
Безграничные возможности физиотерапии | Солнышко
Слово физиотерапия известно каждому почти с детства. В любой поликлинике есть физиотерапевтические кабинеты, но вот чем именно там занимаются, многие ответят лишь приблизительно. А вот о том, что физиотерапией можно заниматься не только в лечебном заведении, но и на дому – лишь бы была нужная аппаратура – для многих точно тайна.
Во-первых, стоит вспомнить, чем, каким направлением в медицине ведает физиотерапия. Если суммировать то, что подчас заумно об этом пишется, то получается следующая картина: если что в природе благотворно влияет на организм человека, то это – физиотерапия. Но есть процессы, которые достигают той же цели, которые можно вызвать искусственно, с помощью различных аппаратов. И это тоже физиотерапия.
Физиотерапевтические аппараты «Солнышко»
Аппараты эти самого разного направления. Одни используют в нужных целях электричество, другие – магнитные или ультрафиолетовые излучения. На самом деле вариантов и приборов, которые все эти свойства подчас используют даже в комплексе, — великое множество.
Так что если у кого-то нет возможности поехать на знаменитые курорты, чтобы воспользоваться всеми природными возможностями физиотерапии в виде грязей, морского воздуха, местных водорослей — нет повода для огорчений. Все, чего не хватает организму, можно получить прямо на дому. А приобретение нужных аппаратов и приборов обойдется дешевле, чем путешествие за несколько морей.
Что могут и чем славятся широко представленные в ассортименте магазинов медтехники физиотерапевтические аппараты? Те, что базируются на ультрафиолетовом облучении, без труда справляются со всяческими простудами, ангинами, воспалениями в суставах и многими прочими болячками. Аппараты, в основе которых магнитотерапия, помогут в борьбе с гипертонией и прочими заболеваниями сердечно-сосудистой системы. Да и нервную систему легко подлечит, и не только ее.
Какие аппараты применяются в физиотерапии?
ДМВ-терапия – технология очень серьезная, основанная на воздействии дециметровых электромагнитных волн, как на проблемные участки организма, так и на весь организм в целом.
И еще одно замечательное свойство такой физиотерапии. Нет возможности поехать в отпуск в знойные края, а хочется выглядеть «на все сто» – в первую очередь, загорелым. Для этого не обязательно регулярно ходить в солярий. Вполне можно устроить себе солярий на дому. И такой прибор существует. Называется он «ОУФк-320/400-03 Солнышко».
Светило здесь упомянуто не случайно. Те, кто им пользовался, уверяют, что это практически мини-солярий на дому. Всего несколько процедур, и лицо приобретает оттенок человека, недавно вернувшегося из южных широт. После этого можно смело идти на работу, и на вопросы сослуживцев о том, уж не из Испании ли вы только что вернулись, можно смело утверждать, что именно так.
Карл Шмитт и возвращение Донбасса: dem_2011 — LiveJournal
Стоит ли готовиться к позапрошлой войне
Кирилл Бенедиктов / Слово главного редактора / 15 марта, 2021
Карл Шмитт | Обработка от Александра Воронина | Fitzroy Magazine“Генералы всегда готовятся к прошлой войне”, сказал однажды Черчилль. Но как показывает практика, это ещё не самый плохой вариант. Иногда генералы на полном серьёзе готовятся к войне, которую выиграли (или проиграли) даже не их отцы, а отцы их отцов.
Но как показывает практика, это ещё не самый плохой вариант. Иногда генералы на полном серьёзе готовятся к войне, которую выиграли (или проиграли) даже не их отцы, а отцы их отцов.
Лет десять-двенадцать назад в среде российских интеллектуалов было модно ссылаться на Карла Шмитта — этого “проклятого философа” охотно переводили и издавали умеренно фрондирующие московские издательства. Иные провозглашали его едва ли не главным теоретиком путинской (и постпутинской, коль скоро речь идёт о временах “тандемократии”) России. Многие введённые Шмиттом в обиход конструкции действительно стали неотъемлемой частью нашего политического словаря — взять хотя бы знаменитую формулировку “гарант Конституции”. Внезапно оказалось, что Шмитт не просто актуален для российской политической философии — он был как-то даже пугающе современен. Конечно, тот факт, что Шмитт в своё время довольно тесно сотрудничал с нацистским режимом и даже считался “главным юристом Третьего рейха”, ставило его популяризаторов в щекотливое положение.
“…в некотором смысле наше положение напоминает Веймарскую Германию после поражения в Первой мировой войне и экономического краха… а если учесть аспект внешнеполитического унижения великой нации в результате Версальского “мира” и экономический аспект мирового кризиса (Великая депрессия), то сравнение обеих ситуаций напрашивается само собой. И хотя подобное сравнение межвоенной Германии с современной Россией и стало общим местом, даже набившим оскомину у многих, всё же применительно к операционализации мысли Шмитта оно вполне релевантно…”
Простите, что?. .
.
Ну, какая, в самом деле, из РФ образца 2010 года Веймарская Германия? Та эпоха теперь кажется едва ли не высшей точкой развития, акме постсоветской России. Ещё не успел забыться триумф над Грузией в августе 2008 года — впечатляющая демонстрация силы, которая, вопреки опасениям, не повлекла за собой ни Третьей мировой войны, ни даже экономических санкций. Уже пройден был пик финансового кризиса 2008–2009 года, хотя и болезненно ударивший по российской экономике, но, в общем, оказавшийся не таким уж и страшным. На международной же арене и вовсе царило благорастворение воздухов — российский и американский президенты, как добрые приятели, ели гамбургеры в Вашингтоне, госсекретарь США привезла в Москву кнопку “Reset”, переведённую каким-то эрудитом из Госдепа как “Перегрузка”, а в ООН делегация РФ рукопожатно воздержалась при принятии резолюции, разрешавшей мировому сообществу бомбёжки Ливии. Сложно было поверить в то, что пройдёт каких-то четыре года и всё изменится до неузнаваемости.
Но — изменилось. Те позиции, которые занимала Россия в 2008–2013, оказались утерянными — если не навсегда, то надолго. Из непослушной, взбрыкивающей, но, в целом, пригодной к сотрудничеству с Западом региональной державы наша страна превратилась едва ли не в государство-изгой (rogue state), и уж точно — в одну из главных составляющих мировой “оси зла”. С точки зрения Запада, разумеется.
Считается, что точкой невозврата стало присоединение Крыма в марте 2014 года, хотя, строго говоря, отношения с США стали серьёзно портиться ещё раньше — как минимум, с июня 2013 года, когда в транзитной зоне Шереметьево поселился Эдвард Сноуден. Но, возможно, сам по себе Крым России бы простили, как простили разгром грузинской армии и признание независимости Южной Осетии и Абхазии — если бы не попытка присоединения Новороссии, которая в случае успеха могла бы привести к значительному расширению территории РФ. Именно этот сценарий взбесил Запад и вынудил его пойти на резкое обострение ситуации. 17 июля 2014 года был сбит малазийский Боинг 777 — расследование этой трагедии продолжается до сих пор, но в нём есть ряд странностей. Весной-летом 2014 года территория, на которой шли бои между ВСУ и силами ополчения Новороссии, находилась под плотным колпаком западных спецслужб — включая и мощные разведывательные ресурсы альянса “Пять глаз”. И если уж вся эта “королевская конница и вся королевская рать” не сумела добыть неопровержимых улик, указывающих на виновность одной из вовлечённых в конфликт сторон — то несложно предположить, что подобные улики всё-таки есть — но выкладывать их на стол Западу невыгодно.
17 июля 2014 года был сбит малазийский Боинг 777 — расследование этой трагедии продолжается до сих пор, но в нём есть ряд странностей. Весной-летом 2014 года территория, на которой шли бои между ВСУ и силами ополчения Новороссии, находилась под плотным колпаком западных спецслужб — включая и мощные разведывательные ресурсы альянса “Пять глаз”. И если уж вся эта “королевская конница и вся королевская рать” не сумела добыть неопровержимых улик, указывающих на виновность одной из вовлечённых в конфликт сторон — то несложно предположить, что подобные улики всё-таки есть — но выкладывать их на стол Западу невыгодно.
А значит, не исключён вариант, при котором почти 300 мирных граждан были принесены в жертву ради того, чтобы выставить Россию исчадием ада и новой “империей зла” и окончательно вытолкать её за красные флажки. Прецеденты такого рода имелись: взять хотя бы историю с южнокорейским Боингом 747, сбитым в 1983 году над Сахалином. Тогда администрация Рейгана пошла на прямой подлог и фальсификацию доказательств, представленных в Совет Безопасности ООН, чтобы обвинить Советский Союз в чудовищном преступлении против человечества.
Как бы то ни было, с лета 2014 года и по настоящее время Россия находится в состоянии глубокого конфликта с Западом, проявляющегося почти во всех сферах — от санкций, нанёсших серьёзный урон экономике и технологическому развитию страны, до “войны вакцин”, когда эффективная и безопасная российская вакцина “Спутник-V” не сертифицируется для распространения на западных рынках.
Возвращаясь к тому, с чего мы начали: вот теперь-то, кажется, действительно пришло время вспомнить Карла Шмитта с его “номосом Земли”, “парадигмой друга и врага” и другими удивительно подходящими к моменту концепциями. И, однако же, именно сейчас о Шмитте странным образом никто не вспоминает. А если и вспоминают — то не в России.
Месяц назад в Италии состоялась интернет-конференция, посвящённая методам ведения современных войн. В докладе одного из участников конференции “Концепции Карла Шмитта и современные частные военные компании”, говорится:
В докладе одного из участников конференции “Концепции Карла Шмитта и современные частные военные компании”, говорится:
“…российские ЧВК отражают общую ориентацию элит страны в их представлении о сути классического реализма (парадигма друга представляет врага, таким образом, поддержание баланса сил защищает суверенитет и порядок). Российские ЧВК используются для принуждения врага к миру (как это случилось с Украиной), для защиты суверенитета страны и её порядка (например, в Сирии и Центральноафриканской Республике), для получения контроля над проблемной страной из хаоса непрерывной войны (на примере Ливии)”.
Причём тут Шмитт? А вот причём.
Автор доклада — журналист Алессандро Сансони — активно ссылается на работу Шмитта “Теория партизана” (в сети доступен русский перевод — Fitzroy Magazine), в которой описываются главные действующие лица современных “гибридных войн” — “партизан” и “пират”. Это, по Шмитту, гражданские лица, не состоящие на военной службе, но активно участвующие в боевых действиях. Разница между ними в том, что “партизан” действует на суше, а “пират” (или “корсар”) — на море. “Партизан” отличается большой мобильностью, интенсивностью политической приверженности и теллурическим характером — то есть неразрывной связью с почвой. И ещё у них, в отличие от “пиратов”, оборонительный modus operandi: например, на Донбассе ополченцы ДНР и ЛНР организовывали не наступление на позиции ВСУ, а оборону, или, в крайнем случае, контрнаступление.
Разница между ними в том, что “партизан” действует на суше, а “пират” (или “корсар”) — на море. “Партизан” отличается большой мобильностью, интенсивностью политической приверженности и теллурическим характером — то есть неразрывной связью с почвой. И ещё у них, в отличие от “пиратов”, оборонительный modus operandi: например, на Донбассе ополченцы ДНР и ЛНР организовывали не наступление на позиции ВСУ, а оборону, или, в крайнем случае, контрнаступление.
В докладе Сансони ещё много всего интересного (в частности, подчёркиваются принципиальные различия между российскими и западными ЧВК, которые выступают, по мнению журналиста, не как инструмент порядка, а наоборот, как инструмент хаоса) — но сейчас важно другое. В Италии (в Италии, Карл!) есть люди, которые всерьёз занимаются теоретическим обоснованием деятельности России и российских “прокси” в зоне её жизненных интересов. А в самой России? Нет, не слышали.
И это обидно. Потому что с марта 2014 года нас энергично прессуют за якобы имевшие место нарушения международного права и прочие преступления — а мы (под “мы” в данном случае следует понимать МИД РФ и ряд других инстанций, включая пресс-секретаря президента) довольно вяло возражаем, не забывая, впрочем, выражать глубокую приверженность Минским соглашениям, которым, как известно, альтернативы нет.
А альтернатива, между тем, есть, и она лежит на поверхности.
Для начала можно как следует перетрясти теоретическое наследие того же Шмитта — наверняка, кроме “теории партизана” там найдётся ещё много чего полезного и интересного. Но, при всём уважении Шмитту, это и будет как раз подготовкой к позапрошлой войне.
Поэтому главное, что следует сделать, чтобы подготовиться к войне завтрашнего дня — это создать новую концепцию жизненных интересов России. Концепцию, которая станет железобетонным фундаментом для любых действий, защищающих эти интересы — включая превентивные удары по позициям вооружённых сил враждебных России государств, или присоединение территорий с русским населением, над которым нависла угроза геноцида.
Семь лет назад Россия сделала важнейший шаг в правильном направлении — присоединила Крым и начала процесс интеграции Донбасса. Однако эти шаги не были как следует осмыслены политической элитой страны, оказавшейся в значительной степени не готовой к такому повороту событий. Я глубоко убеждён, что именно отсутствие теоретической базы Русской Весны-2014 сделало позицию России уязвимой в споре с коллективным Западом. И присоединение Крыма, и попытка реализации проекта “Новороссия” были реакцией Кремля на действия Запада, а не его собственной игрой. Это обусловило трагическую неудачу Русской Весны и фактическое замораживание конфликта на Донбассе. Это стоило республикам Новороссии многих и многих человеческих жизней — в том числе, жизней женщин и детей. Это в конце концов обрушило возникший после 2014 года “крымский консенсус” внутри России. Это привело к росту оппозиционных настроений зимой 2020–2021 года и усилению политической турбулентности в год парламентских выборов. Это, в перспективе, ставит под угрозу предполагаемый транзит власти в 2024 году.
Я глубоко убеждён, что именно отсутствие теоретической базы Русской Весны-2014 сделало позицию России уязвимой в споре с коллективным Западом. И присоединение Крыма, и попытка реализации проекта “Новороссия” были реакцией Кремля на действия Запада, а не его собственной игрой. Это обусловило трагическую неудачу Русской Весны и фактическое замораживание конфликта на Донбассе. Это стоило республикам Новороссии многих и многих человеческих жизней — в том числе, жизней женщин и детей. Это в конце концов обрушило возникший после 2014 года “крымский консенсус” внутри России. Это привело к росту оппозиционных настроений зимой 2020–2021 года и усилению политической турбулентности в год парламентских выборов. Это, в перспективе, ставит под угрозу предполагаемый транзит власти в 2024 году.
И теперь у нас нет иного выхода, кроме как готовиться к завтрашней войне. Вне зависимости от того, начнётся она или нет — готовым к ней быть необходимо. А значит, без собственного Карла Шмитта нам не обойтись.
P.S.
Чтобы всё вышесказанное не показалось читателю досужими рассуждениями — завтра, в день седьмой годовщины референдума о присоединении Крыма к России, Fitzroy Magazine публикует статью Максима Брусиловского о Будапештском меморандуме 1994 года — документе, нарушение буквы которого ставится России в вину на всех международных площадках, где обсуждается проблема Крыма. Отчасти раскрывая карты, скажу: по мнению Максима, Будапештский меморандум не только не запрещает России присоединить Крым, но и позволяет — при определённых условиях — интегрировать Донбасс.
Кирилл Бенедиктов, главный редактор Fitzroy Magazine
Источник
«Мы стали нацией, разучившейся любить». Последнее слово Егора Жукова на суде
В Кунцевском суде Москвы прошло заключительное перед вынесением приговора заседание по делу студента Высшей школы экономики Егора Жукова. Изначально молодому человеку вменяли участие в массовых беспорядках на акции 27 июля, однако позже обвинение переквалифицировали на призывы к экстремизму, которые якобы содержались в его роликах на YouTube.
Сторона обвинения запросила для студента четыре года колонии. Егор Жуков выступил в суде с последним словом. «Ведомости» публикуют его полностью.
«Судебное разбирательство, которое происходит сейчас, посвящено словам и их значениям. Мы обсуждали конкретные фразы, нюансы формулировок, способы толкования. Надеюсь, мы смогли доказать уважаемому суду, что я не являюсь экстремистом как с точки зрения лингвистики, так и здравого смысла.
Но сейчас я хочу затронуть вещь более фундаментальную, чем смысл слов. Я хочу рассказать про мотивы своей деятельности. Благо эксперт также про них высказался. Мотивы подлинные и глубинные. Те, что заставляют меня заниматься политикой. Мотивы, преследуя которые, я и записывал видео для канала «Блог Жукова».
И вот с чего я хочу начать. Российское государство сегодня позиционирует себя как последний защитник традиционных ценностей. Много внимания, как нам говорят, уделяется институту семьи и патриотизма, а ключевой традиционной ценностью называют христианскую веру. Ваша честь, мне кажется, может быть, это даже и хорошо, потому что христианская этика действительно включает в себя те ценности, которые мне поистине близки. Во-первых, это ответственность. В основе христианства лежит история про человека, который решился взвалить страдания всего мира на свои плечи. История про человека, который взял на себя ответственность в максимально возможном смысле этого слова. По сути, центральная идея всей христианской религии – это идея личной ответственности.
Ваша честь, мне кажется, может быть, это даже и хорошо, потому что христианская этика действительно включает в себя те ценности, которые мне поистине близки. Во-первых, это ответственность. В основе христианства лежит история про человека, который решился взвалить страдания всего мира на свои плечи. История про человека, который взял на себя ответственность в максимально возможном смысле этого слова. По сути, центральная идея всей христианской религии – это идея личной ответственности.
А во-вторых – любовь. «Возлюби ближнего, как самого себя» – это главная фраза христианской религии. Любовь есть доверие, сострадание, гуманизм, взаимопомощь и забота. Общество, построенное на такой любви, есть общество сильное. Пожалуй, наиболее сильное из всех в принципе возможных.
Для того чтобы понять мотивы моей деятельности, достаточно всего лишь взглянуть на то, как нынешнее российское государство, гордо выставляющее себя защитником христианских (а значит, и этих ценностей), на самом деле их защищает.
Перед разговором об ответственности сперва надо ответить на вопрос, что из себя представляет этика ответственного человека, какие слова он произносит себе в течение жизни. Мне кажется, такие: «Помни, весь твой путь будет наполнен трудностями подчас невыносимыми. Все твои близкие умрут, все твои планы нарушатся, тебя будут обманывать и бросать, и ты никуда не убежишь от смерти. Жизнь – это страдания, cмирись с этим. Но, смирившись с этим, смирившись с неизбежностью страдания, все равно взвали свой крест на плечи и следуй за своей мечтой. Потому что иначе все станет только хуже. Стань примером. Стань тем, на кого можно положиться. Не подчиняйся деспотам, борись за свободу тела и духа. И строй страну, в которой твои дети смогут стать счастливыми».
Разве такому нас учат? Разве такую этику усваивают дети в школах? Разве таких героев мы чествуем? Нет!
Существующая в стране обстановка уничтожает любые возможности для человеческого процветания. 10% наиболее обеспеченных россиян сосредоточили в своих руках 90% благосостояния страны. Среди них, конечно, есть весьма достойные граждане, но основная их часть, вернее, основная часть этого благосостояния, получена не честным трудом на благо людей, а банальной коррупцией.
Среди них, конечно, есть весьма достойные граждане, но основная их часть, вернее, основная часть этого благосостояния, получена не честным трудом на благо людей, а банальной коррупцией.
Наше общество разделено на два уровня непроницаемым барьером. Все деньги сконцентрированы сверху. И их оттуда никто не отдаст. Снизу же, без преувеличения, осталась лишь безысходность. Понимая, что рассчитывать им не на что, и понимая, что как бы они ни старались, ни себе, ни своей семье они принести счастья не смогут, русские мужчины либо вымещают всю злость на своих женах, либо спиваются, либо вешаются. Россия – первая страна в мире по количеству мужских самоубийств на 100 000 человек. В результате треть всех семей в России – это матери-одиночки с детьми. Это мы так, хочется спросить, традиционный институт семьи защищаем?
Мирон Федоров (рэпер Оxxxymiron. – «Ведомости»), не раз приходивший на мои заседания, очень верно заметил: у нас алкоголь дешевле, чем учебники. Государство создает все условия для того, чтобы между ответственностью и безответственностью россиянин всегда выбирал второе.
А теперь – про любовь. Любовь невозможна без доверия. А настоящее доверие зарождается во время совместной деятельности. Во-первых, совместная деятельность – редкое явление в стране, где не развита ответственность. Во-вторых, если совместная деятельность все-таки где-то проявляется, она тут же начинает восприниматься охранителями как угроза. И неважно, чем ты занимаешься – помогаешь ли заключенным, выступаешь ли за права человека, охраняешь ли природу. Рано или поздно тебя настигнет или статус «иностранного агента», либо тебя просто так закроют. Государство ясно дает понять: ребята, разбредитесь по своим норкам и друг с другом не взаимодействуйте. Собираться друг с другом больше двух на улице нельзя – посадим за митинг. Работать вместе по социально полезной повестке нельзя – дадим статус «иностранного агента». Откуда в такой среде взяться доверию и любви? Не романтической, а гуманистической любви человека к человеку.
Единственная социальная политика, которую последовательно проводит российское государство, – это разобщение. Так государство расчеловечивает нас в глазах друг друга, ибо в его глазах мы уже давно расчеловечены. Как иначе объяснить такое варварское отношение к людям с его стороны? Отношение, которое каждый день подчеркивается избиениями дубинками, пытками в колониях, игнорированием эпидемии ВИЧ, закрытием школ и больниц и так далее. Давайте взглянем на себя в зеркало. Кем мы стали, позволив сотворить с собой такое? Мы стали нацией, разучившейся брать на себя ответственность. Мы стали нацией, разучившейся любить.
Так государство расчеловечивает нас в глазах друг друга, ибо в его глазах мы уже давно расчеловечены. Как иначе объяснить такое варварское отношение к людям с его стороны? Отношение, которое каждый день подчеркивается избиениями дубинками, пытками в колониях, игнорированием эпидемии ВИЧ, закрытием школ и больниц и так далее. Давайте взглянем на себя в зеркало. Кем мы стали, позволив сотворить с собой такое? Мы стали нацией, разучившейся брать на себя ответственность. Мы стали нацией, разучившейся любить.
Более 200 лет назад Александр Радищев, проезжая между Петербургом и Москвой, писал: «Я взглянул окрест меня – душа моя страданиями человечества уязвлена стала. Обратил взоры мои во внутренность мою – и узрел, что бедствия человека происходят от человека». Где сегодня подобные люди? Люди, чья душа так же остро болит за происходящее в родном отечестве? Почему их почти не осталось? А все дело в том, что на проверку оказывается единственный традиционный институт, который подлинно чтит и укрепляет нынешнее российское государство, – это самодержавие. Самодержавие, которое норовит сломать жизнь любому, кто искренне хочет добра своей родине, кто не стесняется любить и брать на себя ответственность. В результате гражданам нашей многострадальной пришлось выучить, что инициатива наказуема, что начальство всегда право просто потому, что оно начальство, что счастье здесь, может быть, и возможно, но только не для них. И, выучив это, они начали постепенно исчезать.
Самодержавие, которое норовит сломать жизнь любому, кто искренне хочет добра своей родине, кто не стесняется любить и брать на себя ответственность. В результате гражданам нашей многострадальной пришлось выучить, что инициатива наказуема, что начальство всегда право просто потому, что оно начальство, что счастье здесь, может быть, и возможно, но только не для них. И, выучив это, они начали постепенно исчезать.
По статистике Росстата, Россия постепенно исчезает со средней скоростью минус 400 000 человек в год. За статистикой не видно людей, так увидьте же их. Это спивающиеся от бессилия, это замерзающие в непрогретых больницах, это убитые кем-то, это убитые самими собой люди – такие же, как мы с вами.
Наверное, к этому моменту мотивы моей деятельности стали ясны. Я действительно желаю видеть в своих гражданах два этих качества: ответственность и любовь. Ответственность за себя, за тех, кто рядом, за всю страну. Любовь к слабому, к ближнему, к человечеству. Это мое желание – еще одна причина, ваша честь, почему я не мог призывать к насилию. Насилие развязывает руки, ведет к безнаказанности, а значит, и к безответственности. Ровно так же насилие и не ведет к любви. Все же, несмотря на все преграды, я ни на секунду не сомневаюсь, что мое желание исполнится. Я смотрю вперед, за горизонт годов и вижу Россию, наполненную ответственными и любящими людьми. Пусть каждый представит себе такую Россию, и пусть этот образ руководит вами в вашей деятельности так же, как он руководит мной.
Насилие развязывает руки, ведет к безнаказанности, а значит, и к безответственности. Ровно так же насилие и не ведет к любви. Все же, несмотря на все преграды, я ни на секунду не сомневаюсь, что мое желание исполнится. Я смотрю вперед, за горизонт годов и вижу Россию, наполненную ответственными и любящими людьми. Пусть каждый представит себе такую Россию, и пусть этот образ руководит вами в вашей деятельности так же, как он руководит мной.
В заключение скажу следующее: если суд все же примет решение, что эти слова сейчас произносит действительно опасный преступник, ближайшие годы моей жизни будут наполнены лишениями и невзгодами. Но я смотрю на ребят, с которыми меня свело «московское дело», – на Костю Котова, на Самариддина Раджабова – и вижу улыбки на их лицах. Леша Миняйло, Даня Конон в минуты нашего общения в СИЗО никогда не позволяли себе жаловаться на жизнь. Я постараюсь последовать их примеру.
Я постараюсь радоваться тому, что мне выпал этот шанс – пройти испытания во имя близких мне ценностей. В конце концов, ваша честь, чем страшнее мое будущее, тем шире улыбка, с которой я смотрю в его сторону».
В конце концов, ваша честь, чем страшнее мое будущее, тем шире улыбка, с которой я смотрю в его сторону».
【решено】Как писать иногда — How.co
Иногда одно слово или два?
Иногда — это one — word наречие, означающее «иногда» или «то и дело».
Что такое иногда?
(Запись 1 из 2) : время от времени : время от времени : время от времени.
Где мы иногда используем?
Иногда несколько отличается тем, что может стоять в начале, в середине или в конце предложения.Например, вы можете сказать: « Иногда он ложится спать поздно», «Он иногда ложится спать поздно» или «Он ложится спать поздно иногда ». Размещение других частотных наречий, как правило, более ограничено.
Как произносится «когда-нибудь»?
Наречие « когда-то » (одно слово) означает неопределенное или неустановленное время в будущем; как прилагательное « когда-то » означает случайное или бывшее. Выражение « какое-то время » (два слова) означает «период времени».Наречие « иногда » (одно слово) означает «иногда, время от времени».
Выражение « какое-то время » (два слова) означает «период времени».Наречие « иногда » (одно слово) означает «иногда, время от времени».
Как пишется слово «люди»?
Как пишется с?
Правильное написание для английского слова «With»: [wˈɪð], [wˈɪð], [w_ˈɪ_ð] (фонетический алфавит IPA).
Сможете написать корову 13 буквами?
Да, слово COW может быть выражено в 13 буквах . Слово КОРОВА может быть записано 13 буквами таким образом: «SEE-O-DOUBLE- YOU » в котором мы просто пишем написание символа мудрое произношение….Таким образом, мы можем записать « COW » в 13 букв как «SEE-O-DOUBLEYOU».
Какое самое длинное слово F?
Floccinaucinihilipilification | Определение Floccinaucinihilipilification на Dictionary.com.
Как пишется любовь?
Как пишется ЛЮБОВЬ ? Правильное написание для английского слова « love »: [lˈʌv], [lˈʌv], [l_ˈʌ_v] (фонетический алфавит IPA).
Как пишется «любовь» не пишется «любовь» вы ее чувствуете?
« Как пишется ‘ любовь ’?» — Пятачок.« Ты не произносишь , это , ты чувствуешь, что это ». – Пух»
Как пишется «счастливый»?
Правильное написание для английского слова « happy »: [hˈapi], [hˈapi], [h_ˈa_p_i] (фонетический алфавит IPA).Аналогично Правописание слов для HAPPY
- подгузник,
- бегемот,
- Хави,
- ХАПП,
- арфа,
- Хаффи,
- час.
Как пишется мама?
Мама и мама два правописания вариантов существительного, означающего мать-родительницу.
- Мама также имеет несколько других значений.
- Mom — версия на американском английском.
- Mum — англо-британская версия.
Что такое сокращение от Мама?
МАМА
| Акроним | Определение |
|---|---|
| МАМ | Месяц в месяце |
| МАМ | Момент безумия (группа) |
| МАМ | Метоксиметил |
| МАМ | Злой старик |
Почему британцы говорят «кровавый»?
Кровавый .Не волнуйтесь, это не жестокое слово… оно не имеет ничего общего с и с «кровью». Кровавый » — обычное слово, чтобы сделать предложение более выразительным, в основном используется как восклицание удивления. Что-то может быть « чертовски чудесно» или « чертовски ужасно». Сказав это, британцев действительно иногда используют его, когда выражают гнев…
Как пишется дочь?
Правильное написание для английского слова « дочь »: [dˈɔːtə], [dˈɔːtə], [d_ˈɔː_t_ə] (фонетический алфавит IPA).
Что такое слово дочь?
1a : человеческая женщина, имеющая отношение ребенка к родителю. б : потомство животного женского пола. 2: атомарная частица, которая является продуктом радиоактивного распада данного элемента радона, является дочерним радия. дочь .
Как пишется «особенный»?
Правильное написание для английского слова « special »: [spˈɛʃə͡l], [spˈɛʃəl], [s_p_ˈɛ_ʃ_əl] (фонетический алфавит IPA).
Как пишется «умер»?
Правильное написание для английского слова « Died »: [dˈa͡ɪd], [dˈaɪd], [d_ˈaɪ_d] (фонетический алфавит IPA).
Умереть — это слово?
Dieing — это слово , но его почти никогда не следует использовать, и оно никогда не относится к смерти. Смерть относится к смерти.
Умер слово?
Смерть это Существительное (наименование слово ) Умереть это Глагол (действие слово ) Умер это прошедшее время глагола Умереть .
Какое настоящее время у слова умер?
Формы глагола Die
| Инфинитив | Настоящее время Причастие | Прошлое Время |
|---|---|---|
| штамп | умирающий | умер |
Как пишется «умереть» по-японски?
Какой глагол умер?
Умер — это глагол .Это прошедшее время и причастие прошедшего времени от die . умереть значит перестать жить.
Он умер или умер?
Мертвый — прилагательное. Умер — это прошедшее время. Умер — настоящее совершенное время.
Что происходит в мозгу, когда кто-то не может писать по буквам — ScienceDaily
Изучая жертв инсульта, которые потеряли способность писать по буквам, исследователи точно определили части мозга, которые контролируют то, как мы пишем слова.
В последнем выпуске журнала Мозг нейробиологи Университета Джона Хопкинса впервые связывают основные трудности правописания с повреждением, казалось бы, несвязанных областей мозга, проливая новый свет на механику языка и памяти.
«Когда что-то идет не так с правописанием, это происходит не всегда — могут происходить разные вещи, и они возникают из-за разных сбоев в работе мозга», — говорит ведущий автор Бренда Рапп, профессор кафедры когнитивных наук.«В зависимости от того, какая деталь сломается, у вас будут разные симптомы».
Команда Раппа изучила случаи за 15 лет, в которых 33 человека остались с нарушениями правописания после перенесенных инсультов. У некоторых людей были проблемы с долговременной памятью, у других — с оперативной памятью.
Из-за проблем с долговременной памятью люди не могут вспомнить, как пишутся слова, которые они когда-то знали, и склонны делать обоснованные предположения. Они, вероятно, могли бы правильно угадать предсказуемое написание слова, такого как «лагерь», но с более непредсказуемым написанием, таким как «соус», они могли бы попробовать «сосс».В тяжелых случаях люди, пытающиеся написать слово «лев», могут предложить такие слова, как «лонп», «линт» и даже «тигр». буквы в правильном порядке — «лев» может быть «лиот», «лин», «лино» или «левт».
Команда использовала компьютерное картирование для картирования поражений головного мозга каждого человека и обнаружила, что в случаях долговременной памяти повреждения появлялись в двух областях левого полушария, одна в передней части мозга, а другая в нижней части. мозг назад.В случаях рабочей памяти поражения в основном также были в левом полушарии, но в совершенно другой области в верхней части мозга ближе к спине.
«Я был удивлен, увидев, насколько далеки и различны области мозга, которые поддерживают эти два подкомпонента процесса письма, особенно два подкомпонента, которые настолько тесно взаимосвязаны во время правописания, что некоторые утверждали, что их не следует рассматривать как отдельные функции», — сказал Рэпп. «Вы могли подумать, что они будут ближе друг к другу и их будет труднее разлучить.»
«Вы могли подумать, что они будут ближе друг к другу и их будет труднее разлучить.»
Хотя науке известно довольно много о том, как мозг справляется с чтением, эти открытия предлагают некоторые из первых четких доказательств того, как это пишется, понимание, которое может привести к улучшению поведенческих методов лечения после повреждения мозга и более эффективным способам обучения правописанию.
Соавторы Рэппа — постдокторант Джонса Хопкинса Джереми Перселл; профессор Медицинской школы Арджи Э. Хиллис; Рита Капассо из S.C.A. Партнеры в Риме, Италия; и Габриэле Микели, профессор Университета Тренто, Италия.
Эта работа была поддержана грантами Национального института здравоохранения DC012283 и DC05375.
Источник истории:
Материалы предоставлены Университетом Джона Хопкинса . Примечание. Содержимое можно редактировать по стилю и длине.
ОРФФОРМАЦИОННАЯ ИСПРАВЛЕНИЕ В ПОИСКЕ
Inf Retr Boston. Авторская рукопись; Доступен в PMC 2007 13 декабря. У.SA
Авторская рукопись; Доступен в PMC 2007 13 декабря. У.SA
Abstract
Известно, что пользователи поисковых систем в Интернете часто вводят запросы с опечатками в одном или нескольких поисковых терминах. Несколько поисковых систем предлагают способы исправления слов с ошибками, но используемые методы являются собственностью и, насколько нам известно, не опубликованы.Здесь мы описываем разработанную нами методологию исправления правописания для поисковой системы PubMed. Наш подход основан на модели зашумленного канала для исправления орфографии и использует статистику, собранную из пользовательских журналов, для оценки вероятности различных типов правок, которые приводят к орфографическим ошибкам. Обсуждаются уникальные проблемы, возникающие при корректировке запросов поисковых систем, и описываются наши решения.
Обсуждаются уникальные проблемы, возникающие при корректировке запросов поисковых систем, и описываются наши решения.
Ключевые слова: модель зашумленного канала, журналы пользовательских запросов, обнаружение несловных ошибок, trie, расстояние редактирования .2001 г.; Ван, Берри и др. 2003). Ван и др. (2003) сообщают о 26% случаев орфографических ошибок в словах на академических сайтах. Вполне возможно, что количество ошибок на общедоступных сайтах может быть еще выше. Нордли (1999) отмечает, что две трети первоначальных запросов не достигают своей цели, а опрос NPD (2000) показывает, что в 77% случаев первоначально неудачный поиск модифицируется и повторяется на том же сайте. Эти результаты предполагают потенциальную выгоду от выполнения некоторой коррекции запроса для пользователя.Орфографическая коррекция — очевидный кандидат на эту роль. Поэтому мы взялись изучить, как можно построить такое средство для поисковой системы PubMed. PubMed, служба Национальной медицинской библиотеки, предоставляет доступ к более чем 16 миллионам цитат MEDLINE за период с 1950 г. , а также к дополнительным журналам по медико-биологическим наукам (McEntyre and Lipman 2001).
, а также к дополнительным журналам по медико-биологическим наукам (McEntyre and Lipman 2001).
Исправление орфографии было предметом исследований в течение многих лет, и проблема была удобно разделена на три подзадачи (Кукич, 1992; Джурафски и Мартин, 2000) в порядке возрастания сложности: 1) обнаружение несловных ошибок; 2) исправление ошибок в отдельных словах; и 3) контекстно-зависимое исправление ошибок.Каждая из этих задач имеет отношение к проблеме исправления орфографии в поисковой системе, и каждая задача подлежит некоторым особым рассмотрениям в этой настройке. Обнаружение несловных ошибок обычно выполняется путем сравнения строки со списком допустимых слов в каком-либо словаре. В настройках поисковой системы словарный запас, потенциально доступный для поиска, служит словарю. Для целей данной статьи давайте будем называть этот словарь словарем базы данных. Если термин отсутствует в базе данных, то для практических целей поиска данных можно предположить, что он написан с ошибкой. Если термин просто имеет низкую частоту в базе данных, он все еще может иметь высокую вероятность того, что он является орфографической ошибкой, и мы можем принести пользу пользователю, предложив термин с более высокой частотой в качестве исправления. Если запрос состоит из одного слова, мы имеем дело со случаем исправления ошибок в отдельных словах. С другой стороны, если запрос состоит из двух или более слов, существует вероятность того, что мы имеем дело с полезным контекстом, который может помочь процессу исправления. Однако запросы обычно состоят не более чем из двух-трех слов (Сильверштейн и Хензингер, 1999), поэтому контекст будет в лучшем случае небольшим, а в худшем — бесполезным.В этой ситуации необходимо разработать стратегию, позволяющую использовать контекст там, где он полезен, и игнорировать его в противном случае. Типичный и практичный подход к использованию контекста при исправлении правописания состоит в том, чтобы применить языковую модель к рассматриваемому жанру текста и использовать ее для улучшения предсказания исправленной строки (Черч и Гейл, 1991; Кукич, 1992; Брилл и Мур, 2000).
Если термин просто имеет низкую частоту в базе данных, он все еще может иметь высокую вероятность того, что он является орфографической ошибкой, и мы можем принести пользу пользователю, предложив термин с более высокой частотой в качестве исправления. Если запрос состоит из одного слова, мы имеем дело со случаем исправления ошибок в отдельных словах. С другой стороны, если запрос состоит из двух или более слов, существует вероятность того, что мы имеем дело с полезным контекстом, который может помочь процессу исправления. Однако запросы обычно состоят не более чем из двух-трех слов (Сильверштейн и Хензингер, 1999), поэтому контекст будет в лучшем случае небольшим, а в худшем — бесполезным.В этой ситуации необходимо разработать стратегию, позволяющую использовать контекст там, где он полезен, и игнорировать его в противном случае. Типичный и практичный подход к использованию контекста при исправлении правописания состоит в том, чтобы применить языковую модель к рассматриваемому жанру текста и использовать ее для улучшения предсказания исправленной строки (Черч и Гейл, 1991; Кукич, 1992; Брилл и Мур, 2000). ; Джурафски и Мартин, 2000). Наш подход похож на языковую модель в том смысле, что когда нам предъявляют запрос из более чем одного слова, мы пытаемся исправить фразу, которая распознается механизмом запросов, и частота этой фразы вступает в игру в процессе.
; Джурафски и Мартин, 2000). Наш подход похож на языковую модель в том смысле, что когда нам предъявляют запрос из более чем одного слова, мы пытаемся исправить фразу, которая распознается механизмом запросов, и частота этой фразы вступает в игру в процессе.
Наш основной подход представляет собой форму модели зашумленного канала для исправления правописания, которая очень похожа на метод, разработанный Черчем и Гейлом (1991). Основное отличие состоит в том, что мы включили букву контекста по обе стороны от предполагаемой поправки при вычислении ее вероятности. В этом мы движемся в направлении, взятом Бриллом и Муром (2000), только мы не допускаем столько контекста, сколько их подход. Модель зашумленного канала пытается вычислить выражение
, где s представляет строку, подлежащую исправлению, а w — потенциальную коррекцию.В нашей реализации w работает со словарем базы данных поисковой системы, а P ( w ) представляет вероятность того, что пользователь намеревался выполнить поиск, используя слово w . Мы следуем Черчу и Гейлу (1991) в оценке P ( s|w ) как произведения вероятностей правок, необходимых для преобразования w в s . Одна из трудностей при построении нашего алгоритма коррекции заключалась в получении полезных контекстно-зависимых оценок этих вероятностей редактирования.Наше решение включает в себя сбор статистики из журналов поисковых систем.
Мы следуем Черчу и Гейлу (1991) в оценке P ( s|w ) как произведения вероятностей правок, необходимых для преобразования w в s . Одна из трудностей при построении нашего алгоритма коррекции заключалась в получении полезных контекстно-зависимых оценок этих вероятностей редактирования.Наше решение включает в себя сбор статистики из журналов поисковых систем.
Документ состоит из следующих разделов:
Сбор статистики редактирования – Как мы определяем вероятности редактирования из журналов запросов пользователей PubMed.
Основные предположения метода – Как мы интерпретируем модель зашумленного канала в настройках PubMed.
Алгоритм: основные функции – Четыре основные функции редактирования, применяемые к строкам в зависимости от их характеристик.
Алгоритм – Как сочетаются базовые функции редактирования для обработки строк из одного, двух или более токенов.

Очистка данных PubMed – Как мы снижаем рейтинг неправильных написаний в словаре поисковой системы PubMed с помощью статистического тестирования.
Проблемы с производительностью — цифры, описывающие текущую реализацию алгоритма и его производительность.
Обсуждение – Успехи и неудачи алгоритма и способы его улучшения.
Выводы.
Прежде чем мы пойдем дальше, несколько слов о терминологии. Под терминами «слово» или «токен» мы будем подразумевать одно и то же, а именно строку печатных символов ASCII, не содержащую пробелов внутри строки. Термины «слово» или «токен» обычно используются взаимозаменяемо (Jurafsky and Martin 2000). Таким образом, «дом» — это слово или токен, как и «ххххх», хотя обычно мы не можем думать о «ххххх» как о слове. Мы также будем использовать слова «термин» и «фраза» взаимозаменяемо для обозначения строки, состоящей из одного или нескольких слов или токенов, разделенных пробелом. Опять же, это обычное использование.
Опять же, это обычное использование.
СБОР СТАТИСТИКИ РЕДАКТИРОВАНИЯ
Хотя исправление орфографии не было в центре внимания, ряд исследователей изучили методы анализа журналов запросов пользователей для поисковых систем с целью сделать полезные предложения по улучшению запроса пользователя. Биферман и Бергер (Beeferman and Berger, 2000) кластеризовали запросы на основе данных о кликах, которые показывают, какие записи на самом деле выбирает пользователь. Когда разные запросы приводят к щелчку одной и той же записи, это считается сходством между запросами.Вен и др. (2002) используют данные «кликабельности», а также показатель лексического сходства двух запросов для одной и той же цели. Такие методы могут использоваться для предложения терминов из одного запроса в дополнение к запросу, который был найден рядом с ним в «пространстве кликов». Лерой и др. (2003) используют текст «нажатие», а не запись «нажатие на», и анализируют слова в тексте, на который нажали, в качестве источника для дополнения запросов пользователя. Хуанг и др. (2003) изучают пары терминов, которые одновременно встречаются в сеансе одного пользователя в веб-журналах, чтобы обнаружить отношения, которые можно использовать для предложения новых терминов для добавления к запросу пользователя.Хотя ни одно из этих исследований не направлено на исправление правописания, все же есть некоторые сходства.
Хуанг и др. (2003) изучают пары терминов, которые одновременно встречаются в сеансе одного пользователя в веб-журналах, чтобы обнаружить отношения, которые можно использовать для предложения новых терминов для добавления к запросу пользователя.Хотя ни одно из этих исследований не направлено на исправление правописания, все же есть некоторые сходства.
Мы анализируем журнал запросов, чтобы обнаружить сеансы отдельных пользователей, содержащие пары терминов, которые мы идентифицируем как термин запроса и его исправление. Один сеанс пользователя определяется одним IP-адресом и условием запроса, и его исправление должно происходить в течение 300 секунд друг от друга. 300-секундный порог оказался полезным (Silverstein and Henzinger 1999; Huang, Chien et al. 2003). Данные показывают, что несколько пар запросов, разделенных более чем 300 секундами, поступают из одного и того же сеанса (Huang, Chien et al.2003). Мы анализируем эти пары терминов запроса, чтобы использовать их не как прямое руководство по исправлению запросов, а для получения статистики правок, приводящих к ошибкам. Метод идентификации таких пар зависит не только от одного и того же IP-адреса и почти параллелизма во времени, но также от меры близости между словами запроса. Для этой цели мы используем монтажное расстояние в один, два или самое большее три редактирования. Мы также настаиваем на том, чтобы при наличии нескольких правок разные правки разделялись хотя бы одним символом, чтобы можно было определить правильный контекст для каждой правки, и сама правка не подвергалась сомнению.Мы обосновываем это на основании первоначального наблюдения Damerau (1964) о том, что 80% орфографических ошибок вызваны единичным редактированием (удалением, вставкой, заменой или транспозицией). Мы не утверждаем, что более сложных операций редактирования не бывает, но мы пытаемся аппроксимировать их комбинацией отдельных правок.
Метод идентификации таких пар зависит не только от одного и того же IP-адреса и почти параллелизма во времени, но также от меры близости между словами запроса. Для этой цели мы используем монтажное расстояние в один, два или самое большее три редактирования. Мы также настаиваем на том, чтобы при наличии нескольких правок разные правки разделялись хотя бы одним символом, чтобы можно было определить правильный контекст для каждой правки, и сама правка не подвергалась сомнению.Мы обосновываем это на основании первоначального наблюдения Damerau (1964) о том, что 80% орфографических ошибок вызваны единичным редактированием (удалением, вставкой, заменой или транспозицией). Мы не утверждаем, что более сложных операций редактирования не бывает, но мы пытаемся аппроксимировать их комбинацией отдельных правок.
Наше утверждение о том, что данные, которые мы собрали, представляют собой орфографические ошибки, подтверждается тем фактом, что если кто-то находит термин в журналах запросов, которого нет в базе данных PubMed, и смотрит на термины, поступающие из запросов того же пользователя до или после во времени и близкие в лексическом пространстве, гораздо более вероятно, что такие термины следуют, чем предшествуют во времени. Это видно из того, где очевидно, что при условии, что термин запроса отсутствует в базе данных PubMed, гораздо более вероятно найти потенциальное исправление, происходящее после термина, чем до него. Мы считаем, что единственное разумное объяснение этому наблюдению состоит в том, что эта асимметрия указывает на то, что люди постоянно вносят исправления в ошибочные запросы, чтобы получить совпадения в базе данных. Тот факт, что некоторые правильные термины появляются перед их ошибочными аналогами, мы приписываем тому факту, что люди нередко набирают термин правильно, а затем вынуждены его повторять и могут сделать опечатку при второй попытке, которой не было при первом наборе.Тем не менее, мы предпочитаем доверять исправлению, которое следует за термином запроса. полностью основан на словах запроса, которых нет в базе данных PubMed. Однако есть также убедительные доказательства того, что люди исправляют не только термины, которых нет в PubMed, но также исправляют термины, которые просто встречаются с низкой частотой в данных PubMed.
Это видно из того, где очевидно, что при условии, что термин запроса отсутствует в базе данных PubMed, гораздо более вероятно найти потенциальное исправление, происходящее после термина, чем до него. Мы считаем, что единственное разумное объяснение этому наблюдению состоит в том, что эта асимметрия указывает на то, что люди постоянно вносят исправления в ошибочные запросы, чтобы получить совпадения в базе данных. Тот факт, что некоторые правильные термины появляются перед их ошибочными аналогами, мы приписываем тому факту, что люди нередко набирают термин правильно, а затем вынуждены его повторять и могут сделать опечатку при второй попытке, которой не было при первом наборе.Тем не менее, мы предпочитаем доверять исправлению, которое следует за термином запроса. полностью основан на словах запроса, которых нет в базе данных PubMed. Однако есть также убедительные доказательства того, что люди исправляют не только термины, которых нет в PubMed, но также исправляют термины, которые просто встречаются с низкой частотой в данных PubMed. Это показано в . Здесь мы видим, что в частотном диапазоне от 1 до 100 терминов запроса, по крайней мере, на порядок более вероятно, что за ними следует высокочастотный лексически близкий термин, чем им предшествует такой термин.Опять же, асимметрия свидетельствует о родстве таких пар терминов запроса и о том, что второй термин в паре присутствует как поправка для первого термина.
Это показано в . Здесь мы видим, что в частотном диапазоне от 1 до 100 терминов запроса, по крайней мере, на порядок более вероятно, что за ними следует высокочастотный лексически близкий термин, чем им предшествует такой термин.Опять же, асимметрия свидетельствует о родстве таких пар терминов запроса и о том, что второй термин в паре присутствует как поправка для первого термина.
Сплошная кривая представляет количество пар терминов запроса, в которых термин, содержащийся в базе данных PubMed, следует за термином, отсутствующим в базе данных. Ломаная кривая представляет те же данные, когда термин, содержащийся в PubMed, предшествует термину, которого не было в базе данных. Во всех случаях термины находятся в пределах трех правок друг от друга.
Количество терминов запроса с разной частотой в данных PubMed, за которыми следует лексически близкий термин с десятикратной частотой (сплошная кривая) или предшествующий близкий термин с десятикратной частотой (пунктирная кривая).
Наши данные являются результатом сбора таких правок, которые мы описали в файлах журналов PubMed за 63 дня. Мы собрали около 1 миллиона правок, как указано в . Все термины многократного редактирования должны были содержать как минимум в четыре раза больше символов, чем правки, чтобы гарантировать, что правки действительно будут исправлениями.Это в дополнение к условию, согласно которому исправления в PubMed встречаются как минимум в десять раз чаще, чем термины, которые они должны исправлять.
Таблица 1
Ошибки, собранные за 63 дня пользовательских журналов PubMed.
| Количество ошибочных слов | Общее количество редактирования | ||
|---|---|---|---|
| 1 редактирование Ошибка | 769128 (87%) | 769128 | 2 Ошибка редактирования | 105860 (12%) | 211720 |
| 3 Ошибка редактирования | 4932 (1%) | ||
| Всего | 879920 | 999920 | 995644 |
Набор данных был собран с одной буквой контекста по обе стороны редактирования. И начало, и конец слова были отмечены специальными символами, чтобы они также могли функционировать в качестве контекста и сделать процесс исправления специфичным для начала и окончания слов соответственно. Можно заметить, что наши данные показывают, что 87% всех слов с ошибками являются результатом одной ошибки редактирования. Это несколько выше, чем цифра 80%, наблюдаемая Damerau (1964), но согласуется с нашим требованием, чтобы множественные ошибочные правки происходили с буквой контекста, разделяющей их.Это естественным образом уменьшает количество видимых ошибок более высокого порядка.
И начало, и конец слова были отмечены специальными символами, чтобы они также могли функционировать в качестве контекста и сделать процесс исправления специфичным для начала и окончания слов соответственно. Можно заметить, что наши данные показывают, что 87% всех слов с ошибками являются результатом одной ошибки редактирования. Это несколько выше, чем цифра 80%, наблюдаемая Damerau (1964), но согласуется с нашим требованием, чтобы множественные ошибочные правки происходили с буквой контекста, разделяющей их.Это естественным образом уменьшает количество видимых ошибок более высокого порядка.
ОСНОВНЫЕ ПРЕДПОЛОЖЕНИЯ МЕТОДА
Для оценки выражения (1) мы должны иметь не только информацию о вероятности правок. Мы также должны уметь оценивать априорные вероятности P ( w ). Это вероятности того, что различные слова, встречающиеся в базе данных PubMed, будут использоваться пользователями в качестве терминов запроса. Мы изучили термины, встречающиеся в базе данных PubMed, и обнаружили, что они используются в качестве терминов запроса прямо пропорционально их частоте в базе данных. Это показано в том месте, где прямая линия указывает на прямую пропорциональность. Линия несколько зашумлена на высоких частотах из-за разреженности данных и имеет небольшой изгиб на низких частотах, что указывает на то, что на самых низких частотах в запросах используется меньше терминов. Мы ожидаем такого отклонения из-за того, что миллионы очень низкочастотных терминов, как правило, неизвестны большинству пользователей. Таким образом, мы можем использовать частоту термина в базе данных в качестве суррогата вероятности того, что этот термин будет предназначен как термин запроса, введенный пользователем, при условии, что мы сбрасываем значение на низких частотах.На самом деле наше дисконтирование на низких частотах более резкое, чем изгиб кривой, потому что на этих низких частотах большая часть того, что вводят пользователи, является орфографической ошибкой, а не тем, что они имели в виду. Мы дисконтируем по формуле
Это показано в том месте, где прямая линия указывает на прямую пропорциональность. Линия несколько зашумлена на высоких частотах из-за разреженности данных и имеет небольшой изгиб на низких частотах, что указывает на то, что на самых низких частотах в запросах используется меньше терминов. Мы ожидаем такого отклонения из-за того, что миллионы очень низкочастотных терминов, как правило, неизвестны большинству пользователей. Таким образом, мы можем использовать частоту термина в базе данных в качестве суррогата вероятности того, что этот термин будет предназначен как термин запроса, введенный пользователем, при условии, что мы сбрасываем значение на низких частотах.На самом деле наше дисконтирование на низких частотах более резкое, чем изгиб кривой, потому что на этих низких частотах большая часть того, что вводят пользователи, является орфографической ошибкой, а не тем, что они имели в виду. Мы дисконтируем по формуле
Термины запроса группируются по логарифму (частота запросов) по оси x, а среднее значение журнала частоты MEDLINE по каждому бину откладывается по оси y.
F ‘ ‘ = F * 10 F * 10 0,075 * ( F -80) , F <80
(2)
, где F — это оригинальная частота базы данных и f ′ дисконтированная частота.Таким образом, наше первое основное предположение состоит в том, что мы можем позволить частоте термина в базе данных стоять на месте P ( w ) в (1) при условии, что мы применяем дисконтирование, заданное (2).
Наше второе основное предположение заключается в том, что люди чаще делают орфографические ошибки при составлении запросов, чем при составлении текста для базы данных PubMed. Это подтверждается приведенными во введении данными о частоте орфографических ошибок в поисковых запросах (до 26%) по сравнению с данными о частоте орфографических ошибок в печатном тексте менее 5% (Кукич, 1992).Печатный текст, который появляется в PubMed, обычно подвергается редакционному процессу, и во многих случаях также применяется автоматическая проверка орфографии. Кроме того, печатный текст часто является продуктом усилий нескольких авторов, и по этой причине можно ожидать, что в нем будет меньше орфографических ошибок. Таким образом, мы считаем, что наше предположение не является необоснованным. Мы используем это предположение, чтобы решить, когда исправлять слово, которое уже есть в базе данных. Предположим, что s — это слово, которое появляется в базе данных, а w — это слово, определенное вычислением выражения (1) для s .Затем, чтобы решить, должны ли мы предложить w в качестве поправки на s , мы спрашиваем, выполняется ли неравенство
Кроме того, печатный текст часто является продуктом усилий нескольких авторов, и по этой причине можно ожидать, что в нем будет меньше орфографических ошибок. Таким образом, мы считаем, что наше предположение не является необоснованным. Мы используем это предположение, чтобы решить, когда исправлять слово, которое уже есть в базе данных. Предположим, что s — это слово, которое появляется в базе данных, а w — это слово, определенное вычислением выражения (1) для s .Затем, чтобы решить, должны ли мы предложить w в качестве поправки на s , мы спрашиваем, выполняется ли неравенство
. Если s является в первую очередь опечаткой w , мы могли бы ожидать равенства в (3) при условии, что P ( s|w ) оценивается на основе частоты ошибок, преобладающих в базе данных PubMed. В этом случае, когда мы оцениваем P ( s|w ) на основе более высоких коэффициентов ошибок, полученных из пользовательских журналов, мы ожидаем, что неравенство (3) будет выполнено. Если это так, мы принимаем это как свидетельство того, что s , вероятно, является опечаткой w . Конечно, только неравенство (3) само по себе дает основание для предложения w в качестве поправки на s , потому что левая часть неравенства представляет собой вероятность того, что пользователь намеревался s в качестве термина запроса, а правая часть есть вероятность того, что пользователь намеревался ввести w в качестве термина запроса, но из-за внесения ошибок получил s .При фактическом применении (3) мы заменяем частоты базы данных s и w на вероятности P ( s ) и P ( w ) и используем дисконтирование в (2 ) там, где это уместно.
Если это так, мы принимаем это как свидетельство того, что s , вероятно, является опечаткой w . Конечно, только неравенство (3) само по себе дает основание для предложения w в качестве поправки на s , потому что левая часть неравенства представляет собой вероятность того, что пользователь намеревался s в качестве термина запроса, а правая часть есть вероятность того, что пользователь намеревался ввести w в качестве термина запроса, но из-за внесения ошибок получил s .При фактическом применении (3) мы заменяем частоты базы данных s и w на вероятности P ( s ) и P ( w ) и используем дисконтирование в (2 ) там, где это уместно.
Чтобы применить формулы (1) и (3), мы должны также оценить вероятность, P ( s|w ), что при попытке произвести w будут внесены ошибки, которые фактически дадут s Обычно мы следуем методу «выравнивания максимальной вероятности» или «минимального расстояния редактирования», как описано в Jurafsky and Martin (2000). Мы оцениваем P ( s|w ) как произведение вероятностей последовательности правок, которая даст s из w . Поскольку таких последовательностей часто бывает несколько, мы берем последовательность, дающую наибольшую вероятность, в качестве нашей оценки для P ( s|w ).
Мы оцениваем P ( s|w ) как произведение вероятностей последовательности правок, которая даст s из w . Поскольку таких последовательностей часто бывает несколько, мы берем последовательность, дающую наибольшую вероятность, в качестве нашей оценки для P ( s|w ).
АЛГОРИТМ: ОСНОВНЫЕ ФУНКЦИИ
Здесь мы начнем описание алгоритма с описания того, как осуществляется исправление орфографии на самом базовом уровне.Наша цель состоит в том, чтобы предложить исправление только в том случае, если мы можем сделать это с гарантией того, что наше предложение будет правильным как минимум в 70% случаев. Это требование в некоторой степени влияет на то, как строятся основные функции. Предположим, что s — это строка, которую необходимо исправить.
OneDit
Мы оцениваем P ( S ) и P ( S | W ) P ( W ( W ) по всем Вт в базе данных, которые находятся в одном редактировании с . Это делается путем использования частот базы данных (с соответствующим дисконтированием) и редактирования вероятностей, а затем нормализации полученных оценочных значений до единицы. Пусть c обозначает термин с наибольшей оценочной вероятностью, а P c обозначает эту вероятность. Если P c >0,7 или P ( s ) <0,05 принять c в качестве коррекции. В противном случае не предлагайте никаких исправлений. Обоснование предложения c в качестве исправления, когда P ( s ) <0.05 заключается в том, что в этом случае мы можем отклонить на уровне 5% гипотезу о том, что s — это то, что имел в виду пользователь, и мы также должны были дать наше лучшее предположение в качестве исправления. Таким образом, наша стратегия состоит в том, чтобы предложить исправление, если мы совершенно уверены, что мы правы, а также когда мы совершенно уверены, что входная строка не предназначалась, даже если в последнем случае мы можем быть гораздо менее уверены, что исправление является правильным.
Это делается путем использования частот базы данных (с соответствующим дисконтированием) и редактирования вероятностей, а затем нормализации полученных оценочных значений до единицы. Пусть c обозначает термин с наибольшей оценочной вероятностью, а P c обозначает эту вероятность. Если P c >0,7 или P ( s ) <0,05 принять c в качестве коррекции. В противном случае не предлагайте никаких исправлений. Обоснование предложения c в качестве исправления, когда P ( s ) <0.05 заключается в том, что в этом случае мы можем отклонить на уровне 5% гипотезу о том, что s — это то, что имел в виду пользователь, и мы также должны были дать наше лучшее предположение в качестве исправления. Таким образом, наша стратегия состоит в том, чтобы предложить исправление, если мы совершенно уверены, что мы правы, а также когда мы совершенно уверены, что входная строка не предназначалась, даже если в последнем случае мы можем быть гораздо менее уверены, что исправление является правильным.
TwoEdit
Мы оцениваем P ( s|w ) P ( w ) по всем w в базе данных, которые находятся на расстоянии двух правок от s .Если такие строки есть, мы возвращаем наиболее вероятную в качестве принятого исправления. В противном случае коррекция не предлагается.
RecursiveEdit
Если бы мы попытались произвести исправление с двумя правками и потерпели неудачу, мы бы произвели выравнивание начального сегмента s с начальным сегментом слова w в базе данных с двумя правками. Мы можем оценить такие попытки по тому, сколько букв в s они используют. Пусть 90 345 м 90 346 обозначают максимальный рейтинг, полученный любым таким частичным выравниванием.Затем мы запрашиваем то частичное выравнивание, которое получает рейтинг м и также имеет самую высокую вероятность среди всех таких частичных выравниваний с рейтингом м . Мы называем это лучшим частичным выравниванием. Затем мы можем повторять эту процедуру каждый раз, начиная с лучшего частичного выравнивания, полученного на предыдущей итерации. Если мы потребуем, чтобы алгоритм делал некоторое продвижение по строке s на каждом этапе и прерывал процесс, если он терпит неудачу в какой-либо точке, мы тогда получаем алгоритм, который либо производит полное выравнивание, либо завершается, не производя никакого выравнивания только с несколько итераций.Если алгоритм завершается предложением, мы требуем, чтобы результат прошел тест на сходство с s , который мы называем проверкой работоспособности (см. ниже). Если да, то это принимается как поправка. В противном случае коррекция не предлагается.
Затем мы можем повторять эту процедуру каждый раз, начиная с лучшего частичного выравнивания, полученного на предыдущей итерации. Если мы потребуем, чтобы алгоритм делал некоторое продвижение по строке s на каждом этапе и прерывал процесс, если он терпит неудачу в какой-либо точке, мы тогда получаем алгоритм, который либо производит полное выравнивание, либо завершается, не производя никакого выравнивания только с несколько итераций.Если алгоритм завершается предложением, мы требуем, чтобы результат прошел тест на сходство с s , который мы называем проверкой работоспособности (см. ниже). Если да, то это принимается как поправка. В противном случае коррекция не предлагается.
StringSplit
Мы пытаемся ввести пробел в какой-то точке строки, чтобы преобразовать ее в два слова. Если оба результирующих слова найдены в базе данных, они становятся кандидатами на разбиение строки с рейтингом, равным наименьшей из частот в базе данных двух слов, полученных в результате разбиения. В случае разделения в качестве исправления может быть предложено разделение с наивысшим рейтингом. Обычно для того, чтобы быть принятым, требуется иметь рейтинг выше некоторого нижнего предела. Если да, то в качестве коррекции предлагается раскол. В противном случае коррекция не предлагается.
В случае разделения в качестве исправления может быть предложено разделение с наивысшим рейтингом. Обычно для того, чтобы быть принятым, требуется иметь рейтинг выше некоторого нижнего предела. Если да, то в качестве коррекции предлагается раскол. В противном случае коррекция не предлагается.
Если такое слово, как «фосфатаза», разделено ошибочным введением внутреннего пробела, как в слове «фосфхатаза», это можно исправить одной операцией редактирования, которая удалит лишний пробел. Таким образом, не требуется никакого специального механизма исправления, кроме функций OneEdit, TwoEdit или RecursiveEdit, описанных выше.Однако, если два слова случайно встречаются вместе, как в слове «яд», операций редактирования может оказаться недостаточно, потому что строка «ядовитый укус» не встречается среди строк, искомых для исправления. Именно по этой причине необходим StringSplit.
В дополнение к только что приведенным основным функциям мы также используем два типа проверок, чтобы убедиться, что строка не была изменена слишком сильно в процессе исправления. Мы называем это проверками на вменяемость.
Мы называем это проверками на вменяемость.
Вменяемость1
Эта проверка сравнивает первые три символа с и предполагаемое исправление.Если при сравнении символов в позиции 0, символов в позиции 1 и символов в позиции 2 между строками есть не более одного различия, то исправление проходит этот тест.
Вменяемость2
Этот тест является более обширным тестом, в котором балл засчитывается, если символ заменяется, балл засчитывается, если один или два символа в строке вставляются или удаляются, но транспозициям присваивается нулевая стоимость. Затем сравнивают строку s и предполагаемое исправление, сравнивая первое слово в каждом, второе слово в каждом и т. д.Тест считается пройденным, если в любом таком сравнении встречается стоимость преобразования, не превышающая двух баллов за каждую сравниваемую пару слов.
Оценка областей успеха
Хотя функций редактирования OneEdit, TwoEdit и RecursiveEdit достаточно для внесения исправлений в строки, они не одинаково эффективны для строк любой длины. Как правило, чем короче строка, тем сложнее ее исправить. Этому есть две причины. Во-первых, более короткая строка имеет менее полезный контекст, окружающий ошибки, по которым можно идентифицировать предполагаемую строку.Во-вторых, пространство всех струн гораздо более плотно заселено в области более коротких струн (Кукич, 1992). Эта проблема густонаселенного пространства явно является проблемой в базе данных PubMed, где очень много строк, возникающих в виде аббревиатур. Из-за этой проблемы мы проверили производительность функций редактирования с помощью моделирования. Отдельные слова были выбраны случайным образом из базы данных с вероятностью, пропорциональной их частоте в базе данных. После выборки слова одно, два или три редактирования случайным образом вносились в слово с использованием зависящих от контекста вероятностей редактирования, которые мы собрали из пользовательских журналов.Затем была предпринята попытка исправить орфографическую ошибку с помощью функций редактирования.
Как правило, чем короче строка, тем сложнее ее исправить. Этому есть две причины. Во-первых, более короткая строка имеет менее полезный контекст, окружающий ошибки, по которым можно идентифицировать предполагаемую строку.Во-вторых, пространство всех струн гораздо более плотно заселено в области более коротких струн (Кукич, 1992). Эта проблема густонаселенного пространства явно является проблемой в базе данных PubMed, где очень много строк, возникающих в виде аббревиатур. Из-за этой проблемы мы проверили производительность функций редактирования с помощью моделирования. Отдельные слова были выбраны случайным образом из базы данных с вероятностью, пропорциональной их частоте в базе данных. После выборки слова одно, два или три редактирования случайным образом вносились в слово с использованием зависящих от контекста вероятностей редактирования, которые мы собрали из пользовательских журналов.Затем была предпринята попытка исправить орфографическую ошибку с помощью функций редактирования. Мы собрали данные в таблицы с подробными результатами для различного количества правок и в зависимости от длины строки, которую алгоритмы должны были исправить. Результаты содержатся в -. Данные показывают, что исправить очень короткие строки очень сложно. На основании этих данных мы не пытаемся исправлять отдельные слова длиной менее пяти или шести. Аналогичным образом предполагается, что для надежного исправления двух правок требуется строка длиной около девяти, и таким же образом предполагается, что для надежного исправления трех правок требуется строка длиной примерно двенадцать.Аналогичные данные можно смоделировать для двухсловных фраз. Мы использовали эти данные при построении нашего алгоритма.
Мы собрали данные в таблицы с подробными результатами для различного количества правок и в зависимости от длины строки, которую алгоритмы должны были исправить. Результаты содержатся в -. Данные показывают, что исправить очень короткие строки очень сложно. На основании этих данных мы не пытаемся исправлять отдельные слова длиной менее пяти или шести. Аналогичным образом предполагается, что для надежного исправления двух правок требуется строка длиной около девяти, и таким же образом предполагается, что для надежного исправления трех правок требуется строка длиной примерно двенадцать.Аналогичные данные можно смоделировать для двухсловных фраз. Мы использовали эти данные при построении нашего алгоритма.
Таблица 2
Для разных длин слов показано количество слов, выбранных и отредактированных для получения орфографических ошибок, а также процент таких слов, которые функции пытались исправить, и процент успеха, который они имели, когда было предложено исправление.
| одиночная лексема — одиночный редактировать | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| длиной | Всего Слова | % попыток | % успех | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | 1 786 | 99 | 24 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | 6701 | 73 | 45 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | 10827 | 88 | 55 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | 14823 | 86 | 72 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7 | 13511 | 94 | 88 | Таблица 3.|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| одиночной лексема — два редактирует | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| длиной | Всего слова | % Ударов | % успех | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | 14408 | 78 | 13 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7 | 13460 | 61 | 25 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 8 | 11938 | 96 | 65 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9 | 10124 | 96 | 80 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 10 | 7974 | 95 | 87 | Таблица 4|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| Одиночный токен — три редактирования | длина | % Попытки | % | % Успех | |
|---|---|---|---|
| 9 | 9485 | 84 | 39 |
| 10 | 7405 | 70 | 52 |
| 11 | 5496 | 69 | 67 |
| 12 | 4000 | 62 | 71 |
| 13 | 2835 | 59 | 76 |
| 14 | 1964 | 57 | 80 |
новая строка — одна из строк, хранящихся в дереве (Sedgewick 1998).
 Чтобы эффективно искать наилучшее исправление для строки запроса s , как требуется в выражении (1), мы используем древовидную структуру (Кукич, 1992; Брилл и Мур, 2000). Все поисковые термины базы данных загружаются в это дерево. Затем, как указали Холл и Доулинг (1980), доступны два основных подхода. Можно сгенерировать все строки, которые близки (скажем, в пределах одного или двух правок) к строке s , и посмотреть, какие из них находятся в дереве. Или можно попытаться выполнить поиск в дереве напрямую, используя строку s , внося необходимые исправления для получения совпадения.Проблема с генерированием всех строк, близких к s в пространстве редактирования, заключается в том, что будет сгенерировано много бессмысленных строк, которые не представляют интереса, и затем придется искать каждую из них, чтобы увидеть, есть ли она в базе данных. Мы предпочитаем прямой поиск дерева из-за его эффективности. Например, если проследить совпадение первых k букв s в дереве и не расширить это совпадение до k + 1-я буква, то можно сделать вывод, что в первых должна быть ошибка.
Чтобы эффективно искать наилучшее исправление для строки запроса s , как требуется в выражении (1), мы используем древовидную структуру (Кукич, 1992; Брилл и Мур, 2000). Все поисковые термины базы данных загружаются в это дерево. Затем, как указали Холл и Доулинг (1980), доступны два основных подхода. Можно сгенерировать все строки, которые близки (скажем, в пределах одного или двух правок) к строке s , и посмотреть, какие из них находятся в дереве. Или можно попытаться выполнить поиск в дереве напрямую, используя строку s , внося необходимые исправления для получения совпадения.Проблема с генерированием всех строк, близких к s в пространстве редактирования, заключается в том, что будет сгенерировано много бессмысленных строк, которые не представляют интереса, и затем придется искать каждую из них, чтобы увидеть, есть ли она в базе данных. Мы предпочитаем прямой поиск дерева из-за его эффективности. Например, если проследить совпадение первых k букв s в дереве и не расширить это совпадение до k + 1-я буква, то можно сделать вывод, что в первых должна быть ошибка. k + 1 символ s .Далее не нужно проверять все возможные правки, а только те, которые расширят совпадение в дереве. Это приводит к значительной экономии времени без упущения какой-либо возможной совпадающей строки в дереве.
k + 1 символ s .Далее не нужно проверять все возможные правки, а только те, которые расширят совпадение в дереве. Это приводит к значительной экономии времени без упущения какой-либо возможной совпадающей строки в дереве. Поскольку мы должны исправлять ошибки во фразах переменной длины, мы фактически используем в алгоритме три разных попытки. Во-первых, мы строим тройку Tr123 из всех фраз, состоящих из одной, двух или трех токенов, распознаваемых поисковой системой. Если строка запроса s состоит из одного или двух токенов, мы ищем исправление в Tr123.Это позволяет исправлению иметь больше или меньше токенов, чем запрос. Например, запрос «апоптоз», ошибочно разбитый на две лексемы, даст поправку «апоптоз», состоящую из одной лексемы, а запрос «bклеточная лимфома», ошибочно объединенный в две лексемы, даст поправку из трех лексем «b». клеточная лимфома». Если строка запроса s состоит из трех или более токенов, мы ищем фразу s ′, состоящую из первых двух токенов в дереве Tr2p. Tr2p — это дерево, содержащее все фразы с одной или двумя токенами, которые являются начальными одной или двумя токенами фраз из трех или более токенов и распознаются поисковой системой.Если мы находим совпадение, даже исправление, мы пытаемся расширить это исправление в дереве Tr3+, которое состоит из всех фраз, состоящих из трех или более токенов, распознаваемых поисковой системой. Например, система не вносит исправления в запрос «доман» (имя человека), но при наличии запроса «домен связывания ДНК» она сначала проверяет, что «связывание ДНК» происходит в Tr2p, а затем расширяет это до исправления «домен связывания ДНК». ” в Тр3+. Таким образом, мы избегаем попытки очень длинного сопоставления, которое было бы затратным по времени, если только у нас нет доказательств того, что длинное сопоставление возможно на основе начальной части s .Если начальное совпадение s ′ с Tr2p не удается, мы ищем совпадение s ′ с Tr123 и т. д. Таким образом, алгоритм организован вокруг числа токенов, содержащихся в строке поиска s .
Tr2p — это дерево, содержащее все фразы с одной или двумя токенами, которые являются начальными одной или двумя токенами фраз из трех или более токенов и распознаются поисковой системой.Если мы находим совпадение, даже исправление, мы пытаемся расширить это исправление в дереве Tr3+, которое состоит из всех фраз, состоящих из трех или более токенов, распознаваемых поисковой системой. Например, система не вносит исправления в запрос «доман» (имя человека), но при наличии запроса «домен связывания ДНК» она сначала проверяет, что «связывание ДНК» происходит в Tr2p, а затем расширяет это до исправления «домен связывания ДНК». ” в Тр3+. Таким образом, мы избегаем попытки очень длинного сопоставления, которое было бы затратным по времени, если только у нас нет доказательств того, что длинное сопоставление возможно на основе начальной части s .Если начальное совпадение s ′ с Tr2p не удается, мы ищем совпадение s ′ с Tr123 и т. д. Таким образом, алгоритм организован вокруг числа токенов, содержащихся в строке поиска s .
Продолжаем давать псевдокод для различных случаев или количества токенов в строке. В дальнейшем мы будем обозначать l ( s ) длину в символах, а f ( s ) обозначать частоту базы данных для любой строки s .Любая строка, отсутствующая в словаре поисковой системы, считается имеющей нулевую частоту в базе данных. Обратите внимание, что мы используем слово RETURN, чтобы сигнализировать об окончании вычисления, когда модуль либо возвращает предложенное исправление, либо нет, но в любом случае все строки, следующие за RETURN до конца модуля, игнорируются. Мы также использовали слово «этап» для обозначения различных частей алгоритма для удобочитаемости, и существует некоторая корреляция в стоимости вычислений с более высокими номерами этапов, коррелирующими с более дорогими вычислениями.
SingleTokenModule {
Этап 1
ЕСЛИ l ( s ) < 5 THEN RETURN без исправления.
ЕСЛИ f ( s ) > 1000 ТОГДА ВОЗВРАТ без исправления.
ИНАЧЕ ЗВОНИТЕ OneEdit для s .
этап 2
, если R = 0 и л ( S ) ≥ 9, затем
Вызов TwoDit для S .
1
Call stringsplit
ИНАЧЕ ЕСЛИ R =1 и l ( c ) ≥ 5 ТОГДА ПОЗВОНИТЕ OneEdit по номеру c .
Этап 3
Если R = 1
R = 1 R = 2 R = 2 R = 2Этап 4
IF L ( S ) ≥ 12 Тогда вызовите рекурсию для S .
ВЫЗОВ StringSplit.
ВОЗВРАТ без исправления.
}
В качестве примера предположим, что строка запроса — «рибонфлавен». Затем, поскольку эта строка имеет длину больше 5 и не встречается в базе данных, SingleTokenModule попытается исправить.На этапе 1 вызывается OneEdit и выдает коррекцию «рибонфлавин», которая встречается в базе данных 1 раз. На этапе 2 для коррекции используется другой OneEdit, который производит «рибофлавин», который встречается в базе данных 7380 раз. На этапе 3 из-за его высокой частоты в базе данных в качестве коррекции возвращается слово «рибофлавин». Этот пример иллюстрирует два основных принципа разработки алгоритма проверки орфографии. Во-первых, небольшие изменения в строке запроса всегда предпочтительнее больших изменений.Во-вторых, изменения, которые приводят к обнаружению слова в данных, всегда более правдоподобны, чем изменения сопоставимой величины, которые этого не делают. Здесь одно редактирование переводит нас из строки «рибонфлавен» в строку «рибонфлавин», которая появляется в данных и, таким образом, может быть в худшем случае опечаткой чего-то в базе данных. Затем еще одно редактирование превращает «рибонфлавин» в высокочастотную строку «рибофлавин». Эта цепочка из двух небольших изменений имеет больше доказательств в поддержку, чем просто запрос результатов TwoEdit.Как правило, решения принимаются на основе правдоподобия результатов, где мы оцениваем правдоподобие по:
На этапе 3 из-за его высокой частоты в базе данных в качестве коррекции возвращается слово «рибофлавин». Этот пример иллюстрирует два основных принципа разработки алгоритма проверки орфографии. Во-первых, небольшие изменения в строке запроса всегда предпочтительнее больших изменений.Во-вторых, изменения, которые приводят к обнаружению слова в данных, всегда более правдоподобны, чем изменения сопоставимой величины, которые этого не делают. Здесь одно редактирование переводит нас из строки «рибонфлавен» в строку «рибонфлавин», которая появляется в данных и, таким образом, может быть в худшем случае опечаткой чего-то в базе данных. Затем еще одно редактирование превращает «рибонфлавин» в высокочастотную строку «рибофлавин». Эта цепочка из двух небольших изменений имеет больше доказательств в поддержку, чем просто запрос результатов TwoEdit.Как правило, решения принимаются на основе правдоподобия результатов, где мы оцениваем правдоподобие по:
Меньшие изменения более правдоподобны.

Изменения, приводящие к появлению строки в базе данных, более правдоподобны, чем изменения того же масштаба, которые этого не делают.
Изменения, которые производят строку с высокой частотой в базе данных, предпочтительнее, чем аналогичные по величине, но не такие.
Модуль SingleTokenModule следует этим принципам, проходя этапы в поисках наиболее правдоподобного решения, а затем постепенно пробуя менее правдоподобные методы, пока либо решение не будет найдено, либо попытка не приведет к исправлению.Все различные методы исправления присутствуют, потому что мы действительно нашли их необходимыми в определенных случаях. В SingleTokenModule (и в других модулях) есть определенные константы, которые были выбраны, потому что они давали разумные результаты в испытаниях. Они были выбраны эмпирическим путем, и формальная оценка не проводилась. Мы вернемся к этому вопросу ниже.
Весь поиск в SingleTokenModule выполняется в дереве Tr123. То же самое верно и для TwoTokenModule, который мы собираемся описать.Когда нам дают запрос из двух слов, в задачу вводится новый элемент. Это вопрос контекста. Вполне возможно, что одно из слов является правильным и может быть использовано в качестве контекста для более эффективного исправления другого. С другой стороны, эти два слова не обязательно должны быть тесно связаны, как это произошло бы в осмысленной фразе. Таким образом, у нас должна быть стратегия, которая подсказывает нам, когда пытаться использовать контекст, а когда его избегать. Эта стратегия является важной частью общего плана исправления многословия.В следующем псевдокоде мы обозначим запрос с двумя токенами как s _ t , где s и t — отдельные токены. В дальнейшем мы будем использовать основные функции редактирования, определенные в предыдущем разделе. Однако есть некоторые ограничения, которые мы сочли полезными при редактировании s и t независимо от l ( s _ t ).
То же самое верно и для TwoTokenModule, который мы собираемся описать.Когда нам дают запрос из двух слов, в задачу вводится новый элемент. Это вопрос контекста. Вполне возможно, что одно из слов является правильным и может быть использовано в качестве контекста для более эффективного исправления другого. С другой стороны, эти два слова не обязательно должны быть тесно связаны, как это произошло бы в осмысленной фразе. Таким образом, у нас должна быть стратегия, которая подсказывает нам, когда пытаться использовать контекст, а когда его избегать. Эта стратегия является важной частью общего плана исправления многословия.В следующем псевдокоде мы обозначим запрос с двумя токенами как s _ t , где s и t — отдельные токены. В дальнейшем мы будем использовать основные функции редактирования, определенные в предыдущем разделе. Однако есть некоторые ограничения, которые мы сочли полезными при редактировании s и t независимо от l ( s _ t ).
Ограничение1
Если длина токена меньше трех, не редактируйте его.Допустим, это правильно.
Ограничение2
Если длина токена меньше семи, внесите в него не более одной правки.
Эти ограничения применяются к данной лексеме независимо от длины другой лексемы во фразе. Мы считаем, что токены из одного или двух символов вряд ли будут написаны с ошибками, и мы используем их в качестве фиксированных точек, с помощью которых можно направлять процесс исправления.
TwoTokenModule {
Этап 1
IF l ( s _ t )<7 ТОГДА ВОЗВРАТ без исправления.
Набор f m = мин( f ( s ), f ( t )).
ЕСЛИ f ( s _ t )>5 и f m >500 ТОГДА ВОЗВРАТ без исправления.
, если F ( S _ T _ T )> 0 и F M > 50 и L ( S ) ≤ 4 или L ( T ) ≤ 4
Этап 2
CALL OneEdit для s _ t и установите R =0.
ЕСЛИ R =1, ТОГДА ПОЗВОНИТЕ OneEdit по номеру c .
ЕСЛИ R =0 ТО ВЫЗВАТЬ TwoEdit для s _ t .
ЕСЛИ R =0 и f m ≥ 100 ТОГДА ВЫЗВАТЬ SingleTokenModule для каждого из s и t отдельно и ВОЗВРАТИТЬ результат.
ИНАЧЕ ЕСЛИ R =1 и f ( c ) ≥ f m ТОГДА ВЕРНИТЕ c в качестве исправления.
этап 3
стрижки вызова на S _ T
IF L ( S _ T )> 20 и F M = 0 или оба L ( s ) ≥ 7 и l ( t ) ≥ 7 THEN
ВЫЗВАТЬ SingleTokenModule для каждого из s и t отдельно и ВОЗВРАТИТЬ результат.
}
В качестве примера действия TwoTokenModule рассмотрим строку запроса «gammg globulin».Эта строка встречается в базе данных только 1 раз, а поскольку «gammg» встречается в базе данных только 2 раза, «gammg globulin» проходит этап 1 обработки и является кандидатом на исправление. OneEdit производит поправку «гамма-глобулин», и повторный вызов OneEdit не приводит к улучшению, поэтому это принимается как окончательная коррекция. Поскольку частота строки изменилась с частоты 2 за одно редактирование до конечной частоты 15 568, исправление имеет высокую вероятность. Теперь рассмотрим строку запроса «академическое отношение».Эта фраза не встречается в базе данных, поэтому проходит этап 1 и становится кандидатом на исправление как фраза. Однако единственное найденное исправление — это строка «академические способности», которая встречается в базе данных 30 раз. Из-за низкой частотности этой фразы она не принимается в качестве исправления. Мы принимаем частоту как меру правдоподобия, и «академический» встречается в базе данных 52 629 раз, а «отношение» — 144 536 раз. Мы сформулируем это как последний принцип правдоподобия при внесении исправлений.
OneEdit производит поправку «гамма-глобулин», и повторный вызов OneEdit не приводит к улучшению, поэтому это принимается как окончательная коррекция. Поскольку частота строки изменилась с частоты 2 за одно редактирование до конечной частоты 15 568, исправление имеет высокую вероятность. Теперь рассмотрим строку запроса «академическое отношение».Эта фраза не встречается в базе данных, поэтому проходит этап 1 и становится кандидатом на исправление как фраза. Однако единственное найденное исправление — это строка «академические способности», которая встречается в базе данных 30 раз. Из-за низкой частотности этой фразы она не принимается в качестве исправления. Мы принимаем частоту как меру правдоподобия, и «академический» встречается в базе данных 52 629 раз, а «отношение» — 144 536 раз. Мы сформулируем это как последний принцип правдоподобия при внесении исправлений.
Псевдокод для SingleTokenModule и TwoTokenModule дает подробное представление о том, как мы обрабатываем одну и две строки токена. Наконец, мы дадим несколько сокращенное описание того, как мы обрабатываем строки с тремя или более токенами. Пусть s _ t _ u обозначает такую строку, где u может обозначать, возможно, более одного токена. Мы делаем несколько шагов:
Наконец, мы дадим несколько сокращенное описание того, как мы обрабатываем строки с тремя или более токенами. Пусть s _ t _ u обозначает такую строку, где u может обозначать, возможно, более одного токена. Мы делаем несколько шагов:
Мы видим, встречается ли s _ t в Tr2p.Если нет, ищем поправку для s _ t в Tr2p. Поиск такой же, как поиск в TwoTokenModule, за исключением того, что на третьем этапе мы разрешаем RecursiveEdit только в качестве опции и нам требуется только l ( s _ t )>20 для его применения. StringSplit и двойное применение SingleTokenModule на данном этапе не являются вариантами, потому что их успех преждевременно исключит другие предпочтительные варианты. Используется более слабое условие для применения RecursiveEdit, поскольку результат не будет окончательным до тех пор, пока не будет получено более длинное совпадение (с большим количеством контекста).

Если в I мы найдем s _ t или поправку на s _ t в Tr2p, то мы попытаемся расширить это начальное совпадение до совпадения s _ u в Tr3+. Для этого расширения мы используем форму RecursiveEdit. Если это дает соответствие, которое проходит Sanity2, мы принимаем это как поправку для s _ t _ u и делаем. Если это не дает совпадения, мы пытаемся отказаться от решения, чтобы найти совпадение в Tr3+, которое не включает все s _ t _ u и проходит Sanity2.Если это возможно, выполняется выравнивание исправления с исходной строкой запроса, чтобы определить, какая часть строки остается для исправления. Затем мы принимаем частичное исправление и рекурсивно вызываем процесс для исправления оставшейся строки.
Если I находит совпадение или исправление c в Tr2p, но II не дает совпадения в Tr3+, и если c состоит из единственной лексемы, мы пытаемся расширить это до совпадения в Tr123.
 Если это удается и совпадение проходит Sanity2, мы принимаем это как исправление и снова должны найти любую оставшуюся строку для соответствия, как в II.
Если это удается и совпадение проходит Sanity2, мы принимаем это как исправление и снова должны найти любую оставшуюся строку для соответствия, как в II.Если в I-III не достигается даже частичное решение, то пытаемся найти поправку для s _ t в Tr123. Это делается путем применения TwoTokenModule, опять же с небольшими изменениями. Модификаций две. Сначала на этапе 2 с высоким пределом частоты, а затем снова на этапе 3 с более низким пределом с помощью StringSplit делается попытка разделить s _ t . Если это успешно, первая часть разделения принимается как часть исправления, и процесс вызывается рекурсивно для второй части разделения и любых оставшихся токенов за ее пределами.Во-вторых, если ничего не помогает, то SingleTokenModule вызывается только для s , и результат принимается как частичное исправление (или, возможно, без исправления), и процесс вызывается рекурсивно для исправления t _ u .

На примере мы проиллюстрируем важность контекста при наличии трех или более токенов. Рассмотрим строку запроса «амитрофический латеральный слерсос». Первые два маркера сначала исправляются на «боковой амиотрофический», а затем система пытается расширить его, исправляя «слерсос».В этой последней строке «slersos» всего семь символов, и три ошибки обычно затруднили бы ее исправление, но здесь есть несколько строк, начинающихся с «амиотрофического латерального», отличного от правильного, и поэтому система легко исправляет «slersos» на « склероз». Благодаря исходным токенам, которые обеспечивают контекст, мы можем ослабить ограничения (Constraint1 и Constraint2) в процессе расширения.
В качестве заключительного комментария к построению алгоритма отметим, что в OneTokenModule и TwoTokenModule и менее заметно при обработке строк запроса из трех и более токенов есть ряд параметров.Эти параметры были выбраны эмпирическим путем, наблюдая за работой алгоритма на запросах, поступающих в поисковую систему PubMed, и внося коррективы. Мы не утверждаем, что включенные здесь варианты являются оптимальными. На самом деле один из сложных вопросов состоит в том, чтобы определить, что должно означать оптимальное в такой обстановке. Можно предположить критерий максимизации числа разумных предложений правописания. С другой стороны, конечной целью является угодить пользователям и оптимально облегчить их поиск.С этой точки зрения за неверные или даже нелепые предложения приходится платить. Если пользователи не верят в разумность предложений, они могут быть менее склонны их использовать. Наш подход был несколько консервативным в попытке избежать предложений с высоким риском и достичь высокой степени точности, а не общего максимального количества разумных предложений с более низкой степенью точности. Другими словами, мы больше заботились о точности, чем о воспроизведении.
Мы не утверждаем, что включенные здесь варианты являются оптимальными. На самом деле один из сложных вопросов состоит в том, чтобы определить, что должно означать оптимальное в такой обстановке. Можно предположить критерий максимизации числа разумных предложений правописания. С другой стороны, конечной целью является угодить пользователям и оптимально облегчить их поиск.С этой точки зрения за неверные или даже нелепые предложения приходится платить. Если пользователи не верят в разумность предложений, они могут быть менее склонны их использовать. Наш подход был несколько консервативным в попытке избежать предложений с высоким риском и достичь высокой степени точности, а не общего максимального количества разумных предложений с более низкой степенью точности. Другими словами, мы больше заботились о точности, чем о воспроизведении.
Это завершает описание алгоритма.
ОЧИСТКА ПУБЛИКУЕМЫХ ДАННЫХ
Как правило, слова с ошибками в базе данных PubMed встречаются редко, и именно это свойство позволяет корректировать орфографию на основе словарного запаса базы данных. Тем не менее, некоторые термины написаны с ошибками или, по крайней мере, не оптимальны в качестве терминов запроса, которые относительно часто встречаются в PubMed. В связи с этим мы взялись попытаться разобраться с этой проблемой. Мы изучили все фразы из одного и двух слов, которые встречались по крайней мере в пороговом количестве документов в PubMed, а также были одним изменением другого термина в PubMed, частота которых в базе данных была как минимум в десять раз выше.Мы сделали предположение, что если два таких термина имели значительную тенденцию встречаться в одном и том же контексте, то член пары с более низкой частотой был написан с ошибкой или, по крайней мере, неоптимальной версией термина с более высокой частотой. Для терминов с одним токеном мы использовали порог низкой частоты 20. Для терминов с двумя токенами, которые встречаются реже, мы использовали порог низкой частоты 9. Важным соображением при выборе порога низкой частоты является просто иметь достаточно данных, чтобы позволить вычисление достоверной статистики.
Тем не менее, некоторые термины написаны с ошибками или, по крайней мере, не оптимальны в качестве терминов запроса, которые относительно часто встречаются в PubMed. В связи с этим мы взялись попытаться разобраться с этой проблемой. Мы изучили все фразы из одного и двух слов, которые встречались по крайней мере в пороговом количестве документов в PubMed, а также были одним изменением другого термина в PubMed, частота которых в базе данных была как минимум в десять раз выше.Мы сделали предположение, что если два таких термина имели значительную тенденцию встречаться в одном и том же контексте, то член пары с более низкой частотой был написан с ошибкой или, по крайней мере, неоптимальной версией термина с более высокой частотой. Для терминов с одним токеном мы использовали порог низкой частоты 20. Для терминов с двумя токенами, которые встречаются реже, мы использовали порог низкой частоты 9. Важным соображением при выборе порога низкой частоты является просто иметь достаточно данных, чтобы позволить вычисление достоверной статистики. Мы сочли полезным обрабатывать случаи с одним токеном и двумя токенами несколько по-разному, а также в том, как они были протестированы.
Мы сочли полезным обрабатывать случаи с одним токеном и двумя токенами несколько по-разному, а также в том, как они были протестированы.
Одиночная лексема
Предположим, что пара терминов, разделенных одним редактированием, представлена как T 1 и T 2 . Затем мы применяем тест, основанный на гипергеометрическом распределении (Larson 1982). Ситуация проиллюстрирована в . Мы вычисляем p -значение, которое два термина могли бы встречаться одновременно в количестве документов, в которых они встречаются или более, если бы эти два термина были только случайными в их отношении друг к другу.Мы нашли в базе данных 62 720 пар, которые удовлетворяли требованиям по частоте и отличались одним редактированием. Когда был применен только что описанный гипергеометрический тест, результат составил 10 922 пары отдельных токенов, которые были связаны с p — значением менее 0,01. Это означает, что мы можем ожидать, что 99% этих пар терминов будут значительно связаны между собой. Пример таких пар показан на . В большинстве случаев низкочастотный член пары является орфографической ошибкой. В некоторых случаях это просто неоптимальный термин запроса, поскольку существует гораздо более частотный термин с практически таким же значением для целей поиска.
Пример таких пар показан на . В большинстве случаев низкочастотный член пары является орфографической ошибкой. В некоторых случаях это просто неоптимальный термин запроса, поскольку существует гораздо более частотный термин с практически таким же значением для целей поиска.
В пространстве всех документов прямоугольник представляет документы, содержащие термин T 1 , а маленький эллипс — набор документов, содержащий термин T 2 . Пересечение этих двух наборов представляет собой перекрытие, представленное I . Статистическая значимость этого перекрытия может быть вычислена как вероятность того, что это перекрытие столь же велико или больше, чем реально наблюдаемое, если предположить, что эти два термина связаны не более чем случайным образом.Это известно как значение p и может быть оценено путем применения гипергеометрического распределения.
Таблица 5
Слева приведены некоторые относительно распространенные слова, а справа исправления, предложенные гипергеометрическим тестом. Во многих случаях слова слева написаны с ошибками.
Во многих случаях слова слева написаны с ошибками.
| Неоптимальные термины и частоты | корректировки & частот | ||
|---|---|---|---|
| acetycholine | 153 | ацетилхолина | 46852 |
| acetycholinesterase | 32 | ацетилхолинэстеразы | 13207 |
| acetyglucosamine | 20 | ацетилглюкозамина | 4995 |
| ацетилирования | 287 | ацетилированный | 6594 |
| ацетилхолина | 64 | ацетилхолина | 46852 |
| ацетилцистеин | 64 | ацетилцистеин | 3879 |
| acetylocholine 20 | ацетилхолин 46852 | ||
| ацетилсалициловая 157 | ацетилсалициловая 5186 | ||
| achalasic 901 74 | 73 | ахалазии | 2955 |
| achatin | 27 | Achatina | 320 |
| дружнее | 42 | достиг | 179735 |
два маркера
В этом случае мы нашли 11 762 пары двух токеновых фраз, которые удовлетворяли требованиям частоты. Сначала мы применили критерий гипергеометрической значимости, как и в случае с одним токеном. Это привело к идентификации 1836 пар, которые были значительно связаны между собой. Если гипергеометрический тест не показал значимость на уровне 0,01, мы применяли более строгий тест. Используемые конструкции изображены там, где мы описали случай пары фраз «инфаркт миокарда» и «инфаркт миокарда». Эти две фразы различаются только своими вторыми словами, и мы использовали общее первое слово «миокардиальный» для определения контекста или набора интересующих документов.
Сначала мы применили критерий гипергеометрической значимости, как и в случае с одним токеном. Это привело к идентификации 1836 пар, которые были значительно связаны между собой. Если гипергеометрический тест не показал значимость на уровне 0,01, мы применяли более строгий тест. Используемые конструкции изображены там, где мы описали случай пары фраз «инфаркт миокарда» и «инфаркт миокарда». Эти две фразы различаются только своими вторыми словами, и мы использовали общее первое слово «миокардиальный» для определения контекста или набора интересующих документов.
Мы применяем наивное байесовское обучение, чтобы узнать разницу между положительным набором, помеченным G , и отрицательным набором, состоящим из объединения наборов, помеченных B1 и B2 . Из изученных весов мы оцениваем как B1 , так и B2 и ранжируем объединение двух наборов. Затем мы применяем тест WMW, чтобы узнать, выше ли сумма рангов членов B1 , чем можно было бы ожидать на случайной основе. Для ответа на этот вопрос вычисляется значение p .
Для ответа на этот вопрос вычисляется значение p .
В этом наборе набор документов, содержащих неправильное написание «инфаркт миокарда», соответствует прямоугольнику, а набор, содержащий правильную фразу «инфаркт миокарда», соответствует эллипсу. Мы случайным образом выбрали три набора: B1 из документов, содержащих фразу с ошибкой, G из документов, содержащих правильную фразу, но без фразы с ошибкой, и B2 из документов, не содержащих ни одной фразы, но содержащих слово «миокард».Каждый из этих наборов состоял из тысячи случайно выбранных документов, если это число попадало в выбранную категорию. Если набор доступных документов был меньше одной тысячи, за образец брался весь набор. Выборка использовалась для ограничения количества вычислений, необходимых для оценки любой пары фраз. Затем мы применили наивное байесовское обучение, чтобы узнать разницу между G и B1 ∪ B2 . С полученными таким образом весами мы оценили все документы в B1 ∪ B2 и расположили их в порядке убывания количества баллов. Затем мы применили критерий Уилкоксона-Манна-Уитни, чтобы увидеть, была ли сумма рангов членов B1 меньше ожидаемой. Это означало бы, что члены B1 набрали больше очков, чем ожидалось, или, другими словами, были более похожи на членов G , чем члены B2 . Мы применили этот тест к 9926 парам, оставшимся после удаления 1836 пар, найденных с помощью гипергеометрического теста. В результате мы определили еще 5628 пар фраз, которые были значимы на уровне 0.01 уровень. Пример найденных таким образом пар фраз приведен в .
Затем мы применили критерий Уилкоксона-Манна-Уитни, чтобы увидеть, была ли сумма рангов членов B1 меньше ожидаемой. Это означало бы, что члены B1 набрали больше очков, чем ожидалось, или, другими словами, были более похожи на членов G , чем члены B2 . Мы применили этот тест к 9926 парам, оставшимся после удаления 1836 пар, найденных с помощью гипергеометрического теста. В результате мы определили еще 5628 пар фраз, которые были значимы на уровне 0.01 уровень. Пример найденных таким образом пар фраз приведен в .
Таблица 6
Образец менее оптимальных фраз запроса слева в паре с их гораздо более частотными аналогами справа. В некоторых случаях фраза слева содержит орфографическую ошибку. В других случаях это просто не самая часто используемая форма и, следовательно, будет относительно плохой запрос на используемую концепцию.
| Неоптимальные термины и частоты | корректировки & частот | ||||
|---|---|---|---|---|---|
| мышечной оболочки кишечника нейронных | 9 | нейронов мышечной оболочки кишечника | 593 | ||
| myocardiac миокарда | 34 | инфаркт миокарда | 114638 | ||
| инфаркт миокарда | 122 | инфаркт миокарда | 114638 | ||
| миокарда ишемическая | 870 | ишемия миокарда | 27214 | ||
| миокарда некрозы | 77 | некроза миокарда | 2055 | ||
| миокарда реваскуляризация | 234 | 234 | Revasasularizate 9174 | 7343 | |
| миогенное выражение | 10 | Myogenin Expression | 119 | ||
| Миопия астигматизм | 914 79 10Миопский астигматизм | 296 | |||
| Мэйониевые пациенты | 19 | 19 | 231 | 231 | 231 |
10 922 Пары одиночных токенов и 7 464 Две два токена не удаляются полностью от рассмотрения. Скорее их частоты уменьшены до единицы для целей вычислений, включающих выражения (1) и (2). Таким образом, гораздо более вероятно, что они не будут выбраны в качестве исправления для запроса. Однако они остаются возможными промежуточными шагами в последовательности операций, ведущих к исправлению. Если они появляются в качестве такого промежуточного звена, шансы на то, что окончательной коррекцией будет высокочастотный член, с которым они связаны в только что описанном статистическом тестировании, возрастают.
Скорее их частоты уменьшены до единицы для целей вычислений, включающих выражения (1) и (2). Таким образом, гораздо более вероятно, что они не будут выбраны в качестве исправления для запроса. Однако они остаются возможными промежуточными шагами в последовательности операций, ведущих к исправлению. Если они появляются в качестве такого промежуточного звена, шансы на то, что окончательной коррекцией будет высокочастотный член, с которым они связаны в только что описанном статистическом тестировании, возрастают.
Можно спросить, почему мы не использовали тест WMW для пар одноточечных фраз. Причина в том, что мы обнаружили много ложных срабатываний, когда пытались его использовать. Наша попытка включала изображение, похожее на . Однако у нас не было контекстного слова, подобного слову «миокардиальный», на этой картинке, чтобы сфокусировать вычисления. Поэтому мы выбрали B2 из всех оставшихся данных PubMed, за исключением тех документов, которые включали один из интересующих токенов. Тогда, если бы низкочастотный токен в паре не был орфографической ошибкой, образец B1 был бы из значимой темы, совершенно не связанной с G.В результате документы в B1 могли быть более или менее связаны с G, чем общая случайная выборка B2. Если бы они были более связаны, статистический тест мог бы быть легко удовлетворен на уровне 0,01, и все же не было бы действительно значимой связи между B1 и G . Таким образом, мы отказались от усилий. Возможно, таким образом можно было бы использовать некоторое уточнение теста. Если это так, то он может оказаться весьма полезным, потому что нельзя ожидать, что гипергеометрический тест будет работать во всех важных случаях.Это верно, потому что, когда опечатка действительно появляется в документе, это может быть постоянной ошибкой, и правильно написанный термин может не отображаться. В таких случаях тест на основе контекста, такой как тест WMW, который мы использовали, имеет гораздо больше шансов обнаружить ошибку.
Тогда, если бы низкочастотный токен в паре не был орфографической ошибкой, образец B1 был бы из значимой темы, совершенно не связанной с G.В результате документы в B1 могли быть более или менее связаны с G, чем общая случайная выборка B2. Если бы они были более связаны, статистический тест мог бы быть легко удовлетворен на уровне 0,01, и все же не было бы действительно значимой связи между B1 и G . Таким образом, мы отказались от усилий. Возможно, таким образом можно было бы использовать некоторое уточнение теста. Если это так, то он может оказаться весьма полезным, потому что нельзя ожидать, что гипергеометрический тест будет работать во всех важных случаях.Это верно, потому что, когда опечатка действительно появляется в документе, это может быть постоянной ошибкой, и правильно написанный термин может не отображаться. В таких случаях тест на основе контекста, такой как тест WMW, который мы использовали, имеет гораздо больше шансов обнаружить ошибку.
ПРОБЛЕМЫ ПРОИЗВОДИТЕЛЬНОСТИ
Для базы данных PubMed попытки, используемые в алгоритме исправления правописания, в настоящее время включают 14 267 366 строк с одним, двумя и тремя маркерами в Tr123; 2 775 111 строк из трех и более токенов в Tr3+; и 1 772 383 начальных сегмента строк из Tr3+ в Tr2p. В обычный рабочий день механизм запросов PubMed получает примерно 3 миллиона пользовательских запросов, и это генерирует более 3 миллионов запросов к алгоритму проверки орфографии. Это связано с тем, что многие запросы являются сложными и включают разбор знаков препинания и логических операторов, в результате чего создаются и проверяются на орфографию несколько фрагментов. Алгоритм проверки орфографии на самом деле предлагает исправления примерно для 10% пользовательских запросов, но любое произведенное предложение проверяется на предмет публикации (если он извлекает какие-либо документы из базы данных).Любое исправление, которое не публикуется, игнорируется. В результате пользователю предлагается исправить около 7% пользовательских запросов. Когда мы впервые начали делать предложения пользователям, они принимались ими в 36% случаев. Примерно через шесть месяцев пользователи принимали предложения со скоростью 40%. Теперь, примерно через год после развертывания, в последний понедельник было 3 275 624 запросов к поисковой системе PubMed, и 243 853 предложения заклинаний PubMed были сделаны для 80 785 уникальных IP-адресов, а 109 526 (45%) предложений заклинаний были нажаты с 45 285 уникальных IP-адресов.
В обычный рабочий день механизм запросов PubMed получает примерно 3 миллиона пользовательских запросов, и это генерирует более 3 миллионов запросов к алгоритму проверки орфографии. Это связано с тем, что многие запросы являются сложными и включают разбор знаков препинания и логических операторов, в результате чего создаются и проверяются на орфографию несколько фрагментов. Алгоритм проверки орфографии на самом деле предлагает исправления примерно для 10% пользовательских запросов, но любое произведенное предложение проверяется на предмет публикации (если он извлекает какие-либо документы из базы данных).Любое исправление, которое не публикуется, игнорируется. В результате пользователю предлагается исправить около 7% пользовательских запросов. Когда мы впервые начали делать предложения пользователям, они принимались ими в 36% случаев. Примерно через шесть месяцев пользователи принимали предложения со скоростью 40%. Теперь, примерно через год после развертывания, в последний понедельник было 3 275 624 запросов к поисковой системе PubMed, и 243 853 предложения заклинаний PubMed были сделаны для 80 785 уникальных IP-адресов, а 109 526 (45%) предложений заклинаний были нажаты с 45 285 уникальных IP-адресов.
Был изучен небольшой набор пользовательских запросов, 1323, и 110 из них содержали предложения, сделанные алгоритмом проверки орфографии. Из 110 предложенных исправлений 96 были признаны двумя судьями (совместно проконсультировавшимися) хорошими и 14 плохими. Это 87% успеха с 95% доверительным интервалом (81%,92%). Это намного выше целевого показателя в 70% правильных ответов, к которому мы стремились, и мы полагаем, что отчасти причина этого заключается в том, что предлагаемые исправления, которые не публикуются, игнорируются системой.
В настоящее время алгоритм проверки орфографии работает на шести компьютерах с процессором Dual Intel Xeon 3,6 ГГц, каждый из которых имеет 6 ГБ ОЗУ. Он написан на C++ и работает под Linux в 64-битном режиме. Его использование в среднем увеличило время отклика механизма запросов PubMed примерно на 25%, но на практике оно очень мало увеличивает время отклика на правильно написанные запросы. Алгоритм проверки орфографии реализован на шести серверах, потому что сейчас он используется для исправления запросов в четырнадцати различных базах данных NCBI, из которых PubMed просто самая большая.
ОБСУЖДЕНИЕ
приведены примеры исправлений, которые алгоритм способен сделать. Эти примеры выбраны потому, что они иллюстрируют влияние контекста и некоторые крайности патологии, а не потому, что опечатки типичны. Конечно, не все предлагаемые исправления так хороши, и небезынтересно посмотреть, какие ошибки допущены. Мы рассмотрели чуть более 500 предложений, сделанных программой проверки орфографии, которые не были приняты пользователями, и нашли, по нашему мнению, самые вопиющие ошибки.Они содержатся в .
Таблица 7
Примеры фраз, которые может исправить алгоритм проверки орфографии, обрабатывающий запросы PubMed, и предлагаемые исправления.
| Опечатки | Коррекция задается алгоритмом |
|---|---|
| инфаркт миокарда | инфаркт миокарда |
| уха нарушение | инфекция уха |
| miocardi alinfraction | инфаркт миокарда |
| terminl illnss | неизлечимой болезни |
| HIG pressue liqud chromatogph | высокого давления жидкостной хроматографии |
| опухоли necrosisactor | фактор некроза опухоли |
| Hmgolbin | гемоглобина |
| Philariosis | filariosis |
Таблица 8
Примеры ошибок алгоритма проверки орфографии при обработке запросов PubMed.
| Фраза | 9 | |
|---|---|---|
| Сапа Бат | Сауна Бат | |
| Periostin | ||
| Daniel Ke | Danieluk M | |
| Bisexual Slest | Smoothest | |
| поджелудочная железа и трансплантация | поджелудочной железы и перевод | |
| стволовой камеры ROS | потерю стволовых клеток | |
| Checper Hair | верхний воздух |
можно отметить, что пять из семи встречаются в фразы, в которых были предприняты две или более попытки редактирования. Тот факт, что «Сапна Бат», имя человека, состоит из двух правок от фразы «баня в сауне», — это просто совпадение, которое не является обычным явлением. Проблема с «периостином» возникает из-за фразы «периоды», которая не должна была быть принята в словарь поисковой системы.
Тот факт, что «Сапна Бат», имя человека, состоит из двух правок от фразы «баня в сауне», — это просто совпадение, которое не является обычным явлением. Проблема с «периостином» возникает из-за фразы «периоды», которая не должна была быть принята в словарь поисковой системы.
Проблемы с «Daniel K E» и «ros стволовых клеток» являются следствием того, что мы не применяем Constraint1 и Constraint2 соответственно, когда фраза имеет более двух токенов. Алгоритм мог бы выиграть с точки зрения точности, если бы мы это сделали, но он был бы более сложным.Как для «бисексуальных растлений», так и для «поджелудочной железы и трансплантации» доступный контекст не используется. Это потому, что ни один из них не исправляет фразу в системе. Скорее «перевод» и «приставание» исправляются изолированно. Конечно, слово «приставать» пишется правильно, но в документах PubMed оно встречается только 23 раза, а слово «скромный» встречается более 28 тысяч раз. Можно видеть, что «приставать» более разумно, чем «скромно» из-за другой части запроса, однако в настоящее время система использует контекст только в том случае, если он является частью допустимой фразы в системе. Наконец, есть случай «медных волос». Здесь слово «купер» встречается в PubMed десять раз (на момент написания статьи и не считая поля author). Один раз это имя человека, а остальные девять раз это неправильное написание слова «медь». Алгоритм исправит «медь» на «медь» (более 53 тысяч вхождений), за исключением того, что он предпочитает исправления фраз, когда контекст может более эффективно управлять процессом. Однако на этот раз выдает ошибку. Пользователя вполне могла заинтересовать болезнь Менке, вызванная нарушением всасывания меди в кишечнике и характеризующаяся курчавыми волосами (бесцветными).К сожалению, «медные волосы» не являются признаком болезни Менке, и эта фраза даже не встречается в базе данных PubMed.
Наконец, есть случай «медных волос». Здесь слово «купер» встречается в PubMed десять раз (на момент написания статьи и не считая поля author). Один раз это имя человека, а остальные девять раз это неправильное написание слова «медь». Алгоритм исправит «медь» на «медь» (более 53 тысяч вхождений), за исключением того, что он предпочитает исправления фраз, когда контекст может более эффективно управлять процессом. Однако на этот раз выдает ошибку. Пользователя вполне могла заинтересовать болезнь Менке, вызванная нарушением всасывания меди в кишечнике и характеризующаяся курчавыми волосами (бесцветными).К сожалению, «медные волосы» не являются признаком болезни Менке, и эта фраза даже не встречается в базе данных PubMed.
Кто-то может спросить, как наша точность исправления орфографии сравнивается с точностью других, которые использовали модель зашумленного канала. Черч и Гейл (1991) сообщают о точности 87% при исправлении набора из 332 орфографических ошибок, выявленных утилитой Unix Spell , исправление которых было одобрено по крайней мере двумя из трех судей-людей. Все эти орфографические ошибки характеризовались ровно двумя возможными однократными исправлениями в списке слов, составленном исследователями из стандартных источников.Когда модель исправления орфографии была дополнена контекстной информацией через языковую модель, они получили улучшение до 89,5%. Здесь мы можем сказать, что наш показатель точности аналогичен их, хотя есть много вопросов относительно того, насколько сопоставимо тестирование. Во-первых, мы используем не языковую модель, а нечто меньшее, хотя контекст в нашем процессе не полностью игнорируется. Во-вторых, они ограничили свой процесс однократным редактированием, тогда как мы разрешили множественное редактирование. Наконец, они ограничили свое тестирование исправлением, когда в качестве ответов было только два варианта, и это, казалось бы, повысило их точность.Поэтому из такого сравнения трудно сделать выводы.
Все эти орфографические ошибки характеризовались ровно двумя возможными однократными исправлениями в списке слов, составленном исследователями из стандартных источников.Когда модель исправления орфографии была дополнена контекстной информацией через языковую модель, они получили улучшение до 89,5%. Здесь мы можем сказать, что наш показатель точности аналогичен их, хотя есть много вопросов относительно того, насколько сопоставимо тестирование. Во-первых, мы используем не языковую модель, а нечто меньшее, хотя контекст в нашем процессе не полностью игнорируется. Во-вторых, они ограничили свой процесс однократным редактированием, тогда как мы разрешили множественное редактирование. Наконец, они ограничили свое тестирование исправлением, когда в качестве ответов было только два варианта, и это, казалось бы, повысило их точность.Поэтому из такого сравнения трудно сделать выводы.
Вторая версия модели зашумленного канала для исправления орфографии была предложена Бриллом и Муром (2000). Они используют более сложную модель редактирования, в которой одно редактирование может привести к исправлению нескольких символов. Они также ссылаются на более широкий контекст, чем одиночный символ, предшествующий исправлению, используемому Черчем и Гейлом, или одиночный символ с обеих сторон, который мы используем. Они изучили корпус из 10 000 слов с распространенными английскими орфографическими ошибками в сочетании с их правильным написанием.Они обучили 8 000 из них и протестировали свою систему на оставшихся 2 000. В процессе тестирования они использовали словарь из 200 000 статей, в который вошли все слова из тестового набора. Они обнаружили точность 95% без языковой модели. Чтобы оценить влияние языковой модели, они рассчитали поправки для тех же тестовых слов, которые встречались в контексте в корпусе Брауна. Это привело к показателю точности 95% и соответствующему показателю 93,9% без языковой модели (поскольку результаты вычисляются для каждого токена, а не для каждого типа).
Они используют более сложную модель редактирования, в которой одно редактирование может привести к исправлению нескольких символов. Они также ссылаются на более широкий контекст, чем одиночный символ, предшествующий исправлению, используемому Черчем и Гейлом, или одиночный символ с обеих сторон, который мы используем. Они изучили корпус из 10 000 слов с распространенными английскими орфографическими ошибками в сочетании с их правильным написанием.Они обучили 8 000 из них и протестировали свою систему на оставшихся 2 000. В процессе тестирования они использовали словарь из 200 000 статей, в который вошли все слова из тестового набора. Они обнаружили точность 95% без языковой модели. Чтобы оценить влияние языковой модели, они рассчитали поправки для тех же тестовых слов, которые встречались в контексте в корпусе Брауна. Это привело к показателю точности 95% и соответствующему показателю 93,9% без языковой модели (поскольку результаты вычисляются для каждого токена, а не для каждого типа). Поскольку наша точность коррекции рассчитывается также для каждого токена, именно эти последние цифры наиболее сопоставимы. Они использовали контекст из 3 символов по обе стороны от редактирования в качестве контекста для получения этого результата. Здесь их показатели производительности лучше, чем у нас. Но следует задаться вопросом, как обработка только самых распространенных ошибок в английском языке повлияет на их производительность. Для сравнения, мы имеем дело с полным спектром ошибок, которые могут возникнуть с использованием нескольких токенов, хотя наиболее распространенные ошибки будут иметь наибольшее влияние на нашу точность.Другим фактором, связанным с этим, является размер словаря, используемого в процессе исправления. В нашем случае количество уникальных токенов превышает 2,5 миллиона, а Брилл и Мур используют список из 200 000 слов. Таким образом, наш словарь более чем на порядок больше их. Пока словарь содержит правильные ответы, чем меньше словарь, тем легче процесс исправления.
Поскольку наша точность коррекции рассчитывается также для каждого токена, именно эти последние цифры наиболее сопоставимы. Они использовали контекст из 3 символов по обе стороны от редактирования в качестве контекста для получения этого результата. Здесь их показатели производительности лучше, чем у нас. Но следует задаться вопросом, как обработка только самых распространенных ошибок в английском языке повлияет на их производительность. Для сравнения, мы имеем дело с полным спектром ошибок, которые могут возникнуть с использованием нескольких токенов, хотя наиболее распространенные ошибки будут иметь наибольшее влияние на нашу точность.Другим фактором, связанным с этим, является размер словаря, используемого в процессе исправления. В нашем случае количество уникальных токенов превышает 2,5 миллиона, а Брилл и Мур используют список из 200 000 слов. Таким образом, наш словарь более чем на порядок больше их. Пока словарь содержит правильные ответы, чем меньше словарь, тем легче процесс исправления. Чем меньше число правильных ответов, тем менее плотно они упакованы (Кукич, 1992) и тем меньше вероятность того, что разные словарные статьи будут конкурировать за исправление строки с ошибкой.
Чем меньше число правильных ответов, тем менее плотно они упакованы (Кукич, 1992) и тем меньше вероятность того, что разные словарные статьи будут конкурировать за исправление строки с ошибкой.
Из-за различий в способах использования контекста в запросе поисковой системы по сравнению с текстом на естественном языке, а также из-за различий в размере словаря сделать четкие выводы из этих сравнений непросто. Одна вещь, которая кажется интересной, — это более широкий контекст внутри строки, который Брилл и Мур используют для условия редактирования. Они обнаружили повышение точности примерно на 2% при использовании окна с тремя символами по обе стороны от редактирования вместо окна только с одним символом с каждой стороны.Это говорит о том, что мы могли бы увидеть подобное улучшение, если бы наш алгоритм использовал более широкий контекст. Чего мы не знаем, так это того, как такое изменение повлияет на скорость алгоритма. Этот вопрос требует дальнейшего изучения.
Другим возможным способом улучшения алгоритма является некоторая форма фонетической коррекции. Признано, что большинство орфографических ошибок (приблизительно 80%) представляют собой единичные ошибки редактирования, когда редактирование понимается в смысле Дамерау (Damerau 1964) вставки буквы, удаления буквы, замены буквы или перестановки. две соседние буквы.Однако фонетические ошибки часто связаны с большим количеством букв и их труднее исправить (Кукич, 1992). Зобель и Дарт (1995) сравнили Soundex и Phonix (Gadd 1990) с методами, основанными на расстоянии редактирования, и пришли к выводу, что методы, основанные на фонетике, уступают подходу на расстоянии редактирования в поиске хороших совпадений для строк в большом словаре. Мы изучили алгоритм Metaphone (Philips, 1990) и попытались использовать его для исправления опечаток в симуляциях, где генерировались ошибки, такие как -. Во всех случаях мы обнаружили, что результаты хуже, чем мы смогли получить, используя модель зашумленного канала и выражения (1) и (2).По нашему опыту, фонетическая коррекция работает хорошо в некоторых случаях, но в других она идентифицирует строки как похожие, которые не должны быть идентифицированы, или не может сделать такую идентификацию, когда мы этого хотим.
Признано, что большинство орфографических ошибок (приблизительно 80%) представляют собой единичные ошибки редактирования, когда редактирование понимается в смысле Дамерау (Damerau 1964) вставки буквы, удаления буквы, замены буквы или перестановки. две соседние буквы.Однако фонетические ошибки часто связаны с большим количеством букв и их труднее исправить (Кукич, 1992). Зобель и Дарт (1995) сравнили Soundex и Phonix (Gadd 1990) с методами, основанными на расстоянии редактирования, и пришли к выводу, что методы, основанные на фонетике, уступают подходу на расстоянии редактирования в поиске хороших совпадений для строк в большом словаре. Мы изучили алгоритм Metaphone (Philips, 1990) и попытались использовать его для исправления опечаток в симуляциях, где генерировались ошибки, такие как -. Во всех случаях мы обнаружили, что результаты хуже, чем мы смогли получить, используя модель зашумленного канала и выражения (1) и (2).По нашему опыту, фонетическая коррекция работает хорошо в некоторых случаях, но в других она идентифицирует строки как похожие, которые не должны быть идентифицированы, или не может сделать такую идентификацию, когда мы этого хотим. Например, Зобель и Дарт отмечают, что «безумный» и «не» кодируются в одну и ту же строку в Soundex и Phonix. Аналогичным образом мы отмечаем, что при использовании Metaphone «фаланги» кодируются в «flnjs», а «hpalanges» кодируются в «hplnjs». Таким образом, одна ошибка редактирования может увеличиться при кодировании. Другой вопрос, который следует задать в этой настройке, заключается в том, сколько орфографических ошибок возникает в запросах PubMed, которые нельзя исправить одним или двумя правками.Это важно, потому что наш алгоритм уже достаточно хорошо работает с ошибками, состоящими из одной или двух правок. Чтобы изучить этот вопрос, мы обработали те же 63-дневные файлы журналов пользователей PubMed, из которых мы получили наши вероятности редактирования, и в аналогичной обработке собрали все пары отдельных токенов, где первый член пары не находился в пределах двух правок любой строки в базе данных PubMed, но вторая появилась в базе данных, в то время как две строки производили одну и ту же кодировку в Metaphone (обратите внимание, что мы используем полную кодировку без усечения).
Например, Зобель и Дарт отмечают, что «безумный» и «не» кодируются в одну и ту же строку в Soundex и Phonix. Аналогичным образом мы отмечаем, что при использовании Metaphone «фаланги» кодируются в «flnjs», а «hpalanges» кодируются в «hplnjs». Таким образом, одна ошибка редактирования может увеличиться при кодировании. Другой вопрос, который следует задать в этой настройке, заключается в том, сколько орфографических ошибок возникает в запросах PubMed, которые нельзя исправить одним или двумя правками.Это важно, потому что наш алгоритм уже достаточно хорошо работает с ошибками, состоящими из одной или двух правок. Чтобы изучить этот вопрос, мы обработали те же 63-дневные файлы журналов пользователей PubMed, из которых мы получили наши вероятности редактирования, и в аналогичной обработке собрали все пары отдельных токенов, где первый член пары не находился в пределах двух правок любой строки в базе данных PubMed, но вторая появилась в базе данных, в то время как две строки производили одну и ту же кодировку в Metaphone (обратите внимание, что мы используем полную кодировку без усечения). Мы идентифицировали 5 781 такое совпадение пар с участием 2 894 уникальных пар. Если кто-то оптимистично предположил, что можно исправить ошибочную строку запроса во всех случаях, используя кодировку Metaphone таким образом, это дало бы не более 92 дополнительных исправлений в день к тому, что мы уже делаем. Учитывая, что мы обычно обнаруживаем, что пользователи принимают более 90 000 исправлений в день, мы ожидаем максимум 0,1% увеличения того, что пользователи принимают, а более реалистично, вероятно, менее половины этого. Таким образом, неясно, стоит ли фонетическая коррекция накладных расходов, которые она повлечет за собой.
Мы идентифицировали 5 781 такое совпадение пар с участием 2 894 уникальных пар. Если кто-то оптимистично предположил, что можно исправить ошибочную строку запроса во всех случаях, используя кодировку Metaphone таким образом, это дало бы не более 92 дополнительных исправлений в день к тому, что мы уже делаем. Учитывая, что мы обычно обнаруживаем, что пользователи принимают более 90 000 исправлений в день, мы ожидаем максимум 0,1% увеличения того, что пользователи принимают, а более реалистично, вероятно, менее половины этого. Таким образом, неясно, стоит ли фонетическая коррекция накладных расходов, которые она повлечет за собой.
ВЫВОДЫ
Мы разработали алгоритм проверки орфографии, который выполняет достаточно точную коррекцию (≅87%) и обрабатывает одно или два редактирования, а также большее количество правок, если исправляемая строка достаточно длинная. Он обрабатывает слова, которые фрагментированы или объединены. Если запросы состоят из более чем одного маркера, алгоритм пытается использовать дополнительную информацию в качестве контекста, чтобы помочь процессу исправления. Алгоритм реализован в поисковой системе PubMed, где он часто делает более 200 000 предложений в день, и около 45% этих предложений принимаются пользователями.Алгоритм эффективно увеличивает среднее время ответа на запрос для пользователей всего на 25%, и большая часть этого наблюдается только для запросов с ошибками. Существует возможность улучшения алгоритма за счет использования большего количества контекста вокруг мест ошибок в словах. Существует также возможность улучшить алгоритм, научившись лучше использовать контекст, предоставляемый запросами, состоящими из нескольких токенов. В обоих случаях такие усилия должны учитывать, как поддерживать эффективность в свете огромного словарного запаса фраз (> 14 миллионов) и отдельных слов (> 2.5 миллионов) распознается поисковой системой. Существует также возможность использовать фонетическое кодирование для улучшения обработки некоторых ошибок, которые в настоящее время вызывают проблемы в системе. Однако предварительные расчеты показывают, что добиться значительного улучшения с помощью фонетических кодировок будет сложно.
Алгоритм реализован в поисковой системе PubMed, где он часто делает более 200 000 предложений в день, и около 45% этих предложений принимаются пользователями.Алгоритм эффективно увеличивает среднее время ответа на запрос для пользователей всего на 25%, и большая часть этого наблюдается только для запросов с ошибками. Существует возможность улучшения алгоритма за счет использования большего количества контекста вокруг мест ошибок в словах. Существует также возможность улучшить алгоритм, научившись лучше использовать контекст, предоставляемый запросами, состоящими из нескольких токенов. В обоих случаях такие усилия должны учитывать, как поддерживать эффективность в свете огромного словарного запаса фраз (> 14 миллионов) и отдельных слов (> 2.5 миллионов) распознается поисковой системой. Существует также возможность использовать фонетическое кодирование для улучшения обработки некоторых ошибок, которые в настоящее время вызывают проблемы в системе. Однако предварительные расчеты показывают, что добиться значительного улучшения с помощью фонетических кодировок будет сложно.
Благодарности
Авторы хотели бы поблагодарить Дэвида Кентона и Прамода Парантамана за содержательные обсуждения и их работу по оценке алгоритма, а также Владимира Сиротинина и Гришу Старченко за их работу по включению алгоритма в обработку запросов поисковых систем.Мы также благодарим анонимных рецензентов за полезные предложения по улучшению статьи. Это исследование было поддержано [частично] Программой внутренних исследований NIH, Национальной медицинской библиотеки.
Ссылки
- Биферман Д., Бергер А. Агломеративная кластеризация журнала запросов поисковой системы. Шестая международная конференция ACM SIGKDD по открытию знаний и интеллектуальному анализу данных; Бостон, Массачусетс, ACM Press. 2000. [Google Scholar]
- Брилл Р., Мур Р.С.Улучшенная модель ошибок для исправления орфографии зашумленного канала. ACL 2000 2000 [Google Scholar]
- Church KW, Gale WA. Оценка вероятности исправления орфографии. Статистика и вычислительная техника.
 1991; 1: 93–103. [Google Scholar]
1991; 1: 93–103. [Google Scholar] - Damerau FJ. Техника компьютерного обнаружения и исправления орфографических ошибок. Коммуникации АКМ. 1964; 7 (3): 171–176. [Google Scholar]
- Gadd TN. ФОНИКС: Алгоритм. Программа: Автоматизированные библиотечно-информационные системы. 1990;24(4):363–366.[Google Scholar]
- Hall PA, Dowling GR. Приблизительное соответствие строк. Компьютерные опросы. 1980;12(4):381–402. [Google Scholar]
- Huang CK, Chien LF, et al. Предложение релевантных терминов в интерактивном веб-поиске на основе контекстной информации в журналах сеансов запросов. Журнал Американского общества информационных наук и технологий. 2003;54(7):638–649. [Google Scholar]
- Джурафски Д., Мартин Дж. Х. Обработка речи и языка. Река Верхнее Седло; Нью-Джерси, Прентис Холл: 2000.[Google Scholar]
- Кукич К. Приемы автоматического исправления слов в тексте. Компьютерные исследования ACM. 1992;24(4):377–439. [Google Scholar]
- Ларсон Х.
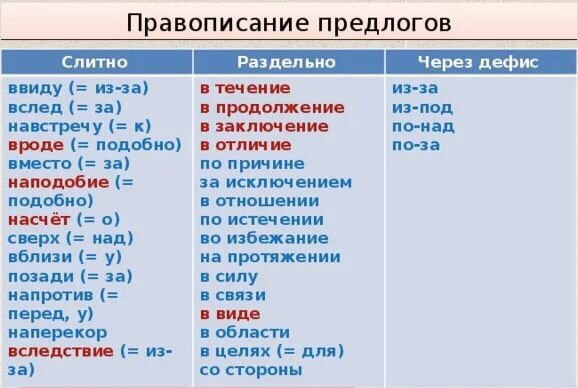 Дж. Введение в теорию вероятностей и статистический вывод. Нью-Йорк: Джон Уайли и сыновья; 1982. [Google Scholar]
Дж. Введение в теорию вероятностей и статистический вывод. Нью-Йорк: Джон Уайли и сыновья; 1982. [Google Scholar] - Leroy G, Lally AM, et al. Использование динамических контекстов для улучшения случайного поиска в Интернете. Транзакции ACM в информационных системах. 2003;21(3):229–253. [Google Scholar]
- Макэнтайр Дж., Липман Д.PubMed: преодоление информационного разрыва. Смаж. 2001;164(9):1317–9. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Нордли Р. «Раскрытие информации о пользователе» — сравнение первоначальных запросов и последующего развития вопросов в онлайн-поиске и в справочных взаимодействиях с людьми. SIGIR’99: 22-я Международная конференция по исследованиям и разработкам в области информационного поиска, Калифорнийский университет; Беркли, ACM Press. 1999. [Google Scholar]
- Филипс Л. Повешение на метафоне. Компьютерный язык.1990;7(12) [Google Scholar]
- Седжвик Р. Алгоритмы на C (части 1–4) Boston: Addison-Wesley; 1998. [Google Scholar]
- Silverstein C, Henzinger M.
 Анализ очень большого журнала запросов поисковой системы. Форум СИГИР. 1999;33(1):6–12. [Google Scholar]
Анализ очень большого журнала запросов поисковой системы. Форум СИГИР. 1999;33(1):6–12. [Google Scholar] - Спинк А., Вольфрам Д. и др. Поиск в Интернете: общественность и ее запросы. Журнал Американского общества информационных наук и технологий. 2001;52(3):226–234. [Google Scholar]
- Опрос. Поиск NPD и обзор сайта портала.2000. Получено 26 сентября 2005 г. с http://www.searchenginewatch.com/sereport/article.php/2162791.
- Ван П., Берри М.В. и др. Анализ продольных веб-запросов: тенденции и закономерности. Журнал Американского общества информационных наук и технологий. 2003;54(8):743–758. [Google Scholar]
- Wen JR, Nie JY и др. Кластеризация запросов с использованием журналов пользователей. Транзакции ACM в информационных системах. 2002;20(1):59–81. [Google Scholar]
- Зобель Дж., Дарт П. Поиск приблизительных совпадений в больших словарях.Программное обеспечение-Практика и опыт. 1995;25(3):331–345. [Google Scholar]
Использование мнемонических приемов для написания букв — видео и расшифровка урока
Примеры существительных
Давайте посмотрим на пару примеров существительных.
1. Спутник
Проблема с написанием слова «спутник» заключается в том, чтобы запомнить, есть ли в слове две буквы «t» или две «l». В следующий раз, когда вам нужно будет произнести слово «спутник», просто помните, что «спутник имеет одну турбину и два лазерных луча». Вы понимаете, как это работает? В предложении одна буква «т» и две буквы «л».
2. Солдат
Слово «солдат» можно запомнить, сказав: «Солдаты умирают на поле боя». Только помните, что слово «умереть» находится в середине слова.
3. Кандидат
Слово «кандидат» можно запомнить, используя метод «слово со словом». В этом случае у нас есть три слова: CAN, DID и ATE. Сложите их вместе, и вы пишете все слово. Запомните это легче, поместив это в предложение: Кандидат может готовить, поэтому он сделал , а затем он съел !
4.Майонез
Вспомните «майонез» и его двойное ns во фразе «Я люблю майонез на моей брокколи». ‘ В следующий раз, когда вы захотите произнести его по буквам, вспомните фразу: «Пьеса была правильной, хотя она была немой».
6. Совесть
Ваша совесть отличает правильное от неправильного, но от этого не легче произносить. Имейте в виду эту фразу, когда вам нужно произнести слово «совесть»: «Вы не можете совести, потому что это всегда правильно.»
7. Жираф
Жираф — великолепное животное, но бывает трудно запомнить, что в этом слове две буквы «ф». В следующий раз, когда вам понадобится произнести слово «жираф», просто помните, что «У всех жирафов есть близнецы по имени Фрэнк и Фиона». можно легко забыть, что оно принадлежит слову. Итак, в следующий раз, когда вы окажетесь посреди викторины и вам нужно будет произнести слово «носовой платок», просто помните «носовой платок держится в руке начальника».
9. Опасность
Иногда лучший способ запомнить одно слово — знать, что несколько слов имеют одинаковое написание. Вы можете написать слово «опасность», если вы можете написать слово «леопард». Просто запомните поговорку: «Остерегайтесь леопарда, иначе вы окажетесь в опасности». как это пишется, поэтому важно, чтобы вы знали, как это пишется. Если забудете, просто запомните фразу: «Вы работаете над экспериментами в лаборатории».»
как это пишется, поэтому важно, чтобы вы знали, как это пишется. Если забудете, просто запомните фразу: «Вы работаете над экспериментами в лаборатории».»
11. Купон
Слово «купон» обычно неправильно пишется как «купон». В слове «купон» та же пара гласных, что и в слове «вы». Если вам нужно написать купон по буквам, запомните фразу «Вам нужна пара для купона». Один из лучших способов запомнить написание этого слова — разбить его на слоги. Просто скажите «против+или+тон+ити».
13. Предубеждение
Самый быстрый способ запомнить слово «предубеждение» — запомнить фразу: «Судья бросил кости, чтобы избежать предрассудков, прежде чем отправить грабителя в тюрьма.
14. Привилегия
Многие люди делают ошибку, когда пишут слово «привилегия» со словом «уступ» как привилегию. Чтобы избежать этой глупой ошибки, помните, что «иметь ноги — это привилегия», и это удержит вас от добавления «d».
15. Вакуум
Кто придумал это слово? «Пылесос» можно запомнить, сказав: «Я вижу двух овец…» или «Я всосал одну букву «С» и две буквы «У» своим новым пылесосом».
Примеры глаголов
примеры глаголов.
1. Отдельный
У большинства из нас возникают проблемы с правописанием средней части слова «отдельный», потому что оно звучит как короткая буква «е», но на самом деле этот звук дает буква «а». Лучший способ запомнить, как пишется слово «отдельный», — это сказать себе: «Буква Р разделена двумя буквами «а». полагать.’ Во-первых, есть общее правило: i перед e, кроме c . Если это не помогло, то вы можете вспомнить, как пишется это слово, сказав: «Не верьте лжи».Слово «лгать» находится внутри слова «верить».
Другие слова с ошибками
Теперь давайте рассмотрим еще пару слов с ошибками.
1. Все в порядке
«Хорошо» так же просто, как помнить, что это всегда два слова, а слово «Все» не пишется с одной «л». Если это не поможет вам запомнить его, попробуйте сказать: «Хорошо всегда противоположно всему неправильному». заклинание это.Среднее слово «конечный», что означает постоянный или точный. Просто определенно напишите это так, и вы никогда не напишете это неправильно.
Просто определенно напишите это так, и вы никогда не напишете это неправильно.
3. Единогласно
Слово «единогласно» такое каверзное! Давайте просто запомним это как «Мы с тобой видели мышь, которая потеряла свой EEEE». Или вы можете вспомнить эту забавную фразу: «Неоригинальное голое животное грустно издевается над нами».
4. Много
Подобно фразе «хорошо», фраза «много» состоит из двух слов, а не из одного. Просто подумайте об этом так: «Многое — это слишком много, чтобы уместиться в одном слове.»
Итоги урока
Хорошо, давайте кратко повторим. Если у вас есть проблемы с запоминанием написания определенных слов, то мнемоническое устройство может стать отличным инструментом, поскольку это техника, которую вы можете использовать, чтобы что-то запомнить, и в данном случае, как написать слово. Иногда речь идет о составлении забавного предложения, а иногда о разделении слова на более мелкие части. На этом уроке мы рассмотрели мнемонику правописания много, единогласно, определенно, хорошо, верю, отделить, вакуум, привилегия, предубеждение, возможность, талон, лаборатория, опасность, носовой платок, жираф, майонез, драматург, совесть, дело, солдат, и, наконец, спутник. Теперь у вас не должно возникнуть проблем с правописанием этих слов!
Теперь у вас не должно возникнуть проблем с правописанием этих слов!
Распространенные орфографические ошибки: слова, которые трудно произносить по буквам
Мы любим правописание в США. Мы даже превратили его в соревновательный вид спорта, но это не значит, что все мы умеем писать. Хотя многие из нас полагаются на проверку орфографии и автокоррекцию, иногда это может привести к непреднамеренным проблемам.Некоторые слова просто сложны, и даже наши двоюродные братья в Великобритании (где изобрели многие слова, сложные для написания) сталкиваются с подобными трудностями.Слова, написанные фонетически, представляют наименьшее количество проблем. Именно те со странными буквосочетаниями, немыми буквами и двойными согласными являются одними из самых сложных, и неудивительно, что они вызывают у людей головную боль.
Смущение в правописании
«Смущение» с двойным «r» и двойным «s» было выбрано британскими участниками опроса как слово, которое им было труднее всего написать. Я согласен, что это неудобно. На самом деле я держу рядом с компьютером список слов, в которых часто допускаю ошибки, и должен признаться, к моему «смущению», что это слово есть в списке.Почему я веду список слов, которые мне трудно написать? Чтобы я мог их выучить, конечно. У каждого должен быть один.
Я согласен, что это неудобно. На самом деле я держу рядом с компьютером список слов, в которых часто допускаю ошибки, и должен признаться, к моему «смущению», что это слово есть в списке.Почему я веду список слов, которые мне трудно написать? Чтобы я мог их выучить, конечно. У каждого должен быть один.
Для тех, кому интересно, ниже приведены остальные десять самых сложных для написания слов Великобритании, в которые входят:
- Флуоресцентный
- Вмещать
- Психиатр
- Изредка
- Необходимо
- Анкета
- Озорной
- Ритм
- Минускул
Я рад сообщить, что в моем списке всего четыре из них, но слово «необходимое» было удалено из него всего несколько лет назад.В качестве орфографического упражнения для наших британских братьев я предлагаю им сто раз написать следующие предложения без проверки орфографии или автозамены:
«Иногда я обращаюсь к психиатру по поводу моей неспособности приспособиться к ритму необходимых дел. Если бы мой дом был чуточку более организованным, я бы не краснел от смущения, когда мой озорной братец приходил в гости».
Если бы мой дом был чуточку более организованным, я бы не краснел от смущения, когда мой озорной братец приходил в гости».
По общему признанию, будучи британцами, им лучше всего использовать британское правописание для слова «организованный».«Хотя большинство британцев хорошо переносят американское правописание, некоторых это приводит в бешенство, поэтому, если вы британец, используйте букву s вместо z.
Слова Американцы борются за правописание
Google задают множество вопросов, а также спрашивают, как правильно писать слова. Десять самых популярных слов, которые пользователи Интернета в США спрашивали у Google, были такими:
.- Серый
- Отменено
- Определенно
- Закуски
- Пневмония
- Ценю
- Ханука
- Ресторан
- Девяносто
- Племянница
Как у вас дела с этим списком? Я рад сообщить, что у меня есть трудности только с двумя из них, а закуска обсуждалась в недавнем сообщении в блоге, поэтому я думаю, что теперь вспомню, как это пишется.
Судя по поиску в Google, жители Айдахо либо хуже всех писали, либо больше всех беспокоились о правописании. Какой бы ни была причина, они задавали Google вопросы, основанные на правописании.
Google также попытался выяснить, какие слова больше всего беспокоят людей, живущих в разных штатах. Некоторые результаты весьма интересны, хотя что нам делать с этим знанием, остается загадкой.
Например, если вы живете на Гавайях, не зная, как пишется слово «птеродактиль», вы не можете уснуть по ночам.С другой стороны, жителей Грузии больше всего беспокоит, как пишется «Пневмония». Жители Солнечного штата так мало знают о плохой погоде, что не знают, как пишется «серый». Затем есть жители штата Мэн. Они хотят, чтобы мы знали, что они сыты по горло, или так может показаться. Их самый часто задаваемый вопрос по правописанию был для «разочарован».
Могут ли американцы произносить «смущенный» по буквам?
Мы не слишком отличаемся от британцев своими орфографическими пороками. Более 60% американцев не могут произнести «е-слово».Другие слова, которые нас смущают, включают:
Более 60% американцев не могут произнести «е-слово».Другие слова, которые нас смущают, включают:
- Связной
- Миллениум
- Друг
- смешной
Единственное, чем мы можем себя утешить, так это тем, что у всех есть слова, в написании которых они не уверены. В конце концов, как мы должны знать, что порода собак, которая произносится как «чивава», на самом деле пишется как «чихуахуа»? Если бы мы произносили это так, как предполагает серия букв, это было бы «Чи-кто-а-кто-а», и именно так я помню правильное написание.Где-то в моей голове есть небольшая схема, которая запоминает это в фонетически произносимой форме.
Существует школа мысли, утверждающая, что нам следует дать свободу действий в логическом написании слов. До изобретения книгопечатания и разработки первых словарей не существовало настоящих правил правописания. С другой стороны, некоторые настаивают на еще большей стандартизации. Но поскольку это означало бы, что либо британцам, либо американцам придется отказаться от своей формы написания, маловероятно, что это когда-либо произойдет.
В качестве последнего утешения вам следует знать, что некоторые из величайших писателей в истории были очень плохими орфографами, которые полагались на редакторов, исправлявших их ошибки, поэтому, если вы с трудом пишете определенные слова, вы в хорошей компании.
(Фото предоставлено elginwx)
американских орфографических ошибок
Азбука — это гораздо больше, чем просто веселая мелодия для учащихся детского сада: Учимся заклинание является одним из наиболее важных строительных блоков, когда речь идет об общем грамотность.Однако в современную эпоху мы настолько полагаемся на безудержную любовь к программе проверки орфографии, прощающая природа и скорострельные текстовые сообщения, которые искусство правописания часто уходит на второй план в повседневной жизни.
Мы хотели взглянуть на общие навыки правописания американцев , а также на то, какие
отрасли населены лучшими орфографами, допускаются ли опечатки в среднем
рабочем месте, и как интеллект играет роль в игре свиданий. Мы обследовали и
провел тест на правописание более чем 1000 американцев, чтобы мы могли получить ответы
один раз и «все туда».
Мы обследовали и
провел тест на правописание более чем 1000 американцев, чтобы мы могли получить ответы
один раз и «все туда».
Суперспеллеры повсюду
Вот что касается средних значений — на любой стороне уравнения. Однако вряд ли это было так, когда мы спросили наших респондентов. считают ли они, что их знания выше или ниже среднего по различным предметам.
Когда дело доходило до чтения, правописания и грамматики, большинство мужчин и женщин считали
у них были способности выше среднего 90 006 : 86 процентов думали, что они понимают прочитанное
виртуозами, 78 % считали себя суперграмотными, а еще 74,7 % считали себя
были гуру грамматики. Во всех остальных категориях, от химии до истории, мужчины показали более высокие результаты. уровень уверенности, чем у женщин.
уровень уверенности, чем у женщин.
Однако правда об американской грамотности не так радужна, как кажется нашим респондентам. Более более 30 миллионов взрослых умеют читать, писать, и математические навыки, которые колеблются на уровне третьего класса, что вызывает тревогу, учитывая, что эти навыки тенденции, влияющие на будущие поколения: Дети неграмотных родителей гораздо чаще получать плохие оценки и испытывать поведенческие проблемы.
Оглядываясь назад на К-12
Учителя — одни из самых перегруженных работой и недооцененных членов общества. рабочая сила, что обескураживает, потому что они также более важны для успеха студентов, чем размер класса, доступные технологии и индивидуальный подход. Иметь отличного учителя в фасад класса может изменить все – так сколько же респондентов удовольствие от получения этого образовательного опыта?
Большинство (40. 8 процентов) сказали, что у них есть от одного до двух выдающихся инструкторов
на протяжении всего их обучения. Еще 35,4% с теплотой вспомнили, что у них было от трех до четырех человек.
отличные учителя. И хотя только 6,9% заявили, что у них нет выдающихся учителей, в то время как
они были в школе, еще меньше сообщили, что у них семь или более.
8 процентов) сказали, что у них есть от одного до двух выдающихся инструкторов
на протяжении всего их обучения. Еще 35,4% с теплотой вспомнили, что у них было от трех до четырех человек.
отличные учителя. И хотя только 6,9% заявили, что у них нет выдающихся учителей, в то время как
они были в школе, еще меньше сообщили, что у них семь или более.
Американские государственные школы точно не имеют лучшей репутации, и в то время как более частные респонденты со средним образованием заявили, что удовлетворены своим образованием (84%), почти три четверти людей с общественным образованием сказали то же самое.Между этими двумя группами почти не было разницы в количестве отличных учителей, которые респонденты сказали, что они было .
Наконец, когда дело дошло до самооценки своих способностей, подавляющее большинство женщин сказали, что их
лучшим предметом в средней школе был английский язык. Математика и история были далеко вторым и третьим.
Реакции мужчин были гораздо более разнообразными: английский язык, математика и история, по сути, носили друг с другом.
шея в сравнении.
Математика и история были далеко вторым и третьим.
Реакции мужчин были гораздо более разнообразными: английский язык, математика и история, по сути, носили друг с другом.
шея в сравнении.
Проблемы с опечатками
Итак, вы отправили электронное письмо с орфографической ошибкой. Опечатки случаются, и вы справится с этим , а может и нет пусть это случится снова. Шестьдесят пять процентов наших респондентов сказали, что этот тип ошибки был неприемлемым в их отрасли, но люди в логистике, рекламе и правительстве были особенно нетерпимы к опечаткам.
С другой стороны, 18,6% населения сказали, что орфографические ошибки — это нормально,
хотя только 2,7 процента оценили их как «полностью приемлемые». В отличие от ошибок, как
наши респонденты, тем не менее, только 8,2 процента сказали, что они были бы в серьезной горячей воде с
своего начальника, если они сделали опечатку, по сравнению с 40,8%, которые предполагали, что их босс только
быть «слегка раздраженным». Еще 24,5 процента были убеждены, что их начальству все равно.
вообще.
В отличие от ошибок, как
наши респонденты, тем не менее, только 8,2 процента сказали, что они были бы в серьезной горячей воде с
своего начальника, если они сделали опечатку, по сравнению с 40,8%, которые предполагали, что их босс только
быть «слегка раздраженным». Еще 24,5 процента были убеждены, что их начальству все равно.
вообще.
Один из худших моментов для орфографической ошибки на рабочем месте, конечно же, еще до того, как вы
выйти на рабочее место: почти 80 процентов респондентов заявили, что не наняли бы человека с
опечатка в их резюме. При этом все становится лучше, когда вы зарабатываете больше влияния, и
чувство шока и ужаса, которое в конце концов сопровождает любое электронное письмо, отправленное с ошибкой
тает со старшинством. Фу.
Фу.
Из любви к грамоте
Партнерство с равным по интеллекту не так просто, как найти кого-то с колледжем диплом или подобная любовь к поэзии — это требует от вас отметить ряд важных пунктов, если вы хотите облегчить здоровые, длительные отношения. По крайней мере, так было бы, если бы вы хотели, чтобы встречаться с кем-то, основываясь на его интеллекте.
Большинство наших респондентов действительно искали мозги, а не красоту, с одним очень важным
исключение: в то время как подавляющее большинство женщин предпочли бы встречаться и выходить замуж за партнера, который
умные, а не привлекательные, у мужчин были другие планы. Количество респондентов-мужчин, которые
предпочел бы встречаться с кем-то из-за их внешности, а не из-за их интеллекта, который был почти расколот
средний (43. 6% против 56,4% соответственно), но когда дело дошло до брака,
последнее число подскочило до 78,1 процента.
6% против 56,4% соответственно), но когда дело дошло до брака,
последнее число подскочило до 78,1 процента.
Влечение может принимать разные формы, и , по мнению наших респондентов, быть необразованным ни один из них . Орфографические и грамматические ошибки также попали в черный список. а также отсутствие базовых математических навыков. Наконец, хотя половина респондентов каждого пола сообщали, что они чувствовали себя такими же умными, как и их партнеры, мужчины в два раза чаще, чем женщины, чувствовали себя умнее своего партнера.В том же ключе гораздо больше женщин (32,2%), чем мужчин (19,5%). процентов) чувствовали себя хуже своей второй половины в мозговом отделе.
Получите оценку правописания
Большинство наших респондентов считали, что их правописание выше среднего. Как вы складываетесь? Мы
предложил респондентам пройти базовый тест по орфографии и грамматике. Прежде чем мы покажем вам, как американцы
да, пройдите наш тест, чтобы узнать, являетесь ли вы звездным правописанием или склонны к опечаткам.
Как вы складываетесь? Мы
предложил респондентам пройти базовый тест по орфографии и грамматике. Прежде чем мы покажем вам, как американцы
да, пройдите наш тест, чтобы узнать, являетесь ли вы звездным правописанием или склонны к опечаткам.
Испытание американцев
Нашим респондентам был предложен орфографический тест, в котором содержалось несколько слов с ошибками, чтобы определить их правописание. В среднем они получили достойную оценку: 75 процентов. или эквивалент C в традиционном классе английского языка в средней школе. Почетные упоминания идут респондентам из сферы рекламы, развлечений, телекоммуникаций, финансов и некоммерческих организаций, которые заработал высший балл в целом.
Между четырьмя поколениями практически не было различий в навыках правописания (хотя
миллениалы и поколение X были немного более подходящими, чем бэби-бумеры и представители поколения Z). Тем не мение,
разница в результатах тестов между выпускниками государственных и частных школ была еще меньше: 75,5% для частных и 75% для государственных – другими словами, полностью
средний в обоих случаях.
Тем не мение,
разница в результатах тестов между выпускниками государственных и частных школ была еще меньше: 75,5% для частных и 75% для государственных – другими словами, полностью
средний в обоих случаях.
В то время как частные школы часто хвалят за то, что они отправляют лучше подготовленных учеников в мире, все больше и больше исследований показывают, что на самом деле может не быть заметной разницы между ними двумя — вместо этого считается, что домашняя жизнь детей намного более сильный детерминант, чем частная школа по сравнению с государственной.
Word Spotlight
В момент жестокой иронии более 1 из 5 человек написали слово с ошибкой. словом, которое в целом привело к наибольшему количеству проблем, было «приспосабливаться», , которое почти поставило в тупик. половина наших испытуемых, за которыми следует «лицемерие», которое имело скромные 64,4 процента успеха.
ставка. При этом большинство респондентов могли написать «видимо» и «получить».
правильно.
половина наших испытуемых, за которыми следует «лицемерие», которое имело скромные 64,4 процента успеха.
ставка. При этом большинство респондентов могли написать «видимо» и «получить».
правильно.
Помимо обычных орфографических ошибок, обнаруженных нашим внутренним тестом, многие другие слова часто ставят в тупик менее сообразительные слова. правописания.Сколько из них вы виновны в орфографических ошибках?
Орфографический Mi(l)le(n)nial
Вы родились между 1981 и 1996 годами? Если да, то вы знаете, что вы принадлежите к поколению миллениалов? Однако независимо от того, в каком поколении вы принадлежат, знаете ли вы, как пишется одно из самых распространенных модных словечек в нашем современном словарь?
Комбинезон, 57. 5 процентов наших респондентов смогли правильно написать слово
«миллениал», , где единственное значимое значение — «миллениал» с одной буквой N
опечатка. Неудивительно, что представители этого поколения чаще всего правильно пишут
часто, за ними следуют представители поколения X.
5 процентов наших респондентов смогли правильно написать слово
«миллениал», , где единственное значимое значение — «миллениал» с одной буквой N
опечатка. Неудивительно, что представители этого поколения чаще всего правильно пишут
часто, за ними следуют представители поколения X.
Какая ведьма какая?
Что касается надоедливых омонимов (не путать с омофонами и омографами), респонденты с легкостью взялись за некоторые слова, в то время как некоторые избранные вызвали гораздо большие разногласия.Вот как они сделали.
Не игнорируйте знаки
Большинство наших респондентов назвали себя выше среднего по орфографии, грамматике и
понимание прочитанного, но реальность была гораздо более тонкой. Пройдя тест на орфографию,
средняя оценка составляла 75 процентов, и некоторые слова, в которых часто писались с ошибками, по-прежнему могли
снять хороший кусок нашего опрошенного населения (мы смотрим на вас, «приспособиться»).
Пройдя тест на орфографию,
средняя оценка составляла 75 процентов, и некоторые слова, в которых часто писались с ошибками, по-прежнему могли
снять хороший кусок нашего опрошенного населения (мы смотрим на вас, «приспособиться»).
Один из самых интересных выводов заключался в том, что практически не было разницы в способности между людьми, которые ходили в частную школу, и людьми, которые были публично образованных , хотя респонденты, получившие частное образование, считают, что получили качественное образование.
О Signs.com
На рабочем месте большинство людей считают опечатки неприемлемыми.Это
важно, чтобы ваша компания представляла себя профессиональной и добросовестной – так
вы можете только представить, что неприглядный или устаревший знак может сделать с вашим бизнесом
достоверность. Signs.com может предоставить решения для всех ваших потребностей в отображении, от
алюминиевые, акриловые и баннерные знаки для оконных наклеек и рекламных флагов. Не позволяй своему
бренд вниз: Сообщите миру свои идеально сформулированные мысли с элегантным,
стильный дизайн.
Signs.com может предоставить решения для всех ваших потребностей в отображении, от
алюминиевые, акриловые и баннерные знаки для оконных наклеек и рекламных флагов. Не позволяй своему
бренд вниз: Сообщите миру свои идеально сформулированные мысли с элегантным,
стильный дизайн.
Методология и ограничения
Как мы создали это исследование
Чтобы создать показанные выше данные, мы создали интерактивный опрос в SurveyMonkey и Его принимают 1000 американцев из академического сообщества Prolific.ac. Опрос содержал общие вопросы об образовании, а также тест на орфографию и грамматику.
Конечно, мы не могли показать вопрос «Как пишется миллениал?» поэтому мы создали
аудиозапись и попросил участников прослушать запись и ввести то, что они
слышал. Другие вопросы задавались: «Какое из следующих слов правильное?» и
респонденты должны были выбрать ответы с несколькими вариантами ответов, как в викторине, показанной выше.
Другие вопросы задавались: «Какое из следующих слов правильное?» и
респонденты должны были выбрать ответы с несколькими вариантами ответов, как в викторине, показанной выше.
Как и в любом опросе, респонденты могли быть предвзяты в некоторых ответах из-за недавних событий, их текущее настроение или ряд предубеждений, характерных для каждого опроса.Мы проверяли внимание во время опрос, чтобы убедиться, что люди обращают внимание и приложили все усилия, чтобы свести к минимуму предвзятость респондентов.
Как мы контролировали мошенничество
Во время викторины нас беспокоили приложения и плагины для проверки орфографии и грамматики.
поэтому мы попросили людей отключить их, прежде чем брать.Единственное, о чем мы попросили людей
в качестве части викторины было слово «миллениал», которого, к счастью, не было в
Корпус слов Google Chrome или SurveyMonkey и всегда отображается красной волнистой линией. под ним, как если бы он был написан с ошибкой. Другие ответы представляли собой множественный выбор и рассматривались как
обычный текст и поэтому не проверялись программой проверки орфографии браузера.
под ним, как если бы он был написан с ошибкой. Другие ответы представляли собой множественный выбор и рассматривались как
обычный текст и поэтому не проверялись программой проверки орфографии браузера.
В конце опроса мы задали вопрос: «В ходе этого опроса вы изменить любые ответы на основе проверки орфографии, волнистых красных линий под словом, которое вы печатали, или есть ли причина, по которой вы не были полностью честны в том, как, по вашему мнению, пишутся вещи? Ты не будет оштрафован за этот ответ.«Более 100 человек, признавшихся в этом, были исключены из любых результатов викторины, что значительно снизило правильные проценты.
Тем не менее, мы не совсем наивны и понимаем, что есть более изобретательные способы обмана.
Некоторые, возможно, исследовали эти способы или не были честны в последнем вопросе, даже если
их заверили, что они не будут наказаны за свои ответы. Мы можем держать людей только в
их слово и подчеркнуть, что этот опрос и исследование предназначены для развлечения, и мы сделали
мы делаем все возможное, чтобы получить максимально точные результаты. Если кто-то хочет,
они могут попытаться наблюдать за фактическим обследованием или провести более масштабное исследование с помощью камер и других средств.
обманные ловушки, хотя, как недавно показали нам новости SAT, люди всегда могут найти способы
изменять.
Мы можем держать людей только в
их слово и подчеркнуть, что этот опрос и исследование предназначены для развлечения, и мы сделали
мы делаем все возможное, чтобы получить максимально точные результаты. Если кто-то хочет,
они могут попытаться наблюдать за фактическим обследованием или провести более масштабное исследование с помощью камер и других средств.
обманные ловушки, хотя, как недавно показали нам новости SAT, люди всегда могут найти способы
изменять.
Демографическая информация
Из 1000 человек, принявших его, разбивка по поколениям была следующей: 101 бэби-бумер, 168
Представители поколения X, 619 миллениалов, 108 представителей поколения Z и еще четыре выбранных варианта. 502 человека и 486
женщины приняли участие в опросе, а остальные дали другие ответы или предпочли не указывать. Все
Отрасли, которые мы учитывали в любых показанных результатах, имели по крайней мере 25 респондентов, которые сказали, что они
в настоящее время заняты в этой отрасли.Возраст респондентов колебался от 18 до 75 лет, в среднем
возраст 33 года и стандартное отклонение 12,28. Никакой информации, позволяющей установить личность, не было
спросили или собрали во время опроса.
Все
Отрасли, которые мы учитывали в любых показанных результатах, имели по крайней мере 25 респондентов, которые сказали, что они
в настоящее время заняты в этой отрасли.Возраст респондентов колебался от 18 до 75 лет, в среднем
возраст 33 года и стандартное отклонение 12,28. Никакой информации, позволяющей установить личность, не было
спросили или собрали во время опроса.
Так же, как мы рекомендуем запускать проверку орфографии во всех курсовых работах и рабочих презентациях, мы
рекомендуем вам поделиться этой статьей и любой связанной с ней графикой в некоммерческих
целей с любой аудиторией, которую вы хотели бы.Мы только просим, чтобы, если вы делаете, пожалуйста, цитировать авторов
и дайте ссылку на эту страницу.
У меня СДВГ, и иногда я не могу написать свое имя по буквам
У меня никогда не было настоящего прозвища, но мой папа иногда называл меня «Жакли», когда я был ребенком. Шутка началась, когда я забыл последнюю букву своего имени в верхней части школьной газеты.
Жаклин из четвертого класса знала, как написать свое имя по буквам — очевидно, — но моего внимания не всегда хватало, чтобы написать все шесть букв.
Это все еще не так. Я до сих пор ловлю себя на том, что пишу «Жакли» на официальных документах. Я также забываю слова в предложениях или пишу слова не по порядку. Иногда я нахожу стикеры с фрагментами предложений или немаркированными телефонными номерами. Я отвлекся, не закончив писать, и теперь не могу понять, что они означают.
В данный момент я не понимаю, что происходят эти потери внимания. Я никак не могу сказать себе: «Эй, сосредоточься!» и предотвратить их. Я называю себя ориентированным на детали.Я горжусь своей способностью правильно и полностью заполнять формы. Тем не менее, я все время делаю странные ошибки, особенно когда пишу от руки.
Тем не менее, я все время делаю странные ошибки, особенно когда пишу от руки.
Не помню, нравилось ли мне, что папа называл меня «Жакли». Я вижу, что ценю то, что кто-то дал мне прозвище. Так же вероятно, что я, возможно, взбесился. Все мучения, которые я помню из своего детства, были связаны с моим СДВГ, хотя в то время я понятия не имел об этом. Причуды и слабости СДВГ — например, неправильное написание собственного имени или бросание на пол одноклассника из третьего класса после того, как он перебежал очередь, — могут определить нас.И это больно. Может быть, дело в том, кто мы есть, но не в том, кем мы себя чувствуем.
Этот диссонанс преследовал меня всю мою молодую жизнь. Я написал в своем дневнике о желании уйти из дома и начать все сначала. Я ненавидел ходить в школу, зная, что у всех есть мнение обо мне. Мне казалось, что я не соответствую другим определениям меня.
Я до сих пор борюсь с этим, но стараюсь сохранять чувство юмора. Я стараюсь искать возможности. Каждый раз, когда я пишу «Жакли», я улыбаюсь и слышу голос отца, когда возвращаюсь, чтобы добавить «н».Я стараюсь рассматривать ошибки как возможность показать себя настоящего: человека, который не является ни эгоистичным, ни безответственным, ни небрежным. Я делаю это, признавая свои ошибки, извиняясь, когда это необходимо, и признавая, как мои действия влияют на других. Я откровенно говорю о своих проблемах с памятью и вниманием. Я надеюсь, что эта открытость поможет людям понять, что дело не в них и не в моих чувствах к ним. Я рассказываю о своих стикерах и организационных системах, потому что хочу, чтобы другие видели, как я стараюсь. Я стараюсь смеяться над глупостями и продолжаю работать над важными вещами.
Каждый раз, когда я пишу «Жакли», я улыбаюсь и слышу голос отца, когда возвращаюсь, чтобы добавить «н».Я стараюсь рассматривать ошибки как возможность показать себя настоящего: человека, который не является ни эгоистичным, ни безответственным, ни небрежным. Я делаю это, признавая свои ошибки, извиняясь, когда это необходимо, и признавая, как мои действия влияют на других. Я откровенно говорю о своих проблемах с памятью и вниманием. Я надеюсь, что эта открытость поможет людям понять, что дело не в них и не в моих чувствах к ним. Я рассказываю о своих стикерах и организационных системах, потому что хочу, чтобы другие видели, как я стараюсь. Я стараюсь смеяться над глупостями и продолжаю работать над важными вещами.
Потому что иногда я всегда ошибаюсь в своем имени. Время от времени мои стикеры — или другая система — меня подводят. Наверное, это будет моя вина. Но я могу практиковать устойчивость. Я могу простить себя и сохранить достойное отношение. Я могу сопротивляться импульсу защищаться, перекладывать вину или направлять всю свою злость внутрь себя.