
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «круг», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
КРУГ, а (у), в кругу и в круге, на кругу и на круге, мн. и, ов, м.
1. (в, на круге). Часть плоскости, ограниченная окружностью.
2. (в, на кругу). Круглая площадка. Молодёжь танцует на кругу.
3. (в круге, на круге, на кругу). Предмет в форме окружности. Спасательный к. (кольцеобразное спасательное средство для упавшего за борт). Резиновый к. (род надувной кольцеобразной подушки). Гончарный к.
4. (в круге и в кругу), чего. Замкнутая область, сфера, очерчивающая в своих границах развитие, совершение чего-н. К. чьих-н. обязанностей. К. вопросов.
5. (в кругу), кого или какой. Совокупность, группа людей, объединённых общими интересами, связями. Широкий к. знакомых. В своём кругу.
6. (в кругу), кого или какой. Лица, объединённые общей социальной средой и общей деятельностью. Широкие круги общественности. Писательские, литературные круги. В кругу учёных, специалистов.
• Голова кругом идёт у кого (разг.)теряется способность ясно соображать от обилия дел, хлопот, впечатлений.
Круги под глазами у когосинева под глазами от усталости, болезни.
В круг (встать)цепочкой, окружающей какое-н. пространство, что-н.
На круг (разг.)в среднем исчислении. По 50 центнеров на круг.
Порочный круг (книжн.)1) доказательство какого-н. положения с помощью другого положения, к-рое само должно быть доказано при посредстве первого; 2) безвыходное положение.
С кругу спиться (прост.)пьянствуя, совсем опуститься.
По кругу (ходить) (разг.)о повторяющемся движении кого-чего-н. от одного лица к другому, из одного места в другое. Жалоба ходит по кругу.
На круги своя (вернуться, возвратиться) (устар. и книжн.)к прежнему положению, состоянию.
| уменьш. кружок, жка, м. (к 1 и 3 знач.).
| прил. круговой, ая, ое (к 1, 2 и 3 знач.). Круговая оборона (созданная для отражения атак противника с любых направлений).
• Круговая порукаответственность всех за каждого и каждого за всех [теперь обычно служит для обозначения взаимного укрывательства в неблаговидных делах].
Фонетический (звуко-буквенный) разбор
кру́г
круг — слово из 1 слога: круг. Ударение ставится однозначно на единственную гласную в слове.
Транскрипция слова: [крук]
к — [к] — согласный, глухой парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
у — [у] — гласный, ударный
г — [к] — согласный, глухой парный, твёрдый (парный)
В слове 4 буквы и 4 звука.
Цветовая схема: круг
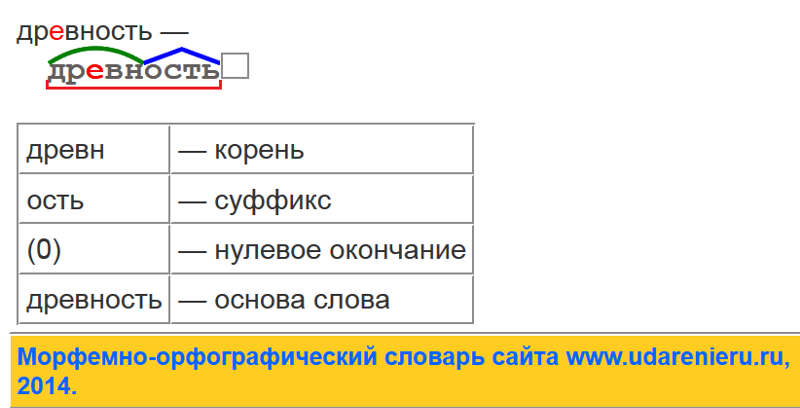
Разбор слова «круг» по составу
круг
Части слова «круг»: круг
Состав слова:
круг — корень,
нулевое окончание,
круг — основа слова.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «кольцо», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
КОЛЬЦО, а, мн. кольца, колец, кольцам, ср.
1. Предмет в форме окружности, ободка из твёрдого материала. Связка ключей на кольце. Гимнастические кольца (спортивный снаряд).
2. Украшение такой формы, надеваемое на палец.
3. То, что имеет форму окружности, обода. Годичное к. (слой, ежегодно нарастающий в стволе дерева). Пускать дым кольцами. Трамвайное к. (поворотный круг на трамвайных путях).
4. перен. Положение, когда кто-н. окружён кем-чем-н., замкнут круговой линией чего-н. К. блокады. Вырваться из кольца окружения. Оказаться в кольце любопытных.
Оказаться в кольце любопытных.
| уменьш. колечко, а, ср. (к 1, 2 и 3 знач.).
| прил. кольцевой, ая, ое (к 1 и 3 знач.). К. трамвайный маршрут (круговой). Кольцевая трасса. Кольцевая дорога.
Фонетический (звуко-буквенный) разбор
кольцо́
кольцо — слово из 2 слогов: коль-цо. Ударение падает на 2-й слог.
Транскрипция слова: [кал’цо]
к — [к] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
л — [л’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
ь — не обозначает звука
ц — [ц] — согласный, глухой непарный, твёрдый (непарный, всегда произноится твёрдо)
о — [о] — гласный, ударный
В слове 6 букв и 5 звуков.
Цветовая схема: кольцо
Ударение в слове проверено администраторами сайта и не может быть изменено.
Разбор слова «кольцо» по составу
кольцо
Части слова «кольцо»: кольц/о
Состав слова:
кольц — корень,
о — окончание,
кольц — основа слова.
Как разобрать по составу слово «Законопослушный»?
Прежде чем займёмся разбором этого слова, вспомним простую истину: существительные в числе единственном имеют окончание, состоящее из двух букв (двух звуков) только в падеже творительном. Во всех остальных падежах их флексии (окончания) однобуквенные, а если буква обозначает сразу два звука, то к окончанию относится лишь второй из них.
Говоря об однозвуковых флексиях, в виду имею лексические единицы, что в форме начальной заканчиваются на -ИЕ, -ИЯ. Слова ЗАКАНЧИВАЮТСЯ и ОКОНЧАНИЕ обозначают вовсе не одно и то же:
- ОКОНЧАНИЕ (флексия) – лингвистический термин;
- глагол ЗАКАНЧИВАЕТСЯ термином не является и обозначает всего лишь концовку слова, которая далеко не всегда равна окончанию.
Можно сказать «слово заканчивается на -ИЕ», но это вовсе не означает, что -ИЕ является окончанием. Флексией в лексемах, оканчивающихся на -ИЕ, является только последний звук, обозначений буквой Е. И это не противоречит самому определению флексии как ИЗМЕНЯЕМОЙ значимой части слова.
И это не противоречит самому определению флексии как ИЗМЕНЯЕМОЙ значимой части слова.
Разбор морфемный (то есть по составу) слов изменяемых (склоняемых и спрягаемых) мы начинаем с выделения их флексий и основ (неизменяемой части) словарной единицы, для чего достаточно сопоставить несколько её словоформ:
- есть чревоугоди[й/э];
- нет чревоугоди[й/а];
- к чревоугоди[й/у].
Отчётливо видно: изменяется лишь последний звук, обозначенный буквой Е, – вот он и является окончанием, неизменной остаётся часть ЧРЕВОУГОДИЙ- – это и есть основа.
Анализируя основу слова, мы ясно видим: разбираемая лексема – сложная, в ней два корня: чревоугодие – угождение чреву, так с помощью словосочетания именовали ещё простое обжорство. Два корня этой лексемы связывает соединительная гласная О.
Чрево
Ко второму корню подбираем такие слова родственные, как угождать, угодить, угодник и учитываем, что со словами «годный, годиться» эти лексемы разошлись давным-давно, как в море корабли, так что корень включает в себя и У: угожд-/угод-.
Что остаётся за вторым корнем? Суффикс -ИЙ-, первый звук которого обозначен полновесной буквой И, а вот второй решил с нами в прятки поиграть: забрался в букву Е, надеясь, что мы его не отыщем, а мы нашли!
В итоге расклад такой:
- окончание – [э], спрятавшееся от нас в букву Е;
- основа – чревоугодий-;
в основе:
- корни – чрев- и угод-;
- соединительная гласная – О;
- суффикс – -ИЙ-.
ПРЕДЛОЖЕНИЯ:
- Чревоугодием мы называем нездоровое пристрастие к пище вкусной и обильной.
- Чревоугодие – слово сложное, состоит из двух корней.
- Существительное чревоугодие относится ко второму склонению, но имеет особую флексию в падеже предложном.
- Чревоугодие – один из семи смертных грехов.
- Художник Босх аллегорично изобразил семь смертных грехов рода людского, в том числе и чревоугодие.
- Чревоугодие – отличительная черта великана Гаргантюа, о котором миру поведал Франсуа Рабле.
- Чревоугодием отличался персонаж гоголевских «Мёртвых душ» по фамилии Собакевич.
- Синоним слова чревоугодие – обжорство.
- Чревоугодие способно довести человека до скотского состояния.
- У нидерландского художника XVI века Питера Брейгеля есть гравюра «Чревоугодие, или Аллегория обжорства».
- Чревоугодием как чертой, присущей представителям рода людского, часто отличаются в литературе персонажи отрицательные.

Символ ноль перечеркнут косой чертой
Диаметр – отрезок (хорда), соединяющий две точки на окружности и проходящий через её центр. Но, обычно, под диаметром подразумевают длину этого отрезка. Равняется двум радиусам. В формулах обозначается латинской буквой «D». Слово «диаметр» происходит от греческого «diametros» (поперечник).
Символ диаметра представляет собой окружность перечёркнутую вышеупомянутым отрезком. Правда, для наглядности, концы отрезка выходят за пределы окружности, что строго говоря неверно. Символ диаметра похож на «о с диагональным штрихом», используемую в некоторых основанных на латинице алфавитах. Кроме того, часто похожим образом пишут цифру «ноль», перечёркивая её, чтобы отличить от буквы «о».
Обычно, знак диаметра используется на чертежах деталей. Символ наносят перед числом на размерной линии: «⌀ 40 см». Диаметр можно указывать, как для цилиндрических деталей, так и для конических. Пример детали с цилиндрической поверхностью – вал. Конической – переходная втулка.
Конической – переходная втулка.
Этот текст также доступен на следующих языках: English;
Đ (латиница) — Буква латиницы Đ, đ (дьже) Латинский алфавит A B C … Википедия
Ð (латиница) — Буква латиницы Ð, ð (eth) Латинский алфавит A B C … Википедия
латиница — алфавит, письмо, латинский алфавит Словарь русских синонимов. латиница см. латинский алфавит Словарь синонимов русского языка. Практический справочник. М.: Русский язык. З. Е. Алексан … Словарь синонимов
Латиница — наряду с кириллицей (см.) и глаголицей (см.) одна из славянских азбук, представляющая применение букв латинского алфавита для начертания славянских звуков. Первые попытки такого применения известны еще до кириллицы и глаголицы, но эти попытки… … Литературная энциклопедия
ЛАТИНИЦА — см. Латинское письмо … Большой Энциклопедический словарь
ЛАТИНИЦА — ЛАТИНИЦА, латиницы, муж. (филол. ). Латинский алфавит, латинское письмо. Толковый словарь Ушакова. Д.Н. Ушаков. 1935 1940 … Толковый словарь Ушакова
). Латинский алфавит, латинское письмо. Толковый словарь Ушакова. Д.Н. Ушаков. 1935 1940 … Толковый словарь Ушакова
ЛАТИНИЦА — ЛАТИНИЦА, ы, жен. Латинский алфавит. Толковый словарь Ожегова. С.И. Ожегов, Н.Ю. Шведова. 1949 1992 … Толковый словарь Ожегова
Ł (латиница) — Польская буква Ł Латинский алфавит A … Википедия
Æ (латиница) — Лигатура Æ Латинский алфавит A … Википедия
IJ (латиница) — Нидерландская буква IJ Латинский алфавит A … Википедия
Œ (латиница) — Латинский алфавит A B C D E F G H I J K … Википедия
Конечно, каждый поклонник группы Twenty One Pilots в тайне желает научиться писать перечеркнутую букву Ø! И многие даже не догадываются, как это на самом деле просто.
Разумеется, есть несколько способов добиться желаемого результата. Самый простой из них — использовать Alt-код символа. Десятичный код перечеркнутой буквы О — 0216. Запомните эту цифру!
Первый способ. Порядок действий такой:
Порядок действий такой:
1. Убедитесь, что у вас включена цифровая клавиатура. Я говорю о блоке клавиш в правой части клавиатуры. Знаю, что это не для всех очевидно, но в данном случае важно, набираете вы цифры используя верхний ряд клавиш или правый (цифровой) блок.
2. Убедитесь, что у вас включена английская раскладка клавиатуры. Нет, конечно у вас будет получаться и с русской раскладкой, только вместо нужного символа будет выходить буква Щ 🙂
3. Нажимаете одной рукой клавишу ALT, а другой набираете волшебный код 0216, после чего отпускаете клавишу ALT.
4. У большинства — все получится с первого раза. Если что-то не вышло, вернитесь на пару строчек выше и перечитайте все внимательно еще раз.
Альтернативным способом является возможность указать HTML — код символа. Суть в том, что вы указываете код специального символа, а браузер уже показывает вместо введенного кода сам символ. Разумеется, если нет браузера, то способ не действует. 🙂 Иначе говоря, если вы пишете в блокноте или редакторе, типа MS Word, то воспользоваться этим способом у вас не получится.
🙂 Иначе говоря, если вы пишете в блокноте или редакторе, типа MS Word, то воспользоваться этим способом у вас не получится.
Второй способ. Порядок действий такой:
1. Просто набираете код символа в поле ввода (например, поле комментария): Ø — если хотите заглавную букву Ø или ø — если хотите прописную (маленькую) букву ø
TWENTY ØNE PILØTS — даст: TWENTY ØNE PILØTS
Twenty øne piløts — даст: Twenty øne piløts
Вот и вся хитрость! Пользуйтесь на здоровье!
Мне будет очень приятно, если ты поделишься этой статьей с друзьями 😉
Word Cloud Visualization for Multiple Text Documents
используется в документах и поддерживает визуальную идентификацию
различий и общих черт. Методы взаимодействия позволяют
дополнительно анализировать визуализацию и предоставлять подробную информацию по запросу
. Подход был реализован и протестирован на нескольких примерах
, а пользовательское исследование было проведено, что
подтверждает его общую ценность.
В принципе, визуализация ConcentriCloud может масштабироваться до
до произвольного количества документов и слов, но
обычно не имеет большого смысла визуализировать слова из
больше, чем горстка или, может быть, дюжина документов, поскольку этот
станет слишком требовательным для зрителя.Более того, важно отметить, что облака слов обычно не отображают все
терминов текстового документа, а только наиболее часто встречающиеся.
Из-за компоновки с заполнением пробелов, слова меньшего размера могут быть добавлены
к облаку слов, если большие слова не помещаются в оставшееся пространство экрана
. Чтобы избежать неправильной интерпретации в этих случаях
, мы рекомендуем по запросу предоставить список реальных терминов и
частот терминов для каждого облака слов.
Кроме того,
должен знать о некоторых крайних случаях при использовании ConcentriCloud. Например, если проанализированные документы
не содержат ни одного общего слова,
внутренние круги будут пустыми, и только облака слов на
внешнего круга будут отображать термины. В противоположном случае
В противоположном случае
текстовых документов, которые разделяют (почти) все слова, внешний круг
будет пустым, а термины появятся только в слове
облаках внутренних кругов.Хотя такие крайние случаи
весьма маловероятны, они иллюстрируют ограничения подхода
и указывают на то, что он не может работать одинаково хорошо во всех ситуациях.
Несмотря на эти ограничения, мы считаем, что общий подход
имеет большой потенциал, тем более что существует очень мало работ
, которые решают проблему объединения нескольких документов в визуализации облака одного слова
(см. Раздел II) .
Качественная оценка выявила некоторые проблемы, которые могут быть решены в будущей работе
, например, оптимальное размещение
слов в средней области.Другим направлением исследований может быть
интеграция ConcentriCloud с соответствующими попытками,
, такими как подход RadCloud [1] или анализатор Word Cloud Ex-
[10] (см. Раздел II). В частности, могут быть добавлены дополнительные интерактивные функции
Раздел II). В частности, могут быть добавлены дополнительные интерактивные функции
, которые расширяют аналитические возможности
ConcentriClouds, такие как поиск терминов, выделение
отношений терминов, а также возможности простого поиска
слов в исходном тексте. контекст.Однако такие расширения
выходят за рамки данной статьи и не зависят от основного вклада
ConcentriCloud.
ССЫЛКИ
[1] М. Берч, С. Ломанн, Ф. Бек, Н. Родригес, Л. Д. Сильвестро и
Д. Вайскопф. RadCloud: визуализация нескольких текстов с объединенными облаками слов
. В 18-й Международной конференции по визуализации информации,
IV ’14, страницы 108–113. IEEE, 2014.
[2] М. Берч, С. Ломанн, Д.Помпе и Д. Вейскопф. Префиксируйте облака тегов.
На 17-й Международной конференции по визуализации информации, IV ’13,
стр. 45–50. IEEE, 2013.
[3] Q. Castell`
a and C. Sutton. Word storms: множество облаков слов для
визуального сравнения документов. На 23-й Международной конференции по
На 23-й Международной конференции по
World Wide Web, WWW ’14, страницы 665–676. ACM, 2014.
[4] Y.-X. Чен, Р. Сантамар
ıa, А. Бутц и Р. Тер
on.TagClusters:
Семантическая агрегация совместных тегов за пределами TagCloud. На 10-м Международном симпозиуме
по интеллектуальной графике, SG ’09, страницы 56–67.
Springer, 2009.
[5] К. Коллинз, М. С. Т. Карпендейл и Г. Пенн. Docuburst: Визуализация содержимого документа
с использованием языковой структуры. Форум компьютерной графики,
28 (3): 1039–1046, 2009.
[6] К. Коллинз, Ф. Б. Ви
egas и М. Ваттенберг. Параллельные облака тегов к
исследуют и анализируют фасетные текстовые корпуса.В симпозиуме IEEE по Visual
Analytics Science and Technology, VAST ’09, страницы 91–98. IEEE, 2009.
[7] W. Cui, Y. Wu, S. Liu, F. Wei, M. X. Zhou и H. Qu. Контекст-
с сохранением, визуализация динамического облака слов. IEEE Computer Graphics
and Applications, 30 (6): 42–53, 2010.
[8] К. Фуджимура, С. Фуджимура, Т. Мацубаяси, Т. Ямада и Х. Окуда.
Топография: визуализация крупномасштабных облаков тегов. В Международной конференции
по всемирной паутине, WWW ’08, страницы 1087–1088, 2008 г.
[9] Я. Хассан-Монтеро и В. Эрреро-Солана. Улучшение облаков тегов как
интерфейсов поиска визуальной информации. В Международной конференции по междисциплинарным информационным наукам и технологиям
, InSciT ’06,
, страницы 25–28, 2006.
[10] Ф. Хеймерл, С. Ломанн, С. Ланге и Т. Эртл. Проводник облака слов:
Аналитика текста на основе облаков слов. На 47-й Гавайской международной конференции
по системным наукам, HICSS ’14, страницы 1833–1842.IEEE,
2014.
[11] О. Касер и Д. Лемир. Отрисовка облака тегов: Алгоритмы визуализации облака
. В WWW ’07 Workshop on Tagging and Metadata for
Social Information Organization, 2007.
[12] К. Кох, Б. Ли, Б. Ким и Дж. Со. ManiWordle: Обеспечение гибкого
ManiWordle: Обеспечение гибкого
контроля над word. IEEE Transactions on Visualization and Computer
Graphics, 16 (6): 1190–1197, 2010.
[13] Б. Ли, Н. Х. Рич, А. К. Карлсон и С.Карпендейл. SparkClouds:
Визуализация тенденций в облаках тегов. IEEE Transactions по визуализации
и компьютерной графике, 16 (6): 1182–1189, 2010.
[14] С. Ломанн, М. Берч, Х. Шмаудер и Д. Вайскопф. Визуальный анализ содержимого микроблогов
с использованием изменяющегося во времени выделения совпадений в облаках тегов
. В Международной рабочей конференции по усовершенствованным интерфейсам Visual
, AVI ’12, страницы 753–756. ACM, 2012.
[15] S. Lohmann, J.Циглер и Л. Тецлафф. Сравнение макетов облака тегов
: производительность в зависимости от задачи и визуальное исследование. На 12-й Международной конференции
IFIP TC 13 по взаимодействию человека и компьютера,
INTERACT ’09, Часть I, страницы 392–404. Springer, 2009.
[16] К. Д. Мэннинг, М. Сурдеану, Дж. Бауэр, Дж. Финкель, С. Дж. Бетард и
Д. МакКлоски. Набор инструментов Stanford CoreNLP для обработки естественного языка
. На 52-м ежегодном собрании Ассоциации вычислительной техники
Лингвистика: системные демонстрации, ACL ’14, страницы 55–60.ACL, 2014.
[17] Ф. В. Паулович, Ф. М. Б. Толедо, Г. П. Теллес, Р. Мингхим и Л. Г.
Нонато. Семантическая словизация коллекций документов. Компьютер
Graphics Forum, 31 (3): 1145–1153, 2012.
[18] К. Зайферт, Дж. Юрговский и М. Гранитцер. FacetScape: визуализация
для исследования пространства поиска. В 18-й Международной конференции по визуализации информации
, IV ’14, страницы 94–101. IEEE, 2014.
[19] К. Зайферт, Б.Камп, В. Кинрайх, Г. Гранитцер и М. Гранитцер. На
красота и удобство использования облака тегов. В 12-й Международной конференции
по визуализации информации, IV ’08, страницы 17–25, 2008.
[20] М. Стефанер. Визуальные инструменты для социо-семантической сети. Магистерская диссертация,
Стефанер. Визуальные инструменты для социо-семантической сети. Магистерская диссертация,
Потсдамский университет прикладных наук, 2007.
[21] Х. Стробельт, М. Спикер, А. Стоффель, Д. Кейм и О. Деуссен. Rolled-
out Wordles: эвристический метод удаления перекрытия 2D-данных
представителей.Computer Graphics Forum, 31 (3): 1135–1144, 2012.
[22] Д. Том, М. В. №
Орнер, и С. Кох. Scatterscopes: понимание событий
в реальном времени с помощью пространственно-временной индикации и иерархической развертки
. В конференции IEEE по науке о визуальной аналитике и технологии
(VAST), страницы 387–388, 2014.
[23] Ф. Б. Виегас, М. Ваттенберг, Ф. ван Хам, Дж. Крисс и М. МакКеон.
ManyEyes: сайт для визуализации в масштабе Интернета.IEEE Transactions
о визуализации и компьютерной графике, 13 (6): 1121–1128, 2007.
[24] Р. Вюйлемот, Т. Клемент, К. Плезант и А. Кумар. Что означает
рядом с «Мартой»? Изучение именных сущностей в коллекциях художественных текстов.
В симпозиуме IEEE по науке и технологиям визуальной аналитики,
VAST ’09, страницы 107–114. IEEE, 2009.
[25] Y. Wu, T. Provan, F. Wei, S. Liu и K.-L. Ма. Семантико-сохраняющие
словесных облаков методом нарезки швов.Форум компьютерной графики, 30 (3): 741–
750, 2011.
[26] Y. Wu, F. Wei, S. Liu, N. Au, W. Cui, H. Zhou, and H. Qu . OpinionSeer:
Интерактивная визуализация отзывов клиентов отеля. IEEE Transactions
о визуализации в компьютерной графике, 16 (6): 1109–1118, 2010.
MEG Доказательства развертывания базовых комбинаторных лингвистических механизмов в ответ на запросы задач
Цитата: Bemis DK, Pylkkänen L ( 2013) Гибкая композиция: данные MEG для развертывания основных комбинаторных лингвистических механизмов в ответ на запросы задач.PLoS ONE 8 (9): e73949. https://doi.org/10.1371/journal.pone.0073949
Редактор: Гарет Роберт Барнс, Университетский колледж Лондона — Институт неврологии, Соединенное Королевство
Поступила: 2 мая 2013 г . ; Одобрена: 25 июля 2013 г .; Опубликовано: 12 сентября 2013 г.
; Одобрена: 25 июля 2013 г .; Опубликовано: 12 сентября 2013 г.
Авторские права: © 2013 Bemis, Pylkkanen. Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Финансирование: Это исследование было поддержано грантами Национального научного фонда BCS-0545186 и BCS-1221723 (LP), грантом G1001 Института NYUAD, Нью-Йоркского университета Абу-Даби (LP) и стипендиями Уайтхеда для Младший факультет биомедицинских и биологических наук (до LP). Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Конкурирующие интересы: Авторы заявили, что конкурирующих интересов не существует.
Введение
Человеческий язык черпает свою выразительную силу в способности творчески конструировать сложные значения из отдельных частей. Хотя это творчество явно проявляется при синтаксическом анализе грамматических выражений, как, например, при конструировании значения для фиолетовых горилл, неловко поющих Вивальди , неясно, в какой степени комбинаторный механизм языка может быть применен за пределами нормальной языковой обработки; вопрос, актуальный как для оценки модульности в языковой архитектуре [3], [4], так и для определения взаимодействия между лингвистическими комбинаторными механизмами и когнитивной сферой в целом [5].В настоящем исследовании мы исследуем, достаточно ли простого изменения требований задачи, независимо от изменений лексических требований или требований к вниманию, для того, чтобы спровоцировать задействование базовых комбинаторных лингвистических механизмов — тех, которые лежат в основе языка и составляют сложные значения из отдельные элементы — за пределами их естественной грамматической области. В частности, мы стремились оценить, могут ли комбинаторные механизмы, составляющие простые фразы, такие как red cup , работать с выражениями, не соответствующими родной грамматике, такими как обратная последовательность cup red , в ситуациях, когда возникает некоторое давление. интерпретировать последовательность комбинаторным образом.Интуитивно комбинаторный механизм действительно обладает такой гибкостью, учитывая, что понимание не носителями языка может быть довольно хорошим даже при наличии множества грамматических ошибок, таких как этот тип изменения порядка слов. Но интуиция еще не говорит нам, является ли механизм, используемый для построения сложных представлений из неграмматического ввода, таким же, как мы используем при обработке грамматического материала. В текущем исследовании мы оценивали это, записывая активность магнитоэнцефалографии (МЭГ) во время обработки грамматических и грамматических фраз в условиях комбинаторных и некомбинаторных задач.Полученные в результате пространственно-временные карты нейронной активности позволили нам оценить, могут ли базовые комбинаторные нейронные механизмы, которые работают во время нормальной грамматической обработки, быть развернуты в новых контекстах в ответ на тонкое изменение требований к задаче.
В частности, мы стремились оценить, могут ли комбинаторные механизмы, составляющие простые фразы, такие как red cup , работать с выражениями, не соответствующими родной грамматике, такими как обратная последовательность cup red , в ситуациях, когда возникает некоторое давление. интерпретировать последовательность комбинаторным образом.Интуитивно комбинаторный механизм действительно обладает такой гибкостью, учитывая, что понимание не носителями языка может быть довольно хорошим даже при наличии множества грамматических ошибок, таких как этот тип изменения порядка слов. Но интуиция еще не говорит нам, является ли механизм, используемый для построения сложных представлений из неграмматического ввода, таким же, как мы используем при обработке грамматического материала. В текущем исследовании мы оценивали это, записывая активность магнитоэнцефалографии (МЭГ) во время обработки грамматических и грамматических фраз в условиях комбинаторных и некомбинаторных задач.Полученные в результате пространственно-временные карты нейронной активности позволили нам оценить, могут ли базовые комбинаторные нейронные механизмы, которые работают во время нормальной грамматической обработки, быть развернуты в новых контекстах в ответ на тонкое изменение требований к задаче.
Предыдущие исследования границ комбинаторной языковой обработки
Несколько предыдущих исследований непосредственно изучали степень, в которой комбинаторные лингвистические механизмы могут быть гибко применены к новым контекстам, хотя многие работы затрагивают этот вопрос косвенно.Очевидно, что на определенном уровне комбинаторные лингвистические процессы могут быть применены к новым контекстам, поскольку люди способны научиться извлекать значение из письменных слов и иностранных языков, ни один из которых не вызывает успешной комбинаторной лингвистической обработки без инструкции. Нейролингвистические исследования обоих типов обработки, хотя и не являются окончательными, указывают на большое совпадение нейронных сигнатур, связанных с комбинаторным пониманием речи, и сигнатур, вызываемых как чтением [2], [6], [7], так и обработкой иностранного языка [8], [9], [10].Что еще более важно, большое количество доказательств предполагает, что лингвистические механизмы в широком смысле могут быть распространены также на обработку искусственных «языков». В парадигме канонического искусственного обучения грамматике (AGL) [11] наборы произвольных символов, начиная от иностранных слов [12], заканчивая буквенными строками [13] и визуальными объектами [14], генерируются с использованием конечного автомата, так что они подчиняться различным синтаксическим ограничениям. Затем испытуемым показывают образцы из этих наборов во время периода обучения и впоследствии просят оценить «грамматичность» тестового набора строк, некоторые из которых генерируются автоматом, а некоторые нет.Существует бесчисленное множество вариантов парадигмы с точки зрения синтаксических ограничений, «языковых» символов, методов обучения и т. Д. (См. Обзор в [15]), однако последовательный вывод из поведенческих [16], [17] и нейронные исследования [18], [12], [13] показывают, что обработка таких искусственных грамматик может показаться похожей на обработку естественного языка во многих отношениях. Таким образом, в общих чертах, исследования AGL предоставляют доказательства того, что лингвистические механизмы могут быть развернуты в новых контекстах при соответствующих требованиях задачи.
В парадигме канонического искусственного обучения грамматике (AGL) [11] наборы произвольных символов, начиная от иностранных слов [12], заканчивая буквенными строками [13] и визуальными объектами [14], генерируются с использованием конечного автомата, так что они подчиняться различным синтаксическим ограничениям. Затем испытуемым показывают образцы из этих наборов во время периода обучения и впоследствии просят оценить «грамматичность» тестового набора строк, некоторые из которых генерируются автоматом, а некоторые нет.Существует бесчисленное множество вариантов парадигмы с точки зрения синтаксических ограничений, «языковых» символов, методов обучения и т. Д. (См. Обзор в [15]), однако последовательный вывод из поведенческих [16], [17] и нейронные исследования [18], [12], [13] показывают, что обработка таких искусственных грамматик может показаться похожей на обработку естественного языка во многих отношениях. Таким образом, в общих чертах, исследования AGL предоставляют доказательства того, что лингвистические механизмы могут быть развернуты в новых контекстах при соответствующих требованиях задачи.
Тем не менее, несколько факторов мешают этим результатам напрямую обратиться к задаче настоящего исследования, которая заключается в определении степени, в которой базовые лингвистические комбинаторные механизмы могут быть гибко и быстро развернуты в новых контекстах. Во-первых, в парадигмах AGL, хотя испытуемые обычно способны отличать «грамматические» строки от «неграмматических» строк с большей чем случайной точностью [15], их исполнение редко бывает идеальным [19], и в некоторых обстоятельствах лежащие в основе грамматические правила не могут быть освоены вообще, несмотря на их очевидное сходство с ограничениями естественного языка [20], [21].Во-вторых, по замыслу эти исследования почти исключительно измеряют обработку, связанную со сложными правилами, такими как иерархические, вложенные структуры [22], [14] и нежесткие дистанционные зависимости [23], и часто оценивают нейронную активность, вызванную нарушением этих правил. (например, [13]). Таким образом, пресловутые трудности с распутыванием множества механизмов, лежащих в основе такой сложной обработки естественного языка [24], [25], преувеличиваются при работе с искусственными языками (см. [26]). Следовательно, возникли обширные разногласия относительно природы нейронных механизмов, управляющих эффектами, наблюдаемыми в парадигмах AGL [27], [28], [29], [30], [23], или даже относительно того, были ли усвоены предполагаемые правила. вообще [20].Таким образом, хотя результаты парадигм AGL предполагают возможность развертывания лингвистических механизмов в новых контекстах, их связь с базовыми лингвистическими комбинаторными процессами, с одной стороны, и нарушение ожиданий [30], рекурсия [19] и механизмы иерархической последовательности, с другой [14 ], [27] еще не решен полностью.
[26]). Следовательно, возникли обширные разногласия относительно природы нейронных механизмов, управляющих эффектами, наблюдаемыми в парадигмах AGL [27], [28], [29], [30], [23], или даже относительно того, были ли усвоены предполагаемые правила. вообще [20].Таким образом, хотя результаты парадигм AGL предполагают возможность развертывания лингвистических механизмов в новых контекстах, их связь с базовыми лингвистическими комбинаторными процессами, с одной стороны, и нарушение ожиданий [30], рекурсия [19] и механизмы иерархической последовательности, с другой [14 ], [27] еще не решен полностью.
Манипуляции с задачами
В рамках парадигм, более прямо направленных на исследование взаимодействия между требованиями задачи и лингвистическими механизмами, основное внимание уделялось определению влияния манипуляций вниманием на обработку языка.В этих исследованиях внимание часто отвлекается от языковых стимулов в целом либо пассивно, например, при просмотре немого фильма во время прослушивания речи [31], [32], либо активно, например, при выполнении задания на слуховое различение во время прослушивания речи [ 33] В качестве альтернативы внимание может быть направлено на различные аспекты стимулов или от них, например, путем выполнения задачи обнаружения шрифта [34] или выборочного мониторинга синтаксических или семантических нарушений [35]. Грубо говоря, эти исследования выявили постепенный эффект внимания на обработку, так что ранние этапы обработки кажутся в значительной степени инвариантными при манипуляциях с вниманием [36], [37], [38], [33], обработка на средней стадии часто может модулироваться. но обычно не устраняется полностью [39], [40], [41], и более поздняя обработка может приходить и уходить в зависимости от задачи [34], [42], [37], [43], [44] для обзора .
Грубо говоря, эти исследования выявили постепенный эффект внимания на обработку, так что ранние этапы обработки кажутся в значительной степени инвариантными при манипуляциях с вниманием [36], [37], [38], [33], обработка на средней стадии часто может модулироваться. но обычно не устраняется полностью [39], [40], [41], и более поздняя обработка может приходить и уходить в зависимости от задачи [34], [42], [37], [43], [44] для обзора .
Этот последний результат, конечно, потенциально предполагает гибкое развертывание лингвистических механизмов. Недавняя работа действительно показала, что более поздние этапы лингвистического анализа, часто связанные с синтаксическим повторным анализом и разрешением неоднозначности, в некоторой степени зависят от задачи и не всегда происходят во время нормальной языковой обработки [45], [46], [47], [48] ]. Эти результаты, однако, в первую очередь были приписаны глубине обработки языковых стимулов и, следовательно, подпадали под заголовок «достаточно хороший» синтаксический анализ — i. е. данные показывают, что во время нормального понимания языка обработка должна быть только «достаточно хорошей» для решения поставленной задачи. Нейрофизиологически общая мера этой обработки, компонент P600 ERP, сильно зависит от того, требуется ли оценка правдоподобия данной задачей (см. [44]). Таким образом, вместо того, чтобы отражать гибкое развертывание процессов вне их естественного контекста, эти результаты, кажется, указывают на то, что синтаксический анализ может остановиться до полного задействования механизмов, связанных с разрешением неоднозначности или синтаксическим реанализом [47].На сегодняшний день нет никаких доказательств того, что лингвистические комбинаторные механизмы работают только с грамматическим вводом, за исключением, возможно, работы с грамматическими иллюзиями, в которых синтаксический анализатор сбивается с толку выражениями, которые кажутся грамматическими, несмотря на то, что они плохо сформированы с точки зрения репрезентации [49]. Таким образом, вместо того, чтобы предполагать гибкое задействование языковых процессов за пределами их обычных границ, результаты, относящиеся к «достаточно хорошему» синтаксическому анализу, больше говорят об их автоматичности в пределах нормальной грамматической области.
е. данные показывают, что во время нормального понимания языка обработка должна быть только «достаточно хорошей» для решения поставленной задачи. Нейрофизиологически общая мера этой обработки, компонент P600 ERP, сильно зависит от того, требуется ли оценка правдоподобия данной задачей (см. [44]). Таким образом, вместо того, чтобы отражать гибкое развертывание процессов вне их естественного контекста, эти результаты, кажется, указывают на то, что синтаксический анализ может остановиться до полного задействования механизмов, связанных с разрешением неоднозначности или синтаксическим реанализом [47].На сегодняшний день нет никаких доказательств того, что лингвистические комбинаторные механизмы работают только с грамматическим вводом, за исключением, возможно, работы с грамматическими иллюзиями, в которых синтаксический анализатор сбивается с толку выражениями, которые кажутся грамматическими, несмотря на то, что они плохо сформированы с точки зрения репрезентации [49]. Таким образом, вместо того, чтобы предполагать гибкое задействование языковых процессов за пределами их обычных границ, результаты, относящиеся к «достаточно хорошему» синтаксическому анализу, больше говорят об их автоматичности в пределах нормальной грамматической области.
Наше исследование
В настоящем исследовании, напротив, мы изучаем, могут ли базовые комбинаторные лингвистические механизмы быть быстро развернуты вне их естественного контекста в пределах родной грамматики и, кроме того, может ли это развертывание быть ускорено простой манипуляцией задачи независимо от изменений в сложности или внимании. . Другими словами, в какой степени можно использовать базовые комбинаторные лингвистические механизмы в качестве гибкого когнитивного инструмента при решении задач? В частности, мы исследовали, можно ли гибко использовать комбинаторные механизмы, действующие при составлении простых именных фраз, для интерпретации минимально контрастирующих грамматических последовательностей, если этого требует задача.В нашей предыдущей работе мы охарактеризовали комбинаторную нейронную активность, вызванную пониманием простых комбинаций прилагательного и существительного, таких как red cup , и обнаружили достоверное усиление активности в левой передней височной доле (LATL) примерно на 200-250 мс по сравнению с обычными. комбинаторные управления [1], [2]. В настоящем исследовании (рис. 1) мы сравнивали такие сочетания прилагательного и существительного с их обратными аналогами, cup red , которые нарушают канонический порядок слов в английском языке для таких фраз.Эта манипуляция стимулом затем была встроена в манипуляцию задачи, которая изменяла необходимость объединения прилагательного и существительного в единое семантическое представление. В комбинаторном задании (Составление) испытуемые оценивали, соответствует ли словесный стимул изображению цветного объекта. В задаче Non-Compose изображение задачи вместо этого изображало отдельную цветовую пятно и контур формы, позволяя испытуемым обрабатывать значения существительных и прилагательных полностью в виде списка, без композиции.Активность LATL, предположительно отражающая состав, измерялась путем последовательного представления каждого слова и сравнения активности, генерируемой во втором слове, с активностью, вызванной во время обработки согласованного некомбинаторного однословного контроля ( frw red или xtp cup ).
Рисунок 1. Схема эксперимента. В каждом блоке испытаний испытуемым предъявляли стимулы из одного и двух слов и просили оценить, соответствует ли следующая целевая картинка предыдущим словам.
В канонических условиях (верхние ряды) стимулы представляли собой фразы прилагательное-существительное ( red cup ) и соответствующие им контрольные элементы из одного слова ( xhl cup ). В перевернутых условиях (нижние ряды) стимулы представляли собой последовательности существительное-прилагательное ( чашка красный, ) и соответствующие им контроли из одного слова ( frw красный ). В задаче «Составить» (левое изображение задачи) целевые изображения содержали одноцветную фигуру. В задаче «Несоставление» (правое изображение задачи) целевые изображения содержали цветную каплю и контур формы.Каждый испытуемый выполнял только одно задание, а канонические и обратные испытания блокировались отдельно.
https://doi.org/10.1371/journal.pone.0073949.g001
Для стимулов канонического порядка слов мы ожидали, что комбинаторная обработка будет происходить автоматически в обеих задачах, учитывая, что почти все модели синтаксического анализа предполагают, что грамматические лингвистические выражения автоматически задействуются комбинаторные механизмы до некоторой степени, независимо от задачи (например, [50], [51]). Это теоретическое утверждение было подтверждено многочисленными нейролингвистическими исследованиями, демонстрирующими, что ранние электрофизиологические компоненты, связанные с комбинаторной обработкой, инвариантны как к задаче [36], [37], так и к манипуляциям внимания [43], [33], [31].Кроме того, гемодинамические эффекты, связанные с комбинаторной обработкой, включая эффекты LATL, управляемые обработкой предложений, остаются наблюдаемыми даже во время задач, специально разработанных для минимизации комбинаторной обработки [52], [53], [54].
Напротив, во время обработки стимулов обратного порядка ( чашка красный ) мы не ожидали, что комбинаторная обработка будет автоматически вызвана. Крайне важно, что мы разработали наши задачи так, чтобы требовать суждений о обозначениях объектов, тем самым удерживая субъектов от интерпретации этих последовательностей как измененных цветов (например,грамм. красное вино — особый оттенок красного, связанный с вином). Далее, мы выбрали словосочетания, которые не были знакомы по цвету существительное-прилагательное (например, свекольный красный не использовался). Следует отметить, что в более широком контексте прилагательные могут, конечно, изменять существительные пост-номинально, например Я видел красную чашку с краской , однако такое употребление обычно требует, чтобы прилагательное было достаточно «тяжелым», и часто требует интонационного перерыва после существительного [55]. Таким образом, мы ожидали, что эти обратные последовательности не должны задействовать комбинаторную обработку, если это не требуется.Следовательно, мы ожидали разницы между канонической и обратной последовательностями с точки зрения комбинаторной обработки во время задачи Non-Compose. Нашим основным вопросом было затем определить степень, в которой обратные последовательности могут задействовать комбинаторную обработку во время задачи Compose.
Чтобы манипулирование задачами было как можно более чистым, эти две задачи были назначены отдельным группам участников. В частности, мы хотели избежать возможности того, что после обработки стимулов в комбинаторной манере испытуемые могут столкнуться с трудностями при отключении комбинаторного режима обработки.Другими словами, такая стоимость переключения задач может привести к комбинаторной обработке канонических порядков слов во время задачи Non-Compose не потому, что композиция для них автоматическая, а из-за вмешательства со стороны недавно выполненной задачи композиции.
В нашей предыдущей работе над грамматическими последовательностями прилагательное-существительное ( red cup ) [1], [2], полный паттерн активности, связанный с комбинаторной обработкой, состоял из раннего эффекта на cup , локализованного в LATL примерно на 200 to 250 мс с последующими более разнообразными эффектами позже в эпоху (~ 400 мс), локализованными как в вентромедиальной префронтальной коре [1]), так и в угловой извилине (AG — [2]).В настоящем исследовании мы решили использовать активность MEG, локализованную в LATL, в качестве основного показателя базовой комбинаторной обработки по двум причинам. Во-первых, довольно обширная литература по гемодинамике предполагает, что эта область играет решающую роль в комбинаторной лингвистической обработке [56], [57], [58], [59], [54], а также в обеих предыдущих версиях этой парадигмы, в визуальной и слуховой областях. презентации, устойчиво продуцируют комбинаторную активность, локализованную в LATL [1], [2]. Последующие эффекты были более разнообразными.Во-вторых, как обсуждалось выше, более поздние компоненты обработки, и особенно те, которые были вызваны во временном окне, окружающем ранее наблюдаемые эффекты vmPFC и AG (350–450 мс), могут сильно зависеть от манипуляций с задачами независимо от каких-либо изменений комбинаторной обработки (см. [ 41]). Таким образом, более ранние компоненты являются лучшими кандидатами для измерений, которые могут более прямо отражать комбинаторную обработку при манипулировании задачами.
Подводя итог, если наши предположения верны и канонические комбинации прилагательное-существительное действительно задействуют комбинаторные механизмы независимо от требований задачи, а обратные последовательности существительного-прилагательного — нет, то мы ожидаем увидеть, что активность LATL в задаче Non-Compose демонстрирует взаимодействие между обратная ( чашка красный ) и каноническая последовательности ( красная чашка ) по сравнению с их сопоставленными однословными контролями ( xhl red и frw cup , соответственно), с повышенной активностью LATL, присутствующей только во время двух- слово каноническое состояние.Если задача Compose затем заставляет базовые комбинаторные механизмы гибко задействоваться во время обработки обратных последовательностей, мы ожидаем увидеть основной эффект количества слов в этой задаче с повышенной активностью LATL, присутствующей в обеих последовательностях из двух слов по сравнению с их согласованными контролирует. С другой стороны, если манипуляции с задачами недостаточно, чтобы вызвать комбинаторную обработку в обратных последовательностях, мы снова ожидаем увидеть взаимодействие между порядком и количеством слов в этой задаче.Чтобы максимизировать силу манипуляции, мы давали каждую задачу отдельно разным испытуемым.
Методы
Участников
Задание Non-Compose выполнили 15 человек (8 женщин; средний возраст 22,4 года). Задание «Составить» выполнили 21 испытуемый (14 женщин; средний возраст 21,4 года). Все испытуемые были правшами, носителями английского языка без дальтонизма, с нормальным или исправленным зрением. Все процедуры были одобрены Комитетом Нью-Йоркского университета по деятельности с участием людей, и от каждого участника было получено информированное письменное согласие.Участники получили гонорар или зачет курса за свое участие.
Материалы
Каждое испытание содержало четыре стимула, которые предъявлялись последовательно: крест фиксации, начальное слово или неслово, существительное или прилагательное и целевое изображение (рис. 1). Испытуемым предлагалось игнорировать все стимулы, не являющиеся словесными, и указывать, содержит ли целевая картинка изображение всех предшествующих лексических элементов. В задаче «Составить» целевое изображение содержало одноцветную фигуру. В задаче Non-Compose цвет и форма были представлены отдельно в виде круглой капли и белого контура соответственно.Лингвистические стимулы различались в зависимости от условий: канонические испытания из двух слов представляли прилагательное, за которым следовало существительное ( красная чашка ), обратные испытания из двух слов представляли существительное, за которым следовало прилагательное ( чашка красный ), а испытания из одного слова заменялись начальные слова с непроизносимыми согласными ( xhl cup, frw red ). Таким образом, второй, критический стимул оставался неизменным между парными одно- и двухсловными условиями. Во время эксперимента Non-Compose испытуемые также выполнили вариант списка каждой задачи, в котором они оценивали, соответствует ли целевая картинка одному из двух предшествующих существительных или прилагательных.Поскольку этот контраст не имеет отношения к гипотезам настоящего исследования, он был опущен в последующем обсуждении.
Во всех условиях использовались девять односложных общих цветных прилагательных ( красный, коричневый, бирюзовый, синий, розовый, черный, коричневый, белый, зеленый ). Каждому прилагательному было присвоено соответствующее соответствие длины существительное ( чашка, машина, замок, башмак, лист, дом, сердце, самолет, крест ) и соответствующая непроизносимая последовательность согласных звуков, соответствующая длине ( xkq, kjw, qxsw, mtpv, vbnw, rjdnw, wvcnz, zbxlv, vtzkn ).Существительные и прилагательные также были сопоставлены по частоте ( p = 0,74; логарифмическая частота HAL; парные t -тест). Каждое слово было отображено непропорциональным шрифтом Courier с отступом примерно 3 °. В задаче «Составить» целевые изображения представляли собой вручную созданные канонические изображения каждой формы, окрашенные в один из девяти цветов и отображаемые в центре экрана под углом примерно 8 °. В задаче Non-Compose круглые капли и контуры (взятые из цветных фигур) были случайным образом размещены в одном из четырех мест с центром +/- 2 ° по горизонтали и вертикали от центра экрана, при этом никакие два объекта не занимали одно и то же место на любом испытании.Для этих стимулов каждый объект сам по себе наклонялся примерно на 4 °. Все стимулы предъявлялись с помощью Psytoolbox [60], [61] и проецировались на экран примерно в 45 см от глаза испытуемого.
В каждой задаче канонические и обратные испытания были заблокированы отдельно, с сбалансированным порядком для каждой группы испытуемых. В каждом условии критические элементы (т. Е. Существительные для канонических испытаний, прилагательные для обратных испытаний) были представлены четыре раза в подходящих испытаниях и четыре раза в несовпадающих испытаниях, в результате чего в общей сложности было 72 испытания в каждом условии и 144 испытания на блок.В испытаниях с несоответствием двух слов целевые изображения соответствовали либо предыдущему цвету, либо термину формы, но не обоим. Для каждого испытуемого были созданы обратные испытания с двумя словами путем простого изменения порядка стимулов в канонических испытаниях с двумя словами. Затем были созданы испытания с одним словом из всех испытаний с двумя словами путем замены согласованной последовательности согласных звуков для каждого начального стимула и перетасовки целевых изображений для соответствия или несоответствия оставшемуся слову по мере необходимости. Списки стимулов были рандомизированы по каждому субъекту.
Процедура
Перед экспериментом испытуемые практиковали свой первый блок за пределами комнаты MEG. Перед записью формы головы испытуемых были оцифрованы с помощью 3D-дигитайзера Polhemus Fastrak (Polhemus, VT, США). Затем оцифрованная форма головы использовалась для ограничения локализации источника во время анализа путем совместной регистрации пяти катушек, расположенных вокруг лица, по отношению к датчикам МЭГ. Кроме того, электроды прикрепляли на 1 см справа и на 1 см ниже середины правого глаза для записи вертикальной и горизонтальной электроокулограммы (EOG) и обнаружения морганий.Оба электрода были привязаны к левому сосцевидному отростку.
ДанныеMEG были собраны с использованием 157-канальной системы осевого градиентометра с цельной головкой (Технологический институт Канадзавы, Токио, Япония) с дискретизацией при 1000 Гц с фильтром нижних частот при 200 Гц и режекторным фильтром при 60 Гц. Все стимулы, кроме целевых изображений, предъявлялись в течение 300 мс, после чего следовало 300 мс пустого экрана. Целевые изображения появлялись в конце каждого испытания и оставались на экране до тех пор, пока испытуемый не принял решение. Последующие испытания начались после того, как пустой экран отображался в течение переменного времени в соответствии с нормальным распределением со средним значением 500 мс и стандартным отклонением 100 мс (см. Рисунок 1).Весь сеанс записи длился приблизительно 50 минут для задачи Non-Compose и 25 минут для задачи Compose (разница объясняется блоками списка, включенными в задачу Non-Compose; см. Материалы выше).
Сбор данных MEG
ДанныеMEG записывались непрерывно, с уменьшением шума с использованием метода непрерывно скорректированных наименьших квадратов (CALM; [62]) и с периодом времени от 100 мс до начала каждого критического элемента до 600 мс после начала. Исходные данные сначала были очищены от потенциальных артефактов путем отклонения испытаний, в которых: а) испытуемый ответил либо неправильно, либо слишком медленно (определено как более двух.Через 5 секунд после появления формы цели), б) максимальная амплитуда превысила 3000 фТл, или в) субъект моргнул в пределах критического временного окна, как определено путем ручной проверки записей EOG. Один из испытуемых в задаче «Несоставление» выполнил случайное выполнение в перевернутом состоянии в одно слово и поэтому был исключен из дальнейшего анализа. Остальные данные были затем усреднены для каждого субъекта для каждого состояния и полосовой фильтрации от 1 до 40 Гц. Для включения в дальнейший анализ мы потребовали, чтобы испытуемые демонстрировали качественно канонический профиль вызванных ответов во время обработки критических вопросов.Этот профиль был определен как появление устойчивых и заметных начальных зрительных реакций — то есть полевой образец M100 или M170 [63], [64] должен был четко присутствовать во временном окне от 100 до 200 мс после критических стимулов. Пять субъектов в целом не выполнили это требование (три в задаче «Составить» и две в задаче «Несоставление») и были исключены из дальнейшего анализа.
Минимальная оценка нормы
В качестве нашей основной зависимой меры мы создали распределенные оценки источников с минимальной нормой для зарегистрированных данных датчиков MEG.Эта мера обеспечивает оценку коркового местоположения электрической активности, лежащей в основе наблюдаемых магнитных полей, зарегистрированных за пределами головы. Оценка источника была построена для каждого среднего состояния с использованием оценок минимальной нормы L2, рассчитанных с использованием BESA 5.1 (MEGIS Software GmbH, Мюнхен, Германия). Ковариационная матрица канального шума для каждой оценки была основана на 100 мс до начала критического элемента в каждом среднем состоянии. Каждая оценка минимальной нормы основывалась на активности 1426 региональных источников, равномерно распределенных в двух оболочках на 10% и 30% ниже сглаженной стандартной поверхности мозга.Региональные источники в MEG можно рассматривать как источники с двумя одиночными диполями в одном месте, но с ортогональной ориентацией. Затем была рассчитана общая активность каждого регионального источника как среднеквадратическое значение активности источника двух его компонентов. Пары диполей в каждом месте сначала были усреднены, а затем было выбрано большее значение из каждой пары источников, создав 713 ненаправленных источников, активацию которых можно было сравнивать для разных субъектов и условий. Изображения с минимальной нормой были взвешены по глубине, а также пространственно-временному взвешиванию с использованием меры корреляции подпространства сигнала [65].Повторный дисперсионный анализ в рамках каждой задачи с факторами Порядок (канонический, обратный) и Количество слов (два, один) не выявил надежных основных эффектов или взаимодействий в отношении сигнал / шум оценок минимальной нормы (все p> .15).
Анализ данных
Чтобы оценить комбинаторную активность, наш первичный анализ исследовал активность источника, локализованную в LATL, как определено ROI, использованным в наших предыдущих экспериментах [1], [2]. Граница этой области интереса изначально была основана на гемодинамических результатах, демонстрирующих повышенную активность LATL во время понимания предложений по сравнению со списками слов [57], [56], [54].Мы проанализировали активность, которая локализовалась в этой области интереса от 0 до 600 мс после представления второго слова, используя кластерный тест перестановки [66], предназначенный для выявления значимых эффектов в любой момент в течение эпохи анализа. Этот тест контролирует множественные сравнения в течение всего временного интервала, используя следующую обобщенную процедуру. Сначала для наблюдаемых данных рассчитывается статистика кластерного теста. Затем эта же статистика теста вычисляется для множества перестановок фактических данных, каждая из которых создается путем случайного перемешивания меток условий внутри каждого участника.Затем значение p наблюдаемой тестовой статистики вычисляется относительно распределения, созданного из 10 000 перестановок исходных данных, и устанавливается равным доле переставленных наборов данных, которые дают тестовую статистику более экстремальную, чем у фактических данных.
Одним из преимуществ этого теста является то, что статистику кластерного теста можно построить специально для того, чтобы соответствовать определенной гипотезе (см. [1]; [66]). В настоящем эксперименте каждая статистика была рассчитана путем первого определения смежных временных точек, для которых статистический точечный тест достиг определенного порога (установлен на p = 0.30, чтобы соответствовать нашему предыдущему анализу), а затем вычислить одну статистику теста на основе полученного кластера точек. Чтобы проверить взаимодействие, предсказанное в некомбинаторной задаче, мы использовали ту же тестовую статистику, что и в нашей предыдущей статье (см. [1] для получения полной информации). Таким образом, каждый кластер был идентифицирован с использованием значения взаимодействия p из поточечного анализа 2 × 2 с повторными измерениями ANOVA с количеством слов (один, два) и порядком слов (канонический, обратный) в качестве факторов. Затем была рассчитана окончательная статистика теста путем суммирования значений t , полученных в результате точечных тестов t между каноническими условиями, и вычитания значений t , полученных в результате точечных тестов t между обратными условиями.Чтобы проверить главный эффект, предсказанный в комбинаторной задаче, мы идентифицировали кластеры, используя значение p из поточечного 2 × 2 дисперсионного анализа с повторными измерениями, который соответствовал основному эффекту количества слов, и мы включили только те точки. для которого значение взаимодействия p также не было выше порогового. Затем мы просто просуммировали статистику t из всех тестов t , выполненных в двух парах условий, чтобы вычислить окончательную статистику теста.
Чтобы выявить эффекты за пределами LATL, мы также выполнили анализ всего мозга, в котором сравнивались показатели активности из двух и одного слова в рамках каждой задачи, выборка за выборкой для каждой исходной временной точки с использованием парного теста t . Различие считалось значимым в этом тесте только в том случае, если оно превышало критерии значимости и размера, так что оно оставалось надежным ( p <0,05) как минимум для 10 образцов (10 мс), наблюдалось как минимум в 10 соседних корковых источниках и было минимум 1.5 нАм по амплитуде. В результатах и на рисунках ниже мы обсуждаем только эффекты, связанные с увеличением активности двух слов.
Результаты
Поведенческие результаты
Поведенческие данные, изображенные на рис. 2, были проанализированы на предмет скорости и точности в ANOVA 2 × 2 × 2 с Задачей (Составить, Не составить) как переменной между субъектами и Порядком (канонический, обратный) × Количество слов ( два, один) как внутри переменных субъектов. За этим последовали запланированные повторные измерения 2 × 2 ANOVA на влияние порядка и количества слов в каждой задаче.
Рисунок 2. Поведенческие результаты.
Для каждой задачи данные о времени реакции и точности были представлены в ANOVA с повторными измерениями 2 × 2 с порядком (канонический, обратный) и количеством слов (один, два) в качестве факторов. В задаче Non-Compose (A) мы наблюдали значительную взаимосвязь между двумя факторами точности и не обнаружили значительного влияния на время реакции. В задаче «Составить» (B) мы наблюдали существенное влияние количества слов на точность и значимое взаимодействие между двумя факторами на время реакции.нс — незначительно; *** p <0,001; ** р <0,01.
https://doi.org/10.1371/journal.pone.0073949.g002
Для точности ANOVA 2 × 2 × 2 выявил значимое трехстороннее взаимодействие между задачей (Составить, Не составлять), порядком (канонический, перевернутый) и количество слов (два, одно) ( F (1,28) = 6,62; p = 0,016). Последующий 2 × 2 ANOVA в рамках задачи Non-compose показал значительную взаимосвязь между порядком и количеством слов для точности ( F (1,11) = 9.03, p = 0,012), с последующими парными t -тесты между парами условий из одного и двух слов показали, что этот эффект был обусловлен значительно более низкой точностью в каноническом условии из двух слов по сравнению с совпадающим. — контроль слов ( p = 0,007; два слова: 91,9% сред. [1,8% стандарт.]; одно слово: 96,8% сред. [0,7% стандарт.]), и нет статистической разницы в точности для перевернутого условия заказа ( p = 0,39; два слова: 97,9% сред. [0,8% стандарт]; одно слово: 97.2% ср. [0,7% стандарт.]). Соответствующий 2 × 2 ANOVA в задаче Compose, с другой стороны, не произвел основного эффекта порядка или взаимодействия между двумя факторами (оба F, s <1), но значительный основной эффект количества слов ( F (1,17) = 13,94; p = 0,0017), с более низкой точностью в обоих условиях, состоящих из двух слов, по сравнению с соответствующими контрольными данными (канонические два слова: 96,4% в среднем [0,8% стандарт]; канонические из одного слова : 98,1% сред. [0,5% стандарт.]; Перевернутые два слова: 97,1% сред.[0,4% стандарт.]; перевернутое одно слово: 98,0% ср. [0,4% стандарт.]). Таким образом, взаимодействие, наблюдаемое в начальном дисперсионном анализе 2 × 2 × 2, было обусловлено значительным влиянием Задачи на взаимодействие между количеством слов и порядком точности.
Что касается времени реакции, то дисперсионный анализ 2 × 2 × 2 показал основной эффект задачи (F (1,28) = 6,96; p <0,01) с более быстрыми ответами в задаче «Составление» по сравнению с задачей «Несоставление» ( Среднее значение 622 мс [стандартное значение 139 мс] и среднее значение 745 мс [стандартное значение 349 мс]). Не было значимого трехстороннего взаимодействия ( F (1,28) = 1.88, p = 0,18), хотя восемь условий снова показали тот же качественный образец, что и для точности, причем каждое условие из двух слов отличается от его парного однословного элемента управления таким же образом (здесь, с более быстрыми ответами), за исключением перевернутое условие из двух слов в задаче «Не составить», которое не отличалось от соответствующего ему элемента управления, состоящего из одного слова (и на самом деле имело немного более медленные ответы). ANOVA 2 × 2 в задаче Non-Compose не выявил значительных эффектов во времени реакции на порядок, количество слов или их взаимодействие (все значения F <1; канонический: два слова: 727 мс ср.[86 мс ст.]; одно слово: 739 мс ср. [Стандартное 98 мс]; перевернутое: два слова: 759 мс ср. [113 мс стандарт.]; одно слово: 757 мс ср. [116 мс стандарт.]). Соответствующий 2 × 2 ANOVA в задаче «Составление», однако, показал значительную взаимосвязь между порядком и количеством слов ( F (1,17) = 8,39; p = 0,01). Последующие парные тесты t показали, что этот эффект был обусловлен значительно более быстрыми ответами в каноническом условии из двух слов по сравнению с подобранным контролем ( p <0.001; двух слов: 579 мс ср. [Стандартное 30 мс]; одно слово: 644 мс ср. [38 мс стандарт.]) И отсутствие статистической разницы между условиями обратного порядка ( p = 0,40; два слова: средн. 625 мс [36 мс стандарт.]; Одно слово: 640 мс сред. [33 мс стандарт. .]).
Таким образом, в целом, наши поведенческие меры предполагают четкую диссоциацию между всеми условиями, состоящими из двух слов, и их элементами управления из одного слова, за исключением условия перевернутого слова из двух слов в задаче Non-Compose, которая, вместо этого, близко соответствовала условиям из одного слова. контроль.Этот шаблон результатов, конечно, в точности соответствует прогнозам для комбинаторной обработки, если комбинаторные механизмы могут быть гибко развернуты в перевернутых последовательностях из двух слов, когда задача требует композиции, и не задействованы автоматически, когда задача этого не делает. Кроме того, более быстрое время отклика, проявляемое составными условиями из двух слов, перекликается с эффектом облегчения, который ранее наблюдался для составных фраз в этой задаче (Bemis & Pylkkänen, 2011). Хотя причина сопутствующего снижения точности для этих условий неясна и предполагает ранее не наблюдаемый компромисс между скоростью и точностью, в целом поведенческие результаты предполагают, что обработка была аналогичной во время канонической и перевернутой последовательности двух слов, когда задача требовала композиции. и не похожи, когда не требовалось никакого состава.
Результаты ROI левой передней височной доли
Результаты без составления LATL.
В задаче Non-Compose тест перестановки взаимодействий выявил значительный кластер активности, локализованный в LATL (рис. 3) от 215 до 266 мс ( p = 0,023; 10 000 перестановок). ANOVA с повторными измерениями 2 × 2, выполненный для активности LATL, усредненной за это временное окно, подтвердил этот результат и продемонстрировал значительную взаимосвязь между порядком и количеством слов ( F (1,11) = 7.361; p = 0,020) с активностью в каноническом условии из двух слов, значительно большей, чем в согласованном контроле из одного слова ( p = 0,009; парные образцы t тест ; два слова: 4,25 нАм средн. [2,14 нАм] стандартное]; одно слово: 2,86 нАм средн. [1,23 нАм стандартное]), и отсутствие статистической разницы между активностью в обратных условиях ( p = 0,732; парные образцы t тест; два слова: 3,70 нАм средн. [1,95 нАм стандарт.]; однословно: 3,51 нАм средн. [0,86 нАм средн.]).
Рисунок 3. Результаты LATL ROI.
Локализованная активность показана для LATL ROI во время обработки критических элементов (существительные в канонической последовательности, прилагательные в обратной последовательности), усредненных по предметам. Заштрихованные области обозначают значительные кластеры комбинаторной активности, что определяется непараметрическим тестом перестановки на основе кластеров (Maris & Oostenveld, 2007), применяемым ко всей эпохе, от 0 до 600 мс после представления критического элемента.Мы наблюдали значительную взаимосвязь между порядком и количеством слов в задаче «Несоставление» (A) и значительный основной эффект количества слов в задаче «Составление» (B) для активности, генерируемой между 200 и 300 мс. нс — незначительно; ** p <0,01; * р <0,05.
https://doi.org/10.1371/journal.pone.0073949.g003
Мы не нашли доказательств увеличения активности LATL во время обработки обратных последовательностей в этой задаче. И тест перестановки основного эффекта, и кластерный тест post-hoc , выполненные только между двумя обратными условиями, не выявили каких-либо значимых кластеров активности (все кластеры p > 0.8). Таким образом, в задаче Non-Compose мы наблюдали значительный комбинаторный эффект во время обработки канонических фраз во время, подобное тому, которое наблюдалось в наших предыдущих экспериментах (Bemis & Pylkkänen, 2011, 2012), и никаких доказательств каких-либо комбинаторных эффектов LATL во время обработка обратных последовательностей в любое время.
Составьте результаты LATL.
В задаче Compose тест перестановки, разработанный для выявления повышенной активности в обоих двух словах, выявил значительный кластер активности, локализованный в LATL (рисунок 3) от 201 до 269 мс ( p = 0.029; 10000 перестановок). ANOVA с повторными измерениями 2 × 2, выполненный для активности, усредненной по этому кластеру, подтвердил этот результат и выявил значимый основной эффект количества слов ( F (1,17) = 4,52; p = 0,0385) с повышенной активностью в оба условия, состоящие из двух слов, по сравнению с их парными контролями из одного слова (каноническое значение из двух слов: средн. 4,00 нАм [1,93 нАм стандарт]; каноническое значение из одного слова: средн. 3,37 нАм [0,97 нАм стандарт]; два слова перевернуты : 4,17 нАм сред. [2,43 нАм стандарт]; перевернутое слово: 3.39 нАм ср. [1,61 нАм стандарт.]). Ни основной эффект порядка, ни взаимодействие между двумя факторами не были значительными в этом тесте (оба F s <1).
Этот тест на перестановку также выявил незначительно значимый кластер активности от 380 до 430 мс ( p = 0,075; 10000 перестановок), подтвержденный маргинальным основным эффектом количества слов согласно ANOVA с повторными измерениями 2 × 2 на активность в течение этого временного окна ( F (1,17) = 3,52; p = 0.078; канонический, состоящий из двух слов: 3,72 нАм ср. [1,96 нАм стандартное]; однословные канонические: 3,13 нАм ср. [1,20 нАм стандарт.]; два слова в обратном порядке: 3,80 нАм средн. [2,32 нАм стандартное]; перевернутое слово: 2,95 нАм ср. [1,33 нАм стандарт.]). Опять же, не было никакого эффекта порядка в этом временном окне и никакого взаимодействия между двумя факторами (оба F с <1). Этот результат снова близко совпадает с нашими предыдущими выводами, в которых мы наблюдали незначительное увеличение комбинаторной активности в LATL примерно с 350 до 400 мс (Bemis & Pylkkänen, 2011).
Единственным эффектом, идентифицированным тестом перестановки взаимодействий в этой задаче, был незначительный кластер активности от 469 до 505 мс ( p = 0,079; 10000 перестановок), в котором активность LATL увеличивалась только во время канонического условия из двух слов (два -слово каноническое: 3,77 нАм средн. [1,43 нАм средн.]; однословное каноническое: 2,70 нАм средн. [0,87 нАм средн.]; двухсловное перевернутое: 2,72 нАм средн. [2,12 нАм средн.]; одно слово обратное: 2,83 нАм среднее [1,52 нАм стандартное]). Это взаимодействие было значимым согласно ANOVA с повторными измерениями 2 × 2 на активность в течение этого временного окна ( F (1,17) = 6.79; p = 0,019). Никаких других значимых эффектов не было обнаружено ни в какой точке эпохи анализа с помощью какого-либо теста.
Таким образом, в целом результаты нашего анализа LATL ROI убедительно указывают на группировку обработки канонической и обратной последовательностей во время задачи Compose и разобщение между ними во время задачи Non-Compose.
Результаты полного мозга
Результаты полного мозга без составления.
Для канонического упорядочивания можно увидеть явное увеличение активности (рис. 4) со 150 до 250 мс в LATL, что подтверждает приведенный выше анализ ROI.Дополнительные эффекты также видны в вентромедиальной префронтальной коре (vmPFC) и правой передней височной доле (RATL) от 450 до 550 мс. Повышенная активность в обеих этих областях также наблюдалась во время обработки фраз прилагательное-существительное в нашем предыдущем исследовании, хотя оба эффекта начались немного раньше в этих результатах, и только активность в vmPFC, по-видимому, отражала комбинаторную обработку, при этом активность RATL, по-видимому, зависела от задача (подробнее см. [1]).
Рисунок 4.Полноценные результаты.
Области, нанесенные на график, обозначают разницу в средней амплитуде между условиями из двух и одного слова для всех пространственно-временных областей, в которых активность двух слов достоверно превышала активность одного слова ( p <0,05, без поправки) как минимум для 10 мс по 10 пространственным соседям, а амплитуда различий была не менее 1,5 нАм. Для наглядности некортикальные источники удалены. В общем, результаты в рамках задач «Несоставить (A)» и «Составить (B)» соответствуют нашему анализу рентабельности инвестиций, выявляя явные эффекты LATL в более раннем временном окне, примерно от 200 до 300 мс.Последующие эффекты также видны в RATL и vmPFC для канонических фраз в задаче «Несоставление» и обратных последовательностей в задаче «Составление».
https://doi.org/10.1371/journal.pone.0073949.g004
В обратных последовательностях мы наблюдали очень небольшое увеличение активности во время обработки двух слов, что дополнительно подтверждает анализ LATL ROI и поведенческие результаты, предполагая, что обработка в двухсловном реверсивном условии не отличался от согласованного однословного контроля в этой задаче.
Составьте результаты полного мозга.
В задаче Compose можно наблюдать явное увеличение активности LATL (рисунок 4) во время обработки канонических фраз из двух слов от 250 до 550 мс. Это полностью соответствует нашему анализу ROI, который выявил повышенную активность в этой области на протяжении более поздней половины эпохи анализа. Никаких других заметных эффектов в этом сравнении не видно.
Для перевернутых выражений полное сравнение мозга снова соответствовало нашему анализу ROI, показывая явное увеличение активности LATL с 150 до 250 мс.Вне этой области интереса эффекты снова были четко видны в RATL, одновременно с эффектом LATL, и в vmPFC, после эффекта LATL. Как упоминалось ранее, этот образец деятельности очень близко соответствует нашим предыдущим открытиям для канонических фраз прилагательное-существительное в рамках той же парадигмы [1].
Обсуждение
В настоящем исследовании мы исследовали, можно ли гибко развернуть базовую комбинаторную лингвистическую обработку для новых выражений при минимальном изменении требований задачи.Мы регистрировали активность МЭГ, когда испытуемые читали простые последовательности прилагательное-существительное в каноническом или обратном порядке ( красная чашка , красная чашка ), и измеряли комбинаторную обработку, сравнивая активность, вызванную предъявлением второго слова, с активностью, вызванной во время обработки слова. согласованные, некомбинаторные элементы управления ( xhl cup , frw red ). Мы использовали нейронную активность, локализованную в LATL, во время обработки совпадающих критических слов в качестве нашей основной меры комбинаторной активности.Предыдущие исследования МЭГ с использованием подобной парадигмы наблюдали последовательные и устойчивые комбинаторные эффекты в этой области во время понимания простых фраз прилагательное-существительное [1], [2], а многие гемодинамические исследования наблюдали повышенную активность LATL во время понимания предложений. по сравнению со списками слов [57], [59], [54] В настоящем исследовании, когда испытуемые должны были судить, соответствуют ли данные языковые стимулы следующему цветному пятну и очертанию формы, комбинаторная активность LATL не наблюдалась для обратных последовательностей, но надежно присутствовал для канонических фраз.Когда вместо этого следующая цель была представлена в виде единой цветной формы, значительная комбинаторная активность наблюдалась для обоих типов последовательностей. Эта модель результатов нашла отражение в наших поведенческих измерениях, которые продемонстрировали устойчивые различия между всеми ответами из двух и одного слова, за исключением двух слов, перевернутых в обратную последовательность в задаче Non-Compose, которые вместо этого были сопоставлены с их элементами управления из одного слова. . Таким образом, настоящие данные, как поведенческие, так и нейронные, показывают, что перевернутые последовательности существительное-прилагательное обрабатывались аналогично каноническим фразам прилагательное-существительное, когда задача требовала композиции, и аналогично некомбинаторным элементам управления, когда этого не происходило.
Эти результаты имеют двоякое значение. Во-первых, устойчивая активность LATL, наблюдаемая во время канонических фраз в задаче Non-Compose, дополнительно подтверждает этот показатель как показатель базовой комбинаторной обработки. Многие предыдущие исследования автоматизма механизмов лингвистического синтаксического анализа показывают, что гемодинамические комбинаторные эффекты, локализованные в LATL [54], и ранние электрофизиологические компоненты, связанные с синтаксическим анализом грамматических выражений [37], [33], остаются устойчивыми даже во время явно некомбинаторных задач. .Таким образом, если ранняя активность, локализованная в LATL в настоящей парадигме, действительно отражает базовую комбинаторную обработку, можно ожидать, что она будет демонстрировать наблюдаемый профиль и оставаться устойчивой во время манипуляции с нашей задачей. Во-вторых, выявление этого эффекта во время обработки обратных последовательностей в задаче Compose, а не в задаче Non-Compose, указывает на то, что комбинаторные лингвистические механизмы, проиндексированные с помощью этой меры, могут гибко задействоваться вне их нормального контекста при минимальном изменение требований к задаче.Интересно, что наблюдаемый эффект в перевернутых последовательностях совпал по времени с эффектом в канонических фразах (оба произошли примерно на интервале от 200 до 250 мс), предполагая схожий временной ход этого комбинаторного механизма для разных типов последовательностей. Хотя эта очевидная легкость в расширении комбинаторной обработки на новый контекст потенциально противоречит интуиции, возможно, ей способствовала заблокированная природа настоящей парадигмы. Дальнейшая работа может указывать на то, что более неожиданное изменение требований к задаче приводит к более отложенному включению комбинаторной обработки.
Прошлые исследования влияния требований задачи на языковую обработку были сосредоточены почти исключительно на манипуляциях вниманием, явно [33] или неявно [32]. Даже несколько исследований, в которых использовались задачи, потенциально способные решить проблему гибкости комбинаторной обработки (например, [67]), вместо этого по-прежнему были явно сосредоточены на измерении эффекта внимания. Напротив, настоящее исследование было направлено на минимизацию изменений внимания, манипулируя только требуемой комбинаторной обработкой.В обеих наших задачах испытуемые должны были получить семантическое представление всех слов, чтобы определить, содержит ли целевая картинка их значение. Таким образом, обработка, связанная с лексическим доступом и вниманием, должна быть относительно эквивалентной для этих двух задач. Поэтому трудно приписать увеличение активности LATL, наблюдаемое во время обработки обратных последовательностей в задаче Compose, изменением внимания, тем более что такая же активность явно присутствовала для канонических фраз и во время задачи Non-Compose.Таким образом, в отличие от предыдущих исследований, настоящее исследование демонстрирует гибкое задействование комбинаторных лингвистических механизмов, вызванное изменением требований к задаче, которое не предполагает явного манипулирования вниманием.
Компоненты последующей обработки
Мы нашли дополнительные доказательства гибкости использования комбинаторной обработки и вне ранней активности LATL. Во время обработки обратных последовательностей в задаче Compose мы наблюдали незначительное увеличение активности LATL примерно с 350 до 400 мс и дополнительную комбинаторную активность, локализованную в vmPFC, с 400 до 500 мс — паттерн эффектов, поразительно похожий на наблюдаемый ранее. для канонических фраз [1].В задаче Non-Compose таких эффектов не наблюдалось. Таким образом, результаты более поздней обработки также подтверждают вывод о том, что основные комбинаторные механизмы были задействованы во время обработки обратных последовательностей в задаче Compose.
Это свидетельство, однако, не так убедительно, как для более ранних эффектов LATL, поскольку эти более поздние результаты не были так надежно воспроизведены в настоящем эксперименте для канонических фраз. Хотя мы наблюдали повышенную активность, локализованную в vmPFC, во время обработки канонических фраз в задаче Non-Compose примерно с 450 до 550 мс, этот эффект также не был воспроизведен в задаче Compose.Вместо этого комбинаторная активность оставалась локализованной в LATL до конца эпохи выполнения этой задачи и не мигрировала в другие регионы, такие как либо vmPFC [1], либо AG [2]. Этот отклоняющийся результат был особенно неожиданным, учитывая, что этот конкретный контраст не отличался каким-либо структурным образом от того, что использовалось в наших предыдущих исследованиях. Одним из возможных объяснений наблюдаемой разницы может быть то, что в настоящем исследовании использовалось только девять критических пунктов, тогда как в обоих предыдущих исследованиях использовалось не менее 20.Это уменьшение лексической изменчивости могло способствовать относительно приглушенному и изменчивому характеру более поздних эффектов в этом контрасте, поскольку уменьшенная лексическая изменчивость часто была связана со сниженной нервной активностью (например, [68]). Однако устойчивый характер более поздних эффектов, наблюдаемых во время обратных последовательностей в этой задаче, предполагает, что это объяснение является неполным. Очевидно, что требуется дополнительная работа, чтобы распутать различные механизмы, лежащие в основе этой более поздней стадии обработки, особенно с учетом изменчивости, наблюдаемой для таких эффектов и в наших предыдущих результатах.
Функция LATL
В то время как настоящие результаты говорят о том, как работает комбинаторный механизм, размещенный в LATL, наши результаты совместимы с несколькими функциональными гипотезами , которые точно вычисляет этот механизм. Предполагается, что даже самая базовая грамматическая обработка включает как синтаксические, так и семантические механизмы, отвечающие за формирование структурных отношений и построение сложных значений из отдельных элементов. Ранее [1], [2] мы предложили предварительное отображение синтаксических и семантических процессов на ранний LATL и поздний vmPFC эффекты соответственно.Это предположение было основано на предыдущей работе, связывающей гемодинамическую активность в LATL с комбинаторной синтаксической обработкой [69], [70], работе MEG, связывающей повышенную активность vmPFC с семантической композицией [71], [72], и моделями нейролингвистической обработки, которые постулируют синтаксическую обработку. комбинация до смысловой композиции [73]. С одной точки зрения, настоящие результаты могут рассматриваться как поддерживающие это предложенное разграничение, поскольку многие прошлые исследования связывают ранние, автоматические электрофизиологические компоненты с синтаксическими процессами [36], [32], [33] и более поздние, более зависимые от задачи компоненты с семантическими обработка [41], [40].Таким образом, наш вывод о том, что ранняя комбинаторная активность в LATL остается устойчивой для разных задач во время обработки канонических фраз, может поддерживать предположение о том, что этот компонент отражает синтаксическую обработку.
С другой стороны, устойчивые к задачам ранние электрофизиологические компоненты также приписывались семантической обработке [74], а недавние исследования гемодинамики утверждают, что повышенная активность LATL во время понимания предложений отражает семантическую, а не синтаксическую комбинаторную обработку [59]. ], [35].В настоящем исследовании характер манипуляции с задачами также предполагает семантическую, а не синтаксическую роль LATL, поскольку единственное различие между этими двумя задачами состоит в том, что в задаче Compose субъекты должны построить единое семантическое представление из индивидуальной формы. и цветные изображения. Никаких очевидных синтаксических манипуляций не требуется, поскольку языковые стимулы остаются постоянными между задачами. Таким образом, трудно дать простое функциональное объяснение того, как или, если уж на то пошло, почему синтаксическая фраза может быть сформирована для обратных последовательностей в этой задаче.Конечно, может случиться так, что синтаксический анализатор формирует такую составляющую, несмотря на обратный порядок составляющих — и некоторые утверждали, что это должно быть так для продолжения семантической композиции (например, [36]) — однако это кажется более сложным. Вероятно, что комбинаторная активность, наблюдаемая во время задачи Compose, просто отражает требования задачи, то есть семантическую композицию двух элементов. Более конкретно, это действие может отражать тип процесса спецификации, в котором базовое концептуальное представление объекта преобразуется в более сложную форму, которая представляет более конкретную концепцию цветной формы.Такая операция могла бы, возможно, продолжаться независимо от порядка, в котором встречаются элементы, и такая симметрия фактически является формальным свойством теоретических представлений о модификации [75]. Кроме того, несколько предыдущих исследований связывали активность в LATL именно с этим типом операции спецификации, хотя и во время обработки отдельных слов [76], [77]. Если эта гипотеза верна, то более поздние комбинаторные эффекты могут составить вторую стадию семантической композиции, сопоставляя несколько моделей концептуальной модификации, основанной на психолингвистических результатах (например,грамм. [78], [79]. Однако в настоящее время этот вывод должен оставаться предварительным, поскольку настоящая манипуляция не была специально предназначена для того, чтобы распутать эти функциональные гипотезы.
Заключение
В настоящем исследовании мы демонстрируем, что основные комбинаторные лингвистические механизмы могут быть гибко развернуты в контексте, выходящем за рамки их естественной грамматической области. В отличие от предыдущих исследований, которые манипулируют вниманием или используют длительные парадигмы неявного обучения, мы показываем здесь, что простого введения релевантности комбинации при сохранении постоянства внимания и лексических факторов достаточно, чтобы вызвать базовую комбинаторную обработку между двумя лексическими элементами, которые естественным образом не задействуются такая обработка.Будущая работа может теперь основываться на этом результате, чтобы определить степень этой гибкости как с точки зрения лингвистических механизмов, так и когнитивных областей.
Примеры фраз прилагательного
Фраза прилагательного — это группа слов, которые описывают существительное или местоимение в предложении. Прилагательное в прилагательной фразе может стоять в начале, конце или середине фразы. Фраза прилагательного может быть помещена в предложение до или после существительного или местоимения.
Примеры фраз прилагательного
Прилагательные фразы могут использоваться для описания людей или любых других существительных или местоимений в предложениях.Термин «прилагательная фраза» означает то же самое, что и термин «прилагательная фраза».
Прилагательные фразы, описывающие людей
Примеры прилагательных, используемых для описания людей, включают:
- Человек умнее меня должен это понять.
- Все были чрезвычайно довольны , когда был объявлен победитель.
- Мама сказала, что стоимость машины на завышена .
- Быстрее, чем мчащаяся пуля , Супермен спас положение.
- Ее глаза были невероятно завораживающими для молодого человека.
- очень эмоциональный актер показал прекрасную игру.
- Она любит кататься на лыжах .
- К концу свидания мне было довольно скучно с ним .
- чрезмерно восторженных фанатов раскрасили свои тела в цвета команды.
- Прощальная была слишком серьезна в отношении своего среднего балла.
- Обветшалые мускулистые ковбои изображены в большинстве вестернов.
- измученных и перегруженных работой человек взял заслуженный перерыв.
- Мой замечательный и талантливый брат выиграл стипендию.
- Я очень сильно в него влюблена .
- Хорхе просто хотелось поехать.
- Сияя радостью , ее лицо озарило комнату.
- Она — главный детский хирург института.
- Разочарованные, перегруженные работой и недоплачиваемые сотрудников часами устроили пикет.
- Молодые, в остальном здоровые человек, скорее всего, быстро выздоровеют.
Прилагательные фразы, описывающие другие существительные
Примеры прилагательных, используемых для описания существительных, отличных от людей, включают:
- Ролик был не так уж и ужасно .
- Выпускные экзамены были невероятно сложными .
- Этот пирог очень вкусный и очень дорогой .
- Новый наряд очень дорогой, но очень красивый .
- Студенты недовольны повышением стоимости обучения на долларов на обучение устроили митинг.
- В этом комплексе довольно небольших, но дешевых квартир.
- Этот яблочный пирог пахнет очень соблазнительно .
- Обычно обедают вне дома не очень полезно .
- Очень усталый котенок заснул у своей тарелки с едой.
- Собака, покрытая липкой и отвратительной грязью , наводит беспорядок в машине.
- Гобелен , красиво сшитый вручную , стоит своих денег.
- Этот фильм абсолютно невероятно плохой.
- Мне очень хотелось покрасить гостиную в глубокий баклажановый оттенок пурпурного.
- Органическая говядина травяного откорма — лучший выбор.
- Она гордилась невероятным, революционным экспериментом своего сына, который выиграл научную ярмарку.
- Животное , прячущееся в углу , было спасено и получило хороший дом.
- Музыка из соседнего дома раздражающе громкая .
- Обожаю вкус сладкого сочного персика .
- Мальчиков раздражали чрезмерно длинные строк.
- Танец был изысканно грациозным .
- Конфеты темно-шоколадно-коричневые .
- Эта старая еда на вкус ужасно плохая .
- очень маленький щенок нес большую палку.
- Стоимость машины была вполне доступной .
Прилагательные фразы в литературе
Использование прилагательных в прозе может быть отличным способом привлечь читателей. Прилагательные фразы часто используются в большой литературе, а также в других письменных произведениях.
- «Была холодная, унылая, суровая погода». — Чарльз Диккенс в Рождественский гимн
- «Он человек необыкновенной внешности, , и все же я действительно не могу назвать ничего особенного». — Роберт Льюис Стивенсон в The Strange Case of Dr.Джекил и мистер Хайд
- «И каждый отдельных угасающих тлеющих углей сотворил свой призрак на полу». — Эдгар Аллан По в «Вороне»
Упражнения для составных фраз
Проверьте свои знания, определив прилагательные в приведенных ниже практических вопросах.
Практические вопросы: найдите прилагательные
Определите, какие слова в предложениях ниже являются прилагательными, затем просмотрите ответы, чтобы проверить свою работу.
- Кислый, терпкий лимон заставил меня сморщить губы.
- Серьезный умоляющий тон заставляет меня поверить, что она говорит правду.
- Невероятно красивые пейзажи захватывали дух.
- Новые котята такие крошечные и нежные.
- Поездка была долгой, утомительной и насыщенной.
Ответы на практические вопросы
После того, как вы проработали пункты выше, проверьте свою работу здесь. Фразы прилагательных выделены жирным шрифтом.
- Кислый, терпкий лимон заставил меня сморщить губы.
- Ее искренний умоляющий тон заставляет меня поверить, что она говорит правду.
- невероятно красивый пейзаж захватывает дух.
- Новые котята такие крошечные и нежные .
- Это было долгое, утомительное и насыщенное событиями путешествие .
Улучшите свое письмо с помощью описательного языка
Как вы можете видеть из примеров, фраза прилагательного может быть очень полезным грамматическим инструментом, чтобы лучше описать предмет предложения и добавить интерес к вашему письму.Чтобы получить больше идей, потратьте некоторое время на изучение примеров предложных фраз, особенно того, как их можно использовать в качестве прилагательных. Оттуда исследуйте другие виды описательных слов.
Анализ структур аргументации в убедительных эссе | Компьютерная лингвистика
Мы моделируем структуру аргументации убедительных эссе как связанную древовидную структуру. Мы используем уровневый подход для моделирования первого уровня дерева и подход с одним утверждением для представления структуры каждого отдельного аргумента.Соответственно, мы моделируем первый уровень дерева с двумя разными типами компонентов аргумента и структуру отдельных аргументов с аргументативными отношениями.
Основная претензия является корневым узлом структуры аргументации и представляет точку зрения автора по теме. Это самоуверенное утверждение, которое обычно делается во введении и повторяется в заключении эссе. Отдельные абзацы основной части эссе включают фактические аргументы.Они либо поддерживают, либо атакуют точку зрения автора, выраженную в основном утверждении. Каждый аргумент состоит из утверждения и как минимум одной посылки. Чтобы различать поддерживающие и атакующие аргументы, каждое утверждение имеет атрибут позиции , который может принимать значения «за» или «против».
Мы моделируем структуру каждого аргумента с помощью подхода с одним утверждением. Утверждение составляет центральный компонент каждого аргумента.Предпосылки — причины аргумента. Фактическая структура аргумента включает направленные аргументированные отношения поддержки и атаки, которые связывают посылку либо с утверждением, либо с другой посылкой (последовательные аргументы). Каждая предпосылка p имеет одно исходящее отношение (т. Е. Есть отношение, которое имеет p в качестве исходного компонента) и ни одного или нескольких входящих отношений (то есть может быть отношение с p в качестве целевого компонента. ). В заявке может быть несколько входящих, но не исходящих отношений.Неоднозначная функция внутренних посылок в последовательных аргументах неявно моделируется структурой аргумента. Внутренняя посылка демонстрирует одно исходящее отношение и по крайней мере одно входящее отношение. Наконец, позиция каждой посылки определяется типом ее исходящего отношения (поддержка или нападение).
Следующий пример иллюстрирует структуру аргументации убедительного эссе. 3 Введение к эссе описывает спорную тему и обычно включает основное утверждение:
С тех пор, как исследователи из Института Рослина в Эдинбурге клонировали взрослую овцу, продолжались споры о том, пригодна ли технология клонирования. морально и этически правильно или нет.Некоторые люди выступают за, а другие — против, и до сих пор нет единого мнения о том, следует ли разрешать технологию клонирования. Однако, насколько я понимаю, [ клонирование — важная технология для человечества ] MajorClaim 1 , поскольку [ это было бы очень полезно для разработки новых лекарств ] Претензия 1 .
Первые два предложения вводят тему и не содержат аргументированного содержания.Третье предложение содержит основную претензию (выделено жирным шрифтом) и утверждение, которое поддерживает основную претензию (подчеркнуто). Следующие основные абзацы эссе включают аргументы, которые либо поддерживают, либо опровергают основное утверждение. Например, следующий основной абзац включает один аргумент, который поддерживает положительную точку зрения автора на клонирование:
Первое предложение содержит утверждение аргумента, которое подтверждается пятью предпосылками в следующих трех предложениях (подчеркнутые волнистой линией ).Второе предложение включает два помещения, из которых Premise 1 поддерживает Claim 2 и Premise 2 поддерживает Premise 1 . Предпосылка 3 в третьем предложении подтверждает утверждение 2 . Четвертое предложение включает Premise 4 и Premise 5 . Оба поддерживают Premise 3 . Следующий абзац иллюстрирует основной абзац с двумя аргументами:
Начальное предложение включает первый аргумент, который состоит из Premise 6 и Claim 3 .Следующие три предложения включают второй аргумент. Premise 7 и Premise 8 оба поддерживают Требование 4 в последнем предложении. Оба аргумента охватывают разные аспекты (развитие науки и клонирование человека), которые поддерживают точку зрения автора на клонирование. Этот пример показывает, что знание аргументативных отношений важно для разделения нескольких аргументов в абзаце. Пример также показывает, что компоненты аргумента часто показывают предшествующие текстовые блоки, которые не имеют отношения к аргументу, но полезны для распознавания типа компонента аргумента.Например, предшествующие соединительные элементы дискурса, такие как «поэтому», «следовательно» или «таким образом», могут сигнализировать о последующем требовании. Такие маркеры дискурса, как «потому что», «с тех пор» или «более того», могут указывать на предпосылку. Формально эти предшествующих токенов компонента аргумента, начиная с токена t i , определяются как токены t i — m ,…, t i — i 1 , которые не охвачены другим компонентом аргумента в предложении s = t 1 , t 2 ,…, t n где 1 ≤ i ≤ n и i — м ≥ 1.Третий основной абзац иллюстрирует противопоставление аргумента и отношения аргументативной атаки:
Абзац начинается с утверждения 5 , которое подвергает критике позицию автора. Он поддерживается Premise 9 во втором предложении. Третье предложение включает две посылки, каждая из которых защищает позицию автора. Premise 11 — атака Claim 5 и Premise 10 поддерживает Premise 11 .Последний абзац (заключение) повторяет основную претензию и резюмирует основные аспекты эссе:
Заключение эссе начинается с критического утверждения, за которым следует повторное изложение основного утверждения. Последнее предложение включает еще одно утверждение, которое резюмирует наиболее важные моменты аргументации автора. На рисунке 2 показана вся структура аргументации примера эссе.Подводя итог, хотя [ разрешение клонирования может нести некоторые риски, такие как неправильное использование в военных целях ] Заявление 6 , я твердо верю, что [ эта технология полезна для человечества ] MajorClaim 2 . Вполне вероятно, что [ эта технология содержит некоторые важные средства лечения, которые значительно улучшат условия жизни. ] Заявление 7 .
5 Принципов визуального дизайна в UX
Глядя на визуальный элемент, мы обычно сразу можем сказать, нравится он или нет. (Потому что они часто проявляются на интуитивном уровне в модели эмоционального дизайна Дона Нормана.) Однако немногие могут выразить словами, почему макет визуально привлекателен. Графика, основанная на принципах хорошего визуального дизайна, может стимулировать взаимодействие и повысить удобство использования.
Принципы визуального дизайна сообщают нам, как элементы дизайна, такие как линия, форма, цвет, сетка или пространство, сочетаются друг с другом для создания хорошо округленных и продуманных визуальных эффектов.
В этой статье определены 5 принципов визуального дизайна, которые влияют на UX:
- Масштаб
- Визуальная иерархия
- Остаток
- Контраст
- Гештальт
Следование этим 5 принципам визуального дизайна может стимулировать взаимодействие и повысить удобство использования.
1. Шкала
Этот принцип широко используется: почти каждый хороший визуальный дизайн использует его преимущества.
Определение: Принцип шкалы относится к использованию относительного размера для обозначения важности и ранга в композиции.
Другими словами, при правильном использовании этого принципа наиболее важные элементы в дизайне больше, чем менее важные. Причина этого принципа проста: когда что-то крупное, это с большей вероятностью будет замечено.
Для визуально приятного дизайна обычно используется не более 3-х различных размеров. Наличие ряда элементов разного размера не только создаст разнообразие в вашем макете, но также установит визуальную иерархию (см. Следующий принцип) на странице. Обязательно подчеркните самые важные аспекты своего дизайна, сделав их самыми большими.
При правильном использовании принципа масштабирования и выделении правильных элементов пользователи легко проанализируют визуальное оформление и узнают, как его использовать.
Medium для iPhone: популярные статьи визуально больше других статей. Шкала направляет пользователей к потенциально более интересным статьям. В этой автостоянке в Кракове самая важная часть информации (зона H — где вы в данный момент находитесь) — самая большая по размеру. (Источник изображения: www.behance.com)2. Визуальная иерархия
Макет с хорошей визуальной иерархией будет легко понят для ваших пользователей.
Определение : Принцип визуальной иерархии относится к направлению взгляда на страницу таким образом, чтобы он обращал внимание на различные элементы дизайна в порядке их важности.
Визуальная иерархия может быть реализована посредством изменения масштаба, значения, цвета, интервала, размещения и множества других сигналов.
Визуальная иерархия контролирует доставку опыта. Если вам сложно понять, где искать страницу, скорее всего, в ее макете отсутствует четкая визуальная иерархия.
Чтобы создать четкую визуальную иерархию, используйте 2–3 размера шрифта, чтобы указать пользователям, какие фрагменты контента являются наиболее важными или находятся на самом высоком уровне в мини-информационной архитектуре страницы.Или рассмотрите возможность использования ярких цветов для важных предметов и приглушенных цветов для менее важных.
Scale также может помочь определить визуальную иерархию, поэтому включите различные масштабы для различных элементов дизайна. Общее практическое правило — включать в проект мелкие, средние и большие компоненты.
Среднее мобильное приложение: имеется четкая визуальная иерархия заголовка, подзаголовка и основного текста. Каждый компонент статьи имеет размер шрифта, равный его важности. Мобильное приложение Uber: в мобильном приложении Uber визуальная иерархия ясна.Экран разделен пополам между картой и формой ввода (нижняя половина экрана), что наводит на мысль, что эти компоненты одинаково важны для пользователя. Взгляд сразу же привлекает внимание к вопросу Куда? поле из-за его серого фона, затем к недавним местоположениям под ним, которые немного меньше по размеру шрифта. Мобильное приложение Dropbox: в мобильном приложении Dropbox визуальная иерархия менее четкая. Несмотря на то, что пояснительный текст меньше по размеру, чем имя файла, трудно различить разные файлы.Миниатюры обеспечивают дополнительный уровень иерархии, но их наличие зависит от доступных типов файлов. В конечном итоге пользователям приходится много разбираться и читать, чтобы найти папку или файл, которые они ищут.3. Остаток
Балансировка похожа на качели: вместо веса вы балансируете элементы дизайна.
Определение : Принцип баланса относится к удовлетворительному расположению или соотношению элементов дизайна. Баланс возникает, когда имеется равномерно распределенное (но не обязательно симметричное) количество визуального сигнала по обе стороны от воображаемой оси, проходящей через середину экрана.Эта ось часто бывает вертикальной, но может быть и горизонтальной.
Как и при балансировке веса, если бы у вас был один маленький элемент дизайна и один большой элемент дизайна с двух сторон от оси, дизайн был бы немного несбалансированным. При создании баланса имеет значение не только количество элементов, но и площадь, занимаемая элементом дизайна.
Воображаемая ось, которую вы устанавливаете на своем визуале, будет точкой отсчета для того, как организовать макет, и поможет вам понять текущее состояние баланса вашего визуала.В сбалансированном дизайне ни одна область не привлекает внимание настолько, чтобы вы не могли видеть другие области (даже если некоторые элементы могут иметь больший визуальный вес и быть фокусом). Остаток может быть:
Тип баланса, который вы используете в своем визуале, зависит от того, что вы хотите передать. Асимметрия динамична и увлекательна. Это создает ощущение энергии и движения. Симметрия тихая и статичная. Радиальный баланс всегда уводит взгляд в центр композиции.
The Hub Style Exploration: композиция кажется стабильной, что особенно уместно, когда вы ищете работу, которая вам нравится.Баланс здесь симметричный. Если бы вы провели воображаемую вертикальную ось по центру веб-сайта, элементы распределялись бы равномерно по обе стороны от оси. (Источник изображения: dribbble.com) Nike: эта страница асимметрично сбалансирована, что дает ощущение энергии и движения, соответствующее бренду Nike. Если бы вы нарисовали вертикальную ось по центру этого визуала, количество элементов по обе стороны от оси будет примерно одинаковым. Однако разница в том, что они не идентичны и находятся в одних и тех же точных местах.Несмотря на то, что технически на левой стороне обуви немного больше текста, он уравновешен более крупным текстом справа, который занимает больше места и визуального веса, что делает их очень похожими. Наручные часы Brathwait: классические часы с радиальной балансировкой. Взгляд сразу же притягивается к центру циферблата, и весь визуальный вес распределяется равномерно, независимо от того, где нарисована воображаемая ось. Этот редакторский разворот не сбалансирован.Если вы проведете вертикальную ось вниз по странице, элементы не будут равномерно распределены по обеим сторонам оси. (Источник изображения: www.behance.net)4. Контрастность
Это еще один часто используемый принцип, который выделяет определенные части вашего дизайна среди пользователей.
Определение : Принцип контрастности относится к сопоставлению визуально непохожих элементов, чтобы передать тот факт, что эти элементы различны (например, принадлежат к разным категориям, имеют разные функции, ведут себя по-разному).
Другими словами, контраст дает глазу заметную разницу (например, по размеру или цвету) между двумя объектами (или между двумя наборами объектов), чтобы подчеркнуть их различие.
Принцип контраста часто применяется через цвет. Например, красный цвет часто используется в дизайне пользовательского интерфейса, особенно в iOS, для обозначения удаления. Яркий цвет сигнализирует о том, что красный элемент отличается от остальных.
Приложение Reminders для iOS: красный цвет, который сильно контрастирует с окружающим контекстом, зарезервирован для удаления.Часто в UX слово «контраст» напоминает о контрасте между текстом и его фоном. Иногда дизайнеры намеренно уменьшают контраст текста, чтобы не акцентировать внимание на менее важном тексте. Но этот подход опасен — уменьшение контрастности текста также снижает разборчивость и может сделать ваш контент недоступным. Используйте средство проверки цветового контраста, чтобы убедиться, что ваш контент все еще может быть прочитан всеми вашими целевыми пользователями.
Greenhouse Juice Co: Читаемость текста на бутылке зависит от цвета сока.Хотя контраст прекрасно работает для некоторых соков, этикетки бутылок со светлыми соками практически невозможно прочитать. (Источник изображения: www.instagram.com)5. Принципы гештальта
Это набор принципов, установленных в начале двадцатого века гештальт-психологами. Они фиксируют, как люди понимают смысл изображений.
Определение : Принципы гештальта объясняют, как люди упрощают и организуют сложные изображения, состоящие из множества элементов, подсознательно объединяя части в организованную систему, которая создает единое целое, а не интерпретирует их как серию разрозненных элементов.Другими словами, принципы гештальт отражают нашу склонность воспринимать целое в отличие от отдельных элементов.
Существует несколько гештальт-принципов, включая сходство, продолжение, завершение, близость, общую область, фигуру / фон, а также симметрию и порядок. Близость особенно важна для UX — это относится к тому факту, что элементы, которые визуально ближе друг к другу, воспринимаются как часть одной группы.
Это принцип гештальт-замыкания, который позволяет нам видеть две целующиеся фигуры вместо случайных фигур на картине Пикассо.Наш мозг заполняет недостающие части, чтобы создать две фигуры. Мы также часто видим приложения теории гештальт в логотипах. В логотипе NBC нет павлина в белом пространстве, но наш мозг понимает, что он есть. В форме регистрации Uber используется принцип гештальт-близости: метки полей расположены рядом с соответствующими текстовыми полями, что позволяет легко понять, какую информацию вводить в какие поля. Если бы между полем и последующей меткой (для следующего поля) оставалось меньше места, пользователям было бы сложно понять, что и чему принадлежит. 2017 Налоговая форма США: из-за недостатка места между полями ее заполнение затруднительно. Вы можете легко пропустить то, к чему относится второе поле «Фамилия». Использование принципа гештальт-близости для различения полей, относящихся к себе и супругу, принесло бы пользу UX.Почему важны принципы визуального дизайна
Почему мы должны заботиться о принципах визуального дизайна и понимать их? Помимо того, чтобы что-то «выглядело красиво», понимание и использование их в интересах:
- Повышение удобства использования. Следование этим принципам визуального дизайна часто приводит к созданию простых в использовании макетов. Например, золотое сечение, которое часто используется для создания красивых произведений искусства, также использовалось при наборе текста, чтобы создать визуально приятную связь между размером шрифта, высотой и шириной линии. Результат обычно приводил к сокращению длины строк, что создавало баланс (через пробелы) на веб-странице и облегчало чтение текста. В сочетании с сильным интерактивным дизайном визуальный дизайн увеличит показатели успешности задач и вовлеченности пользователей.
- Вызвать эмоции и восторг. Красивые вещи вызывают положительные эмоции. (Фактически, эффект эстетики и удобства использования говорит о том, что, когда люди находят дизайн визуально привлекательным, они могут быть более снисходительными к незначительным неудачам с удобством использования.) Следуя принципам хорошего визуального дизайна, дизайнеры могут создавать интерфейсы, которые хорошо выглядят и, таким образом, привлекают пользователей хорошо себя чувствовать.
- Укрепление восприятия бренда. Сильная визуальная система вызывает у пользователей доверие и интерес к продукту, а также надлежащим образом представляет и укрепляет бренд.
Список литературы
Луптон, Э. (2008). Графический дизайн: новые основы. Нью-Йорк: Princeton Architectural Press.
Poulin, R. (2018). Язык графического дизайна. Беверли: Quarto Publishing Group USA, Inc.
Что означает «троллейбус» в виде тарабарщины для языка
Лексикографы — существа настойчивые. Никогда не довольствуясь, они просматривают каждое недавно опубликованное издание ранее не напечатанного текста на предмет предшествующих дат или обнаружения слова в «дикой природе», предшествующего текущей первой цитате в словаре.В прошлом году благодаря их усердию в Среднеанглийском словаре появилась новая запись для слова «тарабарщина», которое, хотя когда-то считалось изобретением середины 16 века, на самом деле впервые появилось около 1450 года. Пороки и добродетели предупреждают своих читателей, что невнимательно или без должного благочестия бормотать молитвы — значит произносить «giberisshe too Godde» (говорить чепуху с Богом). Автор предполагает, что тарабарщина равносильна глупости и неискренности. Но что мы должны думать об этой странной части создания человеческого языка?
Хотя его появление на английском языке было изменено, этимологическое происхождение слова «тарабарщина» остается немного загадочным.Словарь английского языка Сэмюэля Джонсона (1755) популяризировал народную этимологию, связывающую «тарабарщину» с «химическим кантом», технические термины алхимии и науки, используемые в «Гебере», прозападном имени Джабира ибн Хайяна, но не так. много одного автора, но личность, которой приписывалась большая часть средневековых арабских ученых. Истина гораздо более банальна: «тарабарщина», вероятно, происходит от «тарабарщины», одного из множества глаголов, таких как «глотать», «треп», «треп» и «болтать», которые звукоподражательно имитируют звук неразборчивого лепета.Однако первый случай «тарабарщины» — в пьесе Уильяма Шекспира « Гамлет », где «закутанные в брезент мертвые», трупы, поднявшиеся из своих могил, зловеще «пищат и бормочут» на улицах Рима, появляется намного позже, чем « тарабарщина ».
Тарабарщина — язык, который нельзя понять — это не совсем то же самое, что и бессмыслица. При написании бессмыслицы мы читаем отдельные слова, но не можем проанализировать их, придавая им смысл, соответствующий общепринятым ожиданиям. «Бесцветные зеленые идеи яростно спят», — как выразился Ноам Хомский в Syntactic Structures (1957), в примере семантически бессмысленного предложения с присутствующим и правильным синтаксисом.С другой стороны, тарабарщина превращает звуки и буквы языка в неразборчивые слова. Гигант Нимрод, который, согласно святоотеческим преданиям, приказал построить Вавилонскую башню и тем самым раздробил единый язык человечества на все языки мира, наказан непонятно в Inferno из Божественной комедии Данте Алигьери (1308-20). Охраняя Девятый Круг ада, Нимрод кричит: « Raphèl maì amècche zabì almi. — Не обращайте на него внимания, — говорит Вергилий, его проводник, потому что он не может понять нас, как мы не можем понять его слов.
Странная фраза Нимрода в действительности является тарабарщиной, буквы превращены в слова, индивидуальное значение которых ускользает от нас, как бы ученые ни ломали голову и ни выдвигали гипотезы. И все же тарабарщина делает большую часть своей культурной работы как совершенно неточный ярлык. Речь, которую обвиняют в тарабарщине, почти всегда является не тарабарщиной, а полностью функционирующим языком: мы берем внятные высказывания и превращаем их в чепуху, отказываясь распознавать или интерпретировать их.На протяжении веков одна нация глумилась над носителями языка другой нации, принижая язык других как « варварский » (от греческого βάρβαρος , « варварос », слово, которое имитирует звериные звуки baa , как греки якобы воспринимал речь не говорящих на греческом языке). В настоящее время мы отвергаем сложные технические разговоры экспертов как «тарабарщину», потому что считаем их условия и знания устрашающими или угрожающими. Аргументы, которые нам не нравятся, — это «чепуха» или «словесный салат» не потому, что мы не можем их понять, а потому, что мы отвергаем их логику.(«Словесный салат», кстати, является транслитерацией немецкого Wortsalat , первоначально медицинского термина для запутанной речи людей с шизофренией.)
Термин «тарабарщина» в основном несправедливо навязывается другим, это быстрый и простой способ выразить предубеждение и преуменьшить значение языка других как простой шум. Однако тарабарщина иногда создается добровольно в благих целях, и это тоже имеет долгую историю. Некоторые древнеанглийские медицинские амулеты, сохранившиеся в рукописи, написанной около 1000 г. н.э., содержат отрывки тарабарщины, смешанные со словами из древнеирландского, латинского, греческого или иврита.Эти непонятные слова бросили вызов попыткам распутать их значение или этимологию, и поэтому ученые пришли к единому мнению, что они образуют плацебо, как волшебные слова, сопровождающие заклинание. Подобно тому, как причудливое латинское или греческое название на современной упаковке таблеток может заставить нас чувствовать себя более уверенными в излечении, так и эти звуки и слоги, которые отказываются соответствовать чему-либо, узнаваемому в древнеанглийском или любом другом языке, могли убедить тех, кто кто слышал их, что это заклинание обязательно сработает.
Тарабарщины слоги также используются для создания придуманных или вымышленных языков. Многие из этих «conlangs» (слово-портмоне, объединяющее «сконструированный» и «язык») тщательно разрабатываются как искусственные языки, но некоторые изобретенные языки никогда не получают всех своих рабочих частей и, таким образом, остаются по существу тарабарщиной. В сочетании с переводом они могут показаться языком, но без подкрепляющих их слов, они только притворяются, что имеют значение. Немецкая аббатиса XII века Хильдегард Бингенская, композитор, философ и мистик, изобрела lingua ignota , «неизвестный язык», сохранившийся в списке из 1012 этих неизвестных слов с латинским или немецким глоссом, а также в кратком виде. гимн, написанный в основном на латыни, но усыпанный тарабарщиной, которая сверкает, как драгоценности: orzchis , caldemia , loifolum , crizanta , chorzta .
Хильдегард из «lingua ignota» Бингена из Висбаденского кодекса. Предоставлено Hochschule Rhein / Main.Ученые, которые не переносят пустоту или известное неизвестное, искали этимологии — возможно, вы тоже сейчас пытаетесь разгадать их на языках, которые знаете, — но их объяснения являются умозрительными и не позволяют расшифровать очень многие из них. Слова Хильдегард. Другие задавались вопросом, пытаются ли эти неизвестные слова воссоздать язык, на котором Бог говорил с Адамом в Эдеме, или язык, на котором Адам назвал животных.Однако, как указывает ученый-немецкоязычный Джонатан П. Грин из Университета Северной Дакоты, действительно ли нужны такие божественные или адамические языки для обозначения «проституток, блудников, фокусников, пьяниц и воров», как это делает Хильдегард? Объяснение Грина ближе к домашнему: Хильдегард, вероятно, встретила слова и фразы греческого языка (алфавит и язык, которые она мало понимала или не понимала), встроенные в Священные Писания и в стихи, в которых греческие слова смешивались с латинскими стихами. Гимн воссоздает ее собственный опыт столкновения с неизвестным языком.То, что для Хильдегард греческий, является, благодаря ее lingua ignota , греческим для всех нас.
Уловка Томаса Мора состоит в том, чтобы дать нам основную грамматику языка, одетого в странную одежду.
Тарабарщина Хильдегард нуждается в латинском и немецком глоссах, а также в ее латинских стихах, чтобы убедить нас серьезно относиться к ним как к языку. Точно так же сам по себе воображаемый язык Утопия (1516) сэра Томаса Мора — не что иное, как символы. Четыре строки утопической поэмы, произнесенные голосом острова, выступают в качестве дополнения к основному тексту.Транслитерированные в наш алфавит (« Bargol he maglomi baccan »), а затем переведенные на латынь (« Una ego terrarum omnium »), а затем на английский («Я один из всех народов»), эти фразы начинают убеждать нас в том, что они — это языков. В то же время они постоянно уворачиваются от мысли, что они — наш язык . Такой изобретенный язык представляет собой своего рода антианглийский язык, использующий комбинации букв и фонологию, которые редко встречаются в английском или других языках, которые читатели Мора знали бы.
Это несколько сложнее сделать в английском с его смешанным германо-французским наследием и неуправляемой системой правописания. Если бы только вы могли сыграть в скрэббл в Утопии с его любовью к наименее любимым буквам и сочетаниям английского языка (хотя я уверен, что скоро кто-то изменит систему подсчета очков). И все же, избегая знакомых вариантов написания, они полагаются на наше интуитивное знание того, как работает английский язык. В этих утопических фразах есть односложные слова, которые могут быть местоимениями, более длинные слова, которые могут быть глаголами или существительными, и пары многосложных слов, которые заставляют нас подозревать, что прилагательные и наречия выполняют свою работу по определению.Подобно скелету в маскарадном костюме, уловка Мора состоит в том, чтобы дать нам основную грамматику языка, одетого в странную одежду.
Язык Утопии — эзотерическая чушь, но есть более повседневные примеры непонятного языка. Как только мы выучили наш язык в детстве, можно было подумать, что лепет и бормотание прекратятся, но есть слабые места, через которые тарабарщина может легко прорваться. Пение, кажется, балансирует на грани тарабарщины, побуждая нас перейти от слов к звукам.Когда мы забываем текст песни, мы гудим и la и ooo и di-dah . Или, если слов нет, человеческий голос мог бы присоединиться как инструмент: tee-tum , taa-raa . В пении слова часто растягиваются на составляющие их слоги, соблазняя нас полностью потерять границы слов.
Джек Керуак написал в On the Road , что «для Слима Гайяра весь мир был одним большим« Оруни! ».Лингвисты называют эти фрагменты спетой тарабарщины «нелексическими вокалами», звуками, которые мы можем озвучивать, но это не слова в обычном смысле. Вы можете подумать о джазовом пении или музыке, такой как ду-воп или бибоп, в которой вокал сам по себе является названием стиля. В джазе человеческий голос конкурирует с другими инструментами в импровизированных частях, и гораздо легче импровизировать тарабарщиной, чем с настоящими текстами. Точно так же покачивание и пение, чтобы убаюкивать капризного ребенка, когда вы так устали, что едва можете мыслить ровно, создают идеальные условия для появления тарабарщины.Для довербального младенца слова не важны: с незапамятных времен важна музыка, созданная голосом. Средневековые колыбельные гимны голосом Девы Марии, утешающей младенца Христа, сохраняют в припевах некоторые из самых ранних из этих спетых нелексических слов на английском языке: lulley , lollay , lay .
Это слово «колыбельная» происходит от комбинации двух из этих ранних английских словечек: lulla-lulla и bi-bi . Песня XV века, неряшливо сохранившаяся во фрагменте рукописи, содержит хор, полный успокаивающей тарабарщины, которую родитель может петь ребенку:
Lullay, lullow, lully, lullay,
Bewy, bewy, lully, lully,
Bewy, lully, lully, lully,
Lullay, baw baw, my barne [child],
Спи теперь тихо.
Единственный сохранившийся стих дает понять, что это песня, которую поет «maydin moder», Мария, спящему «известному ребенку», младенцу Христу. Только последние фразы припева являются настоящими словами, а остальные — речью, словами, этимология которых невозможна. Записи в среднеанглийском словаре для слов «bewy» и «bau» ничего не могут сказать об их происхождении. lull — слов происходят от глагола «lullen», который сам объясняется как просто «подражательный» (хотя это могло быть легко наоборот, глагол были изобретены голосами).Такие слова являются звукоподражательными, письменными приближениями к звукам «b-b-b» и «l-l-l», которые родители ворковали своим младенцам. Без сознательного мышления или планирования рот изменяет звуки и создает узоры, спонтанную тарабарщину.
В то время как убаюкивающие голоса Марии почитаются и прославляются, другие средневековые тексты не одобряют бессловесные вокалы, встречающиеся в припевах гимнов и народных песен. В Пирс Пахарь (1370-90) — умопомрачительное стихотворение Уильяма Ленгланда, в котором общество 14-го века исследует серию сновидений — рабочие, которые не участвуют в совместной работе на ферме, сидят и поют пивные песни, « помогая » пахать Пол-акра Пьера с надписью «эй! тролли-лолли! », символ их глупости и идиотизма.Центральная фигура поэмы, Пирс, который иногда представляет собой идеализированный портрет честного труженика, а иногда и версию Христа, Святого Петра или доброго самаритянина, сердится и угрожает им голодной смертью.
Не каждый ранний английский писатель настолько догматичен, что крестьяне поют радостную тарабарщину нелексических словечек. Одна из детективных пьес, разыгранных в городе Честер, представляет собой более увлекательную деревенскую жизнь, на этот раз пастухи наблюдают за своими стадами, которые видят Вифлеемскую звезду в рождественской сказке.Каждый спектакль в течение дня спонсировался отдельной гильдией ремесленников: игра пастухов, добавленная к циклу в начале 16 века, была обязанностью художников. В этом театрализованном представлении актер, играющий ангела, поет « Gloria in altissimis Deo, et in terra pax hominibus bonae voluntatis » (Слава Богу во всем; и мир на Земле людям доброй воли). Пастухи, не знающие такого причудливого языка, недоумевают, хотя средневековая аудитория могла бы признать этот отрывок Священного Писания началом знакомого гимна.Небесная песня началась с glore или glere , спрашивают себя пастухи? Или, может быть, glorus , glarus , glorius или glo , glas или glye ?
Так продолжается до voluntatis , превращая ангельскую латынь во что-то похожее на тарабарщину. И все же, хотя они напуганы, они также странным образом воодушевлены и успокаиваются небесной музыкой. Они решают спеть собственную веселую песню, отправляясь в Вифлеем, чтобы следовать за «starre-gleme», светом необыкновенной звезды.Режиссура постановки гласит: «Вот единственное« троли, лоли, лоли, лоу »», и мальчик-пастух призывает публику присоединиться к нему. Это один из тех моментов, смешивающих священное и мирское, в которых средневековая драма, кажется, восхищает. Эта пьеса высмеивает простоватость пастухов, но, может быть, она также намекает на то, что торжественная латынь является в значительной степени тарабарщиной для многих прихожан в английской церкви? Может быть, не имеет значения, тарабарщина ли это ангельская песня или латинская, или поет ли публика гимны или леденцы-тролли.В конце концов, Господь действует таинственными способами…
Три десятилетия спустя протестантские реформаторы не одобряли католических мистерий, а также неодобрительно относились к счастливому пению тарабарщины в народных песнях. Такие словечки, как «тролли-лолли» или «эй, нонни-нонни», символизировали деревенскую, профанную, примитивную пошлость. Майлз Ковердейл, реформатор и переводчик английской церкви, опубликовал книгу псалмов и священных текстов, переведенную и положенную на музыку, свои Добрые псалмы и Духовные песни ( c 1535).В своем предисловии он утверждал, что пахари и другие чернорабочие и женщины с их прялками и прялками лучше петь благочестивые песни, чем развлекаться фантазиями «эй, нони, эй, тролли, лоли и сочлайк». Авторы пасторальной поэзии, жанра, становившегося все более модным в эпоху Возрождения, хотели поставить чистую воду между воображаемой тарабарщиной крестьян и своими собственными поэтическими композициями. Майкл Дрейтон в своем эклоге «Идея: гирлянда пастыря » (1593 г.) отличает «этих noninos [nonny-nos] грязного риболла [мерзкого похоти]» от своих более изысканных стихов.
Младенцы болтают с нами чепухой, и мы отвечаем им, как если бы они сказали что-то совершенно поразительное
В последующие столетия английская тарабарщина постепенно переходит в спячку. Возникают и другие связанные с этим явления: есть мода на бессмысленные стихи, и время от времени появляются изобретенные языки — будь то ангельские, фальшивые, вымышленные или инопланетные. Возможно, век разума и науки смущает непонятный псевдоязык. Тарабарщина снова появляется в поле зрения в начале 20 века.Написанная сначала немецкими и итальянскими поэтами-футуристами и дадаистами, а немного позже британскими и американскими авангардистами , звуковая поэзия написана тарабарщиной, представляя не слова, а чистый звук. Модернизм принимает тарабарщину как часть своего стремления отказаться от традиций и создать все новое, но рискует высмеять в этом процессе. Основное исследование психопатии, проведенное американским психиатром Херви М. Клекли, The Mask of Sanity (1941), назвало книгу Джеймса Джойса Finnegans Wake (1939) «эрудированной тарабарщиной, неотличимой… от знакомого словесного салата, производимого гебефреническими пациентами [т. Е. больные шизофренией] в задней части любой государственной больницы ».Дело не в том, что Клекли высмеивал шедевр Джойса как таковой , а скорее в том, что он хотел указать на то, что его нельзя отличить от безумия. Можно ли серьезно относиться к тарабарщине как к высокому искусству?
Австралийско-американский композитор Перси Грейнджер, которого сейчас, пожалуй, больше всего помнят за постановку народных песен, считал, что самое важное из его произведений — это то, что спето тарабарщиной. Его «Марширующая песня демократии» ( c 1901) стремилась передать в музыкальной композиции «оживленный марш оптимистической гуманитарной демократии», не озвучивая ничего, кроме нелексических речей для пения хора: pum pa, dim pom pom pom pa ti di
.Впервые он был исполнен на Вустерском музыкальном фестивале в Массачусетсе в 1917 году, когда оптимизма по поводу всего, что делали люди, должно быть, не хватало. «Марширующая песня» была хорошо принята, хотя рецензенты всегда были не уверены в том, что один критик вежливо называет ее «эксцентричностью в оценке». Он был возрожден к Last Night of the Proms 2019 года: тарабарщина, возможно, единственный способ найти единство во время войн Brexit после референдума.Тарабарщина всегда, кажется, существует в этом неопределенном состоянии: тривиальна она или ценна, символ безнравственности или своего рода чистое, естественное, музыкальное выражение, возможно, даже божественное? Самое парадоксальное из качеств тарабарщины — это ключевая роль, которую она играет в том, как мы учимся говорить не тарабарщину.Детское бормотание (или «пение младенцев», как его более формально называют) жизненно важно для овладения языком, потому что оно побуждает воспитателей устраивать имитационные беседы с младенцами. Младенцы болтают с нами чепухой, и мы отвечаем им, как если бы они сказали что-то совершенно поразительное. Также для развития речи необходима «случайная имитация», то есть те взаимодействия, при которых воспитатели копируют лепет младенцев и младенцев, которые бормочут им. Недавнее исследование, проведенное в Японии, показывает, что случайное подражание особенно ценно для повышения социальной активности маленьких детей с аутизмом.Если мы воспользуемся природным талантом человечества к тарабарщине, наши дети будут более свободно говорить на понятном языке, и это давно понятая истина. В английском переводе 14-го века латинской энциклопедии 13-го века объясняется, как няни помогают детям научиться говорить, бессмысленно деформируя язык: «скандинавский язык спит и наполовину озвучивает словоis, чтобы больше узнать о ребенке, который не может говорить» ( медсестра шепелявит и наполовину произносит слова, чтобы легче научить ребенка, который не умеет говорить).
Создавать тарабарщину — значит избегать привычных особенностей нашего родного языка и в то же время опираться на наше самое глубокое понимание того, что такое язык и как он работает. Тарабарщина также играет жизненно важную роль в том, чтобы дать нам родной язык, как младенцам, так и младенцам. Людвиг Витгенштейн, описывающий работу и методы философии в своей книге « Philosophical Investigations », ценит «неровности», возникающие у понимания, когда он наталкивается на ограничения языка. Эти неровности заставляют нас увидеть ценность открытия.«Тарабарщина, пожалуй, самая неровная форма человеческого общения, но благодаря ей мы многое узнаем о языке, его возможностях и границах.
Теперь модель, которая изучает визуальные концепции, слова и семантический анализ предложений без явного контроля
Создание компьютерной системы, которая может отвечать, просто глядя на изображения, разрабатывается уже много лет. Исследователи в области искусственного интеллекта работают над этой концепцией, чтобы сделать существующие системы более интеллектуальными, чем когда-либо.Объединение этого с обработкой естественного языка не только сократит время на обучение модели, но также поможет в прогнозировании эмоций, стоящих за объектами.
В мае 2019 года исследователи из IBM, DeepMind и MIT разработали модель глубокого обучения, известную как Neuro-Symbolic Concept Learner. Это тесно связано с совместным изучением зрения и обработкой естественного языка. Эта модель глубокого обучения учится на основе естественного контроля, такого как визуальное восприятие, слова и семантический анализ языка из изображений и пар вопрос-ответ.
Как это работает
Обучающийся нейросимволическим концепциям использует методы искусственных нейронных сетей для извлечения функций из изображений и построения информации в виде символов. Затем к модели применяется квазисимвольный исполнитель программы, чтобы вывести ответ на вопросы, основанный на представлении сцены.
Для визуального восприятия исследователи использовали предварительно обученную технику Mask R-CNN, чтобы генерировать предложения для всех объектов. Затем метод Res-Net применяется для извлечения характеристик на основе регионов и изображений.Для перевода вопросов на естественном языке в исполняемые программы, в основном предназначенные для визуального ответа на вопросы (VQA), применяется модуль семантического синтаксического анализа.
За моделью
Исследователи использовали набор данных, известный как CLEVR, для тестирования модели глубокого обучения. Это набор диагностических данных, который помогает в решении визуальных ответов на вопросы (VQA). Модель учится через изучение учебной программы, так что она начинается с изучения представлений или концепций отдельных объектов из коротких вопросов в простых сценах.Это помогает модели изучать объектно-ориентированные концепции, такие как цвета и формы. Затем модель изучает реляционные концепции, используя эти объектно-ориентированные концепции для интерпретации ссылок на объекты.
Более того, модель естественным образом изучает разрозненные визуальные и языковые концепции, обеспечивая комбинаторное обобщение как для визуальных сцен, так и для семантических программ. В этом случае есть четыре формы обобщения, модель сначала обобщает сцены с большим количеством объектов и более длинными семантическими программами, чем те, что в обучающем наборе.Во-вторых, модель обобщает новые композиции визуальных атрибутов. В-третьих, он обобщается, чтобы обеспечить быструю адаптацию к новым визуальным концепциям и, наконец, выученные визуальные концепции переносятся на новые задачи, такие как поиск подписей к изображениям.
Смотрите такжеNS-CL содержит три модуля, как указано ниже
- Модуль нейронного восприятия: Этот модуль работает путем извлечения представлений на уровне объекта из сцены.
- Визуальный семантический синтаксический анализатор: Этот модуль предназначен для преобразования вопросов в исполняемые программы.
- Символьный исполнитель программы: Этот модуль считывает перцептивное представление объектов, классифицирует их атрибуты или отношения и выполняет программу для получения ответа.
Преимущества NS-CL
- Эта модель глубокого обучения изучает визуальные концепции с большой точностью. Исследователи получили точность классификации почти 99% для всех свойств объекта.
- Эта модель позволяет эффективно использовать данные для визуального анализа набора данных CLEVR.
- NS_CL хорошо обобщается на новые атрибуты, новую визуальную композицию, а также на новые предметно-ориентированные языки.
- Эту модель можно напрямую применить к визуальному ответу на вопросы (VQA).
Внешний вид
Для обучения моделей глубокого обучения необходим большой объем данных, которые мы назвали большими данными. Сбор больших данных и работа над ними — действительно сложная задача. Однако организации собирают данные каждый день, и из этого огромного количества собранных данных организации могут использовать лишь небольшую их часть.Это одна из основных причин, по которой разрабатывается данная модель. Для будущей работы исследователи хотели бы расширить эту структуру на другие области, такие как понимание видео и роботизированные манипуляции.
Вы можете прочитать полный текст статьи здесь .
Присоединяйтесь к нашей группе Telegram. Станьте частью интересного онлайн-сообщества. Присоединиться здесь.
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.Амбика ЧоудхуриТехнический журналист, который любит писать о машинном обучении и искусственном интеллекте. Любитель музыки, сочинения и обучения чему-то нестандартному. Контакт: [адрес электронной почты]
.