
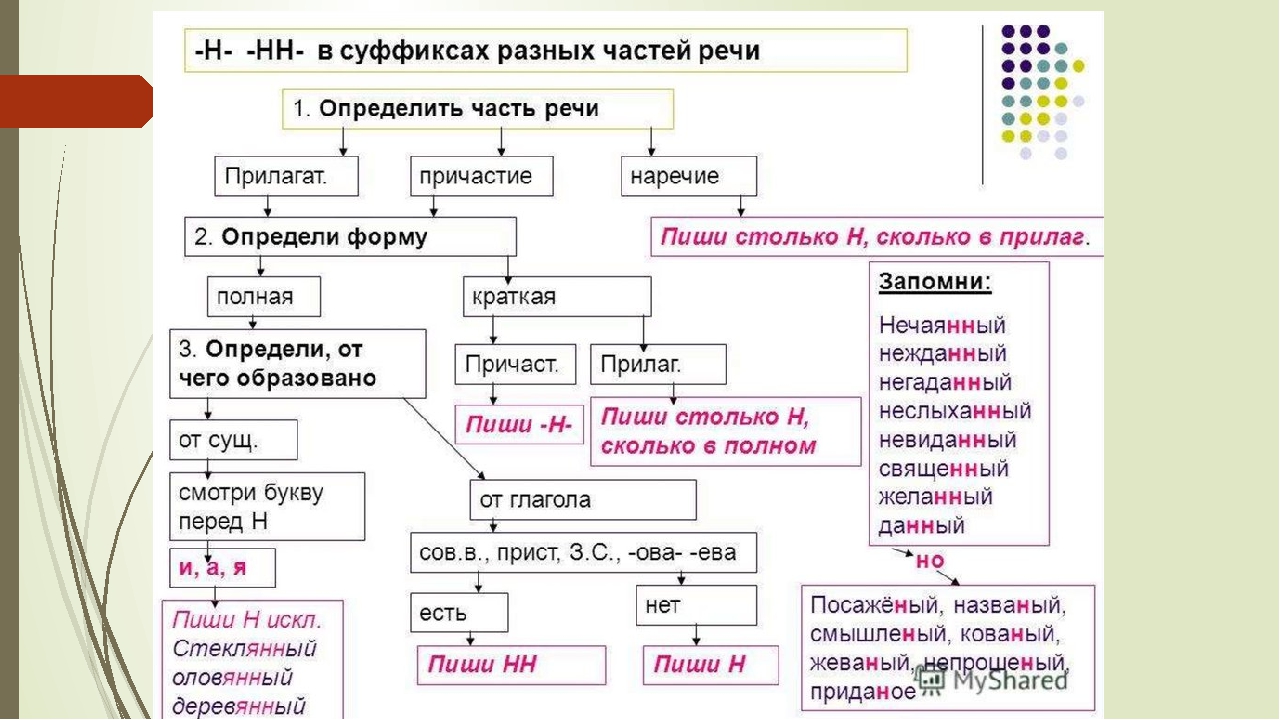
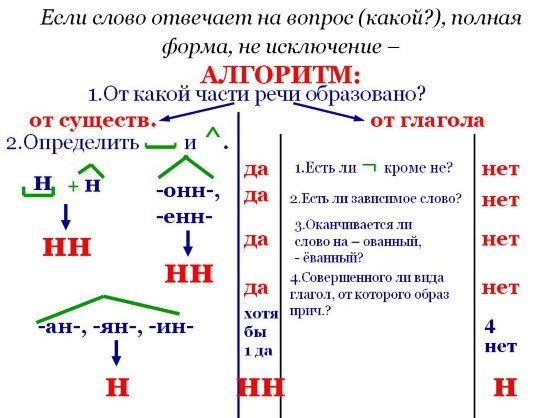
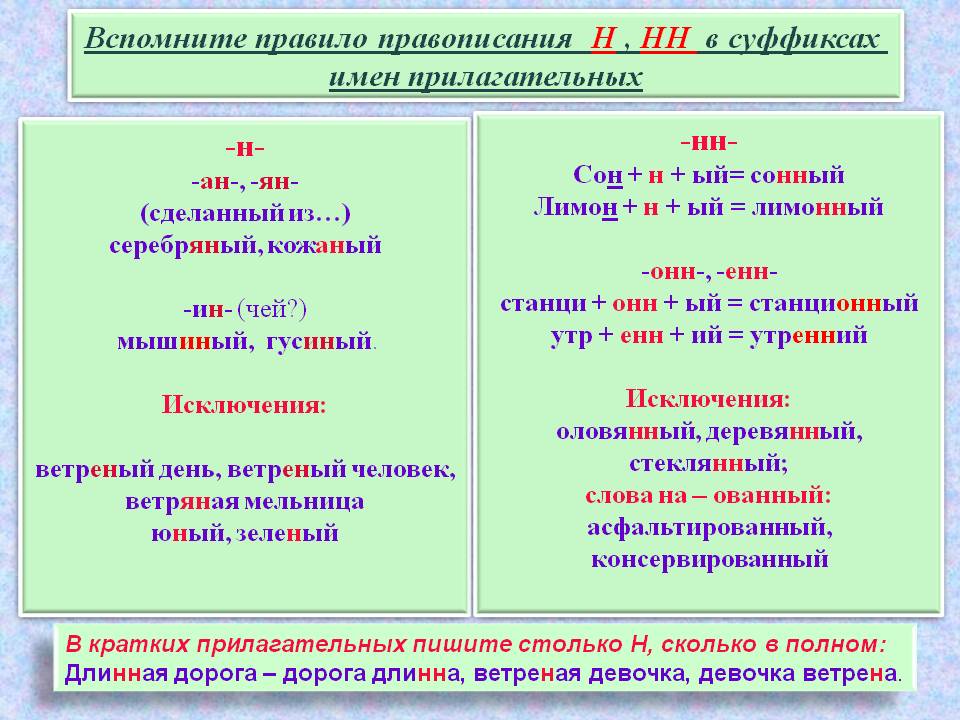
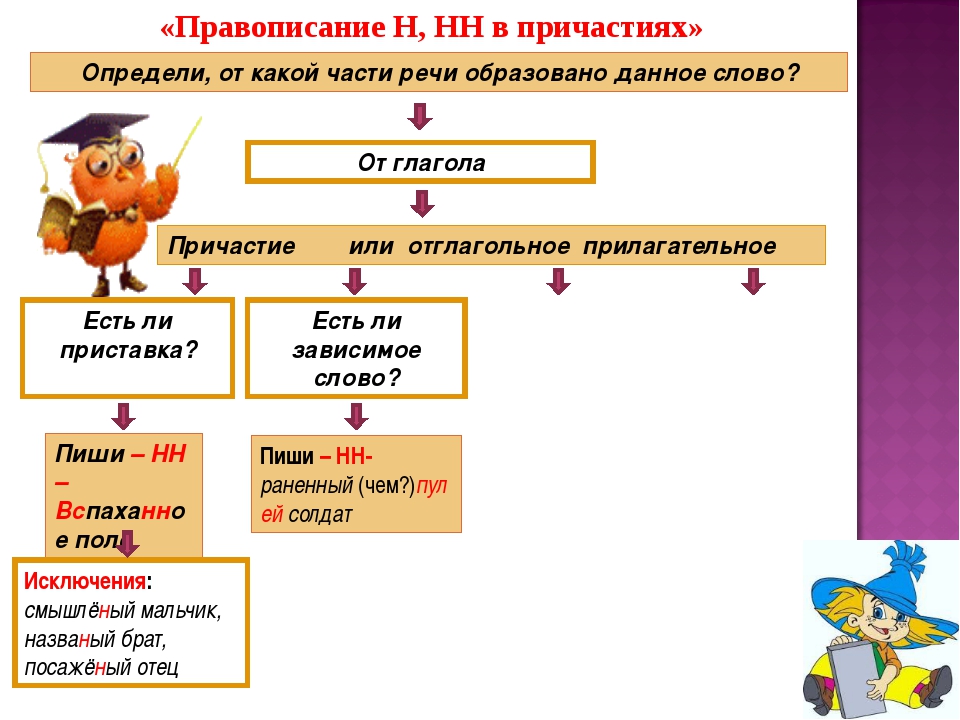
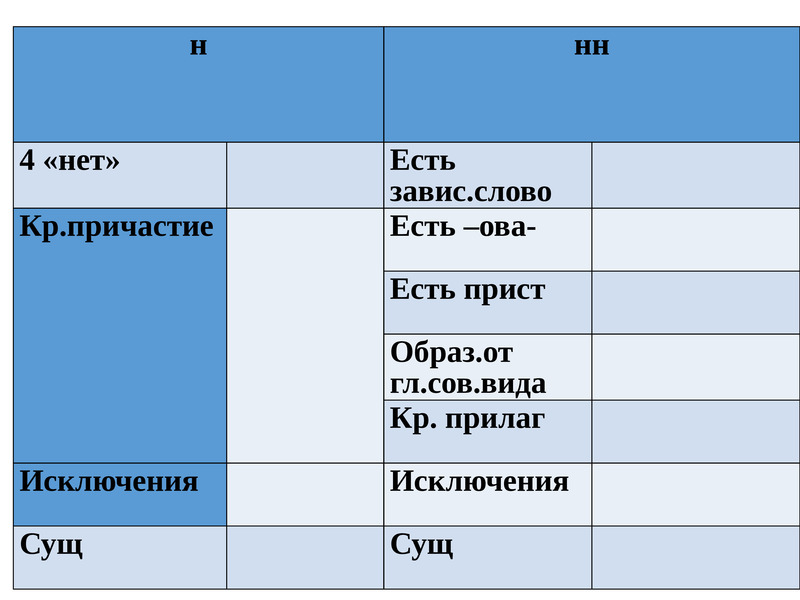
Буквы н — нн в суффиксах прилагательных, причастий и наречий
Цели: учить применять правила написания букв н — нн в суффиксах страдательных причастий прошедшего времени и отглагольных прилагательных; формировать умение отличать краткие прилагательные от кратких причастий, наречий и слов категории состояния; воспитывать культуру грамотного письма.
Планируемые результаты: умения применять алгоритм написания букв н — нн в суффиксах прилагательных, причастий и наречий, объяснять языковые явления и процессы, применять пунктуационные и орфографические правила.
Ход урока
I. Организационный момент
II. Лингвистическая разминка
Словарный диктант
(Два ученика работают у доски, остальные — в тетрадях.)
Блестеть, забираю, горит, равнина, вырастить, Ростов, непромокаемый плащ, гореть, располагать, вычесть, посвятить жизнь науке, блистать на балу, сильное возгорание, подровнять чёлку, цветы увядают, разрядить ружьё, лестное сравнение.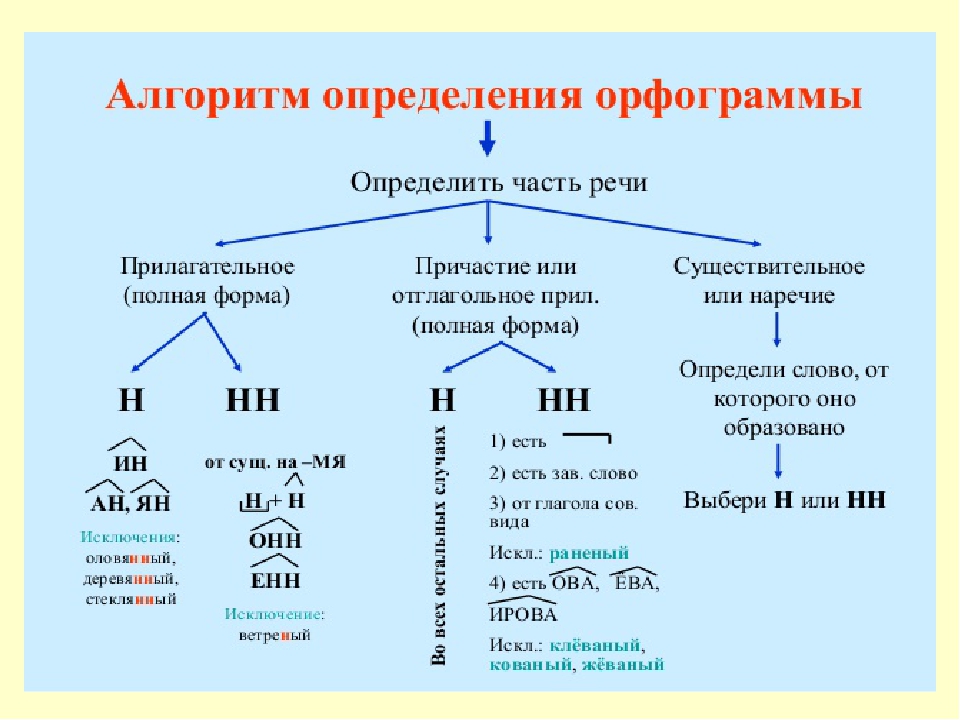
(Проверка, анализ ошибок.)
III. Проверка домашнего задания
(Упр. 19 — составление схем предложений на доске.)
IV. Работа по теме урока
1. Работа по карточкам
— Образуйте от существительных прилагательные.
Длина, письмо, торжество, сукно, кость, дерево, нефть, тыква, окно, авиация, листва, батальон, ветер.
— Вставьте пропущенные буквы, подчеркните их.
Родстве..ый, серебря..ый, тыкве..ый, ремесле..ый, кожа..ый, оловя..ый, станцио..ый, подли..ый, клюкве..ый, отчая..ый, промышле..ый, сан..ый, пустын..ый, несчаст..ый, петуши..ый.
2. Обсуждение вопроса
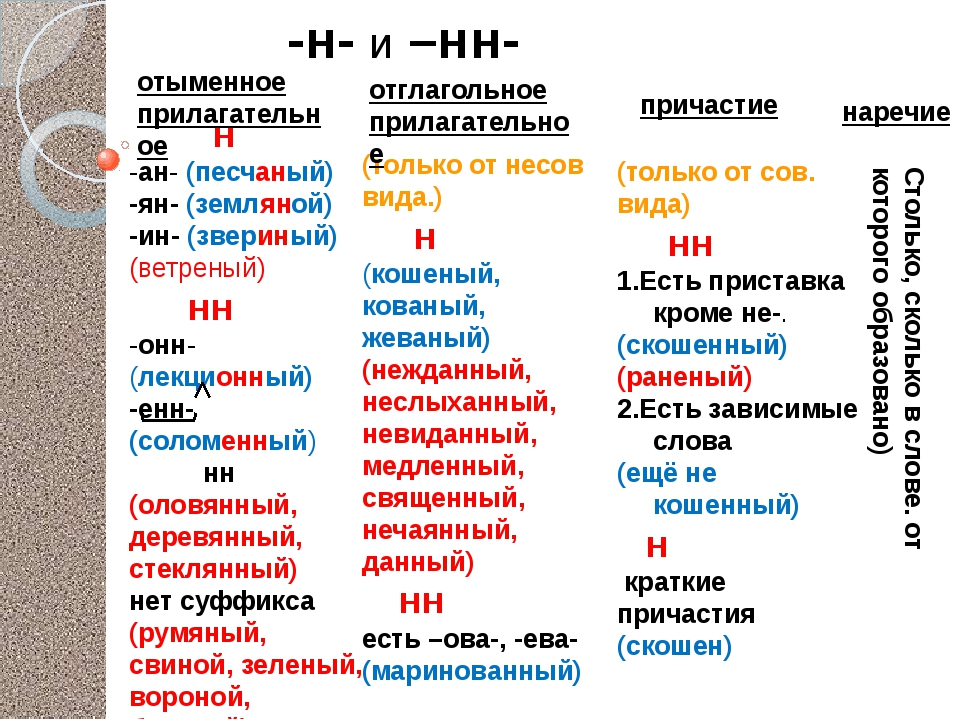
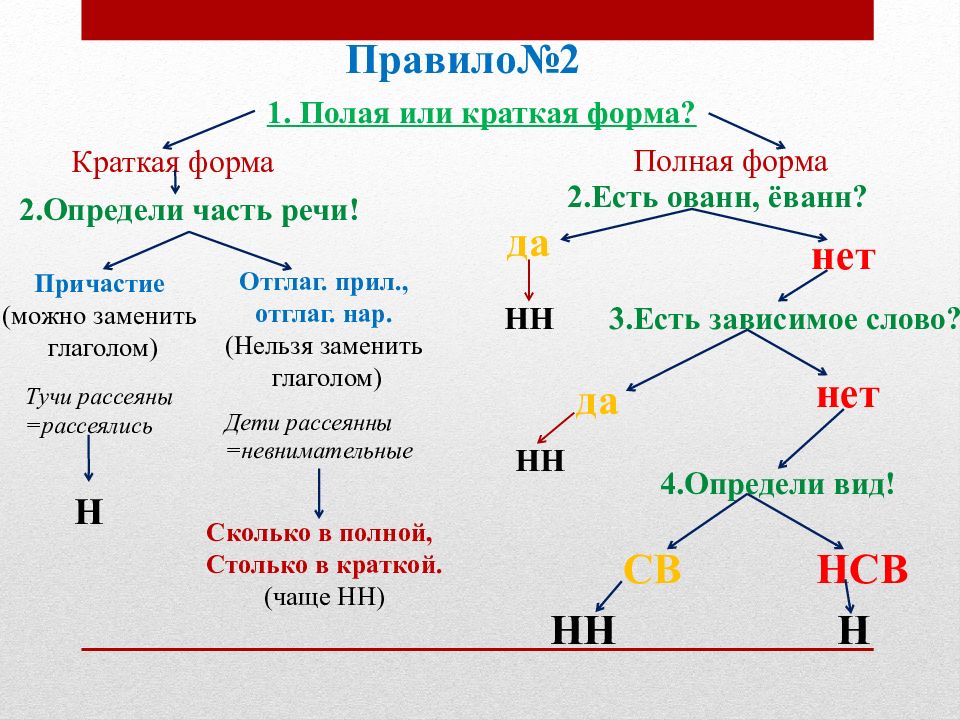
— Почему для написания букв н — нн в суффиксах прилагательных, причастий и наречий важно определить, какой частью речи является слово?
3. Работа по учебнику
1. Чтение и обсуждение материала для самостоятельных наблюдений (с. 18, 19).
2. Упр. 21 — комментированное письмо.
4. Творческий диктант
— Замените словосочетания “сущ. + сущ.” словосочетаниями “сущ. + прил.”, выделите суффиксы. Объясните правописание слов с орфограммами.
+ сущ.” словосочетаниями “сущ. + прил.”, выделите суффиксы. Объясните правописание слов с орфограммами.
Вой зверя, крыша из жести, пробежка по утрам, игрушка из олова, часы для ношения в кармане, погода осенью, шляпка из соломы, забор из камня, статуэтка из глины, напиток из лимона. (Звериный вой, жестяная крыша, утренняя пробежка, оловянная игрушка, карманные часы, осенняя погода, соломенная шляпка, каменный забор, глиняная статуэтка, лимонный напиток.)
5. Работа по учебнику
1. Упр. 22 — обсуждение заданий, самостоятельное выполнение.
2. Упр. 23 — комментированное письмо, выполнение задания.
Комментарии
В упр. 23 нет слов категории состояния, хотя в задании они упоминаются.
6. Тест
(См.: КИМы, тест 4.)
V. Подведение итогов урока
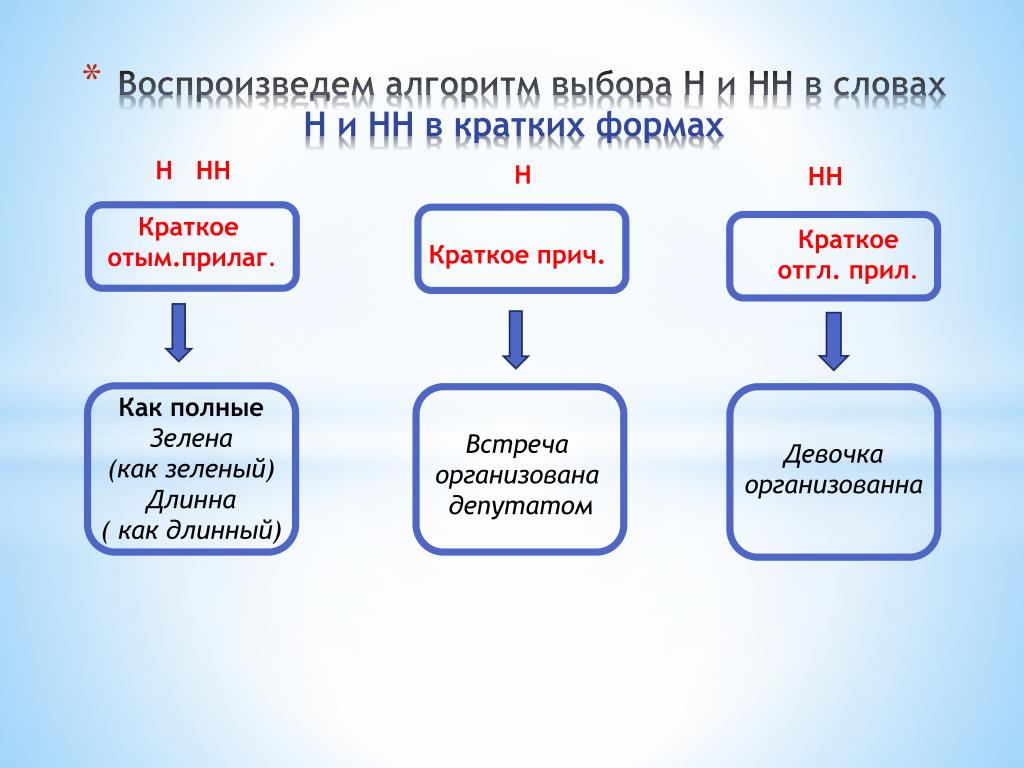
— Как отличить отглагольные прилагательные от страдательных причастий прошедшего времени?
— Сколько н пишется в полных причастиях?
— Сколько н пишется в кратких причастиях?
— В суффиксах каких отглагольных прилагательных пишется две н!
— От чего зависит выбор н и нн в суффиксах наречий?
Домашнее задание
1. Упр. 24.
Упр. 24.
2. Упр. 25, 26 (прочитать тексты).
Подготовка к ЕГЭ по русскому языку
Урок 1. Глагол как часть речи. Правописание глаголов. Разбор заданий ЕГЭ № 11, № 12.
Видео Тест
Урок 2. Причастие как форма глагола. Правописание причастий. Обособление определений. Разбор заданий ЕГЭ № 12, № 17
Видео Тест
Урок 3. Деепричастие как форма глагола. Правописание деепричастий. Обособление обстоятельств. Разбор заданий ЕГЭ № 13, № 17
Видео Тест
Урок 4. Наречие как часть речи. Правописание наречий. Разбор заданий ЕГЭ № 14
Видео Тест
Урок 5. Н и НН во всех частях речи. Разбор заданий ЕГЭ № 15
Видео Тест
Урок 6. Слова категории состояния. Переход одной части речи в другую.
Видео
Урок 7. Служебные части речи. Предлог. Правописание предлогов. Разбор заданий ЕГЭ № 14
Служебные части речи. Предлог. Правописание предлогов. Разбор заданий ЕГЭ № 14
Видео Тест
Урок 8. Союз. Правописание союзов. Разбор заданий ЕГЭ № 14
Видео Тест
Урок 9. Частица. Правописание частиц. Разбор заданий ЕГЭ № 14
Видео Тест
Урок 10. Слитное и раздельное написание НЕ с разными частями речи. Разбор заданий ЕГЭ № 13
Видео Тест
Урок 11. Междометие и звукоподражательные слова. Переход одной части речи в другую
Видео
Урок 12. Вводные и вставные конструкции. Обращения. Разбор заданий ЕГЭ № 18
Видео Тест
Урок 13. Понятие о простом и сложном предложении. Знаки препинания в предложениях с однородными членами. Пунктуация в сложносочинённом предложении. Разбор заданий ЕГЭ № 16
Видео Тест
Урок 14. Знаки препинания в сложноподчинённом предложении и в предложении с разными видами связи. Разбор заданий ЕГЭ № 19,№ 20
Знаки препинания в сложноподчинённом предложении и в предложении с разными видами связи. Разбор заданий ЕГЭ № 19,№ 20
Видео Тест
Урок 15. Знаки препинания в бессоюзном сложном предложении. Разбор заданий ЕГЭ № 21
Видео Тест
Автор и методист
Роман Анатольевич Дощинский, к.п.н., почётный работник образования г. Москвы, автор учебников и методических разработок по русскому языку.Русский язык, 7 класс
Рабочая тетрадь «Русский язык, 7 класс» предназначена для учителей и учащихся 7 классов школ, лицеев, гимназий. Тетрадь представляет собой электронный тренажер, предназначенный для выработки и закрепления знаний и умений по предмету, а также для промежуточной аттестации учащихся в ходе электронных четвертных работ. Рабочая тетрадь состоит из интерактивных заданий, проверка которых производится автоматически – компьютером.
Рабочая тетрадь входит в состав интерактивного мультимедийного учебно-методического комплекса «Облако знаний»; результаты работы с рабочей тетрадью хранятся на облачном сервере проекта.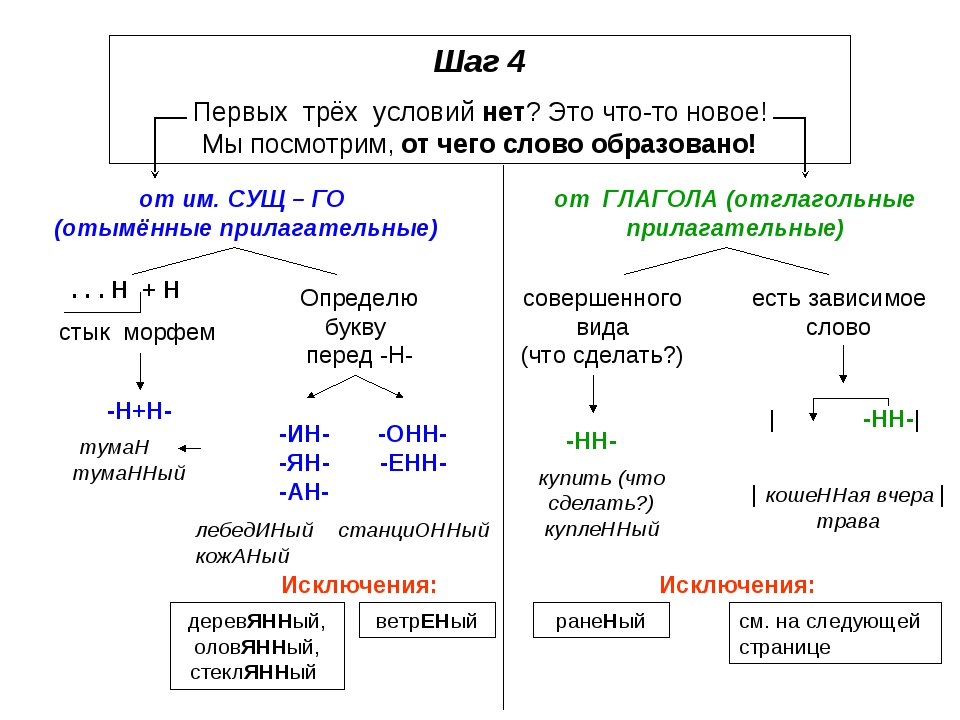
Содержание рабочей тетради :
-
1. Местоимение
-
1.1. Местоимение как часть речи;
1.2. Разряды местоимений;
1.3. Склонение местоимений разных разрядов;
1.4. Правописание местоимений с частицами «то», «либо», «нибудь», «кое»;
1.5. Правописание «не» и «ни» с отрицательными местоимениями.
2. Наречие
Наречие
-
2.1. Наречие как часть речи;
2.2. Степени сравнения наречий;
2.3. Основные способы образования наречий;
2.4. «НЕ» и «НИ» с наречиями;
2.5. «О», «е» на конце наречий;
2.6. «Н» и «НН» в суффиксах наречий;
2.7. Суффиксы «о», «а» на конце наречий;
2.8. Дефис в наречиях;
2.9. «Ь» после шипящих на конце наречий.
3. Категории состояний-
3.1. Категория состояния как часть речи;
3.2. Группы категорий состояния по значению;
3.3. Синтаксическая роль слов категорий состояния.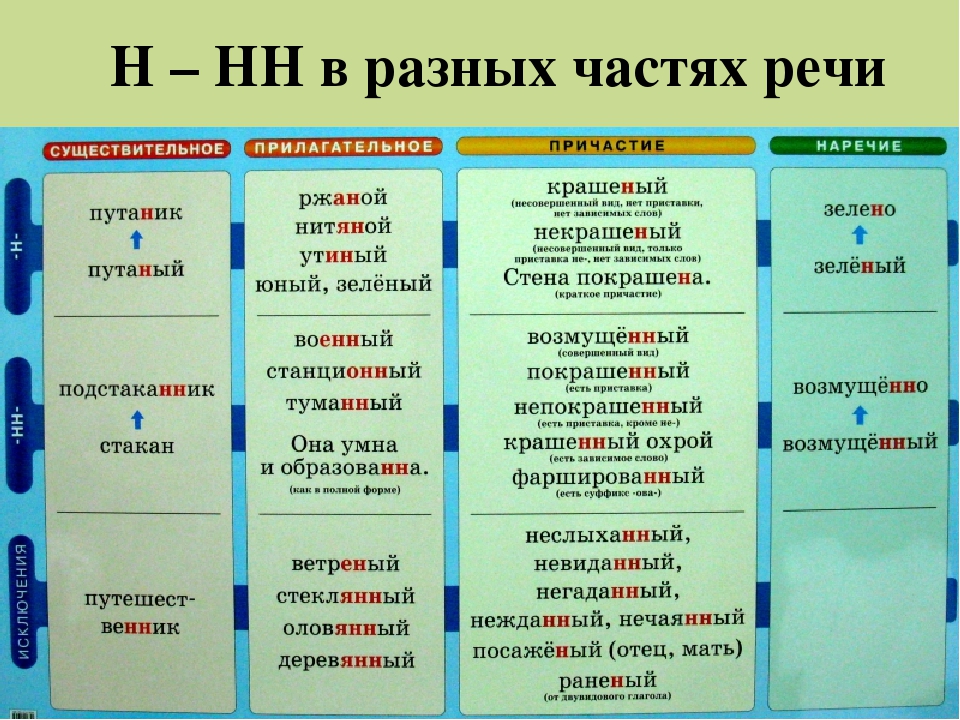
4. Причастие-
4.1. Причастие как часть речи;
4.2. Признаки прилагательного и глагола у причастия;
4.3. Словообразование действительных причастий;
4.4. Словообразование страдательных причастий;
4.5. Причастный оборот;
4.6. Гласные перед «Н» и «НН» в причастиях;
4.7. Правописание «Н» и «НН» в причастиях;
4.8. «НЕ» с причастиями.
5. Деепричастие-
5.
 1. Деепричастие как часть речи;
1. Деепричастие как часть речи;
5.2. Признаки глагола и наречия у деепричастия;
5.3. Деепричастный оборот;
5.4. Словообразование деепричастий.
6. Служебные части речи-
6.1. Понятие о служебных частях речи;
6.2. Функциональные особенности служебных частей речи;
7. Предлог-
7.1. Предлог как часть речи;
7.2. Правописание предлогов;
7.3. Употребление предлогов.
8. Союз
Союз
-
8.1. Союз как часть речи;
8.2. Сочинительные союзы;
8.3. Подчинительные союзы;
8.4. Правописание союзов;
8.5. Слитные и раздельные написания союзов;
8.6. Правописание союзов «зато», «тоже», «также».
9. Частица-
9.1. Частица как часть речи;
9.2. Значения частиц;
9.3. Различение на письме частиц «не» и «ни»;
9.4. Правописание «не» и «ни» с различными частями речи.
10. Междометие
Междометие
-
10.1. Понятие и синтаксическая роль междометий;
10.2. Знаки препинания при междометьях;
10.3. Звукоподражательные слова;
10.4. Правописание междометий.
11. Переход слов из одной части речи в другую-
11.1. Образование слов путем перехода из самостоятельной речи в другую;
11.2. Образование слов путем перехода из самостоятельной части речи в служебную.
-
1.1. Местоимение как часть речи;
В рабочей тетради по каждому параграфу учебной программы представлены 5–10 интерактивных заданий, например тренажер по деепричастию. Помимо этого тетрадь содержит тематические контрольные работы, в которых обобщается и проверяется материал по разделам, пройденным в течение учебной четверти.
Помимо этого тетрадь содержит тематические контрольные работы, в которых обобщается и проверяется материал по разделам, пройденным в течение учебной четверти.
Тетрадь содержит около 290 разноплановых интерактивных заданий (на установление соответствия, заполнение таблиц, упорядочивание и распределение по группам, выбор варианта ответа, ввод численного или строкового ответа, установление связей, указание объекта на рисунке, синтаксический разбор предложения, морфемный разбор слова), сгруппированных
- в 11 разделов учебной программы 7 класса;
- в 4 контрольные тематические работы в двух вариантах каждая.
Перечень контрольных работ:
- Местоимение. Наречие. Категории состояния,
- Причастие. Деепричастие,
-
Предлог.
 Союз,
Союз,
- Частица. Междометие. Переход слов из одной части речи в другую.
Содержание курса соответствует федеральному государственному образовательному стандарту основной школы по русскому языку и примерной программе общеобразовательных учреждений России.
Комплектация продукта:
для ПК:
- приложение для ПК в составе:
- плеер «Облако знаний»,
- рабочая тетрадь по русскому языку для 7 класс,
- индивидуальная лицензия или лицензия на образовательное учреждение.
для СДО:
- рабочая тетрадь по русскому языку для 7 класса в формате SCORM 2004 (ZIP-архив),
- лицензия на образовательное учреждение;
для iPad:
- приложение-плеер «Облако знаний»,
-
рабочая тетрадь по русскому языку для 7 класса.
для Android:
- приложение-плеер «Облако знаний»,
- рабочая тетрадь по русскому языку для 7 класса.
Минимальные системные требования для версии курса для ПК:
Работа с курсом на персональном компьютере возможна как с помощью веб-плеера, функционирующего под управлением веб-браузера, так и с помощью автономного приложения-плеера «Облако знаний». Требования к программному окружению плееров:
Веб-плеер:
Автономный плеер:
- Windows 7/8 + Microsoft Internet Explorer 10/11.
Минимальные требования к видеосистеме: 1024 × 768 пикселей (рекомендуемое разрешение – 1200 × 900 пикселей, цветность системы – не менее 16 миллионов цветов).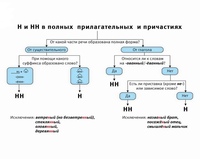
Требования по системам ввода: клавиатура и мышь для персонального компьютера.
Ширина интернет канала 64 кБ/с.
Минимальные системные требования для планшетной версии курса:
Плеер для планшетного компьютера функционирует под следующими платформами:
- iOS 6 и выше;
- Android 4.1 и выше.
Минимальные требования к видеосистеме: 1024 × 768 пикселей (рекомендуемое разрешение – 1200 × 900 пикселей).
Требования по системам ввода: сенсорный экран с виртуальной клавиатурой.
Ширина интернет канала 64 кБ/с.
Минимальные системные требования для SCORM-версии курса:
для клиента:
операционная система Microsoft Windows XP/Vista/7/8; процессор Pentium 4 или аналогичный; 512 МБ оперативной памяти; разрешение экрана 1024 × 768 с глубиной цвета 16 бит; Microsoft Internet Explorer 9/10/11;
для сервера: система управления обучением (LMS), соответствующая сертификационным требованиям SCORM 2004 LMS-RTE3, канал связи с пропускной способностью от 1024 кБ/с на пользователя.
Контрольная работа по теме «Деепричастие», «Наречие», «Категория состояния»
kr.docxВариант №1
1. С каким словом НЕ пишется слитно?
а) (не)спится
б) (не)громко
в) (не)прочитав
г) (не)по-летнему
2. В каком наречии на месте пропуска пишется буква А?
а) досрочн..
б) измученн..
в) искос..
г) влев..
3. Определите, какое слово является наречием.
а) дружно
б) кремом
в) боковой
г) убегая
4. В каком слове ударение падает на последний слог?
а) досиня
б) до смерти
в) запросто
г) дотемна
5. В каком наречии на месте пропуска пишется буква и?
а) торопиться н…зачем
б) н…откуда ждать помощи
в) не уйдёшь н…куда
г) н…где остановиться
6. В каком предложении допущена речевая ошибка?
В каком предложении допущена речевая ошибка?
а) Утреннее солнце греет бережно и ласково.
б) В этом месте речка была перегорожена огромным валуном.
в) Сегодня обратно пошел дождь.
г) Кое-где попадается и белый гриб.
7. В какой строке на месте пропуска в каждом слове пишется Ь?
а) рож.., горяч.., береч.., вскач…
б) отреж.., навзнич.., мыш.., невтерпеж…
в) тиш.., печеш.., товарищ.., замуж…
г) реч.., наотмаш.., стрич.., съеш…
8. Укажите, к какой части речи принадлежит слово «лучше»:
а) Мне уже лучше, чем вчера. _______________________________________
б) Положение наше лучше, чем у них. ________________________________
в) Эту работу он сделал лучше. _____________________________________
II. Прочитайте текст и выполните задания.
(1)Ещё нигде не румянилась заря, но уже забелелось на востоке… (2)Кое-где стали раздаваться живые звуки, голоса, и жидкий, ранний ветерок пошёл бродить и порхать над землёю.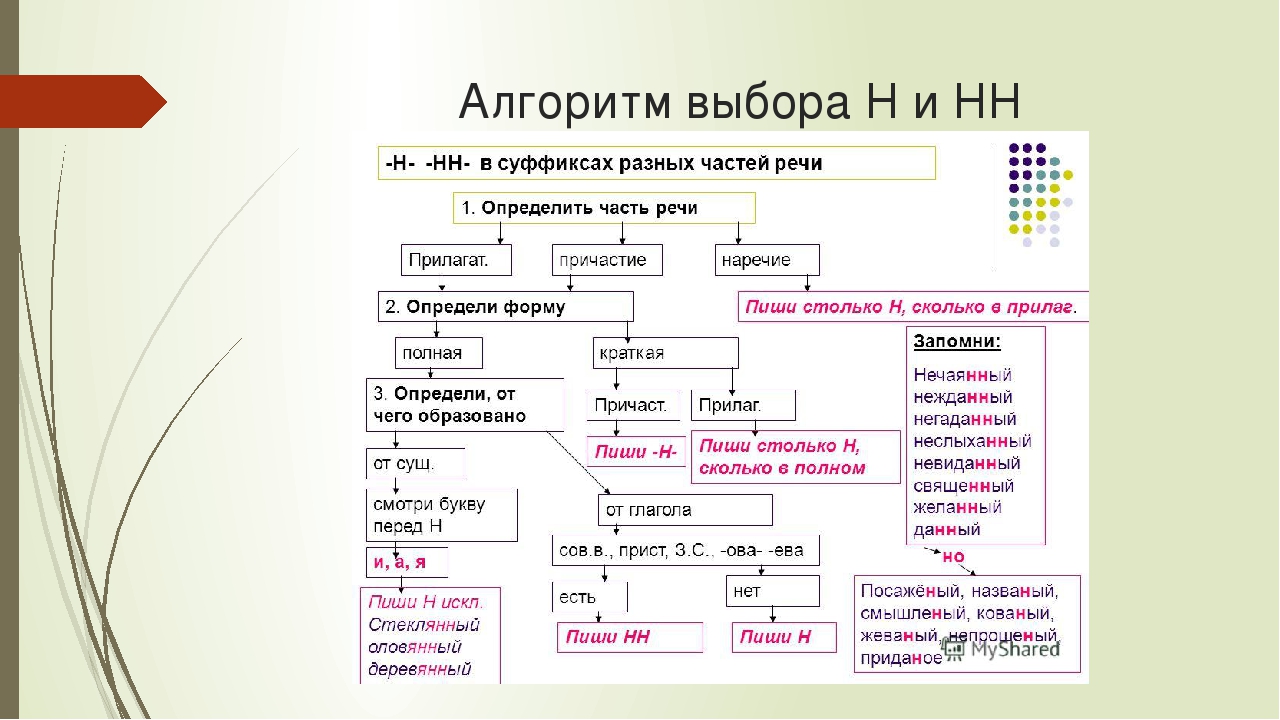 (3)Я, проворно встав, подошёл к мальчикам.
(3)Я, проворно встав, подошёл к мальчикам.
1. Из предложения (1) выпишите слово категории состояния.
2. Из предложения (2) выпишите наречие.
3. Из предложения (3) выпишите неизменяемые части речи.
III. Напишите сочинение-рассуждение на тему : «Нужно ли читать книги вслух в кругу семьи ?»
Ответы
I.
1 б
2 в
3 а
4 г
5 в
6 в
7 г
8.
КС
КР.ПРИЛ
НАРЕЧ
II.
ЗАБЕЛЕЛОСЬ
КОЕ-ГДЕ
ПРОВОРНО
ВСТАВ
МАОУ «Гимназия № 96 г. Челябинска»
Экзаменационные билеты
по русскому языку
для проведения промежуточной аттестации в 7-х классах
2008 – 2009 учебный год
Билет 1
1. Правописание гласных в корне
— проверяемые безударные гласные;
— непроверяемые гласные в корне;
— чередующиеся гласные в корне слова.
2. Анализ текста.
Билет 2
1. Правописание согласных в корне
Правописание согласных в корне
— непроизносимые согласные;
— звонкие и глухие согласные.
— двойные согласные.
2. Анализ текста.
Билет 3
— неизменяемые приставки;
— приставки на –З и – С;
— приставки ПРЕ- и ПРИ-;
— гласные Ы и И после приставок на согласную.
2. Анализ текста.
Билет 4
2. Анализ текста.
Билет 5
2. Анализ текста.
Билет 6
2. Анализ текста.
Билет 7
2. Анализ текста.
Билет 8

2. Анализ текста.
Билет 9
2. Анализ текста.
Билет 10
1. Имя числительное как часть речи;
— правописание числительных;
— склонение количественных числительных;
— употребление числительных.
2. Анализ текста.
Билет 11
1. Местоимение как часть речи;
— разряды местоимений;
— правописание местоимений.
2. Анализ текста.
Билет 12
2. Анализ текста.
Билет 13
2. Анализ текста.
Билет 14
2. Анализ текста.
Билет 15
 Слитное и раздельное написание НЕ с причастиями. Причастный оборот. Выделение причастных оборотов запятыми.
Слитное и раздельное написание НЕ с причастиями. Причастный оборот. Выделение причастных оборотов запятыми. 2. Анализ текста.
Билет 16
2. Анализ текста.
Билет 17
2. Анализ текста.
Билет 18
2. Анализ текста.
Билет 19
2. Анализ текста.
Билет 20
1. Частица как часть речи. Разряды частиц. Правописание частиц.
2. Анализ текста.
Билет 21
1. Отрицательные частицы НЕ и НИ. Частица НИ, Приставка НИ, союз НИ – НИ.
Билет 22
 Н-НН в различных частях речи.
Н-НН в различных частях речи.2. Анализ текста.
Билет 23
2. Анализ текста.
Билет 24
2. Анализ текста.
Билет 25
2. Анализ текста.
Презентация «Слово категории состояния»
(С)начала сентября воздух начинает (по)немногу холодеть. Утром вы замечаете, что трава (чуть)чуть побелела. Свеж… Лужи сплош… засыпа(н,нн)ы листьями. (По)осеннему мелкие дожди совсем (не)похожи на летние: они идут бе..преста(н,нн)о, и земля (не)просыхает скоро. Ветер дует
(С)начала сентября воздух начинает (по)немногу холодеть. Утром вы замечаете, что трава (чуть)чуть побелела. Свеж… Лужи сплош… засыпа(н,нн)ы листьями. (По)осеннему мелкие дожди совсем (не)похожи на летние: они идут бе..преста(н,нн)о, и земля (не)просыхает скоро. Ветер дует
(без)устали, разнося (далеко)далеко созревшие сем. .на дерев..ев. Листья на дерев..ях нач..нают (кое)где желтеть. Поля (мало)помалу желтеют, лиш…(по)прежнему зеленеет озимь.
Словарный диктант
.на дерев..ев. Листья на дерев..ях нач..нают (кое)где желтеть. Поля (мало)помалу желтеют, лиш…(по)прежнему зеленеет озимь.
Словарный диктант
Тихо ответили жители, тихо проехал обоз. Тихо ответили жители, тихо проехал обоз. Тихо в темной деревне. Одинакова ли синтаксическая роль?
СТС
Слово категории состояния (СКС) как? каково?
Слово категории состояния (СКС) как? каково?
категория состояния группы по значению состояние природы состояние человека оценка состояния В джунглях было сыро, душно. А на душе необъятно и чудно… Над старостью смеяться грех. Надо жизнь сначала переделать…
И скучно, и грустно, и некому руку подать.
И скучно, и грустно, и некому руку подать.
В минуту душевной невзгоды…
Шалун уж заморозил пальчик:
Ему и больно, и смешно. А мать грозит ему в окно.
Да, можно выжить в зной, в грозу, в морозы,
Да, можно голодать и холодать,
Идти на смерть…
Но эти три березы
При жизни никому нельзя отдать.
Найдите СКС, что они обозначают?
А мать грозит ему в окно.
Да, можно выжить в зной, в грозу, в морозы,
Да, можно голодать и холодать,
Идти на смерть…
Но эти три березы
При жизни никому нельзя отдать.
Найдите СКС, что они обозначают?
2. Морфологические признаки: 1. Постоянные – неизменяемость Стало теплее. В маленькой комнате стало теплее всего.
3. Синтаксическая роль в предложении: Темно. Душно. Светло.
не путать!
Слова категории состояния
Наречия
Краткие прилагательные
Как здесь
тихо!
Он говорил
тихо.
Озеро тихо.
.
как?
каково?
СКС
наречие
кр. прил.
каково?
прил.
каково?
Хоть тяжело подчас в ней бремя, телега на ходу легка… И тяжело Нева дышала, как с битвы прибежавший конь. «Эй! Пошёл, ямщик!..» — «Нет мочи: коням, барин, тяжело…» Задание 1 скс . . наречие кр. прил. (каково?) (как?) (каково?) +
Зимой без снега скучно. Зимой без снега скучно. Это стихотворение длинно и скучно, как и все, что он пишет. Он пишет длинно и скучно.
Сегодняшнее утро как никогда солнечно. Сегодняшнее утро как никогда солнечно. Ее глаза светились радостно и солнечно. С утра было солнечно, но после обеда заморосил холодный и нудный дождь.
1. Деревья слабо шумят, отлитые тенью.
Вам холодно немножко, вы закрываете
лицо воротником шинели, вам дремлется.
3. Голова томно кружится от избытка благоуханий. 4. Вот уже жарко стало, быстро сохнет трава.
5. Кругом ещё ярко светит солнце.
6. Но вот слабо сверкнула молния.
7. Боже мой, как весело сверкает всё кругом!
4. Вот уже жарко стало, быстро сохнет трава.
5. Кругом ещё ярко светит солнце.
6. Но вот слабо сверкнула молния.
7. Боже мой, как весело сверкает всё кругом!
: что это значит?
Марка автомобиля — это марка транспортного средства, а модель относится к названию автомобильного продукта, а иногда и к ряду продуктов.
Например, Toyota — это марка автомобиля, а Camry — модель автомобиля.
Марка, модель, год выпуска, тип кузова и уровень отделки салона — все это влияет на стоимость автомобиля и его страховые тарифы.
Отличия автомобилей одной модели
Автомобили одной и той же модели могут сильно различаться по типу кузова и уровню отделки салона.Часто просто знать модель автомобиля может быть недостаточно, чтобы правильно идентифицировать автомобиль, когда:
Варианты кузова
Автопроизводители могут выпускать определенную модель автомобиля с несколькими вариантами кузова. Например, вы можете купить Honda Civic 2018 года в кузове седан, купе или хэтчбек. Вот некоторые из наиболее распространенных типов кузова:
Например, вы можете купить Honda Civic 2018 года в кузове седан, купе или хэтчбек. Вот некоторые из наиболее распространенных типов кузова:
Тип кузова определяет общую форму автомобиля, количество дверей и механическую настройку, такую как двигатель, трансмиссия и трансмиссия.Форма кузова может быть самым важным отличием автомобиля, потому что он оказывает большое влияние на то, как лучше всего использовать автомобиль.
{«backgroundColor»:»серый»,»content»:»\u003C\/p\u003E\n\n\u003Ch4\u003EСтили кузова\u003C\/h4\u003E\n\n\u003Cp\u003EПроизводители автомобилей могут сделать определенной модели автомобиля с несколькими вариантами кузова. Например, вы можете купить Honda Civic 2018 года в кузове седан, купе или хэтчбек. Вот некоторые из наиболее распространенных типов кузова:\u003C\/p\u003E\n\n \u003Cp\u003E\u003Cdiv class=\»ShortcodeList—root\»\u003E\n\n \u003Cdiv class=\»ShortcodeList—content ShortcodeList—content-margin\»\u003E\n \u003Cdiv class=\» ShortcodeList—column\»\u003E\n \u003Cul class=\»ListUnordered—root ListUnordered—bullet\»\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n Coupe\ n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n Седан\n \u003C\/li\u003E\n \u003C\/ul\u003E\n \ u003C\/div\u003E\n \u003Cdiv class=\»ShortcodeList—column\»\u003E\n \u003Cul class=\»ListUnordered—root ListUnordered—bullet\» \u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n Hatchback\n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E \n Конвертируемый\n \u003C\/li\u003E\n \u003C\/ul\u003E\n \u003C\/div\u003E\n \u003Cdiv class=\»ShortcodeList—столбец\»\u003E\n \u003Cul class=\»ListUnordered—root ListUnordered—bullet\»\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n Вагон\n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n SUV\n \u003C\/li\u003E\n \u003C\/ul\u003E\n \u003C\/div\u003E\n \u003C\/ div\u003E\n\u003C\/div\u003E\n\n\u003C\/p\u003E\n\n\u003Cp\u003EТип кузова сообщает об общей форме автомобиля, количестве дверей и механической настройке, такой как двигатель , трансмиссия и ходовая часть.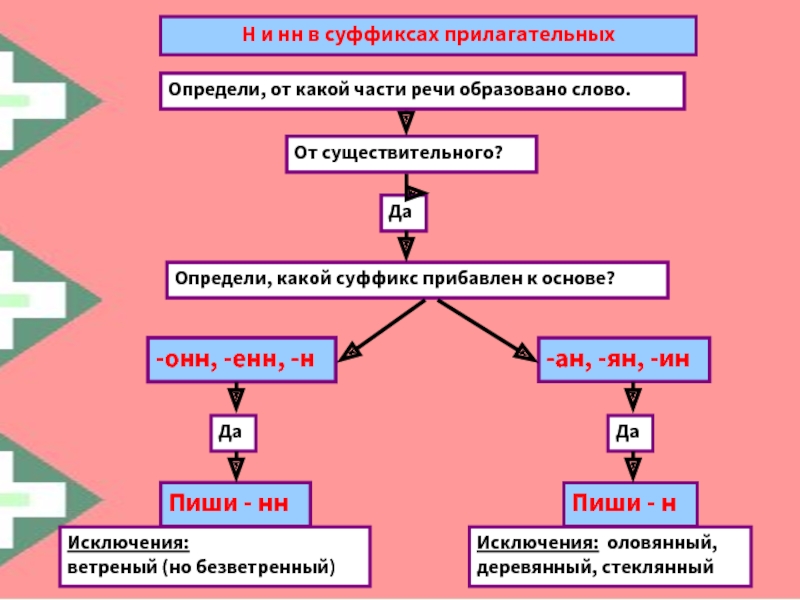 Форма кузова может быть самым важным отличием автомобиля, поскольку от него зависит, как лучше всего использовать автомобиль.\n»,»padding»:»double»}
Форма кузова может быть самым важным отличием автомобиля, поскольку от него зависит, как лучше всего использовать автомобиль.\n»,»padding»:»double»}
Комплектация
Помимо вариантов кузова, производитель автомобилей может предложить несколько вариантов отделки для данной модели. Уровни отделки салона относятся к оборудованию и стилю конкретного автомобиля.
Например, седан Honda Civic 2018 года имеет шесть различных комплектаций:
Общие уровни отделки салона:
- Стандарт: без обновлений.
- Sport: улучшенные характеристики двигателя и управляемость.
- Luxury: модернизированный салон и более плавная подвеска.
Некоторые автомобили имеют буквенно-цифровые обозначения, которые могут затруднить определение разницы между названием модели и комплектацией автомобиля.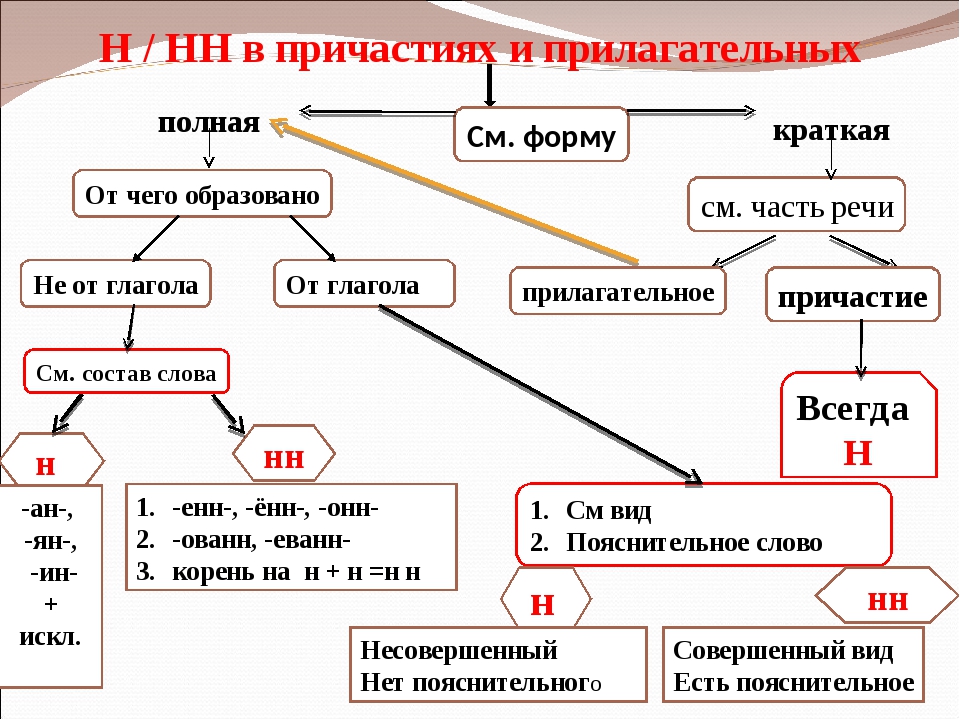 BMW, Mercedes и Lexus практикуют эти соглашения об именах.
BMW, Mercedes и Lexus практикуют эти соглашения об именах.
Для этих автомобилей необходимо расшифровать название автомобиля, чтобы найти название модели и пакет отделки салона.
Например, рассмотрим BMW 540i 2018 года. В «540i» первая цифра указывает на то, что модель относится к 5-й серии, а 40i указывает на уровень отделки салона.
{«backgroundColor»:»серый»,»content»:»\u003C\/p\u003E\n\n\u003Ch4\u003EУровни обрезки\u003C\/h4\u003E\n\n\u003Cp\u003EВ дополнение к стилям кузова , производитель автомобилей может предложить несколько вариантов отделки для данной модели. Уровни отделки салона зависят от оборудования и стиля конкретного автомобиля.\u003C\/p\u003E\n\n\u003Cp\u003EНапример, Honda Civic седан 2018 года имеет шесть различных параметров уровня отделки: \ u003C\/p\u003E\n\n\u003Cp\u003E\u003Cdiv class=\»ShortcodeList—root\»\u003E\n\n \u003Cdiv class=\»ShortcodeList— content ShortcodeList—content-margin\»\u003E\n \u003Cdiv class=\»ShortcodeList—column\»\u003E\n \u003Cul class=\»ListUnordered—root ListUnordered—bullet\»\u003E\n \ u003Cli class=\»ListUnordered—list-item\»\u003E\n LX\n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n EX\n \u003C\/li\u003E\n \u003C\/ul\u003E\n \u003C\/div\u003E\n \u003Cdiv class=\»ShortcodeList—column\»\u003E\n \ u003Cul class=\»ListUnordered—root ListUnordered—bullet\»\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n EX-T\n \u003C\/li\u003E\ n \u003Cli class=\»ListUnordered—list-item\»\u003E\n EX-L\n \u003C\/li\u003E\n \u003C\/ul\u003E\n \u003C\/div\u003E\ n \u003Cdiv class=\»ShortcodeList—column\»\u003E\n \u003Cul class=\»ListUnordered—root ListUnordered—bullet\»\u003E\n \u003Cli class=\»ListUnordered—list-item\ «\u003E\n Si\n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n Touring\n \u003C\/li\u003E\n \u003C\ /ul\u003E\n\u003C\/div\u003E\n\u003C\/div\u003E\n\u003C\/div\u003E\n\n\u003C\/p\u003E\n\n\u003Cp\u003ECommon уровни отделки салона:\u003C\/p\u003E\n\n\u003Cp\u003E\u003Cdiv class=\»ShortcodeList—root\»\u003E\n\n \u003Cdiv class=\»ShortcodeList—content\»\ u003E\n \u003Cdiv class=\»ShortcodeList—column\»\u003E\n \u003Cul class=\» ListUnordered—root ListUnordered—bullet\»\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n \u003Cstrong\u003EStandard:\u003C\/strong\u003E без обновлений. \n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n \u003Cstrong\u003ESport:\u003C\/strong\u003E повышена производительность и управляемость двигателя.\n \ u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n \u003Cstrong\u003ELuxury:\u003C\/strong\u003E модернизированный интерьер и более плавная подвеска.\n \u003C\/ li\u003E\n\u003C\/ul\u003E\n\u003C\/div\u003E\n\u003C\/div\u003E\n\u003C\/div\u003E\n\n\u003C\/p\u003E \n\n\u003Cp\u003E\u003Cdiv class=\»ShortcodeBorder—root ShortcodeBorder—with-padding\»\u003E\u003C\/p\u003E\n\n\u003Cp\u003EНекоторые транспортные средства имеют буквенно-цифровые соглашения об именах, которые могут затрудняют определение разницы между названием модели и комплектацией автомобиля.BMW, Mercedes и Lexus практикуют эти соглашения об именах. p\u003E\n\n\u003Cp\u003EНапример, рассмотрим BMW 540i 2018 года. В «540i» первая цифра указывает на то, что модель относится к 5-й серии, а 40i указывает на уровень отделки салона. \n\u003C\/div\u003E\n»,»padding»:»двойной»}
\n \u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n \u003Cstrong\u003ESport:\u003C\/strong\u003E повышена производительность и управляемость двигателя.\n \ u003C\/li\u003E\n \u003Cli class=\»ListUnordered—list-item\»\u003E\n \u003Cstrong\u003ELuxury:\u003C\/strong\u003E модернизированный интерьер и более плавная подвеска.\n \u003C\/ li\u003E\n\u003C\/ul\u003E\n\u003C\/div\u003E\n\u003C\/div\u003E\n\u003C\/div\u003E\n\n\u003C\/p\u003E \n\n\u003Cp\u003E\u003Cdiv class=\»ShortcodeBorder—root ShortcodeBorder—with-padding\»\u003E\u003C\/p\u003E\n\n\u003Cp\u003EНекоторые транспортные средства имеют буквенно-цифровые соглашения об именах, которые могут затрудняют определение разницы между названием модели и комплектацией автомобиля.BMW, Mercedes и Lexus практикуют эти соглашения об именах. p\u003E\n\n\u003Cp\u003EНапример, рассмотрим BMW 540i 2018 года. В «540i» первая цифра указывает на то, что модель относится к 5-й серии, а 40i указывает на уровень отделки салона. \n\u003C\/div\u003E\n»,»padding»:»двойной»}
Модельный год
Модельный год автомобиля является одним из основных способов дифференциации автомобилей одной марки и модели. Однако год выпуска автомобиля не обязательно совпадает с годом его выпуска. Важно отметить, что стоимость автострахования меняется с возрастом автомобиля.
Однако год выпуска автомобиля не обязательно совпадает с годом его выпуска. Важно отметить, что стоимость автострахования меняется с возрастом автомобиля.
Обычно вы можете приобрести автомобиль определенного модельного года за несколько месяцев до фактического начала календарного года. Например, Honda Civic 2018 года была доступна для покупки с конца лета 2017 года.
{«backgroundColor»:»серый»,»content»:»\u003C\/p\u003E\n\n\u003Ch4\u003EМодельный год\u003C\/h4\u003E\n\n\u003Cp\u003EМодельный год Автомобиль является одним из основных способов дифференциации автомобилей одной марки и модели.Однако год выпуска автомобиля не обязательно совпадает с годом его выпуска. Важно отметить, что \u003Cspan\u003E\u003Ca class=\»ShortcodeLink—root ShortcodeLink—black\» title=\»Как стоимость автострахования меняется с возрастом автомобиля\» href=\»https:\ //www.valuepenguin.com\/how-cost-of-car-insurance-changes-with-age-of-car\»\u003Стоимость автострахования меняется с возрастом автомобиля\u003C\/a\u003E \u003C\/span\u003E.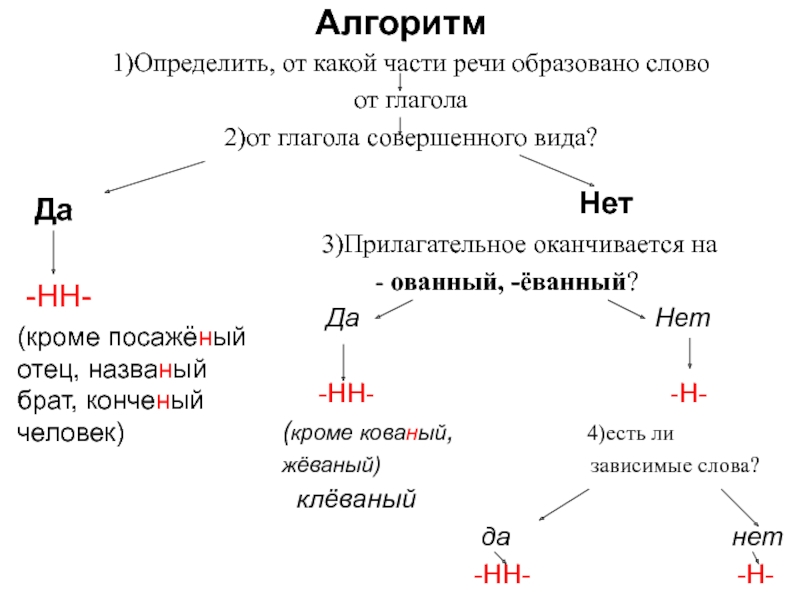 \u003C\/p\u003E\n\n\u003Cp\u003EКак правило, вы можете приобрести автомобиль для данного модельного года за несколько месяцев до фактического начала календарного года.Например, Honda Civic 2018 года была доступна для покупки с конца лета 2017 года.\n»,»padding»:»double»}
\u003C\/p\u003E\n\n\u003Cp\u003EКак правило, вы можете приобрести автомобиль для данного модельного года за несколько месяцев до фактического начала календарного года.Например, Honda Civic 2018 года была доступна для покупки с конца лета 2017 года.\n»,»padding»:»double»}
Как узнать марку и модель автомобиля?
Марка, модель и комплектация автомобиля часто обозначаются значками, эмблемами или наклейками, расположенными на задней части автомобиля.
Это самый простой способ определить марку и модель вашего автомобиля. Если у вас возникли проблемы с определением марки или модели вашего автомобиля путем осмотра автомобиля снаружи, вы можете найти его в свидетельстве о регистрации автомобиля или в руководстве по эксплуатации.
Вы можете использовать свой идентификационный номер автомобиля (VIN), чтобы найти информацию о своем автомобиле, такую как характеристики оборудования, модельный год и даже завод, на котором он был изготовлен. Найдите свой VIN на приборной панели со стороны водителя.
- С 1981 модельного года они были 17-значными.
- Затем вы можете использовать инструмент отслеживания VIN для поиска информации о вашем автомобиле.
Различия между марками автомобилей одного производителя
У производителей может быть несколько разных марок — или марок — автомобилей, которые они производят.Toyota Motor Corp., например, имеет несколько различных марок автомобилей, включая Toyota, Scion и Lexus.
Когда вас спросят о марке вашего автомобиля, вы должны указать марку автомобиля.
Таким образом, хотя ваш Scion может быть произведен Toyota Motor Corp., было бы неверным сказать, что это Toyota.
Автомобильные компании иногда имеют разные бренды, потому что они купили или объединились с другими производителями автомобилей. Например, General Motors Corp.с годами приобрела Chevrolet, Buick и Cadillac.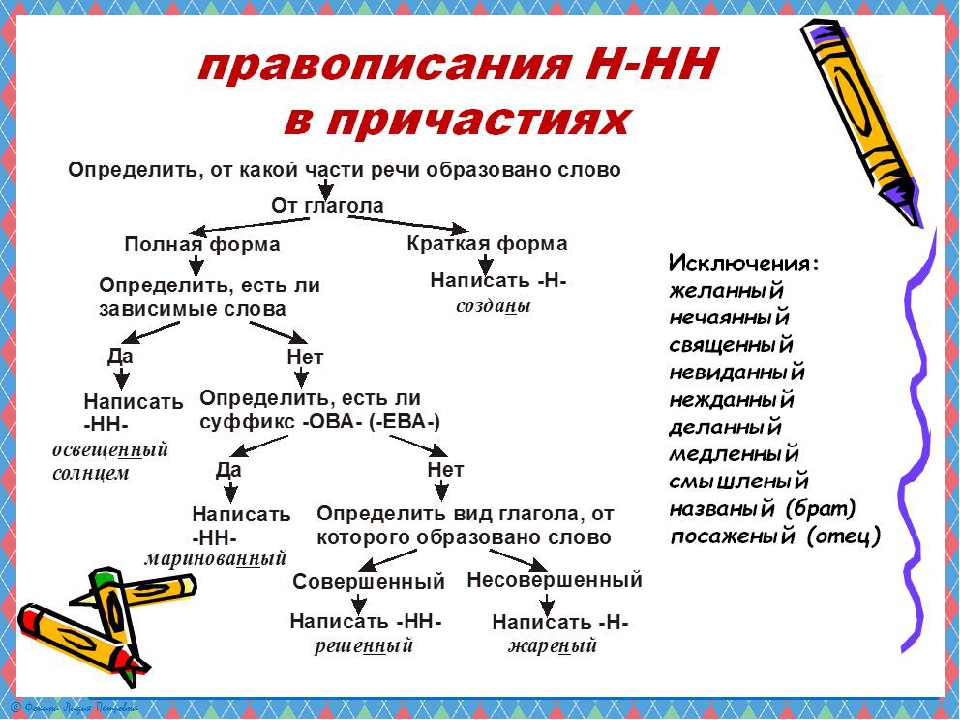 Все они когда-то были автономными производителями автомобилей.
Все они когда-то были автономными производителями автомобилей.
Производители также могут создавать отдельные бренды для разных рынков. Например, Toyota Motor Corp. создала Lexus, чтобы сосредоточиться на рынке роскошных автомобилей.
Когда марка и модель вашего автомобиля имеют значение?
Модель транспортного средства влияет на стоимость вашего автомобиля, поэтому вам следует это знать, если вы планируете продать свой автомобиль или купить новый.
Автомобили одной марки с одним и тем же типом кузова могут иметь совершенно разную стоимость, поэтому просто знать, что у вас есть седан Toyota или вы ищете его, недостаточно.
Например, ниже мы указываем рекомендованную производителем розничную цену на два седана Toyota 2018 года выпуска.
Помимо модели, на стоимость автомобиля влияет тип кузова и комплектация. Рекомендованная производителем розничная цена (MSRP) автомобилей одной и той же марки и модели может отличаться на тысячи долларов в зависимости от типа кузова и уровня отделки салона.
Как вы можете видеть ниже, Honda Civics с одинаковыми уровнями отделки салона могут отличаться на 1950 долларов в зависимости от типа кузова. Кроме того, Civic с одинаковым типом кузова, но разными уровнями отделки салона, различались на целых 8600 долларов.
| 2018 Honda Civic LX | SEDAN | $ 18 840104 | $ 1,6840104 | $ 1,688 | $ 1,688 |
| 2018 Honda Civic LX | 20050 | 1 727 | |||
| 2018 Honda Civic EX | SEDAN | 21,240 | 1,727 | ||
| 2018 Honda Civic ex | Hatchbob | 23,150 | 1,762 | ||
| 2018 Honda Civic Touring | Sedan | 26 700 | |||
| 2018 Honda Civic Sport Touring | Hatchback | 28 650 | 1 850 |
Как марка автомобиля влияет на стоимость автострахования?
Марка и модель вашего автомобиля также влияют на тарифы автострахования.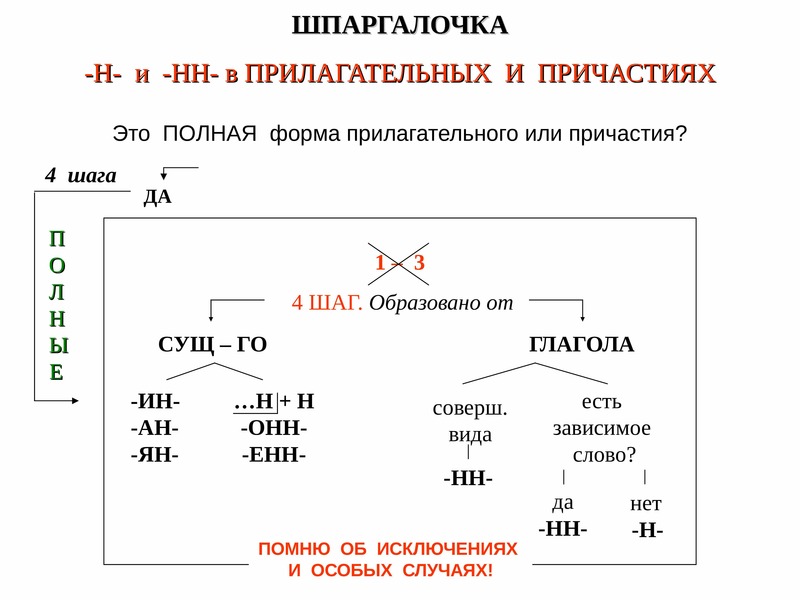 Отчасти это связано с тем, что тарифы на комплексное покрытие и страховое покрытие основаны на стоимости вашего автомобиля.
Отчасти это связано с тем, что тарифы на комплексное покрытие и страховое покрытие основаны на стоимости вашего автомобиля.
Ниже мы приводим среднегодовые ставки страховых расходов по маркам автомобилей, ранжированные от самых дешевых до самых дорогих.
| 1 | Хонда | $ 2736 | ||
| 2 | GMC | $ 2785 | ||
| 3 | Chrysler | $ 2842 | ||
| 4 | Шевроле | $ 2890 | ||
| 5 | KIA | $ 2,907 | $ 2,907 | |
| Toyota | $ 2913 | $ 2913 | 7 | $ 2 998|
| 8 | Dodge | $ 3,006 | ||
| 9 | Ford | $ 3,036 | ||
| 10 | Volkswagen | $ 3,109 | $ 3,109 | |
| 11 | Nissan | $ 3,153 | ||
| 12 | Jeep | $ 3,347 |
- При установлении премий страховщики также учитывают, как часто водители с моделью и типом кузова вашего автомобиля подают заявления о страховании ответственности.

- Чем больше претензий подается к конкретному автомобилю, тем более рискованным он представляется в глазах страховщика.
- Ваш страховщик также посмотрит, насколько безопасен ваш автомобиль для вас и ваших пассажиров. Дополнительные функции безопасности обычно снижают страховые взносы.
Быстрые и роскошные автомобили, которые, вероятно, будут иметь более высокий уровень требований об ответственности, такие как Chevrolet Corvette, часто будут стоить дороже, чем скромные автомобили с более низким уровнем требований об ответственности, такие как Chevrolet Malibu.
{«backgroundColor»:»ice»,»content»:»\u003C\/p\u003E\n\n\u003Cp\u003EБыстрые и яркие автомобили, которые, вероятно, будут иметь более высокий уровень требований об ответственности, например, \u003Cspan\ u003E\u003Ca class=\»ShortcodeLink—root ShortcodeLink—black\» title=\»Сколько стоит застраховать Chevrolet Corvette\» href=\»https:\/\/www. valuepenguin.com\/ corvette-car-insurance \»\u003EChevrolet Corvette\u003C\/a\u003E\u003C\/span\u003E, часто будет стоить дороже, чем покрытие скромных автомобилей с более низким уровнем ответственности, таких как Chevrolet Malibu.\n»,»padding»:»двойной»}
valuepenguin.com\/ corvette-car-insurance \»\u003EChevrolet Corvette\u003C\/a\u003E\u003C\/span\u003E, часто будет стоить дороже, чем покрытие скромных автомобилей с более низким уровнем ответственности, таких как Chevrolet Malibu.\n»,»padding»:»двойной»}
Методология
Мы собрали цитаты из State Farm для 40-летнего мужчины с чистым водительским стажем, проживающего в Нью-Йорке. Полис включал скидки на антиблокировочную систему тормозов, противоугонную сигнализацию и дневные ходовые огни.
У него были следующие пределы покрытия:
- 50 000 долларов США на человека и 100 000 долларов США за несчастный случай за телесные повреждения
- $50 000 ответственности за материальный ущерб
- Комплексный (со стеклом) и столкновение с франшизами в размере 1000 долларов США.
Одеяла для защиты от эрозии – одобренные/сертифицированные продукты
Одеяла для защиты от эрозии
Книга стандартных спецификаций 2018 г. , Спецификация 3885
, Спецификация 3885
Категория 0
ASTM D 4329 Цикл A — 50 часов.0%-25%*
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| Curlex NetFree | Американ Эксельсиор Ко. | 651-783-6320 | 6-2018 |
Категория 3P-солома
ASTM D 4329 Цикл A — 50 часов. 0%-65%*
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| КЭП-С2 | Канзас Эрозия | 919-480-5616 | 6-2018 |
| ЭКС-2 | Противоэрозионные покрытия Восточного побережья | 800-582-4005 | 4-2018 |
| ЭГ-2сРД | Эро-защита | 651-917-0939 | 3-2018 |
| С32 УВД | противоэрозионное покрытие.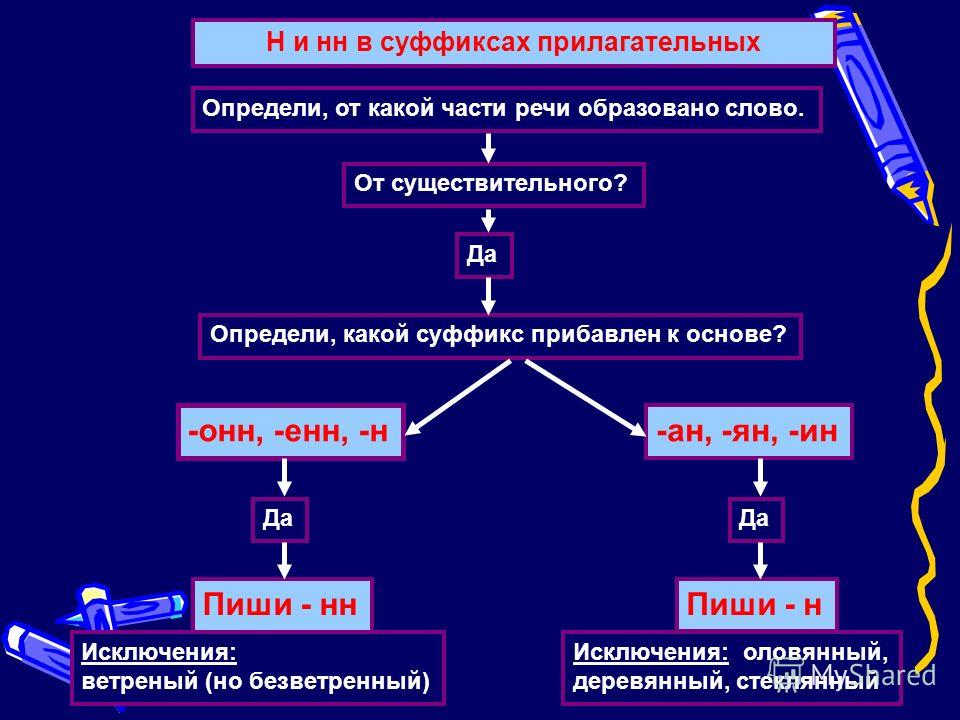 ком ком | 360-910-4800 | 4-2018 |
| SFP-2sRD (Маг 500) | Продукты соломенной фермы | 612-723-5409 | 7-2018 |
| SS-S2 | Silt Sock Inc. | 320-333-6485 | 4-2018 |
| Эронет S150 | Тенсар Североамериканский Зеленый | 800-772-2040 | 5-2018 |
| Excel SS-2 | Вестерн Эксельсиор | 866-540-9810 | 5-2018 |
| С2000 | Enviroscape ЕСМ | 419-278-2000 | 11-2018 |
| С2000Д | Enviroscape ЕСМ | 419-278-2000 | 11-2018 |
Категория 3N-солома
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| KEP-S2 Натуральный | Канзас Эрозия | 919-480-5616 | 6-2018 |
| AEC Premier Straw, Dbl Net, FibreNet | Американ Эксельсиор Ко. | 651-783-6320 | 6-2018 |
| ЭКС-2Б | Противоэрозионные покрытия Восточного побережья | 800-582-4005 | 4-2018 |
| ЭГ-2с НН | Эро-защита | 651-917-0939 | 3-2018 |
| СФП-2сБД | Продукты соломенной фермы | 612-723-5409 | 7-2018 |
| СС-С2-БД | Силт Сок Инк. | 320-333-6485 | 4-2018 |
| С32 БД | эрозияcontrolblanket.com | 360-910-4800 | 4-2018 |
| Эронет S150BN | Тенсар Североамериканский Зеленый | 800-772-2040 | 5-2018 |
| Excel СС-2 Вся натуральная сетка | Вестерн Эксельсиор | 866-540-9810 | 5-2018 |
| С2000БН | Enviroscape ЕСМ | 419-278-2000 | 11-2018 |
Категория 3P-древесина
ASTM D 4329 Цикл A — 50 часов.
 0%-65%*
0%-65%*| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| EG-2xRD | Эро-защита | 651-917-0939 | 3-2018 |
| Excel S-2 | Вестерн Эксельсиор | 866-540-9810 | 5-2018 |
Категория 3N-древесина
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| Curlex II FibreNet | Американ Эксельсиор Ко. | 651-783-6320 | 6-2018 |
| ЭГ-2x НН | Эро-защита | 651-917-0939 | 3-2018 |
| Excel S-2 Вся натуральная сетка | Вестерн Эксельсиор | 866-540-9810 | 5-2018 |
Категория 4P-солома/кокос
ASTM D 4329 Цикл A — 50 часов.
 75%-120%*
75%-120%*| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| СС-СК2-МН | Silt Sock Inc. | 320-333-6485 | 4-2018 |
| ЭГ-2 п/к (MNCAT 4P) | Эро-защита | 651-917-0939 | 3-2018 |
| SC3000 | Enviroscape ЕСМ | 419-278-2000 | 11-2018 |
Категория 4N-солома/кокос
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| KEP-SC2 натуральный | Канзас Эрозия | 919-480-5616 | 7-2018 |
| AEC Premier Straw/Coconut FibreNet | Американ Эксельсиор Ко. | 651-783-6320 | 6-2018 |
| ECSC-2B | Противоэрозионные покрытия Восточного побережья | 800-582-4005 | 4-2018 |
| ЭГ-2с/к НН | Эро-защита | 651-917-0939 | 3-2018 |
| Эронет SC150BN | Тенсар Североамериканский Зеленый | 800-772-2040 | 5-2018 |
| Excel CS-3 Вся натуральная сетка | Вестерн Эксельсиор | 866-540-9810 | 5-2018 |
| СС-СК2-БД | Силт Сок Инк.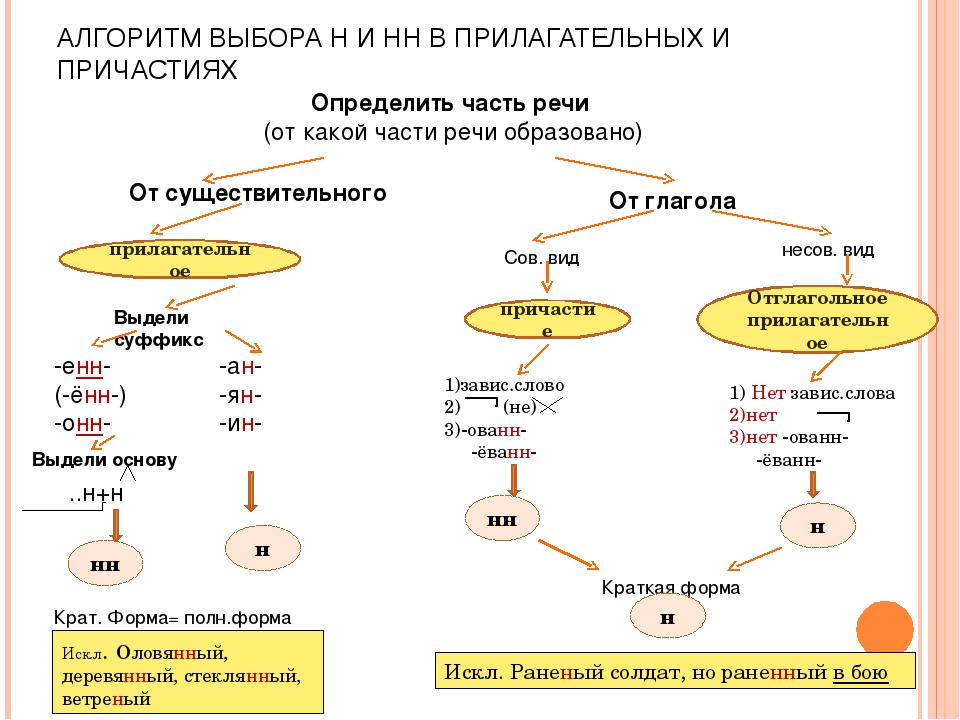 | 320-333-6485 | 4-2018 |
| SC32 БД | эрозияcontrolblanket.com | 360-910-4800 | 4-2018 |
| SC3000BD | Enviroscape ЕСМ | 419-278-2000 | 11-2018 |
Категория 4P-древесина
ASTM D 4329 Цикл A — 50 часов.75%-120%*
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| EG-2x HD | Эро-защита | 651-917-0939 | 3-2018 |
Категория 4N-древесина
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| Curlex III FibreNet | Американ Эксельсиор Ко. | 651-783-6320 | 6-2018 |
| EG-2x NN HD | Эро-защита | 651-917-0939 | 3-2018 |
Категория 6
| Название марки/модели | Производитель | Контактная информация | Дата утверждения |
|---|---|---|---|
| EG-3xtreme-wood EG-3xtreme S/C | Эро-защита | 651-917-0939 | 3-2018 |
| Инфорсер Curlex (натуральный цвет) | Американ Эксельсиор Ко. | 800-777-7645 | 4-2018 |
| ЕСУС-3 | Противоэрозионные одеяла Восточного побережья, ООО | 800-582-4005 | 4-2018 |
| Вмакс SC250 | Тенсар Североамериканский Зеленый | 800-772-2040 | 4-2018 |
* Этот ASTM приблизительно соответствует срокам, указанным в Стандартных спецификациях.
Примечание. Сертификационное письмо от производителя сетки должно сопровождать одеяло при его использовании в проекте.
Примечание. Начиная с ноября 2018 г., представьте результаты испытаний в соответствии со стандартом NTPEP ASTM D 6460, допустимая нагрузка на сдвиг без вегетации для соответствия критериям напряжения сдвига MnDOT. Срок действия списка утвержденных продуктов будет зависеть от истечения этого тестового цикла.
Архив
CS231n Сверточные нейронные сети для визуального распознавания
Содержание:
Сверточные нейронные сети (CNN/ConvNets)
Сверточные нейронные сети очень похожи на обычные нейронные сети из предыдущей главы: они состоят из нейронов, которые имеют обучаемые веса и смещения. Каждый нейрон получает некоторые входные данные, выполняет скалярное произведение и, возможно, следует за ним с нелинейностью. Вся сеть по-прежнему выражает единую дифференцируемую функцию оценки: от необработанных пикселей изображения на одном конце до оценок класса на другом. И у них все еще есть функция потерь (например, SVM/Softmax) на последнем (полностью подключенном) слое, и все советы/рекомендации, которые мы разработали для изучения обычных нейронных сетей, по-прежнему применимы.
Каждый нейрон получает некоторые входные данные, выполняет скалярное произведение и, возможно, следует за ним с нелинейностью. Вся сеть по-прежнему выражает единую дифференцируемую функцию оценки: от необработанных пикселей изображения на одном конце до оценок класса на другом. И у них все еще есть функция потерь (например, SVM/Softmax) на последнем (полностью подключенном) слое, и все советы/рекомендации, которые мы разработали для изучения обычных нейронных сетей, по-прежнему применимы.
Так что же изменилось? Архитектуры ConvNet делают явное предположение, что входные данные являются изображениями, что позволяет нам кодировать определенные свойства в архитектуре.Затем они делают функцию прямой передачи более эффективной для реализации и значительно уменьшают количество параметров в сети.
Обзор архитектуры
Отзыв: Обычные нейронные сети. Как мы видели в предыдущей главе, нейронные сети получают входные данные (один вектор) и преобразуют их через серию из скрытых слоев . Каждый скрытый слой состоит из набора нейронов, где каждый нейрон полностью связан со всеми нейронами предыдущего слоя, а нейроны одного слоя функционируют совершенно независимо и не имеют общих связей.Последний полносвязный слой называется «выходным слоем» и в настройках классификации представляет баллы класса.
Каждый скрытый слой состоит из набора нейронов, где каждый нейрон полностью связан со всеми нейронами предыдущего слоя, а нейроны одного слоя функционируют совершенно независимо и не имеют общих связей.Последний полносвязный слой называется «выходным слоем» и в настройках классификации представляет баллы класса.
Обычные нейронные сети плохо масштабируются до полных изображений . В CIFAR-10 изображения имеют размер только 32x32x3 (32 ширины, 32 высоты, 3 цветовых канала), поэтому один полносвязный нейрон в первом скрытом слое обычной нейронной сети будет иметь 32 * 32 * 3 = 3072 веса. . Это количество все еще кажется управляемым, но ясно, что эта полностью связанная структура не масштабируется для больших изображений.Например, изображение более солидного размера, т.е. 200x200x3 приведет к нейронам, имеющим 200*200*3 = 120 000 весов. Более того, нам почти наверняка хотелось бы иметь несколько таких нейронов, чтобы параметры быстро складывались! Ясно, что такая полная связность расточительна, а огромное количество параметров быстро приведет к переоснащению.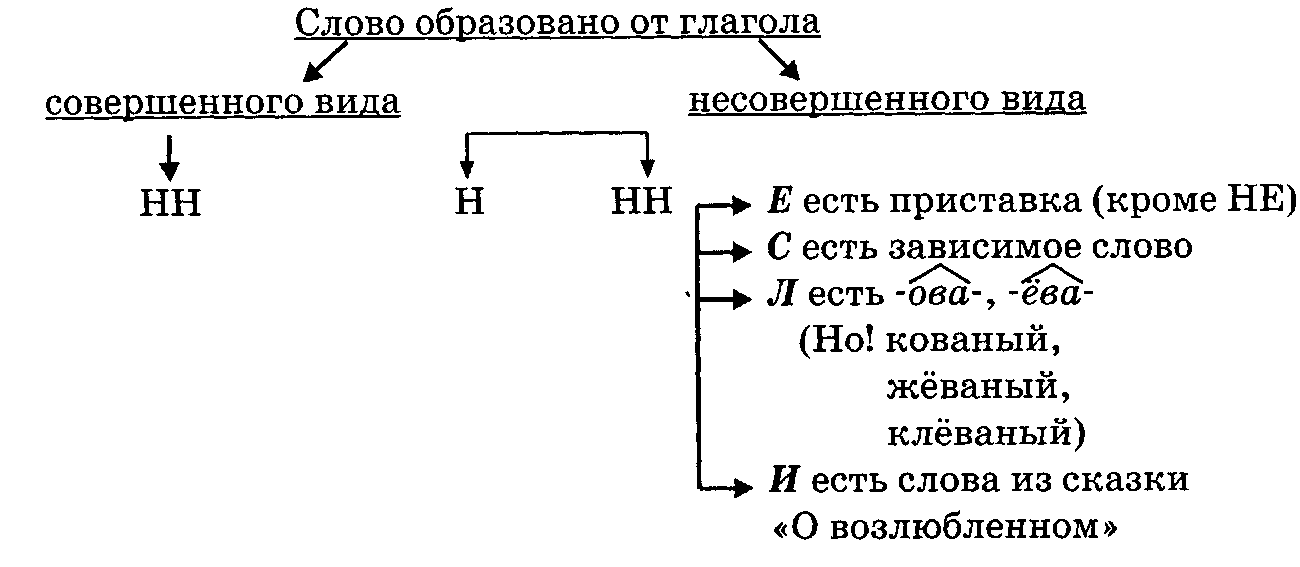
3D объемы нейронов . Сверточные нейронные сети используют тот факт, что входные данные состоят из изображений, и они более разумно ограничивают архитектуру.В частности, в отличие от обычной нейронной сети, слои ConvNet имеют нейроны, расположенные в 3-х измерениях: ширина , высота, глубина . (Обратите внимание, что слово , глубина здесь относится к третьему измерению объема активации, а не к глубине полной нейронной сети, которая может относиться к общему количеству слоев в сети.) Например, входные изображения в ЦИФАР-10 является входным томом активаций, причем объем имеет размеры 32х32х3 (ширина, высота, глубина соответственно).Как мы вскоре увидим, нейроны в слое будут связаны только с небольшой областью слоя перед ним, а не со всеми нейронами полносвязным образом. Более того, окончательный выходной слой для CIFAR-10 будет иметь размеры 1x1x10, потому что к концу архитектуры ConvNet мы сократим полное изображение в единый вектор оценок классов, расположенных по измерению глубины. Вот визуализация:
Вот визуализация:
Слева: обычная трехслойная нейронная сеть. Справа: ConvNet размещает свои нейроны в трех измерениях (ширина, высота, глубина), как показано на одном из слоев.Каждый слой ConvNet преобразует трехмерный входной объем в трехмерный выходной объем активаций нейронов. В этом примере красный входной слой содержит изображение, поэтому его ширина и высота будут размерами изображения, а глубина будет равна 3 (красный, зеленый, синий каналы).
ConvNet состоит из слоев. У каждого слоя есть простой API: он преобразует входной 3D-объем в выходной 3D-объем с помощью некоторой дифференцируемой функции, которая может иметь или не иметь параметров.
Уровни, используемые для построения ConvNets
Как мы описали выше, простая ConvNet представляет собой последовательность слоев, и каждый слой ConvNet преобразует один объем активаций в другой с помощью дифференцируемой функции.Мы используем три основных типа слоев для построения архитектур ConvNet: Convolutional Layer , Pooling Layer и Fully-Connected Layer (точно так же, как это видно в обычных нейронных сетях).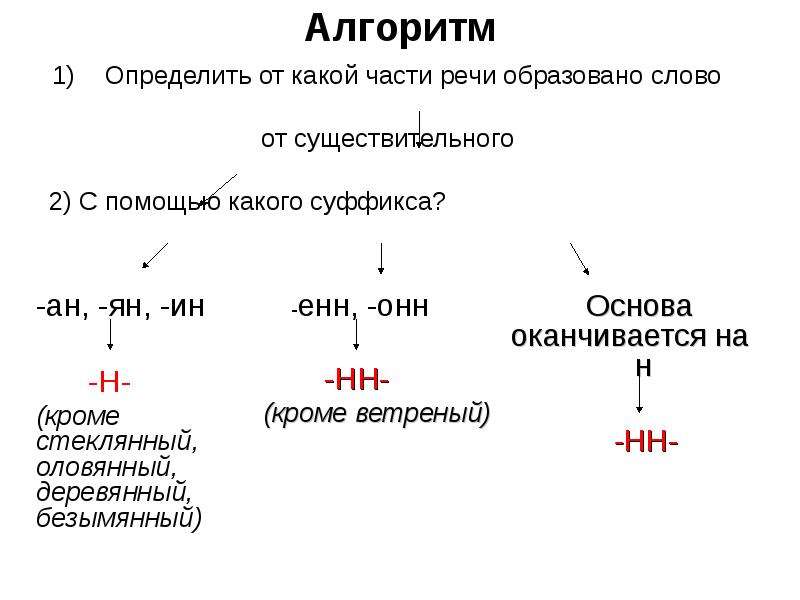 Мы объединим эти слои, чтобы сформировать полную архитектуру ConvNet .
Мы объединим эти слои, чтобы сформировать полную архитектуру ConvNet .
Пример архитектуры: обзор . Мы рассмотрим более подробно ниже, но простая ConvNet для классификации CIFAR-10 может иметь архитектуру [INPUT — CONV — RELU — POOL — FC].Подробнее:
- INPUT [32x32x3] будет содержать необработанные значения пикселей изображения, в данном случае изображение шириной 32, высотой 32 и с тремя цветовыми каналами R,G,B. Слой
- CONV будет вычислять выходные данные нейронов, которые подключены к локальным областям во входных данных, каждый из которых вычисляет скалярное произведение между их весами и небольшой областью, с которой они связаны во входном объеме. Это может привести к такому объему, как [32x32x12], если мы решили использовать 12 фильтров. Уровень
- RELU применит поэлементную функцию активации, такую как пороговое значение \(max(0,x)\) в нуле.Это оставляет размер тома без изменений ([32x32x12]). Слой
- POOL выполнит операцию понижения дискретизации по пространственным измерениям (ширина, высота), в результате чего получится объем, например [16x16x12].
 Уровень
Уровень - FC (т. е. полносвязный) будет вычислять баллы класса, в результате чего получится объем размером [1x1x10], где каждое из 10 чисел соответствует баллу класса, например, среди 10 категорий CIFAR-10. Как и в случае с обычными нейронными сетями и как следует из названия, каждый нейрон в этом слое будет связан со всеми числами в предыдущем томе.
Таким образом, ConvNets трансформируют исходное изображение слой за слоем из исходных значений пикселей в окончательные оценки класса. Обратите внимание, что некоторые слои содержат параметры, а другие нет. В частности, слои CONV/FC выполняют преобразования, которые являются функцией не только активаций во входном объеме, но и параметров (весов и смещений нейронов). С другой стороны, слои RELU/POOL реализуют фиксированную функцию. Параметры в слоях CONV/FC будут обучаться с помощью градиентного спуска, чтобы оценки классов, вычисляемые ConvNet, соответствовали меткам в обучающем наборе для каждого изображения.
Итого:
- Архитектура ConvNet в простейшем случае представляет собой список слоев, которые преобразуют объем изображения в выходной объем (например, хранят оценки класса)
- Существует несколько различных типов слоев (например, CONV/FC/RELU/POOL, безусловно, самые популярные)
- Каждый слой принимает входной 3D-объем и преобразует его в выходной 3D-объем с помощью дифференцируемой функции
- Каждый уровень может иметь или не иметь параметры (например,CONV/FC можно, RELU/POOL нельзя)
- Каждый уровень может иметь или не иметь дополнительные гиперпараметры (например, CONV/FC/POOL имеют, RELU нет)
 В начальном томе хранятся необработанные пиксели изображения (слева), а в последнем томе хранятся оценки класса (справа). Каждый объем активаций на пути обработки отображается в виде столбца. Поскольку визуализировать 3D-объемы сложно, мы располагаем срезы каждого объема рядами. Том последнего слоя содержит баллы для каждого класса, но здесь мы визуализируем только отсортированные 5 лучших баллов и печатаем метки каждого из них.Полная демо-версия показана в шапке нашего веб-сайта. Показанная здесь архитектура представляет собой крошечную сеть VGG, которую мы обсудим позже.
В начальном томе хранятся необработанные пиксели изображения (слева), а в последнем томе хранятся оценки класса (справа). Каждый объем активаций на пути обработки отображается в виде столбца. Поскольку визуализировать 3D-объемы сложно, мы располагаем срезы каждого объема рядами. Том последнего слоя содержит баллы для каждого класса, но здесь мы визуализируем только отсортированные 5 лучших баллов и печатаем метки каждого из них.Полная демо-версия показана в шапке нашего веб-сайта. Показанная здесь архитектура представляет собой крошечную сеть VGG, которую мы обсудим позже.Теперь мы опишем отдельные слои и детали их гиперпараметров и их связей.
Сверточный слой
Слой Conv является основным строительным блоком сверточной сети, который выполняет большую часть тяжелой вычислительной работы.
Обзор и интуиция без мозгов. Давайте сначала обсудим, что вычисляет слой CONV без аналогий с мозгом/нейроном.Параметры слоя CONV состоят из набора обучаемых фильтров.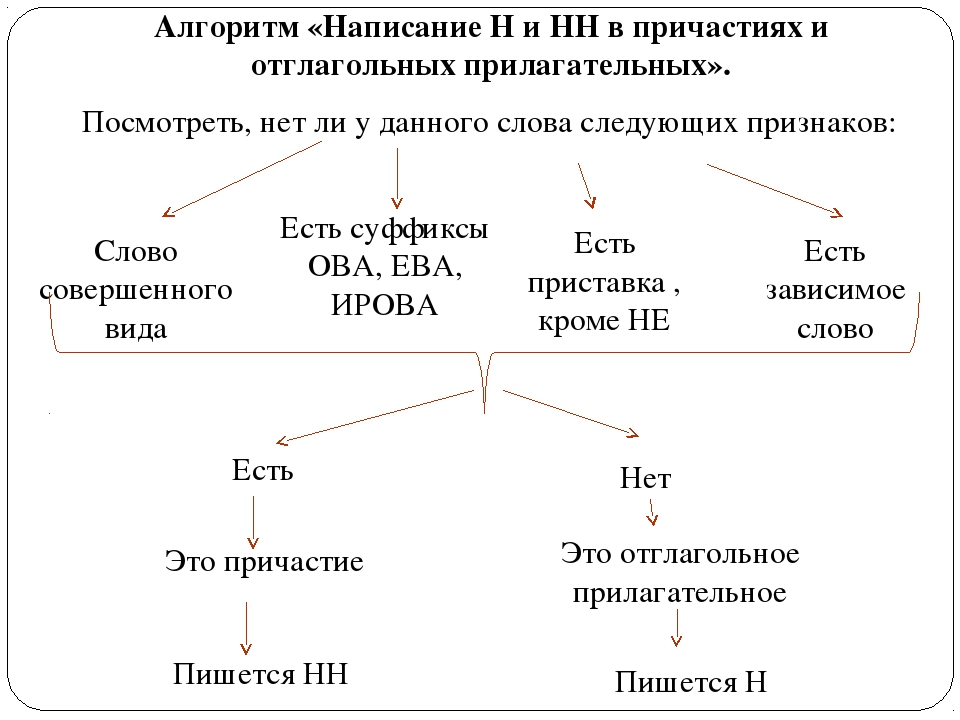 Каждый фильтр мал в пространстве (по ширине и высоте), но распространяется на всю глубину входного объема. Например, типичный фильтр на первом слое ConvNet может иметь размер 5x5x3 (т. е. 5 пикселей в ширину и высоту и 3, поскольку изображения имеют глубину 3, цветовые каналы). Во время прямого прохода мы перемещаем (точнее, сворачиваем) каждый фильтр по ширине и высоте входного объема и вычисляем скалярные произведения между элементами фильтра и входными данными в любой позиции.Когда мы перемещаем фильтр по ширине и высоте входного объема, мы создаем двумерную карту активации, которая дает ответы этого фильтра в каждой пространственной позиции. Интуитивно сеть будет изучать фильтры, которые активируются, когда они видят какой-либо тип визуальной функции, такой как край какой-либо ориентации или пятно определенного цвета на первом слое, или, в конечном итоге, целые соты или колесоподобные узоры на более высоких слоях сети. . Теперь у нас будет полный набор фильтров в каждом слое CONV (т.
Каждый фильтр мал в пространстве (по ширине и высоте), но распространяется на всю глубину входного объема. Например, типичный фильтр на первом слое ConvNet может иметь размер 5x5x3 (т. е. 5 пикселей в ширину и высоту и 3, поскольку изображения имеют глубину 3, цветовые каналы). Во время прямого прохода мы перемещаем (точнее, сворачиваем) каждый фильтр по ширине и высоте входного объема и вычисляем скалярные произведения между элементами фильтра и входными данными в любой позиции.Когда мы перемещаем фильтр по ширине и высоте входного объема, мы создаем двумерную карту активации, которая дает ответы этого фильтра в каждой пространственной позиции. Интуитивно сеть будет изучать фильтры, которые активируются, когда они видят какой-либо тип визуальной функции, такой как край какой-либо ориентации или пятно определенного цвета на первом слое, или, в конечном итоге, целые соты или колесоподобные узоры на более высоких слоях сети. . Теперь у нас будет полный набор фильтров в каждом слое CONV (т. г. 12 фильтров), и каждый из них создаст отдельную 2-мерную карту активации. Мы сложим эти карты активации по измерению глубины и создадим выходной объем.
г. 12 фильтров), и каждый из них создаст отдельную 2-мерную карту активации. Мы сложим эти карты активации по измерению глубины и создадим выходной объем.
Вид мозга . Если вам нравятся аналогии между мозгом и нейроном, то каждая запись в выходном 3D-объеме также может быть интерпретирована как вывод нейрона, который смотрит только на небольшую область на входе и разделяет параметры со всеми нейронами слева и справа. правильно пространственно (поскольку все эти числа являются результатом применения одного и того же фильтра).
Теперь мы обсудим детали соединений нейронов, их расположение в пространстве и схему совместного использования их параметров.
Локальное подключение. При работе с многомерными входными данными, такими как изображения, как мы видели выше, нецелесообразно соединять нейроны со всеми нейронами в предыдущем объеме. Вместо этого мы будем подключать каждый нейрон только к локальной области входного объема. Пространственная протяженность этой связи представляет собой гиперпараметр, называемый рецептивным полем нейрона (что эквивалентно размеру фильтра).Степень связности по оси глубины всегда равна глубине входного объема. Важно еще раз подчеркнуть эту асимметрию в том, как мы относимся к пространственным измерениям (ширине и высоте) и измерению глубины: связи локальны в двумерном пространстве (по ширине и высоте), но всегда полны по всей глубине входного объема. .
Пространственная протяженность этой связи представляет собой гиперпараметр, называемый рецептивным полем нейрона (что эквивалентно размеру фильтра).Степень связности по оси глубины всегда равна глубине входного объема. Важно еще раз подчеркнуть эту асимметрию в том, как мы относимся к пространственным измерениям (ширине и высоте) и измерению глубины: связи локальны в двумерном пространстве (по ширине и высоте), но всегда полны по всей глубине входного объема. .
Пример 1 . Например, предположим, что входной объем имеет размер [32x32x3] (например, изображение RGB CIFAR-10). Если рецептивное поле (или размер фильтра) составляет 5×5, то каждый нейрон в Conv Layer будет иметь веса для области [5x5x3] во входном объеме, всего 5*5*3 = 75 весов (и +1 параметр смещения).Обратите внимание, что экстент связности по оси глубины должен быть равен 3, так как это глубина входного объема.
Пример 2 . Предположим, входной том имеет размер [16x16x20]. Затем, используя пример рецептивного поля размером 3×3, каждый нейрон в Conv Layer теперь будет иметь в общей сложности 3 * 3 * 20 = 180 соединений с входным объемом. Обратите внимание, что, опять же, связность является локальной в 2D-пространстве (например, 3×3), но полной по входной глубине (20).
Затем, используя пример рецептивного поля размером 3×3, каждый нейрон в Conv Layer теперь будет иметь в общей сложности 3 * 3 * 20 = 180 соединений с входным объемом. Обратите внимание, что, опять же, связность является локальной в 2D-пространстве (например, 3×3), но полной по входной глубине (20).
Слева: Пример ввода красного цвета (напр.г. изображение CIFAR-10 размером 32x32x3) и примерный объем нейронов в первом сверточном слое. Каждый нейрон в сверточном слое пространственно связан только с локальной областью входного объема, но на всю глубину (т.е. со всеми цветовыми каналами). Обратите внимание, что по глубине расположено несколько нейронов (5 в этом примере), и все они смотрят на одну и ту же область во входных данных: линии, соединяющие этот столбец из 5 нейронов, не представляют веса (т. е. эти 5 нейронов не имеют одного и того же значения). веса, но они связаны с 5 разными фильтрами), они просто указывают на то, что эти нейроны подключены или смотрят на одно и то же рецептивное поле или область входного объема, т.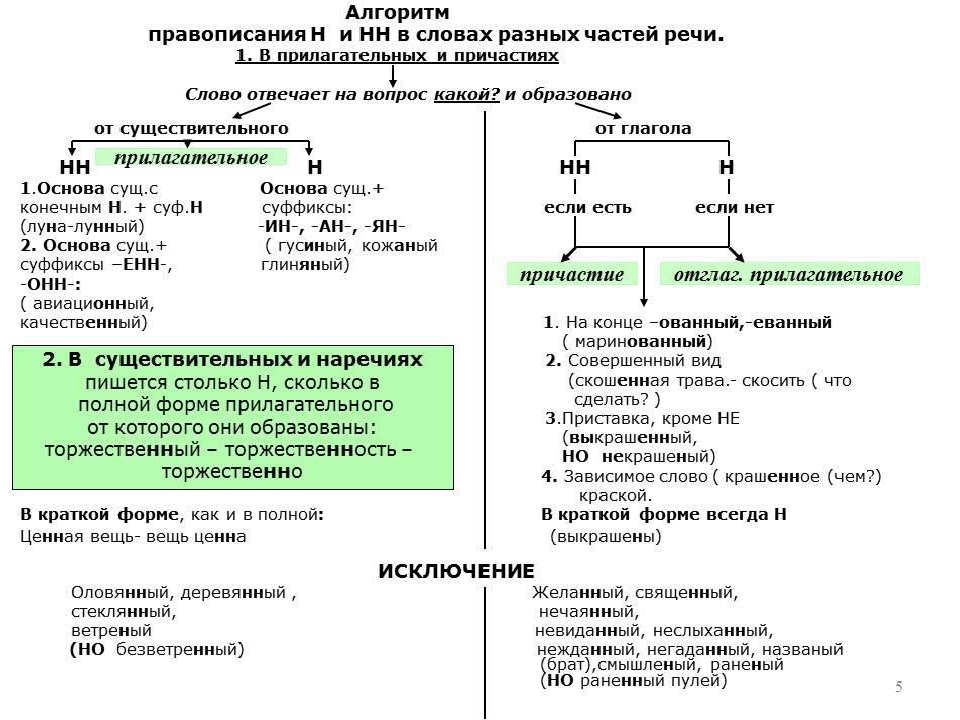 е.е. они имеют одно и то же рецептивное поле, но разный вес. Справа: Нейроны из главы «Нейронная сеть» остались без изменений: они по-прежнему вычисляют скалярное произведение своих весов с входными данными, за которыми следует нелинейность, но их связность теперь ограничена локальной пространственной связью.
е.е. они имеют одно и то же рецептивное поле, но разный вес. Справа: Нейроны из главы «Нейронная сеть» остались без изменений: они по-прежнему вычисляют скалярное произведение своих весов с входными данными, за которыми следует нелинейность, но их связность теперь ограничена локальной пространственной связью.
Пространственное расположение . Мы объяснили связь каждого нейрона в Conv Layer с входным объемом, но еще не обсудили, сколько нейронов находится в выходном объеме или как они расположены.Три гиперпараметра управляют размером выходного тома: глубина , шаг и заполнение нулями . Мы обсудим это далее:
- Во-первых, глубина выходного объема является гиперпараметром: он соответствует количеству фильтров, которые мы хотели бы использовать, каждый из которых учится искать что-то другое во входных данных. Например, если первый сверточный слой принимает в качестве входных данных необработанное изображение, то разные нейроны по измерению глубины могут активироваться при наличии различных ориентированных краев или цветовых пятен.
 Мы будем ссылаться на набор нейронов, которые смотрят на одну и ту же область входных данных, как на столбец глубины (некоторые люди также предпочитают термин волокно ).
Мы будем ссылаться на набор нейронов, которые смотрят на одну и ту же область входных данных, как на столбец глубины (некоторые люди также предпочитают термин волокно ). - Во-вторых, мы должны указать шаг , с которым мы перемещаем фильтр. Когда шаг равен 1, мы перемещаем фильтры по одному пикселю за раз. Когда шаг равен 2 (или редко 3 или более, хотя на практике это редкость), то фильтры прыгают на 2 пикселя за раз, когда мы перемещаем их. Это позволит производить меньшие объемы продукции в пространственном отношении.
- Как мы вскоре увидим, иногда бывает удобно дополнить входной объем нулями вокруг границы. Размер этого заполнения нулями является гиперпараметром. Хорошая особенность нулевого заполнения заключается в том, что оно позволяет нам контролировать пространственный размер выходных объемов (чаще всего, как мы скоро увидим, мы будем использовать его для точного сохранения пространственного размера входного объема, поэтому входная и выходная ширина и высота одинаковая).

Мы можем вычислить пространственный размер выходного объема как функцию размера входного объема (\(W\)), размера рецептивного поля нейронов конв. слоя (\(F\)), шага, с которым они применяются (\(S\)), и количество используемых нулевых отступов (\(P\)) на границе.Вы можете убедиться в том, что правильная формула для подсчета количества «подходящих» нейронов имеет вид \((W — F + 2P)/S + 1\). Например, для ввода 7×7 и фильтра 3×3 с шагом 1 и пэдом 0 мы получим вывод 5×5. С шагом 2 мы получим вывод 3×3. Давайте также посмотрим еще один графический пример:
. Иллюстрация пространственного расположения. В этом примере есть только одно пространственное измерение (ось X), один нейрон с размером рецептивного поля F = 3, размер входного сигнала W = 5 и заполнение нулями P = 1. Слева: Нейрон прошел через вход с шагом S = 1, давая результат размером (5 — 3 + 2)/1+1 = 5. Справа: Нейрон использует шаг S = 2, давая результат размера (5 — 3 + 2)/2+1 = 3. Обратите внимание, что шаг S = 3 нельзя использовать, так как он не будет аккуратно вписываться в объем. С точки зрения уравнения это можно определить, поскольку (5 — 3 + 2) = 4 не делится на 3.
Обратите внимание, что шаг S = 3 нельзя использовать, так как он не будет аккуратно вписываться в объем. С точки зрения уравнения это можно определить, поскольку (5 — 3 + 2) = 4 не делится на 3.
В этом примере веса нейронов равны [1,0,-1] (показаны справа), а его смещение равно нулю.Эти веса являются общими для всех желтых нейронов (см. совместное использование параметров ниже).
Использование заполнения нулями . В приведенном выше примере слева обратите внимание, что входное измерение было равно 5, а выходное измерение было равно: также 5. Это сработало, потому что наши рецептивные поля были 3, и мы использовали заполнение нулями 1. Если бы не использовалось заполнение нулями , то выходной объем имел бы пространственную размерность всего 3, потому что именно столько нейронов «поместилось бы» на исходном входе.В общем, установка нулевого заполнения в \(P = (F — 1)/2\), когда шаг равен \(S = 1\), гарантирует, что входной объем и выходной объем будут иметь одинаковый размер в пространстве. Таким образом очень часто используется заполнение нулями, и мы обсудим все причины, когда будем больше говорить об архитектуре ConvNet.
Таким образом очень часто используется заполнение нулями, и мы обсудим все причины, когда будем больше говорить об архитектуре ConvNet.
Ограничения по шагам . Обратите внимание еще раз, что гиперпараметры пространственного расположения имеют взаимные ограничения. Например, когда вход имеет размер \(W = 10\), не используется заполнение нулями \(P = 0\) и размер фильтра равен \(F = 3\), тогда было бы невозможно использовать шаг \(S = 2\), так как \((W — F + 2P)/S + 1 = (10 — 3 + 0) / 2 + 1 = 4.5\), т. е. не целое число, что указывает на то, что нейроны не «укладываются» аккуратно и симметрично по входным данным. Следовательно, эта настройка гиперпараметров считается недопустимой, и библиотека ConvNet может выдать исключение или дополнить нулями остальные, чтобы они соответствовали, или обрезать входные данные, чтобы они соответствовали, или что-то в этом роде. Как мы увидим в разделе архитектуры ConvNet, правильное определение размера ConvNet, чтобы все измерения «работали», может стать настоящей головной болью, которую значительно облегчит использование заполнения нулями и некоторых рекомендаций по проектированию.
Реальный пример . Крижевский и др. Архитектура, победившая в конкурсе ImageNet в 2012 году, принимала изображения размером [227x227x3]. На первом сверточном слое использовались нейроны с размером рецептивного поля \(F = 11\), шагом \(S = 4\) и без заполнения нулями \(P = 0\). Так как (227 — 11)/4 + 1 = 55 и поскольку слой Conv имел глубину \(K = 96\), выходной объем слоя Conv имел размер [55x55x96]. Каждый из 55*55*96 нейронов в этом объеме был связан с областью размером [11x11x3] во входном объеме.Более того, все 96 нейронов в каждом столбце глубины подключены к одной и той же области [11x11x3] входа, но, конечно, с разными весами. В качестве забавы, если вы читаете настоящую статью, в ней утверждается, что входные изображения были 224×224, что, безусловно, неверно, потому что (224 — 11)/4 + 1 явно не является целым числом. Это сбило с толку многих людей в истории ConvNets, и мало что известно о том, что произошло. Мое личное предположение состоит в том, что Алекс использовал заполнение нулями трех дополнительных пикселей, о которых он не упоминает в статье.
Совместное использование параметров. Схема совместного использования параметров используется в сверточных слоях для управления количеством параметров. Используя приведенный выше реальный пример, мы видим, что в первом Conv Layer 55 * 55 * 96 = 290 400 нейронов, и каждый имеет 11 * 11 * 3 = 363 веса и 1 смещение. Вместе это составляет 2
Оказывается, мы можем значительно сократить количество параметров, сделав одно разумное предположение: если один признак полезно вычислять в некоторой пространственной позиции (x, y), то его также полезно вычислять в другой позиции ( х2,у2).Другими словами, обозначив один двумерный срез глубины как срезов глубины (например, том размером [55x55x96] имеет 96 срезов глубины, каждый размером [55×55]), мы собираемся ограничить нейроны в каждом из них. срез глубины, чтобы использовать те же веса и смещение.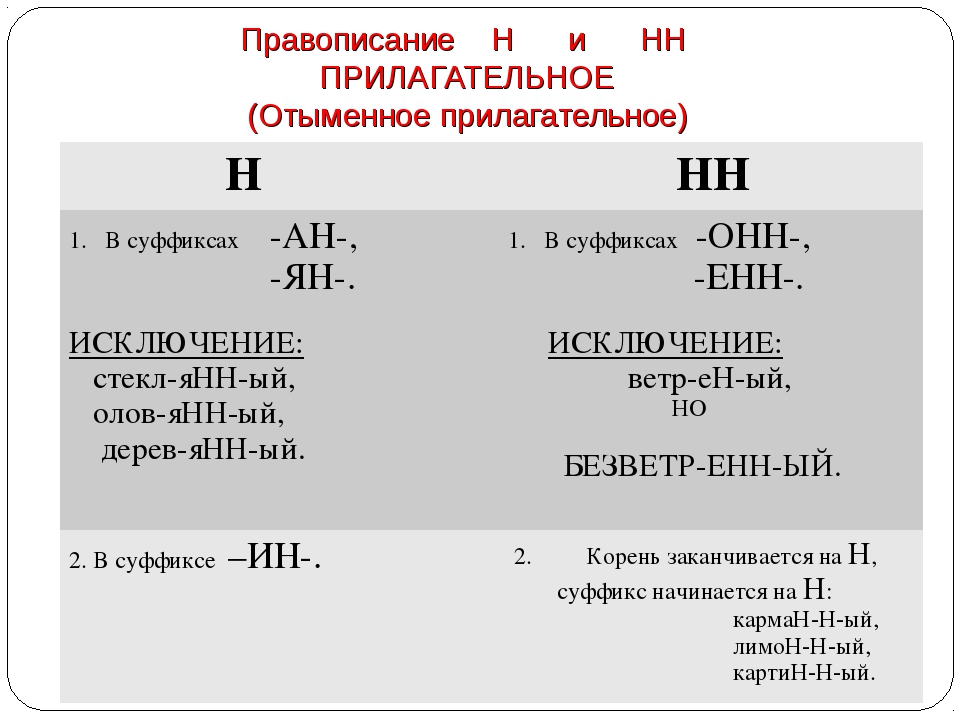 С этой схемой совместного использования параметров первый Conv Layer в нашем примере теперь будет иметь только 96 уникальных наборов весов (по одному для каждого среза глубины), всего 96 * 11 * 11 * 3 = 34 848 уникальных весов или 34 944 параметра ( +96 смещений). Альтернативно, все 55*55 нейронов в каждом глубинном срезе теперь будут использовать одни и те же параметры.На практике во время обратного распространения каждый нейрон в объеме будет вычислять градиент для своих весов, но эти градиенты будут суммироваться по каждому срезу глубины и обновлять только один набор весов на срез.
С этой схемой совместного использования параметров первый Conv Layer в нашем примере теперь будет иметь только 96 уникальных наборов весов (по одному для каждого среза глубины), всего 96 * 11 * 11 * 3 = 34 848 уникальных весов или 34 944 параметра ( +96 смещений). Альтернативно, все 55*55 нейронов в каждом глубинном срезе теперь будут использовать одни и те же параметры.На практике во время обратного распространения каждый нейрон в объеме будет вычислять градиент для своих весов, но эти градиенты будут суммироваться по каждому срезу глубины и обновлять только один набор весов на срез.
Обратите внимание, что если все нейроны в одном срезе глубины используют один и тот же вектор веса, то прямой проход слоя CONV может быть вычислен в каждом срезе глубины как свертка весов нейрона с входным объемом (отсюда и название : сверточный слой).Вот почему наборы весов принято называть фильтром (или ядром ), который свернут с входными данными.
Примеры фильтров, изученных Крижевским и др. Каждый из 96 показанных здесь фильтров имеет размер [11x11x3], и каждый из них используется 55*55 нейронами в одном срезе глубины. Обратите внимание, что предположение о совместном использовании параметров относительно разумно: если обнаружение горизонтального края важно в каком-то месте изображения, оно должно быть интуитивно полезным и в каком-то другом месте из-за трансляционно-инвариантной структуры изображений.Поэтому нет необходимости заново учиться обнаруживать горизонтальный край в каждом из 55*55 различных мест выходного объема Conv-слоя.
Обратите внимание, что иногда предположение о совместном использовании параметров может не иметь смысла. Это особенно актуально, когда входные изображения в ConvNet имеют определенную центрированную структуру, где мы должны ожидать, например, что совершенно разные функции должны быть изучены на одной стороне изображения, чем на другой. Одним из практических примеров является случай, когда входными данными являются лица, расположенные по центру изображения. Вы можете ожидать, что различные особенности, характерные для глаз или волос, могут (и должны) изучаться в разных пространственных положениях. В этом случае принято ослаблять схему совместного использования параметров и вместо этого просто называть уровень Locally-Connected Layer .
Вы можете ожидать, что различные особенности, характерные для глаз или волос, могут (и должны) изучаться в разных пространственных положениях. В этом случае принято ослаблять схему совместного использования параметров и вместо этого просто называть уровень Locally-Connected Layer .
Примеры Numpy. Чтобы сделать обсуждение выше более конкретным, давайте выразим те же идеи, но в коде и на конкретном примере. Предположим, что входной объем представляет собой массив X numpy. Тогда:
- Столбец глубины (или волокно ) в позиции
(x,y)будет активациейX[x,y,:]. - Срез глубины или эквивалентная карта активации на глубине
dбудет активациямиX[:,:,d].
Пример слоя конверсии . Предположим, что входной объем X имеет форму X.shape: (11,11,4) . Предположим далее, что мы не используем заполнение нулями (\(P = 0\)), что размер фильтра равен \(F = 5\) и что шаг равен \(S = 2\). Таким образом, выходной объем будет иметь пространственный размер (11-5)/2+1 = 4, что дает объем с шириной и высотой 4.Карта активации в выходном томе (назовем ее
Таким образом, выходной объем будет иметь пространственный размер (11-5)/2+1 = 4, что дает объем с шириной и высотой 4.Карта активации в выходном томе (назовем ее V ) будет выглядеть следующим образом (в этом примере вычисляются только некоторые элементы):
-
V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0 -
V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0 -
V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0 -
V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0
Помните, что в numpy операция * выше обозначает поэлементное умножение между массивами.Заметьте также, что весовой вектор W0 — это весовой вектор этого нейрона, а b0 — это смещение. Здесь предполагается, что W0 имеет форму W0.shape: (5,5,4) , поскольку размер фильтра равен 5, а глубина входного объема равна 4. Обратите внимание, что в каждой точке мы вычисляем скалярный продукт, как это было показано ранее в обычных нейронных сетях. Кроме того, мы видим, что используем тот же вес и смещение (из-за совместного использования параметров), и где размеры по ширине увеличиваются с шагом 2 (т.е. шаг). Чтобы построить вторую карту активации в выходном томе, у нас будет:
Кроме того, мы видим, что используем тот же вес и смещение (из-за совместного использования параметров), и где размеры по ширине увеличиваются с шагом 2 (т.е. шаг). Чтобы построить вторую карту активации в выходном томе, у нас будет:
-
V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1 -
V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1 -
V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1 -
V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1 -
V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1(пример прохождения по y) -
V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1(или по обоим)
, где мы видим, что мы индексируем второе измерение глубины в V (по индексу 1), потому что мы вычисляем вторую карту активации, и что теперь используется другой набор параметров ( W1 ). В приведенном выше примере мы для краткости опускаем некоторые другие операции, которые Conv Layer будет выполнять для заполнения других частей выходного массива V . Кроме того, вспомните, что эти карты активации часто следуют по элементам через функцию активации, такую как ReLU, но здесь это не показано.
Кроме того, вспомните, что эти карты активации часто следуют по элементам через функцию активации, такую как ReLU, но здесь это не показано.
Сводка . Подводя итог, Conv Layer:
- Принимает том размером \(W_1 \x H_1 \x D_1\)
- Требуется четыре гиперпараметра:
- Количество фильтров \(K\),
- их пространственная протяженность \(F\),
- шаг \(S\),
- количество заполнения нулями \(P\).
- Создает том размером \(W_2 \times H_2 \times D_2\), где:
- \(W_2 = (W_1 — F + 2P)/S + 1\)
- \(H_2 = (H_1 — F + 2P)/S + 1\) (т.е. ширина и высота вычисляются одинаково по симметрии)
- \(Д_2 = К\)
- При совместном использовании параметров он вводит \(F \cdot F \cdot D_1\) весов для каждого фильтра, всего \((F \cdot F \cdot D_1) \cdot K\) весов и \(K\) смещений .
- В выходном объеме \(d\)-й срез глубины (размером \(W_2 \times H_2\)) является результатом корректной свертки \(d\)-го фильтра над входным объемом с шагом \(S\), а затем со смещением на \(d\)-й уклон.

Общая настройка гиперпараметров: \(F = 3, S = 1, P = 1\). Однако существуют общие соглашения и эмпирические правила, которые мотивируют эти гиперпараметры. См. раздел архитектуры ConvNet ниже.
Демонстрация свертки . Ниже приведена работающая демонстрация слоя CONV. Поскольку 3D-объемы трудно визуализировать, все объемы (входной объем (синий), весовые объемы (красный), выходной объем (зеленый)) визуализируются с каждым срезом глубины, сложенным в строки.Входной объем имеет размер \(W_1 = 5, H_1 = 5, D_1 = 3\), а параметры слоя CONV: \(K = 2, F = 3, S = 2, P = 1\). То есть у нас есть два фильтра размера \(3 \times 3\), и они применяются с шагом 2. Следовательно, размер выходного объема имеет пространственный размер (5 — 3 + 2)/2 + 1 = 3 Кроме того, обратите внимание, что к входному объему применяется отступ \(P = 1\), что делает внешнюю границу входного объема нулевой. Визуализация ниже повторяет активацию вывода (зеленый) и показывает, что каждый элемент вычисляется путем поэлементного умножения выделенного ввода (синий) на фильтр (красный), суммирования и последующего смещения результата на смещение.
Реализация как умножение матриц . Обратите внимание, что операция свертки по существу выполняет скалярные произведения между фильтрами и локальными областями ввода. Обычный шаблон реализации слоя CONV состоит в том, чтобы воспользоваться этим фактом и сформулировать прямой проход сверточного слоя как одну большую матрицу, умноженную следующим образом:
- Локальные области входного изображения растягиваются в столбцы в ходе операции, обычно называемой im2col .Например, если входные данные имеют размер [227x227x3] и должны быть свернуты с фильтрами 11x11x3 на шаге 4, тогда мы возьмем [11x11x3] блоков пикселей во входных данных и растянем каждый блок в вектор-столбец размером 11*11*. 3 = 363. Повторение этого процесса на входе с шагом 4 дает (227-11)/4+1 = 55 местоположений как по ширине, так и по высоте, что приводит к выходной матрице
X_colиз im2col размером [363 x 3025], где каждый столбик представляет собой вытянутое рецептивное поле, а всего их 55*55 = 3025. Обратите внимание, что, поскольку рецептивные поля перекрываются, каждое число во входном объеме может дублироваться в нескольких отдельных столбцах.
Обратите внимание, что, поскольку рецептивные поля перекрываются, каждое число во входном объеме может дублироваться в нескольких отдельных столбцах. - Вес слоя CONV аналогичным образом растягивается в строки. Например, если есть 96 фильтров размером [11x11x3], это даст матрицу
W_rowразмера [96 x 363]. - Результат свертки теперь эквивалентен выполнению одной большой матрицы, умноженной на
np.dot(W_row, X_col), которая оценивает скалярное произведение между каждым фильтром и каждым местоположением восприимчивого поля.В нашем примере выход этой операции будет [96 x 3025], что даст результат скалярного произведения каждого фильтра в каждом месте. - Наконец, результат должен быть преобразован обратно в правильный выходной размер [55x55x96].
Недостатком этого подхода является то, что он может использовать много памяти, поскольку некоторые значения во входном томе реплицируются несколько раз в X_col . Однако преимущество заключается в том, что существует множество очень эффективных реализаций умножения матриц, которыми мы можем воспользоваться (например, в широко используемом API BLAS).Более того, ту же идею im2col можно повторно использовать для выполнения операции объединения, которую мы обсудим далее.
Однако преимущество заключается в том, что существует множество очень эффективных реализаций умножения матриц, которыми мы можем воспользоваться (например, в широко используемом API BLAS).Более того, ту же идею im2col можно повторно использовать для выполнения операции объединения, которую мы обсудим далее.
Обратное распространение. Обратный проход для операции свертки (как для данных, так и для весов) также является сверткой (но с пространственно-перевернутыми фильтрами). Это легко вывести в одномерном случае на игрушечном примере (пока не расширяемом).
1×1 свертка . Кроме того, в нескольких статьях используются свертки 1×1, впервые исследованные Network in Network.Некоторые люди сначала сбиты с толку, увидев извилины 1×1, особенно когда они исходят из фона обработки сигналов. Обычно сигналы являются двумерными, поэтому свертки 1×1 не имеют смысла (это просто точечное масштабирование). Однако в ConvNets это не так, потому что нужно помнить, что мы работаем с трехмерными объемами и что фильтры всегда распространяются на всю глубину входного объема. Например, если ввод [32x32x3], то выполнение сверток 1×1 будет эффективно выполнять 3-мерные скалярные произведения (поскольку глубина ввода составляет 3 канала).
Например, если ввод [32x32x3], то выполнение сверток 1×1 будет эффективно выполнять 3-мерные скалярные произведения (поскольку глубина ввода составляет 3 канала).
Расширенные извилины. Недавняя разработка (см., например, статью Фишера Ю и Владлена Колтуна) состоит в том, чтобы ввести еще один гиперпараметр в слой CONV, называемый расширением . До сих пор мы обсуждали только непрерывные фильтры CONV. Однако можно использовать фильтры с промежутками между ячейками, называемыми расширением. Например, в одном измерении фильтр w размера 3 будет вычислять по входным данным x следующее: w[0]*x[0] + w[1]*x[1] + w[2] *x[2] .Это расширение равное 0. Для расширения 1 фильтр вместо этого вычислит w[0]*x[0] + w[1]*x[2] + w[2]*x[4] ; Другими словами, между приложениями существует разрыв в 1. Это может быть очень полезно в некоторых настройках для использования в сочетании с 0-расширенными фильтрами, потому что это позволяет вам объединять пространственную информацию по входным данным гораздо более агрессивно с меньшим количеством слоев. Например, если вы наложите два слоя CONV 3×3 друг на друга, то вы можете убедиться, что нейроны на 2-м слое являются функцией патча 5×5 входных данных (мы бы сказали, что эффективное рецептивное поле этих нейронов 5х5).Если бы мы использовали расширенные извилины, то это эффективное рецептивное поле росло бы гораздо быстрее.
Например, если вы наложите два слоя CONV 3×3 друг на друга, то вы можете убедиться, что нейроны на 2-м слое являются функцией патча 5×5 входных данных (мы бы сказали, что эффективное рецептивное поле этих нейронов 5х5).Если бы мы использовали расширенные извилины, то это эффективное рецептивное поле росло бы гораздо быстрее.
Слой объединения
Общепринято периодически вставлять слой пула между последовательными слоями Conv в архитектуре ConvNet. Его функция состоит в том, чтобы постепенно уменьшать пространственный размер представления, чтобы уменьшить количество параметров и вычислений в сети и, следовательно, контролировать переоснащение. Слой пула работает независимо с каждым срезом глубины входных данных и изменяет его размер в пространстве, используя операцию MAX.Наиболее распространенная форма — это объединяющий слой с фильтрами размером 2×2, применяемыми с шагом в 2 даунсэмплинга каждого среза глубины во входных данных на 2 по ширине и высоте, отбрасывая 75% активаций.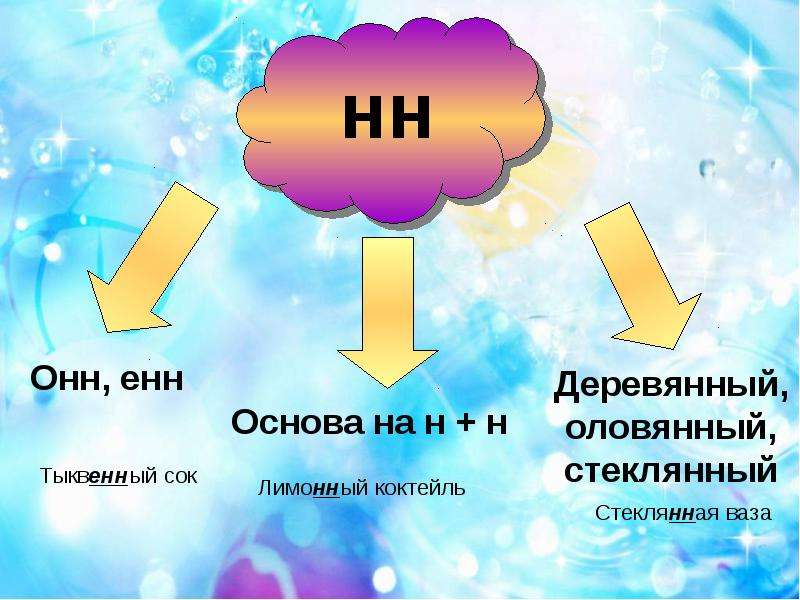 Каждая операция MAX в этом случае будет принимать максимум 4 числа (маленькая область 2×2 в некотором срезе глубины). Размер глубины остается неизменным. В более общем случае слой пула:
Каждая операция MAX в этом случае будет принимать максимум 4 числа (маленькая область 2×2 в некотором срезе глубины). Размер глубины остается неизменным. В более общем случае слой пула:
- Принимает том размером \(W_1 \x H_1 \x D_1\)
- Требуются два гиперпараметра:
- их пространственная протяженность \(F\),
- шаг \(S\),
- Создает том размером \(W_2 \times H_2 \times D_2\), где:
- \(W_2 = (W_1 — F)/S + 1\)
- \(H_2 = (H_1 — F)/S + 1\)
- \(Д_2 = Д_1\)
- Вводит нулевые параметры, поскольку вычисляет фиксированную функцию ввода
- Для объединенных слоев не принято дополнять ввод нулями.
Стоит отметить, что на практике встречаются только два часто встречающихся варианта слоя максимального объединения: слой объединения с \(F = 3, S = 2\) (также называемый перекрывающимся объединением) и чаще \( F = 2, S = 2\). Объединение размеров с большими рецептивными полями слишком разрушительно.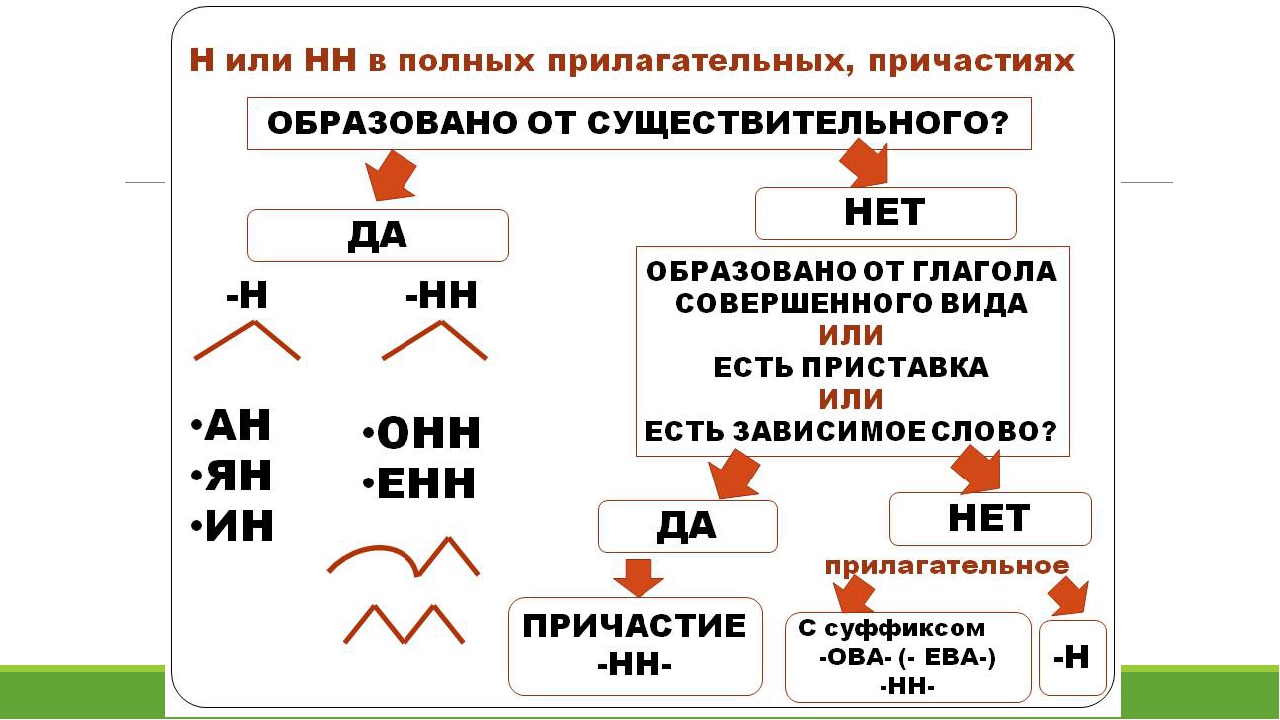
Общий пул . В дополнение к максимальному объединению блоки объединения могут также выполнять другие функции, такие как объединение среднего значения или даже объединение L2-нормы .Среднее объединение часто использовалось исторически, но в последнее время потеряло популярность по сравнению с максимальным объединением, которое, как было показано на практике, работает лучше.
Слой пула уменьшает объем пространственно, независимо в каждом срезе глубины входного объема. Слева: В этом примере входной том размером [224x224x64] объединяется с размером фильтра 2, шагом 2 в выходной том размером [112x112x64]. Обратите внимание, что глубина тома сохраняется. Справа: Наиболее распространенной операцией понижения дискретизации является max, что приводит к max pooling , здесь показано с шагом 2.То есть каждый макс берется за 4 числа (маленький квадратик 2х2).
Обратное распространение .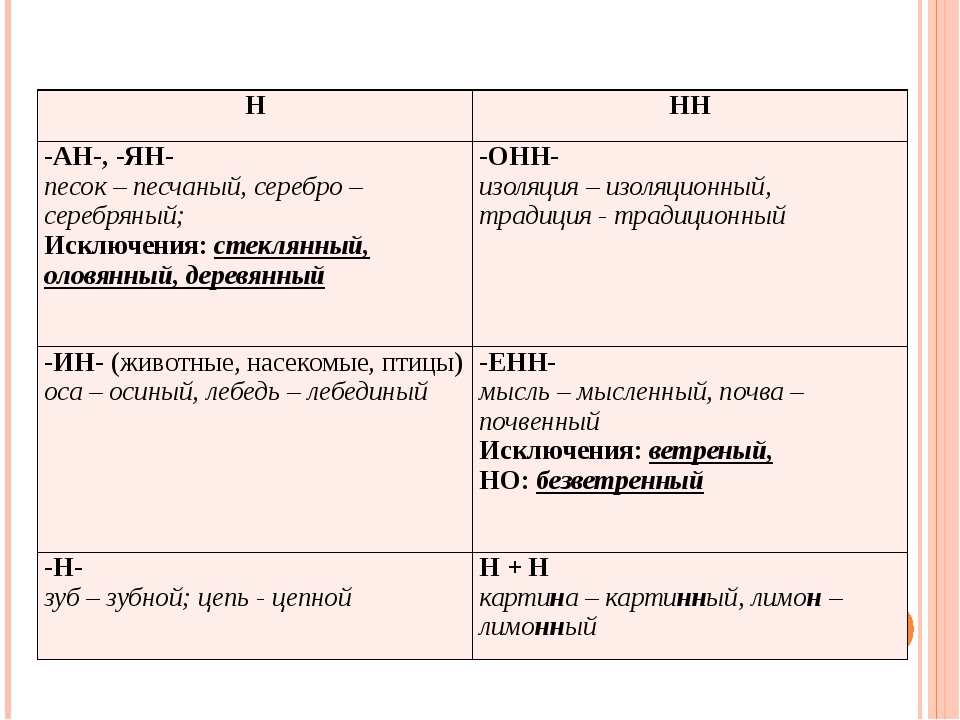 Вспомним из главы об обратном распространении, что обратный проход для операции max(x, y) имеет простую интерпретацию как маршрутизацию градиента только к входу, который имеет наибольшее значение в прямом проходе. Следовательно, во время прямого прохождения уровня пула обычно отслеживают индекс максимальной активации (иногда также называемый переключателями ), чтобы градиентная маршрутизация была эффективной во время обратного распространения.
Вспомним из главы об обратном распространении, что обратный проход для операции max(x, y) имеет простую интерпретацию как маршрутизацию градиента только к входу, который имеет наибольшее значение в прямом проходе. Следовательно, во время прямого прохождения уровня пула обычно отслеживают индекс максимальной активации (иногда также называемый переключателями ), чтобы градиентная маршрутизация была эффективной во время обратного распространения.
Избавление от объединения . Многим не нравится операция объединения, и они думают, что можно обойтись и без нее. Например, «Стремление к простоте: вся сверточная сеть» предлагает отказаться от слоя объединения в пользу архитектуры, состоящей только из повторяющихся слоев CONV. Чтобы уменьшить размер представления, они предлагают время от времени использовать больший шаг в слое CONV. Также было обнаружено, что отказ от группирующих слоев важен для обучения хороших генеративных моделей, таких как вариационные автоэнкодеры (VAE) или генеративно-состязательные сети (GAN). Кажется вероятным, что в будущих архитектурах будет очень мало слоев объединения или вообще не будет.
Кажется вероятным, что в будущих архитектурах будет очень мало слоев объединения или вообще не будет.
Уровень нормализации
Многие типы слоев нормализации были предложены для использования в архитектурах ConvNet, иногда с намерением реализовать схемы торможения, наблюдаемые в биологическом мозге. Однако с тех пор эти слои потеряли популярность, потому что на практике их вклад был минимальным, если вообще был. Различные типы нормализации см. в обсуждении API библиотеки cuda-convnet Алекса Крижевского.
Полносвязный слой
Нейроны в полностью подключенном слое имеют полные подключения ко всем активациям в предыдущем слое, как это видно в обычных нейронных сетях. Следовательно, их активации можно вычислить с помощью матричного умножения, за которым следует смещение смещения. Дополнительную информацию см. в разделе примечаний к нейронной сети .
Преобразование слоев FC в слои CONV
Стоит отметить, что единственная разница между слоями FC и CONV заключается в том, что нейроны в слое CONV связаны только с локальной областью на входе, и что многие нейроны в объеме CONV имеют общие параметры. Однако нейроны в обоих слоях по-прежнему вычисляют скалярные произведения, поэтому их функциональная форма идентична. Следовательно, получается, что можно преобразовать между слоями FC и CONV:
Однако нейроны в обоих слоях по-прежнему вычисляют скалярные произведения, поэтому их функциональная форма идентична. Следовательно, получается, что можно преобразовать между слоями FC и CONV:
- Для любого уровня CONV существует уровень FC, который реализует ту же функцию прямой передачи. Матрица весов будет большой матрицей, которая в основном равна нулю, за исключением некоторых блоков (из-за локальной связи), где веса во многих блоках равны (из-за совместного использования параметров).
- И наоборот, любой слой FC можно преобразовать в слой CONV.Например, слой FC с \(K = 4096\), который просматривает некоторый входной объем размером \(7 \x 7 \times 512\), может быть эквивалентно выражен как слой CONV с \(F = 7, P = 0, S = 1, К = 4096\). Другими словами, мы устанавливаем размер фильтра точно равным размеру входного объема, и, следовательно, на выходе будет просто \(1 \times 1 \times 4096\), так как только один столбец глубины «подходит» для входных данных. объем, что дает тот же результат, что и начальный слой FC.

Преобразование FC->CONV .Из этих двух преобразований возможность преобразования слоя FC в слой CONV особенно полезна на практике. Рассмотрим архитектуру ConvNet, которая берет изображение размером 224x224x3, а затем использует ряд слоев CONV и слоев POOL, чтобы уменьшить изображение до активационного тома размером 7x7x512 (в архитектуре AlexNet , которую мы увидим позже, это делается с помощью использование 5 объединяющих слоев, которые уменьшают входные данные в два раза каждый раз, делая окончательный пространственный размер 224/2/2/2/2/2 = 7).Оттуда AlexNet использует два слоя FC размером 4096 и, наконец, последние слои FC с 1000 нейронами, которые вычисляют оценки класса. Мы можем преобразовать каждый из этих трех слоев FC в слои CONV, как описано выше:
- Замените первый слой FC, который просматривает объем [7x7x512], слоем CONV, который использует размер фильтра \(F = 7\), что дает выходной объем [1x1x4096].
- Замените второй слой FC на слой CONV, который использует размер фильтра \(F = 1\), что дает выходной объем [1x1x4096]
- Аналогично заменить последний слой FC на \(F=1\), что даст окончательный результат [1x1x1000]
Каждое из этих преобразований на практике может включать в себя манипулирование (например,г.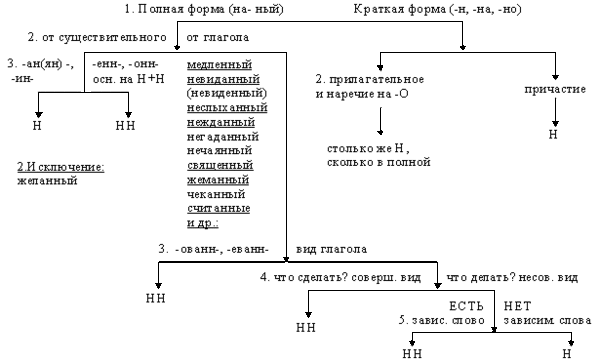 преобразование) весовой матрицы \(W\) в каждом слое FC в фильтры слоя CONV. Оказывается, это преобразование позволяет нам очень эффективно «скользить» исходной ConvNet по многим пространственным позициям в более крупном изображении за один проход вперед.
преобразование) весовой матрицы \(W\) в каждом слое FC в фильтры слоя CONV. Оказывается, это преобразование позволяет нам очень эффективно «скользить» исходной ConvNet по многим пространственным позициям в более крупном изображении за один проход вперед.
Например, если изображение 224×224 дает том размером [7x7x512] — т.е. уменьшение на 32, то пересылка изображения размером 384×384 через преобразованную архитектуру даст эквивалентный том размером [12x12x512], так как 384/32 = 12 , Выполнение следующих трех слоев CONV, которые мы только что преобразовали из слоев FC, теперь даст окончательный объем размером [6x6x1000], поскольку (12 — 7)/1 + 1 = 6.Обратите внимание, что вместо одного вектора оценок классов размером [1x1x1000] теперь мы получаем целый массив оценок классов 6×6 на изображении 384×384.
Независимая оценка исходной ConvNet (со слоями FC) на кадрах 224×224 изображения 384×384 с шагом 32 пикселя дает тот же результат, что и однократная пересылка преобразованной ConvNet.
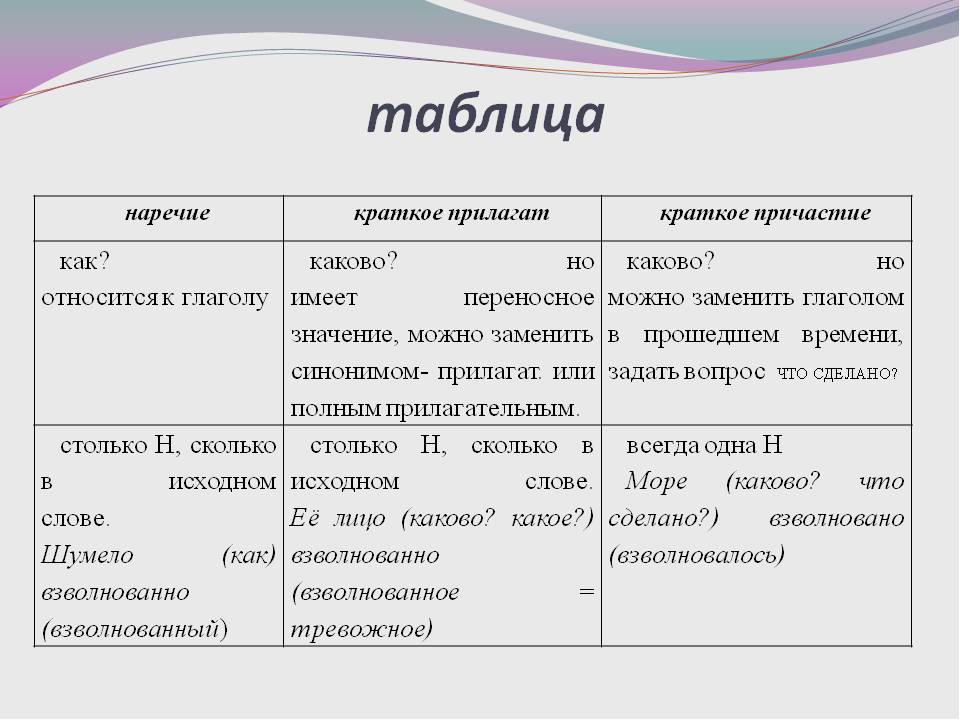
Естественно, однократное перенаправление преобразованной ConvNet намного эффективнее, чем итерация исходной ConvNet по всем этим 36 местоположениям, поскольку 36 вычислений используют общие вычисления.Этот трюк часто используется на практике для повышения производительности, когда, например, обычно изменяют размер изображения, чтобы сделать его больше, используют преобразованную ConvNet для оценки оценок класса во многих пространственных положениях, а затем усредняют оценки класса.
Наконец, что, если мы хотим эффективно применить исходную ConvNet к изображению, но с шагом менее 32 пикселей? Мы могли бы добиться этого с помощью нескольких проходов вперед. Например, обратите внимание, что если бы мы хотели использовать шаг в 16 пикселей, мы могли бы сделать это, объединив объемы, полученные путем пересылки преобразованной ConvNet дважды: сначала поверх исходного изображения, а затем поверх изображения, но с пространственным смещением изображения на 16 пикселей. как по ширине, так и по высоте.
как по ширине, так и по высоте.
- Записная книжка IPython в Net Surgery показывает, как выполнить преобразование на практике в коде (с использованием Caffe)
Архитектуры ConvNet
Мы видели, что сверточные сети обычно состоят только из трех типов слоев: CONV, POOL (мы предполагаем максимальный пул, если не указано иное) и FC (сокращенно от полносвязного). Мы также явно напишем функцию активации RELU в виде слоя, который применяет поэлементную нелинейность. В этом разделе мы обсудим, как они обычно складываются вместе, чтобы сформировать целые ConvNets.
Шаблоны слоев
Наиболее распространенная форма архитектуры ConvNet объединяет несколько слоев CONV-RELU, за которыми следуют слои POOL, и повторяет этот шаблон до тех пор, пока изображение не будет пространственно объединено до небольшого размера. В какой-то момент обычно происходит переход к полносвязным слоям. Последний полносвязный слой содержит выходные данные, такие как баллы класса. Другими словами, наиболее распространенная архитектура ConvNet соответствует шаблону:
Другими словами, наиболее распространенная архитектура ConvNet соответствует шаблону:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
, где * указывает на повторение, а POOL? указывает необязательный слой пула.Более того, N >= 0 (и обычно N <= 3 ), M >= 0 , K >= 0 (и обычно K < 3 ). Например, вот некоторые распространенные архитектуры ConvNet, которые следуют этому шаблону:
-
INPUT -> FC, реализует линейный классификатор. ЗдесьN = M = K = 0. -
ВХОД -> ПРЕОБРАЗОВАТЕЛЬ -> RELU -> FC -
ВХОД -> [ПРЕОБРАЗОВАТЬ -> RELU -> ПУЛ]*2 -> FC -> RELU -> FC.Здесь мы видим, что между каждым слоем POOL есть один слой CONV. -
INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FCЗдесь мы видим два слоя CONV, расположенных перед каждым слоем POOL. Как правило, это хорошая идея для больших и глубоких сетей, потому что несколько сложенных слоев CONV могут развивать более сложные функции входного тома перед операцией деструктивного объединения.
Как правило, это хорошая идея для больших и глубоких сетей, потому что несколько сложенных слоев CONV могут развивать более сложные функции входного тома перед операцией деструктивного объединения.
Предпочитайте стек малых фильтров CONV одному большому слою CONV рецептивного поля .Предположим, вы накладываете три слоя CONV 3x3 друг на друга (конечно, с нелинейностью между ними). При таком расположении каждый нейрон на первом слое CONV имеет представление входного объема 3x3. Нейрон на втором слое CONV имеет представление 3x3 первого слоя CONV и, следовательно, представление входного объема 5x5. Точно так же нейрон на третьем слое CONV имеет представление 3x3 2-го слоя CONV и, следовательно, представление входного объема 7x7. Предположим, что вместо этих трех слоев 3x3 CONV мы хотели использовать только один слой CONV с рецептивными полями 7x7.2\) параметры. Интуитивно понятно, что объединение слоев CONV с крошечными фильтрами вместо одного слоя CONV с большими фильтрами позволяет нам выражать более мощные функции ввода и с меньшим количеством параметров. В качестве практического недостатка нам может потребоваться больше памяти для хранения всех результатов промежуточного слоя CONV, если мы планируем выполнить обратное распространение.
В качестве практического недостатка нам может потребоваться больше памяти для хранения всех результатов промежуточного слоя CONV, если мы планируем выполнить обратное распространение.
Последние отправления. Следует отметить, что общепринятая парадигма линейного списка уровней недавно подверглась сомнению в архитектуре Google Inception, а также в текущих (современных) Residual Networks от Microsoft Research Asia.Оба они (подробности см. ниже в разделе тематических исследований) имеют более сложные и разные структуры подключения.
На практике: используйте то, что лучше всего работает в ImageNet . Если вы чувствуете некоторую усталость при обдумывании архитектурных решений, вам будет приятно узнать, что в 90% или более приложений вам не нужно об этом беспокоиться. Мне нравится резюмировать этот пункт как «, не будь героем »: вместо того, чтобы использовать собственную архитектуру для решения проблемы, вы должны посмотреть на ту архитектуру, которая в настоящее время лучше всего работает в ImageNet, загрузить предварительно обученную модель и настроить ее на свои данные. .Вам редко когда-либо придется обучать ConvNet с нуля или разрабатывать ее с нуля. Я также говорил об этом в школе глубокого обучения.
Шаблоны размеров слоев
До сих пор мы опускали упоминания об общих гиперпараметрах, используемых в каждом из слоев ConvNet. Сначала мы сформулируем общие эмпирические правила определения размеров архитектур, а затем будем следовать этим правилам при обсуждении обозначений:
.Входной слой (содержащий изображение) должен многократно делиться на 2.Общие номера включают 32 (например, CIFAR-10), 64, 96 (например, STL-10) или 224 (например, обычные сети ImageNet ConvNet), 384 и 512.
В свёрнутых слоях должны использоваться небольшие фильтры (например, 3x3 или не более 5x5), с шагом \(S = 1\) и, что особенно важно, дополнять входной объём нулями таким образом, чтобы свёрнутый слой не изменить пространственные размеры ввода. То есть, когда \(F = 3\), то использование \(P = 1\) сохранит исходный размер ввода.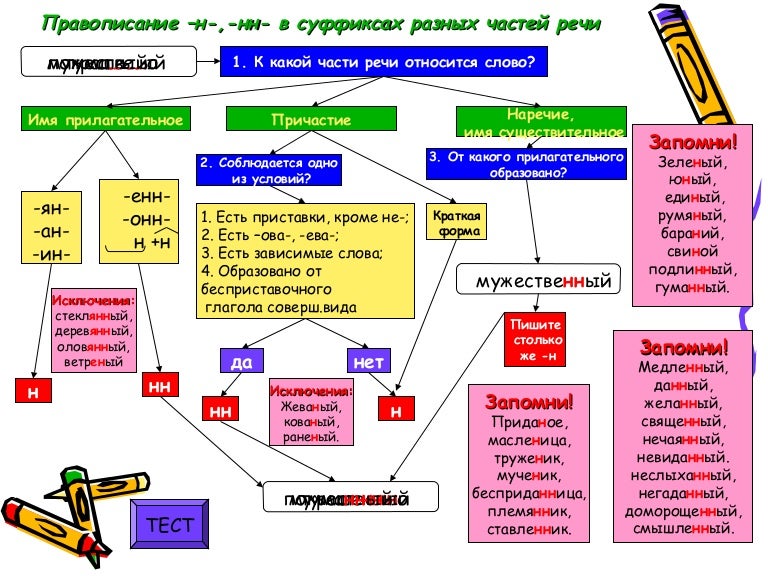 Когда \(F = 5\), \(P = 2\).Для общего \(F\) видно, что \(P = (F - 1)/2\) сохраняет размер ввода. Если вам необходимо использовать фильтр большего размера (например, 7x7 или около того), обычно это можно увидеть только на самом первом конверсионном слое, который просматривает входное изображение.
Когда \(F = 5\), \(P = 2\).Для общего \(F\) видно, что \(P = (F - 1)/2\) сохраняет размер ввода. Если вам необходимо использовать фильтр большего размера (например, 7x7 или около того), обычно это можно увидеть только на самом первом конверсионном слое, который просматривает входное изображение.
Слои пула отвечают за субдискретизацию пространственных измерений входных данных. Наиболее распространенной настройкой является использование максимального пула с рецептивными полями 2x2 (т.е. \(F = 2\)) и с шагом 2 (т.е. \(S = 2\)). Обратите внимание, что это отбрасывает ровно 75% активаций во входном объеме (из-за понижения частоты дискретизации на 2 как по ширине, так и по высоте).Другой немного менее распространенной настройкой является использование рецептивных полей 3x3 с шагом 2, но это усложняет «подгонку» (например, слой 32x32x3 потребует использования нулевого заполнения со слоем максимального объединения с рецептивным полем 3x3 и шагом). 2). Очень редко можно увидеть размеры принимающего поля для максимального объединения, превышающие 3, потому что объединение в этом случае слишком агрессивно и с потерями. Обычно это приводит к ухудшению производительности.
Обычно это приводит к ухудшению производительности.
Уменьшение головной боли при выборе размера. Схема, представленная выше, приятна, потому что все слои CONV сохраняют пространственный размер своих входных данных, в то время как слои POOL сами отвечают за пространственное понижение дискретизации объемов.В альтернативной схеме, где мы используем шаги больше 1 или не заполняем входные данные нулями в слоях CONV, нам пришлось бы очень тщательно отслеживать входные объемы по всей архитектуре CNN и следить за тем, чтобы все шаги и фильтры «работали». out», и что архитектура ConvNet красиво и симметрично подключена.
Зачем использовать шаг 1 в CONV? Меньшие шаги работают лучше на практике. Кроме того, как уже упоминалось, шаг 1 позволяет нам оставить всю пространственную субдискретизацию слоям POOL, а слои CONV только преобразуют входной объем по глубине.
Зачем использовать отступы? В дополнение к вышеупомянутому преимуществу сохранения постоянных пространственных размеров после преобразования, это фактически повышает производительность. Если бы слои CONV не дополняли входы нулями, а выполняли только допустимые свертки, то размер томов уменьшался бы на небольшую величину после каждого CONV, а информация на границах слишком быстро «вымывалась бы».
Если бы слои CONV не дополняли входы нулями, а выполняли только допустимые свертки, то размер томов уменьшался бы на небольшую величину после каждого CONV, а информация на границах слишком быстро «вымывалась бы».
Компрометация на основе ограничений памяти. В некоторых случаях (особенно в ранних архитектурах ConvNet) объем памяти может очень быстро увеличиваться в соответствии с эмпирическими правилами, представленными выше.Например, фильтрация изображения 224x224x3 с тремя слоями CONV 3x3 с 64 фильтрами в каждом и отступом 1 создаст три тома активации размером [224x224x64]. Это составляет в общей сложности около 10 миллионов активаций или 72 МБ памяти (на изображение, как для активаций, так и для градиентов). Поскольку узким местом графических процессоров часто является объем памяти, может потребоваться компромисс. На практике люди предпочитают идти на компромисс только на первом уровне CONV сети. Например, одним из компромиссов может быть использование первого слоя CONV с размером фильтра 7x7 и шагом 2 (как показано в сети ZF). В качестве другого примера, AlexNet использует размер фильтра 11x11 и шаг 4.
В качестве другого примера, AlexNet использует размер фильтра 11x11 и шаг 4.
Тематические исследования
В области сверточных сетей существует несколько архитектур, имеющих названия. Самые распространенные:
- Ленет . Первые успешные приложения сверточных сетей были разработаны Яном Лекуном в 1990-х годах. Из них наиболее известна архитектура LeNet, которая использовалась для чтения почтовых индексов, цифр и т. д.
- AlexNet .Первой работой, которая популяризировала сверточные сети в компьютерном зрении, была AlexNet, разработанная Алексом Крижевским, Ильей Суцкевером и Джеффом Хинтоном. AlexNet был отправлен на конкурс ImageNet ILSVRC в 2012 году и значительно опередил второе место, занявшее второе место (ошибка в пятерке лучших 16% по сравнению с занявшим второе место с ошибкой 26%). Сеть имела очень похожую архитектуру на LeNet, но была глубже, больше и содержала сверточные слои, расположенные друг над другом (ранее было обычным делом иметь только один слой CONV, за которым сразу же следовал слой POOL).
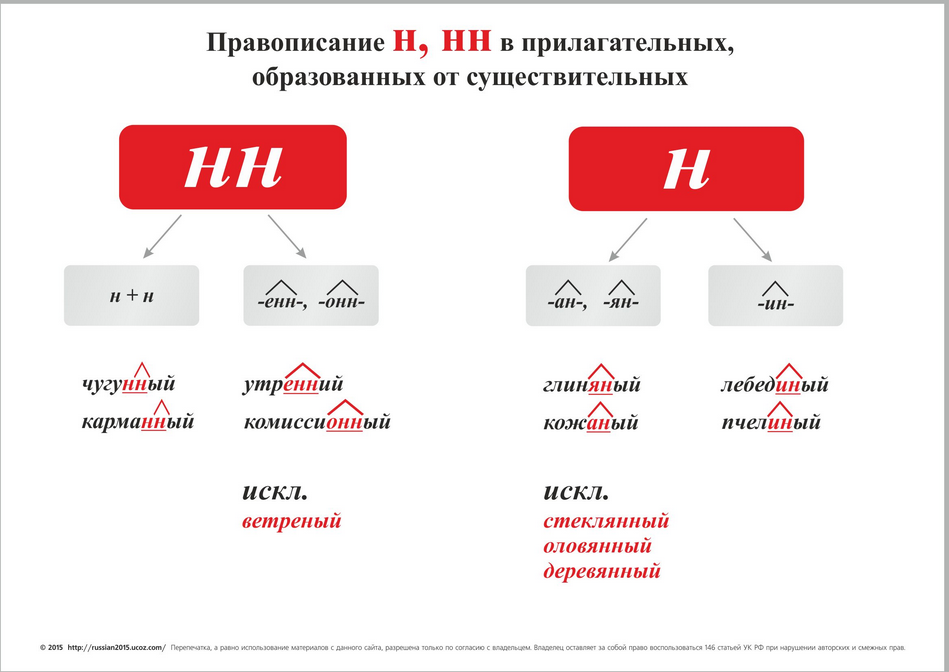
- ZF Net . Победителем ILSVRC 2013 стала сверточная сеть от Мэтью Зейлера и Роба Фергуса. Он стал известен как ZFNet (сокращение от Zeiler & Fergus Net). Это было улучшение AlexNet за счет настройки гиперпараметров архитектуры, в частности, за счет увеличения размера средних сверточных слоев и уменьшения размера шага и фильтра на первом слое.
- ГугЛеНет . Победителем ILSVRC 2014 стала сверточная сеть от Szegedy et al.от Google. Его основным вкладом стала разработка начального модуля , который значительно сократил количество параметров в сети (4M по сравнению с AlexNet с 60M). Кроме того, в этой статье используется средний пул вместо полносвязных слоев в верхней части ConvNet, что устраняет большое количество параметров, которые, кажется, не имеют большого значения. Есть также несколько последующих версий GoogLeNet, последняя из которых — Inception-v4.
- VGGNet . Второе место в ILSVRC 2014 заняла сеть Карена Симоняна и Эндрю Зиссермана, которая стала известна как VGGNet.
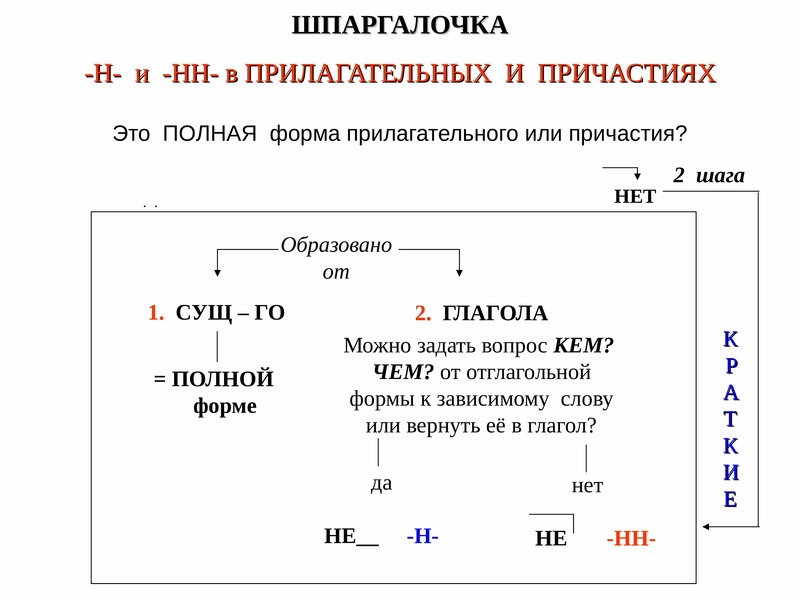 Его основной вклад заключался в демонстрации того, что глубина сети является критическим компонентом для хорошей производительности. Их последняя лучшая сеть содержит 16 слоев CONV/FC и, что интересно, имеет чрезвычайно однородную архитектуру, которая от начала до конца выполняет только свертки 3x3 и пул 2x2. Их предварительно обученная модель доступна для использования в Caffe. Недостатком VGGNet является более высокая стоимость оценки и использование гораздо большего объема памяти и параметров (140 МБ). Большинство этих параметров находятся на первом полносвязном уровне, и с тех пор было обнаружено, что эти уровни FC можно удалить без снижения производительности, что значительно уменьшает количество необходимых параметров.
Его основной вклад заключался в демонстрации того, что глубина сети является критическим компонентом для хорошей производительности. Их последняя лучшая сеть содержит 16 слоев CONV/FC и, что интересно, имеет чрезвычайно однородную архитектуру, которая от начала до конца выполняет только свертки 3x3 и пул 2x2. Их предварительно обученная модель доступна для использования в Caffe. Недостатком VGGNet является более высокая стоимость оценки и использование гораздо большего объема памяти и параметров (140 МБ). Большинство этих параметров находятся на первом полносвязном уровне, и с тех пор было обнаружено, что эти уровни FC можно удалить без снижения производительности, что значительно уменьшает количество необходимых параметров. - Реснет . Остаточная сеть, разработанная Kaiming He et al. стал победителем ILSVRC 2015. Он имеет специальные пропускные соединения и интенсивное использование пакетной нормализации. В архитектуре также отсутствуют полносвязные слои в конце сети.
 Читателю также предлагается презентация Кайминга (видео, слайды) и некоторые недавние эксперименты, воспроизводящие эти сети в Torch. ResNets в настоящее время являются самыми современными моделями сверточных нейронных сетей и являются выбором по умолчанию для использования ConvNets на практике (по состоянию на 10 мая 2016 г.).В частности, также см. более свежие разработки, которые настраивают исходную архитектуру от Kaiming He et al. Отображение идентичности в глубоких остаточных сетях (опубликовано в марте 2016 г.).
Читателю также предлагается презентация Кайминга (видео, слайды) и некоторые недавние эксперименты, воспроизводящие эти сети в Torch. ResNets в настоящее время являются самыми современными моделями сверточных нейронных сетей и являются выбором по умолчанию для использования ConvNets на практике (по состоянию на 10 мая 2016 г.).В частности, также см. более свежие разработки, которые настраивают исходную архитектуру от Kaiming He et al. Отображение идентичности в глубоких остаточных сетях (опубликовано в марте 2016 г.).
VGGNet подробно . Давайте разберем VGGNet более подробно в качестве примера. Вся VGGNet состоит из слоев CONV, которые выполняют свертки 3x3 с шагом 1 и шагом 1, и слоев POOL, которые выполняют максимальное объединение 2x2 с шагом 2 (и без заполнения). Мы можем выписывать размер представления на каждом шаге обработки и отслеживать как размер представления, так и общее количество весов:
ВХОД: [224x224x3] память: 224*224*3=150K веса: 0
CONV3-64: [224x224x64] память: 224*224*64=3. 2M веса: (3*3*3)*64 = 1728
CONV3-64: [224x224x64] память: 224*224*64=3,2 М вес: (3*3*64)*64 = 36 864
POOL2: [112x112x64] память: 112*112*64=800K веса: 0
CONV3-128: [112x112x128] память: 112*112*128=1,6 М вес: (3*3*64)*128 = 73 728
CONV3-128: [112x112x128] память: 112*112*128=1,6 М веса: (3*3*128)*128 = 147 456
POOL2: [56x56x128] память: 56*56*128=400K веса: 0
CONV3-256: [56x56x256] память: 56*56*256=800K веса: (3*3*128)*256 = 294 912
CONV3-256: [56x56x256] память: 56*56*256=800K веса: (3*3*256)*256 = 589 824
CONV3-256: [56x56x256] память: 56*56*256=800K веса: (3*3*256)*256 = 589 824
POOL2: [28x28x256] память: 28*28*256=200K веса: 0
CONV3-512: [28x28x512] память: 28*28*512=400K веса: (3*3*256)*512 = 1 179 648
CONV3-512: [28x28x512] память: 28*28*512=400K веса: (3*3*512)*512 = 2 359 296
CONV3-512: [28x28x512] память: 28*28*512=400K веса: (3*3*512)*512 = 2 359 296
POOL2: [14x14x512] память: 14*14*512=100K веса: 0
CONV3-512: [14x14x512] память: 14*14*512=100K веса: (3*3*512)*512 = 2 359 296
CONV3-512: [14x14x512] память: 14*14*512=100K веса: (3*3*512)*512 = 2 359 296
CONV3-512: [14x14x512] память: 14*14*512=100K веса: (3*3*512)*512 = 2 359 296
POOL2: [7x7x512] память: 7*7*512=25K веса: 0
FC: [1x1x4096] память: 4096 веса: 7*7*512*4096 = 102 760 448
FC: [1x1x4096] память: 4096 веса: 4096*4096 = 16 777 216
FC: [1x1x1000] память: 1000 весов: 4096*1000 = 4 096 000
ВСЕГО памяти: 24M * 4 байта ~= 93MB/образ (только вперед! ~*2 для bwd)
ВСЕГО параметров: 138M параметров
2M веса: (3*3*3)*64 = 1728
CONV3-64: [224x224x64] память: 224*224*64=3,2 М вес: (3*3*64)*64 = 36 864
POOL2: [112x112x64] память: 112*112*64=800K веса: 0
CONV3-128: [112x112x128] память: 112*112*128=1,6 М вес: (3*3*64)*128 = 73 728
CONV3-128: [112x112x128] память: 112*112*128=1,6 М веса: (3*3*128)*128 = 147 456
POOL2: [56x56x128] память: 56*56*128=400K веса: 0
CONV3-256: [56x56x256] память: 56*56*256=800K веса: (3*3*128)*256 = 294 912
CONV3-256: [56x56x256] память: 56*56*256=800K веса: (3*3*256)*256 = 589 824
CONV3-256: [56x56x256] память: 56*56*256=800K веса: (3*3*256)*256 = 589 824
POOL2: [28x28x256] память: 28*28*256=200K веса: 0
CONV3-512: [28x28x512] память: 28*28*512=400K веса: (3*3*256)*512 = 1 179 648
CONV3-512: [28x28x512] память: 28*28*512=400K веса: (3*3*512)*512 = 2 359 296
CONV3-512: [28x28x512] память: 28*28*512=400K веса: (3*3*512)*512 = 2 359 296
POOL2: [14x14x512] память: 14*14*512=100K веса: 0
CONV3-512: [14x14x512] память: 14*14*512=100K веса: (3*3*512)*512 = 2 359 296
CONV3-512: [14x14x512] память: 14*14*512=100K веса: (3*3*512)*512 = 2 359 296
CONV3-512: [14x14x512] память: 14*14*512=100K веса: (3*3*512)*512 = 2 359 296
POOL2: [7x7x512] память: 7*7*512=25K веса: 0
FC: [1x1x4096] память: 4096 веса: 7*7*512*4096 = 102 760 448
FC: [1x1x4096] память: 4096 веса: 4096*4096 = 16 777 216
FC: [1x1x1000] память: 1000 весов: 4096*1000 = 4 096 000
ВСЕГО памяти: 24M * 4 байта ~= 93MB/образ (только вперед! ~*2 для bwd)
ВСЕГО параметров: 138M параметров
Обратите внимание, что, как это часто бывает в сверточных сетях, большая часть памяти (а также времени вычислений) используется на ранних слоях CONV, а большинство параметров находится на последних слоях FC.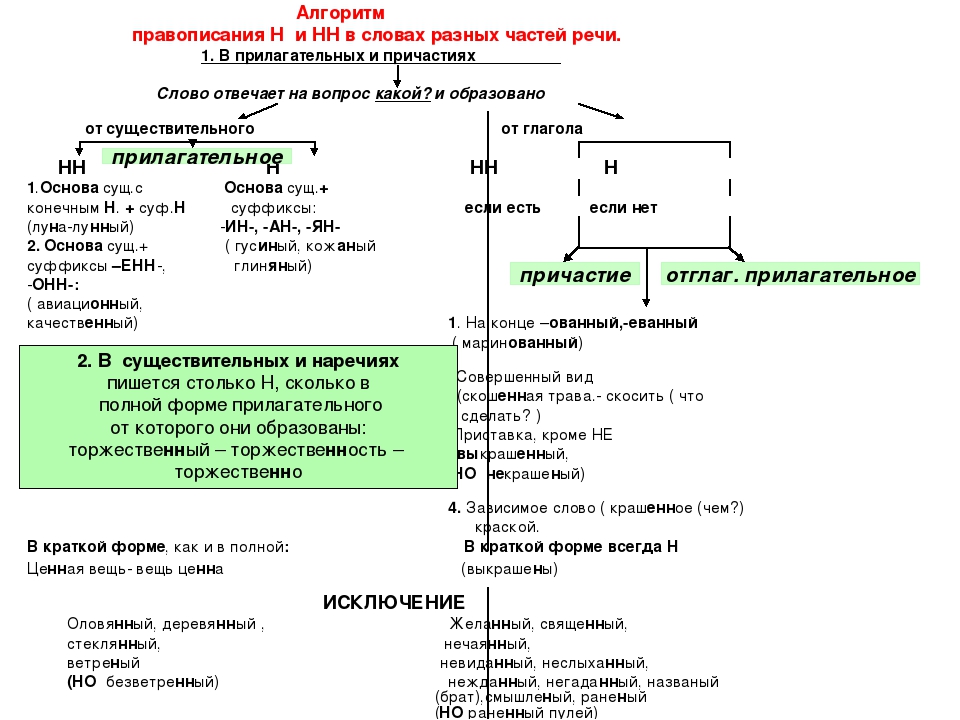 В этом конкретном случае первый слой FC содержит 100 миллионов весов из 140 миллионов.
В этом конкретном случае первый слой FC содержит 100 миллионов весов из 140 миллионов.
Вычислительные соображения
Самым большим узким местом, о котором следует помнить при построении архитектур ConvNet, является узкое место памяти. Многие современные графические процессоры имеют ограничение в 3/4/6 ГБ памяти, а лучшие графические процессоры имеют около 12 ГБ памяти. Необходимо отслеживать три основных источника памяти:
- Из промежуточных размеров тома: Это исходное количество активаций на каждом уровне ConvNet, а также их градиенты (равного размера).Обычно большинство активаций происходит на более ранних уровнях ConvNet (т. е. на первых слоях ConvNet). Они сохраняются, потому что они необходимы для обратного распространения, но умная реализация, которая запускает ConvNet только во время тестирования, может в принципе уменьшить это на огромную величину, сохраняя только текущие активации на любом уровне и отбрасывая предыдущие активации на уровнях ниже.
 .
. - Из размеров параметров: это числа, которые содержат параметры сети , их градиенты во время обратного распространения и обычно также кэш шагов, если оптимизация использует импульс, Adagrad или RMSProp.Следовательно, память для хранения только вектора параметров обычно должна быть умножена по крайней мере на 3 или около того.
- Каждая реализация ConvNet должна поддерживать разную память, такую как пакеты данных изображения, возможно, их расширенные версии и т. д.
После получения приблизительной оценки общего количества значений (для активаций, градиентов и прочего) это число следует преобразовать в размер в ГБ. Возьмите количество значений, умножьте на 4, чтобы получить необработанное количество байтов (поскольку каждая плавающая запятая составляет 4 байта или, возможно, на 8 для двойной точности), а затем разделите на 1024 несколько раз, чтобы получить объем памяти в КБ, МБ и, наконец, ГБ.Если ваша сеть не подходит, обычная эвристика «сделать ее подходящей» — уменьшить размер пакета, поскольку активация обычно потребляет большую часть памяти.
Дополнительные ресурсы
Дополнительные ресурсы, связанные с внедрением:
Что такое списание по категории A, категории B, категории S или категории N?
3. Пройдите техосмотрЭто будет стоить вам более 200 фунтов стерлингов — крупная инвестиция, если вас привлекает машина из-за ее низкой цены, — но она того стоит.Инспектор знает, что нужно проверить, и может обнаружить повреждения, которые вы не заметили. AA, RAC, Dekra и Autolign предлагают услуги по проверке, которые могут уберечь вас от покупки потенциально небезопасного автомобиля.
4. Плата за проверку истории
Ущерб от несчастного случая — не единственное, о чем вам нужно думать. Как и в случае с обычным подержанным автомобилем, проверка истории покажет вам, был ли автомобиль украден или подлежит какой-либо непогашенной финансовой задолженности.
5. Будьте осторожны с более новыми автомобилями, предлагающими действительно большую экономию
Будьте осторожны с более новыми автомобилями, предлагающими действительно большую экономию Старая поговорка: «Если это выглядит слишком хорошо, чтобы быть правдой, возможно, так оно и есть» здесь определенно применима. Действительно низкая цена на новый автомобиль может быть признаком того, что ремонтные работы были выполнены в рамках бюджета и неудовлетворительного качества.
6. Избегайте автомобилей с повреждением шассиПовреждение кузова можно относительно легко исправить, но повреждение шасси будет по-прежнему вызывать головную боль, даже если была предпринята попытка ремонта.Вы должны быть вдвойне осторожны, если обнаружите, что у автомобиля возникла проблема в этой области.
Если вы считаете, что автомобиль Cat N стоит того, чтобы рискнуть, и вы решили его купить, есть еще две вещи, которые следует учитывать:
7. Сообщите своей страховой компании Обязательно сообщите своей страховой компании, что автомобиль категории N. Скорее всего, он должен быть отмечен в вашем полисе; в противном случае вы рискуете получить отказ в любом иске в будущем.
Скорее всего, он должен быть отмечен в вашем полисе; в противном случае вы рискуете получить отказ в любом иске в будущем.
Некоторые подержанные гарантийные поставщики предоставляют покрытие для автомобилей категории N.Это может быть на удивление экономичный способ дать себе душевное спокойствие о новой покупке и любом ремонте, который был сделан.
Чтобы быть в курсе последних обзоров, советов и предложений по новым автомобилям, подпишитесь на What Car? информационный бюллетень здесь
Почему данные One-Hot Encode в машинном обучении?
Последнее обновление: 30 июня 2020 г.
Приступить к прикладному машинному обучению может быть непросто, особенно при работе с реальными данными.
Часто учебные пособия по машинному обучению рекомендуют или требуют, чтобы вы подготовили данные особым образом, прежде чем подгонять модель машинного обучения.
Одним из хороших примеров является использование одноразового кодирования для категориальных данных.
- Почему требуется горячее кодирование?
- Почему вы не можете напрямую подогнать модель к вашим данным?
В этом посте вы найдете ответы на эти важные вопросы и лучше поймете подготовку данных в целом в прикладном машинном обучении.
Начните свой проект с моей новой книги «Подготовка данных для машинного обучения», включающей пошаговые руководства и файлы с исходным кодом Python для всех примеров.
Начнем.
Почему данные One-Hot Encode в машинном обучении?
Фото Карана Джейна, некоторые права защищены.
Что такое категориальные данные?
Категориальные данные — это переменные, которые содержат значения меток, а не числовые значения.
Количество возможных значений часто ограничивается фиксированным набором.
Категориальные переменные часто называют номинальными.
Некоторые примеры включают:
- Переменная « домашнее животное » со значениями: « собака » и « кошка ».

- Переменная « цвет » со значениями: « красный », « зеленый » и « синий ».
- Переменная « место » со значениями: «первый», « второй », и « третий ».
Каждое значение представляет отдельную категорию.
Некоторые категории могут иметь естественную связь друг с другом, например естественное упорядочение.
Переменная « место » выше имеет естественный порядок значений.Этот тип категориальной переменной называется порядковой переменной.
Хотите начать подготовку данных?
Пройдите мой бесплатный 7-дневный экспресс-курс по электронной почте прямо сейчас (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получить бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
В чем проблема с категориальными данными?
Некоторые алгоритмы могут напрямую работать с категориальными данными.
Например, дерево решений может быть получено непосредственно из категориальных данных без необходимости преобразования данных (это зависит от конкретной реализации).
Многие алгоритмы машинного обучения не могут напрямую работать с данными этикетки. Они требуют, чтобы все входные и выходные переменные были числовыми.
В общем, это в основном ограничение эффективной реализации алгоритмов машинного обучения, а не жесткие ограничения самих алгоритмов.
Это означает, что категориальные данные должны быть преобразованы в числовую форму. Если категориальная переменная является выходной переменной, вы также можете преобразовать прогнозы модели обратно в категориальную форму, чтобы представить их или использовать в каком-либо приложении.
Как преобразовать категориальные данные в числовые данные?
Это включает два шага:
- Целочисленное кодирование
- Горячее кодирование
1. Целочисленное кодирование
В качестве первого шага каждому уникальному значению категории присваивается целочисленное значение.
Например, « красный » равен 1, « зеленый » равен 2, а « синий » равен 3.
Это называется кодированием меток или целочисленным кодированием и легко обратимо.
Для некоторых переменных этого может быть достаточно.
Целочисленные значения имеют естественную упорядоченную взаимосвязь между собой, и алгоритмы машинного обучения могут понять и использовать эту взаимосвязь.
Например, порядковые переменные, такие как приведенный выше пример «место», были бы хорошим примером, где было бы достаточно кодировки метки.
2. Горячее кодирование
Для категориальных переменных, для которых не существует такого порядкового отношения, целочисленного кодирования недостаточно.
На самом деле, использование этого кодирования и разрешение модели предполагать естественное упорядочение между категориями может привести к снижению производительности или неожиданным результатам (прогнозы на полпути между категориями).
В этом случае к целочисленному представлению может применяться однократное кодирование. Здесь переменная, закодированная целым числом, удаляется и для каждого уникального целочисленного значения добавляется новая двоичная переменная.
В примере с переменной « цвет » имеется 3 категории, поэтому необходимы 3 двоичные переменные.Значение «1» помещается в двоичную переменную для цвета и значения «0» для других цветов.
Например:
красный, зеленый, синий 1, 0, 0 0, 1, 0 0, 0, 1
красный, зеленый, синий 1, 0, 0 0, 1, 0 0, 0, 1 |
Двоичные переменные часто называют «фиктивными переменными» в других областях, таких как статистика.
Пошаговое руководство по горячему кодированию категориальных данных в Python см. в руководстве:
Дополнительное чтение
Резюме
В этом посте вы узнали, почему категориальные данные часто необходимо кодировать при работе с алгоритмами машинного обучения.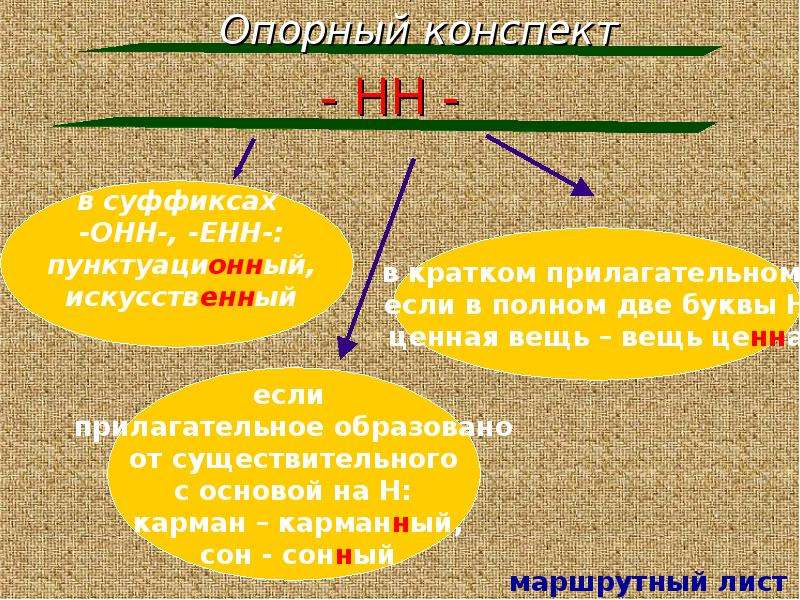
В частности:
- Эти категориальные данные определяются как переменные с конечным набором значений меток.
- Что для большинства алгоритмов машинного обучения требуются числовые входные и выходные переменные.
- Целое число и одно горячее кодирование используются для преобразования категориальных данных в целочисленные данные.
Есть вопросы?
Пишите свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Возьмитесь за современную подготовку данных!
Подготовка данных машинного обучения за считанные минуты
... всего несколькими строками кода Python
Узнайте, как это сделать, в моей новой электронной книге:
Подготовка данных для машинного обучения
Это обеспечивает учебные пособия по самообучению с полный рабочий код на:
Выбор объекта , RFE , Уборка данных , Преобразование данных , Масштабирование , Уменьшение размеров ,
и многое другое. ..
..
Использование современных методов подготовки данных в
проектах машинного обучения
Посмотреть, что внутри
Прикладное глубокое обучение. Часть 4. Сверточные нейронные сети | Арден Дертат
Добро пожаловать в четвертую часть серии статей о прикладном глубоком обучении. Часть 1 представляла собой практическое введение в искусственные нейронные сети, охватывающее как теорию, так и приложения с большим количеством примеров кода и визуализацией. Во второй части мы применили глубокое обучение к реальным наборам данных, охватив 3 наиболее часто встречающиеся проблемы в качестве тематических исследований: бинарную классификацию, многоклассовую классификацию и регрессию.В части 3 была рассмотрена конкретная архитектура глубокого обучения: автоэнкодеры.
Теперь мы рассмотрим самую популярную модель глубокого обучения: сверточные нейронные сети.
- ВВЕДЕНИЕ 5
- ВВЕДЕНИЕ
- Архитектура
- Интуиция
- Реализация
- VGG Model
- Visualization
- Вывод
- Рекомендации
Код для этой статьи доступно здесь как ноутбук Jupyter, не стесняйтесь скачать и попробовать себя.
Сверточные нейронные сети (CNN) повсюду. Это, пожалуй, самая популярная архитектура глубокого обучения. Недавний всплеск интереса к глубокому обучению связан с огромной популярностью и эффективностью консетей. Интерес к CNN начался с AlexNet в 2012 году и с тех пор растет в геометрической прогрессии. Всего за три года исследователи перешли от 8-уровневой AlexNet к 152-уровневой ResNet.
CNN теперь является моделью для решения любой проблемы, связанной с изображением. С точки зрения точности они выбивают конкурентов из воды.Он также успешно применяется в рекомендательных системах, обработке естественного языка и многом другом. Основное преимущество CNN по сравнению со своими предшественниками заключается в том, что она автоматически определяет важные особенности без какого-либо контроля со стороны человека. Например, по множеству изображений кошек и собак он самостоятельно усваивает отличительные признаки каждого класса.
CNN также эффективна в вычислительном отношении. Он использует специальные операции свертки и объединения и выполняет совместное использование параметров. Это позволяет моделям CNN работать на любом устройстве, что делает их универсальными.
Он использует специальные операции свертки и объединения и выполняет совместное использование параметров. Это позволяет моделям CNN работать на любом устройстве, что делает их универсальными.
Все это звучит как чистая магия. Мы имеем дело с очень мощной и эффективной моделью, которая выполняет автоматическое извлечение признаков для достижения сверхчеловеческой точности (да, модели CNN теперь выполняют классификацию изображений лучше, чем люди). Надеюсь, эта статья поможет нам раскрыть секреты этой замечательной техники.
Все модели CNN имеют схожую архитектуру, как показано на рисунке ниже.
Есть входное изображение, с которым мы работаем. Мы выполняем серию операций свертки + пула, за которыми следует ряд полносвязных слоев.Если мы выполняем мультиклассовую классификацию, вывод будет softmax. Теперь мы углубимся в каждый компонент.
2.1) Свертка
Основным строительным блоком CNN является сверточный слой. Свертка — это математическая операция по слиянию двух наборов информации.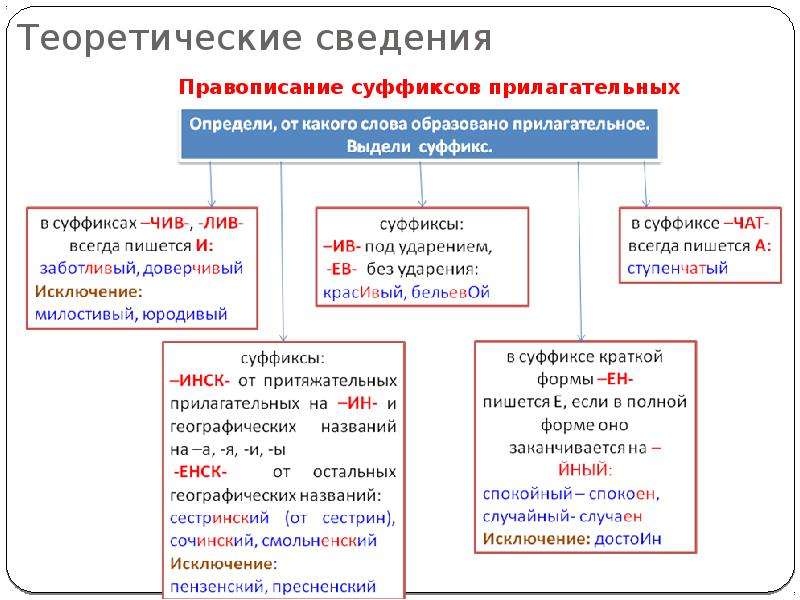 В нашем случае свертка применяется к входным данным с использованием фильтра свертки для создания карты признаков . Здесь используется много терминов, поэтому давайте визуализируем их один за другим.
В нашем случае свертка применяется к входным данным с использованием фильтра свертки для создания карты признаков . Здесь используется много терминов, поэтому давайте визуализируем их один за другим.
С левой стороны находятся входные данные для слоя свертки, например входное изображение.Справа свертка , фильтр , также называемый ядром , мы будем использовать эти термины взаимозаменяемо. Это называется свертка 3x3 из-за формы фильтра.
Мы выполняем операцию свертки, надвигая этот фильтр на вход. В каждом месте мы выполняем поэлементное умножение матриц и суммируем результат. Эта сумма входит в карту объектов. Зеленая область, в которой происходит операция свертки, называется рецептивным полем .Из-за размера фильтра рецептивное поле тоже 3х3.
Здесь фильтр находится вверху слева, результат операции свертки «4» показан на полученной карте признаков. Затем мы сдвигаем фильтр вправо и выполняем ту же операцию, также добавляя этот результат на карту объектов.
Продолжаем в том же духе и объединяем результаты свертки в карту объектов. Вот анимация, которая показывает всю операцию свертки.
Это пример операции свертки, показанный в 2D с использованием фильтра 3x3.Но на самом деле эти свертки выполняются в 3D. На самом деле изображение представляется в виде трехмерной матрицы с размерами высоты, ширины и глубины, где глубина соответствует цветовым каналам (RGB). Сверточный фильтр имеет определенную высоту и ширину, например 3x3 или 5x5, и по своей конструкции он покрывает всю глубину своего ввода, поэтому он также должен быть трехмерным.
Еще один важный момент, прежде чем мы визуализируем реальную операцию свертки. Мы выполняем несколько сверток на входе, каждый из которых использует другой фильтр и в результате получается отдельная карта объектов.Затем мы складываем все эти карты объектов вместе, и это становится окончательным результатом слоя свертки. Но сначала давайте начнем с простого и визуализируем свертку с помощью одного фильтра.
Допустим, у нас есть изображение 32x32x3, и мы используем фильтр размером 5x5x3 (обратите внимание, что глубина фильтра свертки соответствует глубине изображения, оба равны 3). Когда фильтр находится в определенном месте, он покрывает небольшой объем входных данных, и мы выполняем операцию свертки, описанную выше.Единственная разница в том, что на этот раз мы умножаем сумму матриц в 3D, а не в 2D, но результат по-прежнему является скаляром. Мы перемещаем фильтр по входным данным, как указано выше, и выполняем свертку в каждом месте, объединяя результат в карту объектов. Эта карта объектов имеет размер 32x32x1 и показана красным фрагментом справа.
Если бы мы использовали 10 различных фильтров, у нас было бы 10 карт объектов размером 32x32x1, и сложение их по измерению глубины дало бы нам окончательный результат слоя свертки: объем размером 32x32x10, показанный в виде большого синего прямоугольника справа. .Обратите внимание, что высота и ширина карты объектов не изменились и по-прежнему равны 32, это связано с отступами, и мы вскоре остановимся на этом.
Чтобы помочь с визуализацией, мы перемещаем фильтр по входу следующим образом. В каждом месте мы получаем скаляр и собираем их в карту объектов. Анимация показывает операцию скольжения в 4 местах, но на самом деле она выполняется для всего ввода.
Ниже мы можем видеть, как две карты объектов сложены по измерению глубины. Операция свертки для каждого фильтра выполняется независимо, и полученные карты объектов не пересекаются.
2.2) Нелинейность
Чтобы любая нейронная сеть была мощной, она должна содержать нелинейность. И ИНС, и автоэнкодер, которые мы видели ранее, достигли этого, передав взвешенную сумму своих входов через функцию активации, и CNN ничем не отличается. Мы снова пропускаем результат операции свертки через функцию активации relu . Таким образом, значения в окончательных картах объектов на самом деле являются не суммами, а примененной к ним функцией relu. Мы опустили это на рисунках выше для простоты.Но имейте в виду, что любой тип свертки включает в себя операцию relu, без которой сеть не сможет реализовать свой истинный потенциал.
2.3) Шаг и заполнение
Шаг указывает, насколько мы перемещаем сверточный фильтр на каждом шаге. По умолчанию значение равно 1, как вы можете видеть на рисунке ниже.
Мы можем добиться большего шага, если хотим уменьшить перекрытие между рецептивными полями. Это также делает результирующую карту объектов меньше, поскольку мы пропускаем потенциальные местоположения.На следующем рисунке показан шаг 2. Обратите внимание, что карта признаков стала меньше.
Мы видим, что размер карты объектов меньше, чем входные данные, потому что фильтр свертки должен содержаться во входных данных. Если мы хотим сохранить ту же размерность, мы можем использовать дополнение , чтобы окружить ввод нулями. Проверьте анимацию ниже.
Серая область вокруг ввода — это заполнение. Мы либо дополняем нулями, либо значениями на краю. Теперь размерность карты объектов соответствует входным данным.Заполнение обычно используется в CNN для сохранения размера карт объектов, иначе они будут уменьшаться на каждом слое, что нежелательно. Фигуры 3D-свертки, которые мы видели выше, использовали отступы, поэтому высота и ширина карты объектов были такими же, как и входные данные (оба 32x32), и изменилась только глубина.
Фигуры 3D-свертки, которые мы видели выше, использовали отступы, поэтому высота и ширина карты объектов были такими же, как и входные данные (оба 32x32), и изменилась только глубина.
2.4) Пулинг
После операции свертки мы обычно выполняем объединение для уменьшения размерности. Это позволяет нам уменьшить количество параметров, что сокращает время обучения и предотвращает переоснащение.Слои объединения снижают дискретизацию каждой карты объектов независимо друг от друга, уменьшая высоту и ширину, сохраняя глубину неизменной.
Наиболее распространенным типом объединения является максимальное объединение , которое просто принимает максимальное значение в окне объединения. В отличие от операции свертки, объединение не имеет параметров. Он перемещает окно по своему входу и просто берет максимальное значение в окне. Подобно свертке, мы указываем размер окна и шаг.
Вот результат максимального объединения с использованием окна 2x2 и шага 2. Каждый цвет обозначает отдельное окно. Поскольку и размер окна, и шаг равны 2, окна не перекрываются.
Каждый цвет обозначает отдельное окно. Поскольку и размер окна, и шаг равны 2, окна не перекрываются.
Обратите внимание, что это окно и конфигурация шага вдвое уменьшают размер карты признаков. Это основной вариант использования пула, уменьшающий выборку карты объектов при сохранении важной информации.
Теперь давайте разработаем размеры карты объектов до и после объединения. Если входные данные для слоя объединения имеют размерность 32x32x10, используя те же параметры объединения, что и описанные выше, результатом будет карта признаков 16x16x10.И высота, и ширина карты объектов уменьшаются вдвое, но глубина не меняется, потому что объединение работает независимо для каждого среза глубины входных данных.
Уменьшив вдвое высоту и ширину, мы уменьшили количество весов до 1/4 входных данных. Учитывая, что мы обычно имеем дело с миллионами весов в архитектурах CNN, это уменьшение является довольно большим делом.
В архитектурах CNN объединение обычно выполняется с окнами 2x2, шагом 2 и без заполнения. В то время как свертка выполняется с окнами 3x3, шагом 1 и с отступом.
В то время как свертка выполняется с окнами 3x3, шагом 1 и с отступом.
2.5) Гиперпараметры
Давайте теперь рассмотрим только слой свертки, игнорирующий объединение, и рассмотрим выбор гиперпараметров, который нам нужно сделать. У нас есть 4 важных гиперпараметра для выбора:
- Размер фильтра: мы обычно используем фильтры 3x3, но также используются 5x5 или 7x7 в зависимости от приложения. Существуют также фильтры 1x1, которые мы рассмотрим в другой статье, на первый взгляд это может показаться странным, но у них есть интересные применения. Помните, что эти фильтры являются трехмерными и также имеют измерение глубины, но, поскольку глубина фильтра на данном слое равна глубине его входных данных, мы опускаем это.
- Количество фильтров: это наиболее изменчивый параметр, степень двойки где-то между 32 и 1024. Использование большего количества фильтров приводит к более мощной модели, но мы рискуем получить переобучение из-за увеличения количества параметров.
 Обычно мы начинаем с небольшого количества фильтров на начальных слоях и постепенно увеличиваем их количество по мере продвижения вглубь сети.
Обычно мы начинаем с небольшого количества фильтров на начальных слоях и постепенно увеличиваем их количество по мере продвижения вглубь сети. - Шаг: значение по умолчанию 1.
- Заполнение: обычно используется заполнение.
2.6) Fully Connected
После слоев свертки + объединения мы добавляем пару полносвязных слоев, чтобы обернуть архитектуру CNN.Это та же полносвязная архитектура ИНС, о которой мы говорили в части 1.
Помните, что выходные данные слоев свертки и объединения представляют собой трехмерные объемы, но полносвязный слой ожидает одномерный вектор чисел. Таким образом, мы сглаживаем выходные данные последнего объединяющего слоя в вектор, который становится входными данными для полносвязного слоя. Сведение — это просто преобразование трехмерного объема чисел в одномерный вектор, здесь ничего необычного не происходит.
2.7) Обучение
CNN обучается так же, как и ANN, обратное распространение с градиентным спуском. Из-за операции свертки она более сложная с математической точки зрения и выходит за рамки этой статьи. Если вас интересуют подробности, обратитесь сюда.
Из-за операции свертки она более сложная с математической точки зрения и выходит за рамки этой статьи. Если вас интересуют подробности, обратитесь сюда.
Модель CNN можно рассматривать как комбинацию двух компонентов: части извлечения признаков и части классификации. Слои свертки + объединения выполняют извлечение признаков. Например, на изображении сверточный слой обнаруживает такие особенности, как два глаза, длинные уши, четыре ноги, короткий хвост и так далее. Затем полностью связанные слои действуют как классификатор поверх этих функций и присваивают вероятность того, что входное изображение является собакой.
Слои свертки являются основным двигателем модели CNN. Автоматическое обнаружение значимых функций, имеющих только изображение и метку, — непростая задача. Слои свертки изучают такие сложные функции, накладываясь друг на друга. Первые слои обнаруживают края, следующие слои объединяют их для обнаружения форм, а последующие слои объединяют эту информацию, чтобы сделать вывод, что это нос.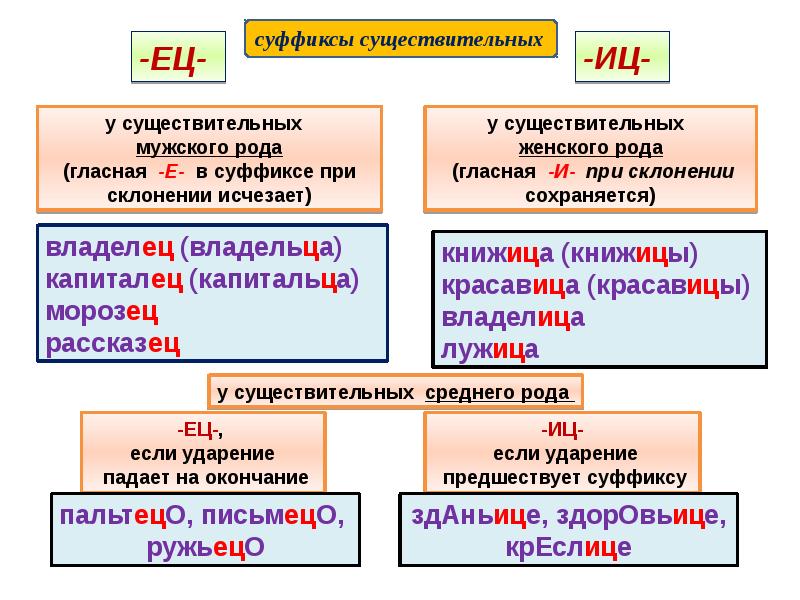 Чтобы было ясно, CNN не знает, что такое нос. Видя многие из них на изображениях, он учится определять это как особенность.Полносвязные слои учатся использовать эти функции, созданные свертками, для правильной классификации изображений.
Чтобы было ясно, CNN не знает, что такое нос. Видя многие из них на изображениях, он учится определять это как особенность.Полносвязные слои учатся использовать эти функции, созданные свертками, для правильной классификации изображений.
Сейчас все это может показаться расплывчатым, но, надеюсь, раздел визуализации сделает все более понятным.
После этого длинного объяснения давайте закодируем нашу CNN. Мы будем использовать набор данных Dogs vs Cats от Kaggle, чтобы отличать фотографии собак от кошек.
Мы будем использовать следующую архитектуру: 4 слоя свертки + пул, за которыми следуют 2 полносвязных слоя.Вход — изображение кошки или собаки, а выход — двоичный.
Вот код для CNN:
Структурно код похож на ИНС, над которой мы работали. Есть 4 новых метода, которых мы раньше не видели:
- Conv2D : этот метод создает сверточный слой. Первый параметр — количество фильтров, а второй — размер фильтра. Например, в первом слое свертки мы создаем 32 фильтра размером 3x3.
 Мы используем нелинейность relu в качестве активации.Мы также включаем отступы. В Keras есть два варианта заполнения: тот же или действительный . То же означает, что мы дополняем числом на краю, а допустимо означает отсутствие заполнения. Шаг по умолчанию для сверточных слоев равен 1, поэтому мы не меняем его. Этот слой можно дополнительно настроить с помощью дополнительных параметров, вы можете проверить документацию здесь.
Мы используем нелинейность relu в качестве активации.Мы также включаем отступы. В Keras есть два варианта заполнения: тот же или действительный . То же означает, что мы дополняем числом на краю, а допустимо означает отсутствие заполнения. Шаг по умолчанию для сверточных слоев равен 1, поэтому мы не меняем его. Этот слой можно дополнительно настроить с помощью дополнительных параметров, вы можете проверить документацию здесь. - MaxPooling2D : создает слой maxpooling, единственным аргументом является размер окна. Мы используем окно 2x2, так как оно наиболее распространено.По умолчанию длина шага равна размеру окна, которое в нашем случае равно 2, поэтому мы не меняем его.
- Flatten : После свертки + объединения слоев мы выравниваем их выходные данные, чтобы передать их в полносвязные слои, как мы обсуждали выше.
- Dropout : мы объясним это в следующем разделе.
4.1) Dropout
Dropout — безусловно, самый популярный метод регуляризации для глубоких нейронных сетей. Даже самые современные модели с точностью 95% получают повышение точности на 2% просто за счет добавления отсева, что является довольно существенным приростом на этом уровне.
Даже самые современные модели с точностью 95% получают повышение точности на 2% просто за счет добавления отсева, что является довольно существенным приростом на этом уровне.
Dropout используется для предотвращения переобучения, и идея очень проста. Во время обучения на каждой итерации нейрон временно «выпадает» или отключается с вероятностью p . Это означает, что все входы и выходы этого нейрона будут отключены на текущей итерации. Выпавшие нейроны передискретизируются с вероятностью p на каждом шаге обучения, поэтому выпавший нейрон на одном шаге может быть активен на следующем. Гиперпараметр p называется коэффициентом отсева и обычно имеет значение около 0.5, что соответствует выпадению 50% нейронов.
Удивительно, что дропаут вообще работает. Мы намеренно отключаем нейроны, и сеть на самом деле работает лучше. Причина в том, что выпадение не позволяет сети слишком зависеть от небольшого числа нейронов и заставляет каждый нейрон работать независимо. Это может показаться знакомым из ограничения размера кода автоэнкодера в части 3, чтобы изучить более интеллектуальные представления.
Это может показаться знакомым из ограничения размера кода автоэнкодера в части 3, чтобы изучить более интеллектуальные представления.
Давайте визуализируем отсев, так будет намного проще понять.
Исключение можно применять к узлам входного или скрытого слоя, но не к узлам вывода. Ребра в и из выпавших узлов отключены. Помните, что выпавшие узлы меняются на каждом шаге обучения. Также мы не применяем отсев во время тестирования после обучения сети, мы делаем это только во время обучения.
Аналогия отсева из реальной жизни может быть следующей: допустим, вы единственный человек в вашей компании, который разбирается в финансах. Если бы вы гарантированно были на работе каждый день, у ваших коллег не было бы стимула приобретать финансовые навыки.Но если вы каждое утро подбрасывали монетку, чтобы решить, пойдете ли вы на работу или нет, то вашим коллегам придется приспосабливаться. В некоторые дни вас может не быть на работе, но финансовые задачи все равно нужно выполнить, поэтому они не могут полагаться только на вас.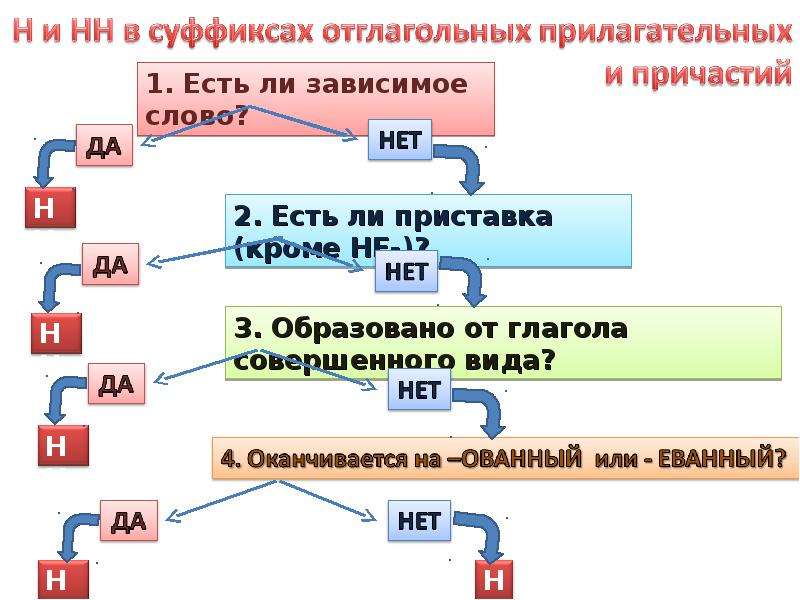 Вашим коллегам нужно будет узнать о финансах, и этот опыт должен быть распределен между разными людьми. Рабочие должны сотрудничать с несколькими другими работниками, а не с фиксированным набором людей. Это делает компанию намного более устойчивой в целом, повышая качество и набор навыков сотрудников.
Вашим коллегам нужно будет узнать о финансах, и этот опыт должен быть распределен между разными людьми. Рабочие должны сотрудничать с несколькими другими работниками, а не с фиксированным набором людей. Это делает компанию намного более устойчивой в целом, повышая качество и набор навыков сотрудников.
Почти все современные глубокие сети теперь включают отсев. Существует еще один очень популярный метод регуляризации, называемый пакетной нормализацией , и мы рассмотрим его в другой статье.
4.2) Производительность модели
Давайте теперь проанализируем производительность нашей модели. Мы рассмотрим кривые потерь и точности, сравнив производительность обучающего набора с проверочным набором.
Потери при обучении продолжают снижаться, но потери при проверке начинают увеличиваться примерно после 10-й эпохи.Это хрестоматийное определение переобучения. Модель запоминает обучающие данные, но не может обобщить их на новые экземпляры, поэтому производительность проверки снижается.
Мы переоснащаемся, несмотря на то, что используем отсев. Причина в том, что мы тренируемся на очень небольшом количестве примеров, 1000 изображений в каждой категории. Обычно нам нужно как минимум 100 тысяч обучающих примеров, чтобы начать думать о глубоком обучении. Независимо от того, какой метод регуляризации мы используем, мы будем работать с таким небольшим набором данных.Но, к счастью, есть решение этой проблемы, которое позволяет нам обучать глубокие модели на небольших наборах данных, и оно называется аугментацией данных .
4.3) Расширение данных
Переоснащение происходит из-за слишком малого количества примеров для обучения, что приводит к плохой производительности обобщения модели. Если бы у нас были бесконечные обучающие данные, мы бы не переобучились, потому что видели бы все возможные экземпляры.
Обычный случай в большинстве приложений машинного обучения, особенно в задачах классификации изображений, заключается в том, что получение новых обучающих данных непросто. Поэтому нам нужно обойтись имеющимся учебным набором. Увеличение данных — это способ генерировать больше обучающих данных из нашего текущего набора. Он обогащает или «дополняет» обучающие данные, генерируя новые примеры путем случайного преобразования существующих. Таким образом, мы искусственно увеличиваем размер тренировочного набора, уменьшая переоснащение. Таким образом, увеличение данных также можно рассматривать как метод регуляризации.
Поэтому нам нужно обойтись имеющимся учебным набором. Увеличение данных — это способ генерировать больше обучающих данных из нашего текущего набора. Он обогащает или «дополняет» обучающие данные, генерируя новые примеры путем случайного преобразования существующих. Таким образом, мы искусственно увеличиваем размер тренировочного набора, уменьшая переоснащение. Таким образом, увеличение данных также можно рассматривать как метод регуляризации.
Увеличение данных выполняется динамически во время обучения. Нам нужно генерировать реалистичные изображения, и преобразования должны быть обучаемыми, простое добавление шума не поможет.Общие преобразования: вращение, смещение, изменение размера, регулировка экспозиции, изменение контраста и т. д. Таким образом, мы можем сгенерировать много новых образцов из одного обучающего примера. Кроме того, аугментация данных выполняется только на обучающих данных, мы не затрагиваем проверочный или тестовый набор.
Визуализация поможет понять концепцию.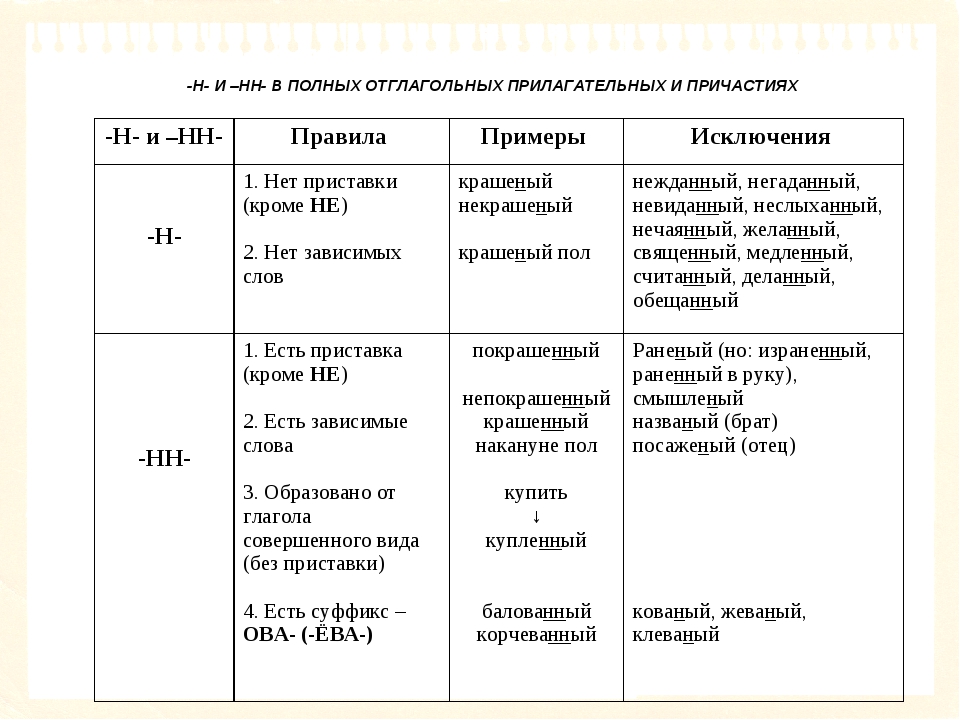 Допустим, это наше исходное изображение.
Допустим, это наше исходное изображение.
Используя увеличение данных, мы создаем эти искусственные обучающие экземпляры. Это новые обучающие экземпляры, применение преобразований к исходному изображению не меняет того факта, что это все еще изображение кошки.Мы можем вывести это как человек, поэтому модель также должна быть в состоянии изучить это.
Расширение данных может увеличить размер обучающей выборки даже в 50 раз. Это очень мощная техника, которая используется во всех без исключения моделях глубокого обучения на основе изображений.
Есть некоторые приемы очистки данных, которые мы обычно используем на изображениях, в основном отбеливание и нормализация среднего . Более подробная информация о них доступна здесь.
4.4) Обновленная модель
Теперь давайте воспользуемся дополнением данных в нашей модели CNN.Код для определения модели вообще не изменится, так как мы не меняем архитектуру нашей модели. Единственное изменение заключается в том, как мы подаем данные, вы можете проверить блокнот Jupyter здесь.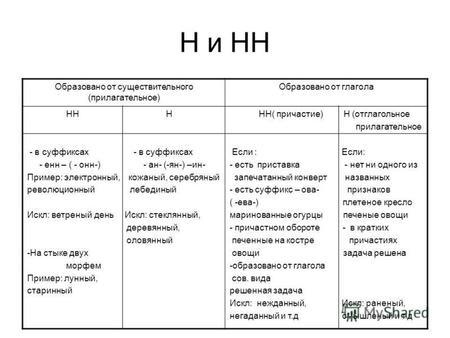
Увеличение данных с помощью Keras довольно просто, он предоставляет класс, который делает всю работу за нас, нам нужно только указать некоторые параметры. Документация доступна здесь.
Кривые потерь и точности выглядят следующим образом с использованием аугментации данных.
На этот раз явной переобучения нет.И точность проверки подскочила с 73 % без дополнения данных до 81 % с дополнением данных, улучшение на 11 %. Это довольно большое дело. Есть две основные причины повышения точности. Во-первых, мы тренируемся на большем количестве изображений с разнообразием. Во-вторых, мы сделали трансформацию модели инвариантной, то есть модель видела много смещенных/повернутых/масштабированных изображений, чтобы лучше их распознавать.
Давайте теперь рассмотрим пример современной модели CNN 2014 года. VGG — это сверточная нейронная сеть, разработанная исследователями из Оксфордской группы визуальной геометрии, отсюда и название VGG.Он занял второе место в классификации ImageNet с частотой ошибок 7,3%. ImageNet — это наиболее полный набор визуальных данных с ручными аннотациями, и каждый год они проводят соревнования, в которых участвуют исследователи со всего мира. На этом конкурсе дебютируют все известные архитектуры CNN.
ImageNet — это наиболее полный набор визуальных данных с ручными аннотациями, и каждый год они проводят соревнования, в которых участвуют исследователи со всего мира. На этом конкурсе дебютируют все известные архитектуры CNN.
Среди самых эффективных моделей CNN модель VGG выделяется своей простотой. Давайте посмотрим на его архитектуру.
VGG — это 16-слойная нейронная сеть, не считая слоев maxpool и softmax в конце.Его также называют VGG16. Это та архитектура, с которой мы работали выше. Сложенная свертка + слои пула, за которыми следует полностью подключенная ИНС. Несколько замечаний об архитектуре:
- Он использует только свертки 3x3 по всей сети. Обратите внимание, что две извилины 3x3 «спина к спине» имеют эффективное рецептивное поле одной извилины 5x5. А три сложенные извилины 3х3 имеют рецептивное поле одиночной извилины 7х7. Вот визуализация двух сложенных сверток 3x3, в результате чего получается 5x5.
- Другим преимуществом объединения двух сверток вместо одной является то, что мы используем две операции relu, а большая нелинейность дает больше мощности модели.

- Количество фильтров увеличивается по мере того, как мы углубляемся в сеть. Пространственный размер карт объектов уменьшается, поскольку мы объединяем их в пул, но глубина объемов увеличивается по мере того, как мы используем больше фильтров.
- Обучение на 4 графических процессорах в течение 3 недель.
VGG — очень фундаментальная модель CNN. Это первое, что приходит на ум, если вам нужно использовать готовую модель для конкретной задачи.Бумага также очень хорошо написана, доступна здесь. Есть гораздо более сложные модели, которые работают лучше, например, модель Microsoft ResNet стала победителем конкурса ImageNet 2015 года с частотой ошибок 3,6%, но модель имеет 152 слоя! Подробности в газете здесь. Мы подробно рассмотрим все эти архитектуры CNN в другой статье, но если вы хотите забежать вперед, вот отличный пост.
Теперь самое веселое и интересное — визуализация сверточных нейронных сетей.Известно, что модели глубокого обучения очень трудно интерпретировать, поэтому их обычно рассматривают как черные ящики. Но модели CNN на самом деле противоположны, и мы можем визуализировать различные компоненты. Это даст нам более глубокий взгляд на их внутреннюю работу и поможет нам лучше понять их.
Но модели CNN на самом деле противоположны, и мы можем визуализировать различные компоненты. Это даст нам более глубокий взгляд на их внутреннюю работу и поможет нам лучше понять их.
Мы визуализируем 3 наиболее важных компонента модели VGG:
- Карты признаков
- Фильтры Convnet
- Выходные данные класса
6.1) Визуализация карт признаков
Напомним архитектуру свертки.Конвертирующий фильтр работает с входными данными, выполняя операцию свертки, и в результате мы получаем карту объектов. Мы используем несколько фильтров и складываем полученные карты объектов вместе, чтобы получить выходной объем. Сначала мы визуализируем карты объектов, а в следующем разделе мы рассмотрим фильтры коннетов.
Мы будем визуализировать карты объектов, чтобы увидеть, как входные данные преобразуются при прохождении через слои свертки. Карты признаков также называются промежуточными активациями , поскольку выходные данные слоя называются активацией.
Помните, что на выходе сверточный слой представляет собой трехмерный объем. Как мы обсуждали выше, высота и ширина соответствуют размерам карты объектов, и каждый канал глубины представляет собой отдельную карту объектов, кодирующую независимые функции. Таким образом, мы будем визуализировать отдельные карты объектов, отображая каждый канал в виде 2D-изображения.
Как визуализировать карты объектов на самом деле довольно просто. Мы пропускаем входное изображение через CNN и записываем промежуточные активации. Затем мы случайным образом выбираем некоторые из карт объектов и наносим их на график.
Сверточные слои VGG именуются следующим образом: blockX_convY. Например, второй фильтр в третьем блоке свертки называется block3_conv2. На схеме архитектуры выше он соответствует второму фиолетовому фильтру.
Например, одна из карт признаков из вывода самого первого слоя (block1_conv1) выглядит следующим образом.
Яркие области — это «активированные» области, что означает, что фильтр обнаружил искомый шаблон. Этот фильтр, кажется, кодирует детектор глаз и носа.
Этот фильтр, кажется, кодирует детектор глаз и носа.
Вместо того, чтобы смотреть на одну карту объектов, было бы интереснее визуализировать несколько карт объектов из слоя свертки. Итак, давайте визуализируем карты признаков, соответствующие первой свёртке каждого блока, красные стрелки на рисунке ниже.
На следующем рисунке показано 8 карт объектов на слой. Block1_conv1 на самом деле содержит 64 карты объектов, так как у нас есть 64 фильтра в этом слое. Но мы визуализируем только первые 8 слоев на этом рисунке.
Есть несколько интересных наблюдений о картах объектов по мере продвижения по слоям.Давайте взглянем на одну карту объектов на слой, чтобы сделать ее более очевидной.
- Карты признаков первого слоя (block1_conv1) сохраняют большую часть информации, представленной на изображении. В архитектурах CNN первые уровни обычно действуют как детекторы границ.
- По мере того, как мы углубляемся в сеть, карты объектов все меньше походят на исходное изображение и больше на его абстрактное представление.
 Как видите, в block3_conv1 кота немного видно, но после этого он становится неузнаваемым.Причина в том, что более глубокие карты признаков кодируют понятия высокого уровня, такие как «кошачий нос» или «собачье ухо», в то время как карты признаков более низкого уровня обнаруживают простые края и формы. Вот почему более глубокие карты признаков содержат меньше информации об изображении и больше о классе изображения. Они по-прежнему кодируют полезные функции, но они менее интерпретируемы нами визуально.
Как видите, в block3_conv1 кота немного видно, но после этого он становится неузнаваемым.Причина в том, что более глубокие карты признаков кодируют понятия высокого уровня, такие как «кошачий нос» или «собачье ухо», в то время как карты признаков более низкого уровня обнаруживают простые края и формы. Вот почему более глубокие карты признаков содержат меньше информации об изображении и больше о классе изображения. Они по-прежнему кодируют полезные функции, но они менее интерпретируемы нами визуально. - Карты объектов становятся все более разреженными по мере того, как мы углубляемся, а это означает, что фильтры обнаруживают меньше объектов. Это имеет смысл, потому что фильтры в первых слоях обнаруживают простые формы, и каждое изображение содержит их.Но по мере того, как мы углубляемся, мы начинаем искать более сложные вещи, такие как «собачий хвост», и они появляются не на каждом изображении. Вот почему на первом рисунке с 8 фильтрами на слой мы видим больше карт объектов пустыми по мере того, как мы углубляемся (block4_conv1 и block5_conv1).

6.2) Визуализация фильтров Convnet
Теперь мы визуализируем основной строительный блок CNN, фильтры. Однако есть одна загвоздка: мы не будем визуализировать сами фильтры, а вместо этого будем отображать шаблоны, на которые максимально реагирует каждый фильтр.Помните, что фильтры имеют размер 3x3, что означает, что они имеют высоту и ширину 3 пикселя, что довольно мало. Поэтому в качестве прокси для визуализации фильтра мы создадим входное изображение, где этот фильтр активируется больше всего.
Полная информация о том, как это сделать, носит технический характер, и вы можете проверить фактический код в блокноте Jupyter. Но вкратце это работает следующим образом:
- Выберите функцию потерь, которая максимизирует значение фильтра коннета.
- Начните с пустого входного изображения.
- Выполните градиентное восхождение во входном пространстве. Значение изменить входные значения так, чтобы фильтр активировался еще больше.

- Повторите это в цикле.
Результатом этого процесса является входное изображение с очень активным фильтром. Помните, что каждый фильтр действует как детектор определенной функции. Сгенерированное нами входное изображение будет содержать множество этих функций.
Мы будем визуализировать фильтры на последнем слое каждого блока свертки. Чтобы устранить любую путаницу, в предыдущем разделе мы визуализировали карты объектов, результат операции свертки.Теперь мы визуализируем фильтры, основную структуру, используемую в операции свертки.
Мы будем визуализировать 8 фильтров на слой.
Они выглядят довольно сюрреалистично! Особенно те, что в последних слоях. Вот некоторые наблюдения о фильтрах:
- Фильтры первого слоя (block1_conv2 и block2_conv2) в основном обнаруживают цвета, края и простые формы.
- По мере того, как мы углубляемся в сеть, фильтры строятся друг над другом и учатся кодировать более сложные шаблоны.Например, фильтр 41 в block5_conv3 кажется детектором птиц.
 Вы можете видеть несколько голов в разных ориентациях, потому что конкретное расположение птицы на изображении не важно, пока она появляется где-то, фильтр активируется. Вот почему фильтр пытается обнаружить голову птицы в нескольких положениях, кодируя ее в нескольких местах фильтра.
Вы можете видеть несколько голов в разных ориентациях, потому что конкретное расположение птицы на изображении не важно, пока она появляется где-то, фильтр активируется. Вот почему фильтр пытается обнаружить голову птицы в нескольких положениях, кодируя ее в нескольких местах фильтра.
Эти наблюдения аналогичны тому, что мы обсуждали в разделе карты объектов. Нижние слои кодируют/обнаруживают простые структуры, по мере того как мы углубляемся, слои строятся друг над другом и учатся кодировать более сложные шаблоны.Именно так мы, люди, тоже начинаем познавать мир в младенчестве. Сначала мы изучаем простые структуры, и с практикой мы преуспеваем в понимании более сложных вещей, опираясь на наши существующие знания.
6.3) Визуализация выходных данных класса
Давайте сделаем последнюю визуализацию, она будет похожа на фильтр коннета. Теперь мы будем визуализировать на последнем слое softmax. Учитывая конкретную категорию, такую как молоток или лампа, мы попросим CNN сгенерировать изображение, которое максимально представляет эту категорию.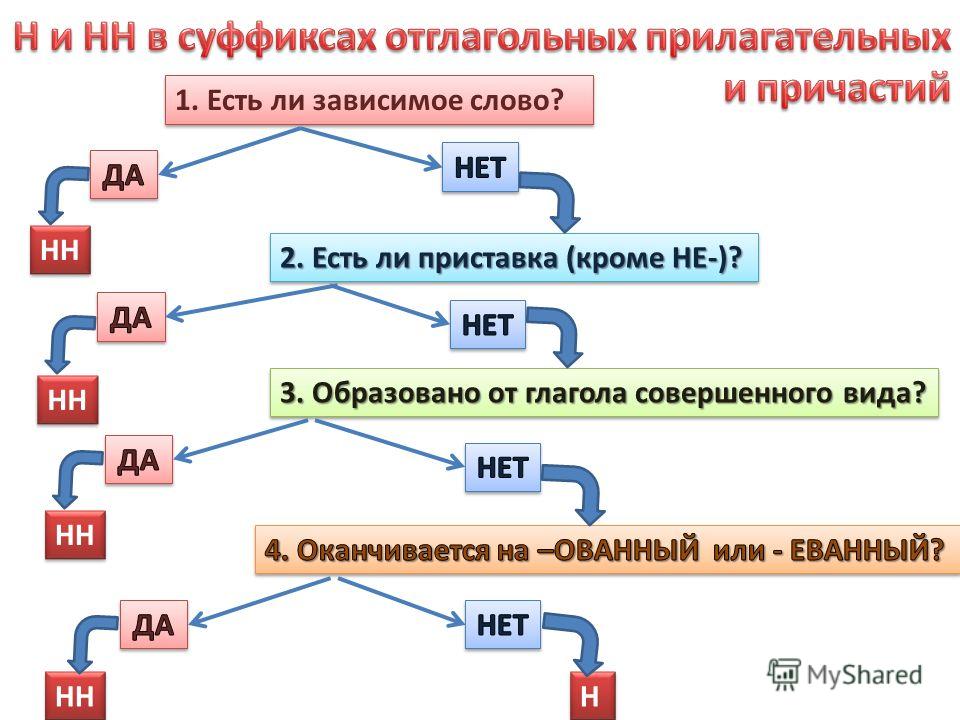 По сути, CNN нарисует нам изображение того, как, по их мнению, выглядит молоток.
По сути, CNN нарисует нам изображение того, как, по их мнению, выглядит молоток.
Этот процесс аналогичен шагам фильтра connet. Мы начинаем с пустого изображения и вносим изменения, чтобы вероятность присвоения определенной категории увеличивалась. Код снова доступен в блокноте.
Давайте представим некоторые категории.
Выглядят довольно убедительно. Объект появляется на изображении несколько раз, так как вероятность класса становится выше. Несколько теннисных мячей на изображении лучше, чем один теннисный мяч.
Все эти визуализации выполнены с использованием библиотеки keras-vis.
CNN — очень фундаментальная техника глубокого обучения. Мы рассмотрели широкий спектр тем, и раздел визуализации, на мой взгляд, самый интересный. В Интернете очень мало ресурсов, которые проводят тщательное визуальное исследование сверточных фильтров и карт функций. Я надеюсь, что это было полезно.
Весь код этой статьи доступен здесь, если вы хотите взломать его самостоятельно. Если у вас есть какие-либо отзывы, не стесняйтесь обращаться ко мне в твиттере.
Если у вас есть какие-либо отзывы, не стесняйтесь обращаться ко мне в твиттере.
В Интернете есть множество учебных пособий по CNN, но наиболее полным из них является курс Stanford CS231N Андрея Карпати. Материалы для чтения доступны здесь, а видеолекции здесь. Отличный источник информации, рекомендую.
Если вы хотите больше узнать о визуализации, Deepvis — отличный ресурс, доступный здесь. Есть интерактивный инструмент, открытый исходный код, бумага и подробная статья.
Отличный учебник по классификации изображений от автора Keras доступен здесь.Эта статья сильно повлияла на этот учебник. Он охватывает много материала, о котором мы подробно говорили.
Очень подробную бесплатную онлайн-книгу о глубоком обучении можно найти здесь, а раздел CNN доступен здесь.
Если вы заинтересованы в применении CNN для обработки естественного языка, это отличная статья. Другой очень подробный доступен здесь.
Здесь можно найти серию статей из трех частей, посвященных последним новостям CNN.
Все статьи Криса Ола наполнены отличной информацией и визуализациями.Сообщения, связанные с CNN, доступны здесь и здесь.
Другой популярный вступительный пост CNN находится здесь.
Очень доступная серия из 3 частей о CNN доступна здесь.
Федеральная резервная система — Положения
Регулирует приобретение контроля над банками и банковскими холдинговыми компаниями компаниями и частными лицами, определяет и регулирует небанковскую деятельность, в которой могут участвовать банковские холдинговые компании (включая финансовые холдинговые компании) и иностранные банковские организации с операциями в США. заниматься, и устанавливает минимальные отношения капитала к активам, которые банковские холдинговые компании должны поддерживать
Предлагаемые поправки
Обязать поднадзорные банковские организации незамедлительно уведомлять свой основной федеральный регулирующий орган в случае инцидента с компьютерной безопасностью (комментарии должны быть представлены 12 апреля 2021 г. )
)
Пресс-релиз и уведомление │ Отправить комментарий
Обновить требования Совета директоров в отношении планирования капитала, чтобы они соответствовали другим правилам Совета директоров, которые были недавно изменены (комментарии должны быть представлены 20 ноября 2020 г.)
Пресс-релиз и уведомление │ Отправить комментарии
Упрощение и повышение прозрачности правил определения подконтрольности банковской организации (замечания до 15.07.2019)
Пресс-релиз и уведомление
О пересмотре основы применения усиленных пруденциальных нормативов, применимых к иностранным банковским организациям в соответствии с Законом Додда-Франка (комментарии до 21 июня 2019 г.)
Пресс-релиз и уведомление
Повышение порога сделок с жилой недвижимостью, требующих оценки, с 250 000 до 400 000 долларов США (комментарии до 5 февраля 2019 г.)
Пресс-релиз и уведомление
Упростить требования к нормативному капиталу для соответствующих организаций местного банковского обслуживания, предоставив им возможность рассчитать коэффициент простого левериджа (комментарии должны быть представлены 9 апреля 2019 г. )
)
Пресс-релиз и уведомление
Установить категории на основе риска для определения пруденциальных нормативов для крупных U.S. банковским организациям, о внесении изменений в отдельные пруденциальные нормативы и внесение соответствующих изменений в формы отчетности (замечания до 22 января 2019 г.)
Пресс-релиз и уведомление
Повысить порог для сделок с коммерческой недвижимостью, требующих оценки, до 400 000 долларов США (комментарии должны быть представлены 29 сентября 2017 г.)
Пресс-релиз и уведомление
Пересмотреть план капитала и правила стресс-тестирования для крупных банковских холдинговых компаний и американских промежуточных холдинговых компаний иностранных банков (комментарии должны быть представлены 25 ноября 2016 г.)
Пресс-релиз и уведомление
Принять дополнительные ограничения на торговую деятельность финансовых холдингов физическими товарами (комментарии до 20 февраля 2017 г.)
Пресс-релиз и уведомление | Продление периода комментариев
Содействовать финансовой стабильности путем повышения платежеспособности и устойчивости крупнейших отечественных и иностранных банковских организаций, работающих в США (комментарии должны быть представлены 1 февраля 2016 г. )
)
Пресс-релиз и уведомление
О пересмотре плана капиталовложений и правил проведения стресс-тестов для крупных банковских холдингов и некоторых банковских организаций с совокупными консолидированными активами более 10 млрд долларов США (комментарии до 24 сентября 2015 г.)
Пресс-релиз и уведомление
Расширить применимость Заявления о политике малых банковских холдинговых компаний для небольших банковских холдинговых компаний и некоторых ссудно-сберегательных холдинговых компаний, а также снизить требования к отчетности (комментарии должны быть представлены 5 марта 2015 г.)
Пресс-релиз и уведомление
Для корректировки сроков ежегодной подачи планов капиталовложений и уточнения других аспектов правила плана капиталовложений (комментарии должны быть представлены 11 августа 2014 г.)
Пресс-релиз и уведомление
Внедрение минимальных требований по государственной регистрации и надзору за оценочными управляющими компаниями (замечания до 9 июня 2014 г. )
)
Пресс-релиз и уведомление
Для внесения изменений в классификации страновых рисков, разъяснения трактовки некоторых торгуемых секьюритизационных позиций, внесения технических поправок в определение покрываемой позиции и уточнения сроков раскрытия информации о рыночных рисках (комментарии должны быть представлены 3 сентября 2013 г.)
Уведомление (PDF)
Пересмотреть минимальные требования к капиталу, основанному на оценке риска, и критерии для регулятивного капитала, а также установить буферную систему сохранения капитала в соответствии с Базелем III (комментарии должны быть представлены 7 сентября 2012 г.)
Пресс-релиз и уведомление | Продление периода комментариев (комментарии принимаются до 22 октября 2012 г.)
В дополнение к предыдущему уведомлению о предлагаемом нормотворчестве (76 FR 7731 (PDF) путем разъяснения требований для определения того, является ли компания «преимущественно финансовой деятельностью» (комментарии должны быть представлены 25 мая 2012 г. )
)
Пресс-релиз и уведомление | Исправление (PDF) )
Внести поправки в предыдущее уведомление о предлагаемом нормотворчестве, предоставив альтернативы для расчета конкретных требований к риску капитала для долговых обязательств и позиций секьюритизации, которые не зависят от кредитных рейтингов (комментарии должны быть представлены 3 февраля 2012 г.)
Пресс-релиз и уведомление
Обязать крупные банковские холдинги представлять на рассмотрение годовые планы капиталовложений (комментарии должны быть представлены 5 августа 2011 г.)
Пресс-релиз и уведомление
Требовать от крупных, системно значимых банковских холдинговых компаний и небанковских финансовых компаний представлять годовые планы урегулирования и квартальные отчеты о кредитных рисках (комментарии должны быть представлены 10 июня 2011 г.)
Пресс-релиз и уведомление
Определить системно значимые небанковские финансовые компании для консолидированного надзора со стороны Совета (комментарии должны быть представлены 30 марта 2011 г.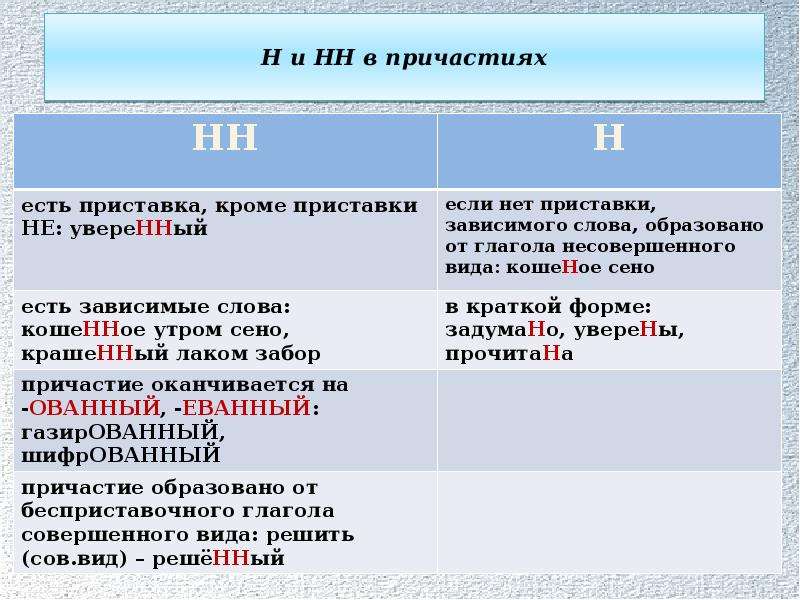 )
)
Пресс-релиз и уведомление
Пересмотреть правила капитала с рыночным риском, чтобы изменить их сферу действия, уменьшить процикличность, повысить чувствительность к определенным рискам и повысить прозрачность
Пресс-релиз и уведомление
Пересмотреть расширенные стандарты достаточности капитала, основанные на оценке рисков, и пересмотреть общие правила достаточности капитала, основанные на оценке рисков
Пресс-релиз и уведомление
Для реализации положений Закона Додда-Франка, которые дают организациям определенный период времени для приведения их деятельности и инвестиций в соответствие с «Правилом Волкера»
Пресс-релиз и уведомление
Межведомственное уведомление об альтернативах использованию кредитных рейтингов в руководстве по капиталу, основанному на риске
Пресс-релиз и уведомление
Межведомственное уведомление о предлагаемом правиле нормативного капитала, связанном с принятием Советом по стандартам финансовой отчетности Заявлений о стандартах финансовой отчетности No. 166 и 167
166 и 167
Пресс-релиз и уведомление
Межведомственное уведомление о предлагаемых поправках к правилам капитала на основе риска, позволяющих банкам, банковским холдинговым компаниям и сберегательным ассоциациям присваивать 10-процентный весовой коэффициент риска требованиям к Fannie Mae или Freddie Mac или их гарантиям (комментарии должны быть представлены 26 ноября 2008 г.). )
Уведомление
Межведомственное уведомление о предлагаемых поправках, позволяющих банкам, банковским холдинговым компаниям и сберегательным ассоциациям уменьшать размер гудвилла, который банковская организация должна вычесть из капитала 1 уровня (комментарии должны быть представлены 30 октября 2008 г.)
Уведомление
Межведомственное уведомление о предлагаемой новой концепции капитала, основанной на оценке рисков, основанной на стандартизированном подходе к кредитному риску и подходе с использованием базовых показателей для операционного риска, описанных в документе Базельского комитета по банковскому надзору «Международная конвергенция показателей капитала и стандартов капитала: пересмотренная концепция».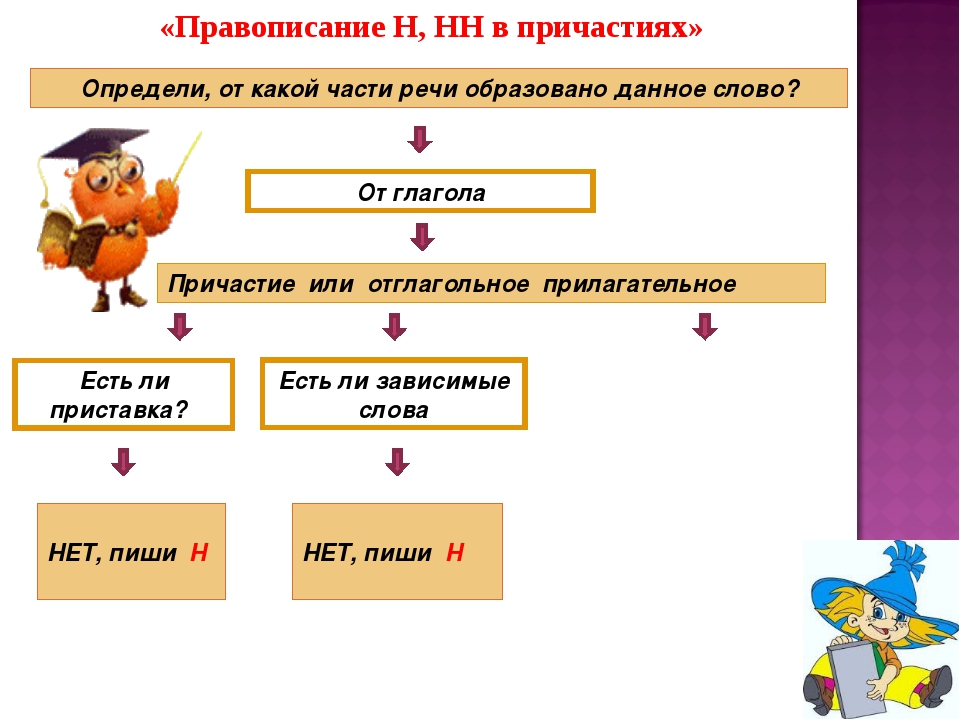 .(комментарии должны быть представлены 27 октября 2008 г.)
.(комментарии должны быть представлены 27 октября 2008 г.)
Уведомление
Проект межведомственного уведомления о предлагаемом нормотворчестве для пересмотра существующей структуры капитала, основанного на риске, путем предоставления подавляющему большинству банков, банковских холдинговых компаний и сберегательных ассоциаций возможности либо продолжать использовать существующее правило капитала, основанное на Базеле I, либо принять более правило, учитывающее риск, известное как Basel IA.
Пресс-релиз и уведомление
Пересмотреть правило рыночного риска капитала для повышения его чувствительности к риску и ввести требования к публичному раскрытию определенной качественной и количественной информации о рыночном риске банка или банковской холдинговой компании (комментарии до 23 января 2007 г.)
Пресс-релиз | Уведомление (162 КБ PDF)
Пересмотреть существующую структуру капитала, основанную на оценке риска, для повышения ее чувствительности к риску (комментарии должны быть представлены 18 января 2006 г. ).
).
Пресс-релиз и уведомление
Толкование ограничений, запрещающих связывание, в разделе 106 Закона о банковских холдинговых компаниях с поправками 1970 г., соответствующие руководящие указания по надзору и исключение в соответствии с разделом 106 для финансовых дочерних компаний государственных банков, не являющихся членами (комментарии должны быть представлены 30 сентября 2003 г.)
Пресс-релиз и уведомление
Разрешить финансовым холдинговым компаниям действовать в качестве брокеров и управляющих недвижимостью
Пресс-релиз и уведомление | Продление периода комментариев (комментарии должны быть представлены 1 мая 2001 г.)
О деятельности по обработке финансовых данных (комментарии должны быть представлены 16 февраля 2001 г.)
Пресс-релиз и уведомление
Для создания «безопасной гавани», позволяющей банку предлагать кредитную карту, которую можно использовать для совершения покупок в розничном магазине, связанном с банком (комментарии должны быть представлены 13 марта 2000 г.