
Приложение 1. Непервообразные предлоги — «Грамота.ру» – справочно-информационный Интернет-портал «Русский язык»
ПУНКТУАЦИЯ ПРИ ОБОРОТАХ С НЕПЕРВООБРАЗНЫМИ ПРЕДЛОГАМИ
Общие правила
Обстоятельственные обороты могут вводиться в предложение при помощи непервообразных (производных) предлогов – простых (благодаря, вопреки, вследствие, наперекор, согласно и др.) и составных (в зависимости от, во избежание, в связи с, за отсутствием и др.). Такие конструкции могут обособляться, однако пунктуационная трудность состоит в том, что их обособление не всегда уместно, а иногда даже ошибочно.
Оборот обособляется, если требуется обозначить его границы (чтобы предложение не выглядело двусмысленным):
Во избежание неверного понимания фразы директором, были внесены изменения в документ. – Во избежание неверного понимания фразы, директором были внесены изменения в документ.
Оборот не обособляется, если он входит в состав сказуемого или тесно связан с ним по смыслу. (Как правило, в таких случаях оборот нельзя изъять из состава предложения, не исказив при этом смысл фразы.) Например:
…Казбич вообразил, будто Азамат с согласия отца украл у него лошадь… М. Лермонтов, Герой нашего времени. (смысл у Лермонтова: Казбич вообразил, будто отец Азамата дал согласие на кражу.) Ср. изменение смысла при обособлении оборота: …Казбич вообразил, будто Азамат, с согласия отца, украл у него лошадь… (=Казбич вообразил, будто Азамат украл лошадь.)
Ср. также: Сыны ветра разделили людей вопреки их желанию. И. Ефремов, На краю Ойкумены. С высоко поднятой головой она идет по жизни наравне с мужчиной , ибо свобода невозможна без полной ответственности за свою судьбу. И. Ефремов, Лезвие бритвы. В комнате Коли вечер наступал согласно законам природы, поскольку свет там давно не горел. Л. Петрушевская, Козел Ваня.
В остальных случаях можно говорить о факультативности обособления оборота (в зависимости от степени его распространенности, близости к основной части предложения, порядка слов в предложении, авторского замысла и других факторов). При этом можно выделить ряд факторов, влияющих на постановку знаков препинания.
Обычно обособляются обороты, которые:
-
располагаются между подлежащим и сказуемым: Достаточно надавить пальцем на глазное яблоко, и все реальные предметы – в отличие от галлюцинаций – раздвоятся
 В. Распутин, Уроки французского. У нас всю ночь горели костры, и корабль, на случай тревоги, был готов к отплытию. В. Ян, Финикийский корабль. Обеденный стол, в зависимости от обстоятельств, превращался то в письменный, то в кровать, когда оставался ночевать кто-нибудь из друзей, приезжавших с фронта. В. Каверин, Открытая книга.
В. Распутин, Уроки французского. У нас всю ночь горели костры, и корабль, на случай тревоги, был готов к отплытию. В. Ян, Финикийский корабль. Обеденный стол, в зависимости от обстоятельств, превращался то в письменный, то в кровать, когда оставался ночевать кто-нибудь из друзей, приезжавших с фронта. В. Каверин, Открытая книга.
-
находятся не в начале и не в конце предложения: Ровно в три часа, в соответствии с трудовым законодательством, принес ключи доктор наук Амвросий Амбруазович Выбегалло.
А. и Б. Стругацкие, Понедельник начинается в субботу. …Я заново изучил ситуацию в Праге, которая должна стать – наравне с Веной и альпийским редутом – центром решительной битвы против большевизма. Ю. Семенов, Семнадцать мгновений весны. На первых порах чего только, наряду с похвалами моему художеству, не наслушался я! В. Катаев, Трава забвенья.
-
содержат объяснение того, о чем говорится в предложении, и выделяются интонационно: …Детям, по причине малолетства, не определили никаких должностей, что, впрочем, нисколько не помешало им совершенно облениться… И. Тургенев, Малиновая вода. Кстати, Бим вовсе не представлял, ввиду отсутствия опыта, что по таким задохлым полупетухам никто никогда не отсчитывает время. Г. Троепольский, Белый Бим Черное Ухо.
Однако возможны и иные варианты пунктуационного оформления, обусловленные замыслом автора. Например: И всё же, выбрав удобный момент, Хижняк в нарушение всех правил пошел на обгон с правой стороны и поравнялся с «виллисом»… (В. Богомолов, Момент истины) – невыделение оборота, находящегося между подлежащим и сказуемым; На следующее утро благодаря многочисленным пришельцам в четверть часа остов новой землянки был закончен (В. Обручев, Земля Санникова) – невыделение оборота, находящегося не в начале и не в конце предложения.
Обручев, Земля Санникова) – невыделение оборота, находящегося не в начале и не в конце предложения.
В спорных случаях окончательное решение о постановке знаков препинания принимает автор текста.
Некоторые закономерности
Обороты со следующими предлогами могут обособляться или не обособляться в зависимости от приведенных выше условий: благодаря, ввиду, в зависимости от, в нарушение, во избежание, во исполнение, в отличие от, вплоть до, в противовес, в противоположность, в связи с, в силу, вследствие, в случае, в соответствии с, за вычетом, за недостаточностью, за неимением, за отсутствием, назло, на основании, наперекор, наравне с, наряду с, на случай, под видом, подобно, под предлогом, по истечении, по мере, по меркам, по праву, по причине, по случаю, по условиям, при наличии, при условии, против (в знач. «вопреки»), сверх (в знач. «кроме, помимо») согласно, соответственно.
Обычно обособляются (за исключением тех случаев, когда оборот входит в состав сказуемого или тесно связан с ним по смыслу) обороты с отглагольными предлогами включая, исключая, исходя из, начиная с, невзирая на, несмотря на, смотря по, судя по, а также ограничительно-выделительные обороты с предлогами
Обычно не обособляются обороты с предлогами вместо, в ответ на, в результате, вроде, за счет, наподобие, напротив, не доходя, по поводу, ради, спустя.
Все предлоги делятся на первообразные и непервообразные (производные). Первообразные предлоги – это небольшая замкнутая группа слов, не связанных живыми словообразовательными отношениями с какими-либо знаменательными словами. К ним относятся такие предлоги, как в, за, к, от, под и др.
Непервообразные предлоги – предлоги, имеющие живые словообразовательные отношения и лексико-семантические связи с знаменательными словами – существительными, наречиями и глаголами (деепричастиями). Непервообразные предлоги гораздо более многочисленны, чем предлоги первообразные. Все они делятся на три группы: предлоги отыменные ( ввиду, вследствие, за исключением, наподобие, насчет, под видом и др.), наречные (напротив, подобно, согласно и др.) и отглагольные (включая, исключая, не считая, спустя и др.).
Непервообразные предлоги гораздо более многочисленны, чем предлоги первообразные. Все они делятся на три группы: предлоги отыменные ( ввиду, вследствие, за исключением, наподобие, насчет, под видом и др.), наречные (напротив, подобно, согласно и др.) и отглагольные (включая, исключая, не считая, спустя и др.).
Некоторые составные отыменные предлоги, сохранившие живые и тесные связи с соответствующим существительным (например: в противоположность, на основании, под предлогом и др.), называют предложными сочетаниями.
Подробнее см.: Русская грамматика. М., 1980. Т. 1. § 1655–1668.
обособление слов на письме запятыми, в каких ситуациях перед конструкцией и после нее они не нужны
Обособление запятыми некоторых слов вызывает затруднение на письме и требует знания пунктуации русского языка. Подобным выражением считается исходя из. Запятая рядом с этой конструкцией ставится в соответствии с определёнными правилами, на которые следует обратить внимание, чтобы избежать ошибок.
Зависимость правописания от части речи
Расстановка запятых возле конструкции напрямую зависит от ее роли в предложении. Это выражение может относиться к разным частям речи. В контексте оно встречается:
- в виде деепричастия, входящего в состав деепричастного оборота;
- в составе союза — исходя из того, что;
- как производный предлог, устанавливающий соотношение сказуемого с обстоятельством условия (причины).
Деепричастие (обстоятельство)
Иногда выражение выступает в контексте как деепричастие исходя с предлогом из (исходя из вышесказанного, вышеизложенного, вышеперечисленного). В этом случае ему присущи определённые признаки. Отличительные черты такой части речи:
- Это самостоятельный член предложения, отвечающий на вопрос «Что делая?», который ставится от сказуемого.

- После деепричастия следует зависимое слово в родительном падеже с вопросом «Чего?».
- Деепричастие и зависимое слово вместе образуют деепричастный оборот, являющийся одновременно добавочным сказуемым и обстоятельством причины или условия (в примере выделен курсивом): «Здешние любители охоты (Что делая?), исходя из (Чего?) необычных повадок лисицы, решили поймать её».
- Относится всегда, как и связанный с ним глагол, к тому же действующему лицу (в примере — любители).
- Его можно заменить синонимом «руководствуясь чем-либо», «наблюдая» («руководствуясь необычными повадками лисицы»).
Чтобы проверить, что выражение действительно является деепричастием, можно попробовать заменить действующее лицо, деепричастный оборот и связанный с ним глагол (сказуемое). Тогда возникнет довольно распространённая ошибка. Правильно: «Любая мама, исходя из её представлений о воспитательном процессе, старается вложить в своего ребёнка только хорошее». Здесь общее действующее лицо, подлежащее — мама.
Ошибочный вариант: «В любой маме, исходя из её представлений о воспитании, возникает стремление вложить в своих детей только хорошее».
В этом случае легко получить ошибку, при которой деепричастие относится к «стремлению». Смысл теряется, поскольку у этого слова нет представлений о воспитательном процессе.
Производный предлог
Конструкция может являться производным предлогом и относиться к служебной части речи. В этом случае деепричастие теряет своё глагольное значение, выступает в роли составного отглагольного предлога и не образует вместе с относящимися к нему словами деепричастный оборот, а значит, не обособляется. Пример: «Определение размера ожидаемой квартальной прибыли производится исходя из существующего положения на рынке». Этот предлог не является членом предложения. Кроме того, его характеризуют следующие признаки:
- Его можно упустить или заменить синонимами «по результатам», «на основании», предлогами «по», «благодаря».
 Примеры: «Проценты на остаток денежных средств были начислены (Как?) исходя из годовой расчётной ставки», «Расчёт по процентам на остаток денег по вкладу производился по годовой ставке».
Примеры: «Проценты на остаток денежных средств были начислены (Как?) исходя из годовой расчётной ставки», «Расчёт по процентам на остаток денег по вкладу производился по годовой ставке». - Он не привязан к действующему лицу, имеющему связь со сказуемым.
С его помощью осуществляется причинная связь сказуемого с обстоятельством условия либо причины или между частями сказуемого.
Он похож на деепричастие и аналогичен таким же предлогам в предложно-именной конструкции (сочетании предлога и имени существительного), например, «благодаря солнцу», «спустя несколько лет».
Понять, что в предложении конструкция используется как предлог, можно, если заменить действующее лицо. Примеры: «Выбирайте нужное количество цветов исходя из этих признаков», «Нужное количество цветов выбирается исходя из этих признаков» (с заменой действующего лица). Ошибки при замене не наблюдается, значит, в контексте использован предлог.
В роли союза
Это выражение в сложноподчинённом предложении способно выступать в роли союза. Подобная конструкция содержит основание для действия в главной части (на том основании, что). В таком случае возможны два варианта его применения в контексте:
Подобная конструкция содержит основание для действия в главной части (на том основании, что). В таком случае возможны два варианта его применения в контексте:
- использование деепричастия и составного союза из того, что;
- сочетание предлога и указанного составного союза.
Выделение запятыми
Обороты с таким сочетанием слов в основном обособляются, если они не входят в состав сказуемого и не связаны с ним по смыслу.
При написании рядом с ними ставят знаки препинания, когда в предложении их можно заменить разными словами или удалить без потери смысла. Пример: «Исходя из этого, доклад оценили высоко». Понять, выделяется ли конструкция пунктуационными знаками, несложно, если провести анализ и выяснить, чем в предложении она является.
Выражение обособляется запятыми в том случае, если оно связано с главным словом в предложении. Чаще всего это касается деепричастия с предлогом. Знаки препинания ставятся:
Чаще всего это касается деепричастия с предлогом. Знаки препинания ставятся:
- Перед оборотом. Если он стоит в конце фразы, его необходимо отделить запятой: «Мужчина сказал, что он заплатит, исходя из действительной стоимости вещи».
- С двух сторон. Когда выражение находится в середине предложения и связано с действующим лицом, его следует обособить запятыми с обеих сторон: «Такие люди выбирают, исходя из своих предпочтений, как и другие тоже».
- После оборота. Если предложение начинается с указанного оборота, то после него ставится знак препинания: «Исходя из сказанного, можно сделать правильный вывод». Обычно подобная конструкция, начинающая предложение, по смыслу продолжает предыдущую мысль: «На почве ожидаются заморозки. Исходя из этого, следует быстрее собрать урожай». В данном случае выражение служит обстоятельством причины и отделяется запятой.
В виде союза при использовании конструкции «деепричастие + составной союз» это выражение служит для присоединения придаточной части в предложении и отделяется запятой от основной части.
В соответствии с правилом пунктуации запятые могут ставиться и перед союзом, и внутри производного союза (перед «что»): «Следователь предполагал всё это, исходя из того, что ему было известно о текущем положении дел».
Иногда перед конструкцией пишется союз а. В подобной ситуации между ним и указанным оборотом запятой быть не может, поскольку нет возможности удалить его из предложения или переместить.
Запятая ставится лишь после оборота: «Ему никогда не приходилось бывать в этой части города, а исходя из того, что в городке улиц немного, заблудиться он не боялся».
Знаки препинания не ставятся
Когда с главным словом в контексте связь не наблюдается, запятые не требуются. Если оборот нельзя переместить или удалить из предложения, тогда он не обособляется запятыми. В этом случае речь идёт о производном предлоге. Он не обособляется, поскольку тесно соединяется со сказуемым по смыслу или входит в его состав (информация из ресурса «Грамота. ру»).
ру»).
На письме конструкция не выделяется запятыми, когда в предложении используется в смысле «благодаря». У нее есть связь со сказуемым, но нет её с главным словом. Примеры:
- Тарифы рассчитываются исходя из общих расходов.
- Эта величина определяется исходя из условий задачи.
- Свои доводы он изложил исходя из накопленного опыта.
Когда выражение используется как составной союз с предлогом, то запятая в таком предложении также не ставится и не отделяет одну часть от другой: «Правильный ответ засчитывался исходя из того, что в каждом вопросе присутствовала скрытая ошибка».
Если внимательно прочитать правила, то нетрудно усвоить, что конструкция отделяется запятыми в зависимости от того, к какой части речи она относится.
запятые — Вводное сочетание «с точки зрения»
Я добавлю еще один ответ, чтобы прояснить ситуацию относительно «обобщенного лица».
1) Это «Словарь вводных слов».
https://popravilam.com/blog/027-ishodja-iz-pravil-i-s-tochki-zrenija-russkogo-jazyka.html
Примечание. В настоящий момент его вполне заменяет Справочник по пунктуации http://www.gramota.tv/spravka/punctum
2) Вот какое правило имеется в виду
Это С ТОЧКИ ЗРЕНИЯ кого-л., устойчивое сочетание.
Невводное, употребляется в функции обстоятельства образа действия в значении «с точки зрения чего-либо» или «с какой-либо точки зрения», а также если имеется в виду мнение обобщенного лица, не обособляется:
Пример: С точки зрения официальных советских культуроохранителей рассказчика довлатовских историй иначе как диссидентствующим охламоном не назовешь.
3) Комментарий
Вызывает сомнение отсутствие обособления в этом предложении. Если это и не вводное сочетание, то это уж точно обстоятельственный оборот, который в данной позиции вполне можно обособить. Он распространенный и является явным аналогом придаточного условного предложения. Читать и быстро понимать всё сообщение без обособления оборота затруднительно.
Тема обобщенного лица в современных правилах (Справочник по пунктуации, Розенталь) не рассматривается. Она не стала официальной, не получила поддержку.
Такая мелочная регламентация попросту вредна. Пользователи должны заучивать дополнительную информацию, которая верна только при определенных условиях.
Существующие правила вполне регламентируют ситуацию с «обобщенным лицом». Предлагается различать вводные слова и обстоятельства, в том числе по логическому ударению, которым выделяется обстоятельство.
5) О правилах
Всё русское правописание фактически регулируется двумя основными источниками — это ПАС и правила Розенталя. Дополнительно можно пользоваться Справочником по пунктуации на сайте Грамота. ру. Никаких других правил обычно не требуется, это официальные источники, на которые принято давать ссылки.
ру. Никаких других правил обычно не требуется, это официальные источники, на которые принято давать ссылки.
При ответах на форуме я по возможности всегда использую именно эти правила.
Есть ли у меня какое-то особенное (моё собственное) правило постановки знаков препинания? Да, есть, хотя я на него, конечно, не ссылаюсь. Правило простое: это дополнительное применение интонационного и структурно-грамматического анализа предложения.
Я могу назвать его правилом равновесных конструкций или правилом пропорциональности. Как архитектор строит дом, исходя из правила общих пропорций (правила золотого сечения), так и писатель должен составлять из слов и фонетических фраз гармоничную (уравновешенную) структуру.
Семантика (смысл) предложения — это то содержание, которое автор хочет донести до читателя, это самое важное. Исходя из семантического принципа, он выбирает структуру предложения, и только потом расставляет знаки препинания по правилам.
Общий путь такой: содержание — форма (структура, грамматика, интонация) — знаки препинания. Таким образом, содержание связано с пунктуацией не напрямую, а через структуру предложения.
Если автор хочет обособить (выделить) оборот, то должен выбрать для него нужную позицию и определенный объем, чтобы его было удобно обособить.
Так в конечном итоге мы должны прийти от смысла (содержания) к гармоничной фонетической форме — равновесной структуре, составленной из нескольких фраз. А чтобы читатель мог правильно прочитать эту структуру, мы используем пунктуационные знаки.
А как же правила постановки знаков препинания? В своем самом общем виде они верны и самодостаточны, то есть позволяют правильно обозначить знаками выбранную автором структуру и грамматику предложения.
Дополнительная регламентация (к примеру, в виде правил для обобщенных лиц) при этом не требуется.
Транслит по-русски
С помощью транслитератора translit.ru из букв латинского алфавита получаются буквы кириллицы, иврита, белорусского, украинского и других алфавитов. Этот транслитератор задумывался как сервис для жителей стран бывшего СССР, находящихся за границей и желающих переписываться на своем компьютере на родном языке. Если кто-нибудь говорит «Я пользуюсь транслитом по-русски», то вероятно речь идет о translit.ru. Еще его называют просто «транслит.ру», «транслитератор» или «конвертер кириллицы». Транслитератор translit.ru не является инструментом, строго следующим различным официально принятым правилам транслитерации, а полагается на собственные решения, которые исходя из опыта их использования обеспечивают определенный комфорт и удобство для сценария транслитерации «из латиницы в кириллицу», который востребован за рубежом.
1. Набор текста кириллицей на латинской клавиатуре или наоборот
2. Набор текста в других алфавитах
Набор текста в других алфавитах
3. Персональная настройка правил транслитерации
4. Виртуальная клавиатура и набор текста «слепым методом»
5. Дополнительные функции
6. Как скопировать текст?
7. Зачем нужен translit.ru (транслит)?
8. Что делать если компьютер в интернет-кафе, на работе или например в университете не может печатать русскими буквами?
9. Как работать с translit.ru (транслит)?
10. Как работать с русской клавиатурой?
11. Как настроить сцои правила транслитерации?
12. Как набрать заглавный мягкий знак, заглавный твердый знак?
13. Как набрать буквосочетания «йо» или «йе»?
14. Проблема со словосочетанинем «сх». Вместо «сxодить» получается «шодить».
15. Проблема со словосочетанинем «йо». Вместо «район» получается «раён».
16. Как ввести знаки препинания в эмуляторе русской клавиатуры?
17. Как напечатать заглавный мягкий или твердый знак?
18. Есть ли на сайте счетчик символов?
Есть ли на сайте счетчик символов?
19. Как вернуть текст если вы случайно его испортили или удалили?
20. Каковы гарантии того, что отконвертированный на translit.ru текст не станет достоянием гласности?
21. Как «превратить» русский текст в латиницу?
22. Как чередовать части текста на латинице и на кириллице?
23. Как включить JavaScript в браузере?
1. Набор текста кириллицей на латинской клавиатуре или наоборот
Убедитесь, что над окошком транслитерации включен режим «Я печатаю по-русски». Режимы переключаются клавишей F12 или ESC. Теперь просто набирайте текст латинскими буквами, в окне транслита он автоматически «переведется» в кириллицу.Если у вас на клавиатуре русская раскладка, а вы хотите набрать текст латиницей, перейдите в режим «Я печатаю на транслите» и печатайте кириллицей, она автоматически «переведется» в латиницу.
Соответствие букв кириллицы и латиницы можно увидеть чуть выше окна транслитерации. Если вас не устраивают правила транслитерации, установленные по умолчанию, вы можете настроить собственные.
2. Набор текста в других алфавитах
Над таблицей соответствия алфавитов выберите в меню язык, на котором вам нужно набрать текст, и пользуйтесь транслитом так же, как для преобразования букв латинского алфавита в кириллицу. Также язык можно выбрать, если кликнуть мышкой на название языка в самом верху страницы справа.
3. Персональная настройка правил транслитерации
Здесь Вы можете настроить собственные правила транслитерации, сохранив их на сайте. Система выдаст Вам персональный номер, по которому Вы всегда сможете получить сохраненные настройки.4. Виртуальная клавиатура и набор текста «слепым методом»
Ссылка русская клавиатура наверху слева в оранжевом поле включает воображаемую, или виртуальную, русифицированную клавиатуру. Вы можете выбрать любую удобную вам раскладку букв: «йцукен», «яверты» и др.С помощью этой клавиатуры вы можете печатать по-русски вслепую на компьютерах без поддержки русского языка, или набирать текст, кликая мышкой по буквам на экране.
5. Дополнительные функции
Над окном транслитерации есть несколько функциональных кнопок, с помощью которых вы можете скопировать набранный текст в буфер обмена, послать на печать и т.п.
6. Как скопировать текст?
Сначала выделите текст который хотите скопировать: нажмите левую кнопку мыши и проведите указателем по тексту, или же можно нажать клавишу shift, и, удерживая ее, клавишами управления курсором выделить текст. Как только требуемый участок текста выделен, его можно копировать в другое место, например в форум или почтовую программу. Есть несколько способов сделать это:а) нажмите кнопку «скопировать» наверху от окошка ввода если вы пользуетесь Internet Explorer
или б) нажмите одновременно клавиши Ctrl и C (немецкая клавиатура: Strg/C; Mac OS X: Apple/C)
или в) нажмите правую кнопку мыши, выберите опцию «Копировать»
Последний шаг. Перейдите курсором в то место, куда в итоге должен попасть текст.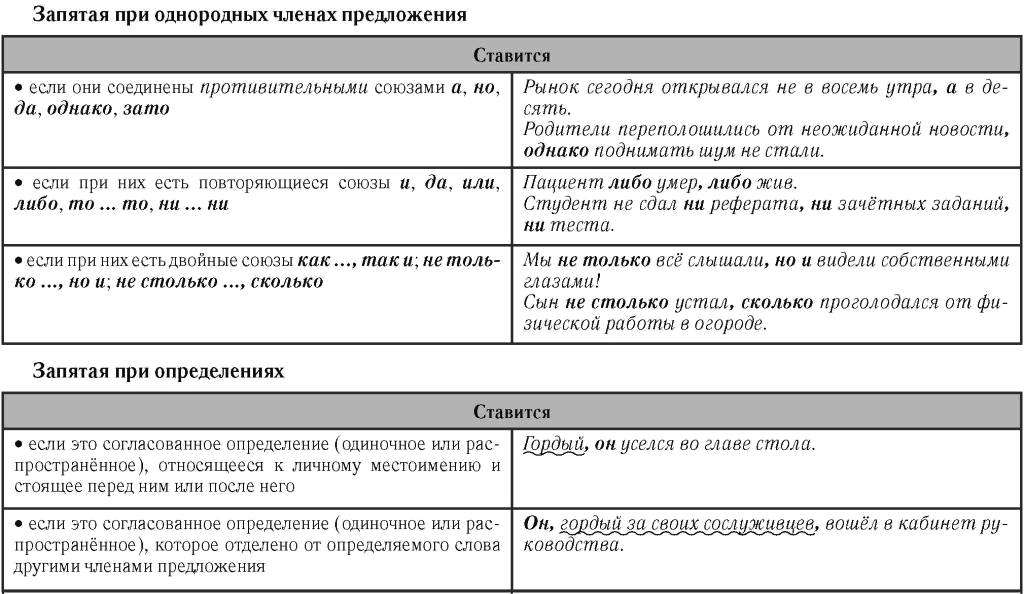 Далее вставьте текст посредством одного из следующих действий:
Далее вставьте текст посредством одного из следующих действий:
а) нажмите одновременно клавиши Ctrl и V (немецкая клавиатура: Strg/V; Mac OS X: Apple/V)
или б) нажмите правую кнопку мыши, выберите опцию «Вставить»
Текст должен появиться в месте назначения — дело сделано.
7. Зачем нужен translit.ru (транслит)?
Если Вы оказались за границей, и на компьютере, которым Вы пользуетесь, нет русской клавиатуры, то напечатать русский текст (например e-mail друзьям или родственникам) технически возможно, но на практике оказывается очень затруднительным. В таких случаях на помощь и приходит транслитератор (он же транслит, конвертер кириллицы). Принцип транслитерации — нажимая клавиши с латинскими буквами, Вы получаете кириллицу.
8. Что делать если компьютер в интернет-кафе, на работе или например в университете не может печатать русскими буквами?
Все очень просто — translit.ru решит вашу проблему. Вы всегда можете печатать по русски, чтобы набрать сообщение в форум, электронную почту родственникам и др.
9. Как работать с translit.ru (транслит)?
Набирайте текст в окне ввода и вводимые латинские символы сами собой конвертируются в кириллицу. Правила транслита приведены в таблице над окошком ввода — каждой кириллической букве соответствует латинская буква или их комбинация. На иконке-индикаторе Вы увидите, какие буквы установлены в данный момент — иконка текущего алфавита подсвечена зеленым цветом. Переключить алфавит между кириллицей и латиницей можно либо кликнув на иконку либо нажав Esc. Кнопка «В кириллицу» конвертирует текст в окошке ввода в русские буквы. Кнопка «В латиницу» — в латинские. Стереть текст в окошке можно нажав на кнопку «Очистить».
10. Как работать с русской клавиатурой?
Если Вы привыкли печатать «вслепую» и помните русскую раскладку клавиатуры наизусть, то эмуляция русской раскладки клавиатуры — это то, что Вам нужно. Специально для Вас была сделана программа, позволяющая печатать так, словно под руками русскоязычная клавиатура, т. е. с раскладкой ЙЦУКЕН. Сайтом пользуется множество людей из Германии, и для них была также сделана немецкая раскладка клавиатуры, которая отличается от американской положением некоторых клавиш и наличием умляутов. Важно! Если Вы работаете с немецкой раскладкой клавиатуры, то необходимо чтобы также системный индикатор раскладки был в положении De (справа внизу на контрольной панели Windows). Знаки препинания эмулятором клавиатуры не обрабатываются. Чтобы ввести латинские буквы либо знаки препинания, используйте индикатор переключатель (Rus-Lat над полем ввода). Нажмите клавишy Esc или кликните по индикатору мышкой.
е. с раскладкой ЙЦУКЕН. Сайтом пользуется множество людей из Германии, и для них была также сделана немецкая раскладка клавиатуры, которая отличается от американской положением некоторых клавиш и наличием умляутов. Важно! Если Вы работаете с немецкой раскладкой клавиатуры, то необходимо чтобы также системный индикатор раскладки был в положении De (справа внизу на контрольной панели Windows). Знаки препинания эмулятором клавиатуры не обрабатываются. Чтобы ввести латинские буквы либо знаки препинания, используйте индикатор переключатель (Rus-Lat над полем ввода). Нажмите клавишy Esc или кликните по индикатору мышкой.
11. Как настроить сцои правила транслитерации?
На главной странице Войдите в свой пользовательский аккаунт или зарегистрируйте новый, кликните ссылку «настроить», введите свои обозначения для букв в пункте «таблица транслитерации», не забудте сохранить настройки.
12. Как набрать заглавный мягкий знак, заглавный твердый знак?
Независимо от используемой таблицы транслитерации, общее правило таково: если буква транслитерируется знаком, или на первом месте в транслитерации стоит знак, то чтобы набрать заглавную букву, надо напечатать знак дважды. Итак, Ъ=##, Ь=»
Итак, Ъ=##, Ь=»
13. Как набрать буквосочетания «йо» или «йе»?
Чтобы вместо буквы «ё» получилось «йо», надо набирать «j+o». По аналогии, набирайте «j+e» чтобы получилось «йе». Всегда используйте + чтобы разделить буквы.
14. Проблема со словосочетанинем «сх». Вместо «сxодить» получается «шодить».
Вместо shodit’ печатайте s+hodit’ — используйте плюс как разделитель букв s и h.
15. Проблема со словосочетанинем «йо». Вместо «район» получается «раён».
Вместо rajon печатайте raj+on — используйте плюс как разделитель букв j и o.
16. Как ввести знаки препинания в эмуляторе русской клавиатуры?
Эмулятор клавиатуры поддерживает только буквы. Чтобы ввести знаки препинания или другие символы, переключитесь на латинский алфавит при помощи клавиши Esc и набирайте знаки препинания в соответствии с их расположением на вашей клавиатуре.
17. Как напечатать заглавный мягкий или твердый знак?
Заглавный мягкий знак получается если вы два раза подряд печатаете прописной мягкий знак. Чтобы получить заглавный твердый знак, напечатайте дважды прописной твердый знак.
Чтобы получить заглавный твердый знак, напечатайте дважды прописной твердый знак.
18. Есть ли на сайте счетчик символов?
Да, вам следует зарегистрироваться, зайти в настройки и включить опцию «считать символы».
19. Как вернуть текст если вы случайно его испортили или удалили?
Нажмите клавиши Ctrl-Z, либо кнопку «Вернуть» в левом верхнем углу окна ввода текста.
20. Каковы гарантии того, что отконвертированный на translit.ru текст не станет достоянием гласности?
Программы «translit.ru», «русская клавиатура», «конвертер регистров»
работают локально в вашем браузере. Т.е. набираемый или редактируемый текст не попадает на сервер, а в процессе набора существует только на вашем компьютере.
Скрипт «классический translit.ru», также как и скрипт печати текста выполняется на удаленном сервере хостинг-провайдера и не производит сохранения транслитерируемого текста на сервере, а лишь обрабатывает текст и выдает его на экран пользователю. Могу заверить Вас, уважаемый пользователь, что никакой текст никем посторонним на сайте translit.ru прочитан не будет.
Могу заверить Вас, уважаемый пользователь, что никакой текст никем посторонним на сайте translit.ru прочитан не будет.
21. Как «превратить» русский текст в латиницу?
Поместите текст в окошко ввода, а затем нажмите кнопку «в латиницу».
22. Как чередовать части текста на латинице и на кириллице?
Чтобы переключить алфавит «на лету», надо нажать клавишу Esc либо кликнуть мышкой на рисунок Lat-Rus над окном ввода. Зеленым цветом подсвечен выбранный алфавит. Если вы работаете с «классическим транслитом», то выделите текст который не должен транслитерироваться знаками подчеркивания _с обоих сторон_.
23. Как включить JavaScript в браузере?
JavaScript – встроенный в браузер язык программирования. Как включить JavaScript написано здесь. В крайнем случае, вы всегда сможте конвертировать текст в «мобильном транслите», не требующем включенного JavaScript.R Заменить последнюю запятую в строке символов знаком & (5 примеров кодов)
Если вы работаете с текстовыми данными, у вас часто будет список или перечисление слов , разделенных запятыми, например:
«Шар, животное, пиво, свинья, повозка, воздушный шар, герой»
Последнюю запятую в таких перечислениях обычно следует заменять на слова и или на & знак . Однако в R это может быть сложно, так как может быть трудно получить только последнюю запятую в вашей строке.
В следующем руководстве я покажу вам в пять примеров , как заменить последнюю запятую символа знаком & в языке программирования R.
Примечание: Исходный код этих примеров получен от других людей, которые ответили на вопрос, который я недавно задал на форуме Stack Overflow. Тема быстро набирала популярность, и по этой причине я решил создать учебник по этой теме.
Давайте погрузимся в…
Пример 1: Заменить последнюю запятую в R (подфункция)
Прежде чем мы начнем с первого примера, я собираюсь создать пример строки символов, которую я собираюсь использовать для всех примеров в этом руководстве:
x <- "word1, word2, word3" # Создать пример символа в R x # Пример вывода символов в R # "word1, word2, word3" |
x <- "word1, word2, word3" # Создать пример символа в R x # Пример вывода символов в R # "word1, word2, word3"
Наш примерный символ состоит из трех слов, разделенных запятыми. ,] *) $ ”,” & \\ 1 ″, x ).
,] *) $ ”,” & \\ 1 ″, x ).
По этой причине я покажу вам еще более простое решение для замены последней запятой символьной строки в следующем примере ...
Пример 2: Замена последней запятой с помощью пакета R stringi (функция stri_replace_last)
Для второго примера нам нужно установить и загрузить дополнительный пакет stringi R:
install.packages ("stringi") # Установить пакет stringi R
library ("stringi") # Загрузить пакет stringi R |
install.packages ("stringi") # Установить пакет stringi R library ("stringi") # Загрузить строку R package
Пакет содержит функцию R stri_replace_last, которая обеспечивает простой синтаксис для замены последней запятой нашего символа:
x2 <- stri_replace_last (x, fixed = ",", "&") # Применить stri_replace_last x2 # Вывод stri_replace_last # "word1, word2 & word3" |
x2 <- stri_replace_last (x, fixed = ",", "&") # Применить stri_replace_last x2 # Вывод stri_replace_last # "word1, word2 & word3"
Тот же вывод, что и раньше, но его гораздо легче понять (если вы спросите меня).
Однако есть еще больше возможностей, как заменить последнюю запятую в символе…
Пример 3: Пакет Stringr R (функции str_locate_all и str_sub)
Другой пакет, который можно использовать для замены запятых, - это stringr Package.
Давайте установим и загрузим пакет:
install.packages ("stringr") # Установить пакет stringr R
library ("stringr") # Загрузить пакет stringr R |
install.packages ("stringr") # Установить пакет stringr R library ("stringr") # Загрузить stringr R package
Мы можем использовать пакет для замены последней запятой нашего символа в два этапа. Во-первых, нам нужно применить функцию str_locate_all, чтобы создать матрицу, содержащую расположение всех запятых в нашем символьном объекте:
x3 <- x # Реплицировать пример символа comma_pos <- str_locate_all (x3, ",") [[1]] # Сохранить все позиции запятых comma_pos # Вывод str_locate_all |
x3 <- x # Реплицировать пример символа comma_pos <- str_locate_all (x3, ",") [[1]] # Сохранить все позиции запятых comma_pos # Вывод str_locate_all
Таблица 1: Матрица, состоящая из всех позиций запятой.
В таблице 1 вы можете увидеть, как выглядит выходная матрица str_locate_all.
Теперь мы можем использовать команду str_sub для замены позиции последней запятой (сохраненной в ранее созданной матрице) знаком &:
comma_pos_last <- comma_pos [nrow (comma_pos),] # Сохранить позицию последней запятой str_sub (x3, comma_pos_last [1], comma_pos_last [2]) <- "&" # Заменить последнюю запятую на знак & x3 # Вывод функции str_sub # "word1, word2 & word3" |
comma_pos_last <- comma_pos [nrow (comma_pos),] # Сохранить позицию последней запятой str_sub (x3, comma_pos_last [1], comma_pos_last [2]) <- "&" # Заменить последнюю запятую на знак & x3 # Вывод функции str_sub # "word1, word2 & word3"
Работает! Но оставайся со мной.Есть даже еще один пример того, как заменить запятую в строке…
Пример 4: Замена запятой за 3 шага (функции strsplit, grep и paste0)
В четвертом примере мы снова будем полагаться на базовую установку R (как мы это делали в примере 1). Пример состоит из трех основных шагов.
Пример состоит из трех основных шагов.
Шаг 1) Используйте strsplit и unlist, чтобы получить вектор из одиночных символов:
x_split <- unlist (strsplit (x, "")) # Разделить символ с помощью strsplit x_split # Вывод функции strsplit # "w" "o" "r" "d" "1" "," "" "w" "o" "r" "d" "2" "," "" "w" "o" "r" "d" "3" |
x_split <- unlist (strsplit (x, "")) # Разделить символ с помощью strsplit x_split # Вывод функции strsplit # "w" "o" "r" "d" "1" "," "" "w" "o" "r" "d" "2" "," "" "w" "o" "r" «д» «3»
Шаг 2) Используйте tail и grep для замены последней запятой:
x_split [tail (grep (",", x_split), 1)] <- "&" # Заменить последнюю запятую на &
x_split
# "w" "o" "r" "d" "1" "," "" "w" "o" "r" "d" "2" "&" "" "" w "" o "" r " "d" "3" |
x_split [tail (grep (",", x_split), 1)] <- "&" # Заменить последнюю запятую на & x_split # "w" "o" "r" "d" "1" "," "" "w" "o" "r" "d" "2" "&" "" "" w "" o "" r " «д» «3»
Шаг 3) Используйте past0, чтобы объединить все символы в один объект данных:
x4 <- paste0 (x_split, collapse = "") # Применить функцию paste0 R x4 # Вывод paste0 # "word1, word2 & word3" |
x4 <- paste0 (x_split, collapse = "") # Применить функцию paste0 R x4 # Вывод paste0 # "word1, word2 & word3"
Тот же результат, но относительно сложный. ,] *) $", "and \\ 1", x) # Замените последнюю запятую на и
# "word1, word2 и word3"
,] *) $", "and \\ 1", x) # Замените последнюю запятую на и
# "word1, word2 и word3"
… с точкой (т.,] *) $ "," \\ 1 ", x) # Полностью удалить последнюю запятую # "слово1, слово2 слово3"
Видео: Работа с персонажами в размере
рэндовВ этом руководстве я показал вам, как заменить последнюю запятую символьной строки на R. Однако основой всех этих функций и команд является понимание класса символов.
Если вы хотите узнать больше о манипулировании персонажами, я могу порекомендовать следующее видео с канала Стива Питтарда на YouTube.В видео он объясняет разницу между символьными векторами и символьными строками.
Получайте удовольствие от видео и дайте мне знать в комментариях, если у вас есть дополнительные вопросы или если у вас есть какие-либо отзывы.
Пожалуйста, примите файлы cookie YouTube для воспроизведения этого видео. Приняв согласие, вы получите доступ к контенту YouTube, услуги, предоставляемой третьей стороной.
Политика конфиденциальности YouTube
Если вы примете это уведомление, ваш выбор будет сохранен, и страница обновится.
Принять контент YouTube
Дополнительная литература
/ * Добавьте свои собственные переопределения стиля формы MailChimp в таблицу стилей вашего сайта или в этот блок стилей.Мы рекомендуем переместить этот блок и предыдущую ссылку CSS в HEAD вашего HTML-файла. * /
]]>
Пунктуация - грамматика английского языка сегодня
Наиболее распространенными знаками препинания в английском языке являются: заглавные буквы и точки, вопросительные знаки, запятые, двоеточия и точки с запятой, восклицательные знаки и кавычки.
В разговоре мы используем паузы и высоту голоса, чтобы прояснить то, что мы говорим. Пунктуация играет аналогичную роль в письме, облегчая чтение.
Пунктуация состоит из правил и условностей. Есть правила пунктуации, которые необходимо соблюдать; но существуют также правила пунктуации, которые предоставляют писателям больший выбор.
Мы используем заглавные буквы для обозначения начала предложения и точек для обозначения конца предложения:
Мы были во Франции прошлым летом.Мы были очень удивлены, что по автомагистралям было так легко путешествовать.
Чемпионат мира по футболу проводится каждые четыре года. Следующий чемпионат мира пройдет в ЮАР. В 2006 году он проходил в Германии.
Мы также используем заглавные буквы в начале имен собственных. Существительные собственные включают личные имена (включая титулы перед именами), национальность и языки, дни недели и месяцы года, государственные праздники, а также географические места:
Доктор Дэвид Джеймс - консультант городской больницы Лидса.
Они планируют длительный отпуск в Новой Зеландии.
Может ли она говорить по-японски?
Следующее собрание группы состоится в четверг.

Какие у вас планы на китайский Новый год?
Мы используем заглавные буквы в названиях книг, журналов и газет, пьес и музыки:
«Оливер» - мюзикл по роману Чарльза Диккенса «Оливер Твист».
The Straits Times - ежедневная англоязычная газета в Сингапуре.
Исполняют Шестую симфонию Бетховена.
В дополнение к заключительным предложениям мы также используем точки в инициалах для личных имен:
GW Dwyer
Дэвид А. Джонстон, бухгалтер
Точки после сокращений также используются , хотя такая практика становится все менее распространенной:
Arr . (прибытие) | и т. Д. . (и т. Д.) |
Dr . | Проф . (профессор) |
 (врач)
(врач)Мы используем вопросительные знаки, чтобы прояснить, что сказанное является вопросом. Когда мы используем вопросительный знак, мы не используем точку:
Почему они делают так много ошибок?
A:
Так вы двоюродный брат Гарри ?
Мы используем восклицательные знаки для обозначения восклицательного предложения или выражения в неформальной письменной форме.Когда мы хотим подчеркнуть что-то в неформальном письме, мы иногда используем более одного восклицательного знака:
Слушайте!
О нет !!! Пожалуйста, не проси меня позвонить ей. Она будет говорить часами !!!
Мы используем запятые для разделения списка похожих слов или фраз:
Важно писать ясными, простыми и точными словами.

Они были более дружелюбными, разговорчивыми, более открытыми, чем в прошлый раз, когда мы встречались с ними.
Обычно мы не используем запятую перед и в конце списка отдельных слов:
Они путешествовали через Болгарию, Словакию, Чехию и Польшу.
Американский английский использует запятую в списках перед и :
Мы взяли с собой хлеб, сыр и фрукты.
Мы используем запятые для разделения слов или фраз, которые отмечают места, где голос мог бы немного остановиться:
Я не могу вам сейчас сказать.Однако все станет известно завтра в полдень.
Фактически мы потеряли все наши деньги.
Джеймс, наш гид, будет сопровождать вас на лодке до острова.
Когда главные предложения разделяются и , или , , но , мы обычно не используем запятую, если предложения имеют один и тот же предмет. Однако мы иногда используем запятые, если пункты имеют разные темы:
Однако мы иногда используем запятые, если пункты имеют разные темы:
Они были очень дружелюбны и пригласили нас на свою виллу в Португалии. (тот же предмет)
Сегодня футболисты зарабатывают больше денег, но они в хорошей физической форме и играют гораздо больше матчей. (та же тема)
Это был дорогой отель в центре Стокгольма, но мы решили, что он того стоит. (разные темы)
Когда подчиненное предложение ставится перед основным предложением, мы обычно используем запятую для разделения предложений. Однако мы не всегда делаем это короткими предложениями:
Если вы заблудились в центре города, не стесняйтесь писать нам или звонить.
Если вы заблудились, просто позвоните нам.
Когда мы используем подчиненные или не конечные предложения комментариев, чтобы дать дополнительную информацию или дополнительную информацию, мы обычно используем запятые для разделения предложений:
Вам действительно нужно носить более темную куртку, если я могу так сказать.

Если честно, мне показалось, что они были очень грубыми.
Мы используем запятые для обозначения не определяющих предложений. Такие предложения обычно добавляют дополнительную, несущественную информацию об существительном или существительном словосочетании:
Машина скорой помощи, прибывшая всего через пять минут, немедленно доставила трех человек в больницу.
Гонконг, где проходила первая встреча АСЕАН, сейчас совсем другой город.
То же самое верно и для не конечных статей:
Шторм, продолжавшийся несколько дней, нанес серьезный ущерб деревням на побережье.
Предупреждение:
Мы не используем запятые для обозначения определяющих предложений:
Барселона была испанским городом, выбранным для проведения Олимпийских игр.
Не:… выбранный испанский город…
Обычно мы разделяем теги и да-нет ответы запятыми:
Они собираются на вечеринку, не так ли?
Нет, спасибо.
Я уже слишком много съел.
Мы также обычно разделяем вокативы, метки дискурса и междометия запятыми:
Открой им дверь, Кейли, можешь ли ты.Спасибо. (звательный падеж)
Что ж, как вы думаете, что мы должны с этим делать? (маркер беседы)
Вау, это звучит действительно захватывающе. (междометие)
Мы используем запятые, чтобы показать, что прямая речь следует или только что произошла:
Он сказал в своей вступительной речи: «Сейчас время планировать будущее». (или Он сказал в своей вступительной речи: «Пришло время планировать будущее .»)
Когда прямая речь идет первой, мы используем запятую перед закрывающими кавычками:
« Мы не хотим каждый год ездить в отпуск в одно и то же место », - нетерпеливо сказал он.
Мы используем двоеточия для обозначения списков:
Есть три основные причины успеха правительства: экономические, социальные и политические.

Мы также используем двоеточия для обозначения подзаголовков или подразделения темы:
Жизнь в Провансе: личное мнение
Мы часто используем двоеточия для обозначения прямой речи:
Затем он сказал: «Я действительно ничем не могу вам помочь».
Мы обычно используем двоеточие между предложениями, когда второе предложение объясняет или оправдывает первое предложение:
Старайтесь содержать свою квартиру в чистоте и порядке: это будет легче продавать.
Мы используем точки с запятой вместо точек для разделения двух основных предложений. В таких случаях предложения связаны по значению, но разделены грамматически:
На испанском языке говорят по всей Южной Америке; в Бразилии основной язык - португальский.
В современном английском языке точки с запятой обычно не используются. Точки и запятые встречаются чаще.
Точки и запятые встречаются чаще.
Кавычки на английском языке - «…» или «…». В прямой речи мы заключаем сказанное в пару одинарных или двойных кавычек, хотя одинарные кавычки становятся все более распространенными.Прямая речь начинается с заглавной буквы, ей может предшествовать запятая или двоеточие:
Она сказала: «Где мы можем найти хороший индийский ресторан?» (или Она сказала: «Где мы можем найти хороший индийский ресторан?» )
Мы можем поместить пункт об отчетности в три разных положения. Обратите внимание на расположение запятых и точек здесь:
Фитнес-тренер сказал: «Не пытайтесь делать слишком много, когда начинаете». (кавычки после запятой, вводящей речь, и после точки)
«Не пытайтесь делать слишком много, когда начинаете», - сказал фитнес-тренер. (запятая перед закрывающей кавычкой)
«Не пытайтесь делать слишком много, - сказал тренер по фитнесу, - когда начинаете.
внутри прямой речи мы используем либо одинарные кавычки внутри двойных кавычек, либо двойные кавычки внутри одинарных кавычек:
«Было очень холодно, - сказал он, - и они говорили:« Когда мы можем идти? » домой? »»
Джая сказала: «Они были очень взволнованы и кричали« Давай! »».
Мы обычно используем вопросительные знаки внутри кавычек, если вопрос не является частью пункта об отчетности:
«Почему они не знают, кто несет ответственность?» - спросили они.
Значит, они действительно сказали: «Мы будем побеждать в каждом матче в течение следующих трех недель»?
Мы также используем одинарные кавычки, чтобы привлечь внимание к слову. Мы можем использовать кавычки таким образом, когда хотим поставить под сомнение точное значение этого слова:
Я очень разочарован его «извинениями».
Я не думаю, что он имел в виду это вообще.
НОВАЯ «ВОЙНА» НАД СЕВЕРНЫМ МОРСКИМ РЫБОЛОВНЫМ ПЛАНОМ
Иногда мы используем кавычки для обозначения названий книг, газет, журналов, фильмов, песен, стихов, видео, компакт-дисков и т. Д .:
Об этом есть специальный репортаж в «Дейли мейл».
Мы можем использовать курсив вместо кавычек для этих цитат:
Обо всем этом есть специальный отчет в Daily Mail.
Статьи или главы в книгах или названия рассказов обычно заключаются в одинарные кавычки:
Самая длинная глава в книге - последняя под названием «Будущее Африки».
В неформальной письменной форме чаще встречаются тире. Их можно использовать аналогично запятым или точкам с запятой. Можно использовать как одиночные, так и множественные тире:
Наш учитель, который часто сердится, когда мы опаздываем, вообще не крестился.Никто не мог в это поверить!
Просто хотел поблагодарить вас за прекрасный вечер - нам очень понравилось.
Скобки имеют те же функции, что и тире. Они часто добавляют дополнительную, несущественную информацию:
Триплоу (произносится как «Триплоу») - небольшая деревня в восточной части Англии.
Мы используем скобки вокруг дат и номеров страниц в академических письмах:
Хитон (1978) дает убедительное объяснение того, как образуются ураганы (страницы 27–32).
Мы часто используем косую черту в интернет-адресах и для обозначения и / или в академических справочниках:
Вы можете найти нужные цифры на www.bbc.co.uk/finance
Бинкс (1995/1997) уже исследовал этот аспект римской истории.
В британском английском дата обычно указывается в следующем порядке: день, месяц, год.
Мы используем точки в датах. Также обычно используются косые черты или тире:
Дата рождения: 1.8.1985 (или 1/8/1985 или 1–8–1985 )
В американском английском день и месяц находятся в другом порядке, поэтому 8 января 1985 года записывается следующим образом:
1–8–1985 (или 1/8/1985 или 1.8.1985 )
Мы обычно не выделяем веса и меры и ссылки на числа:
4 кг (4 кг) 10 м ( 10 метров) 5 миллионов долларов (5 миллионов долларов)
Запятые используются в числах для обозначения тысяч и миллионов:
7,980 (семь тысяч девятьсот восемьдесят)
11,487,562 ( одиннадцать миллионов четыреста восемьдесят семь тысяч пятьсот шестьдесят два)
Для обозначения десятичных знаков мы используем точки, а не запятые:
6.5 (шесть целых пять десятых)
Не: 6,5
Время можно отмечать точками или двоеточиями:
Магазин открывается в 9.30. (или 9:30)
Разговорный английский:
Когда мы говорим по электронной почте и веб-адресам, мы произносим каждое слово отдельно. Чтобы избежать путаницы, мы иногда пишем каждую букву слова:
[email protected] = Hannah dot reeves at l-i-t dot com
miles_hotel.com / home = мили подчеркивание гостиница точка com косая черта дом
www.theplace.org = www точка место (все одним словом) точка org
.
полная остановка
XX
десятичная точка (2.2: две точки два)
,
запятая
*
* 3
0
?
вопросительный знак
()
круглые скобки (или круглые скобки)
!
восклицательный знак
[]
квадратные скобки (или квадратные скобки)
:
двоеточие
{}
фигурные скобки
;
точка с запятой
°
градуса (40º: сорок градусов)
“”
двойные кавычки
%
процентов
''
одинарные кавычки
и
и (также называемый «амперсанд»)
'
4 апостроф
авторское право
-
дефис
<
меньше
-
тире
>
тире
> 9000
+
плюс
@
на
-
минус
✓
тик
×
умножить на (2 × 2: два )
X
крест
÷
разделить на
(6 ÷ 2: шесть разделить на два)
X_X
подчеркивание (ann с подчеркиванием)
=
равно
Функция /
косая черта
\
обратная косая черта
strsplit (x, split, fixed = FALSE)
Разбивает символьную строку или вектор символьных строк, используя регулярное выражение или буквальную (фиксированную) строку.Функция strsplit выводит список, где каждый элемент списка соответствует разделенному элементу x. В простейшем случае x - это строка из одного символа, а strsplit выводит список из одного элемента.
- x - Символьная строка или вектор символьных строк для разделения.
- split - строка символов для разделения x. Если разделение представляет собой пустую строку (""), то x разделяется между каждым символом.
- fixed - Если аргумент разделения должен рассматриваться как фиксированный (т.е. буквально).По умолчанию установлено значение FALSE, что означает, что разделение обрабатывается как регулярное выражение.
Пример. Ниже показаны несколько начальных примеров (обратите внимание, что точка заменяет «любой символ» в регулярных выражениях), за которыми следует пара сценариев, которые немного более практичны. Например, даты делятся на год, месяц и день, а имена в формате Last, First разделяются по запятой.
> x <- "Разделите слова в предложении." > strsplit (x, "") [[1]] [1] "Разделить" "" "слова" "в" [5] «а» «предложение». > > x <- «Разбивать по каждому символу». > strsplit (x, "") [[1]] [1] "S" "p" "l" "i" "t" "" "a" "t" "" "e" "v" "e" "r" "y" [15] "" "c" "h" "a" "r" "a" "c" "t" "e" "r" "." > > x <- «Разделить в каждом пробеле предыдущий символ». > strsplit (x, ".") [[1]] [1] "Spli" "a" "eac" "spac" [5] "остроумие" "" "precedin" "характер." > > x <- "Вы бы хотели быть мистером Джонсом?" > strsplit (x, ".") [[1]] [1] "D" "yo" "wis" "yo" "wer" "Mr" [7] "Джонс?" > strsplit (x, ".", fixed = TRUE) [[1]] [1] «Вы бы хотели быть мистером» «Джонсом?» > > [[1]] [1] «1999» «05» «23» [[2]] [1] «2001» «12» «30» [[3]] [1] «2004» «12» «17» > матрица (unlist (temp), ncol = 3, byrow = TRUE) [, 1] [, 2] [, 3] [1,] "1999" "05" "23" [2,] «2001» «12» «30» [3,] «2004» «12» «17» > >Кончик.Здесь можно найти полезное руководство по регулярным выражениям. Если у вас есть альтернативная рекомендация, отправьте электронное письмо или разместите ссылку ниже, особенно для практических руководств.Регулярных выражений в Python - Интерактивный обзор рунного камня
Введение
Если есть что-то, что у людей хорошо получается, так это сопоставление с образцом. Вы можете распределить числа в следующем списке практически без каких-либо мысль:
321-40-0909 302-555-8754 3-15-66 95135-0448Вы можете сразу сказать, какие из следующих слов не могут быть быть действительными английскими словами по образцу согласных и гласных:
grunion vortenal pskov trebular elibm talusРегулярные выражения - это метод Python, позволяющий вашей программе ищем выкройки:
- Дробь - это последовательность цифр, за которой следует косая черта, за которой следует еще одна последовательность цифр.
- Допустимое имя состоит из серии букв, запятой, за которой следует ноль или более пробелов, за которыми следует еще одна серия букв.
Простейшие выкройки
Чтобы использовать регулярные выражения в Python, вы должны импортировать модуль xpression r egular e с
import re. Самый простой образец для поиска - это одна буква. Если вы хотите посмотрите, содержит ли переменнаясловобуквуe, для Например, вы можете использовать этот код:импорт ре word = input ('Введите строку:') найдено = re.поиск (r'e ', слово) если найдено: print (слово, 'содержит букву «е».') еще: print (слово, 'не содержит буквы «е».')
Шаблон - это строка, которой предшествует буква
r, которая указывает Python интерпретировать строку как регулярное выражение.Конечно, вы можете поместить в свой узор более одной буквы. Ты можешь ищите слово
естьгде угодно в слове. В этом примере используется функция который вызывается повторно для ряда слов.импорт ре def find_eat (слово): найдено = re.search (r'eat ', слово) если найдено: print (слово, 'содержит буквы «есть».') еще: print (слово, 'не содержит букв "есть".') find_eat ('обогреватель') find_eat ('угощение') find_eat ('легко') find_eat ('металл')
Это будет успешно соответствовать словам , есть , нагреватель и относится к , но не соответствует easy , metal или шляпа .Вы можете сказать: «Ну и что? Я могу сделать то же самое с строковая функция
find ()». Да, вы можете, но теперь давайте сделаем то, что не так просто сделать с помощьюfind ():Соответствует любому одиночному символу
Давайте сделаем узор, который будет соответствовать букве
eза которым следует любой символ вообще , за которым следует букват. Чтобы сказать «любой символ», вы используете точку. Вот образец:импорт ре def finder (шаблон, слово): найдено = re.поиск (шаблон, слово) если найдено: print (word, 'содержит шаблон.') еще: print (слово, 'не содержит шаблона.') искатель (r'e.t ',' лучше ') искатель (r'e.t ',' либо ') искатель (r'e.t ',' лучший ') искатель (r'e.t ',' зверь ') искатель (r'e.t ',' etch ') искатель (r'e.t ',' легкость ')
Это будет соответствовать лучше , либо , и лучше (точка будет соответствовать t , i и s в этих слова).Он не будет соответствовать зверь (две буквы между и и t ), etch (нет букв между e и т ), или лёгкость (вообще никакой буквы т !).
Соответствующие классы символов
Теперь давайте узнаем, как немного сузить область поиска. Мы хотели бы быть умеет найти узор, состоящий из буквы b , любой гласной ( a , e , i , o или u ), а затем письмом т .Чтобы сказать «любой из определенной серии символов », заключите их в квадратные скобки:
импорт ре def finder (шаблон, слово): found = re.search (шаблон, слово) если найдено: print (word, 'содержит шаблон.') еще: print (слово, 'не содержит шаблона.') искатель (r'b [aeiou] t ',' летучая мышь ') искатель (r'b [aeiou] t ',' ставка ') искатель (r'b [aeiou] t ',' кролик ') искатель (r'b [aeiou] t ',' робот ') искатель (r'b [aeiou] t ',' опора ') искатель (r'b [aeiou] t ',' boot ') искатель (r'b [aeiou] t ',' красивый ')
Соответствует таким словам, как bat , bet , rab bit , ro bot ic и a , но ment .Не будет совпадать boot или красивый , потому что между b и t , и класс соответствует только одному символу. (Вы увидите, как чтобы позже проверить наличие нескольких гласных.)
Существуют сокращения, обозначающие последовательность букв:
[a-f]совпадает с[abcdef];[A-Gm-p]совпадает с[ABCDEFGmnop];[0-9]соответствует одной цифре (то же, что и[0123456789]).Вы также можете дополнять (отрицать) класс; следующий два узора будут искать букву e , за которым следует что-либо кроме гласной, за которой следует письмо т ; или любой символ , кроме , заглавная буква:
Есть некоторые классы, которые настолько полезны, что Python предоставляет быстрые и удобные сокращения:
Сокращение означает То же, что \ dцифра [0-9]\ w«словесный» символ; прописная буква, строчная буква, цифра или знак подчеркивания [A-Za-z0-9_]\ спробельный символ (пробел, новая строка, табуляция) [\ r \ t \ n]И их дополнения: \ Dнецифровый [^ 0-9]\ Wнесловесный символ [^ A-Za-z0-9_]\ Sнепробельный символ [^ \ r \ t \ n]Таким образом, этот шаблон:
\ d \ d \ d- \ d \ d- \ d \ d \ d \ dсоответствует номеру социального страхования; опять же, позже вы увидите более короткий путь.импорт ре def find_ssn (in_str): found = re.search (r '\ d \ d \ d- \ d \ d- \ d \ d \ d \ d', in_str) если найдено: print (in_str, 'содержит номер социального страхования.') еще: print (in_str, 'не содержит номера социального страхования.') find_ssn ('301-22-0156') # это все выдуманные числа find_ssn ('301-555-1212') find_ssn ('SSN 562-99-6713')
Анкеры
Все шаблоны, которые вы видели до сих пор, найдут соответствие где угодно в пределах строка, которая обычно - но не всегда - является тем, что вы хотите.Например, вы можете настаивать на заглавной букве, но только в качестве самого первого символа в строке. Или вы можете сказать, что идентификационный номер сотрудника должен заканчиваться с цифрой. Или вы можете найти слово и пойти , только если оно стоит в начале слова, так что вы найдете его в . Вы встретили другое, и пффт у вас было иди ne. , но ты не найдешь по ошибке в я за иду т мой зонт . внутри квадратные скобки, это означало бы совсем другое! Шаблон
\ d $соответствует цифре в конце строки. Это границы, которые вы будете использовать чаще всего.Два других якоря -
\ bи\ B, которые обозначают «граница слова» и «граница вне слова». Например, если вы хотите чтобы найти слово встретилось в начале слова, мы пишем узорr '\ bmet', который будет соответствовать Металлическая пластина и Столичный образ жизни , но не Наденьте велосипедный шлем .Шаблонr'ing \ b 'будет соответствовать Пешие прогулки - это весело и Чтение, письмо и арифметика , но не Золотые слитки тяжелые . Наконец, шаблонr '\ bhat \ b'соответствует только Шляпа красная а не Вот вопрос или она ненавидит анчоусы или разбитое стекло .импорт ре def find_boundary (in_str): found1 = re.search (r '\ bmet', in_str) found2 = re.поиск (r'ing \ b ', in_str) found3 = re.search (r '\ bhat \ b', in_str) если найдено1: print (in_str, 'встретился' в начале слова. ') если найдено2: print (in_str, 'имеет "ing" в конце слова.') если найдено3: print (in_str, 'содержит слово «шляпа».') in_str = input ('Введите одно из предыдущих предложений:') find_boundary (in_str)
В то время как
\ bиспользуется для поиска точки останова между словами и не-слова,\ Bнаходит пары букв или не букв;\ Bmetиing \ bсоответствуют противоположному примеры предыдущего абзаца;\ Bhat \ Bсоответствует только разбитому стеклу .Повторение
Все эти классы соответствуют только одному символу; что, если мы хотим сопоставить три цифры подряд или произвольное количество гласных? Вы можете следить за любым классом или персонажем по количеству повторений:
Образец совпадений r'b [aeiou] {2} t 'b, за которыми следуют две гласные, за которыми следуетtr'A \ d {3,} 'Буква A, за которой следует 3 или более цифрr '[A-Z] {, 5}'От нуля до пяти заглавных букв r '\ w {3,7}'От трех до семи «словесных» символов Это позволяет вам переписать соответствие шаблона номера социального страхования как
r '\ d {3} - \ d {2} - \ d {4}'Есть три повторения, которые настолько распространены, что Python специальные символы для них:
*означает «ноль или больше»,+означает «один или несколько» и?означает «ноль или один». начиная с начала строки,\ w +искать один или несколько символов слова,?, за которым следует необязательная запятая (ноль или одна запятая)\ s *ноль или более пробелов[A-Z]и заглавная буква$, который должен быть в конце строки.Группировка
Пока все хорошо, но что, если вы хотите сканировать фамилию, за которым следует необязательная запятая-пробел-инициал; таким образом соответствует только фамилия вроде «Смит» или полное «Смит, Джей»? Вам нужно поставить запятая, пробел и инициал в скобки, а затем следовать за ним с
?, чтобы указать, что вся группа необязательна.\ w + (,? \ s * [A-Z])? $ ', in_str) если найдено: print (in_str, 'содержит шаблон.') еще: print (in_str, 'не содержит шаблона.') действительное_имя ('Смит, J') valid_name ('Мадонна') действительное_имя ('Морган Д')Примечание: если вы хотите, чтобы в шаблоне использовалась круглая скобка, вы должны поставить ее перед с обратной косой чертой, чтобы сделать его неспециализированным.
Модификаторы
Если вы хотите, чтобы при сопоставлении с шаблоном регистр не учитывался, добавьте
flags = re.Яна поиск()звоните. (IозначаетIGNORECASE, который при желании можно указать полностью. В следующем примере показан шаблон, который будет соответствовать любому почтовому отправлению Канады. код в верхнем или нижнем регистре. Почтовые индексы Канады состоят из буквы, цифры, и еще одна буква, за которой следует пробел, цифра, буква и еще одна цифра. Пример действительного почтового индекса:A5B 6R9. Вот какой код выглядит как; он не работает в ActiveCode, но отлично работает в IDLE.[A-Z] \ d [A-Z] \ s + \ d [A-Z] \ d $ ', in_str, flags = re.I) если найдено: print (in_str, 'допустимый почтовый индекс') еще: print (in_str, 'недействительный почтовый индекс.') действительный_почтовый индекс ('A5B 6R9') действительный_почтовый код ('c7H 8j2')На данный момент вы знаете почти все, что вам нужно, чтобы проверить, соответствует определенному шаблону.
Расширенное сопоставление с образцом
Все, что вы сделали до сих пор, это тестировали, соответствует ли шаблон или нет.Теперь, когда вы можете сопоставить фамилию и инициалы человека, вы может захотеть взять их из строки, чтобы вы могли изменить Martinez, A на A. Martinez . Для этого вам понадобится что-то другое, кроме
search (); вам понадобитсяsub ()метод подстановки. Вам также придется использовать скобки группировки, которые имеют побочный эффект: всякий раз, когда вы используете круглые скобки для группировать что-то, операция сопоставления с образцом сохраняет часть строка, которая соответствует группе, чтобы вы могли использовать ее позже.Пришло время раскрыть секрет: возвращаемое значение
search ()не является логическим; это соответствует объекту , который имеет особые свойства, которые вы можете изучить и использовать. В следующем примере мы заключили круглые скобки в часть шаблона «фамилия», а также «запятую и начальная »часть. Если есть совпадение, программа отобразит все, что было найдено в группирующие скобки. Вертикальные полосы находятся вprint (), так что вы можете видеть где есть заготовки (если есть).(\ w +) (,? \ s * [A-Z])? $ ', in_str) если найдено: print ('Результаты сопоставления с шаблоном:') print ('полное совпадение: |', найденная группа (0), '|', sep = '') print ('первый набор (): |', found.group (1), '|', sep = '') print ('второй набор (): |', found.group (2), '|', sep = '') еще: print (in_str, 'не содержит шаблона.') действительное_имя ('Смит, J') # valid_name ('Madonna') # попробуйте раскомментировать и их # valid_name ('Морган Д')В предыдущем коде
найдено.- это объект соответствия, созданныйsearch ()метод.Вызов методаfound.group (0)содержит все соответствует всему шаблону.found.group (1)содержит часть строки, совпал первый набор группирующих скобок - фамилия, и найдено. группа (2)содержит часть строки, соответствующая второму набору группирующих скобок - запятая и начальный, если есть. Если бы в шаблоне было больше групп скобок, вы бы использовали.group (3),.group (4)и так далее.(\ w +) (,? \ s * ([A-Z]))? $ ', in_str) если найдено: print ('Результаты сопоставления с шаблоном:') print ('полное совпадение: |', найденная группа (0), '|', sep = '') print ('первый набор (): |', found.group (1), '|', sep = '') print ('внешний набор (): |', found.group (2), '|', sep = '') print ('внутренний набор (): |', found.group (3), '|', sep = '') еще: print (in_str, 'не содержит шаблона.') действительное_имя ('Смит, J')Если сделать так, то заглавная буква сохраняется в
найдено.(\ w +) (?:,? \ s * ([A-Z]))? $ ', in_str) если найдено: print ('Результаты сопоставления с шаблоном:') print ('полное совпадение: |', найденная группа (0), '|', sep = '') print ('первый набор (): |', found.group (1), '|', sep = '') print ('внутренний набор (): |', found.group (2), '|', sep = '') еще: print (in_str, 'не содержит шаблона.') действительное_имя ('Смит, J')В данном случае инициал находится в
found.group (2), так как внешний набор открытых круглых скобок не сохраняется. в начале строки,(\ w +)искать (и запоминать) один или несколько «словесных» символов(?:запустить группу без сохранения, которая состоит из:
,?необязательная запятая\ s *ноль или более пробелов([A-Z])и заглавная буква, которая запоминается, потому что находится в скобках)?это завершает группу без сохранения; знак вопроса означает, что все это необязательно$, в этот момент мы должны быть в конце строки.Теперь, когда вы знаете, как извлечь фамилию и инициалы, вы можете использовать
sub ()для поменяться местами. Методre.sub ()принимает три аргумента:
- Шаблон для поиска
- Образец замены
- Строка для поиска в
Итак,
re.sub (r '- \ d {4}', r'-XXXX ',' 301-22-0109 ')заменит последние четыре цифры номера социального страхования номер по Xes.Этот пример не работает в ActiveCode (посколькуre.sub ()не реализован), но он будет работать в IDLE.импорт ре результат = re.sub (r '- \ d {4}', r'-XXXX ',' 301-22-0109 ') печать (результат)Если вы используете группировку, вы можете использовать
\ 1и\ 2в шаблоне замены для обозначения первая и вторая совпавшие группы. Вот как можно написать программу, которая будет менять имена как «Gonzales, M» до «M. Гонсалес »; в следующем примере запятая и начальная буква , а не необязательны.(\ w +),? \ s * ([A-Z]) $ ', r' \ 2. \ 1 ', in_str) вернуть результат print (swap_name ('Смит, J')) print (swap_name ('Джо-Боб Смайт-Фаунтлерой')) print (swap_name ('Мадонна')) print (swap_name ('Gonzales M'))Если вы запустите предыдущую программу в IDLE, вы увидите, что если шаблон не совпадает,
re.sub ()возвращает нетронутую копию входной строки.Наконец, еще один пример с группами. Скажем, вы хотите сопоставить номер телефона и найти код города, префикс и номер.В этом случае вместо замены мы возвращаем список с соответствующей информацией или список из трех пустых строк. если ввод недействителен. Обратите внимание, что если вы хотите сопоставить настоящую скобку, вы должны поставить перед ней обратную косую черту, чтобы это «не часть группы». Сделать это можно так:
импорт ре def valid_phone (in_str): "" "Вернуть список с кодом города, префиксом и номером; если не действительное число, вернуть пустые строки для всех трех."" " found = re.search (r '\ ((\ d {3}) \) \ s * (\ d {3}) - (\ d {4})', in_str) если найдено: area_code = найденная группа (1) префикс = найденная группа (2) число = найдено. группа (3) результат = [код_области, префикс, номер] еще: результат = ['', '', ''] вернуть результат данные = действительный_фон ('(408) 555-1212') печать (данные)
Опять же, давайте разберем этот паттерн:
\ (ищите настоящую открывающую скобку(\ d {3}), за которым следуют три цифры (и сохраните их)\)и настоящая закрывающая скобка\ s *, за которым следует ноль или более пробелов(\ d {3})три цифры (сохранить)-тире(\ d {4})и еще четыре цифры (сохраните их)Поиск всех вхождений
Модель
re.search ()находит только первое вхождение шаблона в строке. Если вы хотите найти всех совпадений в строке, используйтеre.findall (), который возвращает список совпадающих подстрок. (В отличие отre.search (), который возвращает объекты соответствия.) Вот шаблон, который находит заглавную букву, за которой следует необязательный тире и одна цифра:Давайте найдем все вхождения этого шаблона в следующей строке:
'Вставьте выступы B3, D-7 и C6 в паз A9.'импорт ре message = 'Вставьте вкладки B3, D-7 и C6 в слот A9.' result = re.findall (r '([A-Z] -? \ d)', сообщение) если результат: для элемента в результате: печать (элемент) еще: print ('findall () не нашла совпадений с шаблоном.')
Заключение
В этом руководстве показаны некоторые основные моменты сопоставления с образцом. Чтобы узнать все тонкости регулярные выражения, см. документацию Python
Изучив регулярные выражения, вы сможете использовать их во многих текстовых редакторах.Например, В диалоговых окнах «Заменить» и «Найти» в IDLE есть флажок, позволяющий использовать регулярные выражения для поиска и замены текста.
Приветствий в письмах и электронной почте
ОБНОВЛЕНО В ДЕКАБРЕ 2016
Уважаемый читатель: Уважаемый читатель, Уважаемая госпожа Читатель:
Уважаемые господин и госпожа Читатель: Привет читатель, читатель,Этот пост посвящен этикету приветствия в деловых письмах и электронной почте.Он посвящен тем, кто посетил этот блог в поисках советов о том, как начать письмо.
Правила для Деловых писем
- Стандартный способ открыть бизнес письмо состоит из Уважаемый, имени человека (с заголовком или без него) и двоеточия, например:
Уважаемая Луиза: Уважаемая г-жа Чу: Уважаемые мистер и доктор Пейдж: Уважаемый профессор Амато: Уважаемый Патрик:
(Более подробное обсуждение Уважаемый, см. В моем сообщении «Должен ли я позвонить вам , дорогой ?»)- Стандартный способ открыть деловое письмо Social состоит из Уважаемый, имени человека (с заголовком или без него) и запятой, например:
Уважаемый Найджел, Уважаемый доктор.Тараби, уважаемый преподобный Янс,
Социальное деловое письмо носит скорее социальный или личный характер, чем бизнес; например, письма с соболезнованиями, личные поздравления (со свадьбами, рождениями, акциями и другими торжествами) и благодарности.- Если вы плохо знаете читателя или если письмо или отношения носят формальный характер, используйте титул и фамилию (Уважаемая мисс Браун). В противном случае используйте имя (Дорогая Гила).
- Если вы не уверены, что женщина предпочитает Miss или Mrs., используйте название Ms.
- Если вы пишете двум людям, используйте оба имени в своем приветствии, например:
Уважаемый мистер Трухильо и мисс Донн: Уважаемые Алекс и Дренда,- Никогда не пишите титулы Мистер, Мисс, Миссис, и Доктор Разбирайте эти и подобные титулы:
Профессор, Декан, Сестра, Раввин, Имам, Сенатор, Губернатор, Капитан, Адмирал , Судья- Если вы не знаете пол человека, используйте полное имя, а не титул:
Уважаемая Дана Симмс: Уважаемая Т.К. Спиназола:- Если вы не знаете имени или пола человека, избегайте слов «Для кого это может касаться». Вместо этого используйте название должности или обычное приветствие:
Уважаемый рекрутер: Уважаемый специалист по урегулированию претензий: Уважаемый сэр или мадам:- Если вы пишете в компанию, а не какому-либо конкретному лицу, используйте название компании:
Уважаемый курс обучения синтаксису: (Это считается немного неформальным).- Для упрощенного делового письма , а не , используйте приветствие. Вместо этого используйте тему, состоящую только из заглавных букв, за которой следует тело письма, например: СПОСОБЫ НАЧАТЬ ДЕЛОВОЕ ПИСЬМО
Я пишу, чтобы поделиться информацией о стандартных письмах.. . .
Упрощенные деловые письма вполне приемлемы, но не распространены.
Правила для электронной почты
Для официальной электронной почты (то есть электронной почты, используемой в качестве делового письма) следуйте правилам 1-7 выше. В противном случае используйте меньше формальностей с такими приветствиями:
Дорогой Хан, Привет Ева, Привет, Кваси, Привет всем, Доброе утро, Энн,
Если вы используете только имя читателя без приветствия, обязательно начинайте с положительного предложения, чтобы ваше сообщение не показалось холодным:
Сью,
Спасибо за помощь с заказом.
Брук:Я рад предоставить вам запрошенную информацию.
Для неформальных сообщений вы также можете вставить приветствие в той же строке, что и вступительное предложение, например:
Привет, Дэвид. Надеюсь, у вас был отличный отпуск.
Доброе утро, Ванда. Я слежу за утренним заседанием.
Или просто используйте имя человека в первом предложении, например:
Yiota, Вы не ошиблись насчет цен.
Если вы ищете настольную справочную информацию о деловых письмах, электронной почте, отчетах и т. Д., Я рекомендую Справочное руководство Грегга, 11-е издание, , также известное как Грегг. Я использовал Gregg для проверки правил и рекомендаций выше.
Если вы хотите, чтобы кто-то отредактировал или вычитал ваши сообщения, обратитесь к моему партнеру, Скрибенди. Я не предоставляю эту услугу, но Scribendi отлично и быстро работает.
Чтобы узнать больше о сообщениях для построения отношений, приобретите мою книгу Business Writing With Heart.
Уважаемый читатель,
Удачи в приветствии!
Lynn
Обучение синтаксисуNew Vision - The Thiagi Group
Вы, вероятно, знакомы с кодами, шифрами и криптограммами.В криптограмме каждая буква сообщения заменяется другой буквой алфавита.
Например, LET THE GAMES BEGIN может быть зашифрован в
YZF FOZ JUKZH CZNQ.
В этой криптограмме Y заменяет L, Z заменяет E, F заменяет T и так далее. Обратите внимание, что в этой криптограмме используются одинаковые буквенные замены: каждая буква E в предложении заменяется буквой Z, а каждая буква T заменяется буквой F.
Решите криптограмму, используя повторяющиеся буквы и шаблоны букв в словах.
Подсказки
Частота букв
- Наиболее часто используемые буквы английского языка - это e, t, a, i, o, n, s, h и r.
- Буквы, которые чаще всего встречаются в начале слов: t, a, o, d и w.
- Буквы, которые чаще всего встречаются в конце слов, - это e, s, d и t.
Частота слов
- Короткие слова дают полезные подсказки. Однобуквенные слова: a или I.
- Самыми распространенными двухбуквенными словами являются to, of, in, it, as, at, be, we, he, so, on, an, or, do, if, up, by и my .
- Наиболее распространенные трехбуквенные слова: the, and, are, for, not, but, had, has, was, all, any, one, man, out, you, his, her, and can .
- Самыми распространенными четырехбуквенными словами являются , которые, with, have, this, will, your, from, they, want, been, good, much, some, and very.
Окончания слов
- Максимум.общие окончания слов: -ed, -ing, -ion, -ist, -ous, -ent, -able, -ment, -tion, -ight и -ance .
Двойные буквы
- Наиболее частые двухбуквенные комбинации: ee, ll, ss, oo, tt, ff, rr, nn, pp и c c.
- Двойные буквы, которые чаще всего встречаются в конце слов: ee, ll, ss и ff .
Пунктуация
- За запятой часто следует but, and, or who .
- Вопрос часто начинается с почему, как, кто, был, сделал, что, где или что.
- Два слова, которые часто предшествуют кавычкам, - это и означает .
- Две буквы, которые обычно следуют за апострофом: t и s.
Решите эту криптограмму
Загрузите эту криптограмму о New Vision (PDF; открывается в новом окне). Распечатайте этот документ и расшифруйте сообщение.
% PDF-1.2 % 323 0 объект > эндобдж xref 323 108 0000000016 00000 н. 0000002530 00000 н. 0000002673 00000 н. 0000002818 00000 н. 0000003605 00000 н. 0000003779 00000 п. 0000003863 00000 н. 0000003951 00000 н. 0000004035 00000 н. 0000004096 00000 н. 0000004241 00000 п. 0000004302 00000 п. 0000004447 00000 н. 0000004530 00000 н. 0000004591 00000 н. 0000004697 00000 н. 0000004758 00000 н. 0000004843 00000 н. 0000004904 00000 н. 0000004965 00000 н. 0000005160 00000 н. 0000005221 00000 н. 0000005366 00000 н. 0000005500 00000 н. 0000005656 00000 н. 0000005788 00000 н. 0000005849 00000 н. 0000005932 00000 н. 0000005993 00000 н. 0000006054 00000 н. 0000006115 00000 н. 0000006226 00000 н. 0000006287 00000 н. 0000006398 00000 п. 0000006494 00000 н. 0000006609 00000 н. 0000006670 00000 н. 0000006731 00000 н. 0000006851 00000 н. 0000006912 00000 н. 0000006973 00000 п. 0000007034 00000 п. 0000007181 00000 н. 0000007242 00000 н. 0000007399 00000 н. 0000007546 00000 н. 0000007662 00000 н. 0000007771 00000 н. 0000007832 00000 н. 0000007960 00000 п. 0000008021 00000 н. 0000008157 00000 н. 0000008218 00000 н. 0000008341 00000 п. 0000008402 00000 п. 0000008463 00000 н. 0000008524 00000 н. 0000008629 00000 н. 0000008774 00000 н. 0000008835 00000 н. 0000008944 00000 н. 0000009047 00000 н. 0000009108 00000 н. 0000009169 00000 н. 0000009230 00000 н. 0000009338 00000 п. 0000009399 00000 н. 0000009489 00000 н. 0000009609 00000 н. 0000009670 00000 н. 0000009831 00000 н. 0000009951 00000 н. 0000010012 00000 п. 0000010098 00000 п. 0000010159 00000 п. 0000010319 00000 п. 0000010380 00000 п. 0000010503 00000 п. 0000010564 00000 п. 0000010697 00000 п. 0000010758 00000 п. 0000010819 00000 п. 0000010880 00000 п. 0000010982 00000 п. 0000011043 00000 п. 0000011144 00000 п. 0000011205 00000 п. 0000011307 00000 п.