
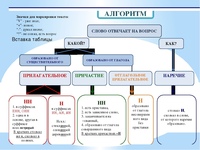
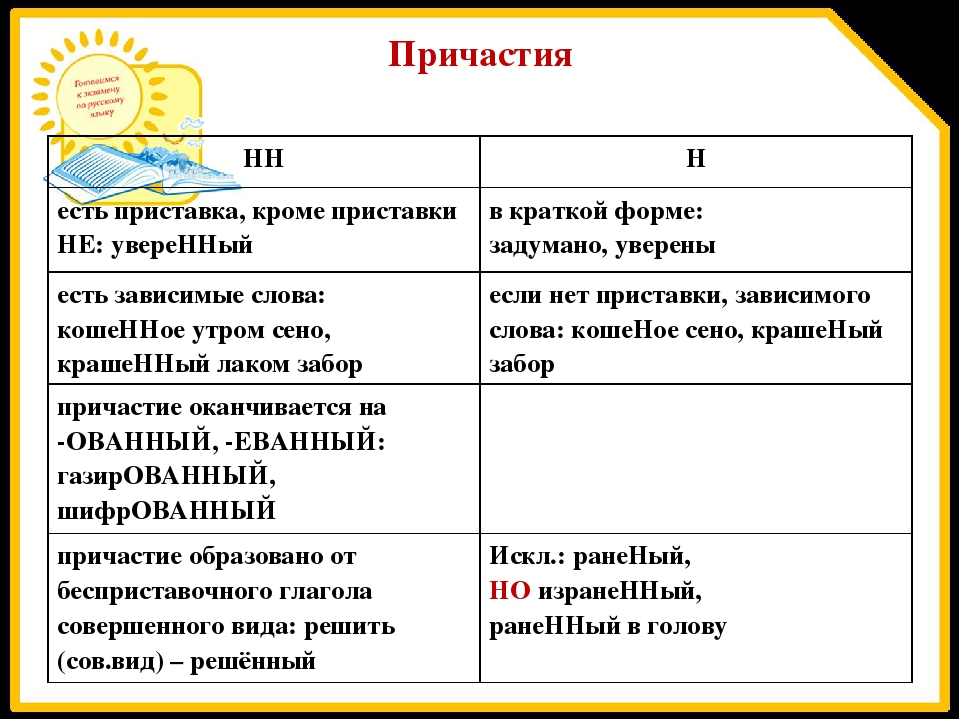
Н-нн в различных частях речи. (11 класс)
1. А14 н-нн в различных частях речи
Занятие элективного курса в 11классе
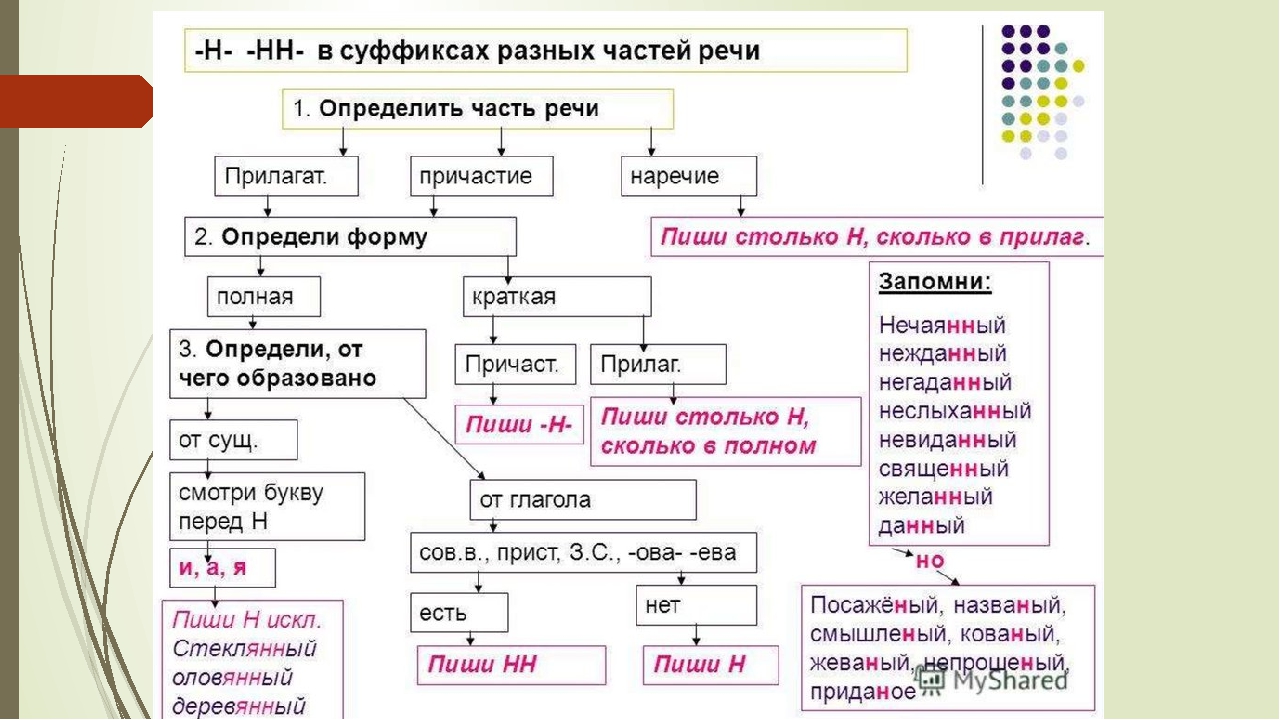
2. Н-НН в отымённых прилагательных
НВ прилагательных, образованных
от существительных
-ан- песчаный
-ян- серебряный
-ин- пчелиный
В притяжательных
прилагательных (олений, кабаний)
Искл! Стеклянный, оловянный,
деревянный
Зап! Румяный, синий, зелёный,
рдяный, свиной, пряный,багряный,
рьяный, юный, но юннат
НН
В прилагательных, образованных
от существительных
-онн- революционный
-енн- безветренный
…нн- старинный
Искл! Ветреный (день, человек)
Зап! Ветряной (двигатель,
мельница, оспа)
3. Объясните написание Н-НН
Багряный цвет, бесчисленное множество, глиняныйкувшин, дискуссионный вопрос, длинная дорога,
дровяной склад, деревянный дом, журавлиное гнездо,
зеленый фонарь, земляной пол, каменная труба,
картинная галерея, клюквенный морс, кожаное пальто,
конный клуб, ледяной покров, монотонный голос,
недюжинной силы, оловянные пуговицы, осенняя пора,
полотняная рубашка, революционный подъем, румяные
щеки, серебряная цепочка, соломенная крыша,
туманное утро, ураганный ветер, юные изобретатели.
Объясните написание Н-НН
4. Вставить пропущенные буквы
Юн..ый участник, песчан..ые дорожки, гостин..ая,свин..ой, гостин..ица, трав..н..ое покрытие, бедствен..ое
положение, серебр..н..ый кулон, машин..ое масло,
ветр..н..ый день, солом..н..ые крыши, умствен..ая
работа, революцион..ый шаг, наш современ..ик,
истин..ые ценности, подлин..ый смысл, мышин..ая нора,
оловян..ый солдатик, лимон..ая кислота, врем..н..ое
отсутствие, безветр..н..ый полдень, сем..н..ой фонд,
кож..н..ый шлем, деревян..ый щит, весен..ий свет,
плем..н..ой скот, дров..н..ой сарай, крысин..ая
мордочка, баран..ий бок, станцион..ый смотритель,
лошадин..ая голова,
Вставить пропущенные буквы
5. Вставить пропущенные буквы
агитацион..ый плакат, сибирская листвен..ица, сезон..ый рабочий,широкий подокон..ик, смелый дружин..ик, кост..н..ой нож,
былин..ый герой, равнин..ый ландшафт, туман..ый вечер,
шерст..н..ой шарф, льн..н..ой комплект, масл.
 .н..ые краски,
.н..ые краски,производствен..ый план, картин..ая галерея, глин..н..ый сосуд,
бесчислен..ые ошибки, ураган..ый ветер, румян..ый малыш,
бесцен..ый экземпляр, кон..ый спорт, петушин..ые бои,
Вставить пропущенные буквы
6. Вставить пропущенные буквы
ответствен..ый подход, прян..ость для борща,карман..ый фонарь, камен..ый дом,
невежествен..ый ученик, фанатичный
поклон..ик, поздравить именин..ика,
искусствен..ый шелк, книга бесцен..а, девочка
юн..а и ветрен..а, ошибки несомнен..ы,
высказывания стран..ы, гора величествен..а,
это свойствен..о всем детям, руки красн..ы и
далекая юн..сть.
Вставить пропущенные буквы
7. Спишите, раскрыв скобки, вставив пропущенные буквы
(Стари…ий) картина, (листве…ый) лес, (традицио…ий)встреча, (кожа…ый) диван, (кожев…ий) промышленность,
(дивизи..ий) артиллерия, (гума..ый) законы, (исти..ий)
гуманизм, (коре..ой) противоречия, (лебеди…ый) стая,
(стекля…ый) витрина, (укоризне…ый) взгляды, (песча…
ый) равнина, (серебря…ый) гнездо, (торжестве…ый)
заседания, (параллель…ый) прямые, (искусстве…ый)
водоемы, (цели…ый) земля, (отечестве…ый)
производство, (муравьи…ый) кислота, (комиссио…ый)
магазин, (оккупацио…ый) войска, (пламе…ый) сердце,
(революцио…ый) теория, (румя.
 .ый) щека, (сенсацио..ый)
.ый) щека, (сенсацио..ый)известие, (масл..ый) трансформатор, (масл…ый) лаки,
(безветр..ый) ночь, (ветр…ый) люди, (ветр..ый) насосы.
Спишите, раскрыв скобки,
вставив пропущенные буквы
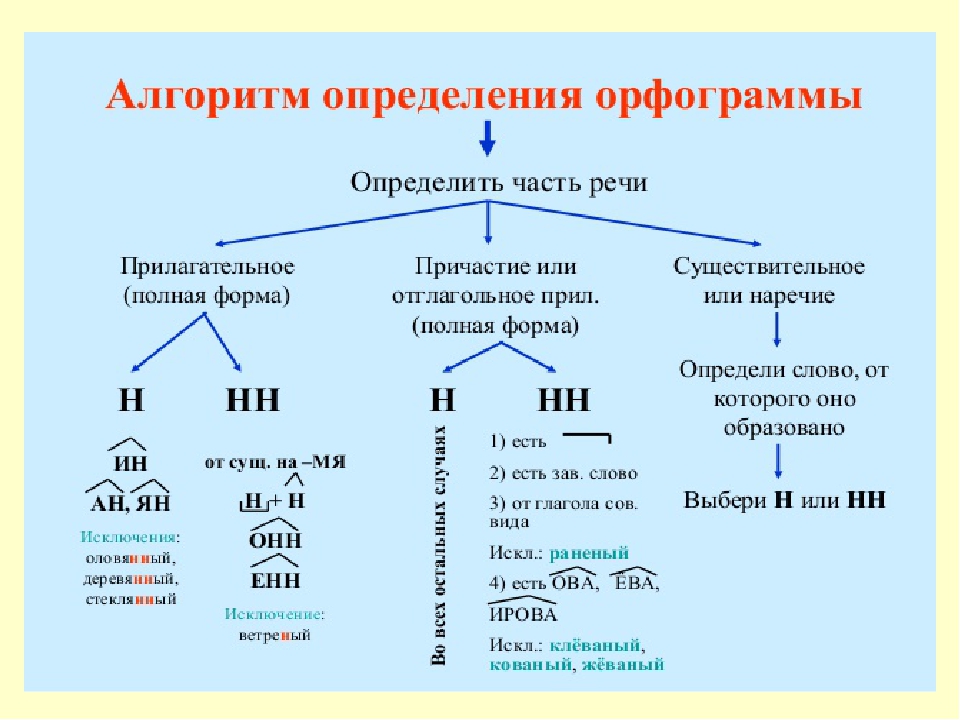
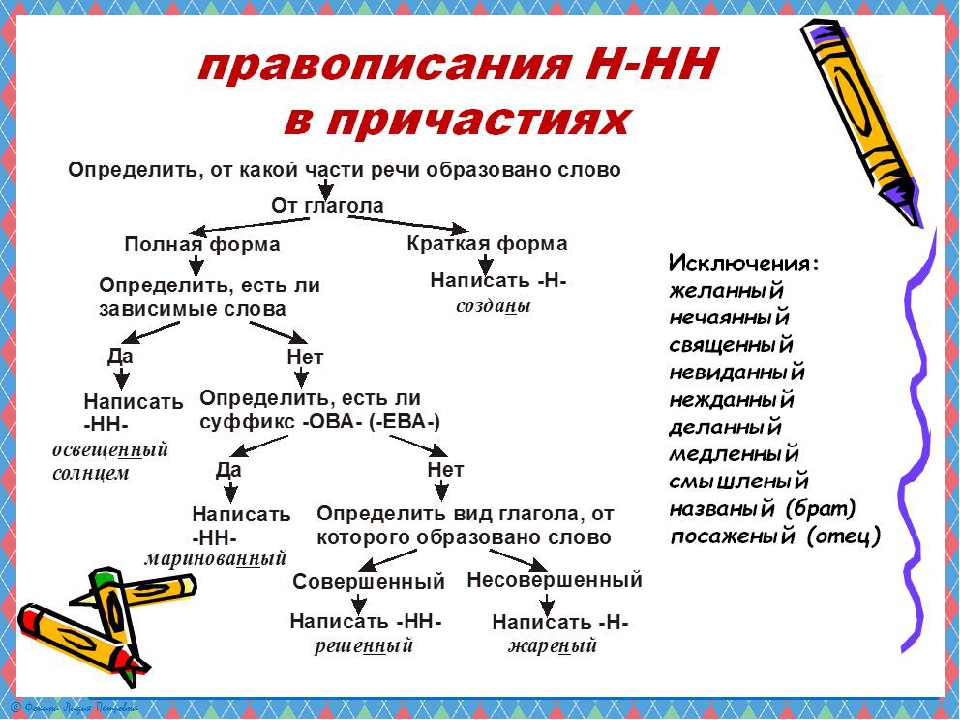
В отглагольных формах
1.Образованные от глаголов
несов вида
Тушить – тушёный
2. В крат прич
калитка покрашена
В отглагольных формах
1.Образованные от глаголов
сов вида
Решить – решённый
Искл! раненый
1.Образованные от глаголов с
приставками (кроме
приставки не-)
Покрасить – покрашенный
1.Если есть зависимое слов
Крашенный краской забор
4. Если есть суффиксы –ова(-ева-), ирова
Маринованный
Искл! Жёваный, кованый
9. Запомнить!
Зап! Смышлёный,бешеный
Нежданный,
неожиданный,
нечаянный, медленный,
желанный, виденный,
нежданный, негаданный,
невиданный,
неслыханный,
священный, обещанный,
отчаянный, деланный.
Запомнить!
10.
 Запомните слова-исключения! Они все есть в задании А14! назваНый (брат)
Запомните слова-исключения! Они все есть в задании А14! назваНый (брат)непрошеНый (гость)
посажёНый (отец)
смышлёНый
11. В кратких формах
Краткие причастияКраткие
прилагательные
Являются сказуемым
Временный
признак
Постоянный
Можно заменить
глаголом
Можно заменить
прилагательным
Н
Столько Н, сколько
в слове, от
которого оно
образовалось
Наречия
Являются
обстоятельством
Столько Н, сколько
в слове, от
которого оно
образовалось
12. Объясните орфограммы
Гашё…ая известь, пута…ые ответы, нежда…ый гость,дублё…ый полушубок, стриже…ая голова, некраше…ый
пол, ране…ый боец, беше…ый кот, гружё…ая баржа,
чище…ые сапоги, плетё…ая корзина, балова…ый малыш,
графлё…ый блокнот, писа…ая красавица,
асфальтирова…ая дорога, незва…ые гости, жёва…ый
хлеб, домотка…ая скатерть, кова…ый меч, стреля…ый
воробей.
Объясните орфограммы
13.
 Объясните орфограммы Поноше…ое пальто, ноше…ые вещи, растеря…ый человек,
Объясните орфограммы Поноше…ое пальто, ноше…ые вещи, растеря…ый человек,отвлечё…ое рассуждение, смышлё…ый малыш,
подстреле…ый воробей, пуга…ая ворона, напуга…ый
зверь, тиснё…ый переплет, тиснё…ый золотом билет,
краше…ые парты, некраше…ый пол, неслыха…ая наглость,
нежда…ый приезд, погаше…ый свет, скоше…ая трава,
коше…ая вчера трава, коше…ый луг, некоше…ые травы.
Объясните орфограммы
14. Объяснить устно пропущенные орфограммы
Растерян..ый человек, мочен..ые яблоки, брошен..ый мяч,стрижен..ый по-мальчишески, книга иллюстрирован..а,
завещан..ый, желан..ый, мощен..ый булыжником,
стремления молодежи возвышен..ы, копчен..ый окорок,
нарушен..ая тишина, жарен..ые в печке семечки, ягоды
рассыпан..ы, недоварен..ый картофель, неслыхан..ые дела,
лыжи заброшен..ы на чердак, известие получен..о утром,
посажён..ый отец, неискушен..ый человек, смышлен..ый
малыш, овощи сварен..ы, публика избалован..а зрителями,
мука просеян.
 .а, топлен..ое в печке, отчаян..ый крик,
.а, топлен..ое в печке, отчаян..ый крик,честный тружен..ик, нехожен..ые тропы, куплен..ый, давно
мазан..ые хаты, она невежествен..а и ограничен..а,
Объяснить устно
пропущенные орфограммы
лица вымазан..ы сажей, квашен..ая капуста, вязан..ая из
шерсти кофта, всё погружен..о в сон, комната обставлен..а,
ранен..ый в руку, нескошен..ый луг, мука рассыпан..а по
столу, топлен..ое масло, зван..ые на вечер гости,
маринован..ые грибы, морожен..ое мясо, манеры
изыскан..ы, асфальтирован..ый, ламинирован..ый,
заплатан..ый полушубок, ткан..ая шелком салфетка,
поломан..ые деревья, зван..ые гости, дорога длин..а, тучи
рассеян..ы, вязан..ая скатерть, средства изыскан..ы,
чекан..ый шаг, усадьба ограничен..а рекой, жеман..ые
манеры, смущен..ая девушка, дорога пройден..а,
воронен..ая сталь, гранен..ый стакан, воспитан..ый
человек, бешен..ый темп, автоматизирован.
 .ый, кован..ый,
.ый, кован..ый,мечен..ые карты, инкрустирован..ый, священ..ик,
маслен..ица, стиран..ый-перестиран..ый, гладкокрашен..ый
материал, воспитан..ик, известный учен..ый, мучен..ик,
варен..ик, варен..ый-переварен..ый
Укажите верное объяснение написания выделенного слова.
Берега Онежского озера были освое..ы ещё в III
тысячелетии до нашей эры.
1)
Пишутся две буквы НН, так как это прилагательное образовано от
местоимения свой с помощью суффикса -ЕНН-.
2)
Пишется одна буква Н, так как это краткая форма причастия,
образованного от глагола освоить.
3)
Пишется одна буква Н, так как это причастие без пояснительных
слов.
4)
Пишутся две буквы НН, так как это прилагательное, а не причастие;
в кратком прилагательном сохраняется написание -НН-.
2
17. В каком ряду в обоих случаях пишется НН:
1. подсуше..ое бельё, стари..ые вещи2. не выуче..ы уроки, связа..ый свитер
3. нечая..ый взгляд, кури.
 .ый бульон
.ый бульон4. ути..ая охота, кова..ая лошадь
18. В суффиксах каких слов следует писать -нн-?
Га) Ошибка исправле_на;
б) полирова_ная мебель;
в) туше_ный картофель;
г) подкова_ная лошадь.
19. На месте каких цифр пишется НН?
Может быть, коньки назва(1)ыконьками именно потому, что в
старину делали деревя(2)ые коньки,
украше(3)ые завитками в виде
лошади(4)ой головы.
2,
3
20. Сколько Н в этих частях речи, столько будет и в наречиях
Вставьте пропущенные буквыОбращаться гума…о; рья…о приняться за
работу; смущё…о отвернуться; пута…о
объяснять; сдержа…о возражать; прийти
нежда…о – негада…о; вести себя легкомысле…о,
ветре…о; отвечать рассея…о; подли…о научный
анализ; жизне…о важное решение.
21. Найдите слова, в которых допущены ошибки.
1. Временый.2. Безветреный.
3. Шерстяной.
4. Напряженость.
5. Соотечественик.
6. Современик.
7.
 Бешеный.
Бешеный.8. Конопляник.
1, 2, 4, 5, 6
22. Вставьте пропущенные н или нн. Обозначьте цифрой 1 слова с н, цифрой 2 – слова с нн.
а) Балова_ый,б) жже_ый,
2, 1, 2, 1, 1, 1, 1, 2, 2, 2, 1, 1, 2, 1, 2
в) взбеше_ый,
г) кипяче_ый,
д) кваше_ый,
е) пута_ый,
ж) копче_ый,
з) припая_ый,
и) прокипяче_ый,
к) рва_ый в нескольких местах,
л) сея_ый,
м) нестриже_ый,
н) туше_ый с пряностями,
о) пуга_ый,
п) засея_ый.
23. Найдите ошибки в следующих словах.
1. Непрошенный.2. Бесприданница.
3. Приданое (невесты).
4. Нежданый.
5. Даный.
6. Гостиная (комната).
7. Желанный.
8. Отчаянный.
9. Названый (брат).
10. Смышленный.
1, 4, 5, 10
24. Перепишите, вставьте н или нн, обозначая суффиксы.
1) Люди тайги сдержа_ы.2) Много войск сосредоточе_о на
этом участке.
3) Оратор говорил убежде_о.
4) Территория около нового дома
еще не благоустрое_а.

5) Ответы легкомысле_ы и
необдума_ы.
25. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Агитацио(1)ые листки, сорва(2)ыеветром, валялись на моще(3)ой
мостовой, были занесе(4)ы снегом.
1) 1, 2, 3
3
3) 3, 4
4) 1, 3
26. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
1) 1, 2, 3, 42
2) 1, 2, 4, 5, 6
3) 3, 5, 6
4) 3, 4, 5, 6
Барская воспита(1)ица была умна и
образова(2)а, да и прида(3)ое за ней
давали невида(4)ое, но нежда(5)о —
негада(6)о случилась небывалая история.
27. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Рассказа(1)ая Петром Ильичом история былаявно им выдума(2)а: у него и в помине не
было назва(3)ого брата, о котором он так
восхище(4)о и взволнова(5)о упоминал.
1) 1, 2
2) 3, 4, 5
3
3) 2, 3
4) 1, 2, 3, 4, 5
28.
 В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н? Постоя(1)ые внутре(2)ие противоречия
В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н? Постоя(1)ые внутре(2)ие противоречиятерзали душу этого труже(3)ика,
муче(4)ика науки, убежде(5)ого только в
том, что избра(6)ый им путь верен.
1) 1, 2, 5, 6
2) 3, 4, 5
1
3) 4, 5, 6
4) 2, 3, 4
29. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
В гости(1)ой чи(2)о сидели наряже(3)ыедетишки, завороже(4)о смотревшие на
хозяйку, чьими руками было выставле(5)о
всё это великолепное угощение.
1) 2, 3, 4
2) 1, 2, 5
3
3) 1, 5
4) 3, 4, 5
30. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Моче(1)ые яблоки особе(2)о вкусны стоплё(3)ным молоком и свежеиспечё(4)ым
хлебом.
1) 1, 2, 3
2) 1, 3
3) 2, 3, 4
2
4) 2, 4
31. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Гранё(1)ые шпили собора былиторжестве(2)о устремле(3)ы в небесную
высь, и, потрясё(4)ые его красотой,
туристы ошеломле(5)о замолчали.

1) 1, 3
2) 2, 3, 5
1
3) 3, 5
4) 1, 5
32. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Урага(1)ый ветер в пусты(2)ых степяхКазахстана поднимает бесчисле(3)ое
множсество семян растений, и они
впоследствии будут рассея(4)ы на многие
десятки километров от места созревания.
1) 3, 4
2
2) 1, 2, 3
3) 1, 2, 4
4) 2, 4
33. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Сплете(1)ые из ивняка корзины былихорошо просуше(2)ы и сложе(3)ы в доме,
недавно построе(4)ом из листве(5)ицы.
1) 1, 4, 5
2) 2, 3, 5
3) 1, 2, 5
1
4) 3, 4, 5
34. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Изнеже(1)ые барские дочки былинабеле(2)ы и напудре(3)ы, наряже(4)ы в
платья, присла(5)ые из Парижа, и
вывезе(6)ы в большой свет.
1) 1, 2, 3
2) 1, 5, 6
3
3) 1, 5
4) 4, 5
35.
 В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н? Запряжё(1)ые кони беше(2)о храпели и били
В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н? Запряжё(1)ые кони беше(2)о храпели и билио мостовую кова(3)ыми копытами; их
пышные гривы были украше(4)ы яркими
лентами, вплете(5) ыми накануне
конюхом Архипом.
1) 1, 5
1
2) 3, 5
3) 1, 3, 5
4) 2, 4
36. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
На пустыре за садом валялись разбитыеглиня(1)ые кувшины, жестя(2)ые банки,
рва(3)ая обувь, полома(4)ая мебель,
какие-то спиле(5)ые деревья.
1) 3, 4, 5
2) 4, 5
2
3) 1, 2, 3
4) 1, 4, 5
37. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Серебря(1)ая фляжка была наполне(2)аосе(3)ей студе(4)ой водой, вкусной, как
драгоце(5)ое выдержа(6)ое вино.
1) 3, 4, 5
2) 1, 3, 6
3) 2, 3, 4
4
4) 1, 2, 4
38. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Ребятишки, искре(1)е обрадова(2)ыенеожида(3)о богатым уловом, немедле(4)о
отправились к сторожке нехоже(5)ыми,
пута(6)ыми тропами.
1) 5, 6
2) 1, 4
1
3) 2, 3
4) 4, 5, 6
39. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Деревушка бала маленькая: несколькорубле(1)ых, давно не краше(2)ых
домиков, расположе(3)ых вдоль
наезжее(4)ой дороги, по которой
проносились груже(5)ые машины.
1) 1, 2, 5
2
2) 1, 5
3) 3, 4
4) 3, 4, 5
40. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Приветливый старик в суко(1)ой рубахе снесвойстве(2)ой ему хлопотливостью
ставит на стол соле(3)ые огурцы,
жаре(4)ую с салом картошку, мочё(5)ую
бруснику.
1) 3, 5
1
2) 2, 3, 4
3) 1, 3, 4, 5
4) 1, 2, 3, 4
41. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Чайки церемо(1)о сидели на чугу(2)ыхшарах, изъеде(3)ых ржавчиной, и
беспреста(4)о выхватывали что-то из
соле(5)ой морской воды.

1) 1, 2, 3, 4
2) 2, 3, 4
1
3) 2, 3, 4, 5
4) 1, 3, 5
42. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Матросы, издавая беше(1)ые горта(2)ыезвуки, подняли рва(3)ые паруса, и
таинстве(4)ое судно мгнове(5)о исчезло в
тума(6)ой дали.
1) 1, 2, 3, 5
2) 1, 2, 3, 4, 6
3
3) 2, 4, 5, 6
4) 2, 3, 5, 6
43. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Я до сих пор помню писа(1)ую масломкартину, висевшую над моей кроваткой:
золочё(2)ую упряжь коней с лебеди(3)ыми
шеями, запряжё(4)ых в разрисова(5)ую
карету.
1) 1, 4, 5
1
2) 2, 3, 4
3) 3, 4, 5
4) 1, 3, 5
44. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Свежескоше(1)ая трава издавала пря(2)ыйаромат, и Иван облегчё(3)о и обессиле(4)о
повалился на неё: стога сена уже были
сложе(5)ы и укрыты от приближающейся
грозы.

1) 2, 3, 4, 5
2
2) 1, 3, 4,
3) 1, 2, 5
4) 3, 4, 5
45. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Живем мы в цивилизова(1)ом миревысотных зданий, моще(2)ых и
асфальтирова(3)ых улиц и площадей,
автобусов и троллейбусов,
переполне(4)ых озабоче(5)ыми людьми.
1) 1, 3, 4, 5
1
2) 2, 3, 4, 5
3) 3, 4, 5
4) 1, 4, 5
46. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Румя(1)ый ю(2)ат протянул мне тетрадь, вкоторой была нарисова(3)а стра(4)ая
птица, будто стриже(5)ая под гребенку.
1) 2, 4, 5
2) 1, 3
3) 2, 4
2
4) 4, 5
47. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Как вкусен зимой компот, сваре(1)ый изсушё(2)ой малины, вяле(3)ой на солнце
вишни и щедро сдобре(4)ый ароматным
липовым медом!
1) 3, 4
2) 2, 3
3
3) 2
4) 3
48.
 В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н? На глиня(1)ом истопта(2)ом полу томился
В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н? На глиня(1)ом истопта(2)ом полу томилсяране(3)ый пле(4)ый с болезне(5)ым
выражением лица.
1) 2, 3, 4
2) 3, 4, 5
3) 1, 2, 5
4
4) 1, 3
49. В каком варианте ответа правильно указаны все цифры, на месте которых пишется одна буква Н?
Охотники остановились у озера,восторже(1)о любуясь его серебря(2)ой
гладью, чистыми песча(3)ыми берегами,
лебеди(4)ой стаей, величаво плавающей у
берега.
1) 1, 2, 3
3
2) 2, 3
3) 2, 3, 4
4) 1, 3, 4
50. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Хозяин, увидев нежда(1)ого и незва(2)огогостя, раздраже(3)о и сконфуже(4)о
поздоровался.
1) 1, 2, 3, 4
2) 2, 3, 4
3) 1, 2
4
4) 1, 3, 4
51. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Сдержа(1)о поздоровавшись с вое(2)ыми,старик с каме(3)ым выражением лица
протянул им кожа(4)ую пастушью сумку с
жестя(5)ыми застежками.

1) 1, 2, 3
2) 3, 5
1
3) 1, 2, 4
4) 2, 3, 5
52. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Сколько песен сложе(1)о про зиму, сколькопоэм посвяще(2)о ю(3)ой писа(4)ой
красавице в тка(5)ом жемчугами и
серебром сарафане!
1) 2, 3, 4
2) 4, 5
4
3) 2, 3, 5
4) 5
53. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Утро было безветре(1)о и румя(2)о; деревья,припороше(3)ые инеем, торжестве(4)о
сияли в лучах утре(5)его солнца.
1) 3, 4, 5
2) 1, 3, 4
3) 1, 3, 4, 5
3
4) 2, 3, 4, 5
54. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Один из аморальных принципов,подмече(1)ых, предсказа(2)ых и
разоблаче(3)ых еще Ф.М.Достоевским,
является принцип «Всё дозволе(4)о».
1) 1, 2, 3
2) 2, 3, 4
1
3) 3, 4
4) 1, 3, 4
55.
 В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н? Материальная обеспече(1)ость, лишние
В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н? Материальная обеспече(1)ость, лишниекарма(2)ые деньги, неограниче(3)ые
возможности и запросы этого конче(4)ого
раскова(5)ого молодого человека сыграли
с ним плохую шутку.
1) 1, 2, 3, 5
1
2) 2, 3, 4, 5
3) 1, 2, 3
4) 3, 4, 5
56. В каком варианте ответа правильно указаны все цифры, на месте которых пишется две буквы Н?
Свяще(1)ая обяза(2)ость нашихсоотечестве(3)иков — в самые студё(4)ые
политические годы помнить о своем
высоком назначении, предначерта(5)ом
свыше.
1) 4, 5
3
2) 1, 3, 4
3) 1, 2, 3, 5
4) 1, 2, 5
| 1. | Какое слово подходит под правило? | 1 вид — рецептивный | лёгкое |
1 Б.
|
Упражнение, проверяющее навык различения условий написания Н/НН в прилагательных. Необходимые умения: правописание Н/НН в прилагательных; владение различными видами анализа языковых единиц, языковых явлений и фактов, в т. ч. лексическим, морфологическим анализом, разбором слова по составу. |
| 2. | Вставь буквы | 1 вид — рецептивный | лёгкое | 1 Б. |
Упражнение, проверяющее навык правописания Н/НН в словах разных частей речи. Необходимые умения:
владение различными видами анализа языковых единиц, языковых явлений и фактов, в т. ч. лексическим, морфологическим анализом, разбором слова по составу.
Необходимые умения:
владение различными видами анализа языковых единиц, языковых явлений и фактов, в т. ч. лексическим, морфологическим анализом, разбором слова по составу.
|
| 3. | Правильные варианты | 2 вид — интерпретация | среднее | 2 Б. |
Упражнение, проверяющее навык правописания Н/НН в словах разных частей речи.
Необходимые умения:
владение различными видами анализа языковых единиц, языковых явлений и фактов, в т.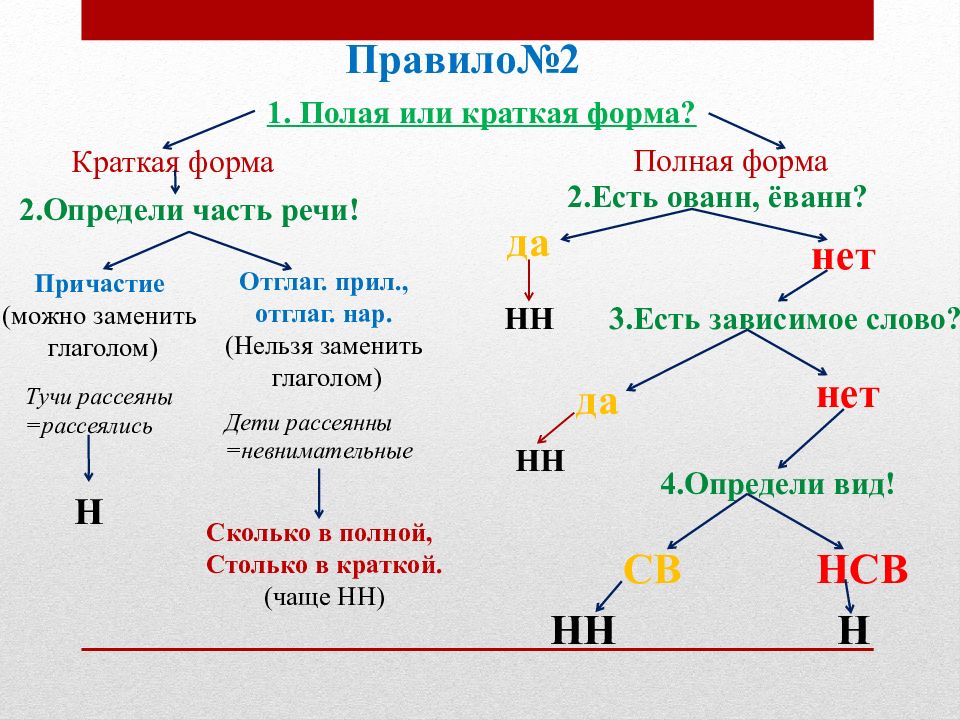 ч. лексическим, морфологическим анализом, разбором слова по составу. ч. лексическим, морфологическим анализом, разбором слова по составу.
|
| 4. | Найди вариант с правильным указанием | 2 вид — интерпретация | среднее | 2 Б. |
Упражнение, проверяющее навык правописания Н/НН в словах разных частей речи.
Необходимые умения:
владение различными видами анализа языковых единиц, языковых явлений и фактов, в т. ч. лексическим, морфологическим анализом, разбором слова по составу.
|
| 5. | Прилагательное или причастие? | 3 вид — анализ | сложное | 4 Б. | Упражнение, проверяющее навык различения кратких отглагольных прилагательных и кратких причастий. Необходимые умения: владение различными видами анализа языковых единиц, языковых явлений и фактов, в т. ч. лексическим, морфологическим анализом, разбором слова по составу. |
6.
|
Найди наречие | 3 вид — анализ | сложное | 4 Б. | Упражнение, проверяющее навык различения наречий, кратких прилагательных и кратких причастий, а также навык правописания Н/НН в словах этих частей речи. Необходимые умения: навыки лексического, морфологического анализа, разбора слова по составу. |
презентация подготовка к егэ правописание н и нн в разных частях речи docagiv
Ссылка:http://abecomi.sabemo.ru/2/63/prezentatsiya-podgotovka-k-ege-pravopisanie-n-i-nn-v-raznyh-chastyah-rechi
 . 12 советов для сочинения в ЕГЭ . Правописание Н и НН в различных частях речи. . Презентация Задание 19 ЕГЭ 2017 по русскому языку: теория и практика состоит из теоретической . Главная Школьные презентации ЕГЭ . Готовимся к ЕГЭ А12 н -нн в различных частях речи . — презентация. Практикум «Правописание Н и НН в суффиксах разных частей речи». Упражнения по теме «Правописание Н и НН в разных частях речи». Упражнение 1. Запишите прилагательные, вставляя -н- или -нн-. Образуйте от них . Предмет презентации : Русский язык Тема: Правописание Н и НН в суффиксах разных частей речи Наличие плана — конспект урока: Да. Цели урока: • формирование языковой, лингвистической и коммуникативной компетентностей при подготовке к ЕГЭ, а именно. .фонетической стороны речи для сдачи ЕГЭ по английскому языку Правописание «НЕ» с различными частями речи Обобщение по теме «НЕ с разными частями речи » Правописание корней (подготовка к ЕГЭ ) Н и НН в разных частях речи Слайды и текст этой презентации. ПОДГОТОВКА К ЕГЭ.
. 12 советов для сочинения в ЕГЭ . Правописание Н и НН в различных частях речи. . Презентация Задание 19 ЕГЭ 2017 по русскому языку: теория и практика состоит из теоретической . Главная Школьные презентации ЕГЭ . Готовимся к ЕГЭ А12 н -нн в различных частях речи . — презентация. Практикум «Правописание Н и НН в суффиксах разных частей речи». Упражнения по теме «Правописание Н и НН в разных частях речи». Упражнение 1. Запишите прилагательные, вставляя -н- или -нн-. Образуйте от них . Предмет презентации : Русский язык Тема: Правописание Н и НН в суффиксах разных частей речи Наличие плана — конспект урока: Да. Цели урока: • формирование языковой, лингвистической и коммуникативной компетентностей при подготовке к ЕГЭ, а именно. .фонетической стороны речи для сдачи ЕГЭ по английскому языку Правописание «НЕ» с различными частями речи Обобщение по теме «НЕ с разными частями речи » Правописание корней (подготовка к ЕГЭ ) Н и НН в разных частях речи Слайды и текст этой презентации. ПОДГОТОВКА К ЕГЭ. Задача учителя — подготовить обучающихся к выполнению заданий ЕГЭ. Цели: 1. . правописании Н и НН в разных частях речи. 2. . М.А., обучающая учительская презентация, индивидуальные планшеты. Подготовка к русскому языку 2017. . 12 советов для сочинения в ЕГЭ . Правописание Н и НН в различных частях речи. . Презентация Задание 19 ЕГЭ 2017 по русскому языку: теория и практика состоит из теоретической . 4 мар 2012 . Урок по теме Правописание Н и НН в суффиксах разных частей речи для 11 класса по . школ и использован при подготовке к ЕГЭ. 1 из 19. Описание презентации по отдельным слайдам Правописание Н и НН в суффиксах имен прилагательных, образованных от существительных. Система работы учителя при подготовке к ЕГЭ по русскому языку. Н-НН в прилагательных НН пишется в суффиксах: -онн-, -енн- . Презентация на тему: Правописание Н-НН в разных частях речи. Н-НН .. Подготовка к ЕГЭ Василенко О. О., учитель русского языка и литературы МОУ СОШ 15 х. Подготовка к тотальному диктанту. Правописание Н и НН в суффиксах различных частей речи.
Задача учителя — подготовить обучающихся к выполнению заданий ЕГЭ. Цели: 1. . правописании Н и НН в разных частях речи. 2. . М.А., обучающая учительская презентация, индивидуальные планшеты. Подготовка к русскому языку 2017. . 12 советов для сочинения в ЕГЭ . Правописание Н и НН в различных частях речи. . Презентация Задание 19 ЕГЭ 2017 по русскому языку: теория и практика состоит из теоретической . 4 мар 2012 . Урок по теме Правописание Н и НН в суффиксах разных частей речи для 11 класса по . школ и использован при подготовке к ЕГЭ. 1 из 19. Описание презентации по отдельным слайдам Правописание Н и НН в суффиксах имен прилагательных, образованных от существительных. Система работы учителя при подготовке к ЕГЭ по русскому языку. Н-НН в прилагательных НН пишется в суффиксах: -онн-, -енн- . Презентация на тему: Правописание Н-НН в разных частях речи. Н-НН .. Подготовка к ЕГЭ Василенко О. О., учитель русского языка и литературы МОУ СОШ 15 х. Подготовка к тотальному диктанту. Правописание Н и НН в суффиксах различных частей речи. Акимова Алла Ивановна, кандидат филологических . Презентация — Подготовка к ЕГЭ — Правописание Н и НН в разных частях речи. Учебный тренажёр и проверочный тест по теме «Правописание НЕ и НИ с разными.
Акимова Алла Ивановна, кандидат филологических . Презентация — Подготовка к ЕГЭ — Правописание Н и НН в разных частях речи. Учебный тренажёр и проверочный тест по теме «Правописание НЕ и НИ с разными.Н и НН в разных частях речи
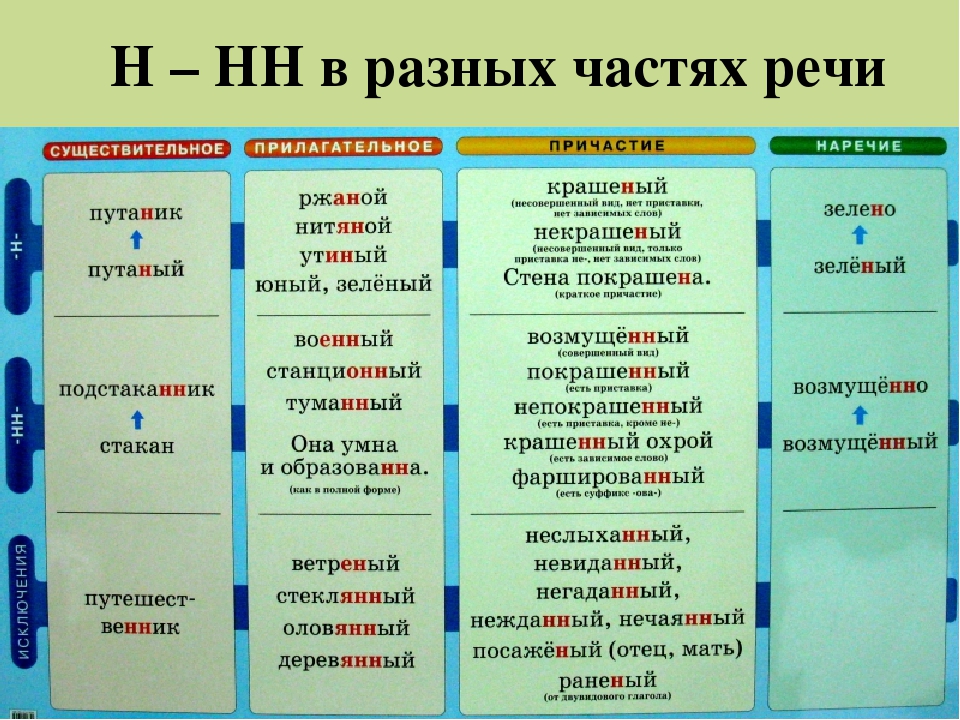
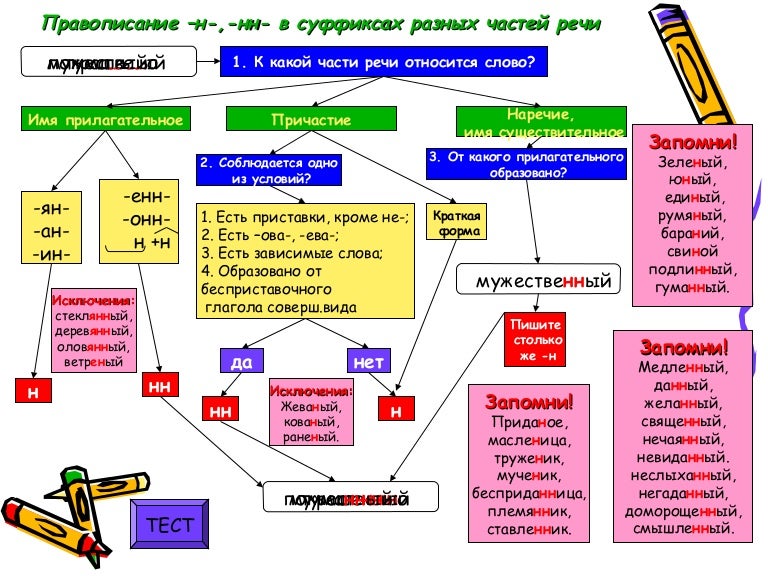
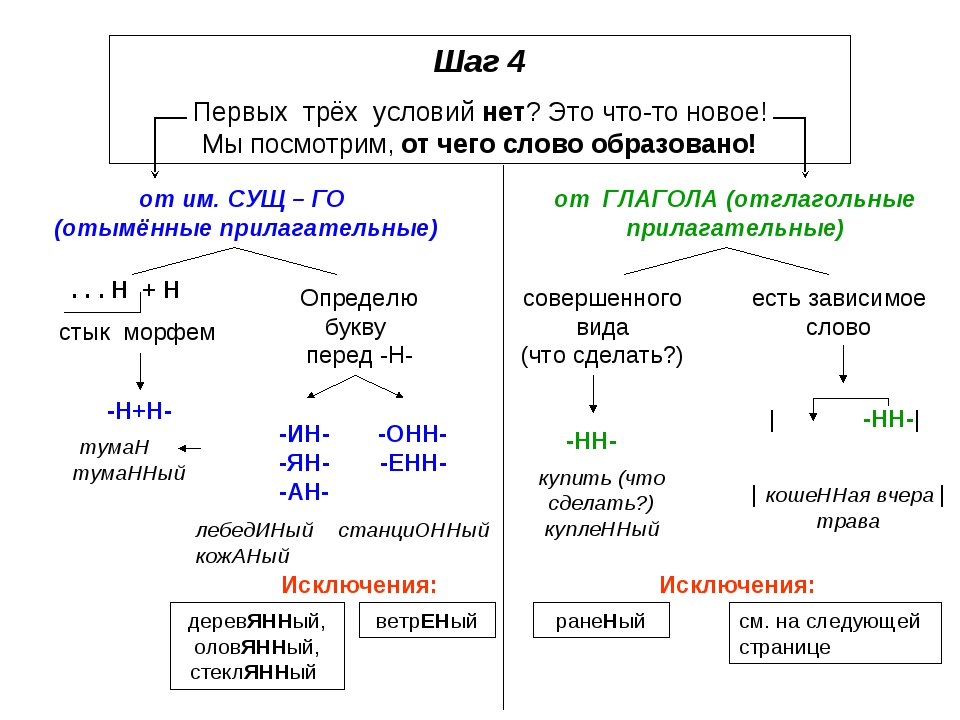
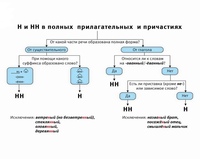
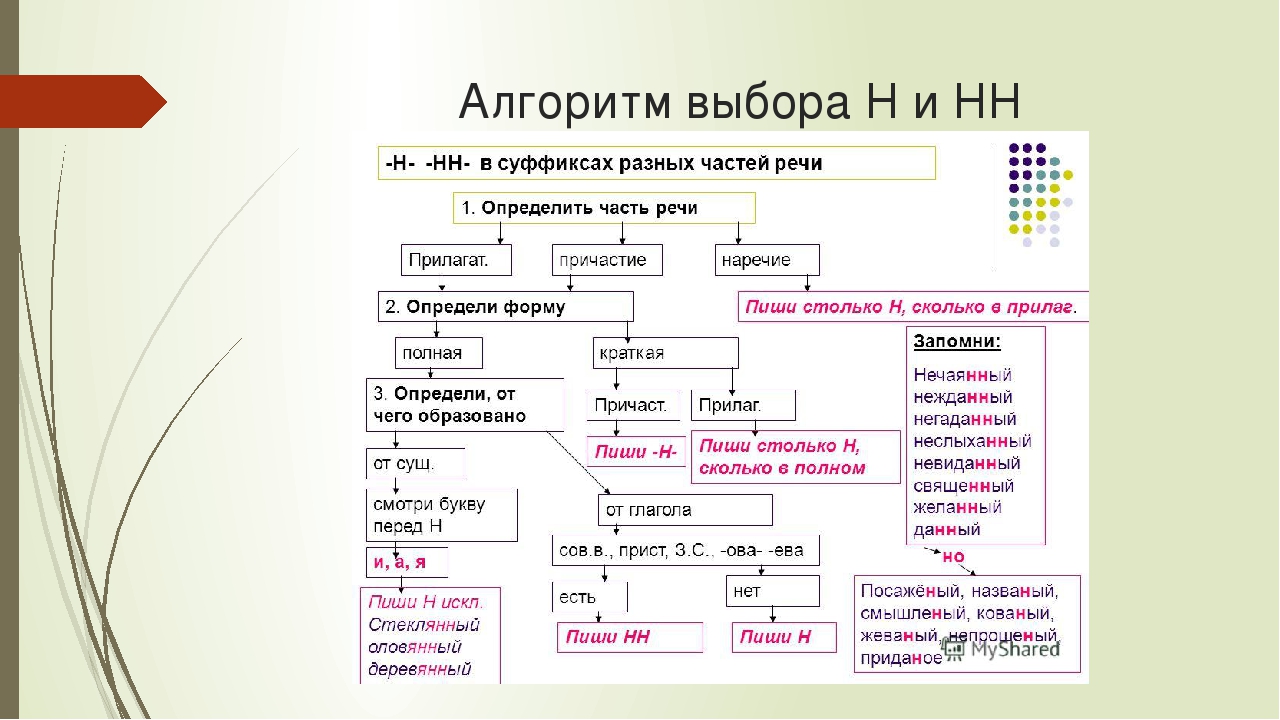
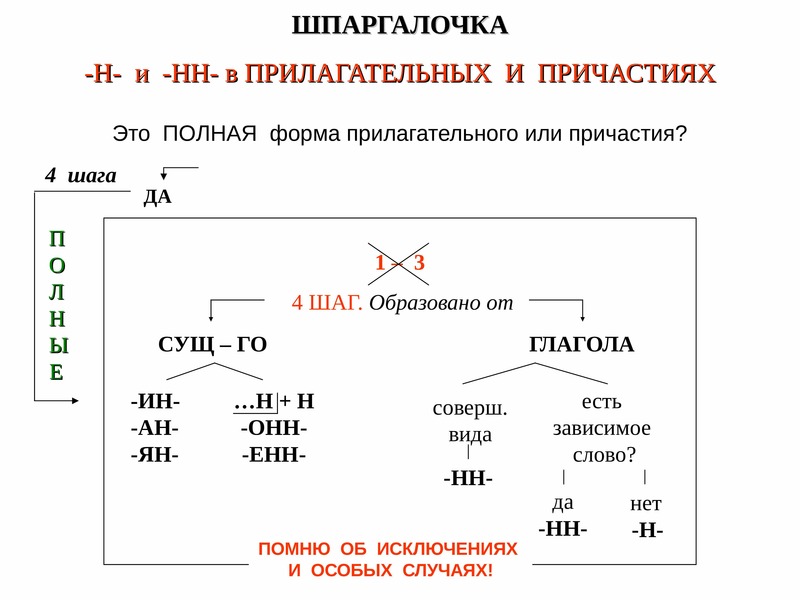
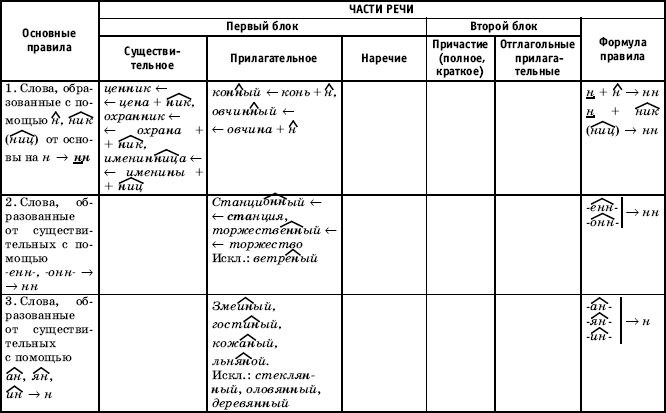
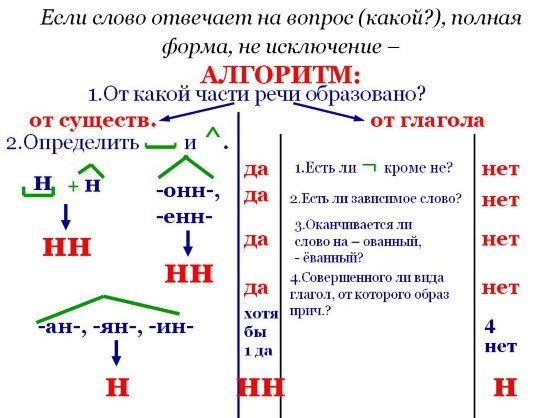
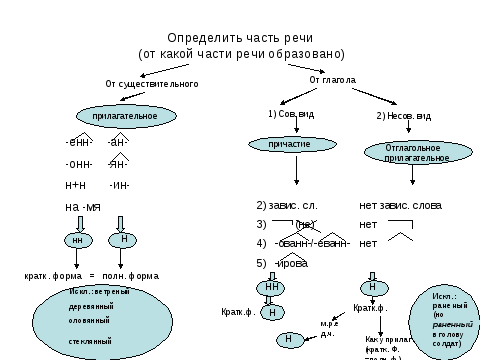
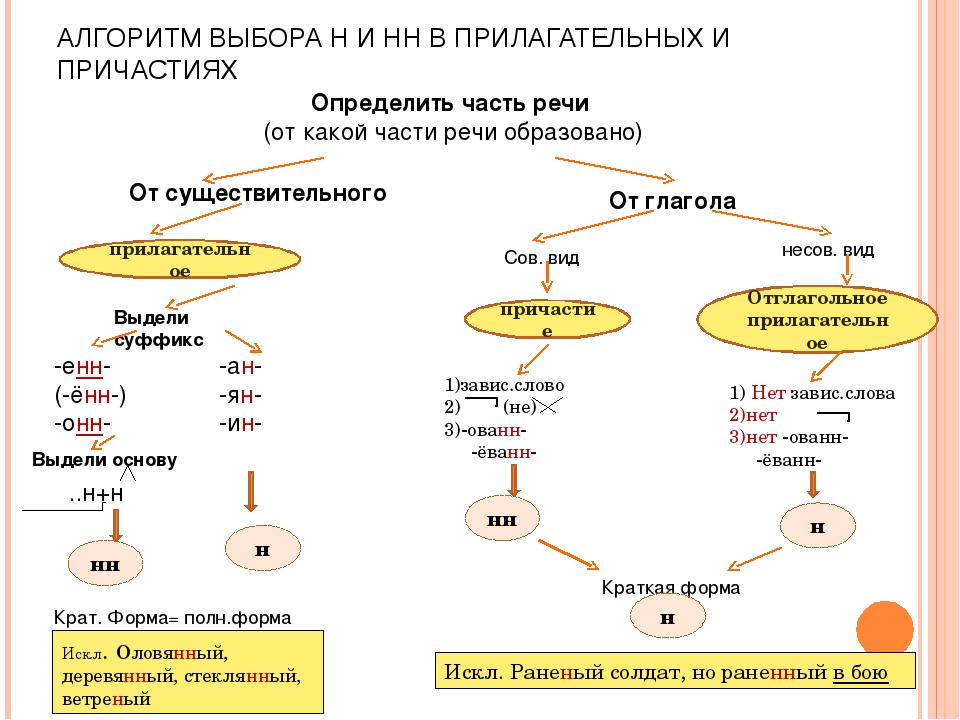
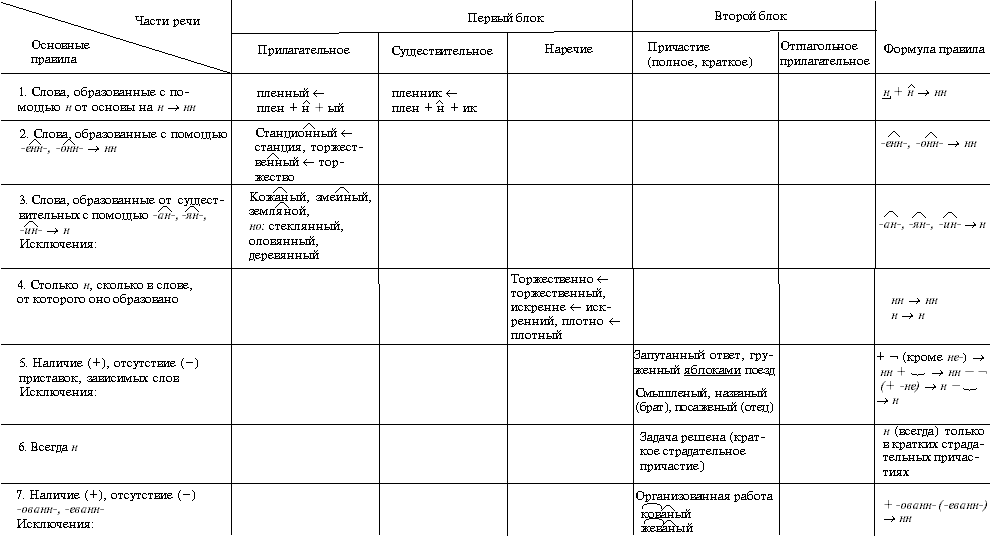
Отымённые прилагательные
Отымённые — образованные от имени. В этом случае от имени существительного.
отымённые прилагательное ← существительное
Исключения:
- Ветреный. Но, если в этом слове есть приставка, то НН: безветренный. Не путайте с «ветряно́й».
- С -янн-: оловянный, стеклянный, деревянный.
- С суффиксом j(-ий): бараний, тараканий, тюлений, пеликаний и т.д.
- Без суффикса: свин-ой ← свин. По аналогии золот-ой ← золот-о
количество Н в краткой форме = количество Н в полной
Непроизводные прилагательные
Эти прилагательные не образовывались от других слов.
непроизводное слово любой части речи ← Х
Всегда одна Н: зелёный, юный, румяный, пряный, единый, багряный (насыщенный краcный цвет), рьяный (очень усердный, ярый), буланый (одна из конских мастей).
Отглагольные прилагательные и причастия
отглагольное прилагательное или причастие ← глагол
Исключения:
- нежданный, негаданный, (не)виданный, виденный, неслыханный, читанный, слыханный, считанный, деланный, чеканный, нетленный, венчанный, обещанный, желанный.
Эти прилагательные образованы от глаголов несовершенного вида, и в них нет приставки, но они пишутся с НН. Такая особенность связана с тем, что раньше производящие глаголы этих слов были совершенного вида или двувидовыми. Например, «венчать» может отвечать на два вопроса в зависимости от контекста: «что делать» и «что сделать».
- Только в этих значениях:
- прощёное воскресенье (православный праздник), НО прощённый долг
- названый брат (не являющийся родственником, но родной в душевном и эмоциональном плане), НО названный в честь кого-то
- посажёный отец (в народном свадебном обряде у православных: мужчина, заменяющий родного отца), НО поса́женное дерево
- конченый человек (пропащий, ни на что не способный), НО конченное дело (завершённое)
- смышлёный ребёнок
- приданое невесты (субстантиви́рованное, т. е. из причастия стало существительным)
В краткой форме у причастий и отглагольных прилагательных всегда одна Н, в том числе в словах-исключениях.
Наречия
количество Н в наречии = количество Н в производящем слове
Ветреный (отымённое прилагательное, исключение) день — сегодня ветрено (наречие).
Монотонная (отымённое прилагательное, моно- + -тон- + -н-) функция — говорить монотонно (наречие).
Нежданный (причастие, исключение) гость — вернуться нежданно (наречие).
Трудные моменты:
- Существуют причастия, перешедшие в разряд прилагательных. Например, «медленный» ← «медлить», «рассеянный» (в знач. прил. «невнимательный») ← «рассеять». Выполняя задания в тренажёре, считайте эти слова причастиями.
- Слова «искусный» и «искуственный» — однокоренные. Искусный ← сущ. иску́с (продолжительная проверка на деле чьих-либо качеств; испытание).
- Есть двувидовые глаголы, они могут отвечать как на вопрос несовершенного вида (что делать?), так и совершенного (что сделать?) в зависимости от контекста. Если нет зависимого слова и приставки, то слово, образованное от двувидового глагола, считается отглагольным прилагательным и пишется с одной Н (раненый боец).
 Если зависимое слово или приставка есть, то это причастие и оно пишется с НН (раненный в руку). Но не забывайте про исключения: обещать (что сделать, сов. вид) → обещанный.
Если зависимое слово или приставка есть, то это причастие и оно пишется с НН (раненный в руку). Но не забывайте про исключения: обещать (что сделать, сов. вид) → обещанный. - Не путайте паронимы (внешне схожие слова) ве́треный и ветряно́й. Ветреный — 1. сопровождаемый ветром (ветреный день) 2. (перен.) легкомысленный, непостоянный, несерьезный (ветреное поведение). Ветряной — приводимый в действие силой ветра (ветряной двигатель).
- У разносклоняемых существительных (на -мя) бремя, время, вымя, знамя, имя, пламя, племя, темя, семя, стремя прилагательные образуются с использованием суффикса -Н- и наращением -ЕН- (как в Родительном падеже: нет времени), суффикс -ЕНН- не используется. Время + -н- → врем-ен-н-ый.
РАЗРАБОТКИ | Страница 2 В категории разработок: 100 Фильтр по целевой аудитории — Целевая аудитория -для 1 классадля 2 классадля 3 классадля 4 классадля 5 классадля 6 классадля 7 классадля 8 классадля 9 классадля 10 классадля 11 классадля учителядля классного руководителядля дошкольниковдля директорадля завучейдля логопедадля психологадля соц. Данная презентация составлена к уроку повторения изученного в 5-6 классах материала по теме «Правописание букв о-ё после шипящих в разных частях речи». Работа предназначена для обучающихся 7 класса по учебнику А.Д. Шмелева. Можно использовать для работы по другому УМК. Цель ресурса: отработка навыков правописание изученных орфограмм. Задача презентации: проверить знания обучающихся по теме. В форме интерактивного теста школьники повторяют написание букв о-ё в корне слова, суффиксе и окончании.
Целевая аудитория: для 7 класса Тренажер подходит как для фронтальной, так и для индивидуальной работы на уроках русского языка в начальной школе. Цель: закрепить знания учащихся в написании слов с разделительными мягким и твердым знаками. Данный ресурс создан в программе Microsoft Office PowerPoint 2007,использован технологический прием «Волшебная труба».
Целевая аудитория: для 3 класса Данная презентация может быть использована учителем при изучении темы «Правописание суффиксов -ЧИК и -ЩИК», а также для организации самостоятельной работы обучающихся по данной теме.
Целевая аудитория: для 5 класса Интерактивный тренажёр предназначен для отработки правописания Ы-И после Ц в 5-6 классах. Может использоваться и в других классах при повторении этой темы. Пособие можно использовать для фронтальной работы на интерактивной доске, индивидуальной и групповой работы в компьютерном классе, самостоятельной работы учащихся дома и в классе для отработки навыков правописания Ы-И после Ц. Пособие содержит теоретический материал, тренировочные упражнения, контрольные тесты.
Целевая аудитория: для 5 класса Интерактивный тест состоит из 15 заданий с выбором одного варианта ответа. Ресурс предназначен для проверки умения определять количество грамматических основ в сложном предложении (ОГЭ – задание 11). В качестве дидактического материала использованы задания из пособия Т.Н. Назаровой «ОГЭ 2016. Практикум по русскому языку: подготовка к выполнению заданий 6-14» / Т.Н. Назарова, Е.Н. Скрипка. – М.: Издательство «Экзамен», 2016
Целевая аудитория: для 9 класса Ресурс представляет собой презентацию-тренажёр. Данный методический ресурс предполагает комплексную работу с текстом. Может быть использован на уроках повторения и обобщения изученного материала Целевая аудитория: обучающиеся 6-го класса. При нажатии на правильный ответ изменяется цвет слов, появляется правильная буква. Неправильный ответ исчезает.
Целевая аудитория: для 6 класса Ресурс представляет собой презентацию-тренажёр. Данный методический ресурс может быть использован на уроках повторения и обобщения изученного материала. Целевая аудитория: обучающиеся 6-го класса. При нажатии на правильный ответ изменяется цвет слов, появляется правильная буква.
Целевая аудитория: для 6 класса Данный тренажер помогает учащимся повторить правила правописания существительных и прилагательных. Если у ученика есть ошибки, ему предлагается повторить орфограммы, а затем перейти к выполнению теста, получить оценку и увидеть допущенные ошибки. Используемый УМК: Русский язык. 6 класс. Учебник для общеобразовательных учреждений. В 2 частях. М.Т. Баранов, Т.А. Ладыженская, Л.А. Тростенцова и др
Целевая аудитория: для 6 класса Интерактивный тест (на основе шаблона А. А. Баженова) для обучающихся 7-го класса «Н и НН в именах прилагательных и причастиях»
Целевая аудитория: для 7 класса Интерактивный тест (на основе шаблона А. А. Баженова) для обучающихся 5-го класса «Знаки препинания в сложносочинённом предложении»
Целевая аудитория: для 5 класса | Конкурсы Диплом и справка о публикации каждому участнику! |
 педагогадля воспитателя
педагогадля воспитателя
 Неправильный ответ исчезает.
Неправильный ответ исчезает.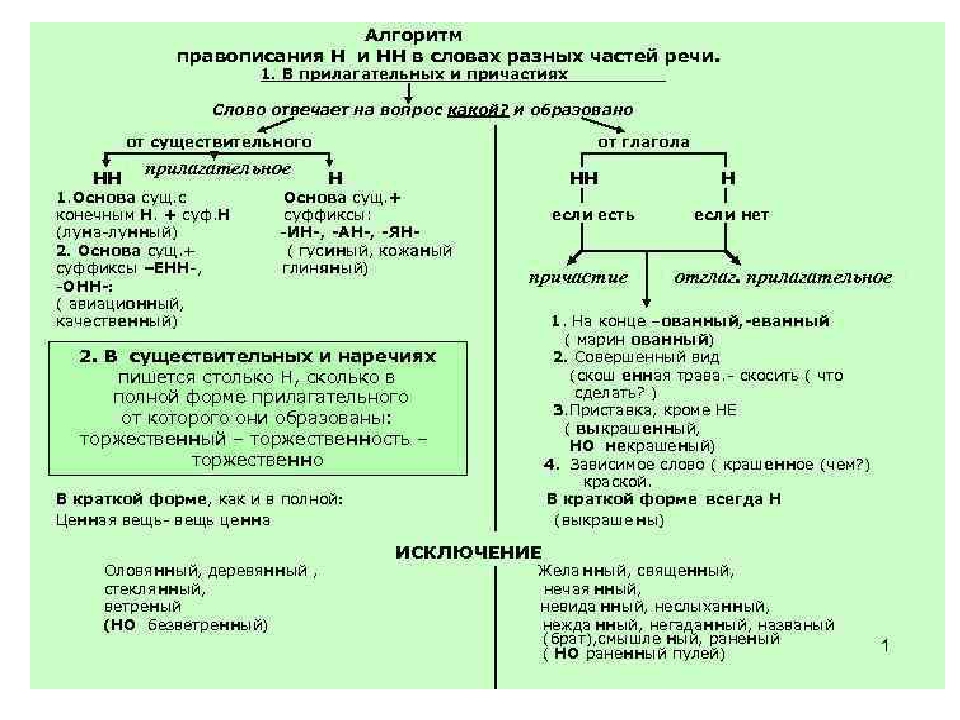
 12.2015 г. Роскомнадзором.
12.2015 г. Роскомнадзором.Генерал Акчурин рассказал, как немец Руст уничтожил командные кадры войск ПВО СССР
СПРАВКА «МК»
Расим Сулейманович Акчурин родился 24 декабря 1931 года в поселке Зангиата Ташкентской области Узбекистана.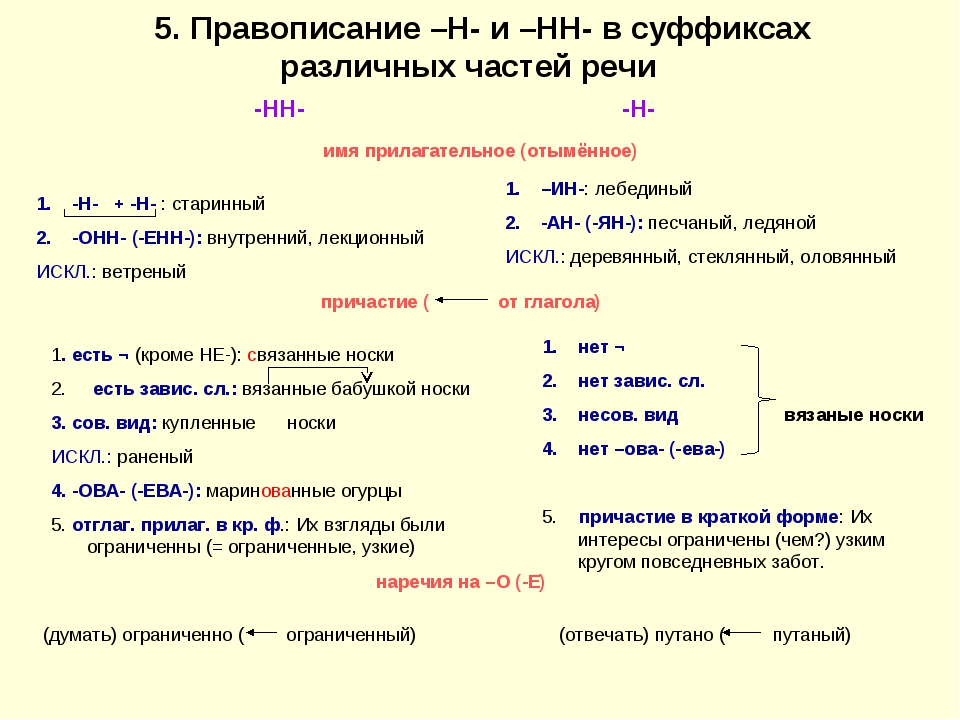 В 1949 году поступил в Ленинградский политехнический институт имени М.И.Калинина. После 2-го курса в 1951 году призван в Советскую армию. Окончил 3-е Балтийское зенитное артиллерийское училище войск ПВО, Военную командную академию ПВО. Служил в Туркестанском военном округе, Московском округе ПВО. С 1985 года командующий зенитными ракетными войсками Войск ПВО страны. В 1992 году уволен в запас по возрасту. Родной брат известного кардиохирурга, академика Рената Акчурина, которому доверили делать операцию Борису Ельцину.
В 1949 году поступил в Ленинградский политехнический институт имени М.И.Калинина. После 2-го курса в 1951 году призван в Советскую армию. Окончил 3-е Балтийское зенитное артиллерийское училище войск ПВО, Военную командную академию ПВО. Служил в Туркестанском военном округе, Московском округе ПВО. С 1985 года командующий зенитными ракетными войсками Войск ПВО страны. В 1992 году уволен в запас по возрасту. Родной брат известного кардиохирурга, академика Рената Акчурина, которому доверили делать операцию Борису Ельцину.
— Вот вы возглавляли зенитные ракетные войска советской сверхдержавы. А могли бы сравнить возможности Войск ПВО СССР и современной ПВО России. Мы хоть приближаемся к тому уровню, который был?
— Я, конечно, слежу за тем, как развивается техника ПВО, в курсе новинок: С-350, С-400, С-500. Но количественного состава зенитных комплексов, разумеется, не знаю — уже не положено. Когда командовал зенитными ракетными войсками страны, в их составе было более 240 зенитных ракетных полков и бригад. Это внушительная цифра. Причем в каждой бригаде было по 12–16 зенитных ракетных дивизионов. Это были мощные бригады, оснащенные зенитно-ракетной техникой различного типа. И огневая плотность была большая. В случае нападения противника вероятность уничтожения его средств очень высокая.
Это внушительная цифра. Причем в каждой бригаде было по 12–16 зенитных ракетных дивизионов. Это были мощные бригады, оснащенные зенитно-ракетной техникой различного типа. И огневая плотность была большая. В случае нападения противника вероятность уничтожения его средств очень высокая.
Мне есть с чем сравнивать. Я начинал службу в 1954 году лейтенантом в зенитной артиллерийской части. Мы прикрывали урановый комбинат в Киргизии, возле городка Майли-Сай. Один отдельный зенитный артиллерийский дивизион стоял на входе в ущелье, в котором располагались этот комбинат и урановые шахты, а второй — на выходе.
Начальником комбината был генерал-майор Данилин. Я даже фамилию его помню, потому что при мне, лейтенанте, мой командир части Бочков часто произносил эту фамилию. И как-то командир ставит задачу дивизионам: «Вот звонил Данилин сейчас. Если полетит американский «Бостон», то сбить…». Дальше военно-матерным языком, чтобы было понятно, как именно сбить.
Он, вообще-то, был артиллеристом, иконостас фронтовых орденов — во всю грудь. Очень заслуженный подполковник.
Очень заслуженный подполковник.
СПРАВКА «МК»
Самолет «Дуглас», или «Бостон», со времен Второй мировой войны стоял на вооружении ВВС США, Великобритании, СССР. По лендлизу в СССР было поставлено более 3000 таких самолетов разных модификаций.
Расим Акчурин, экс-командующий зенитными ракетными силами Войск ПВО СССР. Фото: Из личного архиваАмериканские самолеты в то время, пользуясь тем, что зенитных ракет у нас еще не было, а зенитные пушки до высотных целей достать не могли, часто совершали разведывательные полеты над территорией СССР. Особенно интересовались, конечно, ядерными объектами. Конец такой практике положили только зенитные ракеты, которыми 1 мая 1960 года был сбит над Свердловском самолет U-2 с американским летчиком Пауэрсом.
Мы, конечно, изготовились. Ждем. Летит «Бостон». Открыли огонь из 16 зенитных орудий двух батарей. Море огня. По теории вероятности, на уничтожение одного самолета надо выпустить до 600–800 зенитно-артиллерийских снарядов. Я командовал своим взводом. Видел, что самолет резко маневрировал то вниз, то вверх. Пилот, видимо, сильный был. Понял, что по нему стреляют. И ушел. Мы не сбили его.
Море огня. По теории вероятности, на уничтожение одного самолета надо выпустить до 600–800 зенитно-артиллерийских снарядов. Я командовал своим взводом. Видел, что самолет резко маневрировал то вниз, то вверх. Пилот, видимо, сильный был. Понял, что по нему стреляют. И ушел. Мы не сбили его.
Командир части Бочков приехал, выставил строй офицеров и говорит: «Солдаты тут ни при чем. Вы не научили их воевать». И как пошел чистить! Всем досталось. Особенно прибористам. Сказал: «В боевой обстановке я бы вас расстрелял, можете не сомневаться, но сейчас другая обстановка».
А на следующий день мы узнаем, что это был… наш самолет аэрофоторазведки. Он просто без заявки летал над ущельем, фотографировал урановый комбинат. Так что ему повезло, что мы мазилами оказались.
Это я к тому, насколько возможности противовоздушной обороны выросли, когда у нас на вооружении появились зенитные управляемые ракеты. Это доказано было на Пауэрсе.
— В советское время ваши войска учились отражать массированные налеты авиации противника?
— А вы как думаете? Конечно. Причем воевали, как говорится, насмерть с нашими же авиаторами, которые выступали в роли противника.
Причем воевали, как говорится, насмерть с нашими же авиаторами, которые выступали в роли противника.
Во время командования войсками я много учений проводил. Жизнь проходила больше на полигонах. Это Сары-Шаган в Казахстане, Ашулук в Астраханской области. Все зенитные комплексы дальнего действия работали обычно с Сары-Шагана, а на Ашулуке работали комплексы С-75, С-125.
Служба проходила на полигонах. Генерал Расим Акчурин (в центре) принимает доклады подчиненных. Фото: Из личного архиваОбычно проводили совместные учения с дальней авиацией. Они — нападающие, запускают крылатые ракеты. И стараются нас всячески принизить. Это просто болезнь такая была. До того загрубят чувствительность автопилотов, что крылатые ракеты не то что огибают рельеф местности, а утыкаются в холмы.
Помню, Петр Дейнекин — он тогда был заместителем командующего дальней авиацией — организовывал в Сары-Шагане такую атаку.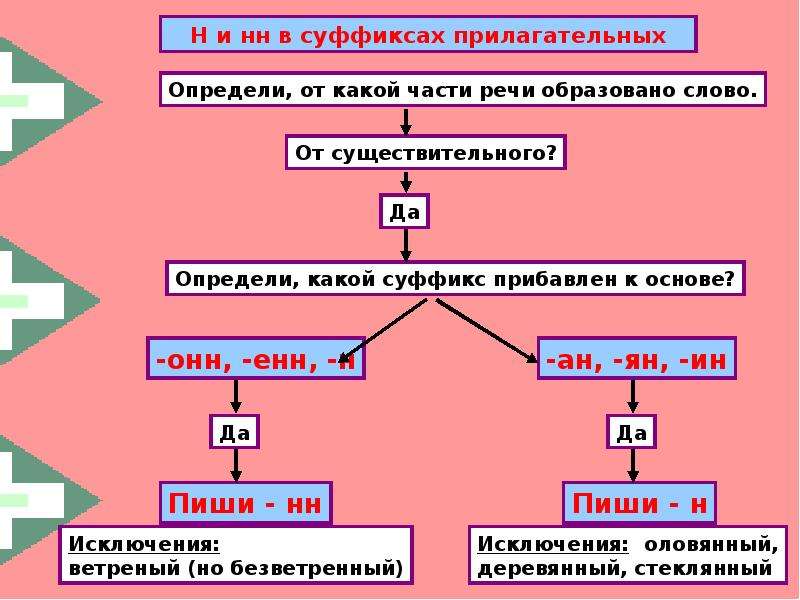 Мои ракетчики готовы, ждут — и все впустую: все крылатые ракеты в бугор уперлись. Мы ни одной ракеты не пускали, а целей нет, к объекту не прошли.
Мои ракетчики готовы, ждут — и все впустую: все крылатые ракеты в бугор уперлись. Мы ни одной ракеты не пускали, а целей нет, к объекту не прошли.
СПРАВКА «МК»
Петр Степанович Дейнекин, командующий дальней авиацией ВВС СССР (1988–1990), главком ВВС СССР (1991), главком ВВС РФ (1992–1998), Герой России, генерал армии. Под его руководством на аэродромах была уничтожена дудаевская военная авиация Ичкерии.
И тут начинается перетягивание канатов: кто виноват, что делать! Это было ужасно. Я уже командовал зенитными ракетными войсками ПВО страны. Говорю Дейнекину: «Петя …, ты что творишь?»
Дальше — решение главковерха: проводить учение повторно. Тут уже авиаторы не рисковали, задали реальные параметры полета ракет. И все крылатые ракеты были положены на землю системой С-300.
Я же предварительно пролетел на вертолете весь полигон. Все маршруты посмотрел: где поставить ракетные дивизионы, где могут пойти крылатые ракеты. И спасибо вертолетчикам, они помогли мне. Я расставил силы так, что крылатые ракеты не прошли.
Я расставил силы так, что крылатые ракеты не прошли.
Тут Дейнекин мне говорит: «Слушай, не торопись докладывать своему Колдунову (главком Войск ПВО страны, Главный маршал авиации Александр Колдунов. — «МК»), потому что он обязательно позвонит моему главкому Кутахову (главком ВВС, Главный маршал авиации Павел Кутахов. — «МК») — и все! Пойдет шум страшный. Я тебя очень прошу».
Я говорю: ладно, как сотоварищ, до вечера не буду докладывать, а вечером — если будет в кабинете, доложу. Если нет — то уже завтра. И тут уже бедный Дейнекин ходил, соображал, как доложить Кутахову, чтобы не очень попало. Так мы с ним в Сары-Шагане мучились.
Понятно, что в целом общее дело выигрывало. Противостояние зенитчиков и авиаторов было только на пользу обороне. У СССР были сильнейшая ПВО и сильнейшая авиация. Но ревность была жуткая…
Работа с молодежью — главная забота советов ветеранов. Фото: Из личного архива— Да, но потом были развал Союза и армии.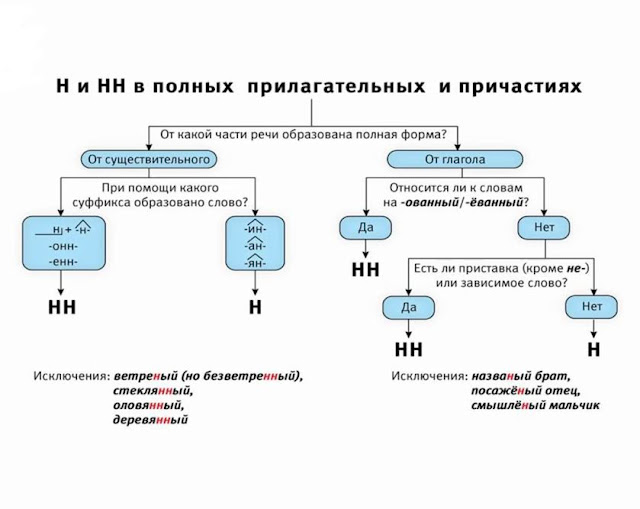 .. Какие чувства испытывали, когда видели, что огромная система ПВО — многоэшелонированная, со всеми радиолокационными полями — рушилась? Что чувствовали?
.. Какие чувства испытывали, когда видели, что огромная система ПВО — многоэшелонированная, со всеми радиолокационными полями — рушилась? Что чувствовали?
— Ужасно было обидно. Мы даже в плохом сне не могли допустить, что все так будет. Меня часто родные потом упрекали: вы, военные, должны были подняться, поднять голову. Но я не допускал, что до такого дойдет. Я был уверен в силе Центрального комитета Коммунистической партии Советского Союза.
В августе 1991 года при мне разговаривал Третьяк (замминистра обороны СССР, главком Войск ПВО. — «МК») с Язовым (министр обороны СССР при Горбачеве маршал Дмитрий Язов. — «МК») и говорил: «Что вы творите? Вы же власть! Решительнее надо».
Этот разговор был в присутствии всех членов военного совета Войск ПВО. Начальник политуправления Войск ПВО тоже по телефону предлагал министру: введите танки, арестуйте всех, вам будет благодарность людей.
Никто не мог предположить такой масштаб предательства и безответственности.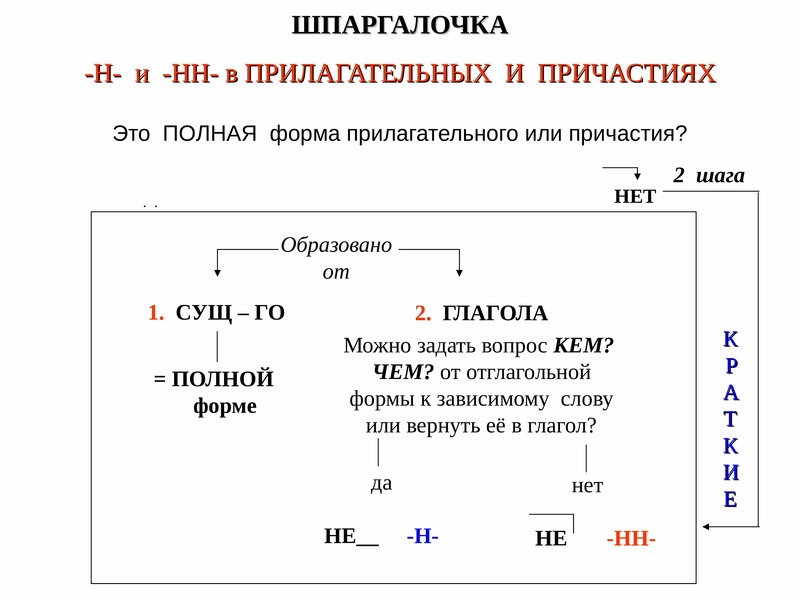
— А перед этим же еще была эпопея с самолетом Руста. Что тогда произошло?
— Скажу грубо: Руст бы яйца свои не нашел, если бы решительнее были некоторые командиры ПВО. Я в тот день был в составе комиссии главкома Войск ПВО, проверял как раз Таллиннскую дивизию ПВО по итогам зимнего периода обучения.
СПРАВКА «МК»
Матиас Руст — немецкий пилот-любитель. В возрасте 18 лет перелетел на легкомоторном самолете «Цессна» из Гамбурга через Хельсинки в Москву. 28 мая 1987 года (День пограничных войск СССР) приземлился на Большом Москворецком мосту. Был обвинен судом в хулиганстве и приговорен к четырем годам лишения свободы. В 1988 году освобожден по амнистии, вернулся в ФРГ. Полет Руста привел к массовым отставкам советского военного руководства.
Утром меня встречает командир дивизии и говорит: вот такая история произошла вчера вечером. Говорю: подожди, почему вечером не доложили? «Ну вот, товарищ командующий, я как-то не придал этому значения».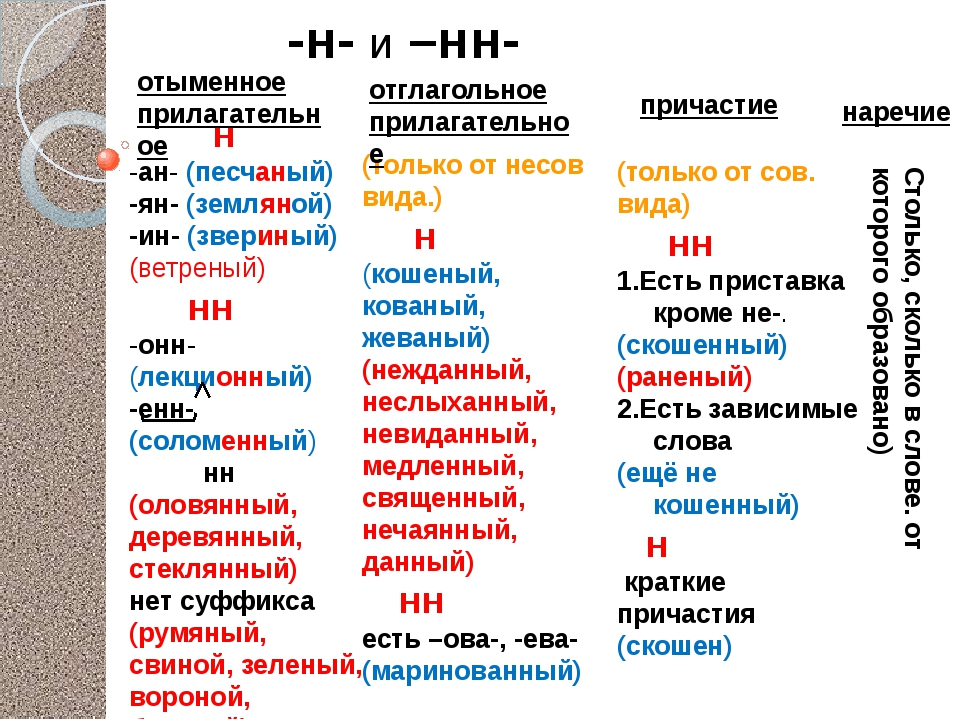 Представляете?!
Представляете?!
После доклада командира дивизии я выехал в дивизионы, которые сопровождали нарушителя.
Сопровождали Руста! Зенитная система С-200 сопровождала и С-125. От него бы ничего не осталось. Одной ракетой бы его сбили. И попадание было бы точное! Абсолютно!
Я разобрался с материалами объективного контроля, показавшими беспровальное сопровождение нарушителя и готовность к уничтожению «гостя».
Спрашиваю командира дивизиона: «Почему не открывали огня?» — «А команды не было, товарищ командующий». — «Подожди, — говорю, — ты представь, что враг летит, ты же сопровождаешь его, видишь, что на сигнал «свой-чужой» не отвечает! Как же ты можешь? Ты же командир огня! Понимаешь?» — «Команды не было, и по легкомоторным самолетам открывать огонь мы не имеем права».
Вот такой примитивный доклад в одном дивизионе. Может, и подготовил его командир дивизии так говорить — не знаю. Но, короче говоря, были два дивизиона, через которые самолет Руста прошел, как говорится, с нулевым параметром.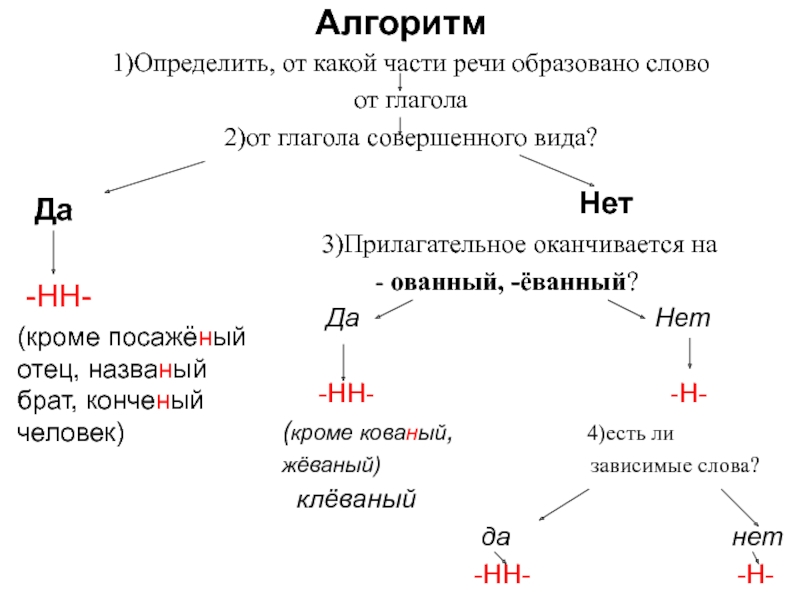 Там была стопроцентная вероятность уничтожения нарушителя. Полностью! И никто бы даже шума не поднял! Ну сбили и сбили.
Там была стопроцентная вероятность уничтожения нарушителя. Полностью! И никто бы даже шума не поднял! Ну сбили и сбили.
— Что ж это было — бардак перестроечный, расслабленность или горбачевская эйфория — «мир, дружба, жвачка»?
— Не знаю, может, все вместе. Как мне потом рассказывали, генерал в главкомате Войск ПВО, которому первому доложили, что легкомоторная «Цессна» летит, умнее ничего не придумал, как сказать: «Вы разберитесь, может, это гуси летят?».
Как могут гуси с севера лететь на юг? Май месяц — гуси летят с юга на север!
Вместо того чтобы спуститься на центральный командный пункт Войск ПВО и там разбираться на месте, он эту «утку» выдал всем командным пунктам — 6-й отдельной армии ПВО, Московскому округу ПВО. Два кольца комплексов С-300 было вокруг столицы.
Короче говоря, прошляпили. Один истребитель только видел, и он доложил четко, что это легкомоторный самолет типа «Цессна». Но ему было приказано сесть. Если бы оперативный дежурный без боязни доложил не случайному генералу, а главнокомандующему Войск ПВО, как это ему положено было сделать, главком бы спустился на ЦКП и принял бы решение либо к принуждению к посадке этого самолета, либо к его уничтожению! Решительность Главного маршала авиации Александра Ивановича Колдунова была известна еще со времен Великой Отечественной. В 1945 году он был уже дважды Героем Советского Союза.
В 1945 году он был уже дважды Героем Советского Союза.
— Многих генералов сняли?
— Сильно подкосили командный состав Войск ПВО. Снято с должности было очень много генералов. Из членов военного совета Войск ПВО страны остался я и начальник штаба, который был в момент ЧП в отпуске. Кстати, того генерала, который запустил версию про стаю гусей, повысили. Вроде бы он был земляком Горбачева, чуть ли не с одной улицы с ним.
Был снят главком Войск ПВО главный маршал авиации Колдунов. Он в тот день был уже дома, а в это время звонок — Руст на Красной площади. Представляете его состояние? Я был у него примерно через год после отставки. Министр обороны поручил его поздравить с днем рождения. Под 9 мая он родился. Я ездил его поздравлять. Он уже был без одной ноги. У него был диабет, и на нервной почве он развился бурно. Потом и вторую ногу отрезали, и он умер. Достойный военачальник. А все из-за Руста.
— После 1991 года вы не захотели служить дальше?
— В 1991 году я написал рапорт на увольнение. Меня пригласил на заседание высшей аттестационной комиссии секретарь Совета безопасности Юрий Владимирович Скоков. Хороший человек был. Беседа была очень долгой. Просили остаться, помочь наладить систему. Но я сказал: «Нет, я не хочу быть при развале Войск ПВО, который начался!».
Меня пригласил на заседание высшей аттестационной комиссии секретарь Совета безопасности Юрий Владимирович Скоков. Хороший человек был. Беседа была очень долгой. Просили остаться, помочь наладить систему. Но я сказал: «Нет, я не хочу быть при развале Войск ПВО, который начался!».
Вот такой простой пример. Скажем, дальневосточное направление у меня прикрывало более 180 зенитных ракетных дивизионов. Осталось 18! Представляете, в десять раз сократить активный род войск — зенитные ракетные войска! Понятно, что ракетные комплексы без эксплуатации, в режиме хранения, теряют свои боевые качества.
Все это было тяжелым ударом и для зенитных ракетных войск, да и в целом Войск ПВО.
— Как вам боевые возможности современных комплексов ПВО?
— Это удивительно! Высота обнаружения целей до 500 километров. Это же вообще немыслимо! Дальность обнаружения воздушных целей увеличилась, уже не говоря об огневых возможностях. И, наверное, правильно делают, что уходят от старой системы управления. Она все-таки свое отслужила и сейчас никак не может действовать эффективно. Мне рассказывали, сколько зенитных ракетных полков могут быть объединены в одну систему. Вы не представляете, какая это мощь под единым управлением. Это легко сказать, но представляю, как трудно было сделать ученым, конструкторам. Это правильно, что президент, военное руководство противоракетной обороне столько внимания уделяют, развитию зенитных ракетных войск.
И, наверное, правильно делают, что уходят от старой системы управления. Она все-таки свое отслужила и сейчас никак не может действовать эффективно. Мне рассказывали, сколько зенитных ракетных полков могут быть объединены в одну систему. Вы не представляете, какая это мощь под единым управлением. Это легко сказать, но представляю, как трудно было сделать ученым, конструкторам. Это правильно, что президент, военное руководство противоракетной обороне столько внимания уделяют, развитию зенитных ракетных войск.
— А если бы довелось с президентом встретиться, что бы покритиковали?
— Да хоть учебники истории. Недавно в нашем совете ветеранов я проводил семинар с людьми, которые возглавляют систему пропаганды в окружных ветеранских организациях. Обсуждали как раз отношение к истории Великой Отечественной войны. И опять ругали школьные учебники, в которых о Сталинградской битве несколько строк только напечатано. Многие вещи даже не перечислены. История — мертвая! И ведь Владимиру Владимировичу Путину уже на каком-то совещании об этом говорили.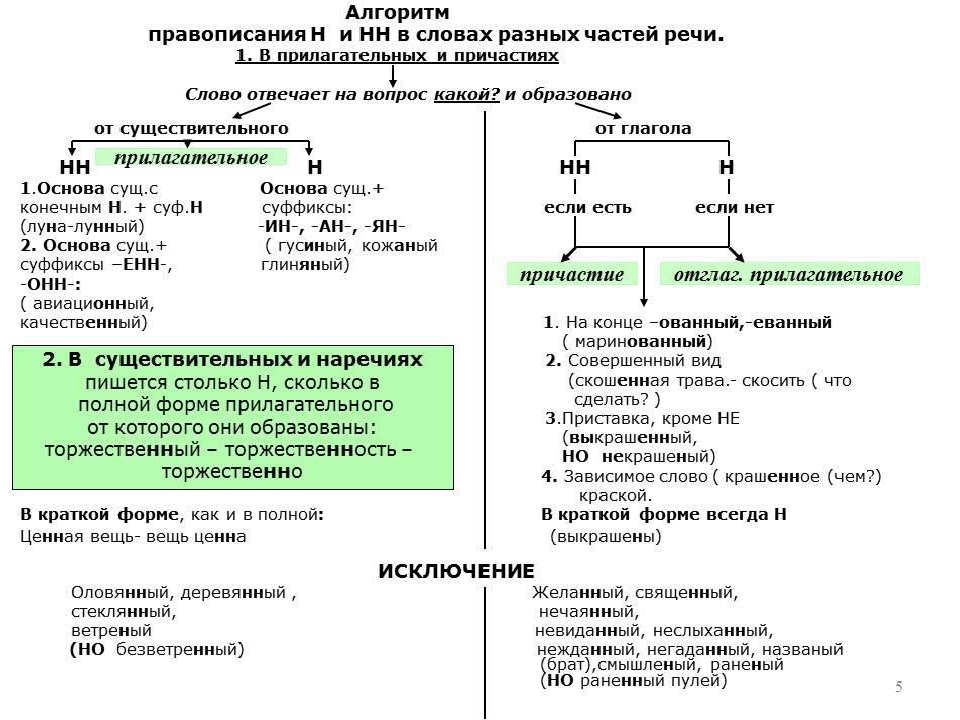 А ничего же не изменилось.
А ничего же не изменилось.
Почему-то сбой происходит в системе исполнения. Надо, чтобы прислушивались к мнению ветеранских организаций. Мы же не критиканством занимаемся. Мы хотим, чтобы Россия была мощной страной, великим государством.
Ну и, конечно, считаю, что войска воздушно-космической обороны должны быть самостоятельным видом Вооруженных сил. И его надо развивать. Надо систему ПВО укреплять. Это система сохранения государства, не говорю уже о городах или важных объектах.
Вспомните Великую Отечественную, 1941 год. Тогда Сталин все сделал, чтобы вокруг Москвы создали непреодолимую систему ПВО. Мощная система зенитного огня была создана, истребительная авиация, зенитная артиллерия, аэростаты заграждения, маскировка. Да, некоторые немецкие самолеты прорывались. Но это не идет ни в какое сравнение, например, с тем, какой ущерб немецкая авиация нанесла английским городам или с последствиями бомбардировок союзников по немецким городам. Надо помнить уроки истории!
Оптимизация имитатора в реальном времени на основе рекуррентных нейронных сетей для прогнозирования переходных процессов компрессора | J.
 Turbomach.
Turbomach. В этой статье изучаются и разрабатываются рекуррентные нейронные сети с прямой связью (RNN) с одним скрытым слоем, обученные с использованием алгоритма обучения с обратным распространением, для моделирования поведения компрессора в нестационарных условиях. Данные, используемые для обучения и тестирования RNN, получены с помощью модели на основе нелинейной физики для динамического моделирования компрессора (смоделированные данные) и измерены на многоступенчатом аксиально-центробежном малогабаритном компрессоре (полевые данные).Анализ смоделированных данных связан с оценкой влияния количества обучающих шаблонов и каждого входа RNN на отклик модели как для данных, не поврежденных, так и для данных, поврежденных ошибками измерения, для различных конфигураций RNN и различных значений общей задержки. время. Для моделей RNN, обученных непосредственно на экспериментальных данных, анализ влияния входной комбинации RNN на отклик модели повторяется, как и для моделей, обученных на имитированных данных, чтобы оценить динамическое поведение реальной системы. Затем разрабатываются RNN-предикторы (то есть те, которые не включают среди входов экзогенные входы, оцениваемые на том же временном шаге, что и выходной вектор), и проводится обсуждение их возможностей. Анализ смоделированных данных привел к выводу, что для улучшения характеристик RNN выгодно использовать RNN с одноразовой задержкой, с как можно меньшим общим временем задержки (в этой статье 0,1 с) и тренировались с максимально возможным количеством тренировочных шаблонов (не менее 500).Анализ влияния каждого входа на ответ RNN, проведенный для моделей RNN, обученных на полевых данных, показал, что предсказатель на один шаг вперед RNN обеспечивает очень хорошую производительность, сравнимую с характеристиками моделей RNN со всеми входами (общая ошибка для каждого единый расчет равен 1,3% и 0,9% для двух рассмотренных тестовых случаев). Более того, анализ возможностей многошагового предсказателя показал, что сокращение количества вычислений RNN является ключевым фактором для повышения его производительности на значительном временном горизонте.
Затем разрабатываются RNN-предикторы (то есть те, которые не включают среди входов экзогенные входы, оцениваемые на том же временном шаге, что и выходной вектор), и проводится обсуждение их возможностей. Анализ смоделированных данных привел к выводу, что для улучшения характеристик RNN выгодно использовать RNN с одноразовой задержкой, с как можно меньшим общим временем задержки (в этой статье 0,1 с) и тренировались с максимально возможным количеством тренировочных шаблонов (не менее 500).Анализ влияния каждого входа на ответ RNN, проведенный для моделей RNN, обученных на полевых данных, показал, что предсказатель на один шаг вперед RNN обеспечивает очень хорошую производительность, сравнимую с характеристиками моделей RNN со всеми входами (общая ошибка для каждого единый расчет равен 1,3% и 0,9% для двух рассмотренных тестовых случаев). Более того, анализ возможностей многошагового предсказателя показал, что сокращение количества вычислений RNN является ключевым фактором для повышения его производительности на значительном временном горизонте. Фактически, когда выбрано высокое время выборки тестовых данных (в этой статье 0,24 с), ошибки предсказания были приемлемыми (менее 1,9%).
Фактически, когда выбрано высокое время выборки тестовых данных (в этой статье 0,24 с), ошибки предсказания были приемлемыми (менее 1,9%).
Приложения и алгоритмы искусственных нейронных сетей
Что такое искусственная нейронная сеть?
Искусственные нейронные сети — это вычислительные модели, созданные человеческим мозгом. Многие из недавних достижений были сделаны в области искусственного интеллекта, включая распознавание голоса, распознавание изображений, робототехнику с использованием искусственных нейронных сетей.Искусственные нейронные сети — это моделирование, основанное на биологической природе, выполняемое на компьютере для выполнения определенных конкретных задач, таких как: Искусственные нейронные сети, в целом — — это биологически вдохновленная сеть искусственных нейронов, сконфигурированных для выполнения определенных задач. Эти биологические методы вычислений известны как следующее крупное достижение в компьютерной индустрии.Что такое нейронная сеть?
Термин «нейронный» происходит от основной функциональной единицы нервной системы человека (животного) «нейрон» или нервных клеток, присутствующих в головном мозге и других частях тела человека (животного).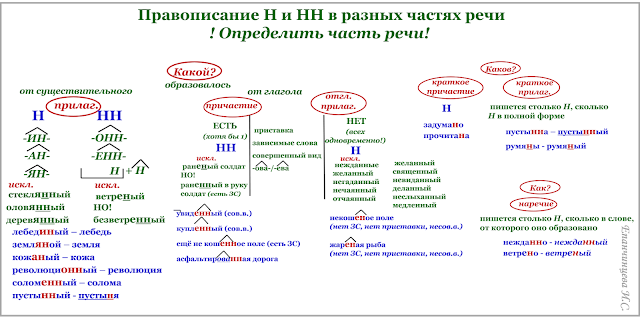 Нейронная сеть — это группа алгоритмов, которые удостоверяют основную взаимосвязь в наборе данных, аналогичных человеческому мозгу. Нейронная сеть помогает изменить ввод так, чтобы сеть давала лучший результат без изменения процедуры вывода. Вы также можете узнать больше о ONNX в этом обзоре.
Нейронная сеть — это группа алгоритмов, которые удостоверяют основную взаимосвязь в наборе данных, аналогичных человеческому мозгу. Нейронная сеть помогает изменить ввод так, чтобы сеть давала лучший результат без изменения процедуры вывода. Вы также можете узнать больше о ONNX в этом обзоре.Части нейрона и их функции
Типичная нервная клетка человеческого мозга состоит из четырех частей: Он получает сигналы от других нейронов. Он суммирует все входящие сигналы для генерации входных данных.Когда сумма достигает порогового значения, нейрон срабатывает, и сигнал проходит по аксону к другим нейронам. Точка соединения одного нейрона с другими нейронами. Количество передаваемого сигнала зависит от силы (синаптического веса) соединений. Связи могут быть тормозящими (уменьшение силы) или возбуждающими (увеличение силы) по своей природе. Итак, нейронная сеть, как правило, имеет связанную сеть из миллиардов нейронов с триллионом взаимосвязей между ними.В чем разница между компьютером и человеческим мозгом?
Искусственные нейронные сети (ИНС) и биологические нейронные сети (BNN) — Разница
| Характеристики | Искусственная нейронная сеть | Биологическая (реальная) нейронная сеть |
| Скорость | Более быстрая обработка информации.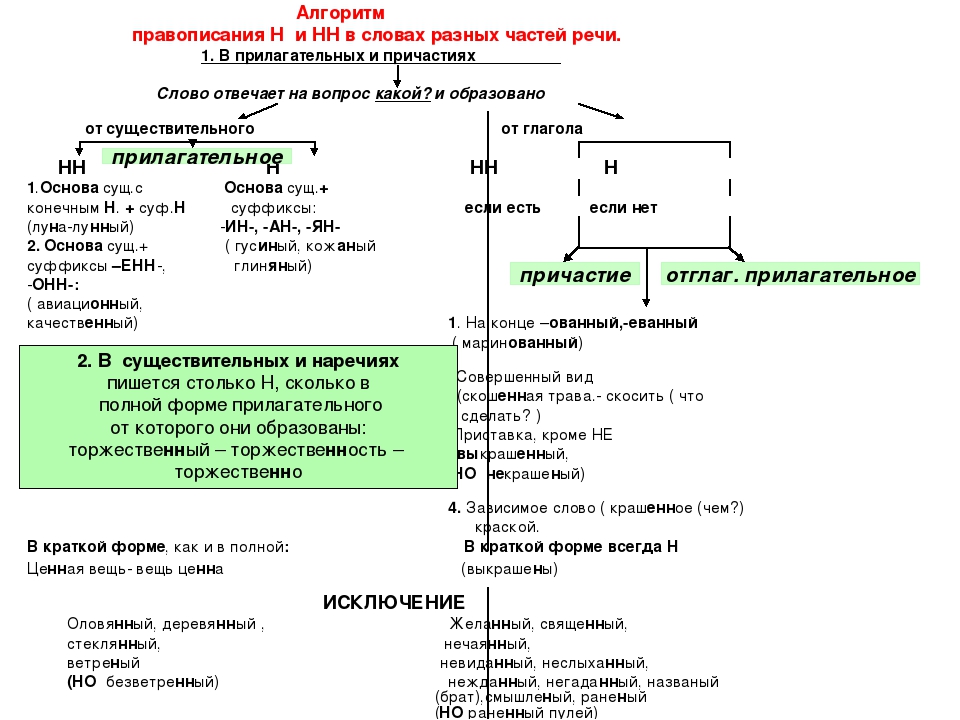 Время отклика в наносекундах. Время отклика в наносекундах. | Медленнее обрабатывает информацию.Время ответа в миллисекундах. |
| Обработка | Последовательная обработка. | Массивно-параллельная обработка. |
| Размер и сложность | Меньше размера и сложности. Он не выполняет сложных задач распознавания образов. | Очень сложная и плотная сеть взаимосвязанных нейронов, содержащая нейроны порядка 1011 с 1015 взаимосвязями. |
| Склад | Хранилище информации заменяемое — это замена новых данных на старые. | Очень сложная и плотная сеть взаимосвязанных нейронов, содержащая нейроны порядка 1011 с 1015 взаимосвязями. |
| Отказоустойчивость | Отказоустойчивый. Поврежденная информация не может быть восстановлена в случае отказа системы. | Хранилище информации является адаптируемым, что означает добавление новой информации путем корректировки силы межсоединений без уничтожения старой информации. |
| Механизм управления | Есть блок управления вычислительной деятельностью | Нет специального механизма управления, внешнего по отношению к вычислительной задаче. |
Искусственные нейронные сети с биологической нейронной сетью — подобие
Нейронные сети напоминают человеческий мозг двумя способами:- Нейронная сеть приобретает знания в процессе обучения.
- Знания нейронной сети — это запас прочности межнейронных связей, известный как синаптические веса.
ВЫЧИСЛЕНИЯ НА ОСНОВЕ АРХИТЕКТУРЫ ФОН НЕЙМАНА | ВЫЧИСЛЕНИЯ НА ОСНОВЕ ИНН |
| Последовательная обработка — инструкция обработки и проблема, правило по одному (последовательное) | Параллельная обработка — несколько процессоров работают одновременно (многозадачность) |
| Функционирование логически с набором правил if и else — подход на основе правил | Функция путем обучения шаблону на заданном входе (изображение, текст, видео и т. Д.)) Д.)) |
| Программируется языками более высокого уровня, такими как C, Java, C ++ и т. Д. | ИНС — это, по сути, сама программа. |
| Требуются либо большие, либо подверженные ошибкам параллельные процессоры | Использование специализированных мультичипов. |
Искусственная нейронная сеть (ИНС) с биологической нейронной сетью (BNN) — Сравнение
- Дендриты биологической нейронной сети аналогичны взвешенным входам, основанным на их синаптических взаимосвязях в искусственной нейронной сети.
- Тело клетки сравнимо с блоком искусственного нейрона в искусственной нейронной сети, состоящим из блока суммирования и порогового значения.
- Axon передает вывод, который аналогичен блоку вывода в случае искусственной нейронной сети. Итак, ИНС — это модель, использующая работу основных биологических нейронов.
Как работает искусственная нейронная сеть?
- Искусственные нейронные сети можно рассматривать как взвешенные ориентированные графы, в которых искусственные нейроны являются узлами, а направленные ребра с весами являются связями между выходами нейронов и входами нейронов.

- Искусственная нейронная сеть получает информацию из внешнего мира в виде рисунков и изображений в векторной форме. Эти входы обозначаются обозначением x (n) для количества входов n.
- Каждый вход умножается на соответствующие веса. Веса — это информация, используемая нейронной сетью для решения проблемы. Обычно вес представляет собой силу взаимосвязи между нейронами внутри нейронной сети.
- Все взвешенные входные данные суммируются внутри вычислительного блока (искусственного нейрона).В случае, если взвешенная сумма равна нулю, добавляется смещение, чтобы выходной сигнал не был нулевым, или для увеличения отклика системы. У смещения вес и вход всегда равны «1».
- Сумма соответствует любому числовому значению от 0 до бесконечности. Чтобы ограничить отклик для достижения желаемого значения, устанавливается пороговое значение. Для этого сумма пересылается через функцию активации.
- Функция активации настроена на передаточную функцию для получения желаемого результата.
 Существуют как линейные, так и нелинейные функции активации.
Существуют как линейные, так и нелинейные функции активации.
Какие функции активации обычно используются?
Некоторые из часто используемых функций активации — это бинарные, сигмоидальные (линейные) и желтовато-гиперболические сигмоидальные функции (нелинейные).- Двоичный — Выход имеет только два значения, либо 0, либо 1. Для этого устанавливается пороговое значение. Если чистый взвешенный вход больше 1, выход считается равным единице, в противном случае — нулю.
- Сигмоидальный гиперболический — Эта функция имеет S-образную кривую.Здесь гиперболическая функция tan используется для аппроксимации выпуска от чистого входа. Функция определяется как — f (x) = (1/1 + exp (- ???? x)), где ???? — параметр крутизны.
Щелкните, чтобы прочитать около Обзор искусственного интеллекта и роли НЛП в больших данных
Типы нейронных сетей в искусственном интеллекте
| Параметр | Типы | Описание |
| По схеме подключения | FeedForward, рекуррентный | Feedforward — в графиках нет циклов. Recurrent — Зацикливание происходит из-за обратной связи. Recurrent — Зацикливание происходит из-за обратной связи. |
| По количеству скрытых слоев | Однослойный, Многослойный | Однослойный — Имеет один секретный слой. Например, Single Perceptron Multilayer — Имеет несколько секретных слоев. Многослойный персептрон |
| По характеру весов | Фиксированный, Адаптивный | Фиксированный — Вес имеет фиксированный приоритет и не изменяется вообще. Adaptive — Обновляет веса и изменения во время тренировки. |
| На основе блока памяти | Статический, динамический | Статический — Блок без памяти. Текущий выход зависит от текущего входа. Например, сеть прямого распространения. Dynamic — Блок памяти — Выход зависит как от токового входа, так и от токового выхода. Например, рекуррентная нейронная сеть |
Типы архитектуры нейронной сети
Модель персептрона в нейронных сетях
 Они также известны как «однослойные перцептроны».
Они также известны как «однослойные перцептроны».Нейронная сеть с радиальной базисной функцией
Многослойная нейронная сеть персептрона
Нейронная сеть с кратковременной памятью (LSTM)
 Сеть обучается с помощью входных шаблонов, устанавливая для нейронов желаемый шаблон. Затем вычисляются его веса. Вес не изменился. После обучения одному или нескольким шаблонам сеть сходится к изученным шаблонам. Он отличается от других нейронных сетей.
Сеть обучается с помощью входных шаблонов, устанавливая для нейронов желаемый шаблон. Затем вычисляются его веса. Вес не изменился. После обучения одному или нескольким шаблонам сеть сходится к изученным шаблонам. Он отличается от других нейронных сетей.Машинная нейронная сеть Больцмана
Сверточная нейронная сеть
 В этом типе искусственной нейронной сети для имитации синапса используется электрически регулируемый материал сопротивления, а не программное моделирование, выполняемое в нейронной сети.
В этом типе искусственной нейронной сети для имитации синапса используется электрически регулируемый материал сопротивления, а не программное моделирование, выполняемое в нейронной сети.Щелкните, чтобы изучить Генеративные состязательные сети
Аппаратная архитектура для нейронных сетей
Для реализации оборудования для нейронных сетей используются два типа методов.- Программное обеспечение для моделирования на обычном компьютере
- Специальное аппаратное решение для уменьшения времени выполнения.
 д. края нейронной сети.В то время как производительность алгоритма обучения измеряется в количестве обновлений соединения в секунду (чашки)
д. края нейронной сети.В то время как производительность алгоритма обучения измеряется в количестве обновлений соединения в секунду (чашки)Методы обучения в искусственных нейронных сетях
Нейронная сеть обучается, итеративно регулируя свои веса и смещение (порог), чтобы получить желаемый результат. Их также называют свободными параметрами. Чтобы обучение происходило, сначала обучается нейронная сеть. Обучение выполняется с использованием определенного набора правил, также известного как алгоритм обучения.Алгоритмы обучения искусственных нейронных сетей
Алгоритм градиентного спуска
Алгоритм обратного распространения
 Здесь, после обнаружения ошибки (разницы между желаемым и целевым), ошибка распространяется в обратном направлении от выходного слоя к входному через скрытый слой.Он используется в случае многослойной нейронной сети.
Здесь, после обнаружения ошибки (разницы между желаемым и целевым), ошибка распространяется в обратном направлении от выходного слоя к входному через скрытый слой.Он используется в случае многослойной нейронной сети.Наборы обучающих данных в искусственных нейронных сетях
Набор примеров, используемых для обучения, соответствует параметрам [т. Е. Весам] сети. Один подход включает один полный цикл тренировки на тренировочной выборке. Набор примеров, используемых для настройки параметров [т. Е. Архитектуры] сети. Например, чтобы выбрать количество скрытых блоков в нейронной сети. Набор примеров используется только для оценки производительности [обобщения] полностью определенной сети или успешно применяется для прогнозирования выходных данных, входные данные которых известны.Подробнее о Лучшие практики и платформы Capsule Networks
Пять алгоритмов для обучения нейронной сети
- Правило обучения на языке хебби
- Правило Кохонена с самоорганизацией
- Закон о сети Хопфилда
- Алгоритм LMS (наименьший средний квадрат)
- Конкурсное обучение
Архитектура искусственной нейронной сети
Типичная нейронная сеть содержит большое количество искусственных нейронов, называемых единицами, расположенными в серии слоев.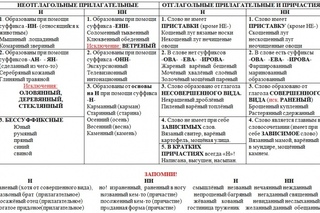 Типичная искусственная нейронная сеть состоит из разных слоев —
Типичная искусственная нейронная сеть состоит из разных слоев —- Входной уровень — Он содержит те блоки (искусственные нейроны), которые получают входные данные из внешнего мира, на которых сеть будет учиться, распознавать или иным образом обрабатывать.
- Выходной слой — Он содержит блоки, которые реагируют на информацию о том, как он изучает какую-либо задачу.
- Скрытый слой — Эти блоки находятся между входным и выходным слоями. Задача скрытого слоя — преобразовать ввод во что-то, что блок вывода может каким-то образом использовать.
Методы обучения в нейронных сетях
В этом обучении данные обучения вводятся в сеть, и желаемый результат известен, веса корректируются до тех пор, пока производство не даст желаемое значение. Используйте входные данные для обучения сети, выход которой известен. Сеть классифицирует входные данные и корректирует вес путем извлечения признаков во входных данных.Здесь выходное значение неизвестно, но сеть предоставляет обратную связь о том, является ли выход правильным или неправильным. Это полу-контролируемое обучение. Регулировка вектора весов и корректировка пороговых значений выполняются только после того, как обучающий набор показан в сети. Это также называется пакетным обучением. Регулировка веса и порога выполняется после представления каждой обучающей выборки в сеть.
Используйте входные данные для обучения сети, выход которой известен. Сеть классифицирует входные данные и корректирует вес путем извлечения признаков во входных данных.Здесь выходное значение неизвестно, но сеть предоставляет обратную связь о том, является ли выход правильным или неправильным. Это полу-контролируемое обучение. Регулировка вектора весов и корректировка пороговых значений выполняются только после того, как обучающий набор показан в сети. Это также называется пакетным обучением. Регулировка веса и порога выполняется после представления каждой обучающей выборки в сеть.Обучение и развитие в нейронных сетях
Обучение происходит, когда веса внутри сети обновляются после многих итераций.Например, предположим, что у нас есть входные данные в виде шаблонов для двух разных классов шаблонов — I & 0, как показано, и b-bias и y в качестве желаемого результата.Узор | y | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | b |
I | 1 | 1 | 1 | 1 | -1 | 1 | -1 | 1 | 1 | 1 | 1 |
O | -1 | 1 | 1 | 1 | 1 | -1 | 1 | 1 | 1 | 1 | 1 |
 ‘Ниже приведены выполняемые шаги:
‘Ниже приведены выполняемые шаги:- Девять входов от x1 — x9 и смещения b (вход со значением веса 1) подаются в сеть для первого шаблона.
- Первоначально веса сбрасываются на ноль.
- Затем веса обновляются для каждого нейрона по формулам: Δ wi = xi y для i = от 1 до 9 (правило Хебба)
- Наконец, новые веса находятся по формулам:
- wi (новый) = wi (старый) + Δwi
- Wi (новый) = [111-11-1 1111]
- Второй шаблон вводится в сеть.На этот раз веса не обнуляются. Используемые здесь начальные веса — это окончательные веса, полученные после представления первого шаблона. Таким образом, network.
- Шаги с 1 по 4 повторяются для вторых входов.
- Новые веса: Wi (новый) = [0 0 0 -2 -2 -2 000]
Какие 4 различных метода создания нейронных сетей?
Классификация нейронной сети
 Он использует сети прямого распространения.
Он использует сети прямого распространения.Нейронная сеть прогнозирования
Кластеризация нейронной сети
- Конкурентные сети
- Сети теории адаптивного резонанса
- Самоорганизующиеся карты Кохонена.
Ассоциация нейронных сетей
Нейронные сети для распознавания образов
Распознавание образов — это исследование того, как машины могут наблюдать за окружающей средой, учиться отличать представляющие интерес закономерности от их фона и принимать обоснованные и разумные решения относительно категорий образов. Некоторые примеры шаблона: изображения отпечатков пальцев, рукописное слово, человеческое лицо или речевой сигнал. Учитывая шаблон ввода, его распознавание включает в себя следующую задачу:
Некоторые примеры шаблона: изображения отпечатков пальцев, рукописное слово, человеческое лицо или речевой сигнал. Учитывая шаблон ввода, его распознавание включает в себя следующую задачу:- Контролируемая классификация — Данный входной шаблон известен как член предопределенного класса.
- Неконтролируемая классификация — Назначить шаблон неизвестному до сих пор классу.
- Сбор и предварительная обработка данных
- Представление данных
- Принятие решений
Подходы к распознаванию образов
- Соответствие шаблона
- Статистический
- Синтаксическое сопоставление
- Искусственные нейронные сети
- Многослойный персептрон
- Kohonen SOM (Самоорганизующаяся карта)
- Сеть радиальных базисных функций (RBF)
Нейронная сеть для глубокого обучения
Вслед за нейронной сетью в глубоком обучении используются архитектуры.
- Нейронные сети с прямой связью
- Рекуррентная нейронная сеть
- Многослойный перцептрон (MLP)
- Сверточные нейронные сети
- Рекурсивные нейронные сети
- Сети глубоких убеждений
- Сверточные сети глубоких убеждений
- Самоорганизующиеся карты
- Станки глубокого Больцмана
- Составные автокодеры с шумоподавлением
Нейронные сети и нечеткая логика
Нечеткая логика относится к логике, разработанной для выражения степени правдивости путем присвоения значений от 0 до 1, в отличие от традиционной булевой логики, представляющей 0 и 1.Нечеткая логика и нейронные сети имеют одну общую черту. Их можно использовать для решения задач распознавания образов и других задач, не связанных с какой-либо математической моделью. Системы, сочетающие нечеткую логику и нейронные сети, являются нейронечеткими системами. Эти системы (гибридные) могут сочетать в себе преимущества как нейронных сетей, так и нечеткой логики, чтобы работать лучше.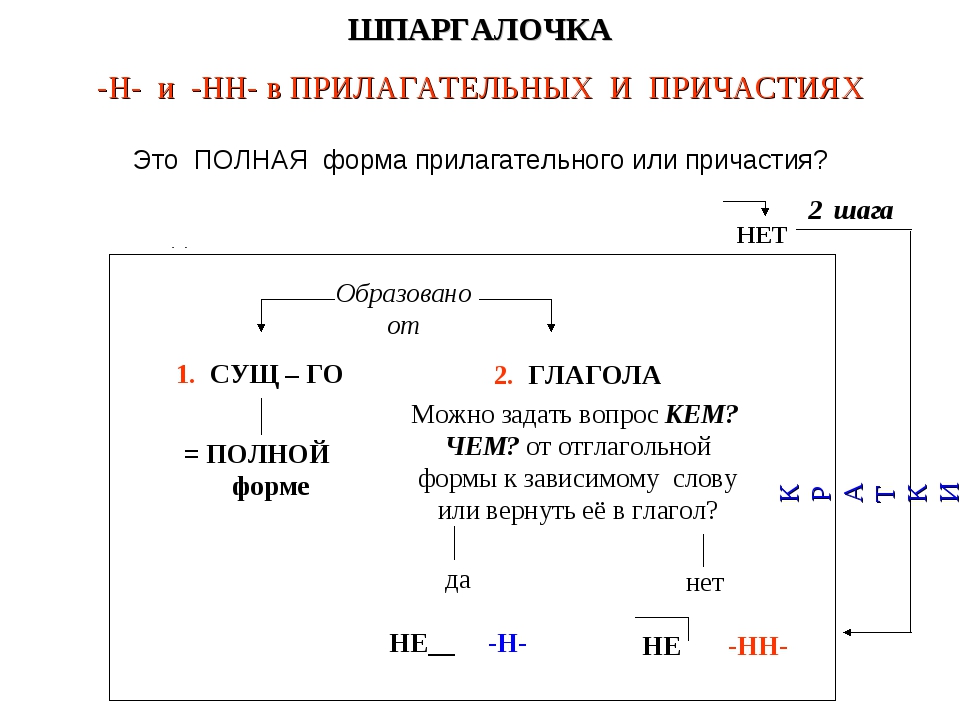 Нечеткая логика и нейронные сети были интегрированы для использования в следующих приложениях:
Нечеткая логика и нейронные сети были интегрированы для использования в следующих приложениях:- Автомобильная техника
- Отбор кандидатов на вакансии
- Управление краном
- Мониторинг глаукомы
Нейронная сеть для машинного обучения
- Многослойный персептрон (контролируемая классификация)
- Сеть обратного распространения (контролируемая классификация)
- Сеть Хопфилда (для ассоциации шаблонов)
- Глубокие нейронные сети (неконтролируемая кластеризация)
Каковы применения нейронных сетей?
Нейронные сети успешно применяются в широком спектре приложений с интенсивным использованием данных, таких как:| Заявка | Архитектура / алгоритм | Функция активации |
| Моделирование и управление процессами | Радиальная базовая сеть | Радиальное основание |
| Диагностика машины | Многослойный персептрон | Tan — сигмовидная функция |
| Управление портфелем | Классификация контролируемых алгоритмов | Tan — сигмовидная функция |
| Распознавание цели | Модульная нейронная сеть | Tan — сигмовидная функция |
| Медицинский диагноз | Многослойный персептрон | Tan — сигмовидная функция |
| Кредитный рейтинг | Логистический дискриминантный анализ с использованием ИНС, машина опорных векторов | Логистическая функция |
| Целевой маркетинг | Алгоритм обратного распространения сигнала | Логистическая функция |
| Распознавание голоса | Многослойный персептрон, глубокие нейронные сети (сверточные нейронные сети) | Логистическая функция |
| Финансовое прогнозирование | Алгоритм обратного распространения ошибки | Логистическая функция |
| Интеллектуальный поиск | Глубокая нейронная сеть | Логистическая функция |
| Обнаружение мошенничества | Градиент — алгоритм спуска и алгоритм наименьшего среднего квадрата (LMS).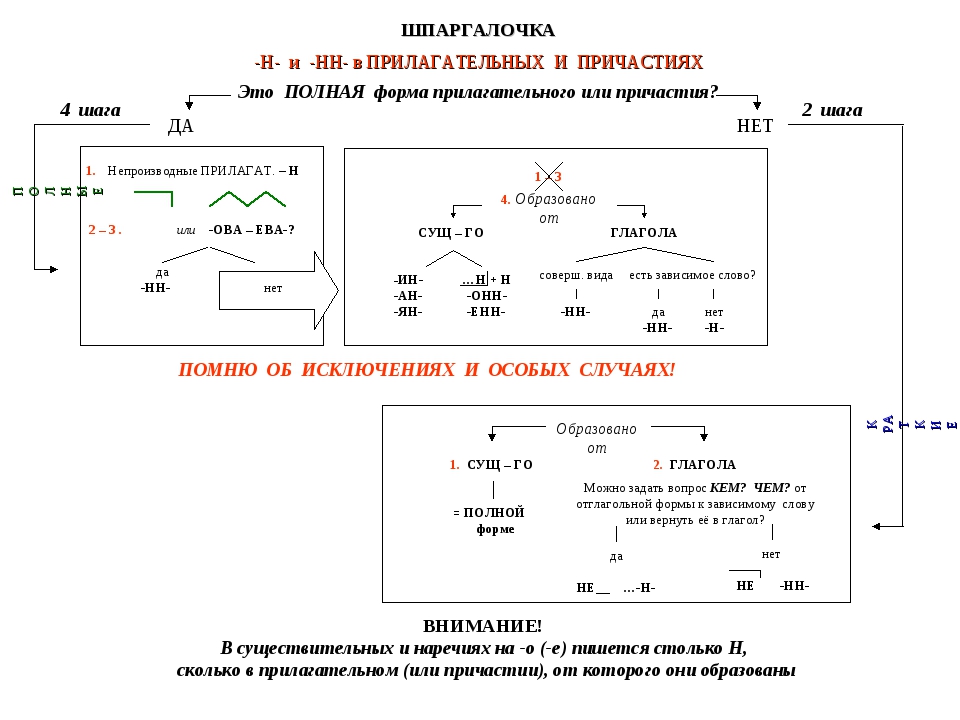 | Логистическая функция |
Каковы преимущества нейронных сетей?
- Нейронная сеть может выполнять задачи, которые не может выполнять линейная программа.
- Когда элемент нейронной сети выходит из строя, его параллельный характер может продолжаться без каких-либо проблем.
- Нейронная сеть обучается, и в перепрограммировании нет необходимости.
- Может быть реализован в любом приложении.
- Это может быть выполнено без проблем.
Каковы ограничения нейронных сетей?
- Для работы нейронной сети необходимо обучение.
- Архитектура нейронной сети отличается от архитектуры микропроцессоров. Следовательно, эмуляция необходима.
- Для больших нейронных сетей требуется много времени обработки.
Распознавание лиц с использованием искусственных нейронных сетей
Распознавание лиц влечет за собой сравнение изображения с базой данных сохраненных лиц для идентификации человека на этом входном изображении. Это механизм, который включает в себя разделение изображений на две части; один содержит цели (лица), а другой — фон.Соответствующее назначение функции обнаружения лиц имеет прямое отношение к тому факту, что изображения необходимо анализировать, а лица идентифицировать раньше, чем они могут быть распознаны.
Это механизм, который включает в себя разделение изображений на две части; один содержит цели (лица), а другой — фон.Соответствующее назначение функции обнаружения лиц имеет прямое отношение к тому факту, что изображения необходимо анализировать, а лица идентифицировать раньше, чем они могут быть распознаны.Правила обучения в нейронной сети
Правило обучения — это разновидность математической логики. Это побуждает нейронную сеть извлекать выгоду из текущих условий и повышать ее эффективность и производительность. Процедура обучения мозга изменяет его нервную структуру. Расширение или уменьшение качества его синаптических ассоциаций зависит от их активности.Правила обучения в нейронной сети:- Правило изучения еврейского языка; Он определяет, как настроить веса узлов системы.
- правило обучения персептрона; Сеть начинает свое обучение с присвоения случайного значения каждой нагрузке.
- Правило обучения дельте; Модификация симпатрического веса узла равна умножению ошибки и ввода.
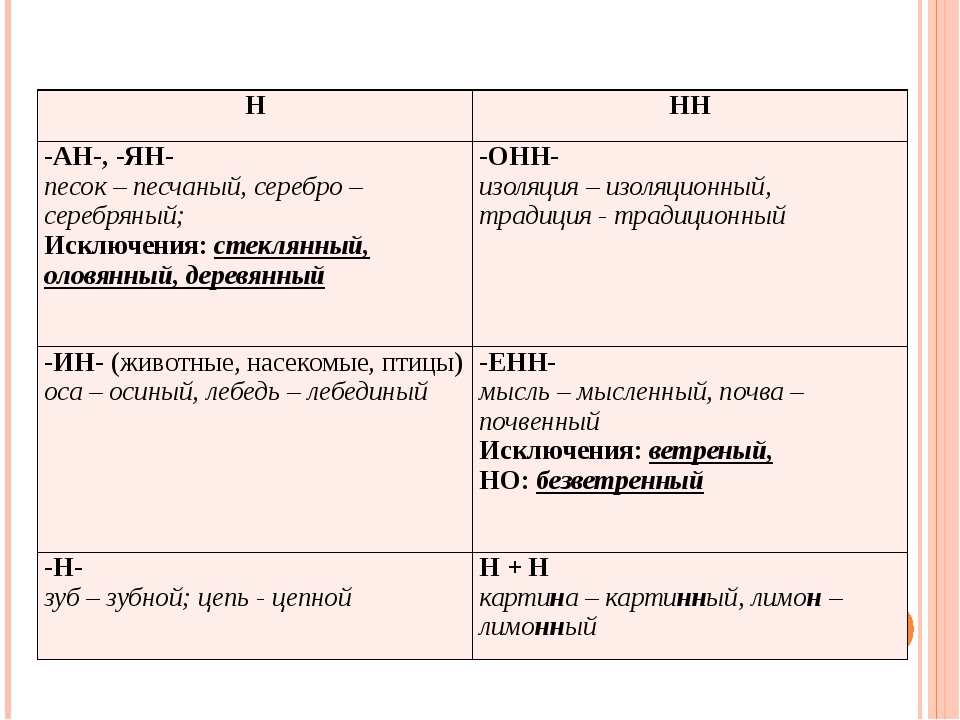
- Правило обучения корреляции; Это похоже на обучение с учителем.
Чем вам может помочь XenonStack?
XenonStack может помочь вам разработать и развернуть ваши модельные решения на основе нейронных сетей.С какой бы проблемой вы не столкнулись — прогнозированием, классификацией или распознаванием образов — у XenonStack есть решение для вас.
Услуги по обнаружению и предотвращению мошенничества
XenonStack Fraud Detection Services предлагает анализ мошенничества в режиме реального времени для повышения прибыльности. Data Mining полезен для быстрого обнаружения мошенничества, поиска шаблонов и обнаружения мошеннических транзакций. Инструменты для интеллектуального анализа данных, такие как машинное обучение, нейронные сети, кластерный анализ, полезны для создания прогнозных моделей для предотвращения потерь от мошенничества.
Услуги моделирования данных
XenonStack предлагает моделирование данных с использованием нейронных сетей, машинного обучения и глубокого обучения. Услуги моделирования данных помогают предприятиям создавать концептуальную модель на основе анализа объектов данных. Разверните свои модели данных на ведущих поставщиках облачных услуг, таких как Google Cloud, Microsoft Azure, AWS, или в контейнерной среде — Kubernetes и Docker.(PDF) Генеративное моделирование шума и имитация каналов для надежного распознавания речи в невидимых условиях
6.Ссылки
[1] В. Митра, Х. Франко, Р. М. Стерн, Дж. Ван Хаут, Л. Феррер, М. Гра-
Сиарена, В. Ван, Д. Вергири, А. Алван и Дж. Х. Хансен, «Особенности Ro-
в распознавании речи на основе глубокого обучения» в New
Era for Robust Speech Recognition. Springer, 2017, стр. 187–
217.
[2] K. Janod, M. Morchid, R. Dufour, G. Linares, R. De Mori,
—
Анализ телефонных разговоров, IEEE / ACM Transactions on Audio,
Speech and Language Processing, vol. 25, нет. 9, pp. 1809–1820,
25, нет. 9, pp. 1809–1820,
2017.
[3] В. Митра, Х. Франко, К. Бартельс, Дж. Ван Хаут, М. Грасиарена и
Д. Вергири, «Распознавание речи в невидимом и зашумленные соединения каналов », в Acoustics, Speech and Signal Processing (ICASSP),
2017 IEEE International Conference on. IEEE, 2017, стр. 5215–
5219.
[4] AL Maas, QV Le, TM O’Neil, O. Vinyals, P. Nguyen и
AY Ng, «Рекуррентные нейронные сети для снижения шума в robust
asr », в Proc.Interspeech, 2012.
[5] Э. Марчи, Ф. Весперини, Ф. Эйбен, С. Сквартини и Б. Шуллер,
«Новый подход к автоматическому обнаружению акустической новизны с использованием
в шумоподавляющем автоматическом кодировщике с двунаправленная нейронная сеть LSTM —
работает ”, в Акустике, обработке речи и сигналов (ICASSP),
Международная конференция IEEE 2015 г. IEEE, 2015, стр. 1996–
2000.
[6] C.-T. До и Й. Стилиану, «Улучшенное автоматическое распознавание речи —
nition с использованием функций временной огибающей поддиапазона и временной задержки
нейросетевой автоэнкодер шумоподавления», Proc. Interspeech 2017,
Interspeech 2017,
pp. 3832–3836, 2017.
[7] Б. Дас и А. Панда, «Надежная интерфейсная обработка для распознавания речи
в шумных условиях», Acoustics, Speech and Signal
Обработка (ICASSP), Международная конференция IEEE 2017 г.
IEEE, 2017, стр. 5235–5239.
[8] В. Митра и Х. Франко, «Использование энтропии активации глубокой нейронной сети для обработки невидимых данных при распознавании речи»,
препринт arXiv arXiv: 1708.09516, 2017.
[9] В. Митра, Г. Сивараман, Х. Нам, К. Эспи-Уилсон, Э. Зальцман,
и М. Тид, «Гибридные сверточные нейронные сети для артикуляторов. Распознавание речи на основе акустической информации », Speech
Communication, vol. 89, стр. 103–112, 2017.
[10] М.Л. Зельцер, Д. Ю и Ю. Ван, «Исследование глубоких нейронных сетей
для устойчивого к шуму распознавания речи», в Acous-
tics, Обработка речи и сигналов (ICASSP), 2013 Национальная конференция IEEE Inter-
по. IEEE, 2013, стр. 7398–7402.
IEEE, 2013, стр. 7398–7402.
[11] Я. Цянь, М. Би, Т. Тан и К. Ю, «Очень глубокие сверточные нейронные сети
для устойчивого к шуму распознавания речи», IEEE / ACM Trans-
, действия на аудио, речи, and Language Processing, vol. 24,
нет. 12, pp. 2263–2276, 2016.
[12] J. Du, Q. Wang, T. Gao, Y. Xu, L.-R. Дай и Ч.-Х. Ли, «Надежное распознавание речи
с помощью глубоких нейронных сетей с улучшенной речью»,
в Proc. Интерспич, 2014.
[13] Y. Qian, M. Yin, Y. You и K. Yu, «Многозадачное совместное обучение
глубоких нейронных сетей для надежного распознавания речи», в Au-
tomatic Speech Recognition and Понимание (ASRU), 2015
IEEE Workshop on. IEEE, 2015, стр. 310–316.
[14] Д. Ю, М. Л. Зельцер, Дж. Ли, Ж.-Т. Хуанг и Ф. Сейде, «Особенность
обучение в глубоких нейронных сетях — исследования по распознаванию речи
задач», препринт arXiv arXiv: 1301.3605, 2013.
[15] Л. Куврёр, К.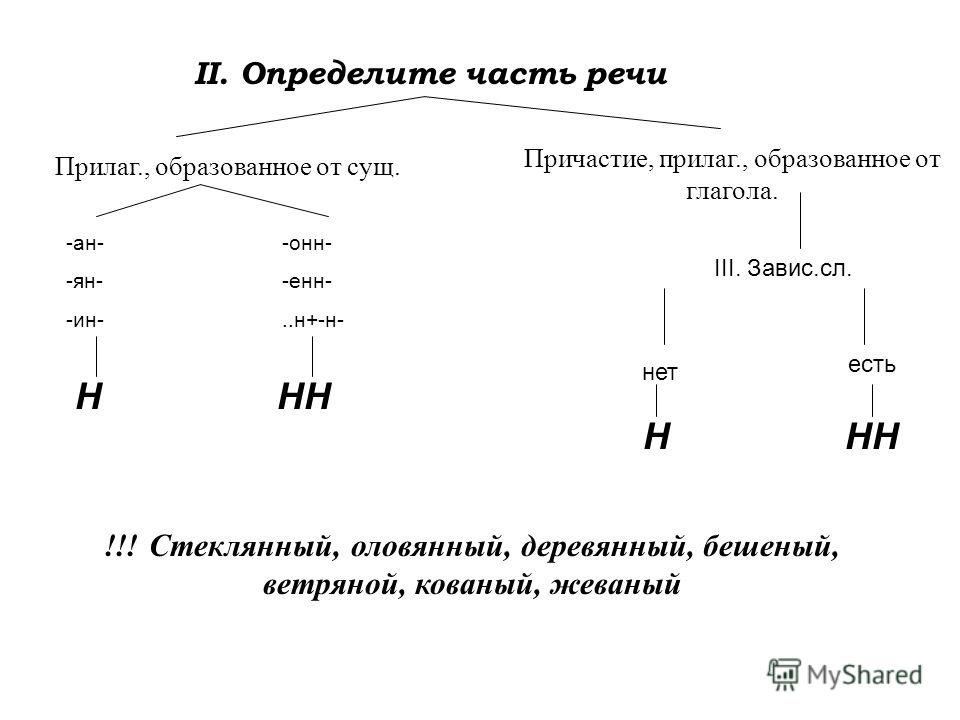 Куврёр и К. Рис, «Корпоративный подход
Куврёр и К. Рис, «Корпоративный подход
для устойчивого asr в реверберирующих средах», в Шестой международной конференции
по обработке разговорной речи, 2000.
[ 16] R. Hsiao, J. Ma, W. Hartmann, M. Kara
at, F. Gr´
ezl, L. Burget,
I. Sz¨
oke, JH ˇ
Cernock`
y, С. Ватанабе, З. Чен и др., «Надежное распознавание речи
в неизвестных реверберирующих и шумных условиях»,
на семинаре IEEE 2015 года по автоматическому распознаванию речи и пониманию
(ASRU).IEEE, 2015, стр. 533–538.
[17] С. Инь, К. Лю, З. Чжан, Ю. Линь, Д. Ван, Дж. Техедор, Т. Ф. Чжэн,
и Ю. Ли, «Шумное обучение глубоких нейронных сетей в речи
признание », EURASIP Journal on Audio, Speech and Music
Processing, vol. 2015, вып. 1, стр. 2, 2015.
[18] Я. Ван, А. Мисра и К.К. Чин, «Частотно-временное маскирование для
крупномасштабного надежного распознавания речи», в Шестнадцатой ежегодной конференции Международной ассоциации речевой коммуникации.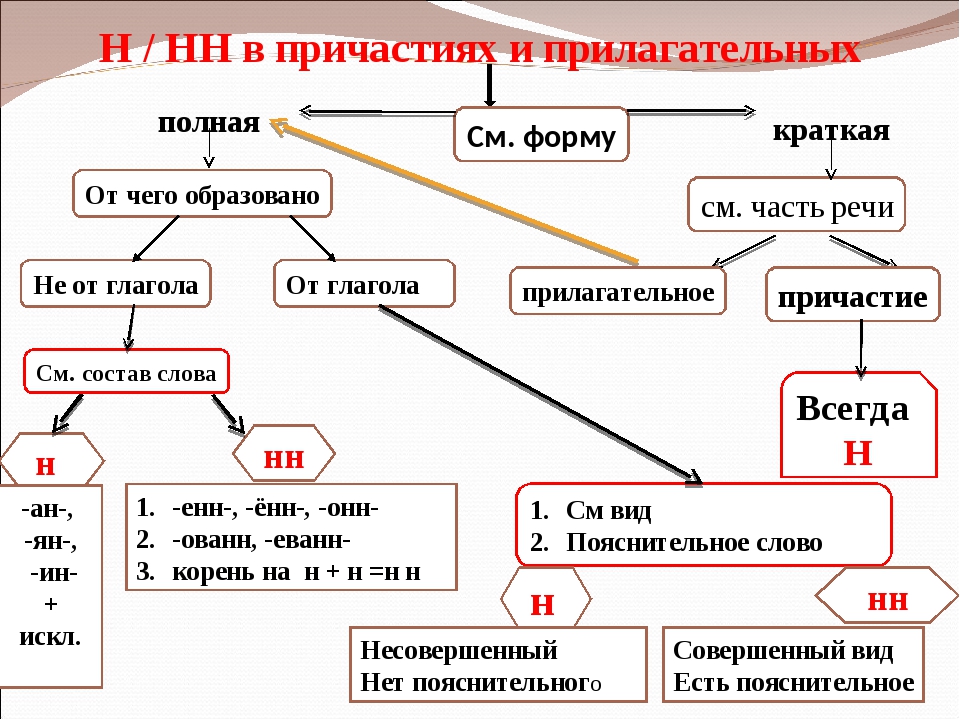 ,
,
2015.
[19] Д. Пирс и Дж. Пиконе, «Рабочая группа Aurora: интерфейс DSR
, оценка lvcsr au / 384/02», Inst. для Сигнал и Информ. Process.,
Mississippi State Univ., Tech. Rep, 2002.
[20] Г. Ху, «100 неречевых звуков окружающей среды,
2004». [Онлайн]. Доступно: http://web.cse.ohio-
state.edu/pnl/corpus/HuNonspeech/HuCorpus.html
[21] А. Варга и Х. Дж. Стинекен, «Оценка автоматической речи
распознавание: Ii.noisex-92: База данных и эксперимент по
по изучению влияния аддитивного шума на системы распознавания речи »,
Speech communication, vol. 12, вып. 3, pp. 247–251, 1993.
[22] Д. Пови, А. Гошал, Г. Булиан, Л. Бургет, О. Глембек,
Н. Гоэль, М. Ханнеманн, П. Мотличек, Ю. Цянь, П. Шварц и др.,
«Набор инструментов распознавания речи Kaldi», на семинаре IEEE 2011
по автоматическому распознаванию и пониманию речи, нет. EPFL-
CONF-192584.IEEE Signal Processing Society, 2011.
[23] А. Нараянан и Д. Ван, «Совместное обучение адаптации к шуму для автоматического распознавания речи ro-
bust», в Acoustics, Speech and Sig-
nal Processing (ICASSP) , 2014 IEEE International Conference
on. IEEE, 2014, стр. 2504–2508.
Распознавание речи: обзор различных подходов к глубокому обучению
Люди общаются предпочтительно с помощью речи, используя один и тот же язык. Распознавание речи можно определить как способность понимать произносимые слова говорящего человека.
Автоматическое распознавание речи (ASR) относится к задаче распознавания человеческой речи и преобразования ее в текст . В последние десятилетия этому направлению исследований уделялось много внимания. Это важная область исследований межмашинного взаимодействия. Ранние методы были сосредоточены на ручном извлечении признаков и традиционных методах, таких как гауссовские модели смеси (GMM), алгоритм динамического искажения времени (DTW) и скрытые марковские модели (HMM).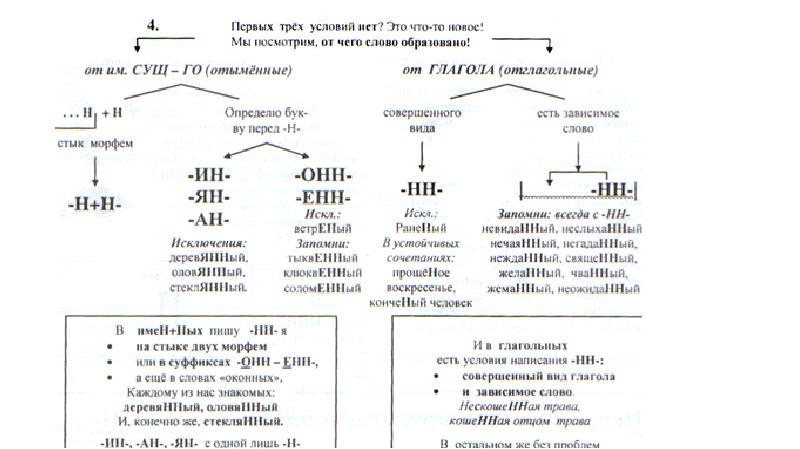
Совсем недавно нейронные сети, такие как рекуррентные нейронные сети (RNN), сверточные нейронные сети (CNN) и в последние годы Transformers, были применены к ASR и достигли высокой производительности.
Как сформулировать автоматическое распознавание речи (ASR)?
Общий поток ASR можно представить, как показано ниже:
Обзор системы ASR
Основная цель системы ASR — преобразовать входной аудиосигнал x = (x1, x2,… xT) \ mathbf {x} = (x_1, x_2, \ dots x_T) x = (x1, x2,… xT) с заданной длиной TTT в последовательность слов или символов (т. е. меток) y = (y1, y2,…, yN \ mathbf {y} = (y_1, y_2, \ точек, y_Ny = (y1, y2,…, yN), yn∈Vy_ {n} \ in \ mathbf {V} yn ∈V, где V \ mathbf {V} V — словарь.= Y∈Vargmax p (y∣x)
Типичная система ASR имеет следующие этапы обработки:
Предварительная обработка
Извлечение признаков
Классификация
Моделирование языка.

Этап предварительной обработки направлен на улучшение аудиосигнала за счет уменьшения отношения сигнал / шум, уменьшения шума и фильтрации сигнала.
Как правило, функции, которые используются для ASR, извлекаются с определенным количеством значений или коэффициентов, которые генерируются путем применения различных методов к входным данным.Этот шаг должен быть надежным в отношении различных факторов качества, таких как шум или эффект эха.
Большинство методов ASR используют следующие методы извлечения признаков:
Модель классификации направлена на поиск речевого текста, который содержится во входном сигнале. Он берет извлеченные функции из этапа предварительной обработки и генерирует выходной текст.
Языковая модель (LM) является важным модулем, поскольку она фиксирует грамматические правила или семантическую информацию языка.Языковые модели важны для распознавания выходного токена из модели классификации, а также для внесения исправлений в выходной текст.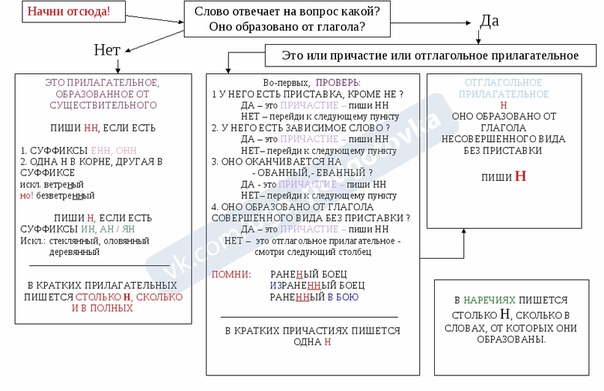
Наборы данных для ASR
Были записаны различные базы данных с текстом из аудиокниг, разговоров и разговоров.
- Английские, испанские и немецкие базы данных CallHome (Post et al. ) содержат разговорные данные с большим количеством слов, которых нет в словарном запасе. Они бросают вызов базам данных с иностранными словами и искажениями телефонных каналов.База данных English CallHome содержит 120 спонтанных телефонных разговоров на английском языке между носителями английского языка. Обучающий набор содержит 80 разговоров по 15 часов речи, в то время как тестовый и развивающий наборы содержат 20 разговоров, каждый из которых содержит 1,8 часа аудиофайлов.
Кроме того, CallHome Spanish состоит из 120 телефонных разговоров соответственно между носителями языка. Учебная часть состоит из 16 часов речи, а тестовая часть — из 20 разговоров по 2 часа речи.Наконец, CallHome German состоит из 100 телефонных разговоров между носителями немецкого языка с 15 часами речи в учебном наборе и 3,7 часами речи в тестовом наборе.
- TIMIT — это большой набор данных с широкополосными записями американского английского языка, где каждый говорящий читает 10 грамматически сложных предложений. TIMIT содержит аудиосигналы, которые были выровнены по времени, исправлены и могут использоваться для распознавания символов или слов. Аудиофайлы кодируются в 16-битном формате.Обучающий набор содержит большое количество аудио от 462 динамиков, в то время как набор для проверки включает аудио от 50 динамиков и тестовый набор аудио из 24 динамиков.
Кепстральные коэффициенты с частотой Mel — наиболее распространенный метод извлечения характеристик речи . Человеческое ухо — это нелинейная система в отношении того, как оно воспринимает звуковой сигнал. Чтобы справиться с изменением частоты, была разработана Mel-шкала для создания линейной модели слуховой системы человека.Только частоты в диапазоне [0,1] кГц могут быть преобразованы в шкалу Mel, а остальные частоты считаются логарифмическими. Частота шкалы mel рассчитывается как:
Частота шкалы mel рассчитывается как:
, где fHzf_ {Hz} fHz — частота исходного сигнала.
Метод извлечения признаков MFCC в основном включает следующие шаги:
Окно сигнала
Применить дискретное преобразование Фурье
Логарифм величины
Преобразовать в шкалу Mel
обратное дискретное косинусное преобразование (DCT)
Глубокие нейронные сети для ASR
В эпоху глубокого обучения нейронные сети продемонстрировали значительное улучшение в решении задач распознавания речи.Были применены различные методы, такие как сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), в то время как недавно сети Transformer достигли высокой производительности.
Рекуррентные нейронные сети
RNN выполняют вычисления во временной последовательности, поскольку их текущее скрытое состояние
зависит от всех предыдущих скрытых состояний. В частности, они предназначены для моделирования сигналов временных рядов, а также для фиксации долгосрочных и краткосрочных зависимостей между различными временными шагами входных данных.
В частности, они предназначены для моделирования сигналов временных рядов, а также для фиксации долгосрочных и краткосрочных зависимостей между различными временными шагами входных данных.
Что касается приложений распознавания речи, входной сигнал x = (x1, x2,… xT) \ mathbf {x} = (x_1, x_2, \ dots x_T) x = (x1, x2,… xT) передается через RNN для вычисления скрытых последовательностей h = (h2, h3,… hN) \ mathbf {h} = (h_1, h_2, \ dots h_N) h = (h2, h3,… hN) и выходных последовательностей y = (y1, y2,… yN) \ mathbf {y} = (y_1, y_2, \ dots y_N) y = (y1, y2,… yN) соответственно. Одним из основных недостатков простой формы RNN является то, что она генерирует следующий вывод только на основе предыдущего контекста.
Двунаправленный RNN
RNN вычисляют последовательность скрытых векторов h \ mathbf {h} h как:
ht = H (Wxhxt + Whhht − 1 + bh) yt = Whyht + by, \ begin {align} h_t = H ~ (W_ {xh} x_t + W_ {hh} h_ {t-1} + b_ {h}) \\ y_t = W_ {hy} h_t + b_ {y}, \ end {align} ht = H (Wxh xt + Whh ht − 1 + bh) yt = Почему ht + by, где W \ mathbf {W} W — веса, b \ mathbf {b} b — векторы смещения, а HHH — нелинейная функция.
Ограничения и решения RNN
Однако при распознавании речи обычно информация будущего контекста не менее важна, чем прошлый контекст (Graves et al. ). Вот почему вместо использования однонаправленной RNN обычно выбирают двунаправленных RNN (BiRNN) , чтобы устранить этот недостаток. BiRNN обрабатывают входные векторы в обоих направлениях, то есть вперед и назад, и сохраняют векторы скрытого состояния для каждого направления, как показано на рисунке выше.
Нейронные сети, как с прямой связью, так и рекуррентные, могут использоваться только для покадровой классификации входящего звука.
Эту проблему можно решить, используя:
Скрытые Марковские модели (HMM) для согласования между входным звуком и его транскрибируемым выходом.
Потеря по временной классификации коннекционистов (CTC), которая является наиболее распространенной техникой.
CTC — это целевая функция, которая вычисляет выравнивание между входным речевым сигналом и выходной последовательностью слов . {T} P (\ alpha_t | \ mathbf {x}) P (α∣x) = Πt = 1T P (αt ∣x)
{T} P (\ alpha_t | \ mathbf {x}) P (α∣x) = Πt = 1T P (αt ∣x)
, где αt \ alpha_tαt — одно выравнивание на временном шаге ttt.
Для данной транскрипционной последовательности существует несколько возможных выравниваний, поскольку метки можно отделить от пробелов по-разному. Например, выравнивания (a, -, b, c, -, -) (a, -, b, c, -, -) (a, -, b, c, -, -) и (-, — (- , — (-, -, a, −a, -a, -, b, c) b, c) b, c), (−-− — пустой символ) оба соответствуют последовательности символов (a, b, в) (а, б, в) (а, б, в).
Наконец, общая вероятность всех путей рассчитывается как:
P (y∣x) = ∑P (α∣x) P (\ mathbf {y} | \ mathbf {x}) = \ sum P (\ boldsymbol {\ alpha} | \ mathbf {x}) P (y∣x) = ∑P (α∣x) CTC стремится максимизировать общую вероятность правильных выравниваний, чтобы получить правильную последовательность выходных слов .Одним из основных преимуществ CTC является то, что он не требует предварительной сегментации или согласования данных. DNN можно использовать непосредственно для моделирования функций и достижения высокой производительности в задачах распознавания речи.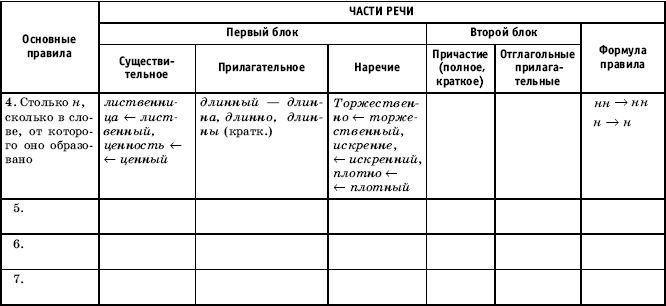 = argmaxP (y∣x)
= argmaxP (y∣x)
Поиск луча также был принят для декодирования CTC.Наиболее вероятный перевод ищется с использованием временных шагов слева направо, и сохраняется небольшое количество BBB частичных гипотез. Каждая гипотеза на самом деле является префиксом выходной последовательности, в то время как на каждом временном шаге она расширяется в луче с каждым возможным словом в словаре.
RNN-Transducer
В других работах (например, Rao et al. ) для ASR также использовалась архитектура, широко известная как RNN-Transducer. Этот метод объединяет RNN с CTC и отдельную RNN, которая предсказывает следующий результат с учетом предыдущего .Он определяет отдельное распределение вероятностей P (yk∣t, u) P (y_k | t, u) P (yk ∣t, u) для каждого временного шага ttt ввода и временного шага uuu вывода для kkk- -й элемент вывода y \ mathbf {y} y.
Сеть кодировщика преобразует акустический элемент xtx_txt на временном шаге ttt в представление het = fenc (xt) he_t = f_ {enc} (x_t) het = fenc (xt). Кроме того, сеть прогнозирования принимает предыдущую метку yu − 1y_ {u-1} yu − 1 и генерирует новое представление hpt = fp (yu − 1) hp_t = f_ {p} (y_ {u-1}) hpt = fp (yu − 1).Совместная сеть — это полносвязный слой, который объединяет два представления и генерирует апостериорную вероятность P (y∣t, u) = fjoint (het: hpt) P (\ mathbf {y} | t, u) = f_ {Joint } (he_t: hp_t) P (y∣t, u) = fjoint (het: hpt). Таким образом, RNN-Transducer может генерировать следующие символы или слова, используя информацию как от кодировщика, так и от сети прогнозирования
Кроме того, сеть прогнозирования принимает предыдущую метку yu − 1y_ {u-1} yu − 1 и генерирует новое представление hpt = fp (yu − 1) hp_t = f_ {p} (y_ {u-1}) hpt = fp (yu − 1).Совместная сеть — это полносвязный слой, который объединяет два представления и генерирует апостериорную вероятность P (y∣t, u) = fjoint (het: hpt) P (\ mathbf {y} | t, u) = f_ {Joint } (he_t: hp_t) P (y∣t, u) = fjoint (het: hpt). Таким образом, RNN-Transducer может генерировать следующие символы или слова, используя информацию как от кодировщика, так и от сети прогнозирования
, в зависимости от того, является ли прогнозируемая метка пустой или непустой меткой. Процедура вывода останавливается, когда на последнем временном шаге генерируется пустая метка.
RNN Обзор преобразователя
Graves et al. протестировал обычные RNN с CTC и RNN-преобразователями в базе данных TIMIT , используя разное количество слоев и скрытых состояний.
Извлечение признаков выполняется с помощью метода банка фильтров преобразования Фурье, состоящего из 40 коэффициентов, которые распределяются по логарифмической мел-шкале, сцепленной с первой и второй производными по времени.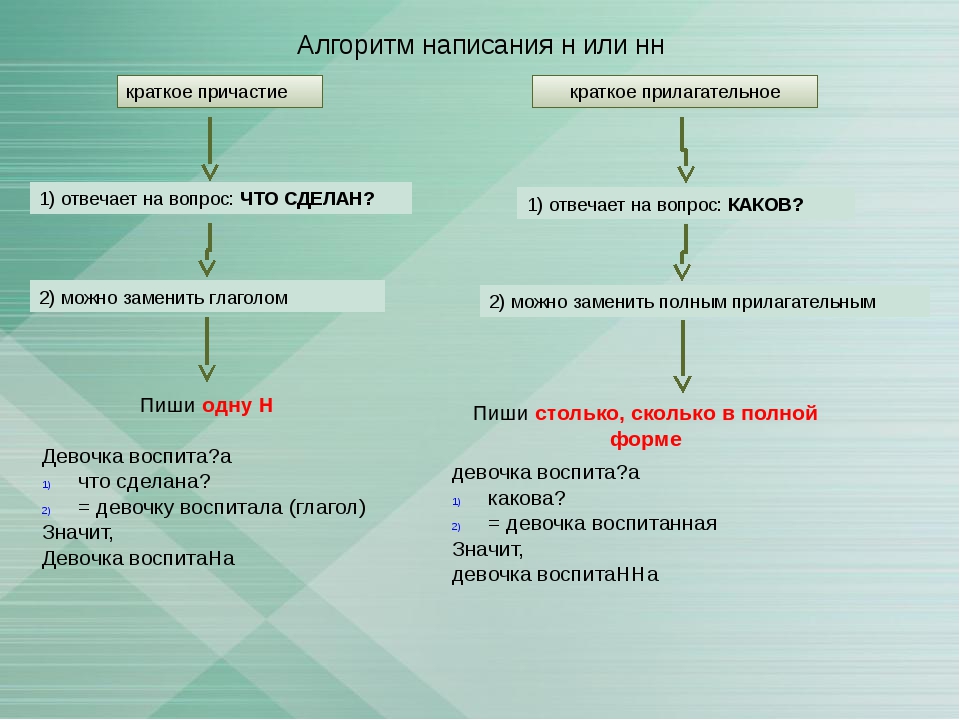
В приведенной ниже таблице показано, что RNN-T с 3 уровнями по 250 скрытых состояний каждый имеет наилучшую производительность из 17.7% 17,7 \% 17,7% коэффициент фонемных ошибок (PER), в то время как простые модели RNN-CTC работают хуже с PER> 18,4%> 18,4 \%> 18,4%.
Производительность RNN на TIMIT
Сквозной ASR с датчиком RNN-T (RNN-T)
Rao et al. предложил кодер-декодер RNN. Предлагаемый метод использует сеть кодировщика, состоящую из нескольких блоков слоев LSTM, которые предварительно обучены с помощью CTC с использованием фонем, графем и слов в качестве выходных данных. Кроме того, 1D-CNN уменьшает длину TTT временной последовательности в 3 раза, используя определенные шаги и размеры ядра.
Сеть декодера представляет собой модель RNN-T, обученную вместе с языковой моделью LSTM, которая также предсказывает слова. Целью сети является следующая метка в последовательности, которая используется при кросс-энтропийных потерях для оптимизации сети. Что касается выделения признаков, 80-мерные особенности мел-шкалы вычисляются каждые 10 мс и складываются каждые 30 мсек в один 240-мерный вектор акустических признаков.
Что касается выделения признаков, 80-мерные особенности мел-шкалы вычисляются каждые 10 мс и складываются каждые 30 мсек в один 240-мерный вектор акустических признаков.
Метод RNN-T
Метод обучен на наборе из 22 миллионов записанных вручную аудиозаписей, извлеченных
из голосового трафика Google US English, что соответствует 18 000 часам обучающих данных.К ним относятся голосовой поиск, а также голосовая диктовка. Языковая модель была предварительно обучена на текстовых предложениях, полученных из набора данных. Метод апробирован на разных конфигурациях. Он достигает 5,2% 5,2 \% 5,2% WER для этого большого набора данных, когда кодер содержит 12 уровней по 700 скрытых единиц, а декодер — 2 уровня по 1000 скрытых единиц в каждом.
Результаты метода RNN-T
Сквозное потоковое распознавание речи для мобильных устройств
RNN-преобразователи также были адаптированы для распознавания речи в реальном времени (He et al. ). В этой работе модель состоит из 8 уровней однонаправленных ячеек LSTM, а в кодировщике используется слой сокращения времени для ускорения обучения и вывода. Методы кэширования памяти также используются, чтобы избежать избыточных вычислений для идентичных историй прогнозов. Это экономит около 50–60% 50–60 \% 50–60% расчетов сети прогнозирования. Кроме того, для кодировщика и сети прогнозирования используются разные потоки, что позволяет объединить конвейеры и сэкономить значительное количество времени.
). В этой работе модель состоит из 8 уровней однонаправленных ячеек LSTM, а в кодировщике используется слой сокращения времени для ускорения обучения и вывода. Методы кэширования памяти также используются, чтобы избежать избыточных вычислений для идентичных историй прогнозов. Это экономит около 50–60% 50–60 \% 50–60% расчетов сети прогнозирования. Кроме того, для кодировщика и сети прогнозирования используются разные потоки, что позволяет объединить конвейеры и сэкономить значительное количество времени.
Процедура вывода кодера разделена на два потока, соответствующих компонентам до и после уровня сокращения времени, который уравновешивает вычисления между двумя компонентами кодировщика
и сетью прогнозирования и имеет ускорение 28% 28 \% 28% по сравнению с однопоточным исполнением. Кроме того, параметры квантуются от 32-битной точности с плавающей запятой до 8-битной, чтобы уменьшить потребление памяти как на диске, так и во время выполнения, а также оптимизировать выполнение модели в реальном времени.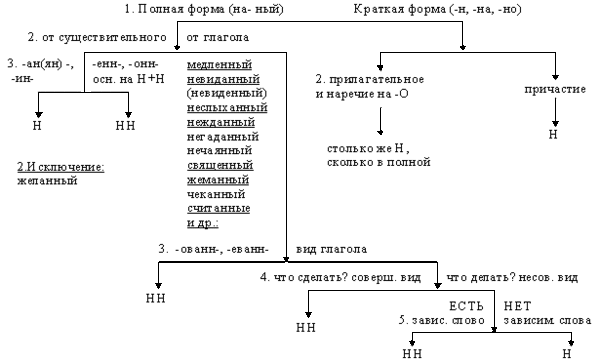
Алгоритм был обучен на наборе данных, который состоит из 35 миллионов английских высказываний продолжительностью 27 500 часов. Обучающие высказывания записаны от руки и получены с помощью голосового поиска и трафика диктовок Google. Он был создан путем искусственного искажения чистых высказываний с помощью симулятора комнаты. Полученные результаты оцениваются на 14800 образцах голосового поиска (VS), извлеченных из помощника по трафику Google, а также на 15700 образцах голосовых команд, обозначенных как набор тестов IME.На этапе извлечения признаков создаются 80-мерные объекты мел-шкалы, вычисляемые каждые 25 мсек. Результаты представлены в виде скорости вывода, деленной на продолжительность звука (RT90) и WER. Модель RNN-T с симметричным квантованием достигает значений WER 7,3% 7,3 \% 7,3% для набора голосового поиска и 4,2% 4,2 \% 4,2% для набора IME.
Результаты квантования
Быстрые и точные акустические модели рекуррентных нейронных сетей для ASR
Sak et al. использует сети длинно-короткой памяти (LSTM) для распознавания речи с большим словарным запасом.Их метод извлекает крупногабаритные объекты с помощью банков мел-фильтров с использованием техники скользящего окна. Кроме того, они включают контекстно-зависимые состояния и дополнительно улучшают производительность модели. Метод оценивается на записанных вручную аудиозаписях из реального трафика голосового поиска Google. В обучающей выборке 3 миллиона высказываний средней продолжительностью 4 секунды. Результаты представлены в таблицах ниже:
использует сети длинно-короткой памяти (LSTM) для распознавания речи с большим словарным запасом.Их метод извлекает крупногабаритные объекты с помощью банков мел-фильтров с использованием техники скользящего окна. Кроме того, они включают контекстно-зависимые состояния и дополнительно улучшают производительность модели. Метод оценивается на записанных вручную аудиозаписях из реального трафика голосового поиска Google. В обучающей выборке 3 миллиона высказываний средней продолжительностью 4 секунды. Результаты представлены в таблицах ниже:
Контекстно-зависимые и независимые результаты
Результаты с другим размером словаря
Модели, основанные на внимании
В других работах принята структура кодировщика-декодера внимания RNN, которая напрямую вычисляет условную вероятность выходной последовательности с учетом входной последовательности, не предполагая фиксированного выравнивания. Метод кодировщика-декодера использует механизм внимания, который не требует предварительного выравнивания данных. Модель, основанная на внимании, использует один декодер для создания распределения по меткам, обусловленного полной последовательностью предыдущих прогнозов и входным звуком. С вниманием, он может неявно изучить мягкое выравнивание между входными и выходными последовательностями , что решает большую проблему для распознавания речи.
Метод кодировщика-декодера использует механизм внимания, который не требует предварительного выравнивания данных. Модель, основанная на внимании, использует один декодер для создания распределения по меткам, обусловленного полной последовательностью предыдущих прогнозов и входным звуком. С вниманием, он может неявно изучить мягкое выравнивание между входными и выходными последовательностями , что решает большую проблему для распознавания речи.
Модель по-прежнему может хорошо влиять на длинные входные последовательности, поэтому такие модели также могут обрабатывать речевой ввод различной длины.{I} P (y_i | y_1, \ dots, y_ {i-1} | \ mathbf {c} _i) P (y∣x) = Πi = 1I P (yi ∣y1,…, yi − 1 ∣ci)
обусловлено предыдущими выходными данными III и контекстом cic_ici.
Апостериорная вероятность символа yiy_iyi вычисляется как:
P (yi∣y1,…, yi − 1∣ci) = g (yi − 1, si, ci) si = f (yi − 1, si − 1 , ci), \ begin {align} P (y_i | y_1, \ точки, y_ {i-1} | c_i) = g (y_ {i-1}, s_i, c_i) \\ s_i = f (y_ {i-1}, s_ {i-1}, c_i), \ end {align} P (yi ∣y1,…, yi − 1 ∣ci) = g (yi − 1, si, ci) si = f (yi − 1, si − 1 , Ci),, где sis_isi — это выход рекуррентного слоя fff, а ggg — функция softmax. {T} a_ {i, t} = 1∑t = 1T ai, t = 1.
{T} a_ {i, t} = 1∑t = 1T ai, t = 1.
Механизм внимания выбирает временные местоположения во входной последовательности, которые должны использоваться для обновления скрытого состояния RNN и прогнозирования следующего выходного значения. Он утверждает веса внимания ai, ta_ {i, t} ai, t для вычисления оценок релевантности между входом и выходом.
Генератор рекуррентных последовательностей на основе внимания
Chorowski et al. использует основанный на внимании генератор рекуррентных последовательностей (ARSG), который генерирует последовательность выходных слов из речевых функций h = (h2, h3, hT) \ mathbf {h} = (h_1, h_2, h_T) h = (h2, h3, hT), которые можно смоделировать с помощью кодировщика любого типа.{L} a_ {i, j} h_j \\ y_i = \ mathrm {generate} (s_ {i-1}, g_i), \ end {align} ai = присутствовать (si − 1, ai − 1, h) gi = j = 1∑L ai, j hj yi = generate (si − 1, gi) ,
, где sis_isi — i-е состояние RNN, aia_iai — веса внимания.
Новое состояние генерируется как:
si = повторение (si − 1, gi, yi) s_i = повторение (s_ {i-1}, g_i, y_i) si = повторение (si − 1, gi, yi)Более подробно, механизм подсчета очков работает следующим образом:
ei, j = score (si − 1, hi) ai, j = exp (ei, j∑j = 1Lexp (ei, je_ {i, j} = оценка ~ (s_ {i-1}, h_i) \\ a_ {i, j} = \ frac {exp ~ (e_ {i, j}} {\ sum_ {j = 1} ^ {L} exp ~ (e_ {i, j}} ei, j = score (si −1, hi) ai, j = ∑j = 1L exp (ei, j exp (ei, j ARSG оценивается в наборе данных TIMIT и достигает WER 15. {j-1}) \ end {align} h = listen (x) hij = BSLTM (hi − 1j, hij − 1)
{j-1}) \ end {align} h = listen (x) hij = BSLTM (hi − 1j, hij − 1)
Декодер (т.е.e., Attend-Spell) — это основанный на внимании модуль, который посещает представление h \ mathbf {h} h и выдает выходную вероятность P (y∣x) P (\ mathbf {y} | \ mathbf {x}) P (y∣x). Более подробно, преобразователь LSTM, основанный на внимании, создает следующий символ на основе предыдущих выходных данных как:
ci = AttentionContext (si, h) si = LSTM (si − 1, yi − 1, ci − 1) P (yi∣ x) = FC (si, ci), \ begin {align} c_i = Контекст внимания ~ (s_i, \ mathbf {h}) \\ s_i = LSTM ~ (s_ {i-1}, y_ {i-1}, c_ {i-1}) \\ P (y_i | \ mathbf {x}) = FC ~ (s_i, c_i), \ end {align} ci = Контекст внимания (si, h) si = LSTM (si − 1, yi − 1, ci − 1) P (yi ∣x) = FC (si, ci ),, где sis_isi, cic_ici — состояние декодера и вектор контекста соответственно.
LAS была оценена на 3 миллионах высказываний голосового поиска Google с 2000 часами речи, из которых 10 часов высказываний были случайным образом выбраны для проверки. Дополнение данных также было выполнено в наборе обучающих данных с использованием шума симулятора помещения, а также путем добавления других типов шума и реверберации. Он смог достичь высоких показателей распознавания с WER 10,3% 10,3 \% 10,3% и 12,0% 12,0 \% 12,0% в чистой и шумной среде соответственно.
Дополнение данных также было выполнено в наборе обучающих данных с использованием шума симулятора помещения, а также путем добавления других типов шума и реверберации. Он смог достичь высоких показателей распознавания с WER 10,3% 10,3 \% 10,3% и 12,0% 12,0 \% 12,0% в чистой и шумной среде соответственно.
Обзор метода LAS
Сквозное распознавание речи с языковыми моделями RNN на основе слов и вниманием
Hori et al., принять совместный декодер с использованием CTC, декодера внимания и языковой модели RNN. Сеть кодировщика CNN принимает входной аудиосигнал x \ mathbf {x} x и выводит скрытую последовательность h \ mathbf {h} h, которая совместно используется модулями декодера. Сеть декодера итеративно предсказывает 0 последовательность меток c \ mathbf {c} c на основе скрытой последовательности. Совместный декодер использует CTC, внимание и языковую модель для обеспечения лучшего согласования между входом и выходом и поиска лучшей выходной последовательности. = argmax [pCTC (c∣x) + (1 − λ) log pAtt (c∣x) + γ logpLM (c)]
= argmax [pCTC (c∣x) + (1 − λ) log pAtt (c∣x) + γ logpLM (c)]
, где также используется вероятность языковой модели. Совместный декодер
Метод оценивается на наборах данных Wall Street Journal (WSJ) и LibriSpeech.
WSJ — хорошо известная база данных чистой речи на английском языке, включающая около 80 часов.
LibriSpeech — это большой набор данных для чтения речи из аудиокниг, содержащий 1000 часов аудио и транскрипций . Экспериментальные результаты предложенного метода на WSJ и Librispeech показаны в следующей таблице соответственно.
Оценка набора данных LibriSpeech
Оценка набора данных WSJ
Сверточные модели
Сверточные нейронные сети изначально были реализованы для задач компьютерного зрения (CV). В последние годы CNN также широко применяются в области обработки естественного языка (NLP) благодаря их хорошей генерации и способности различать.
Очень типичная архитектура CNN состоит из нескольких сверточных и объединяющих слоев с полностью связанными уровнями для классификации.Сверточный слой состоит из ядер, которые свертываются с вводом. Сверточное ядро делит входной сигнал на более мелкие
частей, а именно на рецептивное поле ядра. Кроме того, операция свертки выполняется путем умножения ядра на соответствующие части ввода, которые находятся в принимающем поле. Сверточные методы можно разделить на одномерные и двумерные сети соответственно.
2D-CNN строят двухмерные карты характеристик на основе акустического сигнала .Подобно изображениям, они организуют акустические особенности, то есть особенности MFCC, на 2-мерной карте признаков, где одна ось представляет частотную область, а другая — временную область. Напротив, 1D-CNN принимают акустические характеристики непосредственно в качестве входных данных .
В 1D-CNN для распознавания речи каждая входная карта функций X = (X1,…, XI) X = (X_1, \ dots, X_I) X = (X1,…, XI) связана со многими картами функций O = (O1,…, OJ) O = (O_1, \ dots, O_J) O = (O1,…, OJ). {I} X_i w_ {i, j }), ~ j \ in [1, J] Oj = σ (i = 1∑I Xi wi, j), j∈ [1, J]
{I} X_i w_ {i, j }), ~ j \ in [1, J] Oj = σ (i = 1∑I Xi wi, j), j∈ [1, J]
, где w \ mathbf {w} w — локальный масса.
В 1D-CNN: w \ mathbf {w} w, O \ mathbf {O} O — векторы
В 2D-CNN они являются матрицами.
Abdel et al. были первыми, кто применил CNN для распознавания речи. Их метод использует два типа сверточных слоев. Первый использует с полным распределением веса (FWS), где веса распределяются между всеми. Этот метод широко используется в CNN для распознавания изображений, поскольку одни и те же характеристики могут появляться в любом месте изображения.Однако при распознавании речи сигнал различается на разных частотах и имеет различные характерные черты в разных фильтрах. Для решения этой проблемы используется с ограниченным разделением веса (LWS), где только фильтры свертки, присоединенные к одним и тем же фильтрам объединения, имеют одинаковые веса.
Иллюстрация карты функций 2D-CNN для распознавания речи
Речевой ввод анализировался с помощью окна Хэмминга 25 мс с фиксированной частотой кадров 10 мс.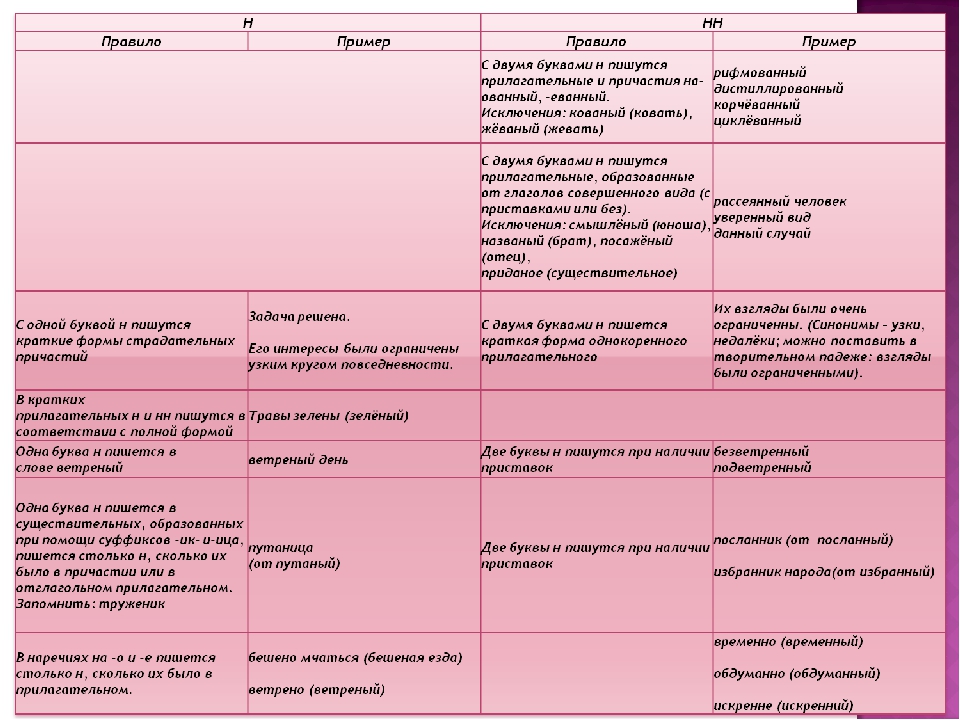 Более конкретно, векторы признаков генерируются посредством анализа банка фильтров на основе преобразования Фурье, который включает в себя 40 логарифмических энергетических коэффициентов, распределенных в мел-шкале, наряду с
Более конкретно, векторы признаков генерируются посредством анализа банка фильтров на основе преобразования Фурье, который включает в себя 40 логарифмических энергетических коэффициентов, распределенных в мел-шкале, наряду с
их первой и второй производными по времени. Все речевые данные были нормализованы так, чтобы каждое измерение вектора имело нулевое среднее и единичную дисперсию.
Строительный блок их архитектуры CNN включает свертки и уровни объединения. Входные объекты организованы в виде нескольких карт объектов. Размер (разрешение) карт функций становится меньше на верхних уровнях по мере того, как применяется больше операций свертки и объединения, как показано на рисунке ниже.Обычно один или несколько полностью связанных скрытых слоев добавляются
поверх последнего слоя CNN, чтобы объединить функции во всех частотных диапазонах перед подачей на выходной слой. Они провели всестороннее исследование с различными конфигурациями CNN и достигли отличных результатов на TIMIT, которые показаны в таблице ниже. Их лучшая модель использует только слои LWS и достигает WER 20,23% 20,23 \% 20,23%.
Их лучшая модель использует только слои LWS и достигает WER 20,23% 20,23 \% 20,23%.
Иллюстрация метода CNN
Результаты метода CNN
Остаточный CNN
Wang et al. принял остаточную 2D-CNN (RCNN) с потерей CTC для распознавания речи. Остаточный блок использует прямые связи между предыдущим и следующим слоем следующим образом:
xi + 1 = f (xi, W) + xi \ mathbf {x} _ {i + 1} = f ~ (\ mathbf {x} _ {i}, \ mathbf {W}) + \ mathbf {x} _ {i} xi + 1 = f (xi, W) + xi, где fff — нелинейная функция. Это помогает сети быстрее сходиться без использования дополнительных параметров. Предлагаемая архитектура изображена на рисунке ниже. Метод остаточного CNN-CTC использует 4 группы остаточных блоков с небольшими фильтрами 3 × 33 \ умножить на 33 × 3.Каждая остаточная группа имеет количество сверточных блоков NNN с 2 уровнями. У каждой остаточной группы также есть разные шаги по снижению вычислительных затрат и моделированию временных зависимостей в разных контекстах. Пакетная нормализация и активация ReLU применяются к каждому слою.
Пакетная нормализация и активация ReLU применяются к каждому слою.
Иллюстрация остаточной архитектуры CNN
RCNN оценивается на WSJ со стандартной конфигурацией (si284 установлен
для обучения, eval92 установлен для проверки, а dev93 установлен для тестирования).Кроме того, он оценивается на наборе данных Tencent Chat, который содержит около 1400 часов речевых данных для обучения и 2000 независимых предложений для тестирования. Результаты экспериментов демонстрируют эффективность остаточных сверточных нейронных сетей. RCNN может достичь WER 4,29% / 7,65% 4,29 \% / 7,65 \% 4,29% / 7,65% на наборах данных проверки и тестирования WSJ и 13,33% 13,33 \% 13,33% на наборе данных Tencent Chat.
Джаспер
Ли и др. реализовал остаточную 1D-CNN с плотными и остаточными блоками, как показано ниже.Сеть извлекает функции mel-filter-bank и использует остаточные блоки, которые содержат пакетную нормализацию и слои исключения для более быстрой сходимости и лучшего обобщения. Вход состоит из характеристик банка фильтров мел, полученных с использованием окон 20 мс с перекрытием 10 мс. Сеть была протестирована с использованием различных типов функций нормализации и активации, при этом каждый блок оптимизирован для работы с одним ядром графического процессора для более быстрого вывода. Jasper оценивается в LibriSpeech с различными настройками конфигурации.Лучшая модель имеет 10 блоков по 4 уровня и BatchNorm + ReLU и достигает значений WER валидации 6,15% 6,15 \ 6,15% и 17,38% 17,38 \% 17,38% на чистых и шумных наборах соответственно.
Вход состоит из характеристик банка фильтров мел, полученных с использованием окон 20 мс с перекрытием 10 мс. Сеть была протестирована с использованием различных типов функций нормализации и активации, при этом каждый блок оптимизирован для работы с одним ядром графического процессора для более быстрого вывода. Jasper оценивается в LibriSpeech с различными настройками конфигурации.Лучшая модель имеет 10 блоков по 4 уровня и BatchNorm + ReLU и достигает значений WER валидации 6,15% 6,15 \ 6,15% и 17,38% 17,38 \% 17,38% на чистых и шумных наборах соответственно.
Иллюстрация Джаспера
Полностью сверточная сеть
Zeghidour et al. реализует полностью сверточную сеть (FCN) с 3 основными модулями. Сверточный интерфейс — это CNN с фильтрами нижних частот, сверточными фильтрами, подобными банкам фильтров, и алгоритмической функцией для извлечения признаков.Второй модуль представляет собой сверточную акустическую модель с несколькими сверточными слоями, функцией активации GELU, выпадением и регуляризацией веса и предсказывает буквы на входе. Наконец, есть сверточная языковая модель с 14 сверточными остаточными блоками и слоями узких мест.
Наконец, есть сверточная языковая модель с 14 сверточными остаточными блоками и слоями узких мест.
Этот модуль используется для оценки возможных транскрипций акустической модели с использованием декодера поиска луча. FCN оценивается на наборах данных WSJ и LibriSpeech. Их лучшая конфигурация использует обучаемый сверточный интерфейс с 80 фильтрами и сверточную языковую модель.FCN достигает WER 6,8% 6,8 \% 6,8% на наборе проверки и 3,5% 3,5 \% 3,5% на наборе тестов WSJ, в то время как в LibriSpeech он достигает значений WER проверки 3,08% / 9,94% 3,08 \% / 9,94 \%. 3,08% / 9,94% на чистых и шумных сетах и WER тестирования 3,26% / 10,47% 3,26 \% / 10,47 \% 3,26% / 10,47% на чистых и шумных сетах соответственно.
Иллюстрация полностью сверточной архитектуры
Свертки с разделением по времени и глубине (TDS)
В отличие от других работ, Hannum et al. используют сверточные сети с временным разделением и ограниченным числом параметров, а также потому, что CNN с временным разделением лучше обобщают и более эффективны. Кодер использует двумерные свертки по глубине наряду с нормализацией слоев. Кодер выводит два вектора, ключи k = k1, k2,… kT \ mathbf {k} = k_1, k_2, \ dots k_Tk = k1, k2,… kT и значения v = v1, v2,… vT \ mathbf {v} = v_1, v_2, \ dots v_Tv = v1, v2,… vT из входной последовательности x \ mathbf {x} x как:
Кодер использует двумерные свертки по глубине наряду с нормализацией слоев. Кодер выводит два вектора, ключи k = k1, k2,… kT \ mathbf {k} = k_1, k_2, \ dots k_Tk = k1, k2,… kT и значения v = v1, v2,… vT \ mathbf {v} = v_1, v_2, \ dots v_Tv = v1, v2,… vT из входной последовательности x \ mathbf {x} x как:
Что касается декодера, используется простой RNN, который выводит следующий токен yuy_uyu как :
Qu = RNN (yu − 1, Qu − 1) Su = посетить (Qu, k, v) yu = softmax ([Su, Qu]), \ begin {выровнено} \ mathbf {Q} _u = RNN ~ (y_ {u-1}, \ mathbf {Q} _ {u-1}) \\ \ mathbf {S} _u = посетить (\ mathbf {Q} _u, \ mathbf {k}, \ mathbf {v}) \\ y_u = softmax ([\ mathbf {S} _u, \ mathbf {Q} _u]), \ end {align} Qu = RNN (yu − 1, Qu − 1) Su = serve (Qu, k, v) yu = softmax ([Su, Qu]),где Su \ mathbf {S} _uSu — это итоговый вектор, а Qu \ mathbf {Q} _uQu — это вектор запроса.
TDS оценивается в LibriSpeech с различными принимающими полями и размерами ядра, чтобы найти наилучшие настройки для сверточных слоев с временным разделением.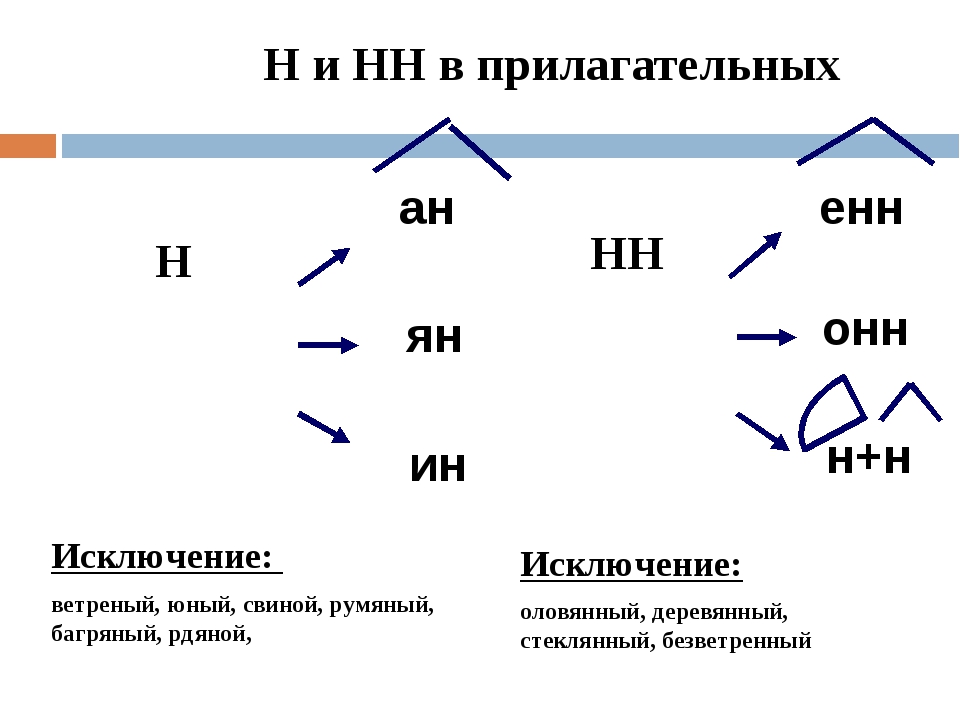 Лучший вариант — 11 блоков с разделением по времени, которые достигают WER 5,04% 5,04 \% 5,04% и 14,46% 14,46 \% 14,46% для dev clean и других наборов соответственно.
Лучший вариант — 11 блоков с разделением по времени, которые достигают WER 5,04% 5,04 \% 5,04% и 14,46% 14,46 \% 14,46% для dev clean и других наборов соответственно.
Двумерный сверточный метод ASR по глубине
ContextNet
ContextNet — это полностью сверточная сеть, которая передает глобальную контекстную информацию в слои с помощью модулей сжатия и возбуждения.CNN имеет слои KKK и генерирует функции как:
h = CK (CK − 1 (… (C1 (x)))), \ mathbf {h} = C_K ~ (C_ {K-1} ~ (\ dots ( ~ C_1 (\ mathbf {x})))), h = CK (CK − 1 (… (C1 (x)))),, где CCC — сверточный блок, за которым следуют функции пакетной нормализации и активации. Кроме того, блок сжатия и возбуждения генерирует глобальный поканальный вес θ \ thetaθ с глобальным средним уровнем объединения, который умножается на вход x \ mathbf {x} x как:
xˉ = 1T∑t = 0Txtθ = fc (xˉ) SE (x) = θ ∗ x \ begin {align} \ mathbf {\ bar {x}} = \ frac {1} {T} \ sum_ {t = 0} ^ {T} x_t \\ \ theta = \ mathrm {fc} ~ (\ mathbf {\ bar {x}}) \\ SE (\ mathbf {x}) = \ theta * \ mathbf {x} \ end {align} xˉ = T1 t = 0∑T xt θ = fc (xˉ) SE (x) = θ ∗ x ContextNet проверяется на LibriSpeech с 3 различными конфигурациями ContextNet, с языком или без него модель. Три конфигурации: ContextNet (малая), ContextNet (средняя) и ContextNet (большая), которые содержат разное количество слоев и фильтров.
Три конфигурации: ContextNet (малая), ContextNet (средняя) и ContextNet (большая), которые содержат разное количество слоев и фильтров.
Результаты в LibriSpeech с 3 различными конфигурациями ContextNet, с языковой моделью или без нее
Transformers
Недавно, с появлением Transformer network , машинный перевод и распознавание речи претерпели значительные улучшения. Модели преобразователей, предназначенные для распознавания речи, обычно основаны на архитектуре кодировщика-декодера, аналогичной моделям seq2seq.T} {\ sqrt {d_k}}) \ mathbf {V}, Attention (Q, K, V) = softmax (dk QKT) V,
, где 1dk \ frac {1} {\ sqrt {d_k}} dk 1 — коэффициент масштабирования. Тем не менее, Transformer использует функцию «Многоголовое внимание», которая вычисляет время самовнимания hhh, по одному для каждой головы iii. Таким образом, каждый модуль внимания фокусируется на разных частях и изучает разные представления. Более того, внимание нескольких голов рассчитывается как:
MHA (Q, K, V) = concat (h2, h3,… hh) W0hi = Attention (QWiQ, KWiK, VWiV), \ begin {align} \ mathrm {MHA} (\ mathbf {Q}, \ mathbf {K}, \ mathbf {V}) = \ mathrm {concat} (h_1, h_2, \ dots h_h) \ mathbf {W} ^ 0 \\ h_i = \ mathrm {Внимание} (\ mathbf {Q} \ mathbf {W} _i ^ Q, \ mathbf {K} \ mathbf {W} _i ^ K, \ mathbf {V} \ mathbf {W} _i ^ V) , \ end {align} MHA (Q, K, V) = concat (h2, h3,… hh) W0hi = Attention (QWiQ, KWiK, VWiV), где WiQ∈Rdmodel × dq \ mathbf {W} _i ^ Q \ in \ mathrm {R} ^ {d_ {модель} \ times d_q} WiQ ∈Rdmodel × dq, WiK∈Rdmodel × dk \ mathbf {W} _i ^ K \ in \ mathrm {R} ^ {d_ {модель} \ times d_k} WiK ∈Rdmodel × dk, WiV∈Rdmodel × dv \ mathbf {W} _i ^ V \ in \ mathrm {R} ^ {d_ {model} \ times d_v} WiV ∈Rdmodel × dv, WO∈Rhdv × dmodel \ mathbf {W} ^ O \ in \ mathrm {R} ^ {hd_v \ times d_ {model}} WO∈Rhdv × dmodel и dmodeld_ { model} dmodel размерности Преобразователя. {2i / d_ {модель}})} {d_ {модель} / 2 \ geq i
{2i / d_ {модель}})} {d_ {модель} / 2 \ geq i
Преобразователь речи
Преобразователь речи преобразует последовательность характеристик речи в соответствующую последовательность символов .Последовательность признаков, которая длиннее, чем последовательность выходных символов, строится из двумерных спектрограмм с временными и частотными измерениями. Более конкретно, CNN используются для использования структурной локальности спектрограмм и смягчения несоответствия длины за счет шага во времени.
Изображение преобразователя речи
Иллюстрация двухмерного внимания
В преобразователе речи используется двухмерное внимание , чтобы присутствовать как в частотном, так и во временном измерении .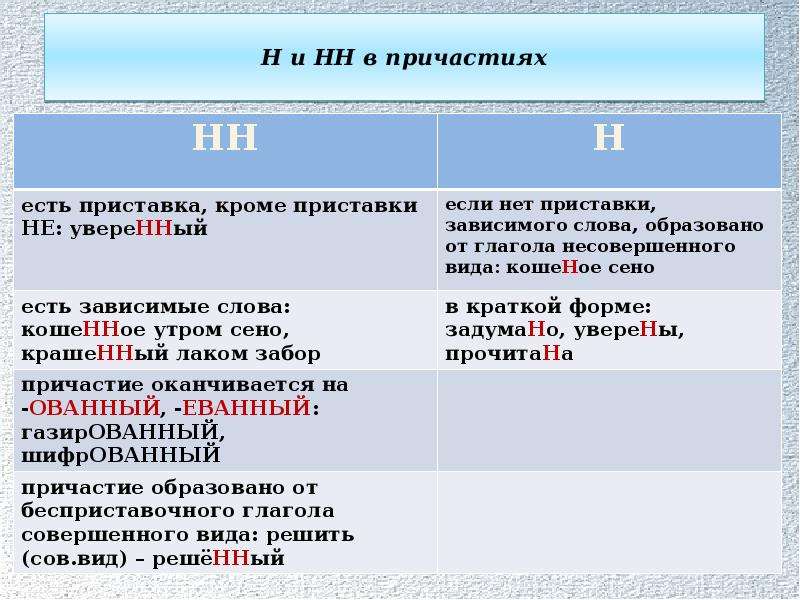 Запросы, ключи и значения извлекаются из сверточных нейронных сетей и передаются в два модуля самовнимания. Речевой преобразователь оценивается на наборах данных WSJ и достигает результатов конкурентного распознавания с WER 10,9% 10,9 \% 10,9%, при этом для него требуется примерно на 80% 80 \% 80% меньше времени на обучение, чем для обычных RNN или CNN.
Запросы, ключи и значения извлекаются из сверточных нейронных сетей и передаются в два модуля самовнимания. Речевой преобразователь оценивается на наборах данных WSJ и достигает результатов конкурентного распознавания с WER 10,9% 10,9 \% 10,9%, при этом для него требуется примерно на 80% 80 \% 80% меньше времени на обучение, чем для обычных RNN или CNN.
Преобразователи со сверточным контекстом
Mohamed et al. использует модель кодера-декодера, сформированную CNN и преобразователем, для изучения локальных взаимосвязей и контекста речевого сигнала.Для кодера используются сверточные 2D-модули с нормализацией слоев и активацией ReLU. Кроме того, каждый двумерный сверточный модуль сформирован сверточными слоями KKK с максимальным объединением. Для декодера одномерные свертки выполняются над вложениями прошлых предсказанных слов.
Transformer-Transducer
Подобно RNN-Transducer, модель Transformer-Transducer также была разработана для распознавания речи. По сравнению с RNN-T, эта модель объединенной сети объединяет выходной сигнал аудиокодера AE \ mathrm {AE} AE на временном шаге tit_iti и ранее предсказанную последовательность меток z0i − 1 = (z1 ,.{i-1}) = \ mathrm {softmax} (\ mathrm {fc} (J)) P (zi ∣x, ti, z0i − 1) = softmax (fc (J))
По сравнению с RNN-T, эта модель объединенной сети объединяет выходной сигнал аудиокодера AE \ mathrm {AE} AE на временном шаге tit_iti и ранее предсказанную последовательность меток z0i − 1 = (z1 ,.{i-1}) = \ mathrm {softmax} (\ mathrm {fc} (J)) P (zi ∣x, ti, z0i − 1) = softmax (fc (J))
Конформер
Conformer — это вариант исходного Transformer, который объединяет CNN и преобразователи для моделирования локальных и глобальных речевых зависимостей с использованием более эффективной архитектуры и меньшего количества параметров. Модуль Conformer содержит два уровня прямой связи (FFN), один сверточный слой (CNN) и модуль внимания с несколькими головами (MHA). Выходные данные Conformer рассчитываются как:
x1 = x + FFN (x) x2 = x1 + MHA (x1) x3 = x2 + CNN (x2) y = LN (x3 + FFN (x3)) \ begin {выровнено} \ mathbf {x} _1 = \ mathbf {x} + \ mathrm {FFN} (\ mathbf {x}) \\ \ mathbf {x} _2 = \ mathbf {x} _1 + \ mathrm {MHA} (\ mathbf {x} _1) \\ \ mathbf {x} _3 = \ mathbf {x} _2 + \ mathrm {CNN} (\ mathbf {x} _2) \\ \ mathbf {y} = \ mathrm {LN} (\ mathbf {x} _3 + \ mathrm {FFN} (\ mathbf {x} _3)) \ end {align} x1 = x + FFN (x) x2 = x1 + MHA (x1) x3 = x2 + CNN (x2) y = LN (x3 + FFN (x3)) Здесь сверточный модуль использует эффективные поточечные и глубинные свертки вместе с нормализацией слоев.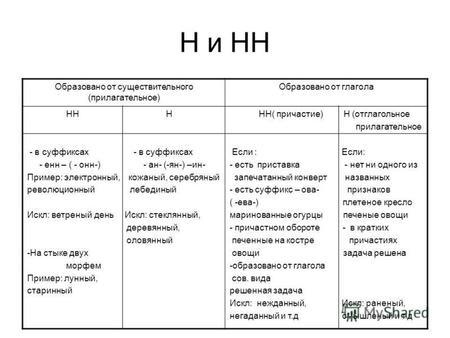
Обзор метода Conformer
CTC и языковые модели также использовались с сетями Transformer .
Семантическая маска для ASR на основе трансформатора
Wang et al. использовал семантическую маску входной речи согласно соответствующим выходным токенам, чтобы сгенерировать следующее слово на основе предыдущего контекста. Сверточный слой, подобный VGG, используется для генерации краткосрочных зависимых признаков из входной спектрограммы, которые затем моделируются преобразователем.В сети декодера кодирование позиции заменяется одномерным сверточным слоем для извлечения локальных признаков.
Подавление слабого внимания или ASR на основе трансформатора
Shi et al. предлагает модуль слабого внимания для подавления неинформативных частей речевого сигнала, например, во время тишины. Модуль слабого внимания устанавливает вероятности внимания меньше порогового значения на ноль и нормализует вероятности остального внимания. 2} {L-1}} \ end {align} θi = mi −γδi θi = L1 −γL − 1∑j = 1L (ai, j −L1) 2
2} {L-1}} \ end {align} θi = mi −γδi θi = L1 −γL − 1∑j = 1L (ai, j −L1) 2
Затем softmax снова применяется к новому вероятности внимания для создания новой матрицы внимания.
Обзор метода семантического маскированного преобразователя
Заключение
Очевидно, что глубокие архитектуры уже оказали значительное влияние на автоматическое распознавание речи. Сверточные нейронные сети, рекуррентные нейронные сети и преобразователи используются с большим успехом. Все современные модели SOTA основаны на некоторой комбинации вышеупомянутых методов. Вы можете найти несколько тестов на популярных наборах данных в статьях с кодом.
Если вы найдете эту статью полезной, вас также может заинтересовать предыдущая, в которой мы рассматриваем лучшие методы синтеза речи. И, как всегда, не стесняйтесь делиться им с друзьями.
Укажите:
@article {papastratis2021speech,
title = "Распознавание речи: обзор различных подходов к глубокому обучению",
author = "Papastratis, Ilias",
journal = "https: // theaisummer .
com / ",
год =" 2021 ",
howpublished = {https: // theaisummer.com / Speech-распознавание /},
}
Ссылки
Deep Learning in Production Book 📖
Узнайте, как создавать, обучать, развертывать, масштабировать и поддерживать модели глубокого обучения. Изучите инфраструктуру машинного обучения и MLOps на практических примерах.
Подробнее* Раскрытие информации: обратите внимание, что некоторые из приведенных выше ссылок могут быть партнерскими ссылками, и мы будем получать комиссию без каких-либо дополнительных затрат с вашей стороны, если вы решите совершить покупку после перехода по ссылке.
Расшифровка моторики человека по нейронным сигналам: обзор | BMC Biomedical Engineering
Нейрофизиология моторного управления
Чтобы расшифровать моторное намерение человека, полезно сначала понять естественную нейрофизиологию моторного управления, чтобы мы могли знать, где перехватить управляющий сигнал и какой тип сигнала что мы можем встретить.
Моторный контроль в организме человека начинается с лобной и задней теменной коры (PPC) [5, 6].Эти области осуществляют высокоуровневое абстрактное мышление, чтобы определить, какие действия следует предпринять в данной ситуации [7]. Например, при столкновении с игроком противоположной команды футболисту может потребоваться решить, вести ли мяч, стрелять или передавать мяч своему товарищу по команде. Выбор наилучшего действия зависит от местоположения игрока, соперника и мяча. Это также зависит от текущих углов суставов коленей и лодыжек по отношению к мячу. PPC получает информацию от соматосенсорной коры для получения информации о текущем состоянии тела.Он также имеет обширную взаимосвязь с префронтальной корой, которая отвечает за абстрактные стратегические мысли. Префронтальной коре, возможно, потребуется учитывать другие факторы помимо сенсорной информации о текущей среде. Например, насколько искусен противник по сравнению со мной? Какова существующая командная стратегия на текущем этапе игры, мне следует играть более агрессивно или в обороне? Комбинация сенсорной информации, прошлого опыта и стратегического решения в лобной и задней теменной коре определяет последовательность действий, которые следует предпринять.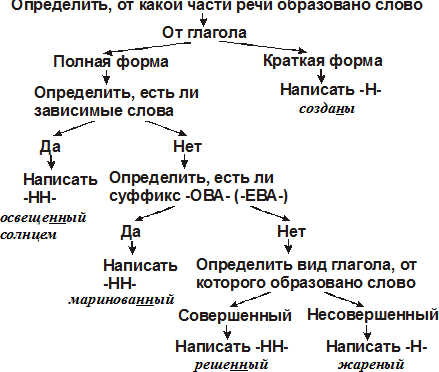
Планирование последовательности действий затем осуществляется премоторной зоной (PMA) и дополнительной моторной зоной (SMA), которые расположены в зоне 6 Бродмана коры головного мозга. Известно, что стимуляция в области 6 вызывает сложную последовательность действий, и внутрикортикальная запись в PMA показывает, что она активируется примерно за 1 секунду до движения и прекращается вскоре после начала движения [8]. Некоторые нейроны в PMA также кажутся настроенными на направление движения, при этом некоторые из них активируются только тогда, когда рука движется в одном направлении, но не в другом.
После того, как последовательность действий запланирована в PMA или SMA, требуется ввод от базальных ганглиев, чтобы фактически инициировать движение. Базальные ганглии содержат прямой и непрямой путь [9–11]. Прямой путь помогает выбрать конкретное действие для инициирования, в то время как косвенный путь отфильтровывает другие неподходящие моторные программы. По прямому пути полосатое тело (скорлупа и хвостатое тело) получает входные данные от коры головного мозга и подавляет внутренний бледный шар (GPi). В состоянии покоя GPi самопроизвольно активируется и подавляет оральную часть вентрального латерального ядра (VLo) таламуса.Таким образом, ингибирование GPi увеличивает активность VLo, что, в свою очередь, возбуждает SMA. При непрямом пути полосатое тело возбуждает GPi через ядро субталамуса (STN), которое затем подавляет активность VLo и, в свою очередь, ингибирует SMA. При некоторых неврологических расстройствах, таких как болезнь Паркинсона, дефицит способности активировать прямой путь приведет к трудностям в инициировании движения (например, брадикинезии), в то время как дефицит непрямого пути приведет к неконтролируемому движению в состоянии покоя (т.е. тремор покоя).
В состоянии покоя GPi самопроизвольно активируется и подавляет оральную часть вентрального латерального ядра (VLo) таламуса.Таким образом, ингибирование GPi увеличивает активность VLo, что, в свою очередь, возбуждает SMA. При непрямом пути полосатое тело возбуждает GPi через ядро субталамуса (STN), которое затем подавляет активность VLo и, в свою очередь, ингибирует SMA. При некоторых неврологических расстройствах, таких как болезнь Паркинсона, дефицит способности активировать прямой путь приведет к трудностям в инициировании движения (например, брадикинезии), в то время как дефицит непрямого пути приведет к неконтролируемому движению в состоянии покоя (т.е. тремор покоя).
После того, как базальные ганглии помогают отфильтровать нежелательные моторные программы и сосредоточиться на выбранных программах, первичная моторная кора (M1) будет отвечать за их выполнение на низком уровне [12]. В слое V M1 есть популяция крупных нейронов пирамидальной формы, которые проецируют свои аксонные связи вниз по спинному мозгу через кортикоспинальный тракт. Эти аксоны моносинаптически соединяются с мотонейронами спинного мозга для активации мышечных волокон. Они также соединяются с тормозными интернейронами в спинном мозге, подавляя антагонистические мышцы.Эта структура позволяет одной пирамидальной клетке генерировать скоординированные движения в нескольких группах мышц.
Эти аксоны моносинаптически соединяются с мотонейронами спинного мозга для активации мышечных волокон. Они также соединяются с тормозными интернейронами в спинном мозге, подавляя антагонистические мышцы.Эта структура позволяет одной пирамидальной клетке генерировать скоординированные движения в нескольких группах мышц.
Моторные нейроны спинного мозга получают входные сигналы от пирамидных клеток M1 через кортикоспинальный тракт [13]. Они также получают входной сигнал косвенно от моторной коры и мозжечка через руброспинальный тракт, проходящий через красное ядро в среднем мозге. Хотя его функции хорошо известны у низших млекопитающих, функции руброспинального пути у человека, по-видимому, рудиментарны.Моторные нейроны в вентральном роге пучка спинного мозга вместе образуют вентральный корешок, который выходит из спинного мозга и соединяется с спинным корешком, образуя смешанный спинномозговой нерв. Спинной нерв разветвляется на более мелкие нервные волокна, которые иннервируют различные мышцы тела. Один двигательный нейрон может снабжать несколько мышечных волокон, вместе известных как одна двигательная единица. Мышца состоит из множества мышечных волокон, сгруппированных в двигательные единицы разного размера, каждая из которых может снабжаться разными двигательными нейронами.В крупных мышцах, например в ногах, один двигательный нейрон может снабжать сотни мышечных волокон. В более мелких мышцах, например, в пальцах, один двигательный нейрон может снабжать только 2 или 3 мышечных волокна, обеспечивая точный контроль движений.
Один двигательный нейрон может снабжать несколько мышечных волокон, вместе известных как одна двигательная единица. Мышца состоит из множества мышечных волокон, сгруппированных в двигательные единицы разного размера, каждая из которых может снабжаться разными двигательными нейронами.В крупных мышцах, например в ногах, один двигательный нейрон может снабжать сотни мышечных волокон. В более мелких мышцах, например, в пальцах, один двигательный нейрон может снабжать только 2 или 3 мышечных волокна, обеспечивая точный контроль движений.
Путь управления моторикой человеческого тела идет от высокоуровневой ассоциативной области мозга, опосредованной моторной корой, через спинной мозг к отдельным мышечным волокнам. Каждый из этапов играет свою роль и использует разные механизмы, чтобы гарантировать, что движение выполняется скоординированным и плавным образом.Каждый из этих этапов также предлагает различные режимы сигнала и функции, которые можно использовать для декодирования двигателя. Теперь мы подробно обсудим эти функции и стратегии их использования ниже. Обзор, показывающий путь управления двигателем и различные способы перехвата управляющего сигнала, показан на (Рис. 1).
Теперь мы подробно обсудим эти функции и стратегии их использования ниже. Обзор, показывающий путь управления двигателем и различные способы перехвата управляющего сигнала, показан на (Рис. 1).
Обзор различных способов перехвата сигналов управления двигателем. Сигнал управления двигателем передается от первичной моторной коры головного мозга через спинной мозг и периферический нерв к мышечным волокнам.Управляющий сигнал может быть перехвачен в различных точках с использованием различных методов. Электроэнцефалография (ЭЭГ) фиксирует наложенные электрические поля, создаваемые нервной активностью на поверхности кожи головы. Электрокортикография (ЭКоГ) измеряет активность под кожей головы на поверхности мозга. Интракортикальные записи проникают в ткань головного мозга для получения многокомпонентных и единичных действий. Электроды также могут быть помещены на периферический нерв для отслеживания сигнала низкого уровня, используемого для сокращения мышц. Наконец, электромиограф (ЭМГ) также может использоваться для непосредственного мониторинга активности мышц (рисунок содержит элементы изображений, адаптированных из Патрика Дж. Линча и Карла Фредрика в соответствии с лицензией Creative Commons Attribution License)
Наконец, электромиограф (ЭМГ) также может использоваться для непосредственного мониторинга активности мышц (рисунок содержит элементы изображений, адаптированных из Патрика Дж. Линча и Карла Фредрика в соответствии с лицензией Creative Commons Attribution License)
Кортикальное декодирование движений конечностей
Все волевые двигательные механизмы исходят из головного мозга. Моторная кора головного мозга играет особенно важную роль в планировании и выполнении моторных команд. Для некоторых пациентов мозг — единственное место, где может быть зафиксировано двигательное намерение, потому что они потеряли двигательные функции во всех своих конечностях (например,г. у пациентов с тетраплегией). Поэтому много усилий было вложено в корковое декодирование.
Электроэнцефалография (ЭЭГ)
ЭЭГ — это измерение слабых электрических сигналов от мозга на поверхности кожи головы. Считается, что его происхождение связано с суммированием постсинаптических потенциалов возбудимых нервных тканей головного мозга [14]. Череп, твердая мозговая оболочка и спинномозговая жидкость между мозгом и электродами ЭЭГ значительно ослабляют электрический сигнал, поэтому сигнал ЭЭГ очень слабый, обычно ниже 150 μ В.Эти структуры также действуют как временные фильтры нижних частот, ограничивая полезную полосу пропускания сигнала ЭЭГ ниже 100 Гц [15]. Кроме того, из-за эффекта объемной проводимости источников тока в голове эффект одного источника тока распространяется на несколько электродов. Результатом является пространственное низкое прохождение исходного сигнала, что приводит к «размытию» источника сигнала и снижению пространственного разрешения. Таким образом, большинство установок ЭЭГ для моторного декодирования включает только 64 или 128 электродов.Установки с более чем 128 электродами встречаются редко.
Череп, твердая мозговая оболочка и спинномозговая жидкость между мозгом и электродами ЭЭГ значительно ослабляют электрический сигнал, поэтому сигнал ЭЭГ очень слабый, обычно ниже 150 μ В.Эти структуры также действуют как временные фильтры нижних частот, ограничивая полезную полосу пропускания сигнала ЭЭГ ниже 100 Гц [15]. Кроме того, из-за эффекта объемной проводимости источников тока в голове эффект одного источника тока распространяется на несколько электродов. Результатом является пространственное низкое прохождение исходного сигнала, что приводит к «размытию» источника сигнала и снижению пространственного разрешения. Таким образом, большинство установок ЭЭГ для моторного декодирования включает только 64 или 128 электродов.Установки с более чем 128 электродами встречаются редко.
Сигнал ЭЭГ традиционно разделяется на несколько частотных диапазонов (дельта: 0–4 Гц, тета: 4–7,5 Гц, альфа: 8–13 Гц, бета: 13–30 Гц, гамма: 30–100 Гц). Особое значение для моторного декодирования имеют колебания мозга в альфа-диапазоне над моторной и соматосенсорной корой, также известные как μ -ритм [16, 17].
Это уменьшение мощности полосы, совпадающее с событием, называется десинхронизацией, связанной с событием (ERD). Противоположное явление называется синхронизацией, связанной с событием (ERS), то есть увеличением мощности диапазона, совпадающим с событием. ERD / ERS обычно рассчитывается по отношению к базовому периоду, обычно когда субъект бодрствует расслабленным и не выполняет никаких задач [21]:
$$ ERD = \ frac {R-A} {R} \ times 100 \% $$
, где R — мощность диапазона в течение базисного периода, а A — мощность в течение интересующего периода времени. Пример топографии ERD во время воображения движения показан на (рис. 2).
Пример топографии ERD во время воображения движения показан на (рис. 2).
Примеры особенностей ЭЭГ при моторной расшифровке. Характеристики ЭЭГ от одного из субъектов из набора данных BCI Competition IV 2a [214]. a Временной ход изменения мощности полосы сигнала ЭЭГ, отфильтрованного в диапазоне 8–12 Гц, в образах движения левой и правой руки, по сравнению с контрольным периодом (0–3 с). Заштрихованные области показывают стандартное отклонение изменений в разных испытаниях.Ниже также показана экспериментальная парадигма. b Частотный спектр сигнала ЭЭГ во время фиксации и воображения движения ( c ) топография распределения ERD / ERS в различных типах воображения движения
Топография ERD во время движения демонстрирует развивающуюся структуру с течением времени [21 ]. ERD обычно начинается примерно за 2 секунды до фактического движения, концентрируясь на контрлатеральной сенсомоторной области, затем распространяется на ипсилатеральную сторону и становится двусторонне симметричной непосредственно перед началом движения. После прекращения движения происходит увеличение мощности бета-диапазона (т.е. ERS) вокруг контралатеральной сенсомоторной области [21–23], также известное как «бета-отскок». Возникновение бета-отскока совпадает со снижением кортикоспинальной возбудимости [24], предполагая, что отскок может быть связан с дезактивацией моторной коры после прекращения движения. Бета-отскок происходит как в реальных, так и в воображаемых движениях. Пример бета-отскока можно наблюдать на (рис. 2а).
После прекращения движения происходит увеличение мощности бета-диапазона (т.е. ERS) вокруг контралатеральной сенсомоторной области [21–23], также известное как «бета-отскок». Возникновение бета-отскока совпадает со снижением кортикоспинальной возбудимости [24], предполагая, что отскок может быть связан с дезактивацией моторной коры после прекращения движения. Бета-отскок происходит как в реальных, так и в воображаемых движениях. Пример бета-отскока можно наблюдать на (рис. 2а).
Различные виды двигательных образов (MI) создают разные топографии ERD и, следовательно, полезны для декодирования двигательного намерения субъекта.Например, визуализация движения руки вызовет ERD возле области моторной коры, которая находится в более латеральном положении. С другой стороны, визуализация движения стопы у некоторых испытуемых вызовет ERD рядом с областью стопы, которая находится ближе к сагиттальной линии [25], что можно наблюдать на (Рис. 2c). Отскок бета после инфаркта миокарда также демонстрирует сходный соматотопический паттерн [22]. Одновременное ERD и ERS в разных частях мозга также очевидно у некоторых испытуемых. Например, у некоторых испытуемых наблюдались ERD в области руки и ERS в области стопы во время произвольного движения руки, и наоборот, во время движения стопы [22].ERD может представлять активацию кортикальной области, контролирующей движение, в то время как ERS может представлять ингибирование других непреднамеренных движений. Как мы помним из нейрофизиологии моторного контроля, непрямой путь базальных ганглиев содержит механизмы для подавления таламической активации SMA, чтобы отфильтровать непреднамеренные движения. Существуют характерные паттерны ERD / ERS во время различных реальных и воображаемых движений, поэтому, изучая эти паттерны, мы можем обнаружить и различить двигательное намерение различных частей тела.
Одновременное ERD и ERS в разных частях мозга также очевидно у некоторых испытуемых. Например, у некоторых испытуемых наблюдались ERD в области руки и ERS в области стопы во время произвольного движения руки, и наоборот, во время движения стопы [22].ERD может представлять активацию кортикальной области, контролирующей движение, в то время как ERS может представлять ингибирование других непреднамеренных движений. Как мы помним из нейрофизиологии моторного контроля, непрямой путь базальных ганглиев содержит механизмы для подавления таламической активации SMA, чтобы отфильтровать непреднамеренные движения. Существуют характерные паттерны ERD / ERS во время различных реальных и воображаемых движений, поэтому, изучая эти паттерны, мы можем обнаружить и различить двигательное намерение различных частей тела.
Наиболее реактивный частотный диапазон, в котором возникает ERD / ERS, может быть специфическим для каждого пациента и даже для типа воображения движения, а его топография может незначительно отличаться в зависимости от подготовки к ЭЭГ.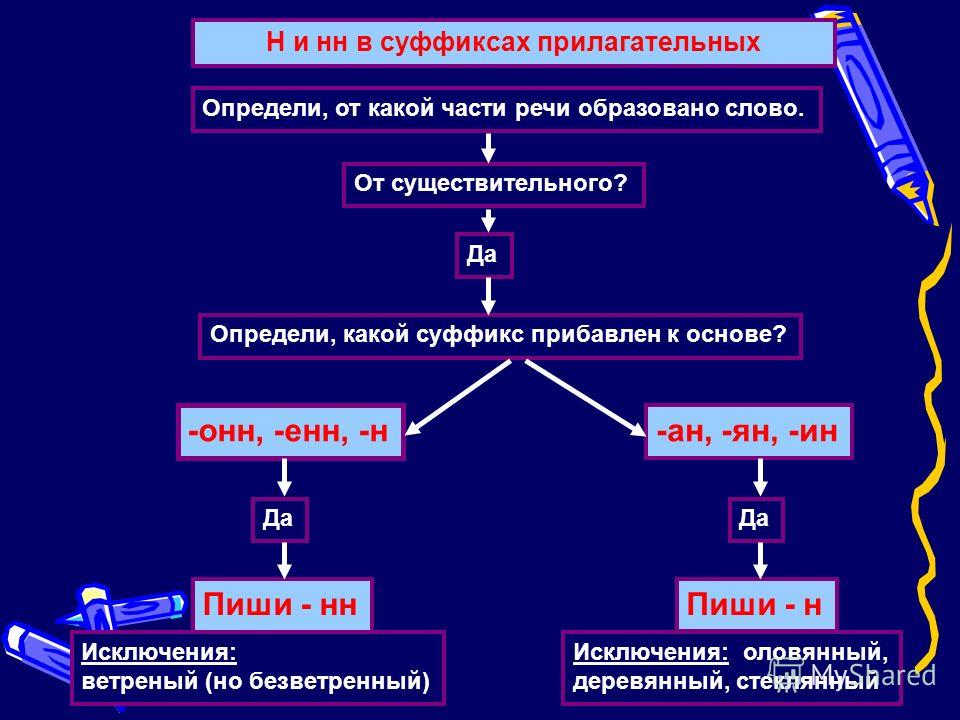 Поэтому для автоматической адаптации к характеристикам сигналов субъектов обычно используются методы обработки сигналов и машинного обучения.
Поэтому для автоматической адаптации к характеристикам сигналов субъектов обычно используются методы обработки сигналов и машинного обучения.
Одним из наиболее важных этапов обработки сигналов при декодировании двигателя на основе SMR является оценка мощности сигнала в выбранном частотном диапазоне, обычно в альфа-диапазоне (8–12 Гц) и бета-диапазоне (12–30 Гц).Для этого есть много способов. Одним из наиболее простых и эффективных с вычислительной точки зрения методов является полосовая фильтрация [3, 26]. Сигнал ЭЭГ сначала подвергается полосовой фильтрации в интересующей полосе частот, затем сумма квадратов сигнала принимается как мощность сигнала в выбранной полосе частот. Сумма квадратов эквивалентна дисперсии сигнала, поэтому обычно вместо нее используется дисперсия сигнала. После определения дисперсии обычно используется логарифмическое преобразование.Лог-преобразование может служить двум целям. Во-первых, он преобразует искаженные данные, чтобы они больше соответствовали нормальному распределению [27], что может помочь улучшить производительность некоторых алгоритмов классификации. Во-вторых, логарифмическое преобразование подчеркивает относительное изменение сигнала, а не абсолютную разницу (например, l o g (110) — l o g (100) = l o g (1100) — l o g (1000)), поэтому он может выполнять неявную нормализацию сигнала и улучшать производительность классификатора.
Во-вторых, логарифмическое преобразование подчеркивает относительное изменение сигнала, а не абсолютную разницу (например, l o g (110) — l o g (100) = l o g (1100) — l o g (1000)), поэтому он может выполнять неявную нормализацию сигнала и улучшать производительность классификатора.
Одним из основных недостатков простого подхода с полосовой фильтрацией является то, что может быть трудно выбрать лучшую полосу частот для выполнения фильтра, поскольку каждый пациент имеет свою собственную специфическую реактивную полосу. Чтобы преодолеть это ограничение, адаптивная авторегрессивная модель (AAR) является еще одним широко используемым методом [28–31]. Он моделирует сигнал в текущий момент времени как линейную комбинацию предыдущих p точек:
$$ Y_ {t} = a_ {1, t} Y_ {t-1} + a_ {2, t} Y_ {t-2} + \ dots + a_ {p, t} Y_ {tp} + X_ {t} $$
, где Y t — сигнал, X t — остаточный белый шум и a p , t коэффициенты авторегрессии.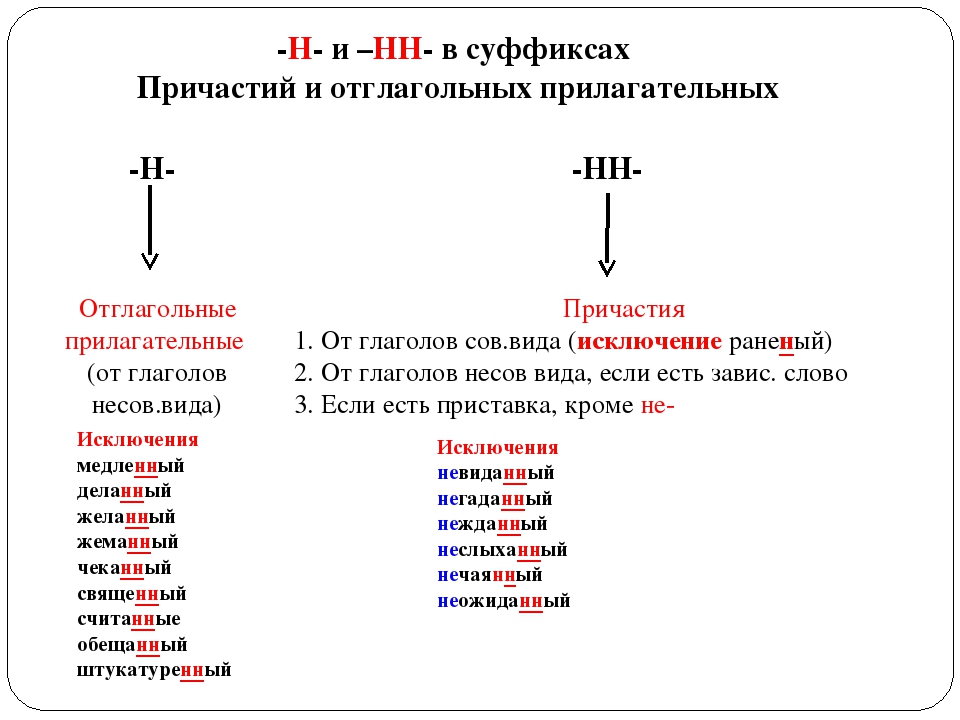 Основное отличие от традиционной модели AR состоит в том, что в модели AAR коэффициенты a p , t зависят от времени и рассчитываются для каждой временной точки сигнала с использованием рекурсивного метода наименьших квадратов [32]. Коэффициенты AAR от нескольких электродов затем объединяются вместе, чтобы сформировать вектор признаков, используемый системой классификации. Коэффициенты AAR можно рассматривать как импульсную характеристику системы, поэтому они содержат информацию о частотном спектре моделируемого сигнала.По сравнению с традиционной полосовой фильтрацией оценка спектра с использованием AAR может быть более устойчивой к шумам. Можно также указать количество пиков спектра на основе знания предметной области (каждый пик требует двух коэффициентов). Еще одно преимущество состоит в том, что нет необходимости заранее выбирать конкретную полосу частот, поскольку для классификации используются все коэффициенты модели. Другой способ автоматического выбора полосы частот для конкретного объекта — использование банка фильтров, состоящего из нескольких полосовых фильтров на разных частотах.
Основное отличие от традиционной модели AR состоит в том, что в модели AAR коэффициенты a p , t зависят от времени и рассчитываются для каждой временной точки сигнала с использованием рекурсивного метода наименьших квадратов [32]. Коэффициенты AAR от нескольких электродов затем объединяются вместе, чтобы сформировать вектор признаков, используемый системой классификации. Коэффициенты AAR можно рассматривать как импульсную характеристику системы, поэтому они содержат информацию о частотном спектре моделируемого сигнала.По сравнению с традиционной полосовой фильтрацией оценка спектра с использованием AAR может быть более устойчивой к шумам. Можно также указать количество пиков спектра на основе знания предметной области (каждый пик требует двух коэффициентов). Еще одно преимущество состоит в том, что нет необходимости заранее выбирать конкретную полосу частот, поскольку для классификации используются все коэффициенты модели. Другой способ автоматического выбора полосы частот для конкретного объекта — использование банка фильтров, состоящего из нескольких полосовых фильтров на разных частотах. После фильтрации наиболее информативная полоса частот и каналы выбираются с использованием некоторых показателей производительности, например приведет ли удаление этой функции к изменению классификационной метки [33, 34].
После фильтрации наиболее информативная полоса частот и каналы выбираются с использованием некоторых показателей производительности, например приведет ли удаление этой функции к изменению классификационной метки [33, 34].
Из-за проблем с объемной проводимостью в голове человека один источник тока часто кажется «размазанным» по нескольким электродам ЭЭГ. Пространственная фильтрация обычно используется для улучшения пространственного разрешения сигнала ЭЭГ. Популярные пространственные фильтры включают в себя общий средний эталон (CAR) и поверхностный лапласиан [35].{LAP} = V_ {j} — \ frac {1} {n} \ sum_ {k \ in S_ {j}} V_ {k} $$
, где В, — напряжение сигнала, N — напряжение сигнала. общее количество электродов, n количество соседних электродов и S набор соседних электродов в поверхностном лапласиане (LAP).
Эти фильтры усиливают фокусную активность, действуя как пространственный фильтр верхних частот. Предлагаются также другие более продвинутые пространственные фильтры.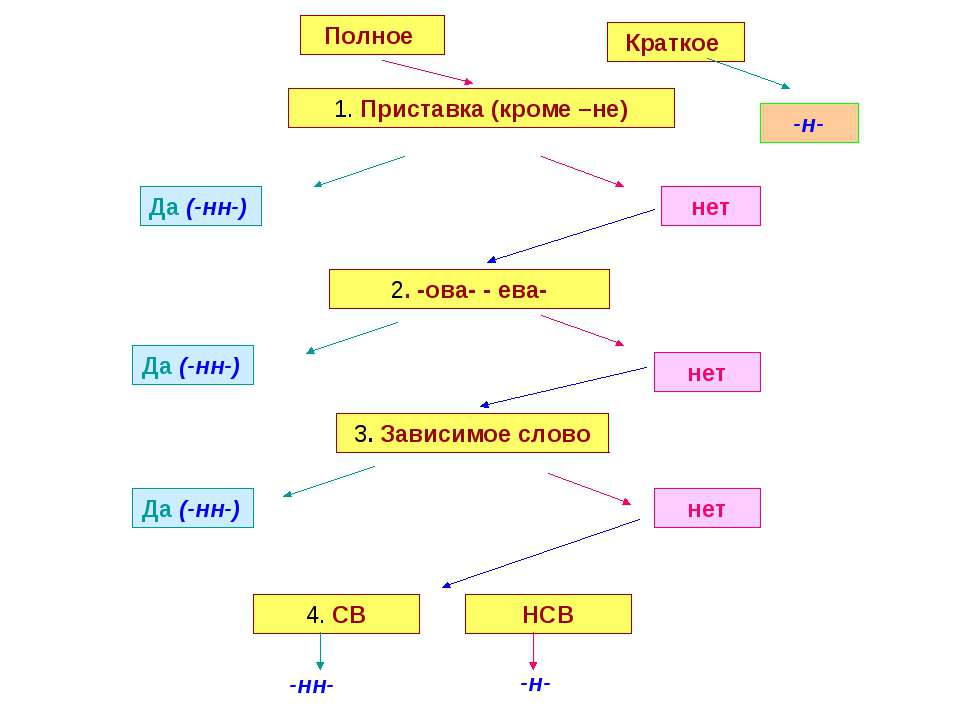 Например, популярный общий пространственный паттерн (CSP) [36, 37] работает, находя проекцию напряжения на электродах, так что различия в дисперсии между двумя классами максимизируются.Еще одна разновидность метода заключается в добавлении частотной информации путем фильтрации сигнала с помощью набора полос фильтров, последующего вычисления CSP для каждой и, наконец, выбора наиболее информативной характеристики с помощью критерия взаимной информации [38].
Например, популярный общий пространственный паттерн (CSP) [36, 37] работает, находя проекцию напряжения на электродах, так что различия в дисперсии между двумя классами максимизируются.Еще одна разновидность метода заключается в добавлении частотной информации путем фильтрации сигнала с помощью набора полос фильтров, последующего вычисления CSP для каждой и, наконец, выбора наиболее информативной характеристики с помощью критерия взаимной информации [38].
Производительность моторного декодирования на основе ЭЭГ неуклонно улучшалась на протяжении многих лет. В то время как более ранние исследования могут различать только отдельные типы воображения движения [39], недавние исследования уже достигли 2D [40] и 3D контроля [41–43].Некоторые из последних исследований даже демонстрируют возможность декодирования различных движений одной и той же конечности [44, 45] или даже отдельных движений пальцев [46].
Помимо использования для замены утраченных функций, моторное декодирование на основе ЭЭГ также может использоваться в качестве инструмента для реабилитации. Например, его можно использовать для управления роботизированной рукой, чтобы помочь в активной тренировке руки в постинсультной реабилитации [4, 47, 48]. Применение моторного декодирования в качестве инструмента для обучения является очень многообещающей областью, поскольку потенциально может распространить его использование на более широкие слои населения.
Например, его можно использовать для управления роботизированной рукой, чтобы помочь в активной тренировке руки в постинсультной реабилитации [4, 47, 48]. Применение моторного декодирования в качестве инструмента для обучения является очень многообещающей областью, поскольку потенциально может распространить его использование на более широкие слои населения.
Электрокортикограмма (ЭКоГ)
ЭКоГ — это измерение электрических сигналов от головного мозга над твердой мозговой оболочкой, но под черепом. Измерение ЭКоГ обычно выполняется перед операцией по поводу эпилепсии, чтобы очертить эпилептогенную область и определить важные области коры, которых следует избегать во время резекции [49]. На сигнал ЭКоГ череп не влияет и, следовательно, он имеет более высокое временное и пространственное разрешение, чем ЭЭГ. Он также имеет большую полосу пропускания (от 0 до 500 Гц) [50, 51] и более высокую амплитуду (максимальная ∼500 μ В [52]).Следовательно, обычно ЭКоГ имеет более высокое отношение сигнал / шум, чем ЭЭГ, хотя она также более инвазивна.
ЭКоГ и ЭЭГ, вероятно, возникают из одних и тех же основных нейронных механизмов, поэтому они имеют много общего друг с другом. Тем не менее, есть две основные особенности сигнала в моторном декодировании, которые уникальны для ЭКоГ и используются специально. Первый — это изменение мощности полосы сигнала в высоком гамма-диапазоне (≥75 Гц). Многие исследования предполагают, что высокий гамма-диапазон содержит более информативные функции для моторного декодирования по сравнению с альфа- и бета-диапазоном, которые обычно используются при декодировании ЭЭГ [53–57].Интересно, что высокий гамма-диапазон имеет тенденцию увеличиваться во время движения, в отличие от альфа- и бета-диапазона, которые обычно показывают десинхронизацию (то есть уменьшение мощности). Следовательно, высокая гамма-мощность может быть произведена другим нейронным механизмом, чем тот, который производит альфа- и бета-десинхронизацию.
Другой уникальной особенностью является низкочастотная амплитудная модуляция необработанного сигнала ЭКоГ, придуманная Шалком и др. Как локальный моторный потенциал (LMP). [30, 51]. Было обнаружено, что огибающая необработанной ЭКоГ показывает поразительную корреляцию с траекторией движения человеческой руки, измеренной с помощью джойстика.Амплитуда также показывает настройку косинуса или синуса по отношению к направлению движения, аналогично тому, что наблюдалось при внутрикортикальных записях. С момента этого открытия многие группы включили LMP в моторное декодирование ЭКоГ в дополнение к другим высокочастотным функциям (например, [53, 56, 58, 59]). LMP — это очень низкочастотный компонент (2-3 Гц) необработанного сигнала ЭКоГ. Обычно его извлекают с помощью фильтра нижних частот Гуасиана, скользящего среднего [30, 53, 59] или фильтра Савицкого-Голея [58, 60, 61].
Как локальный моторный потенциал (LMP). [30, 51]. Было обнаружено, что огибающая необработанной ЭКоГ показывает поразительную корреляцию с траекторией движения человеческой руки, измеренной с помощью джойстика.Амплитуда также показывает настройку косинуса или синуса по отношению к направлению движения, аналогично тому, что наблюдалось при внутрикортикальных записях. С момента этого открытия многие группы включили LMP в моторное декодирование ЭКоГ в дополнение к другим высокочастотным функциям (например, [53, 56, 58, 59]). LMP — это очень низкочастотный компонент (2-3 Гц) необработанного сигнала ЭКоГ. Обычно его извлекают с помощью фильтра нижних частот Гуасиана, скользящего среднего [30, 53, 59] или фильтра Савицкого-Голея [58, 60, 61].
Из-за устойчивости сигнала LMP обычно простой линейной регрессии достаточно для декодирования двигательного намерения во многих предыдущих исследованиях (например, [51, 62, 63]), хотя может потребоваться этап выбора функции или регулирования. чтобы сначала удалить неинформативные функции. Недавнее исследование с использованием глубокой нейронной сети также показало многообещающие [64], однако его улучшение по сравнению с классическими методами не всегда значимо.
Недавнее исследование с использованием глубокой нейронной сети также показало многообещающие [64], однако его улучшение по сравнению с классическими методами не всегда значимо.
Поскольку ЭКоГ имеет лучшее разрешение и более высокое отношение сигнал / шум, она имеет тенденцию давать лучшие и более точные результаты, чем ЭЭГ, при декодировании двигателя.Помимо декодирования движения разных частей тела, как в ЭЭГ [65, 66], также можно различать разные жесты рук [56, 67]. Используя LMP в дополнение к частотным характеристикам, положение и скорость 2D движения руки также могут быть декодированы из сигналов ЭКоГ [30, 51, 58]. Последующие исследования даже демонстрируют, что непрерывные положения пальцев также могут быть декодированы [54, 59, 61, 63, 64, 68]. Коэффициент корреляции между прогнозируемым и фактическим движением пальцев может достигать от 0,4 до 0,7 в некоторых недавних исследованиях [61, 64].
Подавляющее большинство исследований по моторной расшифровке ЭКоГ проводится на пациентах с эпилепсией без определенного двигательного расстройства или травмы конечностей. Однако одна из самых сильных причин для двигательного декодирования заключается в том, что оно может компенсировать потерю двигательной функции пациента. Учитывая, что мозг может реорганизоваться из-за болезни или травмы, жизненно важно, чтобы эксперименты по декодированию были повторены на этой популяции пациентов, чтобы увидеть, можно ли достичь аналогичных характеристик декодирования. Существует всего несколько исследований, в которых пытались опробовать моторную расшифровку ЭКоГ у пациентов с инсультом [57, 69] и парализованных лиц [70], но результаты обнадеживают.
Однако одна из самых сильных причин для двигательного декодирования заключается в том, что оно может компенсировать потерю двигательной функции пациента. Учитывая, что мозг может реорганизоваться из-за болезни или травмы, жизненно важно, чтобы эксперименты по декодированию были повторены на этой популяции пациентов, чтобы увидеть, можно ли достичь аналогичных характеристик декодирования. Существует всего несколько исследований, в которых пытались опробовать моторную расшифровку ЭКоГ у пациентов с инсультом [57, 69] и парализованных лиц [70], но результаты обнадеживают.
Внутрикорковые записи
Проникновение в кортикальную ткань обеспечивает максимальную близость к нейронам и дает наиболее точный сигнал. С момента открытия свойства направленной настройки нейронов в моторной коре [71], многие исследования пытались расшифровать моторное намерение из интракортикальных записей, сначала у нечеловеческих приматов (NHP), а затем у людей в последнее время. годы. В нашем обзоре основное внимание будет уделено внутрикортикальному декодированию у человека, поскольку оно представляет некоторые уникальные проблемы по сравнению с NHP, а также именно там, где в конечном итоге будет применяться технология.
Проникающие электроды для моторного декодирования обычно имплантируются в первичную моторную область мозга. В прецентральной извилине есть структура, напоминающая «ручку», в которой находится большинство нейронов, ответственных за двигательную функцию руки [72]. Эта «ручная моторная ручка» обычно используется в качестве мишени для имплантации электрода (например, в [73–77]). Еще одна потенциальная цель для имплантации — задняя теменная кора (PPC). Хотя долгое время считалось, что PPC играет важную роль в ассоциативных функциях, в последние годы появляется все больше данных, свидетельствующих о том, что он также кодирует моторные намерения высокого уровня [78].Недавнее исследование предполагает, что цель и траектория движения могут быть расшифрованы по нейронной активности в человеческом PPC [79].
Одним из важных свойств нейронов M1 является настройка направления. Некоторые нейроны настроены на определенное направление. Они разряжаются сильнее всего, когда движение идет в их предпочтительном направлении, но они также разряжаются менее энергично, когда движение происходит в других направлениях.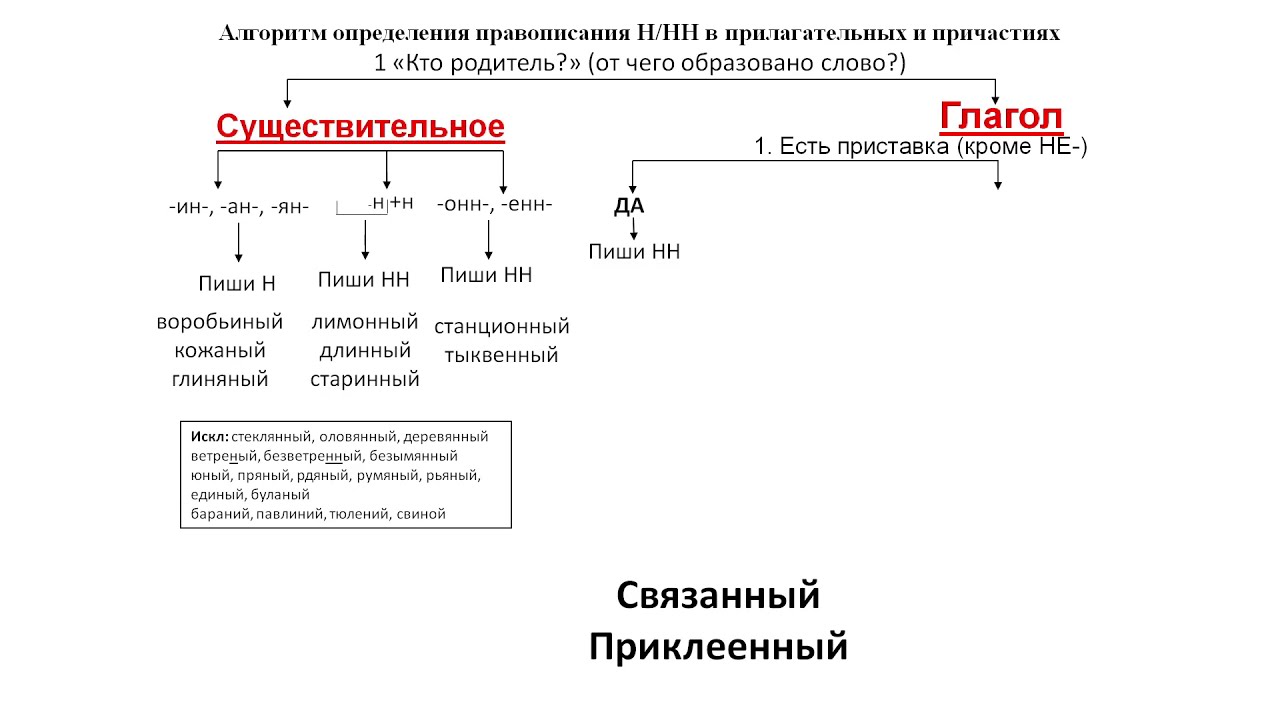 Их скорострельность представляет собой длину их предпочтительного вектора направления.Когда векторы этих нейронов суммируются, это указывает окончательное направление движения. Эта популяционная кодировка движения — поразительное свойство нервной системы. Аналогичный аналог популяционного кодирования также можно найти в суперколликулусе, представляющем направление движения глаз [80]. Пример, показывающий свойство настройки направления M1 у приматов, кроме человека, показан на (рис. 3).
Их скорострельность представляет собой длину их предпочтительного вектора направления.Когда векторы этих нейронов суммируются, это указывает окончательное направление движения. Эта популяционная кодировка движения — поразительное свойство нервной системы. Аналогичный аналог популяционного кодирования также можно найти в суперколликулусе, представляющем направление движения глаз [80]. Пример, показывающий свойство настройки направления M1 у приматов, кроме человека, показан на (рис. 3).
Примеры направленной настройки внутрикортикальных сигналов.Диаграммы, показывающие свойства направленной настройки нейронов у нечеловеческого приматы M1 из данных [215, 216]. — растровые графики Spike от одного из нейронов (Neuron 31). На каждом графике показано время всплеска нейрона, выровненного по моменту времени (t = 0), в котором скорость движения руки превышает заранее определенный порог. Каждая точка на графике представляет собой потенциал действия. Различные графики показывают нейронную активность, когда рука движется в разных направлениях. b Кривая настройки фон Мизеса некоторых репрезентативных нейронов. c Предпочтительное направление всех нейронов. Длина вектора представляет собой глубину модуляции нейрона, определяемую здесь как величину кривой настройки, деленную на угол между максимальной и минимальной точкой кривой.
Различные графики показывают нейронную активность, когда рука движется в разных направлениях. b Кривая настройки фон Мизеса некоторых репрезентативных нейронов. c Предпочтительное направление всех нейронов. Длина вектора представляет собой глубину модуляции нейрона, определяемую здесь как величину кривой настройки, деленную на угол между максимальной и минимальной точкой кривой.
временные (<30 дней) внутрикортикальные записи - это система Neuroport (Blackrock Microsystem, Inc, США). В результате большая часть работы по внутрикортикальному декодированию человека выполняется на этой платформе.Существуют и другие интракортикальные электроды, но они предназначены в основном для интраоперационного мониторинга острых состояний (например, глубинный электрод Спенсера, Ad-Tech; NeuroProbes, Alpha Omega Engineering Ltd.
Активность нейронов в месте имплантации представлена их потенциалами действия, которые проявляются в виде всплесков во внеклеточных записях. Следовательно, обнаружение спайка часто является первым шагом в обработке интракортикального сигнала.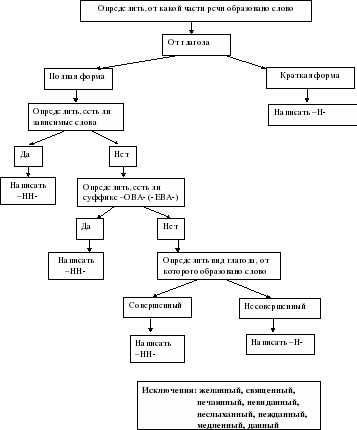 {2}} $$
{2}} $$
, где Thres представляет собой порог обнаружения, выше которого момент времени сигнала считается принадлежащим всплеску. Однако значение RMS может быть легко испорчено артефактами, поэтому другим способом является использование медианы для установки порога обнаружения [83]
$$ \ sigma = median \ left (\ frac {| x |} {0,6745} \ right) $$
Другой популярный метод — нелинейный оператор энергии [83]. Сначала он преобразует сигнал таким образом, что высокочастотная составляющая усиливается для улучшения отношения сигнал / шум.{N} \ psi [x (n)] $$
Другие более продвинутые методы, такие как непрерывное вейвлет-преобразование [84] и обнаружение всплесков EC-PC [82], могут предложить лучшую точность, но с более высокими вычислительными затратами. Хотя существует множество способов точного обнаружения всплесков в автономном режиме, не каждый из них достаточно быстр для использования в режиме реального времени. Поэтому при онлайн-декодировании выбор обычно ограничивается более простыми алгоритмами.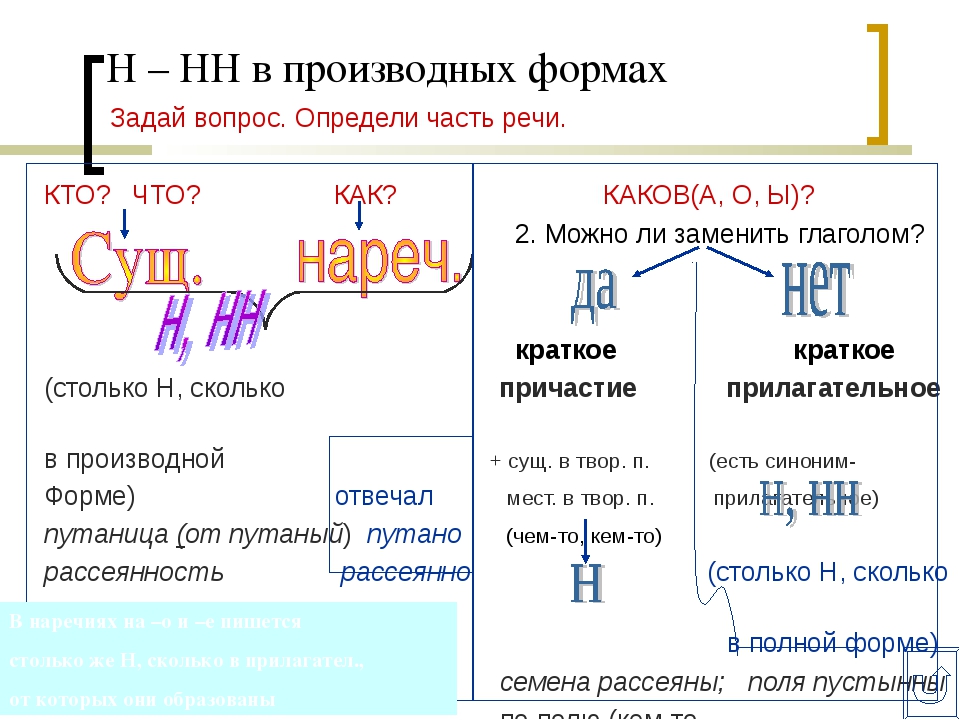 Ручная установка порога оператором по-прежнему остается одним из наиболее часто используемых методов.Еще одним популярным методом онлайн-декодирования является метод RMS из-за его высокой эффективности.
Ручная установка порога оператором по-прежнему остается одним из наиболее часто используемых методов.Еще одним популярным методом онлайн-декодирования является метод RMS из-за его высокой эффективности.
Электрод может записывать сигналы от нескольких соседних нейронов. Выделение активности отдельного нейрона (то есть активности сигнальных единиц) от этой множественной активности обычно приводит к лучшим результатам в моторном декодировании. Этот процесс называется сортировкой по шипам. По сортировке шипов существует обширная литература, которую невозможно исчерпать. Заинтересованным читателям предлагается ознакомиться с другими превосходными обзорами [85–87].На практике наиболее популярным способом онлайн-сортировки всплесков в реальном времени является сопоставление с шаблоном. Набор шаблонов всплесков собирается в течение периода начальной записи, а затем последующие всплески классифицируются, сравнивая их сходство с шаблонами. Однако может не быть действительно необходимым или даже ухудшить результат декодирования, выполнять онлайн-сортировку пиков. Кластеры спайков, полученные из записей, могут быть нестабильными в разных сеансах экспериментов. Общее количество отдельных единиц, отсортированных от записи, может изменяться от сеанса к сеансу [79].Таким образом, декодер, обученный некоторым отсортированным пикам, может не работать в будущих сессиях. Сортировка пиков также может привести к дополнительной задержке при онлайн-декодировании, поскольку точная сортировка пиков является дорогостоящим с точки зрения вычислений процессом. Фактически, многие недавние исследования декодирования вообще не используют сортировку спайков, например [79, 88–94].
Алгоритм декодирования восстанавливает моторную кинематику по нейронной активности. С момента открытия свойства направленной настройки моторных нейронов одним из первых алгоритмов декодирования интракортикального спайкового сигнала является алгоритм вектора популяции [95, 96].В своей простейшей форме частота срабатывания нейрона может быть связана с его предпочтительным направлением на
.$$ f = f_ {0} + f_ {max} cos (\ theta- \ theta_ {p}) $$
, где f — частота нейронного срабатывания, f 0 и f max — константы регрессии, а θ и θ p — текущее и предпочтительное направление соответственно. Однако для функции косинуса ширина модуляции фиксирована.Более гибкой функцией настройки, которая позволяет регулировать ширину модуляции, является функция настройки фон Мизеса [97]:
$$ f = b + k \; exp (\ kappa cos (\ theta- \ mu)) $$
, где b , k , κ , μ — константы регрессии, а θ — текущее направление движения. Когда μ = θ , функция будет максимальной, поэтому μ также можно интерпретировать как предпочтительное направление нейрона.{N} _ {i = 1} w_ {i} (M) C_ {i} $$
, где C i — предпочтительное направление для i -го нейрона, а w i ( M ) — весовая функция, объединяющая вклады каждого нейрона в направлении M в окончательный вектор популяции. Однако этот метод требует большого количества нейронов, чтобы быть точным, и может привести к ошибке, если распределение предпочтительного направления не является равномерным [98].{T} \ mathbf {k} $$
, где R — матрица нейронных откликов (например, интенсивность импульсов), f — линейный фильтр (или константы регрессии), а k — кинематические значения двигателя ( например, углы стыков или положения курсора). Было высказано предположение, что эта схема регрессии может обеспечить более точное предсказание по сравнению с суммированием предпочтительных векторов направления, особенно когда эти векторы не распределены равномерно [98].
В последние годы фильтр Калмана обычно используется вместо простой линейной регрессии (например,г. в [75–77, 99, 100]). Фильтр Калмана включает информацию как из внутренней модели процесса, так и из фактических измерений для оценки состояний системы [101]. Переменная Калмана используется для определения «веса смешения» модели и измерений. Если модель более точная, то она будет больше доверять модели. То же самое и с измерением. Фильтр Калмана особенно полезен, если состояния не наблюдаются напрямую или если измерения очень зашумлены, что часто бывает справедливо при декодировании двигателя.При моторном декодировании субъекты обычно теряли свою конечность или способность двигаться, поэтому внутреннее состояние (например, двигательное намерение) системы напрямую не наблюдаем. Наблюдаемые переменные (например, нейронная активность) также очень шумны. Типичный фильтр Калмана для декодирования двигателя не предполагает никакой управляющей переменной, и систему можно сформулировать как два линейных уравнения [102, 103]):
$$ \ begin {array} {@ {} rcl @ {}} \ vec {x} _ {t} & = & A \ vec {x} _ {t-1} + \ vec {w} _ {t -1} \\ \ vec {y} _ {t} & = & C \ vec {x} _ {t} + \ vec {v} _ {t} \ end {array} $$
где x состояние системы, которую нужно декодировать, например.г. совместная кинематика или положение курсора. y — наблюдаемые переменные, например скорость нейронной стрельбы. \ (\ vec {w} _ {t} \) и \ (\ vec {v} _ {t} \) — это шумы процесса и измерений, взятые из w t ∼ N (0, Q ) и v t ∼ N (0, R ) соответственно. A , C , Q и R — константы Калмана, которые необходимо определить в соответствии с моделью декодирования.{-} \) и \ (\ hat {x} \) — это априорная оценка состояния и апостериорная оценка состояния соответственно. u — управляющая переменная. Обычно при декодировании двигателя он устанавливается на 0, здесь мы включили его для полноты картины.
Одним из важнейших аспектов выполнения декодирования двигателя в режиме онлайн является обучение и повторная калибровка модели декодирования. Хотя нейронные функции для подобных движений относительно стабильны в течение нескольких дней [104], кривая нервной настройки может начать изменяться, когда субъект учится выполнять новую задачу [105].Также очень сложно отслеживать один и тот же нейрон в течение длительного периода времени [106, 107] из-за микродвижения электродов и колебаний других источников шума. Кроме того, обучающие данные часто собираются в режиме разомкнутого цикла, что означает, что во время обучения декодер не обеспечивает обратной связи. Однако в реальном сеансе декодирования обеспечивается обратная связь, и субъект может попытаться изменить свой образ движения, чтобы «изучить» декодер. Это может привести к изменениям основных нейронных функций [108].Поэтому повторная калибровка обученной модели часто бывает необходима, и будет идеальной, если ее можно будет выполнить онлайн. Удачным методом повторной калибровки является алгоритм ReFIT-KF, предложенный Гиля и др. [109]. ReFIT-KF предполагает, что истинное намерение объекта состоит в том, чтобы двигаться к цели, поэтому он может автоматически генерировать ложную истину из декодированного результата, даже если прогноз текущей модели может быть неверным. Затем он может откалибровать модель, используя основную оценку, чтобы адаптироваться к нестабильности нейронных сигналов.Он может дать лучшие результаты, чем один фильтр Калмана [92,93,109].
Благодаря более надежным сигналам, полученным при интракортикальных записях, он был успешно использован, чтобы помочь пациенту с тетраплегией управлять окружающей средой различными способами, включая управление 2D-курсором [73,76,94], виртуальные и настоящие протезы рук [77,79] , 92,110,111] и функциональная электростимуляция собственных парализованных рук пациентов [90,91,93].
Периферийное декодирование движений конечностей
Сигналы от центральной нервной системы (ЦНС) в конечном итоге достигают периферической нервной системы (ПНС) и вызывают сокращение различных мышечных волокон.По сравнению с ЦНС, сигналы в периферических структурах обычно более специфичны. Они содержат подробные инструкции по сокращению отдельных мышечных волокон, поэтому потенциально могут обеспечить эффективное протезирование. Операции на периферическом интерфейсе обычно менее сложны, чем на интракорковых структурах. Поэтому многие исследования также посвящены моторному декодированию в периферических структурах.
Записи периферических нервов
Периферические нервы содержат нейронные сигналы низкого уровня, посылаемые для активации сокращения определенных мышц.Предыдущие исследования периферической нейронной регистрации в основном сосредоточены на афферентной сенсорной информации, потому что получить эфферентные сигналы у анестезированных животных непросто [112]. Однако в последние годы появилось больше исследований, в которых пытались изучить возможность декодирования сигналов эфферентных периферических нервов для управления протезом. Поскольку периферические нервы содержат информацию низкого уровня, нацеленную на каждую мышцу, можно будет восстановить высокую ловкость и естественный контроль, используя эту богатую информацию.
Одной из основных проблем при регистрации периферических нервов является доступ к аксонам в нервах. Аксоны спинномозговых нервов сгруппированы в пучки, а несколько пучков сгруппированы вместе, образуя периферический нерв. Эти аксоны заключены в три оболочки соединительной ткани — эпиневрий, покрывающий весь нерв, и периневрий, который охватывает пучок, и эндоневрий, который удерживает нейроны и кровеносные сосуды вместе внутри пучка. Из-за этих множественных слоев ламинации вокруг аксона амплитуда сигнала периферического нерва обычно очень мала, может составлять около 5-20 мкм В [112].
Существует несколько конфигураций электродов, предназначенных для получения лучшего сигнала от периферических нервов [113]. Электрод-манжета [114], как следует из названия, работает как манжета, оборачивающая нерв. Его главное преимущество заключается в том, что он вызывает минимальное повреждение нервных тканей, так как не требует разреза на самом нерве. Однако, поскольку он измеряет только электрический потенциал на поверхности нерва, он может только получить общую сумму нервной активности в различных пучках.Другой вариант манжетного электрода — это плоский интерфейсный нервный электрод (FINE) [115]. Он работает как зажим, оказывая давление на нерв и придавая ему овальную форму, тем самым увеличивая площадь его поверхности и уменьшая расстояние от электрода до пучков. Есть и другие типы электродов, которые вживляют в нервы. Они предлагают более высокую селективность благодаря прямому контакту с пучками. Однако они также более инвазивны и могут вызвать большее повреждение нерва.Продольные внутрипучковые электроды (LIFE) представляют собой длинные тонкие проволоки, продольно имплантированные в пучки нервов [116]. С другой стороны, поперечные внутрипучковые многоканальные электроды (TIME) имплантируются поперек нервов, обеспечивая одновременный доступ к нескольким пучкам. Также существует матрица наклонных электродов штата Юта [117], которая состоит из набора электродов разной длины, так что, когда матрица вставляется в нерв, кончик электрода может контактировать с различными пучками.В последнее время также разрабатывается регенеративный периферический нейронный интерфейс (RPNI) [118], который использует мышечный трансплантат для обертывания концов отрезанных пучков. Нервные окончания врастают в трансплантат и иннервируют вместе с ним, создавая новый интерфейс для получения нейронного сигнала. Из различных типов представленных электродов только электрод-манжета в настоящее время используется в коммерческих одобренных FDA системах для стимуляции блуждающего нерва (например, VNS Therapy, Cyberonics, США). Большинство других все еще находятся в стадии исследования или клинических испытаний [119].
Исследования по декодированию периферических сигналов человеком все еще очень ограничены, отчасти из-за проблемы получения нервных сигналов с достаточным SNR, а также из-за перекрестных помех между нейронными сигналами и ЭМГ, поскольку периферические нервы обычно расположены в непосредственной близости от мускулатуры конечностей. Большинство существующих исследований сосредоточено на декодировании верхней конечности, поскольку ампутация верхней конечности имеет тенденцию оказывать большее влияние на повседневную жизнь пациентов. Нервная запись выполняется на локтевом, медиальном и / или лучевом нерве.Используются разные типы электродов, но наиболее распространенными в человеческом декодировании являются грифельный электрод штата Юта (например, в [120,121]) и LIFE (например, [122 — 124]).
Анализ периферических сигналов обычно включает обнаружение потенциалов действия в нерве. Процедуры обнаружения аналогичны тем, которые используются во внутрикортикальных исследованиях, но этап кластеризации спайков обычно не выполняется. Из-за низкого отношения сигнал / шум периферийных сигналов иногда необходимо сначала избавиться от шумов (например,г. с помощью вейвлета [124]) до обнаружения. Затем скорость активации потенциала действия может быть введена в регрессор (например, в [103,120 — 122]) или классификатор (например, в [123,124]) для декодирования. Разница в использовании регрессора или классификатора заключается в том, декодируется ли дискретный жест или непрерывная совместная траектория.
Машина опорных векторов (SVM) является наиболее часто используемым классификатором для периферийного декодирования (например, в [123,124]). Для регрессора использовалась простая линейная регрессия или фильтр Калмана ([103,120 — 122]).Фильтр Калмана позволяет рекурсивно обновлять модель в режиме реального времени и особенно полезен, когда измерение целевой переменной зашумлено (как часто бывает в случае моторного декодирования, поскольку невозможно измерить фактическое движение отсутствует конечность).
Вопрос получения достоверной информации для обучения декодера также очень важен. В то время как для классификации типа дискретного захвата может быть достаточно попросить субъекта представить, что он держит конкретный захват, для декодирования положения необходимо использовать более точный подход.Одно из распространенных решений — показать теневую руку на экране и попросить испытуемого попытаться проследить за движением руки либо посредством манипулянда, контролируемого зеркальным движением неповрежденной руки [121], либо только посредством воображаемых фантомных движений конечностей. .
В настоящее время качество декодирования периферических нервов человека все еще не очень удовлетворительное, отчасти из-за сложности получения четкого сигнала и перекрестных помех ЭМГ. В классификации с дискретным хватом задача классификации 4 классов с 3 захватами (силовой захват, захват, сгибание мизинца) и отдыхом достигла точности 85% [124], но современная поверхностная электромиограмма (ЭМГ) уже может различать 7 жестов [125].Декодирование на основе регрессии обеспечивает пропорциональное управление протезом руки и, следовательно, может быть более интуитивным. Декодирование на основе фильтра Калмана может классифицировать 13 различных движений в автономном режиме, но только 2 движения могут быть успешно декодированы онлайн из-за перекрестных помех между различными степенями свободы (DoF) [121].
Периферические нервы представляют собой многообещающую цель для моторного декодирования. Он расположен ниже по пути моторного контроля и содержит более конкретную информацию о мышечной активности.Это свойство потенциально может быть использовано для обеспечения контроля высокой ловкости. Доступ к периферическим нервам также относительно проще, чем к интракортикальным структурам. Однако периферические записи страдают из-за их низкого отношения сигнал / шум из-за множественных уровней ламинирования вокруг аксона. Это может быть улучшено за счет лучшей конструкции электродов и нейронных усилителей со сверхмалым шумом, которые могут разрешать малую амплитуду нервных сигналов (например, [126]).
Электромиограмма (ЭМГ)
Сигналы ЭМГ представляют собой сумму электрических активностей мышечных волокон, которые запускаются последовательностью импульсов, т.е.е. импульсы активации иннервирующих мотонейронов. Сигналы ЭМГ можно измерить двумя способами: либо на поверхности кожи над мышцей (поверхностная ЭМГ), либо непосредственно внутри мышечного волокна с помощью игольчатого электрода (внутримышечная ЭМГ). Пример данных ЭМГ в различных жестах руки показан на (рис. 4).
Рис. 4Примеры сигналов ЭМГ при различных жестах руки. Диаграмма, показывающая сигналы ЭМГ от 12 поверхностных электродов в 3 различных жестах руки. Исходные данные взяты из [217]. a ЭМГ-сигналы как от здоровых людей, так и от лиц с ампутированными конечностями. В последней строке показаны жесты рук, выполненные для соответствующих сегментов ЭМГ. b Расположение 12 электродов ЭМГ
Миоэлектрические сигналы десятилетиями использовались в качестве источника управления в протезах, в которых мышечные сигналы записываются и преобразуются в управляющие команды, вызывающие движения протеза. Считается, что внутримышечные ЭМГ-сигналы имеют более высокое разрешение и менее подвержены перекрестным помехам по сравнению с поверхностной ЭМГ из-за более инвазивного развертывания электродов и прямого воздействия на определенные мышцы.
Несмотря на десятилетия исследований и разработок, инвалиды по-прежнему не используют современные миоэлектрические протезы чаще, чем обычные крючки с питанием от тела [127], и, по оценкам, 40% людей с ампутированными конечностями на самом деле отвергают с помощью протеза [128]. Одним из основных ограничений клинически доступных протезов руки является количество одновременно и пропорционально контролируемых степеней свободы (DoFs), которое редко превышает 2 [129,130] и сосредоточено в основном на DoFs запястья без руки [131], хотя функции движение рук более важно в повседневной жизни.
Миоэлектрический контроль можно разделить на прямой контроль и контроль распознавания образов. Прямой контроль относится к типу методов, которые используют амплитуду двух входных сигналов поверхностной ЭМГ от антагонистической пары мышц для управления двумя направлениями (ВКЛ и ВЫКЛ) на протезной глубине резкости. Из-за неадекватной остающейся мускулатуры, загрязнения перекрестных помех и ослабления сигналов глубоких мышц на уровне кожи количество независимых миозитов в остаточном предплечье обычно ограничивается двумя, что позволяет контролировать только одну глубину резкости за раз.В результате этого ограничения пациентам необходимо переключаться между режимами, используя быстрое совместное сокращение миозитов для последовательного управления несколькими степенями свободы. Управление распознаванием образов основано на алгоритмах машинного обучения для обучения отдельного классификатора для каждой степени свободы. Было предложено и оценено множество классификаторов, включая квадратичный дискриминантный анализ [132], машину опорных векторов [133], искусственную нейронную сеть [134], скрытые модели Маркова [135], модели смеси Гаусса [136] и другие. Однако, поскольку обучение вычислительных моделей включает в себя движение только 1-DoF, обученные классификаторы не поддерживают одновременное управление несколькими DoF.Более многообещающий подход, основанный на машинном обучении, заключается в принятии схемы управления на основе регрессии (вместо классификации), которая по своей сути способствует непрерывному управлению (в отличие от включения и выключения), при котором линейное или нелинейное отображение характеристик сигнала ЭМГ на изменения протез DoFs изучен. Обычно используемые методы для этой цели включают искусственные нейронные сети [137], опорную векторную машину [138] и регрессию гребня ядра [131]. Основным недостатком управления на основе регрессии является потребность в большом количестве обучающих данных, которые включают исчерпывающую комбинацию движений всех степеней свободы протеза, что непрактично для клинической реализации.
Одной из фундаментальных проблем при управлении протезом на основе ЭМГ является недостаток независимых сигналов, с помощью которых можно управлять степенями свободы протеза. ЭМГ-сигналы по своей природе сильно коррелированы и им не хватает разрешения и информационной емкости, необходимых для одновременного и пропорционального управления несколькими степенями свободы. Возможное решение этой проблемы — записывать двигательные команды непосредственно от периферических нервов, таких как локтевые и срединные нервы, которые напрямую иннервируют все пять пальцев. Однако это происходит за счет инвазивной хирургической имплантации электродов и рисков инфицирования тканей и повреждения нервов.
Были проведены работы по извлечению более инвариантной и независимой информации из сигналов ЭМГ без инвазивных записей. Одна из основных групп усилий сосредоточена на извлечении особенностей мышечной синергии из записей ЭМГ, то есть сложных паттернов мышечной активации, которые выполняются пользователями в качестве управляющих сигналов высокого уровня независимо от какого-либо неврологического происхождения [139]. Считается, что мышечная синергия способна описывать сложные модели силы и движения в уменьшенных размерах и может использоваться в качестве надежного представления для декодирования выходных данных в соответствии с намерениями пользователя.Неотрицательная матричная факторизация (NMF) [140] обычно используется для извлечения синергии мышц из многоканальных сигналов ЭМГ для одновременного и пропорционального контроля нескольких степеней свободы [137,141 — 143]. Другая группа работ посвящена непосредственному извлечению нейронных кодов активности двигательных нейронов, которые управляют движениями мышц по нервным путям. Обычно для этого требуются расширенные настройки записи, такие как ЭМГ высокой плотности с достаточным количеством близко расположенных участков записи.Был предложен ряд алгоритмов для извлечения основной нейронной информации [144,145]. Среди них компенсация ядра свертки (CKC) наиболее широко использовалась в качестве типа метода разделения многоканальных слепых источников [146 — 149]. Несмотря на обещание извлечения нейронного содержимого из сигналов ЭМГ высокой плотности, демонстрация использования такой схемы в онлайн-экспериментах остается сложной задачей. Требуются более глубокие исследования и значительные усилия для создания нейронного интерфейса и достижения прямого нейронного управления на основе этой структуры.
Декодирование речевой двигательной активности
Хотя этот обзор в основном посвящен декодированию движений в конечностях, в последнее время появилось еще одно направление исследований по декодированию двигательной речевой активности [150, 151]. Производство речи — сложный процесс, в котором задействованы несколько областей мозга и десятки мышечных волокон. Мышечная деятельность должна быть хорошо скоординирована, чтобы производить различные звуки речи (то есть фонемы), которые соединяются вместе, чтобы образовать понятные слова и предложения.
Множественные области мозга связаны с языковым производством [152], но есть две основные области, которым при декодировании речи уделяется больше внимания. Было высказано предположение, что левая вентральная премоторная кора представляет собой фонемы высокого уровня в речи [153,154], в то время как вентральная сенсомоторная кора содержит богатую репрезентацию различных речевых артикуляторов (например, губ, языка, гортани и т. Д.) [155,156]. Поэтому большая часть усилий по декодированию сосредоточена на этих двух областях мозга.
Исторически для декодирования речи использовались различные нейронные сигналы.ЭЭГ неинвазивна, но ее низкое отношение сигнал / шум и загрязнение ЭМГ лицевыми мышцами очень затрудняют ее использование для декодирования речи [151]. Был достигнут некоторый успех в использовании многоэлектродной матрицы для декодирования явлений из многоэлементной активности [157]. Однако кортикальные представления речевых артикуляторов покрывают большую область, которая может не подходить для очень локализованной области записи многоэлектродной матрицы [156, 158]. Кроме того, декодирование речи часто требует, чтобы открытая речь служила основной истиной, а это требует, чтобы испытуемые были способны говорить четко.Трудно оправдать имплантацию проникающих электродов в здоровую красноречивую кору головного мозга для проведения экспериментов. В настоящее время ECoG получает больший успех в декодировании речи из-за высокого качества сигнала и менее инвазивной природы. Запись ЭКоГ также часто используется во время резекции головного мозга, чтобы избежать повреждения красноречивой коры, поэтому она хорошо интегрирована в существующие хирургические процедуры. Исследования с использованием ЭКоГ для декодирования речи в основном сосредоточены на высоком гамма-диапазоне (70–170 Гц), поскольку было показано, что высокая гамма-активность сильно коррелирует с частотой срабатывания ансамбля [159].
Ранее усилия по декодированию речи были сосредоточены на прямом декодировании простых слов или фонем [150 , 157 , 158 , 160 — 162], но их производительность не очень удовлетворительна. Декодирование из ограниченного словаря или набора фонем может дать более высокую точность (например,> 80% для 10 слов [160] или 9 фонем [157]), но оно может охватывать только очень узкий диапазон человеческих устных выражений. Исследования, пытающиеся расшифровать полный диапазон английских фонем, приводят к более низкой точности классификации (10-50% [150,155 , 162]).Низкую точность классификации можно частично уменьшить, включив словарь произношения и языковую модель (например, в [150]), которые могут ограничить вывод декодера более вероятными словами.
С другой стороны, в последнее время внимание было переключено на декодирование промежуточного представления речи (например, движения артикулятора), а не на прямое декодирование фонем. Частично этот сдвиг может быть мотивирован растущим количеством доказательств, предполагающих, что речевая моторная кора способна генерировать паттерны дифференциальной активации, кодирующие кинематику речевых артикуляторов [156,163 — 165].Достижения в области глубокого обучения сделали предсказание траекторий артикулятора на основе акустического сигнала (то есть акустико-артикуляционной инверсии) достаточно точным, чтобы действовать в качестве основы для декодирования, поскольку традиционные способы имплантации катушек или магнитов во рту с помощью артикулографии являются инвазивными и несовместимо с нейронными записями [166]. В одном недавнем исследовании [167] глубокая нейронная сеть используется для декодирования характеристик ЭКоГ в траектории артикулятора. Затем траектории декодируются другой нейронной сетью в акустические характеристики (например,г. высота тона, мелкочастотные кепстральные коэффициенты и т. д.), которые затем преобразуются в слышимый голос с помощью синтезатора голоса. Даже мимизированная речь может быть декодирована, хотя и с меньшей точностью. В другом исследовании [168] характеристики ЭКоГ декодируются в спектрограммы с мел-масштабированием непосредственно с использованием нейронной сети, затем вокодер нейронной сети используется для преобразования спектрограммы в звуковые сигналы. Эти недавние результаты показывают большие перспективы в декодировании человеческой речи по сигналам ЭКоГ. Сводка различных методов моторного декодирования приведена в таблице 1.
Таблица 1 Сравнение различных методов декодирования моторикиПроблемы и направления на будущее
Несмотря на то, что были достигнуты большие успехи в расшифровке моторного намерения человека, все еще остаются некоторые серьезные проблемы, которые предстоит решить. Одна из самых больших проблем, препятствующих внедрению моторного декодирования за пределами лаборатории, — это ограниченная долговечность модели декодирования. Обычно требуется некоторый сеанс калибровки для сбора данных для обучения модели декодирования, затем модель тестируется на последующих сеансах в тот же или следующие несколько дней.Хотя это приемлемо в научном исследовании из-за ограниченного времени и доступных клинических ресурсов, при повседневном использовании обученная модель должна поддерживать свою производительность в течение длительного периода времени.
Ограниченный срок службы может быть вызван несколькими причинами. Во-первых, это нестабильность границ раздела электродов. Микроперемещение электродов может вызвать сдвиг в пространстве элементов. Если декодер недостаточно устойчив, этот сдвиг может привести к ухудшению производительности декодирования.Другая причина — различные шумы окружающей среды, которые вводятся в полученные сигналы. Нейронные сигналы, используемые для декодирования, обычно имеют очень маленькую амплитуду и поэтому чувствительны к помехам окружающей среды. Сотовый телефон, люминесцентная лампа или другие электроприборы вносят различные типы шума в полученный сигнал. Поскольку испытуемые выполняют различные задачи в повседневной жизни, они могут попадать под влияние различных источников шума, не охваченных обученным набором данных, что приводит к снижению производительности.Третья причина — медленное нарастание иммунного ответа на поверхности раздела электродов. Глиальные рубцы могут покрывать электрод и увеличивать его импеданс [174]. Нейродегенерация в результате иммунного ответа также приведет к более слабому сигналу [175]. Проблема долговечности модели многогранна и требует тщательного решения. Во-первых, лучшая конструкция электродов может помочь закрепить электрод на его анкерной конструкции и уменьшить их относительное перемещение. Имплантируемое решение также будет обеспечивать более стабильную работу, чем решение, требующее повторного демонтажа и повторной установки каждый раз (например,г. ЭЭГ и ЭМГ). Во-вторых, модель следует обучить более надежным функциям и протестировать в среде, типичной для ее повседневного использования. Экранированная камера может помочь получить очень чистые сигналы, которые подходят для демонстрации прототипа. Однако маловероятно, что такое же качество сигналов можно будет получить в повседневной среде. Таким образом, также важно учитывать, как тестируется декодер, а не просто смотреть автономные числовые показатели. В-третьих, развитие электродных материалов или специальных органических покрытий потенциально может снизить иммунный ответ [176].Гибкий электрод вместо жесткого также может вызывать меньшее повреждение нейронов и воспаление [177, 178].
Вторая проблема заключается в том, как учесть разницу в характеристиках при обучении без обратной связи и при управлении с обратной связью. Набор обучающих данных обычно получается по принципу разомкнутого цикла, что означает, что испытуемым инструктируют выполнять определенные двигательные образы без какой-либо обратной связи. Однако при фактическом использовании система будет обеспечивать обратную связь с субъектом на основе выходных данных декодера.Если выходной сигнал декодера неправильный, субъект может попытаться исправить это намеренно, и это может привести к несоответствию в работе офлайн и онлайн [179]. Одним из решений является введение небольшого сеанса калибровки с обратной связью в начале сеанса тестирования, как во многих исследованиях моторного декодирования на основе ЭЭГ. Исходная модель обучается с использованием парадигмы разомкнутого цикла, затем модель дополнительно настраивается с учетом обратной связи в сеансе калибровки. Однако это возможно только в том случае, если доступна неопровержимая истина.В случае, когда достоверная информация недоступна, например В случае пациента с тетраплегией, когда очень трудно узнать истинное намерение субъекта, алгоритм ReFIT является другим подходом к решению этой проблемы [109]. Основная идея алгоритма ReFIT состоит в том, что он пытается построить псевдопочвенную истину, предполагая, что субъект постоянно пытается исправить неправильный вывод декодера. Таким образом, предполагается, что вектор направления двигательного намерения всегда направлен на цель из текущей позиции курсора.Используя этот метод, можно обучить декодер с нуля, используя всего 3 минуты данных [94]. Онлайн-калибровка с обратной связью может предложить более реалистичное предсказание того, как декодер может работать в реальной жизни. Этот подход также может позволить декодеру быстро адаптироваться к любому сдвигу в пространстве признаков из-за изменения интерфейса электродов или шумов окружающей среды. Однако онлайн-калибровка требует быстрого обновления модели, что накладывает ограничение на сложность модели декодирования.Необходимы дополнительные исследования, чтобы изучить, как эффективно обновлять декодер в реальном времени.
Помимо улучшения алгоритмов декодирования, разработка новых электродов и нейронных усилителей также играет очень важную роль в продвижении декодирования двигателей. Последние тенденции в разработке электродов в основном сосредоточены на улучшении четырех областей конструкции электродов: плотности, гибкости, биосовместимости и возможности подключения. Более плотный электрод может улучшить пространственное разрешение нейронных записей. Электрод высокой плотности был создан из кремниевой пластины и моноволокна из углеродного волокна [180, 181].Материал электрода с гибкостью, близкой к гибкости тканей головного мозга, может уменьшить нервное повреждение и воспалительную реакцию. Для изготовления нервных электродов использовалось множество гибких полимеров, включая полиимид [182,183], парилен [184], PDMS [185] и т. Д. Биосовместимость всегда является важной проблемой при разработке электродов, поскольку воспалительная реакция и инкапсуляция ухудшают качество сигнала с течением времени и подрывают качество хронических нейронных записей. Стратегии улучшения биосовместимости, включая использование инертных металлов, таких как золото или платина, использование гибких материалов для уменьшения повреждения тканей или покрытие электрода биосовместимыми материалами, такими как проводящий полимер [186] и углеродные нанотрубки [187].Соединение для считывания с электродов также быстро станет проблемой, когда плотность и количество электродов будут продолжать увеличиваться. Включение транзисторов в электроды напрямую для обеспечения мультиплексирования соединений — один из способов решения этой проблемы [188,189]. Читателям, интересующимся дизайном нейронных электродов, рекомендуется ознакомиться с другими более подробными обзорами в этой области [119, 172, 176, 177, 190].
Разработка нейронных усилителей также играет очень важную роль в развитии науки о моторном декодировании, поскольку нам сначала нужно получить четкий нейронный сигнал, прежде чем можно будет выполнить какую-либо обработку и декодирование.Существует несколько направлений исследований, направленных на улучшение различных аспектов конструкции усилителя. Во-первых, потребляемая мощность усилителя может быть уменьшена путем разделения ресурсов (например, один усилитель с несколькими электродами [191] или несколько усилителей с одним аналого-цифровым преобразователем [192]), планирования мощности (например, отключение неиспользуемых компонентов [193] ], динамически регулируя параметры усилителя [194]) или снижая напряжение питания [195]. Во-вторых, количество каналов можно увеличить путем мультиплексирования или интеграции усилителей непосредственно с электродами [191,196].В-третьих, шум схемы может быть уменьшен за счет подстройки [197], прерывания [198,199], автоматического обнуления [200] или формирования частоты [201] и т. Д. В-четвертых, беспроводная передача энергии или данных может быть достигнута с помощью индуктивной связи [193,202,203], сбор энергии на короткие расстояния [193,204] или даже ультразвук [205]. Наконец, функциональность усилителя также может быть расширена за счет интеграции большего количества процессоров сигналов на кристалле, например обнаружение всплесков [203], сортировка всплесков [206, 207] и сжатие данных [208, 209]. Заинтересованным читателям предлагается ознакомиться с другими более специализированными обзорами в этой области [210 — 213].
Экспертные системы и прикладной искусственный интеллект
Экспертные системы и прикладной искусственный интеллект Глава 11Экспертные системы и прикладное искусственное Разведка
11.1 Что такое искусственный интеллект?
Область искусственного интеллекта (ИИ) касается с методами разработки систем, отображающих аспекты разумного поведения. Эти системы предназначены для имитации человеческих способностей мышления и восприятия.
Характеристики систем искусственного интеллекта
Характеристики систем AI включают:
1. Символьная обработкаВ приложениях искусственного интеллекта компьютеры обрабатывают символы, а не чем цифры или буквы. Приложения AI обрабатывают строки символов, которые представляют сущности или концепции реального мира. Символы могут быть организованы в такие структуры, как списки, иерархии или сети. Эти структуры показывают, как символы соотносятся друг с другом.
2. Неалгоритмическая обработкаКомпьютерные программы, не относящиеся к области ИИ, запрограммированы алгоритмы; то есть полностью определенные пошаговые процедуры, которые определяют решение проблемы проблема.Действия системы ИИ, основанной на знаниях, в гораздо большей степени зависят от ситуация, в которой он используется.
Поле ИИ
Искусственный интеллект — это наука и технология на основе таких дисциплин, как информатика, биология, психология, лингвистика, математика и инженерия. Цель ИИ — разработать компьютеры, которые могут думать, видеть, слышать, ходить, говорить и чувствовать. Основным направлением искусственного интеллекта является развитие компьютерных функций. обычно ассоциируется с человеческим интеллектом, например, с рассуждением, обучением и проблемами решение.
Как развивалась область искусственного интеллекта [Рисунок 11.2]
1950 Тест Тьюринга — машина работает разумно, если дознаватель, использующий удаленные терминалы, не может отличить свои ответы от ответов человек.
Результат: Общие методы решения проблем
1960 Создание искусственного интеллекта как исследовательского направления.
Результат: экспертные системы, основанные на знаниях
1970 Начало коммерциализации ИИ
Результат: обработка транзакций и поддержка принятия решений. системы с использованием ИИ.
1980 Искусственные нейронные сети
Результат: Напоминает взаимосвязанный нейрон. структуры человеческого мозга
1990 Интеллектуальные агенты
Результат: Программное обеспечение, которое выполняет поставленные задачи на от имени пользователей
11.2 Возможности экспертных систем: общий вид
Наиболее важной прикладной областью ИИ является область экспертные системы. экспертная система (ES) — это система, основанная на знаниях, использует знания о своей области приложения и использует процедуру вывода (причины) для решения проблем, которые в противном случае потребовали бы человеческой компетентности или опыта.Сила экспертные системы проистекают в первую очередь из конкретных знаний об узкой области, хранящейся в экспертная система база знаний .
Важно подчеркнуть для студентов, что эксперт системы являются помощниками для лиц, принимающих решения, а не заменяют их. Экспертные системы делают не обладают человеческими возможностями. Они используют базу знаний в определенной области и приносят это знание, чтобы опираться на факты конкретной ситуации под рукой. Знание база ES также содержит эвристических знаний — эмпирических правил, используемых человеческие специалисты, работающие в данной области.
11.3 Приложения экспертных систем
В тесте приводятся наглядные мини-кейсы эксперта. системные приложения. К ним относятся такие области, как кредитные решения с высоким риском, реклама принятие решений и производственные решения.
Общие категории приложений экспертных систем
Таблица 11.1 описывает общие области ES приложения, в которых могут применяться ЭС. Области применения включают классификацию, диагностику, мониторинг, управление процессами, проектирование, составление графиков и планирование, а также создание опций.
Классификация — идентификация объекта на основании заявленных характеристики
Диагностические системы — определение неисправности или заболевания по наблюдаемым данным
Мониторинг — постоянно сравнивайте данные наблюдаемая система для предписания поведения
Process Control — управление физическим процессом на основе на мониторинге
Дизайн — настроить систему в соответствии с характеристики
Scheduling & Planning — разработка или изменение план действий
Генерация опционов — создание альтернативы решения проблемы
11.4 Как работают экспертные системы
Сила ES определяется его знаниями base — организованный сбор фактов и эвристик о предметной области системы. ES создается в процессе, известном как инженерия знаний , во время которого знания о предметной области получены от экспертов-людей и из других источников посредством знаний инженеры.
Накопление знаний в базах знаний, от какие выводы должна сделать машина логических выводов, является отличительной чертой эксперта система.
Представление знаний и база знаний
База знаний ES содержит как фактические, так и эвристическое знание. Представление знаний — метод, используемый для организации знания в базе знаний. Базы знаний должны представлять понятия как действия для приниматься в соответствии с обстоятельствами, причинно-следственной связью, временем, зависимостями, целями и другими высокоуровневыми концепции.
Можно использовать несколько методов представления знаний. обращается на.Два из этих методов включают:
1. Каркасные системы— используются для построения очень мощных ЭС. Рама определяет атрибуты сложного объекта, а рамки для различных типов объектов имеют указанные отношения.
2. Правила производства— это самый распространенный метод познания представительство, используемое в бизнесе. Экспертные системы на основе правил экспертные системы, в которых знания представлены производственными правилами.
Производственное правило или просто правило состоит из IF часть (условие или предпосылка) и ТОГДА часть (действие или вывод).ЕСЛИ условие ТО действие (заключение).
Объяснение объясняет, как система пришла по рекомендации. В зависимости от того, какой инструмент использовался для реализации эксперта системе объяснение может быть либо на естественном языке, либо просто перечислением правил числа.
Механизм вывода [Рисунок 11.4]
Механизм вывода:
1. Сочетает факты по конкретному делу с знания, содержащиеся в базе знаний, чтобы дать рекомендацию.В основанная на правилах экспертная система, механизм вывода контролирует порядок, в котором применяются правила (Afired @) и разрешает конфликты, если используется более одного правила. применимо в данный момент. Это то, что составляет Areasoning @ в системах, основанных на правилах. 2. Указывает пользовательскому интерфейсу запрашивать пользователя. для получения любой информации, необходимой для дальнейшего вывода.Факты по данному делу занесены в рабочий протокол память , которая действует как классная доска, накапливая информацию о кейсе на рука.Механизм вывода многократно применяет правила к рабочей памяти, добавляя новые информацию (полученную из выводов правил) до тех пор, пока не будет произведено целевое состояние или подтвержденный.
Рисунок 11.5 Можно использовать одну из нескольких стратегий. с помощью механизма вывода, чтобы прийти к заключению. Механизмы вывода для систем на основе правил обычно работают с прямым или обратным связыванием правил. Две стратегии:
1. Прямая цепочка— это стратегия, основанная на данных.Процесс вывода переходит от обстоятельств дела к цели (заключению). Таким образом, стратегия основана на факты, имеющиеся в рабочей памяти и по предпосылкам, которые могут быть удовлетворены. В механизм вывода пытается сопоставить часть условия (ЕСЛИ) каждого правила в знаниях. база с фактами, имеющимися на данный момент в оперативной памяти. Если совпадают несколько правил, вызывается процедура разрешения конфликта; например, правило с наименьшим номером, которое добавляет новая информация в рабочей памяти запускается.Добавлен вывод правила стрельбы. в рабочую память.
Системы прямой цепи обычно используются для решения более открытые проблемы дизайна или планирования, такие как, например, создание конфигурации сложного продукта.
2. Обратная цепочка— машина вывода пытается сопоставить предполагаемую (гипотетический) вывод — цель или состояние подцели — с заключительной (ТОГДА) частью правило. Если такое правило будет найдено, его предпосылка становится новой подцелью.В ES с немногими возможные цели, это хорошая стратегия для достижения.
Если состояние гипотетической цели не может быть поддержано предпосылки, система попытается доказать другое целевое состояние. Таким образом, возможные выводы рассматриваются до тех пор, пока не будет достигнуто целевое состояние, которое может быть поддержано предпосылками.
Обратная связь лучше всего подходит для приложений в количество возможных выводов которых ограничено и они четко определены. Классификация или системы типа диагностики, в которых можно проверить каждый из нескольких возможных выводов, чтобы посмотрите, поддерживается ли это данными, являются типичными приложениями.
Неопределенность и нечеткая логика
Нечеткая логика — это метод рассуждений, напоминающий человеческое мышление, поскольку оно допускает приблизительные значения и выводы, а также неполные или неоднозначные данные (нечеткие данные). Нечеткая логика — это предпочтительный метод обработки неопределенности в некоторые экспертные системы.
Экспертные системы с возможностями нечеткой логики, таким образом, позволяют для более гибкого и творческого решения проблем. Эти системы используются, например, для управления производственными процессами.
11.5 Технология экспертных систем [Рисунок 11.6]
Доступно несколько уровней ES-технологий. При выборе инструментов ES следует учитывать две важные вещи:
1. Инструмент, выбранный для проекта, должен соответствовать возможностям и сложности проектируемой ЭС, в частности, необходимости интегрировать его с другими подсистемами, такими как базы данных и другими компонентами более крупного информационная система. 2. Инструмент также должен соответствовать квалификации. команды проекта.Технологии экспертных систем включают:
1. Специализированные экспертные системы— Эти экспертные системы фактически предоставляют рекомендации в конкретной области задач.
2. Оболочки экспертной системы— это наиболее распространенный автомобиль для развития конкретные ЭС. Оболочка — это экспертная система без базы знаний. Оболочка снабжает Разработчик ES с механизмом вывода, пользовательским интерфейсом, объяснением и знаниями возможности приобретения.
Доменные оболочки на самом деле неполные специфические экспертные системы, требующие гораздо меньше усилий для получения актуальных система.
3. Среда разработки экспертных систем— эти системы расширяют возможности снарядов в различные направления. Они работают на рабочих станциях инженеров, мини-компьютерах или мэйнфреймах; предложить тесную интеграцию с большими базами данных; и поддержать строительство большого эксперта системы.
4. Языки программирования высокого уровняПереписано несколько сред разработки ES из LISP на процедурный язык, более часто встречающийся в коммерческой среде, например, C или C ++. ES сейчас редко разрабатываются на языке программирования.
11.6 Роли в разработке экспертных систем
Три основных роли в построении экспертных систем:
1. Expert — Успешные системы ES зависят от опыта и применения знаний, которые могут принести люди во время его развития.Для больших систем обычно требуется несколько экспертов. 2. Инженер по знаниям — Инженер по знаниям выполняет двойную задачу. Этот человек должен уметь извлекать знания из эксперт, постепенно приобретающий понимание области знаний. Интеллект, такт, сочувствие и владение конкретными методами приобретения знаний — все это требуется от инженера по знаниям. Методы приобретения знаний включают проведение интервью разной степени структурированности, анализ протокола, наблюдение экспертов на работа, и разбор дел.С другой стороны, инженер по знаниям также должен выберите инструмент, подходящий для проекта, и используйте его для представления знаний с применение средства приобретения знаний .
3. Пользователь — Система, разработанная конечному пользователю с простой оболочкой, создается довольно быстро и недорого. Более крупные системы построен в результате организованных усилий по разработке. Итеративная разработка, ориентированная на прототипы стратегия обычно используется.ЭС особенно хорошо подходят для создания прототипов.11.7 Разработка и сопровождение экспертных систем [Рисунок 11.7]
Шаги в методологии итеративного процесса Разработка и сопровождение ES включает:
1. Выявление проблемы и ее осуществимость Анализ:— проблема должна подходить для экспертной системы реши.
— необходимо найти эксперта по проекту
— рентабельность системы должна быть установлено (ТЭО)
2.Системный дизайн и ES-технологии Идентификация:— система в разработке. Необходимая степень интеграции с другими подсистемами и базами данных установлено
— концепции, которые лучше всего представляют предметные знания: отработано
— лучший способ представить знания и выполнение логических выводов должно быть установлено с образцами
3. Разработка прототипа:— инженер по знаниям работает с экспертом для размещения исходное ядро знаний в базе знаний.
— знания должны быть выражены на языке конкретный инструмент, выбранный для проекта
4. Тестирование и доработка прототипа:— на примере корпусов испытывается прототип, и Отмечены недостатки в исполнении. Конечные пользователи тестируют прототипы ES.
5. Заполните и отправьте ES:— взаимодействие ЭС со всеми элементами ее среда, включая пользователей и другие информационные системы, гарантирована и протестирована.
— ЭП задокументирована и проводится обучение пользователей
6.Поддерживайте систему:— система поддерживает актуальность прежде всего за счет обновления своего база знаний.
— интерфейсы с другими информационными системами должны быть также поддерживается по мере развития этих систем.
11-8 Экспертные системы в организациях: преимущества и Ограничения
Экспертные системы предлагают как материальные, так и важные нематериальные выгоды для компаний-собственников. Эти преимущества следует соотносить с затраты на разработку и эксплуатацию ЭС, которые высоки для крупных, организационно важные ES.
Преимущества экспертных систем
ES не заменяет в целом специалиста выполнение задачи по решению проблем. Но эти системы могут резко снизить объем работы, который должен выполнить человек, чтобы решить проблему, и они действительно оставляют людей с творческие и новаторские аспекты решения проблем.
Некоторые из возможных организационных преимуществ экспертного системы:
1. Es может выполнять свою часть задач в значительной степени. быстрее, чем человек-эксперт.2. Уровень ошибок успешных систем низок, иногда намного ниже, чем коэффициент ошибок, связанных с человеческим фактором при выполнении той же задачи. 3. ES дают последовательные рекомендации. 4. ЭС — удобное средство для доставки точка приложения трудных в использовании источников знаний. 5. ES могут уловить скудный опыт уникально квалифицированный специалист. 6. ЭС могут стать средством наращивания организационные знания, в отличие от знаний отдельных лиц в организации. 7. При использовании в качестве учебно-тренировочных машин ЭС приводят к более быстрое обучение для новичков.8. Компания может эксплуатировать ЭС в среде. опасны для человека.Ограничения экспертных систем
Никакая технология не предлагает простого и полного решения. Большой системы дороги и требуют значительного времени на разработку и компьютерных ресурсов. ES также имеют свои ограничения, которые включают:
1. Ограничения технологии 2. Проблемы с получением знаний. 3. Операционные домены как основная сфера деятельности Приложение ES 4. Поддержание человеческого опыта в организациях11-9 Обзор прикладного искусственного интеллекта
Экспертные системы — это только одна область ИИ.Другие области включают:
1. Обработка естественного языка 2. Робототехника 3. Компьютерное зрение 4. Компьютеризированное распознавание речи. 5. Машинное обучениеОбработка естественного языка
Способность разговаривать с компьютерами в разговоре с людьми Языки и пусть они понимают @ нас в целях исследователей искусственного интеллекта. Естественный язык системы обработки становятся обычным явлением. Основное приложение для систем естественного языка на данный момент это как пользовательский интерфейс для экспертных систем и систем баз данных.
Робототехника
ИИ, инженерия и физиология являются основными дисциплины робототехники. По этой технологии производятся роботизированные машины с компьютером. интеллект и компьютерное управление, человеческие физические возможности, робототехника приложения
Компьютерное зрение
Имитация человеческих чувств — основная цель области AI. Самая продвинутая сенсорная система ИИ — это компьютерное зрение или визуальная сцена. признание. Задача системы зрения — интерпретировать полученную картинку.Эти системы используются в роботах или в спутниковых системах. Используются более простые системы технического зрения для контроля качества при производстве.
Распознавание речи
Конечная цель соответствующей области ИИ — компьютеризированное распознавание речи, или понимание связной речи неизвестным говорящий, в отличие от систем, которые распознают слова или короткие фразы, произносимые по очереди или системы обучаются конкретным динамиком перед использованием.
Машинное обучение
Система с возможностями обучения — машинное обучение — может автоматически изменяться, чтобы выполнять те же задачи более эффективно и более эффективно в следующий раз.
Разрабатываются различные подходы к обучению. исследованы. Подходы включают:
1. Обучение решению проблем — накапливайте опыт @ о своих правилах с точки зрения их вклада в правильный совет. Правила, которые не внести свой вклад или те, которые, как будет установлено, вносят сомнительный вклад, могут быть автоматически отбрасываются или назначаются факторы низкой достоверности. 2. Обучение на основе кейсов — сбор кейсов в база знаний и решение проблем путем поиска кейса, аналогичного решаемому.3. Индуктивное обучение — обучение на примерах. В этом случае система способна генерировать свои знания, представленные в виде правил.11-10 нейронных сетей
Нейронные сети — это вычислительные системы, смоделированные на основе сетчатая сеть человеческого мозга, состоящая из взаимосвязанных обрабатывающих элементов, называемых нейронами. Из конечно, нейронные сети намного проще человеческого мозга (по оценкам, у них более 100 миллиардов нейронов клеток мозга). Однако, как и мозг, такие сети могут обрабатывать многие фрагменты информации одновременно и могут научиться распознавать шаблоны и программы самостоятельно решать сопутствующие проблемы.
A нейронная сеть представляет собой массив взаимосвязанные элементы обработки, каждый из которых может принимать входные данные, обрабатывать их и производить единичный вывод с целью имитации работы человеческого мозга. Знания представлены в нейронной сети схемой связей между элементы обработки и регулировкой веса этих соединений.
Сила нейронных сетей в приложениях, которые требуют сложного распознавания образов.Самая большая слабость нейронных сетей — это что они не объясняют свои выводы.
Таким образом, нейронную сеть можно обучить распознавать определенные закономерности, а затем применять полученные знания к новым случаям, где это может различать закономерности.