотип сохраняется, если потенциальный ортолог имел приспособленность <-1 и t <-4 в аналогичном эксперименте.
«Прогнозирование» субролей TIGR на основе cofitness или сохраненной cofitness
Мы учитывали только совпадения, которые входили в 10 лучших совпадений cofit для гена, только совпадения с cofitness выше 0,4 (или сохраненные cofitness выше 0,4), и только совпадения, которые были на минимум 10 килобаз от запрашиваемого гена. В этих случаях мы прогнозируем, что ген будет иметь ту же подроль, что и лучший результат. При тестировании cofitness хиты были отсортированы по cofitness. При тестировании сохраненной совместимости совпадения были отсортированы по наименьшей из совместимости в этом организме и по лучшей совместимости для ортологов у других организмов.
Геном и аннотации генов
Для ранее опубликованных геномов аннотации генов были взяты из MicrobesOnline, Integrated Microbial Genomes (IMG) или RefSeq. Недавно секвенированные геномы были аннотированы RAST 49 , за исключением того, что S. koreensis DSMZ 15582 было аннотировано IMG. Сводку аннотаций генома и их регистрационных номеров см. В дополнительной таблице № 16 .
Классификация информативности аннотаций
Чтобы оценить существующие вычислительные аннотации для этих геномов, мы классифицировали все их белки в одну из четырех групп: детализированная роль TIGR, гипотетическая, неопределенная или другая детальная.(1) «Подробная роль TIGR» включает белки, которые относятся к роли TIGRFAM, отличной от «Неклассифицированной», «Неизвестной функции» или «Гипотетических белков», и имели подроль, отличную от «Неизвестный субстрат», «Двухкомпонентные системы», «Ролевая категория еще не назначена», «Другое», «Общие», «Ферменты с неизвестной специфичностью», «Домен» или «Сохраненные». (2) «Гипотетический» включает белки, содержащие описание аннотации «гипотетический белок», «неизвестная функция», «не охарактеризованный» или, если все описание соответствует «белку семейства TIGRnnnnn» или «мембранному белку».(3) Считалось, что белки имеют «расплывчатые» аннотации, если описание гена содержит «семейство», «домен-белок», «родственный белок», «связанный с транспортером» или если все описание соответствует общим неспецифическим аннотациям («abc транспортер атр-связывающий белок »,« abc-транспортер пермеаза »,« abc-транспортер-субстрат-связывающий белок »,« abc-транспортер »,« ацетилтрансфераза »,« альфа / бета-гидролаза »,« аминогидролаза »,« аминотрансфераза »,« атпаза », «Дегидрогеназа», «ДНК-связывающий белок», «fad-зависимая оксидоредуктаза», «связанная с gcn5 н-ацетилтрансфераза», «гистидинкиназа», «гидролаза», «липопротеин», «мембранный белок», «метилтрансфераза», «mfs» транспортер »,« оксидоредуктаза »,« пермеаза »,« порин »,« предсказанный ДНК-связывающий регулятор транскрипции »,« предсказанный мембранный белок »,« вероятный трансмембранный белок »,« предполагаемый мембранный белок »,« белок-приемник регулятора ответа »,« rnd транспортер »,« sam-зависимая метилтрансфераза »,« сенсорная гистидинкиназа »,« серин / треониновый белок k иназа »,« белок сигнального пептида »,« гистидинкиназа сигнальной трансдукции »,« tonb-зависимый рецептор »,« регулятор транскрипции »,« регуляторы транскрипции »или« транспортер »).Считалось, что остальные белки имеют «другие подробные» аннотации.
Чтобы идентифицировать подмножество белков, обозначенных как «гипотетические» или «неопределенные», которые не принадлежат ни к одному из описанных семейств, мы использовали Pfam и TIGRFAM. Pfam считался не охарактеризованным, если его название начиналось с DUF или UPF (что является сокращением от «не охарактеризованного семейства белков»). TIGRFAM считался не охарактеризованным, если у него не было связи с ролью или если роль верхнего уровня была «Неизвестная функция».Чтобы идентифицировать плохо аннотированные белки от различных бактерий (для Fig. 5a ), мы использовали правила только для нечетких аннотаций.
Белки | Биология для неосновных I
Что вы научитесь делать: описывать структуру и функции белков
Белки представляют собой полимеры аминокислот. Каждая аминокислота содержит центральный атом углерода, водород, карбоксильную группу, аминогруппу и переменную группу R. Группа R указывает, к какому классу аминокислот она принадлежит: электрически заряженные гидрофильные боковые цепи, полярные, но незаряженные боковые цепи, неполярные гидрофобные боковые цепи и особые случаи.
Белки имеют разные «слои» структуры: первичный, вторичный, третичный, четвертичный.
Белки выполняют в клетках самые разные функции. Основные функции включают действие в качестве ферментов, рецепторов, транспортных молекул, регулирующих белков для экспрессии генов и так далее. Ферменты — это биологические катализаторы, которые ускоряют химическую реакцию без постоянных изменений. У них есть «активные центры», где связывается субстрат / реагент, и они могут быть либо активированы, либо ингибированы (конкурентные и / или неконкурентные ингибиторы).
Результаты обучения
- Определить составные части белков
- Определите различные слои структуры белка
- Определить несколько основных функций белков
Компоненты белков
Белки являются одними из наиболее распространенных органических молекул в живых системах и обладают самым разнообразным набором функций среди всех макромолекул. Белки могут быть структурными, регуляторными, сократительными или защитными; они могут служить для транспортировки, хранения или перепонки; или они могут быть токсинами или ферментами.Каждая клетка живой системы может содержать тысячи различных белков, каждый из которых выполняет уникальную функцию. Их структуры, как и их функции, сильно различаются. Однако все они представляют собой полимеры аминокислот, расположенных в линейной последовательности.
Белки имеют разную форму и молекулярную массу; некоторые белки имеют глобулярную форму, тогда как другие имеют волокнистую природу. Например, гемоглобин — это глобулярный белок, а коллаген, обнаруженный в нашей коже, — это волокнистый белок. Форма белка имеет решающее значение для его функции.Изменения температуры, pH и воздействие химических веществ могут привести к необратимым изменениям формы белка, что приведет к потере функции или денатурации (более подробно это будет обсуждаться позже). Все белки состоят из 20 одних и тех же аминокислот по-разному.
Аминокислоты — это мономеры, из которых состоят белки. Каждая аминокислота имеет одинаковую фундаментальную структуру, которая состоит из центрального атома углерода, связанного с аминогруппой (–NH 2 ), карбоксильной группы (–COOH) и атома водорода.Каждая аминокислота также имеет другой вариабельный атом или группу атомов, связанных с центральным атомом углерода, известную как группа R. Группа R — единственное различие в структуре между 20 аминокислотами; в остальном аминокислоты идентичны.
Рис. 1. Аминокислоты состоят из центрального углерода, связанного с аминогруппой (–NH 2 ), карбоксильной группы (–COOH) и атома водорода. Четвертая связь центрального углерода варьируется среди различных аминокислот, как видно из этих примеров аланина, валина, лизина и аспарагиновой кислоты.
Химическая природа группы R определяет химическую природу аминокислоты в ее белке (то есть, является ли она кислотной, основной, полярной или неполярной).
Последовательность и количество аминокислот в конечном итоге определяют форму, размер и функцию белка. Каждая аминокислота присоединена к другой аминокислоте ковалентной связью, известной как пептидная связь, которая образуется в результате реакции дегидратации. Карбоксильная группа одной аминокислоты и аминогруппа второй аминокислоты объединяются, высвобождая молекулу воды.Полученная связь представляет собой пептидную связь.
Продукты, образованные такой связью, называются полипептидами. Хотя термины полипептид и белок иногда используются как взаимозаменяемые, полипептид технически представляет собой полимер аминокислот, тогда как термин белок используется для полипептида или полипептидов, которые объединились вместе, имеют различную форму и имеют уникальную функцию.
Эволюционное значение цитохрома c
Цитохром c является важным компонентом цепи переноса электронов, частью клеточного дыхания, и обычно он находится в клеточной органелле, митохондрии.Этот белок имеет простетическую группу гема, а центральный ион гема попеременно восстанавливается и окисляется во время переноса электрона. Поскольку роль этого важного белка в производстве клеточной энергии имеет решающее значение, за миллионы лет он очень мало изменился. Секвенирование белков показало, что существует значительная степень гомологии или сходства аминокислотных последовательностей цитохрома с среди различных видов — другими словами, эволюционное родство можно оценить путем измерения сходства или различий между последовательностями ДНК или белков различных видов.
Ученые определили, что цитохром с человека содержит 104 аминокислоты. Для каждой молекулы цитохрома с от разных организмов, которая была секвенирована на сегодняшний день, 37 из этих аминокислот появляются в одном и том же положении во всех образцах цитохрома с. Это указывает на то, что, возможно, был общий предок. При сравнении последовательностей белков человека и шимпанзе различий в последовательностях не обнаружено. Когда сравнивали последовательности человека и макаки-резуса, единственное обнаруженное различие заключалось в одной аминокислоте.В другом сравнении секвенирование человека и дрожжей показывает разницу в 44-м положении.
Структура белка
Как обсуждалось ранее, форма белка имеет решающее значение для его функции. Чтобы понять, как белок приобретает свою окончательную форму или конформацию, нам необходимо понять четыре уровня структуры белка: первичный, вторичный, третичный и четвертичный (рис. 3).
Уникальная последовательность и количество аминокислот в полипептидной цепи — это ее первичная структура.Уникальная последовательность каждого белка в конечном итоге определяется геном, кодирующим этот белок. Любое изменение в последовательности гена может привести к добавлению другой аминокислоты к полипептидной цепи, вызывая изменение структуры и функции белка. При серповидно-клеточной анемии β-цепь гемоглобина имеет единственную аминокислотную замену, вызывающую изменение как структуры, так и функции белка. Что наиболее примечательно, так это то, что молекула гемоглобина состоит из двух альфа-цепей и двух бета-цепей, каждая из которых состоит примерно из 150 аминокислот.Таким образом, молекула содержит около 600 аминокислот. Структурное различие между нормальной молекулой гемоглобина и молекулой серповидноклеточных клеток, которое резко снижает продолжительность жизни, заключается в одной из 600 аминокислот.
Рис. 2. В этом мазке крови, визуализированном при 535-кратном увеличении с помощью светлопольной микроскопии, серповидные клетки имеют форму полумесяца, а нормальные клетки имеют форму диска. (кредит: модификация работы Эда Усмана; данные шкалы от Мэтта Рассела)
Из-за этого изменения одной аминокислоты в цепи обычно двояковогнутые или дискообразные эритроциты принимают форму полумесяца или «серпа», что закупоривает артерии.Это может привести к множеству серьезных проблем со здоровьем, таких как одышка, головокружение, головные боли и боли в животе у людей, страдающих этим заболеванием.
Паттерны сворачивания, возникающие в результате взаимодействий между частями аминокислот, не относящихся к R-группам, приводят к вторичной структуре белка. Наиболее распространены альфа (α) -спиральные и бета (β)-складчатые листовые структуры. Обе структуры удерживаются в форме водородными связями. В альфа-спирали связи образуются между каждой четвертой аминокислотой и вызывают поворот аминокислотной цепи.
В β-складчатом листе «складки» образованы водородными связями между атомами в основной цепи полипептидной цепи. Группы R прикреплены к атомам углерода и проходят выше и ниже складок складки. Гофрированные сегменты выровнены параллельно друг другу, а водородные связи образуются между одинаковыми парами атомов на каждой из выровненных аминокислот. Структуры α-спирали и β-складчатых листов обнаруживаются во многих глобулярных и волокнистых белках.
Уникальная трехмерная структура полипептида известна как его третичная структура . Эта структура вызвана химическим взаимодействием между различными аминокислотами и участками полипептида. Прежде всего, взаимодействия между группами R создают сложную трехмерную третичную структуру белка. Могут быть ионные связи, образованные между группами R на разных аминокислотах, или водородные связи, помимо тех, которые участвуют во вторичной структуре. Когда происходит сворачивание белка, гидрофобные группы R неполярных аминокислот лежат внутри белка, тогда как гидрофильные группы R лежат снаружи.Первые типы взаимодействий также известны как гидрофобные взаимодействия.
В природе некоторые белки образуются из нескольких полипептидов, также известных как субъединицы, и взаимодействие этих субъединиц образует четвертичную структуру . Слабые взаимодействия между субъединицами помогают стабилизировать общую структуру. Например, гемоглобин представляет собой комбинацию четырех полипептидных субъединиц.
Каждый белок имеет свою уникальную последовательность и форму, удерживаемую химическими взаимодействиями.Если белок подвержен изменениям температуры, pH или воздействию химикатов, структура белка может измениться, потеряв свою форму в результате так называемой денатурации , как обсуждалось ранее. Денатурация часто обратима, поскольку первичная структура сохраняется, если денатурирующий агент удаляется, позволяя белку возобновить свою функцию. Иногда денатурация необратима, что приводит к потере функции. Один из примеров денатурации белка можно увидеть, когда яйцо жарят или варят.Белок альбумина в жидком яичном белке денатурируется при помещении на горячую сковороду, превращаясь из прозрачного вещества в непрозрачное белое вещество. Не все белки денатурируются при высоких температурах; например, бактерии, которые выживают в горячих источниках, имеют белки, которые адаптированы для работы при этих температурах.
Четыре уровня структуры белка (первичный, вторичный, третичный и четвертичный) показаны на рисунке 3.
Рис. 3. На этих иллюстрациях можно увидеть четыре уровня белковой структуры.(кредит: модификация работы Национального исследовательского института генома человека)
Чтобы получить дополнительную информацию о белках, просмотрите анимацию под названием «Биомолекулы: белки».Функция белков
Основные типы и функции белков перечислены в таблице 1.
| Таблица 1. Типы и функции белков | ||
|---|---|---|
| Тип | Примеры | Функции |
| Пищеварительные ферменты | Амилаза, липаза, пепсин, трипсин | Помощь в переваривании пищи за счет катаболизма питательных веществ до мономерных единиц |
| Транспорт | Гемоглобин, альбумин | Переносит вещества в крови или лимфе по всему телу |
| Строительный | Актин, тубулин, кератин | Создавать различные структуры, такие как цитоскелет |
| Гормоны | Инсулин, тироксин | Координировать деятельность различных систем организма |
| Оборона | Иммуноглобулины | Защитите организм от инородных патогенов |
| Сокращение | Актин, миозин | Эффект сокращения мышц |
| Хранение | Запасные белки бобовых, яичный белок (альбумин) | Обеспечить питание на ранних этапах развития зародыша и проростка |
Два специальных и распространенных типа белков — это ферменты и гормоны. Ферменты , которые вырабатываются живыми клетками, являются катализаторами биохимических реакций (например, пищеварения) и обычно представляют собой сложные или конъюгированные белки. Каждый фермент специфичен для субстрата (реагента, который связывается с ферментом), на который он действует. Фермент может помочь в реакциях разложения, перегруппировки или синтеза. Ферменты, которые расщепляют свои субстраты, называются катаболическими ферментами, ферменты, которые строят более сложные молекулы из своих субстратов, называются анаболическими ферментами, а ферменты, влияющие на скорость реакции, называются каталитическими ферментами.Следует отметить, что все ферменты увеличивают скорость реакции и, следовательно, считаются органическими катализаторами. Примером фермента является амилаза слюны, которая гидролизует свою субстратную амилозу, компонент крахмала.
Гормоны — это химические сигнальные молекулы, обычно небольшие белки или стероиды, секретируемые эндокринными клетками, которые контролируют или регулируют определенные физиологические процессы, включая рост, развитие, метаболизм и размножение. Например, инсулин — это белковый гормон, который помогает регулировать уровень глюкозы в крови.
Белки имеют разную форму и молекулярную массу; некоторые белки имеют глобулярную форму, тогда как другие имеют волокнистую природу. Например, гемоглобин — это глобулярный белок, а коллаген, обнаруженный в нашей коже, — это волокнистый белок. Форма белка имеет решающее значение для его функции, и эта форма поддерживается многими различными типами химических связей. Изменения температуры, pH и воздействие химикатов могут привести к необратимым изменениям формы белка, что приведет к потере функции, известной как денатурация.Все белки состоят из 20 одних и тех же аминокислот по-разному.
Вкратце: функция белков
Белки — это класс макромолекул, которые выполняют широкий спектр функций для клетки. Они помогают метаболизму, обеспечивая структурную поддержку и действуя как ферменты, переносчики или гормоны. Строительными блоками белков (мономеров) являются аминокислоты. Каждая аминокислота имеет центральный углерод, связанный с аминогруппой, карбоксильной группой, атомом водорода и R-группой или боковой цепью.Существует 20 обычно встречающихся аминокислот, каждая из которых отличается по группе R. Каждая аминокислота связана со своими соседями пептидной связью. Длинная цепь аминокислот известна как полипептид.
Белки подразделяются на четыре уровня: первичный, вторичный, третичный и (необязательно) четвертичный. Первичная структура — это уникальная последовательность аминокислот. Локальное сворачивание полипептида с образованием таких структур, как спираль α и складчатый лист β , составляет вторичную структуру.Общая трехмерная структура — это третичная структура. Когда два или более полипептида объединяются, чтобы сформировать полную структуру белка, такая конфигурация известна как четвертичная структура белка. Форма и функция белка неразрывно связаны; любое изменение формы, вызванное изменениями температуры или pH, может привести к денатурации белка и потере функции.